Cassandra - Arquitetura
O objetivo do design do Cassandra é lidar com cargas de trabalho de big data em vários nós sem nenhum ponto único de falha. O Cassandra tem sistema distribuído ponto a ponto em seus nós e os dados são distribuídos entre todos os nós em um cluster.
Todos os nós em um cluster desempenham a mesma função. Cada nó é independente e ao mesmo tempo interconectado a outros nós.
Cada nó em um cluster pode aceitar solicitações de leitura e gravação, independentemente de onde os dados estão realmente localizados no cluster.
Quando um nó fica inativo, as solicitações de leitura / gravação podem ser atendidas de outros nós na rede.
Replicação de dados em Cassandra
No Cassandra, um ou mais dos nós em um cluster agem como réplicas para um determinado dado. Se for detectado que algum dos nós respondeu com um valor desatualizado, o Cassandra retornará o valor mais recente ao cliente. Depois de retornar o valor mais recente, Cassandra executa umread repair em segundo plano para atualizar os valores obsoletos.
A figura a seguir mostra uma visão esquemática de como o Cassandra usa a replicação de dados entre os nós em um cluster para garantir nenhum ponto único de falha.
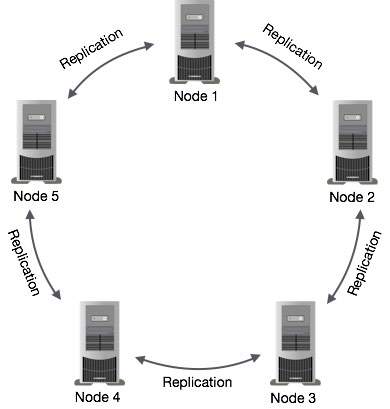
Note - Cassandra usa o Gossip Protocol no plano de fundo para permitir que os nós se comuniquem entre si e detectem quaisquer nós defeituosos no cluster.
Componentes de Cassandra
Os principais componentes do Cassandra são os seguintes -
Node - É o local onde os dados são armazenados.
Data center - É uma coleção de nós relacionados.
Cluster - Um cluster é um componente que contém um ou mais datacenters.
Commit log- O log de confirmação é um mecanismo de recuperação de falha no Cassandra. Cada operação de gravação é gravada no log de confirmação.
Mem-table- Uma mem-table é uma estrutura de dados residente na memória. Após o log de commit, os dados serão gravados na mem-table. Às vezes, para uma família de coluna única, haverá várias tabelas-mem.
SSTable - É um arquivo de disco para o qual os dados são descarregados da mem-table quando seu conteúdo atinge um valor limite.
Bloom filter- Estes são apenas algoritmos rápidos e não determinísticos para testar se um elemento é membro de um conjunto. É um tipo especial de cache. Os filtros Bloom são acessados após cada consulta.
Cassandra Query Language
Os usuários podem acessar o Cassandra por meio de seus nós usando Cassandra Query Language (CQL). CQL trata o banco de dados(Keyspace)como um contêiner de tabelas. Os programadores usamcqlsh: um prompt para trabalhar com CQL ou drivers de linguagem de aplicativo separados.
Os clientes abordam qualquer um dos nós para suas operações de leitura e gravação. Esse nó (coordenador) reproduz um proxy entre o cliente e os nós que contêm os dados.
Operações de gravação
Cada atividade de gravação de nós é capturada pelo commit logsescrito nos nós. Posteriormente, os dados serão capturados e armazenados nomem-table. Sempre que a mem-table estiver cheia, os dados serão gravados no SStablearquivo de dados. Todas as gravações são particionadas e replicadas automaticamente em todo o cluster. O Cassandra consolida periodicamente os SSTables, descartando dados desnecessários.
Ler operações
Durante as operações de leitura, o Cassandra obtém os valores da mem-table e verifica o filtro bloom para encontrar a SSTable apropriada que contém os dados necessários.