Classificação de imagens usando modelo pré-treinado
Nesta lição, você aprenderá a usar um modelo pré-treinado para detectar objetos em uma determinada imagem. Você vai usarsqueezenet Módulo pré-treinado que detecta e classifica os objetos em uma determinada imagem com grande precisão.
Abra um novo Juypter notebook e siga as etapas para desenvolver este aplicativo de classificação de imagens.
Importando Bibliotecas
Primeiro, importamos os pacotes necessários usando o código abaixo -
from caffe2.proto import caffe2_pb2
from caffe2.python import core, workspace, models
import numpy as np
import skimage.io
import skimage.transform
from matplotlib import pyplot
import os
import urllib.request as urllib2
import operatorEm seguida, configuramos alguns variables -
INPUT_IMAGE_SIZE = 227
mean = 128As imagens usadas para o treinamento obviamente serão de tamanhos variados. Todas essas imagens devem ser convertidas em um tamanho fixo para um treinamento preciso. Da mesma forma, as imagens de teste e a imagem que se deseja prever no ambiente de produção também devem ser convertidas para o tamanho igual ao utilizado durante o treinamento. Assim, criamos uma variável acima chamadaINPUT_IMAGE_SIZE tendo valor 227. Portanto, vamos converter todas as nossas imagens para o tamanho227x227 antes de usá-lo em nosso classificador.
Também declaramos uma variável chamada mean tendo valor 128, que é usado posteriormente para melhorar os resultados da classificação.
A seguir, desenvolveremos duas funções para o processamento da imagem.
Processamento de imagem
O processamento da imagem consiste em duas etapas. O primeiro é redimensionar a imagem e o segundo é cortar a imagem centralmente. Para essas duas etapas, escreveremos duas funções para redimensionar e recortar.
Redimensionamento de imagem
Primeiro, vamos escrever uma função para redimensionar a imagem. Como dissemos antes, vamos redimensionar a imagem para227x227. Então, vamos definir a funçãoresize como segue -
def resize(img, input_height, input_width):Obtemos a proporção da imagem dividindo a largura pela altura.
original_aspect = img.shape[1]/float(img.shape[0])Se a relação de aspecto for maior que 1, indica que a imagem é ampla, ou seja, está no modo paisagem. Agora ajustamos a altura da imagem e retornamos a imagem redimensionada usando o seguinte código -
if(original_aspect>1):
new_height = int(original_aspect * input_height)
return skimage.transform.resize(img, (input_width,
new_height), mode='constant', anti_aliasing=True, anti_aliasing_sigma=None)Se a proporção for less than 1, indica o portrait mode. Agora ajustamos a largura usando o seguinte código -
if(original_aspect<1):
new_width = int(input_width/original_aspect)
return skimage.transform.resize(img, (new_width,
input_height), mode='constant', anti_aliasing=True, anti_aliasing_sigma=None)Se a proporção da imagem for igual 1, não fazemos ajustes de altura / largura.
if(original_aspect == 1):
return skimage.transform.resize(img, (input_width,
input_height), mode='constant', anti_aliasing=True, anti_aliasing_sigma=None)O código de função completo é fornecido abaixo para sua referência rápida -
def resize(img, input_height, input_width):
original_aspect = img.shape[1]/float(img.shape[0])
if(original_aspect>1):
new_height = int(original_aspect * input_height)
return skimage.transform.resize(img, (input_width,
new_height), mode='constant', anti_aliasing=True, anti_aliasing_sigma=None)
if(original_aspect<1):
new_width = int(input_width/original_aspect)
return skimage.transform.resize(img, (new_width,
input_height), mode='constant', anti_aliasing=True, anti_aliasing_sigma=None)
if(original_aspect == 1):
return skimage.transform.resize(img, (input_width,
input_height), mode='constant', anti_aliasing=True, anti_aliasing_sigma=None)Agora escreveremos uma função para cortar a imagem em torno de seu centro.
Corte de imagem
Nós declaramos o crop_image funcionar da seguinte forma -
def crop_image(img,cropx,cropy):Extraímos as dimensões da imagem usando a seguinte declaração -
y,x,c = img.shapeCriamos um novo ponto de partida para a imagem usando as duas linhas de código a seguir -
startx = x//2-(cropx//2)
starty = y//2-(cropy//2)Finalmente, retornamos a imagem cortada criando um objeto de imagem com as novas dimensões -
return img[starty:starty+cropy,startx:startx+cropx]Todo o código da função é fornecido abaixo para sua referência rápida -
def crop_image(img,cropx,cropy):
y,x,c = img.shape
startx = x//2-(cropx//2)
starty = y//2-(cropy//2)
return img[starty:starty+cropy,startx:startx+cropx]Agora, vamos escrever o código para testar essas funções.
