Apache Storm - Guia rápido
O que é Apache Storm?
Apache Storm é um sistema de processamento de big data distribuído em tempo real. Storm foi projetado para processar uma grande quantidade de dados em um método tolerante a falhas e escalonável horizontal. É uma estrutura de streaming de dados que possui a capacidade das taxas de ingestão mais altas. Embora Storm não tenha estado, ele gerencia o ambiente distribuído e o estado do cluster por meio do Apache ZooKeeper. É simples e você pode executar todos os tipos de manipulações em dados em tempo real em paralelo.
O Apache Storm continua a ser um líder em análise de dados em tempo real. Storm é fácil de configurar, operar e garante que todas as mensagens serão processadas através da topologia pelo menos uma vez.
Apache Storm vs Hadoop
Basicamente, as estruturas Hadoop e Storm são usadas para analisar big data. Ambos se complementam e diferem em alguns aspectos. O Apache Storm faz todas as operações, exceto a persistência, enquanto o Hadoop é bom em tudo, mas atrasa na computação em tempo real. A tabela a seguir compara os atributos de Storm e Hadoop.
| Tempestade | Hadoop |
|---|---|
| Processamento de stream em tempo real | Processamento em lote |
| Sem estado | Com estado |
| Arquitetura Master / Slave com coordenação baseada em ZooKeeper. O nó mestre é chamado denimbus e escravos são supervisors. | Arquitetura mestre-escravo com / sem coordenação baseada em ZooKeeper. Nó mestre éjob tracker e o nó escravo é task tracker. |
| Um processo de streaming do Storm pode acessar dezenas de milhares de mensagens por segundo no cluster. | O Hadoop Distributed File System (HDFS) usa a estrutura MapReduce para processar uma grande quantidade de dados que leva minutos ou horas. |
| A topologia Storm é executada até o desligamento pelo usuário ou até uma falha inesperada irrecuperável. | Os trabalhos de MapReduce são executados em uma ordem sequencial e concluídos eventualmente. |
| Both are distributed and fault-tolerant | |
| Se o nimbus / supervisor morrer, reiniciar o fará continuar de onde parou, portanto, nada será afetado. | Se o JobTracker morrer, todos os trabalhos em execução serão perdidos. |
Casos de uso do Apache Storm
O Apache Storm é muito famoso pelo processamento de fluxo de big data em tempo real. Por esse motivo, a maioria das empresas está usando Storm como parte integrante de seu sistema. Alguns exemplos notáveis são os seguintes -
Twitter- O Twitter está usando o Apache Storm para sua gama de “produtos de análise de editor”. “Produtos de análise do editor” processam todos os tweets e cliques na plataforma do Twitter. O Apache Storm está profundamente integrado à infraestrutura do Twitter.
NaviSite- NaviSite está usando Storm para o sistema de monitoramento / auditoria de log de eventos. Todos os logs gerados no sistema passarão pelo Storm. Storm irá verificar a mensagem em relação ao conjunto configurado de expressão regular e, se houver uma correspondência, essa mensagem específica será salva no banco de dados.
Wego- Wego é um mecanismo de metabusca de viagens localizado em Cingapura. Os dados relacionados a viagens vêm de muitas fontes em todo o mundo, em tempos diferentes. Storm ajuda o Wego a pesquisar dados em tempo real, resolve problemas de simultaneidade e encontra a melhor correspondência para o usuário final.
Benefícios do Apache Storm
Aqui está uma lista dos benefícios que o Apache Storm oferece -
Storm é um software livre, robusto e amigável. Pode ser utilizado tanto em pequenas empresas quanto em grandes corporações.
Storm é tolerante a falhas, flexível, confiável e oferece suporte a qualquer linguagem de programação.
Permite o processamento de stream em tempo real.
O Storm é incrivelmente rápido porque tem um enorme poder de processamento de dados.
O Storm pode manter o desempenho mesmo sob carga crescente, adicionando recursos linearmente. É altamente escalonável.
Storm executa atualização de dados e resposta de entrega ponta a ponta em segundos ou minutos, dependendo do problema. Possui latência muito baixa.
Storm tem inteligência operacional.
Storm fornece processamento de dados garantido, mesmo se qualquer um dos nós conectados no cluster morrer ou mensagens forem perdidas.
O Apache Storm lê o fluxo bruto de dados em tempo real de uma extremidade e os passa por uma sequência de pequenas unidades de processamento e produz as informações processadas / úteis na outra extremidade.
O diagrama a seguir descreve o conceito central do Apache Storm.

Vamos agora dar uma olhada mais de perto nos componentes do Apache Storm -
| Componentes | Descrição |
|---|---|
| Tupla | Tupla é a estrutura de dados principal do Storm. É uma lista de elementos ordenados. Por padrão, uma Tupla oferece suporte a todos os tipos de dados. Geralmente, ele é modelado como um conjunto de valores separados por vírgula e passado para um cluster do Storm. |
| Corrente | Stream é uma sequência não ordenada de tuplas. |
| Bicos | Fonte de fluxo. Geralmente, Storm aceita dados de entrada de fontes de dados brutos como Twitter Streaming API, fila Apache Kafka, fila Kestrel, etc. Caso contrário, você pode escrever spouts para ler dados de fontes de dados. “ISpout" é a interface principal para a implementação de spouts. Algumas das interfaces específicas são IRichSpout, BaseRichSpout, KafkaSpout, etc. |
| Parafusos | Os parafusos são unidades lógicas de processamento. Spouts passam os dados para os parafusos e parafusos e produzem um novo fluxo de saída. Bolts podem executar as operações de filtragem, agregação, junção, interação com fontes de dados e bancos de dados. Bolt recebe dados e emite para um ou mais parafusos. “IBolt” é a interface principal para a implementação de parafusos. Algumas das interfaces comuns são IRichBolt, IBasicBolt, etc. |
Vamos dar um exemplo em tempo real de “Análise do Twitter” e ver como ele pode ser modelado no Apache Storm. O diagrama a seguir descreve a estrutura.

A entrada para a “Análise do Twitter” vem da API de streaming do Twitter. Spout lerá os tweets dos usuários usando a API de streaming do Twitter e produzirá como um fluxo de tuplas. Uma única tupla do spout terá um nome de usuário do Twitter e um único tweet como valores separados por vírgula. Em seguida, esse fluxo de tuplas será encaminhado para o Bolt e o Bolt dividirá o tweet em palavras individuais, calculará a contagem de palavras e manterá as informações em uma fonte de dados configurada. Agora, podemos obter facilmente o resultado consultando a fonte de dados.
Topologia
Bicos e parafusos são conectados entre si e formam uma topologia. A lógica do aplicativo em tempo real é especificada na topologia do Storm. Em palavras simples, uma topologia é um gráfico direcionado onde os vértices são cálculos e as arestas são fluxos de dados.
Uma topologia simples começa com spouts. O bico emite os dados para um ou mais parafusos. Bolt representa um nó na topologia com a menor lógica de processamento e a saída de um bolt pode ser emitida em outro bolt como entrada.
Storm mantém a topologia sempre em execução, até que você elimine a topologia. A principal tarefa do Apache Storm é executar a topologia e executará qualquer número de topologia em um determinado momento.
Tarefas
Agora você tem uma ideia básica sobre bicos e parafusos. Eles são a menor unidade lógica da topologia e uma topologia é construída usando um único spout e uma matriz de parafusos. Eles devem ser executados adequadamente em uma ordem específica para que a topologia seja executada com êxito. A execução de cada bica e parafuso por Storm é chamada de “Tarefas”. Em palavras simples, uma tarefa é a execução de um bico ou de um parafuso. Em um determinado momento, cada bico e parafuso podem ter várias instâncias em execução em vários segmentos separados.
Trabalhadores
Uma topologia é executada de maneira distribuída, em vários nós de trabalho. Storm distribui as tarefas uniformemente em todos os nós de trabalho. A função do nó de trabalho é escutar trabalhos e iniciar ou interromper os processos sempre que chega um novo trabalho.
Agrupamento de fluxo
O fluxo de dados flui de bicos para parafusos ou de um parafuso para outro. O agrupamento de fluxos controla como as tuplas são roteadas na topologia e nos ajuda a entender o fluxo das tuplas na topologia. Existem quatro agrupamentos embutidos, conforme explicado abaixo.
Agrupamento aleatório
No agrupamento aleatório, um número igual de tuplas é distribuído aleatoriamente entre todos os trabalhadores que executam os parafusos. O diagrama a seguir descreve a estrutura.

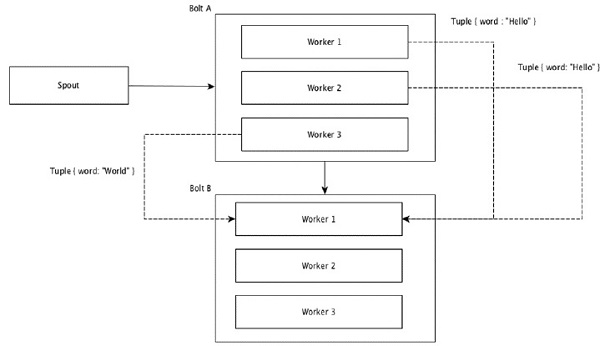
Agrupamento de Campo
Os campos com os mesmos valores nas tuplas são agrupados e as tuplas restantes mantidas fora. Em seguida, as tuplas com os mesmos valores de campo são enviadas para o mesmo trabalhador que executa os bolts. Por exemplo, se o fluxo for agrupado pelo campo “palavra”, então as tuplas com a mesma string, “Olá” serão movidas para o mesmo trabalhador. O diagrama a seguir mostra como funciona o agrupamento de campos.

