Kit de ferramentas de linguagem natural - guia rápido
O que é Processamento de Linguagem Natural (PNL)?
O método de comunicação com a ajuda do qual os humanos podem falar, ler e escrever é a linguagem. Em outras palavras, nós, humanos, podemos pensar, fazer planos, tomar decisões em nossa linguagem natural. Aqui, a grande questão é: na era da inteligência artificial, aprendizado de máquina e aprendizado profundo, os humanos podem se comunicar em linguagem natural com computadores / máquinas? O desenvolvimento de aplicativos de PNL é um grande desafio para nós, porque os computadores exigem dados estruturados, mas, por outro lado, a fala humana não é estruturada e geralmente é ambígua por natureza.
A linguagem natural é o subcampo da ciência da computação, mais especificamente da IA, que permite que computadores / máquinas entendam, processem e manipulem a linguagem humana. Em palavras simples, a PNL é uma forma das máquinas analisar, compreender e derivar significado de línguas naturais humanas como hindi, inglês, francês, holandês, etc.
Como funciona?
Antes de nos aprofundarmos no funcionamento da PNL, devemos entender como os seres humanos usam a linguagem. Todos os dias, nós, humanos, usamos centenas ou milhares de palavras e outros humanos as interpretam e respondem de acordo. É uma comunicação simples para humanos, não é? Mas sabemos que as palavras são muito mais profundas do que isso e sempre derivamos um contexto do que dizemos e como dizemos. É por isso que podemos dizer que, em vez de focar na modulação da voz, a PNL se baseia no padrão contextual.
Vamos entender com um exemplo -
Man is to woman as king is to what?
We can interpret it easily and answer as follows:
Man relates to king, so woman can relate to queen.
Hence the answer is Queen.Como os humanos sabem que palavra significa o quê? A resposta a essa pergunta é que aprendemos com nossa experiência. Mas, como as máquinas / computadores aprendem o mesmo?
Deixe-nos entender seguindo etapas fáceis -
Primeiro, precisamos alimentar as máquinas com dados suficientes para que as máquinas possam aprender com a experiência.
Então, a máquina criará vetores de palavras, usando algoritmos de aprendizado profundo, a partir dos dados que alimentamos anteriormente, bem como de seus dados adjacentes.
Então, ao realizar operações algébricas simples nesses vetores de palavras, a máquina seria capaz de fornecer as respostas como seres humanos.
Componentes da PNL
O diagrama a seguir representa os componentes do processamento de linguagem natural (PNL) -
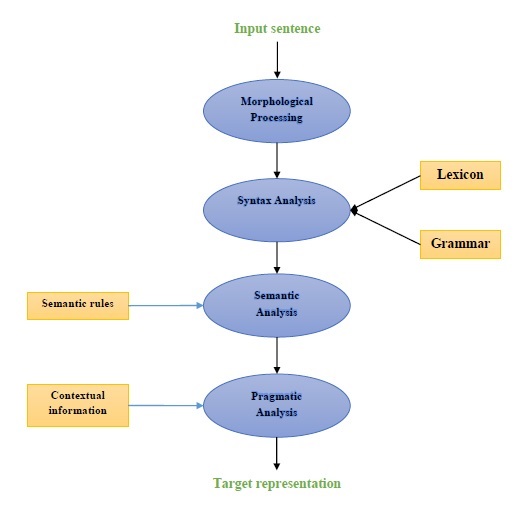
Processamento Morfológico
O processamento morfológico é o primeiro componente da PNL. Inclui a divisão de pedaços de entrada de idioma em conjuntos de tokens correspondentes a parágrafos, frases e palavras. Por exemplo, uma palavra como“everyday” pode ser dividido em dois tokens de subpalavra como “every-day”.
Análise de sintaxe
A análise sintática, o segundo componente, é um dos componentes mais importantes da PNL. Os objetivos deste componente são os seguintes -
Para verificar se uma frase está bem formada ou não.
Para dividi-lo em uma estrutura que mostra as relações sintáticas entre as diferentes palavras.
Por exemplo, as frases como “The school goes to the student” seria rejeitado pelo analisador de sintaxe.
Análise semântica
A Análise Semântica é o terceiro componente da PNL que é usado para verificar a significância do texto. Inclui desenhar o significado exato, ou podemos dizer o significado do dicionário a partir do texto. Por exemplo, frases como “É um sorvete quente”. seria descartado pelo analisador semântico.
Análise pragmática
A análise pragmática é o quarto componente da PNL. Inclui ajustar os objetos reais ou eventos que existem em cada contexto com referências de objeto obtidas por componente anterior, isto é, análise semântica. Por exemplo, as frases como“Put the fruits in the basket on the table” pode ter duas interpretações semânticas, portanto, o analisador pragmático escolherá entre essas duas possibilidades.
Exemplos de aplicativos de PNL
PNL, uma tecnologia emergente, deriva várias formas de IA que costumávamos ver atualmente. Para as aplicações cada vez mais cognitivas de hoje e de amanhã, o uso da PNL na criação de uma interface interativa e contínua entre humanos e máquinas continuará a ser uma prioridade. A seguir estão algumas das aplicações muito úteis da PNL.
Maquina de tradução
A tradução automática (MT) é uma das aplicações mais importantes do processamento de linguagem natural. MT é basicamente um processo de tradução de um idioma ou texto de origem para outro idioma. O sistema de tradução automática pode ser bilíngue ou multilíngue.
Luta contra o spam
Devido ao enorme aumento de e-mails indesejados, os filtros de spam se tornaram importantes porque são a primeira linha de defesa contra esse problema. Considerando seus problemas de falso-positivo e falso-negativo como os principais problemas, a funcionalidade da PNL pode ser usada para desenvolver um sistema de filtragem de spam.
Modelagem de N-gram, Word Stemming e classificação Bayesiana são alguns dos modelos de PNL existentes que podem ser usados para filtragem de spam.
Recuperação de informação e pesquisa na web
A maioria dos mecanismos de pesquisa, como Google, Yahoo, Bing, WolframAlpha, etc., baseiam sua tecnologia de tradução automática (MT) em modelos de aprendizado profundo de PNL. Esses modelos de aprendizagem profunda permitem que os algoritmos leiam o texto na página da Web, interpretem seu significado e o traduzam para outro idioma.
Resumo Automático de Texto
O resumo automático de texto é uma técnica que cria um resumo curto e preciso de documentos de texto mais longos. Portanto, nos ajuda a obter informações relevantes em menos tempo. Nesta era digital, temos uma grande necessidade de sumarização automática de textos porque temos uma enxurrada de informações pela internet que não vai parar. A PNL e suas funcionalidades desempenham um papel importante no desenvolvimento de um resumo automático de texto.
Correção de gramática
A correção ortográfica e gramatical é um recurso muito útil de software de processamento de texto como o Microsoft Word. O processamento de linguagem natural (PNL) é amplamente utilizado para essa finalidade.
Responder perguntas
O atendimento de perguntas, outra aplicação principal do processamento de linguagem natural (PNL), concentra-se na construção de sistemas que respondem automaticamente às perguntas postadas pelo usuário em sua linguagem natural.
Análise de sentimentos
A análise de sentimento está entre uma das outras aplicações importantes do processamento de linguagem natural (PNL). Como o próprio nome indica, a análise de sentimento é usada para -
Identifique os sentimentos entre vários posts e
Identifique o sentimento em que as emoções não são expressas explicitamente.
Empresas de comércio eletrônico online, como Amazon, ebay, etc., estão usando a análise de sentimento para identificar a opinião e o sentimento de seus clientes online. Isso os ajudará a entender o que seus clientes pensam sobre seus produtos e serviços.
Motores de fala
Mecanismos de fala como Siri, Google Voice, Alexa são construídos em PNL para que possamos nos comunicar com eles em nossa linguagem natural.
Implementando PNL
Para construir os aplicativos mencionados acima, precisamos ter um conjunto de habilidades específicas com um grande conhecimento da linguagem e ferramentas para processar a linguagem de forma eficiente. Para isso, temos várias ferramentas de código aberto disponíveis. Alguns deles são de código aberto, enquanto outros são desenvolvidos por organizações para construir seus próprios aplicativos de PNL. A seguir está a lista de algumas ferramentas de PNL -
Kit de ferramentas de linguagem natural (NLTK)
Mallet
GATE
Open NLP
UIMA
Genism
Kit de ferramentas de Stanford
A maioria dessas ferramentas é escrita em Java.
Kit de ferramentas de linguagem natural (NLTK)
Entre as ferramentas de PNL mencionadas acima, o NLTK tem uma pontuação muito alta quando se trata de facilidade de uso e explicação do conceito. A curva de aprendizado do Python é muito rápida e o NLTK é escrito em Python, então o NLTK também tem um kit de aprendizado muito bom. O NLTK incorporou a maioria das tarefas como tokenização, lematização, lematização, pontuação, contagem de caracteres e contagem de palavras. É muito elegante e fácil de trabalhar.
Para instalar o NLTK, devemos ter o Python instalado em nossos computadores. Você pode acessar o link www.python.org/downloads e selecionar a versão mais recente para o seu sistema operacional, ou seja, Windows, Mac e Linux / Unix. Para o tutorial básico sobre Python, você pode consultar o link www.tutorialspoint.com/python3/index.htm .
Agora, depois de instalar o Python em seu sistema de computador, vamos entender como podemos instalar o NLTK.
Instalando NLTK
Podemos instalar o NLTK em vários sistemas operacionais da seguinte maneira -
No Windows
Para instalar o NLTK no sistema operacional Windows, siga as etapas abaixo -
Primeiro, abra o prompt de comando do Windows e navegue até o local do pip pasta.
Em seguida, digite o seguinte comando para instalar o NLTK -
pip3 install nltkAgora, abra o PythonShell no menu Iniciar do Windows e digite o seguinte comando para verificar a instalação do NLTK -
Import nltkSe não obtiver nenhum erro, você instalou com êxito o NLTK em seu sistema operacional Windows com Python3.
No Mac / Linux
Para instalar o NLTK no Mac / Linux OS, escreva o seguinte comando -
sudo pip install -U nltkSe você não tem o pip instalado no seu computador, siga as instruções fornecidas abaixo para instalar primeiro pip -
Primeiro, atualize o índice do pacote seguindo o seguinte comando -
sudo apt updateAgora, digite o seguinte comando para instalar pip para python 3 -
sudo apt install python3-pipAtravés da Anaconda
Para instalar o NLTK através do Anaconda, siga os passos abaixo -
Primeiro, para instalar o Anaconda, vá para o link www.anaconda.com/distribution/#download-section e selecione a versão do Python que você precisa instalar.
Depois de ter o Anaconda no sistema do seu computador, vá para o prompt de comando e escreva o seguinte comando -
conda install -c anaconda nltk
Você precisa revisar a saída e inserir 'sim'. O NLTK será baixado e instalado em seu pacote Anaconda.
Baixando o conjunto de dados e pacotes da NLTK
Agora temos o NLTK instalado em nossos computadores, mas para usá-lo precisamos baixar os conjuntos de dados (corpus) disponíveis nele. Alguns dos conjuntos de dados importantes disponíveis sãostpwords, guntenberg, framenet_v15 e assim por diante.
Com a ajuda dos comandos a seguir, podemos baixar todos os conjuntos de dados NLTK -
import nltk
nltk.download()
Você obterá a seguinte janela de download do NLTK.
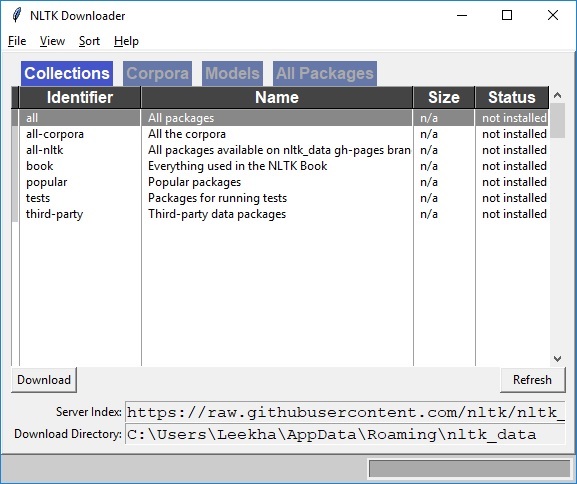
Agora, clique no botão de download para baixar os conjuntos de dados.
Como executar o script NLTK?
A seguir está o exemplo em que estamos implementando o algoritmo Porter Stemmer usando PorterStemmerclasse nltk. com este exemplo, você seria capaz de entender como executar o script NLTK.
Primeiro, precisamos importar o kit de ferramentas de linguagem natural (nltk).
import nltkAgora, importe o PorterStemmer classe para implementar o algoritmo Porter Stemmer.
from nltk.stem import PorterStemmerEm seguida, crie uma instância da classe Porter Stemmer da seguinte maneira -
word_stemmer = PorterStemmer()Agora, insira a palavra que você deseja radicalizar. -
word_stemmer.stem('writing')Resultado
'write'word_stemmer.stem('eating')Resultado
'eat'O que é tokenização?
Pode ser definido como o processo de quebrar um pedaço de texto em partes menores, como frases e palavras. Essas partes menores são chamadas de tokens. Por exemplo, uma palavra é um token em uma frase, e uma frase é um token em um parágrafo.
Como sabemos que a PNL é usada para construir aplicativos como análise de sentimento, sistemas de controle de qualidade, tradução de idiomas, chatbots inteligentes, sistemas de voz, etc., portanto, para construí-los, torna-se vital entender o padrão no texto. Os tokens, mencionados acima, são muito úteis para encontrar e compreender esses padrões. Podemos considerar a tokenização como a etapa base para outras receitas, como lematização e lematização.
Pacote NLTK
nltk.tokenize é o pacote fornecido pelo módulo NLTK para realizar o processo de tokenização.
Tokenização de frases em palavras
Dividir a frase em palavras ou criar uma lista de palavras a partir de uma string é uma parte essencial de toda atividade de processamento de texto. Vamos entendê-lo com a ajuda de várias funções / módulos fornecidos pornltk.tokenize pacote.
módulo word_tokenize
word_tokenizemódulo é usado para tokenização de palavras básicas. O exemplo a seguir usará este módulo para dividir uma frase em palavras.
Exemplo
import nltk
from nltk.tokenize import word_tokenize
word_tokenize('Tutorialspoint.com provides high quality technical tutorials for free.')Resultado
['Tutorialspoint.com', 'provides', 'high', 'quality', 'technical', 'tutorials', 'for', 'free', '.']Classe TreebankWordTokenizer
word_tokenize módulo, usado acima é basicamente uma função de wrapper que chama a função tokenize () como uma instância do TreebankWordTokenizerclasse. Ele dará a mesma saída que obtemos ao usar o módulo word_tokenize () para dividir as sentenças em palavras. Vamos ver o mesmo exemplo implementado acima -
Exemplo
Primeiro, precisamos importar o kit de ferramentas de linguagem natural (nltk).
import nltkAgora, importe o TreebankWordTokenizer classe para implementar o algoritmo de tokenizador de palavras -
from nltk.tokenize import TreebankWordTokenizerEm seguida, crie uma instância da classe TreebankWordTokenizer da seguinte maneira -
Tokenizer_wrd = TreebankWordTokenizer()Agora, insira a frase que deseja converter em tokens -
Tokenizer_wrd.tokenize(
'Tutorialspoint.com provides high quality technical tutorials for free.'
)Resultado
[
'Tutorialspoint.com', 'provides', 'high', 'quality',
'technical', 'tutorials', 'for', 'free', '.'
]Exemplo de implementação completo
Vamos ver o exemplo de implementação completo abaixo
import nltk
from nltk.tokenize import TreebankWordTokenizer
tokenizer_wrd = TreebankWordTokenizer()
tokenizer_wrd.tokenize('Tutorialspoint.com provides high quality technical
tutorials for free.')Resultado
[
'Tutorialspoint.com', 'provides', 'high', 'quality',
'technical', 'tutorials','for', 'free', '.'