Processando imagem
Em primeiro lugar, copie um arquivo de imagem em images subpasta dentro do diretório do projeto. tree.jpgo arquivo é copiado no projeto. O seguinte código Python carrega a imagem e a exibe no console -
img = skimage.img_as_float(skimage.io.imread("images/tree.jpg")).astype(np.float32)
print("Original Image Shape: " , img.shape)
pyplot.figure()
pyplot.imshow(img)
pyplot.title('Original image')O resultado é o seguinte -
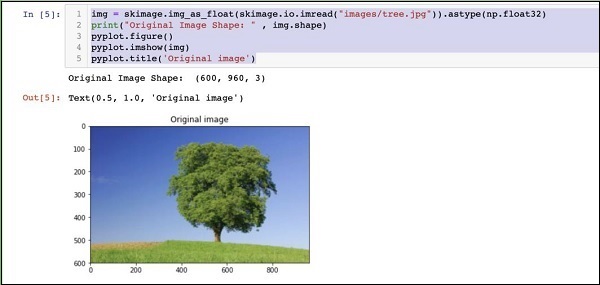
Observe que o tamanho da imagem original é 600 x 960. Precisamos redimensionar isso para nossa especificação de227 x 227. Chamando nosso definido anteriormenteresizefunção faz esse trabalho.
img = resize(img, INPUT_IMAGE_SIZE, INPUT_IMAGE_SIZE)
print("Image Shape after resizing: " , img.shape)
pyplot.figure()
pyplot.imshow(img)
pyplot.title('Resized image')O resultado é o seguinte -
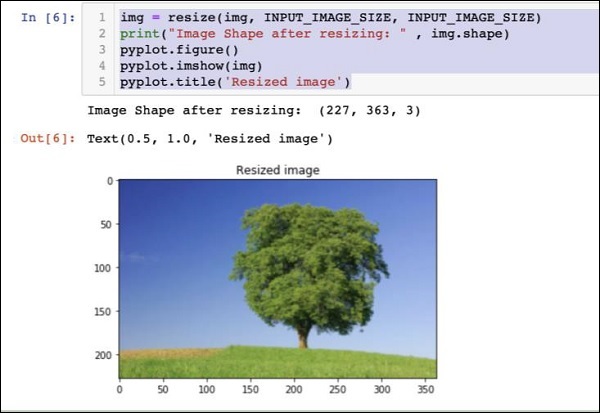
Observe que agora o tamanho da imagem é 227 x 363. Precisamos cortar isso para227 x 227para o feed final do nosso algoritmo. Chamamos a função de corte previamente definida para este propósito.
img = crop_image(img, INPUT_IMAGE_SIZE, INPUT_IMAGE_SIZE)
print("Image Shape after cropping: " , img.shape)
pyplot.figure()
pyplot.imshow(img)
pyplot.title('Center Cropped')Abaixo mencionado está a saída do código -
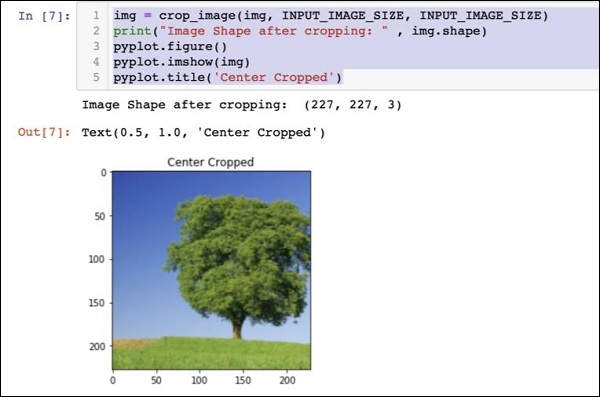
Neste ponto, a imagem está do tamanho 227 x 227e está pronto para processamento posterior. Agora trocamos os eixos da imagem para extrair as três cores em três zonas diferentes.
img = img.swapaxes(1, 2).swapaxes(0, 1)
print("CHW Image Shape: " , img.shape)A seguir está o resultado -
CHW Image Shape: (3, 227, 227)Observe que o último eixo agora se tornou a primeira dimensão na matriz. Vamos agora representar os três canais usando o seguinte código -
pyplot.figure()
for i in range(3):
pyplot.subplot(1, 3, i+1)
pyplot.imshow(img[i])
pyplot.axis('off')
pyplot.title('RGB channel %d' % (i+1))O resultado é declarado abaixo -

Finalmente, fazemos algum processamento adicional na imagem, como a conversão Red Green Blue para Blue Green Red (RGB to BGR), removendo a média para melhores resultados e adicionando eixo de tamanho de lote usando as seguintes três linhas de código -
# convert RGB --> BGR
img = img[(2, 1, 0), :, :]
# remove mean
img = img * 255 - mean
# add batch size axis
img = img[np.newaxis, :, :, :].astype(np.float32)Neste ponto, sua imagem está em NCHW formate está pronto para alimentar nossa rede. A seguir, carregaremos nossos arquivos de modelo pré-treinados e alimentaremos a imagem acima para previsão.
