Projeto do Compilador - Guia Rápido
Os computadores são uma mistura equilibrada de software e hardware. Hardware é apenas uma peça de dispositivo mecânico e suas funções são controladas por um software compatível. O hardware entende instruções na forma de cobrança eletrônica, que é a contraparte da linguagem binária na programação de software. A linguagem binária tem apenas dois alfabetos, 0 e 1. Para instruir, os códigos de hardware devem ser escritos em formato binário, que é simplesmente uma série de 1s e 0s. Seria uma tarefa difícil e enfadonha para os programadores de computador escrever esses códigos, e é por isso que temos compiladores para escrever esses códigos.
Sistema de processamento de linguagem
Aprendemos que qualquer sistema de computador é feito de hardware e software. O hardware entende uma linguagem que os humanos não conseguem entender. Portanto, escrevemos programas em linguagem de alto nível, o que é mais fácil de entender e lembrar. Esses programas são então alimentados em uma série de ferramentas e componentes do sistema operacional para obter o código desejado que pode ser usado pela máquina. Isso é conhecido como Sistema de Processamento de Linguagem.
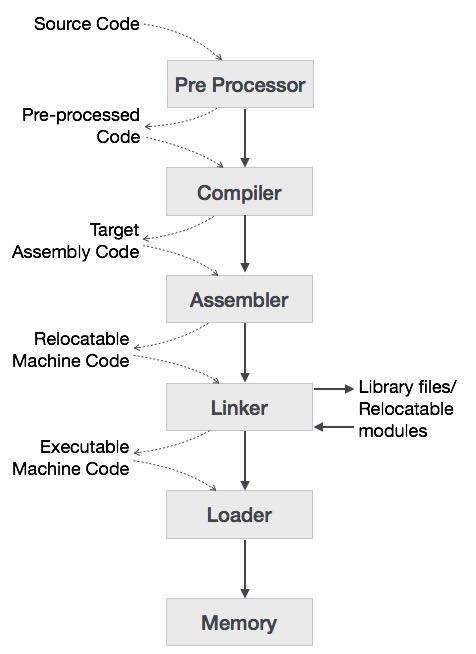
A linguagem de alto nível é convertida em linguagem binária em várias fases. UMAcompileré um programa que converte linguagem de alto nível em linguagem assembly. Da mesma forma, umassembler é um programa que converte a linguagem assembly em linguagem de nível de máquina.
Vamos primeiro entender como um programa, usando o compilador C, é executado em uma máquina host.
O usuário escreve um programa em linguagem C (linguagem de alto nível).
O compilador C compila o programa e o traduz para o programa assembly (linguagem de baixo nível).
Um montador então traduz o programa de montagem em código de máquina (objeto).
Uma ferramenta de vinculação é usada para vincular todas as partes do programa para execução (código de máquina executável).
Um carregador carrega todos eles na memória e então o programa é executado.
Antes de mergulhar direto nos conceitos de compiladores, devemos entender algumas outras ferramentas que funcionam em estreita colaboração com compiladores.
Pré-processador
Um pré-processador, geralmente considerado como parte do compilador, é uma ferramenta que produz entradas para compiladores. Ele lida com macroprocessamento, aumento, inclusão de arquivo, extensão de linguagem, etc.
Intérprete
Um intérprete, como um compilador, traduz a linguagem de alto nível em linguagem de máquina de baixo nível. A diferença está na maneira como lêem o código-fonte ou a entrada. Um compilador lê todo o código-fonte de uma vez, cria tokens, verifica a semântica, gera código intermediário, executa todo o programa e pode envolver muitas passagens. Em contraste, um intérprete lê uma instrução a partir da entrada, converte-a em um código intermediário, executa-a e, a seguir, obtém a próxima instrução na sequência. Se ocorrer um erro, um intérprete interrompe a execução e o relata. enquanto um compilador lê todo o programa, mesmo se encontrar vários erros.
Montador
Um montador traduz programas em linguagem assembly em código de máquina. A saída de um montador é chamada de arquivo-objeto, que contém uma combinação de instruções de máquina e também os dados necessários para colocar essas instruções na memória.
Linker
Linker é um programa de computador que vincula e mescla vários arquivos-objeto para formar um arquivo executável. Todos esses arquivos podem ter sido compilados por montadores separados. A principal tarefa de um vinculador é pesquisar e localizar módulos / rotinas referenciados em um programa e determinar a localização da memória onde esses códigos serão carregados, fazendo com que a instrução do programa tenha referências absolutas.
Carregador
Loader é uma parte do sistema operacional e é responsável por carregar arquivos executáveis na memória e executá-los. Ele calcula o tamanho de um programa (instruções e dados) e cria espaço de memória para ele. Ele inicializa vários registros para iniciar a execução.
Compilador cruzado
Um compilador que roda na plataforma (A) e é capaz de gerar código executável para a plataforma (B) é chamado de compilador cruzado.
Compilador de fonte para fonte
Um compilador que pega o código-fonte de uma linguagem de programação e o traduz no código-fonte de outra linguagem de programação é chamado de compilador fonte-a-fonte.
Arquitetura do Compilador
Um compilador pode ser dividido em duas fases com base na forma como são compilados.
Fase de Análise
Conhecido como front-end do compilador, o analysis fase do compilador lê o programa fonte, divide-o em partes centrais e, em seguida, verifica se há erros lexicais, gramaticais e de sintaxe. A fase de análise gera uma representação intermediária do programa fonte e da tabela de símbolos, que deve ser alimentada para a fase de síntese como entrada .
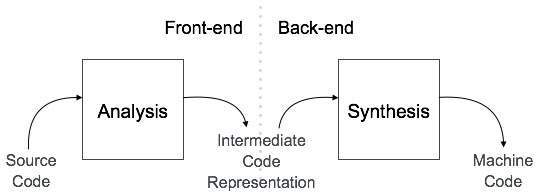
Fase de Síntese
Conhecido como back-end do compilador, o synthesis fase gera o programa de destino com a ajuda da representação do código-fonte intermediário e tabela de símbolos.
Um compilador pode ter várias fases e passos.
Pass : Uma passagem refere-se à passagem de um compilador por todo o programa.
Phase: Uma fase de um compilador é um estágio distinguível, que recebe a entrada do estágio anterior, processa e produz saída que pode ser usada como entrada para o próximo estágio. Um passe pode ter mais de uma fase.
Fases do compilador
O processo de compilação é uma sequência de várias fases. Cada fase recebe a entrada de seu estágio anterior, tem sua própria representação do programa de origem e alimenta sua saída para a próxima fase do compilador. Vamos entender as fases de um compilador.
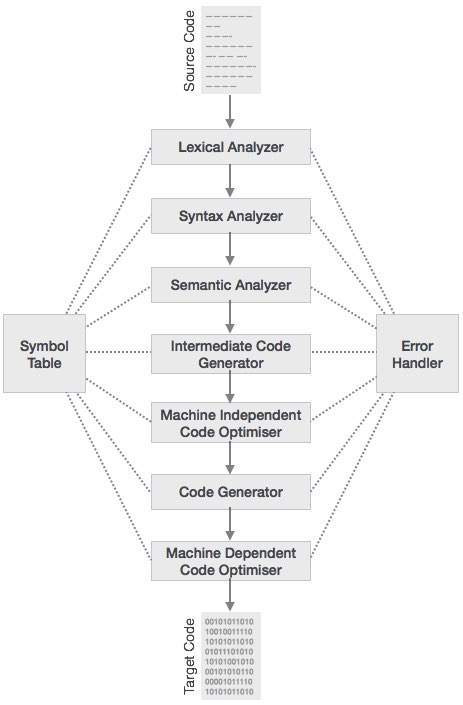
Análise Lexical
A primeira fase do scanner funciona como um scanner de texto. Esta fase verifica o código-fonte como um fluxo de caracteres e o converte em lexemas significativos. O analisador léxico representa esses lexemas na forma de tokens como:
<token-name, attribute-value>Análise de sintaxe
A próxima fase é chamada de análise de sintaxe ou parsing. Ele pega o token produzido pela análise lexical como entrada e gera uma árvore de análise (ou árvore de sintaxe). Nesta fase, os arranjos de tokens são verificados em relação à gramática do código-fonte, ou seja, o analisador verifica se a expressão feita pelos tokens está sintaticamente correta.
Análise Semântica
A análise semântica verifica se a árvore de análise construída segue as regras da linguagem. Por exemplo, a atribuição de valores é entre tipos de dados compatíveis e adição de string a um inteiro. Além disso, o analisador semântico controla os identificadores, seus tipos e expressões; se os identificadores são declarados antes do uso ou não etc. O analisador semântico produz uma árvore de sintaxe anotada como uma saída.
Geração de código intermediário
Após a análise semântica, o compilador gera um código intermediário do código-fonte para a máquina de destino. Ele representa um programa para alguma máquina abstrata. Está entre a linguagem de alto nível e a linguagem de máquina. Este código intermediário deve ser gerado de forma que seja mais fácil de ser traduzido para o código da máquina de destino.
Otimização de Código
A próxima fase faz a otimização do código intermediário. A otimização pode ser assumida como algo que remove linhas de código desnecessárias e organiza a sequência de instruções para acelerar a execução do programa sem desperdiçar recursos (CPU, memória).
Geração de Código
Nesta fase, o gerador de código pega a representação otimizada do código intermediário e mapeia para a linguagem de máquina de destino. O gerador de código traduz o código intermediário em uma sequência de código de máquina (geralmente) realocável. A sequência de instruções do código de máquina executa a tarefa como o código intermediário faria.
Tabela de Símbolos
É uma estrutura de dados mantida ao longo de todas as fases de um compilador. Todos os nomes do identificador junto com seus tipos são armazenados aqui. A tabela de símbolos torna mais fácil para o compilador pesquisar rapidamente o registro do identificador e recuperá-lo. A tabela de símbolos também é usada para gerenciamento de escopo.
A análise lexical é a primeira fase de um compilador. Ele obtém o código-fonte modificado dos pré-processadores de linguagem que são escritos na forma de frases. O analisador léxico divide essas sintaxes em uma série de tokens, removendo qualquer espaço em branco ou comentários no código-fonte.
Se o analisador léxico encontrar um token inválido, ele gerará um erro. O analisador léxico trabalha em estreita colaboração com o analisador de sintaxe. Ele lê os fluxos de caracteres do código-fonte, verifica os tokens legais e passa os dados para o analisador de sintaxe quando necessário.

Tokens
Os lexemes são considerados uma sequência de caracteres (alfanuméricos) em um token. Existem algumas regras predefinidas para que cada lexema seja identificado como um token válido. Essas regras são definidas por regras gramaticais, por meio de um padrão. Um padrão explica o que pode ser um token e esses padrões são definidos por meio de expressões regulares.
Em linguagem de programação, palavras-chave, constantes, identificadores, strings, números, operadores e símbolos de pontuação podem ser considerados tokens.
Por exemplo, na linguagem C, a linha de declaração da variável
int value = 100;contém os tokens:
int (keyword), value (identifier), = (operator), 100 (constant) and ; (symbol).Especificações de tokens
Vamos entender como a teoria da linguagem assume os seguintes termos:
Alfabetos
Qualquer conjunto finito de símbolos {0,1} é um conjunto de alfabetos binários, {0,1,2,3,4,5,6,7,8,9, A, B, C, D, E, F} é um conjunto de alfabetos hexadecimais, {az, AZ} é um conjunto de alfabetos do idioma inglês.