]A convenção mais significativa de um tokenizer é separar as contrações. Por exemplo, se usarmos o módulo word_tokenize () para este propósito, ele dará a saída da seguinte forma -
Exemplo
import nltk
from nltk.tokenize import word_tokenize
word_tokenize('won’t')Resultado
['wo', "n't"]]Esse tipo de convenção por TreebankWordTokenizeré inaceitável. É por isso que temos dois tokenizadores de palavras alternativos, a saberPunktWordTokenizer e WordPunctTokenizer.
Classe WordPunktTokenizer
Um tokenizador de palavra alternativo que divide toda a pontuação em tokens separados. Vamos entender isso com o seguinte exemplo simples -
Exemplo
from nltk.tokenize import WordPunctTokenizer
tokenizer = WordPunctTokenizer()
tokenizer.tokenize(" I can't allow you to go home early")Resultado
['I', 'can', "'", 't', 'allow', 'you', 'to', 'go', 'home', 'early']Tokenização de texto em frases
Nesta seção, vamos dividir o texto / parágrafo em sentenças. NLTK fornecesent_tokenize módulo para este fim.
Por que é necessário?
Uma pergunta óbvia que surgiu em nossa mente é que, quando temos um tokenizador de palavras, por que precisamos do tokenizador de frases ou por que precisamos tokenizar o texto em frases. Suponha que precisemos contar palavras médias em sentenças, como podemos fazer isso? Para realizar esta tarefa, precisamos de tokenização de frase e tokenização de palavra.
Vamos entender a diferença entre frase e tokenizador de palavras com a ajuda do seguinte exemplo simples -
Exemplo
import nltk
from nltk.tokenize import sent_tokenize
text = "Let us understand the difference between sentence & word tokenizer.
It is going to be a simple example."
sent_tokenize(text)Resultado
[
"Let us understand the difference between sentence & word tokenizer.",
'It is going to be a simple example.'
]Tokenização de frases usando expressões regulares
Se você acha que a saída do tokenizer de palavras é inaceitável e deseja controle completo sobre como tokenizar o texto, temos uma expressão regular que pode ser usada ao fazer a tokenização de frases. NLTK fornecerRegexpTokenizer classe para conseguir isso.
Vamos entender o conceito com a ajuda de dois exemplos abaixo.
No primeiro exemplo, usaremos uma expressão regular para combinar tokens alfanuméricos mais aspas simples, de modo que não dividamos as contrações como “won’t”.
Exemplo 1
import nltk
from nltk.tokenize import RegexpTokenizer
tokenizer = RegexpTokenizer("[\w']+")
tokenizer.tokenize("won't is a contraction.")
tokenizer.tokenize("can't is a contraction.")Resultado
["won't", 'is', 'a', 'contraction']
["can't", 'is', 'a', 'contraction']No primeiro exemplo, usaremos uma expressão regular para tokenizar em espaços em branco.
Exemplo 2
import nltk
from nltk.tokenize import RegexpTokenizer
tokenizer = RegexpTokenizer('/s+' , gaps = True)
tokenizer.tokenize("won't is a contraction.")Resultado
["won't", 'is', 'a', 'contraction']Na saída acima, podemos ver que a pontuação permanece nos tokens. O parâmetro gaps = True significa que o padrão identificará os gaps para tokenizar. Por outro lado, se usarmos o parâmetro gaps = False, o padrão será usado para identificar os tokens que podem ser vistos no exemplo a seguir -
import nltk
from nltk.tokenize import RegexpTokenizer
tokenizer = RegexpTokenizer('/s+' , gaps = False)
tokenizer.tokenize("won't is a contraction.")Resultado
[ ]Isso nos dará a saída em branco.
Por que treinar o próprio tokenizer de frase?
Esta é uma questão muito importante: se temos o tokenizador de frase padrão do NLTK, por que precisamos treinar um tokenizador de frase? A resposta a esta pergunta está na qualidade do tokenizer de frase padrão do NLTK. O tokenizer padrão do NLTK é basicamente um tokenizer de uso geral. Embora funcione muito bem, pode não ser uma boa escolha para texto fora do padrão, que talvez seja o nosso texto, ou para um texto que esteja tendo uma formatação única. Para tokenizar esse texto e obter melhores resultados, devemos treinar nosso próprio tokenizer de frase.
Exemplo de Implementação
Para este exemplo, usaremos o corpus do webtext. O arquivo de texto que vamos usar a partir deste corpus está tendo o texto formatado como as caixas de diálogo mostradas abaixo -
Guy: How old are you?
Hipster girl: You know, I never answer that question. Because to me, it's about
how mature you are, you know? I mean, a fourteen year old could be more mature
than a twenty-five year old, right? I'm sorry, I just never answer that question.
Guy: But, uh, you're older than eighteen, right?
Hipster girl: Oh, yeah.Salvamos este arquivo de texto com o nome de training_tokenizer. NLTK fornece uma classe chamadaPunktSentenceTokenizercom a ajuda do qual podemos treinar em texto bruto para produzir um tokenizer de frase personalizado. Podemos obter texto bruto lendo um arquivo ou de um corpus NLTK usando oraw() método.
Vejamos o exemplo abaixo para obter mais informações sobre ele -
Primeiro, importe PunktSentenceTokenizer classe de nltk.tokenize pacote -
from nltk.tokenize import PunktSentenceTokenizerAgora importe webtext corpus de nltk.corpus pacote
from nltk.corpus import webtextEm seguida, usando raw() método, obter o texto bruto de training_tokenizer.txt arquivo da seguinte forma -
text = webtext.raw('C://Users/Leekha/training_tokenizer.txt')Agora, crie uma instância de PunktSentenceTokenizer e imprimir as frases tokenizadas do arquivo de texto da seguinte forma -
sent_tokenizer = PunktSentenceTokenizer(text)
sents_1 = sent_tokenizer.tokenize(text)
print(sents_1[0])Resultado
White guy: So, do you have any plans for this evening?
print(sents_1[1])
Output:
Asian girl: Yeah, being angry!
print(sents_1[670])
Output:
Guy: A hundred bucks?
print(sents_1[675])
Output:
Girl: But you already have a Big Mac...Exemplo de implementação completo
from nltk.tokenize import PunktSentenceTokenizer
from nltk.corpus import webtext
text = webtext.raw('C://Users/Leekha/training_tokenizer.txt')
sent_tokenizer = PunktSentenceTokenizer(text)
sents_1 = sent_tokenizer.tokenize(text)
print(sents_1[0])Resultado
White guy: So, do you have any plans for this evening?Para entender a diferença entre o tokenizer de frase padrão do NLTK e nosso próprio tokenizer de frase treinado, vamos tokenizar o mesmo arquivo com o tokenizer de frase padrão, isto é, sent_tokenize ().
from nltk.tokenize import sent_tokenize
from nltk.corpus import webtext
text = webtext.raw('C://Users/Leekha/training_tokenizer.txt')
sents_2 = sent_tokenize(text)
print(sents_2[0])
Output:
White guy: So, do you have any plans for this evening?
print(sents_2[675])
Output:
Hobo: Y'know what I'd do if I was rich?Com a ajuda da diferença na saída, podemos entender o conceito por que é útil treinar nosso próprio tokenizer de frase.
O que são palavras irrelevantes?
Algumas palavras comuns que estão presentes no texto, mas não contribuem para o significado de uma frase. Essas palavras não são importantes para o propósito de recuperação de informações ou processamento de linguagem natural. As palavras irrelevantes mais comuns são 'o' e 'a'.
Corpus de palavras irrelevantes NLTK
Na verdade, o kit de ferramentas Natural Language vem com um corpus de palavras irrelevantes contendo listas de palavras para vários idiomas. Vamos entender seu uso com a ajuda do seguinte exemplo -
Primeiro, importe as palavras de interrupção Copus de nltk.corpus pacote -
from nltk.corpus import stopwordsAgora, usaremos palavras irrelevantes de idiomas ingleses
english_stops = set(stopwords.words('english'))
words = ['I', 'am', 'a', 'writer']
[word for word in words if word not in english_stops]Resultado
['I', 'writer']Exemplo de implementação completo
from nltk.corpus import stopwords
english_stops = set(stopwords.words('english'))
words = ['I', 'am', 'a', 'writer']
[word for word in words if word not in english_stops]Resultado
['I', 'writer']Encontrando a lista completa de idiomas suportados
Com a ajuda do seguinte script Python, também podemos encontrar a lista completa de linguagens suportadas pelo corpus de palavras irrelevantes NLTK -
from nltk.corpus import stopwords
stopwords.fileids()Resultado
[
'arabic', 'azerbaijani', 'danish', 'dutch', 'english', 'finnish', 'french',
'german', 'greek', 'hungarian', 'indonesian', 'italian', 'kazakh', 'nepali',
'norwegian', 'portuguese', 'romanian', 'russian', 'slovene', 'spanish',
'swedish', 'tajik', 'turkish'
]O que é Wordnet?
Wordnet é um grande banco de dados lexical em inglês, criado por Princeton. Faz parte do corpus NLTK. Substantivos, verbos, adjetivos e advérbios, todos são agrupados em conjuntos de synsets, ou seja, sinônimos cognitivos. Aqui, cada conjunto de synsets expressa um significado distinto. A seguir estão alguns casos de uso do Wordnet -
- Pode ser usado para pesquisar a definição de uma palavra
- Podemos encontrar sinônimos e antônimos de uma palavra
- Relações de palavras e semelhanças podem ser exploradas usando Wordnet
- Desambiguação de sentido de palavra para aquelas palavras com múltiplos usos e definições
Como importar Wordnet?
Wordnet pode ser importado com a ajuda do seguinte comando -
from nltk.corpus import wordnetPara um comando mais compacto, use o seguinte -
from nltk.corpus import wordnet as wnInstâncias Synset
Synset são agrupamentos de palavras sinônimos que expressam o mesmo conceito. Ao usar o Wordnet para pesquisar palavras, você obterá uma lista de ocorrências de Synset.
wordnet.synsets (word)
Para obter uma lista de Synsets, podemos procurar qualquer palavra no Wordnet usando wordnet.synsets(word). Por exemplo, na próxima receita do Python, vamos procurar o Synset para o 'cachorro' junto com algumas propriedades e métodos de Synset -
Exemplo
Primeiro, importe o wordnet da seguinte forma -
from nltk.corpus import wordnet as wnAgora, forneça a palavra que deseja procurar no Synset -
syn = wn.synsets('dog')[0]Aqui, estamos usando o método name () para obter o nome exclusivo do synset, que pode ser usado para obter o Synset diretamente -
syn.name()
Output:
'dog.n.01'Em seguida, estamos usando o método definition () que nos dará a definição da palavra -
syn.definition()
Output:
'a member of the genus Canis (probably descended from the common wolf) that has
been domesticated by man since prehistoric times; occurs in many breeds'Outro método é o examples () que nos dará os exemplos relacionados à palavra -
syn.examples()
Output:
['the dog barked all night']Exemplo de implementação completo
from nltk.corpus import wordnet as wn
syn = wn.synsets('dog')[0]
syn.name()
syn.definition()
syn.examples()Obtendo Hypernyms
Synsets são organizados em uma estrutura semelhante a uma árvore de herança na qual Hypernyms representa termos mais abstratos enquanto Hyponymsrepresenta os termos mais específicos. Uma das coisas importantes é que essa árvore pode ser rastreada até um hiperônimo raiz. Vamos entender o conceito com a ajuda do seguinte exemplo -
from nltk.corpus import wordnet as wn
syn = wn.synsets('dog')[0]
syn.hypernyms()Resultado
[Synset('canine.n.02'), Synset('domestic_animal.n.01')]Aqui, podemos ver que canino e domestic_animal são os hiperônimos de 'cão'.
Agora, podemos encontrar hipônimos de 'cachorro' da seguinte forma -
syn.hypernyms()[0].hyponyms()Resultado
[
Synset('bitch.n.04'),
Synset('dog.n.01'),
Synset('fox.n.01'),
Synset('hyena.n.01'),
Synset('jackal.n.01'),
Synset('wild_dog.n.01'),
Synset('wolf.n.01')
]Na saída acima, podemos ver que 'cachorro' é apenas um dos muitos hipônimos de 'animais_ domésticos'.
Para encontrar a raiz de tudo isso, podemos usar o seguinte comando -
syn.root_hypernyms()Resultado
[Synset('entity.n.01')]Pela saída acima, podemos ver que ele tem apenas uma raiz.
Exemplo de implementação completo
from nltk.corpus import wordnet as wn
syn = wn.synsets('dog')[0]
syn.hypernyms()
syn.hypernyms()[0].hyponyms()
syn.root_hypernyms()Resultado
[Synset('entity.n.01')]Lemas em Wordnet
Em linguística, a forma canônica ou morfológica de uma palavra é chamada de lema. Para encontrar um sinônimo, bem como um antônimo de uma palavra, também podemos pesquisar lemas no WordNet. Vamos ver como.
Encontrar sinônimos
Usando o método lemma (), podemos encontrar o número de sinônimos de um Synset. Vamos aplicar este método no synset 'dog' -
Exemplo
from nltk.corpus import wordnet as wn
syn = wn.synsets('dog')[0]
lemmas = syn.lemmas()
len(lemmas)Resultado
3A saída acima mostra que 'cachorro' tem três lemas.
Obtendo o nome do primeiro lema da seguinte maneira -
lemmas[0].name()
Output:
'dog'Obtendo o nome do segundo lema da seguinte maneira -
lemmas[1].name()
Output:
'domestic_dog'Obtendo o nome do terceiro lema da seguinte maneira -
lemmas[2].name()
Output:
'Canis_familiaris'Na verdade, um Synset representa um grupo de lemas que têm significados semelhantes, enquanto um lema representa uma forma de palavra distinta.
Encontrando antônimos
No WordNet, alguns lemas também têm antônimos. Por exemplo, a palavra 'bom' tem um total de 27 sinets, entre eles, 5 possuem lemas com antônimos. Vamos encontrar os antônimos (quando a palavra 'bom' é usada como substantivo e quando a palavra 'bom' é usada como adjetivo).
Exemplo 1
from nltk.corpus import wordnet as wn
syn1 = wn.synset('good.n.02')
antonym1 = syn1.lemmas()[0].antonyms()[0]
antonym1.name()Resultado
'evil'antonym1.synset().definition()Resultado
'the quality of being morally wrong in principle or practice'O exemplo acima mostra que a palavra 'bom', quando usada como substantivo, tem o primeiro antônimo 'mal'.
Exemplo 2
from nltk.corpus import wordnet as wn
syn2 = wn.synset('good.a.01')
antonym2 = syn2.lemmas()[0].antonyms()[0]
antonym2.name()Resultado
'bad'antonym2.synset().definition()Resultado
'having undesirable or negative qualities’O exemplo acima mostra que a palavra 'bom', quando usada como adjetivo, tem o primeiro antônimo 'ruim'.
O que é Stemming?
Stemming é uma técnica usada para extrair a forma básica das palavras removendo afixos delas. É como cortar os galhos de uma árvore até o caule. Por exemplo, a raiz das palavraseating, eats, eaten é eat.
Os mecanismos de pesquisa usam derivação para indexar as palavras. É por isso que, em vez de armazenar todas as formas de uma palavra, um mecanismo de pesquisa pode armazenar apenas as raízes. Dessa forma, a derivação reduz o tamanho do índice e aumenta a precisão da recuperação.
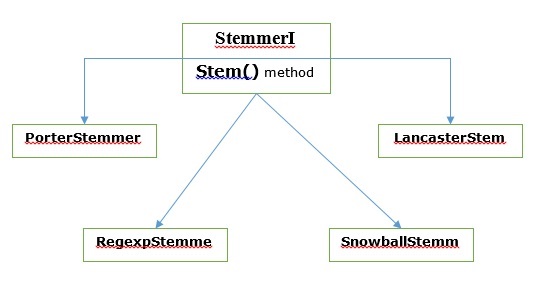
Vários algoritmos de stemming
Em NLTK, stemmerI, que tem stem(), interface tem todos os lematizadores que iremos cobrir a seguir. Vamos entendê-lo com o seguinte diagrama
Algoritmo de lematização de Porter
É um dos algoritmos de lematização mais comuns que basicamente é projetado para remover e substituir sufixos conhecidos de palavras em inglês.
