Simultaneidade em Python - Guia rápido
Neste capítulo, entenderemos o conceito de simultaneidade em Python e aprenderemos sobre os diferentes threads e processos.
O que é simultaneidade?
Em palavras simples, a simultaneidade é a ocorrência de dois ou mais eventos ao mesmo tempo. A simultaneidade é um fenômeno natural porque muitos eventos ocorrem simultaneamente a qualquer momento.
Em termos de programação, a simultaneidade ocorre quando duas tarefas se sobrepõem na execução. Com a programação simultânea, o desempenho de nossos aplicativos e sistemas de software pode ser melhorado porque podemos lidar simultaneamente com as solicitações, em vez de esperar que uma anterior seja concluída.
Revisão histórica de simultaneidade
Os pontos a seguir nos darão uma breve revisão histórica da simultaneidade -
Do conceito de ferrovias
A simultaneidade está intimamente relacionada ao conceito de ferrovias. Com as ferrovias, havia a necessidade de lidar com vários trens no mesmo sistema ferroviário, de forma que cada trem chegasse com segurança ao seu destino.
Computação simultânea na academia
O interesse em simultaneidade em ciência da computação começou com o artigo de pesquisa publicado por Edsger W. Dijkstra em 1965. Nesse artigo, ele identificou e resolveu o problema da exclusão mútua, a propriedade do controle de concorrência.
Primitivas de simultaneidade de alto nível
Recentemente, os programadores estão obtendo soluções concorrentes aprimoradas devido à introdução de primitivas de simultaneidade de alto nível.
Concorrência aprimorada com linguagens de programação
Linguagens de programação como Golang, Rust e Python do Google fizeram desenvolvimentos incríveis em áreas que nos ajudam a obter melhores soluções simultâneas.
O que é thread e multithreading?
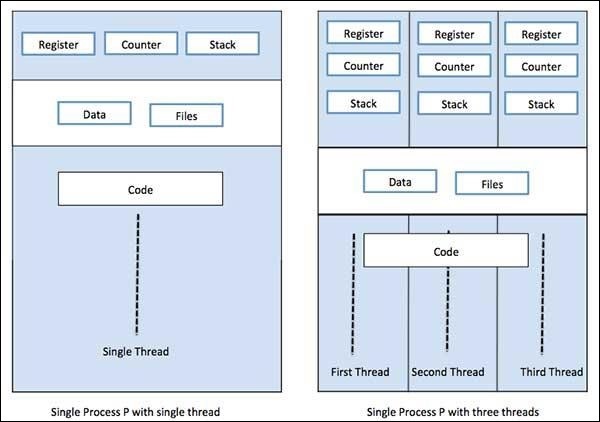
Threadé a menor unidade de execução que pode ser executada em um sistema operacional. Não é um programa em si, mas é executado dentro de um programa. Em outras palavras, os threads não são independentes uns dos outros. Cada thread compartilha seção de código, seção de dados, etc. com outros threads. Eles também são conhecidos como processos leves.
Um thread consiste nos seguintes componentes -
Contador de programa que consiste no endereço da próxima instrução executável
Stack
Conjunto de registros
Um id único
Multithreading, por outro lado, é a capacidade de uma CPU de gerenciar o uso do sistema operacional executando vários threads simultaneamente. A ideia principal do multithreading é atingir o paralelismo dividindo um processo em vários threads. O conceito de multithreading pode ser entendido com a ajuda do exemplo a seguir.
Exemplo
Suponha que estejamos executando um processo específico em que abrimos o MS Word para digitar o conteúdo nele. Um thread será atribuído para abrir o MS Word e outro thread será necessário para digitar o conteúdo nele. E agora, se quisermos editar o existente, então outro thread será necessário para fazer a tarefa de edição e assim por diante.
O que é processo e multiprocessamento?
UMAprocessé definido como uma entidade, que representa a unidade básica de trabalho a ser implementada no sistema. Em termos simples, escrevemos nossos programas de computador em um arquivo de texto e quando executamos este programa, ele se torna um processo que executa todas as tarefas mencionadas no programa. Durante o ciclo de vida do processo, ele passa por diferentes estágios - Iniciar, Pronto, Executando, Esperando e Encerrando.
O diagrama a seguir mostra as diferentes fases de um processo -
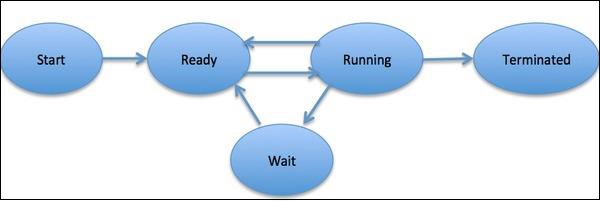
Um processo pode ter apenas uma thread, chamada thread primária, ou múltiplas threads tendo seu próprio conjunto de registradores, contador de programa e pilha. O diagrama a seguir nos mostrará a diferença -
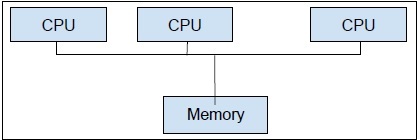
Multiprocessing,por outro lado, é o uso de duas ou mais unidades de CPUs em um único sistema de computador. Nosso principal objetivo é obter todo o potencial de nosso hardware. Para conseguir isso, precisamos utilizar o número total de núcleos de CPU disponíveis em nosso sistema de computador. O multiprocessamento é a melhor abordagem para isso.
Python é uma das linguagens de programação mais populares. A seguir estão alguns motivos que o tornam adequado para aplicativos simultâneos -
Açúcar sintático
Açúcar sintático é a sintaxe de uma linguagem de programação projetada para tornar as coisas mais fáceis de ler ou expressar. Isso torna a linguagem “mais doce” para uso humano: as coisas podem ser expressas de forma mais clara, mais concisa ou em um estilo alternativo baseado na preferência. Python vem com métodos Magic, que podem ser definidos para agir em objetos. Esses métodos mágicos são usados como açúcar sintático e vinculados a palavras-chave mais fáceis de entender.
Grande Comunidade
A linguagem Python testemunhou uma grande taxa de adoção entre cientistas de dados e matemáticos, trabalhando na área de IA, aprendizado de máquina, aprendizado profundo e análise quantitativa.
APIs úteis para programação simultânea
Python 2 e 3 têm grande número de APIs dedicadas para programação paralela / concorrente. Os mais populares deles sãothreading, concurrent.features, multiprocessing, asyncio, gevent and greenlets, etc.
Limitações do Python na implementação de aplicativos simultâneos
Python vem com uma limitação para aplicativos simultâneos. Esta limitação é chamadaGIL (Global Interpreter Lock)está presente no Python. GIL nunca nos permite utilizar múltiplos núcleos de CPU e, portanto, podemos dizer que não há threads verdadeiros no Python. Podemos entender o conceito de GIL da seguinte forma -
GIL (Bloqueio global de intérprete)
É um dos tópicos mais polêmicos no mundo Python. Em CPython, GIL é o mutex - o bloqueio de exclusão mútua, que torna as coisas seguras no thread. Em outras palavras, podemos dizer que GIL evita que vários threads executem código Python em paralelo. O bloqueio pode ser mantido por apenas um encadeamento de cada vez e se quisermos executar um encadeamento, ele deve adquirir o bloqueio primeiro. O diagrama abaixo irá ajudá-lo a entender o funcionamento do GIL.
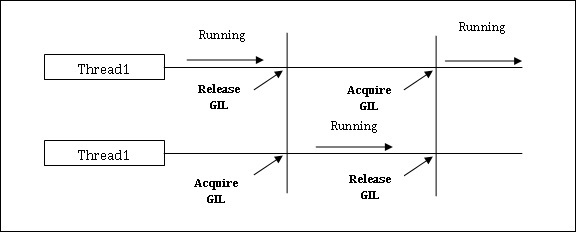
No entanto, existem algumas bibliotecas e implementações em Python, como Numpy, Jpython e IronPytbhon. Essas bibliotecas funcionam sem qualquer interação com GIL.
Tanto a simultaneidade quanto o paralelismo são usados em relação a programas multithread, mas há muita confusão sobre a semelhança e diferença entre eles. A grande questão a esse respeito: é paralelismo de simultaneidade ou não? Embora ambos os termos pareçam bastante semelhantes, mas a resposta à pergunta acima seja NÃO, simultaneidade e paralelismo não são os mesmos. Agora, se eles não são os mesmos, qual é a diferença básica entre eles?
Em termos simples, a simultaneidade lida com o gerenciamento do acesso ao estado compartilhado de diferentes threads e, por outro lado, o paralelismo lida com a utilização de várias CPUs ou seus núcleos para melhorar o desempenho do hardware.
Simultaneidade em detalhes
Simultaneidade ocorre quando duas tarefas se sobrepõem na execução. Pode ser uma situação em que um aplicativo está progredindo em mais de uma tarefa ao mesmo tempo. Podemos entendê-lo esquematicamente; várias tarefas estão progredindo ao mesmo tempo, da seguinte maneira -
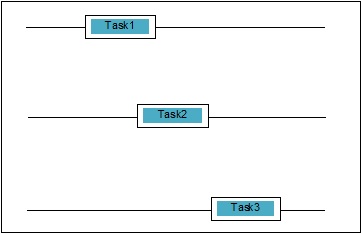
Níveis de simultaneidade
Nesta seção, discutiremos os três níveis importantes de simultaneidade em termos de programação -
Concorrência de baixo nível
Nesse nível de simultaneidade, há uso explícito de operações atômicas. Não podemos usar esse tipo de simultaneidade para a construção de aplicativos, pois é muito sujeito a erros e difícil de depurar. Mesmo Python não suporta esse tipo de simultaneidade.
Simultaneidade de nível médio
Nessa simultaneidade, não há uso de operações atômicas explícitas. Ele usa os bloqueios explícitos. Python e outras linguagens de programação suportam esse tipo de simultaneidade. Principalmente os programadores de aplicativos usam essa simultaneidade.
Concorrência de alto nível
Nessa simultaneidade, nem as operações atômicas explícitas nem os bloqueios explícitos são usados. Python temconcurrent.futures módulo para suportar esse tipo de simultaneidade.
Propriedades de sistemas concorrentes
Para que um programa ou sistema simultâneo seja correto, algumas propriedades devem ser satisfeitas por ele. As propriedades relacionadas ao encerramento do sistema são as seguintes -
Propriedade de correção
A propriedade correctness significa que o programa ou sistema deve fornecer a resposta correta desejada. Para simplificar, podemos dizer que o sistema deve mapear o estado do programa inicial ao estado final corretamente.
Propriedade de segurança
A propriedade de segurança significa que o programa ou sistema deve permanecer em um “good” ou “safe” estado e nunca faz nada “bad”.
Propriedade de vivacidade
Esta propriedade significa que um programa ou sistema deve “make progress” e alcançaria algum estado desejável.
Atores de sistemas concorrentes
Esta é uma propriedade comum do sistema simultâneo no qual pode haver vários processos e threads, que são executados ao mesmo tempo para fazer progresso em suas próprias tarefas. Esses processos e threads são chamados de atores do sistema concorrente.
Recursos de sistemas simultâneos
Os atores devem utilizar recursos como memória, disco, impressora, etc., para realizar suas tarefas.
Certo conjunto de regras
Todo sistema concorrente deve possuir um conjunto de regras para definir o tipo de tarefas a serem realizadas pelos atores e o tempo de cada uma. As tarefas podem ser aquisição de bloqueios, compartilhamento de memória, modificação de estado, etc.
Barreiras de sistemas concorrentes
Compartilhamento de dados
Uma questão importante ao implementar os sistemas simultâneos é o compartilhamento de dados entre vários threads ou processos. Na verdade, o programador deve garantir que os bloqueios protejam os dados compartilhados de forma que todos os acessos a eles sejam serializados e apenas um thread ou processo possa acessar os dados compartilhados por vez. No caso, quando vários threads ou processos estão tentando acessar os mesmos dados compartilhados, nem todos, mas pelo menos um deles, seriam bloqueados e permaneceriam ociosos. Em outras palavras, podemos dizer que seríamos capazes de usar apenas um processo ou thread por vez quando o bloqueio estiver em vigor. Pode haver algumas soluções simples para remover as barreiras mencionadas acima -
Restrição de compartilhamento de dados
A solução mais simples é não compartilhar nenhum dado mutável. Nesse caso, não precisamos usar bloqueio explícito e a barreira de simultaneidade devido a dados mútuos seria resolvida.
Assistência de Estrutura de Dados
Muitas vezes, os processos simultâneos precisam acessar os mesmos dados ao mesmo tempo. Outra solução, além do uso de bloqueios explícitos, é usar uma estrutura de dados que suporte acesso simultâneo. Por exemplo, podemos usar oqueuemódulo, que fornece filas thread-safe. Nós também podemos usarmultiprocessing.JoinableQueue classes para concorrência baseada em multiprocessamento.
Transferência de dados imutáveis
Às vezes, a estrutura de dados que estamos usando, digamos, fila de simultaneidade, não é adequada, então podemos passar os dados imutáveis sem bloqueá-los.
Transferência de dados mutável
Na continuação da solução acima, suponha que se for necessário passar apenas dados mutáveis, em vez de dados imutáveis, então podemos passar dados mutáveis que são somente leitura.
Compartilhamento de recursos de E / S
Outra questão importante na implementação de sistemas concorrentes é o uso de recursos de I / O por threads ou processos. O problema surge quando um thread ou processo está usando E / S por muito tempo e outro está ocioso. Podemos ver esse tipo de barreira ao trabalhar com um aplicativo pesado de E / S. Isso pode ser entendido com a ajuda de um exemplo, a solicitação de páginas do navegador da web. É uma aplicação pesada. Aqui, se a taxa na qual os dados são solicitados for mais lenta do que a taxa em que são consumidos, então temos barreira de E / S em nosso sistema simultâneo.
O seguinte script Python é para solicitar uma página da web e obter o tempo que nossa rede levou para obter a página solicitada -
import urllib.request
import time
ts = time.time()
req = urllib.request.urlopen('http://www.tutorialspoint.com')
pageHtml = req.read()
te = time.time()
print("Page Fetching Time : {} Seconds".format (te-ts))Depois de executar o script acima, podemos obter o tempo de busca da página conforme mostrado abaixo.
Resultado
Page Fetching Time: 1.0991398811340332 SecondsPodemos ver que o tempo para buscar a página é de mais de um segundo. Agora, se quisermos buscar milhares de páginas da web diferentes, você pode entender quanto tempo nossa rede levaria.
O que é paralelismo?
O paralelismo pode ser definido como a arte de dividir as tarefas em subtarefas que podem ser processadas simultaneamente. É o oposto da simultaneidade, conforme discutido acima, em que dois ou mais eventos acontecem ao mesmo tempo. Podemos entendê-lo esquematicamente; uma tarefa é dividida em uma série de subtarefas que podem ser processadas em paralelo, como segue -
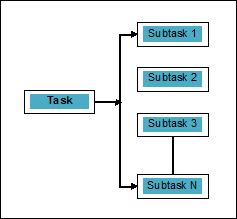
Para ter mais ideia sobre a distinção entre simultaneidade e paralelismo, considere os seguintes pontos -
Simultâneo, mas não paralelo
Um aplicativo pode ser simultâneo, mas não paralelo, significa que ele processa mais de uma tarefa ao mesmo tempo, mas as tarefas não são divididas em subtarefas.
Paralelo, mas não simultâneo
Um aplicativo pode ser paralelo, mas não simultâneo, significa que ele funciona apenas em uma tarefa por vez e as tarefas divididas em subtarefas podem ser processadas em paralelo.
Nem paralelo nem concorrente
Um aplicativo não pode ser paralelo nem simultâneo. Isso significa que ele funciona em apenas uma tarefa por vez e a tarefa nunca é dividida em subtarefas.
Paralelo e simultâneo
Um aplicativo pode ser paralelo e simultâneo significa que ele funciona em várias tarefas ao mesmo tempo e a tarefa é dividida em subtarefas para executá-las em paralelo.
Necessidade de paralelismo
Podemos alcançar o paralelismo distribuindo as subtarefas entre diferentes núcleos de uma única CPU ou entre vários computadores conectados em uma rede.
Considere os seguintes pontos importantes para entender por que é necessário alcançar o paralelismo -
Execução de código eficiente
Com a ajuda do paralelismo, podemos executar nosso código com eficiência. Isso economizará nosso tempo porque o mesmo código em partes está sendo executado em paralelo.
Mais rápido do que a computação sequencial
A computação sequencial é limitada por fatores físicos e práticos, devido aos quais não é possível obter resultados de computação mais rápidos. Por outro lado, esse problema é resolvido pela computação paralela e nos dá resultados de computação mais rápidos do que a computação sequencial.
Menos tempo de execução
O processamento paralelo reduz o tempo de execução do código do programa.
Se falamos de exemplos da vida real de paralelismo, a placa de vídeo do nosso computador é o exemplo que destaca o verdadeiro poder do processamento paralelo, pois possui centenas de núcleos de processamento individuais que funcionam independentemente e podem fazer a execução ao mesmo tempo. Por esse motivo, também podemos executar aplicativos e jogos de última geração.
