Simultaneidade vs paralelismo
Tanto a simultaneidade quanto o paralelismo são usados em relação a programas multithread, mas há muita confusão sobre a semelhança e diferença entre eles. A grande questão a esse respeito: é paralelismo de simultaneidade ou não? Embora ambos os termos pareçam muito semelhantes, mas a resposta à pergunta acima seja NÃO, simultaneidade e paralelismo não são os mesmos. Agora, se eles não são iguais, então qual é a diferença básica entre eles?
Em termos simples, a simultaneidade lida com o gerenciamento do acesso ao estado compartilhado de diferentes threads e, por outro lado, o paralelismo lida com a utilização de várias CPUs ou seus núcleos para melhorar o desempenho do hardware.
Simultaneidade em detalhes
Simultaneidade ocorre quando duas tarefas se sobrepõem na execução. Pode ser uma situação em que um aplicativo está progredindo em mais de uma tarefa ao mesmo tempo. Podemos entendê-lo esquematicamente; várias tarefas estão progredindo ao mesmo tempo, da seguinte maneira -
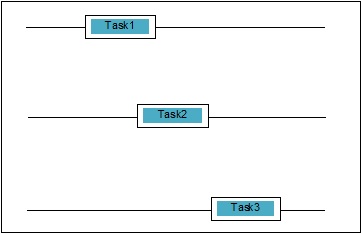
Níveis de simultaneidade
Nesta seção, discutiremos os três níveis importantes de simultaneidade em termos de programação -
Concorrência de baixo nível
Nesse nível de simultaneidade, há o uso explícito de operações atômicas. Não podemos usar esse tipo de concorrência para a construção de aplicativos, pois é muito sujeito a erros e difícil de depurar. Mesmo Python não suporta esse tipo de simultaneidade.
Simultaneidade de nível médio
Nessa simultaneidade, não há uso de operações atômicas explícitas. Ele usa os bloqueios explícitos. Python e outras linguagens de programação suportam esse tipo de simultaneidade. Principalmente os programadores de aplicativos usam essa simultaneidade.
Concorrência de alto nível
Nessa simultaneidade, nem as operações atômicas explícitas nem os bloqueios explícitos são usados. Python temconcurrent.futures módulo para suportar esse tipo de simultaneidade.
Propriedades de sistemas concorrentes
Para que um programa ou sistema simultâneo seja correto, algumas propriedades devem ser satisfeitas por ele. As propriedades relacionadas ao encerramento do sistema são as seguintes -
Propriedade de correção
A propriedade correctness significa que o programa ou sistema deve fornecer a resposta correta desejada. Para simplificar, podemos dizer que o sistema deve mapear o estado do programa inicial ao estado final corretamente.
Propriedade de segurança
A propriedade de segurança significa que o programa ou sistema deve permanecer em um “good” ou “safe” estado e nunca faz nada “bad”.
Propriedade de vivacidade
Esta propriedade significa que um programa ou sistema deve “make progress” e alcançaria algum estado desejável.
Atores de sistemas concorrentes
Esta é uma propriedade comum do sistema simultâneo no qual pode haver vários processos e threads, que são executados ao mesmo tempo para fazer progresso em suas próprias tarefas. Esses processos e threads são chamados de atores do sistema concorrente.
Recursos de sistemas simultâneos
Os atores devem utilizar recursos como memória, disco, impressora, etc., para realizar suas tarefas.
Certo conjunto de regras
Todo sistema concorrente deve possuir um conjunto de regras para definir o tipo de tarefas a serem realizadas pelos atores e o tempo de cada uma. As tarefas podem ser aquisição de bloqueios, compartilhamento de memória, modificação de estado, etc.
