Elasticsearch - Guia rápido
Elasticsearch é um servidor de pesquisa baseado em Apache Lucene. Foi desenvolvido por Shay Banon e publicado em 2010. Agora é mantido pela Elasticsearch BV. Sua versão mais recente é 7.0.0.
Elasticsearch é um mecanismo de pesquisa e análise de texto completo distribuído em tempo real e de código aberto. É acessível a partir da interface de serviço da web RESTful e usa documentos JSON (JavaScript Object Notation) sem esquema para armazenar dados. Ele é construído na linguagem de programação Java e, portanto, Elasticsearch pode ser executado em diferentes plataformas. Ele permite que os usuários explorem uma grande quantidade de dados em alta velocidade.
Características gerais
As características gerais do Elasticsearch são as seguintes -
O Elasticsearch é escalonável até petabytes de dados estruturados e não estruturados.
Elasticsearch pode ser usado como um substituto de armazenamentos de documentos como MongoDB e RavenDB.
Elasticsearch usa desnormalização para melhorar o desempenho da pesquisa.
Elasticsearch é um dos motores de busca corporativa populares e atualmente está sendo usado por muitas grandes organizações como Wikipedia, The Guardian, StackOverflow, GitHub etc.
Elasticsearch é um código aberto e está disponível sob a licença Apache versão 2.0.
Conceitos chave
Os principais conceitos do Elasticsearch são os seguintes -
Nó
Refere-se a uma única instância em execução do Elasticsearch. Um único servidor físico e virtual acomoda vários nós, dependendo dos recursos de seus recursos físicos, como RAM, armazenamento e capacidade de processamento.
Grupo
É uma coleção de um ou mais nós. O cluster fornece indexação coletiva e recursos de pesquisa em todos os nós para dados inteiros.
Índice
É uma coleção de diferentes tipos de documentos e suas propriedades. O índice também usa o conceito de fragmentos para melhorar o desempenho. Por exemplo, um conjunto de documentos contém dados de um aplicativo de rede social.
Documento
É uma coleção de campos de uma maneira específica definida no formato JSON. Cada documento pertence a um tipo e reside dentro de um índice. Cada documento está associado a um identificador único denominado UID.
Fragmento
Os índices são subdivididos horizontalmente em fragmentos. Isso significa que cada fragmento contém todas as propriedades do documento, mas contém menos número de objetos JSON do que o índice. A separação horizontal torna o shard um nó independente, que pode ser armazenado em qualquer nó. O shard primário é a parte horizontal original de um índice e, em seguida, esses shards primários são replicados em shards de réplica.
Réplicas
Elasticsearch permite que um usuário crie réplicas de seus índices e shards. A replicação não só ajuda a aumentar a disponibilidade dos dados em caso de falha, mas também melhora o desempenho da pesquisa ao realizar uma operação de pesquisa paralela nessas réplicas.
Vantagens
Elasticsearch é desenvolvido em Java, o que o torna compatível em quase todas as plataformas.
Elasticsearch é em tempo real, em outras palavras, após um segundo o documento adicionado pode ser pesquisado neste mecanismo
Elasticsearch é distribuído, o que o torna fácil de escalar e integrar em qualquer grande organização.
A criação de backups completos é fácil com o uso do conceito de gateway, que está presente no Elasticsearch.
Manipular a multilocação é muito fácil no Elasticsearch quando comparado ao Apache Solr.
Elasticsearch usa objetos JSON como respostas, o que torna possível invocar o servidor Elasticsearch com um grande número de linguagens de programação diferentes.
Elasticsearch oferece suporte a quase todos os tipos de documentos, exceto aqueles que não oferecem suporte à renderização de texto.
Desvantagens
Elasticsearch não tem suporte a vários idiomas em termos de manipulação de dados de solicitação e resposta (possível apenas em JSON) ao contrário do Apache Solr, onde é possível nos formatos CSV, XML e JSON.
Ocasionalmente, o Elasticsearch tem um problema de situações de cérebro dividido.
Comparação entre Elasticsearch e RDBMS
No Elasticsearch, o índice é semelhante às tabelas do RDBMS (Relation Database Management System). Cada tabela é uma coleção de linhas, assim como todo índice é uma coleção de documentos no Elasticsearch.
A tabela a seguir fornece uma comparação direta entre esses termos-
| Elasticsearch | RDBMS |
|---|---|
| Grupo | Base de dados |
| Fragmento | Fragmento |
| Índice | Mesa |
| Campo | Coluna |
| Documento | Linha |
Neste capítulo, vamos entender o procedimento de instalação do Elasticsearch em detalhes.
Para instalar o Elasticsearch em seu computador local, você terá que seguir os passos abaixo -
Step 1- Verifique a versão do java instalada no seu computador. Deve ser java 7 ou superior. Você pode verificar fazendo o seguinte -
No Sistema Operacional Windows (SO) (usando prompt de comando) -
> java -versionNo sistema operacional UNIX (usando terminal) -
$ echo $JAVA_HOMEStep 2 - Dependendo do seu sistema operacional, baixe Elasticsearch em www.elastic.co conforme mencionado abaixo -
Para o sistema operacional Windows, baixe o arquivo ZIP.
Para o sistema operacional UNIX, faça download do arquivo TAR.
Para o sistema operacional Debian, baixe o arquivo DEB.
Para Red Hat e outras distribuições Linux, baixe o arquivo RPN.
Os utilitários APT e Yum também podem ser usados para instalar o Elasticsearch em muitas distribuições Linux.
Step 3 - O processo de instalação do Elasticsearch é simples e é descrito abaixo para diferentes sistemas operacionais -
Windows OS- Descompacte o pacote zip e o Elasticsearch é instalado.
UNIX OS- Extraia o arquivo tar em qualquer local e o Elasticsearch é instalado.
$wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch7.0.0-linux-x86_64.tar.gz $tar -xzf elasticsearch-7.0.0-linux-x86_64.tar.gzUsing APT utility for Linux OS- Baixe e instale a chave de assinatura pública
$ wget -qo - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo
apt-key add -Salve a definição do repositório conforme mostrado abaixo -
$ echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" |
sudo tee -a /etc/apt/sources.list.d/elastic-7.x.listExecute a atualização usando o seguinte comando -
$ sudo apt-get updateAgora você pode instalar usando o seguinte comando -
$ sudo apt-get install elasticsearchDownload and install the Debian package manually using the command given here −
$wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch7.0.0-amd64.deb $sudo dpkg -i elasticsearch-7.0.0-amd64.deb0Using YUM utility for Debian Linux OS
Baixe e instale a chave de assinatura pública -
$ rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearchADICIONE o seguinte texto no arquivo com sufixo .repo em seu diretório “/etc/yum.repos.d/”. Por exemplo, elasticsearch.repo
elasticsearch-7.x]
name=Elasticsearch repository for 7.x packages
baseurl=https://artifacts.elastic.co/packages/7.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-mdAgora você pode instalar o Elasticsearch usando o seguinte comando
sudo yum install elasticsearchStep 4- Vá para o diretório inicial do Elasticsearch e dentro da pasta bin. Execute o arquivo elasticsearch.bat no caso do Windows ou você pode fazer o mesmo usando o prompt de comando e por meio do terminal no caso do arquivo UNIX rum Elasticsearch.
No Windows
> cd elasticsearch-2.1.0/bin
> elasticsearchEm Linux
$ cd elasticsearch-2.1.0/bin
$ ./elasticsearchNote - No caso do Windows, você pode obter um erro informando que JAVA_HOME não está definido, defina-o nas variáveis de ambiente como “C: \ Arquivos de programas \ Java \ jre1.8.0_31” ou o local onde instalou o java.
Step 5- A porta padrão para a interface da web Elasticsearch é 9200 ou você pode alterá-la alterando http.port dentro do arquivo elasticsearch.yml presente no diretório bin. Você pode verificar se o servidor está funcionando, navegandohttp://localhost:9200. Ele retornará um objeto JSON, que contém as informações sobre o Elasticsearch instalado da seguinte maneira -
{
"name" : "Brain-Child",
"cluster_name" : "elasticsearch", "version" : {
"number" : "2.1.0",
"build_hash" : "72cd1f1a3eee09505e036106146dc1949dc5dc87",
"build_timestamp" : "2015-11-18T22:40:03Z",
"build_snapshot" : false,
"lucene_version" : "5.3.1"
},
"tagline" : "You Know, for Search"
}Step 6- Nesta etapa, vamos instalar o Kibana. Siga o respectivo código fornecido abaixo para instalar no Linux e Windows -
For Installation on Linux −
wget https://artifacts.elastic.co/downloads/kibana/kibana-7.0.0-linuxx86_64.tar.gz
tar -xzf kibana-7.0.0-linux-x86_64.tar.gz
cd kibana-7.0.0-linux-x86_64/
./bin/kibanaFor Installation on Windows −
Baixe Kibana para Windows em https://www.elastic.co/products/kibana. Depois de clicar no link, você encontrará a página inicial conforme mostrado abaixo -
Descompacte e vá para o diretório inicial do Kibana e execute-o.
CD c:\kibana-7.0.0-windows-x86_64
.\bin\kibana.batNeste capítulo, vamos aprender como adicionar algum índice, mapeamento e dados ao Elasticsearch. Observe que alguns desses dados serão usados nos exemplos explicados neste tutorial.
Criar Índice
Você pode usar o seguinte comando para criar um índice -
PUT schoolResposta
Se o índice for criado, você pode ver a seguinte saída -
{"acknowledged": true}Adicionar dados
Elasticsearch armazenará os documentos que adicionamos ao índice, conforme mostrado no código a seguir. Os documentos recebem alguns IDs que são usados na identificação do documento.
Corpo de Solicitação
POST school/_doc/10
{
"name":"Saint Paul School", "description":"ICSE Afiliation",
"street":"Dawarka", "city":"Delhi", "state":"Delhi", "zip":"110075",
"location":[28.5733056, 77.0122136], "fees":5000,
"tags":["Good Faculty", "Great Sports"], "rating":"4.5"
}Resposta
{
"_index" : "school",
"_type" : "_doc",
"_id" : "10",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 2,
"_primary_term" : 1
}Aqui, estamos adicionando outro documento semelhante.
POST school/_doc/16
{
"name":"Crescent School", "description":"State Board Affiliation",
"street":"Tonk Road",
"city":"Jaipur", "state":"RJ", "zip":"176114","location":[26.8535922,75.7923988],
"fees":2500, "tags":["Well equipped labs"], "rating":"4.5"
}Resposta
{
"_index" : "school",
"_type" : "_doc",
"_id" : "16",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 9,
"_primary_term" : 7
}Dessa forma, continuaremos adicionando quaisquer dados de exemplo de que precisamos para nosso trabalho nos próximos capítulos.
Adicionando dados de amostra em Kibana
Kibana é uma ferramenta orientada a GUI para acessar os dados e criar a visualização. Nesta seção, vamos entender como podemos adicionar dados de amostra a ele.
Na página inicial do Kibana, escolha a seguinte opção para adicionar dados de comércio eletrônico de amostra -
A próxima tela mostrará alguma visualização e um botão para adicionar dados -
Clicar em Adicionar dados exibirá a tela a seguir, que confirma que os dados foram adicionados a um índice denominado eCommerce.
Em qualquer sistema ou software, quando estamos atualizando para uma versão mais recente, precisamos seguir algumas etapas para manter as configurações do aplicativo, configurações, dados e outras coisas. Essas etapas são necessárias para tornar o aplicativo estável no novo sistema ou para manter a integridade dos dados (evitar que os dados sejam corrompidos).
Você precisa seguir as seguintes etapas para atualizar o Elasticsearch -
Leia os documentos de atualização de https://www.elastic.co/
Teste a versão atualizada em seus ambientes de não produção, como UAT, E2E, SIT ou ambiente DEV.
Observe que a reversão para a versão anterior do Elasticsearch não é possível sem o backup de dados. Portanto, um backup de dados é recomendado antes de atualizar para uma versão superior.
Podemos atualizar usando a reinicialização completa do cluster ou atualização contínua A atualização contínua é para novas versões. Observe que não há interrupção do serviço quando você está usando o método de atualização sem interrupção para migração.
Etapas para atualização
Teste a atualização em um ambiente de desenvolvimento antes de atualizar seu cluster de produção.
Faça backup de seus dados. Você não pode reverter para uma versão anterior, a menos que tenha um instantâneo de seus dados.
Considere fechar trabalhos de aprendizado de máquina antes de iniciar o processo de atualização. Embora os trabalhos de aprendizado de máquina possam continuar em execução durante uma atualização sem interrupção, isso aumenta a sobrecarga no cluster durante o processo de atualização.
Atualize os componentes do seu Elastic Stack na seguinte ordem -
- Elasticsearch
- Kibana
- Logstash
- Beats
- Servidor APM
Atualizando da 6.6 ou anterior
Para atualizar diretamente para o Elasticsearch 7.1.0 das versões 6.0-6.6, você deve reindexar manualmente todos os índices 5.x que precisar transportar e executar uma reinicialização completa do cluster.
Reinício completo do cluster
O processo de reinicialização total do cluster envolve desligar cada nó do cluster, atualizar cada nó para 7x e, em seguida, reiniciar o cluster.
A seguir estão as etapas de alto nível que precisam ser realizadas para a reinicialização completa do cluster -
- Desativar alocação de fragmentos
- Pare de indexar e execute uma limpeza sincronizada
- Desligue todos os nós
- Atualize todos os nós
- Atualize quaisquer plug-ins
- Comece cada nó atualizado
- Espere todos os nós se juntarem ao cluster e relatar um status de amarelo
- Reativar alocação
Depois que a alocação é reativada, o cluster começa a alocar os shards de réplica para os nós de dados. Neste ponto, é seguro retomar a indexação e a procura, mas seu cluster se recuperará mais rapidamente se você puder esperar até que todos os shards primários e de réplica tenham sido alocados com êxito e o status de todos os nós seja verde.
Interface de programação de aplicativo (API) na web é um grupo de chamadas de função ou outras instruções de programação para acessar o componente de software naquele aplicativo da web específico. Por exemplo, a API do Facebook ajuda um desenvolvedor a criar aplicativos acessando dados ou outras funcionalidades do Facebook; pode ser data de nascimento ou atualização de status.
