Cassandra - Guia Rápido
Apache Cassandra é um banco de dados distribuído de alto desempenho e altamente escalonável, projetado para lidar com grandes quantidades de dados em muitos servidores de commodity, fornecendo alta disponibilidade sem nenhum ponto único de falha. É um tipo de banco de dados NoSQL. Vamos primeiro entender o que um banco de dados NoSQL faz.
NoSQLDatabase
Um banco de dados NoSQL (às vezes chamado de Not Only SQL) é um banco de dados que fornece um mecanismo para armazenar e recuperar dados além das relações tabulares usadas em bancos de dados relacionais. Esses bancos de dados não têm esquemas, suportam replicação fácil, têm API simples, eventualmente consistentes e podem lidar com grandes quantidades de dados.
O objetivo principal de um banco de dados NoSQL é ter
- simplicidade de design,
- escala horizontal e
- controle mais preciso sobre a disponibilidade.
Os bancos de dados NoSql usam estruturas de dados diferentes em comparação aos bancos de dados relacionais. Isso torna algumas operações mais rápidas no NoSQL. A adequação de um determinado banco de dados NoSQL depende do problema que ele deve resolver.
NoSQL x banco de dados relacional
A tabela a seguir lista os pontos que diferenciam um banco de dados relacional de um banco de dados NoSQL.
| Banco de Dados Relacional | Banco de dados NoSql |
|---|---|
| Suporta uma linguagem de consulta poderosa. | Suporta uma linguagem de consulta muito simples. |
| Ele tem um esquema fixo. | Nenhum esquema fixo. |
| Segue ACID (atomicidade, consistência, isolamento e durabilidade). | É apenas “eventualmente consistente”. |
| Suporta transações. | Não suporta transações. |
Além do Cassandra, temos os seguintes bancos de dados NoSQL que são bastante populares -
Apache HBase- HBase é um banco de dados distribuído de código aberto, não relacional, modelado de acordo com o BigTable do Google e escrito em Java. Ele é desenvolvido como parte do projeto Apache Hadoop e é executado no HDFS, fornecendo recursos do tipo BigTable para Hadoop.
MongoDB - MongoDB é um sistema de banco de dados orientado a documentos de plataforma cruzada que evita usar a estrutura de banco de dados relacional tradicional baseada em tabela em favor de documentos do tipo JSON com esquemas dinâmicos tornando a integração de dados em certos tipos de aplicativos mais fácil e rápida.
O que é Apache Cassandra?
Apache Cassandra é um sistema de armazenamento (banco de dados) de código aberto, distribuído e descentralizado / distribuído, para o gerenciamento de grandes quantidades de dados estruturados espalhados pelo mundo. Ele fornece um serviço altamente disponível sem nenhum ponto único de falha.
Listados abaixo estão alguns dos pontos notáveis do Apache Cassandra -
É escalonável, tolerante a falhas e consistente.
É um banco de dados orientado a colunas.
Seu design de distribuição é baseado no Dynamo da Amazon e seu modelo de dados no Bigtable do Google.
Criado no Facebook, ele difere nitidamente dos sistemas de gerenciamento de banco de dados relacional.
O Cassandra implementa um modelo de replicação no estilo Dynamo sem um único ponto de falha, mas adiciona um modelo de dados de “família de colunas” mais poderoso.
Cassandra está sendo usado por algumas das maiores empresas, como Facebook, Twitter, Cisco, Rackspace, ebay, Twitter, Netflix e muito mais.
Características de Cassandra
Cassandra se tornou muito popular por causa de suas características técnicas excepcionais. A seguir estão alguns dos recursos do Cassandra:
Elastic scalability- Cassandra é altamente escalável; permite adicionar mais hardware para acomodar mais clientes e mais dados conforme a necessidade.
Always on architecture - O Cassandra não tem um único ponto de falha e está continuamente disponível para aplicativos essenciais aos negócios que não podem falhar.
Fast linear-scale performance- O Cassandra é linearmente escalonável, ou seja, ele aumenta seu rendimento conforme você aumenta o número de nós no cluster. Portanto, mantém um tempo de resposta rápido.
Flexible data storage- Cassandra acomoda todos os formatos de dados possíveis, incluindo: estruturado, semi-estruturado e não estruturado. Ele pode acomodar alterações dinamicamente em suas estruturas de dados de acordo com sua necessidade.
Easy data distribution - O Cassandra oferece flexibilidade para distribuir dados onde você precisar, replicando dados em vários datacenters.
Transaction support - O Cassandra oferece suporte a propriedades como Atomicidade, Consistência, Isolamento e Durabilidade (ACID).
Fast writes- Cassandra foi projetada para rodar em hardware barato. Ele executa gravações extremamente rápidas e pode armazenar centenas de terabytes de dados, sem sacrificar a eficiência de leitura.
História de cassandra
- O Cassandra foi desenvolvido no Facebook para pesquisa na caixa de entrada.
- O código-fonte foi aberto pelo Facebook em julho de 2008.
- Cassandra foi aceita na Incubadora Apache em março de 2009.
- Tornou-se um projeto de nível superior do Apache desde fevereiro de 2010.
O objetivo do design do Cassandra é lidar com cargas de trabalho de big data em vários nós, sem nenhum ponto único de falha. O Cassandra possui sistema distribuído ponto a ponto em seus nós e os dados são distribuídos entre todos os nós em um cluster.
Todos os nós em um cluster desempenham a mesma função. Cada nó é independente e ao mesmo tempo interconectado a outros nós.
Cada nó em um cluster pode aceitar solicitações de leitura e gravação, independentemente de onde os dados estão realmente localizados no cluster.
Quando um nó fica inativo, as solicitações de leitura / gravação podem ser atendidas de outros nós na rede.
Replicação de dados em Cassandra
No Cassandra, um ou mais nós em um cluster agem como réplicas para um determinado dado. Se for detectado que algum dos nós respondeu com um valor desatualizado, o Cassandra retornará o valor mais recente ao cliente. Depois de retornar o valor mais recente, Cassandra executa umread repair em segundo plano para atualizar os valores obsoletos.
A figura a seguir mostra uma visão esquemática de como o Cassandra usa a replicação de dados entre os nós em um cluster para garantir nenhum ponto único de falha.
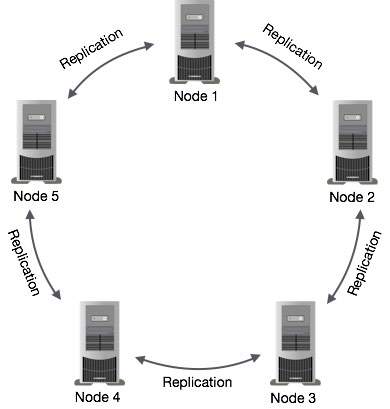
Note - Cassandra usa o Gossip Protocol no plano de fundo para permitir que os nós se comuniquem entre si e detectem quaisquer nós defeituosos no cluster.
Componentes de Cassandra
Os principais componentes do Cassandra são os seguintes -
Node - É o local onde os dados são armazenados.
Data center - É uma coleção de nós relacionados.
Cluster - Um cluster é um componente que contém um ou mais datacenters.
Commit log- O log de confirmação é um mecanismo de recuperação de falha no Cassandra. Cada operação de gravação é gravada no log de confirmação.
Mem-table- Uma mem-table é uma estrutura de dados residente na memória. Após o log de commit, os dados serão gravados na mem-table. Às vezes, para uma família de coluna única, haverá várias tabelas-mem.
SSTable - É um arquivo de disco para o qual os dados são descarregados da tabela mem quando seu conteúdo atinge um valor limite.
Bloom filter- Estes são apenas algoritmos rápidos e não determinísticos para testar se um elemento é membro de um conjunto. É um tipo especial de cache. Os filtros Bloom são acessados após cada consulta.
Cassandra Query Language
Os usuários podem acessar o Cassandra por meio de seus nós usando Cassandra Query Language (CQL). CQL trata o banco de dados(Keyspace)como um contêiner de tabelas. Os programadores usamcqlsh: um prompt para trabalhar com CQL ou drivers de linguagem de aplicativo separados.
Os clientes abordam qualquer um dos nós para suas operações de leitura e gravação. Esse nó (coordenador) reproduz um proxy entre o cliente e os nós que contêm os dados.
Operações de gravação
Cada atividade de gravação de nós é capturada pelo commit logsescrito nos nós. Posteriormente, os dados serão capturados e armazenados nomem-table. Sempre que a mem-table estiver cheia, os dados serão gravados no SStablearquivo de dados. Todas as gravações são particionadas e replicadas automaticamente em todo o cluster. O Cassandra consolida periodicamente os SSTables, descartando dados desnecessários.
Ler operações
Durante as operações de leitura, o Cassandra obtém valores da mem-table e verifica o filtro bloom para encontrar a SSTable apropriada que contém os dados necessários.
O modelo de dados do Cassandra é significativamente diferente do que normalmente vemos em um RDBMS. Este capítulo fornece uma visão geral de como o Cassandra armazena seus dados.
Grupo
O banco de dados Cassandra é distribuído em várias máquinas que operam juntas. O contêiner externo é conhecido como Cluster. Para tratamento de falhas, cada nó contém uma réplica e, no caso de uma falha, a réplica assume o controle. O Cassandra organiza os nós em um cluster, em formato de anel, e atribui dados a eles.
Keyspace
Keyspace é o contêiner externo de dados no Cassandra. Os atributos básicos de um Keyspace no Cassandra são -
Replication factor - É o número de máquinas do cluster que receberão cópias dos mesmos dados.
Replica placement strategy- Nada mais é do que a estratégia de colocar réplicas no ringue. Temos estratégias comosimple strategy (estratégia baseada em rack), old network topology strategy (estratégia baseada em rack), e network topology strategy (estratégia de datacenter compartilhado).
Column families- Keyspace é um contêiner para uma lista de uma ou mais famílias de colunas. Uma família de colunas, por sua vez, é um contêiner de uma coleção de linhas. Cada linha contém colunas ordenadas. Famílias de colunas representam a estrutura de seus dados. Cada keyspace tem pelo menos uma e muitas vezes famílias de colunas.
A sintaxe de criação de um Keyspace é a seguinte -
CREATE KEYSPACE Keyspace name
WITH replication = {'class': 'SimpleStrategy', 'replication_factor' : 3};A ilustração a seguir mostra uma visão esquemática de um Keyspace.
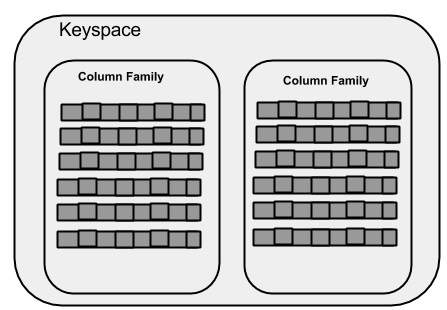
Família de coluna
Uma família de colunas é um contêiner para uma coleção ordenada de linhas. Cada linha, por sua vez, é uma coleção ordenada de colunas. A tabela a seguir lista os pontos que diferenciam um grupo de colunas de uma tabela de bancos de dados relacionais.
| Tabela Relacional | Família da coluna Cassandra |
|---|---|
| Um esquema em um modelo relacional é corrigido. Uma vez que definimos certas colunas para uma tabela, ao inserir dados, em cada linha todas as colunas devem ser preenchidas pelo menos com um valor nulo. | No Cassandra, embora as famílias de colunas sejam definidas, as colunas não são. Você pode adicionar livremente qualquer coluna a qualquer família de colunas a qualquer momento. |
| As tabelas relacionais definem apenas colunas e o usuário preenche a tabela com valores. | No Cassandra, uma tabela contém colunas ou pode ser definida como uma família de supercolunas. |
Uma família de colunas Cassandra tem os seguintes atributos -
keys_cached - Representa o número de locais a serem mantidos em cache por SSTable.
rows_cached - Representa o número de linhas cujo conteúdo inteiro será armazenado em cache na memória.
preload_row_cache - Especifica se você deseja preencher previamente o cache de linha.
Note − Ao contrário das tabelas relacionais em que o esquema de uma família de colunas não é fixo, o Cassandra não força as linhas individuais a ter todas as colunas.
A figura a seguir mostra um exemplo de uma família de colunas Cassandra.
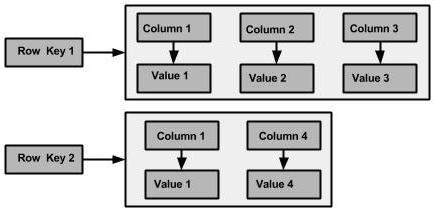
Coluna
Uma coluna é a estrutura de dados básica do Cassandra com três valores, a saber, chave ou nome da coluna, valor e um registro de data e hora. A seguir está a estrutura de uma coluna.

SuperColumn
Uma supercoluna é uma coluna especial, portanto, também é um par de valores-chave. Mas uma supercoluna armazena um mapa de subcolunas.
Geralmente as famílias de colunas são armazenadas no disco em arquivos individuais. Portanto, para otimizar o desempenho, é importante manter as colunas que você provavelmente consultará juntas na mesma família de colunas, e uma supercoluna pode ser útil aqui. Dada a seguir está a estrutura de uma supercoluna.

Modelos de dados de Cassandra e RDBMS
A tabela a seguir lista os pontos que diferenciam o modelo de dados do Cassandra daquele de um RDBMS.
| RDBMS | Cassandra |
|---|---|
| RDBMS lida com dados estruturados. | Cassandra lida com dados não estruturados. |
| Ele tem um esquema fixo. | Cassandra tem um esquema flexível. |
| No RDBMS, uma tabela é um array de arrays. (ROW x COLUMN) | No Cassandra, uma tabela é uma lista de “pares de valores-chave aninhados”. (Tecla ROW x COLUMN x valor COLUMN) |
| O banco de dados é o contêiner externo que contém os dados correspondentes a um aplicativo. | Keyspace é o contêiner mais externo que contém dados correspondentes a um aplicativo. |
| As tabelas são as entidades de um banco de dados. | Tabelas ou famílias de colunas são a entidade de um keyspace. |
| A linha é um registro individual no RDBMS. | Row é uma unidade de replicação em Cassandra. |
| A coluna representa os atributos de uma relação. | A coluna é uma unidade de armazenamento em Cassandra. |
| RDBMS suporta os conceitos de chaves estrangeiras, junções. | Os relacionamentos são representados por meio de coleções. |
O Cassandra pode ser acessado usando cqlsh, bem como drivers de diferentes idiomas. Este capítulo explica como configurar os ambientes cqlsh e java para trabalhar com o Cassandra.
Configuração de pré-instalação
Antes de instalar o Cassandra no ambiente Linux, é necessário configurar o Linux usando ssh(Capsula segura). Siga as etapas fornecidas abaixo para configurar o ambiente Linux.
Criar um usuário
No início, é recomendado criar um usuário separado para o Hadoop para isolar o sistema de arquivos Hadoop do sistema de arquivos Unix. Siga as etapas abaixo para criar um usuário.
Abra a raiz usando o comando “su”.
Crie um usuário a partir da conta root usando o comando “useradd username”.
Agora você pode abrir uma conta de usuário existente usando o comando “su username”.