Compreensão dos processadores para implementação
Nós sabemos sobre simultaneidade, paralelismo e a diferença entre eles, mas e o sistema no qual deve ser implementado. É muito necessário ter a compreensão do sistema, no qual vamos implementar, porque nos dá o benefício de tomar decisões informadas ao projetar o software. Temos os seguintes dois tipos de processadores -
Processadores de núcleo único
Os processadores single-core são capazes de executar um thread a qualquer momento. Esses processadores usamcontext switchingpara armazenar todas as informações necessárias para um thread em um momento específico e, em seguida, restaurar as informações posteriormente. O mecanismo de troca de contexto nos ajuda a progredir em uma série de threads em um determinado segundo e parece que o sistema está trabalhando em várias coisas.
Os processadores de núcleo único apresentam muitas vantagens. Esses processadores requerem menos energia e não existe um protocolo de comunicação complexo entre vários núcleos. Por outro lado, a velocidade dos processadores single-core é limitada e não é adequada para aplicações maiores.
Processadores multi-core
Os processadores multi-core têm várias unidades de processamento independentes também chamadas cores.
Esses processadores não precisam de mecanismo de troca de contexto, pois cada núcleo contém tudo o que precisa para executar uma sequência de instruções armazenadas.
Ciclo de busca-decodificação-execução
Os núcleos dos processadores multi-core seguem um ciclo de execução. Este ciclo é chamado deFetch-Decode-Executeciclo. Envolve as seguintes etapas -
Buscar
Esta é a primeira etapa do ciclo, que envolve a busca de instruções na memória do programa.
Decodificar
As instruções obtidas recentemente seriam convertidas em uma série de sinais que acionariam outras partes da CPU.
Executar
É a etapa final em que as instruções buscadas e decodificadas seriam executadas. O resultado da execução será armazenado em um registro da CPU.
Uma vantagem aqui é que a execução em processadores multi-core é mais rápida do que em processadores single-core. É adequado para aplicações maiores. Por outro lado, o protocolo de comunicação complexo entre vários núcleos é um problema. Vários núcleos requerem mais energia do que processadores de núcleo único.
Existem diferentes estilos de arquitetura de sistema e memória que precisam ser considerados ao projetar o programa ou sistema simultâneo. É muito necessário porque um estilo de sistema e memória pode ser adequado para uma tarefa, mas pode estar sujeito a erros para outra tarefa.
Arquiteturas de sistema de computador com suporte à simultaneidade
Michael Flynn em 1972 forneceu taxonomia para categorizar diferentes estilos de arquitetura de sistema de computador. Esta taxonomia define quatro estilos diferentes da seguinte forma -
- Fluxo de instrução único, fluxo de dados único (SISD)
- Fluxo de instrução única, fluxo de dados múltiplos (SIMD)
- Fluxo de várias instruções, fluxo de dados único (MISD)
- Fluxo de várias instruções, fluxo de dados múltiplos (MIMD).
Fluxo de instrução único, fluxo de dados único (SISD)
Como o nome sugere, esse tipo de sistema teria um fluxo de dados de entrada sequencial e uma única unidade de processamento para executar o fluxo de dados. Eles são como sistemas uniprocessadores com arquitetura de computação paralela. A seguir está a arquitetura do SISD -
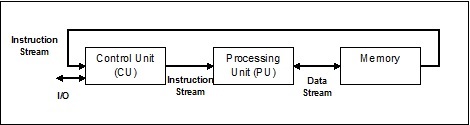
Vantagens do SISD
As vantagens da arquitetura SISD são as seguintes -
- Requer menos energia.
- Não há problema de protocolo de comunicação complexo entre vários núcleos.
Desvantagens do SISD
As desvantagens da arquitetura SISD são as seguintes -
- A velocidade da arquitetura SISD é limitada, assim como os processadores de núcleo único.
- Não é adequado para aplicações maiores.
Fluxo de instrução única, fluxo de dados múltiplos (SIMD)
Como o nome sugere, esse tipo de sistema teria vários fluxos de dados de entrada e um número de unidades de processamento que podem atuar em uma única instrução a qualquer momento. Eles são como sistemas multiprocessadores com arquitetura de computação paralela. A seguir está a arquitetura do SIMD -
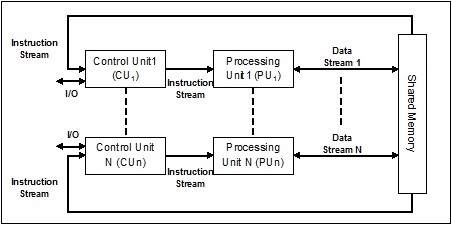
O melhor exemplo de SIMD são as placas gráficas. Esses cartões têm centenas de unidades de processamento individuais. Se falamos sobre a diferença computacional entre SISD e SIMD, então para a adição de matrizes[5, 15, 20] e [15, 25, 10],A arquitetura SISD teria que realizar três operações de adição diferentes. Por outro lado, com a arquitetura SIMD, podemos adicioná-los em uma única operação de adição.
Vantagens do SIMD
As vantagens da arquitetura SIMD são as seguintes -
A mesma operação em vários elementos pode ser realizada usando apenas uma instrução.
A taxa de transferência do sistema pode ser aumentada aumentando o número de núcleos do processador.
A velocidade de processamento é maior do que a arquitetura SISD.
Desvantagens do SIMD
As desvantagens da arquitetura SIMD são as seguintes -
- Existe uma comunicação complexa entre o número de núcleos do processador.
- O custo é maior do que a arquitetura SISD.
Fluxo de dados únicos de instrução múltipla (MISD)
Os sistemas com fluxo MISD têm várias unidades de processamento que executam diferentes operações, executando diferentes instruções no mesmo conjunto de dados. A seguir está a arquitetura do MISD -
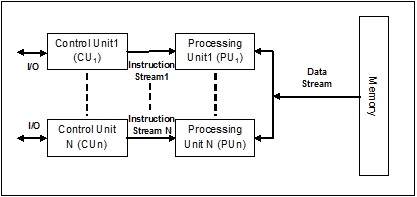
Os representantes da arquitetura MISD ainda não existem comercialmente.
Fluxo de dados múltiplos de instrução múltipla (MIMD)
No sistema que usa a arquitetura MIMD, cada processador em um sistema multiprocessador pode executar diferentes conjuntos de instruções independentemente no conjunto diferente de dados em paralelo. É o oposto da arquitetura SIMD, na qual uma única operação é executada em vários conjuntos de dados. A seguir está a arquitetura do MIMD -
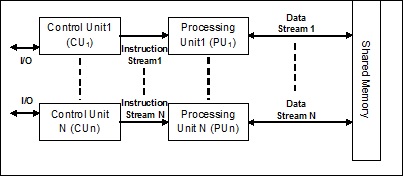
Um multiprocessador normal usa a arquitetura MIMD. Essas arquiteturas são basicamente usadas em uma série de áreas de aplicação, como design / manufatura auxiliada por computador, simulação, modelagem, interruptores de comunicação, etc.
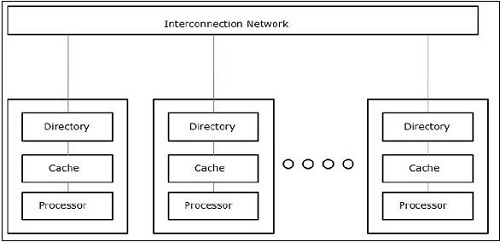
Arquiteturas de memória com suporte à simultaneidade
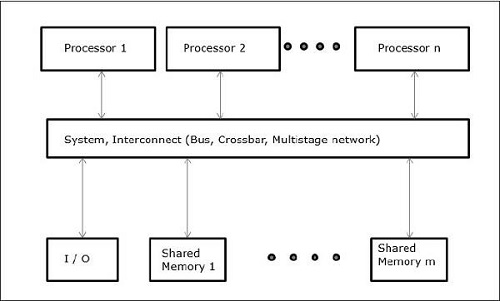
Ao trabalhar com os conceitos de simultaneidade e paralelismo, sempre há a necessidade de acelerar os programas. Uma solução encontrada pelos designers de computador é criar multicomputadores com memória compartilhada, ou seja, computadores com espaço de endereço físico único, que é acessado por todos os núcleos que um processador possui. Neste cenário, pode haver uma série de estilos diferentes de arquitetura, mas a seguir estão os três estilos de arquitetura importantes -
UMA (acesso uniforme à memória)
Neste modelo, todos os processadores compartilham a memória física uniformemente. Todos os processadores têm igual tempo de acesso a todas as palavras de memória. Cada processador pode ter uma memória cache privada. Os dispositivos periféricos seguem um conjunto de regras.
Quando todos os processadores têm acesso igual a todos os dispositivos periféricos, o sistema é chamado de symmetric multiprocessor. Quando apenas um ou alguns processadores podem acessar os dispositivos periféricos, o sistema é chamado deasymmetric multiprocessor.
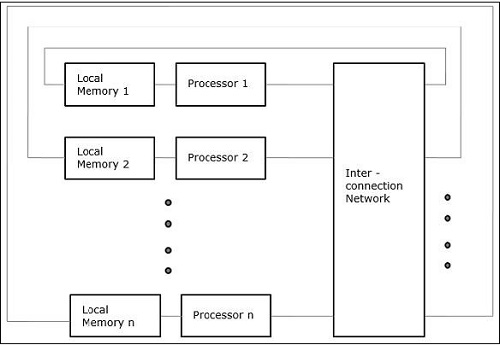
Acesso não uniforme à memória (NUMA)
No modelo de multiprocessador NUMA, o tempo de acesso varia com a localização da palavra de memória. Aqui, a memória compartilhada é fisicamente distribuída entre todos os processadores, chamados de memórias locais. A coleção de todas as memórias locais forma um espaço de endereço global que pode ser acessado por todos os processadores.
Arquitetura de memória somente cache (COMA)
O modelo COMA é uma versão especializada do modelo NUMA. Aqui, todas as memórias principais distribuídas são convertidas em memórias cache.
Em geral, como sabemos, esse fio é um fio torcido muito fino, geralmente feito de tecido de algodão ou seda e usado para costurar roupas e similares. O mesmo termo thread também é usado no mundo da programação de computadores. Agora, como relacionamos a linha usada para costurar roupas e a linha usada para programação de computador? As funções desempenhadas pelos dois threads são semelhantes aqui. Nas roupas, a linha mantém o tecido unido e, do outro lado, na programação de computador, a linha prende o programa de computador e permite que o programa execute ações sequenciais ou várias ações ao mesmo tempo.
Threadé a menor unidade de execução em um sistema operacional. Não é em si um programa, mas é executado dentro de um programa. Em outras palavras, os threads não são independentes uns dos outros e compartilham a seção de código, seção de dados, etc. com outros threads. Esses threads também são conhecidos como processos leves.
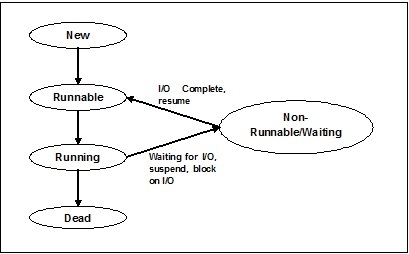
Estados da linha
Para entender a funcionalidade dos threads em profundidade, precisamos aprender sobre o ciclo de vida dos threads ou os diferentes estados de thread. Normalmente, um thread pode existir em cinco estados distintos. Os diferentes estados são mostrados abaixo -
Novo Tópico
Um novo encadeamento inicia seu ciclo de vida no novo estado. No entanto, nesta fase, ainda não foi iniciado e não foram atribuídos quaisquer recursos. Podemos dizer que é apenas uma instância de um objeto.
Executável
Conforme o thread recém-nascido é iniciado, ele se torna executável, ou seja, aguardando para ser executado. Neste estado, ele possui todos os recursos, mas o agendador de tarefas ainda não o programou para ser executado.
Corrida
Nesse estado, o encadeamento avança e executa a tarefa, que foi escolhida pelo planejador de tarefas para ser executada. Agora, o thread pode ir para o estado morto ou para o estado não executável / em espera.
Parado / em espera
Nesse estado, o encadeamento é pausado porque está aguardando a resposta de alguma solicitação de E / S ou pela conclusão da execução de outro encadeamento.
Morto
Um thread executável entra no estado finalizado quando completa sua tarefa ou então termina.
O diagrama a seguir mostra o ciclo de vida completo de um segmento -
Tipos de linha
Nesta seção, veremos os diferentes tipos de thread. Os tipos são descritos abaixo -
Threads de nível de usuário
Esses são threads gerenciados pelo usuário.
Nesse caso, o kernel de gerenciamento de encadeamentos não está ciente da existência de encadeamentos. A biblioteca de threads contém código para criar e destruir threads, para passar mensagens e dados entre threads, para agendar a execução de threads e para salvar e restaurar contextos de threads. O aplicativo começa com um único thread.
Os exemplos de threads de nível de usuário são -
- Threads Java
- Tópicos POSIX
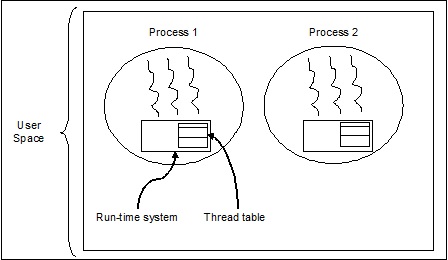
Vantagens de Threads em nível de usuário
A seguir estão as diferentes vantagens de threads em nível de usuário -
- A troca de threads não requer privilégios de modo Kernel.
- O thread no nível do usuário pode ser executado em qualquer sistema operacional.
- O agendamento pode ser específico do aplicativo no thread de nível do usuário.
- Os threads no nível do usuário são rápidos de criar e gerenciar.
Desvantagens de Threads no nível do usuário
A seguir estão as diferentes desvantagens dos threads de nível de usuário -
- Em um sistema operacional típico, a maioria das chamadas do sistema são bloqueadas.
- O aplicativo multithread não pode tirar proveito do multiprocessamento.
Threads de nível de kernel
Threads gerenciados pelo sistema operacional atuam no kernel, que é um núcleo do sistema operacional.
Nesse caso, o Kernel faz o gerenciamento de threads. Não há código de gerenciamento de encadeamento na área de aplicativo. Threads de kernel são suportados diretamente pelo sistema operacional. Qualquer aplicativo pode ser programado para ser multithread. Todos os threads em um aplicativo são suportados em um único processo.
O kernel mantém informações de contexto para o processo como um todo e para threads individuais dentro do processo. O agendamento pelo Kernel é feito com base em threads. O Kernel realiza a criação, programação e gerenciamento de threads no espaço do Kernel. Os threads do kernel geralmente são mais lentos para criar e gerenciar do que os threads do usuário. Os exemplos de threads de nível de kernel são Windows, Solaris.
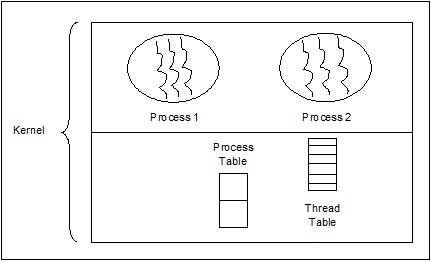
Vantagens de threads de nível de kernel
A seguir estão as diferentes vantagens dos threads de nível de kernel -
O kernel pode agendar simultaneamente vários threads do mesmo processo em vários processos.
Se um thread em um processo for bloqueado, o Kernel pode agendar outro thread do mesmo processo.
As próprias rotinas do kernel podem ser multithread.
Desvantagens dos Threads de Nível de Kernel
Os threads do kernel geralmente são mais lentos para criar e gerenciar do que os threads do usuário.
A transferência de controle de um thread para outro dentro do mesmo processo requer uma mudança de modo para o Kernel.
Bloco de controle de linha - TCB
O Bloco de Controle de Thread (TCB) pode ser definido como a estrutura de dados no kernel do sistema operacional que contém principalmente informações sobre o thread. As informações específicas do thread armazenadas no TCB destacariam algumas informações importantes sobre cada processo.
Considere os seguintes pontos relacionados aos threads contidos no TCB -
Thread identification - É o id de thread exclusivo (tid) atribuído a cada novo thread.
Thread state - Ele contém as informações relacionadas ao estado (Executando, Executável, Não Executando, Morto) do thread.
Program Counter (PC) - Aponta para a instrução de programa atual da thread.
Register set - Ele contém os valores de registro da thread atribuídos a eles para cálculos.
Stack Pointer- Aponta para a pilha do segmento no processo. Ele contém as variáveis locais no escopo do thread.
Pointer to PCB - Ele contém o ponteiro para o processo que criou esse segmento.

Relação entre processo e thread
No multithreading, processo e thread são dois termos intimamente relacionados com o mesmo objetivo de tornar o computador capaz de fazer mais de uma coisa ao mesmo tempo. Um processo pode conter um ou mais threads, mas ao contrário, o thread não pode conter um processo. No entanto, ambos permanecem as duas unidades básicas de execução. Um programa, executando uma série de instruções, inicia o processo e encadeia ambos.
