IMS DB - Guia rápido
Uma breve visão geral
O banco de dados é uma coleção de itens de dados correlacionados. Esses itens de dados são organizados e armazenados de forma a fornecer acesso rápido e fácil. O banco de dados IMS é um banco de dados hierárquico onde os dados são armazenados em diferentes níveis e cada entidade depende de entidades de nível superior. Os elementos físicos em um sistema de aplicativo que usa IMS são mostrados na figura a seguir.
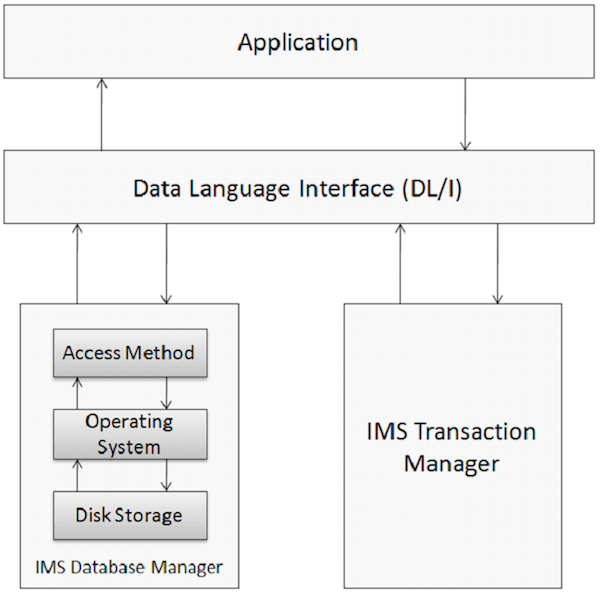
Gerenciamento de banco de dados
Um sistema de gerenciamento de banco de dados é um conjunto de programas aplicativos usados para armazenar, acessar e gerenciar dados no banco de dados. O sistema de gerenciamento de banco de dados IMS mantém a integridade e permite a recuperação rápida de dados, organizando-os de forma que sejam fáceis de recuperar. IMS mantém uma grande quantidade de dados corporativos do mundo com a ajuda de seu sistema de gerenciamento de banco de dados.
Gerente de Transação
A função do gerenciador de transações é fornecer uma plataforma de comunicação entre o banco de dados e os programas aplicativos. O IMS atua como um gerenciador de transações. Um gerenciador de transações lida com o usuário final para armazenar e recuperar dados do banco de dados. IMS pode usar IMS DB ou DB2 como seu banco de dados back-end para armazenar os dados.
DL / I - Interface de linguagem de dados
DL / I é composto por programas aplicativos que concedem acesso aos dados armazenados no banco de dados. O IMS DB usa DL / I, que serve como a linguagem de interface que os programadores usam para acessar o banco de dados em um programa de aplicativo. Discutiremos isso com mais detalhes nos próximos capítulos.
Características do IMS
Pontos a serem observados -
- O IMS oferece suporte a aplicativos de diferentes linguagens, como Java e XML.
- Os aplicativos e dados IMS podem ser acessados em qualquer plataforma.
- O processamento do IMS DB é muito rápido em comparação com o DB2.
Limitações do IMS
Pontos a serem observados -
- A implementação do IMS DB é muito complexa.
- A estrutura de árvore predefinida do IMS reduz a flexibilidade.
- O IMS DB é difícil de gerenciar.
Estrutura hierárquica
Um banco de dados IMS é uma coleção de dados que acomodam arquivos físicos. Em um banco de dados hierárquico, o nível superior contém as informações gerais sobre a entidade. À medida que avançamos do nível superior para os níveis inferiores na hierarquia, obtemos mais e mais informações sobre a entidade.
Cada nível da hierarquia contém segmentos. Em arquivos padrão, é difícil implementar hierarquias, mas DL / I suporta hierarquias. A figura a seguir descreve a estrutura do IMS DB.
Segmento
Pontos a serem observados -
Um segmento é criado agrupando dados semelhantes.
É a menor unidade de informação que DL / I transfere de e para um programa aplicativo durante qualquer operação de entrada-saída.
Um segmento pode ter um ou mais campos de dados agrupados.
No exemplo a seguir, o segmento Aluno possui quatro campos de dados.
| Aluna | |||
|---|---|---|---|
| Número do rolo | Nome | Curso | Número de celular |
Campo
Pontos a serem observados -
Um campo é um único dado em um segmento. Por exemplo, Número do Roll, Nome, Curso e Número do Celular são campos únicos no segmento do Aluno.
Um segmento consiste em campos relacionados para coletar as informações de uma entidade.
Os campos podem ser usados como uma chave para ordenar os segmentos.
Os campos podem ser usados como um qualificador para pesquisar informações sobre um determinado segmento.
Tipo de Segmento
Pontos a serem observados -
Tipo de segmento é uma categoria de dados em um segmento.
Um banco de dados DL / I pode ter 255 tipos de segmento diferentes e 15 níveis de hierarquia.
Na figura a seguir, há três segmentos, a saber, Biblioteca, Informações sobre livros e Informações sobre alunos.
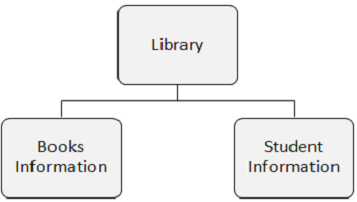
Ocorrência de segmento
Pontos a serem observados -
Uma ocorrência de segmento é um segmento individual de um tipo específico contendo dados do usuário. No exemplo acima, Books Information é um tipo de segmento e pode haver qualquer número de ocorrências dele, pois pode armazenar as informações sobre qualquer número de livros.
No Banco de Dados IMS, há apenas uma ocorrência de cada tipo de segmento, mas pode haver um número ilimitado de ocorrências de cada tipo de segmento.
Os bancos de dados hierárquicos trabalham nos relacionamentos entre dois ou mais segmentos. O exemplo a seguir mostra como os segmentos estão relacionados entre si na estrutura do banco de dados IMS.
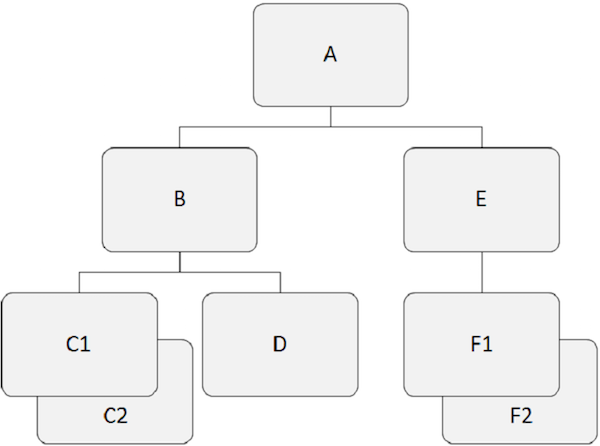
Segmento Raiz
Pontos a serem observados -
O segmento que fica no topo da hierarquia é chamado de segmento raiz.
O segmento raiz é o único segmento por meio do qual todos os segmentos dependentes são acessados.
O segmento raiz é o único segmento no banco de dados que nunca é um segmento filho.
Pode haver apenas um segmento raiz na estrutura do banco de dados IMS.
Por exemplo, 'A' é o segmento raiz no exemplo acima.
Segmento Pai
Pontos a serem observados -
Um segmento pai possui um ou mais segmentos dependentes diretamente abaixo dele.
Por exemplo, 'A', 'B', e 'E' são os segmentos pais no exemplo acima.
Segmento Dependente
Pontos a serem observados -
Todos os segmentos, exceto o segmento raiz, são conhecidos como segmentos dependentes.
Os segmentos dependentes dependem de um ou mais segmentos para apresentar um significado completo.
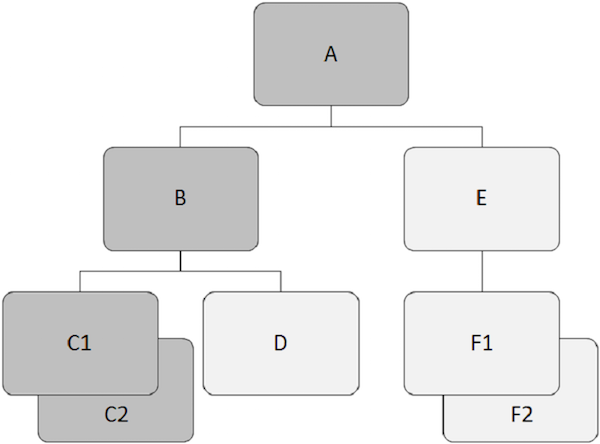
Por exemplo, 'B', 'C1', 'C2', 'D', 'E', 'F1' e 'F2' são segmentos dependentes em nosso exemplo.
Segmento Infantil
Pontos a serem observados -
Qualquer segmento que tenha um segmento diretamente acima dele na hierarquia é conhecido como segmento filho.
Cada segmento dependente na estrutura é um segmento filho.
Por exemplo, 'B', 'C1', 'C2', 'D', 'E', 'F1' e 'F2' são segmentos filhos.
Segmentos gêmeos
Pontos a serem observados -
Duas ou mais ocorrências de segmento de um determinado tipo de segmento em um único segmento pai são chamadas de segmentos gêmeos.
Por exemplo, 'C1' e 'C2' são segmentos gêmeos, então faça 'F1' e 'F2' está.
Segmento de Irmãos
Pontos a serem observados -
Os segmentos irmãos são os segmentos de diferentes tipos e do mesmo pai.
Por exemplo, 'B' e 'E' são segmentos irmãos. Similarmente,'C1', 'C2', e 'D' são segmentos irmãos.
Registro de banco de dados
Pontos a serem observados -
Cada ocorrência do segmento raiz, mais todas as ocorrências do segmento subordinado, formam um registro de banco de dados.
Cada registro de banco de dados possui apenas um segmento raiz, mas pode ter qualquer número de ocorrências de segmento.
No processamento de arquivo padrão, um registro é uma unidade de dados que um programa de aplicativo usa para certas operações. Em DL / I, essa unidade de dados é conhecida como segmento. Um único registro de banco de dados possui muitas ocorrências de segmento.
Caminho do banco de dados
Pontos a serem observados -
Um caminho é a série de segmentos que começa do segmento raiz de um registro de banco de dados até qualquer ocorrência de segmento específico.