Agrupamento Global
Todos os fluxos podem ser agrupados e encaminhados para um parafuso. Esse agrupamento envia tuplas geradas por todas as instâncias da origem para uma única instância de destino (especificamente, escolha o trabalhador com o menor ID).
Todos os agrupamentos
O All Grouping envia uma única cópia de cada tupla para todas as instâncias do bolt receptor. Este tipo de agrupamento é usado para enviar sinais aos parafusos. Todo o agrupamento é útil para operações de junção.

Um dos principais destaques do Apache Storm é que ele é um aplicativo distribuído com tolerância a falhas, rápido e sem “Ponto Único de Falha” (SPOF). Podemos instalar o Apache Storm em quantos sistemas forem necessários para aumentar a capacidade do aplicativo.
Vamos dar uma olhada em como o cluster Apache Storm foi projetado e sua arquitetura interna. O diagrama a seguir descreve o design do cluster.

Apache Storm tem dois tipos de nós, Nimbus (nó mestre) e Supervisor(nó do trabalhador). Nimbus é o componente central do Apache Storm. A principal tarefa do Nimbus é executar a topologia Storm. O Nimbus analisa a topologia e reúne a tarefa a ser executada. Em seguida, ele distribuirá a tarefa para um supervisor disponível.
Um supervisor terá um ou mais processos de trabalho. O supervisor delegará as tarefas aos processos de trabalho. O processo de trabalho gerará quantos executores forem necessários e executará a tarefa. Apache Storm usa um sistema de mensagens distribuído interno para a comunicação entre o nimbus e os supervisores.
| Componentes | Descrição |
|---|---|
| Nimbus | Nimbus é um nó mestre do cluster Storm. Todos os outros nós do cluster são chamados deworker nodes. O nó mestre é responsável por distribuir dados entre todos os nós de trabalho, atribuir tarefas a nós de trabalho e monitorar falhas. |
| Supervisor | Os nós que seguem as instruções dadas pelo nimbo são chamados de Supervisores. UMAsupervisor tem vários processos de trabalho e controla os processos de trabalho para concluir as tarefas atribuídas pelo nimbus. |
| Processo de trabalho | Um processo de trabalho executará tarefas relacionadas a uma topologia específica. Um processo de trabalho não executa uma tarefa sozinho, em vez disso, criaexecutorse pede que realizem uma tarefa específica. Um processo de trabalho terá vários executores. |
| Executor | Um executor nada mais é do que um único thread gerado por um processo de trabalho. Um executor executa uma ou mais tarefas, mas apenas para um bico ou parafuso específico. |
| Tarefa | Uma tarefa executa o processamento de dados real. Portanto, é um bico ou um parafuso. |
| Framework ZooKeeper | Apache ZooKeeper é um serviço usado por um cluster (grupo de nós) para coordenar entre si e manter dados compartilhados com técnicas robustas de sincronização. O Nimbus não tem estado, portanto, depende do ZooKeeper para monitorar o status do nó de trabalho. O ZooKeeper ajuda o supervisor a interagir com o nimbo. É responsável por manter o estado de nimbo e supervisor. |
Storm não tem estado por natureza. Embora a natureza sem estado tenha suas próprias desvantagens, ela realmente ajuda Storm a processar dados em tempo real da melhor maneira possível e mais rápida.
No entanto, Storm não é totalmente sem estado. Ele armazena seu estado no Apache ZooKeeper. Como o estado está disponível no Apache ZooKeeper, um nimbus com falha pode ser reiniciado e colocado em funcionamento de onde saiu. Normalmente, ferramentas de monitoramento de serviço comomonit irá monitorar o Nimbus e reiniciá-lo se houver alguma falha.
Apache Storm também tem uma topologia avançada chamada Trident Topologycom manutenção de estado e também fornece uma API de alto nível como o Pig. Discutiremos todos esses recursos nos próximos capítulos.
Um cluster de trabalho do Storm deve ter um nimbus e um ou mais supervisores. Outro nó importante é o Apache ZooKeeper, que será usado para a coordenação entre o nimbus e os supervisores.
Vamos agora dar uma olhada no fluxo de trabalho do Apache Storm -
Inicialmente, o nimbus aguardará que a “Topologia de tempestade” seja submetido a ele.
Depois que uma topologia é enviada, ele a processa e reúne todas as tarefas que devem ser realizadas e a ordem em que a tarefa deve ser executada.
Então, o nimbo distribuirá uniformemente as tarefas a todos os supervisores disponíveis.
Em um determinado intervalo de tempo, todos os supervisores enviarão batimentos cardíacos ao nimbo para informar que ainda estão vivos.
Quando um supervisor morre e não envia uma pulsação ao nimbo, ele atribui as tarefas a outro supervisor.
Quando o próprio nimbo morrer, os supervisores trabalharão na tarefa já atribuída sem qualquer problema.
Assim que todas as tarefas forem concluídas, o supervisor aguardará a entrada de uma nova tarefa.
Nesse ínterim, o nimbo morto será reiniciado automaticamente por ferramentas de monitoramento de serviço.
O nimbus reiniciado continuará de onde parou. Da mesma forma, o supervisor morto também pode ser reiniciado automaticamente. Como o nimbus e o supervisor podem ser reiniciados automaticamente e ambos continuarão como antes, o Storm tem a garantia de processar todas as tarefas pelo menos uma vez.
Uma vez que todas as topologias são processadas, o nimbus aguarda a chegada de uma nova topologia e, da mesma forma, o supervisor aguarda novas tarefas.
Por padrão, existem dois modos em um cluster Storm -
Local mode- Este modo é usado para desenvolvimento, teste e depuração porque é a maneira mais fácil de ver todos os componentes da topologia trabalhando juntos. Neste modo, podemos ajustar os parâmetros que nos permitem ver como nossa topologia é executada em diferentes ambientes de configuração do Storm. No modo Local, as topologias de tempestade são executadas na máquina local em uma única JVM.
Production mode- Neste modo, enviamos nossa topologia para o cluster de tempestade de trabalho, que é composto de muitos processos, geralmente em execução em máquinas diferentes. Conforme discutido no fluxo de trabalho da tempestade, um cluster de trabalho será executado indefinidamente até que seja encerrado.
O Apache Storm processa dados em tempo real e a entrada normalmente vem de um sistema de enfileiramento de mensagens. Um sistema de mensagens distribuído externo fornecerá a entrada necessária para a computação em tempo real. O Spout lerá os dados do sistema de mensagens e os converterá em tuplas e entrará no Apache Storm. O fato interessante é que o Apache Storm usa seu próprio sistema de mensagens distribuído internamente para a comunicação entre seu nimbus e o supervisor.
O que é sistema de mensagens distribuídas?
O sistema de mensagens distribuído é baseado no conceito de enfileiramento de mensagens confiável. As mensagens são enfileiradas de forma assíncrona entre os aplicativos clientes e os sistemas de mensagens. Um sistema de mensagens distribuído oferece os benefícios de confiabilidade, escalabilidade e persistência.
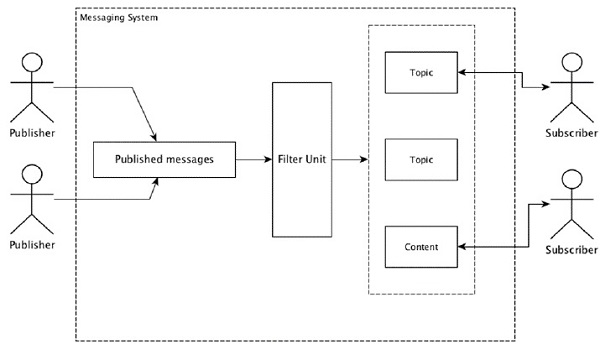
A maioria dos padrões de mensagens segue o publish-subscribe modelo (simplesmente Pub-Sub) onde os remetentes das mensagens são chamados publishers e quem quiser receber as mensagens é chamado subscribers.
Depois de publicada a mensagem pelo remetente, os assinantes podem receber a mensagem selecionada com a ajuda de uma opção de filtragem. Normalmente, temos dois tipos de filtragem, um étopic-based filtering e outro é content-based filtering.
Observe que o modelo pub-sub pode se comunicar apenas por meio de mensagens. É uma arquitetura muito fracamente acoplada; mesmo os remetentes não sabem quem são seus assinantes. Muitos dos padrões de mensagem permitem que o intermediário de mensagem troque mensagens de publicação para acesso oportuno por muitos assinantes. Um exemplo da vida real é a Dish TV, que publica diferentes canais como esportes, filmes, música, etc., e qualquer pessoa pode assinar seu próprio conjunto de canais e obtê-los sempre que seus canais assinados estiverem disponíveis.