A tabela a seguir mostra a comparação entre processo e thread -
| Processo | Fio |
|---|---|
| O processo é pesado ou exige muitos recursos. | O thread é leve e consome menos recursos do que um processo. |
| A comutação de processos precisa de interação com o sistema operacional. | A troca de thread não precisa interagir com o sistema operacional. |
| Em vários ambientes de processamento, cada processo executa o mesmo código, mas tem sua própria memória e recursos de arquivo. | Todos os threads podem compartilhar o mesmo conjunto de arquivos abertos, processos filho. |
| Se um processo for bloqueado, nenhum outro processo poderá ser executado até que o primeiro seja desbloqueado. | Enquanto um encadeamento está bloqueado e esperando, um segundo encadeamento na mesma tarefa pode ser executado. |
| Vários processos sem usar threads usam mais recursos. | Vários processos encadeados usam menos recursos. |
| Em vários processos, cada processo opera independentemente dos outros. | Um thread pode ler, escrever ou alterar os dados de outro thread. |
| Se houver alguma mudança no processo pai, isso não afetará os processos filho. | Se houver alguma alteração no thread principal, isso pode afetar o comportamento de outros threads desse processo. |
| Para se comunicar com processos irmãos, os processos devem usar comunicação entre processos. | Os threads podem se comunicar diretamente com outros threads desse processo. |
Conceito de Multithreading
Como já discutimos, multithreading é a capacidade de uma CPU de gerenciar o uso do sistema operacional executando vários threads simultaneamente. A ideia principal do multithreading é atingir o paralelismo dividindo um processo em vários threads. De forma mais simples, podemos dizer que multithreading é a forma de realizar multitarefa por meio do conceito de threads.
O conceito de multithreading pode ser entendido com a ajuda do exemplo a seguir.
Exemplo
Suponha que estejamos executando um processo. O processo pode ser para abrir a palavra MS para escrever algo. Nesse processo, um thread será atribuído para abrir a palavra MS e outro thread será necessário para escrever. Agora, suponha que se desejamos editar algo, então outro thread será necessário para fazer a tarefa de edição e assim por diante.
O diagrama a seguir nos ajuda a entender como vários threads existem na memória -
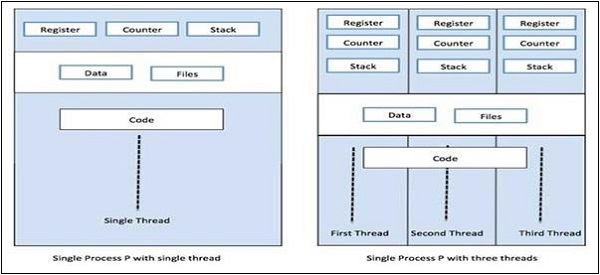
Podemos ver no diagrama acima que mais de um thread pode existir em um processo, onde cada thread contém seu próprio conjunto de registros e variáveis locais. Fora isso, todos os threads em um processo compartilham variáveis globais.
Prós do Multithreading
Vejamos agora algumas vantagens do multithreading. As vantagens são as seguintes -
Speed of communication - O multithreading melhora a velocidade da computação porque cada núcleo ou processador lida com threads diferentes simultaneamente.
Program remains responsive - Permite que um programa permaneça responsivo porque um thread espera pela entrada e outro executa uma GUI ao mesmo tempo.
Access to global variables - No multithreading, todos os threads de um processo específico podem acessar as variáveis globais e se houver qualquer alteração na variável global, ela também será visível para outros threads.
Utilization of resources - A execução de vários threads em cada programa faz melhor uso da CPU e o tempo ocioso da CPU diminui.
Sharing of data - Não há necessidade de espaço extra para cada thread porque os threads dentro de um programa podem compartilhar os mesmos dados.
Contras do multithreading
Vejamos agora algumas desvantagens do multithreading. As desvantagens são as seguintes -
Not suitable for single processor system - O multithreading tem dificuldade em obter desempenho em termos de velocidade de computação em um sistema de processador único em comparação com o desempenho em um sistema com vários processadores.
Issue of security - Como sabemos que todos os threads dentro de um programa compartilham os mesmos dados, portanto, sempre há um problema de segurança porque qualquer thread desconhecido pode alterar os dados.
Increase in complexity - Multithreading pode aumentar a complexidade do programa e a depuração se torna difícil.
Lead to deadlock state - O multithreading pode levar o programa a um risco potencial de atingir o estado de deadlock.
Synchronization required- A sincronização é necessária para evitar exclusão mútua. Isso leva a mais memória e utilização da CPU.
Neste capítulo, aprenderemos como implementar threads em Python.
Módulo Python para implementação de thread
Os threads do Python às vezes são chamados de processos leves porque os threads ocupam muito menos memória do que os processos. Threads permitem realizar várias tarefas ao mesmo tempo. Em Python, temos os dois módulos a seguir que implementam threads em um programa -
<_thread>module
<threading>module
A principal diferença entre esses dois módulos é que <_thread> módulo trata um thread como uma função, enquanto o <threading>O módulo trata cada thread como um objeto e o implementa de uma maneira orientada a objetos. Além disso, o<_thread>módulo é eficaz em threading de baixo nível e tem menos recursos do que o <threading> módulo.
módulo <_thread>
Na versão anterior do Python, tínhamos o <thread>módulo, mas tem sido considerado "obsoleto" por um longo tempo. Os usuários foram incentivados a usar o<threading>módulo em vez disso. Portanto, no Python 3 o módulo "thread" não está mais disponível. Foi renomeado para "<_thread>"para incompatibilidades com versões anteriores em Python3.
Para gerar um novo tópico com a ajuda do <_thread> módulo, precisamos chamar o start_new_threadmétodo disso. O funcionamento deste método pode ser compreendido com a ajuda da seguinte sintaxe -
_thread.start_new_thread ( function, args[, kwargs] )Aqui -
args é uma tupla de argumentos
kwargs é um dicionário opcional de argumentos de palavras-chave
Se quisermos chamar a função sem passar um argumento, então precisamos usar uma tupla vazia de argumentos em args.
Essa chamada de método retorna imediatamente, o thread filho é iniciado e chama a função com a lista passada, se houver, de args. O encadeamento termina como e quando a função retorna.
Exemplo
A seguir está um exemplo para gerar um novo encadeamento usando o <_thread>módulo. Estamos usando o método start_new_thread () aqui.
import _thread
import time
def print_time( threadName, delay):
count = 0
while count < 5:
time.sleep(delay)
count += 1
print ("%s: %s" % ( threadName, time.ctime(time.time()) ))
try:
_thread.start_new_thread( print_time, ("Thread-1", 2, ) )
_thread.start_new_thread( print_time, ("Thread-2", 4, ) )
except:
print ("Error: unable to start thread")
while 1:
passResultado
A saída a seguir nos ajudará a entender a geração de novos threads com a ajuda do <_thread> módulo.
Thread-1: Mon Apr 23 10:03:33 2018
Thread-2: Mon Apr 23 10:03:35 2018
Thread-1: Mon Apr 23 10:03:35 2018
Thread-1: Mon Apr 23 10:03:37 2018
Thread-2: Mon Apr 23 10:03:39 2018
Thread-1: Mon Apr 23 10:03:39 2018
Thread-1: Mon Apr 23 10:03:41 2018
Thread-2: Mon Apr 23 10:03:43 2018
Thread-2: Mon Apr 23 10:03:47 2018
Thread-2: Mon Apr 23 10:03:51 2018Módulo <threading>
o <threading>O módulo implementa de forma orientada a objetos e trata cada thread como um objeto. Portanto, ele fornece um suporte de alto nível muito mais poderoso para threads do que o módulo <_thread>. Este módulo está incluído no Python 2.4.
Métodos adicionais no módulo <threading>
o <threading> módulo compreende todos os métodos do <_thread>módulo, mas fornece métodos adicionais também. Os métodos adicionais são os seguintes -
threading.activeCount() - Este método retorna o número de objetos de thread que estão ativos
threading.currentThread() - Este método retorna o número de objetos de thread no controle de thread do chamador.
threading.enumerate() - Este método retorna uma lista de todos os objetos de thread que estão atualmente ativos.
run() - O método run () é o ponto de entrada para um thread.
start() - O método start () inicia um thread chamando o método run.
join([time]) - O join () espera que os encadeamentos sejam encerrados.
isAlive() - O método isAlive () verifica se uma thread ainda está em execução.
getName() - O método getName () retorna o nome de um thread.
setName() - O método setName () define o nome de um thread.
Para implementar o threading, o <threading> módulo tem o Thread classe que fornece os seguintes métodos -
Como criar threads usando o módulo <threading>?
Nesta seção, aprenderemos como criar threads usando o <threading>módulo. Siga estas etapas para criar um novo tópico usando o módulo <threading> -
Step 1 - Nesta etapa, precisamos definir uma nova subclasse do Thread classe.
Step 2 - Então, para adicionar argumentos adicionais, precisamos substituir o __init__(self [,args]) método.
Step 3 - Nesta etapa, precisamos substituir o método run (self [, args]) para implementar o que o thread deve fazer quando iniciado.
Agora, depois de criar o novo Thread subclasse, podemos criar uma instância dela e, em seguida, iniciar um novo thread invocando o start(), que por sua vez chama o run() método.
Exemplo
Considere este exemplo para aprender como gerar um novo encadeamento usando o <threading> módulo.
import threading
import time
exitFlag = 0
class myThread (threading.Thread):
def __init__(self, threadID, name, counter):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
self.counter = counter
def run(self):
print ("Starting " + self.name)
print_time(self.name, self.counter, 5)
print ("Exiting " + self.name)
def print_time(threadName, delay, counter):
while counter:
if exitFlag:
threadName.exit()
time.sleep(delay)
print ("%s: %s" % (threadName, time.ctime(time.time())))
counter -= 1
thread1 = myThread(1, "Thread-1", 1)
thread2 = myThread(2, "Thread-2", 2)
thread1.start()
thread2.start()
thread1.join()
thread2.join()
print ("Exiting Main Thread")
Starting Thread-1
Starting Thread-2Resultado
Agora, considere a seguinte saída -
Thread-1: Mon Apr 23 10:52:09 2018
Thread-1: Mon Apr 23 10:52:10 2018
Thread-2: Mon Apr 23 10:52:10 2018
Thread-1: Mon Apr 23 10:52:11 2018
Thread-1: Mon Apr 23 10:52:12 2018
Thread-2: Mon Apr 23 10:52:12 2018
Thread-1: Mon Apr 23 10:52:13 2018
Exiting Thread-1
Thread-2: Mon Apr 23 10:52:14 2018
Thread-2: Mon Apr 23 10:52:16 2018
Thread-2: Mon Apr 23 10:52:18 2018
Exiting Thread-2
Exiting Main ThreadPrograma Python para vários estados de thread
Existem cinco estados de thread - novo, executável, em execução, em espera e morto. Entre esses cinco desses cinco, vamos nos concentrar principalmente em três estados - em execução, em espera e morto. Um encadeamento obtém seus recursos no estado de execução, espera pelos recursos no estado de espera; a liberação final do recurso, se em execução e adquirido, está no estado morto.
O programa Python a seguir, com a ajuda dos métodos start (), sleep () e join (), mostrará como uma thread entrou em execução, espera e estado morto, respectivamente.
Step 1 - Importe os módulos necessários, <threading> e <time>
import threading
import timeStep 2 - Defina uma função, que será chamada durante a criação de um segmento.
def thread_states():
print("Thread entered in running state")Step 3 - Estamos usando o método sleep () do módulo time para fazer nosso thread esperar, digamos, 2 segundos.
time.sleep(2)Step 4 - Agora, estamos criando uma thread chamada T1, que leva o argumento da função definida acima.
T1 = threading.Thread(target=thread_states)Step 5- Agora, com a ajuda da função start (), podemos iniciar nosso thread. Ele produzirá a mensagem, que foi definida por nós durante a definição da função.
T1.start()
Thread entered in running stateStep 6 - Agora, finalmente podemos matar a thread com o método join () após terminar sua execução.
T1.join()Iniciando um thread em Python
Em python, podemos iniciar um novo thread de maneiras diferentes, mas a mais fácil entre elas é defini-lo como uma única função. Depois de definir a função, podemos passar isso como o destino para um novothreading.Threadobjeto e assim por diante. Execute o seguinte código Python para entender como a função funciona -
import threading
import time
import random
def Thread_execution(i):
print("Execution of Thread {} started\n".format(i))
sleepTime = random.randint(1,4)
time.sleep(sleepTime)
print("Execution of Thread {} finished".format(i))
for i in range(4):
thread = threading.Thread(target=Thread_execution, args=(i,))
thread.start()
print("Active Threads:" , threading.enumerate())Resultado
Execution of Thread 0 started
Active Threads:
[<_MainThread(MainThread, started 6040)>,
<HistorySavingThread(IPythonHistorySavingThread, started 5968)>,
<Thread(Thread-3576, started 3932)>]
Execution of Thread 1 started
Active Threads:
[<_MainThread(MainThread, started 6040)>,
<HistorySavingThread(IPythonHistorySavingThread, started 5968)>,
<Thread(Thread-3576, started 3932)>,
<Thread(Thread-3577, started 3080)>]
Execution of Thread 2 started
Active Threads:
[<_MainThread(MainThread, started 6040)>,
<HistorySavingThread(IPythonHistorySavingThread, started 5968)>,
<Thread(Thread-3576, started 3932)>,
<Thread(Thread-3577, started 3080)>,
<Thread(Thread-3578, started 2268)>]
Execution of Thread 3 started
Active Threads:
[<_MainThread(MainThread, started 6040)>,
<HistorySavingThread(IPythonHistorySavingThread, started 5968)>,
<Thread(Thread-3576, started 3932)>,
<Thread(Thread-3577, started 3080)>,
<Thread(Thread-3578, started 2268)>,
<Thread(Thread-3579, started 4520)>]
Execution of Thread 0 finished
Execution of Thread 1 finished
Execution of Thread 2 finished
Execution of Thread 3 finishedThreads daemon em Python
Antes de implementar os threads daemon em Python, precisamos saber sobre as threads daemon e seu uso. Em termos de computação, daemon é um processo em segundo plano que lida com as solicitações de vários serviços, como envio de dados, transferência de arquivos, etc. Ele ficaria inativo se não fosse mais necessário. A mesma tarefa também pode ser realizada com a ajuda de threads que não sejam daemon. No entanto, neste caso, a thread principal deve manter o controle das threads que não são daemon manualmente. Por outro lado, se estivermos usando encadeamentos daemon, o encadeamento principal pode esquecer completamente isso e será eliminado quando o encadeamento principal for encerrado. Outro ponto importante sobre os encadeamentos daemon é que podemos optar por usá-los apenas para tarefas não essenciais que não nos afetariam se não fossem concluídos ou fossem eliminados no meio. A seguir está a implementação de threads daemon em python -
import threading
import time
def nondaemonThread():
print("starting my thread")
time.sleep(8)
print("ending my thread")
def daemonThread():
while True:
print("Hello")
time.sleep(2)
if __name__ == '__main__':
nondaemonThread = threading.Thread(target = nondaemonThread)
daemonThread = threading.Thread(target = daemonThread)
daemonThread.setDaemon(True)
daemonThread.start()
nondaemonThread.start()No código acima, existem duas funções, a saber >nondaemonThread() e >daemonThread(). A primeira função imprime seu estado e dorme após 8 segundos, enquanto a função deamonThread () imprime Hello a cada 2 segundos indefinidamente. Podemos entender a diferença entre threads não demoníacos e daemon com a ajuda da seguinte saída -
Hello
starting my thread
Hello
Hello
Hello
Hello
ending my thread
Hello
Hello
Hello
Hello
HelloA sincronização de threads pode ser definida como um método com a ajuda do qual podemos ter certeza de que duas ou mais threads simultâneas não estão acessando simultaneamente o segmento do programa conhecido como seção crítica. Por outro lado, como sabemos, essa seção crítica é a parte do programa onde o recurso compartilhado é acessado. Portanto, podemos dizer que a sincronização é o processo de garantir que dois ou mais threads não façam interface entre si acessando os recursos ao mesmo tempo. O diagrama abaixo mostra que quatro threads estão tentando acessar a seção crítica de um programa ao mesmo tempo.
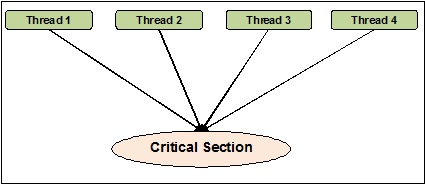
Para tornar isso mais claro, suponha que dois ou mais threads tentando adicionar o objeto na lista ao mesmo tempo. Este ato não pode levar a um final bem-sucedido, porque eliminará um ou todos os objetos ou corromperá completamente o estado da lista. Aqui, a função da sincronização é que apenas um thread de cada vez pode acessar a lista.
Problemas na sincronização do thread
Podemos encontrar problemas ao implementar programação simultânea ou aplicar primitivas de sincronização. Nesta seção, discutiremos duas questões principais. Os problemas são -
- Deadlock
- Condição de corrida
Condição de corrida
Este é um dos principais problemas da programação simultânea. O acesso simultâneo a recursos compartilhados pode levar a uma condição de corrida. Uma condição de corrida pode ser definida como a ocorrência de uma condição em que dois ou mais threads podem acessar dados compartilhados e, em seguida, tentar alterar seu valor ao mesmo tempo. Devido a isso, os valores das variáveis podem ser imprevisíveis e variam dependendo dos tempos de troca de contexto dos processos.
