Mineração de dados - Guia rápido
Há uma grande quantidade de dados disponíveis na Indústria da Informação. Esses dados são inúteis até que sejam convertidos em informações úteis. É necessário analisar essa enorme quantidade de dados e extrair informações úteis deles.
A extração de informações não é o único processo que precisamos realizar; mineração de dados também envolve outros processos, como limpeza de dados, integração de dados, transformação de dados, mineração de dados, avaliação de padrões e apresentação de dados. Depois que todos esses processos terminarem, poderemos usar essas informações em muitos aplicativos, como detecção de fraude, análise de mercado, controle de produção, exploração científica, etc.
O que é mineração de dados?
A mineração de dados é definida como a extração de informações de grandes conjuntos de dados. Em outras palavras, podemos dizer que data mining é o procedimento de mineração de conhecimento a partir de dados. As informações ou conhecimentos extraídos podem ser usados para qualquer uma das seguintes aplicações -
- Análise de mercado
- Detecção de fraude
- Fidelização de clientes
- Controle de produção
- Exploração Científica
Aplicativos de mineração de dados
A mineração de dados é altamente útil nos seguintes domínios -
- Análise e gestão de mercado
- Análise Corporativa e Gestão de Risco
- Detecção de fraude
Além disso, a mineração de dados também pode ser usada nas áreas de controle de produção, retenção de clientes, exploração científica, esportes, astrologia e Internet Web Surf-Aid
Análise e gestão de mercado
Listados abaixo estão os vários campos de mercado onde a mineração de dados é usada -
Customer Profiling - A mineração de dados ajuda a determinar que tipo de pessoa compra que tipo de produto.
Identifying Customer Requirements- A mineração de dados ajuda a identificar os melhores produtos para diferentes clientes. Ele usa a previsão para encontrar os fatores que podem atrair novos clientes.
Cross Market Analysis - A mineração de dados realiza associação / correlações entre vendas de produtos.
Target Marketing - A mineração de dados ajuda a encontrar grupos de clientes modelo que compartilham as mesmas características, como interesses, hábitos de consumo, renda, etc.
Determining Customer purchasing pattern - A mineração de dados ajuda a determinar o padrão de compra do cliente.
Providing Summary Information - A mineração de dados nos fornece vários relatórios de resumo multidimensionais.
Análise Corporativa e Gestão de Riscos
A mineração de dados é usada nas seguintes áreas do Setor Corporativo -
Finance Planning and Asset Evaluation - Envolve análise e previsão de fluxo de caixa, análise de sinistros contingentes para avaliação de ativos.
Resource Planning - Envolve resumir e comparar os recursos e gastos.
Competition - Envolve monitoramento de concorrentes e direções de mercado.
Detecção de fraude
A mineração de dados também é usada nas áreas de serviços de cartão de crédito e telecomunicações para detectar fraudes. Em ligações fraudulentas, ajuda a encontrar o destino da chamada, a duração da chamada, a hora do dia ou da semana, etc. Também analisa os padrões que se desviam das normas esperadas.
A mineração de dados lida com os tipos de padrões que podem ser extraídos. Com base no tipo de dados a serem extraídos, existem duas categorias de funções envolvidas na mineração de dados -
- Descriptive
- Classificação e previsão
Função Descritiva
A função descritiva trata das propriedades gerais dos dados no banco de dados. Aqui está a lista de funções descritivas -
- Descrição da Classe / Conceito
- Mineração de padrões frequentes
- Mineração de Associações
- Mineração de Correlações
- Mineração de Clusters
Descrição da Classe / Conceito
Classe / Conceito refere-se aos dados a serem associados às classes ou conceitos. Por exemplo, em uma empresa, as classes de itens para vendas incluem computador e impressoras, e os conceitos de clientes incluem grandes gastadores e gastadores de orçamento. Essas descrições de uma classe ou conceito são chamadas de descrições de classe / conceito. Essas descrições podem ser derivadas das duas maneiras a seguir -
Data Characterization- Refere-se a resumir os dados da aula em estudo. Esta classe em estudo é chamada de Classe Alvo.
Data Discrimination - Refere-se ao mapeamento ou classificação de uma classe com algum grupo ou classe pré-definida.
Mineração de padrões frequentes
Padrões frequentes são aqueles padrões que ocorrem com frequência em dados transacionais. Aqui está a lista de tipos de padrões frequentes -
Frequent Item Set - Refere-se a um conjunto de itens que freqüentemente aparecem juntos, por exemplo, leite e pão.
Frequent Subsequence - Uma sequência de padrões que ocorre com frequência, como a compra de uma câmera, é seguida por um cartão de memória.
Frequent Sub Structure - Subestrutura refere-se a diferentes formas estruturais, como gráficos, árvores ou reticulados, que podem ser combinados com conjuntos de itens ou subsequências.
Mineração de Associação
As associações são usadas em vendas no varejo para identificar padrões que são frequentemente comprados juntos. Esse processo se refere ao processo de descobrir a relação entre os dados e determinar as regras de associação.
Por exemplo, um varejista gera uma regra de associação que mostra que 70% das vezes o leite é vendido com pão e apenas 30% das vezes os biscoitos são vendidos com pão.
Mineração de Correlações
É um tipo de análise adicional realizada para descobrir correlações estatísticas interessantes entre pares de valores de atributos associados ou entre dois conjuntos de itens para analisar se eles têm efeito positivo, negativo ou nenhum efeito um sobre o outro.
Mineração de Clusters
Cluster se refere a um grupo de tipos de objetos semelhantes. A análise de cluster se refere à formação de grupos de objetos muito semelhantes entre si, mas altamente diferentes dos objetos de outros clusters.
Classificação e previsão
Classificação é o processo de encontrar um modelo que descreva as classes ou conceitos de dados. O objetivo é poder usar este modelo para prever a classe de objetos cujo rótulo de classe é desconhecido. Este modelo derivado é baseado na análise de conjuntos de dados de treinamento. O modelo derivado pode ser apresentado nas seguintes formas -
- Regras de classificação (IF-THEN)
- Árvores de decisão
- Fórmulas Matemáticas
- Redes neurais
A lista de funções envolvidas nestes processos é a seguinte -
Classification- Prevê a classe de objetos cujo rótulo de classe é desconhecido. Seu objetivo é encontrar um modelo derivado que descreve e distingue classes de dados ou conceitos. O modelo derivado é baseado no conjunto de análise de dados de treinamento, ou seja, o objeto de dados cujo rótulo de classe é bem conhecido.
Prediction- É usado para prever valores de dados numéricos ausentes ou indisponíveis em vez de rótulos de classe. A análise de regressão é geralmente usada para previsão. A previsão também pode ser usada para identificar tendências de distribuição com base nos dados disponíveis.
Outlier Analysis - Outliers podem ser definidos como os objetos de dados que não cumprem o comportamento geral ou modelo dos dados disponíveis.
Evolution Analysis - A análise da evolução refere-se à descrição e regularidades do modelo ou tendências para objetos cujo comportamento muda ao longo do tempo.
Data Mining Task Primitivos
- Podemos especificar uma tarefa de mineração de dados na forma de uma consulta de mineração de dados.
- Esta consulta é inserida no sistema.
- Uma consulta de mineração de dados é definida em termos de primitivas de tarefa de mineração de dados.
Note- Essas primitivas nos permitem comunicar de forma interativa com o sistema de mineração de dados. Aqui está a lista de Data Mining Task Primitives -
- Conjunto de dados relevantes da tarefa a serem extraídos.
- Tipo de conhecimento a ser explorado.
- Conhecimento prévio a ser usado no processo de descoberta.
- Medidas de interesse e limites para avaliação de padrões.
- Representação para visualizar os padrões descobertos.
Conjunto de dados relevantes da tarefa a serem extraídos
Esta é a parte do banco de dados na qual o usuário está interessado. Esta parte inclui o seguinte -
- Atributos de banco de dados
- Dimensões de interesse do data warehouse
Tipo de conhecimento a ser explorado
Refere-se ao tipo de funções a serem desempenhadas. Essas funções são -
- Characterization
- Discrimination
- Análise de Associação e Correlação
- Classification
- Prediction
- Clustering
- Análise Outlier
- Análise de Evolução
Conhecimento prévio
O conhecimento prévio permite que os dados sejam extraídos em vários níveis de abstração. Por exemplo, as hierarquias de conceito são um dos conhecimentos básicos que permitem que os dados sejam extraídos em vários níveis de abstração.
Medidas de interesse e limites para avaliação de padrões
Isso é usado para avaliar os padrões que são descobertos pelo processo de descoberta de conhecimento. Existem diferentes medidas interessantes para diferentes tipos de conhecimento.
Representação para visualizar os padrões descobertos
Isso se refere à forma na qual os padrões descobertos devem ser exibidos. Essas representações podem incluir o seguinte. -
- Rules
- Tables
- Charts
- Graphs
- Árvores de decisão
- Cubes
A mineração de dados não é uma tarefa fácil, pois os algoritmos usados podem ficar muito complexos e os dados nem sempre estão disponíveis em um só lugar. Ele precisa ser integrado a partir de várias fontes de dados heterogêneas. Esses fatores também criam alguns problemas. Aqui neste tutorial, discutiremos as principais questões relacionadas a -
- Metodologia de mineração e interação do usuário
- Problemas de desempenho
- Problemas de diversos tipos de dados
O diagrama a seguir descreve os principais problemas.