A tabela a seguir descreve alguns dos sistemas populares de mensagens de alta capacidade -
| Sistema de mensagens distribuídas | Descrição |
|---|---|
| Apache Kafka | Kafka foi desenvolvido na empresa LinkedIn e mais tarde tornou-se um subprojeto da Apache. O Apache Kafka é baseado em um modelo de publicação-assinatura distribuído habilitado para broker, persistente. Kafka é rápido, escalonável e altamente eficiente. |
| RabbitMQ | RabbitMQ é um aplicativo de mensagens robusto distribuído de código aberto. É fácil de usar e roda em todas as plataformas. |
| JMS (Java Message Service) | JMS é uma API de código aberto que oferece suporte à criação, leitura e envio de mensagens de um aplicativo para outro. Ele fornece entrega de mensagem garantida e segue o modelo publicar-assinar. |
| ActiveMQ | O sistema de mensagens ActiveMQ é uma API de código aberto do JMS. |
| ZeroMQ | ZeroMQ é o processamento de mensagens peer-peer sem corretor. Ele fornece padrões de mensagem push-pull, roteador-revendedor. |
| Francelho | Kestrel é uma fila de mensagens distribuída rápida, confiável e simples. |
Protocolo Thrift
O Thrift foi criado no Facebook para desenvolvimento de serviços em várias linguagens e chamada de procedimento remoto (RPC). Mais tarde, tornou-se um projeto Apache de código aberto. Apache Thrift é umInterface Definition Language e permite definir novos tipos de dados e implementação de serviços em cima dos tipos de dados definidos de uma maneira fácil.
Apache Thrift também é uma estrutura de comunicação que oferece suporte a sistemas embarcados, aplicativos móveis, aplicativos da web e muitas outras linguagens de programação. Alguns dos principais recursos associados ao Apache Thrift são sua modularidade, flexibilidade e alto desempenho. Além disso, ele pode executar streaming, mensagens e RPC em aplicativos distribuídos.
Storm usa extensivamente o Thrift Protocol para sua comunicação interna e definição de dados. A topologia do Storm é simplesmenteThrift Structs. Storm Nimbus que executa a topologia no Apache Storm é umThrift service.
Vamos agora ver como instalar o framework Apache Storm em sua máquina. Existem três etapas majo aqui -
- Instale o Java em seu sistema, se ainda não o tiver feito.
- Instale a estrutura ZooKeeper.
- Instale a estrutura Apache Storm.
Etapa 1 - Verificando a instalação do Java
Use o seguinte comando para verificar se você já possui o Java instalado em seu sistema.
$ java -versionSe o Java já estiver lá, você verá seu número de versão. Caso contrário, baixe a versão mais recente do JDK.
Etapa 1.1 - Baixe o JDK
Baixe a versão mais recente do JDK usando o seguinte link - www.oracle.com
A versão mais recente é JDK 8u 60 e o arquivo é “jdk-8u60-linux-x64.tar.gz”. Baixe o arquivo em sua máquina.
Etapa 1.2 - Extrair arquivos
Geralmente, os arquivos estão sendo baixados no downloadspasta. Extraia a configuração do tar usando os seguintes comandos.
$ cd /go/to/download/path
$ tar -zxf jdk-8u60-linux-x64.gzEtapa 1.3 - Mover para o diretório opt
Para tornar o Java disponível para todos os usuários, mova o conteúdo java extraído para a pasta “/ usr / local / java”.
$ su
password: (type password of root user)
$ mkdir /opt/jdk
$ mv jdk-1.8.0_60 /opt/jdk/Etapa 1.4 - Definir caminho
Para definir as variáveis de caminho e JAVA_HOME, adicione os seguintes comandos ao arquivo ~ / .bashrc.
export JAVA_HOME =/usr/jdk/jdk-1.8.0_60
export PATH=$PATH:$JAVA_HOME/binAgora aplique todas as alterações no sistema em execução atual.
$ source ~/.bashrcEtapa 1.5 - Alternativas Java
Use o seguinte comando para alterar as alternativas Java.
update-alternatives --install /usr/bin/java java /opt/jdk/jdk1.8.0_60/bin/java 100Etapa 1.6
Agora verifique a instalação do Java usando o comando de verificação (java -version) explicado na Etapa 1.
Etapa 2 - Instalação do ZooKeeper Framework
Etapa 2.1 - Baixe o ZooKeeper
Para instalar o framework ZooKeeper em sua máquina, visite o seguinte link e baixe a versão mais recente do ZooKeeper http://zookeeper.apache.org/releases.html
A partir de agora, a versão mais recente do ZooKeeper é 3.4.6 (ZooKeeper-3.4.6.tar.gz).
Etapa 2.2 - Extrair o arquivo tar
Extraia o arquivo tar usando os seguintes comandos -
$ cd opt/
$ tar -zxf zookeeper-3.4.6.tar.gz
$ cd zookeeper-3.4.6
$ mkdir dataEtapa 2.3 - Criar arquivo de configuração
Abra o arquivo de configuração denominado “conf / zoo.cfg” usando o comando "vi conf / zoo.cfg" e definindo todos os seguintes parâmetros como ponto de partida.
$ vi conf/zoo.cfg
tickTime=2000
dataDir=/path/to/zookeeper/data
clientPort=2181
initLimit=5
syncLimit=2Assim que o arquivo de configuração for salvo com sucesso, você pode iniciar o servidor ZooKeeper.
Etapa 2.4 - Iniciar o ZooKeeper Server
Use o seguinte comando para iniciar o servidor ZooKeeper.
$ bin/zkServer.sh startDepois de executar este comando, você receberá a seguinte resposta -
$ JMX enabled by default
$ Using config: /Users/../zookeeper-3.4.6/bin/../conf/zoo.cfg
$ Starting zookeeper ... STARTEDEtapa 2.5 - Iniciar CLI
Use o seguinte comando para iniciar o CLI.
$ bin/zkCli.shDepois de executar o comando acima, você será conectado ao servidor ZooKeeper e receberá a seguinte resposta.
Connecting to localhost:2181
................
................
................
Welcome to ZooKeeper!
................
................
WATCHER::
WatchedEvent state:SyncConnected type: None path:null
[zk: localhost:2181(CONNECTED) 0]Etapa 2.6 - Pare o servidor ZooKeeper
Depois de conectar o servidor e realizar todas as operações, você pode parar o servidor ZooKeeper usando o seguinte comando.
bin/zkServer.sh stopVocê instalou o Java e o ZooKeeper com êxito em sua máquina. Vamos agora ver as etapas para instalar o framework Apache Storm.
Etapa 3 - Instalação do Apache Storm Framework
Etapa 3.1 Baixar Storm
Para instalar o Storm framework em sua máquina, visite o seguinte link e baixe a versão mais recente do Storm http://storm.apache.org/downloads.html
A partir de agora, a versão mais recente do Storm é “apache-storm-0.9.5.tar.gz”.
Etapa 3.2 - Extrair o arquivo tar
Extraia o arquivo tar usando os seguintes comandos -
$ cd opt/
$ tar -zxf apache-storm-0.9.5.tar.gz
$ cd apache-storm-0.9.5
$ mkdir dataEtapa 3.3 - Abrir arquivo de configuração
A versão atual do Storm contém um arquivo em “conf / storm.yaml” que configura daemons do Storm. Adicione as seguintes informações a esse arquivo.
$ vi conf/storm.yaml
storm.zookeeper.servers:
- "localhost"
storm.local.dir: “/path/to/storm/data(any path)”
nimbus.host: "localhost"
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703Após aplicar todas as alterações, salve e retorne ao terminal.
Etapa 3.4 - Iniciar o Nimbus
$ bin/storm nimbusEtapa 3.5 - Iniciar o Supervisor
$ bin/storm supervisorEtapa 3.6 Iniciar a IU
$ bin/storm uiDepois de iniciar o aplicativo de interface do usuário Storm, digite o URL http://localhost:8080em seu navegador favorito e você poderia ver as informações do cluster Storm e sua topologia em execução. A página deve ser semelhante à seguinte captura de tela.

Examinamos os principais detalhes técnicos do Apache Storm e agora é hora de codificar alguns cenários simples.
Cenário - Analisador de registro de chamadas móveis
A chamada móvel e sua duração serão fornecidas como entrada para o Apache Storm e o Storm processará e agrupará a chamada entre o mesmo chamador e receptor e seu número total de chamadas.
Criação de bico
Spout é um componente utilizado para geração de dados. Basicamente, um spout implementará uma interface IRichSpout. A interface “IRichSpout” possui os seguintes métodos importantes -
open- Dá à bica um ambiente de execução. Os executores irão executar este método para inicializar o spout.
nextTuple - Emite os dados gerados através do coletor.
close - Este método é chamado quando uma bica vai desligar.
declareOutputFields - Declara o esquema de saída da tupla.
ack - Reconhece que uma tupla específica é processada
fail - Especifica que uma tupla específica não é processada e não deve ser reprocessada.
Abrir
A assinatura do open método é o seguinte -
open(Map conf, TopologyContext context, SpoutOutputCollector collector)conf - Fornece configuração de tempestade para este bico.
context - Fornece informações completas sobre o local do bico na topologia, sua identificação de tarefa, informações de entrada e saída.
collector - Permite emitir a tupla que será processada pelos bolts.
nextTuple
A assinatura do nextTuple método é o seguinte -
nextTuple()nextTuple () é chamado periodicamente do mesmo loop que os métodos ack () e fail (). Ele deve liberar o controle do encadeamento quando não houver trabalho a ser feito, para que os outros métodos tenham a chance de serem chamados. Portanto, a primeira linha de nextTuple verifica se o processamento foi concluído. Nesse caso, ele deve hibernar por pelo menos um milissegundo para reduzir a carga no processador antes de retornar.