Exemplo
Considere este exemplo para entender o conceito de condição de corrida -
Step 1 - Nesta etapa, precisamos importar o módulo de threading -
import threadingStep 2 - Agora, defina uma variável global, digamos x, junto com seu valor como 0 -
x = 0Step 3 - Agora, precisamos definir o increment_global() função, que fará o incremento de 1 nesta função global x -
def increment_global():
global x
x += 1Step 4 - Nesta etapa, vamos definir o taskofThread()função, que irá chamar a função increment_global () por um determinado número de vezes; para o nosso exemplo é 50000 vezes -
def taskofThread():
for _ in range(50000):
increment_global()Step 5- Agora, defina a função main () na qual os threads t1 e t2 são criados. Ambos serão iniciados com a ajuda da função start () e aguardarão até que concluam seus trabalhos com a ajuda da função join ().
def main():
global x
x = 0
t1 = threading.Thread(target= taskofThread)
t2 = threading.Thread(target= taskofThread)
t1.start()
t2.start()
t1.join()
t2.join()Step 6- Agora, precisamos fornecer o intervalo para quantas iterações queremos chamar a função main (). Aqui, estamos chamando por 5 vezes.
if __name__ == "__main__":
for i in range(5):
main()
print("x = {1} after Iteration {0}".format(i,x))Na saída mostrada abaixo, podemos ver o efeito da condição de corrida, pois o valor de x após cada iteração é esperado 100.000. No entanto, há muita variação no valor. Isso se deve ao acesso simultâneo de threads à variável global compartilhada x.
Resultado
x = 100000 after Iteration 0
x = 54034 after Iteration 1
x = 80230 after Iteration 2
x = 93602 after Iteration 3
x = 93289 after Iteration 4Lidando com condição de corrida usando bloqueios
Como vimos o efeito da condição de corrida no programa acima, precisamos de uma ferramenta de sincronização, que pode lidar com a condição de corrida entre vários threads. Em Python, o<threading>módulo fornece classe Lock para lidar com condições de corrida. Além disso, oLockclasse fornece métodos diferentes com a ajuda dos quais podemos lidar com a condição de corrida entre vários threads. Os métodos são descritos abaixo -
método adquirir ()
Este método é usado para adquirir, ou seja, bloquear um bloqueio. Um bloqueio pode ser bloqueador ou não, dependendo do seguinte valor verdadeiro ou falso -
With value set to True - Se o método occur () for chamado com True, que é o argumento padrão, a execução do thread é bloqueada até que o bloqueio seja desbloqueado.
With value set to False - Se o método buyer () é chamado com False, que não é o argumento padrão, a execução da thread não é bloqueada até que seja definida como true, ou seja, até que seja bloqueada.
método release ()
Este método é usado para liberar um bloqueio. A seguir estão algumas tarefas importantes relacionadas a este método -
Se uma fechadura estiver bloqueada, então o release()método iria desbloqueá-lo. Seu trabalho é permitir que exatamente um thread prossiga se mais de um thread estiver bloqueado e esperando o bloqueio ser desbloqueado.
Vai levantar um ThreadError se o bloqueio já estiver desbloqueado.
Agora, podemos reescrever o programa acima com a classe de bloqueio e seus métodos para evitar a condição de corrida. Precisamos definir o método taskofThread () com o argumento lock e, em seguida, usar os métodos activate () e release () para bloquear e não bloquear bloqueios para evitar condição de corrida.
Exemplo
A seguir está um exemplo de programa python para entender o conceito de bloqueios para lidar com a condição de corrida -
import threading
x = 0
def increment_global():
global x
x += 1
def taskofThread(lock):
for _ in range(50000):
lock.acquire()
increment_global()
lock.release()
def main():
global x
x = 0
lock = threading.Lock()
t1 = threading.Thread(target = taskofThread, args = (lock,))
t2 = threading.Thread(target = taskofThread, args = (lock,))
t1.start()
t2.start()
t1.join()
t2.join()
if __name__ == "__main__":
for i in range(5):
main()
print("x = {1} after Iteration {0}".format(i,x))A saída a seguir mostra que o efeito da condição de corrida é negligenciado; já que o valor de x, após cada & toda iteração, é agora 100000, que está de acordo com a expectativa deste programa.
Resultado
x = 100000 after Iteration 0
x = 100000 after Iteration 1
x = 100000 after Iteration 2
x = 100000 after Iteration 3
x = 100000 after Iteration 4Deadlocks - O problema dos Dining Philosophers
Deadlock é uma questão problemática que pode ser enfrentada ao projetar os sistemas concorrentes. Podemos ilustrar esse problema com a ajuda do problema do filósofo jantando da seguinte maneira -
Edsger Dijkstra originalmente introduziu o problema do filósofo jantando, uma das famosas ilustrações de um dos maiores problemas de sistema concorrente chamado impasse.
Neste problema, há cinco filósofos famosos sentados em uma mesa redonda comendo um pouco de comida de suas tigelas. Existem cinco garfos que podem ser usados pelos cinco filósofos para comerem. No entanto, os filósofos decidem usar dois garfos ao mesmo tempo para comer sua comida.
Agora, existem duas condições principais para os filósofos. Primeiro, cada um dos filósofos pode estar comendo ou pensando e, segundo, eles devem primeiro obter os dois garfos, isto é, esquerdo e direito. O problema surge quando cada um dos cinco filósofos consegue escolher a bifurcação esquerda ao mesmo tempo. Agora todos eles estão esperando que o garfo certo seja liberado, mas nunca abrirão mão do garfo até que tenham comido e o garfo certo nunca estará disponível. Conseqüentemente, haveria um estado de impasse na mesa de jantar.
Deadlock no sistema concorrente
Agora, se virmos, o mesmo problema pode surgir em nossos sistemas concorrentes também. As bifurcações no exemplo acima seriam os recursos do sistema e cada filósofo pode representar o processo, que está competindo para obter os recursos.
Solução com programa Python
A solução para este problema pode ser encontrada dividindo os filósofos em dois tipos - greedy philosophers e generous philosophers. Principalmente um filósofo ganancioso tentará pegar o garfo esquerdo e esperar até que ele esteja lá. Ele irá então esperar que o garfo certo esteja lá, pegá-lo, comer e então largá-lo. Por outro lado, um filósofo generoso tentará pegar a bifurcação esquerda e, se não estiver lá, esperará e tentará novamente depois de algum tempo. Se eles pegarem a bifurcação da esquerda, eles tentarão pegar a direita. Se eles pegarem o garfo certo também, eles comerão e soltarão os dois garfos. No entanto, se eles não conseguirem o garfo direito, eles irão liberar o garfo esquerdo.
Exemplo
O seguinte programa Python nos ajudará a encontrar uma solução para o problema do filósofo jantando -
import threading
import random
import time
class DiningPhilosopher(threading.Thread):
running = True
def __init__(self, xname, Leftfork, Rightfork):
threading.Thread.__init__(self)
self.name = xname
self.Leftfork = Leftfork
self.Rightfork = Rightfork
def run(self):
while(self.running):
time.sleep( random.uniform(3,13))
print ('%s is hungry.' % self.name)
self.dine()
def dine(self):
fork1, fork2 = self.Leftfork, self.Rightfork
while self.running:
fork1.acquire(True)
locked = fork2.acquire(False)
if locked: break
fork1.release()
print ('%s swaps forks' % self.name)
fork1, fork2 = fork2, fork1
else:
return
self.dining()
fork2.release()
fork1.release()
def dining(self):
print ('%s starts eating '% self.name)
time.sleep(random.uniform(1,10))
print ('%s finishes eating and now thinking.' % self.name)
def Dining_Philosophers():
forks = [threading.Lock() for n in range(5)]
philosopherNames = ('1st','2nd','3rd','4th', '5th')
philosophers= [DiningPhilosopher(philosopherNames[i], forks[i%5], forks[(i+1)%5]) \
for i in range(5)]
random.seed()
DiningPhilosopher.running = True
for p in philosophers: p.start()
time.sleep(30)
DiningPhilosopher.running = False
print (" It is finishing.")
Dining_Philosophers()O programa acima usa o conceito de filósofos gananciosos e generosos. O programa também usou oacquire() e release() métodos do Lock classe do <threading>módulo. Podemos ver a solução na seguinte saída -
Resultado
4th is hungry.
4th starts eating
1st is hungry.
1st starts eating
2nd is hungry.
5th is hungry.
3rd is hungry.
1st finishes eating and now thinking.3rd swaps forks
2nd starts eating
4th finishes eating and now thinking.
3rd swaps forks5th starts eating
5th finishes eating and now thinking.
4th is hungry.
4th starts eating
2nd finishes eating and now thinking.
3rd swaps forks
1st is hungry.
1st starts eating
4th finishes eating and now thinking.
3rd starts eating
5th is hungry.
5th swaps forks
1st finishes eating and now thinking.
5th starts eating
2nd is hungry.
2nd swaps forks
4th is hungry.
5th finishes eating and now thinking.
3rd finishes eating and now thinking.
2nd starts eating 4th starts eating
It is finishing.Na vida real, se uma equipe de pessoas está trabalhando em uma tarefa comum, deve haver comunicação entre eles para concluir a tarefa corretamente. A mesma analogia também se aplica a threads. Na programação, para reduzir o tempo ideal do processador, criamos vários threads e atribuímos diferentes subtarefas a cada thread. Portanto, deve haver uma facilidade de comunicação e eles devem interagir entre si para terminar o trabalho de forma sincronizada.
Considere os seguintes pontos importantes relacionados à intercomunicação de thread -
No performance gain - Se não conseguirmos uma comunicação adequada entre threads e processos, os ganhos de desempenho com a simultaneidade e o paralelismo são inúteis.
Accomplish task properly - Sem mecanismo de intercomunicação adequado entre threads, a tarefa atribuída não pode ser concluída corretamente.
More efficient than inter-process communication - A comunicação entre threads é mais eficiente e fácil de usar do que a comunicação entre processos porque todos os threads de um processo compartilham o mesmo espaço de endereço e não precisam usar memória compartilhada.
Estruturas de dados Python para comunicação thread-safe
O código multithread surge com o problema de passar informações de um thread para outro. As primitivas de comunicação padrão não resolvem esse problema. Portanto, precisamos implementar nosso próprio objeto composto para compartilhar objetos entre threads para tornar a comunicação segura para threads. A seguir estão algumas estruturas de dados, que fornecem comunicação thread-safe depois de fazer algumas alterações nelas -
Jogos
Para usar a estrutura de dados definida de uma maneira segura para thread, precisamos estender a classe definida para implementar nosso próprio mecanismo de bloqueio.
Exemplo
Aqui está um exemplo Python de extensão da classe -
class extend_class(set):
def __init__(self, *args, **kwargs):
self._lock = Lock()
super(extend_class, self).__init__(*args, **kwargs)
def add(self, elem):
self._lock.acquire()
try:
super(extend_class, self).add(elem)
finally:
self._lock.release()
def delete(self, elem):
self._lock.acquire()
try:
super(extend_class, self).delete(elem)
finally:
self._lock.release()No exemplo acima, um objeto de classe chamado extend_class foi definido, o que é posteriormente herdado do Python set class. Um objeto de bloqueio é criado dentro do construtor desta classe. Agora, existem duas funções -add() e delete(). Essas funções são definidas e são thread-safe. Ambos contam com osuper funcionalidade de classe com uma exceção chave.
Decorador
Este é outro método importante para a comunicação thread-safe é o uso de decoradores.
Exemplo
Considere um exemplo de Python que mostra como usar decoradores & mminus;
def lock_decorator(method):
def new_deco_method(self, *args, **kwargs):
with self._lock:
return method(self, *args, **kwargs)
return new_deco_method
class Decorator_class(set):
def __init__(self, *args, **kwargs):
self._lock = Lock()
super(Decorator_class, self).__init__(*args, **kwargs)
@lock_decorator
def add(self, *args, **kwargs):
return super(Decorator_class, self).add(elem)
@lock_decorator
def delete(self, *args, **kwargs):
return super(Decorator_class, self).delete(elem)No exemplo acima, um método decorador denominado lock_decorator foi definido, o qual é posteriormente herdado da classe de método Python. Em seguida, um objeto de bloqueio é criado dentro do construtor desta classe. Agora, existem duas funções - add () e delete (). Essas funções são definidas e são thread-safe. Ambos contam com a funcionalidade de superclasse com uma exceção chave.
Listas
A estrutura de dados da lista é thread-safe, rápida e fácil para armazenamento temporário na memória. No Cpython, o GIL protege contra acesso simultâneo a eles. Como vimos, essas listas são seguras para threads, mas e os dados que estão nelas. Na verdade, os dados da lista não estão protegidos. Por exemplo,L.append(x)não é garantia de retornar o resultado esperado se outro thread estiver tentando fazer a mesma coisa. Isso porque, emboraappend() é uma operação atômica e segura para threads, mas a outra thread está tentando modificar os dados da lista de maneira simultânea, portanto, podemos ver os efeitos colaterais das condições de corrida na saída.
Para resolver esse tipo de problema e modificar os dados com segurança, devemos implementar um mecanismo de bloqueio adequado, o que garante ainda que vários threads não possam entrar em condições de corrida. Para implementar o mecanismo de bloqueio adequado, podemos estender a classe como fizemos nos exemplos anteriores.
Algumas outras operações atômicas nas listas são as seguintes -
L.append(x)
L1.extend(L2)
x = L[i]
x = L.pop()
L1[i:j] = L2
L.sort()
x = y
x.field = y
D[x] = y
D1.update(D2)
D.keys()Aqui -
- L, L1, L2 são listas
- D, D1, D2 são dictos
- x, y são objetos
- eu, j são ints
Filas
Se os dados da lista não estiverem protegidos, talvez tenhamos que enfrentar as consequências. Podemos obter ou excluir dados errados das condições de corrida. É por isso que é recomendável usar a estrutura de dados da fila. Um exemplo do mundo real de fila pode ser uma estrada de mão única de faixa única, onde o veículo entra primeiro, sai primeiro. Mais exemplos do mundo real podem ser vistos das filas nos guichês e pontos de ônibus.
As filas são, por padrão, estrutura de dados thread-safe e não precisamos nos preocupar com a implementação de um mecanismo de bloqueio complexo. Python nos fornece o
Tipos de filas
Nesta seção, vamos aprender sobre os diferentes tipos de filas. Python oferece três opções de filas para usar a partir do<queue> módulo -
- Filas normais (FIFO, First in First out)
- UEPS, último a entrar, primeiro a sair
- Priority
Aprenderemos sobre as diferentes filas nas seções subsequentes.
Filas normais (FIFO, First in First out)
São as implementações de fila mais comumente usadas oferecidas pelo Python. Nesse mecanismo de enfileiramento, quem vier primeiro obterá o serviço primeiro. FIFO também é chamado de filas normais. As filas FIFO podem ser representadas da seguinte forma -

Implementação Python da Fila FIFO
Em python, a fila FIFO pode ser implementada com thread único, bem como multithreads.
Fila FIFO com thread único
Para implementar a fila FIFO com um único thread, o Queueclasse implementará um contêiner básico primeiro a entrar, primeiro a sair. Os elementos serão adicionados a uma "extremidade" da sequência usandoput(), e removido da outra extremidade usando get().
Exemplo
A seguir está um programa Python para implementação de fila FIFO com thread único -
import queue
q = queue.Queue()
for i in range(8):
q.put("item-" + str(i))
while not q.empty():
print (q.get(), end = " ")Resultado
item-0 item-1 item-2 item-3 item-4 item-5 item-6 item-7A saída mostra que o programa acima usa um único thread para ilustrar que os elementos são removidos da fila na mesma ordem em que são inseridos.
Fila FIFO com vários threads
Para implementar o FIFO com vários threads, precisamos definir a função myqueue (), que é estendida do módulo de fila. O funcionamento dos métodos get () e put () são os mesmos discutidos acima durante a implementação da fila FIFO com uma única thread. Então, para torná-lo multithread, precisamos declarar e instanciar os threads. Esses encadeamentos irão consumir a fila de maneira FIFO.
Exemplo
A seguir está um programa Python para implementação de fila FIFO com vários threads
import threading
import queue
import random
import time
def myqueue(queue):
while not queue.empty():
item = queue.get()
if item is None:
break
print("{} removed {} from the queue".format(threading.current_thread(), item))
queue.task_done()
time.sleep(2)
q = queue.Queue()
for i in range(5):
q.put(i)
threads = []
for i in range(4):
thread = threading.Thread(target=myqueue, args=(q,))
thread.start()
threads.append(thread)
for thread in threads:
thread.join()Resultado
<Thread(Thread-3654, started 5044)> removed 0 from the queue
<Thread(Thread-3655, started 3144)> removed 1 from the queue
<Thread(Thread-3656, started 6996)> removed 2 from the queue
<Thread(Thread-3657, started 2672)> removed 3 from the queue
<Thread(Thread-3654, started 5044)> removed 4 from the queueUEPS, fila de último a entrar, primeiro a sair
Essa fila usa uma analogia totalmente oposta às filas FIFO (First in First Out). Nesse mecanismo de enfileiramento, quem chegar por último receberá o serviço primeiro. Isso é semelhante a implementar a estrutura de dados da pilha. As filas LIFO são úteis ao implementar algoritmos de inteligência artificial como a busca em profundidade.
Implementação Python da fila LIFO
Em python, a fila LIFO pode ser implementada com thread único, bem como multithreads.
Fila LIFO com thread único
Para implementar a fila LIFO com thread único, o Queue classe implementará um contêiner básico último a entrar, primeiro a sair usando a estrutura Queue.LifoQueue. Agora, ao ligarput(), os elementos são adicionados na cabeça do recipiente e removidos da cabeça também ao usar get().
Exemplo
A seguir está um programa Python para implementação da fila LIFO com thread único -
import queue
q = queue.LifoQueue()
for i in range(8):
q.put("item-" + str(i))
while not q.empty():
print (q.get(), end=" ")
Output:
item-7 item-6 item-5 item-4 item-3 item-2 item-1 item-0A saída mostra que o programa acima usa um único thread para ilustrar que os elementos são removidos da fila na ordem oposta em que são inseridos.
