Gensim - Guia Rápido
Este capítulo ajudará você a entender a história e os recursos do Gensim, juntamente com seus usos e vantagens.
O que é Gensim?
Gensim = “Generate Similar”é uma biblioteca popular de processamento de linguagem natural (PNL) de código aberto usada para modelagem de tópicos não supervisionados. Ele usa os melhores modelos acadêmicos e aprendizado de máquina estatístico moderno para realizar várias tarefas complexas, como -
- Construindo documentos ou vetores de palavras
- Corpora
- Executando a identificação do tópico
- Execução de comparação de documentos (recuperação de documentos semanticamente semelhantes)
- Analisando documentos de texto simples para estrutura semântica
Além de realizar as tarefas complexas acima, o Gensim, implementado em Python e Cython, é projetado para lidar com grandes coleções de texto usando streaming de dados, bem como algoritmos online incrementais. Isso o torna diferente dos pacotes de software de aprendizado de máquina que visam apenas o processamento na memória.
História
Em 2008, Gensim começou como uma coleção de vários scripts Python para a matemática digital tcheca. Lá, serviu para gerar uma pequena lista dos artigos mais semelhantes a um determinado artigo. Mas em 2009, a RARE Technologies Ltd. lançou seu lançamento inicial. Então, no final de julho de 2019, obtivemos sua versão estável (3.8.0).
Vários Recursos
A seguir estão alguns dos recursos e capacidades oferecidos pelo Gensim -
Escalabilidade
O Gensim pode processar facilmente corpora grandes e em escala da web usando seus algoritmos de treinamento online incremental. É escalonável por natureza, pois não há necessidade de todo o corpus de entrada residir totalmente na memória de acesso aleatório (RAM) a qualquer momento. Em outras palavras, todos os seus algoritmos são independentes da memória em relação ao tamanho do corpus.
Robusto
O Gensim é robusto por natureza e tem sido usado em vários sistemas por várias pessoas, bem como por organizações, por mais de 4 anos. Podemos facilmente conectar nosso próprio corpus de entrada ou fluxo de dados. Também é muito fácil de estender com outros algoritmos de espaço vetorial.
Agnóstico de plataforma
Como sabemos que Python é uma linguagem muito versátil por ser puro Python Gensim roda em todas as plataformas (como Windows, Mac OS, Linux) que suportam Python e Numpy.
Implementações multicore eficientes
A fim de acelerar o processamento e a recuperação em clusters de máquina, Gensim fornece implementações multicore eficientes de vários algoritmos populares, como Latent Semantic Analysis (LSA), Latent Dirichlet Allocation (LDA), Random Projections (RP), Hierarchical Dirichlet Process (HDP).
Código aberto e abundância de apoio comunitário
O Gensim é licenciado sob a licença GNU LGPL aprovada pela OSI, que permite que seja usado tanto para uso pessoal quanto comercial gratuitamente. Quaisquer modificações feitas no Gensim são, por sua vez, de código-fonte aberto e também contam com amplo apoio da comunidade.
Usos de Gensim
O Gensim foi usado e citado em mais de mil aplicações comerciais e acadêmicas. Também é citado por vários trabalhos de pesquisa e teses de alunos. Inclui implementações paralelizadas em fluxo contínuo do seguinte -
fastText
fastText, usa uma rede neural para incorporação de palavras, é uma biblioteca para aprender a incorporação de palavras e classificação de textos. Ele é criado pelo laboratório AI Research (FAIR) do Facebook. Este modelo, basicamente, nos permite criar um algoritmo supervisionado ou não supervisionado para a obtenção de representações vetoriais para palavras.
Word2vec
Word2vec, usado para produzir incorporação de palavras, é um grupo de modelos de redes neurais superficiais e de duas camadas. Os modelos são basicamente treinados para reconstruir contextos linguísticos de palavras.
LSA (Análise Semântica Latente)
É uma técnica em PNL (Processamento de Linguagem Natural) que nos permite analisar as relações entre um conjunto de documentos e seus termos. Isso é feito produzindo um conjunto de conceitos relacionados aos documentos e termos.
LDA (alocação de Dirichlet latente)
É uma técnica em PNL que permite que conjuntos de observações sejam explicados por grupos não observados. Esses grupos não observados explicam porque algumas partes dos dados são semelhantes. Essa é a razão, é um modelo estatístico generativo.
tf-idf (termo frequência-frequência inversa do documento)
tf-idf, uma estatística numérica na recuperação de informações, reflete a importância de uma palavra para um documento em um corpus. É frequentemente usado por mecanismos de pesquisa para pontuar e classificar a relevância de um documento de acordo com uma consulta do usuário. Também pode ser usado para filtrar palavras irrelevantes em resumos e classificações de texto.
Todos eles serão explicados em detalhes nas próximas seções.
Vantagens
Gensim é um pacote de PNL que faz modelagem de tópicos. As vantagens importantes do Gensim são as seguintes -
Podemos obter as facilidades de modelagem de tópicos e incorporação de palavras em outros pacotes, como ‘scikit-learn’ e ‘R’, mas os recursos fornecidos pela Gensim para construir modelos de tópicos e incorporação de palavras são incomparáveis. Ele também fornece recursos mais convenientes para processamento de texto.
Outra vantagem mais significativa do Gensim é que ele nos permite lidar com grandes arquivos de texto, mesmo sem carregar o arquivo inteiro na memória.
O Gensim não requer anotações caras ou marcação manual de documentos porque usa modelos não supervisionados.
O capítulo esclarece sobre os pré-requisitos para a instalação do Gensim, suas dependências principais e informações sobre sua versão atual.
Pré-requisitos
Para instalar o Gensim, devemos ter o Python instalado em nossos computadores. Você pode acessar o link www.python.org/downloads/ e selecionar a versão mais recente para o seu sistema operacional, ou seja, Windows e Linux / Unix. Você pode consultar o link www.tutorialspoint.com/python3/index.htm para um tutorial básico sobre Python. Gensim é compatível com Linux, Windows e Mac OS X.
Dependências de código
Gensim deve ser executado em qualquer plataforma que suporte Python 2.7 or 3.5+ e NumPy. Na verdade, depende do seguinte software -
Pitão
Gensim é testado com versões Python 2.7, 3.5, 3.6 e 3.7.
Numpy
Como sabemos disso, o NumPy é um pacote para computação científica com Python. Ele também pode ser usado como um contêiner multidimensional eficiente de dados genéricos. O Gensim depende do pacote NumPy para processamento de números. Para o tutorial básico sobre Python, você pode consultar o link www.tutorialspoint.com/numpy/index.htm .
smart_open
smart_open, uma biblioteca Python 2 e Python 3, é usada para streaming eficiente de arquivos muito grandes. Ele suporta streaming de / para armazenamentos como S3, HDFS, WebHDFS, HTTP, HTTPS, SFTP ou sistemas de arquivos locais. Gensim depende desmart_open Biblioteca Python para abrir arquivos de forma transparente em armazenamento remoto, bem como arquivos compactados.
Versão Atual
A versão atual do Gensim é 3.8.0 que foi lançado em julho de 2019.
Instalando usando o Terminal
Uma das maneiras mais simples de instalar o Gensim é executar o seguinte comando em seu terminal -
pip install --upgrade gensimInstalando usando o ambiente Conda
Uma forma alternativa de baixar Gensim é usar condameio Ambiente. Execute o seguinte comando em seuconda terminal -
conda install –c conda-forge gensim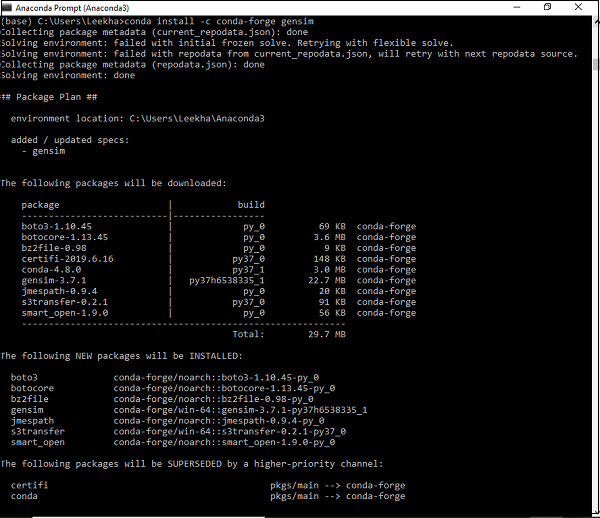
Instalando usando o pacote fonte
Suponha que, se você baixou e descompactou o pacote de origem, você precisa executar os seguintes comandos -
python setup.py test
python setup.py installAqui, aprenderemos sobre os principais conceitos do Gensim, com foco principal nos documentos e no corpus.
Conceitos Básicos de Gensim
A seguir estão os principais conceitos e termos que são necessários para entender e usar o Gensim -
Document - ZIt se refere a algum texto.
Corpus - Refere-se a uma coleção de documentos.
Vector - A representação matemática de um documento é chamada de vetor.
Model - Refere-se a um algoritmo usado para transformar vetores de uma representação para outra.
O que é documento?
Conforme discutido, refere-se a algum texto. Se formos em alguns detalhes, é um objeto do tipo de sequência de texto que é conhecido como‘str’ em Python 3. Por exemplo, em Gensim, um documento pode ser qualquer coisa como -
- Tuíte curto de 140 caracteres
- Parágrafo único, ou seja, artigo ou resumo de artigo de pesquisa
- Artigo de notícias
- Book
- Novel
- Theses
Sequência de Texto
Um tipo de sequência de texto é comumente conhecido como ‘str’ em Python 3. Como sabemos que em Python, os dados textuais são tratados com strings ou mais especificamente ‘str’objetos. Strings são basicamente sequências imutáveis de pontos de código Unicode e podem ser escritas das seguintes maneiras -
Single quotes - Por exemplo, ‘Hi! How are you?’. Também nos permite inserir aspas duplas. Por exemplo,‘Hi! “How” are you?’
Double quotes - Por exemplo, "Hi! How are you?". Também nos permite inserir aspas simples. Por exemplo,"Hi! 'How' are you?"
Triple quotes - Pode ter três aspas simples, como, '''Hi! How are you?'''. ou três aspas duplas como,"""Hi! 'How' are you?"""
Todos os espaços em branco serão incluídos no literal da string.
Exemplo
A seguir está um exemplo de um documento no Gensim -
Document = “Tutorialspoint.com is the biggest online tutorials library and it’s all free also”O que é Corpus?
Um corpus pode ser definido como o conjunto grande e estruturado de textos legíveis por máquina produzidos em um ambiente comunicativo natural. No Gensim, uma coleção de objetos de documentos é chamada de corpus. O plural de corpus écorpora.
Papel do Corpus em Gensim
Um corpus em Gensim desempenha as duas funções a seguir -
Serve como entrada para treinar um modelo
O primeiro e importante papel que um corpus desempenha no Gensim é como uma entrada para treinar um modelo. Para inicializar os parâmetros internos do modelo, durante o treinamento, o modelo procura alguns temas e tópicos comuns do corpus de treinamento. Como discutido acima, Gensim se concentra em modelos não supervisionados, portanto, não requer nenhum tipo de intervenção humana.
Serve como extrator de tópicos
Depois que o modelo é treinado, ele pode ser usado para extrair tópicos dos novos documentos. Aqui, os novos documentos são aqueles que não são utilizados na fase de treinamento.
Exemplo
O corpus pode incluir todos os tweets de uma determinada pessoa, lista de todos os artigos de um jornal ou todos os trabalhos de pesquisa sobre um determinado tópico etc.
Coletando Corpus
A seguir está um exemplo de pequeno corpus que contém 5 documentos. Aqui, todo documento é uma string que consiste em uma única frase.
t_corpus = [
"A survey of user opinion of computer system response time",
"Relation of user perceived response time to error measurement",
"The generation of random binary unordered trees",
"The intersection graph of paths in trees",
"Graph minors IV Widths of trees and well quasi ordering",
]Preprocessing Collecting Corpus
Depois de coletar o corpus, algumas etapas de pré-processamento devem ser realizadas para manter o corpus simples. Podemos simplesmente remover algumas palavras em inglês comumente usadas, como 'o'. Também podemos remover palavras que ocorrem apenas uma vez no corpus.
Por exemplo, o seguinte script Python é usado para colocar cada documento em minúsculas, dividi-lo por espaço em branco e filtrar palavras de interrupção -
Exemplo
import pprint
t_corpus = [
"A survey of user opinion of computer system response time",
"Relation of user perceived response time to error measurement",
"The generation of random binary unordered trees",
"The intersection graph of paths in trees",
"Graph minors IV Widths of trees and well quasi ordering",
]
stoplist = set('for a of the and to in'.split(' '))
processed_corpus = [[word for word in document.lower().split() if word not in stoplist]
for document in t_corpus]
pprint.pprint(processed_corpus)
]Resultado
[['survey', 'user', 'opinion', 'computer', 'system', 'response', 'time'],
['relation', 'user', 'perceived', 'response', 'time', 'error', 'measurement'],
['generation', 'random', 'binary', 'unordered', 'trees'],
['intersection', 'graph', 'paths', 'trees'],
['graph', 'minors', 'iv', 'widths', 'trees', 'well', 'quasi', 'ordering']]Pré-processamento eficaz
O Gensim também fornece funções para um pré-processamento mais eficaz do corpus. Nesse tipo de pré-processamento, podemos converter um documento em uma lista de tokens minúsculos. Também podemos ignorar tokens muito curtos ou muito longos. Essa função égensim.utils.simple_preprocess(doc, deacc=False, min_len=2, max_len=15).
gensim.utils.simple_preprocess() fucntion
O Gensim fornece essa função para converter um documento em uma lista de tokens minúsculos e também para ignorar tokens que são muito curtos ou muito longos. Possui os seguintes parâmetros -
doc (str)
Refere-se ao documento de entrada no qual o pré-processamento deve ser aplicado.
deacc (bool, opcional)
Este parâmetro é usado para remover as marcas de acento dos tokens. Usadeaccent() para fazer isso.
min_len (int, opcional)
Com a ajuda deste parâmetro, podemos definir o comprimento mínimo de um token. Os tokens menores que o comprimento definido serão descartados.
max_len (int, opcional)
Com a ajuda deste parâmetro, podemos definir o comprimento máximo de um token. Os tokens maiores que o comprimento definido serão descartados.
A saída desta função seriam os tokens extraídos do documento de entrada.
Aqui, aprenderemos sobre os principais conceitos do Gensim, com foco principal no vetor e no modelo.
O que é vetor?
E se quisermos inferir a estrutura latente em nosso corpus? Para isso, precisamos representar os documentos de tal forma que possamos manipular os mesmos matematicamente. Um tipo popular de representação é representar cada documento do corpus como um vetor de recursos. É por isso que podemos dizer que o vetor é uma representação matemática conveniente de um documento.
Para dar um exemplo, vamos representar um único recurso, de nosso corpus usado acima, como um par de controle de qualidade -
Q - Quantas vezes a palavra Hello aparece no documento?
A - Zero (0).
Q - Quantos parágrafos existem no documento?
A - Dois (2)
A questão é geralmente representada por seu id inteiro, portanto, a representação deste documento é uma série de pares como (1, 0.0), (2, 2.0). Essa representação vetorial é conhecida como umdensevetor. Por quêdense, porque compreende uma resposta explícita a todas as questões formuladas acima.
A representação pode ser simples como (0, 2), se soubermos todas as questões com antecedência. Essa sequência de respostas (claro se as perguntas são conhecidas com antecedência) é ovector para o nosso documento.
Outro tipo popular de representação é o bag-of-word (BoW)modelo. Nessa abordagem, cada documento é basicamente representado por um vetor que contém a contagem de frequência de cada palavra do dicionário.
Para dar um exemplo, suponha que temos um dicionário que contém as palavras ['Olá', 'Como', 'são', 'você']. Um documento consistindo na string “How are you how” seria então representado pelo vetor [0, 2, 1, 1]. Aqui, as entradas do vetor estão na ordem das ocorrências de “Hello”, “How”, “are” e “you”.
Vetor versus documento
A partir da explicação acima sobre vetor, a distinção entre um documento e um vetor é quase compreendida. Mas, para deixar mais claro,document é texto e vectoré uma representação matematicamente conveniente desse texto. Infelizmente, às vezes muitas pessoas usam esses termos alternadamente.
Por exemplo, suponha que temos algum documento arbitrário A então, em vez de dizer, “o vetor que corresponde ao documento A”, eles costumavam dizer “o vetor A” ou “o documento A”. Isso leva a uma grande ambigüidade. Mais uma coisa importante a ser observada aqui é que dois documentos diferentes podem ter a mesma representação vetorial.
Convertendo corpus em lista de vetores
Antes de tomar um exemplo de implementação de conversão de corpus na lista de vetores, precisamos associar cada palavra do corpus a um ID inteiro único. Para isso, estenderemos o exemplo do capítulo anterior.