Um caminho na estrutura de hierarquia não precisa ser concluído até o nível mais baixo. Depende de quantas informações exigimos sobre uma entidade.
Um caminho deve ser contínuo e não podemos pular níveis intermediários na estrutura.
Na figura a seguir, os registros filhos em cinza escuro mostram um caminho que começa a partir de 'A' e passa 'C2'.
O IMS DB armazena dados em níveis diferentes. Os dados são recuperados e inseridos emitindo chamadas DL / I de um programa aplicativo. Discutiremos sobre as chamadas DL / I em detalhes nos próximos capítulos. Os dados podem ser processados das duas maneiras a seguir -
- Processamento Sequencial
- Processamento Aleatório
Processamento Sequencial
Quando os segmentos são recuperados sequencialmente do banco de dados, DL / I segue um padrão predefinido. Vamos entender o processamento sequencial do banco de dados IMS.
Listados abaixo estão os pontos a serem observados sobre o processamento sequencial -
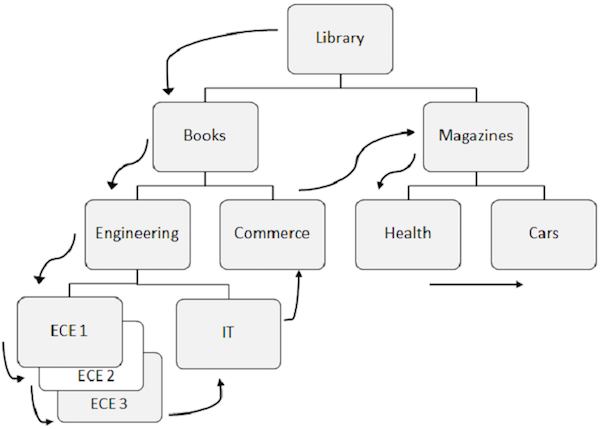
O padrão predefinido para acessar dados em DL / I é primeiro descer na hierarquia, depois da esquerda para a direita.
O segmento raiz é recuperado primeiro, então DL / I se move para o primeiro filho à esquerda e desce até o nível mais baixo. No nível mais baixo, ele recupera todas as ocorrências de segmentos gêmeos. Em seguida, ele vai para o segmento certo.
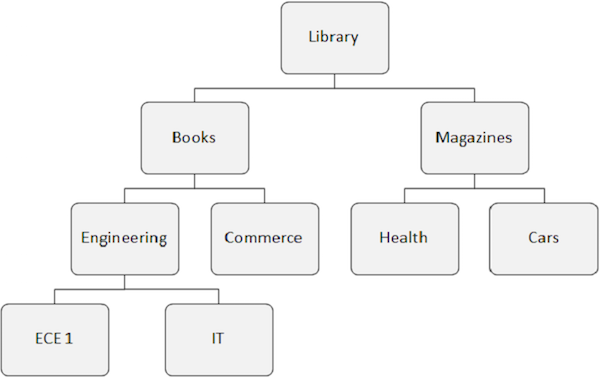
Para entender melhor, observe as setas da figura acima que mostram o fluxo de acesso aos segmentos. Biblioteca é o segmento raiz e o fluxo começa a partir daí e vai até carros para acessar um único registro. O mesmo processo é repetido para todas as ocorrências para obter todos os registros de dados.
Ao acessar os dados, o programa usa o position no banco de dados que ajuda a recuperar e inserir segmentos.
Processamento Aleatório
O processamento aleatório também é conhecido como processamento direto de dados no banco de dados IMS. Vamos dar um exemplo para entender o processamento aleatório em IMS DB -
Listados abaixo estão os pontos a serem observados sobre o processamento aleatório -
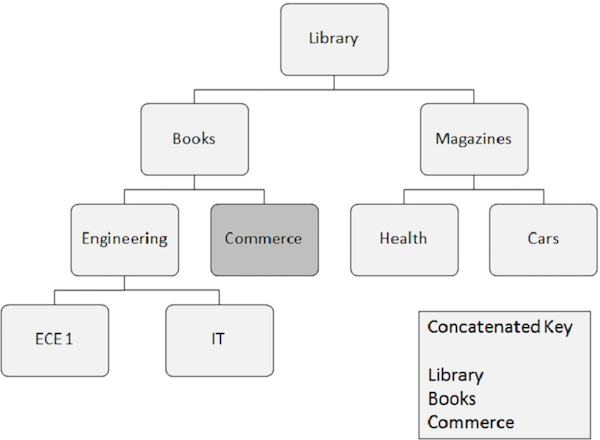
A ocorrência de segmento que precisa ser recuperada aleatoriamente requer campos-chave de todos os segmentos dos quais depende. Esses campos-chave são fornecidos pelo programa aplicativo.
Uma chave concatenada identifica completamente o caminho do segmento raiz para o segmento que você deseja recuperar.
Suponha que você deseje recuperar uma ocorrência do segmento Commerce, então você precisa fornecer os valores do campo-chave concatenado dos segmentos dos quais ele depende, como Biblioteca, Livros e Comércio.
O processamento aleatório é mais rápido do que o processamento sequencial. No cenário do mundo real, os aplicativos combinam métodos de processamento sequencial e aleatório para obter os melhores resultados.
Campo Chave
Pontos a serem observados -
Um campo-chave também é conhecido como campo de sequência.
Um campo-chave está presente em um segmento e é usado para recuperar a ocorrência do segmento.
Um campo-chave gerencia a ocorrência do segmento em ordem crescente.
Em cada segmento, apenas um único campo pode ser usado como um campo-chave ou campo de sequência.
Campo de Pesquisa
Conforme mencionado, apenas um único campo pode ser usado como um campo-chave. Se você deseja pesquisar o conteúdo de outros campos de segmento que não são campos-chave, o campo usado para recuperar os dados é conhecido como campo de pesquisa.
Os Blocos de Controle IMS definem a estrutura do banco de dados IMS e o acesso de um programa a eles. O diagrama a seguir mostra a estrutura dos blocos de controle IMS.
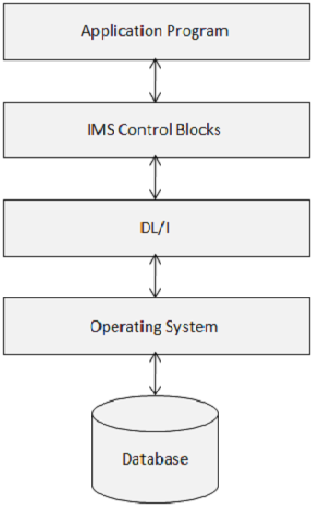
DL / I usa os seguintes três tipos de blocos de controle -
- Descritor de banco de dados (DBD)
- Bloco de Especificação de Programa (PSB)
- Bloco de controle de acesso (ACB)
Descritor de banco de dados (DBD)
Pontos a serem observados -
DBD descreve a estrutura física completa do banco de dados uma vez que todos os segmentos tenham sido definidos.
Ao instalar um banco de dados DL / I, um DBD deve ser criado, pois é necessário para acessar o banco de dados IMS.
Os aplicativos podem usar diferentes visões do DBD. Eles são chamados de Estruturas de Dados de Aplicativos e são especificados no Bloco de Especificação do Programa.
O administrador do banco de dados cria um DBD codificando DBDGEN declarações de controle.
DBDGEN
DBDGEN é um gerador de descritor de banco de dados. A criação de blocos de controle é responsabilidade do Administrador do Banco de Dados. Todos os módulos de carregamento são armazenados na biblioteca IMS. As instruções de macro da linguagem Assembly são usadas para criar blocos de controle. A seguir é fornecido um código de amostra que mostra como criar um DBD usando instruções de controle DBDGEN -
PRINT NOGEN
DBD NAME=LIBRARY,ACCESS=HIDAM
DATASET DD1=LIB,DEVICE=3380
SEGM NAME=LIBSEG,PARENT=0,BYTES=10
FIELD NAME=(LIBRARY,SEQ,U),BYTES=10,START=1,TYPE=C
SEGM NAME=BOOKSEG,PARENT=LIBSEG,BYTES=5
FIELD NAME=(BOOKS,SEQ,U),BYTES=10,START=1,TYPE=C
SEGM NAME=MAGSEG,PARENT=LIBSEG,BYTES=9
FIELD NAME=(MAGZINES,SEQ),BYTES=8,START=1,TYPE=C
DBDGEN
FINISH
ENDVamos entender os termos usados no DBDGEN acima -
Quando você executa as instruções de controle acima em JCL, ele cria uma estrutura física onde LIBRARY é o segmento raiz e BOOKS e MAGZINES são seus segmentos filhos.
A primeira instrução de macro DBD identifica o banco de dados. Aqui, precisamos mencionar o NOME e o ACESSO que é usado por DL / I para acessar este banco de dados.
A segunda instrução macro DATASET identifica o arquivo que contém o banco de dados.
Os tipos de segmento são definidos usando a instrução macro SEGM. Precisamos especificar o PAI desse segmento. Se for um segmento raiz, mencione PARENT = 0.
A tabela a seguir mostra os parâmetros usados na instrução da macro FIELD -
| S.No | Parâmetro e Descrição |
|---|---|
| 1 | Name Nome do campo, normalmente de 1 a 8 caracteres |
| 2 | Bytes Comprimento do campo |
| 3 | Start Posição do campo dentro do segmento |
| 4 | Type Tipo de dados do campo |
| 5 | Type C Tipo de dados de personagem |
| 6 | Type P Tipo de dados decimais compactados |
| 7 | Type Z Tipo de dados decimais zoneados |
| 8 | Type X Tipo de dados hexadecimal |
| 9 | Type H Tipo de dados binários de meia palavra |
| 10 | Type F Tipo de dados binários de palavra completa |
Bloco de Especificação de Programa (PSB)
Os fundamentos do PSB são os dados abaixo -
Um banco de dados possui uma única estrutura física definida por um DBD, mas os programas aplicativos que o processam podem ter diferentes visualizações do banco de dados. Essas visualizações são chamadas de estrutura de dados do aplicativo e são definidas no PSB.
Nenhum programa pode usar mais de um PSB em uma única execução.
Os programas de aplicativos têm seu próprio PSB e é comum que os programas de aplicativos com requisitos de processamento de banco de dados semelhantes compartilhem um PSB.