Previsão de objetos em imagem processada
Primeiro configuramos os caminhos para o init e predict redes definidas nos modelos pré-treinados da Caffe.
Configurando caminhos de arquivo de modelo
Lembre-se de nossa discussão anterior, todos os modelos pré-treinados são instalados no modelspasta. Configuramos o caminho para esta pasta da seguinte maneira -
CAFFE_MODELS = os.path.expanduser("/anaconda3/lib/python3.7/site-packages/caffe2/python/models")Nós montamos o caminho para o init_net arquivo protobuf do squeezenet modelo da seguinte forma -
INIT_NET = os.path.join(CAFFE_MODELS, 'squeezenet', 'init_net.pb')Da mesma forma, configuramos o caminho para o predict_net protobuf da seguinte forma -
PREDICT_NET = os.path.join(CAFFE_MODELS, 'squeezenet', 'predict_net.pb')Imprimimos os dois caminhos para fins de diagnóstico -
print(INIT_NET)
print(PREDICT_NET)O código acima, junto com a saída, é fornecido aqui para sua referência rápida -
CAFFE_MODELS = os.path.expanduser("/anaconda3/lib/python3.7/site-packages/caffe2/python/models")
INIT_NET = os.path.join(CAFFE_MODELS, 'squeezenet', 'init_net.pb')
PREDICT_NET = os.path.join(CAFFE_MODELS, 'squeezenet', 'predict_net.pb')
print(INIT_NET)
print(PREDICT_NET)O resultado é mencionado abaixo -
/anaconda3/lib/python3.7/site-packages/caffe2/python/models/squeezenet/init_net.pb
/anaconda3/lib/python3.7/site-packages/caffe2/python/models/squeezenet/predict_net.pbA seguir, criaremos um preditor.
Criando Predictor
Lemos os arquivos de modelo usando as duas declarações a seguir -
with open(INIT_NET, "rb") as f:
init_net = f.read()
with open(PREDICT_NET, "rb") as f:
predict_net = f.read()O preditor é criado passando ponteiros para os dois arquivos como parâmetros para o Predictor função.
p = workspace.Predictor(init_net, predict_net)o pobject é o preditor, que é usado para predizer os objetos em qualquer imagem. Observe que cada imagem de entrada deve estar no formato NCHW como o que fizemos anteriormente para nossotree.jpg Arquivo.
Objetos de previsão
Prever os objetos em uma determinada imagem é trivial - basta executar uma única linha de comando. Nós chamamosrun método no predictor objeto para a detecção de um objeto em uma determinada imagem.
results = p.run({'data': img})Os resultados da previsão agora estão disponíveis no results objeto, que convertemos em uma matriz para nossa legibilidade.
results = np.asarray(results)Imprima as dimensões da matriz para sua compreensão usando a seguinte declaração -
print("results shape: ", results.shape)O resultado é mostrado abaixo -
results shape: (1, 1, 1000, 1, 1)Vamos agora remover o eixo desnecessário -
preds = np.squeeze(results)A predicação superior agora pode ser recuperada tomando o max valor no preds array.
curr_pred, curr_conf = max(enumerate(preds), key=operator.itemgetter(1))
print("Prediction: ", curr_pred)
print("Confidence: ", curr_conf)O resultado é o seguinte -
Prediction: 984
Confidence: 0.89235985Como você pode ver, o modelo previu um objeto com um valor de índice 984 com 89%confiança. O índice de 984 não faz muito sentido para nós na compreensão do tipo de objeto detectado. Precisamos obter o nome stringificado para o objeto usando seu valor de índice. Os tipos de objetos que o modelo reconhece junto com seus valores de índice correspondentes estão disponíveis em um repositório github.
Agora, veremos como recuperar o nome do nosso objeto com valor de índice de 984.