Exemplo
from gensim import corpora
dictionary = corpora.Dictionary(processed_corpus)
print(dictionary)Resultado
Dictionary(25 unique tokens: ['computer', 'opinion', 'response', 'survey', 'system']...)Isso mostra que em nosso corpus existem 25 tokens diferentes neste gensim.corpora.Dictionary.
Exemplo de Implementação
Podemos usar o dicionário para transformar documentos tokenizados nesses vetores 5-diemsionais da seguinte maneira -
pprint.pprint(dictionary.token2id)Resultado
{
'binary': 11,
'computer': 0,
'error': 7,
'generation': 12,
'graph': 16,
'intersection': 17,
'iv': 19,
'measurement': 8,
'minors': 20,
'opinion': 1,
'ordering': 21,
'paths': 18,
'perceived': 9,
'quasi': 22,
'random': 13,
'relation': 10,
'response': 2,
'survey': 3,
'system': 4,
'time': 5,
'trees': 14,
'unordered': 15,
'user': 6,
'well': 23,
'widths': 24
}E da mesma forma, podemos criar a representação do saco de palavras para um documento da seguinte maneira -
BoW_corpus = [dictionary.doc2bow(text) for text in processed_corpus]
pprint.pprint(BoW_corpus)Resultado
[
[(0, 1), (1, 1), (2, 1), (3, 1), (4, 1), (5, 1), (6, 1)],
[(2, 1), (5, 1), (6, 1), (7, 1), (8, 1), (9, 1), (10, 1)],
[(11, 1), (12, 1), (13, 1), (14, 1), (15, 1)],
[(14, 1), (16, 1), (17, 1), (18, 1)],
[(14, 1), (16, 1), (19, 1), (20, 1), (21, 1), (22, 1), (23, 1), (24, 1)]
]O que é modelo?
Depois de vetorizar o corpus, o que fazer? Agora, podemos transformá-lo usando modelos. O modelo pode ser referido a um algoritmo usado para transformar uma representação de documento em outra.
Como já discutimos, os documentos, no Gensim, são representados como vetores, portanto, podemos, embora modelar como uma transformação entre dois espaços vetoriais. Sempre há uma fase de treinamento em que os modelos aprendem os detalhes de tais transformações. O modelo lê o corpus de treinamento durante a fase de treinamento.
Inicializando um modelo
Vamos inicializar tf-idfmodelo. Este modelo transforma vetores da representação BoW (Bag of Words) para outro espaço vetorial onde as contagens de frequência são ponderadas de acordo com a raridade relativa de cada palavra no corpus.
Exemplo de Implementação
No exemplo a seguir, vamos inicializar o tf-idfmodelo. Vamos treiná-lo em nosso corpus e depois transformar a string “grafo de árvores”.
Exemplo
from gensim import models
tfidf = models.TfidfModel(BoW_corpus)
words = "trees graph".lower().split()
print(tfidf[dictionary.doc2bow(words)])Resultado
[(3, 0.4869354917707381), (4, 0.8734379353188121)]Agora, uma vez que criamos o modelo, podemos transformar todo o corpus via tfidf e indexá-lo, e consultar a similaridade do nosso documento de consulta (estamos dando ao documento de consulta 'sistema de árvores') em relação a cada documento no corpus -
Exemplo
from gensim import similarities
index = similarities.SparseMatrixSimilarity(tfidf[BoW_corpus],num_features=5)
query_document = 'trees system'.split()
query_bow = dictionary.doc2bow(query_document)
simils = index[tfidf[query_bow]]
print(list(enumerate(simils)))Resultado
[(0, 0.0), (1, 0.0), (2, 1.0), (3, 0.4869355), (4, 0.4869355)]Da saída acima, o documento 4 e o documento 5 têm uma pontuação de similaridade de cerca de 49%.
Além disso, também podemos classificar essa saída para maior legibilidade da seguinte maneira -
Exemplo
for doc_number, score in sorted(enumerate(sims), key=lambda x: x[1], reverse=True):
print(doc_number, score)Resultado
2 1.0
3 0.4869355
4 0.4869355
0 0.0
1 0.0No último capítulo, onde discutimos sobre vetor e modelo, você teve uma ideia sobre o dicionário. Aqui, vamos discutirDictionary objeto com um pouco mais de detalhes.
O que é dicionário?
Antes de nos aprofundarmos no conceito de dicionário, vamos entender alguns conceitos simples de PNL -
Token - Um token significa uma 'palavra'.
Document - Um documento refere-se a uma frase ou parágrafo.
Corpus - Refere-se a uma coleção de documentos como um saco de palavras (BoW).
Para todos os documentos, um corpus sempre contém o id do token de cada palavra junto com sua contagem de frequência no documento.
Vamos passar para o conceito de dicionário no Gensim. Para trabalhar em documentos de texto, o Gensim também exige que as palavras, ou seja, tokens, sejam convertidos em seus ids exclusivos. Para conseguir isso, nos dá a facilidade deDictionary object, que mapeia cada palavra para seu id de número inteiro exclusivo. Ele faz isso convertendo o texto de entrada na lista de palavras e, em seguida, passando-o para ocorpora.Dictionary() objeto.
Necessidade de Dicionário
Agora surge a pergunta: qual é realmente a necessidade do objeto de dicionário e onde ele pode ser usado? No Gensim, o objeto de dicionário é usado para criar um corpus de saco de palavras (BoW) que posteriormente é usado como entrada para a modelagem de tópicos e outros modelos também.
Formas de entrada de texto
Existem três formas diferentes de texto de entrada que podemos fornecer ao Gensim -
Como as sentenças armazenadas no objeto de lista nativa do Python (conhecido como str em Python 3)
Como um único arquivo de texto (pode ser pequeno ou grande)
Vários arquivos de texto
Criação de um dicionário usando Gensim
Conforme discutido, no Gensim, o dicionário contém o mapeamento de todas as palavras, também conhecidas como tokens para seu id de número inteiro único. Podemos criar um dicionário a partir de uma lista de frases, de um ou mais arquivos de texto (arquivo de texto contendo várias linhas de texto). Então, primeiro vamos começar criando um dicionário usando uma lista de frases.
De uma lista de frases
No exemplo a seguir, estaremos criando um dicionário a partir de uma lista de frases. Quando temos uma lista de frases ou você pode dizer várias frases, devemos converter cada frase em uma lista de palavras e as compreensões é uma das maneiras muito comuns de fazer isso.
Exemplo de Implementação
Primeiro, importe os pacotes necessários e necessários da seguinte forma -
import gensim
from gensim import corpora
from pprint import pprintEm seguida, faça a lista de compreensão da lista de frases / documento para usá-la criando o dicionário -
doc = [
"CNTK formerly known as Computational Network Toolkit",
"is a free easy-to-use open-source commercial-grade toolkit",
"that enable us to train deep learning algorithms to learn like the human brain."
]Em seguida, precisamos dividir as frases em palavras. É chamado de tokenização.
text_tokens = [[text for text in doc.split()] for doc in doc]Agora, com a ajuda do seguinte script, podemos criar o dicionário -
dict_LoS = corpora.Dictionary(text_tokens)Agora vamos obter mais algumas informações, como número de tokens no dicionário -
print(dict_LoS)Resultado
Dictionary(27 unique tokens: ['CNTK', 'Computational', 'Network', 'Toolkit', 'as']...)Também podemos ver a palavra para mapeamento inteiro único da seguinte maneira -
print(dict_LoS.token2id)Resultado
{
'CNTK': 0, 'Computational': 1, 'Network': 2, 'Toolkit': 3, 'as': 4,
'formerly': 5, 'known': 6, 'a': 7, 'commercial-grade': 8, 'easy-to-use': 9,
'free': 10, 'is': 11, 'open-source': 12, 'toolkit': 13, 'algorithms': 14,
'brain.': 15, 'deep': 16, 'enable': 17, 'human': 18, 'learn': 19, 'learning': 20,
'like': 21, 'that': 22, 'the': 23, 'to': 24, 'train': 25, 'us': 26
}Exemplo de implementação completo
import gensim
from gensim import corpora
from pprint import pprint
doc = [
"CNTK formerly known as Computational Network Toolkit",
"is a free easy-to-use open-source commercial-grade toolkit",
"that enable us to train deep learning algorithms to learn like the human brain."
]
text_tokens = [[text for text in doc.split()] for doc in doc]
dict_LoS = corpora.Dictionary(text_tokens)
print(dict_LoS.token2id)Do arquivo de texto único
No exemplo a seguir, estaremos criando um dicionário a partir de um único arquivo de texto. Da mesma forma, também podemos criar dicionário a partir de mais de um arquivo de texto (ou seja, diretório de arquivos).
Para isso, salvamos o documento, usado no exemplo anterior, no arquivo de texto denominado doc.txt. Gensim irá ler o arquivo linha por linha e processar uma linha de cada vez usandosimple_preprocess. Dessa forma, não é necessário carregar o arquivo completo na memória de uma só vez.
Exemplo de Implementação
Primeiro, importe os pacotes necessários e necessários da seguinte forma -
import gensim
from gensim import corpora
from pprint import pprint
from gensim.utils import simple_preprocess
from smart_open import smart_open
import osA próxima linha de códigos fará o dicionário gensim usando o único arquivo de texto denominado doc.txt -
dict_STF = corpora.Dictionary(
simple_preprocess(line, deacc =True) for line in open(‘doc.txt’, encoding=’utf-8’)
)Agora vamos obter mais algumas informações, como número de tokens no dicionário -
print(dict_STF)Resultado
Dictionary(27 unique tokens: ['CNTK', 'Computational', 'Network', 'Toolkit', 'as']...)Também podemos ver a palavra para mapeamento inteiro único da seguinte maneira -
print(dict_STF.token2id)Resultado
{
'CNTK': 0, 'Computational': 1, 'Network': 2, 'Toolkit': 3, 'as': 4,
'formerly': 5, 'known': 6, 'a': 7, 'commercial-grade': 8, 'easy-to-use': 9,
'free': 10, 'is': 11, 'open-source': 12, 'toolkit': 13, 'algorithms': 14,
'brain.': 15, 'deep': 16, 'enable': 17, 'human': 18, 'learn': 19,
'learning': 20, 'like': 21, 'that': 22, 'the': 23, 'to': 24, 'train': 25, 'us': 26
}Exemplo de implementação completo
import gensim
from gensim import corpora
from pprint import pprint
from gensim.utils import simple_preprocess
from smart_open import smart_open
import os
dict_STF = corpora.Dictionary(
simple_preprocess(line, deacc =True) for line in open(‘doc.txt’, encoding=’utf-8’)
)
dict_STF = corpora.Dictionary(text_tokens)
print(dict_STF.token2id)De vários arquivos de texto
Agora vamos criar um dicionário a partir de vários arquivos, ou seja, mais de um arquivo de texto salvo no mesmo diretório. Para este exemplo, criamos três arquivos de texto diferentes, a saberfirst.txt, second.txt e third.txtcontendo as três linhas do arquivo de texto (doc.txt), usamos no exemplo anterior. Todos esses três arquivos de texto são salvos em um diretório chamadoABC.
Exemplo de Implementação
Para implementar isso, precisamos definir uma classe com um método que possa iterar por todos os três arquivos de texto (Primeiro, Segundo e Terceiro.txt) no diretório (ABC) e produzir a lista processada de tokens de palavras.
Vamos definir a classe chamada Read_files tendo um método chamado __iteration__ () como segue -
class Read_files(object):
def __init__(self, directoryname):
elf.directoryname = directoryname
def __iter__(self):
for fname in os.listdir(self.directoryname):
for line in open(os.path.join(self.directoryname, fname), encoding='latin'):
yield simple_preprocess(line)Em seguida, precisamos fornecer o caminho do diretório da seguinte forma -
path = "ABC"#provide the path as per your computer system where you saved the directory.
As próximas etapas são semelhantes às que fizemos nos exemplos anteriores. A próxima linha de códigos criará o diretório Gensim usando o diretório com três arquivos de texto -
dict_MUL = corpora.Dictionary(Read_files(path))Resultado
Dictionary(27 unique tokens: ['CNTK', 'Computational', 'Network', 'Toolkit', 'as']...)Agora também podemos ver a palavra para o mapeamento inteiro único da seguinte maneira -
print(dict_MUL.token2id)Resultado
{
'CNTK': 0, 'Computational': 1, 'Network': 2, 'Toolkit': 3, 'as': 4,
'formerly': 5, 'known': 6, 'a': 7, 'commercial-grade': 8, 'easy-to-use': 9,
'free': 10, 'is': 11, 'open-source': 12, 'toolkit': 13, 'algorithms': 14,
'brain.': 15, 'deep': 16, 'enable': 17, 'human': 18, 'learn': 19,
'learning': 20, 'like': 21, 'that': 22, 'the': 23, 'to': 24, 'train': 25, 'us': 26
}Salvar e carregar um dicionário Gensim
Gensim apóia seu próprio nativo save() método para salvar o dicionário no disco e load() método para carregar de volta o dicionário do disco.
Por exemplo, podemos salvar o dicionário com a ajuda do seguinte script -
Gensim.corpora.dictionary.save(filename)#provide the path where you want to save the dictionary.
Da mesma forma, podemos carregar o dicionário salvo usando o método load (). O seguinte script pode fazer isso -
Gensim.corpora.dictionary.load(filename)#provide the path where you have saved the dictionary.
Compreendemos como criar dicionário a partir de uma lista de documentos e de arquivos de texto (tanto de um como de mais de um). Agora, nesta seção, criaremos um corpus bag-of-words (BoW). Para trabalhar com Gensim, é um dos objetos mais importantes com que precisamos nos familiarizar. Basicamente, é o corpus que contém a palavra id e sua frequência em cada documento.
Criando um BoW Corpus
Conforme discutido, no Gensim, o corpus contém a palavra id e sua frequência em todos os documentos. Podemos criar um corpus BoW a partir de uma lista simples de documentos e de arquivos de texto. O que precisamos fazer é passar a lista de palavras tokenizadas para o objeto denominadoDictionary.doc2bow(). Então, primeiro, vamos começar criando um corpus BoW usando uma lista simples de documentos.
De uma lista simples de frases
No exemplo a seguir, criaremos um corpus BoW a partir de uma lista simples contendo três sentenças.
Primeiro, precisamos importar todos os pacotes necessários da seguinte forma -
import gensim
import pprint
from gensim import corpora
from gensim.utils import simple_preprocessAgora forneça a lista contendo as frases. Temos três frases em nossa lista -
doc_list = [
"Hello, how are you?", "How do you do?",
"Hey what are you doing? yes you What are you doing?"
]Em seguida, faça a tokenização das sentenças da seguinte forma -
doc_tokenized = [simple_preprocess(doc) for doc in doc_list]Crie um objeto de corpora.Dictionary() como segue -
dictionary = corpora.Dictionary()Agora passe essas frases tokenizadas para dictionary.doc2bow() objectcomo segue -
BoW_corpus = [dictionary.doc2bow(doc, allow_update=True) for doc in doc_tokenized]Por fim, podemos imprimir Saco de corpus de palavras -
print(BoW_corpus)Resultado
[
[(0, 1), (1, 1), (2, 1), (3, 1)],
[(2, 1), (3, 1), (4, 2)], [(0, 2), (3, 3), (5, 2), (6, 1), (7, 2), (8, 1)]
]A saída acima mostra que a palavra com id = 0 aparece uma vez no primeiro documento (porque obtivemos (0,1) na saída) e assim por diante.
A saída acima, de alguma forma, não é possível para humanos lerem. Também podemos converter esses ids em palavras, mas para isso precisamos de nosso dicionário para fazer a conversão da seguinte maneira -
id_words = [[(dictionary[id], count) for id, count in line] for line in BoW_corpus]
print(id_words)Resultado
[
[('are', 1), ('hello', 1), ('how', 1), ('you', 1)],
[('how', 1), ('you', 1), ('do', 2)],
[('are', 2), ('you', 3), ('doing', 2), ('hey', 1), ('what', 2), ('yes', 1)]
]Agora, a saída acima é de alguma forma legível por humanos.
Exemplo de implementação completo
import gensim
import pprint
from gensim import corpora
from gensim.utils import simple_preprocess
doc_list = [
"Hello, how are you?", "How do you do?",
"Hey what are you doing? yes you What are you doing?"
]
doc_tokenized = [simple_preprocess(doc) for doc in doc_list]
dictionary = corpora.Dictionary()
BoW_corpus = [dictionary.doc2bow(doc, allow_update=True) for doc in doc_tokenized]
print(BoW_corpus)
id_words = [[(dictionary[id], count) for id, count in line] for line in BoW_corpus]
print(id_words)De um arquivo de texto
No exemplo a seguir, estaremos criando corpus BoW a partir de um arquivo de texto. Para isso, salvamos o documento, usado no exemplo anterior, no arquivo de texto denominadodoc.txt..
Gensim irá ler o arquivo linha por linha e processar uma linha de cada vez usando simple_preprocess. Dessa forma, não é necessário carregar o arquivo completo na memória de uma só vez.
