DBMS Distribuído - Recuperação de Banco de Dados
Para se recuperar de falhas de banco de dados, os sistemas de gerenciamento de banco de dados recorrem a uma série de técnicas de gerenciamento de recuperação. Neste capítulo, estudaremos as diferentes abordagens para recuperação de banco de dados.
As estratégias típicas para recuperação de banco de dados são -
No caso de falhas leves que resultam em inconsistência do banco de dados, a estratégia de recuperação inclui desfazer ou reverter a transação. No entanto, às vezes, refazer a transação também pode ser adotado para recuperar a um estado consistente da transação.
No caso de falhas graves, resultando em danos extensos ao banco de dados, as estratégias de recuperação abrangem a restauração de uma cópia anterior do banco de dados a partir do backup de arquivamento. Um estado mais atual do banco de dados é obtido por meio de operações de refazer de transações confirmadas do log de transações.
Recuperação de falha de energia
Falha de energia causa perda de informações na memória não persistente. Quando a energia é restaurada, o sistema operacional e o sistema de gerenciamento de banco de dados são reiniciados. O gerenciador de recuperação inicia a recuperação a partir dos logs de transações.
No caso do modo de atualização imediata, o gerenciador de recuperação executa as seguintes ações -
As transações que estão na lista ativa e na lista com falha são desfeitas e gravadas na lista de abortos.
As transações que estão na lista antes do commit são refeitas.
Nenhuma ação é realizada para transações em listas de confirmação ou anulação.
No caso de modo de atualização adiada, o gerenciador de recuperação executa as seguintes ações -
As transações que estão na lista ativa e na lista com falha são gravadas na lista de abortos. Nenhuma operação de desfazer é necessária, pois as alterações ainda não foram gravadas no disco.
As transações que estão na lista antes do commit são refeitas.
Nenhuma ação é realizada para transações em listas de confirmação ou anulação.
Recuperação de falha de disco
Uma falha de disco ou travamento do disco rígido causa uma perda total do banco de dados. Para se recuperar dessa falha de disco rígido, um novo disco é preparado, o sistema operacional é restaurado e, finalmente, o banco de dados é recuperado usando o backup do banco de dados e o log de transações. O método de recuperação é o mesmo para os modos de atualização imediata e adiada.
O gerenciador de recuperação executa as seguintes ações -
As transações na lista de confirmação e na lista de confirmação anterior são refeitas e gravadas na lista de confirmação no log de transações.
As transações na lista ativa e na lista com falha são desfeitas e gravadas na lista de abortos no log de transações.
Ponto de verificação
Checkpointé um momento em que um registro é gravado no banco de dados a partir dos buffers. Como consequência, no caso de uma falha do sistema, o gerenciador de recuperação não precisa refazer as transações que foram confirmadas antes do ponto de verificação. Os pontos de verificação periódicos reduzem o processo de recuperação.
Os dois tipos de técnicas de checkpoint são -
- Ponto de verificação consistente
- Ponto de verificação difuso
Ponto de verificação consistente
Um ponto de verificação consistente cria uma imagem consistente do banco de dados no ponto de verificação. Durante a recuperação, apenas as transações que estão do lado direito do último ponto de verificação são desfeitas ou refeitas. As transações à esquerda do último ponto de verificação consistente já foram confirmadas e não precisam ser processadas novamente. As ações realizadas para o checkpoint são -
- As transações ativas estão suspensas temporariamente.
- Todas as mudanças nos buffers da memória principal são gravadas no disco.
- Um registro de “ponto de verificação” é gravado no log de transações.
- O log de transações é gravado no disco.
- As transações suspensas são retomadas.
Se na etapa 4, o log de transações também for arquivado, este ponto de verificação ajuda na recuperação de falhas de disco e de energia, caso contrário, ajuda na recuperação apenas de falhas de energia.
Ponto de verificação difuso
No ponto de verificação difuso, no momento do ponto de verificação, todas as transações ativas são gravadas no log. Em caso de falha de energia, o gerenciador de recuperação processa apenas as transações que estavam ativas durante o ponto de verificação e posteriormente. As transações que foram confirmadas antes do ponto de verificação são gravadas no disco e, portanto, não precisam ser refeitas.
Exemplo de Checkpointing
Vamos considerar que no sistema o tempo de checkpointing é tcheck e o tempo de travamento do sistema é tfail. Que haja quatro transações T a , T b , T c e T d tais que -
T a confirma antes do ponto de verificação.
T b começa antes do ponto de verificação e se compromete antes da falha do sistema.
T c começa após o ponto de verificação e confirma antes da falha do sistema.
T d começa após o ponto de verificação e estava ativo no momento da falha do sistema.
A situação é ilustrada no diagrama a seguir -
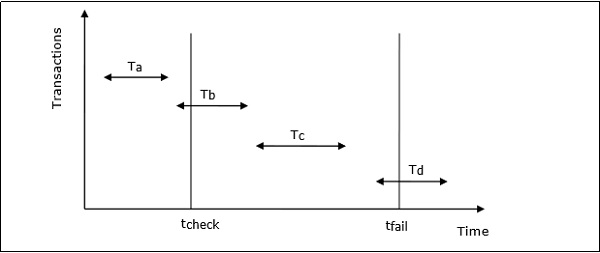
As ações tomadas pelo gerente de recuperação são -
- Nada é feito com T a .
- O refazer da transação é executado para T b e T c .
- O desfazer da transação é executado para T d .
Recuperação de transação usando UNDO / REDO
A recuperação da transação é feita para eliminar os efeitos adversos de transações com falha, e não para recuperar de uma falha. As transações com defeito incluem todas as transações que alteraram o banco de dados para um estado indesejado e as transações que usaram valores gravados pelas transações com defeito.
A recuperação da transação nesses casos é um processo de duas etapas -
DESFAZER todas as transações com falha e transações que podem ser afetadas pelas transações com falha.
REDO todas as transações que não estão com defeito, mas foram desfeitas devido às transações com defeito.
As etapas para a operação UNDO são -
Se a transação com falha tiver feito INSERT, o gerenciador de recuperação exclui o (s) item (ns) de dados inserido (s).
Se a transação com falha tiver feito DELETE, o gerenciador de recuperação insere o (s) item (ns) de dados apagado (s) do log.
Se a transação com falha tiver feito UPDATE, o gerenciador de recuperação elimina o valor gravando o valor antes da atualização do log.
As etapas para a operação REDO são -
Se a transação tiver feito INSERT, o gerenciador de recuperação gera uma inserção a partir do log.
Se a transação tiver executado DELETE, o gerenciador de recuperação gerará uma exclusão do log.
Se a transação tiver feito UPDATE, o gerenciador de recuperação gera uma atualização do log.