Funções de criptografia Hash
As funções de hash são extremamente úteis e aparecem em quase todos os aplicativos de segurança da informação.
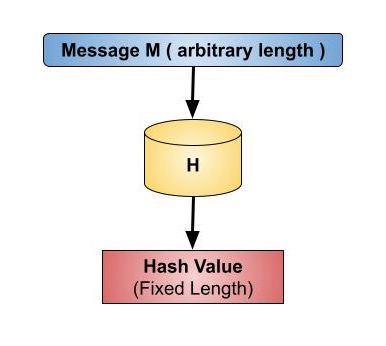
Uma função hash é uma função matemática que converte um valor de entrada numérico em outro valor numérico compactado. A entrada para a função hash é de comprimento arbitrário, mas a saída é sempre de comprimento fixo.
Os valores retornados por uma função hash são chamados message digest ou simplesmente hash values. A seguinte imagem ilustrada função hash -
Recursos de funções de hash
As características típicas das funções hash são -
Fixed Length Output (Hash Value)
A função hash cobre dados de comprimento arbitrário para um comprimento fixo. Este processo é frequentemente referido comohashing the data.
Em geral, o hash é muito menor do que os dados de entrada, portanto, as funções hash às vezes são chamadas compression functions.
Uma vez que um hash é uma representação menor de dados maiores, ele também é conhecido como digest.
A função hash com saída de n bits é chamada de n-bit hash function. As funções hash populares geram valores entre 160 e 512 bits.
Efficiency of Operation
Geralmente, para qualquer função hash h com entrada x, o cálculo de h (x) é uma operação rápida.
As funções hash computacionalmente são muito mais rápidas do que uma criptografia simétrica.
Propriedades das funções hash
Para ser uma ferramenta criptográfica eficaz, a função hash deve possuir as seguintes propriedades -
Pre-Image Resistance
Essa propriedade significa que deve ser computacionalmente difícil reverter uma função hash.
Em outras palavras, se uma função hash h produziu um valor hash z, então deve ser um processo difícil encontrar qualquer valor de entrada x que hash para z.
Esta propriedade protege contra um invasor que possui apenas um valor de hash e está tentando encontrar a entrada.
Second Pre-Image Resistance
Esta propriedade significa que, dada uma entrada e seu hash, deve ser difícil encontrar uma entrada diferente com o mesmo hash.
Em outras palavras, se uma função hash h para uma entrada x produz um valor hash h (x), então deve ser difícil encontrar qualquer outro valor de entrada y tal que h (y) = h (x).
Esta propriedade da função hash protege contra um invasor que possui um valor de entrada e seu hash e deseja substituir um valor diferente como valor legítimo no lugar do valor de entrada original.
Collision Resistance
Essa propriedade significa que deve ser difícil encontrar duas entradas diferentes de qualquer comprimento que resultem no mesmo hash. Essa propriedade também é conhecida como função hash livre de colisão.
Em outras palavras, para uma função hash h, é difícil encontrar quaisquer duas entradas diferentes xey tais que h (x) = h (y).
Visto que a função hash é a função de compressão com comprimento de hash fixo, é impossível para uma função hash não ter colisões. Esta propriedade de livre de colisão apenas confirma que essas colisões devem ser difíceis de encontrar.
Essa propriedade torna muito difícil para um invasor encontrar dois valores de entrada com o mesmo hash.
Além disso, se uma função hash for resistente à colisão then it is second pre-image resistant.
Projeto de Algoritmos de Hashing
No centro de um hashing está uma função matemática que opera em dois blocos de dados de tamanho fixo para criar um código hash. Esta função hash faz parte do algoritmo de hash.