Fechar
A assinatura do close método é o seguinte -
close()declareOutputFields
A assinatura do declareOutputFields método é o seguinte -
declareOutputFields(OutputFieldsDeclarer declarer)declarer - É usado para declarar ids de fluxo de saída, campos de saída, etc.
Este método é usado para especificar o esquema de saída da tupla.
ack
A assinatura do ack método é o seguinte -
ack(Object msgId)Este método reconhece que uma tupla específica foi processada.
falhou
A assinatura do nextTuple método é o seguinte -
ack(Object msgId)Este método informa que uma tupla específica não foi totalmente processada. Storm irá reprocessar a tupla específica.
FakeCallLogReaderSpout
Em nosso cenário, precisamos coletar os detalhes do registro de chamadas. A informação do registro de chamadas contém.
- número do chamador
- número do receptor
- duration
Como não temos informações em tempo real de registros de chamadas, geraremos registros de chamadas falsos. As informações falsas serão criadas usando a classe Random. O código completo do programa é fornecido abaixo.
Codificação - FakeCallLogReaderSpout.java
import java.util.*;
//import storm tuple packages
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
//import Spout interface packages
import backtype.storm.topology.IRichSpout;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
//Create a class FakeLogReaderSpout which implement IRichSpout interface
to access functionalities
public class FakeCallLogReaderSpout implements IRichSpout {
//Create instance for SpoutOutputCollector which passes tuples to bolt.
private SpoutOutputCollector collector;
private boolean completed = false;
//Create instance for TopologyContext which contains topology data.
private TopologyContext context;
//Create instance for Random class.
private Random randomGenerator = new Random();
private Integer idx = 0;
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.context = context;
this.collector = collector;
}
@Override
public void nextTuple() {
if(this.idx <= 1000) {
List<String> mobileNumbers = new ArrayList<String>();
mobileNumbers.add("1234123401");
mobileNumbers.add("1234123402");
mobileNumbers.add("1234123403");
mobileNumbers.add("1234123404");
Integer localIdx = 0;
while(localIdx++ < 100 && this.idx++ < 1000) {
String fromMobileNumber = mobileNumbers.get(randomGenerator.nextInt(4));
String toMobileNumber = mobileNumbers.get(randomGenerator.nextInt(4));
while(fromMobileNumber == toMobileNumber) {
toMobileNumber = mobileNumbers.get(randomGenerator.nextInt(4));
}
Integer duration = randomGenerator.nextInt(60);
this.collector.emit(new Values(fromMobileNumber, toMobileNumber, duration));
}
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("from", "to", "duration"));
}
//Override all the interface methods
@Override
public void close() {}
public boolean isDistributed() {
return false;
}
@Override
public void activate() {}
@Override
public void deactivate() {}
@Override
public void ack(Object msgId) {}
@Override
public void fail(Object msgId) {}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}Criação de Parafuso
Bolt é um componente que recebe tuplas como entrada, processa a tupla e produz novas tuplas como saída. Os parafusos irão implementarIRichBoltinterface. Neste programa, duas classes de boltCallLogCreatorBolt e CallLogCounterBolt são usados para realizar as operações.
A interface IRichBolt tem os seguintes métodos -
prepare- Fornece ao parafuso um ambiente para execução. Os executores irão executar este método para inicializar o spout.
execute - Processa uma única tupla de entrada.
cleanup - Chamado quando um parafuso vai desligar.
declareOutputFields - Declara o esquema de saída da tupla.
Preparar
A assinatura do prepare método é o seguinte -
prepare(Map conf, TopologyContext context, OutputCollector collector)conf - Fornece configuração Storm para este parafuso.
context - Fornece informações completas sobre o local do parafuso dentro da topologia, sua identificação de tarefa, informações de entrada e saída, etc.
collector - Permite-nos emitir a tupla processada.
executar
A assinatura do execute método é o seguinte -
execute(Tuple tuple)Aqui tuple é a tupla de entrada a ser processada.
o executemétodo processa uma única tupla por vez. Os dados da tupla podem ser acessados pelo método getValue da classe Tupla. Não é necessário processar a tupla de entrada imediatamente. Várias tuplas podem ser processadas e geradas como uma única tupla de saída. A tupla processada pode ser emitida usando a classe OutputCollector.
Limpar
A assinatura do cleanup método é o seguinte -
cleanup()declareOutputFields
A assinatura do declareOutputFields método é o seguinte -
declareOutputFields(OutputFieldsDeclarer declarer)Aqui o parâmetro declarer é usado para declarar ids de fluxo de saída, campos de saída, etc.
Este método é usado para especificar o esquema de saída da tupla
Parafuso do criador do registro de chamadas
O bolt do criador do registro de chamadas recebe a tupla do registro de chamadas. A tupla do registro de chamadas tem o número do chamador, o número do receptor e a duração da chamada. Este parafuso simplesmente cria um novo valor combinando o número do chamador e o número do receptor. O formato do novo valor é "Número do chamador - Número do receptor" e é denominado como um novo campo, "ligar". O código completo é fornecido abaixo.
Codificação - CallLogCreatorBolt.java
//import util packages
import java.util.HashMap;
import java.util.Map;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
//import Storm IRichBolt package
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Tuple;
//Create a class CallLogCreatorBolt which implement IRichBolt interface
public class CallLogCreatorBolt implements IRichBolt {
//Create instance for OutputCollector which collects and emits tuples to produce output
private OutputCollector collector;
@Override
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
@Override
public void execute(Tuple tuple) {
String from = tuple.getString(0);
String to = tuple.getString(1);
Integer duration = tuple.getInteger(2);
collector.emit(new Values(from + " - " + to, duration));
}
@Override
public void cleanup() {}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("call", "duration"));
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}Parafuso do contador do registro de chamadas
O parafuso do contador de registro de chamadas recebe a chamada e sua duração como uma tupla. Este parafuso inicializa um objeto de dicionário (Mapa) no método de preparação. Dentroexecute, ele verifica a tupla e cria uma nova entrada no objeto de dicionário para cada novo valor de “chamada” na tupla e define um valor 1 no objeto de dicionário. Para a entrada já disponível no dicionário, basta incrementar seu valor. Em termos simples, esse parafuso salva a chamada e sua contagem no objeto de dicionário. Em vez de salvar a chamada e sua contagem no dicionário, também podemos salvá-la em uma fonte de dados. O código completo do programa é o seguinte -
Codificação - CallLogCounterBolt.java
import java.util.HashMap;
import java.util.Map;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Tuple;
public class CallLogCounterBolt implements IRichBolt {
Map<String, Integer> counterMap;
private OutputCollector collector;
@Override
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
this.counterMap = new HashMap<String, Integer>();
this.collector = collector;
}
@Override
public void execute(Tuple tuple) {
String call = tuple.getString(0);
Integer duration = tuple.getInteger(1);
if(!counterMap.containsKey(call)){
counterMap.put(call, 1);
}else{
Integer c = counterMap.get(call) + 1;
counterMap.put(call, c);
}
collector.ack(tuple);
}
@Override
public void cleanup() {
for(Map.Entry<String, Integer> entry:counterMap.entrySet()){
System.out.println(entry.getKey()+" : " + entry.getValue());
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("call"));
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}Criando Topologia
A topologia Storm é basicamente uma estrutura Thrift. A classe TopologyBuilder fornece métodos simples e fáceis para criar topologias complexas. A classe TopologyBuilder tem métodos para definir spout(setSpout) e para definir o parafuso (setBolt). Finalmente, TopologyBuilder tem createTopology para criar topologia. Use o seguinte snippet de código para criar uma topologia -
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("call-log-reader-spout", new FakeCallLogReaderSpout());
builder.setBolt("call-log-creator-bolt", new CallLogCreatorBolt())
.shuffleGrouping("call-log-reader-spout");
builder.setBolt("call-log-counter-bolt", new CallLogCounterBolt())
.fieldsGrouping("call-log-creator-bolt", new Fields("call"));shuffleGrouping e fieldsGrouping métodos ajudam a definir o agrupamento de fluxo para bico e parafusos.