Aula PorterStemmer
NLTK tem PorterStemmercom a ajuda da qual podemos facilmente implementar algoritmos de Porter Stemmer para a palavra que queremos derivar. Esta classe conhece várias formas de palavras regulares e sufixos com a ajuda dos quais ela pode transformar a palavra de entrada em um radical final. O radical resultante geralmente é uma palavra mais curta com o mesmo significado de raiz. Vamos ver um exemplo -
Primeiro, precisamos importar o kit de ferramentas de linguagem natural (nltk).
import nltkAgora, importe o PorterStemmer classe para implementar o algoritmo Porter Stemmer.
from nltk.stem import PorterStemmerEm seguida, crie uma instância da classe Porter Stemmer da seguinte maneira -
word_stemmer = PorterStemmer()Agora, insira a palavra que você deseja radicalizar.
word_stemmer.stem('writing')Resultado
'write'word_stemmer.stem('eating')Resultado
'eat'Exemplo de implementação completo
import nltk
from nltk.stem import PorterStemmer
word_stemmer = PorterStemmer()
word_stemmer.stem('writing')Resultado
'write'Lancaster stemming algoritmo
Foi desenvolvido na Lancaster University e é outro algoritmo de derivação muito comum.
Classe LancasterStemmer
NLTK tem LancasterStemmerclasse com a ajuda da qual podemos facilmente implementar algoritmos Lancaster Stemmer para a palavra que queremos derivar. Vamos ver um exemplo -
Primeiro, precisamos importar o kit de ferramentas de linguagem natural (nltk).
import nltkAgora, importe o LancasterStemmer classe para implementar o algoritmo Lancaster Stemmer
from nltk.stem import LancasterStemmerEm seguida, crie uma instância de LancasterStemmer classe como segue -
Lanc_stemmer = LancasterStemmer()Agora, insira a palavra que você deseja radicalizar.
Lanc_stemmer.stem('eats')Resultado
'eat'Exemplo de implementação completo
import nltk
from nltk.stem import LancatserStemmer
Lanc_stemmer = LancasterStemmer()
Lanc_stemmer.stem('eats')Resultado
'eat'Algoritmo de lematização de expressão regular
Com a ajuda deste algoritmo de lematização, podemos construir nosso próprio lematizador.
Classe RegexpStemmer
NLTK tem RegexpStemmerclasse com a ajuda da qual podemos facilmente implementar algoritmos de Stemmer de expressão regular. Basicamente, ele pega uma única expressão regular e remove qualquer prefixo ou sufixo que corresponda à expressão. Vamos ver um exemplo -
Primeiro, precisamos importar o kit de ferramentas de linguagem natural (nltk).
import nltkAgora, importe o RegexpStemmer classe para implementar o algoritmo Regular Expression Stemmer.
from nltk.stem import RegexpStemmerEm seguida, crie uma instância de RegexpStemmer classe e fornece o sufixo ou prefixo que você deseja remover da palavra da seguinte maneira -
Reg_stemmer = RegexpStemmer(‘ing’)Agora, insira a palavra que você deseja radicalizar.
Reg_stemmer.stem('eating')Resultado
'eat'Reg_stemmer.stem('ingeat')Resultado
'eat'
Reg_stemmer.stem('eats')Resultado
'eat'Exemplo de implementação completo
import nltk
from nltk.stem import RegexpStemmer
Reg_stemmer = RegexpStemmer()
Reg_stemmer.stem('ingeat')Resultado
'eat'Algoritmo de stemming bola de neve
É outro algoritmo de lematização muito útil.
Aula SnowballStemmer
NLTK tem SnowballStemmerclasse com a ajuda da qual podemos facilmente implementar algoritmos Snowball Stemmer. Ele suporta 15 idiomas diferentes do inglês. Para usar essa classe fumegante, precisamos criar uma instância com o nome da linguagem que estamos usando e, em seguida, chamar o método stem (). Vamos ver um exemplo -
Primeiro, precisamos importar o kit de ferramentas de linguagem natural (nltk).
import nltkAgora, importe o SnowballStemmer classe para implementar o algoritmo Snowball Stemmer
from nltk.stem import SnowballStemmerVamos ver os idiomas que ele suporta -
SnowballStemmer.languagesResultado
(
'arabic',
'danish',
'dutch',
'english',
'finnish',
'french',
'german',
'hungarian',
'italian',
'norwegian',
'porter',
'portuguese',
'romanian',
'russian',
'spanish',
'swedish'
)Em seguida, crie uma instância da classe SnowballStemmer com o idioma que deseja usar. Aqui, estamos criando o lematizador para o idioma 'francês'.
French_stemmer = SnowballStemmer(‘french’)Agora, chame o método stem () e insira a palavra que você deseja transformar.
French_stemmer.stem (‘Bonjoura’)Resultado
'bonjour'Exemplo de implementação completo
import nltk
from nltk.stem import SnowballStemmer
French_stemmer = SnowballStemmer(‘french’)
French_stemmer.stem (‘Bonjoura’)Resultado
'bonjour'O que é Lemmatização?
A técnica de lematização é como uma derivação. A saída que obteremos após a lematização é chamada de 'lema', que é uma palavra raiz em vez de radical, a saída da lematização. Após a lematização, estaremos obtendo uma palavra válida que significa a mesma coisa.
NLTK fornece WordNetLemmatizer classe que é um invólucro fino em torno do wordnetcorpus. Esta classe usamorphy() função para o WordNet CorpusReaderclasse para encontrar um lema. Vamos entender com um exemplo -
Exemplo
Primeiro, precisamos importar o kit de ferramentas de linguagem natural (nltk).
import nltkAgora, importe o WordNetLemmatizer aula para implementar a técnica de lematização.
from nltk.stem import WordNetLemmatizerEm seguida, crie uma instância de WordNetLemmatizer classe.
lemmatizer = WordNetLemmatizer()Agora, chame o método lemmatize () e insira a palavra da qual deseja encontrar o lema.
lemmatizer.lemmatize('eating')Resultado
'eating'lemmatizer.lemmatize('books')Resultado
'book'Exemplo de implementação completo
import nltk
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
lemmatizer.lemmatize('books')Resultado
'book'Diferença entre Stemming e Lemmatization
Vamos entender a diferença entre Stemming e Lemmatization com a ajuda do seguinte exemplo -
import nltk
from nltk.stem import PorterStemmer
word_stemmer = PorterStemmer()
word_stemmer.stem('believes')Resultado
believimport nltk
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
lemmatizer.lemmatize(' believes ')Resultado
believA saída de ambos os programas indica a principal diferença entre lematização e lematização. PorterStemmera classe corta os 'es' da palavra. Por outro lado,WordNetLemmatizerclasse encontra uma palavra válida. Em palavras simples, a técnica de lematização analisa apenas a forma da palavra, enquanto a técnica de lematização analisa o significado da palavra. Isso significa que depois de aplicar a lematização, sempre teremos uma palavra válida.
O stemming e a lematização podem ser considerados um tipo de compressão linguística. No mesmo sentido, a substituição de palavras pode ser considerada como normalização de texto ou correção de erros.
Mas por que precisamos de substituição de palavras? Suponha que se falamos sobre tokenização, então ele está tendo problemas com contrações (como não consigo, não vou, etc.). Portanto, para lidar com essas questões, precisamos substituir palavras. Por exemplo, podemos substituir as contrações por suas formas expandidas.
Substituição de palavras usando expressão regular
Primeiro, vamos substituir palavras que correspondem à expressão regular. Mas, para isso, devemos ter um conhecimento básico das expressões regulares, bem como do módulo python re. No exemplo abaixo, estaremos substituindo a contração por suas formas expandidas (por exemplo, “não posso” será substituído por “não posso”), tudo isso usando expressões regulares.
Exemplo
Primeiro, importe o pacote necessário para trabalhar com expressões regulares.
import re
from nltk.corpus import wordnetEm seguida, defina os padrões de substituição de sua escolha da seguinte forma -
R_patterns = [
(r'won\'t', 'will not'),
(r'can\'t', 'cannot'),
(r'i\'m', 'i am'),
r'(\w+)\'ll', '\g<1> will'),
(r'(\w+)n\'t', '\g<1> not'),
(r'(\w+)\'ve', '\g<1> have'),
(r'(\w+)\'s', '\g<1> is'),
(r'(\w+)\'re', '\g<1> are'),
]Agora, crie uma classe que pode ser usada para substituir palavras -
class REReplacer(object):
def __init__(self, pattern = R_patterns):
self.pattern = [(re.compile(regex), repl) for (regex, repl) in patterns]
def replace(self, text):
s = text
for (pattern, repl) in self.pattern:
s = re.sub(pattern, repl, s)
return sSalve este programa python (digamos repRE.py) e execute-o no prompt de comando python. Depois de executá-lo, importe a classe REReplacer quando quiser substituir palavras. Vamos ver como.
from repRE import REReplacer
rep_word = REReplacer()
rep_word.replace("I won't do it")
Output:
'I will not do it'
rep_word.replace("I can’t do it")
Output:
'I cannot do it'Exemplo de implementação completo
import re
from nltk.corpus import wordnet
R_patterns = [
(r'won\'t', 'will not'),
(r'can\'t', 'cannot'),
(r'i\'m', 'i am'),
r'(\w+)\'ll', '\g<1> will'),
(r'(\w+)n\'t', '\g<1> not'),
(r'(\w+)\'ve', '\g<1> have'),
(r'(\w+)\'s', '\g<1> is'),
(r'(\w+)\'re', '\g<1> are'),
]
class REReplacer(object):
def __init__(self, patterns=R_patterns):
self.patterns = [(re.compile(regex), repl) for (regex, repl) in patterns]
def replace(self, text):
s = text
for (pattern, repl) in self.patterns:
s = re.sub(pattern, repl, s)
return sAgora, depois de salvar o programa acima e executá-lo, você pode importar a classe e usá-la da seguinte maneira -
from replacerRE import REReplacer
rep_word = REReplacer()
rep_word.replace("I won't do it")Resultado
'I will not do it'Substituição antes do processamento do texto
Uma das práticas comuns ao trabalhar com processamento de linguagem natural (PNL) é limpar o texto antes de processá-lo. Nesse sentido, também podemos usar nossoREReplacer classe criada acima no exemplo anterior, como uma etapa preliminar antes do processamento de texto, ou seja, a tokenização.
Exemplo
from nltk.tokenize import word_tokenize
from replacerRE import REReplacer
rep_word = REReplacer()
word_tokenize("I won't be able to do this now")
Output:
['I', 'wo', "n't", 'be', 'able', 'to', 'do', 'this', 'now']
word_tokenize(rep_word.replace("I won't be able to do this now"))
Output:
['I', 'will', 'not', 'be', 'able', 'to', 'do', 'this', 'now']Na receita Python acima, podemos entender facilmente a diferença entre a saída do tokenizer de palavras sem e com o uso de substituição de expressão regular.
Remoção de caracteres repetidos
Nós estritamente gramaticais em nossa linguagem cotidiana? Não, nós não somos. Por exemplo, às vezes escrevemos 'Hiiiiiiiiiiii Mohan' para enfatizar a palavra 'Hi'. Mas o sistema de computador não sabe que 'Hiiiiiiiiiiii' é uma variação da palavra “Oi”. No exemplo abaixo, estaremos criando uma classe chamadarep_word_removal que pode ser usado para remover as palavras repetidas.
Exemplo
Primeiro, importe o pacote necessário para trabalhar com expressões regulares
import re
from nltk.corpus import wordnetAgora, crie uma classe que pode ser usada para remover as palavras repetidas -
class Rep_word_removal(object):
def __init__(self):
self.repeat_regexp = re.compile(r'(\w*)(\w)\2(\w*)')
self.repl = r'\1\2\3'
def replace(self, word):
if wordnet.synsets(word):
return word
repl_word = self.repeat_regexp.sub(self.repl, word)
if repl_word != word:
return self.replace(repl_word)
else:
return repl_wordSalve este programa python (digamos, removerepeat.py) e execute-o no prompt de comando do python. Depois de executá-lo, importeRep_word_removalclasse quando você deseja remover as palavras repetidas. Vamos ver como?
from removalrepeat import Rep_word_removal
rep_word = Rep_word_removal()
rep_word.replace ("Hiiiiiiiiiiiiiiiiiiiii")
Output:
'Hi'
rep_word.replace("Hellooooooooooooooo")
Output:
'Hello'Exemplo de implementação completo
import re
from nltk.corpus import wordnet
class Rep_word_removal(object):
def __init__(self):
self.repeat_regexp = re.compile(r'(\w*)(\w)\2(\w*)')
self.repl = r'\1\2\3'
def replace(self, word):
if wordnet.synsets(word):
return word
replace_word = self.repeat_regexp.sub(self.repl, word)
if replace_word != word:
return self.replace(replace_word)
else:
return replace_wordAgora, depois de salvar o programa acima e executá-lo, você pode importar a classe e usá-la da seguinte maneira -
from removalrepeat import Rep_word_removal
rep_word = Rep_word_removal()
rep_word.replace ("Hiiiiiiiiiiiiiiiiiiiii")Resultado
'Hi'Substituindo palavras por sinônimos comuns
Ao trabalhar com PNL, especialmente no caso de análise de frequência e indexação de texto, é sempre benéfico compactar o vocabulário sem perder o significado, pois isso economiza muita memória. Para conseguir isso, devemos definir o mapeamento de uma palavra para seus sinônimos. No exemplo abaixo, estaremos criando uma classe chamadaword_syn_replacer que pode ser usado para substituir as palavras por seus sinônimos comuns.
Exemplo
Primeiro, importe o pacote necessário re para trabalhar com expressões regulares.
import re
from nltk.corpus import wordnetEm seguida, crie a classe que usa um mapeamento de substituição de palavras -
class word_syn_replacer(object):
def __init__(self, word_map):
self.word_map = word_map
def replace(self, word):
return self.word_map.get(word, word)Salve este programa python (digamos, replacesyn.py) e execute-o no prompt de comando python. Depois de executá-lo, importeword_syn_replacerclasse quando você deseja substituir palavras por sinônimos comuns. Vamos ver como.
from replacesyn import word_syn_replacer
rep_syn = word_syn_replacer ({‘bday’: ‘birthday’)
rep_syn.replace(‘bday’)Resultado
'birthday'Exemplo de implementação completo
import re
from nltk.corpus import wordnet
class word_syn_replacer(object):
def __init__(self, word_map):
self.word_map = word_map
def replace(self, word):
return self.word_map.get(word, word)Agora, depois de salvar o programa acima e executá-lo, você pode importar a classe e usá-la da seguinte maneira -
from replacesyn import word_syn_replacer
rep_syn = word_syn_replacer ({‘bday’: ‘birthday’)
rep_syn.replace(‘bday’)Resultado
'birthday'A desvantagem do método acima é que devemos codificar os sinônimos em um dicionário Python. Temos duas alternativas melhores na forma de arquivo CSV e YAML. Podemos salvar nosso vocabulário de sinônimos em qualquer um dos arquivos mencionados acima e podemos construirword_mapdicionário deles. Vamos entender o conceito com a ajuda de exemplos.
Usando arquivo CSV
Para utilizar o arquivo CSV para este fim, o arquivo deve ter duas colunas, a primeira coluna consiste em palavra e a segunda coluna consiste nos sinônimos destinados a substituí-la. Vamos salvar este arquivo comosyn.csv. No exemplo abaixo, estaremos criando uma classe chamada CSVword_syn_replacer que irá estender word_syn_replacer dentro replacesyn.py arquivo e será usado para construir o word_map dicionário de syn.csv Arquivo.