Elasticsearch fornece uma API REST, que é acessada por JSON sobre HTTP. Elasticsearch usa algumas convenções que discutiremos agora.
Múltiplos índices
A maioria das operações, principalmente de pesquisa e outras operações, em APIs são para um ou mais índices. Isso ajuda o usuário a pesquisar em vários locais ou em todos os dados disponíveis, executando uma consulta apenas uma vez. Muitas notações diferentes são usadas para realizar operações em vários índices. Discutiremos alguns deles aqui neste capítulo.
Notação separada por vírgulas
POST /index1,index2,index3/_searchCorpo de Solicitação
{
"query":{
"query_string":{
"query":"any_string"
}
}
}Resposta
Objetos JSON de index1, index2, index3 contendo any_string.
_todas as palavras-chave para todos os índices
POST /_all/_searchCorpo de Solicitação
{
"query":{
"query_string":{
"query":"any_string"
}
}
}Resposta
Objetos JSON de todos os índices e contendo any_string.
Caracteres curinga (*, +, -)
POST /school*/_searchCorpo de Solicitação
{
"query":{
"query_string":{
"query":"CBSE"
}
}
}Resposta
Objetos JSON de todos os índices que começam com a escola contendo CBSE.
Como alternativa, você também pode usar o seguinte código -
POST /school*,-schools_gov /_searchCorpo de Solicitação
{
"query":{
"query_string":{
"query":"CBSE"
}
}
}Resposta
Objetos JSON de todos os índices que começam com “school”, mas não dechools_gov e tendo CBSE nele.
Existem também alguns parâmetros de string de consulta de URL -
- ignore_unavailable- Nenhum erro ocorrerá ou nenhuma operação será interrompida, se um ou mais índice (s) presente (s) na URL não existirem. Por exemplo, existe índice de escolas, mas livrarias não existe.
POST /school*,book_shops/_searchCorpo de Solicitação
{
"query":{
"query_string":{
"query":"CBSE"
}
}
}Corpo de Solicitação
{
"error":{
"root_cause":[{
"type":"index_not_found_exception", "reason":"no such index",
"resource.type":"index_or_alias", "resource.id":"book_shops",
"index":"book_shops"
}],
"type":"index_not_found_exception", "reason":"no such index",
"resource.type":"index_or_alias", "resource.id":"book_shops",
"index":"book_shops"
},"status":404
}Considere o seguinte código -
POST /school*,book_shops/_search?ignore_unavailable = trueCorpo de Solicitação
{
"query":{
"query_string":{
"query":"CBSE"
}
}
}Resposta (sem erro)
Objetos JSON de todos os índices que começam com a escola contendo CBSE.
allow_no_indices
truevalor deste parâmetro evitará erro, se um URL com curinga resultar em nenhum índice. Por exemplo, não há índice que comece comchools_pri -
POST /schools_pri*/_search?allow_no_indices = trueCorpo de Solicitação
{
"query":{
"match_all":{}
}
}Resposta (sem erros)
{
"took":1,"timed_out": false, "_shards":{"total":0, "successful":0, "failed":0},
"hits":{"total":0, "max_score":0.0, "hits":[]}
}expand_wildcards
Este parâmetro decide se os curingas precisam ser expandidos para abrir índices ou índices fechados ou executar ambos. O valor deste parâmetro pode ser aberto e fechado ou nenhum e todos.
Por exemplo, feche escolas de índice -
POST /schools/_closeResposta
{"acknowledged":true}Considere o seguinte código -
POST /school*/_search?expand_wildcards = closedCorpo de Solicitação
{
"query":{
"match_all":{}
}
}Resposta
{
"error":{
"root_cause":[{
"type":"index_closed_exception", "reason":"closed", "index":"schools"
}],
"type":"index_closed_exception", "reason":"closed", "index":"schools"
}, "status":403
}Suporte de matemática de datas em nomes de índice
Elasticsearch oferece uma funcionalidade para pesquisar índices de acordo com data e hora. Precisamos especificar a data e a hora em um formato específico. Por exemplo, accountdetail-2015.12.30, index armazenará os detalhes da conta bancária de 30 de dezembro de 2015. As operações matemáticas podem ser realizadas para obter detalhes para uma data específica ou um intervalo de data e hora.
Formato para o nome do índice matemático de data -
<static_name{date_math_expr{date_format|time_zone}}>
/<accountdetail-{now-2d{YYYY.MM.dd|utc}}>/_searchstatic_name é uma parte da expressão que permanece a mesma em todos os índices matemáticos de data, como os detalhes da conta. date_math_expr contém a expressão matemática que determina a data e a hora dinamicamente como now-2d. date_format contém o formato no qual a data é gravada em um índice como AAAA.MM.dd. Se a data de hoje for 30 de dezembro de 2015, então <accountdetail- {now-2d {AAAA.MM.dd}}> retornará accountdetail-2015.12.28.
| Expressão | Resolve para |
|---|---|
| <accountdetail- {now-d}> | accountdetail-2015.12.29 |
| <detalhes da conta- {now-M}> | accountdetail-2015.11.30 |
| <detalhes da conta- {agora {AAAA.MM}}> | accountdetail-2015.12 |
Agora veremos algumas das opções comuns disponíveis no Elasticsearch que podem ser usadas para obter a resposta em um formato especificado.
Resultados bonitos
Podemos obter resposta em um objeto JSON bem formatado apenas acrescentando um parâmetro de consulta de URL, ou seja, pretty = true.
POST /schools/_search?pretty = trueCorpo de Solicitação
{
"query":{
"match_all":{}
}
}Resposta
……………………..
{
"_index" : "schools", "_type" : "school", "_id" : "1", "_score" : 1.0,
"_source":{
"name":"Central School", "description":"CBSE Affiliation",
"street":"Nagan", "city":"paprola", "state":"HP", "zip":"176115",
"location": [31.8955385, 76.8380405], "fees":2000,
"tags":["Senior Secondary", "beautiful campus"], "rating":"3.5"
}
}
………………….Saída legível por humanos
Esta opção pode alterar as respostas estatísticas para a forma legível por humanos (se humano = verdadeiro) ou forma legível por computador (se humano = falso). Por exemplo, se human = true então distance_kilometer = 20KM e se human = false então distance_meter = 20000, quando a resposta precisar ser usada por outro programa de computador.
Filtro de Resposta
Podemos filtrar a resposta para menos campos, adicionando-os no parâmetro field_path. Por exemplo,
POST /schools/_search?filter_path = hits.totalCorpo de Solicitação
{
"query":{
"match_all":{}
}
}Resposta
{"hits":{"total":3}}Elasticsearch fornece APIs de documento único e APIs de documentos múltiplos, onde a chamada de API tem como alvo um único documento e vários documentos, respectivamente.
API de índice
Isso ajuda a adicionar ou atualizar o documento JSON em um índice quando uma solicitação é feita a esse respectivo índice com mapeamento específico. Por exemplo, a solicitação a seguir adicionará o objeto JSON para indexar escolas e mapeamento de escolas -
PUT schools/_doc/5
{
name":"City School", "description":"ICSE", "street":"West End",
"city":"Meerut",
"state":"UP", "zip":"250002", "location":[28.9926174, 77.692485],
"fees":3500,
"tags":["fully computerized"], "rating":"4.5"
}Ao executar o código acima, obtemos o seguinte resultado -
{
"_index" : "schools",
"_type" : "_doc",
"_id" : "5",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 2,
"_primary_term" : 1
}Criação Automática de Índice
Quando uma solicitação é feita para adicionar um objeto JSON a um índice específico e esse índice não existe, esta API cria automaticamente esse índice e também o mapeamento subjacente para esse objeto JSON específico. Essa funcionalidade pode ser desativada alterando os valores dos parâmetros a seguir para false, que estão presentes no arquivo elasticsearch.yml.
action.auto_create_index:false
index.mapper.dynamic:falseVocê também pode restringir a criação automática de índice, onde apenas o nome do índice com padrões específicos são permitidos, alterando o valor do seguinte parâmetro -
action.auto_create_index:+acc*,-bank*Note - Aqui + indica permitido e - indica não permitido.
Controle de versão
Elasticsearch também fornece facilidade de controle de versão. Podemos usar um parâmetro de consulta de versão para especificar a versão de um determinado documento.
PUT schools/_doc/5?version=7&version_type=external
{
"name":"Central School", "description":"CBSE Affiliation", "street":"Nagan",
"city":"paprola", "state":"HP", "zip":"176115", "location":[31.8955385, 76.8380405],
"fees":2200, "tags":["Senior Secondary", "beautiful campus"], "rating":"3.3"
}Ao executar o código acima, obtemos o seguinte resultado -
{
"_index" : "schools",
"_type" : "_doc",
"_id" : "5",
"_version" : 7,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 3,
"_primary_term" : 1
}O controle de versão é um processo em tempo real e não é afetado pelas operações de pesquisa em tempo real.
Existem dois tipos mais importantes de controle de versão -
Controle de versão interno
O controle de versão interno é a versão padrão que começa com 1 e aumenta a cada atualização, incluindo exclusões.
Controle de versão externo
É usado quando a versão dos documentos é armazenada em um sistema externo, como sistemas de versão de terceiros. Para habilitar essa funcionalidade, precisamos definir version_type como externo. Aqui, o Elasticsearch armazenará o número da versão conforme designado pelo sistema externo e não os incrementará automaticamente.
Tipo de operação
O tipo de operação é usado para forçar uma operação de criação. Isso ajuda a evitar a substituição de documentos existentes.
PUT chapter/_doc/1?op_type=create
{
"Text":"this is chapter one"
}Ao executar o código acima, obtemos o seguinte resultado -
{
"_index" : "chapter",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}Geração automática de ID
Quando o ID não é especificado na operação de índice, o Elasticsearch gera automaticamente o id para esse documento.
POST chapter/_doc/
{
"user" : "tpoint",
"post_date" : "2018-12-25T14:12:12",
"message" : "Elasticsearch Tutorial"
}Ao executar o código acima, obtemos o seguinte resultado -
{
"_index" : "chapter",
"_type" : "_doc",
"_id" : "PVghWGoB7LiDTeV6LSGu",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1
}Obter API
A API ajuda a extrair o objeto JSON do tipo executando uma solicitação get para um documento específico.
pre class="prettyprint notranslate" > GET schools/_doc/5Ao executar o código acima, obtemos o seguinte resultado -
{
"_index" : "schools",
"_type" : "_doc",
"_id" : "5",
"_version" : 7,
"_seq_no" : 3,
"_primary_term" : 1,
"found" : true,
"_source" : {
"name" : "Central School",
"description" : "CBSE Affiliation",
"street" : "Nagan",
"city" : "paprola",
"state" : "HP",
"zip" : "176115",
"location" : [
31.8955385,
76.8380405
],
"fees" : 2200,
"tags" : [
"Senior Secondary",
"beautiful campus"
],
"rating" : "3.3"
}
}Esta operação é em tempo real e não é afetada pela taxa de atualização do Índice.
Você também pode especificar a versão, então o Elasticsearch buscará apenas essa versão do documento.
Você também pode especificar _all na solicitação, de modo que o Elasticsearch possa pesquisar esse id de documento em todos os tipos e retornar o primeiro documento correspondente.
Você também pode especificar os campos que deseja no resultado desse documento específico.
GET schools/_doc/5?_source_includes=name,feesAo executar o código acima, obtemos o seguinte resultado -
{
"_index" : "schools",
"_type" : "_doc",
"_id" : "5",
"_version" : 7,
"_seq_no" : 3,
"_primary_term" : 1,
"found" : true,
"_source" : {
"fees" : 2200,
"name" : "Central School"
}
}Você também pode buscar a parte fonte em seu resultado apenas adicionando parte _source em sua solicitação get.
GET schools/_doc/5?_sourceAo executar o código acima, obtemos o seguinte resultado -
{
"_index" : "schools",
"_type" : "_doc",
"_id" : "5",
"_version" : 7,
"_seq_no" : 3,
"_primary_term" : 1,
"found" : true,
"_source" : {
"name" : "Central School",
"description" : "CBSE Affiliation",
"street" : "Nagan",
"city" : "paprola",
"state" : "HP",
"zip" : "176115",
"location" : [
31.8955385,
76.8380405
],
"fees" : 2200,
"tags" : [
"Senior Secondary",
"beautiful campus"
],
"rating" : "3.3"
}
}Você também pode atualizar o fragmento antes de executar a operação get, definindo o parâmetro de atualização como true.
Apagar API
Você pode excluir um índice, mapeamento ou documento específico enviando uma solicitação HTTP DELETE para Elasticsearch.
DELETE schools/_doc/4Ao executar o código acima, obtemos o seguinte resultado -
{
"found":true, "_index":"schools", "_type":"school", "_id":"4", "_version":2,
"_shards":{"total":2, "successful":1, "failed":0}
}A versão do documento pode ser especificada para excluir essa versão particular. O parâmetro de roteamento pode ser especificado para excluir o documento de um determinado usuário e a operação falhará se o documento não pertencer a esse usuário específico. Nesta operação, você pode especificar a opção de atualização e tempo limite da mesma forma que a API GET.
API de atualização
O script é usado para executar esta operação e o controle de versão é usado para garantir que nenhuma atualização tenha ocorrido durante a obtenção e reindexação. Por exemplo, você pode atualizar as taxas escolares usando o script -
POST schools/_update/4
{
"script" : {
"source": "ctx._source.name = params.sname",
"lang": "painless",
"params" : {
"sname" : "City Wise School"
}
}
}Ao executar o código acima, obtemos o seguinte resultado -
{
"_index" : "schools",
"_type" : "_doc",
"_id" : "4",
"_version" : 3,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 4,
"_primary_term" : 2
}Você pode verificar a atualização enviando uma solicitação get para o documento atualizado.
Esta API é usada para pesquisar conteúdo no Elasticsearch. Um usuário pode pesquisar enviando uma solicitação get com string de consulta como parâmetro ou pode postar uma consulta no corpo da mensagem da solicitação de postagem. Principalmente todos os APIS de pesquisa são multi-índice, multi-tipo.