Fila LIFO com vários threads
A implementação é semelhante, pois fizemos a implementação de filas FIFO com vários threads. A única diferença é que precisamos usar oQueue classe que implementará um contêiner básico último a entrar, primeiro a sair usando a estrutura Queue.LifoQueue.
Exemplo
A seguir está um programa Python para implementação de fila LIFO com vários threads -
import threading
import queue
import random
import time
def myqueue(queue):
while not queue.empty():
item = queue.get()
if item is None:
break
print("{} removed {} from the queue".format(threading.current_thread(), item))
queue.task_done()
time.sleep(2)
q = queue.LifoQueue()
for i in range(5):
q.put(i)
threads = []
for i in range(4):
thread = threading.Thread(target=myqueue, args=(q,))
thread.start()
threads.append(thread)
for thread in threads:
thread.join()Resultado
<Thread(Thread-3882, started 4928)> removed 4 from the queue
<Thread(Thread-3883, started 4364)> removed 3 from the queue
<Thread(Thread-3884, started 6908)> removed 2 from the queue
<Thread(Thread-3885, started 3584)> removed 1 from the queue
<Thread(Thread-3882, started 4928)> removed 0 from the queueFila de prioridade
Nas filas FIFO e LIFO, a ordem dos itens está relacionada à ordem de inserção. No entanto, existem muitos casos em que a prioridade é mais importante do que a ordem de inserção. Vamos considerar um exemplo do mundo real. Suponha que a segurança do aeroporto esteja verificando pessoas de diferentes categorias. Pessoas do VVIP, pessoal da companhia aérea, oficial de alfândega, categorias podem ser verificadas com prioridade em vez de serem verificadas com base na chegada, como acontece com os plebeus.
Outro aspecto importante que precisa ser considerado para fila de prioridade é como desenvolver um agendador de tarefas. Um design comum é atender à maioria das tarefas do agente com base na prioridade na fila. Essa estrutura de dados pode ser usada para selecionar os itens da fila com base em seu valor de prioridade.
Implementação Python da fila prioritária
Em python, a fila de prioridade pode ser implementada com thread único, bem como multithreads.
Fila de prioridade com thread único
Para implementar a fila de prioridade com um único thread, o Queue classe irá implementar uma tarefa no recipiente de prioridade usando a estrutura Queue.Fila de prioridade. Agora, ao ligarput(), os elementos são adicionados com um valor em que o valor mais baixo terá a prioridade mais alta e, portanto, recuperado primeiro usando get().
Exemplo
Considere o seguinte programa Python para implementação da fila Priority com thread único -
import queue as Q
p_queue = Q.PriorityQueue()
p_queue.put((2, 'Urgent'))
p_queue.put((1, 'Most Urgent'))
p_queue.put((10, 'Nothing important'))
prio_queue.put((5, 'Important'))
while not p_queue.empty():
item = p_queue.get()
print('%s - %s' % item)Resultado
1 – Most Urgent
2 - Urgent
5 - Important
10 – Nothing importantNa saída acima, podemos ver que a fila armazenou os itens com base na prioridade - o valor menos prioritário tem alta prioridade.
Fila de prioridade com vários threads
A implementação é semelhante à implementação de filas FIFO e LIFO com vários threads. A única diferença é que precisamos usar oQueue classe para inicializar a prioridade usando a estrutura Queue.PriorityQueue. Outra diferença está na forma como a fila seria gerada. No exemplo dado abaixo, ele será gerado com dois conjuntos de dados idênticos.
Exemplo
O programa Python a seguir ajuda na implementação da fila de prioridade com vários threads -
import threading
import queue
import random
import time
def myqueue(queue):
while not queue.empty():
item = queue.get()
if item is None:
break
print("{} removed {} from the queue".format(threading.current_thread(), item))
queue.task_done()
time.sleep(1)
q = queue.PriorityQueue()
for i in range(5):
q.put(i,1)
for i in range(5):
q.put(i,1)
threads = []
for i in range(2):
thread = threading.Thread(target=myqueue, args=(q,))
thread.start()
threads.append(thread)
for thread in threads:
thread.join()Resultado
<Thread(Thread-4939, started 2420)> removed 0 from the queue
<Thread(Thread-4940, started 3284)> removed 0 from the queue
<Thread(Thread-4939, started 2420)> removed 1 from the queue
<Thread(Thread-4940, started 3284)> removed 1 from the queue
<Thread(Thread-4939, started 2420)> removed 2 from the queue
<Thread(Thread-4940, started 3284)> removed 2 from the queue
<Thread(Thread-4939, started 2420)> removed 3 from the queue
<Thread(Thread-4940, started 3284)> removed 3 from the queue
<Thread(Thread-4939, started 2420)> removed 4 from the queue
<Thread(Thread-4940, started 3284)> removed 4 from the queueNeste capítulo, aprenderemos sobre o teste de aplicativos de thread. Também aprenderemos a importância do teste.
Por que testar?
Antes de mergulharmos na discussão sobre a importância do teste, precisamos saber o que é teste. Em termos gerais, o teste é uma técnica para descobrir se algo está funcionando bem. Por outro lado, especificamente se falamos de programas de computador ou software, o teste é a técnica de acessar a funcionalidade de um programa de software.
Nesta seção, discutiremos a importância do teste de software. No desenvolvimento de software, deve haver uma dupla verificação antes da liberação do software para o cliente. É por isso que é muito importante testar o software por uma equipe de teste experiente. Considere os seguintes pontos para entender a importância do teste de software -
Melhoria da qualidade do software
Certamente, nenhuma empresa deseja fornecer software de baixa qualidade e nenhum cliente deseja comprar software de baixa qualidade. O teste melhora a qualidade do software, encontrando e corrigindo os bugs nele.
Satisfação dos clientes
A parte mais importante de qualquer negócio é a satisfação de seus clientes. Ao fornecer software de boa qualidade e sem bugs, as empresas podem alcançar a satisfação do cliente.
Reduza o impacto de novos recursos
Suponha que fizemos um sistema de software de 10.000 linhas e precisamos adicionar um novo recurso, então a equipe de desenvolvimento se preocuparia com o impacto desse novo recurso em todo o software. Aqui, também, o teste desempenha um papel vital, porque se a equipe de teste fez um bom conjunto de testes, ele pode nos salvar de quaisquer interrupções catastróficas potenciais.
Experiência de usuário
Outra parte mais importante de qualquer negócio é a experiência dos usuários desse produto. Somente os testes podem garantir que o usuário final ache simples e fácil de usar o produto.
Reduzindo despesas
O teste pode reduzir o custo total do software, encontrando e corrigindo os bugs na fase de teste de seu desenvolvimento, em vez de corrigi-lo após a entrega. Se houver um grande bug após a entrega do software, isso aumentaria seu custo tangível, digamos em termos de despesas e custo intangível, digamos, em termos de insatisfação do cliente, reputação negativa da empresa etc.
O que testar?
É sempre recomendável ter conhecimento adequado do que deve ser testado. Nesta seção, primeiro entenderemos ser o motivo principal do testador ao testar qualquer software. A cobertura de código, ou seja, quantas linhas de código nosso conjunto de testes atinge, durante o teste, deve ser evitada. É porque, durante o teste, focar apenas no número de linhas de códigos não adiciona nenhum valor real ao nosso sistema. Podem permanecer alguns bugs, que refletem posteriormente em um estágio posterior, mesmo após a implantação.
Considere os seguintes pontos importantes relacionados ao que testar -
Precisamos nos concentrar em testar a funcionalidade do código em vez da cobertura do código.
Precisamos testar as partes mais importantes do código primeiro e, em seguida, passar para as partes menos importantes do código. Isso definitivamente vai economizar tempo.
O testador deve ter vários testes diferentes que podem levar o software até seus limites.
Abordagens para testar programas de software simultâneos
Devido à capacidade de utilizar a verdadeira capacidade da arquitetura multi-core, os sistemas de software simultâneos estão substituindo os sistemas sequenciais. Nos últimos tempos, programas de sistema simultâneos estão sendo usados em tudo, de telefones celulares a máquinas de lavar, de carros a aviões, etc. Precisamos ser mais cuidadosos ao testar os programas de software simultâneos, porque se adicionamos vários threads a um aplicativo de thread único, já é um bug, então acabaríamos com vários bugs.
As técnicas de teste para programas de software simultâneos concentram-se extensivamente na seleção de intercalações que expõem padrões potencialmente prejudiciais, como condições de corrida, impasses e violação de atomicidade. A seguir estão duas abordagens para testar programas de software simultâneos -
Exploração sistemática
Essa abordagem visa explorar o espaço das intercalações da forma mais ampla possível. Essas abordagens podem adotar uma técnica de força bruta e outras adotam uma técnica de redução de ordem parcial ou técnica heurística para explorar o espaço de intercalações.
Orientado à propriedade
Abordagens baseadas em propriedade contam com a observação de que falhas de simultaneidade são mais prováveis de ocorrer em intercalações que expõem propriedades específicas, como padrão de acesso à memória suspeito. Diferentes abordagens baseadas em propriedades visam falhas diferentes, como condições de corrida, impasses e violação de atomicidade, que ainda depende de uma ou outras propriedades específicas.
Estratégias de teste
Estratégia de teste também é conhecida como abordagem de teste. A estratégia define como o teste será realizado. A abordagem de teste tem duas técnicas -
Proativo
Uma abordagem em que o processo de design de teste é iniciado o mais cedo possível para localizar e corrigir os defeitos antes da criação do build.
Reativo
Uma abordagem em que o teste não começa até a conclusão do processo de desenvolvimento.
Antes de aplicar qualquer estratégia ou abordagem de teste no programa python, devemos ter uma ideia básica sobre os tipos de erros que um programa de software pode ter. Os erros são os seguintes -
Erros sintáticos
Durante o desenvolvimento do programa, pode haver muitos pequenos erros. Os erros são principalmente devido a erros de digitação. Por exemplo, falta de dois pontos ou grafia incorreta de uma palavra-chave, etc. Esses erros se devem a um erro na sintaxe do programa e não na lógica. Portanto, esses erros são chamados de erros sintáticos.
Erros semânticos
Os erros semânticos também são chamados de erros lógicos. Se houver um erro lógico ou semântico no programa de software, a instrução será compilada e executada corretamente, mas não dará a saída desejada porque a lógica não está correta.
Teste de Unidade
Esta é uma das estratégias de teste mais usadas para testar programas Python. Essa estratégia é usada para testar unidades ou componentes do código. Por unidades ou componentes, queremos dizer classes ou funções do código. O teste de unidade simplifica o teste de grandes sistemas de programação testando unidades “pequenas”. Com a ajuda do conceito acima, o teste de unidade pode ser definido como um método onde unidades individuais de código-fonte são testadas para determinar se elas retornam a saída desejada.
Em nossas seções subsequentes, aprenderemos sobre os diferentes módulos Python para teste de unidade.
módulo de teste de unidade
O primeiro módulo para teste de unidade é o módulo de teste de unidade. Ele é inspirado no JUnit e incluído por padrão no Python3.6. Ele suporta automação de teste, compartilhamento de configuração e código de desligamento para testes, agregação de testes em coleções e independência dos testes da estrutura de relatório.
A seguir estão alguns conceitos importantes suportados pelo módulo de teste de unidade
Fixação de texto
É usado para configurar um teste de forma que ele possa ser executado antes de iniciar o teste e desmontado após o término do teste. Pode envolver a criação de banco de dados temporário, diretórios, etc. necessários antes de iniciar o teste.
Caso de teste
O caso de teste verifica se uma resposta necessária está vindo de um conjunto específico de entradas ou não. O módulo unittest inclui uma classe base chamada TestCase que pode ser usada para criar novos casos de teste. Inclui dois métodos padrão -
setUp()- um método de gancho para configurar o dispositivo de teste antes de exercitá-lo. Isso é chamado antes de chamar os métodos de teste implementados.
tearDown( - um método de gancho para desconstruir a fixação da classe depois de executar todos os testes da classe.
Suíte de teste
É uma coleção de suítes de teste, casos de teste ou ambos.
Corredor de teste
Ele controla a execução dos casos de teste ou trajes e fornece o resultado ao usuário. Ele pode usar GUI ou interface de texto simples para fornecer o resultado.
Example
O seguinte programa Python usa o módulo unittest para testar um módulo chamado Fibonacci. O programa ajuda a calcular a série de Fibonacci de um número. Neste exemplo, criamos uma classe chamada Fibo_test, para definir os casos de teste usando métodos diferentes. Esses métodos são herdados de unittest.TestCase. Estamos usando dois métodos padrão - setUp () e tearDown (). Também definimos o método testfibocal. O nome do teste deve ser iniciado com a letra teste. No bloco final, unittest.main () fornece uma interface de linha de comando para o script de teste.
import unittest
def fibonacci(n):
a, b = 0, 1
for i in range(n):
a, b = b, a + b
return a
class Fibo_Test(unittest.TestCase):
def setUp(self):
print("This is run before our tests would be executed")
def tearDown(self):
print("This is run after the completion of execution of our tests")
def testfibocal(self):
self.assertEqual(fib(0), 0)
self.assertEqual(fib(1), 1)
self.assertEqual(fib(5), 5)
self.assertEqual(fib(10), 55)
self.assertEqual(fib(20), 6765)
if __name__ == "__main__":
unittest.main()Quando executado a partir da linha de comando, o script acima produz uma saída semelhante a esta -
Resultado
This runs before our tests would be executed.
This runs after the completion of execution of our tests.
.
----------------------------------------------------------------------
Ran 1 test in 0.006s
OKAgora, para deixar mais claro, estamos mudando nosso código que ajudou na definição do módulo Fibonacci.
Considere o seguinte bloco de código como exemplo -
def fibonacci(n):
a, b = 0, 1
for i in range(n):
a, b = b, a + b
return aAlgumas mudanças no bloco de código são feitas conforme mostrado abaixo -
def fibonacci(n):
a, b = 1, 1
for i in range(n):
a, b = b, a + b
return aAgora, depois de executar o script com o código alterado, obteremos a seguinte saída -
This runs before our tests would be executed.
This runs after the completion of execution of our tests.
F
======================================================================
FAIL: testCalculation (__main__.Fibo_Test)
----------------------------------------------------------------------
Traceback (most recent call last):
File "unitg.py", line 15, in testCalculation
self.assertEqual(fib(0), 0)
AssertionError: 1 != 0
----------------------------------------------------------------------
Ran 1 test in 0.007s
FAILED (failures = 1)A saída acima mostra que o módulo falhou em fornecer a saída desejada.
Módulo Docktest
O módulo docktest também ajuda no teste de unidade. Ele também vem pré-empacotado com python. É mais fácil de usar do que o módulo unittest. O módulo unittest é mais adequado para testes complexos. Para usar o módulo doctest, precisamos importá-lo. A docstring da função correspondente deve ter uma sessão Python interativa junto com suas saídas.
Se tudo estiver bem em nosso código, não haverá saída do módulo docktest; caso contrário, ele fornecerá a saída.
Exemplo
O exemplo Python a seguir usa o módulo docktest para testar um módulo denominado Fibonacci, que ajuda a calcular a série Fibonacci de um número.
import doctest
def fibonacci(n):
"""
Calculates the Fibonacci number
>>> fibonacci(0)
0
>>> fibonacci(1)
1
>>> fibonacci(10)
55
>>> fibonacci(20)
6765
>>>
"""
a, b = 1, 1
for i in range(n):
a, b = b, a + b
return a
if __name__ == "__main__":
doctest.testmod()Podemos ver que a docstring da função correspondente chamada fib teve uma sessão Python interativa junto com as saídas. Se nosso código estiver bom, não haverá saída do módulo doctest. Mas para ver como funciona, podemos executá-lo com a opção –v.
(base) D:\ProgramData>python dock_test.py -v
Trying:
fibonacci(0)
Expecting:
0
ok
Trying:
fibonacci(1)
Expecting:
1
ok
Trying:
fibonacci(10)
Expecting:
55
ok
Trying:
fibonacci(20)
Expecting:
6765
ok
1 items had no tests:
__main__
1 items passed all tests:
4 tests in __main__.fibonacci
4 tests in 2 items.
4 passed and 0 failed.
Test passed.Agora, vamos mudar o código que ajudou na definição do módulo Fibonacci
Considere o seguinte bloco de código como exemplo -
def fibonacci(n):
a, b = 0, 1
for i in range(n):
a, b = b, a + b
return aO seguinte bloco de código ajuda com as mudanças -
def fibonacci(n):
a, b = 1, 1
for i in range(n):
a, b = b, a + b
return aDepois de executar o script mesmo sem a opção –v, com o código alterado, obteremos a saída conforme mostrado abaixo.
Resultado
(base) D:\ProgramData>python dock_test.py
**********************************************************************
File "unitg.py", line 6, in __main__.fibonacci
Failed example:
fibonacci(0)
Expected:
0
Got:
1
**********************************************************************
File "unitg.py", line 10, in __main__.fibonacci
Failed example:
fibonacci(10)
Expected:
55
Got:
89
**********************************************************************
File "unitg.py", line 12, in __main__.fibonacci
Failed example:
fibonacci(20)
Expected:
6765
Got:
10946
**********************************************************************
1 items had failures:
3 of 4 in __main__.fibonacci
***Test Failed*** 3 failures.Podemos ver na saída acima que três testes falharam.
Neste capítulo, aprenderemos como depurar aplicativos de thread. Também aprenderemos a importância da depuração.