Exemplo
Primeiro, importe os pacotes necessários.
import csvEm seguida, crie a classe que usa um mapeamento de substituição de palavras -
class CSVword_syn_replacer(word_syn_replacer):
def __init__(self, fname):
word_map = {}
for line in csv.reader(open(fname)):
word, syn = line
word_map[word] = syn
super(Csvword_syn_replacer, self).__init__(word_map)Depois de executá-lo, importe CSVword_syn_replacerclasse quando você deseja substituir palavras por sinônimos comuns. Vamos ver como?
from replacesyn import CSVword_syn_replacer
rep_syn = CSVword_syn_replacer (‘syn.csv’)
rep_syn.replace(‘bday’)Resultado
'birthday'Exemplo de implementação completo
import csv
class CSVword_syn_replacer(word_syn_replacer):
def __init__(self, fname):
word_map = {}
for line in csv.reader(open(fname)):
word, syn = line
word_map[word] = syn
super(Csvword_syn_replacer, self).__init__(word_map)Agora, depois de salvar o programa acima e executá-lo, você pode importar a classe e usá-la da seguinte maneira -
from replacesyn import CSVword_syn_replacer
rep_syn = CSVword_syn_replacer (‘syn.csv’)
rep_syn.replace(‘bday’)Resultado
'birthday'Usando arquivo YAML
Como usamos o arquivo CSV, também podemos usar o arquivo YAML para essa finalidade (devemos ter o PyYAML instalado). Vamos salvar o arquivo comosyn.yaml. No exemplo abaixo, estaremos criando uma classe chamada YAMLword_syn_replacer que irá estender word_syn_replacer dentro replacesyn.py arquivo e será usado para construir o word_map dicionário de syn.yaml Arquivo.
Exemplo
Primeiro, importe os pacotes necessários.
import yamlEm seguida, crie a classe que usa um mapeamento de substituição de palavras -
class YAMLword_syn_replacer(word_syn_replacer):
def __init__(self, fname):
word_map = yaml.load(open(fname))
super(YamlWordReplacer, self).__init__(word_map)Depois de executá-lo, importe YAMLword_syn_replacerclasse quando você deseja substituir palavras por sinônimos comuns. Vamos ver como?
from replacesyn import YAMLword_syn_replacer
rep_syn = YAMLword_syn_replacer (‘syn.yaml’)
rep_syn.replace(‘bday’)Resultado
'birthday'Exemplo de implementação completo
import yaml
class YAMLword_syn_replacer(word_syn_replacer):
def __init__(self, fname):
word_map = yaml.load(open(fname))
super(YamlWordReplacer, self).__init__(word_map)Agora, depois de salvar o programa acima e executá-lo, você pode importar a classe e usá-la da seguinte maneira -
from replacesyn import YAMLword_syn_replacer
rep_syn = YAMLword_syn_replacer (‘syn.yaml’)
rep_syn.replace(‘bday’)Resultado
'birthday'Substituto do antônimo
Como sabemos, um antônimo é uma palavra que tem o significado oposto de outra palavra, e o oposto de substituição de sinônimo é chamado de substituição de antônimo. Nesta seção, estaremos lidando com a substituição de antônimos, isto é, substituindo palavras por antônimos inequívocos usando o WordNet. No exemplo abaixo, estaremos criando uma classe chamadaword_antonym_replacer que possuem dois métodos, um para substituir a palavra e outro para remover as negações.
Exemplo
Primeiro, importe os pacotes necessários.
from nltk.corpus import wordnetEm seguida, crie a classe chamada word_antonym_replacer -
class word_antonym_replacer(object):
def replace(self, word, pos=None):
antonyms = set()
for syn in wordnet.synsets(word, pos=pos):
for lemma in syn.lemmas():
for antonym in lemma.antonyms():
antonyms.add(antonym.name())
if len(antonyms) == 1:
return antonyms.pop()
else:
return None
def replace_negations(self, sent):
i, l = 0, len(sent)
words = []
while i < l:
word = sent[i]
if word == 'not' and i+1 < l:
ant = self.replace(sent[i+1])
if ant:
words.append(ant)
i += 2
continue
words.append(word)
i += 1
return wordsSalve este programa python (por exemplo, replaceeantonym.py) e execute-o no prompt de comando do python. Depois de executá-lo, importeword_antonym_replacerclasse quando você deseja substituir palavras por seus antônimos inequívocos. Vamos ver como.
from replacerantonym import word_antonym_replacer
rep_antonym = word_antonym_replacer ()
rep_antonym.replace(‘uglify’)Resultado
['beautify'']
sentence = ["Let us", 'not', 'uglify', 'our', 'country']
rep_antonym.replace _negations(sentence)Resultado
["Let us", 'beautify', 'our', 'country']Exemplo de implementação completo
nltk.corpus import wordnet
class word_antonym_replacer(object):
def replace(self, word, pos=None):
antonyms = set()
for syn in wordnet.synsets(word, pos=pos):
for lemma in syn.lemmas():
for antonym in lemma.antonyms():
antonyms.add(antonym.name())
if len(antonyms) == 1:
return antonyms.pop()
else:
return None
def replace_negations(self, sent):
i, l = 0, len(sent)
words = []
while i < l:
word = sent[i]
if word == 'not' and i+1 < l:
ant = self.replace(sent[i+1])
if ant:
words.append(ant)
i += 2
continue
words.append(word)
i += 1
return wordsAgora, depois de salvar o programa acima e executá-lo, você pode importar a classe e usá-la da seguinte maneira -
from replacerantonym import word_antonym_replacer
rep_antonym = word_antonym_replacer ()
rep_antonym.replace(‘uglify’)
sentence = ["Let us", 'not', 'uglify', 'our', 'country']
rep_antonym.replace _negations(sentence)Resultado
["Let us", 'beautify', 'our', 'country']O que é um corpus?
Um corpus é uma grande coleção, em formato estruturado, de textos legíveis por máquina que foram produzidos em um ambiente comunicativo natural. A palavra Corpora é o plural de Corpus. Corpus pode ser derivado de várias maneiras, como segue -
- Do texto que era originalmente eletrônico
- Das transcrições da língua falada
- Do reconhecimento óptico de caracteres e assim por diante
Representatividade do Corpus, Equilíbrio do Corpus, Amostragem, Tamanho do Corpus são os elementos que desempenham um papel importante na concepção do corpus. Alguns dos corpus mais populares para tarefas de PNL são TreeBank, PropBank, VarbNet e WordNet.
Como construir corpus customizado?
Durante o download do NLTK, também instalamos o pacote de dados do NLTK. Portanto, já temos o pacote de dados NLTK instalado em nosso computador. Se falarmos sobre o Windows, vamos supor que este pacote de dados está instalado emC:\natural_language_toolkit_data e se falarmos sobre Linux, Unix e Mac OS X, vamos assumir que este pacote de dados está instalado em /usr/share/natural_language_toolkit_data.
Na receita Python a seguir, vamos criar corpora customizados que devem estar dentro de um dos caminhos definidos por NLTK. É assim porque pode ser encontrado pelo NLTK. Para evitar conflito com o pacote de dados NLTK oficial, vamos criar um diretório natural_language_toolkit_data personalizado em nosso diretório inicial.
import os, os.path
path = os.path.expanduser('~/natural_language_toolkit_data')
if not os.path.exists(path):
os.mkdir(path)
os.path.exists(path)Resultado
TrueAgora, vamos verificar se temos o diretório natural_language_toolkit_data em nosso diretório inicial ou não -
import nltk.data
path in nltk.data.pathResultado
TrueComo temos a saída True, significa que temos nltk_data diretório em nosso diretório inicial.
Agora faremos um arquivo de lista de palavras, chamado wordfile.txt e colocá-lo em uma pasta, chamada corpus em nltk_data diretório (~/nltk_data/corpus/wordfile.txt) e irá carregá-lo usando nltk.data.load -
import nltk.data
nltk.data.load(‘corpus/wordfile.txt’, format = ‘raw’)Resultado
b’tutorialspoint\n’Leitores corpus
O NLTK oferece várias classes CorpusReader. Vamos abordá-los nas seguintes receitas de python
Criando um corpus de lista de palavras
NLTK tem WordListCorpusReaderclasse que fornece acesso ao arquivo que contém uma lista de palavras. Para a seguinte receita do Python, precisamos criar um arquivo de lista de palavras que pode ser CSV ou arquivo de texto normal. Por exemplo, criamos um arquivo chamado 'lista' que contém os seguintes dados -
tutorialspoint
Online
Free
TutorialsAgora vamos instanciar um WordListCorpusReader classe produzindo a lista de palavras de nosso arquivo criado ‘list’.
from nltk.corpus.reader import WordListCorpusReader
reader_corpus = WordListCorpusReader('.', ['list'])
reader_corpus.words()Resultado
['tutorialspoint', 'Online', 'Free', 'Tutorials']Criação de corpus de palavras marcadas em PDV
NLTK tem TaggedCorpusReaderclasse com a ajuda da qual podemos criar um corpus de palavras marcadas POS. Na verdade, a marcação de POS é o processo de identificar a etiqueta da classe gramatical para uma palavra.
Um dos formatos mais simples para um corpus marcado é no formato 'palavra / tag', como o trecho do corpus marrom -
The/at-tl expense/nn and/cc time/nn involved/vbn are/ber
astronomical/jj ./.No trecho acima, cada palavra possui uma tag que denota seu PDV. Por exemplo,vb refere-se a um verbo.
Agora vamos instanciar um TaggedCorpusReaderclasse que produz palavras marcadas em POS formam o arquivo ‘list.pos’, que contém o trecho acima.
from nltk.corpus.reader import TaggedCorpusReader
reader_corpus = TaggedCorpusReader('.', r'.*\.pos')
reader_corpus.tagged_words()Resultado
[('The', 'AT-TL'), ('expense', 'NN'), ('and', 'CC'), ...]Criando um corpus de frase fragmentada
NLTK tem ChnkedCorpusReaderclasse com a ajuda da qual podemos criar um corpus de frases fragmentadas. Na verdade, um pedaço é uma frase curta em uma frase.
Por exemplo, temos o seguinte trecho do treebank corpus -
[Earlier/JJR staff-reduction/NN moves/NNS] have/VBP trimmed/VBN about/
IN [300/CD jobs/NNS] ,/, [the/DT spokesman/NN] said/VBD ./.No trecho acima, cada bloco é um sintagma nominal, mas as palavras que não estão entre colchetes fazem parte da árvore de frases e não de nenhuma subárvore do sintagma nominal.
Agora vamos instanciar um ChunkedCorpusReader classe produzindo frase fragmentada do arquivo ‘list.chunk’, que contém o trecho acima.
from nltk.corpus.reader import ChunkedCorpusReader
reader_corpus = TaggedCorpusReader('.', r'.*\.chunk')
reader_corpus.chunked_words()Resultado
[
Tree('NP', [('Earlier', 'JJR'), ('staff-reduction', 'NN'), ('moves', 'NNS')]),
('have', 'VBP'), ...
]Criação de corpus de texto categorizado
NLTK tem CategorizedPlaintextCorpusReaderclasse com a ajuda da qual podemos criar um corpus de texto categorizado. É muito útil no caso em que temos um grande corpus de texto e queremos categorizá-lo em seções separadas.
Por exemplo, o corpus marrom tem várias categorias diferentes. Vamos descobri-los com a ajuda do seguinte código Python -
from nltk.corpus import brown^M
brown.categories()Resultado
[
'adventure', 'belles_lettres', 'editorial', 'fiction', 'government',
'hobbies', 'humor', 'learned', 'lore', 'mystery', 'news', 'religion',
'reviews', 'romance', 'science_fiction'
]Uma das maneiras mais fáceis de categorizar um corpus é ter um arquivo para cada categoria. Por exemplo, vamos ver os dois trechos domovie_reviews corpus -
movie_pos.txt
A fina linha vermelha é falha, mas provoca.
movie_neg.txt
Uma produção brilhante e de grande orçamento não pode compensar a falta de espontaneidade que permeia seu programa de TV.
Então, dos dois arquivos acima, temos duas categorias, a saber pos e neg.
Agora vamos instanciar um CategorizedPlaintextCorpusReader classe.
from nltk.corpus.reader import CategorizedPlaintextCorpusReader
reader_corpus = CategorizedPlaintextCorpusReader('.', r'movie_.*\.txt',
cat_pattern = r'movie_(\w+)\.txt')
reader_corpus.categories()
reader_corpus.fileids(categories = [‘neg’])
reader_corpus.fileids(categories = [‘pos’])Resultado
['neg', 'pos']
['movie_neg.txt']
['movie_pos.txt']O que é marcação de PDV?
A marcação, um tipo de classificação, é a atribuição automática da descrição dos tokens. Chamamos o descritor de 'tag', que representa uma das classes gramaticais (substantivos, verbo, advérbios, adjetivos, pronomes, conjunção e suas subcategorias), informação semântica e assim por diante.
Por outro lado, se falamos de tagging Part-of-Speech (POS), pode ser definido como o processo de conversão de uma frase na forma de uma lista de palavras, em uma lista de tuplas. Aqui, as tuplas estão na forma de (palavra, tag). Também podemos chamar de marcação POS um processo de atribuição de uma das classes gramaticais à palavra dada.
A tabela a seguir representa a notificação de PDV mais frequente usada no Penn Treebank corpus -
| Sr. Não | Tag | Descrição |
|---|---|---|
| 1 | NNP | Nome próprio, singular |
| 2 | NNPS | Substantivo próprio, plural |
| 3 | PDT | Pré determinante |
| 4 | POS | Final possessivo |
| 5 | PRP | Pronome pessoal |
| 6 | PRP $ | Pronome possessivo |
| 7 | RB | Advérbio |
| 8 | RBR | Advérbio, comparativo |
| 9 | RBS | Advérbio, superlativo |
| 10 | RP | Partícula |
| 11 | SYM | Símbolo (matemático ou científico) |
| 12 | PARA | para |
| 13 | UH | Interjeição |
| 14 | VB | Verbo, forma básica |
| 15 | VBD | Verbo, pretérito |
| 16 | VBG | Verbo, gerúndio / particípio presente |
| 17 | VBN | Verbo, passado |
| 18 | WP | Pronome Wh |
| 19 | WP $ | Pronome wh possessivo |
| 20 | WRB | Wh-advérbio |
| 21 | # | Sinal de libra |
| 22 | $ | Cifrão |
| 23 | . | Pontuação final de frase |
| 24 | , | Vírgula |
| 25 | : | Cólon, ponto e vírgula |
| 26 | ( | Parêntese esquerdo |
| 27 | ) | Caráter de colchete direito |
| 28 | " | Aspas duplas diretas |
| 29 | ' | Aspas simples abertas |
| 30 | " | Aspas duplas abertas |
| 31 | ' | Aspas simples fechadas à direita |
| 32 | " | Aspas duplas abertas à direita |
Exemplo
Vamos entender isso com um experimento Python -
import nltk
from nltk import word_tokenize
sentence = "I am going to school"
print (nltk.pos_tag(word_tokenize(sentence)))Resultado
[('I', 'PRP'), ('am', 'VBP'), ('going', 'VBG'), ('to', 'TO'), ('school', 'NN')]Por que marcação de PDV?
A marcação de POS é uma parte importante da PNL porque funciona como um pré-requisito para análises adicionais da PNL da seguinte maneira -
- Chunking
- Análise sintática
- Extração de informação
- Maquina de tradução
- Análise de sentimentos
- Análise gramatical e desambiguação do sentido das palavras
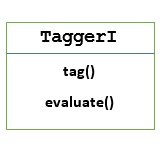
TaggerI - classe base
Todos os taggers residem no pacote nltk.tag da NLTK. A classe base desses taggers éTaggerI, significa que todos os marcadores herdam desta classe.
Methods - A classe TaggerI tem os dois métodos a seguir que devem ser implementados por todas as suas subclasses -
tag() method - Como o nome indica, este método pega uma lista de palavras como entrada e retorna uma lista de palavras marcadas como saída.
evaluate() method - Com a ajuda deste método, podemos avaliar a precisão do tagger.