PSB consiste em um ou mais blocos de controle chamados blocos de comunicação de programa (PCBs). O PSB contém um PCB para cada banco de dados DL / I que o programa aplicativo acessará. Discutiremos mais sobre PCBs nos próximos módulos.
PSBGEN deve ser executado para criar um PSB para o programa.
PSBGEN
PSBGEN é conhecido como Program Specification Block Generator. O exemplo a seguir cria um PSB usando PSBGEN -
PRINT NOGEN
PCB TYPE=DB,DBDNAME=LIBRARY,KEYLEN=10,PROCOPT=LS
SENSEG NAME=LIBSEG
SENSEG NAME=BOOKSEG,PARENT=LIBSEG
SENSEG NAME=MAGSEG,PARENT=LIBSEG
PSBGEN PSBNAME=LIBPSB,LANG=COBOL
ENDVamos entender os termos usados no DBDGEN acima -
A primeira macroinstrução é o Bloco de Comunicação do Programa (PCB) que descreve o Tipo, Nome, Comprimento da Chave e Opção de Processamento do banco de dados.
O parâmetro DBDNAME na macro PCB especifica o nome do DBD. KEYLEN especifica o comprimento da chave concatenada mais longa. O programa pode processar no banco de dados. O parâmetro PROCOPT especifica as opções de processamento do programa. Por exemplo, LS significa apenas Operações LOAD.
SENSEG é conhecido como Segment Level Sensitivity. Ele define o acesso do programa a partes do banco de dados e é identificado no nível do segmento. O programa tem acesso a todos os campos dos segmentos aos quais é sensível. Um programa também pode ter sensibilidade em nível de campo. Neste, definimos um nome de segmento e o nome pai do segmento.
A última macroinstrução é PCBGEN. PSBGEN é a última instrução informando que não há mais instruções para processar. PSBNAME define o nome dado ao módulo PSB de saída. O parâmetro LANG especifica o idioma no qual o programa de aplicativo é escrito, por exemplo, COBOL.
Bloco de controle de acesso (ACB)
Listados abaixo estão os pontos a serem observados sobre os bloqueios de controle de acesso -
Os blocos de controle de acesso para um programa aplicativo combinam o descritor do banco de dados e o bloco de especificação do programa em um formato executável.
ACBGEN é conhecido como Gerador de Blocos de Controle de Acesso. É usado para gerar ACBs.
Para programas online, precisamos pré-construir ACBs. Portanto, o utilitário ACBGEN é executado antes de executar o programa aplicativo.
Para programas em lote, os ACBs também podem ser gerados em tempo de execução.
Um programa aplicativo que inclui chamadas DL / I não pode ser executado diretamente. Em vez disso, uma JCL é necessária para acionar o módulo de lote IMS DL / I. O módulo de inicialização em lote no IMS é DFSRRC00. O programa aplicativo e o módulo DL / I são executados juntos. O diagrama a seguir mostra a estrutura de um programa aplicativo que inclui chamadas DL / I para acessar um banco de dados.
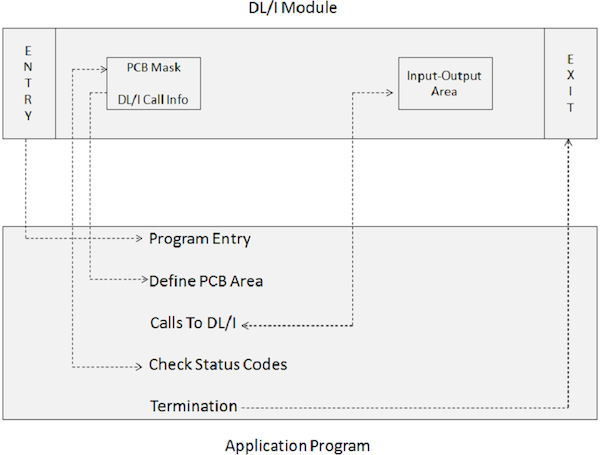
O programa de aplicação faz interface com os módulos IMS DL / I por meio dos seguintes elementos do programa -
Uma instrução ENTRY especifica que os PCBs são utilizados pelo programa.
Uma máscara de PCB co-relaciona-se com a informação preservada na PCB pré-construída que recebe informação de retorno do IMS.
Uma área de entrada-saída é usada para passar segmentos de dados de e para o banco de dados IMS.
Chamadas para DL / I especificam as funções de processamento, como buscar, inserir, excluir, substituir, etc.
Verificar Códigos de Status é usado para verificar o código de retorno SQL da opção de processamento especificada para informar se a operação foi bem-sucedida ou não.
Uma instrução Terminate é usada para encerrar o processamento do programa aplicativo que inclui o DL / I.
Layout de segmentos
A partir de agora, aprendemos que o IMS consiste em segmentos que são usados em linguagens de programação de alto nível para acessar dados. Considere a seguinte estrutura de banco de dados IMS de uma biblioteca que vimos anteriormente e aqui vemos o layout de seus segmentos em COBOL -
01 LIBRARY-SEGMENT.
05 BOOK-ID PIC X(5).
05 ISSUE-DATE PIC X(10).
05 RETURN-DATE PIC X(10).
05 STUDENT-ID PIC A(25).
01 BOOK-SEGMENT.
05 BOOK-ID PIC X(5).
05 BOOK-NAME PIC A(30).
05 AUTHOR PIC A(25).
01 STUDENT-SEGMENT.
05 STUDENT-ID PIC X(5).
05 STUDENT-NAME PIC A(25).
05 DIVISION PIC X(10).Visão geral do programa de aplicação
A estrutura de um programa de aplicativo IMS é diferente daquela de um programa de aplicativo não IMS. Um programa IMS não pode ser executado diretamente; em vez disso, é sempre chamado de sub-rotina. Um programa de aplicativo IMS consiste em Blocos de Especificação de Programa para fornecer uma visão do banco de dados IMS.
O programa aplicativo e os PSBs vinculados a esse programa são carregados quando executamos um programa aplicativo que inclui módulos IMS DL / I. Em seguida, as solicitações CALL acionadas pelos programas aplicativos são executadas pelo módulo IMS.
Serviços IMS
Os seguintes serviços IMS são usados pelo programa de aplicação -
- Acessando registros de banco de dados
- Emissão de comandos IMS
- Emissão de chamadas de serviço IMS
- Chamadas de checkpoint
- Sincronizar chamadas
- Enviar ou receber mensagens de terminais de usuário online
Incluímos chamadas DL / I dentro do programa de aplicação COBOL para se comunicar com o banco de dados IMS. Usamos as seguintes instruções DL / I no programa COBOL para acessar o banco de dados -
- Declaração de entrada
- Declaração Goback
- Declaração de Chamada
Declaração de entrada
É usado para passar o controle do DL / I para o programa COBOL. Aqui está a sintaxe da instrução de entrada -
ENTRY 'DLITCBL' USING pcb-name1
[pcb-name2]A declaração acima está codificada no Procedure Divisionde um programa COBOL. Vamos entrar em detalhes da instrução de entrada no programa COBOL -
O módulo de inicialização em lote aciona o programa aplicativo e é executado sob seu controle.
O DL / I carrega os blocos de controle e módulos necessários e o programa aplicativo, e o controle é fornecido ao programa aplicativo.
DLITCBL significa DL/I to COBOL. A instrução de entrada é usada para definir o ponto de entrada no programa.
Quando chamamos um subprograma em COBOL, seu endereço também é fornecido. Da mesma forma, quando o DL / I passa o controle para o programa aplicativo, ele também fornece o endereço de cada PCB definido no PSB do programa.
Todos os PCBs usados no programa aplicativo devem ser definidos dentro do Linkage Section do programa COBOL porque o PCB reside fora do programa aplicativo.
A definição de PCB dentro da seção de ligação é chamada de PCB Mask.
A relação entre as máscaras de PCB e os PCBs reais no armazenamento é criada listando os PCBs na instrução de entrada. A seqüência de listagem na declaração de entrada deve ser a mesma que aparece no PSBGEN.
Declaração Goback
É usado para passar o controle de volta ao programa de controle IMS. A seguir está a sintaxe da instrução Goback -
GOBACKListados abaixo estão os pontos fundamentais a serem observados sobre a declaração Goback -
GOBACK é codificado no final do programa aplicativo. Ele retorna o controle para DL / I do programa.
Não devemos usar STOP RUN, pois ele retorna o controle para o sistema operacional. Se usarmos STOP RUN, o DL / I nunca terá a chance de executar suas funções de terminação. É por isso que, em programas de aplicativos DL / I, a instrução Goback é usada.
Antes de emitir uma instrução Goback, todos os conjuntos de dados não DL / I usados no programa de aplicativo COBOL devem ser fechados, caso contrário, o programa será encerrado de forma anormal.
Declaração de Chamada
A instrução de chamada é usada para solicitar serviços DL / I, como a execução de certas operações no banco de dados IMS. Aqui está a sintaxe da instrução de chamada -
CALL 'CBLTDLI' USING DLI Function Code
PCB Mask
Segment I/O Area
[Segment Search Arguments]A sintaxe acima mostra os parâmetros que você pode usar com a instrução call. Discutiremos cada um deles na tabela a seguir -
| S.No. | Parâmetro e Descrição |
|---|---|
| 1 | DLI Function Code Identifica a função DL / I a ser executada. Este argumento é o nome dos quatro campos de caracteres que descrevem a operação de E / S. |
| 2 | PCB Mask A definição de PCB dentro da seção de ligação é chamada de máscara de PCB. Eles são usados na declaração de entrada. Não são necessárias instruções SELECT, ASSIGN, OPEN ou CLOSE. |
| 3 | Segment I/O Area Nome de uma área de trabalho de entrada / saída. Esta é uma área do programa aplicativo na qual o DL / I coloca um segmento solicitado. |
| 4 | Segment Search Arguments Esses são parâmetros opcionais, dependendo do tipo de chamada emitida. Eles são usados para pesquisar segmentos de dados dentro do banco de dados IMS. |
A seguir estão os pontos a serem observados sobre a declaração de convocação -
CBLTDLI significa COBOL to DL/I. É o nome de um módulo de interface editado por link com o módulo de objeto do seu programa.
Após cada chamada DL / I, o DLI armazena um código de status no PCB. O programa pode usar esse código para determinar se a chamada foi bem-sucedida ou falhou.
