Otimização de consulta em sistemas centralizados
Uma vez que os caminhos de acesso alternativos para cálculo de uma expressão de álgebra relacional são derivados, o caminho de acesso ideal é determinado. Neste capítulo, examinaremos a otimização de consultas em um sistema centralizado, enquanto no próximo capítulo estudaremos a otimização de consultas em um sistema distribuído.
Em um sistema centralizado, o processamento de consultas é feito com o seguinte objetivo -
Minimização do tempo de resposta da consulta (tempo gasto para produzir os resultados da consulta do usuário).
Maximize a taxa de transferência do sistema (o número de solicitações que são processadas em um determinado período de tempo).
Reduza a quantidade de memória e armazenamento necessários para o processamento.
Aumente o paralelismo.
Análise e tradução de consultas
Inicialmente, a consulta SQL é verificada. Em seguida, ele é analisado para procurar erros sintáticos e exatidão dos tipos de dados. Se a consulta passar nesta etapa, a consulta será decomposta em blocos de consulta menores. Cada bloco é então traduzido para uma expressão de álgebra relacional equivalente.
Etapas para otimização de consulta
A otimização de consulta envolve três etapas, a saber, geração de árvore de consulta, geração de plano e geração de código de plano de consulta.
Step 1 − Query Tree Generation
Uma árvore de consulta é uma estrutura de dados em árvore que representa uma expressão de álgebra relacional. As tabelas da consulta são representadas como nós folha. As operações de álgebra relacional são representadas como nós internos. A raiz representa a consulta como um todo.
Durante a execução, um nó interno é executado sempre que suas tabelas de operandos estiverem disponíveis. O nó é então substituído pela tabela de resultados. Este processo continua para todos os nós internos até que o nó raiz seja executado e substituído pela tabela de resultados.
Por exemplo, vamos considerar os seguintes esquemas -
EMPREGADO
| EmpID | EName | Salário | DeptNo | Data de adesão |
DEPARTAMENTO
| DNo | DName | Localização |
Exemplo 1
Vamos considerar a pergunta da seguinte maneira.
$$ \ pi_ {EmpID} (\ sigma_ {EName = \ small "ArunKumar"} {(FUNCIONÁRIO)}) $$
A árvore de comando correspondente será -
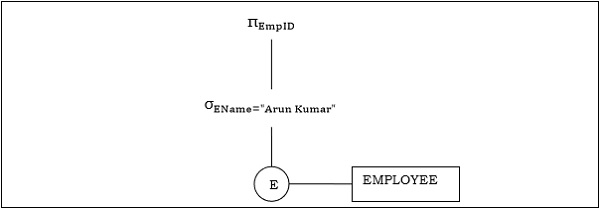
Exemplo 2
Vamos considerar outra consulta envolvendo uma junção.
$ \ pi_ {EName, Salário} (\ sigma_ {DName = \ small "Marketing"} {(DEPARTAMENTO)}) \ bowtie_ {DNo = DeptNo} {(FUNCIONÁRIO)} $
A seguir está a árvore de consulta para a consulta acima.

Step 2 − Query Plan Generation
Depois que a árvore de consulta é gerada, um plano de consulta é feito. Um plano de consulta é uma árvore de consulta estendida que inclui caminhos de acesso para todas as operações na árvore de consulta. Os caminhos de acesso especificam como as operações relacionais na árvore devem ser realizadas. Por exemplo, uma operação de seleção pode ter um caminho de acesso que fornece detalhes sobre o uso do índice de árvore B + para seleção.
Além disso, um plano de consulta também indica como as tabelas intermediárias devem ser passadas de um operador para o outro, como as tabelas temporárias devem ser usadas e como as operações devem ser combinadas / pipeline.
Step 3− Code Generation
A geração de código é a etapa final na otimização da consulta. É a forma executável da consulta, cuja forma depende do tipo de sistema operacional subjacente. Depois que o código da consulta é gerado, o Execution Manager o executa e produz os resultados.
Abordagens para otimização de consulta
Entre as abordagens para otimização de consulta, busca exaustiva e algoritmos baseados em heurística são os mais usados.
Otimização de pesquisa exaustiva
Nessas técnicas, para uma consulta, todos os planos de consulta possíveis são gerados inicialmente e, em seguida, o melhor plano é selecionado. Embora essas técnicas forneçam a melhor solução, elas têm uma complexidade de tempo e espaço exponencial devido ao grande espaço de solução. Por exemplo, técnica de programação dinâmica.
Otimização Baseada em Heurística
A otimização baseada em heurística usa abordagens de otimização baseadas em regras para otimização de consulta. Esses algoritmos têm complexidade polinomial de tempo e espaço, que é menor do que a complexidade exponencial de algoritmos exaustivos baseados em pesquisa. No entanto, esses algoritmos não produzem necessariamente o melhor plano de consulta.
Algumas das regras heurísticas comuns são -
Execute operações de seleção e projeto antes das operações de junção. Isso é feito movendo as operações de seleção e projeto para baixo na árvore de comando. Isso reduz o número de tuplas disponíveis para junção.
Realize as operações de seleção / projeto mais restritivas primeiro, antes das outras operações.
Evite a operação de produtos cruzados, pois eles resultam em tabelas intermediárias de tamanho muito grande.