Cluster Local
Para fins de desenvolvimento, podemos criar um cluster local usando o objeto "LocalCluster" e, em seguida, enviar a topologia usando o método "submitTopology" da classe "LocalCluster". Um dos argumentos para "submitTopology" é uma instância da classe "Config". A classe "Config" é usada para definir opções de configuração antes de enviar a topologia. Esta opção de configuração será mesclada com a configuração do cluster em tempo de execução e enviada para todas as tarefas (spout e bolt) com o método prepare. Assim que a topologia for enviada ao cluster, esperaremos 10 segundos para que o cluster calcule a topologia enviada e, em seguida, encerraremos o cluster usando o método de “desligamento” de "LocalCluster". O código completo do programa é o seguinte -
Codificação - LogAnalyserStorm.java
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
//import storm configuration packages
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.topology.TopologyBuilder;
//Create main class LogAnalyserStorm submit topology.
public class LogAnalyserStorm {
public static void main(String[] args) throws Exception{
//Create Config instance for cluster configuration
Config config = new Config();
config.setDebug(true);
//
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("call-log-reader-spout", new FakeCallLogReaderSpout());
builder.setBolt("call-log-creator-bolt", new CallLogCreatorBolt())
.shuffleGrouping("call-log-reader-spout");
builder.setBolt("call-log-counter-bolt", new CallLogCounterBolt())
.fieldsGrouping("call-log-creator-bolt", new Fields("call"));
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("LogAnalyserStorm", config, builder.createTopology());
Thread.sleep(10000);
//Stop the topology
cluster.shutdown();
}
}Construindo e executando o aplicativo
O aplicativo completo possui quatro códigos Java. Eles são -
- FakeCallLogReaderSpout.java
- CallLogCreaterBolt.java
- CallLogCounterBolt.java
- LogAnalyerStorm.java
O aplicativo pode ser construído usando o seguinte comando -
javac -cp “/path/to/storm/apache-storm-0.9.5/lib/*” *.javaO aplicativo pode ser executado usando o seguinte comando -
java -cp “/path/to/storm/apache-storm-0.9.5/lib/*”:. LogAnalyserStormResultado
Assim que o aplicativo for iniciado, ele produzirá os detalhes completos sobre o processo de inicialização do cluster, processamento de spout e bolt e, finalmente, o processo de desligamento do cluster. Em "CallLogCounterBolt" imprimimos a chamada e seus detalhes de contagem. Essas informações serão exibidas no console da seguinte forma -
1234123402 - 1234123401 : 78
1234123402 - 1234123404 : 88
1234123402 - 1234123403 : 105
1234123401 - 1234123404 : 74
1234123401 - 1234123403 : 81
1234123401 - 1234123402 : 81
1234123403 - 1234123404 : 86
1234123404 - 1234123401 : 63
1234123404 - 1234123402 : 82
1234123403 - 1234123402 : 83
1234123404 - 1234123403 : 86
1234123403 - 1234123401 : 93Linguagens não JVM
Topologias Storm são implementadas por interfaces Thrift, o que facilita o envio de topologias em qualquer idioma. Storm suporta Ruby, Python e muitas outras linguagens. Vamos dar uma olhada na vinculação python.
Ligação Python
Python é uma linguagem de programação de alto nível interpretada de propósito geral, interativa, orientada a objetos. Storm suporta Python para implementar sua topologia. Python oferece suporte a operações de emissão, ancoragem, reconhecimento e registro.
Como você sabe, os parafusos podem ser definidos em qualquer idioma. Bolts escritos em outro idioma são executados como subprocessos e Storm se comunica com esses subprocessos com mensagens JSON por stdin / stdout. Primeiro, pegue um parafuso de amostra WordCount que ofereça suporte à vinculação Python.
public static class WordCount implements IRichBolt {
public WordSplit() {
super("python", "splitword.py");
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}Aqui a aula WordCount implementa o IRichBoltinterface e executando com a implementação python especificado argumento do super método "splitword.py". Agora crie uma implementação python chamada "splitword.py".
import storm
class WordCountBolt(storm.BasicBolt):
def process(self, tup):
words = tup.values[0].split(" ")
for word in words:
storm.emit([word])
WordCountBolt().run()Este é o exemplo de implementação para Python que conta as palavras em uma determinada frase. Da mesma forma, você também pode se vincular a outras linguagens de suporte.
Trident é uma extensão do Storm. Assim como o Storm, o Trident também foi desenvolvido pelo Twitter. A principal razão por trás do desenvolvimento do Trident é fornecer uma abstração de alto nível sobre o Storm junto com processamento de stream com estado e consulta distribuída de baixa latência.
O Trident usa bico e parafuso, mas esses componentes de baixo nível são gerados automaticamente pelo Trident antes da execução. O Trident possui funções, filtros, junções, agrupamento e agregação.
O Trident processa fluxos como uma série de lotes que são chamados de transações. Geralmente, o tamanho desses pequenos lotes será da ordem de milhares ou milhões de tuplas, dependendo do fluxo de entrada. Dessa forma, o Trident é diferente do Storm, que executa o processamento tupla por tupla.
O conceito de processamento em lote é muito semelhante às transações de banco de dados. Cada transação recebe um ID de transação. A transação é considerada bem-sucedida, uma vez que todo o seu processamento seja concluído. No entanto, uma falha no processamento de uma das tuplas da transação fará com que toda a transação seja retransmitida. Para cada lote, o Trident chamará beginCommit no início da transação e fará o commit no final dela.
Topologia Trident
A API Trident expõe uma opção fácil para criar topologia Trident usando a classe “TridentTopology”. Basicamente, a topologia Trident recebe o fluxo de entrada do spout e faz a sequência ordenada de operação (filtro, agregação, agrupamento, etc.) no fluxo. Storm Tuple é substituído por Trident Tuple e Bolts são substituídos por operações. Uma topologia Trident simples pode ser criada da seguinte forma -
TridentTopology topology = new TridentTopology();Tuplas de tridente
A tupla de tridente é uma lista nomeada de valores. A interface TridentTuple é o modelo de dados de uma topologia Trident. A interface TridentTuple é a unidade básica de dados que pode ser processada por uma topologia Trident.
Bico Trident
O bico Trident é semelhante ao bico Storm, com opções adicionais para usar os recursos do Trident. Na verdade, ainda podemos usar o IRichSpout, que usamos na topologia Storm, mas será de natureza não transacional e não poderemos usar as vantagens fornecidas pelo Trident.
O bico básico com todas as funcionalidades para usar os recursos do Trident é o "ITridentSpout". Ele oferece suporte a semânticas transacionais opacas e transacionais. Os outros spouts são IBatchSpout, IPartitionedTridentSpout e IOpaquePartitionedTridentSpout.
Além desses bicos genéricos, o Trident tem muitos exemplos de implementação de bicos tridentes. Um deles é o spout FeederBatchSpout, que podemos usar para enviar listas nomeadas de tuplas de tridentes facilmente, sem nos preocuparmos com processamento em lote, paralelismo etc.
A criação do FeederBatchSpout e a alimentação de dados podem ser feitas conforme mostrado abaixo -
TridentTopology topology = new TridentTopology();
FeederBatchSpout testSpout = new FeederBatchSpout(
ImmutableList.of("fromMobileNumber", "toMobileNumber", “duration”));
topology.newStream("fixed-batch-spout", testSpout)
testSpout.feed(ImmutableList.of(new Values("1234123401", "1234123402", 20)));Operações Trident
O Trident depende da “Operação Trident” para processar o fluxo de entrada das tuplas de tridente. A API Trident tem várias operações integradas para lidar com o processamento de fluxo simples a complexo. Essas operações variam de validação simples a agrupamento complexo e agregação de tuplas de tridentes. Vamos examinar as operações mais importantes e mais usadas.
Filtro
O filtro é um objeto utilizado para realizar a tarefa de validação de entrada. Um filtro Trident obtém um subconjunto de campos de tupla trident como entrada e retorna verdadeiro ou falso dependendo se certas condições são satisfeitas ou não. Se true for retornado, a tupla será mantida no fluxo de saída; caso contrário, a tupla é removida do fluxo. O filtro basicamente herdará doBaseFilter Classifique e implemente o isKeepmétodo. Aqui está um exemplo de implementação da operação do filtro -
public class MyFilter extends BaseFilter {
public boolean isKeep(TridentTuple tuple) {
return tuple.getInteger(1) % 2 == 0;
}
}
input
[1, 2]
[1, 3]
[1, 4]
output
[1, 2]
[1, 4]A função de filtro pode ser chamada na topologia usando o método “each”. A classe “Fields” pode ser usada para especificar a entrada (subconjunto da tupla tridente). O código de amostra é o seguinte -
TridentTopology topology = new TridentTopology();
topology.newStream("spout", spout)
.each(new Fields("a", "b"), new MyFilter())Função
Functioné um objeto usado para realizar uma operação simples em uma única tupla de tridente. Ele pega um subconjunto de campos de tupla tridente e emite zero ou mais novos campos de tupla tridente.
Function basicamente herda do BaseFunction classe e implementa o executemétodo. Um exemplo de implementação é fornecido abaixo -
public class MyFunction extends BaseFunction {
public void execute(TridentTuple tuple, TridentCollector collector) {
int a = tuple.getInteger(0);
int b = tuple.getInteger(1);
collector.emit(new Values(a + b));
}
}
input
[1, 2]
[1, 3]
[1, 4]
output
[1, 2, 3]
[1, 3, 4]
[1, 4, 5]Assim como a operação de filtro, a operação de função pode ser chamada em uma topologia usando o eachmétodo. O código de amostra é o seguinte -
TridentTopology topology = new TridentTopology();
topology.newStream("spout", spout)
.each(new Fields(“a, b"), new MyFunction(), new Fields(“d")));Agregação
Agregação é um objeto usado para executar operações de agregação em um lote de entrada ou partição ou fluxo. O Trident possui três tipos de agregação. Eles são os seguintes -
aggregate- Agrega cada lote de tupla de tridente isoladamente. Durante o processo de agregação, as tuplas são inicialmente reparticionadas usando o agrupamento global para combinar todas as partições do mesmo lote em uma única partição.
partitionAggregate- Agrega cada partição em vez de todo o lote de tupla tridente. A saída do agregado de partição substitui completamente a tupla de entrada. A saída do agregado de partição contém uma única tupla de campo.
persistentaggregate - Agrega em todas as tuplas de tridente em todo o lote e armazena o resultado na memória ou no banco de dados.