Exemplo
Para entender melhor o COBOL, você pode consultar nosso tutorial COBOL aqui . O exemplo a seguir mostra a estrutura de um programa COBOL que usa o banco de dados IMS e chamadas DL / I. Discutiremos em detalhes cada um dos parâmetros usados no exemplo nos próximos capítulos.
IDENTIFICATION DIVISION.
PROGRAM-ID. TEST1.
DATA DIVISION.
WORKING-STORAGE SECTION.
01 DLI-FUNCTIONS.
05 DLI-GU PIC X(4) VALUE 'GU '.
05 DLI-GHU PIC X(4) VALUE 'GHU '.
05 DLI-GN PIC X(4) VALUE 'GN '.
05 DLI-GHN PIC X(4) VALUE 'GHN '.
05 DLI-GNP PIC X(4) VALUE 'GNP '.
05 DLI-GHNP PIC X(4) VALUE 'GHNP'.
05 DLI-ISRT PIC X(4) VALUE 'ISRT'.
05 DLI-DLET PIC X(4) VALUE 'DLET'.
05 DLI-REPL PIC X(4) VALUE 'REPL'.
05 DLI-CHKP PIC X(4) VALUE 'CHKP'.
05 DLI-XRST PIC X(4) VALUE 'XRST'.
05 DLI-PCB PIC X(4) VALUE 'PCB '.
01 SEGMENT-I-O-AREA PIC X(150).
LINKAGE SECTION.
01 STUDENT-PCB-MASK.
05 STD-DBD-NAME PIC X(8).
05 STD-SEGMENT-LEVEL PIC XX.
05 STD-STATUS-CODE PIC XX.
05 STD-PROC-OPTIONS PIC X(4).
05 FILLER PIC S9(5) COMP.
05 STD-SEGMENT-NAME PIC X(8).
05 STD-KEY-LENGTH PIC S9(5) COMP.
05 STD-NUMB-SENS-SEGS PIC S9(5) COMP.
05 STD-KEY PIC X(11).
PROCEDURE DIVISION.
ENTRY 'DLITCBL' USING STUDENT-PCB-MASK.
A000-READ-PARA.
110-GET-INVENTORY-SEGMENT.
CALL ‘CBLTDLI’ USING DLI-GN
STUDENT-PCB-MASK
SEGMENT-I-O-AREA.
GOBACK.A função DL / I é o primeiro parâmetro usado em uma chamada DL / I. Esta função informa qual operação será executada no banco de dados IMS pela chamada IMS DL / I. A sintaxe da função DL / I é a seguinte -
01 DLI-FUNCTIONS.
05 DLI-GU PIC X(4) VALUE 'GU '.
05 DLI-GHU PIC X(4) VALUE 'GHU '.
05 DLI-GN PIC X(4) VALUE 'GN '.
05 DLI-GHN PIC X(4) VALUE 'GHN '.
05 DLI-GNP PIC X(4) VALUE 'GNP '.
05 DLI-GHNP PIC X(4) VALUE 'GHNP'.
05 DLI-ISRT PIC X(4) VALUE 'ISRT'.
05 DLI-DLET PIC X(4) VALUE 'DLET'.
05 DLI-REPL PIC X(4) VALUE 'REPL'.
05 DLI-CHKP PIC X(4) VALUE 'CHKP'.
05 DLI-XRST PIC X(4) VALUE 'XRST'.
05 DLI-PCB PIC X(4) VALUE 'PCB '.Esta sintaxe representa os seguintes pontos-chave -
Para este parâmetro, podemos fornecer qualquer nome de quatro caracteres como um campo de armazenamento para armazenar o código da função.
O parâmetro de função DL / I é codificado na seção de armazenamento de trabalho do programa COBOL.
Para especificar a função DL / I, o programador precisa codificar um dos nomes de dados de nível 05, como DLI-GU em uma chamada DL / I, uma vez que COBOL não permite codificar literais em uma instrução CALL.
As funções DL / I são divididas em três categorias: Obter, Atualizar e Outras funções. Vamos discutir cada um deles em detalhes.
Obter funções
As funções get são semelhantes à operação de leitura suportada por qualquer linguagem de programação. A função Get é usada para buscar segmentos de um banco de dados IMS DL / I. As seguintes funções Get são usadas no IMS DB -
- Seja único
- Avançar
- Seja o próximo no pai
- Get Hold Unique
- Segure-se em seguida
- Obtenha o próximo passo no pai
Vamos considerar a seguinte estrutura de banco de dados IMS para entender as chamadas de função DL / I -
Seja único
O código 'GU' é usado para a função Get Unique. Funciona de forma semelhante à instrução de leitura aleatória em COBOL. É usado para buscar uma ocorrência de segmento particular com base nos valores do campo. Os valores de campo podem ser fornecidos usando argumentos de pesquisa de segmento. A sintaxe de uma chamada GU é a seguinte -
CALL 'CBLTDLI' USING DLI-GU
PCB Mask
Segment I/O Area
[Segment Search Arguments]Se você executar a instrução de chamada acima fornecendo os valores apropriados para todos os parâmetros no programa COBOL, poderá recuperar o segmento na área de E / S do segmento do banco de dados. No exemplo acima, se você fornecer os valores dos campos Biblioteca, Revistas e Saúde, obterá a ocorrência desejada do segmento Saúde.
Avançar
O código 'GN' é usado para a função Get Next. Funciona de forma semelhante à instrução read next em COBOL. É usado para buscar ocorrências de segmento em uma sequência. O padrão predefinido para acessar ocorrências de segmento de dados é inferior na hierarquia e, a seguir, da esquerda para a direita. A sintaxe de uma chamada GN é a seguinte -
CALL 'CBLTDLI' USING DLI-GN
PCB Mask
Segment I/O Area
[Segment Search Arguments]Se você executar a instrução de chamada acima, fornecendo valores apropriados para todos os parâmetros no programa COBOL, você pode recuperar a ocorrência do segmento na área de E / S do segmento do banco de dados em uma ordem sequencial. No exemplo acima, ele começa acessando o segmento Biblioteca, depois o segmento Livros e assim por diante. Executamos a chamada GN repetidamente, até chegarmos à ocorrência do segmento que desejamos.
Seja o próximo no pai
O código 'GNP' é usado para Get Next dentro do Parent. Esta função é usada para recuperar ocorrências de segmento em sequência subordinada a um segmento pai estabelecido. A sintaxe de uma chamada GNP é a seguinte -
CALL 'CBLTDLI' USING DLI-GNP
PCB Mask
Segment I/O Area
[Segment Search Arguments]Get Hold Unique
O código 'GHU' é usado para Get Hold Unique. A função Hold especifica que vamos atualizar o segmento após a recuperação. A função Get Hold Unique corresponde à chamada Get Unique. A seguir está a sintaxe de uma chamada GHU -
CALL 'CBLTDLI' USING DLI-GHU
PCB Mask
Segment I/O Area
[Segment Search Arguments]Segure-se em seguida
O código 'GHN' é usado para Get Hold Next. A função Hold especifica que vamos atualizar o segmento após a recuperação. A função Get Hold Next corresponde à chamada Get Next. Dada abaixo está a sintaxe de uma chamada GHN -
CALL 'CBLTDLI' USING DLI-GHN
PCB Mask
Segment I/O Area
[Segment Search Arguments]Obtenha o próximo passo no pai
O código 'GHNP' é usado para Get Hold Next no Parent. A função Hold especifica que vamos atualizar o segmento após a recuperação. A função Get Hold Next no Parent corresponde à chamada Get Next dentro do Parent. Dada abaixo está a sintaxe de uma chamada GHNP -
CALL 'CBLTDLI' USING DLI-GHNP
PCB Mask
Segment I/O Area
[Segment Search Arguments]Atualizar funções
As funções de atualização são semelhantes às operações de reescrever ou inserir em qualquer outra linguagem de programação. As funções de atualização são usadas para atualizar segmentos em um banco de dados IMS DL / I. Antes de usar a função de atualização, deve haver uma chamada bem-sucedida com a cláusula Hold para a ocorrência do segmento. As seguintes funções de atualização são usadas no IMS DB -
- Insert
- Delete
- Replace
Inserir
O código 'ISRT' é usado para a função Inserir. A função ISRT é usada para adicionar um novo segmento ao banco de dados. É usado para alterar um banco de dados existente ou carregar um novo banco de dados. A seguir está a sintaxe de uma chamada ISRT -
CALL 'CBLTDLI' USING DLI-ISRT
PCB Mask
Segment I/O Area
[Segment Search Arguments]Excluir
O código 'DLET' é usado para a função Excluir. É usado para remover um segmento de um banco de dados IMS DL / I. A seguir está a sintaxe de uma chamada DLET -
CALL 'CBLTDLI' USING DLI-DLET
PCB Mask
Segment I/O Area
[Segment Search Arguments]Substituir
O código 'REPL' é usado para Get Hold Next no Parent. A função Substituir é usada para substituir um segmento no banco de dados IMS DL / I. A seguir está a sintaxe de uma chamada REPL -
CALL 'CBLTDLI' USING DLI-REPL
PCB Mask
Segment I/O Area
[Segment Search Arguments]Outras funções
As outras funções a seguir são usadas em chamadas IMS DL / I -
- Checkpoint
- Restart
- PCB
Checkpoint
O código 'CHKP' é usado para a função Checkpoint. Ele é usado nos recursos de recuperação do IMS. A seguir está a sintaxe de uma chamada CHKP -
CALL 'CBLTDLI' USING DLI-CHKP
PCB Mask
Segment I/O Area
[Segment Search Arguments]Reiniciar
O código 'XRST' é usado para a função Reiniciar. Ele é usado nos recursos de reinicialização do IMS. A seguir está a sintaxe de uma chamada XRST -
CALL 'CBLTDLI' USING DLI-XRST
PCB Mask
Segment I/O Area
[Segment Search Arguments]PCB
A função PCB é usada em programas CICS no banco de dados IMS DL / I. A seguir está a sintaxe de uma chamada PCB -
CALL 'CBLTDLI' USING DLI-PCB
PCB Mask
Segment I/O Area
[Segment Search Arguments]Você pode encontrar mais detalhes sobre essas funções no capítulo de recuperação.