A linha de base da marcação de PDV
A linha de base ou a etapa básica da marcação de POS é Default Tagging, que pode ser executado usando a classe DefaultTagger do NLTK. A marcação padrão simplesmente atribui a mesma tag POS a cada token. A marcação padrão também fornece uma linha de base para medir as melhorias de precisão.
Classe DefaultTagger
A marcação padrão é realizada usando DefaultTagging classe, que recebe um único argumento, ou seja, a tag que queremos aplicar.
Como funciona?
Como dito anteriormente, todos os etiquetadores são herdados de TaggerIclasse. oDefaultTagger é herdado de SequentialBackoffTagger que é uma subclasse de TaggerI class. Vamos entender isso com o seguinte diagrama -
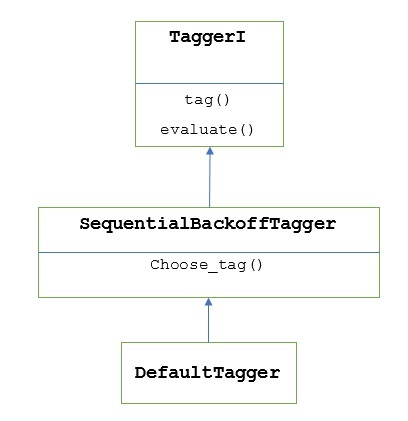
Como sendo parte de SeuentialBackoffTagger, a DefaultTagger deve implementar o método choose_tag () que leva os três argumentos a seguir.
- Lista de token
- Índice do token atual
- Lista do token anterior, ou seja, o histórico
Exemplo
import nltk
from nltk.tag import DefaultTagger
exptagger = DefaultTagger('NN')
exptagger.tag(['Tutorials','Point'])Resultado
[('Tutorials', 'NN'), ('Point', 'NN')]Neste exemplo, escolhemos uma tag de substantivo porque é o tipo de palavra mais comum. Além disso,DefaultTagger também é mais útil quando escolhemos a tag de PDV mais comum.
Avaliação de precisão
o DefaultTaggertambém é a linha de base para avaliar a precisão dos etiquetadores. Essa é a razão pela qual podemos usá-lo junto comevaluate()método para medir a precisão. oevaluate() O método usa uma lista de tokens marcados como padrão-ouro para avaliar o marcador.
A seguir está um exemplo em que usamos nosso tagger padrão, chamado exptagger, criado acima, para avaliar a precisão de um subconjunto de treebank frases marcadas com corpus -
Exemplo
import nltk
from nltk.tag import DefaultTagger
exptagger = DefaultTagger('NN')
from nltk.corpus import treebank
testsentences = treebank.tagged_sents() [1000:]
exptagger.evaluate (testsentences)Resultado
0.13198749536374715A saída acima mostra que escolhendo NN para cada tag, podemos atingir cerca de 13% de teste de precisão em 1000 entradas do treebank corpus.
Marcando uma lista de frases
Em vez de marcar uma única frase, o NLTK's TaggerI classe também nos fornece um tag_sents()método com a ajuda do qual podemos marcar uma lista de frases. A seguir está o exemplo em que marcamos duas frases simples
Exemplo
import nltk
from nltk.tag import DefaultTagger
exptagger = DefaultTagger('NN')
exptagger.tag_sents([['Hi', ','], ['How', 'are', 'you', '?']])Resultado
[
[
('Hi', 'NN'),
(',', 'NN')
],
[
('How', 'NN'),
('are', 'NN'),
('you', 'NN'),
('?', 'NN')
]
]No exemplo acima, usamos nosso tagger padrão criado anteriormente, denominado exptagger.
Desmarcando uma frase
Também podemos desmarcar uma frase. O NLTK fornece o método nltk.tag.untag () para esse propósito. Receberá uma frase com tags como entrada e fornece uma lista de palavras sem tags. Vamos ver um exemplo -
Exemplo
import nltk
from nltk.tag import untag
untag([('Tutorials', 'NN'), ('Point', 'NN')])Resultado
['Tutorials', 'Point']O que é Unigram Tagger?
Como o nome indica, unigram tagger é um tagger que usa apenas uma única palavra como contexto para determinar a tag POS (Part-of-Speech). Em palavras simples, Unigram Tagger é um tagger baseado em contexto cujo contexto é uma única palavra, ou seja, Unigram.
Como funciona?
NLTK fornece um módulo chamado UnigramTaggerpara este propósito. Mas antes de nos aprofundarmos em seu funcionamento, vamos entender a hierarquia com a ajuda do diagrama a seguir -
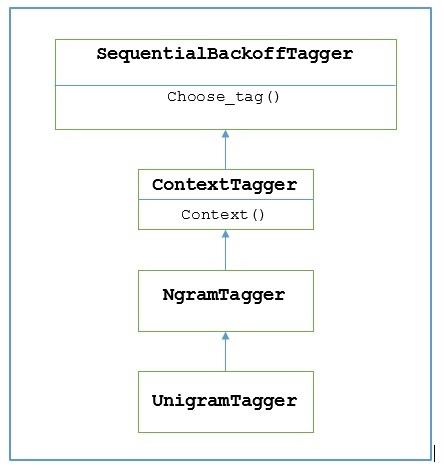
A partir do diagrama acima, entende-se que UnigramTagger é herdado de NgramTagger que é uma subclasse de ContextTagger, que herda de SequentialBackoffTagger.
O trabalho de UnigramTagger é explicado com a ajuda das seguintes etapas -
Como nós vimos, UnigramTagger herda de ContextTagger, ele implementa um context()método. estecontext() método leva os mesmos três argumentos que choose_tag() método.
O resultado de context()método será a palavra token que será usada posteriormente para criar o modelo. Depois que o modelo é criado, a palavra token também é usada para pesquisar a melhor tag.
Nesse caminho, UnigramTagger irá construir um modelo de contexto a partir da lista de frases marcadas.
Treinando um Unigram Tagger
NLTK's UnigramTaggerpode ser treinado fornecendo uma lista de frases marcadas no momento da inicialização. No exemplo abaixo, vamos usar as frases marcadas do treebank corpus. Estaremos usando as primeiras 2.500 frases desse corpus.
Exemplo
Primeiro importe o módulo UniframTagger do nltk -
from nltk.tag import UnigramTaggerEm seguida, importe o corpus que deseja usar. Aqui, estamos usando treebank corpus -
from nltk.corpus import treebankAgora, pegue as frases para fins de treinamento. Estamos pegando as primeiras 2.500 frases para fins de treinamento e as marcaremos -
train_sentences = treebank.tagged_sents()[:2500]Em seguida, aplique UnigramTagger nas sentenças usadas para fins de treinamento -
Uni_tagger = UnigramTagger(train_sentences)Tome algumas sentenças, iguais ou menores, para fins de treinamento, ou seja, 2500, para fins de teste. Aqui estamos pegando os primeiros 1500 para fins de teste -
test_sentences = treebank.tagged_sents()[1500:]
Uni_tagger.evaluate(test_sents)Resultado
0.8942306156033808Aqui, obtivemos cerca de 89 por cento de precisão para um tagger que usa pesquisa de palavra única para determinar a tag POS.
Exemplo de implementação completo
from nltk.tag import UnigramTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
Uni_tagger = UnigramTagger(train_sentences)
test_sentences = treebank.tagged_sents()[1500:]
Uni_tagger.evaluate(test_sentences)Resultado
0.8942306156033808Substituindo o modelo de contexto
Do diagrama acima, mostrando a hierarquia para UnigramTagger, conhecemos todos os etiquetadores que herdam de ContextTagger, em vez de treinar seu próprio, pode usar um modelo pré-construído. Este modelo pré-construído é simplesmente um mapeamento de dicionário Python de uma chave de contexto para uma tag. E paraUnigramTagger, as chaves de contexto são palavras individuais, enquanto para outras NgramTagger subclasses, serão tuplas.
Podemos substituir este modelo de contexto, passando outro modelo simples para o UnigramTaggerclasse em vez de passar no conjunto de treinamento. Vamos entender com a ajuda de um exemplo fácil abaixo -
Exemplo
from nltk.tag import UnigramTagger
from nltk.corpus import treebank
Override_tagger = UnigramTagger(model = {‘Vinken’ : ‘NN’})
Override_tagger.tag(treebank.sents()[0])Resultado
[
('Pierre', None),
('Vinken', 'NN'),
(',', None),
('61', None),
('years', None),
('old', None),
(',', None),
('will', None),
('join', None),
('the', None),
('board', None),
('as', None),
('a', None),
('nonexecutive', None),
('director', None),
('Nov.', None),
('29', None),
('.', None)
]Como nosso modelo contém 'Vinken' como a única chave de contexto, você pode observar a partir da saída acima que apenas essa palavra tem tag e todas as outras palavras têm None como tag.
Definir um limite mínimo de frequência
Para decidir qual tag é mais provável para um determinado contexto, o ContextTaggerclasse usa frequência de ocorrência. Ele fará isso por padrão, mesmo se a palavra de contexto e a tag ocorrerem apenas uma vez, mas podemos definir um limite mínimo de frequência passando umcutoff valor para o UnigramTaggerclasse. No exemplo abaixo, estamos passando o valor de corte na receita anterior em que treinamos um UnigramTagger -
Exemplo
from nltk.tag import UnigramTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
Uni_tagger = UnigramTagger(train_sentences, cutoff = 4)
test_sentences = treebank.tagged_sents()[1500:]
Uni_tagger.evaluate(test_sentences)Resultado
0.7357651629613641Combinando Taggers
Combinar taggers ou encadear taggers entre si é uma das características importantes do NLTK. O principal conceito por trás da combinação de taggers é que, caso um tagger não saiba como rotular uma palavra, ela será passada para o tagger encadeado. Para alcançar este propósito,SequentialBackoffTagger nos fornece o Backoff tagging característica.
Marcação de backoff
Como dito anteriormente, a marcação de backoff é uma das características importantes do SequentialBackoffTagger, que nos permite combinar etiquetadores de uma forma que, se um etiquetador não souber como etiquetar uma palavra, a palavra será passada para o próximo etiquetador e assim por diante até que não haja mais etiquetadores de backoff para verificar.
Como funciona?
Na verdade, cada subclasse de SequentialBackoffTaggerpode usar um argumento de palavra-chave 'recuar'. O valor deste argumento de palavra-chave é outra instância de umSequentialBackoffTagger. Agora, sempre que issoSequentialBackoffTaggerclasse é inicializada, uma lista interna de taggers de backoff (com ele mesmo como o primeiro elemento) será criada. Além disso, se um tagger de backoff for fornecido, a lista interna desses taggers de backoff será anexada.
No exemplo abaixo, estamos pegando DefaulTagger como o tagger de backoff na receita Python acima com a qual treinamos o UnigramTagger.
Exemplo
Neste exemplo, estamos usando DefaulTaggercomo o identificador de backoff. Sempre queUnigramTagger é incapaz de marcar uma palavra, backoff tagger, ou seja, DefaulTagger, no nosso caso, irá marcá-lo com 'NN'.
from nltk.tag import UnigramTagger
from nltk.tag import DefaultTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
back_tagger = DefaultTagger('NN')
Uni_tagger = UnigramTagger(train_sentences, backoff = back_tagger)
test_sentences = treebank.tagged_sents()[1500:]
Uni_tagger.evaluate(test_sentences)Resultado
0.9061975746536931A partir da saída acima, você pode observar que ao adicionar um tagger de backoff a precisão aumenta em cerca de 2%.
Salvando picles com picles
Como vimos, treinar um tagger é muito complicado e também leva tempo. Para economizar tempo, podemos escolher um tagger treinado para usá-lo mais tarde. No exemplo abaixo, vamos fazer isso com nosso tagger já treinado chamado‘Uni_tagger’.
Exemplo
import pickle
f = open('Uni_tagger.pickle','wb')
pickle.dump(Uni_tagger, f)
f.close()
f = open('Uni_tagger.pickle','rb')
Uni_tagger = pickle.load(f)Classe NgramTagger
A partir do diagrama de hierarquia discutido na unidade anterior, UnigramTagger é herdado de NgarmTagger classe, mas temos mais duas subclasses de NgarmTagger classe -
Subclasse BigramTagger
Na verdade, um ngram é uma subsequência de n itens, portanto, como o nome indica, BigramTaggera subclasse analisa os dois itens. O primeiro item é a palavra marcada anterior e o segundo item é a palavra marcada atual.
Subclasse TrigramTagger
Na mesma nota de BigramTagger, TrigramTagger subclass olha para os três itens, ou seja, duas palavras marcadas anteriores e uma palavra marcada atual.
Praticamente se aplicarmos BigramTagger e TrigramTaggersubclasses individualmente como fizemos com a subclasse UnigramTagger, ambas têm um desempenho muito ruim. Vejamos nos exemplos abaixo:
Usando a subclasse BigramTagger
from nltk.tag import BigramTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
Bi_tagger = BigramTagger(train_sentences)
test_sentences = treebank.tagged_sents()[1500:]
Bi_tagger.evaluate(test_sentences)Resultado
0.44669191071913594Usando a subclasse TrigramTagger
from nltk.tag import TrigramTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
Tri_tagger = TrigramTagger(train_sentences)
test_sentences = treebank.tagged_sents()[1500:]
Tri_tagger.evaluate(test_sentences)Resultado
0.41949863394526193Você pode comparar o desempenho do UnigramTagger, que usamos anteriormente (forneceu cerca de 89% de precisão) com BigramTagger (deu cerca de 44% de precisão) e TrigramTagger (deu cerca de 41% de precisão). A razão é que os marcadores Bigram e Trigram não podem aprender o contexto da (s) primeira (s) palavra (s) em uma frase. Por outro lado, a classe UnigramTagger não se preocupa com o contexto anterior e adivinha a tag mais comum para cada palavra, portanto, capaz de ter alta precisão de linha de base.
Combinando ngram taggers
A partir dos exemplos acima, é óbvio que os etiquetadores Bigram e Trigram podem contribuir quando os combinamos com etiquetagem de backoff. No exemplo abaixo, estamos combinando os identificadores Unigram, Bigram e Trigram com a marcação de backoff. O conceito é o mesmo da receita anterior, combinando o UnigramTagger com o backoff tagger. A única diferença é que estamos usando a função chamada backoff_tagger () de tagger_util.py, fornecida abaixo, para a operação de backoff.
def backoff_tagger(train_sentences, tagger_classes, backoff=None):
for cls in tagger_classes:
backoff = cls(train_sentences, backoff=backoff)
return backoffExemplo
from tagger_util import backoff_tagger
from nltk.tag import UnigramTagger
from nltk.tag import BigramTagger
from nltk.tag import TrigramTagger
from nltk.tag import DefaultTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
back_tagger = DefaultTagger('NN')
Combine_tagger = backoff_tagger(train_sentences,
[UnigramTagger, BigramTagger, TrigramTagger], backoff = back_tagger)
test_sentences = treebank.tagged_sents()[1500:]
Combine_tagger.evaluate(test_sentences)Resultado
0.9234530029238365Pelo resultado acima, podemos ver que aumenta a precisão em cerca de 3%.
Affix Tagger
Uma outra classe importante da subclasse ContextTagger é AffixTagger. Na classe AffixTagger, o contexto é prefixo ou sufixo de uma palavra. Essa é a razão pela qual a classe AffixTagger pode aprender tags com base em substrings de comprimento fixo do início ou do final de uma palavra.
Como funciona?
Seu funcionamento depende do argumento denominado affix_length que especifica o comprimento do prefixo ou sufixo. O valor padrão é 3. Mas como ele distingue se a classe AffixTagger aprendeu o prefixo ou o sufixo da palavra?
affix_length=positive - Se o valor de affix_lenght for positivo, significa que a classe AffixTagger aprenderá os prefixos das palavras.
affix_length=negative - Se o valor de affix_lenght for negativo, significa que a classe AffixTagger aprenderá os sufixos da palavra.
Para deixar mais claro, no exemplo abaixo, estaremos usando a classe AffixTagger em frases de treebank marcadas.