Abra o terminal Linux e digite os seguintes comandos para criar um usuário.
$ su
password:
# useradd hadoop
# passwd hadoop
New passwd:
Retype new passwdConfiguração e geração de chave SSH
A configuração do SSH é necessária para executar diferentes operações em um cluster, como iniciar, parar e operações de shell daemon distribuído. Para autenticar diferentes usuários do Hadoop, é necessário fornecer um par de chaves pública / privada para um usuário do Hadoop e compartilhá-lo com diferentes usuários.
Os seguintes comandos são usados para gerar um par de valores-chave usando SSH -
- copie o formulário de chaves públicas id_rsa.pub para authorized_keys,
- e fornecer proprietário,
- permissões de leitura e gravação para o arquivo authorized_keys respectivamente.
$ ssh-keygen -t rsa
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys $ chmod 0600 ~/.ssh/authorized_keys- Verifique o ssh:
ssh localhostInstalando Java
Java é o principal pré-requisito do Cassandra. Em primeiro lugar, você deve verificar a existência de Java em seu sistema usando o seguinte comando -
$ java -versionSe tudo funcionar bem, você receberá a seguinte saída.
java version "1.7.0_71"
Java(TM) SE Runtime Environment (build 1.7.0_71-b13)
Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)Se você não tiver o Java em seu sistema, siga as etapas abaixo para instalar o Java.
Passo 1
Faça download do java (JDK <versão mais recente> - X64.tar.gz) no seguinte link:
Then jdk-7u71-linux-x64.tar.gz will be downloaded onto your system.
Passo 2
Geralmente, você encontrará o arquivo java baixado na pasta Downloads. Verifique e extraia ojdk-7u71-linux-x64.gz arquivo usando os seguintes comandos.
$ cd Downloads/
$ ls jdk-7u71-linux-x64.gz $ tar zxf jdk-7u71-linux-x64.gz
$ ls
jdk1.7.0_71 jdk-7u71-linux-x64.gzetapa 3
Para disponibilizar o Java para todos os usuários, você deve movê-lo para o local “/ usr / local /”. Abra o root e digite os seguintes comandos.
$ su
password:
# mv jdk1.7.0_71 /usr/local/
# exitPasso 4
Para configurar PATH e JAVA_HOME variáveis, adicione os seguintes comandos para ~/.bashrc Arquivo.
export JAVA_HOME = /usr/local/jdk1.7.0_71
export PATH = $PATH:$JAVA_HOME/binAgora aplique todas as alterações no sistema em execução atual.
$ source ~/.bashrcEtapa 5
Use os seguintes comandos para configurar alternativas java.
# alternatives --install /usr/bin/java java usr/local/java/bin/java 2
# alternatives --install /usr/bin/javac javac usr/local/java/bin/javac 2
# alternatives --install /usr/bin/jar jar usr/local/java/bin/jar 2
# alternatives --set java usr/local/java/bin/java
# alternatives --set javac usr/local/java/bin/javac
# alternatives --set jar usr/local/java/bin/jarAgora use o java -version comando do terminal como explicado acima.
Definindo o caminho
Defina o caminho do caminho do Cassandra em “/.bashrc” como mostrado abaixo.
[hadoop@linux ~]$ gedit ~/.bashrc
export CASSANDRA_HOME = ~/cassandra
export PATH = $PATH:$CASSANDRA_HOME/binBaixar Cassandra
O Apache Cassandra está disponível em Download Link Cassandra usando o seguinte comando.
$ wget http://supergsego.com/apache/cassandra/2.1.2/apache-cassandra-2.1.2-bin.tar.gzDescompacte o Cassandra usando o comando zxvf como mostrado abaixo.
$ tar zxvf apache-cassandra-2.1.2-bin.tar.gz.Crie um novo diretório chamado cassandra e mova o conteúdo do arquivo baixado para ele, conforme mostrado abaixo.
$ mkdir Cassandra $ mv apache-cassandra-2.1.2/* cassandra.Configure Cassandra
Abra o cassandra.yaml: arquivo, que estará disponível no bin diretório de Cassandra.
$ gedit cassandra.yamlNote - Se você instalou o Cassandra a partir de um pacote deb ou rpm, os arquivos de configuração estarão localizados em /etc/cassandra diretório de Cassandra.
O comando acima abre o cassandra.yamlArquivo. Verifique as seguintes configurações. Por padrão, esses valores serão definidos para os diretórios especificados.
data_file_directories “/var/lib/cassandra/data”
commitlog_directory “/var/lib/cassandra/commitlog”
save_caches_directory “/var/lib/cassandra/saved_caches”
Certifique-se de que esses diretórios existam e possam ser gravados, conforme mostrado abaixo.
Criar diretórios
Como superusuário, crie os dois diretórios /var/lib/cassandra e /var./log/cassandra no qual Cassandra grava seus dados.
[root@linux cassandra]# mkdir /var/lib/cassandra
[root@linux cassandra]# mkdir /var/log/cassandraDê permissões às pastas
Dê permissões de leitura e gravação às pastas recém-criadas, conforme mostrado abaixo.
[root@linux /]# chmod 777 /var/lib/cassandra
[root@linux /]# chmod 777 /var/log/cassandraComece Cassandra
Para iniciar o Cassandra, abra a janela do terminal, navegue até o diretório inicial / inicial do Cassandra, onde você descompactou o Cassandra, e execute o seguinte comando para iniciar o servidor Cassandra.
$ cd $CASSANDRA_HOME $./bin/cassandra -fUsar a opção –f informa ao Cassandra para permanecer em primeiro plano em vez de ser executado como um processo em segundo plano. Se tudo correr bem, você pode ver o servidor Cassandra sendo inicializado.
Ambiente de Programação
Para configurar o Cassandra programaticamente, baixe os seguintes arquivos jar -
- slf4j-api-1.7.5.jar
- cassandra-driver-core-2.0.2.jar
- guava-16.0.1.jar
- metrics-core-3.0.2.jar
- netty-3.9.0.Final.jar
Coloque-os em uma pasta separada. Por exemplo, estamos baixando esses jars para uma pasta chamada“Cassandra_jars”.
Defina o caminho de classe para esta pasta em “.bashrc”arquivo como mostrado abaixo.
[hadoop@linux ~]$ gedit ~/.bashrc //Set the following class path in the .bashrc file. export CLASSPATH = $CLASSPATH:/home/hadoop/Cassandra_jars/*Ambiente Eclipse
Abra o Eclipse e crie um novo projeto chamado Cassandra _Examples.
Clique com o botão direito no projeto, selecione Build Path→Configure Build Path como mostrado abaixo.
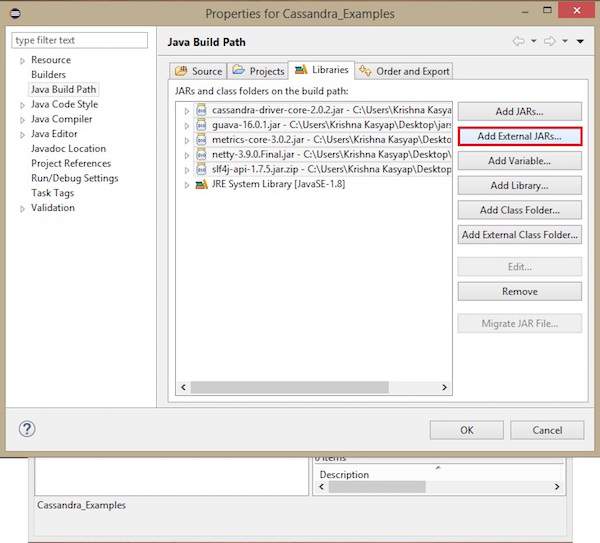
Isso abrirá a janela de propriedades. Na guia Bibliotecas, selecioneAdd External JARs. Navegue até o diretório onde você salvou seus arquivos jar. Selecione todos os cinco arquivos jar e clique em OK conforme mostrado abaixo.
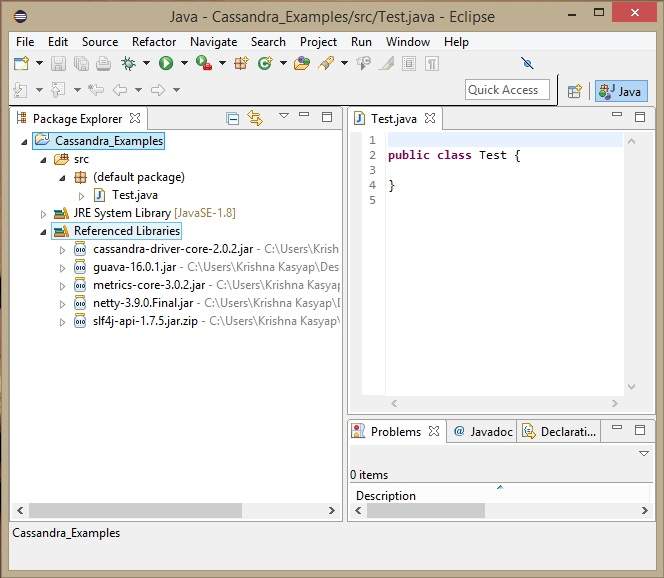
Em Bibliotecas referenciadas, você pode ver todos os jars necessários adicionados conforme mostrado abaixo -
Dependências Maven
Abaixo está o pom.xml para construir um projeto Cassandra usando o maven.
<project xmlns = "http://maven.apache.org/POM/4.0.0"
xmlns:xsi = "http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation = "http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<build>
<sourceDirectory>src</sourceDirectory>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>1.7</source>
<target>1.7</target>
</configuration>
</plugin>
</plugins>
</build>
<dependencies>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.5</version>
</dependency>
<dependency>
<groupId>com.datastax.cassandra</groupId>
<artifactId>cassandra-driver-core</artifactId>
<version>2.0.2</version>
</dependency>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>16.0.1</version>
</dependency>
<dependency>
<groupId>com.codahale.metrics</groupId>
<artifactId>metrics-core</artifactId>
<version>3.0.2</version>
</dependency>
<dependency>
<groupId>io.netty</groupId>
<artifactId>netty</artifactId>
<version>3.9.0.Final</version>
</dependency>
</dependencies>
</project>Este capítulo cobre todas as classes importantes do Cassandra.
Grupo
Esta classe é a principal porta de entrada do motorista. Isso pertence acom.datastax.driver.core pacote.
Métodos
| S. No. | Métodos e Descrição |
|---|---|
| 1 | Session connect() Ele cria uma nova sessão no cluster atual e o inicializa. |
| 2 | void close() Ele é usado para fechar a instância do cluster. |
| 3 | static Cluster.Builder builder() Ele é usado para criar uma nova instância Cluster.Builder. |
Cluster.Builder
Esta classe é usada para instanciar o Cluster.Builder classe.
Métodos
| S. Não | Métodos e Descrição |
|---|---|
| 1 | Cluster.Builder addContactPoint(String address) Este método adiciona um ponto de contato ao cluster. |
| 2 | Cluster build() Este método constrói o cluster com os pontos de contato fornecidos. |
Sessão
Esta interface mantém as conexões com o cluster Cassandra. Usando esta interface, você pode executarCQLconsultas. Isso pertence acom.datastax.driver.core pacote.
Métodos
| S. No. | Métodos e Descrição |
|---|---|
| 1 | void close() Este método é usado para fechar a instância da sessão atual. |
| 2 | ResultSet execute(Statement statement) Este método é usado para executar uma consulta. Requer um objeto de instrução. |
| 3 | ResultSet execute(String query) Este método é usado para executar uma consulta. Requer uma consulta na forma de um objeto String. |
| 4 | PreparedStatement prepare(RegularStatement statement) Este método prepara a consulta fornecida. A consulta deve ser fornecida na forma de uma Declaração. |
| 5 | PreparedStatement prepare(String query) Este método prepara a consulta fornecida. A consulta deve ser fornecida na forma de uma String. |
Este capítulo apresenta o shell da linguagem de consulta Cassandra e explica como usar seus comandos.
Por padrão, o Cassandra fornece um prompt de shell de linguagem de consulta do Cassandra (cqlsh)que permite aos usuários se comunicarem com ele. Usando este shell, você pode executarCassandra Query Language (CQL).
Usando cqlsh, você pode
- definir um esquema,
- inserir dados e
- execute uma consulta.
Iniciando cqlsh
Inicie o cqlsh usando o comando cqlshcomo mostrado abaixo. Ele fornece o prompt Cassandra cqlsh como saída.
[hadoop@linux bin]$ cqlsh
Connected to Test Cluster at 127.0.0.1:9042.
[cqlsh 5.0.1 | Cassandra 2.1.2 | CQL spec 3.2.0 | Native protocol v3]
Use HELP for help.
cqlsh>Cqlsh- Conforme discutido acima, este comando é usado para iniciar o prompt cqlsh. Além disso, ele oferece suporte a mais algumas opções. A tabela a seguir explica todas as opções decqlsh e seu uso.
| Opções | Uso |
|---|---|
| cqlsh --help | Mostra tópicos de ajuda sobre as opções de cqlsh comandos. |
| cqlsh --version | Fornece a versão do cqlsh que você está usando. |
| cqlsh --color | Direciona o shell para usar saída colorida. |
| cqlsh --debug | Mostra informações adicionais de depuração. |
| cqlsh --execute cql_statement |
Direciona o shell para aceitar e executar um comando CQL. |
| cqlsh --file = “file name” | Se você usar esta opção, o Cassandra executa o comando no arquivo fornecido e sai. |
| cqlsh - sem cor | Instrui Cassandra a não usar saída colorida. |
| cqlsh -u “user name” | Usando esta opção, você pode autenticar um usuário. O nome de usuário padrão é: cassandra. |
| cqlsh-p “pass word” | Usando esta opção, você pode autenticar um usuário com uma senha. A senha padrão é: cassandra. |
Comandos Cqlsh
Cqlsh possui alguns comandos que permitem aos usuários interagir com ele. Os comandos estão listados abaixo.
Comandos de Shell documentados
A seguir estão os comandos shell documentados do Cqlsh. Esses são os comandos usados para realizar tarefas como exibir tópicos de ajuda, sair do cqlsh, descrever, etc.
HELP - Exibe tópicos de ajuda para todos os comandos cqlsh.
CAPTURE - Captura a saída de um comando e adiciona a um arquivo.
CONSISTENCY - Mostra o nível de consistência atual ou define um novo nível de consistência.
COPY - Copia dados de e para Cassandra.
DESCRIBE - Descreve o cluster atual de Cassandra e seus objetos.
EXPAND - Expande a saída de uma consulta verticalmente.
EXIT - Usando este comando, você pode encerrar o cqlsh.
PAGING - Ativa ou desativa a paginação da consulta.
SHOW - Exibe os detalhes da sessão cqlsh atual, como versão do Cassandra, host ou suposições de tipo de dados.
SOURCE - Executa um arquivo que contém instruções CQL.
TRACING - Habilita ou desabilita o rastreamento de solicitação.
Comandos de definição de dados CQL
CREATE KEYSPACE - Cria um KeySpace no Cassandra.
USE - Conecta-se a um KeySpace criado.
ALTER KEYSPACE - Altera as propriedades de um KeySpace.