Metodologia de mineração e problemas de interação do usuário
Refere-se aos seguintes tipos de problemas -
Mining different kinds of knowledge in databases- Diferentes usuários podem estar interessados em diferentes tipos de conhecimento. Portanto, é necessário que a mineração de dados cubra uma ampla gama de tarefas de descoberta de conhecimento.
Interactive mining of knowledge at multiple levels of abstraction - O processo de mineração de dados precisa ser interativo porque permite que os usuários concentrem a busca por padrões, fornecendo e refinando as solicitações de mineração de dados com base nos resultados retornados.
Incorporation of background knowledge- Para guiar o processo de descoberta e expressar os padrões descobertos, o conhecimento de fundo pode ser usado. O conhecimento prévio pode ser usado para expressar os padrões descobertos não apenas em termos concisos, mas em vários níveis de abstração.
Data mining query languages and ad hoc data mining - Linguagem de consulta de mineração de dados que permite ao usuário descrever tarefas de mineração ad hoc, deve ser integrada com uma linguagem de consulta de data warehouse e otimizada para mineração de dados eficiente e flexível.
Presentation and visualization of data mining results- Uma vez que os padrões são descobertos, eles precisam ser expressos em linguagens de alto nível e representações visuais. Essas representações devem ser facilmente compreensíveis.
Handling noisy or incomplete data- Os métodos de limpeza de dados são necessários para lidar com o ruído e objetos incompletos durante a mineração das regularidades dos dados. Se os métodos de limpeza de dados não estiverem lá, a precisão dos padrões descobertos será ruim.
Pattern evaluation - Os padrões descobertos devem ser interessantes porque representam um conhecimento comum ou carecem de novidade.
Problemas de desempenho
Pode haver problemas relacionados ao desempenho, como segue -
Efficiency and scalability of data mining algorithms - Para extrair efetivamente as informações de uma grande quantidade de dados em bancos de dados, o algoritmo de mineração de dados deve ser eficiente e escalonável.
Parallel, distributed, and incremental mining algorithms- Os fatores como o grande tamanho dos bancos de dados, ampla distribuição de dados e a complexidade dos métodos de mineração de dados motivam o desenvolvimento de algoritmos de mineração de dados paralelos e distribuídos. Esses algoritmos dividem os dados em partições que são posteriormente processadas de maneira paralela. Em seguida, os resultados das partições são mesclados. Os algoritmos incrementais atualizam bancos de dados sem minerar os dados novamente do zero.
Problemas de diversos tipos de dados
Handling of relational and complex types of data - O banco de dados pode conter objetos de dados complexos, objetos de dados multimídia, dados espaciais, dados temporais, etc. Não é possível para um sistema extrair todos esses tipos de dados.
Mining information from heterogeneous databases and global information systems- Os dados estão disponíveis em diferentes fontes de dados na LAN ou WAN. Essas fontes de dados podem ser estruturadas, semiestruturadas ou não estruturadas. Portanto, extrair o conhecimento deles adiciona desafios à mineração de dados.
Armazém de dados
Um data warehouse exibe as seguintes características para apoiar o processo de tomada de decisão da gestão -
Subject Oriented- O data warehouse é orientado por assunto porque nos fornece as informações em torno de um assunto, em vez das operações em andamento da organização. Esses assuntos podem ser produtos, clientes, fornecedores, vendas, receita, etc. O data warehouse não se concentra nas operações em andamento, mas sim na modelagem e análise de dados para a tomada de decisões.
Integrated - O data warehouse é construído pela integração de dados de fontes heterogêneas, como bancos de dados relacionais, arquivos simples, etc. Essa integração aprimora a análise eficaz dos dados.
Time Variant- Os dados coletados em um data warehouse são identificados com um determinado período de tempo. Os dados em um data warehouse fornecem informações de um ponto de vista histórico.
Non-volatile- Não volátil significa que os dados anteriores não são removidos quando novos dados são adicionados a eles. O data warehouse é mantido separado do banco de dados operacional, portanto, mudanças frequentes no banco de dados operacional não são refletidas no data warehouse.
Armazenamento de dados
Armazenamento de dados é o processo de construção e uso do armazenamento de dados. Um data warehouse é construído integrando os dados de várias fontes heterogêneas. Suporta relatórios analíticos, consultas estruturadas e / ou ad hoc e tomada de decisões.
O armazenamento de dados envolve limpeza de dados, integração de dados e consolidações de dados. Para integrar bancos de dados heterogêneos, temos as seguintes duas abordagens -
- Abordagem Orientada por Consulta
- Abordagem orientada para atualização
Abordagem baseada em consulta
Esta é a abordagem tradicional para integrar bancos de dados heterogêneos. Essa abordagem é usada para construir wrappers e integradores sobre vários bancos de dados heterogêneos. Esses integradores também são conhecidos como mediadores.
Processo de abordagem orientada a consultas
Quando uma consulta é emitida para um lado do cliente, um dicionário de metadados traduz a consulta em consultas, apropriadas para o site heterogêneo individual envolvido.
Agora, essas consultas são mapeadas e enviadas para o processador de consultas local.
Os resultados de sites heterogêneos são integrados em um conjunto de respostas global.
Desvantagens
Essa abordagem tem as seguintes desvantagens -
A Abordagem Orientada por Consulta precisa de processos complexos de integração e filtragem.
É muito ineficiente e muito caro para consultas frequentes.
Essa abordagem é cara para consultas que requerem agregações.
Abordagem baseada em atualização
Os sistemas de data warehouse de hoje seguem uma abordagem baseada em atualizações, em vez da abordagem tradicional discutida anteriormente. Na abordagem baseada em atualização, as informações de várias fontes heterogêneas são integradas antecipadamente e armazenadas em um warehouse. Essas informações estão disponíveis para consulta e análise direta.
Vantagens
Essa abordagem tem as seguintes vantagens -
Essa abordagem oferece alto desempenho.
Os dados podem ser copiados, processados, integrados, anotados, resumidos e reestruturados no armazenamento de dados semânticos com antecedência.
O processamento da consulta não requer interface com o processamento nas fontes locais.
De Data Warehousing (OLAP) a Data Mining (OLAM)
Online Analytical Mining integra-se com Online Analytical Processing com data mining e conhecimento de mineração em bancos de dados multidimensionais. Aqui está o diagrama que mostra a integração de OLAP e OLAM -

Importância do OLAM
OLAM é importante pelas seguintes razões -
High quality of data in data warehouses- As ferramentas de mineração de dados são necessárias para trabalhar em dados integrados, consistentes e limpos. Essas etapas são muito caras no pré-processamento de dados. Os data warehouses construídos por esse pré-processamento são fontes valiosas de dados de alta qualidade para OLAP e mineração de dados também.
Available information processing infrastructure surrounding data warehouses - A infraestrutura de processamento de informações refere-se ao acesso, integração, consolidação e transformação de vários bancos de dados heterogêneos, acesso à web e facilidades de serviço, relatórios e ferramentas de análise OLAP.
OLAP−based exploratory data analysis- A análise exploratória de dados é necessária para a mineração de dados eficaz. OLAM fornece facilidade para mineração de dados em vários subconjuntos de dados e em diferentes níveis de abstração.
Online selection of data mining functions - A integração do OLAP com várias funções de mineração de dados e mineração analítica online fornece aos usuários a flexibilidade de selecionar as funções de mineração de dados desejadas e trocar tarefas de mineração de dados dinamicamente.
Mineração de dados
A mineração de dados é definida como a extração de informações de um grande conjunto de dados. Em outras palavras, podemos dizer que a mineração de dados está extraindo o conhecimento dos dados. Essas informações podem ser usadas para qualquer um dos seguintes aplicativos -
- Análise de mercado
- Detecção de fraude
- Fidelização de clientes
- Controle de produção
- Exploração Científica
Motor de mineração de dados
O motor de mineração de dados é muito essencial para o sistema de mineração de dados. Consiste em um conjunto de módulos funcionais que realizam as seguintes funções -
- Characterization
- Análise de Associação e Correlação
- Classification
- Prediction
- Análise de cluster
- Análise de outlier
- Análise de evolução
Base de Conhecimento
Este é o conhecimento do domínio. Esse conhecimento é usado para orientar a busca ou avaliar a importância dos padrões resultantes.
Descoberta de conhecimento
Algumas pessoas tratam a mineração de dados como descoberta de conhecimento, enquanto outras veem a mineração de dados como uma etapa essencial no processo de descoberta de conhecimento. Aqui está a lista de etapas envolvidas no processo de descoberta de conhecimento -
- Limpeza de Dados
- Integração de dados
- Seleção de Dados
- Transformação de Dados
- Mineração de dados
- Avaliação de Padrão
- Apresentação de Conhecimento
Interface de usuário
Interface de usuário é o módulo do sistema de mineração de dados que auxilia na comunicação entre os usuários e o sistema de mineração de dados. A interface do usuário permite as seguintes funcionalidades -
- Interaja com o sistema especificando uma tarefa de consulta de mineração de dados.
- Fornecendo informações para ajudar a focar a pesquisa.
- Mineração com base nos resultados de mineração de dados intermediários.
- Navegue por bancos de dados e esquemas de data warehouse ou estruturas de dados.
- Avalie os padrões extraídos.
- Visualize os padrões em diferentes formas.
Integração de dados
Integração de dados é uma técnica de pré-processamento de dados que mescla os dados de várias fontes de dados heterogêneas em um armazenamento de dados coerente. A integração de dados pode envolver dados inconsistentes e, portanto, precisa de limpeza de dados.