Cordas
Qualquer sequência finita de alfabetos é chamada de string. O comprimento da string é o número total de ocorrências de alfabetos, por exemplo, o comprimento do string tutorialspoint é 14 e é denotado por | tutorialspoint | = 14. Uma string sem alfabetos, ou seja, uma string de comprimento zero, é conhecida como string vazia e é denotada por ε (épsilon).
Símbolos Especiais
Uma linguagem típica de alto nível contém os seguintes símbolos: -
| Símbolos Aritméticos | Adição (+), Subtração (-), Módulo (%), Multiplicação (*), Divisão (/) |
| Pontuação | Vírgula (,), Ponto e vírgula (;), Ponto (.), Seta (->) |
| Tarefa | = |
| Seguimento especial | + =, / =, * =, - = |
| Comparação | ==,! =, <, <=,>,> = |
| Pré-processador | # |
| Especificador de localização | E |
| Lógico | &, &&, |, ||,! |
| Operador de turno | >>, >>>, <<, <<< |
Língua
Uma linguagem é considerada um conjunto finito de strings sobre um conjunto finito de alfabetos. As linguagens de computador são consideradas conjuntos finitos e operações com conjuntos matemáticos podem ser realizadas nelas. Linguagens finitas podem ser descritas por meio de expressões regulares.
Expressões regulares
O analisador léxico precisa verificar e identificar apenas um conjunto finito de string / token / lexema válido que pertence ao idioma em questão. Ele procura o padrão definido pelas regras de linguagem.
As expressões regulares têm a capacidade de expressar linguagens finitas, definindo um padrão para cadeias finitas de símbolos. A gramática definida por expressões regulares é conhecida comoregular grammar. A linguagem definida pela gramática regular é conhecida comoregular language.
A expressão regular é uma notação importante para especificar padrões. Cada padrão corresponde a um conjunto de strings, portanto, as expressões regulares servem como nomes para um conjunto de strings. Os tokens de linguagem de programação podem ser descritos por linguagens regulares. A especificação de expressões regulares é um exemplo de definição recursiva. Linguagens regulares são fáceis de entender e têm implementação eficiente.
Existem várias leis algébricas que são obedecidas por expressões regulares, que podem ser usadas para manipular expressões regulares em formas equivalentes.
Operações
As várias operações em idiomas são:
A união de duas línguas L e M é escrita como
LUM = {s | s está em L ou s está em M}
A concatenação de duas linguagens L e M é escrita como
LM = {st | s está em L e t está em M}
O fechamento de Kleene de uma linguagem L é escrito como
L * = Zero ou mais ocorrências do idioma L.
Notações
Se r e s são expressões regulares denotando as linguagens L (r) e L (s), então
Union : (r) | (s) é uma expressão regular denotando L (r) UL (s)
Concatenation : (r) (s) é uma expressão regular denotando L (r) L (s)
Kleene closure : (r) * é uma expressão regular denotando (L (r)) *
(r) é uma expressão regular denotando L (r)
Precedência e Associatividade
- *, concatenação (.) e | (sinal de pipe) são associativos à esquerda
- * tem a maior precedência
- A concatenação (.) Tem a segunda precedência mais alta.
- | (sinal de pipe) tem a precedência mais baixa de todas.
Representando tokens válidos de uma linguagem em expressões regulares
Se x for uma expressão regular, então:
x * significa zero ou mais ocorrências de x.
ou seja, pode gerar {e, x, xx, xxx, xxxx,…}
x + significa uma ou mais ocorrências de x.
ou seja, pode gerar {x, xx, xxx, xxxx…} ou xx *
x? significa no máximo uma ocorrência de x
ou seja, pode gerar {x} ou {e}.
[az] são todos os alfabetos minúsculos do idioma inglês.
[AZ] são todas as letras maiúsculas do idioma inglês.
[0-9] são todos os dígitos naturais usados em matemática.
Representando a ocorrência de símbolos usando expressões regulares
letra = [a - z] ou [A - Z]
dígito = 0 | 1 | 2 | 3 | 4 5 | 6 7 8 9 ou [0-9]
sinal = [+ | -]
Representando tokens de linguagem usando expressões regulares
Decimal = (sinal) ? (dígito) +
Identificador = (letra) (letra | dígito) *
O único problema que resta ao analisador léxico é como verificar a validade de uma expressão regular usada na especificação dos padrões de palavras-chave de uma linguagem. Uma solução bem aceita é usar autômatos finitos para verificação.
Autômatos Finitos
Os autômatos finitos são uma máquina de estado que pega uma sequência de símbolos como entrada e muda seu estado de acordo. Autômatos finitos são um reconhecedor de expressões regulares. Quando uma string de expressão regular é alimentada em autômatos finitos, ela muda seu estado para cada literal. Se a string de entrada for processada com sucesso e o autômato atingir seu estado final, ela será aceita, ou seja, a string que acabou de ser alimentada foi considerada um token válido da linguagem em questão.
O modelo matemático de autômatos finitos consiste em:
- Conjunto finito de estados (Q)
- Conjunto finito de símbolos de entrada (Σ)
- Um estado inicial (q0)
- Conjunto de estados finais (qf)
- Função de transição (δ)
A função de transição (δ) mapeia o conjunto finito de estado (Q) para um conjunto finito de símbolos de entrada (Σ), Q × Σ ➔ Q
Construção de autômatos finitos
Seja L (r) uma linguagem regular reconhecida por alguns autômatos finitos (FA).
States: Os estados de FA são representados por círculos. Os nomes dos estados são escritos dentro de círculos.
Start state: O estado a partir do qual o autômato começa é conhecido como estado inicial. O estado inicial tem uma seta apontada para ele.
Intermediate states: Todos os estados intermediários têm pelo menos duas setas; um apontando para e outro apontando a partir deles.
Final state: Se a string de entrada for analisada com sucesso, espera-se que o autômato esteja neste estado. O estado final é representado por círculos duplos. Ele pode ter qualquer número ímpar de setas apontando para ele e um número par de setas apontando para ele. O número de setas ímpares é um maior do que par, ou seja,odd = even+1.
Transition: A transição de um estado para outro ocorre quando um símbolo desejado na entrada é encontrado. Na transição, os autômatos podem passar para o próximo estado ou permanecer no mesmo estado. O movimento de um estado para outro é mostrado como uma seta direcionada, onde as setas apontam para o estado de destino. Se o autômato permanece no mesmo estado, uma seta apontando de um estado para si mesmo é desenhada.
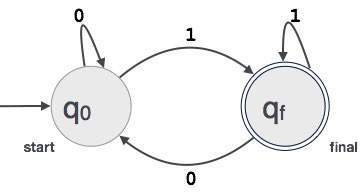
Example: Assumimos que FA aceita qualquer valor binário de três dígitos terminando no dígito 1. FA = {Q (q 0 , q f ), Σ (0,1), q 0 , q f , δ}
Regra de correspondência mais longa
Quando o analisador léxico lê o código-fonte, ele verifica o código letra por letra; e quando encontra um espaço em branco, símbolo de operador ou símbolos especiais, decide que uma palavra foi completada.
For example:
int intvalue;Durante a varredura de ambos os lexemas até 'int', o analisador léxico não pode determinar se é uma palavra-chave int ou as iniciais do valor int do identificador.
A regra de correspondência mais longa afirma que o lexema verificado deve ser determinado com base na correspondência mais longa entre todos os tokens disponíveis.
O analisador léxico também segue rule priorityonde uma palavra reservada, por exemplo, uma palavra-chave, de um idioma tem prioridade sobre a entrada do usuário. Ou seja, se o analisador léxico encontrar um lexema que corresponda a qualquer palavra reservada existente, ele deve gerar um erro.
A análise de sintaxe ou análise sintática é a segunda fase de um compilador. Neste capítulo, aprenderemos os conceitos básicos usados na construção de um parser.
Vimos que um analisador léxico pode identificar tokens com a ajuda de expressões regulares e regras de padrão. Mas um analisador léxico não pode verificar a sintaxe de uma determinada frase devido às limitações das expressões regulares. Expressões regulares não podem verificar tokens de balanceamento, como parênteses. Portanto, esta fase usa gramática livre de contexto (CFG), que é reconhecida por autômatos push-down.
CFG, por outro lado, é um superconjunto da Gramática Regular, conforme ilustrado abaixo:

Isso implica que toda gramática regular também é livre de contexto, mas existem alguns problemas, que estão além do escopo da gramática regular. CFG é uma ferramenta útil para descrever a sintaxe das linguagens de programação.
Gramática Livre de Contexto
Nesta seção, veremos primeiro a definição de gramática livre de contexto e apresentaremos as terminologias usadas na tecnologia de análise.
Uma gramática livre de contexto tem quatro componentes:
Um conjunto de non-terminals(V). Não terminais são variáveis sintáticas que denotam conjuntos de strings. Os não terminais definem conjuntos de strings que ajudam a definir a linguagem gerada pela gramática.
Um conjunto de tokens, conhecido como terminal symbols(Σ). Terminais são os símbolos básicos a partir dos quais as strings são formadas.
Um conjunto de productions(P). As produções de uma gramática especificam a maneira pela qual os terminais e não terminais podem ser combinados para formar strings. Cada produção consiste em umnon-terminal chamado de lado esquerdo da produção, uma seta e uma sequência de tokens e / ou on- terminals, chamado de lado direito da produção.
Um dos não terminais é designado como o símbolo de início (S); de onde a produção começa.
As strings são derivadas do símbolo de início substituindo repetidamente um não terminal (inicialmente o símbolo de início) pelo lado direito de uma produção, para aquele não terminal.
Exemplo
Tomamos o problema da linguagem palíndromo, que não pode ser descrita por meio da Expressão Regular. Ou seja, L = {w | w = w R } não é uma linguagem regular. Mas pode ser descrito por meio do CFG, conforme ilustrado a seguir:
G = ( V, Σ, P, S )Onde:
V = { Q, Z, N }
Σ = { 0, 1 }
P = { Q → Z | Q → N | Q → ℇ | Z → 0Q0 | N → 1Q1 }
S = { Q }Esta gramática descreve a linguagem do palíndromo, como: 1001, 11100111, 00100, 1010101, 11111, etc.
Analisadores de sintaxe
Um analisador de sintaxe ou analisador obtém a entrada de um analisador léxico na forma de fluxos de token. O analisador analisa o código-fonte (fluxo de token) em relação às regras de produção para detectar quaisquer erros no código. A saída desta fase é umparse tree.

Dessa forma, o analisador realiza duas tarefas, ou seja, analisar o código, procurar erros e gerar uma árvore de análise como saída da fase.
Espera-se que os analisadores analisem todo o código, mesmo que existam alguns erros no programa. Analisadores usam estratégias de recuperação de erros, que aprenderemos mais tarde neste capítulo.
Derivação
Uma derivação é basicamente uma sequência de regras de produção, a fim de obter a string de entrada. Durante a análise, tomamos duas decisões para alguma forma sentencial de entrada:
- Decidir o não terminal que deve ser substituído.
- Decidir a regra de produção, pela qual, o não terminal será substituído.
Para decidir qual não-terminal será substituído pela regra de produção, podemos ter duas opções.