TridentTopology topology = new TridentTopology();
// aggregate operation
topology.newStream("spout", spout)
.each(new Fields(“a, b"), new MyFunction(), new Fields(“d”))
.aggregate(new Count(), new Fields(“count”))
// partitionAggregate operation
topology.newStream("spout", spout)
.each(new Fields(“a, b"), new MyFunction(), new Fields(“d”))
.partitionAggregate(new Count(), new Fields(“count"))
// persistentAggregate - saving the count to memory
topology.newStream("spout", spout)
.each(new Fields(“a, b"), new MyFunction(), new Fields(“d”))
.persistentAggregate(new MemoryMapState.Factory(), new Count(), new Fields("count"));A operação de agregação pode ser criada usando CombinerAggregator, ReducerAggregator ou interface Aggregator genérica. O agregador "count" usado no exemplo acima é um dos agregadores integrados. Ele é implementado usando "CombinerAggregator". A implementação é a seguinte -
public class Count implements CombinerAggregator<Long> {
@Override
public Long init(TridentTuple tuple) {
return 1L;
}
@Override
public Long combine(Long val1, Long val2) {
return val1 + val2;
}
@Override
public Long zero() {
return 0L;
}
}Agrupamento
A operação de agrupamento é uma operação embutida e pode ser chamada pelo groupBymétodo. O método groupBy reparticiona o fluxo fazendo um partitionBy nos campos especificados e, em seguida, dentro de cada partição, ele agrupa tuplas cujos campos de grupo são iguais. Normalmente, usamos “groupBy” junto com “persistentAggregate” para obter a agregação agrupada. O código de amostra é o seguinte -
TridentTopology topology = new TridentTopology();
// persistentAggregate - saving the count to memory
topology.newStream("spout", spout)
.each(new Fields(“a, b"), new MyFunction(), new Fields(“d”))
.groupBy(new Fields(“d”)
.persistentAggregate(new MemoryMapState.Factory(), new Count(), new Fields("count"));Mesclar e unir
A fusão e a junção podem ser feitas usando os métodos “merge” e “join” respectivamente. A mesclagem combina um ou mais fluxos. A união é semelhante à fusão, exceto pelo fato de que a união usa um campo de tupla tridente de ambos os lados para verificar e unir dois fluxos. Além disso, a união funcionará apenas no nível de lote. O código de amostra é o seguinte -
TridentTopology topology = new TridentTopology();
topology.merge(stream1, stream2, stream3);
topology.join(stream1, new Fields("key"), stream2, new Fields("x"),
new Fields("key", "a", "b", "c"));Manutenção do Estado
O Trident fornece um mecanismo para manutenção do estado. As informações de estado podem ser armazenadas na própria topologia, caso contrário, você também pode armazená-las em um banco de dados separado. O motivo é manter um estado de que, se alguma tupla falhar durante o processamento, a tupla com falha será repetida. Isso cria um problema ao atualizar o estado, porque você não tem certeza se o estado desta tupla foi atualizado anteriormente ou não. Se a tupla falhou antes de atualizar o estado, tentar novamente a tupla tornará o estado estável. No entanto, se a tupla falhar após a atualização do estado, tentar novamente a mesma tupla aumentará novamente a contagem no banco de dados e tornará o estado instável. É necessário realizar as seguintes etapas para garantir que uma mensagem seja processada apenas uma vez -
Processe as tuplas em pequenos lotes.
Atribua um ID exclusivo a cada lote. Se o lote for repetido, ele receberá o mesmo ID exclusivo.
As atualizações de estado são ordenadas entre lotes. Por exemplo, a atualização de estado do segundo lote não será possível até que a atualização de estado do primeiro lote seja concluída.
RPC distribuído
O RPC distribuído é usado para consultar e recuperar o resultado da topologia Trident. Storm tem um servidor RPC distribuído embutido. O servidor RPC distribuído recebe a solicitação RPC do cliente e a passa para a topologia. A topologia processa a solicitação e envia o resultado para o servidor RPC distribuído, que é redirecionado pelo servidor RPC distribuído para o cliente. A consulta RPC distribuída do Trident é executada como uma consulta RPC normal, exceto pelo fato de que essas consultas são executadas em paralelo.
Quando usar o Trident?
Como em muitos casos de uso, se o requisito é processar uma consulta apenas uma vez, podemos alcançá-lo escrevendo uma topologia no Trident. Por outro lado, será difícil conseguir exatamente um processamento no caso do Storm. Conseqüentemente, o Trident será útil para os casos de uso em que você precisa de exatamente um processamento. O Trident não é para todos os casos de uso, especialmente casos de uso de alto desempenho, porque adiciona complexidade ao Storm e gerencia o estado.
Exemplo de trabalho do tridente
Vamos converter nosso aplicativo analisador de registro de chamadas desenvolvido na seção anterior para a estrutura Trident. O aplicativo Trident será relativamente fácil em comparação com o plain storm, graças à sua API de alto nível. Storm será basicamente necessário para executar qualquer uma das operações de Função, Filtro, Agregação, GroupBy, Join e Merge no Trident. Finalmente, iniciaremos o servidor DRPC usando oLocalDRPC classe e pesquisar alguma palavra-chave usando o execute método da classe LocalDRPC.
Formatando as informações da chamada
O objetivo da classe FormatCall é formatar as informações da chamada compreendendo “Número do chamador” e “Número do receptor”. O código completo do programa é o seguinte -
Codificação: FormatCall.java
import backtype.storm.tuple.Values;
import storm.trident.operation.BaseFunction;
import storm.trident.operation.TridentCollector;
import storm.trident.tuple.TridentTuple;
public class FormatCall extends BaseFunction {
@Override
public void execute(TridentTuple tuple, TridentCollector collector) {
String fromMobileNumber = tuple.getString(0);
String toMobileNumber = tuple.getString(1);
collector.emit(new Values(fromMobileNumber + " - " + toMobileNumber));
}
}CSVSplit
O objetivo da classe CSVSplit é dividir a string de entrada com base em “vírgula (,)” e emitir todas as palavras da string. Esta função é usada para analisar o argumento de entrada da consulta distribuída. O código completo é o seguinte -
Codificação: CSVSplit.java
import backtype.storm.tuple.Values;
import storm.trident.operation.BaseFunction;
import storm.trident.operation.TridentCollector;
import storm.trident.tuple.TridentTuple;
public class CSVSplit extends BaseFunction {
@Override
public void execute(TridentTuple tuple, TridentCollector collector) {
for(String word: tuple.getString(0).split(",")) {
if(word.length() > 0) {
collector.emit(new Values(word));
}
}
}
}Log Analyzer
Este é o aplicativo principal. Inicialmente, o aplicativo irá inicializar o TridentTopology e alimentar as informações do chamador usandoFeederBatchSpout. O fluxo de topologia Trident pode ser criado usando onewStreammétodo da classe TridentTopology. Da mesma forma, o fluxo DRPC da topologia Trident pode ser criado usando onewDRCPStreammétodo da classe TridentTopology. Um servidor DRCP simples pode ser criado usando a classe LocalDRPC.LocalDRPCtem método execute para pesquisar alguma palavra-chave. O código completo é fornecido abaixo.