O tamanho de cada bloco de dados varia dependendo do algoritmo. Normalmente, os tamanhos de bloco são de 128 bits a 512 bits. A ilustração a seguir demonstra a função hash -
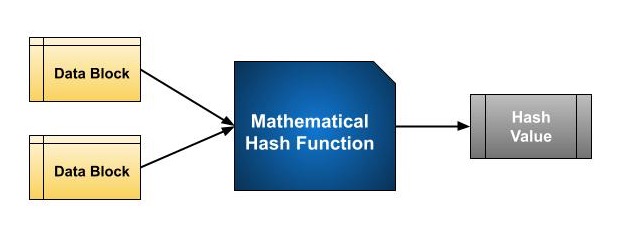
O algoritmo de hash envolve rodadas da função hash acima, como uma cifra de bloco. Cada rodada recebe uma entrada de tamanho fixo, normalmente uma combinação do bloco de mensagem mais recente e a saída da última rodada.
Esse processo é repetido por quantas rodadas forem necessárias para o hash de toda a mensagem. O esquema do algoritmo de hashing é representado na ilustração a seguir -

Desde então, o valor hash do primeiro bloco de mensagem torna-se uma entrada para a segunda operação hash, saída que altera o resultado da terceira operação e assim por diante. Este efeito, conhecido comoavalanche efeito de hashing.
O efeito de avalanche resulta em valores de hash substancialmente diferentes para duas mensagens que diferem até mesmo por um único bit de dados.
Entenda a diferença entre função hash e algoritmo corretamente. A função hash gera um código hash operando em dois blocos de dados binários de comprimento fixo.
O algoritmo de hash é um processo para usar a função hash, especificando como a mensagem será dividida e como os resultados dos blocos de mensagens anteriores são encadeados.
Funções Hash populares
Vejamos brevemente algumas funções hash populares -
Message Digest (MD)
MD5 foi a função hash mais popular e amplamente usada por alguns anos.
A família MD compreende as funções hash MD2, MD4, MD5 e MD6. Foi adotado como Internet Standard RFC 1321. É uma função hash de 128 bits.
Os resumos MD5 têm sido amplamente usados no mundo do software para fornecer garantia sobre a integridade do arquivo transferido. Por exemplo, os servidores de arquivos geralmente fornecem uma soma de verificação MD5 pré-calculada para os arquivos, de forma que um usuário possa comparar a soma de verificação do arquivo baixado.
Em 2004, foram encontradas colisões no MD5. Um ataque analítico foi relatado como bem-sucedido apenas em uma hora usando um cluster de computador. Este ataque de colisão resultou em comprometimento do MD5 e, portanto, não é mais recomendado para uso.
Função Secure Hash (SHA)
Família de SHA composta por quatro algoritmos SHA; SHA-0, SHA-1, SHA-2 e SHA-3. Embora sejam da mesma família, são estruturalmente diferentes.
A versão original é SHA-0, uma função hash de 160 bits, publicada pelo Instituto Nacional de Padrões e Tecnologia (NIST) em 1993. Ela tinha poucos pontos fracos e não se tornou muito popular. Mais tarde, em 1995, o SHA-1 foi projetado para corrigir alegadas fraquezas do SHA-0.
SHA-1 é a função hash SHA existente mais amplamente usada. É empregado em vários aplicativos e protocolos amplamente usados, incluindo segurança Secure Socket Layer (SSL).
Em 2005, um método foi encontrado para descobrir colisões para SHA-1 dentro de um prazo prático, tornando a empregabilidade de longo prazo do SHA-1 duvidosa.
A família SHA-2 tem mais quatro variantes SHA, SHA-224, SHA-256, SHA-384 e SHA-512, dependendo do número de bits em seu valor de hash. Nenhum ataque bem-sucedido foi relatado na função hash SHA-2.
Embora SHA-2 seja uma função de hash forte. Embora significativamente diferente, seu design básico ainda segue o design de SHA-1. Portanto, o NIST solicitou novos designs de função hash competitivos.
Em outubro de 2012, o NIST escolheu o algoritmo Keccak como o novo padrão SHA-3. Keccak oferece muitos benefícios, como desempenho eficiente e boa resistência a ataques.