Exemplo
Neste exemplo, AffixTagger aprenderá o prefixo da palavra porque não estamos especificando nenhum valor para o argumento affix_length. O argumento terá o valor padrão 3 -
from nltk.tag import AffixTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
Prefix_tagger = AffixTagger(train_sentences)
test_sentences = treebank.tagged_sents()[1500:]
Prefix_tagger.evaluate(test_sentences)Resultado
0.2800492099250667Vamos ver no exemplo abaixo qual será a precisão quando fornecermos o valor 4 para o argumento affix_length -
from nltk.tag import AffixTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
Prefix_tagger = AffixTagger(train_sentences, affix_length=4 )
test_sentences = treebank.tagged_sents()[1500:]
Prefix_tagger.evaluate(test_sentences)Resultado
0.18154947354966527Exemplo
Neste exemplo, AffixTagger aprenderá o sufixo da palavra porque especificaremos o valor negativo para o argumento affix_length.
from nltk.tag import AffixTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
Suffix_tagger = AffixTagger(train_sentences, affix_length = -3)
test_sentences = treebank.tagged_sents()[1500:]
Suffix_tagger.evaluate(test_sentences)Resultado
0.2800492099250667Brill Tagger
Brill Tagger é um tagger baseado em transformação. NLTK forneceBrillTagger classe que é o primeiro tagger que não é uma subclasse de SequentialBackoffTagger. Ao contrário, uma série de regras para corrigir os resultados de um tagger inicial é usada porBrillTagger.
Como funciona?
Para treinar um BrillTagger classe usando BrillTaggerTrainer definimos a seguinte função -
def train_brill_tagger(initial_tagger, train_sentences, **kwargs) -
templates = [
brill.Template(brill.Pos([-1])),
brill.Template(brill.Pos([1])),
brill.Template(brill.Pos([-2])),
brill.Template(brill.Pos([2])),
brill.Template(brill.Pos([-2, -1])),
brill.Template(brill.Pos([1, 2])),
brill.Template(brill.Pos([-3, -2, -1])),
brill.Template(brill.Pos([1, 2, 3])),
brill.Template(brill.Pos([-1]), brill.Pos([1])),
brill.Template(brill.Word([-1])),
brill.Template(brill.Word([1])),
brill.Template(brill.Word([-2])),
brill.Template(brill.Word([2])),
brill.Template(brill.Word([-2, -1])),
brill.Template(brill.Word([1, 2])),
brill.Template(brill.Word([-3, -2, -1])),
brill.Template(brill.Word([1, 2, 3])),
brill.Template(brill.Word([-1]), brill.Word([1])),
]
trainer = brill_trainer.BrillTaggerTrainer(initial_tagger, templates, deterministic=True)
return trainer.train(train_sentences, **kwargs)Como podemos ver, esta função requer initial_tagger e train_sentences. Leva uminitial_tagger argumento e uma lista de modelos, que implementa o BrillTemplateinterface. oBrillTemplate interface é encontrada no nltk.tbl.templatemódulo. Uma dessas implementações ébrill.Template classe.
A principal função do identificador baseado em transformação é gerar regras de transformação que corrigem a saída do identificador inicial para ficar mais alinhado com as frases de treinamento. Deixe-nos ver o fluxo de trabalho abaixo -
Exemplo
Para este exemplo, usaremos combine_tagger que criamos ao pentear etiquetadores (na receita anterior) de uma cadeia de backoff de NgramTagger aulas, como initial_tagger. Primeiro, vamos avaliar o resultado usandoCombine.tagger e usar isso como initial_tagger treinar marcador de rodovalho.
from tagger_util import backoff_tagger
from nltk.tag import UnigramTagger
from nltk.tag import BigramTagger
from nltk.tag import TrigramTagger
from nltk.tag import DefaultTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
back_tagger = DefaultTagger('NN')
Combine_tagger = backoff_tagger(
train_sentences, [UnigramTagger, BigramTagger, TrigramTagger], backoff = back_tagger
)
test_sentences = treebank.tagged_sents()[1500:]
Combine_tagger.evaluate(test_sentences)Resultado
0.9234530029238365Agora, vamos ver o resultado da avaliação quando Combine_tagger é usado como initial_tagger treinar o marcador de brill -
from tagger_util import train_brill_tagger
brill_tagger = train_brill_tagger(combine_tagger, train_sentences)
brill_tagger.evaluate(test_sentences)Resultado
0.9246832510505041Podemos notar que BrillTagger classe tem um ligeiro aumento de precisão em relação ao Combine_tagger.
Exemplo de implementação completo
from tagger_util import backoff_tagger
from nltk.tag import UnigramTagger
from nltk.tag import BigramTagger
from nltk.tag import TrigramTagger
from nltk.tag import DefaultTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
back_tagger = DefaultTagger('NN')
Combine_tagger = backoff_tagger(train_sentences,
[UnigramTagger, BigramTagger, TrigramTagger], backoff = back_tagger)
test_sentences = treebank.tagged_sents()[1500:]
Combine_tagger.evaluate(test_sentences)
from tagger_util import train_brill_tagger
brill_tagger = train_brill_tagger(combine_tagger, train_sentences)
brill_tagger.evaluate(test_sentences)Resultado
0.9234530029238365
0.9246832510505041TnT Tagger
TnT Tagger, que significa Trigrams'nTags, é um tagger estatístico baseado em modelos de Markov de segunda ordem.
Como funciona?
Podemos entender o funcionamento do tagger TnT com a ajuda das seguintes etapas -
Com base em dados de treinamento, a TnT tegger mantém vários FreqDist e ConditionalFreqDist instâncias.
Depois disso, os unigramas, bigramas e trigramas serão contados por essas distribuições de frequência.
Agora, durante a marcação, por meio de frequências, ele calculará as probabilidades de possíveis marcações para cada palavra.
É por isso que, em vez de construir uma cadeia de backoff de NgramTagger, ele usa todos os modelos ngram juntos para escolher a melhor tag para cada palavra. Vamos avaliar a precisão com o tagger TnT no exemplo a seguir -
from nltk.tag import tnt
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
tnt_tagger = tnt.TnT()
tnt_tagger.train(train_sentences)
test_sentences = treebank.tagged_sents()[1500:]
tnt_tagger.evaluate(test_sentences)Resultado
0.9165508316157791Temos menos precisão do que com Brill Tagger.
Por favor, note que precisamos ligar train() antes evaluate() caso contrário, obteremos precisão de 0%.
Análise e sua relevância na PNL
A palavra 'análise', cuja origem é da palavra latina ‘pars’ (que significa ‘part’), é usado para extrair significado exato ou significado de dicionário do texto. É também chamada de análise sintática ou análise de sintaxe. Comparando as regras da gramática formal, a análise de sintaxe verifica se o texto é significativo. Uma frase como “Dê-me um sorvete quente”, por exemplo, seria rejeitada pelo analisador ou analisador sintático.
Nesse sentido, podemos definir análise sintática ou análise sintática ou análise de sintaxe da seguinte maneira -
Pode ser definido como o processo de análise das cadeias de símbolos na linguagem natural em conformidade com as regras da gramática formal.
Podemos entender a relevância da análise em PNL com a ajuda dos seguintes pontos -
Parser é usado para relatar qualquer erro de sintaxe.
Ajuda na recuperação de erros comuns, de forma que o processamento do restante do programa possa continuar.
A árvore de análise é criada com a ajuda de um analisador.
O analisador é usado para criar uma tabela de símbolos, que desempenha um papel importante na PNL.
Parser também é usado para produzir representações intermediárias (IR).
Análise Profunda Vs Rasa
| Análise Profunda | Análise superficial |
|---|---|
| Na análise profunda, a estratégia de pesquisa fornecerá uma estrutura sintática completa para uma frase. | É a tarefa de analisar uma parte limitada das informações sintáticas da tarefa fornecida. |
| É adequado para aplicativos de PNL complexos. | Ele pode ser usado para aplicativos NLP menos complexos. |
| Os sistemas de diálogo e resumos são exemplos de aplicativos de PNL em que a análise profunda é usada. | Extração de informações e mineração de texto são os exemplos de aplicativos de PNL em que a análise profunda é usada. |
| Também é chamado de análise completa. | Também é chamado de fragmentação. |
Vários tipos de analisadores
Conforme discutido, um analisador é basicamente uma interpretação procedimental da gramática. Ele encontra uma árvore ideal para a frase dada após pesquisar no espaço de uma variedade de árvores. Vamos ver alguns dos analisadores disponíveis abaixo -
Analisador descendente recursivo
A análise descendente recursiva é uma das formas mais simples de análise. A seguir estão alguns pontos importantes sobre o analisador descendente recursivo -
Ele segue um processo de cima para baixo.
Ele tenta verificar se a sintaxe do fluxo de entrada está correta ou não.
Ele lê a frase de entrada da esquerda para a direita.
Uma operação necessária para o analisador descendente recursivo é ler os caracteres do fluxo de entrada e combiná-los com os terminais da gramática.
Analisador de redução de deslocamento
A seguir estão alguns pontos importantes sobre o analisador shift-reduce -
Ele segue um processo simples de baixo para cima.
Ele tenta encontrar uma sequência de palavras e frases que correspondam ao lado direito de uma produção gramatical e as substitui pelo lado esquerdo da produção.
A tentativa acima de encontrar uma sequência de palavras continua até que toda a frase seja reduzida.
Em outras palavras simples, o analisador shift-reduce começa com o símbolo de entrada e tenta construir a árvore do analisador até o símbolo inicial.
Analisador de gráfico
A seguir estão alguns pontos importantes sobre o analisador de gráfico -
É principalmente útil ou adequado para gramáticas ambíguas, incluindo gramáticas de línguas naturais.
Ele aplica programação dinâmica aos problemas de análise.
Por causa da programação dinâmica, os resultados hipotéticos parciais são armazenados em uma estrutura chamada de 'gráfico'.
O 'gráfico' também pode ser reutilizado.
Analisador regexp
A análise regexp é uma das técnicas de análise mais usadas. A seguir estão alguns pontos importantes sobre o analisador Regexp -
Como o nome indica, ele usa uma expressão regular definida na forma de gramática no topo de uma string marcada com POS.
Basicamente, ele usa essas expressões regulares para analisar as sentenças de entrada e gerar uma árvore de análise a partir disso.
Exemplo
A seguir está um exemplo de trabalho do Regexp Parser -
import nltk
sentence = [
("a", "DT"),
("clever", "JJ"),
("fox","NN"),
("was","VBP"),
("jumping","VBP"),
("over","IN"),
("the","DT"),
("wall","NN")
]
grammar = "NP:{<DT>?<JJ>*<NN>}"
Reg_parser = nltk.RegexpParser(grammar)
Reg_parser.parse(sentence)
Output = Reg_parser.parse(sentence)
Output.draw()Resultado
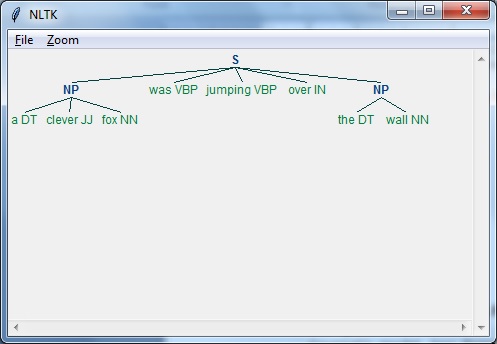
Análise de Dependência
Análise de dependência (DP), um mecanismo moderno de análise sintática, cujo conceito principal é que cada unidade linguística, ou seja, as palavras se relacionam entre si por uma ligação direta. Esses links diretos são na verdade‘dependencies’em linguística. Por exemplo, o diagrama a seguir mostra a gramática de dependência para a frase“John can hit the ball”.

Pacote NLTK
Seguimos as duas maneiras de fazer análise de dependência com NLTK -
Probabilístico, analisador de dependência projetiva
Esta é a primeira maneira de fazer análise de dependência com NLTK. Mas esse analisador tem a restrição de treinamento com um conjunto limitado de dados de treinamento.
Analisador de Stanford
Esta é outra maneira de fazer análise de dependência com NLTK. O analisador de Stanford é um analisador de dependência de última geração. O NLTK contém um invólucro. Para usá-lo, precisamos fazer o download de duas coisas -
O analisador Stanford CoreNLP .
Modelo de idioma para o idioma desejado. Por exemplo, modelo de idioma inglês.
Exemplo
Depois de fazer o download do modelo, podemos usá-lo por meio do NLTK da seguinte maneira -
from nltk.parse.stanford import StanfordDependencyParser
path_jar = 'path_to/stanford-parser-full-2014-08-27/stanford-parser.jar'
path_models_jar = 'path_to/stanford-parser-full-2014-08-27/stanford-parser-3.4.1-models.jar'
dep_parser = StanfordDependencyParser(
path_to_jar = path_jar, path_to_models_jar = path_models_jar
)
result = dep_parser.raw_parse('I shot an elephant in my sleep')
depndency = result.next()
list(dependency.triples())Resultado
[
((u'shot', u'VBD'), u'nsubj', (u'I', u'PRP')),
((u'shot', u'VBD'), u'dobj', (u'elephant', u'NN')),
((u'elephant', u'NN'), u'det', (u'an', u'DT')),
((u'shot', u'VBD'), u'prep', (u'in', u'IN')),
((u'in', u'IN'), u'pobj', (u'sleep', u'NN')),
((u'sleep', u'NN'), u'poss', (u'my', u'PRP$'))
]O que é Chunking?
Chunking, um dos processos importantes no processamento de linguagem natural, é usado para identificar classes gramaticais (POS) e frases curtas. Em outras palavras simples, com chunking, podemos obter a estrutura da frase. Também é chamadopartial parsing.
Padrões de pedaços e fendas
Chunk patternssão os padrões de tags de classes gramaticais (POS) que definem que tipo de palavras compõem um pedaço. Podemos definir padrões de chunk com a ajuda de expressões regulares modificadas.
Além disso, também podemos definir padrões para que tipo de palavras não devem estar em um bloco e essas palavras não separadas são conhecidas como chinks.
Exemplo de implementação
No exemplo abaixo, junto com o resultado da análise da frase “the book has many chapters”, existe uma gramática para sintagmas nominais que combina um padrão chunk e um chink -
import nltk
sentence = [
("the", "DT"),
("book", "NN"),
("has","VBZ"),
("many","JJ"),
("chapters","NNS")
]
chunker = nltk.RegexpParser(
r'''
NP:{<DT><NN.*><.*>*<NN.*>}
}<VB.*>{
'''
)
chunker.parse(sentence)
Output = chunker.parse(sentence)
Output.draw()Resultado
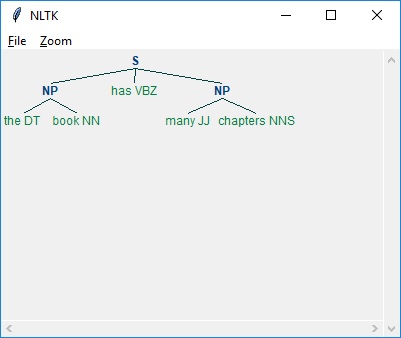
Como visto acima, o padrão para especificar um pedaço é usar chaves da seguinte maneira -
{<DT><NN>}E para especificar uma fenda, podemos virar as chaves da seguinte maneira -
}<VB>{.Agora, para um tipo de frase específico, essas regras podem ser combinadas em uma gramática.
Extração de Informação
Passamos por taggers e analisadores que podem ser usados para construir um mecanismo de extração de informações. Vamos ver um pipeline de extração de informações básicas -
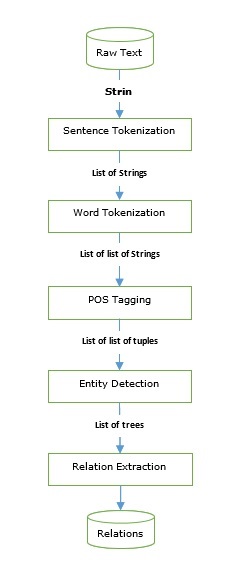
A extração de informações tem muitas aplicações, incluindo -
- Business Intelligence
- Retomar a colheita
- Análise de mídia
- Detecção de sentimento
- Pesquisa de patentes
- Verificação de email
Reconhecimento de entidade nomeada (NER)
O reconhecimento de entidade nomeada (NER) é na verdade uma maneira de extrair algumas das entidades mais comuns, como nomes, organizações, localização, etc. Vejamos um exemplo que executou todas as etapas de pré-processamento, como tokenização de frase, marcação de POS, agrupamento, NER, e segue o pipeline fornecido na figura acima.