PCB significa Bloco de Comunicação do Programa. A máscara PCB é o segundo parâmetro usado na chamada DL / I. É declarado na seção de ligação. A seguir está a sintaxe de uma máscara PCB -
01 PCB-NAME.
05 DBD-NAME PIC X(8).
05 SEG-LEVEL PIC XX.
05 STATUS-CODE PIC XX.
05 PROC-OPTIONS PIC X(4).
05 RESERVED-DLI PIC S9(5).
05 SEG-NAME PIC X(8).
05 LENGTH-FB-KEY PIC S9(5).
05 NUMB-SENS-SEGS PIC S9(5).
05 KEY-FB-AREA PIC X(n).Aqui estão os pontos-chave a serem observados -
Para cada banco de dados, o DL / I mantém uma área de armazenamento que é conhecida como bloco de comunicação do programa. Ele armazena as informações sobre o banco de dados que são acessadas dentro dos programas aplicativos.
A instrução ENTRY cria uma conexão entre as máscaras PCB na seção de ligação e as PCBs dentro do PSB do programa. As máscaras de PCB usadas em uma chamada DL / I informam qual banco de dados usar para a operação.
Você pode assumir que isso é semelhante a especificar um nome de arquivo em uma instrução COBOL READ ou um nome de registro em uma instrução de gravação COBOL. Não são necessárias instruções SELECT, ASSIGN, OPEN ou CLOSE.
Após cada chamada DL / I, o DL / I armazena um código de status no PCB e o programa pode usar esse código para determinar se a chamada foi bem-sucedida ou falhou.
Nome PCB
Pontos a serem observados -
Nome do PCB é o nome da área que se refere a toda a estrutura dos campos do PCB.
O nome do PCB é usado nas declarações do programa.
O nome do PCB não é um campo do PCB.
Nome DBD
Pontos a serem observados -
O nome DBD contém os dados do caractere. Tem oito bytes de comprimento.
O primeiro campo no PCB é o nome do banco de dados sendo processado e fornece o nome DBD da biblioteca de descrições de banco de dados associadas a um banco de dados específico.
Nível de segmento
Pontos a serem observados -
O nível de segmento é conhecido como Indicador de nível de hierarquia de segmento. Ele contém dados de caracteres e tem dois bytes de comprimento.
Um campo de nível de segmento armazena o nível do segmento que foi processado. Quando um segmento é recuperado com sucesso, o número do nível do segmento recuperado é armazenado aqui.
Um campo de nível de segmento nunca tem um valor maior que 15 porque esse é o número máximo de níveis permitidos em um banco de dados DL / I.
Código de Status
Pontos a serem observados -
O campo de código de status contém dois bytes de dados de caractere.
O código de status contém o código de status DL / I.
Os espaços são movidos para o campo de código de status quando DL / I conclui o processamento de chamadas com êxito.
Valores sem espaço indicam que a chamada não foi bem-sucedida.
O código de status GB indica o fim do arquivo e o código de status GE indica que o segmento solicitado não foi encontrado.
Opções Proc
Pontos a serem observados -
As opções de processo são conhecidas como opções de processamento que contêm campos de dados de quatro caracteres.
Um campo Opção de Processamento indica que tipo de processamento o programa está autorizado a fazer no banco de dados.
DL / I reservado
Pontos a serem observados -
DL / I reservado é conhecido como a área reservada do IMS. Ele armazena dados binários de quatro bytes.
O IMS usa essa área para sua própria ligação interna relacionada a um programa de aplicativo.
Nome do Segmento
Pontos a serem observados -
O nome SEG é conhecido como área de feedback do nome do segmento. Ele contém 8 bytes de dados de caracteres.
O nome do segmento é armazenado neste campo após cada chamada DL / I.
Comprimento da chave FB
Pontos a serem observados -
O comprimento da tecla FB é conhecido como o comprimento da área de feedback da tecla. Ele armazena quatro bytes de dados binários.
Este campo é usado para relatar o comprimento da chave concatenada do segmento de nível mais baixo processado durante a chamada anterior.
É usado com a área de feedback de chave.
Número de segmentos de sensibilidade
Pontos a serem observados -
O número de segmentos de sensibilidade armazena dados binários de quatro bytes.
Ele define a qual nível um programa de aplicativo é sensível. Ele representa uma contagem do número de segmentos na estrutura de dados lógica.
Área de feedback chave
Pontos a serem observados -
A área de feedback da chave varia em comprimento de um PCB para outro.
Ele contém a chave concatenada mais longa possível que pode ser usada com a visualização do banco de dados do programa.
Após uma operação de banco de dados, DL / I retorna a chave concatenada do segmento de nível mais baixo processado neste campo e retorna o comprimento da chave na área de feedback do comprimento da chave.
SSA significa Segment Search Arguments. SSA é usado para identificar a ocorrência do segmento que está sendo acessada. É um parâmetro opcional. Podemos incluir qualquer número de SSAs, dependendo do requisito. Existem dois tipos de SSAs -
- SSA não qualificado
- SSA qualificado
SSA não qualificado
Um SSA não qualificado fornece o nome do segmento que está sendo usado na chamada. A seguir está a sintaxe de um SSA não qualificado -
01 UNQUALIFIED-SSA.
05 SEGMENT-NAME PIC X(8).
05 FILLER PIC X VALUE SPACE.Os pontos principais do SSA não qualificado são os seguintes -
Um SSA básico não qualificado tem 9 bytes de comprimento.
Os primeiros 8 bytes contêm o nome do segmento que está sendo usado para processamento.
O último byte sempre contém espaço.
DL / I usa o último byte para determinar o tipo de SSA.
Para acessar um determinado segmento, mova o nome do segmento no campo SEGMENT-NAME.
As imagens a seguir mostram as estruturas de SSAs não qualificados e qualificados -
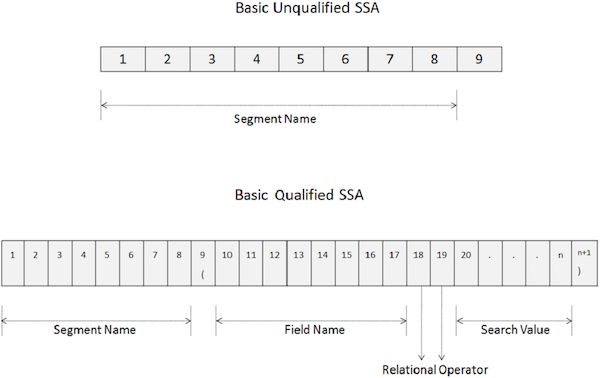
SSA qualificado
Um SSA qualificado fornece o tipo de segmento com a ocorrência de banco de dados específica de um segmento. A seguir está a sintaxe de um SSA qualificado -
01 QUALIFIED-SSA.
05 SEGMENT-NAME PIC X(8).
05 FILLER PIC X(01) VALUE '('.
05 FIELD-NAME PIC X(8).
05 REL-OPR PIC X(2).
05 SEARCH-VALUE PIC X(n).
05 FILLER PIC X(n+1) VALUE ')'.Os pontos principais do SSA qualificado são os seguintes -
Os primeiros 8 bytes de um SSA qualificado contêm o nome do segmento que está sendo usado para processamento.
O nono byte é um parêntese esquerdo '('.
Os próximos 8 bytes a partir da décima posição especificam o nome do campo que queremos pesquisar.
Após o nome do campo, na 18 ª e 19 ª posições, especificamos de dois caracteres código de operador relacional.
Então especificamos o valor do campo e no último byte, há um parêntese direito ')'.
A tabela a seguir mostra os operadores relacionais usados em um SSA qualificado.
| Operador Relacional | Símbolo | Descrição |
|---|---|---|
| EQ | = | Igual |
| NE | ~ = ˜ | Não igual |
| GT | > | Maior que |
| GE | > = | Maior ou igual |
| LT | << | Menor que |
| LE | <= | Menor ou igual |
Códigos de Comando
Os códigos de comando são usados para aprimorar a funcionalidade das chamadas DL / I. Os códigos de comando reduzem o número de chamadas DL / I, tornando os programas simples. Além disso, melhora o desempenho à medida que o número de chamadas é reduzido. A imagem a seguir mostra como os códigos de comando são usados em SSAs não qualificados e qualificados -
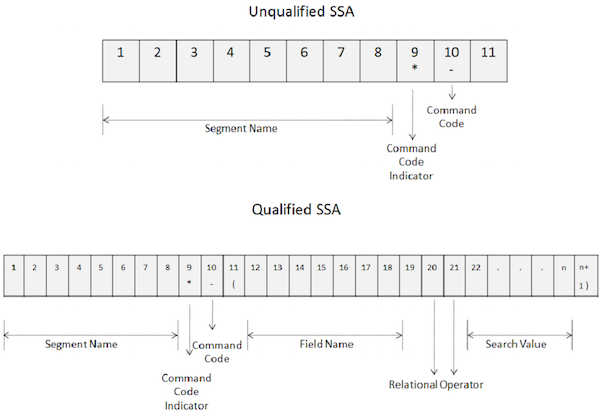
Os pontos-chave dos códigos de comando são os seguintes -
Para utilizar os códigos de comando, especificar um asterisco na 9 th posição da SSA, como mostrado na imagem acima.
O código de comando é codificado na décima posição.
De 10 ª posição em diante, DL / I considera todos os caracteres sejam códigos de comando até encontrar um espaço para uma SSA não qualificado e um parêntese esquerdo para um SSA qualificado.
A tabela a seguir mostra a lista de códigos de comando usados em SSA -
| Código de Comando | Descrição |
|---|---|
| C | Chave Concatenada |
| D | Path Call |
| F | Primeira Ocorrência |
| eu | Última Ocorrência |
| N | Ignorar chamada de caminho |
| P | Definir parentesco |
| Q | Segmento Enqueue |
| você | Manter posição neste nível |
| V | Mantenha a posição neste e em todos os níveis acima |
| - | Código de Comando Nulo |
Múltiplas Qualificações
Os pontos fundamentais de múltiplas qualificações são os seguintes -
Múltiplas qualificações são necessárias quando precisamos usar duas ou mais qualificações ou campos para comparação.
Usamos operadores booleanos como AND e OR para conectar duas ou mais qualificações.
Várias qualificações podem ser usadas quando queremos processar um segmento com base em uma gama de valores possíveis para um único campo.