Exemplo de Implementação
Primeiro, importe os pacotes necessários e necessários da seguinte forma -
import gensim
from gensim import corpora
from pprint import pprint
from gensim.utils import simple_preprocess
from smart_open import smart_open
import osEm seguida, a seguinte linha de códigos fará com que os documentos sejam lidos em doc.txt e o tokenizado -
doc_tokenized = [
simple_preprocess(line, deacc =True) for line in open(‘doc.txt’, encoding=’utf-8’)
]
dictionary = corpora.Dictionary()Agora precisamos passar essas palavras tokenizadas para dictionary.doc2bow() objeto (como no exemplo anterior)
BoW_corpus = [
dictionary.doc2bow(doc, allow_update=True) for doc in doc_tokenized
]
print(BoW_corpus)Resultado
[
[(9, 1), (10, 1), (11, 1), (12, 1), (13, 1), (14, 1), (15, 1)],
[
(15, 1), (16, 1), (17, 1), (18, 1), (19, 1), (20, 1), (21, 1),
(22, 1), (23, 1), (24, 1)
],
[
(23, 2), (25, 1), (26, 1), (27, 1), (28, 1), (29, 1),
(30, 1), (31, 1), (32, 1), (33, 1), (34, 1), (35, 1), (36, 1)
],
[(3, 1), (18, 1), (37, 1), (38, 1), (39, 1), (40, 1), (41, 1), (42, 1), (43, 1)],
[
(18, 1), (27, 1), (31, 2), (32, 1), (38, 1), (41, 1), (43, 1),
(44, 1), (45, 1), (46, 1), (47, 1), (48, 1), (49, 1), (50, 1), (51, 1), (52, 1)
]
]o doc.txt arquivo tem o seguinte conteúdo -
O CNTK, anteriormente conhecido como Computational Network Toolkit, é um kit de ferramentas de nível comercial de código-fonte aberto e gratuito que nos permite treinar algoritmos de aprendizagem profunda para aprender como o cérebro humano.
Você pode encontrar seu tutorial gratuito em tutorialspoint.com e também fornecer os melhores tutoriais técnicos sobre tecnologias como o aprendizado de máquina de aprendizado profundo de IA gratuitamente.
Exemplo de implementação completo
import gensim
from gensim import corpora
from pprint import pprint
from gensim.utils import simple_preprocess
from smart_open import smart_open
import os
doc_tokenized = [
simple_preprocess(line, deacc =True) for line in open(‘doc.txt’, encoding=’utf-8’)
]
dictionary = corpora.Dictionary()
BoW_corpus = [dictionary.doc2bow(doc, allow_update=True) for doc in doc_tokenized]
print(BoW_corpus)Salvar e carregar um Gensim Corpus
Podemos salvar o corpus com a ajuda do seguinte script -
corpora.MmCorpus.serialize(‘/Users/Desktop/BoW_corpus.mm’, bow_corpus)#provide the path and the name of the corpus. The name of corpus is BoW_corpus and we saved it in Matrix Market format.
Da mesma forma, podemos carregar o corpus salvo usando o seguinte script -
corpus_load = corpora.MmCorpus(‘/Users/Desktop/BoW_corpus.mm’)
for line in corpus_load:
print(line)Este capítulo irá ajudá-lo a aprender sobre as várias transformações no Gensim. Vamos começar entendendo os documentos em transformação.
Transformando Documentos
Transformar documentos significa representar o documento de tal forma que o documento possa ser manipulado matematicamente. Além de deduzir a estrutura latente do corpus, a transformação de documentos também atenderá aos seguintes objetivos -
Ele descobre a relação entre as palavras.
Ele traz à tona a estrutura oculta no corpus.
Ele descreve os documentos de uma maneira nova e mais semântica.
Torna a representação dos documentos mais compacta.
Ele melhora a eficiência porque a nova representação consome menos recursos.
Ele melhora a eficácia porque, na nova representação, as tendências de dados marginais são ignoradas.
O ruído também é reduzido na nova representação do documento.
Vamos ver as etapas de implementação para transformar os documentos de uma representação de espaço vetorial para outra.
Etapas de Implementação
Para transformar documentos, devemos seguir as seguintes etapas -
Etapa 1: Criação do Corpus
A primeira e básica etapa é criar o corpus dos documentos. Já criamos o corpus em exemplos anteriores. Vamos criar outro com algumas melhorias (removendo palavras comuns e as palavras que aparecem apenas uma vez) -
import gensim
import pprint
from collections import defaultdict
from gensim import corporaAgora forneça os documentos para criar o corpus -
t_corpus = ["CNTK anteriormente conhecido como Computational Network Toolkit", "é um kit de ferramentas de nível comercial de código aberto gratuito e fácil de usar", "que nos permite treinar algoritmos de aprendizagem profunda para aprender como o cérebro humano.", " Você pode encontrar seu tutorial gratuito em tutorialspoint.com "," Tutorialspoint.com também fornece os melhores tutoriais técnicos sobre tecnologias como o aprendizado de máquina de aprendizado profundo de IA gratuitamente "]
Em seguida, precisamos fazer tokenise e junto com ele removeremos também as palavras comuns -
stoplist = set('for a of the and to in'.split(' '))
processed_corpus = [
[
word for word in document.lower().split() if word not in stoplist
]
for document in t_corpus
]O script a seguir removerá aquelas palavras que aparecem apenas -
frequency = defaultdict(int)
for text in processed_corpus:
for token in text:
frequency[token] += 1
processed_corpus = [
[token for token in text if frequency[token] > 1]
for text in processed_corpus
]
pprint.pprint(processed_corpus)Resultado
[
['toolkit'],
['free', 'toolkit'],
['deep', 'learning', 'like'],
['free', 'on', 'tutorialspoint.com'],
['tutorialspoint.com', 'on', 'like', 'deep', 'learning', 'learning', 'free']
]Agora passe para o corpora.dictionary() objeto para obter os objetos únicos em nosso corpus -
dictionary = corpora.Dictionary(processed_corpus)
print(dictionary)Resultado
Dictionary(7 unique tokens: ['toolkit', 'free', 'deep', 'learning', 'like']...)Em seguida, a seguinte linha de códigos criará o modelo Bag of Word para nosso corpus -
BoW_corpus = [dictionary.doc2bow(text) for text in processed_corpus]
pprint.pprint(BoW_corpus)Resultado
[
[(0, 1)],
[(0, 1), (1, 1)],
[(2, 1), (3, 1), (4, 1)],
[(1, 1), (5, 1), (6, 1)],
[(1, 1), (2, 1), (3, 2), (4, 1), (5, 1), (6, 1)]
]Etapa 2: Criação de uma transformação
As transformações são alguns objetos padrão do Python. Podemos inicializar essas transformações, ou seja, objetos Python usando um corpus treinado. Aqui vamos usartf-idf modelo para criar uma transformação do nosso corpus treinado, ou seja, BoW_corpus.
Primeiro, precisamos importar o pacote de modelos do gensim.
from gensim import modelsAgora, precisamos inicializar o modelo da seguinte maneira -
tfidf = models.TfidfModel(BoW_corpus)Etapa 3: Transformando Vetores
Agora, nesta última etapa, os vetores serão convertidos da representação antiga para a nova representação. Como inicializamos o modelo tfidf na etapa acima, o tfidf agora será tratado como um objeto somente leitura. Aqui, usando este objeto tfidf, converteremos nosso vetor de representação do pacote de palavras (representação antiga) para pesos de valor real Tfidf (nova representação).
doc_BoW = [(1,1),(3,1)]
print(tfidf[doc_BoW]Resultado
[(1, 0.4869354917707381), (3, 0.8734379353188121)]Aplicamos a transformação em dois valores do corpus, mas também podemos aplicá-la a todo o corpus da seguinte forma -
corpus_tfidf = tfidf[BoW_corpus]
for doc in corpus_tfidf:
print(doc)Resultado
[(0, 1.0)]
[(0, 0.8734379353188121), (1, 0.4869354917707381)]
[(2, 0.5773502691896257), (3, 0.5773502691896257), (4, 0.5773502691896257)]
[(1, 0.3667400603126873), (5, 0.657838022678017), (6, 0.657838022678017)]
[
(1, 0.19338287240886842), (2, 0.34687949360312714), (3, 0.6937589872062543),
(4, 0.34687949360312714), (5, 0.34687949360312714), (6, 0.34687949360312714)
]Exemplo de implementação completo
import gensim
import pprint
from collections import defaultdict
from gensim import corpora
t_corpus = [
"CNTK formerly known as Computational Network Toolkit",
"is a free easy-to-use open-source commercial-grade toolkit",
"that enable us to train deep learning algorithms to learn like the human brain.",
"You can find its free tutorial on tutorialspoint.com",
"Tutorialspoint.com also provide best technical tutorials on
technologies like AI deep learning machine learning for free"
]
stoplist = set('for a of the and to in'.split(' '))
processed_corpus = [
[word for word in document.lower().split() if word not in stoplist]
for document in t_corpus
]
frequency = defaultdict(int)
for text in processed_corpus:
for token in text:
frequency[token] += 1
processed_corpus = [
[token for token in text if frequency[token] > 1]
for text in processed_corpus
]
pprint.pprint(processed_corpus)
dictionary = corpora.Dictionary(processed_corpus)
print(dictionary)
BoW_corpus = [dictionary.doc2bow(text) for text in processed_corpus]
pprint.pprint(BoW_corpus)
from gensim import models
tfidf = models.TfidfModel(BoW_corpus)
doc_BoW = [(1,1),(3,1)]
print(tfidf[doc_BoW])
corpus_tfidf = tfidf[BoW_corpus]
for doc in corpus_tfidf:
print(doc)Várias transformações em Gensim
Usando Gensim, podemos implementar várias transformações populares, ou seja, algoritmos de modelo de espaço vetorial. Alguns deles são os seguintes -
Tf-Idf (Frequência do termo-frequência inversa do documento)
Durante a inicialização, este algoritmo de modelo tf-idf espera um corpus de treinamento com valores inteiros (como o modelo Bag-of-Words). Depois disso, no momento da transformação, ele pega uma representação vetorial e retorna outra representação vetorial.
O vetor de saída terá a mesma dimensionalidade, mas o valor dos recursos raros (no momento do treinamento) será aumentado. Ele basicamente converte vetores de valor inteiro em vetores de valor real. A seguir está a sintaxe da transformação Tf-idf -
Model=models.TfidfModel(corpus, normalize=True)LSI (Indexação Semântica Latente)
O algoritmo do modelo LSI pode transformar o documento de um modelo vetorial de valor inteiro (como o modelo Bag-of-Words) ou espaço ponderado Tf-Idf em espaço latente. O vetor de saída será de menor dimensionalidade. A seguir está a sintaxe da transformação LSI -
Model=models.LsiModel(tfidf_corpus, id2word=dictionary, num_topics=300)LDA (alocação de Dirichlet latente)
O algoritmo do modelo LDA é outro algoritmo que transforma o documento do espaço do modelo Bag-of-Words em um espaço de tópico. O vetor de saída será de menor dimensionalidade. A seguir está a sintaxe da transformação LSI -
Model=models.LdaModel(corpus, id2word=dictionary, num_topics=100)Projeções Aleatórias (RP)
RP, uma abordagem muito eficiente, visa reduzir a dimensionalidade do espaço vetorial. Essa abordagem é basicamente aproximada das distâncias Tf-Idf entre os documentos. Ele faz isso acrescentando um pouco de aleatoriedade.
Model=models.RpModel(tfidf_corpus, num_topics=500)Processo Hierárquico de Dirichlet (HDP)
HDP é um método Bayesiano não paramétrico que é uma nova adição ao Gensim. Devemos ter cuidado ao usá-lo.
Model=models.HdpModel(corpus, id2word=dictionaryAqui, aprenderemos como criar a matriz de frequência de documento inverso de frequência (TF-IDF) com a ajuda do Gensim.
O que é TF-IDF?
É o modelo Term Frequency-Inverse Document Frequency, que também é um modelo de saco de palavras. É diferente do corpus regular porque diminui o peso dos tokens, ou seja, palavras que aparecem com frequência nos documentos. Durante a inicialização, este algoritmo de modelo tf-idf espera um corpus de treinamento com valores inteiros (como o modelo Bag-of-Words).
Depois disso, no momento da transformação, ele pega uma representação vetorial e retorna outra representação vetorial. O vetor de saída terá a mesma dimensionalidade, mas o valor dos recursos raros (no momento do treinamento) será aumentado. Basicamente, ele converte vetores de valor inteiro em vetores de valor real.
Como é calculado?
O modelo TF-IDF calcula tfidf com a ajuda de seguir duas etapas simples -
Etapa 1: Multiplicando o componente local e global
Nesta primeira etapa, o modelo irá multiplicar um componente local como TF (Term Frequency) por um componente global como IDF (Inverse Document Frequency).
Etapa 2: normalizar o resultado
Uma vez feita a multiplicação, na próxima etapa o modelo TFIDF normalizará o resultado para o comprimento da unidade.
Como resultado dessas duas etapas acima, as palavras ocorridas com frequência nos documentos serão reduzidas.
Como obter pesos TF-IDF?
Aqui, iremos implementar um exemplo para ver como podemos obter pesos TF-IDF. Basicamente, para obter pesos TF-IDF, primeiro precisamos treinar o corpus e depois aplicar esse corpus dentro do modelo tfidf.
Treine o Corpus
Como dito acima, para obter o TF-IDF, primeiro precisamos treinar nosso corpus. Primeiro, precisamos importar todos os pacotes necessários da seguinte forma -
import gensim
import pprint
from gensim import corpora
from gensim.utils import simple_preprocessAgora forneça a lista contendo as frases. Temos três frases em nossa lista -
doc_list = [
"Hello, how are you?", "How do you do?",
"Hey what are you doing? yes you What are you doing?"
]Em seguida, faça a tokenização das sentenças da seguinte forma -
doc_tokenized = [simple_preprocess(doc) for doc in doc_list]Crie um objeto de corpora.Dictionary() como segue -
dictionary = corpora.Dictionary()Agora passe essas frases tokenizadas para dictionary.doc2bow() objeto da seguinte forma -
BoW_corpus = [dictionary.doc2bow(doc, allow_update=True) for doc in doc_tokenized]A seguir, obteremos as palavras ids e suas frequências em nossos documentos.
for doc in BoW_corpus:
print([[dictionary[id], freq] for id, freq in doc])Resultado
[['are', 1], ['hello', 1], ['how', 1], ['you', 1]]
[['how', 1], ['you', 1], ['do', 2]]
[['are', 2], ['you', 3], ['doing', 2], ['hey', 1], ['what', 2], ['yes', 1]]Assim treinamos nosso corpus (Bag-of-Word corpus).
Em seguida, precisamos aplicar este corpus treinado dentro do modelo tfidf models.TfidfModel().
Primeiro importe o pacote numpay -
import numpy as npAgora aplicando nosso corpus treinado (BoW_corpus) dentro dos colchetes de models.TfidfModel()
tfidf = models.TfidfModel(BoW_corpus, smartirs='ntc')A seguir, obteremos as palavras ids e suas frequências em nosso corpus modelado tfidf -
for doc in tfidf[BoW_corpus]:
print([[dictionary[id], np.around(freq,decomal=2)] for id, freq in doc])Resultado
[['are', 0.33], ['hello', 0.89], ['how', 0.33]]
[['how', 0.18], ['do', 0.98]]
[['are', 0.23], ['doing', 0.62], ['hey', 0.31], ['what', 0.62], ['yes', 0.31]]
[['are', 1], ['hello', 1], ['how', 1], ['you', 1]]
[['how', 1], ['you', 1], ['do', 2]]
[['are', 2], ['you', 3], ['doing', 2], ['hey', 1], ['what', 2], ['yes', 1]]
[['are', 0.33], ['hello', 0.89], ['how', 0.33]]
[['how', 0.18], ['do', 0.98]]
[['are', 0.23], ['doing', 0.62], ['hey', 0.31], ['what', 0.62], ['yes', 0.31]]A partir das saídas acima, vemos a diferença nas frequências das palavras em nossos documentos.
Exemplo de implementação completo
import gensim
import pprint
from gensim import corpora
from gensim.utils import simple_preprocess
doc_list = [
"Hello, how are you?", "How do you do?",
"Hey what are you doing? yes you What are you doing?"
]
doc_tokenized = [simple_preprocess(doc) for doc in doc_list]
dictionary = corpora.Dictionary()
BoW_corpus = [dictionary.doc2bow(doc, allow_update=True) for doc in doc_tokenized]
for doc in BoW_corpus:
print([[dictionary[id], freq] for id, freq in doc])
import numpy as np
tfidf = models.TfidfModel(BoW_corpus, smartirs='ntc')
for doc in tfidf[BoW_corpus]:
print([[dictionary[id], np.around(freq,decomal=2)] for id, freq in doc])Diferença no peso das palavras
Conforme discutido acima, as palavras que ocorrerão com mais frequência no documento terão pesos menores. Vamos entender a diferença nos pesos das palavras das duas saídas acima. A palavra‘are’ocorre em dois documentos e foram ponderados. Da mesma forma, a palavra‘you’ aparecendo em todos os documentos e removidos por completo.
