Bela Sopa - Expandindo a Página
No exemplo de código anterior, analisamos o documento por meio de um belo construtor usando um método de string. Outra maneira é passar o documento por meio de um gerenciador de arquivos aberto.
from bs4 import BeautifulSoup
with open("example.html") as fp:
soup = BeautifulSoup(fp)
soup = BeautifulSoup("<html>data</html>")Primeiro, o documento é convertido em Unicode e as entidades HTML são convertidas em caracteres Unicode: </p>
import bs4
html = '''<b>tutorialspoint</b>, <i>&web scraping &data science;</i>'''
soup = bs4.BeautifulSoup(html, 'lxml')
print(soup)Resultado
<html><body><b>tutorialspoint</b>, <i>&web scraping &data science;</i></body></html>BeautifulSoup analisa os dados usando um analisador HTML ou você explicitamente diz a ele para analisar usando um analisador XML.
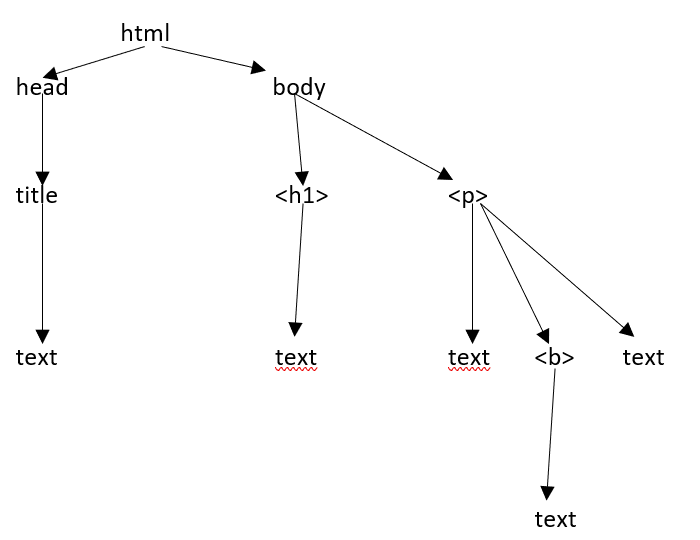
Estrutura da árvore HTML
Antes de examinarmos os diferentes componentes de uma página HTML, vamos primeiro entender a estrutura da árvore HTML.
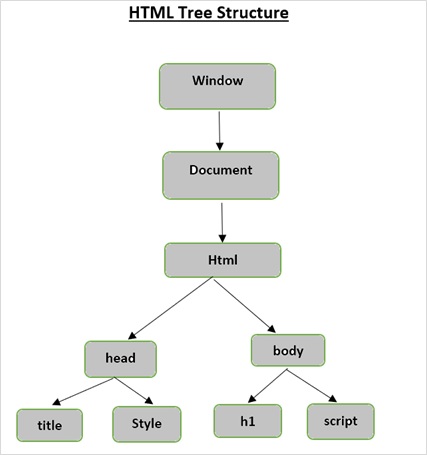
O elemento raiz na árvore do documento é o html, que pode ter pais, filhos e irmãos e isso é determinado por sua posição na estrutura da árvore. Para mover-se entre os elementos, atributos e texto HTML, você deve mover-se entre os nós da estrutura em árvore.
Suponhamos que a página da web seja conforme mostrado abaixo -
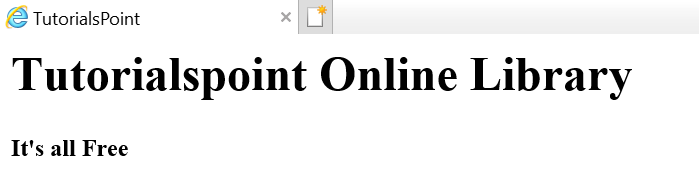
Que se traduz em um documento html da seguinte maneira -
<html><head><title>TutorialsPoint</title></head><h1>Tutorialspoint Online Library</h1><p<<b>It's all Free</b></p></body></html>O que significa simplesmente que, para o documento html acima, temos uma estrutura de árvore html como segue -