Multi-índice
Elasticsearch permite-nos pesquisar os documentos presentes em todos os índices ou em alguns índices específicos. Por exemplo, se precisarmos pesquisar todos os documentos com um nome que contenha central, podemos fazer como mostrado aqui -
GET /_all/_search?q=city:paprolaAo executar o código acima, obtemos a seguinte resposta -
{
"took" : 33,
"timed_out" : false,
"_shards" : {
"total" : 7,
"successful" : 7,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.9808292,
"hits" : [
{
"_index" : "schools",
"_type" : "school",
"_id" : "5",
"_score" : 0.9808292,
"_source" : {
"name" : "Central School",
"description" : "CBSE Affiliation",
"street" : "Nagan",
"city" : "paprola",
"state" : "HP",
"zip" : "176115",
"location" : [
31.8955385,
76.8380405
],
"fees" : 2200,
"tags" : [
"Senior Secondary",
"beautiful campus"
],
"rating" : "3.3"
}
}
]
}
}Pesquisa URI
Muitos parâmetros podem ser passados em uma operação de pesquisa usando o Uniform Resource Identifier -
| S.No | Parâmetro e Descrição |
|---|---|
| 1 | Q Este parâmetro é usado para especificar a string de consulta. |
| 2 | lenient Este parâmetro é usado para especificar a string de consulta. Erros baseados em formato podem ser ignorados apenas configurando este parâmetro como verdadeiro. É falso por padrão. |
| 3 | fields Este parâmetro é usado para especificar a string de consulta. |
| 4 | sort Podemos obter resultados classificados usando este parâmetro, os valores possíveis para este parâmetro são fieldName, fieldName: asc / fieldname: desc |
| 5 | timeout Podemos restringir o tempo de pesquisa usando este parâmetro e a resposta contém apenas os resultados naquele tempo especificado. Por padrão, não há tempo limite. |
| 6 | terminate_after Podemos restringir a resposta a um número especificado de documentos para cada fragmento, ao atingir o qual a consulta será encerrada mais cedo. Por padrão, não há terminate_after. |
| 7 | from O início do índice dos hits a serem retornados. O padrão é 0. |
| 8 | size Ele denota o número de acertos a serem retornados. O padrão é 10. |
Solicitar busca corporal
Também podemos especificar a consulta usando DSL de consulta no corpo da solicitação e há muitos exemplos já fornecidos nos capítulos anteriores. Um exemplo é dado aqui -
POST /schools/_search
{
"query":{
"query_string":{
"query":"up"
}
}
}Ao executar o código acima, obtemos a seguinte resposta -
{
"took" : 11,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.47000363,
"hits" : [
{
"_index" : "schools",
"_type" : "school",
"_id" : "4",
"_score" : 0.47000363,
"_source" : {
"name" : "City Best School",
"description" : "ICSE",
"street" : "West End",
"city" : "Meerut",
"state" : "UP",
"zip" : "250002",
"location" : [
28.9926174,
77.692485
],
"fees" : 3500,
"tags" : [
"fully computerized"
],
"rating" : "4.5"
}
}
]
}
}A estrutura de agregações coleta todos os dados selecionados pela consulta de pesquisa e consiste em muitos blocos de construção, que ajudam na construção de resumos complexos dos dados. A estrutura básica de uma agregação é mostrada aqui -
"aggregations" : {
"" : {
"" : {
}
[,"meta" : { [] } ]?
[,"aggregations" : { []+ } ]?
}
[,"" : { ... } ]*
}Existem diferentes tipos de agregações, cada uma com sua própria finalidade. Eles são discutidos em detalhes neste capítulo.
Agregações de métricas
Essas agregações ajudam a calcular matrizes a partir dos valores do campo dos documentos agregados e, às vezes, alguns valores podem ser gerados a partir de scripts.
As matrizes numéricas são de valor único, como agregação média, ou de vários valores, como estatísticas.
Agregação média
Essa agregação é usada para obter a média de qualquer campo numérico presente nos documentos agregados. Por exemplo,
POST /schools/_search
{
"aggs":{
"avg_fees":{"avg":{"field":"fees"}}
}
}Ao executar o código acima, obtemos o seguinte resultado -
{
"took" : 41,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "schools",
"_type" : "school",
"_id" : "5",
"_score" : 1.0,
"_source" : {
"name" : "Central School",
"description" : "CBSE Affiliation",
"street" : "Nagan",
"city" : "paprola",
"state" : "HP",
"zip" : "176115",
"location" : [
31.8955385,
76.8380405
],
"fees" : 2200,
"tags" : [
"Senior Secondary",
"beautiful campus"
],
"rating" : "3.3"
}
},
{
"_index" : "schools",
"_type" : "school",
"_id" : "4",
"_score" : 1.0,
"_source" : {
"name" : "City Best School",
"description" : "ICSE",
"street" : "West End",
"city" : "Meerut",
"state" : "UP",
"zip" : "250002",
"location" : [
28.9926174,
77.692485
],
"fees" : 3500,
"tags" : [
"fully computerized"
],
"rating" : "4.5"
}
}
]
},
"aggregations" : {
"avg_fees" : {
"value" : 2850.0
}
}
}Agregação de cardinalidade
Essa agregação fornece a contagem de valores distintos de um campo específico.
POST /schools/_search?size=0
{
"aggs":{
"distinct_name_count":{"cardinality":{"field":"fees"}}
}
}Ao executar o código acima, obtemos o seguinte resultado -
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"distinct_name_count" : {
"value" : 2
}
}
}Note - O valor da cardinalidade é 2 porque existem dois valores distintos nas taxas.
Agregação de estatísticas estendidas
Essa agregação gera todas as estatísticas sobre um campo numérico específico em documentos agregados.
POST /schools/_search?size=0
{
"aggs" : {
"fees_stats" : { "extended_stats" : { "field" : "fees" } }
}
}Ao executar o código acima, obtemos o seguinte resultado -
{
"took" : 8,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"fees_stats" : {
"count" : 2,
"min" : 2200.0,
"max" : 3500.0,
"avg" : 2850.0,
"sum" : 5700.0,
"sum_of_squares" : 1.709E7,
"variance" : 422500.0,
"std_deviation" : 650.0,
"std_deviation_bounds" : {
"upper" : 4150.0,
"lower" : 1550.0
}
}
}
}Agregação máxima
Essa agregação encontra o valor máximo de um campo numérico específico em documentos agregados.
POST /schools/_search?size=0
{
"aggs" : {
"max_fees" : { "max" : { "field" : "fees" } }
}
}Ao executar o código acima, obtemos o seguinte resultado -
{
"took" : 16,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"max_fees" : {
"value" : 3500.0
}
}
}Agregação mínima
Essa agregação encontra o valor mínimo de um campo numérico específico em documentos agregados.
POST /schools/_search?size=0
{
"aggs" : {
"min_fees" : { "min" : { "field" : "fees" } }
}
}Ao executar o código acima, obtemos o seguinte resultado -
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"min_fees" : {
"value" : 2200.0
}
}
}Soma de agregação
Essa agregação calcula a soma de um campo numérico específico em documentos agregados.
POST /schools/_search?size=0
{
"aggs" : {
"total_fees" : { "sum" : { "field" : "fees" } }
}
}Ao executar o código acima, obtemos o seguinte resultado -
{
"took" : 8,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"total_fees" : {
"value" : 5700.0
}
}
}Existem algumas outras agregações de métricas que são usadas em casos especiais, como agregação de limites geográficos e agregação de centróides geográficos para fins de localização geográfica.
Agregações de estatísticas
Uma agregação de métricas de vários valores que calcula estatísticas sobre valores numéricos extraídos dos documentos agregados.
POST /schools/_search?size=0
{
"aggs" : {
"grades_stats" : { "stats" : { "field" : "fees" } }
}
}Ao executar o código acima, obtemos o seguinte resultado -
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"grades_stats" : {
"count" : 2,
"min" : 2200.0,
"max" : 3500.0,
"avg" : 2850.0,
"sum" : 5700.0
}
}
}Metadados de agregação
Você pode adicionar alguns dados sobre a agregação no momento da solicitação usando meta tag e pode obter isso em resposta.
POST /schools/_search?size=0
{
"aggs" : {
"min_fees" : { "avg" : { "field" : "fees" } ,
"meta" :{
"dsc" :"Lowest Fees This Year"
}
}
}
}Ao executar o código acima, obtemos o seguinte resultado -
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"min_fees" : {
"meta" : {
"dsc" : "Lowest Fees This Year"
},
"value" : 2850.0
}
}
}Essas APIs são responsáveis por gerenciar todos os aspectos do índice, como configurações, aliases, mapeamentos, modelos de índice.
Criar Índice
Esta API ajuda você a criar um índice. Um índice pode ser criado automaticamente quando um usuário está passando objetos JSON para qualquer índice ou pode ser criado antes disso. Para criar um índice, basta enviar uma solicitação PUT com configurações, mapeamentos e aliases ou apenas uma solicitação simples sem corpo.
PUT collegesAo executar o código acima, obtemos a saída conforme mostrado abaixo -
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "colleges"
}Também podemos adicionar algumas configurações ao comando acima -
PUT colleges
{
"settings" : {
"index" : {
"number_of_shards" : 3,
"number_of_replicas" : 2
}
}
}Ao executar o código acima, obtemos a saída conforme mostrado abaixo -
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "colleges"
}Apagar o Índice
Esta API ajuda você a excluir qualquer índice. Você só precisa passar uma solicitação de exclusão com o nome desse índice específico.
DELETE /collegesVocê pode excluir todos os índices usando apenas _all ou *.
Obter índice
Essa API pode ser chamada apenas enviando a solicitação get para um ou mais índices. Isso retorna as informações sobre o índice.
GET collegesAo executar o código acima, obtemos a saída conforme mostrado abaixo -
{
"colleges" : {
"aliases" : {
"alias_1" : { },
"alias_2" : {
"filter" : {
"term" : {
"user" : "pkay"
}
},
"index_routing" : "pkay",
"search_routing" : "pkay"
}
},
"mappings" : { },
"settings" : {
"index" : {
"creation_date" : "1556245406616",
"number_of_shards" : "1",
"number_of_replicas" : "1",
"uuid" : "3ExJbdl2R1qDLssIkwDAug",
"version" : {
"created" : "7000099"
},
"provided_name" : "colleges"
}
}
}
}Você pode obter as informações de todos os índices usando _all ou *.
Índice existe
A existência de um índice pode ser determinada apenas enviando uma solicitação get para esse índice. Se a resposta HTTP for 200, ela existe; se for 404, não existe.
HEAD collegesAo executar o código acima, obtemos a saída conforme mostrado abaixo -
200-OKConfigurações de índice
Você pode obter as configurações de índice apenas anexando a palavra-chave _settings no final do URL.
GET /colleges/_settingsAo executar o código acima, obtemos a saída conforme mostrado abaixo -
{
"colleges" : {
"settings" : {
"index" : {
"creation_date" : "1556245406616",
"number_of_shards" : "1",
"number_of_replicas" : "1",
"uuid" : "3ExJbdl2R1qDLssIkwDAug",
"version" : {
"created" : "7000099"
},
"provided_name" : "colleges"
}
}
}
}Estatísticas de índice
Esta API ajuda a extrair estatísticas sobre um índice específico. Você só precisa enviar uma solicitação get com a URL de índice e a palavra-chave _stats no final.
GET /_statsAo executar o código acima, obtemos a saída conforme mostrado abaixo -
………………………………………………
},
"request_cache" : {
"memory_size_in_bytes" : 849,
"evictions" : 0,
"hit_count" : 1171,
"miss_count" : 4
},
"recovery" : {
"current_as_source" : 0,
"current_as_target" : 0,
"throttle_time_in_millis" : 0
}
} ………………………………………………Rubor
O processo de limpeza de um índice garante que todos os dados que atualmente persistem apenas no log de transações também sejam permanentemente persistidos no Lucene. Isso reduz os tempos de recuperação, pois os dados não precisam ser reindexados dos logs de transações depois que o Lucene indexado é aberto.
POST colleges/_flushAo executar o código acima, obtemos a saída conforme mostrado abaixo -
{
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
}
}Normalmente, os resultados de várias APIs Elasticsearch são exibidos no formato JSON. Mas JSON nem sempre é fácil de ler. Portanto, o recurso cat APIs está disponível no Elasticsearch e ajuda a fornecer um formato de impressão dos resultados mais fácil de ler e compreender. Existem vários parâmetros usados na API cat que servem para diferentes finalidades, por exemplo - o termo V torna a saída detalhada.
Vamos aprender sobre cat APIs mais detalhadamente neste capítulo.
Verboso
A saída detalhada fornece uma boa exibição dos resultados de um comando cat. No exemplo abaixo, obtemos os detalhes de vários índices presentes no cluster.
GET /_cat/indices?vAo executar o código acima, obtemos a resposta conforme mostrado abaixo -
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
yellow open schools RkMyEn2SQ4yUgzT6EQYuAA 1 1 2 1 21.6kb 21.6kb
yellow open index_4_analysis zVmZdM1sTV61YJYrNXf1gg 1 1 0 0 283b 283b
yellow open sensor-2018-01-01 KIrrHwABRB-ilGqTu3OaVQ 1 1 1 0 4.2kb 4.2kb
yellow open colleges 3ExJbdl2R1qDLssIkwDAug 1 1 0 0 283b 283bCabeçalhos
O parâmetro h, também chamado de cabeçalho, é usado para exibir apenas as colunas mencionadas no comando.
GET /_cat/nodes?h=ip,portAo executar o código acima, obtemos a resposta conforme mostrado abaixo -
127.0.0.1 9300Ordenar
O comando sort aceita uma string de consulta que pode classificar a tabela pela coluna especificada na consulta. A classificação padrão é crescente, mas isso pode ser alterado adicionando: desc a uma coluna.
O exemplo a seguir dá um resultado de modelos organizados em ordem decrescente dos padrões de índice arquivados.
GET _cat/templates?v&s=order:desc,index_patternsAo executar o código acima, obtemos a resposta conforme mostrado abaixo -
name index_patterns order version
.triggered_watches [.triggered_watches*] 2147483647
.watch-history-9 [.watcher-history-9*] 2147483647
.watches [.watches*] 2147483647
.kibana_task_manager [.kibana_task_manager] 0 7000099Contagem
O parâmetro de contagem fornece a contagem do número total de documentos em todo o cluster.