Este capítulo trata da modelagem de tópicos em relação ao Gensim.
Para anotar nossos dados e entender a estrutura das frases, um dos melhores métodos é usar algoritmos linguísticos computacionais. Sem dúvida, com a ajuda desses algoritmos linguísticos computacionais, podemos entender alguns detalhes mais sutis sobre nossos dados, mas,
Podemos saber que tipo de palavras aparecem com mais frequência do que outras em nosso corpus?
Podemos agrupar nossos dados?
Podemos ser temas subjacentes em nossos dados?
Seríamos capazes de alcançar tudo isso com a ajuda da modelagem de tópicos. Então, vamos mergulhar fundo no conceito de modelos de tópicos.
O que são modelos de tópicos?
Um modelo de tópico pode ser definido como o modelo probabilístico contendo informações sobre os tópicos em nosso texto. Mas aqui, surgem duas questões importantes que são as seguintes -
Primeiro, what exactly a topic is?
Tópico, como o nome indica, são ideias subjacentes ou os temas representados em nosso texto. Para dar um exemplo, o corpus contendonewspaper articles teria os tópicos relacionados a finance, weather, politics, sports, various states news e assim por diante.
Segundo, what is the importance of topic models in text processing?
Como sabemos que, para identificar semelhanças no texto, podemos fazer técnicas de recuperação e pesquisa de informação por meio de palavras. Mas, com a ajuda de modelos de tópicos, agora podemos pesquisar e organizar nossos arquivos de texto usando tópicos em vez de palavras.
Nesse sentido, podemos dizer que os tópicos são a distribuição probabilística de palavras. É por isso que, usando modelos de tópicos, podemos descrever nossos documentos como distribuições probabilísticas de tópicos.
Objetivos dos modelos de tópico
Conforme discutido acima, o foco da modelagem de tópicos é sobre ideias e temas subjacentes. Seus principais objetivos são os seguintes -
Os modelos de tópicos podem ser usados para resumos de texto.
Eles podem ser usados para organizar os documentos. Por exemplo, podemos usar a modelagem de tópicos para agrupar artigos de notícias em uma seção organizada / interconectada, como organizar todos os artigos de notícias relacionados acricket.
Eles podem melhorar o resultado da pesquisa. Quão? Para uma consulta de pesquisa, podemos usar modelos de tópicos para revelar o documento com uma combinação de palavras-chave diferentes, mas são sobre a mesma ideia.
O conceito de recomendações é muito útil para o marketing. É usado por vários sites de compras online, sites de notícias e muitos mais. Os modelos de tópicos ajudam a fazer recomendações sobre o que comprar, o que ler em seguida, etc. Eles fazem isso encontrando materiais com um tópico comum na lista.
Algoritmos de modelagem de tópicos em Gensim
Sem dúvida, Gensim é o kit de ferramentas de modelagem de tópico mais popular. Sua disponibilidade gratuita e estar em Python o tornam mais popular. Nesta seção, discutiremos alguns algoritmos de modelagem de tópicos mais populares. Aqui, vamos nos concentrar em "o quê", em vez de "como", porque Gensim os abstrai muito bem para nós.
Alocação Latent Dirichlet (LDA)
A alocação de Dirichlet latente (LDA) é a técnica mais comum e popular atualmente em uso para modelagem de tópicos. É o que os pesquisadores do Facebook usaram em seu artigo de pesquisa publicado em 2013. Foi proposto pela primeira vez por David Blei, Andrew Ng e Michael Jordan em 2003. Eles propuseram LDA em seu artigo intitulado simplesmenteLatent Dirichlet allocation.
Características do LDA
Vamos saber mais sobre esta maravilhosa técnica através de suas características -
Probabilistic topic modeling technique
LDA é uma técnica de modelagem de tópicos probabilísticos. Como discutimos acima, na modelagem de tópicos assumimos que em qualquer coleção de documentos inter-relacionados (podem ser artigos acadêmicos, artigos de jornais, postagens no Facebook, Tweets, e-mails e assim por diante), existem algumas combinações de tópicos incluídos em cada documento .
O principal objetivo da modelagem de tópicos probabilísticos é descobrir a estrutura de tópicos ocultos para a coleção de documentos inter-relacionados. A seguir, três coisas geralmente estão incluídas em uma estrutura de tópico -
Topics
Distribuição estatística de tópicos entre os documentos
Palavras em um documento que abrangem o tópico
Work in an unsupervised way
O LDA funciona de forma não supervisionada. É porque o LDA usa probabilidades condicionais para descobrir a estrutura oculta do tópico. Ele pressupõe que os tópicos estão distribuídos de forma desigual em toda a coleção de documentos inter-relacionados.
Very easy to create it in Gensim
No Gensim, é muito fácil criar o modelo LDA. precisamos apenas especificar o corpus, o mapeamento do dicionário e o número de tópicos que gostaríamos de usar em nosso modelo.
Model=models.LdaModel(corpus, id2word=dictionary, num_topics=100)May face computationally intractable problem
Calcular a probabilidade de cada estrutura de tópico possível é um desafio computacional enfrentado pelo LDA. É um desafio porque precisa calcular a probabilidade de cada palavra observada em cada estrutura de tópico possível. Se tivermos um grande número de tópicos e palavras, LDA pode enfrentar problemas computacionalmente intratáveis.
Indexação semântica latente (LSI)
Os algoritmos de modelagem de tópicos que foram implementados pela primeira vez no Gensim com Latent Dirichlet Allocation (LDA) é Latent Semantic Indexing (LSI). Também é chamadoLatent Semantic Analysis (LSA).
Foi patenteado em 1988 por Scott Deerwester, Susan Dumais, George Furnas, Richard Harshman, Thomas Landaur, Karen Lochbaum e Lynn Streeter. Nesta seção, vamos configurar nosso modelo LSI. Isso pode ser feito da mesma forma que configurar o modelo LDA. precisamos importar o modelo LSI degensim.models.
Papel do LSI
Na verdade, LSI é uma técnica de PNL, especialmente em semântica distributiva. Ele analisa a relação entre um conjunto de documentos e os termos que esses documentos contêm. Se falarmos sobre seu funcionamento, ele constrói uma matriz que contém contagens de palavras por documento a partir de um grande pedaço de texto.
Uma vez construído, para reduzir o número de linhas, o modelo LSI usa uma técnica matemática chamada decomposição de valor singular (SVD). Além de reduzir o número de linhas, também preserva a estrutura de similaridade entre as colunas. Na matriz, as linhas representam palavras únicas e as colunas representam cada documento. Funciona com base na hipótese de distribuição, ou seja, assume que as palavras com significado próximo ocorrerão no mesmo tipo de texto.
Model=models.LsiModel(corpus, id2word=dictionary, num_topics=100)Processo Hierárquico de Dirichlet (HDP)
Modelos de tópicos como LDA e LSI ajudam a resumir e organizar grandes arquivos de textos que não são possíveis de serem analisados manualmente. Além do LDA e do LSI, um outro modelo de tópico poderoso no Gensim é o HDP (Processo Hierárquico de Dirichlet). É basicamente um modelo de associação mista para análise não supervisionada de dados agrupados. Ao contrário do LDA (sua contraparte finita), o HDP infere o número de tópicos a partir dos dados.
Model=models.HdpModel(corpus, id2word=dictionaryEste capítulo o ajudará a aprender como criar um modelo de tópico de alocação de Dirichlet latente (LDA) no Gensim.
Extração automática de informações sobre tópicos de grande volume de textos em uma das principais aplicações de PNL (processamento de linguagem natural). Um grande volume de textos pode ser alimentado por avaliações de hotéis, tweets, postagens no Facebook, feeds de qualquer outro canal de mídia social, resenhas de filmes, notícias, feedbacks de usuários, e-mails, etc.
Nesta era digital, saber do que as pessoas / clientes estão falando, entender suas opiniões e seus problemas pode ser muito valioso para empresas, campanhas políticas e administradores. Mas, é possível ler manualmente esses grandes volumes de texto e, em seguida, extrair as informações dos tópicos?
Não, não é. Ele requer um algoritmo automático que pode ler esse grande volume de documentos de texto e extrair automaticamente as informações / tópicos discutidos a partir deles.
Papel da LDA
A abordagem do LDA para a modelagem de tópicos é classificar o texto em um documento para um tópico específico. Modelado como distribuições Dirichlet, compilações LDA -
- Um tópico por modelo de documento e
- Palavras por modelo de tópico
Depois de fornecer o algoritmo de modelo de tópico LDA, a fim de obter uma boa composição de distribuição de tópico-palavra-chave, ele reorganiza -
- As distribuições de tópicos dentro do documento e
- Distribuição de palavras-chave dentro dos tópicos
Durante o processamento, algumas das suposições feitas pela LDA são -
- Cada documento é modelado como distribuições multi-nominais de tópicos.
- Cada tópico é modelado como distribuições multi-nominais de palavras.
- Deveríamos ter que escolher o corpus correto de dados porque LDA assume que cada pedaço de texto contém as palavras relacionadas.
- O LDA também assume que os documentos são produzidos a partir de uma mistura de tópicos.
Implementação com Gensim
Aqui, vamos usar LDA (Latent Dirichlet Allocation) para extrair os tópicos naturalmente discutidos do conjunto de dados.
Carregando conjunto de dados
O conjunto de dados que vamos usar é o conjunto de dados de ’20 Newsgroups’tendo milhares de artigos de notícias de várias seções de uma reportagem. Está disponível emSklearnconjuntos de dados. Podemos fazer download facilmente com a ajuda do seguinte script Python -
from sklearn.datasets import fetch_20newsgroups
newsgroups_train = fetch_20newsgroups(subset='train')Vejamos alguns exemplos de notícias com a ajuda do seguinte script -
newsgroups_train.data[:4]["From: [email protected] (where's my thing)\nSubject:
WHAT car is this!?\nNntp-Posting-Host: rac3.wam.umd.edu\nOrganization:
University of Maryland, College Park\nLines:
15\n\n I was wondering if anyone out there could enlighten me on this car
I saw\nthe other day. It was a 2-door sports car, looked to be from the
late 60s/\nearly 70s. It was called a Bricklin. The doors were really small.
In addition,\nthe front bumper was separate from the rest of the body.
This is \nall I know. If anyone can tellme a model name,
engine specs, years\nof production, where this car is made, history, or
whatever info you\nhave on this funky looking car, please e-mail.\n\nThanks,
\n- IL\n ---- brought to you by your neighborhood Lerxst ----\n\n\n\n\n",
"From: [email protected] (Guy Kuo)\nSubject: SI Clock Poll - Final
Call\nSummary: Final call for SI clock reports\nKeywords:
SI,acceleration,clock,upgrade\nArticle-I.D.: shelley.1qvfo9INNc3s\nOrganization:
University of Washington\nLines: 11\nNNTP-Posting-Host: carson.u.washington.edu\n\nA
fair number of brave souls who upgraded their SI clock oscillator have\nshared their
experiences for this poll. Please send a brief message detailing\nyour experiences with
the procedure. Top speed attained, CPU rated speed,\nadd on cards and adapters, heat
sinks, hour of usage per day, floppy disk\nfunctionality with 800 and 1.4 m floppies
are especially requested.\n\nI will be summarizing in the next two days, so please add
to the network\nknowledge base if you have done the clock upgrade and haven't answered
this\npoll. Thanks.\n\nGuy Kuo <;[email protected]>\n",
'From: [email protected] (Thomas E Willis)\nSubject:
PB questions...\nOrganization: Purdue University Engineering
Computer Network\nDistribution: usa\nLines: 36\n\nwell folks,
my mac plus finally gave up the ghost this weekend after\nstarting
life as a 512k way back in 1985. sooo, i\'m in the market for
a\nnew machine a bit sooner than i intended to be...\n\ni\'m looking
into picking up a powerbook 160 or maybe 180 and have a bunch\nof
questions that (hopefully) somebody can answer:\n\n* does anybody
know any dirt on when the next round of powerbook\nintroductions
are expected? i\'d heard the 185c was supposed to make an\nappearence
"this summer" but haven\'t heard anymore on it - and since i\ndon\'t
have access to macleak, i was wondering if anybody out there had\nmore
info...\n\n* has anybody heard rumors about price drops to the powerbook
line like the\nones the duo\'s just went through recently?\n\n* what\'s
the impression of the display on the 180? i could probably swing\na 180
if i got the 80Mb disk rather than the 120, but i don\'t really have\na
feel for how much "better" the display is (yea, it looks great in the\nstore,
but is that all "wow" or is it really that good?). could i solicit\nsome
opinions of people who use the 160 and 180 day-to-day on if its
worth\ntaking the disk size and money hit to get the active display?
(i realize\nthis is a real subjective question, but i\'ve only played around
with the\nmachines in a computer store breifly and figured the opinions
of somebody\nwho actually uses the machine daily might prove helpful).\n\n*
how well does hellcats perform? ;)\n\nthanks a bunch in advance for any info -
if you could email, i\'ll post a\nsummary (news reading time is at a premium
with finals just around the\ncorner... :
( )\n--\nTom Willis \\ [email protected] \\ Purdue Electrical
Engineering\n---------------------------------------------------------------------------\
n"Convictions are more dangerous enemies of truth than lies." - F. W.\nNietzsche\n',
'From: jgreen@amber (Joe Green)\nSubject: Re: Weitek P9000 ?\nOrganization:
Harris Computer Systems Division\nLines: 14\nDistribution: world\nNNTP-Posting-Host:
amber.ssd.csd.harris.com\nX-Newsreader: TIN [version 1.1 PL9]\n\nRobert
J.C. Kyanko ([email protected]) wrote:\n >[email protected] writes in article
<[email protected] >:\n> > Anyone know about the
Weitek P9000 graphics chip?\n > As far as the low-level stuff goes, it looks
pretty nice. It\'s got this\n> quadrilateral fill command that requires just
the four points.\n\nDo you have Weitek\'s address/phone number? I\'d like to get
some information\nabout this chip.\n\n--\nJoe Green\t\t\t\tHarris
Corporation\[email protected]\t\t\tComputer Systems Division\n"The only
thing that really scares me is a person with no sense of humor.