Barreiras de sistemas concorrentes
Ao implementar sistemas simultâneos, o programador deve levar em consideração as seguintes duas questões importantes, que podem ser as barreiras de sistemas concorrentes -Compartilhamento de dados
Uma questão importante ao implementar os sistemas simultâneos é o compartilhamento de dados entre vários threads ou processos. Na verdade, o programador deve garantir que os bloqueios protejam os dados compartilhados de modo que todos os acessos a eles sejam serializados e apenas um thread ou processo possa acessar os dados compartilhados por vez. Nesse caso, quando vários threads ou processos estão tentando acessar os mesmos dados compartilhados, nem todos, exceto pelo menos um deles, seriam bloqueados e permaneceriam ociosos. Em outras palavras, podemos dizer que seríamos capazes de usar apenas um processo ou thread por vez quando o bloqueio estiver em vigor. Pode haver algumas soluções simples para remover as barreiras mencionadas acima -
Restrição de compartilhamento de dados
A solução mais simples é não compartilhar nenhum dado mutável. Nesse caso, não precisamos usar bloqueio explícito e a barreira de simultaneidade devido a dados mútuos seria resolvida.
Assistência de Estrutura de Dados
Muitas vezes, os processos simultâneos precisam acessar os mesmos dados ao mesmo tempo. Outra solução, além do uso de bloqueios explícitos, é usar uma estrutura de dados que suporte acesso simultâneo. Por exemplo, podemos usar oqueuemódulo, que fornece filas thread-safe. Também podemos usarmultiprocessing.JoinableQueue classes para concorrência baseada em multiprocessamento.
Transferência de dados imutáveis
Às vezes, a estrutura de dados que estamos usando, digamos, fila de simultaneidade, não é adequada, então podemos passar os dados imutáveis sem bloqueá-los.
Transferência de dados mutável
Na continuação da solução acima, suponha que se for necessário passar apenas dados mutáveis, em vez de dados imutáveis, então podemos passar dados mutáveis que são somente leitura.
Compartilhamento de recursos de E / S
Outra questão importante na implementação de sistemas concorrentes é o uso de recursos de I / O por threads ou processos. O problema surge quando um thread ou processo está usando E / S por um longo tempo e outro está ocioso. Podemos ver esse tipo de barreira ao trabalhar com um aplicativo pesado de E / S. Pode ser entendido com a ajuda de um exemplo, a solicitação de páginas do navegador da web. É uma aplicação pesada. Aqui, se a taxa na qual os dados são solicitados for mais lenta do que a taxa em que são consumidos, temos uma barreira de E / S em nosso sistema simultâneo.
O seguinte script Python é para solicitar uma página da web e obter o tempo que nossa rede levou para obter a página solicitada -
import urllib.request
import time
ts = time.time()
req = urllib.request.urlopen('http://www.tutorialspoint.com')
pageHtml = req.read()
te = time.time()
print("Page Fetching Time : {} Seconds".format (te-ts))Depois de executar o script acima, podemos obter o tempo de busca da página conforme mostrado abaixo.
Resultado
Page Fetching Time: 1.0991398811340332 SecondsPodemos ver que o tempo para buscar a página é de mais de um segundo. E se quisermos buscar milhares de páginas da web diferentes, você pode entender quanto tempo nossa rede levaria.
O que é paralelismo?
O paralelismo pode ser definido como a arte de dividir as tarefas em subtarefas que podem ser processadas simultaneamente. É o oposto da simultaneidade, conforme discutido acima, em que dois ou mais eventos acontecem ao mesmo tempo. Podemos entendê-lo esquematicamente; uma tarefa é dividida em uma série de subtarefas que podem ser processadas em paralelo, como segue -
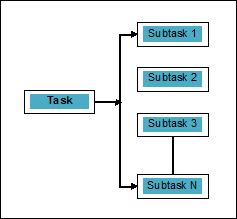
Para ter mais ideia sobre a distinção entre simultaneidade e paralelismo, considere os seguintes pontos -
Simultâneo, mas não paralelo
Um aplicativo pode ser simultâneo, mas não paralelo, significa que ele processa mais de uma tarefa ao mesmo tempo, mas as tarefas não são divididas em subtarefas.