GET /_cat/count?vAo executar o código acima, obtemos a resposta conforme mostrado abaixo -
epoch timestamp count
1557633536 03:58:56 17809A API do cluster é usada para obter informações sobre o cluster e seus nós e para fazer alterações neles. Para chamar esta API, precisamos especificar o nome do nó, endereço ou _local.
GET /_nodes/_localAo executar o código acima, obtemos a resposta conforme mostrado abaixo -
………………………………………………
cluster_name" : "elasticsearch",
"nodes" : {
"FKH-5blYTJmff2rJ_lQOCg" : {
"name" : "ubuntu",
"transport_address" : "127.0.0.1:9300",
"host" : "127.0.0.1",
"ip" : "127.0.0.1",
"version" : "7.0.0",
"build_flavor" : "default",
"build_type" : "tar",
"build_hash" : "b7e28a7",
"total_indexing_buffer" : 106502553,
"roles" : [
"master",
"data",
"ingest"
],
"attributes" : {
………………………………………………Saúde do Cluster
Esta API é usada para obter o status da integridade do cluster, anexando a palavra-chave 'integridade'.
GET /_cluster/healthAo executar o código acima, obtemos a resposta conforme mostrado abaixo -
{
"cluster_name" : "elasticsearch",
"status" : "yellow",
"timed_out" : false,
"number_of_nodes" : 1,
"number_of_data_nodes" : 1,
"active_primary_shards" : 7,
"active_shards" : 7,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 4,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 63.63636363636363
}Estado do Cluster
Esta API é usada para obter informações de estado sobre um cluster anexando a URL de palavra-chave 'estado'. As informações de estado contêm versão, nó mestre, outros nós, tabela de roteamento, metadados e blocos.
GET /_cluster/stateAo executar o código acima, obtemos a resposta conforme mostrado abaixo -
………………………………………………
{
"cluster_name" : "elasticsearch",
"cluster_uuid" : "IzKu0OoVTQ6LxqONJnN2eQ",
"version" : 89,
"state_uuid" : "y3BlwvspR1eUQBTo0aBjig",
"master_node" : "FKH-5blYTJmff2rJ_lQOCg",
"blocks" : { },
"nodes" : {
"FKH-5blYTJmff2rJ_lQOCg" : {
"name" : "ubuntu",
"ephemeral_id" : "426kTGpITGixhEzaM-5Qyg",
"transport
}
………………………………………………Estatísticas de cluster
Esta API ajuda a recuperar estatísticas sobre o cluster usando a palavra-chave 'estatísticas'. Esta API retorna o número do shard, tamanho do armazenamento, uso de memória, número de nós, funções, SO e sistema de arquivos.
GET /_cluster/statsAo executar o código acima, obtemos a resposta conforme mostrado abaixo -
………………………………………….
"cluster_name" : "elasticsearch",
"cluster_uuid" : "IzKu0OoVTQ6LxqONJnN2eQ",
"timestamp" : 1556435464704,
"status" : "yellow",
"indices" : {
"count" : 7,
"shards" : {
"total" : 7,
"primaries" : 7,
"replication" : 0.0,
"index" : {
"shards" : {
"min" : 1,
"max" : 1,
"avg" : 1.0
},
"primaries" : {
"min" : 1,
"max" : 1,
"avg" : 1.0
},
"replication" : {
"min" : 0.0,
"max" : 0.0,
"avg" : 0.0
}
………………………………………….Configurações de atualização de cluster
Esta API permite que você atualize as configurações de um cluster usando a palavra-chave 'settings'. Existem dois tipos de configurações - persistente (aplicada nas reinicializações) e transitória (não sobrevive a uma reinicialização completa do cluster).
Node Stats
Esta API é usada para recuperar as estatísticas de mais um nó do cluster. As estatísticas do nó são quase iguais às do cluster.
GET /_nodes/statsAo executar o código acima, obtemos a resposta conforme mostrado abaixo -
{
"_nodes" : {
"total" : 1,
"successful" : 1,
"failed" : 0
},
"cluster_name" : "elasticsearch",
"nodes" : {
"FKH-5blYTJmff2rJ_lQOCg" : {
"timestamp" : 1556437348653,
"name" : "ubuntu",
"transport_address" : "127.0.0.1:9300",
"host" : "127.0.0.1",
"ip" : "127.0.0.1:9300",
"roles" : [
"master",
"data",
"ingest"
],
"attributes" : {
"ml.machine_memory" : "4112797696",
"xpack.installed" : "true",
"ml.max_open_jobs" : "20"
},
………………………………………………………….Nodes hot_threads
Esta API ajuda a recuperar informações sobre os threads ativos atuais em cada nó do cluster.
GET /_nodes/hot_threadsAo executar o código acima, obtemos a resposta conforme mostrado abaixo -
:::{ubuntu}{FKH-5blYTJmff2rJ_lQOCg}{426kTGpITGixhEzaM5Qyg}{127.0.0.1}{127.0.0.1:9300}{ml.machine_memory=4112797696,
xpack.installed=true, ml.max_open_jobs=20}
Hot threads at 2019-04-28T07:43:58.265Z, interval=500ms, busiestThreads=3,
ignoreIdleThreads=true:No Elasticsearch, a pesquisa é realizada por meio de consulta baseada em JSON. Uma consulta é composta por duas cláusulas -
Leaf Query Clauses - Essas cláusulas são correspondência, termo ou intervalo, que procuram um valor específico em um campo específico.
Compound Query Clauses - Essas consultas são uma combinação de cláusulas de consulta folha e outras consultas compostas para extrair as informações desejadas.
Elasticsearch oferece suporte a um grande número de consultas. Uma consulta começa com uma palavra-chave de consulta e, em seguida, tem condições e filtros dentro da forma de objeto JSON. Os diferentes tipos de consultas foram descritos a seguir.
Corresponder a todas as consultas
Esta é a consulta mais básica; retorna todo o conteúdo e com pontuação de 1,0 para cada objeto.
POST /schools/_search
{
"query":{
"match_all":{}
}
}Ao executar o código acima, obtemos o seguinte resultado -
{
"took" : 7,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "schools",
"_type" : "school",
"_id" : "5",
"_score" : 1.0,
"_source" : {
"name" : "Central School",
"description" : "CBSE Affiliation",
"street" : "Nagan",
"city" : "paprola",
"state" : "HP",
"zip" : "176115",
"location" : [
31.8955385,
76.8380405
],
"fees" : 2200,
"tags" : [
"Senior Secondary",
"beautiful campus"
],
"rating" : "3.3"
}
},
{
"_index" : "schools",
"_type" : "school",
"_id" : "4",
"_score" : 1.0,
"_source" : {
"name" : "City Best School",
"description" : "ICSE",
"street" : "West End",
"city" : "Meerut",
"state" : "UP",
"zip" : "250002",
"location" : [
28.9926174,
77.692485
],
"fees" : 3500,
"tags" : [
"fully computerized"
],
"rating" : "4.5"
}
}
]
}
}Consultas de texto completo
Essas consultas são usadas para pesquisar um corpo de texto completo, como um capítulo ou um artigo de notícias. Essa consulta funciona de acordo com o analisador associado a esse índice ou documento específico. Nesta seção, discutiremos os diferentes tipos de consultas de texto completo.
Consulta de correspondência
Esta consulta combina um texto ou frase com os valores de um ou mais campos.
POST /schools*/_search
{
"query":{
"match" : {
"rating":"4.5"
}
}
}Ao executar o código acima, obtemos a resposta conforme mostrado abaixo -
{
"took" : 44,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.47000363,
"hits" : [
{
"_index" : "schools",
"_type" : "school",
"_id" : "4",
"_score" : 0.47000363,
"_source" : {
"name" : "City Best School",
"description" : "ICSE",
"street" : "West End",
"city" : "Meerut",
"state" : "UP",
"zip" : "250002",
"location" : [
28.9926174,
77.692485
],
"fees" : 3500,
"tags" : [
"fully computerized"
],
"rating" : "4.5"
}
}
]
}
}Consulta Multi Match
Esta consulta corresponde a um texto ou frase com mais de um campo.
POST /schools*/_search
{
"query":{
"multi_match" : {
"query": "paprola",
"fields": [ "city", "state" ]
}
}
}Ao executar o código acima, obtemos a resposta conforme mostrado abaixo -
{
"took" : 12,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.9808292,
"hits" : [
{
"_index" : "schools",
"_type" : "school",
"_id" : "5",
"_score" : 0.9808292,
"_source" : {
"name" : "Central School",
"description" : "CBSE Affiliation",
"street" : "Nagan",
"city" : "paprola",
"state" : "HP",
"zip" : "176115",
"location" : [
31.8955385,
76.8380405
],
"fees" : 2200,
"tags" : [
"Senior Secondary",
"beautiful campus"
],
"rating" : "3.3"
}
}
]
}
}Query String Query
Esta consulta usa analisador de consulta e palavra-chave query_string.
POST /schools*/_search
{
"query":{
"query_string":{
"query":"beautiful"
}
}
}Ao executar o código acima, obtemos a resposta conforme mostrado abaixo -
{
"took" : 60,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
………………………………….Consultas de nível de termo
Essas consultas lidam principalmente com dados estruturados como números, datas e enumerações.
POST /schools*/_search
{
"query":{
"term":{"zip":"176115"}
}
}Ao executar o código acima, obtemos a resposta conforme mostrado abaixo -
……………………………..
hits" : [
{
"_index" : "schools",
"_type" : "school",
"_id" : "5",
"_score" : 0.9808292,
"_source" : {
"name" : "Central School",
"description" : "CBSE Affiliation",
"street" : "Nagan",
"city" : "paprola",
"state" : "HP",
"zip" : "176115",
"location" : [
31.8955385,
76.8380405
],
}
}
]
…………………………………………..Consulta de intervalo
Esta consulta é usada para encontrar os objetos que possuem valores entre os intervalos de valores fornecidos. Para isso, precisamos usar operadores como -
- gte - maior que igual a
- gt - maior que
- lte - menor que igual a
- lt - menos que
Por exemplo, observe o código fornecido abaixo -
POST /schools*/_search
{
"query":{
"range":{
"rating":{
"gte":3.5
}
}
}
}Ao executar o código acima, obtemos a resposta conforme mostrado abaixo -
{
"took" : 24,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "schools",
"_type" : "school",
"_id" : "4",
"_score" : 1.0,
"_source" : {
"name" : "City Best School",
"description" : "ICSE",
"street" : "West End",
"city" : "Meerut",
"state" : "UP",
"zip" : "250002",
"location" : [
28.9926174,
77.692485
],
"fees" : 3500,
"tags" : [
"fully computerized"
],
"rating" : "4.5"
}
}
]
}
}Existem outros tipos de consultas de nível de termo também, como -
Exists query - Se um determinado campo tiver valor não nulo.
Missing query - Isto é completamente oposto à consulta existente, esta consulta procura objetos sem campos específicos ou campos com valor nulo.
Wildcard or regexp query - Esta consulta usa expressões regulares para encontrar padrões nos objetos.
Consultas compostas
Essas consultas são uma coleção de consultas diferentes mescladas entre si usando operadores booleanos como e, ou, não ou para diferentes índices ou tendo chamadas de função etc.
POST /schools/_search
{
"query": {
"bool" : {
"must" : {
"term" : { "state" : "UP" }
},
"filter": {
"term" : { "fees" : "2200" }
},
"minimum_should_match" : 1,
"boost" : 1.0
}
}
}Ao executar o código acima, obtemos a resposta conforme mostrado abaixo -
{
"took" : 6,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 0,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
}
}Consultas geográficas
Essas consultas lidam com localizações geográficas e pontos geográficos. Essas consultas ajudam a descobrir escolas ou qualquer outro objeto geográfico próximo a qualquer local. Você precisa usar o tipo de dados de ponto geográfico.
PUT /geo_example
{
"mappings": {
"properties": {
"location": {
"type": "geo_shape"
}
}
}
}Ao executar o código acima, obtemos a resposta conforme mostrado abaixo -
{ "acknowledged" : true,
"shards_acknowledged" : true,
"index" : "geo_example"
}Agora postamos os dados no índice criado acima.
POST /geo_example/_doc?refresh
{
"name": "Chapter One, London, UK",
"location": {
"type": "point",
"coordinates": [11.660544, 57.800286]
}
}Ao executar o código acima, obtemos a resposta conforme mostrado abaixo -
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
"_index" : "geo_example",
"_type" : "_doc",
"_id" : "hASWZ2oBbkdGzVfiXHKD",
"_score" : 1.0,
"_source" : {
"name" : "Chapter One, London, UK",
"location" : {
"type" : "point",
"coordinates" : [
11.660544,
57.800286
]
}
}
}
}O mapeamento é o esboço dos documentos armazenados em um índice. Ele define o tipo de dados como geo_point ou string e o formato dos campos presentes nos documentos e regras para controlar o mapeamento de campos adicionados dinamicamente.
PUT bankaccountdetails
{
"mappings":{
"properties":{
"name": { "type":"text"}, "date":{ "type":"date"},
"balance":{ "type":"double"}, "liability":{ "type":"double"}
}
}
}Quando executamos o código acima, obtemos a resposta conforme mostrado abaixo -
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "bankaccountdetails"
}Tipos de dados de campo
Elasticsearch oferece suporte a vários tipos de dados diferentes para os campos em um documento. Os tipos de dados usados para armazenar campos no Elasticsearch são discutidos em detalhes aqui.
Tipos de dados centrais
Estes são os tipos de dados básicos como texto, palavra-chave, data, longo, duplo, booleano ou ip, que são suportados por quase todos os sistemas.
