Processamento de linguagem natural - Python
Neste capítulo, aprenderemos sobre o processamento de linguagem usando Python.
Os seguintes recursos tornam o Python diferente de outras linguagens -
Python is interpreted - Não precisamos compilar nosso programa Python antes de executá-lo porque o interpretador processa Python em tempo de execução.
Interactive - Podemos interagir diretamente com o interpretador para escrever nossos programas Python.
Object-oriented - Python é orientado a objetos por natureza e torna esta linguagem mais fácil de escrever programas porque com a ajuda desta técnica de programação encapsula código dentro de objetos.
Beginner can easily learn - Python também é chamada de linguagem de iniciante porque é muito fácil de entender e suporta o desenvolvimento de uma ampla gama de aplicações.
Pré-requisitos
A versão mais recente do Python 3 lançado é Python 3.7.1 está disponível para Windows, Mac OS e a maioria dos tipos de Linux OS.
Para Windows, podemos acessar o link www.python.org/downloads/windows/ para baixar e instalar o Python.
Para o MAC OS, podemos usar o link www.python.org/downloads/mac-osx/ .
No caso do Linux, diferentes sabores de Linux usam gerenciadores de pacotes diferentes para a instalação de novos pacotes.
Por exemplo, para instalar o Python 3 no Ubuntu Linux, podemos usar o seguinte comando do terminal -
$sudo apt-get install python3-minimalPara estudar mais sobre a programação Python, leia o tutorial básico do Python 3 - Python 3
Primeiros passos com NLTK
Estaremos usando a biblioteca Python NLTK (Natural Language Toolkit) para fazer análise de texto na língua inglesa. O kit de ferramentas de linguagem natural (NLTK) é uma coleção de bibliotecas Python projetadas especialmente para identificar e marcar partes do discurso encontradas no texto de linguagem natural como o inglês.
Instalando NLTK
Antes de começar a usar o NLTK, precisamos instalá-lo. Com a ajuda do seguinte comando, podemos instalá-lo em nosso ambiente Python -
pip install nltkSe estivermos usando o Anaconda, então um pacote Conda para NLTK pode ser construído usando o seguinte comando -
conda install -c anaconda nltkBaixando dados do NLTK
Depois de instalar o NLTK, outra tarefa importante é fazer o download de seus repositórios de texto predefinidos para que possam ser usados facilmente. No entanto, antes disso, precisamos importar NLTK da mesma forma que importamos qualquer outro módulo Python. O comando a seguir nos ajudará a importar NLTK -
import nltkAgora, baixe os dados NLTK com a ajuda do seguinte comando -
nltk.download()Levará algum tempo para instalar todos os pacotes disponíveis do NLTK.
Outros Pacotes Necessários
Alguns outros pacotes Python, como gensim e patterntambém são muito necessários para análise de texto, bem como para construir aplicativos de processamento de linguagem natural usando NLTK. os pacotes podem ser instalados conforme mostrado abaixo -
gensim
gensim é uma biblioteca de modelagem semântica robusta que pode ser usada para muitos aplicativos. Podemos instalá-lo seguindo o comando -
pip install gensimpadronizar
Pode ser usado para fazer gensimpacote funcionar corretamente. O seguinte comando ajuda na instalação do padrão -
pip install patternTokenização
A tokenização pode ser definida como o processo de quebrar o texto fornecido em unidades menores chamadas de tokens. Palavras, números ou sinais de pontuação podem ser tokens. Também pode ser chamado de segmentação de palavras.
Exemplo
Input - Cama e cadeira são tipos de móveis.

Temos diferentes pacotes de tokenização fornecidos pela NLTK. Podemos usar esses pacotes com base em nossos requisitos. Os pacotes e os detalhes de sua instalação são os seguintes -
pacote sent_tokenize
Este pacote pode ser usado para dividir o texto de entrada em sentenças. Podemos importá-lo usando o seguinte comando -
from nltk.tokenize import sent_tokenizepacote word_tokenize
Este pacote pode ser usado para dividir o texto de entrada em palavras. Podemos importá-lo usando o seguinte comando -
from nltk.tokenize import word_tokenizePacote WordPunctTokenizer
Este pacote pode ser usado para dividir o texto de entrada em palavras e sinais de pontuação. Podemos importá-lo usando o seguinte comando -
from nltk.tokenize import WordPuncttokenizerStemming
Por razões gramaticais, a linguagem inclui muitas variações. Variações no sentido de que a língua, o inglês e também outras línguas, têm diferentes formas de palavra. Por exemplo, as palavras comodemocracy, democratic, e democratization. Para projetos de aprendizado de máquina, é muito importante que as máquinas entendam que essas palavras diferentes, como acima, têm a mesma forma básica. Por isso é muito útil extrair as formas básicas das palavras durante a análise do texto.