Limpeza de Dados
A limpeza de dados é uma técnica aplicada para remover os dados ruidosos e corrigir as inconsistências nos dados. A limpeza de dados envolve transformações para corrigir os dados errados. A limpeza de dados é executada como uma etapa de pré-processamento de dados enquanto prepara os dados para um data warehouse.
Seleção de Dados
Seleção de dados é o processo onde os dados relevantes para a tarefa de análise são recuperados do banco de dados. Às vezes, a transformação e a consolidação de dados são realizadas antes do processo de seleção de dados.
Clusters
Cluster se refere a um grupo de tipos de objetos semelhantes. A análise de cluster se refere à formação de grupos de objetos muito semelhantes entre si, mas altamente diferentes dos objetos de outros clusters.
Transformação de Dados
Nesta etapa, os dados são transformados ou consolidados em formas adequadas para mineração, executando operações de resumo ou agregação.
O que é descoberta de conhecimento?
Algumas pessoas não diferenciam a mineração de dados da descoberta de conhecimento, enquanto outras veem a mineração de dados como uma etapa essencial no processo de descoberta de conhecimento. Aqui está a lista de etapas envolvidas no processo de descoberta de conhecimento -
Data Cleaning - Nesta etapa, o ruído e dados inconsistentes são removidos.
Data Integration - Nesta etapa, várias fontes de dados são combinadas.
Data Selection - Nesta etapa, os dados relevantes para a tarefa de análise são recuperados do banco de dados.
Data Transformation - Nesta etapa, os dados são transformados ou consolidados em formas apropriadas para mineração, executando operações de resumo ou agregação.
Data Mining - Nesta etapa, métodos inteligentes são aplicados para extrair padrões de dados.
Pattern Evaluation - Nesta etapa, os padrões de dados são avaliados.
Knowledge Presentation - Nesta etapa, o conhecimento é representado.
O diagrama a seguir mostra o processo de descoberta de conhecimento -

Existe uma grande variedade de sistemas de mineração de dados disponíveis. Os sistemas de mineração de dados podem integrar técnicas das seguintes -
- Análise de Dados Espaciais
- Recuperação de informação
- Reconhecimento de padrões
- Análise de imagem
- Processamento de Sinal
- Computação Gráfica
- Tecnologia da Web
- Business
- Bioinformatics
Classificação do sistema de mineração de dados
Um sistema de mineração de dados pode ser classificado de acordo com os seguintes critérios -
- Tecnologia de Banco de Dados
- Statistics
- Aprendizado de Máquina
- Ciência da Informação
- Visualization
- Outras Disciplinas

Além disso, um sistema de mineração de dados também pode ser classificado com base no tipo de (a) bancos de dados extraídos, (b) conhecimento extraído, (c) técnicas utilizadas e (d) aplicativos adaptados.
Classificação com base nos bancos de dados extraídos
Podemos classificar um sistema de mineração de dados de acordo com o tipo de banco de dados extraído. O sistema de banco de dados pode ser classificado de acordo com diferentes critérios, como modelos de dados, tipos de dados, etc. E o sistema de mineração de dados pode ser classificado de acordo.
Por exemplo, se classificarmos um banco de dados de acordo com o modelo de dados, podemos ter um sistema de mineração relacional, transacional, objeto-relacional ou data warehouse.
Classificação com base no tipo de conhecimento extraído
Podemos classificar um sistema de mineração de dados de acordo com o tipo de conhecimento extraído. Isso significa que o sistema de mineração de dados é classificado com base em funcionalidades como -
- Characterization
- Discrimination
- Análise de Associação e Correlação
- Classification
- Prediction
- Análise Outlier
- Análise de Evolução
Classificação com base nas técnicas utilizadas
Podemos classificar um sistema de mineração de dados de acordo com o tipo de técnicas utilizadas. Podemos descrever essas técnicas de acordo com o grau de interação do usuário envolvido ou os métodos de análise empregados.
Classificação com base nos aplicativos adaptados
Podemos classificar um sistema de mineração de dados de acordo com as aplicações adaptadas. Esses aplicativos são os seguintes -
- Finance
- Telecommunications
- DNA
- Mercado de ações
Integrando um Sistema de Mineração de Dados com um Sistema DB / DW
Se um sistema de mineração de dados não estiver integrado a um banco de dados ou a um sistema de data warehouse, não haverá sistema com o qual se comunicar. Este esquema é conhecido como esquema de não acoplamento. Neste esquema, o foco principal está no projeto de mineração de dados e no desenvolvimento de algoritmos eficientes e eficazes para minerar os conjuntos de dados disponíveis.
A lista de Esquemas de Integração é a seguinte -
No Coupling- Neste esquema, o sistema de mineração de dados não utiliza nenhuma das funções de banco de dados ou data warehouse. Ele busca os dados de uma fonte específica e os processa usando alguns algoritmos de mineração de dados. O resultado da mineração de dados é armazenado em outro arquivo.
Loose Coupling- Neste esquema, o sistema de mineração de dados pode usar algumas das funções do banco de dados e do sistema de data warehouse. Ele busca os dados respiratórios gerenciados por esses sistemas e executa a mineração de dados nesses dados. Em seguida, ele armazena o resultado da mineração em um arquivo ou em um local designado em um banco de dados ou em um data warehouse.
Semi−tight Coupling - Neste esquema, o sistema de mineração de dados é vinculado a um banco de dados ou sistema de data warehouse e, além disso, implementações eficientes de algumas primitivas de mineração de dados podem ser fornecidas no banco de dados.
Tight coupling- Neste esquema de acoplamento, o sistema de mineração de dados é perfeitamente integrado ao banco de dados ou sistema de data warehouse. O subsistema de mineração de dados é tratado como um componente funcional de um sistema de informação.
O Data Mining Query Language (DMQL) foi proposto por Han, Fu, Wang, et al. para o sistema de mineração de dados DBMiner. A linguagem de consulta de mineração de dados é, na verdade, baseada na linguagem de consulta estruturada (SQL). Linguagens de consulta de mineração de dados podem ser projetadas para oferecer suporte à mineração de dados ad hoc e interativa. Este DMQL fornece comandos para especificar primitivos. O DMQL também pode funcionar com bancos de dados e data warehouses. DMQL pode ser usado para definir tarefas de mineração de dados. Em particular, examinamos como definir data warehouses e data marts em DMQL.
Sintaxe para especificação de dados relevantes para a tarefa
Aqui está a sintaxe do DMQL para especificar dados relevantes para a tarefa -
use database database_name
or
use data warehouse data_warehouse_name
in relevance to att_or_dim_list
from relation(s)/cube(s) [where condition]
order by order_list
group by grouping_listSintaxe para especificar o tipo de conhecimento
Aqui, discutiremos a sintaxe para caracterização, discriminação, associação, classificação e previsão.
Caracterização
A sintaxe para caracterização é -
mine characteristics [as pattern_name]
analyze {measure(s) }A cláusula de análise especifica medidas agregadas, como contagem, soma ou% de contagem.
Por exemplo -
Description describing customer purchasing habits.
mine characteristics as customerPurchasing
analyze count%Discriminação
A sintaxe para Discriminação é -
mine comparison [as {pattern_name]}
For {target_class } where {t arget_condition }
{versus {contrast_class_i }
where {contrast_condition_i}}
analyze {measure(s) }Por exemplo, um usuário pode definir grandes gastadores como clientes que compram itens que custam $100 or more on an average; and budget spenders as customers who purchase items at less than $100 em média. A mineração de descrições discriminantes para clientes de cada uma dessas categorias pode ser especificada no DMQL como -
mine comparison as purchaseGroups
for bigSpenders where avg(I.price) ≥$100 versus budgetSpenders where avg(I.price)< $100
analyze countAssociação
A sintaxe para associação é -
mine associations [ as {pattern_name} ]
{matching {metapattern} }Por exemplo -
mine associations as buyingHabits
matching P(X:customer,W) ^ Q(X,Y) ≥ buys(X,Z)onde X é a chave da relação com o cliente; P e Q são variáveis predicativas; e W, Y e Z são variáveis de objeto.