Tipos de dados complexos
Esses tipos de dados são uma combinação de tipos de dados principais. Isso inclui array, objeto JSON e tipo de dados aninhados. Um exemplo de tipo de dados aninhado é mostrado abaixo e menos
POST /tabletennis/_doc/1
{
"group" : "players",
"user" : [
{
"first" : "dave", "last" : "jones"
},
{
"first" : "kevin", "last" : "morris"
}
]
}Quando executamos o código acima, obtemos a resposta conforme mostrado abaixo -
{
"_index" : "tabletennis",
"_type" : "_doc",
"_id" : "1",
_version" : 2,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1
}Outro exemplo de código é mostrado abaixo -
POST /accountdetails/_doc/1
{
"from_acc":"7056443341", "to_acc":"7032460534",
"date":"11/1/2016", "amount":10000
}Quando executamos o código acima, obtemos a resposta conforme mostrado abaixo -
{ "_index" : "accountdetails",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1
}Podemos verificar o documento acima usando o seguinte comando -
GET /accountdetails/_mappings?include_type_name=falseRemoção de tipos de mapeamento
Os índices criados no Elasticsearch 7.0.0 ou posterior não aceitam mais um mapeamento _default_. Os índices criados em 6.x continuarão a funcionar como antes no Elasticsearch 6.x. Os tipos foram descontinuados nas APIs no 7.0.
Quando uma consulta é processada durante uma operação de pesquisa, o conteúdo de qualquer índice é analisado pelo módulo de análise. Este módulo consiste em analisador, tokenizer, tokenfilters e charfilters. Se nenhum analisador for definido, então, por padrão, os analisadores, token, filtros e tokenizers integrados são registrados com o módulo de análise.
No exemplo a seguir, usamos um analisador padrão que é usado quando nenhum outro analisador é especificado. Ele irá analisar a frase com base na gramática e produzir palavras usadas na frase.
POST _analyze
{
"analyzer": "standard",
"text": "Today's weather is beautiful"
}Ao executar o código acima, obtemos a resposta conforme mostrado abaixo -
{
"tokens" : [
{
"token" : "today's",
"start_offset" : 0,
"end_offset" : 7,
"type" : "",
"position" : 0
},
{
"token" : "weather",
"start_offset" : 8,
"end_offset" : 15,
"type" : "",
"position" : 1
},
{
"token" : "is",
"start_offset" : 16,
"end_offset" : 18,
"type" : "",
"position" : 2
},
{
"token" : "beautiful",
"start_offset" : 19,
"end_offset" : 28,
"type" : "",
"position" : 3
}
]
}Configurando o analisador padrão
Podemos configurar o analisador padrão com vários parâmetros para obter nossos requisitos personalizados.
No exemplo a seguir, configuramos o analisador padrão para ter um max_token_length de 5.
Para isso, primeiro criamos um índice com o analisador tendo o parâmetro max_length_token.
PUT index_4_analysis
{
"settings": {
"analysis": {
"analyzer": {
"my_english_analyzer": {
"type": "standard",
"max_token_length": 5,
"stopwords": "_english_"
}
}
}
}
}Em seguida, aplicamos o analisador com um texto conforme mostrado abaixo. Observe como o token não aparece, pois tem dois espaços no início e dois espaços no final. Para a palavra “é”, há um espaço no início e um espaço no final. Tomando todas elas, torna-se 4 letras com espaços e isso não significa uma palavra. Deve haver um caractere sem espaço pelo menos no início ou no final, para torná-lo uma palavra a ser contada.
POST index_4_analysis/_analyze
{
"analyzer": "my_english_analyzer",
"text": "Today's weather is beautiful"
}Ao executar o código acima, obtemos a resposta conforme mostrado abaixo -
{
"tokens" : [
{
"token" : "today",
"start_offset" : 0,
"end_offset" : 5,
"type" : "",
"position" : 0
},
{
"token" : "s",
"start_offset" : 6,
"end_offset" : 7,
"type" : "",
"position" : 1
},
{
"token" : "weath",
"start_offset" : 8,
"end_offset" : 13,
"type" : "",
"position" : 2
},
{
"token" : "er",
"start_offset" : 13,
"end_offset" : 15,
"type" : "",
"position" : 3
},
{
"token" : "beaut",
"start_offset" : 19,
"end_offset" : 24,
"type" : "",
"position" : 5
},
{
"token" : "iful",
"start_offset" : 24,
"end_offset" : 28,
"type" : "",
"position" : 6
}
]
}A lista de vários analisadores e suas descrições são fornecidas na tabela mostrada abaixo -
| S.No | Analisador e descrição |
|---|---|
| 1 | Standard analyzer (standard) stopwords e configuração max_token_length podem ser definidas para este analisador. Por padrão, a lista de palavras de interrupção está vazia e max_token_length é 255. |
| 2 | Simple analyzer (simple) Este analisador é composto de um tokenizador em minúsculas. |
| 3 | Whitespace analyzer (whitespace) Este analisador é composto de tokenizer de espaço em branco. |
| 4 | Stop analyzer (stop) stopwords e stopwords_path podem ser configurados. Por padrão, as palavras irrelevantes são inicializadas com palavras irrelevantes em inglês e stopwords_path contém o caminho para um arquivo de texto com palavras irrelevantes. |
Tokenizers
Tokenizers são usados para gerar tokens de um texto no Elasticsearch. O texto pode ser dividido em tokens levando em consideração o espaço em branco ou outras pontuações. Elasticsearch tem muitos tokenizers integrados, que podem ser usados em analisadores personalizados.
Um exemplo de tokenizer que divide o texto em termos sempre que encontra um caractere que não é uma letra, mas também em minúsculas todos os termos, é mostrado abaixo -
POST _analyze
{
"tokenizer": "lowercase",
"text": "It Was a Beautiful Weather 5 Days ago."
}Ao executar o código acima, obtemos a resposta conforme mostrado abaixo -
{
"tokens" : [
{
"token" : "it",
"start_offset" : 0,
"end_offset" : 2,
"type" : "word",
"position" : 0
},
{
"token" : "was",
"start_offset" : 3,
"end_offset" : 6,
"type" : "word",
"position" : 1
},
{
"token" : "a",
"start_offset" : 7,
"end_offset" : 8,
"type" : "word",
"position" : 2
},
{
"token" : "beautiful",
"start_offset" : 9,
"end_offset" : 18,
"type" : "word",
"position" : 3
},
{
"token" : "weather",
"start_offset" : 19,
"end_offset" : 26,
"type" : "word",
"position" : 4
},
{
"token" : "days",
"start_offset" : 29,
"end_offset" : 33,
"type" : "word",
"position" : 5
},
{
"token" : "ago",
"start_offset" : 34,
"end_offset" : 37,
"type" : "word",
"position" : 6
}
]
}Uma lista de Tokenizers e suas descrições são mostradas aqui na tabela abaixo -
| S.No | Tokenizer e descrição |
|---|---|
| 1 | Standard tokenizer (standard) Isso é construído em um tokenizer baseado em gramática e max_token_length pode ser configurado para este tokenizer. |
| 2 | Edge NGram tokenizer (edgeNGram) Configurações como min_gram, max_gram, token_chars podem ser definidas para este tokenizer. |
| 3 | Keyword tokenizer (keyword) Isso gera toda a entrada como uma saída e buffer_size pode ser definido para isso. |
| 4 | Letter tokenizer (letter) Isso captura a palavra inteira até que uma não letra seja encontrada. |
Elasticsearch é composto por vários módulos responsáveis por sua funcionalidade. Esses módulos têm dois tipos de configurações, como segue -
Static Settings- Essas configurações precisam ser definidas no arquivo de configuração (elasticsearch.yml) antes de iniciar o Elasticsearch. Você precisa atualizar todos os nós de preocupação no cluster para refletir as mudanças por essas configurações.
Dynamic Settings - Essas configurações podem ser definidas no Elasticsearch ao vivo.
Discutiremos os diferentes módulos do Elasticsearch nas seções seguintes deste capítulo.
Roteamento em nível de cluster e alocação de fragmentos
As configurações de nível de cluster decidem a alocação de shards para nós diferentes e a realocação de shards para rebalancear o cluster. Estas são as configurações a seguir para controlar a alocação de shard.
Alocação de Fragmentos em Nível de Cluster
| Configuração | Valor possível | Descrição |
|---|---|---|
| cluster.routing.allocation.enable | ||
| todos | Este valor padrão permite a alocação de shards para todos os tipos de shards. | |
| primárias | Isso permite a alocação de fragmentos apenas para fragmentos primários. | |
| new_primaries | Isso permite a alocação de shard apenas para shards primários para novos índices. | |
| Nenhum | Isso não permite nenhuma alocação de shard. | |
| cluster.routing.allocation .node_concurrent_recoveries | Valor numérico (por padrão 2) | Isso restringe o número de recuperação simultânea de shard. |
| cluster.routing.allocation .node_initial_primaries_recoveries | Valor numérico (por padrão 4) | Isso restringe o número de recuperações primárias iniciais paralelas. |
| cluster.routing.allocation .same_shard.host | Valor booleano (por padrão, falso) | Isso restringe a alocação de mais de uma réplica do mesmo shard no mesmo nó físico. |
| indices.recovery.concurrent _streams | Valor numérico (por padrão 3) | Isso controla o número de fluxos de rede abertos por nó no momento da recuperação de shards de peer. |
| indices.recovery.concurrent _small_file_streams | Valor numérico (por padrão 2) | Isso controla o número de fluxos abertos por nó para arquivos pequenos com tamanho inferior a 5 MB no momento da recuperação de shard. |
| cluster.routing.rebalance.enable | ||
| todos | Este valor padrão permite o equilíbrio para todos os tipos de fragmentos. | |
| primárias | Isso permite o balanceamento de shards apenas para shards primários. | |
| réplicas | Isso permite o balanceamento de fragmentos apenas para fragmentos de réplica. | |
| Nenhum | Isso não permite qualquer tipo de balanceamento de fragmentos. | |
| cluster.routing.allocation .allow_rebalance | ||
| sempre | Este valor padrão sempre permite o rebalanceamento. | |
| indices_primaries _active | Isso permite o rebalanceamento quando todos os shards primários no cluster são alocados. | |
| Indices_all_active | Isso permite o rebalanceamento quando todos os shards primários e de réplica são alocados. | |
| cluster.routing.allocation.cluster _concurrent_rebalance | Valor numérico (por padrão 2) | Isso restringe o número de balanceamento de shard simultâneos no cluster. |
| cluster.routing.allocation .balance.shard | Valor flutuante (por padrão 0,45f) | Isso define o fator de peso para shards alocados em cada nó. |
| cluster.routing.allocation .balance.index | Valor flutuante (por padrão 0,55f) | Isso define a proporção do número de shards por índice alocado em um nó específico. |
| cluster.routing.allocation .balance.threshold | Valor flutuante não negativo (por padrão 1.0f) | Este é o valor mínimo de otimização das operações que devem ser realizadas. |
Alocação de fragmentos baseada em disco
| Configuração | Valor possível | Descrição |
|---|---|---|
| cluster.routing.allocation.disk.threshold_enabled | Valor booleano (verdadeiro por padrão) | Isso ativa e desativa o decisor de alocação de disco. |
| cluster.routing.allocation.disk.watermark.low | Valor da string (por padrão 85%) | Isso denota o uso máximo do disco; após este ponto, nenhum outro fragmento pode ser alocado para esse disco. |
| cluster.routing.allocation.disk.watermark.high | Valor da string (por padrão 90%) | Isso denota o uso máximo no momento da alocação; se esse ponto for atingido no momento da alocação, o Elasticsearch alocará esse fragmento para outro disco. |
| cluster.info.update.interval | Valor da string (por padrão, 30s) | Este é o intervalo entre as verificações de uso do disco. |
| cluster.routing.allocation.disk.include_relocations | Valor booleano (verdadeiro por padrão) | Isso decide se deve considerar os fragmentos atualmente sendo alocados, ao calcular o uso do disco. |
Descoberta
Este módulo ajuda um cluster a descobrir e manter o estado de todos os nós nele. O estado do cluster muda quando um nó é adicionado ou excluído dele. A configuração do nome do cluster é usada para criar diferença lógica entre diferentes clusters. Existem alguns módulos que ajudam você a usar as APIs fornecidas por fornecedores de nuvem e aqueles são fornecidos abaixo -
- Descoberta do Azure
- Descoberta EC2
- Descoberta do Google Compute Engine
- Descoberta zen
Porta de entrada
Este módulo mantém o estado do cluster e os dados de shard nas reinicializações completas do cluster. A seguir estão as configurações estáticas deste módulo -
| Configuração | Valor possível | Descrição |
|---|---|---|
| gateway.expected_nodes | valor numérico (por padrão 0) | O número de nós que se espera que estejam no cluster para a recuperação de shards locais. |
| gateway.expected_master_nodes | valor numérico (por padrão 0) | O número de nós mestres que devem estar no cluster antes de iniciar a recuperação. |
| gateway.expected_data_nodes | valor numérico (por padrão 0) | O número de nós de dados esperados no cluster antes de iniciar a recuperação. |
| gateway.recover_after_time | Valor da string (por padrão 5m) | Este é o intervalo entre as verificações de uso do disco. |
| cluster.routing.allocation. disk.include_relocations | Valor booleano (verdadeiro por padrão) | Isso especifica o tempo pelo qual o processo de recuperação aguardará para iniciar, independentemente do número de nós unidos no cluster. gateway.recover_ after_nodes |
HTTP
Este módulo gerencia a comunicação entre o cliente HTTP e as APIs Elasticsearch. Este módulo pode ser desativado alterando o valor de http.enabled para false.
A seguir estão as configurações (definidas em elasticsearch.yml) para controlar este módulo -
| S.No | Configuração e descrição |
|---|---|
| 1 | http.port Esta é uma porta para acessar o Elasticsearch e varia de 9200-9300. |
| 2 | http.publish_port Esta porta é para clientes http e também é útil no caso de firewall. |
| 3 | http.bind_host Este é um endereço de host para serviço http. |
| 4 | http.publish_host Este é um endereço de host para o cliente http. |
| 5 | http.max_content_length Este é o tamanho máximo de conteúdo em uma solicitação http. Seu valor padrão é 100 MB. |
| 6 | http.max_initial_line_length Este é o tamanho máximo da URL e seu valor padrão é 4kb. |
| 7 | http.max_header_size Este é o tamanho máximo do cabeçalho http e seu valor padrão é 8kb. |
| 8 | http.compression Isso ativa ou desativa o suporte para compactação e seu valor padrão é falso. |
| 9 | http.pipelinig Isso ativa ou desativa o pipelining HTTP. |
| 10 | http.pipelining.max_events Isso restringe o número de eventos a serem enfileirados antes de fechar uma solicitação HTTP. |
Índices
Este módulo mantém as configurações, que são definidas globalmente para cada índice. As configurações a seguir estão relacionadas principalmente ao uso de memória -
Disjuntor
Isso é usado para evitar que a operação cause um OutOfMemroyError. A configuração restringe principalmente o tamanho de heap da JVM. Por exemplo, a configuração indices.breaker.total.limit, cujo padrão é 70% do heap da JVM.