"\n\t\t\t\t\t\t-- Jonathan Winters\n']Pré-requisito
Precisamos de Stopwords da NLTK e do modelo em inglês da Scapy. Ambos podem ser baixados da seguinte forma -
import nltk;
nltk.download('stopwords')
nlp = spacy.load('en_core_web_md', disable=['parser', 'ner'])Importando Pacotes Necessários
Para construir o modelo LDA, precisamos importar o seguinte pacote necessário -
import re
import numpy as np
import pandas as pd
from pprint import pprint
import gensim
import gensim.corpora as corpora
from gensim.utils import simple_preprocess
from gensim.models import CoherenceModel
import spacy
import pyLDAvis
import pyLDAvis.gensim
import matplotlib.pyplot as pltPreparando palavras irrelevantes
Agora, precisamos importar as palavras irrelevantes e usá-las -
from nltk.corpus import stopwords
stop_words = stopwords.words('english')
stop_words.extend(['from', 'subject', 're', 'edu', 'use'])Limpe o texto
Agora, com a ajuda de Gensim's simple_preprocess()precisamos tokenizar cada frase em uma lista de palavras. Devemos também remover as pontuações e caracteres desnecessários. Para fazer isso, vamos criar uma função chamadasent_to_words() -
def sent_to_words(sentences):
for sentence in sentences:
yield(gensim.utils.simple_preprocess(str(sentence), deacc=True))
data_words = list(sent_to_words(data))Construindo modelos de bigramas e trigramas
Como sabemos, bigrams são duas palavras que ocorrem frequentemente juntas no documento e trigrama são três palavras que ocorrem frequentemente juntas no documento. Com a ajuda de Gensim'sPhrases modelo, podemos fazer isso -
bigram = gensim.models.Phrases(data_words, min_count=5, threshold=100)
trigram = gensim.models.Phrases(bigram[data_words], threshold=100)
bigram_mod = gensim.models.phrases.Phraser(bigram)
trigram_mod = gensim.models.phrases.Phraser(trigram)Filtrar palavras irrelevantes
Em seguida, precisamos filtrar as palavras irrelevantes. Junto com isso, também criaremos funções para fazer bigramas, trigramas e para lematização -
def remove_stopwords(texts):
return [[word for word in simple_preprocess(str(doc))
if word not in stop_words] for doc in texts]
def make_bigrams(texts):
return [bigram_mod[doc] for doc in texts]
def make_trigrams(texts):
return [trigram_mod[bigram_mod[doc]] for doc in texts]
def lemmatization(texts, allowed_postags=['NOUN', 'ADJ', 'VERB', 'ADV']):
texts_out = []
for sent in texts:
doc = nlp(" ".join(sent))
texts_out.append([token.lemma_ for token in doc if token.pos_ in allowed_postags])
return texts_outConstruindo Dicionário e Corpus para Modelo de Tópico
Agora precisamos construir o dicionário e corpus. Também fizemos isso nos exemplos anteriores -
id2word = corpora.Dictionary(data_lemmatized)
texts = data_lemmatized
corpus = [id2word.doc2bow(text) for text in texts]Construindo Modelo de Tópico LDA
Já implementamos tudo o que é necessário para treinar o modelo LDA. Agora é a hora de construir o modelo de tópico do LDA. Para o nosso exemplo de implementação, isso pode ser feito com a ajuda da seguinte linha de códigos -
lda_model = gensim.models.ldamodel.LdaModel(
corpus=corpus, id2word=id2word, num_topics=20, random_state=100,
update_every=1, chunksize=100, passes=10, alpha='auto', per_word_topics=True
)Exemplo de Implementação
Vamos ver o exemplo de implementação completo para construir o modelo de tópico LDA -
import re
import numpy as np
import pandas as pd
from pprint import pprint
import gensim
import gensim.corpora as corpora
from gensim.utils import simple_preprocess
from gensim.models import CoherenceModel
import spacy
import pyLDAvis
import pyLDAvis.gensim
import matplotlib.pyplot as plt
from nltk.corpus import stopwords
stop_words = stopwords.words('english')
stop_words.extend(['from', 'subject', 're', 'edu', 'use'])
from sklearn.datasets import fetch_20newsgroups
newsgroups_train = fetch_20newsgroups(subset='train')
data = newsgroups_train.data
data = [re.sub('\S*@\S*\s?', '', sent) for sent in data]
data = [re.sub('\s+', ' ', sent) for sent in data]
data = [re.sub("\'", "", sent) for sent in data]
print(data_words[:4]) #it will print the data after prepared for stopwords
bigram = gensim.models.Phrases(data_words, min_count=5, threshold=100)
trigram = gensim.models.Phrases(bigram[data_words], threshold=100)
bigram_mod = gensim.models.phrases.Phraser(bigram)
trigram_mod = gensim.models.phrases.Phraser(trigram)
def remove_stopwords(texts):
return [[word for word in simple_preprocess(str(doc))
if word not in stop_words] for doc in texts]
def make_bigrams(texts):
return [bigram_mod[doc] for doc in texts]
def make_trigrams(texts):
[trigram_mod[bigram_mod[doc]] for doc in texts]
def lemmatization(texts, allowed_postags=['NOUN', 'ADJ', 'VERB', 'ADV']):
texts_out = []
for sent in texts:
doc = nlp(" ".join(sent))
texts_out.append([token.lemma_ for token in doc if token.pos_ in allowed_postags])
return texts_out
data_words_nostops = remove_stopwords(data_words)
data_words_bigrams = make_bigrams(data_words_nostops)
nlp = spacy.load('en_core_web_md', disable=['parser', 'ner'])
data_lemmatized = lemmatization(data_words_bigrams, allowed_postags=[
'NOUN', 'ADJ', 'VERB', 'ADV'
])
print(data_lemmatized[:4]) #it will print the lemmatized data.
id2word = corpora.Dictionary(data_lemmatized)
texts = data_lemmatized
corpus = [id2word.doc2bow(text) for text in texts]
print(corpus[:4]) #it will print the corpus we created above.
[[(id2word[id], freq) for id, freq in cp] for cp in corpus[:4]]
#it will print the words with their frequencies.
lda_model = gensim.models.ldamodel.LdaModel(
corpus=corpus, id2word=id2word, num_topics=20, random_state=100,
update_every=1, chunksize=100, passes=10, alpha='auto', per_word_topics=True
)Agora podemos usar o modelo LDA criado acima para obter os tópicos, para calcular a perplexidade do modelo.
Neste capítulo, vamos entender como usar o modelo de tópico Latent Dirichlet Allocation (LDA).
Visualizando Tópicos no Modelo LDA
O modelo LDA (lda_model) que criamos acima pode ser usado para visualizar os tópicos dos documentos. Isso pode ser feito com a ajuda do seguinte script -
pprint(lda_model.print_topics())
doc_lda = lda_model[corpus]Resultado
[
(0,
'0.036*"go" + 0.027*"get" + 0.021*"time" + 0.017*"back" + 0.015*"good" + '
'0.014*"much" + 0.014*"be" + 0.013*"car" + 0.013*"well" + 0.013*"year"'),
(1,
'0.078*"screen" + 0.067*"video" + 0.052*"character" + 0.046*"normal" + '
'0.045*"mouse" + 0.034*"manager" + 0.034*"disease" + 0.031*"processor" + '
'0.028*"excuse" + 0.028*"choice"'),
(2,
'0.776*"ax" + 0.079*"_" + 0.011*"boy" + 0.008*"ticket" + 0.006*"red" + '
'0.004*"conservative" + 0.004*"cult" + 0.004*"amazing" + 0.003*"runner" + '
'0.003*"roughly"'),
(3,
'0.086*"season" + 0.078*"fan" + 0.072*"reality" + 0.065*"trade" + '
'0.045*"concept" + 0.040*"pen" + 0.028*"blow" + 0.025*"improve" + '
'0.025*"cap" + 0.021*"penguin"'),
(4,
'0.027*"group" + 0.023*"issue" + 0.016*"case" + 0.016*"cause" + '
'0.014*"state" + 0.012*"whole" + 0.012*"support" + 0.011*"government" + '
'0.010*"year" + 0.010*"rate"'),
(5,
'0.133*"evidence" + 0.047*"believe" + 0.044*"religion" + 0.042*"belief" + '
'0.041*"sense" + 0.041*"discussion" + 0.034*"atheist" + 0.030*"conclusion" +
'
'0.029*"explain" + 0.029*"claim"'),
(6,
'0.083*"space" + 0.059*"science" + 0.031*"launch" + 0.030*"earth" + '
'0.026*"route" + 0.024*"orbit" + 0.024*"scientific" + 0.021*"mission" + '
'0.018*"plane" + 0.017*"satellite"'),
(7,
'0.065*"file" + 0.064*"program" + 0.048*"card" + 0.041*"window" + '
'0.038*"driver" + 0.037*"software" + 0.034*"run" + 0.029*"machine" + '
'0.029*"entry" + 0.028*"version"'),
(8,
'0.078*"publish" + 0.059*"mount" + 0.050*"turkish" + 0.043*"armenian" + '
'0.027*"western" + 0.026*"russian" + 0.025*"locate" + 0.024*"proceed" + '
'0.024*"electrical" + 0.022*"terrorism"'),
(9,
'0.023*"people" + 0.023*"child" + 0.021*"kill" + 0.020*"man" + 0.019*"death" '
'+ 0.015*"die" + 0.015*"live" + 0.014*"attack" + 0.013*"age" + '
'0.011*"church"'),
(10,
'0.092*"cpu" + 0.085*"black" + 0.071*"controller" + 0.039*"white" + '
'0.028*"water" + 0.027*"cold" + 0.025*"solid" + 0.024*"cool" + 0.024*"heat" '
'+ 0.023*"nuclear"'),
(11,
'0.071*"monitor" + 0.044*"box" + 0.042*"option" + 0.041*"generate" + '
'0.038*"vote" + 0.032*"battery" + 0.029*"wave" + 0.026*"tradition" + '
'0.026*"fairly" + 0.025*"task"'),
(12,
'0.048*"send" + 0.045*"mail" + 0.036*"list" + 0.033*"include" + '
'0.032*"price" + 0.031*"address" + 0.027*"email" + 0.026*"receive" + '
'0.024*"book" + 0.024*"sell"'),
(13,
'0.515*"drive" + 0.052*"laboratory" + 0.042*"blind" + 0.020*"investment" + '
'0.011*"creature" + 0.010*"loop" + 0.005*"dialog" + 0.000*"slave" + '
'0.000*"jumper" + 0.000*"sector"'),
(14,
'0.153*"patient" + 0.066*"treatment" + 0.062*"printer" + 0.059*"doctor" + '
'0.036*"medical" + 0.031*"energy" + 0.029*"study" + 0.029*"probe" + '
'0.024*"mph" + 0.020*"physician"'),
(15,
'0.068*"law" + 0.055*"gun" + 0.039*"government" + 0.036*"right" + '
'0.029*"state" + 0.026*"drug" + 0.022*"crime" + 0.019*"person" + '
'0.019*"citizen" + 0.019*"weapon"'),
(16,
'0.107*"team" + 0.102*"game" + 0.078*"play" + 0.055*"win" + 0.052*"player" + '
'0.051*"year" + 0.030*"score" + 0.025*"goal" + 0.023*"wing" + 0.023*"run"'),
(17,
'0.031*"say" + 0.026*"think" + 0.022*"people" + 0.020*"make" + 0.017*"see" + '
'0.016*"know" + 0.013*"come" + 0.013*"even" + 0.013*"thing" + 0.013*"give"'),
(18,
'0.039*"system" + 0.034*"use" + 0.023*"key" + 0.016*"bit" + 0.016*"also" + '
'0.015*"information" + 0.014*"source" + 0.013*"chip" + 0.013*"available" + '
'0.010*"provide"'),
(19,
'0.085*"line" + 0.073*"write" + 0.053*"article" + 0.046*"organization" + '
'0.034*"host" + 0.023*"be" + 0.023*"know" + 0.017*"thank" + 0.016*"want" + '
'0.014*"help"')
]Perplexidade do modelo de computação
O modelo LDA (lda_model) que criamos acima pode ser usado para calcular a perplexidade do modelo, ou seja, quão bom é o modelo. Quanto menor a pontuação, melhor será o modelo. Isso pode ser feito com a ajuda do seguinte script -
print('\nPerplexity: ', lda_model.log_perplexity(corpus))Resultado
Perplexity: -12.338664984332151Pontuação de Coerência de Computação
O modelo LDA (lda_model)que criamos acima pode ser usado para calcular a pontuação de coerência do modelo, ou seja, a média / mediana das pontuações de similaridade de palavras dos pares das palavras no tópico. Isso pode ser feito com a ajuda do seguinte script -
coherence_model_lda = CoherenceModel(
model=lda_model, texts=data_lemmatized, dictionary=id2word, coherence='c_v'
)
coherence_lda = coherence_model_lda.get_coherence()
print('\nCoherence Score: ', coherence_lda)Resultado
Coherence Score: 0.510264381411751Visualizando os Tópicos-Palavras-chave
O modelo LDA (lda_model)que criamos acima pode ser usado para examinar os tópicos produzidos e as palavras-chave associadas. Pode ser visualizado usandopyLDAvispacote da seguinte forma -
pyLDAvis.enable_notebook()
vis = pyLDAvis.gensim.prepare(lda_model, corpus, id2word)
visResultado
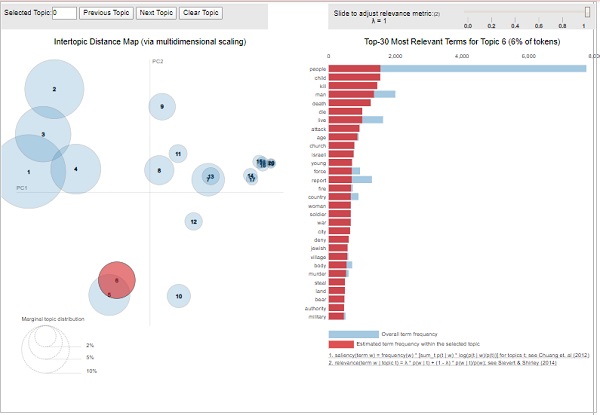
A partir da saída acima, as bolhas no lado esquerdo representam um tópico e quanto maior a bolha, mais prevalente é esse tópico. O modelo de tópico será bom se o modelo de tópico tiver bolhas grandes e não sobrepostas espalhadas por todo o gráfico.
Este capítulo irá explicar o que é um modelo Mallet de alocação de Dirichlet latente (LDA) e como criar o mesmo no Gensim.
Na seção anterior, implementamos o modelo LDA e obtemos os tópicos dos documentos do conjunto de dados 20Newsgroup. Essa era a versão embutida de Gensim do algoritmo LDA. Existe também uma versão Mallet do Gensim, que oferece melhor qualidade dos tópicos. Aqui, vamos aplicar o LDA de Mallet no exemplo anterior que já implementamos.
O que é o modelo LDA Mallet?
Mallet, um kit de ferramentas de código aberto, foi escrito por Andrew McCullum. É basicamente um pacote baseado em Java que é usado para NLP, classificação de documentos, clustering, modelagem de tópicos e muitos outros aplicativos de aprendizado de máquina para texto. Ele nos fornece o kit de ferramentas Mallet Topic Modeling, que contém implementações eficientes e baseadas em amostragem de LDA, bem como LDA hierárquica.
Mallet2.0 é a versão atual do MALLET, o kit de ferramentas de modelagem de tópicos java. Antes de começar a usá-lo com o Gensim for LDA, devemos baixar o pacote mallet-2.0.8.zip em nosso sistema e descompactá-lo. Depois de instalado e descompactado, defina a variável de ambiente% MALLET_HOME% para o ponto para o diretório MALLET manualmente ou pelo código que forneceremos, ao implementar o LDA com Mallet a seguir.
Gensim Wrapper
Python fornece wrapper Gensim para Latent Dirichlet Allocation (LDA). A sintaxe desse wrapper égensim.models.wrappers.LdaMallet. Este módulo, amostragem de gibbs recolhidos do MALLET, permite a estimativa do modelo LDA a partir de um corpus de treinamento e inferência da distribuição de tópicos em documentos novos e não vistos.
Exemplo de Implementação
Usaremos o LDA Mallet no modelo LDA previamente construído e verificaremos a diferença no desempenho calculando a pontuação de Coerência.
Fornecendo o caminho para o arquivo Mallet
Antes de aplicar o modelo Mallet LDA em nosso corpus construído no exemplo anterior, devemos ter que atualizar as variáveis de ambiente e fornecer o caminho do arquivo Mallet também. Isso pode ser feito com a ajuda do seguinte código -
import os
from gensim.models.wrappers import LdaMallet
os.environ.update({'MALLET_HOME':r'C:/mallet-2.0.8/'})
#You should update this path as per the path of Mallet directory on your system.
mallet_path = r'C:/mallet-2.0.8/bin/mallet'
#You should update this path as per the path of Mallet directory on your system.Depois de fornecer o caminho para o arquivo Mallet, podemos usá-lo no corpus. Isso pode ser feito com a ajuda deldamallet.show_topics() funcionar da seguinte forma -
ldamallet = gensim.models.wrappers.LdaMallet(
mallet_path, corpus=corpus, num_topics=20, id2word=id2word
)
pprint(ldamallet.show_topics(formatted=False))Resultado
[
(4,
[('gun', 0.024546225966016102),
('law', 0.02181426826996709),
('state', 0.017633545129043606),
('people', 0.017612848479831116),
('case', 0.011341763768445888),
('crime', 0.010596684396796159),
('weapon', 0.00985160502514643),
('person', 0.008671896020034356),
('firearm', 0.00838214293105946),
('police', 0.008257963035784506)]),
(9,
[('make', 0.02147966482730431),
('people', 0.021377478029838543),
('work', 0.018557122419783363),
('money', 0.016676885346413244),
('year', 0.015982015123646026),
('job', 0.012221540976905783),
('pay', 0.010239117106069897),
('time', 0.008910688739014919),
('school', 0.0079092581238504),
('support', 0.007357449417535254)]),
(14,
[('power', 0.018428398507941996),
('line', 0.013784244460364121),
('high', 0.01183271164249895),
('work', 0.011560979224821522),
('ground', 0.010770484918850819),
('current', 0.010745781971789235),
('wire', 0.008399002000938712),
('low', 0.008053160742076529),
('water', 0.006966231071366814),
('run', 0.006892122230182061)]),
(0,
[('people', 0.025218349201353372),
('kill', 0.01500904870564167),
('child', 0.013612400660948935),
('armenian', 0.010307655991816822),
('woman', 0.010287984892595798),
('start', 0.01003226060272248),
('day', 0.00967818081674404),
('happen', 0.009383114328428673),
('leave', 0.009383114328428673),
('fire', 0.009009363443229208)]),
(1,
[('file', 0.030686386604212003),
('program', 0.02227713642901929),
('window', 0.01945561169918489),
('set', 0.015914874783314277),
('line', 0.013831003577619592),
('display', 0.013794120901412606),
('application', 0.012576992586582082),
('entry', 0.009275993066056873),
('change', 0.00872275292295209),
('color', 0.008612104894331132)]),
(12,
[('line', 0.07153810971508515),
('buy', 0.02975597944523662),
('organization', 0.026877236406682988),
('host', 0.025451316957679788),
('price', 0.025182275552207485),
('sell', 0.02461728860071565),
('mail', 0.02192687454599263),
('good', 0.018967419085797303),
('sale', 0.017998870026097017),
('send', 0.013694207538540181)]),
(11,
[('thing', 0.04901329901329901),
('good', 0.0376018876018876),
('make', 0.03393393393393394),
('time', 0.03326898326898327),
('bad', 0.02664092664092664),
('happen', 0.017696267696267698),
('hear', 0.015615615615615615),
('problem', 0.015465465465465466),
('back', 0.015143715143715144),
('lot', 0.01495066495066495)]),
(18,
[('space', 0.020626317374284855),
('launch', 0.00965716006366413),
('system', 0.008560244332602057),
('project', 0.008173097603991913),
('time', 0.008108573149223556),
('cost', 0.007764442723792318),
('year', 0.0076784101174345075),
('earth', 0.007484836753129436),
('base', 0.0067535595990880545),
('large', 0.006689035144319697)]),
(5,
[('government', 0.01918437232469453),
('people', 0.01461203206475212),
('state', 0.011207097828624796),
('country', 0.010214802708381975),
('israeli', 0.010039691804809714),
('war', 0.009436532025838587),
('force', 0.00858043427504086),
('attack', 0.008424780138532182),
('land', 0.0076659662230523775),
('world', 0.0075103120865437)]),
(2,
[('car', 0.041091194044470564),
('bike', 0.015598981291017729),
('ride', 0.011019688510138114),
('drive', 0.010627877363110981),
('engine', 0.009403467528651191),
('speed', 0.008081104907434616),
('turn', 0.007738270153785875),
('back', 0.007738270153785875),
('front', 0.007468899990204721),
('big', 0.007370947203447938)])
]Avaliação de desempenho
Agora também podemos avaliar seu desempenho calculando a pontuação de coerência da seguinte forma -
ldamallet = gensim.models.wrappers.LdaMallet(
mallet_path, corpus=corpus, num_topics=20, id2word=id2word
)
pprint(ldamallet.show_topics(formatted=False))Resultado
Coherence Score: 0.5842762900901401Este capítulo discute os documentos e o modelo LDA no Gensim.