Classificação
A sintaxe para classificação é -
mine classification [as pattern_name]
analyze classifying_attribute_or_dimensionPor exemplo, para padrões de mineração, classificando a classificação de crédito do cliente onde as classes são determinadas pelo atributo credit_rating e a classificação da mina é determinada como classifyCustomerCreditRating.
analyze credit_ratingPredição
A sintaxe para predição é -
mine prediction [as pattern_name]
analyze prediction_attribute_or_dimension
{set {attribute_or_dimension_i= value_i}}Sintaxe para especificação de hierarquia de conceito
Para especificar hierarquias de conceito, use a seguinte sintaxe -
use hierarchy <hierarchy> for <attribute_or_dimension>Usamos diferentes sintaxes para definir diferentes tipos de hierarquias, como -
-schema hierarchies
define hierarchy time_hierarchy on date as [date,month quarter,year]
-
set-grouping hierarchies
define hierarchy age_hierarchy for age on customer as
level1: {young, middle_aged, senior} < level0: all
level2: {20, ..., 39} < level1: young
level3: {40, ..., 59} < level1: middle_aged
level4: {60, ..., 89} < level1: senior
-operation-derived hierarchies
define hierarchy age_hierarchy for age on customer as
{age_category(1), ..., age_category(5)}
:= cluster(default, age, 5) < all(age)
-rule-based hierarchies
define hierarchy profit_margin_hierarchy on item as
level_1: low_profit_margin < level_0: all
if (price - cost)< $50 level_1: medium-profit_margin < level_0: all if ((price - cost) > $50) and ((price - cost) ≤ $250))
level_1: high_profit_margin < level_0: allSintaxe para especificação de medidas de interesse
Medidas de interesse e limites podem ser especificados pelo usuário com a declaração -
with <interest_measure_name> threshold = threshold_valuePor exemplo -
with support threshold = 0.05
with confidence threshold = 0.7Sintaxe para apresentação de padrões e especificação de visualização
Temos uma sintaxe que permite aos usuários especificar a exibição dos padrões descobertos em uma ou mais formas.
display as <result_form>Por exemplo -
display as tableEspecificação completa de DMQL
Como gerente de mercado de uma empresa, você gostaria de caracterizar os hábitos de compra dos clientes que podem comprar itens com preços não inferiores a $ 100; com relação à idade do cliente, tipo de item adquirido e local onde o item foi adquirido. Você gostaria de saber a porcentagem de clientes com essa característica. Em particular, você está interessado apenas em compras feitas no Canadá e pagas com um cartão de crédito American Express. Você gostaria de ver as descrições resultantes na forma de uma tabela.
use database AllElectronics_db
use hierarchy location_hierarchy for B.address
mine characteristics as customerPurchasing
analyze count%
in relevance to C.age,I.type,I.place_made
from customer C, item I, purchase P, items_sold S, branch B
where I.item_ID = S.item_ID and P.cust_ID = C.cust_ID and
P.method_paid = "AmEx" and B.address = "Canada" and I.price ≥ 100
with noise threshold = 5%
display as tablePadronização de Linguagens de Mineração de Dados
A padronização das linguagens de mineração de dados atenderá aos seguintes propósitos -
Ajuda no desenvolvimento sistemático de soluções de mineração de dados.
Melhora a interoperabilidade entre vários sistemas e funções de mineração de dados.
Promove a educação e o aprendizado rápido.
Promove o uso de sistemas de mineração de dados na indústria e na sociedade.
Existem duas formas de análise de dados que podem ser usadas para extrair modelos que descrevem classes importantes ou para prever tendências de dados futuras. Essas duas formas são as seguintes -
- Classification
- Prediction
Os modelos de classificação prevêem rótulos de classe categóricos; e os modelos de previsão prevêem funções de valor contínuo. Por exemplo, podemos construir um modelo de classificação para categorizar os pedidos de empréstimo bancário como seguros ou arriscados, ou um modelo de previsão para prever os gastos em dólares de clientes potenciais em equipamentos de informática, de acordo com sua renda e ocupação.
O que é classificação?
A seguir estão os exemplos de casos em que a tarefa de análise de dados é Classificação -
Um oficial de crédito bancário deseja analisar os dados para saber qual cliente (solicitante do empréstimo) é arriscado ou seguro.
O gerente de marketing de uma empresa precisa analisar um cliente com determinado perfil, que vai comprar um novo computador.
Em ambos os exemplos acima, um modelo ou classificador é construído para prever os rótulos categóricos. Esses rótulos são arriscados ou seguros para dados de solicitação de empréstimo e sim ou não para dados de marketing.
O que é previsão?
A seguir estão os exemplos de casos em que a tarefa de análise de dados é Predição -
Suponha que o gerente de marketing precise prever quanto um determinado cliente gastará durante uma venda em sua empresa. Neste exemplo, estamos preocupados em prever um valor numérico. Portanto, a tarefa de análise de dados é um exemplo de previsão numérica. Nesse caso, um modelo ou preditor será construído para prever uma função de valor contínuo ou valor ordenado.
Note - A análise de regressão é uma metodologia estatística usada com mais frequência para previsão numérica.
Como funciona a classificação?
Com a ajuda do aplicativo de empréstimo bancário que discutimos acima, vamos entender o funcionamento da classificação. O processo de classificação de dados inclui duas etapas -
- Construindo o Classificador ou Modelo
- Usando classificador para classificação
Construindo o Classificador ou Modelo
Esta etapa é a etapa de aprendizagem ou a fase de aprendizagem.
Nesta etapa, os algoritmos de classificação constroem o classificador.
O classificador é construído a partir do conjunto de treinamento composto de tuplas de banco de dados e seus rótulos de classe associados.
Cada tupla que constitui o conjunto de treinamento é referida como uma categoria ou classe. Essas tuplas também podem ser chamadas de amostra, objeto ou pontos de dados.

Usando classificador para classificação
Nesta etapa, o classificador é usado para classificação. Aqui, os dados de teste são usados para estimar a precisão das regras de classificação. As regras de classificação podem ser aplicadas às novas tuplas de dados se a precisão for considerada aceitável.

Problemas de classificação e previsão
O principal problema é preparar os dados para Classificação e Previsão. A preparação dos dados envolve as seguintes atividades -
Data Cleaning- A limpeza de dados envolve a remoção do ruído e o tratamento dos valores ausentes. O ruído é removido aplicando técnicas de suavização e o problema de valores ausentes é resolvido substituindo um valor ausente pelo valor de ocorrência mais comum para esse atributo.
Relevance Analysis- O banco de dados também pode ter atributos irrelevantes. A análise de correlação é usada para saber se dois atributos dados estão relacionados.
Data Transformation and reduction - Os dados podem ser transformados por qualquer um dos seguintes métodos.
Normalization- Os dados são transformados usando normalização. A normalização envolve o dimensionamento de todos os valores de determinado atributo para fazê-los cair dentro de um pequeno intervalo especificado. A normalização é usada quando na etapa de aprendizagem são utilizadas as redes neurais ou os métodos que envolvem medições.
Generalization- Os dados também podem ser transformados generalizando-os para o conceito superior. Para isso, podemos usar as hierarquias de conceitos.
Note - Os dados também podem ser reduzidos por alguns outros métodos, como transformação wavelet, binning, análise de histograma e clustering.
Comparação de métodos de classificação e previsão
Aqui estão os critérios para comparar os métodos de classificação e previsão -
Accuracy- A precisão do classificador se refere à capacidade do classificador. Ele prevê o rótulo da classe corretamente e a precisão do preditor se refere a quão bem um determinado preditor pode adivinhar o valor do atributo predito para um novo dado.
Speed - Refere-se ao custo computacional na geração e uso do classificador ou preditor.
Robustness - Refere-se à capacidade do classificador ou preditor de fazer previsões corretas a partir de dados com ruído fornecidos.
Scalability- Escalabilidade refere-se à capacidade de construir o classificador ou preditor de forma eficiente; dada grande quantidade de dados.
Interpretability - Refere-se a até que ponto o classificador ou preditor entende.
Uma árvore de decisão é uma estrutura que inclui um nó raiz, ramos e nós folha. Cada nó interno denota um teste em um atributo, cada ramificação denota o resultado de um teste e cada nó folha contém um rótulo de classe. O nó superior da árvore é o nó raiz.
A árvore de decisão a seguir é para o conceito buy_computer, que indica se um cliente de uma empresa provavelmente comprará um computador ou não. Cada nó interno representa um teste em um atributo. Cada nó folha representa uma classe.

Os benefícios de ter uma árvore de decisão são os seguintes -
- Não requer nenhum conhecimento de domínio.
- É fácil de compreender.
- As etapas de aprendizagem e classificação de uma árvore de decisão são simples e rápidas.
Algoritmo de indução de árvore de decisão
Um pesquisador de máquina chamado J. Ross Quinlan em 1980 desenvolveu um algoritmo de árvore de decisão conhecido como ID3 (Dicotomizador Iterativo). Posteriormente, ele apresentou o C4.5, que foi o sucessor do ID3. ID3 e C4.5 adotam uma abordagem gananciosa. Nesse algoritmo, não há retrocesso; as árvores são construídas de uma maneira recursiva de divisão e conquista de cima para baixo.
Generating a decision tree form training tuples of data partition D
Algorithm : Generate_decision_tree
Input:
Data partition, D, which is a set of training tuples
and their associated class labels.
attribute_list, the set of candidate attributes.
Attribute selection method, a procedure to determine the
splitting criterion that best partitions that the data
tuples into individual classes. This criterion includes a
splitting_attribute and either a splitting point or splitting subset.
Output:
A Decision Tree
Method
create a node N;
if tuples in D are all of the same class, C then
return N as leaf node labeled with class C;
if attribute_list is empty then
return N as leaf node with labeled
with majority class in D;|| majority voting
apply attribute_selection_method(D, attribute_list)
to find the best splitting_criterion;
label node N with splitting_criterion;
if splitting_attribute is discrete-valued and
multiway splits allowed then // no restricted to binary trees
attribute_list = splitting attribute; // remove splitting attribute
for each outcome j of splitting criterion
// partition the tuples and grow subtrees for each partition
let Dj be the set of data tuples in D satisfying outcome j; // a partition
if Dj is empty then
attach a leaf labeled with the majority
class in D to node N;
else
attach the node returned by Generate
decision tree(Dj, attribute list) to node N;
end for
return N;Poda de árvores
A poda de árvores é realizada para remover anomalias nos dados de treinamento devido a ruídos ou outliers. As árvores podadas são menores e menos complexas.
Abordagens de poda de árvores
Existem duas abordagens para podar uma árvore -
Pre-pruning - A árvore é podada interrompendo-se precocemente a sua construção.
Post-pruning - Esta abordagem remove uma subárvore de uma árvore totalmente crescida.