O que é depuração?
Na programação de computadores, a depuração é o processo de localização e remoção de bugs, erros e anormalidades do programa de computador. Este processo começa assim que o código é escrito e continua em estágios sucessivos conforme o código é combinado com outras unidades de programação para formar um produto de software. A depuração faz parte do processo de teste de software e é parte integrante de todo o ciclo de vida de desenvolvimento de software.
Depurador Python
O depurador Python ou o pdbfaz parte da biblioteca padrão do Python. É uma boa ferramenta de fallback para rastrear bugs difíceis de encontrar e nos permite consertar códigos defeituosos de forma rápida e confiável. A seguir são as duas tarefas mais importantes dopdp depurador -
- Ele nos permite verificar os valores das variáveis em tempo de execução.
- Podemos percorrer o código e definir pontos de interrupção também.
Podemos trabalhar com PDB das duas maneiras a seguir -
- Por meio da linha de comando; isso também é chamado de depuração post mortem.
- Executando pdb interativamente.
Trabalhando com PDB
Para trabalhar com o depurador Python, precisamos usar o seguinte código no local onde queremos entrar no depurador -
import pdb;
pdb.set_trace()Considere os seguintes comandos para trabalhar com pdb por meio da linha de comando.
- h(help)
- d(down)
- u(up)
- b(break)
- cl(clear)
- l(list))
- n(next))
- c(continue)
- s(step)
- r(return))
- b(break)
A seguir está uma demonstração do comando h (ajuda) do depurador Python -
import pdb
pdb.set_trace()
--Call--
>d:\programdata\lib\site-packages\ipython\core\displayhook.py(247)__call__()
-> def __call__(self, result = None):
(Pdb) h
Documented commands (type help <topic>):
========================================
EOF c d h list q rv undisplay
a cl debug help ll quit s unt
alias clear disable ignore longlist r source until
args commands display interact n restart step up
b condition down j next return tbreak w
break cont enable jump p retval u whatis
bt continue exit l pp run unalias where
Miscellaneous help topics:
==========================
exec pdbExemplo
Enquanto trabalhamos com o depurador Python, podemos definir o ponto de interrupção em qualquer lugar do script usando as seguintes linhas -
import pdb;
pdb.set_trace()Depois de definir o ponto de interrupção, podemos executar o script normalmente. O script será executado até certo ponto; até onde uma linha foi definida. Considere o exemplo a seguir, onde executaremos o script usando as linhas mencionadas acima em vários lugares no script -
import pdb;
a = "aaa"
pdb.set_trace()
b = "bbb"
c = "ccc"
final = a + b + c
print (final)Quando o script acima for executado, ele executará o programa até a = “aaa”, podemos verificar isso na saída a seguir.
Resultado
--Return--
> <ipython-input-7-8a7d1b5cc854>(3)<module>()->None
-> pdb.set_trace()
(Pdb) p a
'aaa'
(Pdb) p b
*** NameError: name 'b' is not defined
(Pdb) p c
*** NameError: name 'c' is not definedApós usar o comando 'p (imprimir)' em pdb, este script está imprimindo apenas 'aaa'. Isso é seguido por um erro porque definimos o ponto de interrupção até a = "aaa".
Da mesma forma, podemos executar o script alterando os pontos de interrupção e ver a diferença na saída -
import pdb
a = "aaa"
b = "bbb"
c = "ccc"
pdb.set_trace()
final = a + b + c
print (final)Resultado
--Return--
> <ipython-input-9-a59ef5caf723>(5)<module>()->None
-> pdb.set_trace()
(Pdb) p a
'aaa'
(Pdb) p b
'bbb'
(Pdb) p c
'ccc'
(Pdb) p final
*** NameError: name 'final' is not defined
(Pdb) exitNo script a seguir, estamos definindo o ponto de interrupção na última linha do programa -
import pdb
a = "aaa"
b = "bbb"
c = "ccc"
final = a + b + c
pdb.set_trace()
print (final)O resultado é o seguinte -
--Return--
> <ipython-input-11-8019b029997d>(6)<module>()->None
-> pdb.set_trace()
(Pdb) p a
'aaa'
(Pdb) p b
'bbb'
(Pdb) p c
'ccc'
(Pdb) p final
'aaabbbccc'
(Pdb)Neste capítulo, aprenderemos como benchmarking e criação de perfil ajudam a resolver problemas de desempenho.
Suponha que tenhamos escrito um código e ele esteja dando o resultado desejado também, mas e se quisermos executar esse código um pouco mais rápido porque as necessidades mudaram. Nesse caso, precisamos descobrir quais partes de nosso código estão tornando todo o programa mais lento. Nesse caso, benchmarking e criação de perfil podem ser úteis.
O que é Benchmarking?
O benchmarking visa avaliar algo em comparação com um padrão. No entanto, a questão que se coloca aqui é qual seria o benchmarking e por que precisamos dele no caso de programação de software. O benchmarking do código significa quão rápido o código está sendo executado e onde está o gargalo. Um dos principais motivos para o benchmarking é que ele otimiza o código.
Como funciona o benchmarking?
Se falamos sobre o funcionamento do benchmarking, precisamos começar fazendo o benchmarking de todo o programa como um estado atual, então podemos combinar micro benchmarks e então decompor um programa em programas menores. Para encontrar os gargalos dentro do nosso programa e otimizá-lo. Em outras palavras, podemos entendê-lo como a divisão do grande e difícil problema em uma série de problemas menores e um pouco mais fáceis para otimizá-los.
Módulo Python para benchmarking
Em Python, temos um módulo padrão para benchmarking que é chamado timeit. Com a ajuda dotimeit módulo, podemos medir o desempenho de um pequeno pedaço de código Python dentro do nosso programa principal.
Exemplo
No seguinte script Python, estamos importando o timeit módulo, que mede ainda mais o tempo gasto para executar duas funções - functionA e functionB -
import timeit
import time
def functionA():
print("Function A starts the execution:")
print("Function A completes the execution:")
def functionB():
print("Function B starts the execution")
print("Function B completes the execution")
start_time = timeit.default_timer()
functionA()
print(timeit.default_timer() - start_time)
start_time = timeit.default_timer()
functionB()
print(timeit.default_timer() - start_time)Após executar o script acima, obteremos o tempo de execução de ambas as funções conforme mostrado abaixo.
Resultado
Function A starts the execution:
Function A completes the execution:
0.0014599495514175942
Function B starts the execution
Function B completes the execution
0.0017024724827479076Escrevendo nosso próprio cronômetro usando a função decorador
Em Python, podemos criar nosso próprio cronômetro, que funcionará exatamente como o timeitmódulo. Isso pode ser feito com a ajuda dodecoratorfunção. A seguir está um exemplo de cronômetro personalizado -
import random
import time
def timer_func(func):
def function_timer(*args, **kwargs):
start = time.time()
value = func(*args, **kwargs)
end = time.time()
runtime = end - start
msg = "{func} took {time} seconds to complete its execution."
print(msg.format(func = func.__name__,time = runtime))
return value
return function_timer
@timer_func
def Myfunction():
for x in range(5):
sleep_time = random.choice(range(1,3))
time.sleep(sleep_time)
if __name__ == '__main__':
Myfunction()O script python acima ajuda na importação de módulos de tempo aleatório. Criamos a função decoradora timer_func (). Ele contém a função function_timer (). Agora, a função aninhada pegará o tempo antes de chamar a função passada. Em seguida, ele aguarda o retorno da função e agarra o horário de término. Desta forma, podemos finalmente fazer o script python imprimir o tempo de execução. O script irá gerar a saída conforme mostrado abaixo.
Resultado
Myfunction took 8.000457763671875 seconds to complete its execution.O que é criação de perfil?
Às vezes, o programador deseja medir alguns atributos como o uso de memória, complexidade de tempo ou uso de instruções específicas sobre os programas para medir a capacidade real desse programa. Esse tipo de medição sobre o programa é chamado de criação de perfil. A criação de perfil usa análise de programa dinâmica para fazer tal medição.
Nas seções subsequentes, aprenderemos sobre os diferentes módulos Python para criação de perfil.
cProfile - o módulo embutido
cProfileé um módulo integrado do Python para criação de perfil. O módulo é uma extensão C com sobrecarga razoável que o torna adequado para criar perfis de programas de longa execução. Após executá-lo, ele registra todas as funções e tempos de execução. É muito poderoso, mas às vezes um pouco difícil de interpretar e agir. No exemplo a seguir, estamos usando cProfile no código abaixo -
Exemplo
def increment_global():
global x
x += 1
def taskofThread(lock):
for _ in range(50000):
lock.acquire()
increment_global()
lock.release()
def main():
global x
x = 0
lock = threading.Lock()
t1 = threading.Thread(target=taskofThread, args=(lock,))
t2 = threading.Thread(target= taskofThread, args=(lock,))
t1.start()
t2.start()
t1.join()
t2.join()
if __name__ == "__main__":
for i in range(5):
main()
print("x = {1} after Iteration {0}".format(i,x))O código acima é salvo no thread_increment.pyArquivo. Agora, execute o código com cProfile na linha de comando da seguinte maneira -
(base) D:\ProgramData>python -m cProfile thread_increment.py
x = 100000 after Iteration 0
x = 100000 after Iteration 1
x = 100000 after Iteration 2
x = 100000 after Iteration 3
x = 100000 after Iteration 4
3577 function calls (3522 primitive calls) in 1.688 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
5 0.000 0.000 0.000 0.000 <frozen importlib._bootstrap>:103(release)
5 0.000 0.000 0.000 0.000 <frozen importlib._bootstrap>:143(__init__)
5 0.000 0.000 0.000 0.000 <frozen importlib._bootstrap>:147(__enter__)
… … … …A partir da saída acima, fica claro que cProfile imprime todas as funções 3577 chamadas, com o tempo gasto em cada uma e o número de vezes que foram chamadas. A seguir estão as colunas que obtivemos na saída -
ncalls - É o número de ligações feitas.
tottime - É o tempo total gasto na função dada.
percall - Refere-se ao quociente de tottime dividido por ncalls.
cumtime- É o tempo acumulado gasto nesta e em todas as subfunções. É preciso até mesmo para funções recursivas.
percall - É o quociente de tempo cum dividido por chamadas primitivas.
filename:lineno(function) - Fornece basicamente os respectivos dados de cada função.
Suponha que tenhamos que criar um grande número de threads para nossas tarefas multithread. Seria computacionalmente mais caro, pois pode haver muitos problemas de desempenho devido a muitos threads. Um grande problema pode ser a limitação do rendimento. Podemos resolver esse problema criando um pool de threads. Um pool de threads pode ser definido como o grupo de threads pré-instanciados e ociosos, que estão prontos para receberem trabalho. A criação de pool de threads é preferível a instanciar novas threads para cada tarefa quando precisamos realizar um grande número de tarefas. Um pool de threads pode gerenciar a execução simultânea de um grande número de threads da seguinte forma -
Se um encadeamento em um pool de encadeamentos conclui sua execução, esse encadeamento pode ser reutilizado.
Se um encadeamento for encerrado, outro encadeamento será criado para substituí-lo.
Módulo Python - Concurrent.futures
A biblioteca padrão do Python inclui o concurrent.futuresmódulo. Este módulo foi adicionado ao Python 3.2 para fornecer aos desenvolvedores uma interface de alto nível para iniciar tarefas assíncronas. É uma camada de abstração no topo dos módulos de threading e multiprocessamento do Python para fornecer a interface para executar as tarefas usando pool de thread ou processos.
Em nossas seções subsequentes, aprenderemos sobre as diferentes classes do módulo concurrent.futures.
Classe Executor
Executoré uma classe abstrata de concurrent.futuresMódulo Python. Não pode ser usado diretamente e precisamos usar uma das seguintes subclasses concretas -
- ThreadPoolExecutor
- ProcessPoolExecutor
ThreadPoolExecutor - uma subclasse concreta
É uma das subclasses concretas da classe Executor. A subclasse usa multi-threading e obtemos um pool de threads para enviar as tarefas. Este pool atribui tarefas aos threads disponíveis e os programa para execução.
Como criar um ThreadPoolExecutor?
Com a ajuda de concurrent.futures módulo e sua subclasse concreta Executor, podemos criar facilmente um pool de threads. Para isso, precisamos construir umThreadPoolExecutorcom o número de threads que queremos no pool. Por padrão, o número é 5. Então, podemos enviar uma tarefa para o pool de threads. Quando nóssubmit() uma tarefa, voltamos a Future. O objeto Future tem um método chamadodone(), que informa se o futuro foi resolvido. Com isso, um valor foi definido para esse objeto futuro específico. Quando uma tarefa termina, o executor do pool de threads define o valor para o objeto futuro.
Exemplo
from concurrent.futures import ThreadPoolExecutor
from time import sleep
def task(message):
sleep(2)
return message
def main():
executor = ThreadPoolExecutor(5)
future = executor.submit(task, ("Completed"))
print(future.done())
sleep(2)
print(future.done())
print(future.result())
if __name__ == '__main__':
main()Resultado
False
True
CompletedNo exemplo acima, um ThreadPoolExecutorfoi construído com 5 fios. Em seguida, uma tarefa, que aguardará 2 segundos antes de dar a mensagem, é enviada ao executor do pool de threads. Como visto na saída, a tarefa não é concluída até 2 segundos, então a primeira chamada paradone()retornará False. Após 2 segundos, a tarefa está concluída e obtemos o resultado do futuro chamando oresult() método sobre ele.
Instanciando ThreadPoolExecutor - Gerenciador de Contexto
Outra forma de instanciar ThreadPoolExecutoré com a ajuda do gerenciador de contexto. Funciona de forma semelhante ao método usado no exemplo acima. A principal vantagem de usar o gerenciador de contexto é que ele parece sintaticamente bom. A instanciação pode ser feita com a ajuda do seguinte código -
with ThreadPoolExecutor(max_workers = 5) as executorExemplo
O exemplo a seguir é emprestado da documentação do Python. Neste exemplo, em primeiro lugar, oconcurrent.futuresmódulo tem que ser importado. Em seguida, uma função chamadaload_url()é criado, o que carregará o url solicitado. A função então criaThreadPoolExecutorcom os 5 threads no pool. oThreadPoolExecutorfoi utilizado como gerenciador de contexto. Podemos obter o resultado do futuro chamando oresult() método sobre ele.
import concurrent.futures
import urllib.request
URLS = ['http://www.foxnews.com/',
'http://www.cnn.com/',
'http://europe.wsj.com/',
'http://www.bbc.co.uk/',
'http://some-made-up-domain.com/']
def load_url(url, timeout):
with urllib.request.urlopen(url, timeout = timeout) as conn:
return conn.read()
with concurrent.futures.ThreadPoolExecutor(max_workers = 5) as executor:
future_to_url = {executor.submit(load_url, url, 60): url for url in URLS}
for future in concurrent.futures.as_completed(future_to_url):
url = future_to_url[future]
try:
data = future.result()
except Exception as exc:
print('%r generated an exception: %s' % (url, exc))
else:
print('%r page is %d bytes' % (url, len(data)))Resultado
A seguir está a saída do script Python acima -
'http://some-made-up-domain.com/' generated an exception: <urlopen error [Errno 11004] getaddrinfo failed>
'http://www.foxnews.com/' page is 229313 bytes
'http://www.cnn.com/' page is 168933 bytes
'http://www.bbc.co.uk/' page is 283893 bytes
'http://europe.wsj.com/' page is 938109 bytesUso da função Executor.map ()
O Python map()função é amplamente utilizada em várias tarefas. Uma dessas tarefas é aplicar uma determinada função a cada elemento dentro dos iteráveis. Da mesma forma, podemos mapear todos os elementos de um iterador para uma função e enviá-los como trabalhos independentes paraThreadPoolExecutor. Considere o seguinte exemplo de script Python para entender como a função funciona.
Exemplo
Neste exemplo abaixo, a função de mapa é usada para aplicar o square() função para cada valor na matriz de valores.
from concurrent.futures import ThreadPoolExecutor
from concurrent.futures import as_completed
values = [2,3,4,5]
def square(n):
return n * n
def main():
with ThreadPoolExecutor(max_workers = 3) as executor:
results = executor.map(square, values)
for result in results:
print(result)
if __name__ == '__main__':
main()Resultado
O script Python acima gera a seguinte saída -
4
9
16
25O pool de processos pode ser criado e usado da mesma maneira que criamos e usamos o pool de threads. O pool de processos pode ser definido como o grupo de processos pré-instanciados e ociosos, que estão prontos para receber trabalho. A criação de pool de processos é preferível em vez de instanciar novos processos para cada tarefa quando precisamos fazer um grande número de tarefas.
Módulo Python - Concurrent.futures
A biblioteca padrão do Python tem um módulo chamado concurrent.futures. Este módulo foi adicionado ao Python 3.2 para fornecer aos desenvolvedores uma interface de alto nível para iniciar tarefas assíncronas. É uma camada de abstração no topo dos módulos de threading e multiprocessamento do Python para fornecer a interface para executar as tarefas usando pool de thread ou processos.
Em nossas seções subsequentes, examinaremos as diferentes subclasses do módulo concurrent.futures.
Classe Executor
Executor é uma classe abstrata de concurrent.futuresMódulo Python. Não pode ser usado diretamente e precisamos usar uma das seguintes subclasses concretas -
- ThreadPoolExecutor
- ProcessPoolExecutor
ProcessPoolExecutor - uma subclasse concreta
É uma das subclasses concretas da classe Executor. Ele usa multiprocessamento e obtemos um conjunto de processos para enviar as tarefas. Este pool atribui tarefas aos processos disponíveis e os programa para execução.