Stemming é um processo heurístico que ajuda a extrair as formas básicas das palavras cortando suas pontas.
Os diferentes pacotes de lematização fornecidos pelo módulo NLTK são os seguintes -
Pacote PorterStemmer
O algoritmo de Porter é usado por este pacote de lematização para extrair a forma básica das palavras. Com a ajuda do seguinte comando, podemos importar este pacote -
from nltk.stem.porter import PorterStemmerPor exemplo, ‘write’ seria a saída da palavra ‘writing’ fornecido como entrada para este lematizador.
Pacote LancasterStemmer
O algoritmo de Lancaster é usado por este pacote de lematização para extrair a forma básica das palavras. Com a ajuda do seguinte comando, podemos importar este pacote -
from nltk.stem.lancaster import LancasterStemmerPor exemplo, ‘writ’ seria a saída da palavra ‘writing’ fornecido como entrada para este lematizador.
Pacote SnowballStemmer
O algoritmo de Snowball é usado por este pacote de lematização para extrair a forma básica das palavras. Com a ajuda do seguinte comando, podemos importar este pacote -
from nltk.stem.snowball import SnowballStemmerPor exemplo, ‘write’ seria a saída da palavra ‘writing’ fornecido como entrada para este lematizador.
Lemmatização
É outra forma de extrair a forma base das palavras, normalmente com o objetivo de remover terminações flexionais usando vocabulário e análise morfológica. Após a lematização, a forma básica de qualquer palavra é chamada de lema.
O módulo NLTK fornece o seguinte pacote para lematização -
Pacote WordNetLemmatizer
Este pacote irá extrair a forma básica da palavra dependendo se é usada como substantivo ou verbo. O seguinte comando pode ser usado para importar este pacote -
from nltk.stem import WordNetLemmatizerContando tags de PDV - Chunking
A identificação de classes gramaticais (POS) e frases curtas pode ser feita com o auxílio de chunking. É um dos processos importantes no processamento de linguagem natural. Como estamos cientes do processo de tokenização para a criação de tokens, a fragmentação, na verdade, é fazer a rotulação desses tokens. Em outras palavras, podemos dizer que podemos obter a estrutura da frase com a ajuda do processo de chunking.
Exemplo
No exemplo a seguir, implementaremos o chunking de frase substantiva, uma categoria de chunking que encontrará os chunks de frase nominal na frase, usando o módulo NLTK Python.
Considere as seguintes etapas para implementar chunking substantivo-frase -
Step 1: Chunk grammar definition
Nesta etapa, precisamos definir a gramática para chunking. Consistiria nas regras que devemos seguir.
Step 2: Chunk parser creation
Em seguida, precisamos criar um analisador de chunk. Ele analisaria a gramática e forneceria a saída.
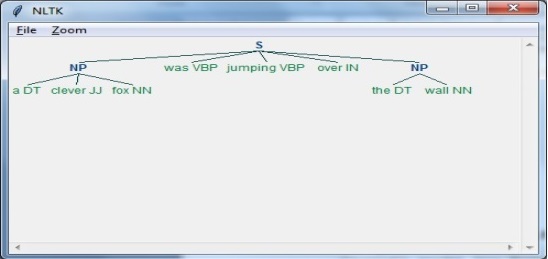
Step 3: The Output
Nesta etapa, obteremos a saída em formato de árvore.
Executando o Script de PNL
Comece importando o pacote NLTK -
import nltkAgora, precisamos definir a frase.
Aqui,
DT é o determinante
VBP é o verbo
JJ é o adjetivo
IN é a preposição
NN é o substantivo
sentence = [("a", "DT"),("clever","JJ"),("fox","NN"),("was","VBP"),
("jumping","VBP"),("over","IN"),("the","DT"),("wall","NN")]Em seguida, a gramática deve ser fornecida na forma de expressão regular.
grammar = "NP:{<DT>?<JJ>*<NN>}"Agora, precisamos definir um analisador para analisar a gramática.
parser_chunking = nltk.RegexpParser(grammar)Agora, o analisador analisará a frase da seguinte maneira -
parser_chunking.parse(sentence)Em seguida, a saída estará na variável da seguinte maneira: -
Output = parser_chunking.parse(sentence)Agora, o código a seguir o ajudará a desenhar sua saída na forma de uma árvore.
output.draw()