Codificação: LogAnalyserTrident.java
import java.util.*;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.LocalDRPC;
import backtype.storm.utils.DRPCClient;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import storm.trident.TridentState;
import storm.trident.TridentTopology;
import storm.trident.tuple.TridentTuple;
import storm.trident.operation.builtin.FilterNull;
import storm.trident.operation.builtin.Count;
import storm.trident.operation.builtin.Sum;
import storm.trident.operation.builtin.MapGet;
import storm.trident.operation.builtin.Debug;
import storm.trident.operation.BaseFilter;
import storm.trident.testing.FixedBatchSpout;
import storm.trident.testing.FeederBatchSpout;
import storm.trident.testing.Split;
import storm.trident.testing.MemoryMapState;
import com.google.common.collect.ImmutableList;
public class LogAnalyserTrident {
public static void main(String[] args) throws Exception {
System.out.println("Log Analyser Trident");
TridentTopology topology = new TridentTopology();
FeederBatchSpout testSpout = new FeederBatchSpout(ImmutableList.of("fromMobileNumber",
"toMobileNumber", "duration"));
TridentState callCounts = topology
.newStream("fixed-batch-spout", testSpout)
.each(new Fields("fromMobileNumber", "toMobileNumber"),
new FormatCall(), new Fields("call"))
.groupBy(new Fields("call"))
.persistentAggregate(new MemoryMapState.Factory(), new Count(),
new Fields("count"));
LocalDRPC drpc = new LocalDRPC();
topology.newDRPCStream("call_count", drpc)
.stateQuery(callCounts, new Fields("args"), new MapGet(), new Fields("count"));
topology.newDRPCStream("multiple_call_count", drpc)
.each(new Fields("args"), new CSVSplit(), new Fields("call"))
.groupBy(new Fields("call"))
.stateQuery(callCounts, new Fields("call"), new MapGet(),
new Fields("count"))
.each(new Fields("call", "count"), new Debug())
.each(new Fields("count"), new FilterNull())
.aggregate(new Fields("count"), new Sum(), new Fields("sum"));
Config conf = new Config();
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("trident", conf, topology.build());
Random randomGenerator = new Random();
int idx = 0;
while(idx < 10) {
testSpout.feed(ImmutableList.of(new Values("1234123401",
"1234123402", randomGenerator.nextInt(60))));
testSpout.feed(ImmutableList.of(new Values("1234123401",
"1234123403", randomGenerator.nextInt(60))));
testSpout.feed(ImmutableList.of(new Values("1234123401",
"1234123404", randomGenerator.nextInt(60))));
testSpout.feed(ImmutableList.of(new Values("1234123402",
"1234123403", randomGenerator.nextInt(60))));
idx = idx + 1;
}
System.out.println("DRPC : Query starts");
System.out.println(drpc.execute("call_count","1234123401 - 1234123402"));
System.out.println(drpc.execute("multiple_call_count", "1234123401 -
1234123402,1234123401 - 1234123403"));
System.out.println("DRPC : Query ends");
cluster.shutdown();
drpc.shutdown();
// DRPCClient client = new DRPCClient("drpc.server.location", 3772);
}
}Construindo e executando o aplicativo
O aplicativo completo possui três códigos Java. Eles são os seguintes -
- FormatCall.java
- CSVSplit.java
- LogAnalyerTrident.java
O aplicativo pode ser construído usando o seguinte comando -
javac -cp “/path/to/storm/apache-storm-0.9.5/lib/*” *.javaO aplicativo pode ser executado usando o seguinte comando -
java -cp “/path/to/storm/apache-storm-0.9.5/lib/*”:. LogAnalyserTridentResultado
Assim que o aplicativo for iniciado, ele produzirá os detalhes completos sobre o processo de inicialização do cluster, processamento de operações, servidor DRPC e informações do cliente e, finalmente, o processo de desligamento do cluster. Esta saída será exibida no console conforme mostrado abaixo.
DRPC : Query starts
[["1234123401 - 1234123402",10]]
DEBUG: [1234123401 - 1234123402, 10]
DEBUG: [1234123401 - 1234123403, 10]
[[20]]
DRPC : Query endsAqui neste capítulo, discutiremos uma aplicação em tempo real do Apache Storm. Veremos como o Storm é usado no Twitter.
O Twitter é um serviço de rede social online que fornece uma plataforma para enviar e receber tweets de usuários. Usuários registrados podem ler e postar tweets, mas usuários não registrados podem apenas ler tweets. Hashtag é usado para categorizar tweets por palavra-chave, acrescentando # antes da palavra-chave relevante. Agora, vejamos um cenário em tempo real para encontrar a hashtag mais usada por tópico.
Criação de bico
O objetivo do spout é fazer com que os tweets sejam enviados pelas pessoas o mais rápido possível. O Twitter fornece “Twitter Streaming API”, uma ferramenta baseada em serviço da web para recuperar os tweets enviados por pessoas em tempo real. A API de streaming do Twitter pode ser acessada em qualquer linguagem de programação.
twitter4j é uma biblioteca Java não oficial de código aberto, que fornece um módulo baseado em Java para acessar facilmente a API de streaming do Twitter. twitter4jfornece uma estrutura baseada em ouvinte para acessar os tweets. Para acessar a API de streaming do Twitter, precisamos entrar na conta de desenvolvedor do Twitter e obter os seguintes detalhes de autenticação OAuth.
- Customerkey
- CustomerSecret
- AccessToken
- AccessTookenSecret
Storm fornece um bico de Twitter, TwitterSampleSpout,em seu kit inicial. Estaremos usando para recuperar os tweets. O spout precisa de detalhes de autenticação OAuth e pelo menos uma palavra-chave. O spout emitirá tweets em tempo real com base em palavras-chave. O código completo do programa é fornecido abaixo.
Codificação: TwitterSampleSpout.java
import java.util.Map;
import java.util.concurrent.LinkedBlockingQueue;
import twitter4j.FilterQuery;
import twitter4j.StallWarning;
import twitter4j.Status;
import twitter4j.StatusDeletionNotice;
import twitter4j.StatusListener;
import twitter4j.TwitterStream;
import twitter4j.TwitterStreamFactory;
import twitter4j.auth.AccessToken;
import twitter4j.conf.ConfigurationBuilder;
import backtype.storm.Config;
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichSpout;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.utils.Utils;
@SuppressWarnings("serial")
public class TwitterSampleSpout extends BaseRichSpout {
SpoutOutputCollector _collector;
LinkedBlockingQueue<Status> queue = null;
TwitterStream _twitterStream;
String consumerKey;
String consumerSecret;
String accessToken;
String accessTokenSecret;
String[] keyWords;
public TwitterSampleSpout(String consumerKey, String consumerSecret,
String accessToken, String accessTokenSecret, String[] keyWords) {
this.consumerKey = consumerKey;
this.consumerSecret = consumerSecret;
this.accessToken = accessToken;
this.accessTokenSecret = accessTokenSecret;
this.keyWords = keyWords;
}
public TwitterSampleSpout() {
// TODO Auto-generated constructor stub
}
@Override
public void open(Map conf, TopologyContext context,
SpoutOutputCollector collector) {
queue = new LinkedBlockingQueue<Status>(1000);
_collector = collector;
StatusListener listener = new StatusListener() {
@Override
public void onStatus(Status status) {
queue.offer(status);
}
@Override
public void onDeletionNotice(StatusDeletionNotice sdn) {}
@Override
public void onTrackLimitationNotice(int i) {}
@Override
public void onScrubGeo(long l, long l1) {}
@Override
public void onException(Exception ex) {}
@Override
public void onStallWarning(StallWarning arg0) {
// TODO Auto-generated method stub
}
};
ConfigurationBuilder cb = new ConfigurationBuilder();
cb.setDebugEnabled(true)
.setOAuthConsumerKey(consumerKey)
.setOAuthConsumerSecret(consumerSecret)
.setOAuthAccessToken(accessToken)
.setOAuthAccessTokenSecret(accessTokenSecret);
_twitterStream = new TwitterStreamFactory(cb.build()).getInstance();
_twitterStream.addListener(listener);
if (keyWords.length == 0) {
_twitterStream.sample();
}else {
FilterQuery query = new FilterQuery().track(keyWords);
_twitterStream.filter(query);
}
}
@Override
public void nextTuple() {
Status ret = queue.poll();
if (ret == null) {
Utils.sleep(50);
} else {
_collector.emit(new Values(ret));
}
}
@Override
public void close() {
_twitterStream.shutdown();
}
@Override
public Map<String, Object> getComponentConfiguration() {
Config ret = new Config();
ret.setMaxTaskParallelism(1);
return ret;
}
@Override
public void ack(Object id) {}
@Override
public void fail(Object id) {}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("tweet"));
}
}Parafuso do leitor de hashtag
O tweet emitido pelo bico será encaminhado para HashtagReaderBolt, que irá processar o tweet e emitir todas as hashtags disponíveis. HashtagReaderBolt usagetHashTagEntitiesmétodo fornecido pelo twitter4j. getHashTagEntities lê o tweet e retorna a lista de hashtag. O código completo do programa é o seguinte -
Codificação: HashtagReaderBolt.java
import java.util.HashMap;
import java.util.Map;
import twitter4j.*;
import twitter4j.conf.*;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Tuple;
public class HashtagReaderBolt implements IRichBolt {
private OutputCollector collector;
@Override
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
@Override
public void execute(Tuple tuple) {
Status tweet = (Status) tuple.getValueByField("tweet");
for(HashtagEntity hashtage : tweet.getHashtagEntities()) {
System.out.println("Hashtag: " + hashtage.getText());
this.collector.emit(new Values(hashtage.getText()));
}
}
@Override
public void cleanup() {}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("hashtag"));
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}Parafuso do contador de hashtag
A hashtag emitida será encaminhada para HashtagCounterBolt. Este bolt irá processar todas as hashtags e salvar cada uma e todas as hashtags e sua contagem na memória usando o objeto Java Map. O código completo do programa é fornecido abaixo.
Codificação: HashtagCounterBolt.java
import java.util.HashMap;
import java.util.Map;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Tuple;
public class HashtagCounterBolt implements IRichBolt {
Map<String, Integer> counterMap;
private OutputCollector collector;
@Override
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
this.counterMap = new HashMap<String, Integer>();
this.collector = collector;
}
@Override
public void execute(Tuple tuple) {
String key = tuple.getString(0);
if(!counterMap.containsKey(key)){
counterMap.put(key, 1);
}else{
Integer c = counterMap.get(key) + 1;
counterMap.put(key, c);
}
collector.ack(tuple);
}
@Override
public void cleanup() {
for(Map.Entry<String, Integer> entry:counterMap.entrySet()){
System.out.println("Result: " + entry.getKey()+" : " + entry.getValue());
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("hashtag"));
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}Enviando uma Topologia
O envio de uma topologia é o aplicativo principal. A topologia do Twitter consiste emTwitterSampleSpout, HashtagReaderBolt, e HashtagCounterBolt. O código de programa a seguir mostra como enviar uma topologia.