Complexidade de custos
A complexidade do custo é medida pelos dois parâmetros a seguir -
- Número de folhas na árvore, e
- Taxa de erro da árvore.
A classificação bayesiana é baseada no Teorema de Bayes. Os classificadores bayesianos são os classificadores estatísticos. Os classificadores bayesianos podem prever probabilidades de associação de classe, como a probabilidade de uma determinada tupla pertencer a uma classe específica.
Teorema de Baye
O teorema de Bayes tem o nome de Thomas Bayes. Existem dois tipos de probabilidades -
- Probabilidade posterior [P (H / X)]
- Probabilidade anterior [P (H)]
onde X é a tupla de dados e H é alguma hipótese.
De acordo com o Teorema de Bayes,
Bayesian Belief Network
As redes de crenças bayesianas especificam distribuições conjuntas de probabilidade condicional. Eles também são conhecidos como Redes de Crenças, Redes Bayesianas ou Redes Probabilísticas.
Uma Rede de Crenças permite que independências condicionais de classe sejam definidas entre subconjuntos de variáveis.
Ele fornece um modelo gráfico de relacionamento causal no qual o aprendizado pode ser realizado.
Podemos usar uma Rede Bayesiana treinada para classificação.
Existem dois componentes que definem uma Rede de Crenças Bayesiana -
- Gráfico acíclico direcionado
- Um conjunto de tabelas de probabilidade condicional
Gráfico Acíclico Direcionado
- Cada nó em um gráfico acíclico direcionado representa uma variável aleatória.
- Essas variáveis podem ser discretas ou de valor contínuo.
- Essas variáveis podem corresponder ao atributo real fornecido nos dados.
Representação gráfica acíclica dirigida
O diagrama a seguir mostra um gráfico acíclico direcionado para seis variáveis booleanas.

O arco no diagrama permite a representação do conhecimento causal. Por exemplo, o câncer de pulmão é influenciado pela história familiar de câncer de pulmão de uma pessoa, bem como pelo fato de a pessoa ser ou não fumante. É importante ressaltar que a variável PositiveXray independe de o paciente ter história familiar de câncer de pulmão ou ser tabagista, visto que sabemos que o paciente tem câncer de pulmão.
Tabela de Probabilidade Condicional
A tabela de probabilidade condicional para os valores da variável LungCancer (LC) mostrando cada combinação possível dos valores de seus nós pais, FamilyHistory (FH) e Smoker (S) é a seguinte -

Regras IF-THEN
O classificador baseado em regras usa um conjunto de regras IF-THEN para classificação. Podemos expressar uma regra no seguinte de -
Vamos considerar uma regra R1,
R1: IF age = youth AND student = yes
THEN buy_computer = yesPoints to remember −
A parte IF da regra é chamada rule antecedent ou precondition.
A parte ENTÃO da regra é chamada rule consequent.
A parte antecedente da condição consiste em um ou mais testes de atributo e esses testes são logicamente ligados por AND.
A parte conseqüente consiste na previsão da classe.
Note - Também podemos escrever a regra R1 da seguinte forma -
R1: (age = youth) ^ (student = yes))(buys computer = yes)Se a condição for verdadeira para uma dada tupla, o antecedente está satisfeito.
Extração de regra
Aqui, aprenderemos como construir um classificador baseado em regras, extraindo regras IF-THEN de uma árvore de decisão.
Points to remember −
Para extrair uma regra de uma árvore de decisão -
Uma regra é criada para cada caminho da raiz ao nó folha.
Para formar um antecedente de regra, cada critério de divisão é logicamente ligado por AND.
O nó folha contém a predição da classe, formando a regra consequente.
Indução de regra usando algoritmo de cobertura sequencial
O Algoritmo de Cobertura Sequencial pode ser usado para extrair regras IF-THEN dos dados de treinamento. Não é necessário gerar uma árvore de decisão primeiro. Nesse algoritmo, cada regra para uma determinada classe cobre muitas das tuplas dessa classe.
Alguns dos algoritmos de cobertura sequenciais são AQ, CN2 e RIPPER. De acordo com a estratégia geral, as regras são aprendidas uma de cada vez. Para cada vez que as regras são aprendidas, uma tupla coberta pela regra é removida e o processo continua para o restante das tuplas. Isso ocorre porque o caminho para cada folha em uma árvore de decisão corresponde a uma regra.
Note - A indução da árvore de decisão pode ser considerada como o aprendizado de um conjunto de regras simultaneamente.
A seguir está o Algoritmo de aprendizado sequencial, em que as regras são aprendidas para uma classe de cada vez. Ao aprender uma regra de uma classe Ci, queremos que a regra cubra todas as tuplas da classe C apenas e nenhuma tupla de qualquer outra classe.
Algorithm: Sequential Covering
Input:
D, a data set class-labeled tuples,
Att_vals, the set of all attributes and their possible values.
Output: A Set of IF-THEN rules.
Method:
Rule_set={ }; // initial set of rules learned is empty
for each class c do
repeat
Rule = Learn_One_Rule(D, Att_valls, c);
remove tuples covered by Rule form D;
until termination condition;
Rule_set=Rule_set+Rule; // add a new rule to rule-set
end for
return Rule_Set;Poda de regra
A regra foi removida devido ao seguinte motivo -
A avaliação da qualidade é feita no conjunto original de dados de treinamento. A regra pode funcionar bem em dados de treinamento, mas não tão bem em dados subsequentes. É por isso que a poda de regra é necessária.
A regra é podada removendo o conjunto. A regra R é removida, se a versão removida de R tiver maior qualidade do que o que foi avaliado em um conjunto independente de tuplas.
FOIL é um dos métodos simples e eficazes para a poda de réguas. Para uma dada regra R,
onde pos e neg é o número de tuplas positivas cobertas por R, respectivamente.
Note- Este valor aumentará com a precisão de R no conjunto de poda. Portanto, se o valor FOIL_Prune for maior para a versão podada de R, então podamos R.
Aqui, discutiremos outros métodos de classificação, como Algoritmos Genéticos, Abordagem de Conjunto Bruto e Abordagem de Conjunto Fuzzy.
Algorítmos genéticos
A ideia de algoritmo genético é derivada da evolução natural. No algoritmo genético, em primeiro lugar, a população inicial é criada. Essa população inicial consiste em regras geradas aleatoriamente. Podemos representar cada regra por uma sequência de bits.
Por exemplo, em um determinado conjunto de treinamento, as amostras são descritas por dois atributos booleanos, como A1 e A2. E este determinado conjunto de treinamento contém duas classes, como C1 e C2.
Podemos codificar a regra IF A1 AND NOT A2 THEN C2 em uma pequena corda 100. Nesta representação de bit, os dois bits mais à esquerda representam o atributo A1 e A2, respectivamente.
Da mesma forma, a regra IF NOT A1 AND NOT A2 THEN C1 pode ser codificado como 001.
Note- Se o atributo tiver K valores onde K> 2, então podemos usar os K bits para codificar os valores do atributo. As classes também são codificadas da mesma maneira.
Pontos a lembrar -
Com base na noção de sobrevivência do mais apto, uma nova população é formada que consiste nas regras mais aptas na população atual e também nos valores descendentes dessas regras.
A adequação de uma regra é avaliada por sua precisão de classificação em um conjunto de amostras de treinamento.
Os operadores genéticos, como crossover e mutação, são aplicados para criar descendentes.
No crossover, a substring do par de regras é trocada para formar um novo par de regras.
Na mutação, bits selecionados aleatoriamente em uma string de regra são invertidos.
Abordagem de conjunto aproximado
Podemos usar a abordagem do conjunto aproximado para descobrir a relação estrutural em dados imprecisos e com ruído.
Note- Esta abordagem só pode ser aplicada em atributos de valor discreto. Portanto, atributos de valor contínuo devem ser discretizados antes de seu uso.
A Rough Set Theory é baseada no estabelecimento de classes de equivalência dentro dos dados de treinamento fornecidos. As tuplas que formam a classe de equivalência são indiscerníveis. Isso significa que as amostras são idênticas em relação aos atributos que descrevem os dados.
Existem algumas classes nos dados do mundo real fornecidos, que não podem ser distinguidas em termos de atributos disponíveis. Podemos usar os conjuntos básicos pararoughly definir essas classes.
Para uma determinada classe C, a definição do conjunto aproximado é aproximada por dois conjuntos da seguinte forma -
Lower Approximation of C - A aproximação inferior de C consiste em todas as tuplas de dados, que com base no conhecimento do atributo, certamente pertencem à classe C.
Upper Approximation of C - A aproximação superior de C consiste em todas as tuplas, que com base no conhecimento dos atributos, não podem ser descritas como não pertencentes a C.
O diagrama a seguir mostra a aproximação superior e inferior da classe C -

Abordagens de conjuntos difusos
A Teoria dos Conjuntos Fuzzy também é chamada de Teoria das Possibilidades. Esta teoria foi proposta por Lotfi Zadeh em 1965 como uma alternativa aotwo-value logic e probability theory. Essa teoria nos permite trabalhar em um alto nível de abstração. Também nos fornece os meios para lidar com medições imprecisas de dados.