Resultado de Stringificação
Criamos um objeto de URL para o repositório github da seguinte maneira -
codes = "https://gist.githubusercontent.com/aaronmarkham/cd3a6b6ac0
71eca6f7b4a6e40e6038aa/raw/9edb4038a37da6b5a44c3b5bc52e448ff09bfe5b/alexnet_codes"Lemos o conteúdo do URL -
response = urllib2.urlopen(codes)A resposta conterá uma lista de todos os códigos e suas descrições. Algumas linhas da resposta são mostradas abaixo para sua compreensão do que ela contém -
5: 'electric ray, crampfish, numbfish, torpedo',
6: 'stingray',
7: 'cock',
8: 'hen',
9: 'ostrich, Struthio camelus',
10: 'brambling, Fringilla montifringilla',Agora iteramos todo o array para localizar nosso código desejado de 984 usando um for loop da seguinte forma -
for line in response:
mystring = line.decode('ascii')
code, result = mystring.partition(":")[::2]
code = code.strip()
result = result.replace("'", "")
if (code == str(curr_pred)):
name = result.split(",")[0][1:]
print("Model predicts", name, "with", curr_conf, "confidence")Ao executar o código, você verá a seguinte saída -
Model predicts rapeseed with 0.89235985 confidenceAgora você pode experimentar o modelo em outra imagem.
Previsão de uma imagem diferente
Para prever outra imagem, basta copiar o arquivo de imagem para o imagespasta do diretório do seu projeto. Este é o diretório no qual nossotree.jpgarquivo é armazenado. Altere o nome do arquivo de imagem no código. Apenas uma alteração é necessária conforme mostrado abaixo
img = skimage.img_as_float(skimage.io.imread("images/pretzel.jpg")).astype(np.float32)A imagem original e o resultado da previsão são mostrados abaixo -

O resultado é mencionado abaixo -
Model predicts pretzel with 0.99999976 confidenceComo você pode ver, o modelo pré-treinado é capaz de detectar objetos em uma determinada imagem com grande precisão.
Full Source
O código-fonte completo do código acima que usa um modelo pré-treinado para detecção de objetos em uma determinada imagem é mencionado aqui para sua referência rápida -
def crop_image(img,cropx,cropy):
y,x,c = img.shape
startx = x//2-(cropx//2)
starty = y//2-(cropy//2)
return img[starty:starty+cropy,startx:startx+cropx]
img = skimage.img_as_float(skimage.io.imread("images/pretzel.jpg")).astype(np.float32)
print("Original Image Shape: " , img.shape)
pyplot.figure()
pyplot.imshow(img)
pyplot.title('Original image')
img = resize(img, INPUT_IMAGE_SIZE, INPUT_IMAGE_SIZE)
print("Image Shape after resizing: " , img.shape)
pyplot.figure()
pyplot.imshow(img)
pyplot.title('Resized image')
img = crop_image(img, INPUT_IMAGE_SIZE, INPUT_IMAGE_SIZE)
print("Image Shape after cropping: " , img.shape)
pyplot.figure()
pyplot.imshow(img)
pyplot.title('Center Cropped')
img = img.swapaxes(1, 2).swapaxes(0, 1)
print("CHW Image Shape: " , img.shape)
pyplot.figure()
for i in range(3):
pyplot.subplot(1, 3, i+1)
pyplot.imshow(img[i])
pyplot.axis('off')
pyplot.title('RGB channel %d' % (i+1))
# convert RGB --> BGR
img = img[(2, 1, 0), :, :]
# remove mean
img = img * 255 - mean
# add batch size axis
img = img[np.newaxis, :, :, :].astype(np.float32)
CAFFE_MODELS = os.path.expanduser("/anaconda3/lib/python3.7/site-packages/caffe2/python/models")
INIT_NET = os.path.join(CAFFE_MODELS, 'squeezenet', 'init_net.pb')
PREDICT_NET = os.path.join(CAFFE_MODELS, 'squeezenet', 'predict_net.pb')
print(INIT_NET)
print(PREDICT_NET)
with open(INIT_NET, "rb") as f:
init_net = f.read()
with open(PREDICT_NET, "rb") as f:
predict_net = f.read()
p = workspace.Predictor(init_net, predict_net)
results = p.run({'data': img})
results = np.asarray(results)
print("results shape: ", results.shape)
preds = np.squeeze(results)
curr_pred, curr_conf = max(enumerate(preds), key=operator.itemgetter(1))
print("Prediction: ", curr_pred)
print("Confidence: ", curr_conf)
codes = "https://gist.githubusercontent.com/aaronmarkham/cd3a6b6ac071eca6f7b4a6e40e6038aa/raw/9edb4038a37da6b5a44c3b5bc52e448ff09bfe5b/alexnet_codes"
response = urllib2.urlopen(codes)
for line in response:
mystring = line.decode('ascii')
code, result = mystring.partition(":")[::2]
code = code.strip()
result = result.replace("'", "")
if (code == str(curr_pred)):
name = result.split(",")[0][1:]
print("Model predicts", name, "with", curr_conf, "confidence")A esta altura, você já sabe como usar um modelo pré-treinado para fazer as previsões em seu conjunto de dados.
O que vem a seguir é aprender como definir seu neural network (NN) arquiteturas em Caffe2e treine-os em seu conjunto de dados. Agora aprenderemos como criar um NN de camada única trivial.