Cache Fielddata
Isso é usado principalmente ao agregar em um campo. Recomenda-se ter memória suficiente para alocá-lo. A quantidade de memória usada para o cache de dados de campo pode ser controlada usando a configuração indices.fielddata.cache.size.
Cache de consulta de nó
Essa memória é usada para armazenar em cache os resultados da consulta. Este cache usa a política de despejo de menos usados recentemente (LRU). A configuração Indices.queries.cahce.size controla o tamanho da memória deste cache.
Buffer de indexação
Este buffer armazena os documentos recém-criados no índice e os libera quando o buffer está cheio. Definir como indices.memory.index_buffer_size controla a quantidade de heap alocada para este buffer.
Cache de solicitação de fragmento
Esse cache é usado para armazenar os dados de pesquisa local para cada fragmento. O cache pode ser habilitado durante a criação do índice ou pode ser desabilitado enviando um parâmetro de URL.
Disable cache - ?request_cache = true
Enable cache "index.requests.cache.enable": trueRecuperação de Índices
Ele controla os recursos durante o processo de recuperação. A seguir estão as configurações -
| Configuração | Valor padrão |
|---|---|
| indices.recovery.concurrent_streams | 3 |
| indices.recovery.concurrent_small_file_streams | 2 |
| indices.recovery.file_chunk_size | 512kb |
| indices.recovery.translog_ops | 1000 |
| indices.recovery.translog_size | 512kb |
| indices.recovery.compress | verdadeiro |
| indices.recovery.max_bytes_per_sec | 40mb |
Intervalo TTL
O intervalo de tempo de vida (TTL) define o tempo de um documento, após o qual o documento é excluído. A seguir estão as configurações dinâmicas para controlar este processo -
| Configuração | Valor padrão |
|---|---|
| indices.ttl.interval | anos 60 |
| indices.ttl.bulk_size | 1000 |
Nó
Cada nó tem a opção de ser nó de dados ou não. Você pode alterar esta propriedade alterandonode.dataconfiguração. Definindo o valor comofalse define que o nó não é um nó de dados.
Estes são os módulos que são criados para cada índice e controlam as configurações e o comportamento dos índices. Por exemplo, quantos fragmentos um índice pode usar ou o número de réplicas que um fragmento primário pode ter para esse índice, etc. Existem dois tipos de configurações de índice -
- Static - Eles podem ser definidos apenas no momento da criação do índice ou em um índice fechado.
- Dynamic - Isso pode ser alterado em um índice ativo.
Configurações de índice estático
A tabela a seguir mostra a lista de configurações de índice estático -
| Configuração | Valor possível | Descrição |
|---|---|---|
| index.number_of_shards | O padrão é 5, máximo 1024 | O número de shards primários que um índice deve ter. |
| index.shard.check_on_startup | O padrão é falso. Pode ser verdade | Se os shards devem ou não ser verificados quanto à corrupção antes de abrir. |
| index.codec | Compressão LZ4. | Tipo de compactação usado para armazenar dados. |
| index.routing_partition_size | 1 | O número de fragmentos para os quais um valor de roteamento customizado pode ir. |
| index.load_fixed_bitset_filters_eagerly | falso | Indica se os filtros em cache são pré-carregados para consultas aninhadas |
Configurações de índice dinâmico
A tabela a seguir mostra a lista de configurações de índice dinâmico -
| Configuração | Valor possível | Descrição |
|---|---|---|
| index.number_of_replicas | Padrões para 1 | O número de réplicas que cada shard primário possui. |
| index.auto_expand_replicas | Um traço delimitado pelos limites inferior e superior (0-5) | Expanda automaticamente o número de réplicas com base no número de nós de dados no cluster. |
| index.search.idle.after | 30 segundos | Por quanto tempo um fragmento não pode receber uma solicitação de busca ou obtenção até que seja considerado busca ociosa. |
| index.refresh_interval | 1 segundo | Com que frequência realizar uma operação de atualização, o que torna as alterações recentes no índice visíveis para pesquisa. |
| index.blocks.read_only | 1 verdadeiro / falso | Defina como verdadeiro para tornar o índice e metadados do índice somente leitura, falso para permitir gravações e alterações nos metadados. |
Às vezes, precisamos transformar um documento antes de indexá-lo. Por exemplo, queremos remover um campo do documento ou renomear um campo e depois indexá-lo. Isso é tratado pelo nó Ingest.
Cada nó no cluster tem a capacidade de receber, mas também pode ser customizado para ser processado apenas por nós específicos.
Etapas Envolvidas
Existem duas etapas envolvidas no funcionamento do nó de ingestão -
- Criação de um pipeline
- Criação de um documento
Crie um pipeline
Criar primeiro um pipeline que contém os processadores e, em seguida, executar o pipeline, conforme mostrado abaixo -
PUT _ingest/pipeline/int-converter
{
"description": "converts the content of the seq field to an integer",
"processors" : [
{
"convert" : {
"field" : "seq",
"type": "integer"
}
}
]
}Ao executar o código acima, obtemos o seguinte resultado -
{
"acknowledged" : true
}Criar um Documento
Em seguida, criamos um documento usando o conversor de pipeline.
PUT /logs/_doc/1?pipeline=int-converter
{
"seq":"21",
"name":"Tutorialspoint",
"Addrs":"Hyderabad"
}Ao executar o código acima, obtemos a resposta conforme mostrado abaixo -
{
"_index" : "logs",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}Em seguida, procuramos o documento criado acima usando o comando GET conforme mostrado abaixo -
GET /logs/_doc/1Ao executar o código acima, obtemos o seguinte resultado -
{
"_index" : "logs",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"_seq_no" : 0,
"_primary_term" : 1,
"found" : true,
"_source" : {
"Addrs" : "Hyderabad",
"name" : "Tutorialspoint",
"seq" : 21
}
}Você pode ver acima que 21 se tornou um número inteiro.
Sem Pipeline
Agora criamos um documento sem usar o pipeline.
PUT /logs/_doc/2
{
"seq":"11",
"name":"Tutorix",
"Addrs":"Secunderabad"
}
GET /logs/_doc/2Ao executar o código acima, obtemos o seguinte resultado -
{
"_index" : "logs",
"_type" : "_doc",
"_id" : "2",
"_version" : 1,
"_seq_no" : 1,
"_primary_term" : 1,
"found" : true,
"_source" : {
"seq" : "11",
"name" : "Tutorix",
"Addrs" : "Secunderabad"
}
}Você pode ver acima que 11 é uma string sem o pipeline sendo usado.
Gerenciar o ciclo de vida do índice envolve a execução de ações de gerenciamento com base em fatores como tamanho do fragmento e requisitos de desempenho. As APIs de gerenciamento do ciclo de vida do índice (ILM) permitem que você automatize a maneira como deseja gerenciar seus índices ao longo do tempo.
Este capítulo fornece uma lista de APIs de ILM e seu uso.
APIs de gerenciamento de políticas
| Nome API | Objetivo | Exemplo |
|---|---|---|
| Crie uma política de ciclo de vida. | Cria uma política de ciclo de vida. Se a política especificada existir, a política será substituída e a versão da política será incrementada. | PUT_ilm / policy / policy_id |
| Obtenha a política de ciclo de vida. | Retorna a definição de política especificada. Inclui a versão da política e a data da última modificação. Se nenhuma política for especificada, retorna todas as políticas definidas. | GET_ilm / policy / policy_id |
| Excluir política de ciclo de vida | Exclui a definição de política de ciclo de vida especificada. Você não pode excluir políticas que estão atualmente em uso. Se a política estiver sendo usada para gerenciar quaisquer índices, a solicitação falhará e retornará um erro. | DELETE_ilm / policy / policy_id |
APIs de gerenciamento de índice
| Nome API | Objetivo | Exemplo |
|---|---|---|
| Mova para a API da etapa do ciclo de vida. | Move manualmente um índice para a etapa especificada e executa essa etapa. | POST_ilm / mover / index |
| Repita a política. | Define a política de volta para a etapa em que ocorreu o erro e executa a etapa. | Índice POST / _ilm / repetir |
| Remova a política da edição da API do índice. | Remove a política de ciclo de vida atribuída e interrompe o gerenciamento do índice especificado. Se um padrão de índice for especificado, remove as políticas atribuídas de todos os índices correspondentes. | Índice POST / _ilm / remover |
APIs de gerenciamento de operação
| Nome API | Objetivo | Exemplo |
|---|---|---|
| Obtenha a API de status de gerenciamento do ciclo de vida do índice. | Retorna o status do plugin ILM. O campo operation_mode na resposta mostra um dos três estados: STARTED, STOPPING ou STOPPED. | GET / _ilm / status |
| Inicie a API de gerenciamento do ciclo de vida do índice. | Inicia o plugin ILM se estiver parado. O ILM é iniciado automaticamente quando o cluster é formado. | POST / _ilm / start |
| Pare a API de gerenciamento do ciclo de vida do índice. | Interrompe todas as operações de gerenciamento do ciclo de vida e interrompe o plug-in ILM. Isso é útil quando você está realizando manutenção no cluster e precisa evitar que o ILM execute qualquer ação em seus índices. | POST / _ilm / stop |
| Explique a API do ciclo de vida. | Recupera informações sobre o estado atual do ciclo de vida do índice, como a fase, ação e etapa em execução no momento. Mostra quando o índice entrou em cada um, a definição da fase de execução e as informações sobre quaisquer falhas. | Índice GET / _ilm / explicação |
É um componente que permite que consultas semelhantes a SQL sejam executadas em tempo real no Elasticsearch. Você pode pensar no Elasticsearch SQL como um tradutor, que entende tanto SQL quanto Elasticsearch e facilita a leitura e o processamento de dados em tempo real, em escala, aproveitando os recursos do Elasticsearch.
Vantagens do Elasticsearch SQL
It has native integration - Cada consulta é executada com eficiência nos nós relevantes de acordo com o armazenamento subjacente.
No external parts - Não há necessidade de hardware, processos, tempos de execução ou bibliotecas adicionais para consultar o Elasticsearch.
Lightweight and efficient - abraça e expõe SQL para permitir a busca de texto completo adequada, em tempo real.
Exemplo
PUT /schoollist/_bulk?refresh
{"index":{"_id": "CBSE"}}
{"name": "GleanDale", "Address": "JR. Court Lane", "start_date": "2011-06-02",
"student_count": 561}
{"index":{"_id": "ICSE"}}
{"name": "Top-Notch", "Address": "Gachibowli Main Road", "start_date": "1989-
05-26", "student_count": 482}
{"index":{"_id": "State Board"}}
{"name": "Sunshine", "Address": "Main Street", "start_date": "1965-06-01",
"student_count": 604}Ao executar o código acima, obtemos a resposta conforme mostrado abaixo -
{
"took" : 277,
"errors" : false,
"items" : [
{
"index" : {
"_index" : "schoollist",
"_type" : "_doc",
"_id" : "CBSE",
"_version" : 1,
"result" : "created",
"forced_refresh" : true,
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1,
"status" : 201
}
},
{
"index" : {
"_index" : "schoollist",
"_type" : "_doc",
"_id" : "ICSE",
"_version" : 1,
"result" : "created",
"forced_refresh" : true,
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1,
"status" : 201
}
},
{
"index" : {
"_index" : "schoollist",
"_type" : "_doc",
"_id" : "State Board",
"_version" : 1,
"result" : "created",
"forced_refresh" : true,
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 2,
"_primary_term" : 1,
"status" : 201
}
}
]
}Consulta SQL
O exemplo a seguir mostra como estruturamos a consulta SQL -
POST /_sql?format=txt
{
"query": "SELECT * FROM schoollist WHERE start_date < '2000-01-01'"
}Ao executar o código acima, obtemos a resposta conforme mostrado abaixo -
Address | name | start_date | student_count
--------------------+---------------+------------------------+---------------
Gachibowli Main Road|Top-Notch |1989-05-26T00:00:00.000Z|482
Main Street |Sunshine |1965-06-01T00:00:00.000Z|604Note - Alterando a consulta SQL acima, você pode obter diferentes conjuntos de resultados.
Para monitorar a saúde do cluster, o recurso de monitoramento coleta as métricas de cada nó e as armazena nos índices Elasticsearch. Todas as configurações associadas ao monitoramento no Elasticsearch devem ser definidas no arquivo elasticsearch.yml para cada nó ou, quando possível, nas configurações de cluster dinâmico.
Para iniciar o monitoramento, precisamos verificar as configurações do cluster, o que pode ser feito da seguinte maneira -
GET _cluster/settings
{
"persistent" : { },
"transient" : { }
}Cada componente na pilha é responsável por monitorar a si mesmo e, em seguida, encaminhar esses documentos para o cluster de produção Elasticsearch para roteamento e indexação (armazenamento). Os processos de roteamento e indexação no Elasticsearch são gerenciados pelos chamados coletores e exportadores.
Colecionadores
O Collector é executado uma vez a cada intervalo de coleta para obter dados das APIs públicas no Elasticsearch que ele escolhe monitorar. Quando a coleta de dados é finalizada, os dados são entregues em massa aos exportadores para serem enviados ao cluster de monitoramento.
Existe apenas um coletor por tipo de dados reunido. Cada coletor pode criar zero ou mais documentos de monitoramento.
Exportadores
Os exportadores pegam os dados coletados de qualquer origem do Elastic Stack e os encaminham para o cluster de monitoramento. É possível configurar mais de um exportador, mas a configuração geral e padrão é usar um único exportador. Os exportadores são configuráveis no nível do nó e do cluster.
Existem dois tipos de exportadores no Elasticsearch -
local - Este exportador encaminha os dados de volta para o mesmo cluster
http - O exportador preferido, que você pode usar para rotear dados em qualquer cluster Elasticsearch compatível acessível via HTTP.