DROP KEYSPACE - Remove um KeySpace
CREATE TABLE - Cria uma tabela em um KeySpace.
ALTER TABLE - Modifica as propriedades da coluna de uma tabela.
DROP TABLE - Remove uma mesa.
TRUNCATE - Remove todos os dados de uma tabela.
CREATE INDEX - Define um novo índice em uma única coluna de uma tabela.
DROP INDEX - Exclui um índice nomeado.
Comandos de manipulação de dados CQL
INSERT - Adiciona colunas para uma linha em uma tabela.
UPDATE - Atualiza uma coluna de uma linha.
DELETE - Exclui dados de uma tabela.
BATCH - Executa várias instruções DML de uma vez.
Cláusulas CQL
SELECT - Esta cláusula lê dados de uma tabela
WHERE - A cláusula where é usada junto com select para ler dados específicos.
ORDERBY - A cláusula orderby é usada junto com select para ler dados específicos em uma ordem específica.
O Cassandra fornece comandos shell documentados, além dos comandos CQL. A seguir estão os comandos shell documentados do Cassandra.
Socorro
O comando HELP exibe uma sinopse e uma breve descrição de todos os comandos cqlsh. A seguir está o uso do comando help.
cqlsh> help
Documented shell commands:
===========================
CAPTURE COPY DESCRIBE EXPAND PAGING SOURCE
CONSISTENCY DESC EXIT HELP SHOW TRACING.
CQL help topics:
================
ALTER CREATE_TABLE_OPTIONS SELECT
ALTER_ADD CREATE_TABLE_TYPES SELECT_COLUMNFAMILY
ALTER_ALTER CREATE_USER SELECT_EXPR
ALTER_DROP DELETE SELECT_LIMIT
ALTER_RENAME DELETE_COLUMNS SELECT_TABLECapturar
Este comando captura a saída de um comando e a adiciona a um arquivo. Por exemplo, dê uma olhada no código a seguir que captura a saída para um arquivo denominadoOutputfile.
cqlsh> CAPTURE '/home/hadoop/CassandraProgs/Outputfile'Quando digitamos qualquer comando no terminal, a saída será capturada pelo arquivo fornecido. A seguir está o comando usado e o instantâneo do arquivo de saída.
cqlsh:tutorialspoint> select * from emp;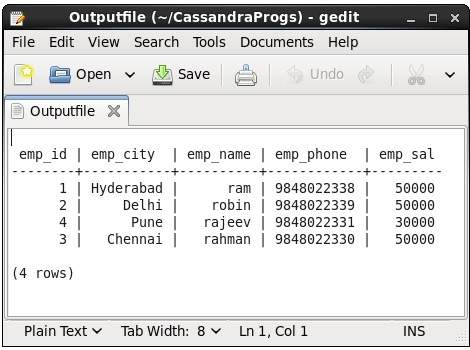
Você pode desativar a captura usando o seguinte comando.
cqlsh:tutorialspoint> capture off;Consistência
Este comando mostra o nível de consistência atual ou define um novo nível de consistência.
cqlsh:tutorialspoint> CONSISTENCY
Current consistency level is 1.cópia de
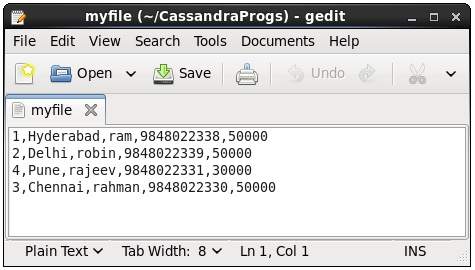
Este comando copia dados de e para Cassandra para um arquivo. Dada a seguir é um exemplo para copiar a tabela chamadaemp para o arquivo myfile.
cqlsh:tutorialspoint> COPY emp (emp_id, emp_city, emp_name, emp_phone,emp_sal) TO ‘myfile’;
4 rows exported in 0.034 seconds.Se você abrir e verificar o arquivo fornecido, poderá encontrar os dados copiados conforme mostrado abaixo.
Descrever
Este comando descreve o cluster atual do Cassandra e seus objetos. As variantes deste comando são explicadas a seguir.
Describe cluster - Este comando fornece informações sobre o cluster.
cqlsh:tutorialspoint> describe cluster;
Cluster: Test Cluster
Partitioner: Murmur3Partitioner
Range ownership:
-658380912249644557 [127.0.0.1]
-2833890865268921414 [127.0.0.1]
-6792159006375935836 [127.0.0.1]Describe Keyspaces- Este comando lista todos os espaços-chave em um cluster. Dada a seguir é o uso deste comando.
cqlsh:tutorialspoint> describe keyspaces;
system_traces system tp tutorialspointDescribe tables- Este comando lista todas as tabelas em um keyspace. Dada a seguir é o uso deste comando.
cqlsh:tutorialspoint> describe tables;
empDescribe table- Este comando fornece a descrição de uma tabela. Dada a seguir é o uso deste comando.
cqlsh:tutorialspoint> describe table emp;
CREATE TABLE tutorialspoint.emp (
emp_id int PRIMARY KEY,
emp_city text,
emp_name text,
emp_phone varint,
emp_sal varint
) WITH bloom_filter_fp_chance = 0.01
AND caching = '{"keys":"ALL", "rows_per_partition":"NONE"}'
AND comment = ''
AND compaction = {'min_threshold': '4', 'class':
'org.apache.cassandra.db.compaction.SizeTieredCompactionStrategy',
'max_threshold': '32'}
AND compression = {'sstable_compression':
'org.apache.cassandra.io.compress.LZ4Compressor'}
AND dclocal_read_repair_chance = 0.1
AND default_time_to_live = 0
AND gc_grace_seconds = 864000
AND max_index_interval = 2048
AND memtable_flush_period_in_ms = 0
AND min_index_interval = 128
AND read_repair_chance = 0.0
AND speculative_retry = '99.0PERCENTILE';
CREATE INDEX emp_emp_sal_idx ON tutorialspoint.emp (emp_sal);Descrever o tipo
Este comando é usado para descrever um tipo de dados definido pelo usuário. Dada a seguir é o uso deste comando.
cqlsh:tutorialspoint> describe type card_details;
CREATE TYPE tutorialspoint.card_details (
num int,
pin int,
name text,
cvv int,
phone set<int>,
mail text
);Descrever Tipos
Este comando lista todos os tipos de dados definidos pelo usuário. Dada a seguir é o uso deste comando. Suponha que haja dois tipos de dados definidos pelo usuário:card e card_details.
cqlsh:tutorialspoint> DESCRIBE TYPES;
card_details cardExpandir
Este comando é usado para expandir a saída. Antes de usar este comando, você deve ativar o comando de expansão. Dada a seguir é o uso deste comando.
cqlsh:tutorialspoint> expand on;
cqlsh:tutorialspoint> select * from emp;
@ Row 1
-----------+------------
emp_id | 1
emp_city | Hyderabad
emp_name | ram
emp_phone | 9848022338
emp_sal | 50000
@ Row 2
-----------+------------
emp_id | 2
emp_city | Delhi
emp_name | robin
emp_phone | 9848022339
emp_sal | 50000
@ Row 3
-----------+------------
emp_id | 4
emp_city | Pune
emp_name | rajeev
emp_phone | 9848022331
emp_sal | 30000
@ Row 4
-----------+------------
emp_id | 3
emp_city | Chennai
emp_name | rahman
emp_phone | 9848022330
emp_sal | 50000
(4 rows)Note - Você pode desativar a opção de expansão usando o seguinte comando.
cqlsh:tutorialspoint> expand off;
Disabled Expanded output.Saída
Este comando é usado para encerrar o shell cql.
exposição
Este comando exibe os detalhes da sessão cqlsh atual, como versão do Cassandra, host ou suposições de tipo de dados. Dada a seguir é o uso deste comando.
cqlsh:tutorialspoint> show host;
Connected to Test Cluster at 127.0.0.1:9042.
cqlsh:tutorialspoint> show version;
[cqlsh 5.0.1 | Cassandra 2.1.2 | CQL spec 3.2.0 | Native protocol v3]Fonte
Usando este comando, você pode executar os comandos em um arquivo. Suponha que nosso arquivo de entrada seja o seguinte -
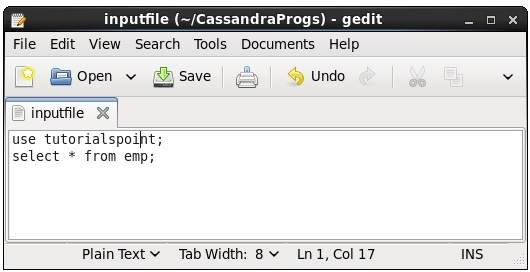
Então você pode executar o arquivo que contém os comandos conforme mostrado abaixo.
cqlsh:tutorialspoint> source '/home/hadoop/CassandraProgs/inputfile';
emp_id | emp_city | emp_name | emp_phone | emp_sal
--------+-----------+----------+------------+---------
1 | Hyderabad | ram | 9848022338 | 50000
2 | Delhi | robin | 9848022339 | 50000
3 | Pune | rajeev | 9848022331 | 30000
4 | Chennai | rahman | 9848022330 | 50000
(4 rows)Criando um Keyspace usando Cqlsh
Um keyspace no Cassandra é um namespace que define a replicação de dados em nós. Um cluster contém um keyspace por nó. Dada abaixo está a sintaxe para criar um keyspace usando a instruçãoCREATE KEYSPACE.
Sintaxe
CREATE KEYSPACE <identifier> WITH <properties>ie
CREATE KEYSPACE “KeySpace Name”
WITH replication = {'class': ‘Strategy name’, 'replication_factor' : ‘No.Of replicas’};
CREATE KEYSPACE “KeySpace Name”
WITH replication = {'class': ‘Strategy name’, 'replication_factor' : ‘No.Of replicas’}
AND durable_writes = ‘Boolean value’;A instrução CREATE KEYSPACE tem duas propriedades: replication e durable_writes.
Replicação
A opção de replicação é especificar o Replica Placement strategye o número de réplicas desejadas. A tabela a seguir lista todas as estratégias de posicionamento de réplicas.
| Nome da estratégia | Descrição |
|---|---|
| Simple Strategy' | Especifica um fator de replicação simples para o cluster. |
| Network Topology Strategy | Usando esta opção, você pode definir o fator de replicação para cada datacenter independentemente. |
| Old Network Topology Strategy | Esta é uma estratégia de replicação legada. |
Usando esta opção, você pode instruir Cassandra se deve usar commitlogpara atualizações no KeySpace atual. Esta opção não é obrigatória e, por padrão, é definida como verdadeira.
Exemplo
Abaixo está um exemplo de criação de um KeySpace.
Aqui estamos criando um KeySpace chamado TutorialsPoint.
Estamos usando a estratégia de colocação da primeira réplica, ou seja, Simple Strategy.
E estamos escolhendo o fator de replicação para 1 replica.
cqlsh.> CREATE KEYSPACE tutorialspoint
WITH replication = {'class':'SimpleStrategy', 'replication_factor' : 3};Verificação
Você pode verificar se a tabela é criada ou não usando o comando Describe. Se você usar este comando sobre os espaços-chave, ele exibirá todos os espaços-chave criados conforme mostrado abaixo.
cqlsh> DESCRIBE keyspaces;
tutorialspoint system system_tracesAqui você pode observar o KeySpace recém-criado tutorialspoint.
Durable_writes
Por padrão, as propriedades duráveis_writes de uma tabela são definidas como true,no entanto, pode ser definido como falso. Você não pode definir esta propriedade parasimplex strategy.
Exemplo
A seguir está o exemplo que demonstra o uso da propriedade de gravações duráveis.
cqlsh> CREATE KEYSPACE test
... WITH REPLICATION = { 'class' : 'NetworkTopologyStrategy', 'datacenter1' : 3 }
... AND DURABLE_WRITES = false;Verificação
Você pode verificar se a propriedade tough_writes do KeySpace de teste foi definida como falsa consultando o KeySpace do sistema. Esta consulta fornece todos os KeySpaces junto com suas propriedades.
cqlsh> SELECT * FROM system_schema.keyspaces;
keyspace_name | durable_writes | strategy_class | strategy_options
----------------+----------------+------------------------------------------------------+----------------------------
test | False | org.apache.cassandra.locator.NetworkTopologyStrategy | {"datacenter1" : "3"}
tutorialspoint | True | org.apache.cassandra.locator.SimpleStrategy | {"replication_factor" : "4"}
system | True | org.apache.cassandra.locator.LocalStrategy | { }
system_traces | True | org.apache.cassandra.locator.SimpleStrategy | {"replication_factor" : "2"}
(4 rows)Aqui você pode observar que a propriedade tough_writes do teste KeySpace foi definida como falsa.
Usando um Keyspace
Você pode usar um KeySpace criado usando a palavra-chave USE. Sua sintaxe é a seguinte -
Syntax:USE <identifier>Exemplo
No exemplo a seguir, estamos usando o KeySpace tutorialspoint.
cqlsh> USE tutorialspoint;
cqlsh:tutorialspoint>Criação de um Keyspace usando a API Java
Você pode criar um Keyspace usando o execute() método de Sessionclasse. Siga as etapas fornecidas abaixo para criar um keyspace usando a API Java.
Etapa 1: Criar um objeto de cluster
Primeiro de tudo, crie uma instância de Cluster.builder classe de com.datastax.driver.core pacote conforme mostrado abaixo.
//Creating Cluster.Builder object
Cluster.Builder builder1 = Cluster.builder();Adicione um ponto de contato (endereço IP do nó) usando addContactPoint() método de Cluster.Builderobjeto. Este método retornaCluster.Builder.
//Adding contact point to the Cluster.Builder object
Cluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );Usando o novo objeto construtor, crie um objeto de cluster. Para fazer isso, você tem um método chamadobuild() no Cluster.Builderclasse. O código a seguir mostra como criar um objeto de cluster.
//Building a cluster
Cluster cluster = builder.build();Você pode construir um objeto de cluster em uma única linha de código, conforme mostrado abaixo.
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();Etapa 2: Criar um objeto de sessão
Crie uma instância de Session objeto usando o connect() método de Cluster classe como mostrado abaixo.
Session session = cluster.connect( );Este método cria uma nova sessão e a inicializa. Se você já tiver um keyspace, poderá defini-lo como o existente passando o nome do keyspace no formato de string para este método, conforme mostrado abaixo.
Session session = cluster.connect(“ Your keyspace name ” );Etapa 3: Executar consulta
Você pode executar CQL consultas usando o execute() método de Sessionclasse. Passe a consulta em formato de string ou como umStatement objeto de classe para o execute()método. Tudo o que você passar para este método em formato de string será executado nocqlsh.
Neste exemplo, estamos criando um KeySpace chamado tp. Estamos usando a estratégia de colocação da primeira réplica, ou seja, Estratégia Simples, e estamos escolhendo o fator de replicação para 1 réplica.
Você deve armazenar a consulta em uma variável de string e passá-la para o método execute () como mostrado abaixo.
