IMS DB - Processamento DL / I
O IMS DB armazena dados em níveis diferentes. Os dados são recuperados e inseridos emitindo chamadas DL / I de um programa aplicativo. Discutiremos sobre as chamadas DL / I em detalhes nos próximos capítulos. Os dados podem ser processados das duas maneiras a seguir -
- Processamento Sequencial
- Processamento Aleatório
Processamento Sequencial
Quando os segmentos são recuperados sequencialmente do banco de dados, DL / I segue um padrão predefinido. Vamos entender o processamento sequencial do banco de dados IMS.
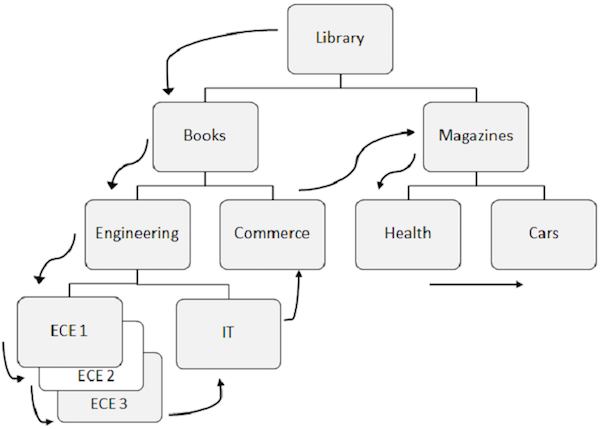
Listados abaixo estão os pontos a serem observados sobre o processamento sequencial -
O padrão predefinido para acessar dados em DL / I é primeiro descer na hierarquia, depois da esquerda para a direita.
O segmento raiz é recuperado primeiro, então DL / I se move para o primeiro filho à esquerda e desce até o nível mais baixo. No nível mais baixo, ele recupera todas as ocorrências de segmentos gêmeos. Em seguida, ele vai para o segmento certo.
Para entender melhor, observe as setas da figura acima que mostram o fluxo de acesso aos segmentos. Biblioteca é o segmento raiz e o fluxo começa a partir daí e vai até carros para acessar um único registro. O mesmo processo é repetido para todas as ocorrências para obter todos os registros de dados.
Ao acessar os dados, o programa usa o position no banco de dados que ajuda a recuperar e inserir segmentos.
Processamento Aleatório
O processamento aleatório também é conhecido como processamento direto de dados no banco de dados IMS. Vamos dar um exemplo para entender o processamento aleatório em IMS DB -
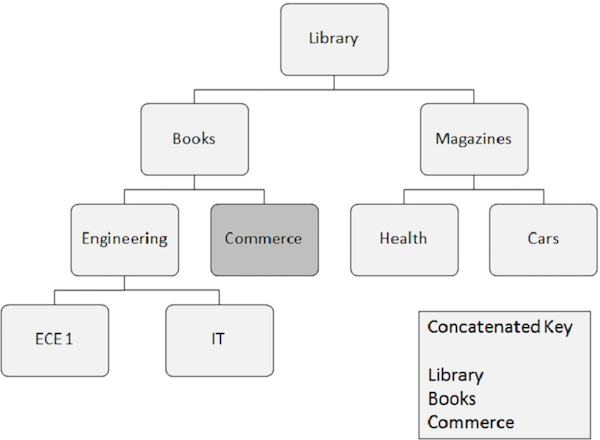
Listados abaixo estão os pontos a serem observados sobre o processamento aleatório -
A ocorrência de segmento que precisa ser recuperada aleatoriamente requer campos-chave de todos os segmentos dos quais depende. Esses campos-chave são fornecidos pelo programa aplicativo.
Uma chave concatenada identifica completamente o caminho do segmento raiz para o segmento que você deseja recuperar.
Suponha que você deseje recuperar uma ocorrência do segmento Commerce, então você precisa fornecer os valores do campo-chave concatenado dos segmentos dos quais ele depende, como Biblioteca, Livros e Comércio.
O processamento aleatório é mais rápido do que o processamento sequencial. No cenário do mundo real, os aplicativos combinam métodos de processamento sequencial e aleatório para obter os melhores resultados.
Campo Chave
Pontos a serem observados -
Um campo-chave também é conhecido como campo de sequência.
Um campo-chave está presente em um segmento e é usado para recuperar a ocorrência do segmento.
Um campo-chave gerencia a ocorrência do segmento em ordem crescente.
Em cada segmento, apenas um único campo pode ser usado como um campo-chave ou campo de sequência.
Campo de Pesquisa
Conforme mencionado, apenas um único campo pode ser usado como um campo-chave. Se você deseja pesquisar o conteúdo de outros campos de segmento que não são campos-chave, o campo usado para recuperar os dados é conhecido como campo de pesquisa.