Encontrando o número ideal de tópicos para LDA
Podemos encontrar o número ideal de tópicos para LDA criando muitos modelos de LDA com vários valores de tópicos. Entre esses LDAs, podemos escolher um com o maior valor de coerência.
A seguir função chamada coherence_values_computation()treinará vários modelos de LDA. Ele também fornecerá os modelos, bem como sua pontuação de coerência correspondente -
def coherence_values_computation(dictionary, corpus, texts, limit, start=2, step=3):
coherence_values = []
model_list = []
for num_topics in range(start, limit, step):
model = gensim.models.wrappers.LdaMallet(
mallet_path, corpus=corpus, num_topics=num_topics, id2word=id2word
)
model_list.append(model)
coherencemodel = CoherenceModel(
model=model, texts=texts, dictionary=dictionary, coherence='c_v'
)
coherence_values.append(coherencemodel.get_coherence())
return model_list, coherence_valuesAgora, com a ajuda do código a seguir, podemos obter o número ideal de tópicos que podemos mostrar com a ajuda de um gráfico também -
model_list, coherence_values = coherence_values_computation (
dictionary=id2word, corpus=corpus, texts=data_lemmatized,
start=1, limit=50, step=8
)
limit=50; start=1; step=8;
x = range(start, limit, step)
plt.plot(x, coherence_values)
plt.xlabel("Num Topics")
plt.ylabel("Coherence score")
plt.legend(("coherence_values"), loc='best')
plt.show()Resultado
Em seguida, também podemos imprimir os valores de coerência para vários tópicos, como segue -
for m, cv in zip(x, coherence_values):
print("Num Topics =", m, " is having Coherence Value of", round(cv, 4))Resultado
Num Topics = 1 is having Coherence Value of 0.4866
Num Topics = 9 is having Coherence Value of 0.5083
Num Topics = 17 is having Coherence Value of 0.5584
Num Topics = 25 is having Coherence Value of 0.5793
Num Topics = 33 is having Coherence Value of 0.587
Num Topics = 41 is having Coherence Value of 0.5842
Num Topics = 49 is having Coherence Value of 0.5735Agora, surge a questão de qual modelo devemos escolher agora? Uma das boas práticas é escolher o modelo, que está dando o maior valor de coerência antes de elogiar. Por isso, estaremos escolhendo o modelo com 25 tópicos que está no número 4 da lista acima.
optimal_model = model_list[3]
model_topics = optimal_model.show_topics(formatted=False)
pprint(optimal_model.print_topics(num_words=10))
[
(0,
'0.018*"power" + 0.011*"high" + 0.010*"ground" + 0.009*"current" + '
'0.008*"low" + 0.008*"wire" + 0.007*"water" + 0.007*"work" + 0.007*"design" '
'+ 0.007*"light"'),
(1,
'0.036*"game" + 0.029*"team" + 0.029*"year" + 0.028*"play" + 0.020*"player" '
'+ 0.019*"win" + 0.018*"good" + 0.013*"season" + 0.012*"run" + 0.011*"hit"'),
(2,
'0.020*"image" + 0.019*"information" + 0.017*"include" + 0.017*"mail" + '
'0.016*"send" + 0.015*"list" + 0.013*"post" + 0.012*"address" + '
'0.012*"internet" + 0.012*"system"'),
(3,
'0.986*"ax" + 0.002*"_" + 0.001*"tm" + 0.000*"part" + 0.000*"biz" + '
'0.000*"mb" + 0.000*"mbs" + 0.000*"pne" + 0.000*"end" + 0.000*"di"'),
(4,
'0.020*"make" + 0.014*"work" + 0.013*"money" + 0.013*"year" + 0.012*"people" '
'+ 0.011*"job" + 0.010*"group" + 0.009*"government" + 0.008*"support" + '
'0.008*"question"'),
(5,
'0.011*"study" + 0.011*"drug" + 0.009*"science" + 0.008*"food" + '
'0.008*"problem" + 0.008*"result" + 0.008*"effect" + 0.007*"doctor" + '
'0.007*"research" + 0.007*"patient"'),
(6,
'0.024*"gun" + 0.024*"law" + 0.019*"state" + 0.015*"case" + 0.013*"people" + '
'0.010*"crime" + 0.010*"weapon" + 0.010*"person" + 0.008*"firearm" + '
'0.008*"police"'),
(7,
'0.012*"word" + 0.011*"question" + 0.011*"exist" + 0.011*"true" + '
'0.010*"religion" + 0.010*"claim" + 0.008*"argument" + 0.008*"truth" + '
'0.008*"life" + 0.008*"faith"'),
(8,
'0.077*"time" + 0.029*"day" + 0.029*"call" + 0.025*"back" + 0.021*"work" + '
'0.019*"long" + 0.015*"end" + 0.015*"give" + 0.014*"year" + 0.014*"week"'),
(9,
'0.048*"thing" + 0.041*"make" + 0.038*"good" + 0.037*"people" + '
'0.028*"write" + 0.019*"bad" + 0.019*"point" + 0.018*"read" + 0.018*"post" + '
'0.016*"idea"'),
(10,
'0.022*"book" + 0.020*"_" + 0.013*"man" + 0.012*"people" + 0.011*"write" + '
'0.011*"find" + 0.010*"history" + 0.010*"armenian" + 0.009*"turkish" + '
'0.009*"number"'),
(11,
'0.064*"line" + 0.030*"buy" + 0.028*"organization" + 0.025*"price" + '
'0.025*"sell" + 0.023*"good" + 0.021*"host" + 0.018*"sale" + 0.017*"mail" + '
'0.016*"cost"'),
(12,
'0.041*"car" + 0.015*"bike" + 0.011*"ride" + 0.010*"engine" + 0.009*"drive" '
'+ 0.008*"side" + 0.008*"article" + 0.007*"turn" + 0.007*"front" + '
'0.007*"speed"'),
(13,
'0.018*"people" + 0.011*"attack" + 0.011*"state" + 0.011*"israeli" + '
'0.010*"war" + 0.010*"country" + 0.010*"government" + 0.009*"live" + '
'0.009*"give" + 0.009*"land"'),
(14,
'0.037*"file" + 0.026*"line" + 0.021*"read" + 0.019*"follow" + '
'0.018*"number" + 0.015*"program" + 0.014*"write" + 0.012*"entry" + '
'0.012*"give" + 0.011*"check"'),
(15,
'0.196*"write" + 0.172*"line" + 0.165*"article" + 0.117*"organization" + '
'0.086*"host" + 0.030*"reply" + 0.010*"university" + 0.008*"hear" + '
'0.007*"post" + 0.007*"news"'),
(16,
'0.021*"people" + 0.014*"happen" + 0.014*"child" + 0.012*"kill" + '
'0.011*"start" + 0.011*"live" + 0.010*"fire" + 0.010*"leave" + 0.009*"hear" '
'+ 0.009*"home"'),
(17,
'0.038*"key" + 0.018*"system" + 0.015*"space" + 0.015*"technology" + '
'0.014*"encryption" + 0.010*"chip" + 0.010*"bit" + 0.009*"launch" + '
'0.009*"public" + 0.009*"government"'),
(18,
'0.035*"drive" + 0.031*"system" + 0.027*"problem" + 0.027*"card" + '
'0.020*"driver" + 0.017*"bit" + 0.017*"work" + 0.016*"disk" + '
'0.014*"monitor" + 0.014*"machine"'),
(19,
'0.031*"window" + 0.020*"run" + 0.018*"color" + 0.018*"program" + '
'0.017*"application" + 0.016*"display" + 0.015*"set" + 0.015*"version" + '
'0.012*"screen" + 0.012*"problem"')
]Encontrar tópicos dominantes em frases
Encontrar tópicos dominantes em frases é uma das aplicações práticas mais úteis da modelagem de tópicos. Ele determina o tópico de um determinado documento. Aqui, encontraremos o número do tópico que tem a maior contribuição percentual naquele documento específico. A fim de agregar as informações em uma tabela, estaremos criando uma função chamadadominant_topics() -
def dominant_topics(ldamodel=lda_model, corpus=corpus, texts=data):
sent_topics_df = pd.DataFrame()A seguir, obteremos os principais tópicos de cada documento -
for i, row in enumerate(ldamodel[corpus]):
row = sorted(row, key=lambda x: (x[1]), reverse=True)A seguir, obteremos o tópico dominante, contribuição de Perc e palavras-chave para cada documento -
for j, (topic_num, prop_topic) in enumerate(row):
if j == 0: # => dominant topic
wp = ldamodel.show_topic(topic_num)
topic_keywords = ", ".join([word for word, prop in wp])
sent_topics_df = sent_topics_df.append(
pd.Series([int(topic_num), round(prop_topic,4), topic_keywords]), ignore_index=True
)
else:
break
sent_topics_df.columns = ['Dominant_Topic', 'Perc_Contribution', 'Topic_Keywords']Com a ajuda do código a seguir, adicionaremos o texto original ao final da saída -
contents = pd.Series(texts)
sent_topics_df = pd.concat([sent_topics_df, contents], axis=1)
return(sent_topics_df)
df_topic_sents_keywords = dominant_topics(
ldamodel=optimal_model, corpus=corpus, texts=data
)Agora, faça a formatação dos tópicos nas frases da seguinte maneira -
df_dominant_topic = df_topic_sents_keywords.reset_index()
df_dominant_topic.columns = [
'Document_No', 'Dominant_Topic', 'Topic_Perc_Contrib', 'Keywords', 'Text'
]Finalmente, podemos mostrar os tópicos dominantes da seguinte forma -
df_dominant_topic.head(15)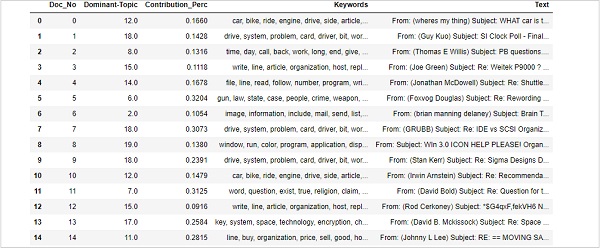
Encontrando o Documento Mais Representativo
Para entendermos mais sobre o tema, também podemos localizar os documentos para os quais um determinado tema mais contribuiu. Podemos inferir esse tópico lendo esse (s) documento (s) específico (s).
sent_topics_sorteddf_mallet = pd.DataFrame()
sent_topics_outdf_grpd = df_topic_sents_keywords.groupby('Dominant_Topic')
for i, grp in sent_topics_outdf_grpd:
sent_topics_sorteddf_mallet = pd.concat([sent_topics_sorteddf_mallet,
grp.sort_values(['Perc_Contribution'], ascending=[0]).head(1)], axis=0)
sent_topics_sorteddf_mallet.reset_index(drop=True, inplace=True)
sent_topics_sorteddf_mallet.columns = [
'Topic_Number', "Contribution_Perc", "Keywords", "Text"
]
sent_topics_sorteddf_mallet.head()Resultado
Volume e distribuição de tópicos
Às vezes, também queremos avaliar com que extensão o tópico é discutido nos documentos. Para isso, precisamos entender o volume e a distribuição dos tópicos nos documentos.
Primeiro calcule o número de documentos para cada tópico da seguinte forma -
topic_counts = df_topic_sents_keywords['Dominant_Topic'].value_counts()Em seguida, calcule a porcentagem de Documentos para cada Tópico da seguinte maneira -;
topic_contribution = round(topic_counts/topic_counts.sum(), 4)Agora encontre o tópico Número e Palavras-chave da seguinte maneira -
topic_num_keywords = df_topic_sents_keywords[['Dominant_Topic', 'Topic_Keywords']]Agora, concatene e depois em coluna da seguinte maneira -
df_dominant_topics = pd.concat(
[topic_num_keywords, topic_counts, topic_contribution], axis=1
)Em seguida, vamos alterar os nomes das colunas da seguinte maneira -
df_dominant_topics.columns = [
'Dominant-Topic', 'Topic-Keywords', 'Num_Documents', 'Perc_Documents'
]
df_dominant_topicsResultado
Este capítulo trata da criação de um modelo de tópico de Indexação semântica latente (LSI) e Processo de Dirichlet hierárquico (HDP) com relação ao Gensim.
Os algoritmos de modelagem de tópicos que foram implementados pela primeira vez no Gensim com Latent Dirichlet Allocation (LDA) são Latent Semantic Indexing (LSI). Também é chamadoLatent Semantic Analysis (LSA). Foi patenteado em 1988 por Scott Deerwester, Susan Dumais, George Furnas, Richard Harshman, Thomas Landaur, Karen Lochbaum e Lynn Streeter.
Nesta seção, vamos configurar nosso modelo LSI. Isso pode ser feito da mesma forma que configurar o modelo LDA. Precisamos importar o modelo LSI degensim.models.
Papel do LSI
Na verdade, LSI é uma técnica de PNL, especialmente em semântica distributiva. Ele analisa a relação entre um conjunto de documentos e os termos que esses documentos contêm. Se falarmos sobre seu funcionamento, ele constrói uma matriz que contém contagens de palavras por documento a partir de um grande pedaço de texto.
Uma vez construído, para reduzir o número de linhas, o modelo LSI usa uma técnica matemática chamada decomposição de valor singular (SVD). Além de reduzir o número de linhas, também preserva a estrutura de similaridade entre as colunas.
Na matriz, as linhas representam palavras únicas e as colunas representam cada documento. Funciona com base na hipótese de distribuição, ou seja, assume que as palavras com significado próximo ocorrerão no mesmo tipo de texto.
Implementação com Gensim
Aqui, vamos usar LSI (Latent Semantic Indexing) para extrair os tópicos naturalmente discutidos do conjunto de dados.
Carregando conjunto de dados
O conjunto de dados que vamos usar é o conjunto de dados de ’20 Newsgroups’tendo milhares de artigos de notícias de várias seções de uma reportagem. Está disponível emSklearnconjuntos de dados. Podemos fazer download facilmente com a ajuda do seguinte script Python -
from sklearn.datasets import fetch_20newsgroups
newsgroups_train = fetch_20newsgroups(subset='train')Vejamos alguns exemplos de notícias com a ajuda do seguinte script -
newsgroups_train.data[:4]
["From: [email protected] (where's my thing)\nSubject:
WHAT car is this!?\nNntp-Posting-Host: rac3.wam.umd.edu\nOrganization:
University of Maryland, College Park\nLines: 15\n\n
I was wondering if anyone out there could enlighten me on this car
I saw\nthe other day. It was a 2-door sports car,
looked to be from the late 60s/\nearly 70s. It was called a Bricklin.