String query = "CREATE KEYSPACE tp WITH replication "
+ "= {'class':'SimpleStrategy', 'replication_factor':1}; ";
session.execute(query);Passo 4: Use o KeySpace
Você pode usar um KeySpace criado usando o método execute () conforme mostrado abaixo.
execute(“ USE tp ” );A seguir está o programa completo para criar e usar um keyspace no Cassandra usando a API Java.
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Create_KeySpace {
public static void main(String args[]){
//Query
String query = "CREATE KEYSPACE tp WITH replication "
+ "= {'class':'SimpleStrategy', 'replication_factor':1};";
//creating Cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect();
//Executing the query
session.execute(query);
//using the KeySpace
session.execute("USE tp");
System.out.println("Keyspace created");
}
}Salve o programa acima com o nome da classe seguido por .java, navegue até o local onde ele foi salvo. Compile e execute o programa conforme mostrado abaixo.
$javac Create_KeySpace.java
$java Create_KeySpaceEm condições normais, ele produzirá a seguinte saída -
Keyspace createdAlterando um KeySpace
ALTER KEYSPACE pode ser usado para alterar propriedades, como o número de réplicas e o tough_writes de um KeySpace. A seguir está a sintaxe deste comando.
Sintaxe
ALTER KEYSPACE <identifier> WITH <properties>ie
ALTER KEYSPACE “KeySpace Name”
WITH replication = {'class': ‘Strategy name’, 'replication_factor' : ‘No.Of replicas’};As propriedades de ALTER KEYSPACEsão iguais a CREATE KEYSPACE. Possui duas propriedades:replication e durable_writes.
Replicação
A opção de replicação especifica a estratégia de posicionamento da réplica e o número de réplicas desejadas.
Durable_writes
Usando esta opção, você pode instruir Cassandra se deve usar o commitlog para atualizações no KeySpace atual. Esta opção não é obrigatória e, por padrão, é definida como verdadeira.
Exemplo
A seguir está um exemplo de alteração de um KeySpace.
Aqui estamos alterando um KeySpace chamado TutorialsPoint.
Estamos mudando o fator de replicação de 1 para 3.
cqlsh.> ALTER KEYSPACE tutorialspoint
WITH replication = {'class':'NetworkTopologyStrategy', 'replication_factor' : 3};Alterando Durable_writes
Você também pode alterar a propriedade tough_writes de um KeySpace. Dada a seguir é a propriedade tough_writes dotest KeySpace.
SELECT * FROM system_schema.keyspaces;
keyspace_name | durable_writes | strategy_class | strategy_options
----------------+----------------+------------------------------------------------------+----------------------------
test | False | org.apache.cassandra.locator.NetworkTopologyStrategy | {"datacenter1":"3"}
tutorialspoint | True | org.apache.cassandra.locator.SimpleStrategy | {"replication_factor":"4"}
system | True | org.apache.cassandra.locator.LocalStrategy | { }
system_traces | True | org.apache.cassandra.locator.SimpleStrategy | {"replication_factor":"2"}
(4 rows)ALTER KEYSPACE test
WITH REPLICATION = {'class' : 'NetworkTopologyStrategy', 'datacenter1' : 3}
AND DURABLE_WRITES = true;Mais uma vez, se você verificar as propriedades de KeySpaces, ele produzirá a seguinte saída.
SELECT * FROM system_schema.keyspaces;
keyspace_name | durable_writes | strategy_class | strategy_options
----------------+----------------+------------------------------------------------------+----------------------------
test | True | org.apache.cassandra.locator.NetworkTopologyStrategy | {"datacenter1":"3"}
tutorialspoint | True | org.apache.cassandra.locator.SimpleStrategy | {"replication_factor":"4"}
system | True | org.apache.cassandra.locator.LocalStrategy | { }
system_traces | True | org.apache.cassandra.locator.SimpleStrategy | {"replication_factor":"2"}
(4 rows)Alterando um Keyspace usando a API Java
Você pode alterar um keyspace usando o execute() método de Sessionclasse. Siga as etapas fornecidas abaixo para alterar um keyspace usando a API Java
Etapa 1: Criar um objeto de cluster
Primeiro de tudo, crie uma instância de Cluster.builder classe de com.datastax.driver.core pacote conforme mostrado abaixo.
//Creating Cluster.Builder object
Cluster.Builder builder1 = Cluster.builder();Adicione um ponto de contato (endereço IP do nó) usando o addContactPoint() método de Cluster.Builderobjeto. Este método retornaCluster.Builder.
//Adding contact point to the Cluster.Builder object
Cluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );Usando o novo objeto construtor, crie um objeto de cluster. Para fazer isso, você tem um método chamadobuild() no Cluster.Builderclasse. O código a seguir mostra como criar um objeto de cluster.
//Building a cluster
Cluster cluster = builder.build();Você pode construir o objeto de cluster usando uma única linha de código, conforme mostrado abaixo.
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();Etapa 2: Criar um objeto de sessão
Crie uma instância de Session objeto usando o connect() método de Clusterclasse como mostrado abaixo.
Session session = cluster.connect( );Este método cria uma nova sessão e a inicializa. Se você já tiver um keyspace, poderá defini-lo como o existente passando o nome do keyspace no formato de string para este método, conforme mostrado abaixo.
Session session = cluster.connect(“ Your keyspace name ” );Etapa 3: Executar consulta
Você pode executar consultas CQL usando o método execute () da classe Session. Passe a consulta em formato de string ou como umStatementobjeto de classe para o método execute (). Tudo o que você passar para este método em formato de string será executado nocqlsh.
Neste exemplo,
Estamos alterando um keyspace chamado tp. Estamos alterando a opção de replicação de Estratégia Simples para Estratégia de Topologia de Rede.
Estamos alterando o durable_writes para falso
Você deve armazenar a consulta em uma variável de string e passá-la para o método execute () como mostrado abaixo.
//Query
String query = "ALTER KEYSPACE tp WITH replication " + "= {'class':'NetworkTopologyStrategy', 'datacenter1':3}" +" AND DURABLE_WRITES = false;";
session.execute(query);A seguir está o programa completo para criar e usar um keyspace no Cassandra usando a API Java.
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Alter_KeySpace {
public static void main(String args[]){
//Query
String query = "ALTER KEYSPACE tp WITH replication " + "= {'class':'NetworkTopologyStrategy', 'datacenter1':3}"
+ "AND DURABLE_WRITES = false;";
//Creating Cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect();
//Executing the query
session.execute(query);
System.out.println("Keyspace altered");
}
}Salve o programa acima com o nome da classe seguido por .java, navegue até o local onde ele foi salvo. Compile e execute o programa conforme mostrado abaixo.
$javac Alter_KeySpace.java
$java Alter_KeySpaceEm condições normais, ele produz a seguinte saída -
Keyspace AlteredLargando um Keyspace
Você pode soltar um KeySpace usando o comando DROP KEYSPACE. A seguir está a sintaxe para descartar um KeySpace.
Sintaxe
DROP KEYSPACE <identifier>ie
DROP KEYSPACE “KeySpace name”Exemplo
O código a seguir exclui o keyspace tutorialspoint.
cqlsh> DROP KEYSPACE tutorialspoint;Verificação
Verifique os espaços de chave usando o comando Describe e verifique se a tabela foi eliminada conforme mostrado abaixo.
cqlsh> DESCRIBE keyspaces;
system system_tracesComo excluímos o ponto de tutorial do keyspace, você não o encontrará na lista de keyspaces.
Eliminando um Keyspace usando a API Java
Você pode criar um keyspace usando o método execute () da classe Session. Siga as etapas fornecidas abaixo para eliminar um keyspace usando a API Java.
Etapa 1: Criar um objeto de cluster
Primeiro de tudo, crie uma instância de Cluster.builder classe de com.datastax.driver.core pacote conforme mostrado abaixo.
//Creating Cluster.Builder object
Cluster.Builder builder1 = Cluster.builder();Adicione um ponto de contato (endereço IP do nó) usando o addContactPoint() método de Cluster.Builderobjeto. Este método retornaCluster.Builder.
//Adding contact point to the Cluster.Builder object
Cluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );Usando o novo objeto construtor, crie um objeto de cluster. Para fazer isso, você tem um método chamadobuild() no Cluster.Builderclasse. O código a seguir mostra como criar um objeto de cluster.
//Building a cluster
Cluster cluster = builder.build();Você pode construir um objeto de cluster usando uma única linha de código, conforme mostrado abaixo.
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();Etapa 2: Criar um objeto de sessão
Crie uma instância do objeto Session usando o método connect () da classe Cluster como mostrado abaixo.
Session session = cluster.connect( );Este método cria uma nova sessão e a inicializa. Se você já tiver um keyspace, poderá defini-lo como o existente passando o nome do keyspace no formato de string para este método, conforme mostrado abaixo.
Session session = cluster.connect(“ Your keyspace name”);Etapa 3: Executar consulta
Você pode executar consultas CQL usando o método execute () da classe Session. Passe a consulta no formato de string ou como um objeto da classe Statement para o método execute (). Tudo o que você passar para este método em formato de string será executado no cqlsh.
No exemplo a seguir, estamos excluindo um keyspace chamado tp. Você deve armazenar a consulta em uma variável de string e passá-la para o método execute () como mostrado abaixo.
String query = "DROP KEYSPACE tp; ";
session.execute(query);A seguir está o programa completo para criar e usar um keyspace no Cassandra usando a API Java.
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Drop_KeySpace {
public static void main(String args[]){
//Query
String query = "Drop KEYSPACE tp";
//creating Cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect();
//Executing the query
session.execute(query);
System.out.println("Keyspace deleted");
}
}Salve o programa acima com o nome da classe seguido por .java, navegue até o local onde ele foi salvo. Compile e execute o programa conforme mostrado abaixo.
$javac Delete_KeySpace.java
$java Delete_KeySpaceEm condições normais, ele deve produzir a seguinte saída -
Keyspace deletedCriação de uma mesa
Você pode criar uma tabela usando o comando CREATE TABLE. A seguir está a sintaxe para a criação de uma tabela.
Sintaxe
CREATE (TABLE | COLUMNFAMILY) <tablename>
('<column-definition>' , '<column-definition>')
(WITH <option> AND <option>)Definindo uma coluna
Você pode definir uma coluna conforme mostrado abaixo.
column name1 data type,
column name2 data type,
example:
age int,
name textChave primária
A chave primária é uma coluna usada para identificar exclusivamente uma linha. Portanto, definir uma chave primária é obrigatório ao criar uma tabela. Uma chave primária é composta por uma ou mais colunas de uma tabela. Você pode definir uma chave primária de uma tabela conforme mostrado abaixo.
CREATE TABLE tablename(
column1 name datatype PRIMARYKEY,
column2 name data type,
column3 name data type.
)or
CREATE TABLE tablename(
column1 name datatype PRIMARYKEY,
column2 name data type,
column3 name data type,
PRIMARY KEY (column1)
)Exemplo
Dada a seguir é um exemplo para criar uma tabela no Cassandra usando cqlsh. Aqui estamos nós -
Usando o keyspace tutorialspoint
Criação de uma mesa chamada emp
Ele terá detalhes como nome do funcionário, id, cidade, salário e número de telefone. A identificação do funcionário é a chave primária.
cqlsh> USE tutorialspoint;
cqlsh:tutorialspoint>; CREATE TABLE emp(
emp_id int PRIMARY KEY,
emp_name text,
emp_city text,
emp_sal varint,
emp_phone varint
);Verificação
A instrução select fornecerá o esquema. Verifique a tabela usando a instrução select conforme mostrado abaixo.
cqlsh:tutorialspoint> select * from emp;
emp_id | emp_city | emp_name | emp_phone | emp_sal
--------+----------+----------+-----------+---------
(0 rows)Aqui você pode observar a tabela criada com as colunas fornecidas. Como excluímos o ponto de tutorial do keyspace, você não o encontrará na lista de keyspaces.
Criação de uma tabela usando a API Java
Você pode criar uma tabela usando o método execute () da classe Session. Siga as etapas fornecidas a seguir para criar uma tabela usando a API Java.
Etapa 1: Criar um objeto de cluster
Primeiro de tudo, crie uma instância do Cluster.builder classe de com.datastax.driver.core pacote conforme mostrado abaixo.
//Creating Cluster.Builder object
Cluster.Builder builder1 = Cluster.builder();Adicione um ponto de contato (endereço IP do nó) usando o addContactPoint() método de Cluster.Builderobjeto. Este método retornaCluster.Builder.
//Adding contact point to the Cluster.Builder object
Cluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );Usando o novo objeto construtor, crie um objeto de cluster. Para fazer isso, você tem um método chamadobuild() no Cluster.Builderclasse. O código a seguir mostra como criar um objeto de cluster.
//Building a cluster
Cluster cluster = builder.build();Você pode construir um objeto de cluster usando uma única linha de código, conforme mostrado abaixo.
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();Etapa 2: Criar um objeto de sessão
Crie uma instância do objeto Session usando o connect() método de Cluster classe como mostrado abaixo.
Session session = cluster.connect( );Este método cria uma nova sessão e a inicializa. Se você já tiver um keyspace, poderá defini-lo como o existente passando o nome do keyspace no formato de string para este método, conforme mostrado abaixo.
Session session = cluster.connect(“ Your keyspace name ” );Aqui estamos usando o keyspace chamado tp. Portanto, crie o objeto de sessão conforme mostrado abaixo.
Session session = cluster.connect(“ tp” );Etapa 3: Executar consulta
Você pode executar consultas CQL usando o método execute () da classe Session. Passe a consulta no formato de string ou como um objeto da classe Statement para o método execute (). Tudo o que você passar para este método em formato de string será executado no cqlsh.
No exemplo a seguir, estamos criando uma tabela chamada emp. Você deve armazenar a consulta em uma variável de string e passá-la para o método execute () como mostrado abaixo.
//Query
String query = "CREATE TABLE emp(emp_id int PRIMARY KEY, "
+ "emp_name text, "
+ "emp_city text, "
+ "emp_sal varint, "
+ "emp_phone varint );";
session.execute(query);A seguir está o programa completo para criar e usar um keyspace no Cassandra usando a API Java.
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Create_Table {
public static void main(String args[]){
//Query
String query = "CREATE TABLE emp(emp_id int PRIMARY KEY, "
+ "emp_name text, "
+ "emp_city text, "
+ "emp_sal varint, "
+ "emp_phone varint );";
//Creating Cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect("tp");
//Executing the query
session.execute(query);
System.out.println("Table created");
}
}Salve o programa acima com o nome da classe seguido por .java, navegue até o local onde ele foi salvo. Compile e execute o programa conforme mostrado abaixo.
$javac Create_Table.java
$java Create_TableEm condições normais, ele deve produzir a seguinte saída -
Table createdAlterando uma Mesa
Você pode alterar uma tabela usando o comando ALTER TABLE. A seguir está a sintaxe para a criação de uma tabela.
Sintaxe
ALTER (TABLE | COLUMNFAMILY) <tablename> <instruction>Usando o comando ALTER, você pode realizar as seguintes operações -
Adicione uma coluna
Solte uma coluna
Adicionando uma coluna
Usando o comando ALTER, você pode adicionar uma coluna a uma tabela. Ao adicionar colunas, você deve tomar cuidado para que o nome da coluna não entre em conflito com os nomes das colunas existentes e que a tabela não seja definida com a opção de armazenamento compacto. A seguir está a sintaxe para adicionar uma coluna a uma tabela.