Antes que os exportadores possam rotear os dados de monitoramento, eles devem configurar certos recursos do Elasticsearch. Esses recursos incluem modelos e pipelines de ingestão
Um trabalho de rollup é uma tarefa periódica que resume os dados de índices especificados por um padrão de índice e os converte em um novo índice. No exemplo a seguir, criamos um índice denominado sensor com diferentes carimbos de data e hora. Em seguida, criamos um rollup job para fazer rollup dos dados desses índices periodicamente usando cron job.
PUT /sensor/_doc/1
{
"timestamp": 1516729294000,
"temperature": 200,
"voltage": 5.2,
"node": "a"
}Ao executar o código acima, obtemos o seguinte resultado -
{
"_index" : "sensor",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}Agora, adicione um segundo documento e assim por diante para outros documentos também.
PUT /sensor-2018-01-01/_doc/2
{
"timestamp": 1413729294000,
"temperature": 201,
"voltage": 5.9,
"node": "a"
}Criar um trabalho de rollup
PUT _rollup/job/sensor
{
"index_pattern": "sensor-*",
"rollup_index": "sensor_rollup",
"cron": "*/30 * * * * ?",
"page_size" :1000,
"groups" : {
"date_histogram": {
"field": "timestamp",
"interval": "60m"
},
"terms": {
"fields": ["node"]
}
},
"metrics": [
{
"field": "temperature",
"metrics": ["min", "max", "sum"]
},
{
"field": "voltage",
"metrics": ["avg"]
}
]
}O parâmetro cron controla quando e com que frequência o trabalho é ativado. Quando o cronograma de um job de rollup dispara, ele começa a rolar de onde parou após a última ativação
Depois que o trabalho foi executado e processado alguns dados, podemos usar a consulta DSL para fazer algumas pesquisas.
GET /sensor_rollup/_rollup_search
{
"size": 0,
"aggregations": {
"max_temperature": {
"max": {
"field": "temperature"
}
}
}
}Os índices que são pesquisados com frequência são mantidos na memória porque leva tempo para reconstruí-los e ajudar em uma pesquisa eficiente. Por outro lado, pode haver índices que raramente acessamos. Esses índices não precisam ocupar a memória e podem ser reconstruídos quando necessário. Esses índices são conhecidos como índices congelados.
Elasticsearch constrói as estruturas de dados transitórios de cada fragmento de um índice congelado cada vez que esse fragmento é pesquisado e descarta essas estruturas de dados assim que a pesquisa é concluída. Como o Elasticsearch não mantém essas estruturas de dados transitórios na memória, os índices congelados consomem muito menos heap do que os índices normais. Isso permite uma proporção de disco para heap muito maior do que seria possível.
Exemplo para congelamento e descongelamento
O exemplo a seguir congela e descongela um índice -
POST /index_name/_freeze
POST /index_name/_unfreezeAs pesquisas em índices congelados devem ser executadas lentamente. Os índices congelados não se destinam a uma alta carga de pesquisa. É possível que uma pesquisa de um índice congelado leve segundos ou minutos para ser concluída, mesmo que as mesmas pesquisas sejam concluídas em milissegundos quando os índices não foram congelados.
Pesquisando um índice congelado
O número de índices congelados carregados simultaneamente por nó é limitado pelo número de threads no pool de threads search_throttled, que é 1 por padrão. Para incluir índices congelados, uma solicitação de pesquisa deve ser executada com o parâmetro de consulta - ignore_throttled = false.
GET /index_name/_search?q=user:tpoint&ignore_throttled=falseMonitorando Índices de Congelamento
Índices congelados são índices comuns que usam otimização de pesquisa e uma implementação de shard com eficiência de memória.
GET /_cat/indices/index_name?v&h=i,sthElasticsearch fornece um arquivo jar, que pode ser adicionado a qualquer IDE Java e pode ser usado para testar o código relacionado ao Elasticsearch. Uma variedade de testes pode ser realizada usando a estrutura fornecida pelo Elasticsearch. Neste capítulo, discutiremos esses testes em detalhes -
- Teste de unidade
- Teste de integração
- Teste Randomizado
Pré-requisitos
Para começar o teste, você precisa adicionar a dependência de teste Elasticsearch ao seu programa. Você pode usar o maven para essa finalidade e pode adicionar o seguinte em pom.xml.
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>2.1.0</version>
</dependency>EsSetup foi inicializado para iniciar e parar o nó Elasticsearch e também para criar índices.
EsSetup esSetup = new EsSetup();A função esSetup.execute () com createIndex irá criar os índices, você precisa especificar as configurações, tipo e dados.
Teste de Unidade
O teste de unidade é realizado usando a estrutura de teste JUnit e Elasticsearch. Nó e índices podem ser criados usando classes Elasticsearch e no método de teste podem ser usados para realizar o teste. As classes ESTestCase e ESTokenStreamTestCase são usadas para este teste.
Teste de integração
O teste de integração usa vários nós em um cluster. A classe ESIntegTestCase é usada para este teste. Existem vários métodos que facilitam o trabalho de preparação de um caso de teste.
| S.No | Método e Descrição |
|---|---|
| 1 | refresh() Todos os índices em um cluster são atualizados |
| 2 | ensureGreen() Garante um estado de cluster de integridade verde |
| 3 | ensureYellow() Garante um estado de cluster de integridade amarelo |
| 4 | createIndex(name) Crie um índice com o nome passado para este método |
| 5 | flush() Todos os índices no cluster são liberados |
| 6 | flushAndRefresh() limpar () e atualizar () |
| 7 | indexExists(name) Verifica a existência de índice especificado |
| 8 | clusterService() Retorna a classe java do serviço de cluster |
| 9 | cluster() Retorna a classe de cluster de teste |
Métodos de cluster de teste
| S.No | Método e Descrição |
|---|---|
| 1 | ensureAtLeastNumNodes(n) Garante que o número mínimo de nós em um cluster seja maior ou igual ao número especificado. |
| 2 | ensureAtMostNumNodes(n) Garante que o número máximo de nós em um cluster seja menor ou igual ao número especificado. |
| 3 | stopRandomNode() Para parar um nó aleatório em um cluster |
| 4 | stopCurrentMasterNode() Para parar o nó mestre |
| 5 | stopRandomNonMaster() Para parar um nó aleatório em um cluster, que não é um nó mestre. |
| 6 | buildNode() Crie um novo nó |
| 7 | startNode(settings) Inicie um novo nó |
| 8 | nodeSettings() Substitua este método para alterar as configurações do nó. |
Acessando clientes
Um cliente é usado para acessar diferentes nós em um cluster e realizar alguma ação. O método ESIntegTestCase.client () é usado para obter um cliente aleatório. Elasticsearch oferece outros métodos também para acessar o cliente e esses métodos podem ser acessados usando o método ESIntegTestCase.internalCluster ().
| S.No | Método e Descrição |
|---|---|
| 1 | iterator() Isso ajuda você a acessar todos os clientes disponíveis. |
| 2 | masterClient() Isso retorna um cliente, que está se comunicando com o nó mestre. |
| 3 | nonMasterClient() Isso retorna um cliente, que não está se comunicando com o nó mestre. |
| 4 | clientNodeClient() Isso retorna um cliente atualmente ativo no nó cliente. |
Teste Randomizado
Este teste é usado para testar o código do usuário com todos os dados possíveis, para que não haja falha no futuro com nenhum tipo de dado. Dados aleatórios são a melhor opção para realizar este teste.
Gerando Dados Aleatórios
Nesse teste, a classe Random é instanciada pela instância fornecida por RandomizedTest e oferece muitos métodos para obter diferentes tipos de dados.
| Método | Valor de retorno |
|---|---|
| getRandom () | Instância de classe aleatória |
| randomBoolean () | Booleano aleatório |
| randomByte () | Byte aleatório |
| randomShort () | Curto aleatório |
| randomInt () | Inteiro aleatório |
| randomLong () | Aleatório longo |
| randomFloat () | Flutuação aleatória |
| randomDouble () | Duplo aleatório |
| randomLocale () | Localidade aleatória |
| randomTimeZone () | Fuso horário aleatório |
| randomFrom () | Elemento aleatório da matriz |
Afirmações
As classes ElasticsearchAssertions e ElasticsearchGeoAssertions contêm asserções, que são usadas para realizar algumas verificações comuns no momento do teste. Por exemplo, observe o código fornecido aqui -
SearchResponse seearchResponse = client().prepareSearch();
assertHitCount(searchResponse, 6);
assertFirstHit(searchResponse, hasId("6"));
assertSearchHits(searchResponse, "1", "2", "3", "4",”5”,”6”);Um painel Kibana é uma coleção de visualizações e pesquisas. Você pode organizar, redimensionar e editar o conteúdo do painel e depois salvá-lo para compartilhá-lo. Neste capítulo, veremos como criar e editar um painel.
Criação de painel
Na página inicial do Kibana, selecione a opção de painel nas barras de controle à esquerda, conforme mostrado abaixo. Isso solicitará que você crie um novo painel.
Para adicionar visualizações ao painel, escolhemos o menu Adicionar e a selecionamos entre as visualizações pré-construídas disponíveis. Escolhemos as seguintes opções de visualização na lista.
Ao selecionar as visualizações acima, obtemos o painel conforme mostrado aqui. Posteriormente, podemos adicionar e editar o painel para alterar os elementos e adicionar os novos elementos.
Inspecionando Elementos
Podemos inspecionar os elementos do Dashboard escolhendo o menu do painel de visualizações e selecionando Inspect. Isso trará os dados por trás do elemento, que também podem ser baixados.
Painel de Compartilhamento
Podemos compartilhar o painel, escolhendo o menu de compartilhamento e selecionando a opção para obter um hiperlink conforme mostrado abaixo -

A funcionalidade de descoberta disponível na página inicial do Kibana nos permite explorar os conjuntos de dados de vários ângulos. Você pode pesquisar e filtrar dados para os padrões de índice selecionados. Os dados geralmente estão disponíveis na forma de distribuição de valores ao longo de um período de tempo.
Para explorar a amostra de dados de comércio eletrônico, clicamos no Discoverícone como mostrado na imagem abaixo. Isso trará os dados junto com o gráfico.
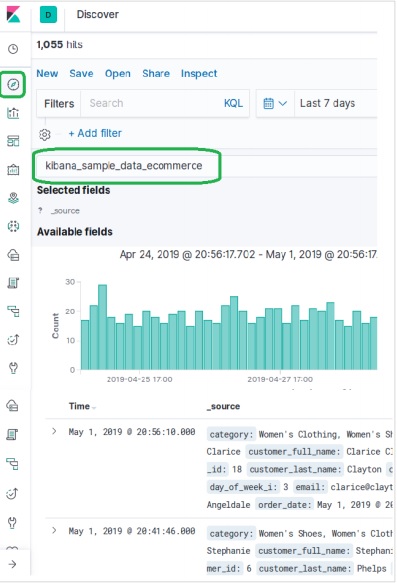
Filtrando por Tempo
Para filtrar os dados por intervalo de tempo específico, usamos a opção de filtro de tempo conforme mostrado abaixo. Por padrão, o filtro é definido em 15 minutos.
Filtrando por Campos
O conjunto de dados também pode ser filtrado por campos usando o Add Filteropção como mostrado abaixo. Aqui, adicionamos um ou mais campos e obtemos o resultado correspondente depois que os filtros são aplicados. Em nosso exemplo, escolhemos o campoday_of_week e então o operador desse campo como is e valor como Sunday.
Em seguida, clicamos em Salvar com as condições de filtro acima. O conjunto de resultados contendo as condições de filtro aplicadas é mostrado abaixo.
A tabela de dados é um tipo de visualização usado para exibir os dados brutos de uma agregação composta. Existem vários tipos de agregações que são apresentados usando tabelas de dados. Para criar uma tabela de dados, devemos seguir as etapas que são discutidas aqui em detalhes.
Visualizar
Na tela inicial do Kibana encontramos a opção de nome Visualize que nos permite criar visualizações e agregações a partir dos índices armazenados no Elasticsearch. A imagem a seguir mostra a opção.
Selecione a tabela de dados
Em seguida, selecionamos a opção Tabela de dados entre as várias opções de visualização disponíveis. A opção é mostrada na imagem a seguir & miuns;
Selecione as métricas
Em seguida, selecionamos as métricas necessárias para criar a visualização da tabela de dados. Essa escolha decide o tipo de agregação que vamos usar. Selecionamos os campos específicos mostrados abaixo a partir do conjunto de dados de comércio eletrônico para isso.
Ao executar a configuração acima para a Tabela de Dados, obtemos o resultado conforme mostrado na imagem aqui -
Mapas de região mostram métricas em um mapa geográfico. É útil para observar os dados ancorados em diferentes regiões geográficas com intensidade variável. Os tons mais escuros geralmente indicam valores mais altos e os tons mais claros indicam valores mais baixos.
As etapas para criar esta visualização são explicadas em detalhes a seguir -
Visualizar
Nesta etapa vamos ao botão Visualizar disponível na barra esquerda da tela inicial do Kibana e a seguir escolhemos a opção de adicionar uma nova Visualização.
A tela a seguir mostra como escolhemos a opção Mapa da região.
Escolha as métricas
A próxima tela nos pede para escolher as métricas que serão usadas na criação do Mapa da Região. Aqui, escolhemos o preço médio como a métrica e country_iso_code como o campo no intervalo que será usado na criação da visualização.
O resultado final abaixo mostra o Mapa da Região, uma vez que aplicamos a seleção. Observe as tonalidades da cor e seus valores mencionados na etiqueta.
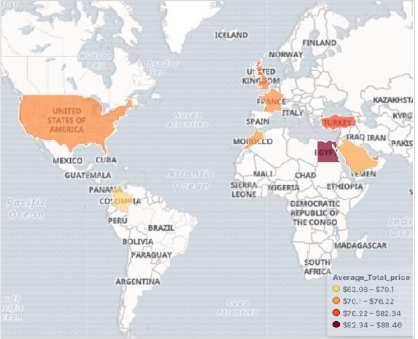
Os gráficos de pizza são uma das ferramentas de visualização mais simples e famosas. Ele representa os dados como fatias de um círculo, cada uma com uma cor diferente. Os rótulos junto com os valores percentuais dos dados podem ser apresentados junto com o círculo. O círculo também pode assumir a forma de um donut.