RIPEMD
O RIPEMD é um acrônimo para RACE Integrity Primitives Evaluation Message Digest. Este conjunto de funções hash foi projetado por uma comunidade de pesquisa aberta e geralmente conhecido como uma família de funções hash europeias.
O conjunto inclui RIPEMD, RIPEMD-128 e RIPEMD-160. Também existem versões de 256 e 320 bits desse algoritmo.
O RIPEMD original (128 bits) é baseado nos princípios de design usados no MD4 e fornece segurança questionável. A versão RIPEMD de 128 bits veio como uma substituição de correção rápida para superar vulnerabilidades no RIPEMD original.
RIPEMD-160 é uma versão aprimorada e a versão mais usada na família. As versões de 256 e 320 bits reduzem a chance de colisão acidental, mas não têm níveis mais altos de segurança em comparação com RIPEMD-128 e RIPEMD-160, respectivamente.
Hidromassagem
Esta é uma função hash de 512 bits.
É derivado da versão modificada do Advanced Encryption Standard (AES). Um dos estilistas foi Vincent Rijmen, co-criador do AES.
Três versões do Whirlpool foram lançadas; nomeadamente WHIRLPOOL-0, WHIRLPOOL-T e WHIRLPOOL.
Aplicações de funções hash
Existem duas aplicações diretas da função hash com base em suas propriedades criptográficas.
Armazenamento de senha
As funções de hash fornecem proteção ao armazenamento de senha.
Em vez de armazenar a senha em claro, principalmente todos os processos de logon armazenam os valores de hash das senhas no arquivo.
O arquivo de senha consiste em uma tabela de pares que estão na forma (id do usuário, h (P)).
O processo de logon é descrito na ilustração a seguir -
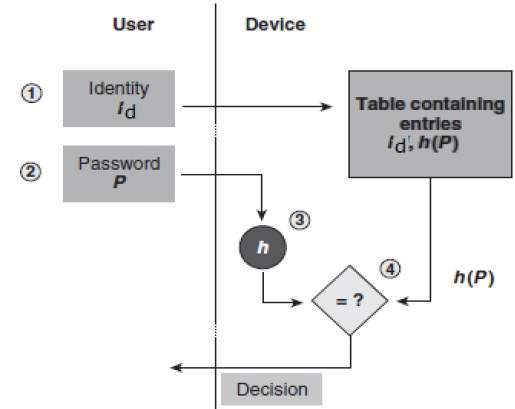
Um intruso só pode ver os hashes das senhas, mesmo que tenha acessado a senha. Ele não pode fazer logon usando hash nem derivar a senha do valor de hash, pois a função de hash possui a propriedade de resistência à pré-imagem.
Verificação de integridade de dados
A verificação de integridade de dados é a aplicação mais comum das funções hash. É usado para gerar somas de verificação em arquivos de dados. Este aplicativo fornece garantia ao usuário sobre a exatidão dos dados.
O processo é descrito na ilustração a seguir -
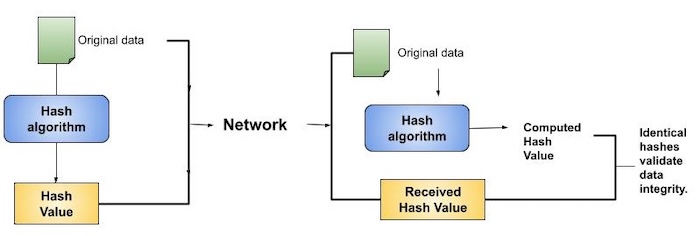
A verificação de integridade ajuda o usuário a detectar quaisquer alterações feitas no arquivo original. No entanto, não oferece nenhuma garantia de originalidade. O invasor, em vez de modificar os dados do arquivo, pode alterar o arquivo inteiro e calcular o novo hash e enviar ao receptor. Este aplicativo de verificação de integridade só é útil se o usuário tiver certeza da originalidade do arquivo.