Como criar um ProcessPoolExecutor?
Com a ajuda do concurrent.futures módulo e sua subclasse concreta Executor, podemos criar facilmente um pool de processos. Para isso, precisamos construir umProcessPoolExecutorcom o número de processos que queremos no pool. Por padrão, o número é 5. Isso é seguido pelo envio de uma tarefa ao pool de processos.
Exemplo
Vamos agora considerar o mesmo exemplo que usamos durante a criação do pool de threads, a única diferença é que agora usaremos ProcessPoolExecutor ao invés de ThreadPoolExecutor .
from concurrent.futures import ProcessPoolExecutor
from time import sleep
def task(message):
sleep(2)
return message
def main():
executor = ProcessPoolExecutor(5)
future = executor.submit(task, ("Completed"))
print(future.done())
sleep(2)
print(future.done())
print(future.result())
if __name__ == '__main__':
main()Resultado
False
False
CompletedNo exemplo acima, um ProcessoPoolExecutorfoi construído com 5 fios. Em seguida, uma tarefa, que aguardará 2 segundos antes de dar a mensagem, é enviada ao executor do pool de processos. Como visto na saída, a tarefa não é concluída até 2 segundos, então a primeira chamada paradone()retornará False. Após 2 segundos, a tarefa está concluída e obtemos o resultado do futuro chamando oresult() método sobre ele.
Instanciar ProcessPoolExecutor - Gerenciador de Contexto
Outra maneira de instanciar ProcessPoolExecutor é com a ajuda do gerenciador de contexto. Funciona de forma semelhante ao método usado no exemplo acima. A principal vantagem de usar o gerenciador de contexto é que ele parece sintaticamente bom. A instanciação pode ser feita com a ajuda do seguinte código -
with ProcessPoolExecutor(max_workers = 5) as executorExemplo
Para melhor compreensão, estamos usando o mesmo exemplo usado durante a criação do pool de threads. Neste exemplo, precisamos começar importando oconcurrent.futuresmódulo. Em seguida, uma função chamadaload_url()é criado, o que carregará o url solicitado. oProcessPoolExecutoré então criado com o número 5 de threads no pool. O processoPoolExecutorfoi utilizado como gerenciador de contexto. Podemos obter o resultado do futuro chamando oresult() método sobre ele.
import concurrent.futures
from concurrent.futures import ProcessPoolExecutor
import urllib.request
URLS = ['http://www.foxnews.com/',
'http://www.cnn.com/',
'http://europe.wsj.com/',
'http://www.bbc.co.uk/',
'http://some-made-up-domain.com/']
def load_url(url, timeout):
with urllib.request.urlopen(url, timeout = timeout) as conn:
return conn.read()
def main():
with concurrent.futures.ProcessPoolExecutor(max_workers=5) as executor:
future_to_url = {executor.submit(load_url, url, 60): url for url in URLS}
for future in concurrent.futures.as_completed(future_to_url):
url = future_to_url[future]
try:
data = future.result()
except Exception as exc:
print('%r generated an exception: %s' % (url, exc))
else:
print('%r page is %d bytes' % (url, len(data)))
if __name__ == '__main__':
main()Resultado
O script Python acima irá gerar a seguinte saída -
'http://some-made-up-domain.com/' generated an exception: <urlopen error [Errno 11004] getaddrinfo failed>
'http://www.foxnews.com/' page is 229476 bytes
'http://www.cnn.com/' page is 165323 bytes
'http://www.bbc.co.uk/' page is 284981 bytes
'http://europe.wsj.com/' page is 967575 bytesUso da função Executor.map ()
O Python map()função é amplamente usada para realizar uma série de tarefas. Uma dessas tarefas é aplicar uma determinada função a cada elemento dentro dos iteráveis. Da mesma forma, podemos mapear todos os elementos de um iterador para uma função e enviá-los como trabalhos independentes para oProcessPoolExecutor. Considere o seguinte exemplo de script Python para entender isso.
Exemplo
Vamos considerar o mesmo exemplo que usamos ao criar pool de threads usando o Executor.map()função. No exemplo dado abaixo, a função de mapa é usada para aplicarsquare() função para cada valor na matriz de valores.
from concurrent.futures import ProcessPoolExecutor
from concurrent.futures import as_completed
values = [2,3,4,5]
def square(n):
return n * n
def main():
with ProcessPoolExecutor(max_workers = 3) as executor:
results = executor.map(square, values)
for result in results:
print(result)
if __name__ == '__main__':
main()Resultado
O script Python acima irá gerar a seguinte saída
4
9
16
25Quando usar ProcessPoolExecutor e ThreadPoolExecutor?
Agora que estudamos sobre as classes do Executor - ThreadPoolExecutor e ProcessPoolExecutor, precisamos saber quando usar qual executor. Precisamos escolher ProcessPoolExecutor no caso de cargas de trabalho vinculadas à CPU e ThreadPoolExecutor no caso de cargas de trabalho vinculadas a E / S.
Se usarmos ProcessPoolExecutor, então não precisamos nos preocupar com o GIL porque ele usa multiprocessamento. Além disso, o tempo de execução será menor quando comparado aoThreadPoolExecution. Considere o seguinte exemplo de script Python para entender isso.
Exemplo
import time
import concurrent.futures
value = [8000000, 7000000]
def counting(n):
start = time.time()
while n > 0:
n -= 1
return time.time() - start
def main():
start = time.time()
with concurrent.futures.ProcessPoolExecutor() as executor:
for number, time_taken in zip(value, executor.map(counting, value)):
print('Start: {} Time taken: {}'.format(number, time_taken))
print('Total time taken: {}'.format(time.time() - start))
if __name__ == '__main__':
main()Resultado
Start: 8000000 Time taken: 1.5509998798370361
Start: 7000000 Time taken: 1.3259999752044678
Total time taken: 2.0840001106262207
Example- Python script with ThreadPoolExecutor:
import time
import concurrent.futures
value = [8000000, 7000000]
def counting(n):
start = time.time()
while n > 0:
n -= 1
return time.time() - start
def main():
start = time.time()
with concurrent.futures.ThreadPoolExecutor() as executor:
for number, time_taken in zip(value, executor.map(counting, value)):
print('Start: {} Time taken: {}'.format(number, time_taken))
print('Total time taken: {}'.format(time.time() - start))
if __name__ == '__main__':
main()Resultado
Start: 8000000 Time taken: 3.8420000076293945
Start: 7000000 Time taken: 3.6010000705718994
Total time taken: 3.8480000495910645Pelas saídas de ambos os programas acima, podemos ver a diferença do tempo de execução ao usar ProcessPoolExecutor e ThreadPoolExecutor.
Neste capítulo, vamos nos concentrar mais na comparação entre multiprocessamento e multithreading.
Multiprocessamento
É o uso de duas ou mais unidades de CPU em um único sistema de computador. É a melhor abordagem para obter todo o potencial de nosso hardware, utilizando o número total de núcleos de CPU disponíveis em nosso sistema de computador.
Multithreading
É a capacidade de uma CPU de gerenciar o uso do sistema operacional executando vários threads simultaneamente. A ideia principal do multithreading é atingir o paralelismo dividindo um processo em vários threads.
A tabela a seguir mostra algumas das diferenças importantes entre eles -
| Multiprocessamento | Multiprogramação |
|---|---|
| Multiprocessamento refere-se ao processamento de vários processos ao mesmo tempo por várias CPUs. | A multiprogramação mantém vários programas na memória principal ao mesmo tempo e os executa simultaneamente utilizando uma única CPU. |
| Ele utiliza várias CPUs. | Ele utiliza uma única CPU. |
| Ele permite o processamento paralelo. | A troca de contexto ocorre. |
| Menos tempo para processar os trabalhos. | Mais tempo para processar os trabalhos. |
| Facilita a utilização muito eficiente de dispositivos do sistema de computador. | Menos eficiente do que o multiprocessamento. |
| Normalmente mais caro. | Esses sistemas são mais baratos. |
Eliminando o impacto do bloqueio global do intérprete (GIL)
Ao trabalhar com aplicativos simultâneos, há uma limitação presente no Python chamada de GIL (Global Interpreter Lock). GIL nunca nos permite utilizar múltiplos núcleos de CPU e, portanto, podemos dizer que não há threads verdadeiros no Python. GIL é o mutex - bloqueio de exclusão mútua, que torna as coisas thread-safe. Em outras palavras, podemos dizer que GIL evita que vários threads executem código Python em paralelo. O bloqueio pode ser mantido por apenas um encadeamento de cada vez e se quisermos executar um encadeamento, ele deve adquirir o bloqueio primeiro.
Com o uso de multiprocessamento, podemos efetivamente contornar a limitação causada pelo GIL -
Ao usar multiprocessamento, estamos utilizando a capacidade de vários processos e, portanto, estamos utilizando várias instâncias do GIL.
Devido a isso, não há restrição de executar o bytecode de um thread em nossos programas a qualquer momento.
Iniciando processos em Python
Os três métodos a seguir podem ser usados para iniciar um processo em Python dentro do módulo de multiprocessamento -
- Fork
- Spawn
- Forkserver
Criando um processo com Fork
O comando Fork é um comando padrão encontrado no UNIX. É usado para criar novos processos chamados processos filhos. Este processo filho é executado simultaneamente com o processo denominado processo pai. Esses processos filho também são idênticos aos processos pai e herdam todos os recursos disponíveis para o pai. As seguintes chamadas de sistema são usadas durante a criação de um processo com Fork -
fork()- É uma chamada de sistema geralmente implementada no kernel. É usado para criar uma cópia do process.p>
getpid() - Esta chamada de sistema retorna o ID do processo (PID) do processo de chamada.
Exemplo
O seguinte exemplo de script Python irá ajudá-lo a compreender como criar um novo processo filho e obter os PIDs dos processos filho e pai -
import os
def child():
n = os.fork()
if n > 0:
print("PID of Parent process is : ", os.getpid())
else:
print("PID of Child process is : ", os.getpid())
child()Resultado
PID of Parent process is : 25989
PID of Child process is : 25990Criando um processo com Spawn
Spawn significa começar algo novo. Portanto, gerar um processo significa a criação de um novo processo por um processo pai. O processo pai continua sua execução de forma assíncrona ou espera até que o processo filho termine sua execução. Siga estas etapas para gerar um processo -
Importando módulo de multiprocessamento.
Criando o processo de objeto.
Iniciando a atividade do processo chamando start() método.
Esperar até que o processo termine seu trabalho e sair chamando join() método.
Exemplo
O exemplo a seguir de script Python ajuda na geração de três processos
import multiprocessing
def spawn_process(i):
print ('This is process: %s' %i)
return
if __name__ == '__main__':
Process_jobs = []
for i in range(3):
p = multiprocessing.Process(target = spawn_process, args = (i,))
Process_jobs.append(p)
p.start()
p.join()Resultado
This is process: 0
This is process: 1
This is process: 2Criando um processo com o Forkserver
O mecanismo Forkserver está disponível apenas nas plataformas UNIX selecionadas que suportam a passagem de descritores de arquivo por Pipes Unix. Considere os seguintes pontos para entender o funcionamento do mecanismo Forkserver -
Um servidor é instanciado usando o mecanismo Forkserver para iniciar um novo processo.
O servidor então recebe o comando e trata de todas as solicitações de criação de novos processos.
Para criar um novo processo, nosso programa python enviará uma solicitação ao Forkserver e criará um processo para nós.
Por fim, podemos usar este novo processo criado em nossos programas.
Processos daemon em Python
Pitão multiprocessingmódulo nos permite ter processos daemon por meio de sua opção daemônica. Os processos daemon ou os processos que estão sendo executados em segundo plano seguem um conceito semelhante aos encadeamentos daemon. Para executar o processo em segundo plano, precisamos definir o sinalizador daemonic como verdadeiro. O processo daemon continuará a ser executado enquanto o processo principal estiver em execução e será encerrado após o término de sua execução ou quando o programa principal for encerrado.
Exemplo
Aqui, estamos usando o mesmo exemplo usado nas threads daemon. A única diferença é a mudança de módulo demultithreading para multiprocessinge definindo o sinalizador demoníaco como verdadeiro. No entanto, haveria uma mudança na saída conforme mostrado abaixo -
import multiprocessing
import time
def nondaemonProcess():
print("starting my Process")
time.sleep(8)
print("ending my Process")
def daemonProcess():
while True:
print("Hello")
time.sleep(2)
if __name__ == '__main__':
nondaemonProcess = multiprocessing.Process(target = nondaemonProcess)
daemonProcess = multiprocessing.Process(target = daemonProcess)
daemonProcess.daemon = True
nondaemonProcess.daemon = False
daemonProcess.start()
nondaemonProcess.start()Resultado
starting my Process
ending my ProcessA saída é diferente quando comparada àquela gerada pelos encadeamentos daemon, porque o processo em nenhum modo daemon tem uma saída. Portanto, o processo daemônico termina automaticamente após o término dos programas principais para evitar a persistência dos processos em execução.
Encerrando processos em Python
Podemos matar ou encerrar um processo imediatamente usando o terminate()método. Usaremos este método para encerrar o processo filho, que foi criado com a ajuda da função, imediatamente antes de concluir sua execução.
Exemplo
import multiprocessing
import time
def Child_process():
print ('Starting function')
time.sleep(5)
print ('Finished function')
P = multiprocessing.Process(target = Child_process)
P.start()
print("My Process has terminated, terminating main thread")
print("Terminating Child Process")
P.terminate()
print("Child Process successfully terminated")Resultado
My Process has terminated, terminating main thread
Terminating Child Process
Child Process successfully terminatedA saída mostra que o programa termina antes da execução do processo filho que foi criado com a ajuda da função Child_process (). Isso significa que o processo filho foi encerrado com sucesso.
Identificar o processo atual em Python
Cada processo no sistema operacional tem uma identidade de processo conhecida como PID. Em Python, podemos descobrir o PID do processo atual com a ajuda do seguinte comando -
import multiprocessing
print(multiprocessing.current_process().pid)Exemplo
O seguinte exemplo de script Python ajuda a descobrir o PID do processo principal, bem como o PID do processo filho -
import multiprocessing
import time
def Child_process():
print("PID of Child Process is: {}".format(multiprocessing.current_process().pid))
print("PID of Main process is: {}".format(multiprocessing.current_process().pid))
P = multiprocessing.Process(target=Child_process)
P.start()
P.join()Resultado
PID of Main process is: 9401
PID of Child Process is: 9402Usando um processo na subclasse
Podemos criar tópicos subclassificando o threading.Threadclasse. Além disso, também podemos criar processos subclassificando omultiprocessing.Processclasse. Para usar um processo na subclasse, precisamos considerar os seguintes pontos -
Precisamos definir uma nova subclasse do Process classe.
Precisamos substituir o _init_(self [,args] ) classe.
Precisamos substituir o do run(self [,args] ) método para implementar o que Process
Precisamos iniciar o processo invocando ostart() método.
Exemplo
import multiprocessing
class MyProcess(multiprocessing.Process):
def run(self):
print ('called run method in process: %s' %self.name)
return
if __name__ == '__main__':
jobs = []
for i in range(5):
P = MyProcess()
jobs.append(P)
P.start()
P.join()Resultado
called run method in process: MyProcess-1
called run method in process: MyProcess-2
called run method in process: MyProcess-3
called run method in process: MyProcess-4
called run method in process: MyProcess-5Módulo de multiprocessamento Python - classe Pool
Se falarmos sobre paralelo simples processingtarefas em nossos aplicativos Python, então o módulo de multiprocessamento nos fornece a classe Pool. Os seguintes métodos dePool classe pode ser usada para aumentar o número de processos filho dentro do nosso programa principal
método apply ()
Este método é semelhante ao.submit()método de .ThreadPoolExecutor.Bloqueia até que o resultado esteja pronto.
método apply_async ()
Quando precisamos da execução paralela de nossas tarefas, precisamos usar oapply_async()método para enviar tarefas ao pool. É uma operação assíncrona que não bloqueará o thread principal até que todos os processos filho sejam executados.
método map ()
Assim como o apply()método, ele também bloqueia até que o resultado esteja pronto. É equivalente ao embutidomap() função que divide os dados iteráveis em vários blocos e os envia ao pool de processos como tarefas separadas.
método map_async ()
É uma variante do map() método como apply_async() é para o apply()método. Ele retorna um objeto de resultado. Quando o resultado fica pronto, um chamável é aplicado a ele. O chamável deve ser concluído imediatamente; caso contrário, o thread que lida com os resultados será bloqueado.
Exemplo
O exemplo a seguir o ajudará a implementar um pool de processos para realizar a execução paralela. Um cálculo simples do quadrado do número foi realizado aplicando osquare() função através do multiprocessing.Poolmétodo. Entãopool.map() foi usado para enviar o 5, porque a entrada é uma lista de inteiros de 0 a 4. O resultado seria armazenado em p_outputs e é impresso.
def square(n):
result = n*n
return result
if __name__ == '__main__':
inputs = list(range(5))
p = multiprocessing.Pool(processes = 4)
p_outputs = pool.map(function_square, inputs)
p.close()
p.join()
print ('Pool :', p_outputs)Resultado
Pool : [0, 1, 4, 9, 16]Intercomunicação de processos significa a troca de dados entre processos. É necessário trocar os dados entre os processos para o desenvolvimento da aplicação paralela. O diagrama a seguir mostra os vários mecanismos de comunicação para sincronização entre vários subprocessos -

Vários mecanismos de comunicação
Nesta seção, aprenderemos sobre os vários mecanismos de comunicação. Os mecanismos são descritos abaixo -
Filas
As filas podem ser usadas com programas multiprocessos. A classe Queue demultiprocessing módulo é semelhante ao Queue.Queueclasse. Portanto, a mesma API pode ser usada.Multiprocessing.Queue nos fornece um mecanismo de comunicação entre processos FIFO (first-in first-out) seguro para processos e threads.