Visualizar
Na tela inicial do Kibana, encontramos a opção de nome Visualize que nos permite criar visualizações e agregações a partir dos índices armazenados no Elasticsearch. Escolhemos adicionar uma nova visualização e selecionar gráfico de pizza como a opção mostrada abaixo.
Escolha as métricas
A próxima tela nos pede para escolher as métricas que serão usadas na criação do gráfico de pizza. Aqui, escolhemos a contagem do preço unitário básico como a métrica e a Agregação do intervalo como histograma. Além disso, o intervalo mínimo é escolhido como 20. Portanto, os preços serão exibidos como blocos de valores com 20 como um intervalo.
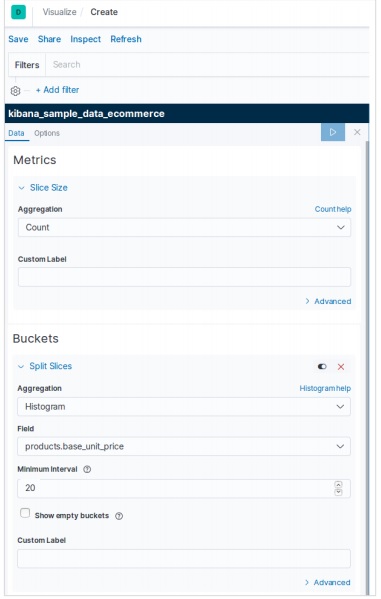
O resultado abaixo mostra o gráfico de pizza após aplicarmos a seleção. Observe as tonalidades da cor e seus valores mencionados na etiqueta.

Opções de gráfico de pizza
Ao passar para a guia de opções no gráfico de pizza, podemos ver várias opções de configuração para alterar a aparência, bem como a organização da exibição de dados no gráfico de pizza. No exemplo a seguir, o gráfico de pizza aparece como uma rosquinha e os rótulos aparecem no topo.
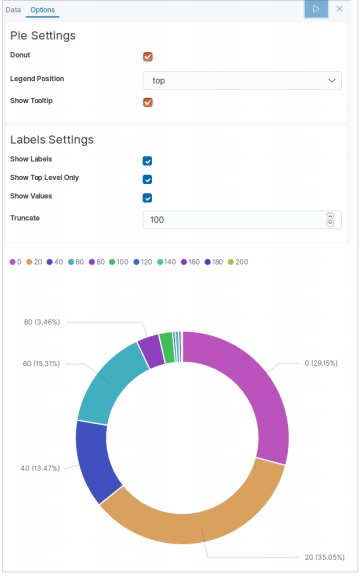
Um gráfico de área é uma extensão do gráfico de linha em que a área entre o gráfico de linha e os eixos é destacada com algumas cores. Um gráfico de barras representa os dados organizados em uma faixa de valores e, a seguir, plotados em relação aos eixos. Pode consistir em barras horizontais ou verticais.
Neste capítulo, veremos todos esses três tipos de gráficos criados com o Kibana. Conforme discutido nos capítulos anteriores, continuaremos a usar os dados no índice de comércio eletrônico.
Gráfico de Área
Na tela inicial do Kibana, encontramos a opção de nome Visualize que nos permite criar visualizações e agregações a partir dos índices armazenados no Elasticsearch. Optamos por adicionar uma nova visualização e selecionar Gráfico de área como a opção mostrada na imagem abaixo.
Escolha as métricas
A próxima tela nos pede para escolher as métricas que serão usadas na criação do Gráfico de Área. Aqui, escolhemos a soma como o tipo de métrica de agregação. Em seguida, escolhemos o campo total_quantity como o campo a ser usado como métrica. No eixo X, escolhemos o campo order_date e dividimos a série com a métrica fornecida em um tamanho de 5.

Ao executar a configuração acima, obtemos o seguinte gráfico de área como saída -
Gráfico de Barras Horizontais
Da mesma forma, para o gráfico de barras horizontal, escolhemos uma nova visualização na tela inicial do Kibana e escolhemos a opção Barra horizontal. Em seguida, escolhemos as métricas conforme mostrado na imagem abaixo. Aqui, escolhemos Soma como a agregação para a quantidade do produto nomeado arquivado. Em seguida, escolhemos intervalos com histograma de data para a data do pedido de campo.
Ao executar a configuração acima, podemos ver um gráfico de barras horizontais conforme mostrado abaixo -
Gráfico de Barras Verticais
Para o gráfico de barras verticais, escolhemos uma nova visualização na tela inicial do Kibana e escolhemos a opção Barra vertical. Em seguida, escolhemos as métricas conforme mostrado na imagem abaixo.
Aqui, escolhemos Soma como a agregação para o campo denominado quantidade do produto. Em seguida, escolhemos intervalos com histograma de data para a data do pedido de campo com um intervalo semanal.
Ao executar a configuração acima, um gráfico será gerado conforme mostrado abaixo -
A série temporal é uma representação da sequência de dados em uma sequência temporal específica. Por exemplo, os dados de cada dia, começando do primeiro dia do mês até o último dia. O intervalo entre os pontos de dados permanece constante. Qualquer conjunto de dados que possui um componente de tempo pode ser representado como uma série de tempo.
Neste capítulo, usaremos o conjunto de dados de e-commerce de amostra e plotaremos a contagem do número de pedidos para cada dia para criar uma série temporal.
Escolha as métricas
Primeiro, escolhemos o padrão de índice, campo de dados e intervalo que será usado para criar a série temporal. No conjunto de dados de comércio eletrônico de amostra, escolhemos order_date como o campo e 1d como o intervalo. Nós usamos oPanel Optionsguia para fazer essas escolhas. Além disso, deixamos os outros valores nesta guia como padrão para obter uma cor e formato padrão para a série temporal.
No Data guia, escolhemos contar como a opção de agregação, agrupar por opção como tudo e colocar um rótulo para o gráfico de série temporal.
Resultado
O resultado final desta configuração aparece da seguinte forma. Observe que estamos usando um período de tempo deMonth to Datepara este gráfico. Diferentes períodos de tempo darão resultados diferentes.
Uma nuvem de tags representa o texto que consiste principalmente em palavras-chave e metadados em um formato visualmente atraente. Eles são alinhados em diferentes ângulos e representados em diferentes cores e tamanhos de fonte. Ajuda a descobrir os termos mais proeminentes nos dados. O destaque pode ser decidido por um ou mais fatores como frequência do termo, exclusividade da tag ou com base em alguma ponderação anexada a termos específicos, etc. Abaixo, vemos as etapas para criar uma Tag Cloud.
Visualizar
Na tela inicial do Kibana, encontramos a opção de nome Visualize que nos permite criar visualizações e agregações a partir dos índices armazenados no Elasticsearch. Escolhemos adicionar uma nova visualização e selecionar Tag Cloud como a opção mostrada abaixo -
Escolha as métricas
A próxima tela nos pede para escolher as métricas que serão usadas na criação da Tag Cloud. Aqui, escolhemos a contagem como o tipo de métrica de agregação. Em seguida, escolhemos o campo productname como a palavra-chave a ser usada como tags.
O resultado mostrado aqui mostra o gráfico de pizza após aplicarmos a seleção. Observe as tonalidades da cor e seus valores mencionados na etiqueta.

Opções de nuvem de tag
Sobre a mudança para o optionsguia em Tag Cloud podemos ver várias opções de configuração para alterar a aparência, bem como a disposição da exibição de dados na Tag Cloud. No exemplo abaixo, a Tag Cloud aparece com tags espalhadas nas direções horizontal e vertical.
Mapa de calor é um tipo de visualização em que diferentes tons de cor representam diferentes áreas no gráfico. Os valores podem variar continuamente e, portanto, as cores r tonalidades de uma cor variam junto com os valores. Eles são muito úteis para representar dados que variam continuamente, bem como dados discretos.
Neste capítulo, usaremos o conjunto de dados denominado sample_data_flights para construir um gráfico de mapa de calor. Nele consideramos as variáveis denominadas país de origem e país de destino dos voos e fazemos uma contagem.
Na tela inicial do Kibana, encontramos a opção de nome Visualize que nos permite criar visualizações e agregações a partir dos índices armazenados no Elasticsearch. Escolhemos adicionar uma nova visualização e selecionar Mapa de Calor como a opção mostrada abaixo do & mimus;
Escolha as métricas
A próxima tela nos pede para escolher as métricas que serão usadas na criação do Gráfico de Mapa de Calor. Aqui, escolhemos a contagem como o tipo de métrica de agregação. Então, para os buckets no eixo Y, escolhemos Termos como a agregação para o campo OriginCountry. Para o eixo X, escolhemos a mesma agregação, mas DestCountry como o campo a ser usado. Em ambos os casos, escolhemos o tamanho do intervalo como 5.

Ao executar a configuração mostrada acima, obtemos o gráfico de mapa de calor gerado como segue.
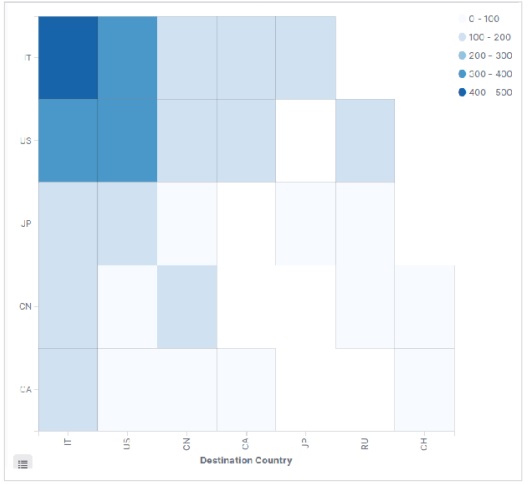
Note - Você deve permitir o intervalo de datas como Este ano para que o gráfico reúna os dados de um ano para produzir um gráfico de mapa de calor efetivo.
O aplicativo Canvas é uma parte do Kibana que nos permite criar exibições de dados dinâmicas, com várias páginas e perfeitas em pixels. Sua capacidade de criar infográficos e não apenas gráficos e métricas é o que o torna único e atraente. Neste capítulo, veremos vários recursos do canvas e como usar os painéis de trabalho do canvas.
Abrindo uma tela
Vá para a página inicial do Kibana e selecione a opção conforme mostrado no diagrama abaixo. Ele abre a lista de painéis de trabalho de tela que você possui. Escolhemos o rastreamento da receita de comércio eletrônico para nosso estudo.
Clonando um Workpad
Nós clonamos o [eCommerce] Revenue Trackingworkpad a ser usada em nosso estudo. Para cloná-lo, destacamos a linha com o nome deste workpad e, em seguida, usamos o botão de clonagem conforme mostrado no diagrama abaixo -
Como resultado do clone acima, teremos uma nova plataforma de trabalho chamada [eCommerce] Revenue Tracking – Copy que na abertura mostrará os infográficos abaixo.
Ele descreve o total de vendas e receita por categoria, juntamente com belas fotos e gráficos.
Modificando o Workpad
Podemos alterar o estilo e as figuras no workpad usando as opções disponíveis na guia do lado direito. Aqui, nosso objetivo é alterar a cor de fundo do painel de trabalho, escolhendo uma cor diferente, conforme mostrado no diagrama abaixo. A seleção de cores entra em vigor imediatamente e obtemos o resultado conforme mostrado abaixo -

Kibana também pode ajudar na visualização de dados de log de várias fontes. Os logs são fontes importantes de análise para a integridade da infraestrutura, necessidades de desempenho e análise de violação de segurança, etc. Kibana pode se conectar a vários logs, como logs de servidor web, logs de elasticsearch e logs de Cloudwatch, etc.
Logs Logstash
No Kibana, podemos nos conectar aos logs logstash para visualização. Primeiro, escolhemos o botão Logs na tela inicial do Kibana, conforme mostrado abaixo -
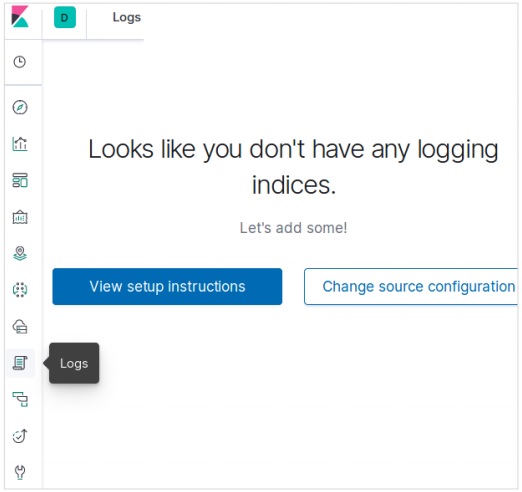
Em seguida, escolhemos a opção Change Source Configuration que nos traz a opção de escolher Logstash como uma fonte. A tela abaixo também mostra outros tipos de opções que temos como fonte de log.
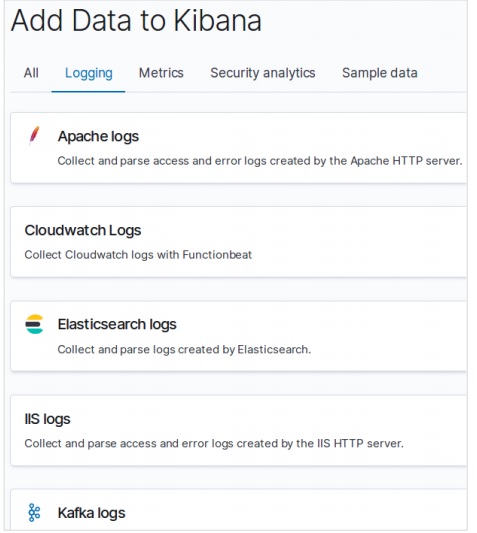
Você pode transmitir dados para acompanhamento de log ao vivo ou pausar o streaming para se concentrar nos dados de log históricos. Quando você está transmitindo logs, o log mais recente aparece na parte inferior do console.
Para mais referências, você pode consultar nosso tutorial Logstash .