A seguir está a sintaxe de Qualificações Múltiplas -
01 QUALIFIED-SSA.
05 SEGMENT-NAME PIC X(8).
05 FILLER PIC X(01) VALUE '('.
05 FIELD-NAME1 PIC X(8).
05 REL-OPR PIC X(2).
05 SEARCH-VALUE1 PIC X(m).
05 MUL-QUAL PIC X VALUE '&'.
05 FIELD-NAME2 PIC X(8).
05 REL-OPR PIC X(2).
05 SEARCH-VALUE2 PIC X(n).
05 FILLER PIC X(n+1) VALUE ')'.MUL-QUAL é um termo curto para MULtiple QUALIification no qual podemos fornecer operadores booleanos como AND ou OR.
Os vários métodos de recuperação de dados usados em chamadas IMS DL / I são os seguintes -
- Chamada GU
- GN Call
- Usando códigos de comando
- Processamento Múltiplo
Vamos considerar a seguinte estrutura de banco de dados IMS para entender as chamadas de função de recuperação de dados -
Chamada GU
Os fundamentos da chamada GU são os seguintes -
A chamada GU é conhecida como chamada Get Unique. É usado para processamento aleatório.
Se um aplicativo não atualizar o banco de dados regularmente ou se o número de atualizações do banco de dados for menor, usamos o processamento aleatório.
A chamada GU é usada para colocar o ponteiro em uma posição particular para posterior recuperação sequencial.
As chamadas GU são independentes da posição do ponteiro estabelecida pelas chamadas anteriores.
O processamento de chamadas GU é baseado nos campos-chave exclusivos fornecidos na instrução de chamada.
Se fornecermos um campo-chave que não seja único, DL / I retornará a primeira ocorrência de segmento do campo-chave.
CALL 'CBLTDLI' USING DLI-GU
PCB-NAME
IO-AREA
LIBRARY-SSA
BOOKS-SSA
ENGINEERING-SSA
IT-SSAO exemplo acima mostra que emitimos uma chamada GU fornecendo um conjunto completo de SSAs qualificados. Inclui todos os campos-chave, começando do nível raiz até a ocorrência do segmento que desejamos recuperar.
Considerações sobre a chamada GU
Se não fornecermos o conjunto completo de SSAs qualificados na chamada, DL / I funcionará da seguinte maneira -
Quando usamos um SSA não qualificado em uma chamada GU, DL / I acessa a primeira ocorrência de segmento no banco de dados que atende aos critérios que você especificar.
Quando emitimos uma chamada GU sem SSAs, DL / I retorna a primeira ocorrência do segmento raiz no banco de dados.
Se alguns SSAs em níveis intermediários não forem mencionados na chamada, DL / I usa a posição estabelecida ou o valor padrão de um SSA não qualificado para o segmento.
Códigos de status
A tabela a seguir mostra os códigos de status relevantes após uma chamada GU -
| S.No | Código de status e descrição |
|---|---|
| 1 | Spaces Chamada bem sucedida |
| 2 | GE DL / I não consegui encontrar um segmento que atendesse aos critérios especificados na chamada |
GN Call
Os fundamentos da chamada GN são os seguintes -
A chamada GN é conhecida como chamada Get Next. É usado para processamento sequencial básico.
A posição inicial do ponteiro no banco de dados é antes do segmento raiz do primeiro registro do banco de dados.
A posição do ponteiro do banco de dados é antes da próxima ocorrência de segmento na sequência, após uma chamada GN com sucesso.
A chamada GN começa através do banco de dados a partir da posição estabelecida na chamada anterior.
Se uma chamada GN não for qualificada, ela retornará a próxima ocorrência de segmento no banco de dados independente de seu tipo, em seqüência hierárquica.
Se uma chamada GN incluir SSAs, DL / I recupera apenas segmentos que atendem aos requisitos de todos os SSAs especificados.
CALL 'CBLTDLI' USING DLI-GN
PCB-NAME
IO-AREA
BOOKS-SSAO exemplo acima mostra que emitimos uma chamada GN fornecendo a posição inicial para ler os registros sequencialmente. Ele busca a primeira ocorrência do segmento LIVROS.
Códigos de status
A tabela a seguir mostra os códigos de status relevantes após uma chamada GN -
| S.No | Código de status e descrição |
|---|---|
| 1 | Spaces Chamada bem sucedida |
| 2 | GE DL / I não consegui encontrar um segmento que atendesse aos critérios especificados na chamada. |
| 3 | GA Uma chamada GN não qualificada sobe um nível na hierarquia do banco de dados para buscar o segmento. |
| 4 | GB O fim do banco de dados foi alcançado e o segmento não foi encontrado. |
GK Uma chamada GN não qualificada tenta buscar um segmento de um tipo específico diferente daquele que acabou de ser recuperado, mas permanece no mesmo nível hierárquico. |
Códigos de Comando
Os códigos de comando são usados com chamadas para buscar uma ocorrência de segmento. Os vários códigos de comando usados com chamadas são discutidos abaixo.
Código de Comando F
Pontos a serem observados -
Quando um código de comando F é especificado em uma chamada, a chamada processa a primeira ocorrência do segmento.
Os códigos de comando F podem ser usados quando queremos processar sequencialmente e podem ser usados com chamadas GN e GNP.
Se especificarmos um código de comando F com uma chamada GU, ele não terá qualquer significado, pois as chamadas GU buscam a primeira ocorrência de segmento por padrão.
Código de Comando L
Pontos a serem observados -
Quando um código de comando L é especificado em uma chamada, a chamada processa a última ocorrência do segmento.
Códigos de comando L podem ser usados quando queremos processar sequencialmente e podem ser usados com chamadas GN e chamadas GNP.
Código de Comando D
Pontos a serem observados -
O código de comando D é usado para buscar mais de uma ocorrência de segmento usando apenas uma única chamada.
Normalmente DL / I opera no segmento de nível mais baixo especificado em um SSA, mas em muitos casos, queremos dados de outros níveis também. Nesses casos, podemos usar o código de comando D.
O código de comando D facilita a recuperação de todo o caminho dos segmentos.
Código de Comando C
Pontos a serem observados -
O código de comando C é usado para concatenar chaves.
Usar operadores relacionais é um pouco complexo, já que precisamos especificar um nome de campo, um operador relacional e um valor de pesquisa. Em vez disso, podemos usar um código de comando C para fornecer uma chave concatenada.
O exemplo a seguir mostra o uso do código de comando C -
01 LOCATION-SSA.
05 FILLER PIC X(11) VALUE ‘INLOCSEG*C(‘.
05 LIBRARY-SSA PIC X(5).
05 BOOKS-SSA PIC X(4).
05 ENGINEERING-SSA PIC X(6).
05 IT-SSA PIC X(3)
05 FILLER PIC X VALUE ‘)’.
CALL 'CBLTDLI' USING DLI-GU
PCB-NAME
IO-AREA
LOCATION-SSACódigo de Comando P
Pontos a serem observados -
Quando emitimos uma chamada GU ou GN, o DL / I estabelece sua ascendência no segmento de nível mais baixo que é recuperado.
Se incluirmos um código de comando P, o DL / I estabelece sua ascendência em um segmento de nível superior no caminho hierárquico.
Código de Comando U
Pontos a serem observados -
Quando um código de comando U é especificado em um SSA não qualificado em uma chamada GN, o DL / I restringe a busca pelo segmento.
O código de comando U será ignorado se for usado com um SSA qualificado.
Código de Comando V
Pontos a serem observados -
O código de comando V funciona de forma semelhante ao código de comando U, mas restringe a busca de um segmento em um nível particular e todos os níveis acima da hierarquia.
O código de comando V é ignorado quando usado com um SSA qualificado.
Código de Comando Q
Pontos a serem observados -
O código de comando Q é usado para enfileirar ou reservar um segmento para uso exclusivo de seu programa aplicativo.
O código de comando Q é usado em um ambiente interativo onde outro programa pode fazer uma alteração em um segmento.
Processamento Múltiplo
Um programa pode ter várias posições no banco de dados IMS, o que é conhecido como processamento múltiplo. O processamento múltiplo pode ser feito de duas maneiras -
- Múltiplos PCBs
- Posicionamento Múltiplo
Múltiplos PCBs
Vários PCBs podem ser definidos para um único banco de dados. Se houver vários PCBs, um programa de aplicativo pode ter visualizações diferentes dele. Este método de implementação de processamento múltiplo é ineficiente por causa dos overheads impostos pelos PCBs extras.
Posicionamento Múltiplo
Um programa pode manter várias posições em um banco de dados usando um único PCB. Isso é conseguido mantendo uma posição distinta para cada caminho hierárquico. O posicionamento múltiplo é usado para acessar segmentos de dois ou mais tipos sequencialmente ao mesmo tempo.
Os diferentes métodos de manipulação de dados usados em chamadas IMS DL / I são os seguintes -
- Chamada ISRT
- Receber chamadas em espera
- REPL Call
- Chamada DLET
Vamos considerar a seguinte estrutura de banco de dados IMS para entender as chamadas de função de manipulação de dados -
Chamada ISRT
Pontos a serem observados -
A chamada ISRT é conhecida como chamada Insert, que é usada para adicionar ocorrências de segmento a um banco de dados.
As chamadas ISRT são usadas para carregar um novo banco de dados.
Emitimos uma chamada ISRT quando um campo de descrição de segmento é carregado com dados.
Um SSA não qualificado ou qualificado deve ser especificado na chamada para que o DL / I saiba onde colocar uma ocorrência de segmento.
Podemos usar uma combinação de SSA não qualificado e qualificado na chamada. Um SSA qualificado pode ser especificado para todos os níveis acima. Vamos considerar o seguinte exemplo -
CALL 'CBLTDLI' USING DLI-ISRT
PCB-NAME
IO-AREA
LIBRARY-SSA
BOOKS-SSA
UNQUALIFIED-ENGINEERING-SSAO exemplo acima mostra que estamos emitindo uma chamada ISRT fornecendo uma combinação de SSAs qualificados e não qualificados.
Quando um novo segmento que estamos inserindo tem um campo-chave exclusivo, ele é adicionado na posição adequada. Se o campo-chave não for exclusivo, ele será adicionado pelas regras definidas por um administrador de banco de dados.
Quando emitimos uma chamada ISRT sem especificar um campo-chave, a regra de inserção informa onde colocar os segmentos em relação aos segmentos gêmeos existentes. Abaixo estão as regras de inserção -
First - Se a regra for a primeira, o novo segmento será adicionado antes de quaisquer gêmeos existentes.