Derivação mais à esquerda
Se a forma sentencial de uma entrada for digitalizada e substituída da esquerda para a direita, é chamada de derivação mais à esquerda. A forma sentencial derivada da derivação mais à esquerda é chamada de forma sentencial à esquerda.
Derivação mais à direita
Se digitalizarmos e substituirmos a entrada por regras de produção, da direita para a esquerda, isso é conhecido como derivação mais à direita. A forma sentencial derivada da derivação mais à direita é chamada de forma sentencial à direita.
Example
Regras de produção:
E → E + E
E → E * E
E → idString de entrada: id + id * id
A derivação mais à esquerda é:
E → E * E
E → E + E * E
E → id + E * E
E → id + id * E
E → id + id * idObserve que o não terminal mais à esquerda é sempre processado primeiro.
A derivação mais à direita é:
E → E + E
E → E + E * E
E → E + E * id
E → E + id * id
E → id + id * idAnalisar árvore
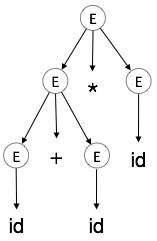
Uma árvore de análise é uma representação gráfica de uma derivação. É conveniente ver como as strings são derivadas do símbolo inicial. O símbolo inicial da derivação se torna a raiz da árvore de análise. Vamos ver isso por um exemplo do último tópico.
Tomamos a derivação mais à esquerda de a + b * c
A derivação mais à esquerda é:
E → E * E
E → E + E * E
E → id + E * E
E → id + id * E
E → id + id * idPasso 1:
| E → E * E |
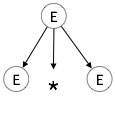
|
Passo 2:
| E → E + E * E |
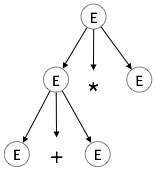
|
Etapa 3:
| E → id + E * E |
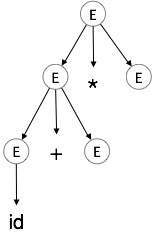
|
Passo 4:
| E → id + id * E |
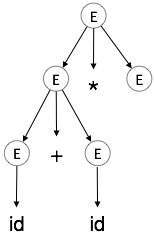
|
Etapa 5:
| E → id + id * id |
|
Em uma árvore de análise:
- Todos os nós folha são terminais.
- Todos os nós internos são não terminais.
- O percurso em ordem fornece a string de entrada original.
Uma árvore de análise descreve associatividade e precedência de operadores. A subárvore mais profunda é percorrida primeiro, portanto, o operador dessa subárvore tem precedência sobre o operador que está nos nós pais.
Tipos de análise
Os analisadores de sintaxe seguem regras de produção definidas por meio de gramática livre de contexto. A maneira como as regras de produção são implementadas (derivação) divide a análise em dois tipos: análise de cima para baixo e análise de baixo para cima.
Análise de cima para baixo
Quando o analisador começa a construir a árvore de análise a partir do símbolo inicial e tenta transformar o símbolo inicial na entrada, isso é chamado de análise de cima para baixo.
Recursive descent parsing: É uma forma comum de análise de cima para baixo. É chamado de recursivo porque usa procedimentos recursivos para processar a entrada. A análise descendente recursiva sofre de retrocesso.
Backtracking: Significa que, se uma derivação de uma produção falhar, o analisador de sintaxe reinicia o processo usando regras diferentes da mesma produção. Esta técnica pode processar a string de entrada mais de uma vez para determinar a produção correta.
Análise de baixo para cima
Como o nome sugere, a análise de baixo para cima começa com os símbolos de entrada e tenta construir a árvore de análise até o símbolo inicial.
Example:
String de entrada: a + b * c
Regras de produção:
S → E
E → E + T
E → E * T
E → T
T → idVamos começar a análise de baixo para cima
a + b * cLeia a entrada e verifique se alguma produção corresponde à entrada:
a + b * c
T + b * c
E + b * c
E + T * c
E * c
E * T
E
SAmbiguidade
Uma gramática G é considerada ambígua se tiver mais de uma árvore de análise (derivação esquerda ou direita) para pelo menos uma string.
Example
E → E + E
E → E – E
E → idPara a string id + id - id, a gramática acima gera duas árvores de análise:

A linguagem gerada por uma gramática ambígua é considerada inherently ambiguous. A ambigüidade na gramática não é boa para a construção de um compilador. Nenhum método pode detectar e remover a ambigüidade automaticamente, mas pode ser removido reescrevendo toda a gramática sem ambigüidade ou configurando e seguindo as restrições de associatividade e precedência.
Associatividade
Se um operando possui operadores em ambos os lados, o lado em que o operador assume esse operando é decidido pela associatividade desses operadores. Se a operação for associativa à esquerda, o operando será obtido pelo operador esquerdo ou, se a operação for associativa à direita, o operador direito obterá o operando.
Example
Operações como adição, multiplicação, subtração e divisão são associativas à esquerda. Se a expressão contiver:
id op id op idserá avaliado como:
(id op id) op idPor exemplo, (id + id) + id
Operações como exponenciação são associativas à direita, ou seja, a ordem de avaliação na mesma expressão será:
id op (id op id)Por exemplo, id ^ (id ^ id)
Precedência
Se dois operadores diferentes compartilham um operando comum, a precedência dos operadores decide quem ficará com o operando. Ou seja, 2 + 3 * 4 pode ter duas árvores de análise sintática diferentes, uma correspondendo a (2 + 3) * 4 e outra correspondendo a 2+ (3 * 4). Ao definir a precedência entre os operadores, esse problema pode ser facilmente removido. Como no exemplo anterior, matematicamente * (multiplicação) tem precedência sobre + (adição), então a expressão 2 + 3 * 4 sempre será interpretada como:
2 + (3 * 4)Esses métodos diminuem as chances de ambiguidade em um idioma ou sua gramática.
Recursão à esquerda
Uma gramática torna-se recursiva à esquerda se tiver qualquer 'A' não terminal cuja derivação contém o próprio 'A' como o símbolo mais à esquerda. A gramática recursiva à esquerda é considerada uma situação problemática para analisadores top-down. Os analisadores top-down começam a analisar a partir do símbolo Start, que por si só não é terminal. Portanto, quando o analisador encontra o mesmo não terminal em sua derivação, torna-se difícil para ele julgar quando parar de analisar o não terminal esquerdo e ele entra em um loop infinito.
Example:
(1) A => Aα | β
(2) S => Aα | β
A => Sd(1) é um exemplo de recursão imediata à esquerda, onde A é qualquer símbolo não terminal e α representa uma sequência de não terminais.
(2) é um exemplo de recursão indireta à esquerda.
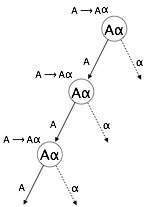
Um analisador de cima para baixo primeiro analisará o A, que por sua vez produzirá uma string consistindo no próprio A e o analisador poderá entrar em um loop para sempre.
Remoção da recursão à esquerda
Uma maneira de remover a recursão à esquerda é usar a seguinte técnica:
A produção
A => Aα | βé convertido nas seguintes produções
A => βA’
A => αA’ | εIsso não afeta as cadeias de caracteres derivadas da gramática, mas remove a recursão à esquerda imediata.
O segundo método é usar o seguinte algoritmo, que deve eliminar todas as recursões diretas e indiretas à esquerda.
Algorithm
START
Arrange non-terminals in some order like A1, A2, A3,…, An
for each i from 1 to n
{
for each j from 1 to i-1
{
replace each production of form Ai⟹Aj
with Ai ⟹ δ1 | δ2 | δ3 |…|
where Aj ⟹ δ1 | δ2|…| δn are current Aj productions
}
}
eliminate immediate left-recursion
ENDExample
O conjunto de produção
S => Aα | β
A => Sddepois de aplicar o algoritmo acima, deve se tornar
S => Aα | β
A => Aαd | βde, em seguida, remova a recursão à esquerda imediata usando a primeira técnica.
A => βdA’
A => αdA’ | εAgora, nenhuma parte da produção tem recursão à esquerda direta ou indireta.
Fatoração à esquerda
Se mais de uma regra de produção de gramática tem uma string de prefixo comum, o analisador de cima para baixo não pode fazer uma escolha sobre qual produção deve ser realizada para analisar a string em questão.
Example
Se um analisador top-down encontra uma produção como
A ⟹ αβ | α | …Então, ele não pode determinar qual produção seguir para analisar a string, já que ambas as produções estão iniciando no mesmo terminal (ou não). Para remover essa confusão, usamos uma técnica chamada fatoração à esquerda.
A fatoração à esquerda transforma a gramática para torná-la útil para analisadores de cima para baixo. Nesta técnica, fazemos uma produção para cada prefixo comum e o resto da derivação é adicionado por novas produções.
Example
As produções acima podem ser escritas como
A => αA’
A’=> β | | …Agora, o analisador tem apenas uma produção por prefixo, o que torna mais fácil a tomada de decisões.
Conjuntos de primeiros e seguintes
Uma parte importante da construção da tabela do analisador é criar primeiro e seguir os conjuntos. Esses conjuntos podem fornecer a posição real de qualquer terminal na derivação. Isso é feito para criar a tabela de análise em que a decisão de substituir T [A, t] = α por alguma regra de produção.
Primeiro set
Este conjunto é criado para saber qual símbolo terminal é derivado na primeira posição por um não terminal. Por exemplo,
α → t βOu seja, α deriva t (terminal) na primeira posição. Portanto, t ∈ PRIMEIRO (α).
Algoritmo para calcular o primeiro conjunto
Observe a definição do conjunto FIRST (α):
- se α for um terminal, então FIRST (α) = {α}.
- se α é um não terminal e α → ℇ é uma produção, então FIRST (α) = {ℇ}.
- se α é um não terminal e α → 1 2 3… n e qualquer FIRST () contém t então t está em FIRST (α).
O primeiro conjunto pode ser visto como: FIRST (α) = {t | α → * t β} ∪ {ℇ | α → * ε}
Seguir Set
Da mesma forma, calculamos qual símbolo terminal segue imediatamente um α não terminal nas regras de produção. Não consideramos o que o não-terminal pode gerar, mas, em vez disso, vemos qual seria o próximo símbolo do terminal que segue as produções de um não-terminal.
Algoritmo para calcular o conjunto de acompanhamento:
se α é um símbolo inicial, então FOLLOW () = $
se α é um não terminal e tem uma produção α → AB, então FIRST (B) está em FOLLOW (A) exceto ℇ.
se α é um não terminal e tem uma produção α → AB, onde B ℇ, então FOLLOW (A) está em FOLLOW (α).
O conjunto seguinte pode ser visto como: FOLLOW (α) = {t | S * αt *}
Estratégias de recuperação de erros
Um analisador deve ser capaz de detectar e relatar qualquer erro no programa. Espera-se que, quando um erro for encontrado, o analisador seja capaz de tratá-lo e continue a analisar o resto da entrada. Normalmente, espera-se que o analisador verifique se há erros, mas podem ser encontrados erros em vários estágios do processo de compilação. Um programa pode ter os seguintes tipos de erros em vários estágios:
Lexical : nome de algum identificador digitado incorretamente
Syntactical : ponto e vírgula ausente ou parêntese não balanceado
Semantical : atribuição de valor incompatível
Logical : código não alcançável, loop infinito
Existem quatro estratégias comuns de recuperação de erros que podem ser implementadas no analisador para lidar com erros no código.