Codificação: TwitterHashtagStorm.java
import java.util.*;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.topology.TopologyBuilder;
public class TwitterHashtagStorm {
public static void main(String[] args) throws Exception{
String consumerKey = args[0];
String consumerSecret = args[1];
String accessToken = args[2];
String accessTokenSecret = args[3];
String[] arguments = args.clone();
String[] keyWords = Arrays.copyOfRange(arguments, 4, arguments.length);
Config config = new Config();
config.setDebug(true);
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("twitter-spout", new TwitterSampleSpout(consumerKey,
consumerSecret, accessToken, accessTokenSecret, keyWords));
builder.setBolt("twitter-hashtag-reader-bolt", new HashtagReaderBolt())
.shuffleGrouping("twitter-spout");
builder.setBolt("twitter-hashtag-counter-bolt", new HashtagCounterBolt())
.fieldsGrouping("twitter-hashtag-reader-bolt", new Fields("hashtag"));
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("TwitterHashtagStorm", config,
builder.createTopology());
Thread.sleep(10000);
cluster.shutdown();
}
}Construindo e executando o aplicativo
O aplicativo completo possui quatro códigos Java. Eles são os seguintes -
- TwitterSampleSpout.java
- HashtagReaderBolt.java
- HashtagCounterBolt.java
- TwitterHashtagStorm.java
Você pode compilar o aplicativo usando o seguinte comando -
javac -cp “/path/to/storm/apache-storm-0.9.5/lib/*”:”/path/to/twitter4j/lib/*” *.javaExecute o aplicativo usando os seguintes comandos -
javac -cp “/path/to/storm/apache-storm-0.9.5/lib/*”:”/path/to/twitter4j/lib/*”:.
TwitterHashtagStorm <customerkey> <customersecret> <accesstoken> <accesstokensecret>
<keyword1> <keyword2> … <keywordN>Resultado
O aplicativo imprimirá a hashtag atualmente disponível e sua contagem. O resultado deve ser semelhante ao seguinte -
Result: jazztastic : 1
Result: foodie : 1
Result: Redskins : 1
Result: Recipe : 1
Result: cook : 1
Result: android : 1
Result: food : 2
Result: NoToxicHorseMeat : 1
Result: Purrs4Peace : 1
Result: livemusic : 1
Result: VIPremium : 1
Result: Frome : 1
Result: SundayRoast : 1
Result: Millennials : 1
Result: HealthWithKier : 1
Result: LPs30DaysofGratitude : 1
Result: cooking : 1
Result: gameinsight : 1
Result: Countryfile : 1
Result: androidgames : 1Yahoo! Finance é o site de notícias de negócios e dados financeiros líder na Internet. É uma parte do Yahoo! e fornece informações sobre notícias financeiras, estatísticas de mercado, dados de mercado internacional e outras informações sobre recursos financeiros que qualquer pessoa pode acessar.
Se você é um usuário registrado do Yahoo! usuário, então você pode personalizar o Yahoo! Finanças para aproveitar as vantagens de certas ofertas. Yahoo! A API Finance é usada para consultar dados financeiros do Yahoo!
Esta API exibe dados que estão atrasados em 15 minutos em relação ao tempo real e atualiza seu banco de dados a cada 1 minuto, para acessar informações atuais relacionadas ao estoque. Agora, consideremos um cenário em tempo real de uma empresa e vejamos como emitir um alerta quando o valor das ações cair abaixo de 100.
Criação de bico
O objetivo da bica é pegar os detalhes da empresa e emitir os preços para parafusos. Você pode usar o seguinte código de programa para criar um bico.
Codificação: YahooFinanceSpout.java
import java.util.*;
import java.io.*;
import java.math.BigDecimal;
//import yahoofinace packages
import yahoofinance.YahooFinance;
import yahoofinance.Stock;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.topology.IRichSpout;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
public class YahooFinanceSpout implements IRichSpout {
private SpoutOutputCollector collector;
private boolean completed = false;
private TopologyContext context;
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector){
this.context = context;
this.collector = collector;
}
@Override
public void nextTuple() {
try {
Stock stock = YahooFinance.get("INTC");
BigDecimal price = stock.getQuote().getPrice();
this.collector.emit(new Values("INTC", price.doubleValue()));
stock = YahooFinance.get("GOOGL");
price = stock.getQuote().getPrice();
this.collector.emit(new Values("GOOGL", price.doubleValue()));
stock = YahooFinance.get("AAPL");
price = stock.getQuote().getPrice();
this.collector.emit(new Values("AAPL", price.doubleValue()));
} catch(Exception e) {}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("company", "price"));
}
@Override
public void close() {}
public boolean isDistributed() {
return false;
}
@Override
public void activate() {}
@Override
public void deactivate() {}
@Override
public void ack(Object msgId) {}
@Override
public void fail(Object msgId) {}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}Criação de Parafuso
Aqui, o objetivo do bolt é processar os preços fornecidos pela empresa quando os preços caem abaixo de 100. Ele usa o objeto Java Map para definir o alerta de limite de preço truequando os preços das ações caem abaixo de 100; caso contrário, false. O código completo do programa é o seguinte -
Codificação: PriceCutOffBolt.java
import java.util.HashMap;
import java.util.Map;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Tuple;
public class PriceCutOffBolt implements IRichBolt {
Map<String, Integer> cutOffMap;
Map<String, Boolean> resultMap;
private OutputCollector collector;
@Override
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
this.cutOffMap = new HashMap <String, Integer>();
this.cutOffMap.put("INTC", 100);
this.cutOffMap.put("AAPL", 100);
this.cutOffMap.put("GOOGL", 100);
this.resultMap = new HashMap<String, Boolean>();
this.collector = collector;
}
@Override
public void execute(Tuple tuple) {
String company = tuple.getString(0);
Double price = tuple.getDouble(1);
if(this.cutOffMap.containsKey(company)){
Integer cutOffPrice = this.cutOffMap.get(company);
if(price < cutOffPrice) {
this.resultMap.put(company, true);
} else {
this.resultMap.put(company, false);
}
}
collector.ack(tuple);
}
@Override
public void cleanup() {
for(Map.Entry<String, Boolean> entry:resultMap.entrySet()){
System.out.println(entry.getKey()+" : " + entry.getValue());
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("cut_off_price"));
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}Enviando uma Topologia
Este é o aplicativo principal onde YahooFinanceSpout.java e PriceCutOffBolt.java estão conectados e produzem uma topologia. O código de programa a seguir mostra como você pode enviar uma topologia.
Codificação: YahooFinanceStorm.java
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.topology.TopologyBuilder;
public class YahooFinanceStorm {
public static void main(String[] args) throws Exception{
Config config = new Config();
config.setDebug(true);
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("yahoo-finance-spout", new YahooFinanceSpout());
builder.setBolt("price-cutoff-bolt", new PriceCutOffBolt())
.fieldsGrouping("yahoo-finance-spout", new Fields("company"));
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("YahooFinanceStorm", config, builder.createTopology());
Thread.sleep(10000);
cluster.shutdown();
}
}Construindo e executando o aplicativo
O aplicativo completo possui três códigos Java. Eles são os seguintes -
- YahooFinanceSpout.java
- PriceCutOffBolt.java
- YahooFinanceStorm.java
O aplicativo pode ser construído usando o seguinte comando -
javac -cp “/path/to/storm/apache-storm-0.9.5/lib/*”:”/path/to/yahoofinance/lib/*” *.javaO aplicativo pode ser executado usando o seguinte comando -
javac -cp “/path/to/storm/apache-storm-0.9.5/lib/*”:”/path/to/yahoofinance/lib/*”:.
YahooFinanceStormResultado
O resultado será semelhante ao seguinte -
GOOGL : false
AAPL : false
INTC : trueA estrutura do Apache Storm oferece suporte a muitos dos melhores aplicativos industriais da atualidade. Forneceremos uma breve visão geral de algumas das aplicações mais notáveis do Storm neste capítulo.
Klout
Klout é um aplicativo que usa análise de mídia social para classificar seus usuários com base na influência social online através de Klout Score, que é um valor numérico entre 1 e 100. Klout usa a abstração Trident embutida do Apache Storm para criar topologias complexas que transmitem dados.
O canal do tempo
O Weather Channel usa topologias Storm para ingerir dados meteorológicos. Associou-se ao Twitter para permitir publicidade informada sobre o tempo no Twitter e em aplicativos móveis.OpenSignal é uma empresa especializada em mapeamento de cobertura sem fio. StormTag e WeatherSignalsão projetos baseados no clima criados pela OpenSignal. StormTag é uma estação meteorológica Bluetooth que se conecta a um chaveiro. Os dados meteorológicos coletados pelo dispositivo são enviados para o aplicativo WeatherSignal e servidores OpenSignal.
Indústria de Telecom
Os provedores de telecomunicações processam milhões de chamadas por segundo. Eles realizam perícia em chamadas perdidas e baixa qualidade de som. Os registros de detalhes de chamadas fluem a uma taxa de milhões por segundo e o Apache Storm os processa em tempo real e identifica quaisquer padrões problemáticos. A análise de tempestade pode ser usada para melhorar continuamente a qualidade da chamada.