Exemplo
A seguir está um exemplo simples retirado da documentação oficial do python sobre multiprocessamento para entender o conceito da classe Queue de multiprocessamento.
from multiprocessing import Process, Queue
import queue
import random
def f(q):
q.put([42, None, 'hello'])
def main():
q = Queue()
p = Process(target = f, args = (q,))
p.start()
print (q.get())
if __name__ == '__main__':
main()Resultado
[42, None, 'hello']Tubos
É uma estrutura de dados usada para a comunicação entre processos em programas multiprocessos. A função Pipe () retorna um par de objetos de conexão conectados por um pipe que por padrão é duplex (bidirecional). Funciona da seguinte maneira -
Ele retorna um par de objetos de conexão que representam as duas extremidades do tubo.
Cada objeto tem dois métodos - send() e recv(), para se comunicar entre processos.
Exemplo
A seguir está um exemplo simples retirado da documentação oficial do python sobre multiprocessamento para entender o conceito de Pipe() função de multiprocessamento.
from multiprocessing import Process, Pipe
def f(conn):
conn.send([42, None, 'hello'])
conn.close()
if __name__ == '__main__':
parent_conn, child_conn = Pipe()
p = Process(target = f, args = (child_conn,))
p.start()
print (parent_conn.recv())
p.join()Resultado
[42, None, 'hello']Gerente
Manager é uma classe de módulo de multiprocessamento que fornece uma maneira de coordenar informações compartilhadas entre todos os seus usuários. Um objeto gerenciador controla um processo do servidor, que gerencia objetos compartilhados e permite que outros processos os manipulem. Em outras palavras, os gerentes fornecem uma maneira de criar dados que podem ser compartilhados entre diferentes processos. A seguir estão as diferentes propriedades do objeto gerente -
A principal propriedade do gerenciador é controlar um processo do servidor, que gerencia os objetos compartilhados.
Outra propriedade importante é atualizar todos os objetos compartilhados quando algum processo os modifica.
Exemplo
A seguir está um exemplo que usa o objeto gerenciador para criar um registro de lista no processo do servidor e, em seguida, adicionar um novo registro nessa lista.
import multiprocessing
def print_records(records):
for record in records:
print("Name: {0}\nScore: {1}\n".format(record[0], record[1]))
def insert_record(record, records):
records.append(record)
print("A New record is added\n")
if __name__ == '__main__':
with multiprocessing.Manager() as manager:
records = manager.list([('Computers', 1), ('Histoty', 5), ('Hindi',9)])
new_record = ('English', 3)
p1 = multiprocessing.Process(target = insert_record, args = (new_record, records))
p2 = multiprocessing.Process(target = print_records, args = (records,))
p1.start()
p1.join()
p2.start()
p2.join()Resultado
A New record is added
Name: Computers
Score: 1
Name: Histoty
Score: 5
Name: Hindi
Score: 9
Name: English
Score: 3Conceito de namespaces no Manager
O Manager Class vem com o conceito de namespaces, que é um método de maneira rápida para compartilhar vários atributos em vários processos. Os namespaces não apresentam nenhum método público, que pode ser chamado, mas possuem atributos graváveis.
Exemplo
O exemplo de script Python a seguir nos ajuda a utilizar namespaces para compartilhar dados entre o processo principal e o processo filho -
import multiprocessing
def Mng_NaSp(using_ns):
using_ns.x +=5
using_ns.y *= 10
if __name__ == '__main__':
manager = multiprocessing.Manager()
using_ns = manager.Namespace()
using_ns.x = 1
using_ns.y = 1
print ('before', using_ns)
p = multiprocessing.Process(target = Mng_NaSp, args = (using_ns,))
p.start()
p.join()
print ('after', using_ns)Resultado
before Namespace(x = 1, y = 1)
after Namespace(x = 6, y = 10)Ctypes-Array and Value
O módulo de multiprocessamento fornece objetos Array e Value para armazenar os dados em um mapa de memória compartilhada. Array é uma matriz ctypes alocada da memória compartilhada e Value é um objeto ctypes alocado da memória compartilhada.
Para estar com, importe Process, Value, Array do multiprocessamento.
Exemplo
Seguindo o script Python, está um exemplo tirado da documentação do python para utilizar Ctypes Array and Value para compartilhar alguns dados entre processos.
def f(n, a):
n.value = 3.1415927
for i in range(len(a)):
a[i] = -a[i]
if __name__ == '__main__':
num = Value('d', 0.0)
arr = Array('i', range(10))
p = Process(target = f, args = (num, arr))
p.start()
p.join()
print (num.value)
print (arr[:])Resultado
3.1415927
[0, -1, -2, -3, -4, -5, -6, -7, -8, -9]Processos de comunicação sequencial (CSP)
CSP é usado para ilustrar a interação de sistemas com outros sistemas apresentando modelos concorrentes. CSP é uma estrutura para escrever programas concorrentes ou por meio de passagem de mensagens e, portanto, é eficaz para descrever a simultaneidade.
Biblioteca Python - PyCSP
Para implementar as primitivas centrais encontradas no CSP, o Python tem uma biblioteca chamada PyCSP. Ele mantém a implementação muito curta e legível para que possa ser entendida facilmente. A seguir está a rede de processos básicos do PyCSP -
Na rede de processos PyCSP acima, há dois processos - Processo 1 e Processo 2. Esses processos se comunicam passando mensagens por meio de dois canais - canal 1 e canal 2.
Instalando PyCSP
Com a ajuda do seguinte comando, podemos instalar a biblioteca Python PyCSP -
pip install PyCSPExemplo
Seguir o script Python é um exemplo simples para executar dois processos em paralelo um ao outro. Isso é feito com a ajuda da libabary PyCSP python -
from pycsp.parallel import *
import time
@process
def P1():
time.sleep(1)
print('P1 exiting')
@process
def P2():
time.sleep(1)
print('P2 exiting')
def main():
Parallel(P1(), P2())
print('Terminating')
if __name__ == '__main__':
main()No script acima, duas funções são P1 e P2 foram criados e então decorados com @process para convertê-los em processos.
Resultado
P2 exiting
P1 exiting
TerminatingA programação orientada a eventos concentra-se em eventos. Eventualmente, o fluxo do programa depende de eventos. Até agora, estávamos lidando com um modelo de execução sequencial ou paralelo, mas o modelo com o conceito de programação orientada a eventos é chamado de modelo assíncrono. A programação orientada a eventos depende de um loop de eventos que está sempre ouvindo os novos eventos de entrada. O funcionamento da programação orientada a eventos depende de eventos. Depois que um evento entra em loop, os eventos decidem o que executar e em que ordem. O fluxograma a seguir ajudará você a entender como isso funciona -
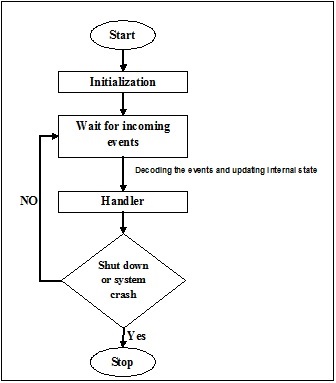
Módulo Python - Asyncio
O módulo Asyncio foi adicionado ao Python 3.4 e fornece infraestrutura para escrever código simultâneo de thread único usando co-rotinas. A seguir estão os diferentes conceitos usados pelo módulo Asyncio -
O loop de eventos
O loop de eventos é uma funcionalidade para manipular todos os eventos em um código computacional. Ele atua durante a execução de todo o programa e acompanha a entrada e a execução de eventos. O módulo Asyncio permite um único loop de eventos por processo. A seguir estão alguns métodos fornecidos pelo módulo Asyncio para gerenciar um loop de evento -
loop = get_event_loop() - Este método fornecerá o loop de eventos para o contexto atual.
loop.call_later(time_delay,callback,argument) - Este método organiza o retorno de chamada que deve ser chamado após os segundos de time_delay fornecidos.
loop.call_soon(callback,argument)- Este método organiza um retorno de chamada que deve ser chamado assim que possível. O retorno de chamada é chamado após call_soon () retornar e quando o controle retornar ao loop de eventos.
loop.time() - Este método é usado para retornar a hora atual de acordo com o relógio interno do loop de eventos.
asyncio.set_event_loop() - Este método definirá o loop de eventos do contexto atual para o loop.
asyncio.new_event_loop() - Este método irá criar e retornar um novo objeto de loop de evento.
loop.run_forever() - Este método será executado até que o método stop () seja chamado.
Exemplo
O seguinte exemplo de loop de evento ajuda na impressão hello worldusando o método get_event_loop (). Este exemplo foi retirado da documentação oficial do Python.
import asyncio
def hello_world(loop):
print('Hello World')
loop.stop()
loop = asyncio.get_event_loop()
loop.call_soon(hello_world, loop)
loop.run_forever()
loop.close()Resultado
Hello WorldFuturos
Isso é compatível com a classe concurrent.futures.Future que representa um cálculo que não foi realizado. Existem as seguintes diferenças entre asyncio.futures.Future e concurrent.futures.Future -
Os métodos result () e exception () não usam um argumento de tempo limite e geram uma exceção quando o futuro ainda não está pronto.
Callbacks registrados com add_done_callback () são sempre chamados via call_soon () do loop de evento.
A classe asyncio.futures.Future não é compatível com as funções wait () e as_completed () no pacote concurrent.futures.
Exemplo
A seguir está um exemplo que ajudará você a entender como usar a classe asyncio.futures.future.
import asyncio
async def Myoperation(future):
await asyncio.sleep(2)
future.set_result('Future Completed')
loop = asyncio.get_event_loop()
future = asyncio.Future()
asyncio.ensure_future(Myoperation(future))
try:
loop.run_until_complete(future)
print(future.result())
finally:
loop.close()Resultado
Future CompletedCorrotinas
O conceito de co-rotinas no Asyncio é semelhante ao conceito de objeto Thread padrão no módulo de threading. Esta é a generalização do conceito de sub-rotina. Uma co-rotina pode ser suspensa durante a execução para que aguarde o processamento externo e retorne do ponto em que parou quando o processamento externo foi concluído. As duas maneiras a seguir nos ajudam na implementação de corrotinas -
função def assíncrona ()
Este é um método para implementação de co-rotinas no módulo Asyncio. A seguir está um script Python para o mesmo -
import asyncio
async def Myoperation():
print("First Coroutine")
loop = asyncio.get_event_loop()
try:
loop.run_until_complete(Myoperation())
finally:
loop.close()Resultado
First Coroutinedecorador @ asyncio.coroutine
Outro método para implementação de co-rotinas é utilizar geradores com o decorador @ asyncio.coroutine. A seguir está um script Python para o mesmo -
import asyncio
@asyncio.coroutine
def Myoperation():
print("First Coroutine")
loop = asyncio.get_event_loop()
try:
loop.run_until_complete(Myoperation())
finally:
loop.close()Resultado
First CoroutineTarefas
Esta subclasse do módulo Asyncio é responsável pela execução de co-rotinas em um loop de eventos de maneira paralela. Seguir o script Python é um exemplo de processamento de algumas tarefas em paralelo.
import asyncio
import time
async def Task_ex(n):
time.sleep(1)
print("Processing {}".format(n))
async def Generator_task():
for i in range(10):
asyncio.ensure_future(Task_ex(i))
int("Tasks Completed")
asyncio.sleep(2)
loop = asyncio.get_event_loop()
loop.run_until_complete(Generator_task())
loop.close()Resultado
Tasks Completed
Processing 0
Processing 1
Processing 2
Processing 3
Processing 4
Processing 5
Processing 6
Processing 7
Processing 8
Processing 9Transportes
O módulo Asyncio fornece classes de transporte para a implementação de vários tipos de comunicação. Essas classes não são thread-safe e sempre emparelhadas com uma instância de protocolo após o estabelecimento do canal de comunicação.
A seguir estão os tipos distintos de transportes herdados do BaseTransport -
ReadTransport - Esta é uma interface para transportes somente leitura.
WriteTransport - Esta é uma interface para transportes somente gravação.
DatagramTransport - Esta é uma interface para envio de dados.
BaseSubprocessTransport - Semelhante à classe BaseTransport.
A seguir estão cinco métodos distintos da classe BaseTransport que são subsequentemente transitórios entre os quatro tipos de transporte -
close() - Fecha o transporte.
is_closing() - Este método retornará verdadeiro se o transporte estiver fechando ou já estiver fechado.transports.
get_extra_info(name, default = none) - Isso nos dará algumas informações extras sobre transporte.
get_protocol() - Este método retornará o protocolo atual.
Protocolos
O módulo Asyncio fornece classes básicas que você pode criar em subclasses para implementar seus protocolos de rede. Essas classes são usadas em conjunto com transportes; o protocolo analisa os dados de entrada e pede a gravação dos dados de saída, enquanto o transporte é responsável pela E / S real e pelo armazenamento em buffer. A seguir estão três classes de protocolo -
Protocol - Esta é a classe base para implementar protocolos de streaming para uso com transportes TCP e SSL.
DatagramProtocol - Esta é a classe base para implementação de protocolos de datagrama para uso com transportes UDP.
SubprocessProtocol - Esta é a classe base para implementar protocolos que se comunicam com processos filhos por meio de um conjunto de tubos unidirecionais.
A programação reativa é um paradigma de programação que lida com fluxos de dados e a propagação da mudança. Isso significa que quando um fluxo de dados é emitido por um componente, a mudança será propagada para outros componentes pela biblioteca de programação reativa. A propagação da mudança continuará até atingir o receptor final. A diferença entre a programação orientada a eventos e reativa é que a programação orientada a eventos gira em torno de eventos e a programação reativa gira em torno de dados.
ReactiveX ou RX para programação reativa
ReactiveX ou Raective Extension é a implementação mais famosa de programação reativa. O funcionamento do ReactiveX depende das duas classes a seguir -
Classe observável
Essa classe é a fonte do fluxo de dados ou eventos e empacota os dados de entrada para que os dados possam ser passados de um thread para outro. Ele não fornecerá dados até que algum observador se inscreva nele.
Classe observador
Esta classe consome o fluxo de dados emitido por observable. Pode haver vários observadores com observáveis e cada observador receberá cada item de dados que é emitido. O observador pode receber três tipos de eventos, inscrevendo-se em observáveis -
on_next() event - Isso implica que há um elemento no fluxo de dados.
on_completed() event - Implica o fim da emissão e não há mais itens chegando.
on_error() event - Implica também no fim da emissão, mas no caso de ocorrer um erro por observable.
RxPY - Módulo Python para Programação Reativa
RxPY é um módulo Python que pode ser usado para programação reativa. Precisamos garantir que o módulo esteja instalado. O seguinte comando pode ser usado para instalar o módulo RxPY -
pip install RxPYExemplo
A seguir está um script Python, que usa RxPY módulo e suas classes Observable e Observe forprogramação reativa. Existem basicamente duas classes -
get_strings() - para obter as strings do observador.
PrintObserver()- para imprimir as strings do observador. Ele usa todos os três eventos da classe observador. Ele também usa a classe subscribe ().
from rx import Observable, Observer
def get_strings(observer):
observer.on_next("Ram")
observer.on_next("Mohan")
observer.on_next("Shyam")
observer.on_completed()
class PrintObserver(Observer):
def on_next(self, value):
print("Received {0}".format(value))
def on_completed(self):
print("Finished")
def on_error(self, error):
print("Error: {0}".format(error))
source = Observable.create(get_strings)
source.subscribe(PrintObserver())Resultado
Received Ram
Received Mohan
Received Shyam
FinishedBiblioteca PyFunctional para programação reativa
PyFunctionalé outra biblioteca Python que pode ser usada para programação reativa. Ele nos permite criar programas funcionais usando a linguagem de programação Python. É útil porque nos permite criar pipelines de dados usando operadores funcionais encadeados.
Diferença entre RxPY e PyFunctional
Ambas as bibliotecas são usadas para programação reativa e manipulam o fluxo de maneira semelhante, mas a principal diferença entre as duas depende da manipulação de dados. RxPY lida com dados e eventos no sistema enquanto PyFunctional está focado na transformação de dados usando paradigmas de programação funcional.
Instalando Módulo PyFunctional
Precisamos instalar este módulo antes de usá-lo. Ele pode ser instalado com a ajuda do comando pip da seguinte maneira -
pip install pyfunctionalExemplo
O exemplo a seguir usa the PyFunctional módulo e seu seqclasse que atua como o objeto de fluxo com o qual podemos iterar e manipular. Neste programa, ele mapeia a sequência usando a função lamda que dobra todos os valores, então filtra o valor onde x é maior que 4 e finalmente reduz a sequência em uma soma de todos os valores restantes.
from functional import seq
result = seq(1,2,3).map(lambda x: x*2).filter(lambda x: x > 4).reduce(lambda x, y: x + y)
print ("Result: {}".format(result))Resultado
Result: 6