The doors were really small. In addition,\nthe front bumper was separate from
the rest of the body. This is \nall I know. If anyone can tellme a model name,
engine specs, years\nof production, where this car is made, history, or
whatever info you\nhave on this funky looking car,
please e-mail.\n\nThanks,\n- IL\n ---- brought to you by your neighborhood
Lerxst ----\n\n\n\n\n",
"From: [email protected] (Guy Kuo)\nSubject:
SI Clock Poll - Final Call\nSummary: Final call for SI clock reports\nKeywords:
SI,acceleration,clock,upgrade\nArticle-I.D.: shelley.1qvfo9INNc3s\nOrganization:
University of Washington\nLines: 11\nNNTP-Posting-Host: carson.u.washington.edu\n\nA
fair number of brave souls who upgraded their SI clock oscillator have\nshared their
experiences for this poll. Please send a brief message detailing\nyour experiences with
the procedure. Top speed attained, CPU rated speed,\nadd on cards and adapters, heat
sinks, hour of usage per day, floppy disk\nfunctionality with 800 and 1.4 m floppies
are especially requested.\n\nI will be summarizing in the next two days, so please add
to the network\nknowledge base if you have done the clock upgrade and haven't answered
this\npoll. Thanks.\n\nGuy Kuo <[email protected]>\n",
'From: [email protected] (Thomas E Willis)\nSubject:
PB questions...\nOrganization: Purdue University Engineering Computer
Network\nDistribution: usa\nLines: 36\n\nwell folks, my mac plus finally gave up the
ghost this weekend after\nstarting life as a 512k way back in 1985. sooo, i\'m in the
market for a\nnew machine a bit sooner than i intended to be...\n\ni\'m looking into
picking up a powerbook 160 or maybe 180 and have a bunch\nof questions that (hopefully)
somebody can answer:\n\n* does anybody know any dirt on when the next round of
powerbook\nintroductions are expected? i\'d heard the 185c was supposed to make
an\nappearence "this summer" but haven\'t heard anymore on it - and since i\ndon\'t
have access to macleak, i was wondering if anybody out there had\nmore info...\n\n* has
anybody heard rumors about price drops to the powerbook line like the\nones the duo\'s
just went through recently?\n\n* what\'s the impression of the display on the 180? i
could probably swing\na 180 if i got the 80Mb disk rather than the 120, but i don\'t
really have\na feel for how much "better" the display is (yea, it looks great in
the\nstore, but is that all "wow" or is it really that good?). could i solicit\nsome
opinions of people who use the 160 and 180 day-to-day on if its worth\ntaking the disk
size and money hit to get the active display? (i realize\nthis is a real subjective
question, but i\'ve only played around with the\nmachines in a computer store breifly
and figured the opinions of somebody\nwho actually uses the machine daily might prove
helpful).\n\n* how well does hellcats perform? ;)\n\nthanks a bunch in advance for any
info - if you could email, i\'ll post a\nsummary (news reading time is at a premium
with finals just around the\ncorner... :( )\n--\nTom Willis \\ [email protected]
\\ Purdue Electrical
Engineering\n---------------------------------------------------------------------------\
n"Convictions are more dangerous enemies of truth than lies." - F. W.\nNietzsche\n',
'From: jgreen@amber (Joe Green)\nSubject: Re: Weitek P9000 ?\nOrganization: Harris
Computer Systems Division\nLines: 14\nDistribution: world\nNNTP-Posting-Host:
amber.ssd.csd.harris.com\nX-Newsreader: TIN [version 1.1 PL9]\n\nRobert J.C. Kyanko
([email protected]) wrote:\n > [email protected] writes in article <
[email protected]>:\n> > Anyone know about the Weitek P9000
graphics chip?\n > As far as the low-level stuff goes, it looks pretty nice. It\'s
got this\n > quadrilateral fill command that requires just the four
points.\n\nDo you have Weitek\'s address/phone number? I\'d like to get some
information\nabout this chip.\n\n--\nJoe Green\t\t\t\tHarris
Corporation\[email protected]\t\t\tComputer Systems Division\n"The only thing that
really scares me is a person with no sense of humor."\n\t\t\t\t\t\t-- Jonathan
Winters\n']Pré-requisito
Precisamos de Stopwords da NLTK e do modelo em inglês da Scapy. Ambos podem ser baixados da seguinte forma -
import nltk;
nltk.download('stopwords')
nlp = spacy.load('en_core_web_md', disable=['parser', 'ner'])Importando Pacotes Necessários
Para construir o modelo LSI, precisamos importar o seguinte pacote necessário -
import re
import numpy as np
import pandas as pd
from pprint import pprint
import gensim
import gensim.corpora as corpora
from gensim.utils import simple_preprocess
from gensim.models import CoherenceModel
import spacy
import matplotlib.pyplot as pltPreparando palavras irrelevantes
Agora precisamos importar as palavras irrelevantes e usá-las -
from nltk.corpus import stopwords
stop_words = stopwords.words('english')
stop_words.extend(['from', 'subject', 're', 'edu', 'use'])Limpe o Texto
Agora, com a ajuda de Gensim's simple_preprocess()precisamos tokenizar cada frase em uma lista de palavras. Devemos também remover as pontuações e caracteres desnecessários. Para fazer isso, vamos criar uma função chamadasent_to_words() -
def sent_to_words(sentences):
for sentence in sentences:
yield(gensim.utils.simple_preprocess(str(sentence), deacc=True))
data_words = list(sent_to_words(data))Construindo modelos de bigramas e trigramas
Como sabemos, bigramas são duas palavras que ocorrem frequentemente juntas no documento e trigrama são três palavras que ocorrem frequentemente juntas no documento. Com a ajuda do modelo de frases de Gensim, podemos fazer isso -
bigram = gensim.models.Phrases(data_words, min_count=5, threshold=100)
trigram = gensim.models.Phrases(bigram[data_words], threshold=100)
bigram_mod = gensim.models.phrases.Phraser(bigram)
trigram_mod = gensim.models.phrases.Phraser(trigram)Filtrar palavras irrelevantes
Em seguida, precisamos filtrar as palavras irrelevantes. Junto com isso, também criaremos funções para fazer bigramas, trigramas e para lematização -
def remove_stopwords(texts):
return [[word for word in simple_preprocess(str(doc))
if word not in stop_words] for doc in texts]
def make_bigrams(texts):
return [bigram_mod[doc] for doc in texts]
def make_trigrams(texts):
return [trigram_mod[bigram_mod[doc]] for doc in texts]
def lemmatization(texts, allowed_postags=['NOUN', 'ADJ', 'VERB', 'ADV']):
texts_out = []
for sent in texts:
doc = nlp(" ".join(sent))
texts_out.append([token.lemma_ for token in doc if token.pos_ in allowed_postags])
return texts_outConstruindo Dicionário e Corpus para Modelo de Tópico
Agora precisamos construir o dicionário e corpus. Também fizemos isso nos exemplos anteriores -
id2word = corpora.Dictionary(data_lemmatized)
texts = data_lemmatized
corpus = [id2word.doc2bow(text) for text in texts]Construindo Modelo de Tópico LSI
Já implementamos tudo o que é necessário para treinar o modelo LSI. Agora é a hora de construir o modelo de tópico do LSI. Para o nosso exemplo de implementação, isso pode ser feito com a ajuda da seguinte linha de códigos -
lsi_model = gensim.models.lsimodel.LsiModel(
corpus=corpus, id2word=id2word, num_topics=20,chunksize=100
)Exemplo de Implementação
Vamos ver o exemplo de implementação completo para construir o modelo de tópico LDA -
import re
import numpy as np
import pandas as pd
from pprint import pprint
import gensim
import gensim.corpora as corpora
from gensim.utils import simple_preprocess
from gensim.models import CoherenceModel
import spacy
import matplotlib.pyplot as plt
from nltk.corpus import stopwords
stop_words = stopwords.words('english')
stop_words.extend(['from', 'subject', 're', 'edu', 'use'])
from sklearn.datasets import fetch_20newsgroups
newsgroups_train = fetch_20newsgroups(subset='train')
data = newsgroups_train.data
data = [re.sub('\S*@\S*\s?', '', sent) for sent in data]
data = [re.sub('\s+', ' ', sent) for sent in data]
data = [re.sub("\'", "", sent) for sent in data]
print(data_words[:4]) #it will print the data after prepared for stopwords
bigram = gensim.models.Phrases(data_words, min_count=5, threshold=100)
trigram = gensim.models.Phrases(bigram[data_words], threshold=100)
bigram_mod = gensim.models.phrases.Phraser(bigram)
trigram_mod = gensim.models.phrases.Phraser(trigram)
def remove_stopwords(texts):
return [[word for word in simple_preprocess(str(doc))
if word not in stop_words] for doc in texts]
def make_bigrams(texts):
return [bigram_mod[doc] for doc in texts]
def make_trigrams(texts):
return [trigram_mod[bigram_mod[doc]] for doc in texts]
def lemmatization(texts, allowed_postags=['NOUN', 'ADJ', 'VERB', 'ADV']):
texts_out = []
for sent in texts:
doc = nlp(" ".join(sent))
texts_out.append([token.lemma_ for token in doc if token.pos_ in allowed_postags])
return texts_out
data_words_nostops = remove_stopwords(data_words)
data_words_bigrams = make_bigrams(data_words_nostops)
nlp = spacy.load('en_core_web_md', disable=['parser', 'ner'])
data_lemmatized = lemmatization(
data_words_bigrams, allowed_postags=['NOUN', 'ADJ', 'VERB', 'ADV']
)
print(data_lemmatized[:4]) #it will print the lemmatized data.
id2word = corpora.Dictionary(data_lemmatized)
texts = data_lemmatized
corpus = [id2word.doc2bow(text) for text in texts]
print(corpus[:4]) #it will print the corpus we created above.
[[(id2word[id], freq) for id, freq in cp] for cp in corpus[:4]]
#it will print the words with their frequencies.
lsi_model = gensim.models.lsimodel.LsiModel(
corpus=corpus, id2word=id2word, num_topics=20,chunksize=100
)Agora podemos usar o modelo LSI criado acima para obter os tópicos.
Visualizando Tópicos no Modelo LSI
O modelo LSI (lsi_model)que criamos acima pode ser usado para visualizar os tópicos dos documentos. Isso pode ser feito com a ajuda do seguinte script -
pprint(lsi_model.print_topics())
doc_lsi = lsi_model[corpus]Resultado
[
(0,
'1.000*"ax" + 0.001*"_" + 0.000*"tm" + 0.000*"part" + 0.000*"pne" + '
'0.000*"biz" + 0.000*"mbs" + 0.000*"end" + 0.000*"fax" + 0.000*"mb"'),
(1,
'0.239*"say" + 0.222*"file" + 0.189*"go" + 0.171*"know" + 0.169*"people" + '
'0.147*"make" + 0.140*"use" + 0.135*"also" + 0.133*"see" + 0.123*"think"')
]Processo Hierárquico de Dirichlet (HPD)
Modelos de tópicos como LDA e LSI ajudam a resumir e organizar grandes arquivos de textos que não podem ser analisados manualmente. Além do LDA e do LSI, um outro modelo de tópico poderoso no Gensim é o HDP (Processo Hierárquico de Dirichlet). É basicamente um modelo de associação mista para análise não supervisionada de dados agrupados. Ao contrário do LDA (sua contraparte finita), o HDP infere o número de tópicos a partir dos dados.
Implementação com Gensim
Para implementar HDP no Gensim, precisamos treinar corpus e dicionário (como fizemos nos exemplos acima durante a implementação de modelos de tópico LDA e LSI) modelo de tópico HDP que podemos importar de gensim.models.HdpModel. Aqui também implementaremos o modelo de tópico HDP nos dados do 20Newsgroup e as etapas também serão as mesmas.
Para nosso corpus e dicionário (criado nos exemplos acima para o modelo LSI e LDA), podemos importar HdpModel da seguinte maneira -
Hdp_model = gensim.models.hdpmodel.HdpModel(corpus=corpus, id2word=id2word)Visualizando Tópicos no Modelo LSI
O modelo HDP (Hdp_model)pode ser usado para visualizar os tópicos dos documentos. Isso pode ser feito com a ajuda do seguinte script -
pprint(Hdp_model.print_topics())Resultado
[
(0,
'0.009*line + 0.009*write + 0.006*say + 0.006*article + 0.006*know + '
'0.006*people + 0.005*make + 0.005*go + 0.005*think + 0.005*be'),
(1,
'0.016*line + 0.011*write + 0.008*article + 0.008*organization + 0.006*know '
'+ 0.006*host + 0.006*be + 0.005*get + 0.005*use + 0.005*say'),
(2,
'0.810*ax + 0.001*_ + 0.000*tm + 0.000*part + 0.000*mb + 0.000*pne + '
'0.000*biz + 0.000*end + 0.000*wwiz + 0.000*fax'),
(3,
'0.015*line + 0.008*write + 0.007*organization + 0.006*host + 0.006*know + '
'0.006*article + 0.005*use + 0.005*thank + 0.004*get + 0.004*problem'),
(4,
'0.004*line + 0.003*write + 0.002*believe + 0.002*think + 0.002*article + '
'0.002*belief + 0.002*say + 0.002*see + 0.002*look + 0.002*organization'),
(5,
'0.005*line + 0.003*write + 0.003*organization + 0.002*article + 0.002*time '
'+ 0.002*host + 0.002*get + 0.002*look + 0.002*say + 0.001*number'),
(6,
'0.003*line + 0.002*say + 0.002*write + 0.002*go + 0.002*gun + 0.002*get + '
'0.002*organization + 0.002*bill + 0.002*article + 0.002*state'),
(7,
'0.003*line + 0.002*write + 0.002*article + 0.002*organization + 0.001*none '
'+ 0.001*know + 0.001*say + 0.001*people + 0.001*host + 0.001*new'),
(8,
'0.004*line + 0.002*write + 0.002*get + 0.002*team + 0.002*organization + '
'0.002*go + 0.002*think + 0.002*know + 0.002*article + 0.001*well'),
(9,
'0.004*line + 0.002*organization + 0.002*write + 0.001*be + 0.001*host + '
'0.001*article + 0.001*thank + 0.001*use + 0.001*work + 0.001*run'),
(10,
'0.002*line + 0.001*game + 0.001*write + 0.001*get + 0.001*know + '
'0.001*thing + 0.001*think + 0.001*article + 0.001*help + 0.001*turn'),
(11,
'0.002*line + 0.001*write + 0.001*game + 0.001*organization + 0.001*say + '
'0.001*host + 0.001*give + 0.001*run + 0.001*article + 0.001*get'),
(12,
'0.002*line + 0.001*write + 0.001*know + 0.001*time + 0.001*article + '
'0.001*get + 0.001*think + 0.001*organization + 0.001*scope + 0.001*make'),
(13,
'0.002*line + 0.002*write + 0.001*article + 0.001*organization + 0.001*make '
'+ 0.001*know + 0.001*see + 0.001*get + 0.001*host + 0.001*really'),
(14,
'0.002*write + 0.002*line + 0.002*know + 0.001*think + 0.001*say + '
'0.001*article + 0.001*argument + 0.001*even + 0.001*card + 0.001*be'),
(15,
'0.001*article + 0.001*line + 0.001*make + 0.001*write + 0.001*know + '
'0.001*say + 0.001*exist + 0.001*get + 0.001*purpose + 0.001*organization'),
(16,
'0.002*line + 0.001*write + 0.001*article + 0.001*insurance + 0.001*go + '
'0.001*be + 0.001*host + 0.001*say + 0.001*organization + 0.001*part'),
(17,
'0.001*line + 0.001*get + 0.001*hit + 0.001*go + 0.001*write + 0.001*say + '
'0.001*know + 0.001*drug + 0.001*see + 0.001*need'),
(18,
'0.002*option + 0.001*line + 0.001*flight + 0.001*power + 0.001*software + '
'0.001*write + 0.001*add + 0.001*people + 0.001*organization + 0.001*module'),
(19,
'0.001*shuttle + 0.001*line + 0.001*roll + 0.001*attitude + 0.001*maneuver + '
'0.001*mission + 0.001*also + 0.001*orbit + 0.001*produce + 0.001*frequency')
]O capítulo nos ajudará a entender o desenvolvimento da incorporação de palavras no Gensim.
A incorporação de palavras, abordagem para representar palavras e documentos, é uma representação vetorial densa para texto em que palavras com o mesmo significado têm uma representação semelhante. A seguir estão algumas características da incorporação de palavras -
É uma classe de técnica que representa as palavras individuais como vetores de valor real em um espaço vetorial predefinido.
Esta técnica é frequentemente agrupada no campo de DL (aprendizado profundo) porque cada palavra é mapeada para um vetor e os valores do vetor são aprendidos da mesma forma que um NN (Redes Neurais).
A abordagem chave da técnica de incorporação de palavras é uma representação distribuída densa para cada palavra.
Métodos / algoritmos de incorporação de palavras diferentes
Conforme discutido acima, os métodos / algoritmos de incorporação de palavras aprendem uma representação vetorial de valor real a partir de um corpus de texto. Este processo de aprendizagem pode ser usado com o modelo NN em tarefas, como classificação de documentos, ou é um processo não supervisionado, como estatísticas de documentos. Aqui, vamos discutir dois métodos / algoritmos que podem ser usados para aprender a incorporação de palavras a partir de um texto -
Word2Vec do Google
Word2Vec, desenvolvido por Tomas Mikolov, et. al. no Google em 2013, é um método estatístico para aprender com eficiência a incorporação de palavras a partir de um corpus de texto. Na verdade, ele foi desenvolvido como uma resposta para tornar o treinamento de incorporação de palavras baseado em NN mais eficiente. Tornou-se o padrão de fato para incorporação de palavras.