Last - Se a regra for a última, o novo segmento será adicionado após todos os gêmeos existentes.
Here - Se a regra estiver aqui, ela será adicionada na posição atual em relação aos gêmeos existentes, que podem ser o primeiro, o último ou em qualquer lugar.
Códigos de status
A tabela a seguir mostra os códigos de status relevantes após uma chamada ISRT -
| S.No | Código de status e descrição |
|---|---|
| 1 | Spaces Chamada bem sucedida |
| 2 | GE Vários SSAs são usados e o DL / I não pode atender à chamada com o caminho especificado. |
| 3 | II Tente adicionar uma ocorrência de segmento que já está presente no banco de dados. |
| 4 | LB / LC LD / LE Recebemos esses códigos de status durante o processamento do carregamento. Na maioria dos casos, eles indicam que você não está inserindo os segmentos em uma seqüência hierárquica exata. |
Chamada em espera
Pontos a serem observados -
Existem três tipos de chamada Get Hold que especificamos em uma chamada DL / I:
Get Hold Unique (GHU)
Get Hold Next (GHN)
Get Hold Next dentro do Parent (GHNP)
A função Hold especifica que vamos atualizar o segmento após a recuperação. Portanto, antes de uma chamada REPL ou DLET, uma chamada em espera bem-sucedida deve ser emitida informando ao DL / I a intenção de atualizar o banco de dados.
REPL Call
Pontos a serem observados -
Depois de obter uma chamada em espera com êxito, emitimos uma chamada REPL para atualizar uma ocorrência de segmento.
Não podemos alterar o comprimento de um segmento usando uma chamada REPL.
Não podemos alterar o valor de um campo-chave usando uma chamada REPL.
Não podemos usar um SSA qualificado com uma chamada REPL. Se especificarmos um SSA qualificado, a chamada falhará.
CALL 'CBLTDLI' USING DLI-GHU
PCB-NAME
IO-AREA
LIBRARY-SSA
BOOKS-SSA
ENGINEERING-SSA
IT-SSA.
*Move the values which you want to update in IT segment occurrence*
CALL ‘CBLTDLI’ USING DLI-REPL
PCB-NAME
IO-AREA.O exemplo acima atualiza a ocorrência do segmento de TI usando uma chamada REPL. Primeiro, emitimos uma chamada GHU para obter a ocorrência do segmento que desejamos atualizar. Em seguida, emitimos uma chamada REPL para atualizar os valores desse segmento.
Chamada DLET
Pontos a serem observados -
A chamada DLET funciona da mesma maneira que uma chamada REPL.
Depois de obter uma chamada em espera com êxito, emitimos uma chamada DLET para excluir uma ocorrência de segmento.
Não podemos usar um SSA qualificado com uma chamada DLET. Se especificarmos um SSA qualificado, a chamada falhará.
CALL 'CBLTDLI' USING DLI-GHU
PCB-NAME
IO-AREA
LIBRARY-SSA
BOOKS-SSA
ENGINEERING-SSA
IT-SSA.
CALL ‘CBLTDLI’ USING DLI-DLET
PCB-NAME
IO-AREA.O exemplo acima exclui a ocorrência do segmento de TI usando uma chamada DLET. Primeiro, emitimos uma chamada GHU para obter a ocorrência do segmento que desejamos excluir. Em seguida, emitimos uma chamada DLET para atualizar os valores desse segmento.
Códigos de status
A tabela a seguir mostra os códigos de status relevantes após uma chamada REPL ou DLET -
| S.No | Código de status e descrição |
|---|---|
| 1 | Spaces Chamada bem sucedida |
| 2 | AJ SSA qualificado usado em chamadas REPL ou DLET. |
| 3 | DJ O programa emite uma chamada de substituição sem uma chamada de espera imediatamente anterior. |
| 4 | DA O programa faz uma alteração no campo-chave do segmento antes de emitir a chamada REPL ou DLET |
A indexação secundária é usada quando queremos acessar um banco de dados sem usar a chave concatenada completa ou quando não queremos usar os campos primários de sequência.
Segmento de ponteiro de índice
DL / I armazena o ponteiro para segmentos do banco de dados indexado em um banco de dados separado. O segmento de ponteiro de índice é o único tipo de índice secundário. Consiste em duas partes -
- Elemento de Prefixo
- Elemento de Dados
Elemento de Prefixo
A parte do prefixo do segmento de ponteiro de índice contém um ponteiro para o segmento de destino do índice. O segmento de destino do índice é o segmento que pode ser acessado por meio do índice secundário.
Elemento de Dados
O elemento de dados contém o valor da chave do segmento no banco de dados indexado sobre o qual o índice é construído. Isso também é conhecido como segmento de origem do índice.
Aqui estão os pontos-chave a serem observados sobre a indexação secundária -
O segmento de origem do índice e o segmento de origem de destino não precisam ser iguais.
Quando configuramos um índice secundário, ele é mantido automaticamente pelo DL / I.
O DBA define muitos índices secundários de acordo com os vários caminhos de acesso. Esses índices secundários são armazenados em um banco de dados de índice separado.
Não devemos criar mais índices secundários, pois eles impõem sobrecarga de processamento adicional no DL / I.
Chaves Secundárias
Pontos a serem observados -
O campo no segmento de origem do índice sobre o qual o índice secundário é construído é chamado de chave secundária.
Qualquer campo pode ser usado como chave secundária. Não precisa ser o campo de sequência de segmentos.
As chaves secundárias podem ser qualquer combinação de campos únicos dentro do segmento de origem do índice.
Os valores-chave secundários não precisam ser exclusivos.
Estruturas de dados secundárias
Pontos a serem observados -
Quando construímos um índice secundário, a aparente estrutura hierárquica do banco de dados também é alterada.
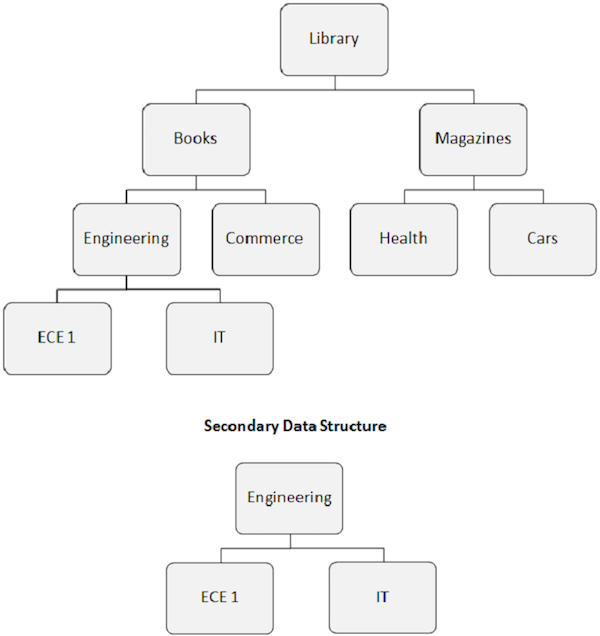
O segmento de destino do índice se torna o segmento raiz aparente. Conforme mostrado na imagem a seguir, o segmento de Engenharia torna-se o segmento raiz, mesmo que não seja um segmento raiz.
O rearranjo da estrutura do banco de dados causado pelo índice secundário é conhecido como estrutura de dados secundária.
As estruturas de dados secundárias não fazem nenhuma alteração na estrutura física do banco de dados principal presente no disco. É apenas uma forma de alterar a estrutura do banco de dados na frente do programa aplicativo.
Operador E Independente
Pontos a serem observados -
Quando um operador AND (* ou &) é usado com índices secundários, ele é conhecido como um operador AND dependente.
Um AND independente (#) nos permite especificar qualificações que seriam impossíveis com um AND dependente.
Este operador pode ser usado apenas para índices secundários em que o segmento de origem do índice depende do segmento de destino do índice.
Podemos codificar um SSA com um AND independente para especificar que uma ocorrência do segmento de destino seja processada com base nos campos em dois ou mais segmentos de origem dependentes.
01 ITEM-SELECTION-SSA.
05 FILLER PIC X(8).
05 FILLER PIC X(1) VALUE '('.
05 FILLER PIC X(10).
05 SSA-KEY-1 PIC X(8).
05 FILLER PIC X VALUE '#'.
05 FILLER PIC X(10).
05 SSA-KEY-2 PIC X(8).
05 FILLER PIC X VALUE ')'.Sequenciamento Esparso
Pontos a serem observados -
O sequenciamento esparso também é conhecido como indexação esparsa. Podemos remover alguns dos segmentos de origem do índice do índice usando sequenciamento esparso com banco de dados de índice secundário.
O sequenciamento esparso é usado para melhorar o desempenho. Quando algumas ocorrências do segmento de origem do índice não são usadas, podemos remover isso.
DL / I usa um valor de supressão ou uma rotina de supressão ou ambos para determinar se um segmento deve ser indexado.
Se o valor de um campo de sequência no segmento de origem do índice corresponder a um valor de supressão, nenhum relacionamento de índice será estabelecido.
A rotina de supressão é um programa escrito pelo usuário que avalia o segmento e determina se ele deve ou não ser indexado.
Quando a indexação esparsa é usada, suas funções são gerenciadas pelo DL / I. Não precisamos fazer provisões especiais para isso no programa de aplicação.
Requisitos DBDGEN
Conforme discutido em módulos anteriores, DBDGEN é usado para criar um DBD. Quando criamos índices secundários, dois bancos de dados estão envolvidos. Um DBA precisa criar dois DBDs usando dois DBDGENs para criar um relacionamento entre um banco de dados indexado e um banco de dados indexado secundário.
Requisitos PSBGEN
Depois de criar o índice secundário para um banco de dados, o DBA precisa criar os PSBs. PSBGEN para o programa especifica a seqüência de processamento apropriada para o banco de dados no parâmetro PROCSEQ da macro PSB. Para o parâmetro PROCSEQ, o DBA codifica o nome do DBD para o banco de dados de índice secundário.
O banco de dados IMS tem uma regra de que cada tipo de segmento pode ter apenas um pai. Isso limita a complexidade do banco de dados físico. Muitos aplicativos DL / I requerem uma estrutura complexa que permite que um segmento tenha dois tipos de segmento pai. Para superar essa limitação, DL / I permite que o DBA implemente relacionamentos lógicos nos quais um segmento pode ter pais físicos e lógicos. Podemos criar relacionamentos adicionais em um banco de dados físico. A nova estrutura de dados após a implementação do relacionamento lógico é conhecida como Banco de Dados Lógico.