Exemplo
Import nltk
file = open (
# provide here the absolute path for the file of text for which we want NER
)
data_text = file.read()
sentences = nltk.sent_tokenize(data_text)
tokenized_sentences = [nltk.word_tokenize(sentence) for sentence in sentences]
tagged_sentences = [nltk.pos_tag(sentence) for sentence in tokenized_sentences]
for sent in tagged_sentences:
print nltk.ne_chunk(sent)Parte do reconhecimento de entidade nomeada (NER) modificado também pode ser usado para extrair entidades como nomes de produtos, entidades biomédicas, nome de marca e muito mais.
Extração de relação
Extração de relação, outra operação de extração de informação comumente usada, é o processo de extração de diferentes relacionamentos entre várias entidades. Pode haver diferentes relações como herança, sinônimos, análogos, etc., cuja definição depende da necessidade de informação. Por exemplo, suponha que se desejamos escrever um livro, então a autoria seria uma relação entre o nome do autor e o nome do livro.
Exemplo
No exemplo a seguir, usamos o mesmo pipeline do IE, conforme mostrado no diagrama acima, que usamos até a relação de entidade nomeada (NER) e o estendemos com um padrão de relação baseado nas tags NER.
import nltk
import re
IN = re.compile(r'.*\bin\b(?!\b.+ing)')
for doc in nltk.corpus.ieer.parsed_docs('NYT_19980315'):
for rel in nltk.sem.extract_rels('ORG', 'LOC', doc, corpus = 'ieer',
pattern = IN):
print(nltk.sem.rtuple(rel))Resultado
[ORG: 'WHYY'] 'in' [LOC: 'Philadelphia']
[ORG: 'McGlashan & Sarrail'] 'firm in' [LOC: 'San Mateo']
[ORG: 'Freedom Forum'] 'in' [LOC: 'Arlington']
[ORG: 'Brookings Institution'] ', the research group in' [LOC: 'Washington']
[ORG: 'Idealab'] ', a self-described business incubator based in' [LOC: 'Los Angeles']
[ORG: 'Open Text'] ', based in' [LOC: 'Waterloo']
[ORG: 'WGBH'] 'in' [LOC: 'Boston']
[ORG: 'Bastille Opera'] 'in' [LOC: 'Paris']
[ORG: 'Omnicom'] 'in' [LOC: 'New York']
[ORG: 'DDB Needham'] 'in' [LOC: 'New York']
[ORG: 'Kaplan Thaler Group'] 'in' [LOC: 'New York']
[ORG: 'BBDO South'] 'in' [LOC: 'Atlanta']
[ORG: 'Georgia-Pacific'] 'in' [LOC: 'Atlanta']No código acima, usamos um corpus embutido chamado ieer. Neste corpus, as sentenças são marcadas até relação de entidade nomeada (NER). Aqui, só precisamos especificar o padrão de relação que queremos e o tipo de NER que queremos que a relação defina. Em nosso exemplo, definimos o relacionamento entre uma organização e um local. Extraímos todas as combinações desses padrões.
Por que transformar Chunks?
Até agora, temos pedaços ou frases de sentenças, mas o que devemos fazer com eles. Uma das tarefas importantes é transformá-los. Mas por que? É fazer o seguinte -
- correção gramatical e
- reorganizando frases
Filtrando palavras insignificantes / inúteis
Suponha que se você deseja julgar o significado de uma frase, então existem muitas palavras comumente usadas, como 'o', 'a', são insignificantes ou inúteis. Por exemplo, veja a seguinte frase -
'O filme foi bom'.
Aqui, as palavras mais significativas são 'filme' e 'bom'. Outras palavras, 'o' e 'era' são ambos inúteis ou insignificantes. É porque sem eles também podemos obter o mesmo significado da frase. 'Bom filme'.
Na receita python a seguir, aprenderemos como remover palavras inúteis / insignificantes e manter as palavras significativas com a ajuda de tags POS.
Exemplo
Primeiro, olhando através treebankcorpus para palavras irrelevantes, precisamos decidir quais tags de classes gramaticais são significativas e quais não são. Vejamos a seguinte tabela de palavras e tags insignificantes -
| Palavra | Tag |
|---|---|
| uma | DT |
| Todos | PDT |
| A | DT |
| E | CC |
| Ou | CC |
| que | WDT |
| o | DT |
Na tabela acima, podemos ver, além de CC, todas as outras tags terminam com DT, o que significa que podemos filtrar palavras insignificantes observando o sufixo da tag.
Para este exemplo, vamos usar uma função chamada filter()que pega um único pedaço e retorna um novo pedaço sem nenhuma palavra com tag insignificante. Esta função filtra quaisquer tags que terminam com DT ou CC.
Exemplo
import nltk
def filter(chunk, tag_suffixes=['DT', 'CC']):
significant = []
for word, tag in chunk:
ok = True
for suffix in tag_suffixes:
if tag.endswith(suffix):
ok = False
break
if ok:
significant.append((word, tag))
return (significant)Agora, vamos usar esta função filter () em nossa receita Python para excluir palavras insignificantes -
from chunk_parse import filter
filter([('the', 'DT'),('good', 'JJ'),('movie', 'NN')])Resultado
[('good', 'JJ'), ('movie', 'NN')]Correção de Verbo
Muitas vezes, na linguagem do mundo real, vemos formas verbais incorretas. Por exemplo, 'você está bem?' não está correto. A forma do verbo não está correta nesta frase. A frase deve ser 'você está bem?' O NLTK nos fornece a maneira de corrigir esses erros criando mapeamentos de correção de verbos. Esses mapeamentos de correção são usados dependendo se há um substantivo no plural ou no singular no trecho.
Exemplo
Para implementar a receita Python, primeiro precisamos definir os mapeamentos de correção de verbo. Vamos criar dois mapeamentos da seguinte maneira -
Plural to Singular mappings
plural= {
('is', 'VBZ'): ('are', 'VBP'),
('was', 'VBD'): ('were', 'VBD')
}Singular to Plural mappings
singular = {
('are', 'VBP'): ('is', 'VBZ'),
('were', 'VBD'): ('was', 'VBD')
}Como visto acima, cada mapeamento possui um verbo marcado que mapeia para outro verbo marcado. Os mapeamentos iniciais em nosso exemplo cobrem o básico dos mapeamentosis to are, was to were, e vice versa.
A seguir, definiremos uma função chamada verbs(), no qual você pode passar um trecho com a forma verbal incorreta e obter um trecho corrigido de volta. Para fazer isso,verb() função usa uma função auxiliar chamada index_chunk() que irá pesquisar o pedaço para a posição da primeira palavra marcada.
Vamos ver essas funções -
def index_chunk(chunk, pred, start = 0, step = 1):
l = len(chunk)
end = l if step > 0 else -1
for i in range(start, end, step):
if pred(chunk[i]):
return i
return None
def tag_startswith(prefix):
def f(wt):
return wt[1].startswith(prefix)
return f
def verbs(chunk):
vbidx = index_chunk(chunk, tag_startswith('VB'))
if vbidx is None:
return chunk
verb, vbtag = chunk[vbidx]
nnpred = tag_startswith('NN')
nnidx = index_chunk(chunk, nnpred, start = vbidx+1)
if nnidx is None:
nnidx = index_chunk(chunk, nnpred, start = vbidx-1, step = -1)
if nnidx is None:
return chunk
noun, nntag = chunk[nnidx]
if nntag.endswith('S'):
chunk[vbidx] = plural.get((verb, vbtag), (verb, vbtag))
else:
chunk[vbidx] = singular.get((verb, vbtag), (verb, vbtag))
return chunkSalve essas funções em um arquivo Python em seu diretório local onde Python ou Anaconda está instalado e execute-o. Eu salvei comoverbcorrect.py.
Agora vamos ligar verbs() função em um POS marcado is you fine pedaço -
from verbcorrect import verbs
verbs([('is', 'VBZ'), ('you', 'PRP$'), ('fine', 'VBG')])Resultado
[('are', 'VBP'), ('you', 'PRP$'), ('fine','VBG')]Eliminando voz passiva de frases
Outra tarefa útil é eliminar a voz passiva das frases. Isso pode ser feito com a ajuda de trocar as palavras em torno de um verbo. Por exemplo,‘the tutorial was great’ pode ser transformado em ‘the great tutorial’.
Exemplo
Para conseguir isso, estamos definindo uma função chamada eliminate_passive()que irá trocar o lado direito do trecho com o lado esquerdo usando o verbo como ponto de pivô. A fim de encontrar o verbo para girar, ele também usará oindex_chunk() função definida acima.
def eliminate_passive(chunk):
def vbpred(wt):
word, tag = wt
return tag != 'VBG' and tag.startswith('VB') and len(tag) > 2
vbidx = index_chunk(chunk, vbpred)
if vbidx is None:
return chunk
return chunk[vbidx+1:] + chunk[:vbidx]Agora vamos ligar eliminate_passive() função em um POS marcado the tutorial was great pedaço -
from passiveverb import eliminate_passive
eliminate_passive(
[
('the', 'DT'), ('tutorial', 'NN'), ('was', 'VBD'), ('great', 'JJ')
]
)Resultado
[('great', 'JJ'), ('the', 'DT'), ('tutorial', 'NN')]Troca de cardinais substantivos
Como sabemos, uma palavra cardinal como 5 é marcada como CD em um bloco. Essas palavras cardinais geralmente ocorrem antes ou depois de um substantivo, mas para fins de normalização, é útil colocá-las sempre antes do substantivo. Por exemplo, a dataJanuary 5 pode ser escrito como 5 January. Vamos entender isso com o exemplo a seguir.
Exemplo
Para conseguir isso, estamos definindo uma função chamada swapping_cardinals()que irá trocar qualquer cardinal que ocorra imediatamente após um substantivo pelo substantivo. Com isso, o cardeal ocorrerá imediatamente antes do substantivo. Para fazer comparação de igualdade com a tag fornecida, ele usa uma função auxiliar que chamamos detag_eql().
def tag_eql(tag):
def f(wt):
return wt[1] == tag
return fAgora podemos definir swapping_cardinals () -
def swapping_cardinals (chunk):
cdidx = index_chunk(chunk, tag_eql('CD'))
if not cdidx or not chunk[cdidx-1][1].startswith('NN'):
return chunk
noun, nntag = chunk[cdidx-1]
chunk[cdidx-1] = chunk[cdidx]
chunk[cdidx] = noun, nntag
return chunkAgora, vamos ligar swapping_cardinals() função em um encontro “January 5” -
from Cardinals import swapping_cardinals()
swapping_cardinals([('Janaury', 'NNP'), ('5', 'CD')])Resultado
[('10', 'CD'), ('January', 'NNP')]
10 JanuaryA seguir estão as duas razões para transformar as árvores -
- Para modificar a árvore de análise profunda e
- Para achatar árvores de análise profunda
Convertendo Árvore ou Subárvore em Frase
A primeira receita que vamos discutir aqui é converter uma Árvore ou subárvore em uma frase ou string de bloco. Isso é muito simples, vejamos no exemplo a seguir -
Exemplo
from nltk.corpus import treebank_chunk
tree = treebank_chunk.chunked_sents()[2]
' '.join([w for w, t in tree.leaves()])Resultado
'Rudolph Agnew , 55 years old and former chairman of Consolidated Gold Fields
PLC , was named a nonexecutive director of this British industrial
conglomerate .'Achatamento profundo da árvore
Árvores profundas de frases aninhadas não podem ser usadas para treinar um pedaço, portanto, devemos achatá-las antes de usar. No exemplo a seguir, vamos usar a terceira frase analisada, que é uma árvore profunda de frases aninhadas, dotreebank corpus.
Exemplo
Para conseguir isso, estamos definindo uma função chamada deeptree_flat()isso pegará uma única árvore e retornará uma nova árvore que mantém apenas as árvores de nível mais baixo. Para fazer a maior parte do trabalho, ele usa uma função auxiliar que chamamos dechildtree_flat().
from nltk.tree import Tree
def childtree_flat(trees):
children = []
for t in trees:
if t.height() < 3:
children.extend(t.pos())
elif t.height() == 3:
children.append(Tree(t.label(), t.pos()))
else:
children.extend(flatten_childtrees([c for c in t]))
return children
def deeptree_flat(tree):
return Tree(tree.label(), flatten_childtrees([c for c in tree]))Agora vamos ligar deeptree_flat() função na terceira frase analisada, que é uma árvore profunda de frases aninhadas, do treebankcorpus. Salvamos essas funções em um arquivo denominado deeptree.py.
from deeptree import deeptree_flat
from nltk.corpus import treebank
deeptree_flat(treebank.parsed_sents()[2])Resultado
Tree('S', [Tree('NP', [('Rudolph', 'NNP'), ('Agnew', 'NNP')]),
(',', ','), Tree('NP', [('55', 'CD'),
('years', 'NNS')]), ('old', 'JJ'), ('and', 'CC'),
Tree('NP', [('former', 'JJ'),
('chairman', 'NN')]), ('of', 'IN'), Tree('NP', [('Consolidated', 'NNP'),
('Gold', 'NNP'), ('Fields', 'NNP'), ('PLC',
'NNP')]), (',', ','), ('was', 'VBD'),
('named', 'VBN'), Tree('NP-SBJ', [('*-1', '-NONE-')]),
Tree('NP', [('a', 'DT'), ('nonexecutive', 'JJ'), ('director', 'NN')]),
('of', 'IN'), Tree('NP',
[('this', 'DT'), ('British', 'JJ'),
('industrial', 'JJ'), ('conglomerate', 'NN')]), ('.', '.')])Construção de árvore rasa
Na seção anterior, nivelamos uma árvore profunda de frases aninhadas mantendo apenas as subárvores de nível mais baixo. Nesta seção, vamos manter apenas as subárvores de nível mais alto, ou seja, construir a árvore rasa. No exemplo a seguir, vamos usar a terceira frase analisada, que é uma árvore profunda de frases aninhadas, dotreebank corpus.
Exemplo
Para conseguir isso, estamos definindo uma função chamada tree_shallow() isso eliminará todas as subárvores aninhadas, mantendo apenas os rótulos das subárvores superiores.
from nltk.tree import Tree
def tree_shallow(tree):
children = []
for t in tree:
if t.height() < 3:
children.extend(t.pos())
else:
children.append(Tree(t.label(), t.pos()))
return Tree(tree.label(), children)Agora vamos ligar tree_shallow()função em 3 rd frase analisado, o que é profundo árvore de frases aninhadas, a partir dotreebankcorpus. Salvamos essas funções em um arquivo chamado shallowtree.py.
from shallowtree import shallow_tree
from nltk.corpus import treebank
tree_shallow(treebank.parsed_sents()[2])Resultado
Tree('S', [Tree('NP-SBJ-1', [('Rudolph', 'NNP'), ('Agnew', 'NNP'), (',', ','),
('55', 'CD'), ('years', 'NNS'), ('old', 'JJ'), ('and', 'CC'),
('former', 'JJ'), ('chairman', 'NN'), ('of', 'IN'), ('Consolidated', 'NNP'),
('Gold', 'NNP'), ('Fields', 'NNP'), ('PLC', 'NNP'), (',', ',')]),
Tree('VP', [('was', 'VBD'), ('named', 'VBN'), ('*-1', '-NONE-'), ('a', 'DT'),
('nonexecutive', 'JJ'), ('director', 'NN'), ('of', 'IN'), ('this', 'DT'),
('British', 'JJ'), ('industrial', 'JJ'), ('conglomerate', 'NN')]), ('.', '.')])Podemos ver a diferença com a ajuda de obter a altura das árvores -
from nltk.corpus import treebank
tree_shallow(treebank.parsed_sents()[2]).height()Resultado
3from nltk.corpus import treebank
treebank.parsed_sents()[2].height()Resultado
9Conversão de rótulos de árvore
Em árvores de análise, há uma variedade de Treetipos de rótulo que não estão presentes em árvores de bloco. Mas ao usar a árvore de análise para treinar um chunker, gostaríamos de reduzir essa variedade convertendo alguns dos rótulos da Árvore em tipos de rótulos mais comuns. Por exemplo, temos duas subárvores NP alternativas, nomeadamente NP-SBL e NP-TMP. Podemos converter ambos em NP. Vamos ver como fazer isso no exemplo a seguir.