ALTER TABLE table name
ADD new column datatype;Example
A seguir é fornecido um exemplo para adicionar uma coluna a uma tabela existente. Aqui estamos adicionando uma coluna chamadaemp_email de tipo de dados de texto para a tabela chamada emp.
cqlsh:tutorialspoint> ALTER TABLE emp
... ADD emp_email text;Verification
Use a instrução SELECT para verificar se a coluna foi adicionada ou não. Aqui você pode observar a coluna emp_email recém-adicionada.
cqlsh:tutorialspoint> select * from emp;
emp_id | emp_city | emp_email | emp_name | emp_phone | emp_sal
--------+----------+-----------+----------+-----------+---------Soltando uma coluna
Usando o comando ALTER, você pode excluir uma coluna de uma tabela. Antes de eliminar uma coluna de uma tabela, verifique se a tabela não está definida com a opção de armazenamento compacto. A seguir é fornecida a sintaxe para excluir uma coluna de uma tabela usando o comando ALTER.
ALTER table name
DROP column name;Example
A seguir, é fornecido um exemplo para eliminar uma coluna de uma tabela. Aqui estamos excluindo a coluna chamadaemp_email.
cqlsh:tutorialspoint> ALTER TABLE emp DROP emp_email;Verification
Verifique se a coluna foi excluída usando o select declaração, conforme mostrado abaixo.
cqlsh:tutorialspoint> select * from emp;
emp_id | emp_city | emp_name | emp_phone | emp_sal
--------+----------+----------+-----------+---------
(0 rows)Desde a emp_email coluna foi excluída, você não pode mais encontrá-la.
Alterando uma tabela usando a API Java
Você pode criar uma tabela usando o método execute () da classe Session. Siga as etapas fornecidas a seguir para alterar uma tabela usando a API Java.
Etapa 1: Criar um objeto de cluster
Primeiro de tudo, crie uma instância de Cluster.builder classe de com.datastax.driver.core pacote conforme mostrado abaixo.
//Creating Cluster.Builder object
Cluster.Builder builder1 = Cluster.builder();Adicione um ponto de contato (endereço IP do nó) usando o addContactPoint() método de Cluster.Builderobjeto. Este método retornaCluster.Builder.
//Adding contact point to the Cluster.Builder object
Cluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );Usando o novo objeto construtor, crie um objeto de cluster. Para fazer isso, você tem um método chamadobuild() no Cluster.Builderclasse. O código a seguir mostra como criar um objeto de cluster.
//Building a cluster
Cluster cluster = builder.build();Você pode construir um objeto de cluster usando uma única linha de código, conforme mostrado abaixo.
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();Etapa 2: Criar um objeto de sessão
Crie uma instância do objeto Session usando o método connect () da classe Cluster como mostrado abaixo.
Session session = cluster.connect( );Este método cria uma nova sessão e a inicializa. Se você já tiver um keyspace, poderá defini-lo como o existente passando o nome do KeySpace em formato de string para este método, conforme mostrado abaixo.
Session session = cluster.connect(“ Your keyspace name ” );
Session session = cluster.connect(“ tp” );Aqui, estamos usando o KeySpace chamado tp. Portanto, crie o objeto de sessão conforme mostrado abaixo.
Etapa 3: Executar consulta
Você pode executar consultas CQL usando o método execute () da classe Session. Passe a consulta no formato de string ou como um objeto da classe Statement para o método execute (). Tudo o que você passar para este método em formato de string será executado nocqlsh.
No exemplo a seguir, estamos adicionando uma coluna a uma tabela chamada emp. Para fazer isso, você deve armazenar a consulta em uma variável de string e passá-la para o método execute () conforme mostrado abaixo.
//Query
String query1 = "ALTER TABLE emp ADD emp_email text";
session.execute(query);A seguir está o programa completo para adicionar uma coluna a uma tabela existente.
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Add_column {
public static void main(String args[]){
//Query
String query = "ALTER TABLE emp ADD emp_email text";
//Creating Cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect("tp");
//Executing the query
session.execute(query);
System.out.println("Column added");
}
}Salve o programa acima com o nome da classe seguido por .java, navegue até o local onde ele foi salvo. Compile e execute o programa conforme mostrado abaixo.
$javac Add_Column.java
$java Add_ColumnEm condições normais, ele deve produzir a seguinte saída -
Column addedExcluindo uma Coluna
A seguir está o programa completo para excluir uma coluna de uma tabela existente.
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Delete_Column {
public static void main(String args[]){
//Query
String query = "ALTER TABLE emp DROP emp_email;";
//Creating Cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect("tp");
//executing the query
session.execute(query);
System.out.println("Column deleted");
}
}Salve o programa acima com o nome da classe seguido por .java, navegue até o local onde ele foi salvo. Compile e execute o programa conforme mostrado abaixo.
$javac Delete_Column.java
$java Delete_ColumnEm condições normais, ele deve produzir a seguinte saída -
Column deletedDeixando cair uma mesa
Você pode eliminar uma tabela usando o comando Drop Table. Sua sintaxe é a seguinte -
Sintaxe
DROP TABLE <tablename>Exemplo
O código a seguir remove uma tabela existente de um KeySpace.
cqlsh:tutorialspoint> DROP TABLE emp;Verificação
Use o comando Descrever para verificar se a tabela foi excluída ou não. Como a tabela emp foi excluída, você não a encontrará na lista de famílias de colunas.
cqlsh:tutorialspoint> DESCRIBE COLUMNFAMILIES;
employeeExcluindo uma tabela usando a API Java
Você pode deletar uma tabela usando o método execute () da classe Session. Siga as etapas fornecidas a seguir para excluir uma tabela usando a API Java.
Etapa 1: Criar um objeto de cluster
Primeiro de tudo, crie uma instância de Cluster.builder classe de com.datastax.driver.core pacote como mostrado abaixo -
//Creating Cluster.Builder object
Cluster.Builder builder1 = Cluster.builder();Adicione um ponto de contato (endereço IP do nó) usando addContactPoint() método de Cluster.Builderobjeto. Este método retornaCluster.Builder.
//Adding contact point to the Cluster.Builder object
Cluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );Usando o novo objeto construtor, crie um objeto de cluster. Para fazer isso, você tem um método chamadobuild() no Cluster.Builderclasse. O código a seguir mostra como criar um objeto de cluster.
//Building a cluster
Cluster cluster = builder.build();Você pode construir um objeto de cluster usando uma única linha de código, conforme mostrado abaixo.
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();Etapa 2: Criar um objeto de sessão
Crie uma instância do objeto Session usando o método connect () da classe Cluster como mostrado abaixo.
Session session = cluster.connect( );Este método cria uma nova sessão e a inicializa. Se você já tiver um keyspace, poderá defini-lo como o existente passando o nome do KeySpace em formato de string para este método, conforme mostrado abaixo.
Session session = cluster.connect(“Your keyspace name”);Aqui estamos usando o keyspace chamado tp. Portanto, crie o objeto de sessão conforme mostrado abaixo.
Session session = cluster.connect(“tp”);Etapa 3: Executar consulta
Você pode executar consultas CQL usando o método execute () da classe Session. Passe a consulta no formato de string ou como um objeto da classe Statement para o método execute (). Tudo o que você passar para este método em formato de string será executado nocqlsh.
No exemplo a seguir, estamos excluindo uma tabela chamada emp. Você deve armazenar a consulta em uma variável de string e passá-la para o método execute () como mostrado abaixo.
// Query
String query = "DROP TABLE emp1;”;
session.execute(query);A seguir está o programa completo para eliminar uma tabela no Cassandra usando a API Java.
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Drop_Table {
public static void main(String args[]){
//Query
String query = "DROP TABLE emp1;";
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect("tp");
//Executing the query
session.execute(query);
System.out.println("Table dropped");
}
}Salve o programa acima com o nome da classe seguido por .java, navegue até o local onde ele foi salvo. Compile e execute o programa conforme mostrado abaixo.
$javac Drop_Table.java
$java Drop_TableEm condições normais, ele deve produzir a seguinte saída -
Table droppedTruncando uma mesa
Você pode truncar uma tabela usando o comando TRUNCATE. Quando você trunca uma tabela, todas as linhas da tabela são excluídas permanentemente. A seguir está a sintaxe deste comando.
Sintaxe
TRUNCATE <tablename>Exemplo
Vamos supor que existe uma mesa chamada student com os seguintes dados.
| s_id | s_name | s_branch | s_aggregate |
|---|---|---|---|
| 1 | RAM | ISTO | 70 |
| 2 | rahman | EEE | 75 |
| 3 | robbin | Mech | 72 |
Quando você executa a instrução select para obter a tabela student, ele lhe dará a seguinte saída.
cqlsh:tp> select * from student;
s_id | s_aggregate | s_branch | s_name
------+-------------+----------+--------
1 | 70 | IT | ram
2 | 75 | EEE | rahman
3 | 72 | MECH | robbin
(3 rows)Agora trunque a tabela usando o comando TRUNCATE.
cqlsh:tp> TRUNCATE student;Verificação
Verifique se a tabela está truncada executando o selectdeclaração. A seguir, está a saída da instrução select na mesa do aluno após o truncamento.
cqlsh:tp> select * from student;
s_id | s_aggregate | s_branch | s_name
------+-------------+----------+--------
(0 rows)Truncando uma tabela usando a API Java
Você pode truncar uma tabela usando o método execute () da classe Session. Siga as etapas fornecidas abaixo para truncar uma tabela.
Etapa 1: Criar um objeto de cluster
Primeiro de tudo, crie uma instância de Cluster.builder classe de com.datastax.driver.core pacote conforme mostrado abaixo.
//Creating Cluster.Builder object
Cluster.Builder builder1 = Cluster.builder();Adicione um ponto de contato (endereço IP do nó) usando o addContactPoint() método de Cluster.Builderobjeto. Este método retornaCluster.Builder.
//Adding contact point to the Cluster.Builder object
Cluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );Usando o novo objeto construtor, crie um objeto de cluster. Para fazer isso, você tem um método chamadobuild() no Cluster.Builderclasse. O código a seguir mostra como criar um objeto de cluster.
//Building a cluster
Cluster cluster = builder.build();Você pode construir um objeto de cluster usando uma única linha de código, conforme mostrado abaixo.
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();Etapa 2: Criação de um objeto de sessão
Crie uma instância do objeto Session usando o método connect () da classe Cluster como mostrado abaixo.
Session session = cluster.connect( );Este método cria uma nova sessão e a inicializa. Se você já tiver um keyspace, poderá defini-lo como o existente passando o nome do KeySpace em formato de string para este método, conforme mostrado abaixo.
Session session = cluster.connect(“ Your keyspace name ” );
Session session = cluster.connect(“ tp” );Aqui, estamos usando o keyspace chamado tp. Portanto, crie o objeto de sessão conforme mostrado abaixo.
Etapa 3: Executar consulta
Você pode executar consultas CQL usando o método execute () da classe Session. Passe a consulta no formato de string ou como um objeto da classe Statement para o método execute (). Tudo o que você passar para este método em formato de string será executado nocqlsh.
No exemplo a seguir, estamos truncando uma tabela chamada emp. Você tem que armazenar a consulta em uma variável de string e passá-la para oexecute() método conforme mostrado abaixo.
//Query
String query = "TRUNCATE emp;;”;
session.execute(query);A seguir está o programa completo para truncar uma tabela no Cassandra usando a API Java.
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Truncate_Table {
public static void main(String args[]){
//Query
String query = "Truncate student;";
//Creating Cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect("tp");
//Executing the query
session.execute(query);
System.out.println("Table truncated");
}
}Salve o programa acima com o nome da classe seguido por .java, navegue até o local onde ele foi salvo. Compile e execute o programa conforme mostrado abaixo.
$javac Truncate_Table.java
$java Truncate_TableEm condições normais, ele deve produzir a seguinte saída -
Table truncatedCriação de um índice usando Cqlsh
Você pode criar um índice no Cassandra usando o comando CREATE INDEX. Sua sintaxe é a seguinte -
CREATE INDEX <identifier> ON <tablename>Abaixo está um exemplo para criar um índice para uma coluna. Aqui estamos criando um índice para uma coluna 'emp_name' em uma tabela chamada emp.
cqlsh:tutorialspoint> CREATE INDEX name ON emp1 (emp_name);Criação de um índice usando a API Java
Você pode criar um índice para uma coluna de uma tabela usando o método execute () da classe Session. Siga as etapas fornecidas abaixo para criar um índice para uma coluna em uma tabela.
Etapa 1: Criar um objeto de cluster
Primeiro de tudo, crie uma instância de Cluster.builder classe de com.datastax.driver.core pacote conforme mostrado abaixo.
//Creating Cluster.Builder object
Cluster.Builder builder1 = Cluster.builder();Adicione um ponto de contato (endereço IP do nó) usando o addContactPoint() método de Cluster.Builderobjeto. Este método retornaCluster.Builder.
//Adding contact point to the Cluster.Builder object
Cluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );Usando o novo objeto construtor, crie um objeto de cluster. Para fazer isso, você tem um método chamadobuild() no Cluster.Builderclasse. O código a seguir mostra como criar um objeto de cluster.
//Building a cluster
Cluster cluster = builder.build();Você pode construir o objeto de cluster usando uma única linha de código, conforme mostrado abaixo.
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();Etapa 2: Criar um objeto de sessão
Crie uma instância do objeto Session usando o método connect () de Cluster classe como mostrado abaixo.
Session session = cluster.connect( );Este método cria uma nova sessão e a inicializa. Se você já tiver um keyspace, poderá defini-lo como o existente passando o nome do KeySpace em formato de string para este método, conforme mostrado abaixo.
Session session = cluster.connect(“ Your keyspace name ” );Aqui estamos usando o KeySpace chamado tp. Portanto, crie o objeto de sessão conforme mostrado abaixo.
Session session = cluster.connect(“ tp” );Etapa 3: Executar consulta
Você pode executar consultas CQL usando o método execute () da classe Session. Passe a consulta no formato de string ou como um objeto da classe Statement para o método execute (). Tudo o que você passar para este método em formato de string será executado nocqlsh.
No exemplo a seguir, estamos criando um índice para uma coluna chamada emp_name, em uma tabela chamada emp. Você deve armazenar a consulta em uma variável de string e passá-la para o método execute () como mostrado abaixo.
//Query
String query = "CREATE INDEX name ON emp1 (emp_name);";
session.execute(query);A seguir está o programa completo para criar um índice de uma coluna em uma tabela no Cassandra usando a API Java.
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Create_Index {
public static void main(String args[]){
//Query
String query = "CREATE INDEX name ON emp1 (emp_name);";
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect("tp");
//Executing the query
session.execute(query);
System.out.println("Index created");
}
}Salve o programa acima com o nome da classe seguido por .java, navegue até o local onde ele foi salvo. Compile e execute o programa conforme mostrado abaixo.