Relação Lógica
Um relacionamento lógico tem as seguintes propriedades -
Um relacionamento lógico é um caminho entre dois segmentos que estão relacionados logicamente e não fisicamente.
Normalmente, um relacionamento lógico é estabelecido entre bancos de dados separados. Mas é possível ter um relacionamento entre os segmentos de um determinado banco de dados.
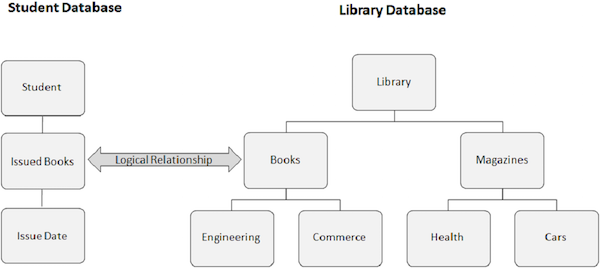
A imagem a seguir mostra dois bancos de dados diferentes. Um é o banco de dados do Aluno e o outro é um banco de dados da Biblioteca. Criamos uma relação lógica entre o segmento Livros publicados da base de dados do Aluno e o segmento Livros da base de dados da Biblioteca.
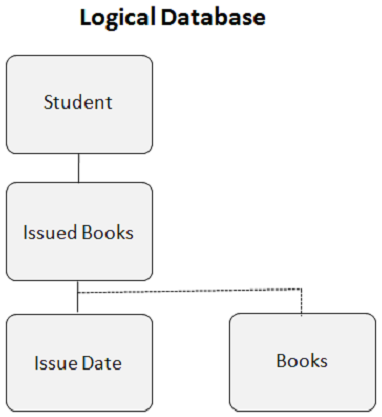
Esta é a aparência do banco de dados lógico quando você cria um relacionamento lógico -
Segmento Lógico Criança
O segmento filho lógico é a base de um relacionamento lógico. É um segmento de dados físico, mas para DL / I, parece que tem dois pais. O segmento Livros no exemplo acima possui dois segmentos pais. O segmento dos livros emitidos é o pai lógico e o segmento da Biblioteca é o pai físico. Uma ocorrência de segmento filho lógico tem apenas uma ocorrência de segmento pai lógico e uma ocorrência de segmento pai lógico pode ter muitas ocorrências de segmento filho lógico.
Logical Twins
Os gêmeos lógicos são as ocorrências de um tipo de segmento filho lógico, todas subordinadas a uma única ocorrência do tipo de segmento pai lógico. DL / I faz o segmento filho lógico parecer semelhante a um segmento filho físico real. Isso também é conhecido como um segmento filho lógico virtual.
Tipos de relacionamentos lógicos
Um DBA cria relacionamentos lógicos entre segmentos. Para implementar um relacionamento lógico, o DBA deve especificá-lo nos DBDGENs dos bancos de dados físicos envolvidos. Existem três tipos de relacionamentos lógicos -
- Unidirectional
- Virtual bidirecional
- Físico bidirecional
Unidirecional
A conexão lógica vai do filho lógico para o pai lógico e não pode acontecer o contrário.
Virtual bidirecional
Permite acesso em ambas as direções. O filho lógico em sua estrutura física e o filho lógico virtual correspondente podem ser vistos como segmentos emparelhados.
Físico bidirecional
A criança lógica é um subordinado fisicamente armazenado tanto para seus pais físicos quanto lógicos. Para programas de aplicativos, ele aparece da mesma forma que um filho lógico virtual bidirecional.
Considerações de programação
As considerações de programação para usar um banco de dados lógico são as seguintes -
As chamadas DL / I para acessar o banco de dados permanecem iguais com o banco de dados lógico também.
O bloco de especificação do programa indica a estrutura que usamos em nossas chamadas. Em alguns casos, não podemos identificar que estamos usando um banco de dados lógico.
Os relacionamentos lógicos adicionam uma nova dimensão à programação do banco de dados.
Você deve ter cuidado ao trabalhar com bancos de dados lógicos, pois dois bancos de dados são integrados. Se você modificar um banco de dados, as mesmas modificações devem ser refletidas no outro banco de dados.
As especificações do programa devem indicar qual processamento é permitido em um banco de dados. Se uma regra de processamento for violada, você receberá um código de status não em branco.
Segmento Concatenado
Um segmento filho lógico sempre começa com a chave concatenada completa do pai de destino. Isso é conhecido como a chave concatenada pai de destino (DPCK). Você precisa sempre codificar o DPCK no início de sua área de E / S de segmento para um filho lógico. Em um banco de dados lógico, o segmento concatenado faz a conexão entre segmentos definidos em diferentes bancos de dados físicos. Um segmento concatenado consiste nas duas partes a seguir -
- Segmento filho lógico
- Segmento pai de destino
Um segmento filho lógico consiste nas duas partes a seguir -
- Chave concatenada principal de destino (DPCK)
- Dados lógicos do usuário filho

Quando trabalhamos com segmentos concatenados durante a atualização, pode ser possível adicionar ou alterar os dados no filho lógico e no pai de destino com uma única chamada. Isso também depende das regras que o DBA especificou para o banco de dados. Para uma inserção, coloque o DPCK na posição correta. Para uma substituição ou exclusão, não altere o DPCK ou os dados do campo de sequência em nenhuma parte do segmento concatenado.
O administrador do banco de dados precisa planejar a recuperação do banco de dados em caso de falhas do sistema. As falhas podem ser de vários tipos, como travamentos de aplicativos, erros de hardware, falhas de energia, etc.
Abordagem Simples
Algumas abordagens simples para recuperação de banco de dados são as seguintes -
Faça cópias de backup periódicas de conjuntos de dados importantes para que todas as transações postadas nos conjuntos de dados sejam retidas.
Se um conjunto de dados for danificado devido a uma falha do sistema, esse problema será corrigido com a restauração da cópia de backup. Em seguida, as transações acumuladas são postadas novamente na cópia de backup para serem atualizadas.
Desvantagens da abordagem simples
As desvantagens da abordagem simples para recuperação de banco de dados são as seguintes -
O reenvio das transações acumuladas consome muito tempo.
Todos os outros aplicativos precisam aguardar a execução até que a recuperação seja concluída.
A recuperação do banco de dados é mais longa do que a recuperação do arquivo, se relacionamentos lógicos e de índice secundário estiverem envolvidos.
Rotinas de rescisão anormais
Um programa DL / I trava de uma maneira diferente da forma como um programa padrão trava porque um programa padrão é executado diretamente pelo sistema operacional, enquanto um programa DL / I não é. Ao empregar uma rotina de término anormal, o sistema interfere para que a recuperação possa ser feita após o FIM ANormal (ABEND). A rotina de encerramento anormal executa as seguintes ações -
- Fecha todos os conjuntos de dados
- Cancela todos os trabalhos pendentes na fila
- Cria um dump de armazenamento para descobrir a causa raiz de ABEND
A limitação dessa rotina é que ela não garante se os dados em uso são precisos ou não.
Log DL / I
Quando um programa aplicativo é ABEND, é necessário reverter as alterações feitas pelo programa aplicativo, corrigir o erro e executar novamente o programa aplicativo. Para fazer isso, é necessário ter o log DL / I. Aqui estão os pontos-chave sobre o registro DL / I -
Um DL / I registra todas as alterações feitas por um programa aplicativo em um arquivo conhecido como arquivo de log.
Quando o programa de aplicação altera um segmento, sua pré-imagem e pós-imagem são criadas pelo DL / I.
Essas imagens de segmento podem ser usadas para restaurar os segmentos, no caso de o aplicativo travar.
DL / I usa uma técnica chamada log write-ahead para registrar as alterações do banco de dados. Com o log de write-ahead, uma alteração do banco de dados é gravada no conjunto de dados do log antes de ser gravada no conjunto de dados real.
Como o log está sempre à frente do banco de dados, os utilitários de recuperação podem determinar o status de qualquer alteração no banco de dados.
Quando o programa executa uma chamada para alterar um segmento de banco de dados, o DL / I cuida de sua parte de registro.
Recuperação - para frente e para trás
As duas abordagens de recuperação de banco de dados são -
Forward Recovery - DL / I usa o arquivo de log para armazenar os dados de alteração. As transações acumuladas são postadas novamente usando este arquivo de log.
Backward Recovery- A recuperação reversa também é conhecida como recuperação reversa. Os registros de log do programa são lidos de trás para frente e seus efeitos são revertidos no banco de dados. Quando a restauração for concluída, os bancos de dados estarão no mesmo estado em que estavam antes da falha, assumindo que nenhum outro programa de aplicativo alterou o banco de dados nesse meio tempo.
Checkpoint
Um ponto de verificação é um estágio em que as alterações do banco de dados feitas pelo programa aplicativo são consideradas completas e precisas. Listados abaixo estão os pontos a serem observados sobre um checkpoint -
As alterações do banco de dados feitas antes do ponto de verificação mais recente não são revertidas pela recuperação reversa.
As alterações do banco de dados registradas após o ponto de verificação mais recente não são aplicadas a uma cópia de imagem do banco de dados durante a recuperação direta.
Usando o método de ponto de verificação, o banco de dados é restaurado à sua condição no ponto de verificação mais recente quando o processo de recuperação é concluído.
O padrão para programas em lote é que o ponto de verificação é o início do programa.
Um ponto de verificação pode ser estabelecido usando uma chamada de ponto de verificação (CHKP).
Uma chamada de ponto de verificação faz com que um registro de ponto de verificação seja escrito no log DL / I.
Abaixo é mostrada a sintaxe de uma chamada CHKP -
CALL 'CBLTDLI' USING DLI-CHKP
PCB-NAME
CHECKPOINT-IDExistem dois métodos de checkpoint -
Basic Checkpointing - Permite ao programador emitir chamadas de ponto de verificação que os utilitários de recuperação DL / I usam durante o processamento de recuperação.
Symbolic Checkpointing- É uma forma avançada de ponto de verificação usada em combinação com o recurso de reinicialização estendida. O ponto de verificação simbólico e o reinício estendido juntos permitem que o programador do aplicativo codifique os programas para que eles possam retomar o processamento no ponto logo após o ponto de verificação.