Exemplo
Para conseguir isso, estamos definindo uma função chamada tree_convert() isso leva os seguintes dois argumentos -
- Árvore para converter
- Um mapeamento de conversão de rótulo
Esta função retornará uma nova árvore com todos os rótulos correspondentes substituídos com base nos valores do mapeamento.
from nltk.tree import Tree
def tree_convert(tree, mapping):
children = []
for t in tree:
if isinstance(t, Tree):
children.append(convert_tree_labels(t, mapping))
else:
children.append(t)
label = mapping.get(tree.label(), tree.label())
return Tree(label, children)Agora vamos ligar tree_convert() função na terceira frase analisada, que é uma árvore profunda de frases aninhadas, do treebankcorpus. Salvamos essas funções em um arquivo chamadoconverttree.py.
from converttree import tree_convert
from nltk.corpus import treebank
mapping = {'NP-SBJ': 'NP', 'NP-TMP': 'NP'}
convert_tree_labels(treebank.parsed_sents()[2], mapping)Resultado
Tree('S', [Tree('NP-SBJ-1', [Tree('NP', [Tree('NNP', ['Rudolph']),
Tree('NNP', ['Agnew'])]), Tree(',', [',']),
Tree('UCP', [Tree('ADJP', [Tree('NP', [Tree('CD', ['55']),
Tree('NNS', ['years'])]),
Tree('JJ', ['old'])]), Tree('CC', ['and']),
Tree('NP', [Tree('NP', [Tree('JJ', ['former']),
Tree('NN', ['chairman'])]), Tree('PP', [Tree('IN', ['of']),
Tree('NP', [Tree('NNP', ['Consolidated']),
Tree('NNP', ['Gold']), Tree('NNP', ['Fields']),
Tree('NNP', ['PLC'])])])])]), Tree(',', [','])]),
Tree('VP', [Tree('VBD', ['was']),Tree('VP', [Tree('VBN', ['named']),
Tree('S', [Tree('NP', [Tree('-NONE-', ['*-1'])]),
Tree('NP-PRD', [Tree('NP', [Tree('DT', ['a']),
Tree('JJ', ['nonexecutive']), Tree('NN', ['director'])]),
Tree('PP', [Tree('IN', ['of']), Tree('NP',
[Tree('DT', ['this']), Tree('JJ', ['British']), Tree('JJ', ['industrial']),
Tree('NN', ['conglomerate'])])])])])])]), Tree('.', ['.'])])O que é classificação de texto?
A classificação de texto, como o nome indica, é a maneira de categorizar pedaços de texto ou documentos. Mas aqui surge a questão de por que precisamos usar classificadores de texto? Depois de examinar o uso da palavra em um documento ou parte do texto, os classificadores serão capazes de decidir qual rótulo de classe deve ser atribuído a ele.
Classificador Binário
Como o nome indica, o classificador binário decidirá entre dois rótulos. Por exemplo, positivo ou negativo. Nesse caso, o trecho de texto ou documento pode ser uma etiqueta ou outra, mas não ambas.
Classificador Multi-rótulo
Oposto ao classificador binário, o classificador de vários rótulos pode atribuir um ou mais rótulos a um trecho de texto ou documento.
Conjunto de recursos rotulados x não rotulados
Um mapeamento de valor-chave de nomes de recursos para valores de recursos é chamado de conjunto de recursos. Conjuntos de recursos rotulados ou dados de treinamento são muito importantes para o treinamento de classificação para que ele possa posteriormente classificar conjuntos de recursos não rotulados.
| Conjunto de recursos rotulados | Conjunto de recursos não rotulados |
|---|---|
| É uma tupla semelhante a (feat, label). | É uma façanha em si. |
| É uma instância com um rótulo de classe conhecido. | Sem rótulo associado, podemos chamá-lo de instância. |
| Usado para treinar um algoritmo de classificação. | Uma vez treinado, o algoritmo de classificação pode classificar um conjunto de recursos não rotulado. |
Extração de recurso de texto
A extração de recursos de texto, como o nome indica, é o processo de transformar uma lista de palavras em um conjunto de recursos que pode ser usado por um classificador. Devemos ter que transformar nosso texto em‘dict’ conjuntos de recursos de estilo porque o Natural Language Tool Kit (NLTK) espera ‘dict’ conjuntos de recursos de estilo.
Modelo Saco de Palavras (BoW)
BoW, um dos modelos mais simples em PNL, é usado para extrair os recursos de um trecho de texto ou documento para que possa ser usado na modelagem, como em algoritmos de ML. Basicamente, ele constrói um conjunto de recursos de presença de palavras a partir de todas as palavras de uma instância. O conceito por trás desse método é que ele não se importa com quantas vezes uma palavra ocorre ou com a ordem das palavras, ele só se importa se a palavra está presente em uma lista de palavras ou não.
Exemplo
Para este exemplo, vamos definir uma função chamada bow () -
def bow(words):
return dict([(word, True) for word in words])Agora vamos ligar bow()função em palavras. Salvamos essas funções em um arquivo chamado bagwords.py.
from bagwords import bow
bow(['we', 'are', 'using', 'tutorialspoint'])Resultado
{'we': True, 'are': True, 'using': True, 'tutorialspoint': True}Classificadores de treinamento
Nas seções anteriores, aprendemos como extrair recursos do texto. Agora podemos treinar um classificador. O primeiro e mais fácil classificador éNaiveBayesClassifier classe.
Classificador Naïve Bayes
Para prever a probabilidade de que um determinado conjunto de características pertença a um rótulo específico, ele usa o teorema de Bayes. A fórmula do teorema de Bayes é a seguinte.
$$P(A|B)=\frac{P(B|A)P(A)}{P(B)}$$Aqui,
P(A|B) - É também chamada de probabilidade posterior, ou seja, a probabilidade do primeiro evento, ou seja, A ocorrer, dado que o segundo evento, ou seja, B ocorreu.
P(B|A) - É a probabilidade do segundo evento, ou seja, B ocorrer após o primeiro evento, ou seja, A ocorrer.
P(A), P(B) - É também chamada de probabilidade anterior, ou seja, a probabilidade de ocorrer o primeiro evento, ou seja, A, ou o segundo evento, ou seja, B.
Para treinar o classificador Naïve Bayes, estaremos usando o movie_reviewscorpus de NLTK. Este corpus possui duas categorias de texto, a saber:pos e neg. Essas categorias fazem de um classificador treinado nelas um classificador binário. Cada arquivo no corpus é composto de dois, um é uma crítica positiva do filme e outro é uma crítica negativa do filme. Em nosso exemplo, vamos usar cada arquivo como uma instância única para treinar e testar o classificador.
Exemplo
Para o classificador de treinamento, precisamos de uma lista de conjuntos de recursos rotulados, que estarão na forma [(featureset, label)]. Aqui ofeatureset variável é um dict e rótulo é o rótulo de classe conhecido para o featureset. Vamos criar uma função chamadalabel_corpus() que levará um corpus chamado movie_reviewse também uma função chamada feature_detector, cujo padrão é bag of words. Ele construirá e retornará um mapeamento do formulário, {rótulo: [conjunto de recursos]}. Depois disso, usaremos esse mapeamento para criar uma lista de instâncias de treinamento rotuladas e instâncias de teste.
import collections
def label_corpus(corp, feature_detector=bow):
label_feats = collections.defaultdict(list)
for label in corp.categories():
for fileid in corp.fileids(categories=[label]):
feats = feature_detector(corp.words(fileids=[fileid]))
label_feats[label].append(feats)
return label_featsCom a ajuda da função acima, obteremos um mapeamento {label:fetaureset}. Agora vamos definir mais uma função chamadasplit isso levará um mapeamento retornado de label_corpus() função e divide cada lista de conjuntos de recursos em treinamento rotulado, bem como instâncias de teste.
def split(lfeats, split=0.75):
train_feats = []
test_feats = []
for label, feats in lfeats.items():
cutoff = int(len(feats) * split)
train_feats.extend([(feat, label) for feat in feats[:cutoff]])
test_feats.extend([(feat, label) for feat in feats[cutoff:]])
return train_feats, test_featsAgora, vamos usar essas funções em nosso corpus, ou seja, movie_reviews -
from nltk.corpus import movie_reviews
from featx import label_feats_from_corpus, split_label_feats
movie_reviews.categories()Resultado
['neg', 'pos']Exemplo
lfeats = label_feats_from_corpus(movie_reviews)
lfeats.keys()Resultado
dict_keys(['neg', 'pos'])Exemplo
train_feats, test_feats = split_label_feats(lfeats, split = 0.75)
len(train_feats)Resultado
1500Exemplo
len(test_feats)Resultado
500Nós vimos isso em movie_reviewscorpus, existem 1000 arquivos pos e 1000 arquivos neg. Também acabamos com 1500 instâncias de treinamento rotuladas e 500 instâncias de teste rotuladas.
Agora vamos treinar NaïveBayesClassifier usando seu train() método de classe -
from nltk.classify import NaiveBayesClassifier
NBC = NaiveBayesClassifier.train(train_feats)
NBC.labels()Resultado
['neg', 'pos']Classificador de árvore de decisão
Outro classificador importante é o classificador da árvore de decisão. Aqui para treiná-loDecisionTreeClassifierclasse criará uma estrutura em árvore. Nesta estrutura de árvore, cada nó corresponde a um nome de recurso e os ramos correspondem aos valores do recurso. E descendo os galhos chegaremos às folhas da árvore, ou seja, aos rótulos de classificação.
Para treinar o classificador da árvore de decisão, usaremos os mesmos recursos de treinamento e teste, ou seja, train_feats e test_feats, variáveis que criamos a partir de movie_reviews corpus.
Exemplo
Para treinar este classificador, vamos chamar DecisionTreeClassifier.train() método de classe da seguinte forma -
from nltk.classify import DecisionTreeClassifier
decisiont_classifier = DecisionTreeClassifier.train(
train_feats, binary = True, entropy_cutoff = 0.8,
depth_cutoff = 5, support_cutoff = 30
)
accuracy(decisiont_classifier, test_feats)Resultado
0.725Classificador de Entropia Máxima
Outro classificador importante é MaxentClassifier que também é conhecido como conditional exponential classifier ou logistic regression classifier. Aqui para treiná-lo, oMaxentClassifier classe irá converter conjuntos de recursos rotulados em vetor usando codificação.
Para treinar o classificador da árvore de decisão, usaremos os mesmos recursos de treinamento e teste, ou seja, train_featse test_feats, variáveis que criamos a partir de movie_reviews corpus.
Exemplo
Para treinar este classificador, vamos chamar MaxentClassifier.train() método de classe da seguinte forma -
from nltk.classify import MaxentClassifier
maxent_classifier = MaxentClassifier
.train(train_feats,algorithm = 'gis', trace = 0, max_iter = 10, min_lldelta = 0.5)
accuracy(maxent_classifier, test_feats)Resultado
0.786Classificador Scikit-learn
Uma das melhores bibliotecas de aprendizado de máquina (ML) é o Scikit-learn. Na verdade, ele contém todos os tipos de algoritmos de ML para várias finalidades, mas todos eles têm o mesmo padrão de design de ajuste da seguinte maneira -
- Ajustando o modelo aos dados
- E use esse modelo para fazer previsões
Em vez de acessar os modelos scikit-learn diretamente, aqui vamos usar o NLTK SklearnClassifierclasse. Esta classe é uma classe wrapper em torno de um modelo scikit-learn para torná-lo compatível com a interface Classifier do NLTK.
Seguiremos as seguintes etapas para treinar um SklearnClassifier classe -
Step 1 - Primeiro criaremos recursos de treinamento como fizemos nas receitas anteriores.
Step 2 - Agora, escolha e importe um algoritmo de aprendizagem Scikit.
Step 3 - Em seguida, precisamos construir um SklearnClassifier classe com o algoritmo escolhido.
Step 4 - Por último, vamos treinar SklearnClassifier aula com nossos recursos de treinamento.
Vamos implementar essas etapas na receita Python abaixo -
from nltk.classify.scikitlearn import SklearnClassifier
from sklearn.naive_bayes import MultinomialNB
sklearn_classifier = SklearnClassifier(MultinomialNB())
sklearn_classifier.train(train_feats)
<SklearnClassifier(MultinomialNB(alpha = 1.0,class_prior = None,fit_prior = True))>
accuracy(sk_classifier, test_feats)Resultado
0.885Medindo precisão e recall
Ao treinar vários classificadores, também medimos sua precisão. Mas, além da precisão, há várias outras métricas que são usadas para avaliar os classificadores. Duas dessas métricas sãoprecision e recall.
Exemplo
Neste exemplo, vamos calcular a precisão e a recuperação da classe NaiveBayesClassifier que treinamos anteriormente. Para conseguir isso, criaremos uma função chamada metrics_PR () que terá dois argumentos, um é o classificador treinado e o outro são os recursos de teste rotulados. Ambos os argumentos são os mesmos que passamos ao calcular a precisão dos classificadores -
import collections
from nltk import metrics
def metrics_PR(classifier, testfeats):
refsets = collections.defaultdict(set)
testsets = collections.defaultdict(set)
for i, (feats, label) in enumerate(testfeats):
refsets[label].add(i)
observed = classifier.classify(feats)
testsets[observed].add(i)
precisions = {}
recalls = {}
for label in classifier.labels():
precisions[label] = metrics.precision(refsets[label],testsets[label])
recalls[label] = metrics.recall(refsets[label], testsets[label])
return precisions, recallsVamos chamar esta função para encontrar a precisão e recuperação -
from metrics_classification import metrics_PR
nb_precisions, nb_recalls = metrics_PR(nb_classifier,test_feats)
nb_precisions['pos']Resultado
0.6713532466435213Exemplo
nb_precisions['neg']Resultado
0.9676271186440678Exemplo
nb_recalls['pos']Resultado
0.96Exemplo
nb_recalls['neg']Resultado
0.478Combinação de classificador e votação
Combinar classificadores é uma das melhores maneiras de melhorar o desempenho da classificação. E votar é uma das melhores maneiras de combinar vários classificadores. Para votar, precisamos ter um número ímpar de classificadores. Na seguinte receita do Python, vamos combinar três classificadores, a saber, a classe NaiveBayesClassifier, a classe DecisionTreeClassifier e a classe MaxentClassifier.
Para conseguir isso, vamos definir uma função chamada vote_classifiers () como segue.
import itertools
from nltk.classify import ClassifierI
from nltk.probability import FreqDist
class Voting_classifiers(ClassifierI):
def __init__(self, *classifiers):
self._classifiers = classifiers
self._labels = sorted(set(itertools.chain(*[c.labels() for c in classifiers])))
def labels(self):
return self._labels
def classify(self, feats):
counts = FreqDist()
for classifier in self._classifiers:
counts[classifier.classify(feats)] += 1
return counts.max()Vamos chamar esta função para combinar três classificadores e encontrar a precisão -
from vote_classification import Voting_classifiers
combined_classifier = Voting_classifiers(NBC, decisiont_classifier, maxent_classifier)
combined_classifier.labels()Resultado
['neg', 'pos']Exemplo
accuracy(combined_classifier, test_feats)Resultado
0.948A partir da saída acima, podemos ver que os classificadores combinados obtiveram a maior precisão do que os classificadores individuais.