Modo de pânico
Quando um analisador encontra um erro em qualquer lugar da instrução, ele ignora o resto da instrução, não processando a entrada de entrada incorreta para delimitador, como ponto e vírgula. Esta é a maneira mais fácil de recuperação de erros e também evita que o analisador desenvolva loops infinitos.
Modo de declaração
Quando um analisador encontra um erro, ele tenta tomar medidas corretivas para que o resto das entradas da instrução permitam que o analisador analise adiante. Por exemplo, inserir um ponto-e-vírgula ausente, substituir a vírgula por um ponto-e-vírgula, etc. Os projetistas do analisador devem ser cuidadosos aqui porque uma correção errada pode levar a um loop infinito.
Produções de erro
Alguns erros comuns são conhecidos pelos designers do compilador que podem ocorrer no código. Além disso, os designers podem criar gramática aumentada para ser usada, como produções que geram construções errôneas quando esses erros são encontrados.
Correção global
O analisador considera o programa em mãos como um todo e tenta descobrir o que o programa se destina a fazer e tenta descobrir uma correspondência mais próxima para ele, que é livre de erros. Quando uma entrada errônea (instrução) X é alimentada, ele cria uma árvore de análise para alguma instrução Y livre de erros mais próxima. Isso pode permitir que o analisador faça alterações mínimas no código-fonte, mas devido à complexidade (tempo e espaço) de esta estratégia, ainda não foi implementada na prática.
Árvores de sintaxe abstrata
As representações da árvore de análise não são fáceis de serem analisadas pelo compilador, pois contêm mais detalhes do que o realmente necessário. Veja a seguinte árvore de análise como exemplo:
Se observado de perto, descobrimos que a maioria dos nós folha são filhos únicos de seus nós pais. Essas informações podem ser eliminadas antes de passar para a próxima fase. Ao ocultar informações extras, podemos obter uma árvore conforme mostrado abaixo:
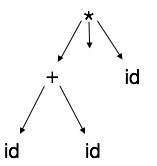
A árvore abstrata pode ser representada como:
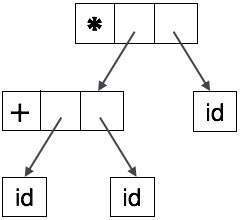
ASTs são estruturas de dados importantes em um compilador com menos informações desnecessárias. Os ASTs são mais compactos do que uma árvore de análise e podem ser facilmente usados por um compilador.
Limitações dos analisadores de sintaxe
Os analisadores de sintaxe recebem suas entradas, na forma de tokens, de analisadores lexicais. Os analisadores lexicais são responsáveis pela validade de um token fornecido pelo analisador de sintaxe. Os analisadores de sintaxe têm as seguintes desvantagens:
- não pode determinar se um token é válido,
- ele não pode determinar se um token é declarado antes de ser usado,
- ele não pode determinar se um token foi inicializado antes de ser usado,
- ele não pode determinar se uma operação executada em um tipo de token é válida ou não.
Essas tarefas são realizadas pelo analisador semântico, que estudaremos na Análise Semântica.
Aprendemos como um analisador constrói árvores de análise na fase de análise de sintaxe. A árvore de análise simples construída nessa fase geralmente não tem utilidade para um compilador, pois não contém nenhuma informação de como avaliar a árvore. As produções de gramática livre de contexto, que fazem as regras da língua, não acomodam como interpretá-las.
Por exemplo
E → E + TA produção CFG acima não tem nenhuma regra semântica associada a ela e não pode ajudar a dar qualquer sentido à produção.
Semântica
A semântica de uma linguagem fornece significado para suas construções, como tokens e estrutura de sintaxe. A semântica ajuda a interpretar os símbolos, seus tipos e suas relações uns com os outros. A análise semântica avalia se a estrutura de sintaxe construída no programa de origem obtém algum significado ou não.
CFG + semantic rules = Syntax Directed DefinitionsPor exemplo:
int a = “value”;não deve emitir um erro na fase de análise lexical e de sintaxe, pois é lexical e estruturalmente correto, mas deve gerar um erro semântico conforme o tipo de atribuição difere. Essas regras são definidas pela gramática da língua e avaliadas na análise semântica. As seguintes tarefas devem ser realizadas na análise semântica:
- Resolução de escopo
- Verificação de tipo
- Verificação de limite de matriz
Erros Semânticos
Mencionamos alguns dos erros de semântica que se espera que o analisador semântico reconheça:
- Tipo incompatível
- Variável não declarada
- Uso indevido do identificador reservado.
- Declaração múltipla de variável em um escopo.
- Acessando uma variável fora do escopo.
- Incompatibilidade de parâmetro real e formal.
Gramática de Atributos
A gramática de atributos é uma forma especial de gramática livre de contexto em que algumas informações adicionais (atributos) são anexadas a um ou mais de seus não terminais para fornecer informações sensíveis ao contexto. Cada atributo possui um domínio de valores bem definido, como inteiro, flutuante, caractere, string e expressões.
A gramática de atributos é um meio para fornecer semântica à gramática livre de contexto e pode ajudar a especificar a sintaxe e a semântica de uma linguagem de programação. A gramática de atributos (quando vista como uma árvore de análise) pode passar valores ou informações entre os nós de uma árvore.
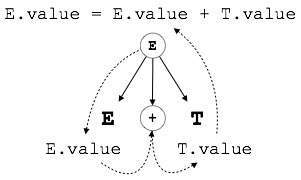
Example:
E → E + T { E.value = E.value + T.value }A parte direita do CFG contém as regras semânticas que especificam como a gramática deve ser interpretada. Aqui, os valores dos não terminais E e T são somados e o resultado é copiado para o não terminal E.
Os atributos semânticos podem ser atribuídos aos seus valores de seu domínio no momento da análise e avaliados no momento da atribuição ou condições. Com base na maneira como os atributos obtêm seus valores, eles podem ser amplamente divididos em duas categorias: atributos sintetizados e atributos herdados.
Atributos sintetizados
Esses atributos obtêm valores dos valores de atributo de seus nós filhos. Para ilustrar, assuma a seguinte produção:
S → ABCSe S está pegando valores de seus nós filhos (A, B, C), então é dito ser um atributo sintetizado, já que os valores de ABC são sintetizados em S.
Como em nosso exemplo anterior (E → E + T), o nó pai E obtém seu valor de seu nó filho. Os atributos sintetizados nunca obtêm valores de seus nós pais ou de quaisquer nós irmãos.
Atributos herdados
Em contraste com os atributos sintetizados, os atributos herdados podem receber valores dos pais e / ou irmãos. Como na produção a seguir,
S → ABCA pode obter valores de S, B e C. B pode obter valores de S, A e C. Da mesma forma, C pode obter valores de S, A e B.
Expansion : Quando um não terminal é expandido para terminais de acordo com uma regra gramatical
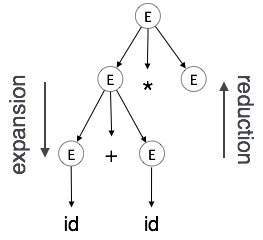
Reduction: Quando um terminal é reduzido ao seu não terminal correspondente de acordo com as regras gramaticais. Árvores de sintaxe são analisadas de cima para baixo e da esquerda para a direita. Sempre que ocorre redução, aplicamos suas regras semânticas correspondentes (ações).
A análise semântica usa traduções direcionadas por sintaxe para realizar as tarefas acima.
O analisador semântico recebe AST (Abstract Syntax Tree) de seu estágio anterior (análise de sintaxe).
O analisador semântico anexa informações de atributo com AST, que são chamados de AST atribuído.
Os atributos são dois valores de tupla, <nome do atributo, valor do atributo>
Por exemplo:
int value = 5;
<type, “integer”>
<presentvalue, “5”>Para cada produção, anexamos uma regra semântica.
SDT atribuído a S
Se um SDT usa apenas atributos sintetizados, é chamado de SDT atribuído a S. Esses atributos são avaliados usando SDTs atribuídos a S que têm suas ações semânticas escritas após a produção (lado direito).
Conforme descrito acima, os atributos em SDTs atribuídos a S são avaliados na análise de baixo para cima, já que os valores dos nós pais dependem dos valores dos nós filhos.
SDT atribuído a L
Esta forma de SDT usa atributos sintetizados e herdados com restrição de não receber valores de irmãos certos.
Em SDTs atribuídos a L, um não terminal pode obter valores de seus nós pai, filho e irmão. Como na seguinte produção
S → ABCS pode obter valores de A, B e C (sintetizado). A pode obter valores de S apenas. B pode obter valores de S e A. C pode obter valores de S, A e B. Nenhum não terminal pode obter valores do irmão à sua direita.
Os atributos em SDTs atribuídos a L são avaliados pela maneira de análise de profundidade e da esquerda para a direita.
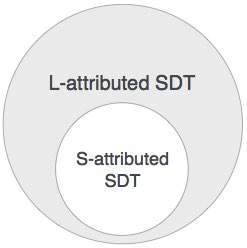
Podemos concluir que se uma definição é atribuída a S, então também é atribuída a L, pois a definição atribuída a L inclui as definições atribuídas a S.
No capítulo anterior, entendemos os conceitos básicos envolvidos na análise. Neste capítulo, aprenderemos os vários tipos de métodos de construção de analisadores disponíveis.
A análise pode ser definida de cima para baixo ou de baixo para cima com base em como a árvore de análise é construída.

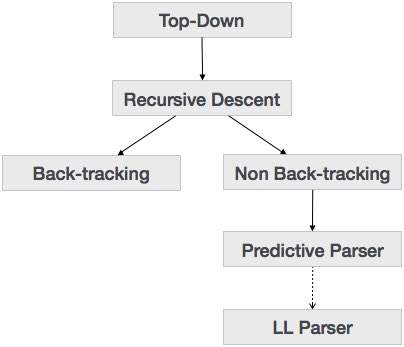
Análise Top-Down
Aprendemos no último capítulo que a técnica de análise de cima para baixo analisa a entrada e começa a construir uma árvore de análise a partir do nó raiz, movendo-se gradualmente para os nós folha. Os tipos de análise de cima para baixo são descritos abaixo:
Análise descendente recursiva
A descida recursiva é uma técnica de análise de cima para baixo que constrói a árvore de análise a partir do topo e a entrada é lida da esquerda para a direita. Ele usa procedimentos para cada entidade terminal e não terminal. Esta técnica de análise analisa recursivamente a entrada para fazer uma árvore de análise, que pode ou não exigir rastreamento posterior. Mas a gramática associada a ele (se não for fatorada à esquerda) não pode evitar o retrocesso. Uma forma de análise descendente recursiva que não requer nenhum rastreamento posterior é conhecida comopredictive parsing.
Essa técnica de análise é considerada recursiva, pois usa gramática livre de contexto, que é recursiva por natureza.