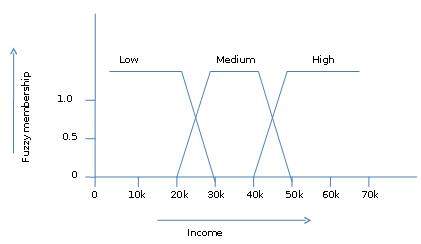
A teoria dos conjuntos difusos também nos permite lidar com fatos vagos ou inexatos. Por exemplo, ser membro de um conjunto de altas rendas é exato (por exemplo, se$50,000 is high then what about $49.000 e $ 48.000). Ao contrário do conjunto CRISP tradicional em que o elemento pertence a S ou a seu complemento, mas na teoria dos conjuntos difusos o elemento pode pertencer a mais de um conjunto difuso.
Por exemplo, o valor da receita $ 49.000 pertence aos conjuntos difusos médio e alto, mas em graus diferentes. A notação de conjunto difuso para este valor de renda é a seguinte -
mmedium_income($49k)=0.15 and mhigh_income($49k)=0.96onde 'm' é a função de pertinência que opera nos conjuntos difusos de renda_média e renda_ alta, respectivamente. Esta notação pode ser mostrada em diagrama da seguinte forma -
Cluster é um grupo de objetos que pertence à mesma classe. Em outras palavras, objetos semelhantes são agrupados em um cluster e objetos diferentes são agrupados em outro cluster.
O que é clustering?
Clustering é o processo de transformar um grupo de objetos abstratos em classes de objetos semelhantes.
Points to Remember
Um cluster de objetos de dados pode ser tratado como um grupo.
Ao fazer a análise de cluster, primeiro particionamos o conjunto de dados em grupos com base na similaridade de dados e, em seguida, atribuímos os rótulos aos grupos.
A principal vantagem do agrupamento em relação à classificação é que ele é adaptável a mudanças e ajuda a destacar recursos úteis que distinguem grupos diferentes.
Aplicações de Análise de Cluster
A análise de agrupamento é amplamente usada em muitas aplicações, como pesquisa de mercado, reconhecimento de padrões, análise de dados e processamento de imagens.
O agrupamento também pode ajudar os profissionais de marketing a descobrir grupos distintos em sua base de clientes. E eles podem caracterizar seus grupos de clientes com base nos padrões de compra.
No campo da biologia, pode ser usado para derivar taxonomias de plantas e animais, categorizar genes com funcionalidades semelhantes e obter informações sobre as estruturas inerentes às populações.
O agrupamento também ajuda na identificação de áreas de uso da terra semelhantes em um banco de dados de observação da Terra. Também ajuda na identificação de grupos de casas em uma cidade de acordo com o tipo de casa, valor e localização geográfica.
O clustering também ajuda a classificar documentos na web para descoberta de informações.
O clustering também é usado em aplicativos de detecção de outliers, como detecção de fraude de cartão de crédito.
Como uma função de mineração de dados, a análise de cluster serve como uma ferramenta para obter insights sobre a distribuição de dados para observar as características de cada cluster.
Requisitos de Clustering em Data Mining
Os pontos a seguir lançam luz sobre por que o clustering é necessário na mineração de dados -
Scalability - Precisamos de algoritmos de clustering altamente escalonáveis para lidar com grandes bancos de dados.
Ability to deal with different kinds of attributes - Os algoritmos devem ser capazes de ser aplicados em qualquer tipo de dados, como dados baseados em intervalos (numéricos), dados categóricos e binários.
Discovery of clusters with attribute shape- O algoritmo de agrupamento deve ser capaz de detectar clusters de forma arbitrária. Eles não devem ser limitados apenas a medidas de distância que tendem a encontrar aglomerados esféricos de tamanhos pequenos.
High dimensionality - O algoritmo de agrupamento deve ser capaz de lidar não apenas com dados de baixa dimensão, mas também com o espaço de alta dimensão.
Ability to deal with noisy data- Os bancos de dados contêm dados ruidosos, ausentes ou errôneos. Alguns algoritmos são sensíveis a esses dados e podem levar a clusters de baixa qualidade.
Interpretability - Os resultados do agrupamento devem ser interpretáveis, compreensíveis e utilizáveis.
Métodos de agrupamento
Os métodos de agrupamento podem ser classificados nas seguintes categorias -
- Método de Particionamento
- Método Hierárquico
- Método baseado em densidade
- Método baseado em grade
- Método baseado em modelo
- Método baseado em restrições
Método de Particionamento
Suponha que recebamos um banco de dados de 'n' objetos e o método de particionamento construa uma partição 'k' de dados. Cada partição representará um cluster ek ≤ n. Isso significa que ele classificará os dados em k grupos, que satisfazem os seguintes requisitos -
Cada grupo contém pelo menos um objeto.
Cada objeto deve pertencer a exatamente um grupo.
Points to remember −
Para um determinado número de partições (digamos k), o método de particionamento criará um particionamento inicial.
Em seguida, ele usa a técnica de realocação iterativa para melhorar o particionamento movendo objetos de um grupo para outro.
Métodos Hierárquicos
Este método cria uma decomposição hierárquica de um determinado conjunto de objetos de dados. Podemos classificar os métodos hierárquicos com base em como a decomposição hierárquica é formada. Existem duas abordagens aqui -
- Abordagem Aglomerativa
- Abordagem Divisiva
Abordagem Aglomerativa
Essa abordagem também é conhecida como abordagem ascendente. Neste, começamos com cada objeto formando um grupo separado. Ele continua mesclando os objetos ou grupos que estão próximos uns dos outros. Isso continuará até que todos os grupos sejam mesclados em um ou até que a condição de encerramento seja mantida.
Abordagem Divisiva
Essa abordagem também é conhecida como abordagem de cima para baixo. Neste, começamos com todos os objetos no mesmo cluster. Na iteração contínua, um cluster é dividido em clusters menores. Ele está inativo até que cada objeto em um cluster ou a condição de terminação seja mantida. Este método é rígido, ou seja, uma vez que uma fusão ou divisão é feita, ela nunca pode ser desfeita.
Abordagens para melhorar a qualidade do cluster hierárquico
Aqui estão as duas abordagens que são usadas para melhorar a qualidade do clustering hierárquico -
Realize uma análise cuidadosa das ligações de objetos em cada partição hierárquica.
Integre a aglomeração hierárquica usando primeiro um algoritmo aglomerativo hierárquico para agrupar objetos em micro-clusters e, em seguida, executando macro-clustering nos micro-clusters.
Método baseado em densidade
Este método é baseado na noção de densidade. A ideia básica é continuar crescendo o dado cluster enquanto a densidade na vizinhança exceder algum limite, ou seja, para cada ponto de dados dentro de um determinado cluster, o raio de um determinado cluster deve conter pelo menos um número mínimo de pontos.
Método baseado em grade
Neste, os objetos juntos formam uma grade. O espaço do objeto é quantizado em um número finito de células que formam uma estrutura de grade.
Advantages
A principal vantagem desse método é o tempo de processamento rápido.
Depende apenas do número de células em cada dimensão no espaço quantizado.
Métodos baseados em modelo
Neste método, um modelo é hipotetizado para cada cluster para encontrar o melhor ajuste de dados para um determinado modelo. Este método localiza os clusters agrupando a função de densidade. Ele reflete a distribuição espacial dos pontos de dados.
Este método também fornece uma maneira de determinar automaticamente o número de clusters com base em estatísticas padrão, levando em consideração valores discrepantes ou ruído. Portanto, produz métodos de agrupamento robustos.
Método baseado em restrições
Nesse método, o clustering é realizado pela incorporação de restrições orientadas ao usuário ou à aplicação. Uma restrição refere-se à expectativa do usuário ou às propriedades dos resultados de agrupamento desejados. As restrições nos fornecem uma forma interativa de comunicação com o processo de agrupamento. As restrições podem ser especificadas pelo usuário ou pelo requisito do aplicativo.
Bancos de dados de texto consistem em uma grande coleção de documentos. Eles coletam essas informações de várias fontes, como artigos de notícias, livros, bibliotecas digitais, mensagens de e-mail, páginas da web, etc. Devido ao aumento da quantidade de informações, as bases de dados de texto estão crescendo rapidamente. Em muitas das bases de dados de texto, os dados são semiestruturados.
Por exemplo, um documento pode conter alguns campos estruturados, como título, autor, data_de_publicação, etc. Mas junto com os dados da estrutura, o documento também contém componentes de texto não estruturados, como resumo e conteúdo. Sem saber o que poderia estar nos documentos, é difícil formular consultas eficazes para analisar e extrair informações úteis dos dados. Os usuários precisam de ferramentas para comparar os documentos e classificar sua importância e relevância. Portanto, a mineração de texto se tornou popular e um tema essencial na mineração de dados.
Recuperação de informação
A recuperação de informações trata da recuperação de informações de um grande número de documentos baseados em texto. Alguns dos sistemas de banco de dados geralmente não estão presentes em sistemas de recuperação de informações porque ambos lidam com diferentes tipos de dados. Exemplos de sistema de recuperação de informação incluem -
- Sistema de catálogo da biblioteca online
- Sistemas de gerenciamento de documentos online
- Sistemas de pesquisa na web etc.
Note- O principal problema em um sistema de recuperação de informação é localizar documentos relevantes em uma coleção de documentos com base na consulta do usuário. Este tipo de consulta do usuário consiste em algumas palavras-chave que descrevem uma necessidade de informação.
Em tais problemas de pesquisa, o usuário toma a iniciativa de extrair informações relevantes de uma coleção. Isso é apropriado quando o usuário tem uma necessidade de informações ad-hoc, ou seja, uma necessidade de curto prazo. Mas se o usuário tiver uma necessidade de informação de longo prazo, o sistema de recuperação também pode tomar a iniciativa de enviar qualquer item de informação recém-chegado ao usuário.
