Derivação e lematização
O que é Stemming?
Stemming é uma técnica usada para extrair a forma básica das palavras removendo afixos delas. É como cortar os galhos de uma árvore até o caule. Por exemplo, a raiz das palavraseating, eats, eaten é eat.
Os motores de busca usam derivação para indexar as palavras. É por isso que, em vez de armazenar todas as formas de uma palavra, um mecanismo de pesquisa pode armazenar apenas as raízes. Dessa forma, a derivação reduz o tamanho do índice e aumenta a precisão da recuperação.
Vários algoritmos de Stemming
Em NLTK, stemmerI, que tem stem(), interface tem todos os lematizadores que iremos cobrir a seguir. Vamos entender isso com o seguinte diagrama
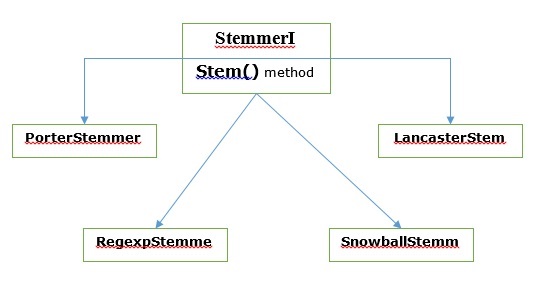
Algoritmo de lematização de Porter
É um dos algoritmos de lematização mais comuns que é basicamente projetado para remover e substituir sufixos conhecidos de palavras em inglês.
Aula PorterStemmer
NLTK tem PorterStemmercom a ajuda da qual podemos facilmente implementar algoritmos de Porter Stemmer para a palavra que queremos derivar. Esta classe conhece várias formas de palavras regulares e sufixos com a ajuda dos quais pode transformar a palavra de entrada em um radical final. O radical resultante geralmente é uma palavra mais curta com o mesmo significado de raiz. Vamos ver um exemplo -
Primeiro, precisamos importar o kit de ferramentas de linguagem natural (nltk).
import nltkAgora, importe o PorterStemmer classe para implementar o algoritmo Porter Stemmer.
from nltk.stem import PorterStemmerEm seguida, crie uma instância da classe Porter Stemmer da seguinte maneira -
word_stemmer = PorterStemmer()Agora, insira a palavra que você deseja radicalizar.
word_stemmer.stem('writing')Resultado
'write'word_stemmer.stem('eating')Resultado
'eat'Exemplo de implementação completo
import nltk
from nltk.stem import PorterStemmer
word_stemmer = PorterStemmer()
word_stemmer.stem('writing')Resultado
'write'Algoritmo de lematização de Lancaster
Ele foi desenvolvido na Lancaster University e é outro algoritmo de derivação muito comum.
Classe LancasterStemmer
NLTK tem LancasterStemmerclasse com a ajuda da qual podemos implementar facilmente algoritmos Lancaster Stemmer para a palavra que queremos derivar. Vamos ver um exemplo -
Primeiro, precisamos importar o kit de ferramentas de linguagem natural (nltk).
import nltkAgora, importe o LancasterStemmer classe para implementar o algoritmo Lancaster Stemmer
from nltk.stem import LancasterStemmerEm seguida, crie uma instância de LancasterStemmer classe como segue -
Lanc_stemmer = LancasterStemmer()Agora, insira a palavra que você deseja radicalizar.
Lanc_stemmer.stem('eats')Resultado
'eat'Exemplo de implementação completo
import nltk
from nltk.stem import LancatserStemmer
Lanc_stemmer = LancasterStemmer()
Lanc_stemmer.stem('eats')Resultado
'eat'Algoritmo de lematização de expressão regular
Com a ajuda deste algoritmo de lematização, podemos construir nosso próprio lematizador.
Classe RegexpStemmer
NLTK tem RegexpStemmerclasse com a ajuda da qual podemos implementar facilmente algoritmos de Stemmer de Expressão Regular. Basicamente, ele pega uma única expressão regular e remove qualquer prefixo ou sufixo que corresponda à expressão. Vamos ver um exemplo -
Primeiro, precisamos importar o kit de ferramentas de linguagem natural (nltk).
import nltkAgora, importe o RegexpStemmer classe para implementar o algoritmo Regular Expression Stemmer.
from nltk.stem import RegexpStemmerEm seguida, crie uma instância de RegexpStemmer classe e fornece o sufixo ou prefixo que você deseja remover da palavra da seguinte maneira -
Reg_stemmer = RegexpStemmer(‘ing’)Agora, insira a palavra que você deseja radicalizar.