Back-tracking
Os analisadores de cima para baixo começam no nó raiz (símbolo de início) e comparam a string de entrada com as regras de produção para substituí-las (se houver correspondência). Para entender isso, pegue o seguinte exemplo de CFG:
S → rXd | rZd
X → oa | ea
Z → aiPara uma string de entrada: read, um analisador de cima para baixo, se comportará assim:
Ele começará com S nas regras de produção e corresponderá seu rendimento à letra mais à esquerda da entrada, ou seja, 'r'. A própria produção de S (S → rXd) corresponde a ele. Portanto, o analisador de cima para baixo avança para a próxima letra de entrada (ou seja, 'e'). O analisador tenta expandir o 'X' não terminal e verifica sua produção a partir da esquerda (X → oa). Ele não corresponde ao próximo símbolo de entrada. Portanto, o analisador de cima para baixo retrocede para obter a próxima regra de produção de X, (X → ea).
Agora, o analisador combina todas as letras de entrada de maneira ordenada. A string é aceita.
|
|
|
|
|
Analisador Preditivo
O analisador preditivo é um analisador descendente recursivo, que tem a capacidade de prever qual produção será usada para substituir a string de entrada. O analisador preditivo não sofre retrocessos.
Para realizar suas tarefas, o analisador preditivo usa um ponteiro de antecipação, que aponta para os próximos símbolos de entrada. Para tornar o rastreamento retroativo do analisador livre, o analisador preditivo impõe algumas restrições à gramática e aceita apenas uma classe de gramática conhecida como gramática LL (k).
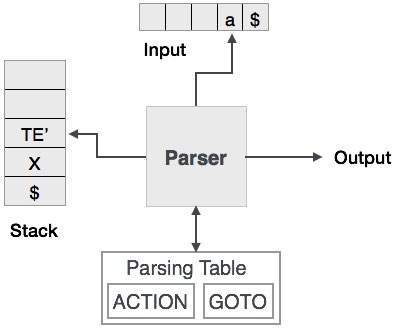
A análise preditiva usa uma pilha e uma tabela de análise para analisar a entrada e gerar uma árvore de análise. Tanto a pilha quanto a entrada contêm um símbolo de fim$para denotar que a pilha está vazia e a entrada foi consumida. O analisador se refere à tabela de análise para tomar qualquer decisão sobre a combinação de entrada e elemento de pilha.
Na análise descendente recursiva, o analisador pode ter mais de uma produção para escolher para uma única instância de entrada, enquanto no analisador preditivo, cada etapa tem no máximo uma produção para escolher. Pode haver instâncias em que não haja produção correspondente à string de entrada, fazendo com que o procedimento de análise falhe.
LL Parser
Um analisador LL aceita a gramática LL. A gramática LL é um subconjunto da gramática livre de contexto, mas com algumas restrições para obter a versão simplificada, a fim de obter uma implementação fácil. A gramática LL pode ser implementada por meio de ambos os algoritmos, a saber, descida recursiva ou baseada em tabelas.
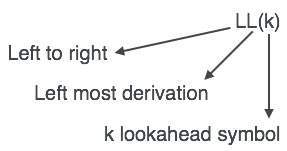
O analisador LL é denotado como LL (k). O primeiro L em LL (k) analisa a entrada da esquerda para a direita, o segundo L em LL (k) representa a derivação mais à esquerda e o próprio k representa o número de olhares à frente. Geralmente k = 1, então LL (k) também pode ser escrito como LL (1).
Algoritmo de análise LL
Podemos nos ater ao determinístico LL (1) para a explicação do analisador, já que o tamanho da tabela cresce exponencialmente com o valor de k. Em segundo lugar, se uma dada gramática não é LL (1), então geralmente não é LL (k), para qualquer k dado.
É fornecido a seguir um algoritmo para análise LL (1):
Input:
string ω
parsing table M for grammar G
Output:
If ω is in L(G) then left-most derivation of ω,
error otherwise.
Initial State : $S on stack (with S being start symbol) ω$ in the input buffer
SET ip to point the first symbol of ω$.
repeat
let X be the top stack symbol and a the symbol pointed by ip.
if X∈ Vt or $
if X = a
POP X and advance ip.
else
error()
endif
else /* X is non-terminal */
if M[X,a] = X → Y1, Y2,... Yk
POP X
PUSH Yk, Yk-1,... Y1 /* Y1 on top */
Output the production X → Y1, Y2,... Yk
else
error()
endif
endif
until X = $ /* empty stack */Uma gramática G é LL (1) se A-> alfa | b são duas produções distintas de G:
para nenhum terminal, tanto alfa quanto beta derivam strings que começam com a.
no máximo, um de alfa e beta pode derivar uma string vazia.
se beta => t, então alfa não deriva nenhuma string começando com um terminal em FOLLOW (A).
Análise de baixo para cima
A análise de baixo para cima começa nos nós folha de uma árvore e funciona na direção ascendente até atingir o nó raiz. Aqui, começamos a partir de uma frase e, em seguida, aplicamos as regras de produção de maneira reversa para chegar ao símbolo inicial. A imagem abaixo mostra os analisadores bottom-up disponíveis.

Análise Shift-Reduce
A análise de redução de deslocamento usa duas etapas exclusivas para análise de baixo para cima. Essas etapas são conhecidas como etapa de mudança e etapa de redução.
Shift step: A etapa de deslocamento refere-se ao avanço do ponteiro de entrada para o próximo símbolo de entrada, que é chamado de símbolo deslocado. Este símbolo é colocado na pilha. O símbolo deslocado é tratado como um único nó da árvore de análise.
Reduce step: Quando o analisador encontra uma regra gramatical completa (RHS) e a substitui por (LHS), isso é conhecido como etapa de redução. Isso ocorre quando o topo da pilha contém uma alça. Para reduzir, uma função POP é executada na pilha que sai da alça e a substitui pelo símbolo não terminal LHS.
LR Parser
O analisador LR é um analisador não recursivo, de redução de deslocamento, de baixo para cima. Ele usa uma ampla classe de gramática livre de contexto, o que o torna a técnica de análise de sintaxe mais eficiente. Os analisadores LR também são conhecidos como analisadores LR (k), onde L representa a varredura da esquerda para a direita do fluxo de entrada; R representa a construção da derivação mais à direita ao contrário, e k denota o número de símbolos de antevisão para tomar decisões.
Existem três algoritmos amplamente usados disponíveis para construir um analisador LR:
- SLR (1) - Analisador LR Simples:
- Funciona na menor classe de gramática
- Poucos estados, portanto, uma mesa muito pequena
- Construção simples e rápida
- LR (1) - Analisador LR:
- Funciona no conjunto completo de gramática LR (1)
- Gera uma grande tabela e um grande número de estados
- Construção lenta
- LALR (1) - Analisador LR Look-Ahead:
- Funciona no tamanho intermediário da gramática
- O número de estados é o mesmo que em SLR (1)
Algoritmo de análise LR
Aqui, descrevemos um algoritmo de esqueleto de um analisador LR:
token = next_token()
repeat forever
s = top of stack
if action[s, token] = “shift si” then
PUSH token
PUSH si
token = next_token()
else if action[s, tpken] = “reduce A::= β“ then
POP 2 * |β| symbols
s = top of stack
PUSH A
PUSH goto[s,A]
else if action[s, token] = “accept” then
return
else
error()LL vs. LR
| LL | LR |
|---|---|
| Faz uma derivação mais à esquerda. | Faz uma derivação mais à direita ao contrário. |
| Começa com o não terminal raiz na pilha. | Termina com o não terminal raiz na pilha. |
| Termina quando a pilha está vazia. | Começa com uma pilha vazia. |
| Usa a pilha para designar o que ainda é esperado. | Usa a pilha para designar o que já é visto. |
| Constrói a árvore de análise de cima para baixo. | Constrói a árvore de análise de baixo para cima. |
| Retira continuamente um não-terminal da pilha e empurra o lado direito correspondente. | Tenta reconhecer um lado direito da pilha, abre-o e empurra o não terminal correspondente. |
| Expande os não terminais. | Reduz os não terminais. |
| Lê os terminais quando ele o tira da pilha. | Lê os terminais enquanto os empurra para a pilha. |
| Pré-encomende a travessia da árvore de análise. | Travessia pós-pedido da árvore de análise. |
Um programa como código-fonte é apenas uma coleção de texto (código, instruções etc.) e, para torná-lo vivo, requer que ações sejam executadas na máquina de destino. Um programa precisa de recursos de memória para executar as instruções. Um programa contém nomes para procedimentos, identificadores etc., que requerem mapeamento com a localização real da memória em tempo de execução.
Por tempo de execução, queremos dizer um programa em execução. O ambiente de tempo de execução é um estado da máquina de destino, que pode incluir bibliotecas de software, variáveis de ambiente, etc., para fornecer serviços aos processos em execução no sistema.
O sistema de suporte em tempo de execução é um pacote, geralmente gerado com o próprio programa executável e facilita a comunicação do processo entre o processo e o ambiente de execução. Ele cuida da alocação e desalocação de memória enquanto o programa está sendo executado.
Árvores de Ativação
Um programa é uma sequência de instruções combinadas em vários procedimentos. As instruções em um procedimento são executadas sequencialmente. Um procedimento tem um delimitador de início e fim e tudo dentro dele é chamado de corpo do procedimento. O identificador do procedimento e a sequência de instruções finitas dentro dele constituem o corpo do procedimento.
A execução de um procedimento é chamada de ativação. Um registro de ativação contém todas as informações necessárias para chamar um procedimento. Um registro de ativação pode conter as seguintes unidades (dependendo do idioma de origem usado).
| Temporários | Armazena valores temporários e intermediários de uma expressão. |
| Dados Locais | Armazena dados locais do procedimento chamado. |
| Status da máquina | Armazena o status da máquina, como registros, contador de programa, etc., antes que o procedimento seja chamado. |
| Link de controle | Armazena o endereço de registro de ativação do procedimento do chamador. |
| Link de acesso | Armazena as informações de dados que estão fora do escopo local. |
| Parâmetros reais | Armazena parâmetros reais, ou seja, parâmetros que são usados para enviar entrada para o procedimento chamado. |
| Valor de retorno | Armazena valores de retorno. |
Sempre que um procedimento é executado, seu registro de ativação é armazenado na pilha, também conhecida como pilha de controle. Quando um procedimento chama outro procedimento, a execução do chamador é suspensa até que o procedimento chamado termine a execução. Nesse momento, o registro de ativação do procedimento chamado é armazenado na pilha.
Assumimos que o controle do programa flui de maneira sequencial e quando um procedimento é chamado, seu controle é transferido para o procedimento chamado. Quando um procedimento chamado é executado, ele retorna o controle ao chamador. Esse tipo de fluxo de controle facilita a representação de uma série de ativações em forma de árvore, conhecida comoactivation tree.
Para entender esse conceito, tomamos um trecho de código como exemplo:
. . .
printf(“Enter Your Name: “);
scanf(“%s”, username);
show_data(username);
printf(“Press any key to continue…”);
. . .
int show_data(char *user)
{
printf(“Your name is %s”, username);
return 0;
}
. . .Abaixo está a árvore de ativação do código fornecido.

Agora entendemos que os procedimentos são executados em primeiro lugar em profundidade, portanto, a alocação de pilha é a melhor forma adequada de armazenamento para ativações de procedimento.
Alocação de armazenamento
O ambiente de tempo de execução gerencia os requisitos de memória do tempo de execução para as seguintes entidades:
Code: É conhecido como a parte de texto de um programa que não muda durante a execução. Seus requisitos de memória são conhecidos no momento da compilação.
Procedures: Sua parte de texto é estática, mas eles são chamados de maneira aleatória. É por isso que o armazenamento em pilha é usado para gerenciar chamadas e ativações de procedimento.