Esse tipo de acesso à informação é denominado Filtragem de Informações. E os sistemas correspondentes são conhecidos como Sistemas de Filtragem ou Sistemas de Recomendação.
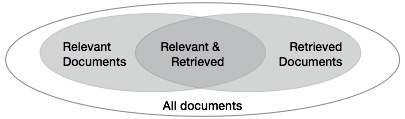
Medidas básicas para recuperação de texto
Precisamos verificar a precisão de um sistema quando ele recupera uma série de documentos com base na entrada do usuário. Deixe o conjunto de documentos relevantes para uma consulta ser denotado como {Relevante} e o conjunto de documentos recuperados como {Recuperado}. O conjunto de documentos que são relevantes e recuperados pode ser denotado como {Relevante} ∩ {Recuperado}. Isso pode ser mostrado na forma de um diagrama de Venn como segue -
Existem três medidas fundamentais para avaliar a qualidade da recuperação de texto -
- Precision
- Recall
- F-score
Precisão
A precisão é a porcentagem de documentos recuperados que são de fato relevantes para a consulta. A precisão pode ser definida como -
Precision= |{Relevant} ∩ {Retrieved}| / |{Retrieved}|Recall
A recuperação é a porcentagem de documentos que são relevantes para a consulta e foram de fato recuperados. Recall é definido como -
Recall = |{Relevant} ∩ {Retrieved}| / |{Relevant}|Pontuação F
A pontuação F é a compensação comumente usada. O sistema de recuperação de informações frequentemente precisa ser compensado pela precisão ou vice-versa. A pontuação F é definida como média harmônica de recall ou precisão da seguinte forma -
F-score = recall x precision / (recall + precision) / 2A World Wide Web contém grandes quantidades de informações que fornecem uma fonte rica para mineração de dados.
Desafios em Web Mining
A web apresenta grandes desafios para a descoberta de recursos e conhecimento com base nas seguintes observações -
The web is too huge- O tamanho da web é muito grande e está aumentando rapidamente. Parece que a web é muito grande para armazenamento e mineração de dados.
Complexity of Web pages- As páginas da web não possuem estrutura unificadora. Eles são muito complexos em comparação com documentos de texto tradicionais. Existe uma grande quantidade de documentos na biblioteca digital da web. Essas bibliotecas não são organizadas de acordo com nenhuma ordem de classificação específica.
Web is dynamic information source- As informações na web são atualizadas rapidamente. Os dados como notícias, bolsas de valores, clima, esportes, compras, etc., são atualizados regularmente.
Diversity of user communities- A comunidade de usuários na web está se expandindo rapidamente. Esses usuários têm diferentes origens, interesses e finalidades de uso. Existem mais de 100 milhões de estações de trabalho conectadas à Internet e ainda aumentando rapidamente.
Relevancy of Information - Considera-se que uma determinada pessoa geralmente está interessada em apenas uma pequena parte da web, enquanto o resto da parte da web contém as informações que não são relevantes para o usuário e podem atrapalhar os resultados desejados.
Estrutura de layout de página da Web de mineração
A estrutura básica da página da web é baseada no Document Object Model (DOM). A estrutura DOM refere-se a uma estrutura semelhante a uma árvore, em que a tag HTML na página corresponde a um nó na árvore DOM. Podemos segmentar a página da web usando tags predefinidas em HTML. A sintaxe HTML é flexível, portanto, as páginas da web não seguem as especificações W3C. O não cumprimento das especificações do W3C pode causar erros na estrutura da árvore DOM.
A estrutura DOM foi inicialmente introduzida para apresentação no navegador e não para descrição da estrutura semântica da página da web. A estrutura DOM não pode identificar corretamente a relação semântica entre as diferentes partes de uma página da web.
Segmentação de página baseada em visão (VIPS)
O objetivo do VIPS é extrair a estrutura semântica de uma página da web com base em sua apresentação visual.
Essa estrutura semântica corresponde a uma estrutura de árvore. Nesta árvore, cada nó corresponde a um bloco.
Um valor é atribuído a cada nó. Este valor é denominado Grau de Coerência. Este valor é atribuído para indicar o conteúdo coerente no bloco com base na percepção visual.
O algoritmo VIPS primeiro extrai todos os blocos adequados da árvore HTML DOM. Depois disso, ele encontra os separadores entre esses blocos.
Os separadores referem-se às linhas horizontais ou verticais em uma página da web que se cruzam visualmente sem blocos.
A semântica da página da web é construída com base nesses blocos.
A figura a seguir mostra o procedimento do algoritmo VIPS -

A mineração de dados é amplamente utilizada em diversas áreas. Existem vários sistemas de mineração de dados comerciais disponíveis hoje e, ainda assim, existem muitos desafios neste campo. Neste tutorial, discutiremos os aplicativos e a tendência da mineração de dados.
Aplicativos de mineração de dados
Aqui está a lista de áreas onde a mineração de dados é amplamente usada -
- Análise de Dados Financeiros
- Indústria de varejo
- Indústria de Telecomunicações
- Análise de dados biológicos
- Outras aplicações científicas
- Detecção de intruso
Análise de Dados Financeiros
Os dados financeiros no setor bancário e financeiro são geralmente confiáveis e de alta qualidade, o que facilita a análise sistemática de dados e a mineração de dados. Alguns dos casos típicos são os seguintes -
Projeto e construção de data warehouses para análise de dados multidimensionais e mineração de dados.
Previsão de pagamento de empréstimos e análise da política de crédito do cliente.
Classificação e agrupamento de clientes para marketing direcionado.
Detecção de lavagem de dinheiro e outros crimes financeiros.
Indústria de varejo
A mineração de dados tem sua grande aplicação no setor de varejo porque coleta grande quantidade de dados sobre vendas, histórico de compras de clientes, transporte de mercadorias, consumo e serviços. É natural que a quantidade de dados coletados continue a se expandir rapidamente devido à crescente facilidade, disponibilidade e popularidade da web.
A mineração de dados no setor de varejo ajuda a identificar padrões e tendências de compra do cliente que levam à melhoria da qualidade do atendimento ao cliente e boa retenção e satisfação do cliente. Aqui está a lista de exemplos de mineração de dados no setor de varejo -
Projeto e construção de data warehouses com base nos benefícios da mineração de dados.
Análise multidimensional de vendas, clientes, produtos, tempo e região.
Análise de eficácia de campanhas de vendas.
Fidelização de clientes.
Recomendação de produtos e referência cruzada de itens.
Indústria de Telecomunicações
Hoje a indústria de telecomunicações é uma das indústrias mais emergentes, fornecendo vários serviços, como fax, pager, telefone celular, mensageiro de internet, imagens, e-mail, transmissão de dados web, etc. Devido ao desenvolvimento de novas tecnologias de informática e comunicação, o A indústria de telecomunicações está se expandindo rapidamente. Esta é a razão pela qual a mineração de dados se tornou muito importante para ajudar e entender o negócio.
A mineração de dados no setor de telecomunicações ajuda a identificar os padrões de telecomunicações, detectar atividades fraudulentas, fazer melhor uso dos recursos e melhorar a qualidade do serviço. Aqui está a lista de exemplos para os quais a mineração de dados melhora os serviços de telecomunicações -
Análise multidimensional de dados de telecomunicações.
Análise de padrões fraudulentos.
Identificação de padrões incomuns.
Associação multidimensional e análise de padrões sequenciais.
Serviços de telecomunicações móveis.
Uso de ferramentas de visualização na análise de dados de telecomunicações.
Análise de dados biológicos
Nos últimos tempos, temos visto um enorme crescimento no campo da biologia, como genômica, proteômica, genômica funcional e pesquisa biomédica. A mineração de dados biológicos é uma parte muito importante da Bioinformática. A seguir estão os aspectos em que a mineração de dados contribui para a análise de dados biológicos -
Integração semântica de bancos de dados genômicos e proteômicos heterogêneos e distribuídos.
Alinhamento, indexação, busca por similaridade e análise comparativa de múltiplas sequências de nucleotídeos.
Descoberta de padrões estruturais e análise de redes genéticas e vias de proteínas.
Associação e análise de caminhos.
Ferramentas de visualização em análise de dados genéticos.
Outras aplicações científicas
Os aplicativos discutidos acima tendem a lidar com conjuntos de dados relativamente pequenos e homogêneos para os quais as técnicas estatísticas são apropriadas. Uma grande quantidade de dados foi coletada de domínios científicos, como geociências, astronomia, etc. Uma grande quantidade de conjuntos de dados está sendo gerada por causa das rápidas simulações numéricas em vários campos, como modelagem de clima e ecossistema, engenharia química, dinâmica de fluidos, etc. A seguir estão as aplicações de mineração de dados no campo das Aplicações Científicas -
- Armazéns de dados e pré-processamento de dados.
- Mineração baseada em grafos.
- Visualização e conhecimento específico do domínio.
Detecção de intruso
A intrusão se refere a qualquer tipo de ação que ameace a integridade, confidencialidade ou a disponibilidade dos recursos da rede. Neste mundo de conectividade, a segurança se tornou o principal problema. Com o aumento do uso da Internet e a disponibilidade de ferramentas e truques para intrusão e ataque à rede, a detecção de intrusão tornou-se um componente crítico da administração da rede. Aqui está a lista de áreas nas quais a tecnologia de mineração de dados pode ser aplicada para detecção de intrusão -
Desenvolvimento de algoritmo de mineração de dados para detecção de intrusão.