A incorporação de palavras pelo Word2Vec envolve a análise dos vetores aprendidos, bem como a exploração da matemática vetorial na representação de palavras. A seguir estão os dois métodos de aprendizagem diferentes que podem ser usados como parte do método Word2Vec -
- Modelo CBoW (Continuous Bag of Words)
- Modelo Contínuo Skip-Gram
GloVe by Standford
GloVe (vetores globais para representação de palavras), é uma extensão do método Word2Vec. Foi desenvolvido por Pennington et al. em Stanford. O algoritmo GloVe é uma mistura de ambos -
- Estatísticas globais de técnicas de fatoração de matrizes como LSA (Latent Semantic Analysis)
- Aprendizagem baseada no contexto local em Word2Vec.
Se falarmos sobre seu funcionamento, em vez de usar uma janela para definir o contexto local, o GloVe constrói uma matriz de coocorrência de palavras explícitas usando estatísticas em todo o corpo do texto.
Desenvolvimento de incorporação de Word2Vec
Aqui, desenvolveremos a incorporação de Word2Vec usando Gensim. Para trabalhar com um modelo Word2Vec, Gensim nos forneceWord2Vec classe que pode ser importada de models.word2vec. Para sua implementação, o word2vec requer muito texto, por exemplo, todo o corpus de revisão da Amazon. Mas aqui, vamos aplicar este princípio em texto de memória pequena.
Exemplo de Implementação
Primeiro, precisamos importar a classe Word2Vec de gensim.models da seguinte maneira -
from gensim.models import Word2VecEm seguida, precisamos definir os dados de treinamento. Ao invés de pegar um grande arquivo de texto, estamos usando algumas sentenças para implementar este princípio.
sentences = [
['this', 'is', 'gensim', 'tutorial', 'for', 'free'],
['this', 'is', 'the', 'tutorials' 'point', 'website'],
['you', 'can', 'read', 'technical','tutorials', 'for','free'],
['we', 'are', 'implementing','word2vec'],
['learn', 'full', 'gensim', 'tutorial']
]Assim que os dados de treinamento forem fornecidos, precisamos treinar o modelo. pode ser feito da seguinte maneira -
model = Word2Vec(sentences, min_count=1)Podemos resumir o modelo da seguinte forma -;
print(model)Podemos resumir o vocabulário da seguinte forma -
words = list(model.wv.vocab)
print(words)A seguir, vamos acessar o vetor de uma palavra. Estamos fazendo isso pela palavra 'tutorial'.
print(model['tutorial'])Em seguida, precisamos salvar o modelo -
model.save('model.bin')Em seguida, precisamos carregar o modelo -
new_model = Word2Vec.load('model.bin')Finalmente, imprima o modelo salvo da seguinte forma -
print(new_model)Exemplo de implementação completo
from gensim.models import Word2Vec
sentences = [
['this', 'is', 'gensim', 'tutorial', 'for', 'free'],
['this', 'is', 'the', 'tutorials' 'point', 'website'],
['you', 'can', 'read', 'technical','tutorials', 'for','free'],
['we', 'are', 'implementing','word2vec'],
['learn', 'full', 'gensim', 'tutorial']
]
model = Word2Vec(sentences, min_count=1)
print(model)
words = list(model.wv.vocab)
print(words)
print(model['tutorial'])
model.save('model.bin')
new_model = Word2Vec.load('model.bin')
print(new_model)Resultado
Word2Vec(vocab=20, size=100, alpha=0.025)
[
'this', 'is', 'gensim', 'tutorial', 'for', 'free', 'the', 'tutorialspoint',
'website', 'you', 'can', 'read', 'technical', 'tutorials', 'we', 'are',
'implementing', 'word2vec', 'learn', 'full'
]
[
-2.5256255e-03 -4.5352755e-03 3.9024993e-03 -4.9509313e-03
-1.4255195e-03 -4.0217536e-03 4.9407515e-03 -3.5925603e-03
-1.1933431e-03 -4.6682903e-03 1.5440651e-03 -1.4101702e-03
3.5070938e-03 1.0914479e-03 2.3334436e-03 2.4452661e-03
-2.5336299e-04 -3.9676363e-03 -8.5054158e-04 1.6443320e-03
-4.9968651e-03 1.0974540e-03 -1.1123562e-03 1.5393364e-03
9.8941079e-04 -1.2656028e-03 -4.4471184e-03 1.8309267e-03
4.9302122e-03 -1.0032534e-03 4.6892050e-03 2.9563988e-03
1.8730218e-03 1.5343715e-03 -1.2685956e-03 8.3664013e-04
4.1721235e-03 1.9445885e-03 2.4097660e-03 3.7517555e-03
4.9687522e-03 -1.3598346e-03 7.1032363e-04 -3.6595813e-03
6.0000515e-04 3.0872561e-03 -3.2115565e-03 3.2270295e-03
-2.6354722e-03 -3.4988276e-04 1.8574356e-04 -3.5757164e-03
7.5391348e-04 -3.5205986e-03 -1.9795434e-03 -2.8321696e-03
4.7155009e-03 -4.3349937e-04 -1.5320212e-03 2.7013756e-03
-3.7055744e-03 -4.1658725e-03 4.8034848e-03 4.8594419e-03
3.7129463e-03 4.2385766e-03 2.4612297e-03 5.4920948e-04
-3.8912550e-03 -4.8226118e-03 -2.2763973e-04 4.5571579e-03
-3.4609400e-03 2.7903817e-03 -3.2709218e-03 -1.1036445e-03
2.1492650e-03 -3.0384419e-04 1.7709908e-03 1.8429896e-03
-3.4038599e-03 -2.4872608e-03 2.7693063e-03 -1.6352943e-03
1.9182395e-03 3.7772327e-03 2.2769428e-03 -4.4629495e-03
3.3151123e-03 4.6509290e-03 -4.8521687e-03 6.7615538e-04
3.1034781e-03 2.6369948e-05 4.1454583e-03 -3.6932561e-03
-1.8769916e-03 -2.1958587e-04 6.3395966e-04 -2.4969708e-03
]
Word2Vec(vocab=20, size=100, alpha=0.025)Visualizando a incorporação de palavras
Também podemos explorar a palavra incorporação com visualização. Isso pode ser feito usando um método de projeção clássico (como PCA) para reduzir os vetores de palavras de alta dimensão a gráficos 2-D. Uma vez reduzidos, podemos traçá-los no gráfico.
Plotagem de vetores de palavras usando PCA
Primeiro, precisamos recuperar todos os vetores de um modelo treinado da seguinte forma -
Z = model[model.wv.vocab]Em seguida, precisamos criar um modelo 2-D PCA de vetores de palavras usando a classe PCA da seguinte maneira -
pca = PCA(n_components=2)
result = pca.fit_transform(Z)Agora, podemos plotar a projeção resultante usando o matplotlib da seguinte forma -
Pyplot.scatter(result[:,0],result[:,1])Também podemos anotar os pontos do gráfico com as próprias palavras. Trace a projeção resultante usando o matplotlib da seguinte forma -
words = list(model.wv.vocab)
for i, word in enumerate(words):
pyplot.annotate(word, xy=(result[i, 0], result[i, 1]))Exemplo de implementação completo
from gensim.models import Word2Vec
from sklearn.decomposition import PCA
from matplotlib import pyplot
sentences = [
['this', 'is', 'gensim', 'tutorial', 'for', 'free'],
['this', 'is', 'the', 'tutorials' 'point', 'website'],
['you', 'can', 'read', 'technical','tutorials', 'for','free'],
['we', 'are', 'implementing','word2vec'],
['learn', 'full', 'gensim', 'tutorial']
]
model = Word2Vec(sentences, min_count=1)
X = model[model.wv.vocab]
pca = PCA(n_components=2)
result = pca.fit_transform(X)
pyplot.scatter(result[:, 0], result[:, 1])
words = list(model.wv.vocab)
for i, word in enumerate(words):
pyplot.annotate(word, xy=(result[i, 0], result[i, 1]))
pyplot.show()Resultado
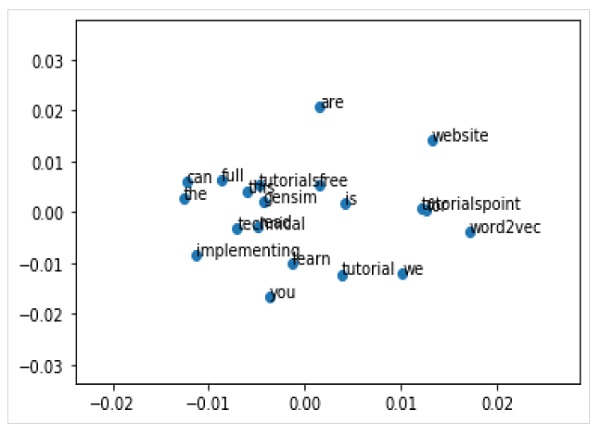
O modelo Doc2Vec, ao contrário do modelo Word2Vec, é usado para criar uma representação vetorizada de um grupo de palavras tomadas coletivamente como uma única unidade. Não fornece apenas a média simples das palavras da frase.
Criação de vetores de documentos usando Doc2Vec
Aqui, para criar vetores de documentos usando Doc2Vec, usaremos um conjunto de dados text8 que pode ser baixado de gensim.downloader.
Baixando o conjunto de dados
Podemos baixar o conjunto de dados text8 usando os seguintes comandos -
import gensim
import gensim.downloader as api
dataset = api.load("text8")
data = [d for d in dataset]Levará algum tempo para baixar o conjunto de dados text8.
Treine o Doc2Vec
Para treinar o modelo, precisamos do documento marcado, que pode ser criado usando models.doc2vec.TaggedDcument() como segue -
def tagged_document(list_of_list_of_words):
for i, list_of_words in enumerate(list_of_list_of_words):
yield gensim.models.doc2vec.TaggedDocument(list_of_words, [i])
data_for_training = list(tagged_document(data))Podemos imprimir o conjunto de dados treinado da seguinte forma -
print(data_for_training [:1])Resultado
[TaggedDocument(words=['anarchism', 'originated', 'as', 'a', 'term', 'of',
'abuse', 'first', 'used', 'against', 'early', 'working', 'class', 'radicals',
'including', 'the', 'diggers', 'of', 'the', 'english', 'revolution',
'and', 'the', 'sans', 'culottes', 'of', 'the', 'french', 'revolution',
'whilst', 'the', 'term', 'is', 'still', 'used', 'in', 'a', 'pejorative',
'way', 'to', 'describe', 'any', 'act', 'that', 'used', 'violent',
'means', 'to', 'destroy',
'the', 'organization', 'of', 'society', 'it', 'has', 'also', 'been'
, 'taken', 'up', 'as', 'a', 'positive', 'label', 'by', 'self', 'defined',
'anarchists', 'the', 'word', 'anarchism', 'is', 'derived', 'from', 'the',
'greek', 'without', 'archons', 'ruler', 'chief', 'king', 'anarchism',
'as', 'a', 'political', 'philosophy', 'is', 'the', 'belief', 'that',
'rulers', 'are', 'unnecessary', 'and', 'should', 'be', 'abolished',
'although', 'there', 'are', 'differing', 'interpretations', 'of',
'what', 'this', 'means', 'anarchism', 'also', 'refers', 'to',
'related', 'social', 'movements', 'that', 'advocate', 'the',
'elimination', 'of', 'authoritarian', 'institutions', 'particularly',
'the', 'state', 'the', 'word', 'anarchy', 'as', 'most', 'anarchists',
'use', 'it', 'does', 'not', 'imply', 'chaos', 'nihilism', 'or', 'anomie',
'but', 'rather', 'a', 'harmonious', 'anti', 'authoritarian', 'society',
'in', 'place', 'of', 'what', 'are', 'regarded', 'as', 'authoritarian',
'political', 'structures', 'and', 'coercive', 'economic', 'institutions',
'anarchists', 'advocate', 'social', 'relations', 'based', 'upon', 'voluntary',
'association', 'of', 'autonomous', 'individuals', 'mutual', 'aid', 'and',
'self', 'governance', 'while', 'anarchism', 'is', 'most', 'easily', 'defined',
'by', 'what', 'it', 'is', 'against', 'anarchists', 'also', 'offer',
'positive', 'visions', 'of', 'what', 'they', 'believe', 'to', 'be', 'a',
'truly', 'free', 'society', 'however', 'ideas', 'about', 'how', 'an', 'anarchist',
'society', 'might', 'work', 'vary', 'considerably', 'especially', 'with',
'respect', 'to', 'economics', 'there', 'is', 'also', 'disagreement', 'about',
'how', 'a', 'free', 'society', 'might', 'be', 'brought', 'about', 'origins',
'and', 'predecessors', 'kropotkin', 'and', 'others', 'argue', 'that', 'before',
'recorded', 'history', 'human', 'society', 'was', 'organized', 'on', 'anarchist',
'principles', 'most', 'anthropologists', 'follow', 'kropotkin', 'and', 'engels',
'in', 'believing', 'that', 'hunter', 'gatherer', 'bands', 'were', 'egalitarian',
'and', 'lacked', 'division', 'of', 'labour', 'accumulated', 'wealth', 'or', 'decreed',
'law', 'and', 'had', 'equal', 'access', 'to', 'resources', 'william', 'godwin',
'anarchists', 'including', 'the', 'the', 'anarchy', 'organisation', 'and', 'rothbard',
'find', 'anarchist', 'attitudes', 'in', 'taoism', 'from', 'ancient', 'china',
'kropotkin', 'found', 'similar', 'ideas', 'in', 'stoic', 'zeno', 'of', 'citium',
'according', 'to', 'kropotkin', 'zeno', 'repudiated', 'the', 'omnipotence', 'of',
'the', 'state', 'its', 'intervention', 'and', 'regimentation', 'and', 'proclaimed',
'the', 'sovereignty', 'of', 'the', 'moral', 'law', 'of', 'the', 'individual', 'the',
'anabaptists', 'of', 'one', 'six', 'th', 'century', 'europe', 'are', 'sometimes',
'considered', 'to', 'be', 'religious', 'forerunners', 'of', 'modern', 'anarchism',
'bertrand', 'russell', 'in', 'his', 'history', 'of', 'western', 'philosophy',
'writes', 'that', 'the', 'anabaptists', 'repudiated', 'all', 'law', 'since',
'they', 'held', 'that', 'the', 'good', 'man', 'will', 'be', 'guided', 'at',
'every', 'moment', 'by', 'the', 'holy', 'spirit', 'from', 'this', 'premise',
'they', 'arrive', 'at', 'communism', 'the', 'diggers', 'or', 'true', 'levellers',
'were', 'an', 'early', 'communistic', 'movement',
(truncated…)Inicialize o modelo
Depois de treinados, agora precisamos inicializar o modelo. pode ser feito da seguinte maneira -
model = gensim.models.doc2vec.Doc2Vec(vector_size=40, min_count=2, epochs=30)Agora, construa o vocabulário da seguinte forma -
model.build_vocab(data_for_training)Agora, vamos treinar o modelo Doc2Vec da seguinte maneira -
model.train(data_for_training, total_examples=model.corpus_count, epochs=model.epochs)Analisando o resultado
Finalmente, podemos analisar a saída usando model.infer_vector () da seguinte maneira -
print(model.infer_vector(['violent', 'means', 'to', 'destroy', 'the','organization']))Exemplo de implementação completo
import gensim
import gensim.downloader as api
dataset = api.load("text8")
data = [d for d in dataset]
def tagged_document(list_of_list_of_words):
for i, list_of_words in enumerate(list_of_list_of_words):
yield gensim.models.doc2vec.TaggedDocument(list_of_words, [i])
data_for_training = list(tagged_document(data))
print(data_for_training[:1])
model = gensim.models.doc2vec.Doc2Vec(vector_size=40, min_count=2, epochs=30)
model.build_vocab(data_training)
model.train(data_training, total_examples=model.corpus_count, epochs=model.epochs)
print(model.infer_vector(['violent', 'means', 'to', 'destroy', 'the','organization']))Resultado
[
-0.2556166 0.4829361 0.17081228 0.10879577 0.12525807 0.10077011
-0.21383236 0.19294572 0.11864349 -0.03227958 -0.02207291 -0.7108424
0.07165232 0.24221905 -0.2924459 -0.03543589 0.21840079 -0.1274817
0.05455418 -0.28968817 -0.29146606 0.32885507 0.14689675 -0.06913587
-0.35173815 0.09340707 -0.3803535 -0.04030455 -0.10004586 0.22192696
0.2384828 -0.29779273 0.19236489 -0.25727913 0.09140676 0.01265439
0.08077634 -0.06902497 -0.07175519 -0.22583418 -0.21653089 0.00347822
-0.34096122 -0.06176808 0.22885063 -0.37295452 -0.08222228 -0.03148199
-0.06487323 0.11387568
]