Variables: As variáveis são conhecidas apenas no tempo de execução, a menos que sejam globais ou constantes. O esquema de alocação de memória heap é usado para gerenciar a alocação e desalocação de memória para variáveis em tempo de execução.
Alocação estática
Nesse esquema de alocação, os dados de compilação são vinculados a um local fixo na memória e não mudam quando o programa é executado. Como o requisito de memória e os locais de armazenamento são conhecidos com antecedência, o pacote de suporte de tempo de execução para alocação e desalocação de memória não é necessário.
Alocação de pilha
As chamadas de procedimento e suas ativações são gerenciadas por meio da alocação de memória da pilha. Ele funciona no método LIFO (last-in-first-out) e essa estratégia de alocação é muito útil para chamadas de procedimento recursivas.
Alocação de heap
Variáveis locais para um procedimento são alocadas e desalocadas apenas em tempo de execução. A alocação de heap é usada para alocar memória dinamicamente às variáveis e reivindicá-la de volta quando as variáveis não forem mais necessárias.
Exceto a área de memória alocada estaticamente, as memórias de pilha e heap podem aumentar e diminuir de forma dinâmica e inesperada. Portanto, eles não podem ser fornecidos com uma quantidade fixa de memória no sistema.
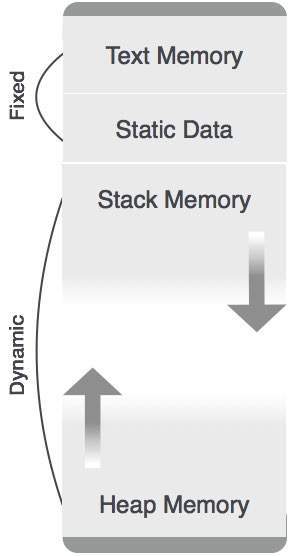
Conforme mostrado na imagem acima, a parte de texto do código é alocada a uma quantidade fixa de memória. As memórias de pilha e heap são organizadas nos extremos da memória total alocada para o programa. Ambos encolhem e crescem um contra o outro.
Passagem de parâmetro
O meio de comunicação entre procedimentos é conhecido como passagem de parâmetros. Os valores das variáveis de um procedimento de chamada são transferidos para o procedimento chamado por algum mecanismo. Antes de prosseguir, primeiro analise algumas terminologias básicas relativas aos valores em um programa.
valor r
O valor de uma expressão é chamado de valor r. O valor contido em uma única variável também se torna um valor r se aparecer no lado direito do operador de atribuição. Os valores r podem sempre ser atribuídos a alguma outra variável.
valor-l
A localização da memória (endereço) onde uma expressão é armazenada é conhecida como o valor l dessa expressão. Ele sempre aparece no lado esquerdo de um operador de atribuição.
Por exemplo:
day = 1;
week = day * 7;
month = 1;
year = month * 12;A partir deste exemplo, entendemos que valores constantes como 1, 7, 12 e variáveis como dia, semana, mês e ano, todos têm valores r. Apenas as variáveis têm valores-l, pois também representam a localização da memória atribuída a elas.
Por exemplo:
7 = x + y;é um erro de valor l, pois a constante 7 não representa nenhum local da memória.
Parâmetros Formais
Variáveis que pegam as informações passadas pelo procedimento do chamador são chamadas de parâmetros formais. Essas variáveis são declaradas na definição da função chamada.
Parâmetros reais
Variáveis cujos valores ou endereços estão sendo passados para o procedimento chamado são chamadas de parâmetros reais. Essas variáveis são especificadas na chamada de função como argumentos.
Example:
fun_one()
{
int actual_parameter = 10;
call fun_two(int actual_parameter);
}
fun_two(int formal_parameter)
{
print formal_parameter;
}Os parâmetros formais contêm as informações do parâmetro real, dependendo da técnica de passagem de parâmetro usada. Pode ser um valor ou um endereço.
Passe por valor
No mecanismo de passagem por valor, o procedimento de chamada passa o valor r dos parâmetros reais e o compilador coloca isso no registro de ativação do procedimento chamado. Os parâmetros formais, então, contêm os valores passados pelo procedimento de chamada. Se os valores mantidos pelos parâmetros formais forem alterados, isso não deve ter impacto nos parâmetros reais.
Passe por referência
No mecanismo de passagem por referência, o valor l do parâmetro real é copiado para o registro de ativação do procedimento chamado. Desta forma, o procedimento chamado passa a ter o endereço (local da memória) do parâmetro atual e o parâmetro formal refere-se ao mesmo local da memória. Portanto, se o valor apontado pelo parâmetro formal for alterado, o impacto deve ser visto no parâmetro real, pois eles também devem apontar para o mesmo valor.
Passe por cópia-restauração
Este mecanismo de passagem de parâmetro funciona de forma semelhante à 'passagem por referência', exceto que as alterações nos parâmetros reais são feitas quando o procedimento chamado termina. Na chamada da função, os valores dos parâmetros reais são copiados no registro de ativação do procedimento chamado. Parâmetros formais, se manipulados, não têm efeito em tempo real sobre os parâmetros reais (conforme os valores l são passados), mas quando o procedimento chamado termina, os valores l dos parâmetros formais são copiados para os valores l dos parâmetros reais.
Example:
int y;
calling_procedure()
{
y = 10;
copy_restore(y); //l-value of y is passed
printf y; //prints 99
}
copy_restore(int x)
{
x = 99; // y still has value 10 (unaffected)
y = 0; // y is now 0
}Quando esta função termina, o valor-l do parâmetro formal x é copiado para o parâmetro real y. Mesmo se o valor de y for alterado antes do término do procedimento, o valor l de x é copiado para o valor l de y, fazendo com que se comporte como uma chamada por referência.
Passe por Nome
Linguagens como Algol fornecem um novo tipo de mecanismo de passagem de parâmetro que funciona como um pré-processador na linguagem C. No mecanismo de passagem por nome, o nome do procedimento que está sendo chamado é substituído por seu corpo real. A passagem por nome substitui textualmente as expressões de argumento em uma chamada de procedimento para os parâmetros correspondentes no corpo do procedimento para que agora possa funcionar em parâmetros reais, bem como passagem por referência.
A tabela de símbolos é uma estrutura de dados importante criada e mantida por compiladores para armazenar informações sobre a ocorrência de várias entidades, como nomes de variáveis, nomes de funções, objetos, classes, interfaces, etc. A tabela de símbolos é usada tanto pela análise quanto pela síntese partes de um compilador.
Uma tabela de símbolos pode servir aos seguintes propósitos, dependendo do idioma em mãos:
Para armazenar os nomes de todas as entidades em um formulário estruturado em um só lugar.
Para verificar se uma variável foi declarada.
Para implementar a verificação de tipo, verificando as atribuições e expressões no código-fonte estão semanticamente corretas.
Para determinar o escopo de um nome (resolução de escopo).
Uma tabela de símbolos é simplesmente uma tabela que pode ser linear ou uma tabela hash. Ele mantém uma entrada para cada nome no seguinte formato:
<symbol name, type, attribute>Por exemplo, se uma tabela de símbolos tiver que armazenar informações sobre a seguinte declaração de variável:
static int interest;então ele deve armazenar a entrada como:
<interest, int, static>A cláusula de atributo contém as entradas relacionadas ao nome.
Implementação
Se um compilador deve lidar com uma pequena quantidade de dados, a tabela de símbolos pode ser implementada como uma lista não ordenada, que é fácil de codificar, mas só é adequada para pequenas tabelas. Uma tabela de símbolos pode ser implementada de uma das seguintes maneiras:
- Lista linear (classificada ou não)
- Árvore de pesquisa binária
- Tabela de hash
Entre todas, as tabelas de símbolos são implementadas principalmente como tabelas hash, onde o próprio símbolo do código-fonte é tratado como uma chave para a função hash e o valor de retorno é a informação sobre o símbolo.
Operações
Uma tabela de símbolos, linear ou hash, deve fornecer as seguintes operações.
inserir()
Esta operação é mais frequentemente utilizada pela fase de análise, ou seja, a primeira metade do compilador onde os tokens são identificados e os nomes são armazenados na tabela. Esta operação é usada para adicionar informações na tabela de símbolos sobre nomes exclusivos que ocorrem no código-fonte. O formato ou estrutura em que os nomes são armazenados depende do compilador em mãos.
Um atributo para um símbolo no código-fonte é a informação associada a esse símbolo. Essas informações contêm o valor, estado, escopo e tipo do símbolo. A função insert () pega o símbolo e seus atributos como argumentos e armazena as informações na tabela de símbolos.
Por exemplo:
int a;deve ser processado pelo compilador como:
insert(a, int);olho para cima()
A operação lookup () é usada para pesquisar um nome na tabela de símbolos para determinar:
- se o símbolo existe na tabela.
- se for declarado antes de ser usado.
- se o nome for usado no escopo.
- se o símbolo for inicializado.
- se o símbolo for declarado várias vezes.
O formato da função lookup () varia de acordo com a linguagem de programação. O formato básico deve corresponder ao seguinte:
lookup(symbol)Este método retorna 0 (zero) se o símbolo não existir na tabela de símbolos. Se o símbolo existe na tabela de símbolos, ele retorna seus atributos armazenados na tabela.
Gerenciamento do escopo
Um compilador mantém dois tipos de tabelas de símbolos: a global symbol table que pode ser acessado por todos os procedimentos e scope symbol tables que são criados para cada escopo no programa.
Para determinar o escopo de um nome, as tabelas de símbolos são organizadas em estrutura hierárquica, conforme mostrado no exemplo abaixo:
. . .
int value=10;
void pro_one()
{
int one_1;
int one_2;
{ \
int one_3; |_ inner scope 1
int one_4; |
} /
int one_5;
{ \
int one_6; |_ inner scope 2
int one_7; |
} /
}
void pro_two()
{
int two_1;
int two_2;
{ \
int two_3; |_ inner scope 3
int two_4; |
} /
int two_5;
}
. . .O programa acima pode ser representado em uma estrutura hierárquica de tabelas de símbolos:

A tabela de símbolos globais contém nomes para uma variável global (valor int) e dois nomes de procedimento, que devem estar disponíveis para todos os nós filhos mostrados acima. Os nomes mencionados na tabela de símbolos pro_one (e todas as suas tabelas filho) não estão disponíveis para os símbolos pro_two e suas tabelas filho.
Esta hierarquia da estrutura de dados da tabela de símbolos é armazenada no analisador semântico e sempre que um nome precisa ser pesquisado em uma tabela de símbolos, ele é pesquisado usando o seguinte algoritmo:
primeiro, um símbolo será pesquisado no escopo atual, ou seja, na tabela de símbolos atual.
se um nome for encontrado, a pesquisa é concluída, caso contrário, ele será pesquisado na tabela de símbolos pai até,
o nome foi encontrado ou o nome foi pesquisado na tabela de símbolos global.
Um código-fonte pode ser traduzido diretamente em seu código de máquina-alvo, então por que precisamos traduzir o código-fonte em um código intermediário que é então traduzido para seu código-alvo? Vamos ver as razões pelas quais precisamos de um código intermediário.