$javac Create_Index.java
$java Create_IndexEm condições normais, ele deve produzir a seguinte saída -
Index createdDescartando um índice
Você pode eliminar um índice usando o comando DROP INDEX. Sua sintaxe é a seguinte -
DROP INDEX <identifier>Dada a seguir é um exemplo para descartar um índice de uma coluna em uma tabela. Aqui estamos eliminando o índice do nome da coluna na tabela emp.
cqlsh:tp> drop index name;Eliminando um índice usando a API Java
Você pode eliminar um índice de uma tabela usando o método execute () da classe Session. Siga as etapas fornecidas a seguir para remover um índice de uma tabela.
Etapa 1: Criar um objeto de cluster
Crie uma instância de Cluster.builder classe de com.datastax.driver.core pacote conforme mostrado abaixo.
//Creating Cluster.Builder object
Cluster.Builder builder1 = Cluster.builder();Adicione um ponto de contato (endereço IP do nó) usando o addContactPoint() método de Cluster.Builder object. Este método retornaCluster.Builder.
//Adding contact point to the Cluster.Builder object
Cluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );Usando o novo objeto construtor, crie um objeto de cluster. Para fazer isso, você tem um método chamadobuild() no Cluster.Builderclasse. O código a seguir mostra como criar um objeto de cluster.
//Building a cluster
Cluster cluster = builder.build();Você pode construir um objeto de cluster usando uma única linha de código, conforme mostrado abaixo.
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();Etapa 2: Criar um objeto de sessão
Crie uma instância do objeto Session usando o método connect () da classe Cluster como mostrado abaixo.
Session session = cluster.connect( );Este método cria uma nova sessão e a inicializa. Se você já tiver um keyspace, poderá defini-lo como o existente passando o nome do KeySpace em formato de string para este método, conforme mostrado abaixo.
Session session = cluster.connect(“ Your keyspace name ” );Aqui estamos usando o KeySpace chamado tp. Portanto, crie o objeto de sessão conforme mostrado abaixo.
Session session = cluster.connect(“ tp” );Etapa 3: Executar consulta
Você pode executar consultas CQL usando o método execute () da classe Session. Passe a consulta em formato de string ou como umStatementobjeto de classe para o método execute (). Tudo o que você passar para este método em formato de string será executado nocqlsh.
No exemplo a seguir, estamos eliminando um índice “nome” de empmesa. Você deve armazenar a consulta em uma variável de string e passá-la para o método execute () como mostrado abaixo.
//Query
String query = "DROP INDEX user_name;";
session.execute(query);A seguir está o programa completo para eliminar um índice no Cassandra usando a API Java.
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Drop_Index {
public static void main(String args[]){
//Query
String query = "DROP INDEX user_name;";
//Creating cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();.
//Creating Session object
Session session = cluster.connect("tp");
//Executing the query
session.execute(query);
System.out.println("Index dropped");
}
}Salve o programa acima com o nome da classe seguido por .java, navegue até o local onde ele foi salvo. Compile e execute o programa conforme mostrado abaixo.
$javac Drop_index.java
$java Drop_indexEm condições normais, ele deve produzir a seguinte saída -
Index droppedUsando extratos de lote
Usando BATCH,você pode executar várias instruções de modificação (inserir, atualizar, excluir) simultaneamente. Sua sintaxe é a seguinte -
BEGIN BATCH
<insert-stmt>/ <update-stmt>/ <delete-stmt>
APPLY BATCHExemplo
Suponha que haja uma tabela no Cassandra chamada emp com os seguintes dados -
| emp_id | emp_name | emp_city | emp_phone | emp_sal |
|---|---|---|---|---|
| 1 | RAM | Hyderabad | 9848022338 | 50000 |
| 2 | tordo | Délhi | 9848022339 | 50000 |
| 3 | rahman | Chennai | 9848022330 | 45000 |
Neste exemplo, vamos realizar as seguintes operações -
- Insira uma nova linha com os seguintes detalhes (4, rajeev, pune, 9848022331, 30000).
- Atualize o salário do funcionário com a linha id 3 para 50000.
- Exclua a cidade do funcionário com a id de linha 2.
Para realizar as operações acima de uma vez, use o seguinte comando BATCH -
cqlsh:tutorialspoint> BEGIN BATCH
... INSERT INTO emp (emp_id, emp_city, emp_name, emp_phone, emp_sal) values( 4,'Pune','rajeev',9848022331, 30000);
... UPDATE emp SET emp_sal = 50000 WHERE emp_id =3;
... DELETE emp_city FROM emp WHERE emp_id = 2;
... APPLY BATCH;Verificação
Depois de fazer as alterações, verifique a tabela usando a instrução SELECT. Ele deve produzir a seguinte saída -
cqlsh:tutorialspoint> select * from emp;
emp_id | emp_city | emp_name | emp_phone | emp_sal
--------+-----------+----------+------------+---------
1 | Hyderabad | ram | 9848022338 | 50000
2 | null | robin | 9848022339 | 50000
3 | Chennai | rahman | 9848022330 | 50000
4 | Pune | rajeev | 9848022331 | 30000
(4 rows)Aqui você pode observar a tabela com os dados modificados.
Instruções de lote usando a API Java
As instruções em lote podem ser escritas programaticamente em uma tabela usando o método execute () da classe Session. Siga as etapas fornecidas a seguir para executar várias instruções usando a instrução batch com a ajuda da API Java.
Etapa 1: Criar um objeto de cluster
Crie uma instância de Cluster.builder classe de com.datastax.driver.core pacote conforme mostrado abaixo.
//Creating Cluster.Builder object
Cluster.Builder builder1 = Cluster.builder();Adicione um ponto de contato (endereço IP do nó) usando o addContactPoint() método de Cluster.Builderobjeto. Este método retornaCluster.Builder.
//Adding contact point to the Cluster.Builder object
Cluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );Usando o novo objeto construtor, crie um objeto de cluster. Para fazer isso, você tem um método chamadobuild() no Cluster.Builderclasse. Use o seguinte código para criar o objeto de cluster -
//Building a cluster
Cluster cluster = builder.build();Você pode construir o objeto de cluster usando uma única linha de código, conforme mostrado abaixo.
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();Etapa 2: Criar um objeto de sessão
Crie uma instância do objeto Session usando o método connect () da classe Cluster como mostrado abaixo.
Session session = cluster.connect( );Este método cria uma nova sessão e a inicializa. Se você já tiver um keyspace, poderá defini-lo como o existente passando o nome do KeySpace em formato de string para este método, conforme mostrado abaixo.
Session session = cluster.connect(“ Your keyspace name ”);Aqui estamos usando o KeySpace chamado tp. Portanto, crie o objeto de sessão conforme mostrado abaixo.
Session session = cluster.connect(“tp”);Etapa 3: Executar consulta
Você pode executar consultas CQL usando o método execute () da classe Session. Passe a consulta no formato de string ou como um objeto da classe Statement para o método execute (). Tudo o que você passar para este método em formato de string será executado nocqlsh.
Neste exemplo, vamos realizar as seguintes operações -
- Insira uma nova linha com os seguintes detalhes (4, rajeev, pune, 9848022331, 30000).
- Atualize o salário do funcionário com a linha id 3 para 50000.
- Exclua a cidade do funcionário com a linha 2.
Você deve armazenar a consulta em uma variável de string e passá-la para o método execute () como mostrado abaixo.
String query1 = ” BEGIN BATCH INSERT INTO emp (emp_id, emp_city, emp_name, emp_phone, emp_sal) values( 4,'Pune','rajeev',9848022331, 30000);
UPDATE emp SET emp_sal = 50000 WHERE emp_id =3;
DELETE emp_city FROM emp WHERE emp_id = 2;
APPLY BATCH;”;A seguir está o programa completo para executar várias instruções simultaneamente em uma tabela no Cassandra usando a API Java.
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Batch {
public static void main(String args[]){
//query
String query =" BEGIN BATCH INSERT INTO emp (emp_id, emp_city,
emp_name, emp_phone, emp_sal) values( 4,'Pune','rajeev',9848022331, 30000);"
+ "UPDATE emp SET emp_sal = 50000 WHERE emp_id =3;"
+ "DELETE emp_city FROM emp WHERE emp_id = 2;"
+ "APPLY BATCH;";
//Creating Cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect("tp");
//Executing the query
session.execute(query);
System.out.println("Changes done");
}
}Salve o programa acima com o nome da classe seguido por .java, navegue até o local onde ele foi salvo. Compile e execute o programa conforme mostrado abaixo.
$javac Batch.java
$java BatchEm condições normais, ele deve produzir a seguinte saída -
Changes doneCriação de dados em uma tabela
Você pode inserir dados nas colunas de uma linha em uma tabela usando o comando INSERT. A seguir está a sintaxe para a criação de dados em uma tabela.
INSERT INTO <tablename>
(<column1 name>, <column2 name>....)
VALUES (<value1>, <value2>....)
USING <option>Exemplo
Vamos supor que existe uma mesa chamada emp com colunas (emp_id, emp_name, emp_city, emp_phone, emp_sal) e você tem que inserir os seguintes dados no emp mesa.
| emp_id | emp_name | emp_city | emp_phone | emp_sal |
|---|---|---|---|---|
| 1 | RAM | Hyderabad | 9848022338 | 50000 |
| 2 | tordo | Hyderabad | 9848022339 | 40.000 |
| 3 | rahman | Chennai | 9848022330 | 45000 |
Use os comandos fornecidos abaixo para preencher a tabela com os dados necessários.
cqlsh:tutorialspoint> INSERT INTO emp (emp_id, emp_name, emp_city,
emp_phone, emp_sal) VALUES(1,'ram', 'Hyderabad', 9848022338, 50000);
cqlsh:tutorialspoint> INSERT INTO emp (emp_id, emp_name, emp_city,
emp_phone, emp_sal) VALUES(2,'robin', 'Hyderabad', 9848022339, 40000);
cqlsh:tutorialspoint> INSERT INTO emp (emp_id, emp_name, emp_city,
emp_phone, emp_sal) VALUES(3,'rahman', 'Chennai', 9848022330, 45000);Verificação
Após inserir os dados, use a instrução SELECT para verificar se os dados foram inseridos ou não. Se você verificar a tabela emp usando a instrução SELECT, ela fornecerá a seguinte saída.
cqlsh:tutorialspoint> SELECT * FROM emp;
emp_id | emp_city | emp_name | emp_phone | emp_sal
--------+-----------+----------+------------+---------
1 | Hyderabad | ram | 9848022338 | 50000
2 | Hyderabad | robin | 9848022339 | 40000
3 | Chennai | rahman | 9848022330 | 45000
(3 rows)Aqui você pode observar que a tabela foi preenchida com os dados que inserimos.
Criação de dados usando Java API
Você pode criar dados em uma tabela usando o método execute () da classe Session. Siga as etapas fornecidas a seguir para criar dados em uma tabela usando a API Java.
Etapa 1: Criar um objeto de cluster
Crie uma instância de Cluster.builder classe de com.datastax.driver.core pacote conforme mostrado abaixo.
//Creating Cluster.Builder object
Cluster.Builder builder1 = Cluster.builder();Adicione um ponto de contato (endereço IP do nó) usando o addContactPoint() método de Cluster.Builderobjeto. Este método retornaCluster.Builder.
//Adding contact point to the Cluster.Builder object
Cluster.Builder builder2 = build.addContactPoint("127.0.0.1");Usando o novo objeto construtor, crie um objeto de cluster. Para fazer isso, você tem um método chamadobuild() no Cluster.Builderclasse. O código a seguir mostra como criar um objeto de cluster.
//Building a cluster
Cluster cluster = builder.build();Você pode construir um objeto de cluster usando uma única linha de código, conforme mostrado abaixo.
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();Etapa 2: Criar um objeto de sessão
Crie uma instância do objeto Session usando o método connect () da classe Cluster como mostrado abaixo.
Session session = cluster.connect( );Este método cria uma nova sessão e a inicializa. Se você já tiver um keyspace, poderá defini-lo como o existente passando o nome do KeySpace em formato de string para este método, conforme mostrado abaixo.
Session session = cluster.connect(“ Your keyspace name ” );Aqui estamos usando o KeySpace chamado tp. Portanto, crie o objeto de sessão conforme mostrado abaixo.
Session session = cluster.connect(“ tp” );Etapa 3: Executar consulta
Você pode executar consultas CQL usando o método execute () da classe Session. Passe a consulta em formato de string ou como umStatementobjeto de classe para o método execute (). Tudo o que você passar para este método em formato de string será executado nocqlsh.
No exemplo a seguir, estamos inserindo dados em uma tabela chamada emp. Você deve armazenar a consulta em uma variável de string e passá-la para o método execute () como mostrado abaixo.
String query1 = “INSERT INTO emp (emp_id, emp_name, emp_city, emp_phone, emp_sal)
VALUES(1,'ram', 'Hyderabad', 9848022338, 50000);” ;
String query2 = “INSERT INTO emp (emp_id, emp_name, emp_city, emp_phone, emp_sal)
VALUES(2,'robin', 'Hyderabad', 9848022339, 40000);” ;
String query3 = “INSERT INTO emp (emp_id, emp_name, emp_city, emp_phone, emp_sal)
VALUES(3,'rahman', 'Chennai', 9848022330, 45000);” ;
session.execute(query1);
session.execute(query2);
session.execute(query3);A seguir está o programa completo para inserir dados em uma tabela no Cassandra usando a API Java.
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Create_Data {
public static void main(String args[]){
//queries
String query1 = "INSERT INTO emp (emp_id, emp_name, emp_city, emp_phone, emp_sal)"
+ " VALUES(1,'ram', 'Hyderabad', 9848022338, 50000);" ;
String query2 = "INSERT INTO emp (emp_id, emp_name, emp_city,
emp_phone, emp_sal)"
+ " VALUES(2,'robin', 'Hyderabad', 9848022339, 40000);" ;
String query3 = "INSERT INTO emp (emp_id, emp_name, emp_city, emp_phone, emp_sal)"
+ " VALUES(3,'rahman', 'Chennai', 9848022330, 45000);" ;
//Creating Cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect("tp");
//Executing the query
session.execute(query1);
session.execute(query2);
session.execute(query3);
System.out.println("Data created");
}
}Salve o programa acima com o nome da classe seguido por .java, navegue até o local onde ele foi salvo. Compile e execute o programa conforme mostrado abaixo.
$javac Create_Data.java
$java Create_DataEm condições normais, ele deve produzir a seguinte saída -
Data createdAtualizar dados em uma tabela
UPDATEé o comando usado para atualizar dados em uma tabela. As seguintes palavras-chave são usadas durante a atualização de dados em uma tabela -
Where - Esta cláusula é usada para selecionar a linha a ser atualizada.
Set - Defina o valor usando esta palavra-chave.
Must - Inclui todas as colunas que compõem a chave primária.
Durante a atualização de linhas, se uma determinada linha não estiver disponível, então UPDATE cria uma nova linha. A seguir está a sintaxe do comando UPDATE -
UPDATE <tablename>
SET <column name> = <new value>
<column name> = <value>....