Reg_stemmer.stem('eating')Resultado
'eat'Reg_stemmer.stem('ingeat')Resultado
'eat'
Reg_stemmer.stem('eats')Resultado
'eat'Exemplo de implementação completo
import nltk
from nltk.stem import RegexpStemmer
Reg_stemmer = RegexpStemmer()
Reg_stemmer.stem('ingeat')Resultado
'eat'Algoritmo de stemming bola de neve
É outro algoritmo de derivação muito útil.
Aula SnowballStemmer
NLTK tem SnowballStemmerclasse com a ajuda da qual podemos facilmente implementar algoritmos Snowball Stemmer. Ele suporta 15 idiomas diferentes do inglês. Para usar essa classe fumegante, precisamos criar uma instância com o nome da linguagem que estamos usando e, em seguida, chamar o método stem (). Vamos ver um exemplo -
Primeiro, precisamos importar o kit de ferramentas de linguagem natural (nltk).
import nltkAgora, importe o SnowballStemmer classe para implementar o algoritmo Snowball Stemmer
from nltk.stem import SnowballStemmerVamos ver os idiomas que ele suporta -
SnowballStemmer.languagesResultado
(
'arabic',
'danish',
'dutch',
'english',
'finnish',
'french',
'german',
'hungarian',
'italian',
'norwegian',
'porter',
'portuguese',
'romanian',
'russian',
'spanish',
'swedish'
)Em seguida, crie uma instância da classe SnowballStemmer com o idioma que deseja usar. Aqui, estamos criando o lematizador para o idioma 'francês'.
French_stemmer = SnowballStemmer(‘french’)Agora, chame o método stem () e insira a palavra que você deseja transformar.
French_stemmer.stem (‘Bonjoura’)Resultado
'bonjour'Exemplo de implementação completo
import nltk
from nltk.stem import SnowballStemmer
French_stemmer = SnowballStemmer(‘french’)
French_stemmer.stem (‘Bonjoura’)Resultado
'bonjour'O que é Lemmatização?
A técnica de lematização é como uma derivação. A saída que obteremos após a lematização é chamada de 'lema', que é uma palavra raiz em vez de radical, a saída da lematização. Após a lematização, estaremos obtendo uma palavra válida que significa a mesma coisa.
NLTK fornece WordNetLemmatizer classe que é um invólucro fino em torno do wordnetcorpus. Esta classe usamorphy() função para o WordNet CorpusReaderclasse para encontrar um lema. Vamos entender isso com um exemplo -
Exemplo
Primeiro, precisamos importar o kit de ferramentas de linguagem natural (nltk).
import nltkAgora, importe o WordNetLemmatizer aula para implementar a técnica de lematização.
from nltk.stem import WordNetLemmatizerEm seguida, crie uma instância de WordNetLemmatizer classe.
lemmatizer = WordNetLemmatizer()Agora, chame o método lemmatize () e insira a palavra da qual deseja encontrar o lema.
lemmatizer.lemmatize('eating')Resultado
'eating'lemmatizer.lemmatize('books')Resultado
'book'Exemplo de implementação completo
import nltk
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
lemmatizer.lemmatize('books')Resultado
'book'Diferença entre Stemming e Lemmatization
Vamos entender a diferença entre Stemming e Lemmatization com a ajuda do seguinte exemplo -
import nltk
from nltk.stem import PorterStemmer
word_stemmer = PorterStemmer()
word_stemmer.stem('believes')Resultado
believimport nltk
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
lemmatizer.lemmatize(' believes ')Resultado
believA saída de ambos os programas indica a principal diferença entre lematização e lematização. PorterStemmerclasse corta os 'es' da palavra. Por outro lado,WordNetLemmatizerclasse encontra uma palavra válida. Em palavras simples, a técnica de lematização analisa apenas a forma da palavra, enquanto a técnica de lematização analisa o significado da palavra. Isso significa que depois de aplicar a lematização, sempre obteremos uma palavra válida.