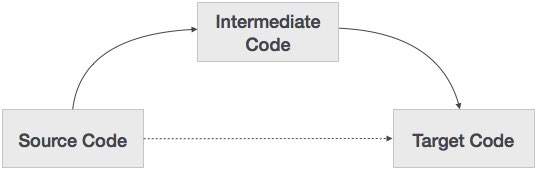
Se um compilador traduz a linguagem fonte para a linguagem da máquina de destino sem ter a opção de gerar código intermediário, então, para cada nova máquina, um compilador nativo completo é necessário.
O código intermediário elimina a necessidade de um novo compilador completo para cada máquina exclusiva, mantendo a parte de análise igual para todos os compiladores.
A segunda parte do compilador, síntese, é alterada de acordo com a máquina de destino.
Torna-se mais fácil aplicar as modificações do código-fonte para melhorar o desempenho do código, aplicando técnicas de otimização de código no código intermediário.
Representação Intermediária
Os códigos intermediários podem ser representados de várias maneiras e têm seus próprios benefícios.
High Level IR- A representação do código intermediário de alto nível é muito próxima da linguagem de origem. Eles podem ser facilmente gerados a partir do código-fonte e podemos facilmente aplicar modificações de código para melhorar o desempenho. Mas para otimização de máquina alvo, é menos preferido.
Low Level IR - Este está perto da máquina de destino, o que o torna adequado para alocação de registro e memória, seleção de conjunto de instruções, etc. É bom para otimizações dependentes de máquina.
O código intermediário pode ser específico da linguagem (por exemplo, Byte Code para Java) ou independente da linguagem (código de três endereços).
Código de três endereços
O gerador de código intermediário recebe dados de sua fase predecessora, o analisador semântico, na forma de uma árvore de sintaxe anotada. Essa árvore de sintaxe pode então ser convertida em uma representação linear, por exemplo, notação pós-fixada. O código intermediário tende a ser um código independente de máquina. Portanto, o gerador de código assume que tem um número ilimitado de armazenamento de memória (registro) para gerar o código.
Por exemplo:
a = b + c * d;O gerador de código intermediário tentará dividir esta expressão em subexpressões e então gerar o código correspondente.
r1 = c * d;
r2 = b + r1;
a = r2r sendo usado como registrador no programa de destino.
Um código de três endereços tem no máximo três localizações de endereço para calcular a expressão. Um código de três endereços pode ser representado em duas formas: quádruplos e triplos.
Quádruplos
Cada instrução na apresentação quádrupla é dividida em quatro campos: operador, arg1, arg2 e resultado. O exemplo acima é representado abaixo em formato quádruplo:
| Op | arg 1 | arg 2 | resultado |
| * | c | d | r1 |
| + | b | r1 | r2 |
| + | r2 | r1 | r3 |
| = | r3 | uma |
Triplos
Cada instrução na apresentação tripla tem três campos: op, arg1 e arg2. Os resultados das respectivas subexpressões são denotados pela posição da expressão. Os triplos representam semelhanças com o DAG e a árvore de sintaxe. Eles são equivalentes ao DAG enquanto representam expressões.
| Op | arg 1 | arg 2 |
| * | c | d |
| + | b | (0) |
| + | (1) | (0) |
| = | (2) |
Os triplos enfrentam o problema da imobilidade do código durante a otimização, pois os resultados são posicionais e alterar a ordem ou posição de uma expressão pode causar problemas.
Triplos indiretos
Essa representação é um aprimoramento da representação tripla. Ele usa ponteiros em vez de posição para armazenar os resultados. Isso permite que os otimizadores reposicionem livremente a subexpressão para produzir um código otimizado.
Declarações
Uma variável ou procedimento deve ser declarado antes de poder ser usado. A declaração envolve a alocação de espaço na memória e a entrada do tipo e nome na tabela de símbolos. Um programa pode ser codificado e projetado mantendo a estrutura da máquina-alvo em mente, mas nem sempre é possível converter com precisão um código-fonte em sua linguagem-alvo.
Tomando todo o programa como uma coleção de procedimentos e subprocedimentos, é possível declarar todos os nomes locais para o procedimento. A alocação de memória é feita de maneira consecutiva e os nomes são alocados na memória na seqüência em que são declarados no programa. Usamos a variável de deslocamento e definimos como zero {deslocamento = 0} que denota o endereço de base.
A linguagem de programação de origem e a arquitetura da máquina de destino podem variar na maneira como os nomes são armazenados, portanto, o endereçamento relativo é usado. Enquanto o primeiro nome é memória alocada a partir da localização de memória 0 {deslocamento = 0}, o próximo nome declarado posteriormente, deve ser alocado em memória ao lado do primeiro.
Example:
Pegamos o exemplo da linguagem de programação C onde uma variável inteira é atribuída a 2 bytes de memória e uma variável float é atribuída a 4 bytes de memória.
int a;
float b;
Allocation process:
{offset = 0}
int a;
id.type = int
id.width = 2
offset = offset + id.width
{offset = 2}
float b;
id.type = float
id.width = 4
offset = offset + id.width
{offset = 6}Para inserir este detalhe em uma tabela de símbolos, um procedimento enter pode ser usado. Este método pode ter a seguinte estrutura:
enter(name, type, offset)Este procedimento deve criar uma entrada na tabela de símbolos, para o nome da variável , tendo seu tipo configurado para tipo e relativo deslocamento do endereço em sua área de dados.
A geração de código pode ser considerada a fase final da compilação. Por meio da geração do código postal, o processo de otimização pode ser aplicado ao código, mas isso pode ser visto como parte da própria fase de geração do código. O código gerado pelo compilador é um código-objeto de alguma linguagem de programação de nível inferior, por exemplo, linguagem assembly. Vimos que o código-fonte escrito em uma linguagem de nível superior é transformado em uma linguagem de nível inferior que resulta em um código-objeto de nível inferior, que deve ter as seguintes propriedades mínimas:
- Deve conter o significado exato do código-fonte.
- Deve ser eficiente em termos de uso de CPU e gerenciamento de memória.
Veremos agora como o código intermediário é transformado em código de objeto de destino (código de montagem, neste caso).
Gráfico Acíclico Direcionado
O Directed Acyclic Graph (DAG) é uma ferramenta que descreve a estrutura dos blocos básicos, ajuda a ver o fluxo de valores fluindo entre os blocos básicos e também oferece otimização. O DAG fornece transformação fácil em blocos básicos. O DAG pode ser entendido aqui:
Os nós folha representam identificadores, nomes ou constantes.
Os nós internos representam operadores.
Os nós internos também representam os resultados das expressões ou os identificadores / nome onde os valores devem ser armazenados ou atribuídos.
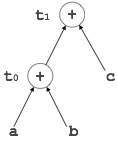
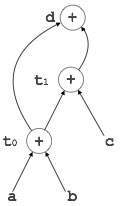
Example:
t0 = a + b
t1 = t0 + c
d = t0 + t1

[t 0 = a + b] |
[t 1 = t 0 + c] |
[d = t 0 + t 1 ] |
Otimização de olho mágico
Essa técnica de otimização funciona localmente no código-fonte para transformá-lo em um código otimizado. Por localmente, queremos dizer uma pequena parte do bloco de código em questão. Esses métodos podem ser aplicados em códigos intermediários, bem como em códigos de destino. Um monte de declarações é analisado e verificado para a seguinte otimização possível:
Eliminação de instrução redundante
No nível do código-fonte, o seguinte pode ser feito pelo usuário:
|
|
|
|
No nível de compilação, o compilador procura instruções redundantes por natureza. O carregamento e o armazenamento múltiplo de instruções podem ter o mesmo significado, mesmo se alguns deles forem removidos. Por exemplo:
- MOV x, R0
- MOV R0, R1
Podemos excluir a primeira instrução e reescrever a frase como:
MOV x, R1Código inacessível
O código inacessível é uma parte do código do programa que nunca é acessada devido a construções de programação. Os programadores podem ter escrito acidentalmente um trecho de código que nunca pode ser alcançado.
Example:
void add_ten(int x)
{
return x + 10;
printf(“value of x is %d”, x);
}Neste segmento de código, o printf instrução nunca será executada, pois o controle do programa retorna antes de poder ser executado, portanto printf pode ser removido.
Otimização do fluxo de controle
Existem instâncias em um código em que o controle do programa salta para frente e para trás sem realizar nenhuma tarefa significativa. Esses saltos podem ser removidos. Considere o seguinte pedaço de código:
...
MOV R1, R2
GOTO L1
...
L1 : GOTO L2
L2 : INC R1Neste código, o rótulo L1 pode ser removido conforme ele passa o controle para L2. Então, em vez de pular para L1 e depois para L2, o controle pode alcançar diretamente L2, conforme mostrado abaixo:
...
MOV R1, R2
GOTO L2
...
L2 : INC R1Simplificação da expressão algébrica
Existem ocasiões em que as expressões algébricas podem ser simplificadas. Por exemplo, a expressãoa = a + 0 pode ser substituído por a em si e a expressão a = a + 1 podem simplesmente ser substituídas por INC a.
Redução de força
Existem operações que consomem mais tempo e espaço. Sua 'força' pode ser reduzida substituindo-os por outras operações que consomem menos tempo e espaço, mas produzem o mesmo resultado.
Por exemplo, x * 2 pode ser substituído por x << 1, que envolve apenas um deslocamento à esquerda. Embora a saída de a * a e 2 seja a mesma, a 2 é muito mais eficiente de implementar.
Acessando as instruções da máquina
A máquina de destino pode implantar instruções mais sofisticadas, que podem ter a capacidade de executar operações específicas com muita eficiência. Se o código de destino puder acomodar essas instruções diretamente, isso não apenas melhorará a qualidade do código, mas também produzirá resultados mais eficientes.
Gerador de código
Espera-se que um gerador de código tenha uma compreensão do ambiente de tempo de execução da máquina de destino e seu conjunto de instruções. O gerador de código deve levar em consideração os seguintes itens para gerar o código:
Target language: O gerador de código deve estar ciente da natureza do idioma de destino para o qual o código será transformado. Essa linguagem pode facilitar algumas instruções específicas da máquina para ajudar o compilador a gerar o código de uma maneira mais conveniente. A máquina de destino pode ter arquitetura de processador CISC ou RISC.
IR Type: A representação intermediária tem várias formas. Pode ser na estrutura Abstract Syntax Tree (AST), Reverse Polish Notation ou código de 3 endereços.
Selection of instruction: O gerador de código pega a Representação Intermediária como entrada e a converte (mapeia) no conjunto de instruções da máquina de destino. Uma representação pode ter várias maneiras (instruções) de convertê-la, portanto, torna-se responsabilidade do gerador de código escolher as instruções apropriadas com sabedoria.
Register allocation: Um programa possui vários valores que devem ser mantidos durante a execução. A arquitetura da máquina alvo pode não permitir que todos os valores sejam mantidos na memória da CPU ou nos registros. O gerador de código decide quais valores manter nos registros. Além disso, ele decide os registros a serem usados para manter esses valores.
Ordering of instructions: Por fim, o gerador de código decide a ordem em que a instrução será executada. Ele cria agendas para instruções para executá-los.
Descritores
O gerador de código deve rastrear os registros (para disponibilidade) e endereços (localização de valores) enquanto gera o código. Para ambos, os seguintes dois descritores são usados:
Register descriptor: O descritor de registro é usado para informar ao gerador de código sobre a disponibilidade de registros. O descritor de registro mantém o controle dos valores armazenados em cada registro. Sempre que for necessário um novo registro durante a geração do código, este descritor é consultado para verificar a disponibilidade do registro.