WHERE <condition>Exemplo
Suponha que haja uma mesa chamada emp. Esta tabela armazena os detalhes dos funcionários de uma determinada empresa, e possui os seguintes detalhes -
| emp_id | emp_name | emp_city | emp_phone | emp_sal |
|---|---|---|---|---|
| 1 | RAM | Hyderabad | 9848022338 | 50000 |
| 2 | tordo | Hyderabad | 9848022339 | 40.000 |
| 3 | rahman | Chennai | 9848022330 | 45000 |
Vamos agora atualizar emp_city de robin para Delhi e seu salário para 50000. Dada a seguir está a consulta para realizar as atualizações necessárias.
cqlsh:tutorialspoint> UPDATE emp SET emp_city='Delhi',emp_sal=50000
WHERE emp_id=2;Verificação
Use a instrução SELECT para verificar se os dados foram atualizados ou não. Se você verificar a tabela emp usando a instrução SELECT, ela produzirá a seguinte saída.
cqlsh:tutorialspoint> select * from emp;
emp_id | emp_city | emp_name | emp_phone | emp_sal
--------+-----------+----------+------------+---------
1 | Hyderabad | ram | 9848022338 | 50000
2 | Delhi | robin | 9848022339 | 50000
3 | Chennai | rahman | 9848022330 | 45000
(3 rows)Aqui você pode observar que os dados da tabela foram atualizados.
Atualização de dados usando a API Java
Você pode atualizar os dados em uma tabela usando o método execute () da classe Session. Siga as etapas fornecidas abaixo para atualizar os dados em uma tabela usando a API Java.
Etapa 1: Criar um objeto de cluster
Crie uma instância de Cluster.builder classe de com.datastax.driver.core pacote conforme mostrado abaixo.
//Creating Cluster.Builder object
Cluster.Builder builder1 = Cluster.builder();Adicione um ponto de contato (endereço IP do nó) usando o addContactPoint() método de Cluster.Builderobjeto. Este método retornaCluster.Builder.
//Adding contact point to the Cluster.Builder object
Cluster.Builder builder2 = build.addContactPoint("127.0.0.1");Usando o novo objeto construtor, crie um objeto de cluster. Para fazer isso, você tem um método chamadobuild() no Cluster.Builderclasse. Use o código a seguir para criar o objeto de cluster.
//Building a cluster
Cluster cluster = builder.build();Você pode construir o objeto de cluster usando uma única linha de código, conforme mostrado abaixo.
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();Etapa 2: Criar um objeto de sessão
Crie uma instância do objeto Session usando o método connect () da classe Cluster como mostrado abaixo.
Session session = cluster.connect( );Este método cria uma nova sessão e a inicializa. Se você já tiver um keyspace, poderá defini-lo como o existente passando o nome do KeySpace em formato de string para este método, conforme mostrado abaixo.
Session session = cluster.connect(“ Your keyspace name”);Aqui estamos usando o KeySpace chamado tp. Portanto, crie o objeto de sessão conforme mostrado abaixo.
Session session = cluster.connect(“tp”);Etapa 3: Executar consulta
Você pode executar consultas CQL usando o método execute () da classe Session. Passe a consulta no formato de string ou como um objeto da classe Statement para o método execute (). Tudo o que você passar para este método em formato de string será executado nocqlsh.
No exemplo a seguir, estamos atualizando a tabela emp. Você deve armazenar a consulta em uma variável de string e passá-la para o método execute () conforme mostrado abaixo:
String query = “ UPDATE emp SET emp_city='Delhi',emp_sal=50000
WHERE emp_id = 2;” ;A seguir está o programa completo para atualizar dados em uma tabela usando a API Java.
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Update_Data {
public static void main(String args[]){
//query
String query = " UPDATE emp SET emp_city='Delhi',emp_sal=50000"
//Creating Cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect("tp");
//Executing the query
session.execute(query);
System.out.println("Data updated");
}
}Salve o programa acima com o nome da classe seguido por .java, navegue até o local onde ele foi salvo. Compile e execute o programa conforme mostrado abaixo.
$javac Update_Data.java
$java Update_DataEm condições normais, ele deve produzir a seguinte saída -
Data updatedLeitura de dados usando cláusula de seleção
A cláusula SELECT é usada para ler dados de uma tabela no Cassandra. Usando esta cláusula, você pode ler uma tabela inteira, uma única coluna ou uma célula específica. A seguir está a sintaxe da cláusula SELECT.
SELECT FROM <tablename>Exemplo
Suponha que haja uma tabela no keyspace chamada emp com os seguintes detalhes -
| emp_id | emp_name | emp_city | emp_phone | emp_sal |
|---|---|---|---|---|
| 1 | RAM | Hyderabad | 9848022338 | 50000 |
| 2 | tordo | nulo | 9848022339 | 50000 |
| 3 | rahman | Chennai | 9848022330 | 50000 |
| 4 | Rajeev | Pune | 9848022331 | 30000 |
O exemplo a seguir mostra como ler uma tabela inteira usando a cláusula SELECT. Aqui estamos lendo uma tabela chamadaemp.
cqlsh:tutorialspoint> select * from emp;
emp_id | emp_city | emp_name | emp_phone | emp_sal
--------+-----------+----------+------------+---------
1 | Hyderabad | ram | 9848022338 | 50000
2 | null | robin | 9848022339 | 50000
3 | Chennai | rahman | 9848022330 | 50000
4 | Pune | rajeev | 9848022331 | 30000
(4 rows)Leitura de colunas obrigatórias
O exemplo a seguir mostra como ler uma coluna específica em uma tabela.
cqlsh:tutorialspoint> SELECT emp_name, emp_sal from emp;
emp_name | emp_sal
----------+---------
ram | 50000
robin | 50000
rajeev | 30000
rahman | 50000
(4 rows)Cláusula Where
Usando a cláusula WHERE, você pode colocar uma restrição nas colunas obrigatórias. Sua sintaxe é a seguinte -
SELECT FROM <table name> WHERE <condition>;Note - Uma cláusula WHERE pode ser usada apenas nas colunas que fazem parte da chave primária ou têm um índice secundário nelas.
No exemplo a seguir, estamos lendo os detalhes de um funcionário cujo salário é 50000. Em primeiro lugar, defina o índice secundário para a coluna emp_sal.
cqlsh:tutorialspoint> CREATE INDEX ON emp(emp_sal);
cqlsh:tutorialspoint> SELECT * FROM emp WHERE emp_sal=50000;
emp_id | emp_city | emp_name | emp_phone | emp_sal
--------+-----------+----------+------------+---------
1 | Hyderabad | ram | 9848022338 | 50000
2 | null | robin | 9848022339 | 50000
3 | Chennai | rahman | 9848022330 | 50000Lendo dados usando a API Java
Você pode ler dados de uma tabela usando o método execute () da classe Session. Siga as etapas fornecidas a seguir para executar várias instruções usando a instrução batch com a ajuda da API Java.
Etapa 1: Criar um objeto de cluster
Crie uma instância de Cluster.builder classe de com.datastax.driver.core pacote conforme mostrado abaixo.
//Creating Cluster.Builder object
Cluster.Builder builder1 = Cluster.builder();Adicione um ponto de contato (endereço IP do nó) usando o addContactPoint() método de Cluster.Builderobjeto. Este método retornaCluster.Builder.
//Adding contact point to the Cluster.Builder object
Cluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );Usando o novo objeto construtor, crie um objeto de cluster. Para fazer isso, você tem um método chamadobuild() no Cluster.Builderclasse. Use o código a seguir para criar o objeto de cluster.
//Building a cluster
Cluster cluster = builder.build();Você pode construir o objeto de cluster usando uma única linha de código, conforme mostrado abaixo.
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();Etapa 2: Criar um objeto de sessão
Crie uma instância do objeto Session usando o método connect () da classe Cluster como mostrado abaixo.
Session session = cluster.connect( );Este método cria uma nova sessão e a inicializa. Se você já tiver um keyspace, poderá defini-lo como o existente passando o nome do KeySpace em formato de string para este método, conforme mostrado abaixo.
Session session = cluster.connect(“Your keyspace name”);Aqui estamos usando o KeySpace chamado tp. Portanto, crie o objeto de sessão conforme mostrado abaixo.
Session session = cluster.connect(“tp”);Etapa 3: Executar consulta
Você pode executar consultas CQL usando o método execute () da classe Session. Passe a consulta no formato de string ou como um objeto da classe Statement para o método execute (). Tudo o que você passar para este método em formato de string será executado nocqlsh.
Neste exemplo, estamos recuperando os dados de empmesa. Armazene a consulta em uma string e passe-a para o método execute () da classe de sessão, conforme mostrado abaixo.
String query = ”SELECT 8 FROM emp”;
session.execute(query);Execute a consulta usando o método execute () da classe Session.
Etapa 4: obtenha o objeto ResultSet
As consultas selecionadas retornarão o resultado na forma de um ResultSet objeto, portanto, armazene o resultado no objeto de RESULTSET classe como mostrado abaixo.
ResultSet result = session.execute( );A seguir está o programa completo para ler dados de uma tabela.
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.ResultSet;
import com.datastax.driver.core.Session;
public class Read_Data {
public static void main(String args[])throws Exception{
//queries
String query = "SELECT * FROM emp";
//Creating Cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect("tutorialspoint");
//Getting the ResultSet
ResultSet result = session.execute(query);
System.out.println(result.all());
}
}Salve o programa acima com o nome da classe seguido por .java, navegue até o local onde ele foi salvo. Compile e execute o programa conforme mostrado abaixo.
$javac Read_Data.java
$java Read_DataEm condições normais, ele deve produzir a seguinte saída -
[Row[1, Hyderabad, ram, 9848022338, 50000], Row[2, Delhi, robin,
9848022339, 50000], Row[4, Pune, rajeev, 9848022331, 30000], Row[3,
Chennai, rahman, 9848022330, 50000]]Leitura de dados usando cláusula de seleção
A cláusula SELECT é usada para ler dados de uma tabela no Cassandra. Usando esta cláusula, você pode ler uma tabela inteira, uma única coluna ou uma célula específica. A seguir está a sintaxe da cláusula SELECT.
SELECT FROM <tablename>Exemplo
Suponha que haja uma tabela no keyspace chamada emp com os seguintes detalhes -
| emp_id | emp_name | emp_city | emp_phone | emp_sal |
|---|---|---|---|---|
| 1 | RAM | Hyderabad | 9848022338 | 50000 |
| 2 | tordo | nulo | 9848022339 | 50000 |
| 3 | rahman | Chennai | 9848022330 | 50000 |
| 4 | Rajeev | Pune | 9848022331 | 30000 |
O exemplo a seguir mostra como ler uma tabela inteira usando a cláusula SELECT. Aqui estamos lendo uma tabela chamadaemp.
cqlsh:tutorialspoint> select * from emp;
emp_id | emp_city | emp_name | emp_phone | emp_sal
--------+-----------+----------+------------+---------
1 | Hyderabad | ram | 9848022338 | 50000
2 | null | robin | 9848022339 | 50000
3 | Chennai | rahman | 9848022330 | 50000
4 | Pune | rajeev | 9848022331 | 30000
(4 rows)Leitura de colunas obrigatórias
O exemplo a seguir mostra como ler uma coluna específica em uma tabela.
cqlsh:tutorialspoint> SELECT emp_name, emp_sal from emp;
emp_name | emp_sal
----------+---------
ram | 50000
robin | 50000
rajeev | 30000
rahman | 50000
(4 rows)Cláusula Where
Usando a cláusula WHERE, você pode colocar uma restrição nas colunas obrigatórias. Sua sintaxe é a seguinte -
SELECT FROM <table name> WHERE <condition>;Note - Uma cláusula WHERE pode ser usada apenas nas colunas que fazem parte da chave primária ou têm um índice secundário nelas.
No exemplo a seguir, estamos lendo os detalhes de um funcionário cujo salário é 50000. Em primeiro lugar, defina o índice secundário para a coluna emp_sal.
cqlsh:tutorialspoint> CREATE INDEX ON emp(emp_sal);
cqlsh:tutorialspoint> SELECT * FROM emp WHERE emp_sal=50000;
emp_id | emp_city | emp_name | emp_phone | emp_sal
--------+-----------+----------+------------+---------
1 | Hyderabad | ram | 9848022338 | 50000
2 | null | robin | 9848022339 | 50000
3 | Chennai | rahman | 9848022330 | 50000Lendo dados usando a API Java
Você pode ler dados de uma tabela usando o método execute () da classe Session. Siga as etapas fornecidas a seguir para executar várias instruções usando a instrução batch com a ajuda da API Java.
Etapa 1: Criar um objeto de cluster
Crie uma instância de Cluster.builder classe de com.datastax.driver.core pacote conforme mostrado abaixo.
//Creating Cluster.Builder object
Cluster.Builder builder1 = Cluster.builder();Adicione um ponto de contato (endereço IP do nó) usando o addContactPoint() método de Cluster.Builderobjeto. Este método retornaCluster.Builder.
//Adding contact point to the Cluster.Builder object
Cluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );Usando o novo objeto construtor, crie um objeto de cluster. Para fazer isso, você tem um método chamadobuild() no Cluster.Builderclasse. Use o código a seguir para criar o objeto de cluster.
//Building a cluster
Cluster cluster = builder.build();Você pode construir o objeto de cluster usando uma única linha de código, conforme mostrado abaixo.
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();Etapa 2: Criar um objeto de sessão
Crie uma instância do objeto Session usando o método connect () da classe Cluster como mostrado abaixo.
Session session = cluster.connect( );Este método cria uma nova sessão e a inicializa. Se você já tiver um keyspace, poderá defini-lo como o existente passando o nome do KeySpace em formato de string para este método, conforme mostrado abaixo.
Session session = cluster.connect(“Your keyspace name”);Aqui estamos usando o KeySpace chamado tp. Portanto, crie o objeto de sessão conforme mostrado abaixo.
Session session = cluster.connect(“tp”);Etapa 3: Executar consulta
Você pode executar consultas CQL usando o método execute () da classe Session. Passe a consulta no formato de string ou como um objeto da classe Statement para o método execute (). Tudo o que você passar para este método em formato de string será executado nocqlsh.
Neste exemplo, estamos recuperando os dados de empmesa. Armazene a consulta em uma string e passe-a para o método execute () da classe de sessão, conforme mostrado abaixo.
String query = ”SELECT 8 FROM emp”;
session.execute(query);Execute a consulta usando o método execute () da classe Session.
Etapa 4: obtenha o objeto ResultSet
As consultas selecionadas retornarão o resultado na forma de um ResultSet objeto, portanto, armazene o resultado no objeto de RESULTSET classe como mostrado abaixo.
ResultSet result = session.execute( );A seguir está o programa completo para ler dados de uma tabela.
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.ResultSet;
import com.datastax.driver.core.Session;
public class Read_Data {
public static void main(String args[])throws Exception{
//queries
String query = "SELECT * FROM emp";
//Creating Cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect("tutorialspoint");
//Getting the ResultSet
ResultSet result = session.execute(query);
System.out.println(result.all());
}
}Salve o programa acima com o nome da classe seguido por .java, navegue até o local onde ele foi salvo. Compile e execute o programa conforme mostrado abaixo.