Análise de associação e correlação, agregação para ajudar a selecionar e construir atributos discriminantes.
Análise de dados de fluxo.
Mineração de dados distribuída.
Ferramentas de visualização e consulta.
Produtos de sistema de mineração de dados
Existem muitos produtos de sistema de mineração de dados e aplicativos de mineração de dados específicos de domínio. Os novos sistemas e aplicativos de mineração de dados estão sendo adicionados aos sistemas anteriores. Além disso, esforços estão sendo feitos para padronizar as linguagens de mineração de dados.
Escolhendo um sistema de mineração de dados
A seleção de um sistema de mineração de dados depende dos seguintes recursos -
Data Types- O sistema de mineração de dados pode lidar com texto formatado, dados baseados em registros e dados relacionais. Os dados também podem ser em texto ASCII, dados de banco de dados relacional ou dados de armazém de dados. Portanto, devemos verificar qual formato exato o sistema de mineração de dados pode manipular.
System Issues- Devemos considerar a compatibilidade de um sistema de mineração de dados com diferentes sistemas operacionais. Um sistema de mineração de dados pode ser executado em apenas um sistema operacional ou em vários. Existem também sistemas de mineração de dados que fornecem interfaces de usuário baseadas na web e permitem dados XML como entrada.
Data Sources- As fontes de dados referem-se aos formatos de dados nos quais o sistema de mineração de dados irá operar. Alguns sistemas de mineração de dados podem funcionar apenas em arquivos de texto ASCII, enquanto outros em várias fontes relacionais. O sistema de mineração de dados também deve oferecer suporte a conexões ODBC ou OLE DB para conexões ODBC.
Data Mining functions and methodologies - Existem alguns sistemas de mineração de dados que fornecem apenas uma função de mineração de dados, como classificação, enquanto alguns fornecem várias funções de mineração de dados, como descrição de conceito, análise OLAP orientada por descoberta, mineração de associação, análise de ligação, análise estatística, classificação, previsão, clustering, análise de outlier, pesquisa de similaridade, etc.
Coupling data mining with databases or data warehouse systems- Os sistemas de mineração de dados precisam ser acoplados a um banco de dados ou sistema de data warehouse. Os componentes acoplados são integrados em um ambiente de processamento de informações uniforme. Aqui estão os tipos de acoplamento listados abaixo -
- Sem acoplamento
- Acoplamento solto
- Acoplamento semi-apertado
- Acoplamento Tenso
Scalability - Existem dois problemas de escalabilidade na mineração de dados -
Row (Database size) Scalability- Um sistema de mineração de dados é considerado escalonável por linha quando o número ou as linhas são aumentados 10 vezes. Não leva mais de 10 vezes para executar uma consulta.
Column (Dimension) Salability - Um sistema de mineração de dados é considerado escalonável em coluna se o tempo de execução da consulta de mineração aumentar linearmente com o número de colunas.
Visualization Tools - A visualização na mineração de dados pode ser categorizada da seguinte forma -
- Visualização de dados
- Visualização de resultados de mineração
- Visualização do processo de mineração
- Mineração de dados visuais
Data Mining query language and graphical user interface- Uma interface gráfica de usuário fácil de usar é importante para promover a mineração de dados interativa e guiada pelo usuário. Ao contrário dos sistemas de banco de dados relacionais, os sistemas de mineração de dados não compartilham a linguagem de consulta de mineração de dados subjacente.
Tendências em mineração de dados
Os conceitos de mineração de dados ainda estão evoluindo e aqui estão as últimas tendências que vemos neste campo -
Exploração de aplicativos.
Métodos de mineração de dados escaláveis e interativos.
Integração de data mining com sistemas de banco de dados, sistemas de data warehouse e sistemas de banco de dados web.
SStandardização da linguagem de consulta de mineração de dados.
Mineração de dados visuais.
Novos métodos de mineração de tipos complexos de dados.
Mineração de dados biológicos.
Mineração de dados e engenharia de software.
Mineração da web.
Mineração de dados distribuída.
Mineração de dados em tempo real.
Mineração de dados de vários bancos de dados.
Proteção de privacidade e segurança da informação na mineração de dados.
Fundamentos teóricos de mineração de dados
Os fundamentos teóricos da mineração de dados incluem os seguintes conceitos -
Data Reduction- A ideia básica desta teoria é reduzir a representação de dados que troca precisão por velocidade em resposta à necessidade de obter respostas aproximadas rápidas a consultas em bancos de dados muito grandes. Algumas das técnicas de redução de dados são as seguintes -
Decomposição de valor singular
Wavelets
Regression
Modelos log-lineares
Histograms
Clustering
Sampling
Construção de Árvores de Índice
Data Compression - A ideia básica desta teoria é compactar os dados fornecidos pela codificação nos termos do seguinte -
Bits
Regras de Associação
Árvores de decisão
Clusters
Pattern Discovery- A ideia básica desta teoria é descobrir padrões que ocorrem em um banco de dados. A seguir estão as áreas que contribuem para esta teoria -
Aprendizado de Máquina
Rede neural
Associação de Mineração
Correspondência de padrões sequenciais
Clustering
Probability Theory- Esta teoria é baseada na teoria estatística. A ideia básica por trás dessa teoria é descobrir distribuições de probabilidade conjuntas de variáveis aleatórias.
Probability Theory - De acordo com esta teoria, a mineração de dados encontra os padrões que são interessantes apenas na medida em que podem ser usados no processo de tomada de decisão de alguma empresa.
Microeconomic View- De acordo com esta teoria, um esquema de banco de dados consiste em dados e padrões que são armazenados em um banco de dados. Portanto, data mining é a tarefa de realizar indução em bancos de dados.
Inductive databases- Além das técnicas orientadas a banco de dados, existem técnicas estatísticas disponíveis para a análise de dados. Essas técnicas podem ser aplicadas a dados científicos e também a dados de ciências econômicas e sociais.
Mineração de dados estatísticos
Algumas das Técnicas de Mineração de Dados Estatísticos são as seguintes -
Regression- Métodos de regressão são usados para prever o valor da variável de resposta de uma ou mais variáveis de previsão onde as variáveis são numéricas. Listadas abaixo estão as formas de regressão -
Linear
Multiple
Weighted
Polynomial
Nonparametric
Robust
Generalized Linear Models - O modelo linear generalizado inclui -
Regressão Logística
Regressão de Poisson
A generalização do modelo permite que uma variável de resposta categórica seja relacionada a um conjunto de variáveis preditoras de maneira semelhante à modelagem da variável de resposta numérica usando regressão linear.
Analysis of Variance - Esta técnica analisa -
Dados experimentais para duas ou mais populações descritas por uma variável de resposta numérica.
Uma ou mais variáveis categóricas (fatores).
Mixed-effect Models- Esses modelos são usados para analisar dados agrupados. Esses modelos descrevem a relação entre uma variável de resposta e algumas covariáveis nos dados agrupados de acordo com um ou mais fatores.
Factor Analysis- A análise fatorial é usada para prever uma variável de resposta categórica. Este método assume que as variáveis independentes seguem uma distribuição normal multivariada.
Time Series Analysis - A seguir estão os métodos para analisar dados de série temporal -
Métodos de auto-regressão.
Modelagem Univariada ARIMA (AutoRegressive Integrated Moving Average).
Modelagem de séries temporais com memória longa.
Visual Data Mining
Visual Data Mining usa técnicas de visualização de dados e / ou conhecimento para descobrir o conhecimento implícito de grandes conjuntos de dados. A mineração de dados visual pode ser vista como uma integração das seguintes disciplinas -
Visualização de dados
Mineração de dados
A mineração de dados visuais está intimamente relacionada ao seguinte -
Computação Gráfica
Sistemas Multimídia
Interação Humano-Computador
Reconhecimento de padrões
Computação de alto desempenho
Geralmente, a visualização de dados e a mineração de dados podem ser integradas das seguintes maneiras -
Data Visualization - Os dados em um banco de dados ou armazém de dados podem ser visualizados em várias formas visuais que estão listadas abaixo -
Boxplots
Cubos 3-D
Gráficos de distribuição de dados
Curves
Surfaces
Gráficos de links etc.
Data Mining Result Visualization- Data Mining Result Visualization é a apresentação dos resultados da mineração de dados em formas visuais. Essas formas visuais podem ser gráficos dispersos, boxplots, etc.
Data Mining Process Visualization- Data Mining Process Visualization apresenta os diversos processos de data mining. Ele permite que os usuários vejam como os dados são extraídos. Também permite que os usuários vejam de qual banco de dados ou data warehouse os dados são limpos, integrados, pré-processados e extraídos.
Mineração de dados de áudio
A mineração de dados de áudio faz uso de sinais de áudio para indicar os padrões de dados ou os recursos dos resultados da mineração de dados. Ao transformar padrões em sons e reflexões, podemos ouvir tons e melodias, em vez de assistir a imagens, a fim de identificar algo interessante.
Mineração de dados e filtragem colaborativa
Os consumidores hoje encontram uma variedade de produtos e serviços enquanto fazem compras. Durante as transações do cliente ao vivo, um sistema de recomendação ajuda o consumidor fazendo recomendações de produtos. A Abordagem de Filtragem Colaborativa geralmente é usada para recomendar produtos aos clientes. Essas recomendações são baseadas nas opiniões de outros clientes.