Address descriptor: Os valores dos nomes (identificadores) usados no programa podem ser armazenados em locais diferentes durante a execução. Os descritores de endereço são usados para rastrear as localizações da memória onde os valores dos identificadores são armazenados. Esses locais podem incluir registros de CPU, heaps, pilhas, memória ou uma combinação dos locais mencionados.
O gerador de código mantém o descritor atualizado em tempo real. Para uma instrução de carga, LD R1, x, o gerador de código:
- atualiza o Descritor de Registro R1 que tem valor de x e
- atualiza o Descritor de Endereço (x) para mostrar que uma instância de x está em R1.
Geração de Código
Os blocos básicos são compostos por uma sequência de instruções de três endereços. O gerador de código recebe essa sequência de instruções como entrada.
Note: Se o valor de um nome for encontrado em mais de um lugar (registro, cache ou memória), o valor do registro terá preferência sobre o cache e a memória principal. Da mesma forma, o valor do cache terá preferência sobre a memória principal. A memória principal quase não tem preferência.
getReg: O gerador de código usa a função getReg para determinar o status dos registros disponíveis e a localização dos valores de nome. getReg funciona da seguinte maneira:
Se a variável Y já estiver no registro R, ela usa esse registro.
Caso contrário, se algum registro R estiver disponível, ele usará esse registro.
Caso contrário, se ambas as opções acima não forem possíveis, ele escolhe um registro que requer um número mínimo de instruções de carregamento e armazenamento.
Para uma instrução x = y OP z, o gerador de código pode executar as seguintes ações. Vamos supor que L é o local (de preferência registrador) onde a saída de y OP z deve ser salva:
Chame a função getReg, para decidir a localização de L.
Determine a localização atual (registro ou memória) de y consultando o Descritor de Endereço de y. E sey não está atualmente registrado L, então gere a seguinte instrução para copiar o valor de y para L:
MOV y ', L
Onde y’ representa o valor copiado de y.
Determine a localização atual de z usando o mesmo método usado na etapa 2 para y e gere a seguinte instrução:
OP z ', L
Onde z’ representa o valor copiado de z.
Agora L contém o valor de y OP z, que se destina a ser atribuído a x. Então, se L é um registrador, atualize seu descritor para indicar que ele contém o valor dex. Atualize o descritor dex para indicar que está armazenado no local L.
Se yez não tiver mais uso, eles podem ser devolvidos ao sistema.
Outras construções de código, como loops e instruções condicionais, são transformadas em linguagem assembly de maneira geral.
Otimização é uma técnica de transformação de programa, que tenta melhorar o código fazendo-o consumir menos recursos (ou seja, CPU, memória) e entregar alta velocidade.
Na otimização, construções de programação geral de alto nível são substituídas por códigos de programação de baixo nível muito eficientes. Um processo de otimização de código deve seguir as três regras fornecidas abaixo:
O código de saída não deve, de forma alguma, alterar o significado do programa.
A otimização deve aumentar a velocidade do programa e, se possível, o programa deve demandar menos número de recursos.
A otimização em si deve ser rápida e não deve atrasar o processo geral de compilação.
Esforços para um código otimizado podem ser feitos em vários níveis de compilação do processo.
No início, os usuários podem alterar / reorganizar o código ou usar algoritmos melhores para escrever o código.
Depois de gerar o código intermediário, o compilador pode modificar o código intermediário por meio de cálculos de endereço e melhoria de loops.
Ao produzir o código da máquina de destino, o compilador pode fazer uso da hierarquia da memória e dos registros da CPU.
A otimização pode ser categorizada amplamente em dois tipos: independente da máquina e dependente da máquina.
Otimização independente da máquina
Nessa otimização, o compilador pega o código intermediário e transforma uma parte do código que não envolve nenhum registro da CPU e / ou locais de memória absolutos. Por exemplo:
do
{
item = 10;
value = value + item;
}while(value<100);Este código envolve a atribuição repetida do item identificador, que se colocarmos desta forma:
Item = 10;
do
{
value = value + item;
} while(value<100);não deve apenas salvar os ciclos da CPU, mas pode ser usado em qualquer processador.
Otimização dependente da máquina
A otimização dependente da máquina é feita depois que o código de destino foi gerado e quando o código é transformado de acordo com a arquitetura da máquina de destino. Envolve registros de CPU e pode ter referências de memória absolutas em vez de referências relativas. Os otimizadores dependentes de máquina se esforçam para tirar o máximo proveito da hierarquia de memória.
Blocos Básicos
Os códigos-fonte geralmente possuem uma série de instruções, que são sempre executadas em sequência e são consideradas os blocos básicos do código. Estes blocos básicos não possuem nenhuma instrução de salto entre eles, ou seja, quando a primeira instrução for executada, todas as instruções do mesmo bloco básico serão executadas em sua seqüência de aparecimento sem perder o controle de fluxo do programa.
Um programa pode ter várias construções como blocos básicos, como instruções condicionais IF-THEN-ELSE, SWITCH-CASE e loops como DO-WHILE, FOR e REPEAT-UNTIL, etc.
Identificação de bloco básico
Podemos usar o seguinte algoritmo para encontrar os blocos básicos em um programa:
Pesquisar declarações de cabeçalho de todos os blocos básicos de onde um bloco básico começa:
- Primeira declaração de um programa.
- Declarações que são alvo de qualquer ramificação (condicional / incondicional).
- Declarações que seguem qualquer declaração de ramo.
As instruções de cabeçalho e as instruções que as seguem formam um bloco básico.
Um bloco básico não inclui nenhuma declaração de cabeçalho de qualquer outro bloco básico.
Os blocos básicos são conceitos importantes do ponto de vista de geração e otimização de código.
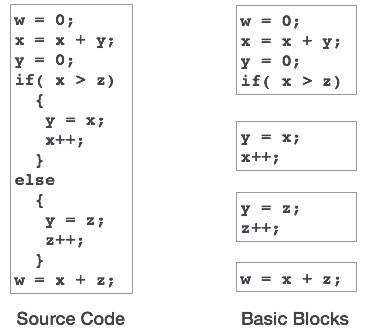
Os blocos básicos desempenham um papel importante na identificação de variáveis, que estão sendo usadas mais de uma vez em um único bloco básico. Se alguma variável estiver sendo usada mais de uma vez, a memória do registro alocada para aquela variável não precisa ser esvaziada, a menos que o bloco termine a execução.
Gráfico de fluxo de controle
Os blocos básicos de um programa podem ser representados por meio de gráficos de fluxo de controle. Um gráfico de fluxo de controle mostra como o controle do programa está sendo passado entre os blocos. É uma ferramenta útil que ajuda na otimização, ajudando a localizar quaisquer loops indesejados no programa.
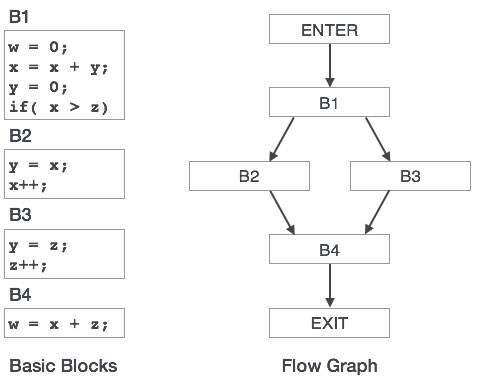
Otimização de Loop
A maioria dos programas é executada como um loop no sistema. Torna-se necessário otimizar os loops para economizar ciclos de CPU e memória. Os loops podem ser otimizados pelas seguintes técnicas:
Invariant code: Um fragmento de código que reside no loop e calcula o mesmo valor em cada iteração é chamado de código invariante do loop. Esse código pode ser movido para fora do loop salvando-o para ser calculado apenas uma vez, em vez de a cada iteração.
Induction analysis : Uma variável é chamada de variável de indução se seu valor for alterado dentro do loop por um valor invariante do loop.
Strength reduction: Existem expressões que consomem mais ciclos de CPU, tempo e memória. Essas expressões devem ser substituídas por expressões mais baratas sem comprometer a saída da expressão. Por exemplo, a multiplicação (x * 2) é mais cara em termos de ciclos de CPU do que (x << 1) e produz o mesmo resultado.
Eliminação de código morto
Código morto é uma ou mais declarações de código, que são:
- Nunca executado ou inacessível,
- Ou, se executado, sua saída nunca é usada.
Assim, o código morto não desempenha nenhum papel em qualquer operação do programa e, portanto, pode ser simplesmente eliminado.
Código parcialmente morto
Existem algumas instruções de código cujos valores calculados são usados apenas em certas circunstâncias, ou seja, às vezes os valores são usados e às vezes não. Esses códigos são conhecidos como código parcialmente morto.
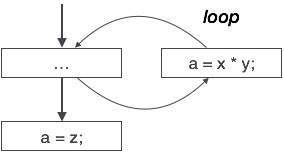
O gráfico de fluxo de controle acima representa um pedaço do programa onde a variável 'a' é usada para atribuir a saída da expressão 'x * y'. Vamos supor que o valor atribuído a 'a' nunca seja usado dentro do loop. Imediatamente após o controle sair do loop, 'a' recebe o valor da variável 'z', que seria usada posteriormente no programa. Concluímos aqui que o código de atribuição de 'a' nunca é usado em qualquer lugar, portanto, pode ser eliminado.
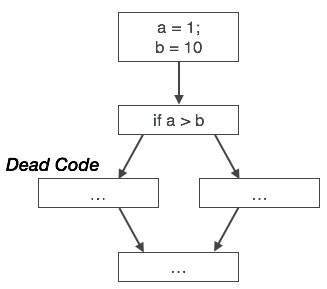
Da mesma forma, a imagem acima mostra que a declaração condicional é sempre falsa, o que implica que o código, escrito no caso verdadeiro, nunca será executado, portanto, pode ser removido.
Redundância Parcial
Expressões redundantes são calculadas mais de uma vez no caminho paralelo, sem qualquer mudança nos operandos. Ao passo que as expressões redundantes parciais são calculadas mais de uma vez em um caminho, sem qualquer mudança nos operandos. Por exemplo,
[expressão redundante] |
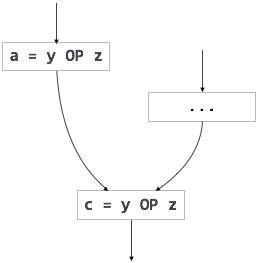
[expressão parcialmente redundante] |
O código invariante de loop é parcialmente redundante e pode ser eliminado usando uma técnica de movimento de código.
Outro exemplo de código parcialmente redundante pode ser:
If (condition)
{
a = y OP z;
}
else
{
...
}
c = y OP z;Assumimos que os valores dos operandos (y e z) não são alterados a partir da atribuição de variável a para variável c. Aqui, se a declaração da condição for verdadeira, y OP z é calculado duas vezes, caso contrário, uma vez. O movimento do código pode ser usado para eliminar essa redundância, conforme mostrado abaixo:
If (condition)
{
...
tmp = y OP z;
a = tmp;
...
}
else
{
...
tmp = y OP z;
}
c = tmp;Aqui, se a condição é verdadeira ou falsa; y OP z deve ser calculado apenas uma vez.