$javac Read_Data.java
$java Read_DataEm condições normais, ele deve produzir a seguinte saída -
[Row[1, Hyderabad, ram, 9848022338, 50000], Row[2, Delhi, robin,
9848022339, 50000], Row[4, Pune, rajeev, 9848022331, 30000], Row[3,
Chennai, rahman, 9848022330, 50000]]Excluindo dados de uma tabela
Você pode deletar dados de uma tabela usando o comando DELETE. Sua sintaxe é a seguinte -
DELETE FROM <identifier> WHERE <condition>;Exemplo
Vamos supor que haja uma mesa em Cassandra chamada emp tendo os seguintes dados -
| emp_id | emp_name | emp_city | emp_phone | emp_sal |
|---|---|---|---|---|
| 1 | RAM | Hyderabad | 9848022338 | 50000 |
| 2 | tordo | Hyderabad | 9848022339 | 40.000 |
| 3 | rahman | Chennai | 9848022330 | 45000 |
A seguinte declaração exclui a coluna emp_sal da última linha -
cqlsh:tutorialspoint> DELETE emp_sal FROM emp WHERE emp_id=3;Verificação
Use a instrução SELECT para verificar se os dados foram excluídos ou não. Se você verificar a tabela emp usando SELECT, ela produzirá a seguinte saída -
cqlsh:tutorialspoint> select * from emp;
emp_id | emp_city | emp_name | emp_phone | emp_sal
--------+-----------+----------+------------+---------
1 | Hyderabad | ram | 9848022338 | 50000
2 | Delhi | robin | 9848022339 | 50000
3 | Chennai | rahman | 9848022330 | null
(3 rows)Como excluímos o salário de Rahman, você observará um valor nulo no lugar do salário.
Excluindo uma linha inteira
O comando a seguir exclui uma linha inteira de uma tabela.
cqlsh:tutorialspoint> DELETE FROM emp WHERE emp_id=3;Verificação
Use a instrução SELECT para verificar se os dados foram excluídos ou não. Se você verificar a tabela emp usando SELECT, ela produzirá a seguinte saída -
cqlsh:tutorialspoint> select * from emp;
emp_id | emp_city | emp_name | emp_phone | emp_sal
--------+-----------+----------+------------+---------
1 | Hyderabad | ram | 9848022338 | 50000
2 | Delhi | robin | 9848022339 | 50000
(2 rows)Como excluímos a última linha, restam apenas duas linhas na tabela.
Exclusão de dados usando a API Java
Você pode deletar dados em uma tabela usando o método execute () da classe Session. Siga as etapas fornecidas a seguir para excluir dados de uma tabela usando a API Java.
Etapa 1: Criar um objeto de cluster
Crie uma instância de Cluster.builder classe de com.datastax.driver.core pacote conforme mostrado abaixo.
//Creating Cluster.Builder object
Cluster.Builder builder1 = Cluster.builder();Adicione um ponto de contato (endereço IP do nó) usando o addContactPoint() método de Cluster.Builderobjeto. Este método retornaCluster.Builder.
//Adding contact point to the Cluster.Builder object
Cluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );Usando o novo objeto construtor, crie um objeto de cluster. Para fazer isso, você tem um método chamadobuild() no Cluster.Builderclasse. Use o código a seguir para criar um objeto de cluster.
//Building a cluster
Cluster cluster = builder.build();Você pode construir o objeto de cluster usando uma única linha de código, conforme mostrado abaixo.
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();Etapa 2: Criar um objeto de sessão
Crie uma instância do objeto Session usando o método connect () da classe Cluster como mostrado abaixo.
Session session = cluster.connect();Este método cria uma nova sessão e a inicializa. Se você já tiver um keyspace, poderá defini-lo como o existente passando o nome do KeySpace em formato de string para este método, conforme mostrado abaixo.
Session session = cluster.connect(“ Your keyspace name ”);Aqui estamos usando o KeySpace chamado tp. Portanto, crie o objeto de sessão conforme mostrado abaixo.
Session session = cluster.connect(“tp”);Etapa 3: Executar consulta
Você pode executar consultas CQL usando o método execute () da classe Session. Passe a consulta no formato de string ou como um objeto da classe Statement para o método execute (). Tudo o que você passar para este método em formato de string será executado nocqlsh.
No exemplo a seguir, estamos excluindo dados de uma tabela chamada emp. Você tem que armazenar a consulta em uma variável de string e passá-la para o execute() método conforme mostrado abaixo.
String query1 = ”DELETE FROM emp WHERE emp_id=3; ”;
session.execute(query);A seguir está o programa completo para deletar dados de uma tabela no Cassandra usando a API Java.
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Delete_Data {
public static void main(String args[]){
//query
String query = "DELETE FROM emp WHERE emp_id=3;";
//Creating Cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect("tp");
//Executing the query
session.execute(query);
System.out.println("Data deleted");
}
}Salve o programa acima com o nome da classe seguido por .java, navegue até o local onde ele foi salvo. Compile e execute o programa conforme mostrado abaixo.
$javac Delete_Data.java
$java Delete_DataEm condições normais, ele deve produzir a seguinte saída -
Data deletedCQL fornece um rico conjunto de tipos de dados integrados, incluindo tipos de coleção. Junto com esses tipos de dados, os usuários também podem criar seus próprios tipos de dados personalizados. A tabela a seguir fornece uma lista de tipos de dados integrados disponíveis em CQL.
| Tipo de dados | Constantes | Descrição |
|---|---|---|
| ascii | cordas | Representa string de caracteres ASCII |
| bigint | bigint | Representa 64 bits com assinatura longa |
| blob | bolhas | Representa bytes arbitrários |
| boleano | booleanos | Representa verdadeiro ou falso |
| counter | inteiros | Representa coluna de contador |
| decimal | inteiros, flutuantes | Representa decimal de precisão variável |
| em dobro | inteiros | Representa ponto flutuante IEEE-754 de 64 bits |
| flutuador | inteiros, flutuantes | Representa ponto flutuante IEEE-754 de 32 bits |
| inet | cordas | Representa um endereço IP, IPv4 ou IPv6 |
| int | inteiros | Representa int assinado de 32 bits |
| texto | cordas | Representa string codificada em UTF8 |
| timestamp | inteiros, strings | Representa um carimbo de data / hora |
| timeuuid | uuidas | Representa UUID tipo 1 |
| uuid | uuidas | Representa tipo 1 ou tipo 4 |
| UUID | ||
| varchar | cordas | Representa string codificada em uTF8 |
| Varint | inteiros | Representa um inteiro de precisão arbitrária |
Tipos de coleção
Cassandra Query Language também fornece uma coleção de tipos de dados. A tabela a seguir fornece uma lista de coleções disponíveis em CQL.
| Coleção | Descrição |
|---|---|
| Lista | Uma lista é uma coleção de um ou mais elementos ordenados. |
| mapa | Um mapa é uma coleção de pares de valores-chave. |
| conjunto | Um conjunto é uma coleção de um ou mais elementos. |
Tipos de dados definidos pelo usuário
Cqlsh fornece aos usuários a facilidade de criar seus próprios tipos de dados. A seguir são fornecidos os comandos usados ao lidar com tipos de dados definidos pelo usuário.
CREATE TYPE - Cria um tipo de dados definido pelo usuário.
ALTER TYPE - Modifica um tipo de dados definido pelo usuário.
DROP TYPE - Descarta um tipo de dados definido pelo usuário.
DESCRIBE TYPE - Descreve um tipo de dados definido pelo usuário.
DESCRIBE TYPES - Descreve tipos de dados definidos pelo usuário.
CQL fornece a facilidade de usar tipos de dados de coleção. Usando esses tipos de coleção, você pode armazenar vários valores em uma única variável. Este capítulo explica como usar coleções no Cassandra.
Lista
A lista é usada nos casos em que
- a ordem dos elementos deve ser mantida, e
- um valor deve ser armazenado várias vezes.
Você pode obter os valores de um tipo de dados de lista usando o índice dos elementos da lista.
Criando uma Tabela com Lista
Abaixo está um exemplo para criar uma tabela de amostra com duas colunas, nome e e-mail. Para armazenar vários e-mails, estamos usando a lista.
cqlsh:tutorialspoint> CREATE TABLE data(name text PRIMARY KEY, email list<text>);Inserindo dados em uma lista
Ao inserir dados nos elementos de uma lista, insira todos os valores separados por vírgula entre colchetes [], conforme mostrado abaixo.
cqlsh:tutorialspoint> INSERT INTO data(name, email) VALUES ('ramu',
['[email protected]','[email protected]'])Atualizando uma lista
Abaixo está um exemplo para atualizar o tipo de dados da lista em uma tabela chamada data. Aqui estamos adicionando outro e-mail à lista.
cqlsh:tutorialspoint> UPDATE data
... SET email = email +['[email protected]']
... where name = 'ramu';Verificação
Se você verificar a tabela usando a instrução SELECT, obterá o seguinte resultado -
cqlsh:tutorialspoint> SELECT * FROM data;
name | email
------+--------------------------------------------------------------
ramu | ['[email protected]', '[email protected]', '[email protected]']
(1 rows)CONJUNTO
Conjunto é um tipo de dados usado para armazenar um grupo de elementos. Os elementos de um conjunto serão retornados em uma ordem de classificação.
Criando uma mesa com conjunto
O exemplo a seguir cria uma tabela de amostra com duas colunas, nome e telefone. Para armazenar vários números de telefone, estamos usando o conjunto.
cqlsh:tutorialspoint> CREATE TABLE data2 (name text PRIMARY KEY, phone set<varint>);Inserindo Dados em um Conjunto
Ao inserir dados nos elementos de um conjunto, insira todos os valores separados por vírgula entre chaves {} conforme mostrado abaixo.
cqlsh:tutorialspoint> INSERT INTO data2(name, phone)VALUES ('rahman', {9848022338,9848022339});Atualizando um Conjunto
O código a seguir mostra como atualizar um conjunto em uma tabela chamada data2. Aqui estamos adicionando outro número de telefone ao conjunto.
cqlsh:tutorialspoint> UPDATE data2
... SET phone = phone + {9848022330}
... where name = 'rahman';Verificação
Se você verificar a tabela usando a instrução SELECT, obterá o seguinte resultado -
cqlsh:tutorialspoint> SELECT * FROM data2;
name | phone
--------+--------------------------------------
rahman | {9848022330, 9848022338, 9848022339}
(1 rows)MAPA
Mapa é um tipo de dados usado para armazenar um par de elementos chave-valor.
Criando uma Tabela com Mapa
O exemplo a seguir mostra como criar uma tabela de amostra com duas colunas, nome e endereço. Para armazenar vários valores de endereço, estamos usando o mapa.
cqlsh:tutorialspoint> CREATE TABLE data3 (name text PRIMARY KEY, address
map<timestamp, text>);Inserindo Dados em um Mapa
Ao inserir dados nos elementos de um mapa, insira todos os key : value pares separados por vírgulas entre chaves {} conforme mostrado abaixo.
cqlsh:tutorialspoint> INSERT INTO data3 (name, address)
VALUES ('robin', {'home' : 'hyderabad' , 'office' : 'Delhi' } );Atualizando um Conjunto
O código a seguir mostra como atualizar o tipo de dados do mapa em uma tabela chamada data3. Aqui estamos mudando o valor do escritório principal, ou seja, estamos mudando o endereço do escritório de uma pessoa chamada robin.
cqlsh:tutorialspoint> UPDATE data3
... SET address = address+{'office':'mumbai'}
... WHERE name = 'robin';Verificação
Se você verificar a tabela usando a instrução SELECT, obterá o seguinte resultado -
cqlsh:tutorialspoint> select * from data3;
name | address
-------+-------------------------------------------
robin | {'home': 'hyderabad', 'office': 'mumbai'}
(1 rows)CQL fornece a facilidade de criar e usar tipos de dados definidos pelo usuário. Você pode criar um tipo de dados para lidar com vários campos. Este capítulo explica como criar, alterar e excluir um tipo de dados definido pelo usuário.
Criação de um tipo de dados definido pelo usuário
O comando CREATE TYPEé usado para criar um tipo de dados definido pelo usuário. Sua sintaxe é a seguinte -
CREATE TYPE <keyspace name>. <data typename>
( variable1, variable2).Exemplo
Abaixo é fornecido um exemplo para a criação de um tipo de dados definido pelo usuário. Neste exemplo, estamos criando umcard_details tipo de dados contendo os seguintes detalhes.
| Campo | Nome do campo | Tipo de dados |
|---|---|---|
| Cartão de Crédito No | num | int |
| PIN do cartão de crédito | PIN | int |
| Nome no cartão de crédito | nome | texto |
| cvv | cvv | int |
| Detalhes de contato do titular do cartão | telefone | conjunto |
cqlsh:tutorialspoint> CREATE TYPE card_details (
... num int,
... pin int,
... name text,
... cvv int,
... phone set<int>
... );Note - O nome usado para o tipo de dados definido pelo usuário não deve coincidir com os nomes de tipo reservados.
Verificação
Use o DESCRIBE comando para verificar se o tipo criado foi criado ou não.
CREATE TYPE tutorialspoint.card_details (
num int,
pin int,
name text,
cvv int,
phone set<int>
);Alterando um tipo de dados definido pelo usuário
ALTER TYPE- o comando é usado para alterar um tipo de dados existente. Usando ALTER, você pode adicionar um novo campo ou renomear um campo existente.
Adicionando um campo a um tipo
Use a seguinte sintaxe para adicionar um novo campo a um tipo de dados definido pelo usuário existente.
ALTER TYPE typename
ADD field_name field_type;O código a seguir adiciona um novo campo ao Card_detailstipo de dados. Aqui estamos adicionando um novo campo chamado email.
cqlsh:tutorialspoint> ALTER TYPE card_details ADD email text;Verificação
Use o DESCRIBE comando para verificar se o novo campo é adicionado ou não.
cqlsh:tutorialspoint> describe type card_details;
CREATE TYPE tutorialspoint.card_details (
num int,
pin int,
name text,
cvv int,
phone set<int>,
);Renomeando um campo em um tipo
Use a seguinte sintaxe para renomear um tipo de dados definido pelo usuário existente.
ALTER TYPE typename
RENAME existing_name TO new_name;O código a seguir altera o nome do campo em um tipo. Aqui estamos renomeando o campo email para mail.
cqlsh:tutorialspoint> ALTER TYPE card_details RENAME email TO mail;Verificação
Use o DESCRIBE comando para verificar se o nome do tipo mudou ou não.
cqlsh:tutorialspoint> describe type card_details;
CREATE TYPE tutorialspoint.card_details (
num int,
pin int,
name text,
cvv int,
phone set<int>,
mail text
);Excluindo um tipo de dados definido pelo usuário
DROP TYPEé o comando usado para excluir um tipo de dados definido pelo usuário. A seguir, é fornecido um exemplo para excluir um tipo de dados definido pelo usuário.
Exemplo
Antes de excluir, verifique a lista de todos os tipos de dados definidos pelo usuário usando DESCRIBE_TYPES comando como mostrado abaixo.
cqlsh:tutorialspoint> DESCRIBE TYPES;
card_details cardDos dois tipos, exclua o tipo chamado card como mostrado abaixo.
cqlsh:tutorialspoint> drop type card;Use o DESCRIBE comando para verificar se o tipo de dados caiu ou não.
cqlsh:tutorialspoint> describe types;
card_details