Paralelo, mas não simultâneo
Um aplicativo pode ser paralelo, mas não simultâneo, significa que ele funciona apenas em uma tarefa por vez e as tarefas divididas em subtarefas podem ser processadas em paralelo.
Nem paralelo nem concorrente
Um aplicativo não pode ser paralelo nem simultâneo. Isso significa que ele funciona em apenas uma tarefa por vez e a tarefa nunca é dividida em subtarefas.
Paralelo e simultâneo
Um aplicativo pode ser paralelo e simultâneo significa que ele funciona em várias tarefas ao mesmo tempo e a tarefa é dividida em subtarefas para executá-las em paralelo.
Necessidade de paralelismo
Podemos alcançar o paralelismo distribuindo as subtarefas entre diferentes núcleos de uma única CPU ou entre vários computadores conectados em uma rede.
Considere os seguintes pontos importantes para entender por que é necessário alcançar o paralelismo -
Execução de código eficiente
Com a ajuda do paralelismo, podemos executar nosso código com eficiência. Isso economizará nosso tempo porque o mesmo código em partes está sendo executado em paralelo.
Mais rápido do que a computação sequencial
A computação sequencial é limitada por fatores físicos e práticos, devido aos quais não é possível obter resultados de computação mais rápidos. Por outro lado, esse problema é resolvido pela computação paralela e nos dá resultados de computação mais rápidos do que a computação sequencial.
Menos tempo de execução
O processamento paralelo reduz o tempo de execução do código do programa.
Se falamos de exemplo de paralelismo da vida real, a placa gráfica do nosso computador é o exemplo que destaca o verdadeiro poder do processamento paralelo, pois possui centenas de núcleos de processamento individuais que funcionam de forma independente e podem fazer a execução ao mesmo tempo. Por esse motivo, também podemos executar aplicativos e jogos de última geração.
Compreensão dos processadores para implementação
Nós sabemos sobre simultaneidade, paralelismo e a diferença entre eles, mas e o sistema no qual ele deve ser implementado. É muito necessário ter a compreensão do sistema, no qual vamos implementar, porque nos dá o benefício de tomar decisões informadas ao projetar o software. Temos os seguintes dois tipos de processadores -
Processadores de núcleo único
Os processadores single-core são capazes de executar um thread a qualquer momento. Esses processadores usamcontext switchingpara armazenar todas as informações necessárias para um thread em um momento específico e, em seguida, restaurar as informações posteriormente. O mecanismo de troca de contexto nos ajuda a progredir em uma série de threads em um determinado segundo e parece que o sistema está trabalhando em várias coisas.
Os processadores de núcleo único apresentam muitas vantagens. Esses processadores requerem menos energia e não existe um protocolo de comunicação complexo entre vários núcleos. Por outro lado, a velocidade dos processadores single-core é limitada e não é adequada para aplicações maiores.
Processadores multi-core
Os processadores multi-core têm várias unidades de processamento independentes também chamadas cores.
Esses processadores não precisam de mecanismo de troca de contexto, pois cada núcleo contém tudo o que precisa para executar uma sequência de instruções armazenadas.
Ciclo de busca-decodificação-execução
Os núcleos dos processadores multi-core seguem um ciclo de execução. Este ciclo é chamado deFetch-Decode-Executeciclo. Envolve as seguintes etapas -
Buscar
Esta é a primeira etapa do ciclo, que envolve a busca de instruções na memória do programa.
Decodificar
As instruções obtidas recentemente seriam convertidas em uma série de sinais que acionariam outras partes da CPU.
Executar
É a etapa final em que as instruções buscadas e decodificadas seriam executadas. O resultado da execução será armazenado em um registro da CPU.
Uma vantagem aqui é que a execução em processadores multi-core é mais rápida do que em processadores single-core. É adequado para aplicações maiores. Por outro lado, o protocolo de comunicação complexo entre vários núcleos é um problema. Vários núcleos requerem mais energia do que processadores de núcleo único.