OBIEE - Guia Rápido
No mercado competitivo de hoje, as empresas mais bem-sucedidas respondem rapidamente às mudanças e oportunidades do mercado. O requisito para responder rapidamente é por meio do uso eficaz e eficiente de dados e informações.“Data Warehouse”é um repositório central de dados organizado por categoria para apoiar os tomadores de decisão da organização. Depois que os dados são armazenados em um data warehouse, eles podem ser acessados para análise.
O termo "Data Warehouse" foi inventado pela primeira vez por Bill Inmon em 1990. De acordo com ele, “Data warehouse é uma coleção de dados orientada ao assunto, integrada, com variação no tempo e não volátil para apoiar o processo de tomada de decisão da administração”.
Ralph Kimball forneceu uma definição de data warehouse com base em sua funcionalidade. Ele disse: “Data warehouse é uma cópia dos dados de transações especificamente estruturados para consulta e análise”.
Data Warehouse (DW ou DWH) é um sistema usado para análise de dados e fins de relatório. Eles são repositórios que salvam dados de uma ou mais fontes de dados heterogêneas. Eles armazenam dados atuais e históricos e são usados para criar relatórios analíticos. O DW pode ser usado para criar painéis interativos para a alta administração.
Por exemplo, os relatórios analíticos podem conter dados para comparações trimestrais ou para comparação anual do relatório de vendas de uma empresa.
Os dados no DW vêm de vários sistemas operacionais como vendas, recursos humanos, marketing, gerenciamento de armazém, etc. Ele contém dados históricos de diferentes sistemas de transação, mas também pode incluir dados de outras fontes. O DW é usado para separar o processamento de dados e a carga de trabalho de análise da carga de trabalho da transação e permite consolidar os dados de várias fontes de dados.
A necessidade de data warehouse
Por exemplo - você tem uma agência de crédito imobiliário, onde os dados vêm de vários aplicativos SAP / não SAP, como marketing, vendas, ERP, HRM, etc. Esses dados são extraídos, transformados e carregados no DW. Se você tiver que fazer uma comparação de vendas trimestral / anual de um produto, não poderá usar um banco de dados operacional, pois isso travará o sistema de transações. É aqui que surge a necessidade de usar DW.
Características de um Data Warehouse
Algumas das principais características do DW são -
- É usado para relatórios e análise de dados.
- Ele fornece um repositório central com dados integrados de uma ou mais fontes.
- Ele armazena dados atuais e históricos.
Data Warehouse vs. Sistema Transacional
A seguir estão algumas diferenças entre Data Warehouse e Banco de Dados Operacional (Sistema de Transação) -
O sistema transacional é projetado para cargas de trabalho e transações conhecidas, como atualização de um registro de usuário, pesquisa de um registro, etc. No entanto, as transações DW são mais complexas e apresentam uma forma geral de dados.
O sistema transacional contém os dados atuais de uma organização, enquanto o DW normalmente contém dados históricos.
O sistema transacional oferece suporte ao processamento paralelo de várias transações. Os mecanismos de controle e recuperação de simultaneidade são necessários para manter a consistência do banco de dados.
A consulta de banco de dados operacional permite ler e modificar operações (excluir e atualizar), enquanto uma consulta OLAP precisa apenas de acesso somente leitura dos dados armazenados (instrução select).
O DW envolve limpeza de dados, integração de dados e consolidações de dados.
O DW tem uma arquitetura de três camadas - Camada de fonte de dados, Camada de integração e Camada de apresentação. O diagrama a seguir mostra a arquitetura comum de um sistema de Data Warehouse.

Tipos de sistema de data warehouse
A seguir estão os tipos de sistema DW -
- Data Mart
- Processamento Analítico Online (OLAP)
- Processamento de transações online (OLTP)
- Análise Preditiva
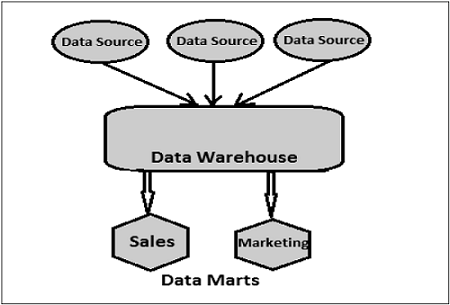
Data Mart
Data Mart é a forma mais simples de DW e normalmente se concentra em uma única área funcional, como vendas, finanças ou marketing. Conseqüentemente, o data mart geralmente obtém dados apenas de algumas fontes de dados.
As fontes podem ser um sistema de transação interno, um armazém de dados central ou um aplicativo de fonte de dados externa. A desnormalização é a norma para as técnicas de modelagem de dados neste sistema.
Processamento Analítico Online (OLAP)
Um sistema OLAP contém menos número de transações, mas envolve cálculos complexos como o uso de agregações - soma, contagem, média, etc.
O que é agregação?
Salvamos tabelas com dados agregados como anual (1 linha), trimestral (4 linhas), mensal (12 linhas) e agora queremos comparar os dados, como Anual, apenas 1 linha será processada. No entanto, em dados não agregados, todas as linhas serão processadas.
O sistema OLAP normalmente armazena dados em esquemas multidimensionais como Star Schema, Galaxy schemas (com tabelas Fact e Dimensional unidas de maneira lógica).
Em um sistema OLAP, o tempo de resposta para executar uma consulta é uma medida de eficácia. Os aplicativos OLAP são amplamente usados por técnicas de mineração de dados para obter dados de sistemas OLAP. Os bancos de dados OLAP armazenam dados históricos agregados em esquemas multidimensionais. Os sistemas OLAP têm latência de dados de algumas horas, em comparação com Data Marts, onde a latência é normalmente mais próxima de alguns dias.
Processamento de transações online (OLTP)
Um sistema OLTP é conhecido por um grande número de transações curtas on-line, como inserir, atualizar, excluir, etc. Os sistemas OLTP fornecem processamento rápido de consultas e também são responsáveis por fornecer integridade de dados em ambiente multiacesso.
Para sistemas OLTP, a eficácia é medida pelo número de transações processadas por segundo. Os sistemas OLTP normalmente contêm apenas dados atuais. O esquema usado para armazenar bancos de dados transacionais é o modelo de entidade. A normalização é usada para técnicas de modelagem de dados no sistema OLTP.
OLTP vs OLAP
A ilustração a seguir mostra as principais diferenças entre um sistema OLTP e OLAP.

Indexes - Em um sistema OLTP, existem apenas alguns índices, enquanto em um sistema OLAP existem muitos índices para otimização de desempenho.
Joins- Em um sistema OLTP, grande número de junções e dados são normalizados; entretanto, em um sistema OLAP, há menos junções e desnormalizados.
Aggregation - Em um sistema OLTP, os dados não são agregados, enquanto em um banco de dados OLAP mais agregações são usadas.
A modelagem dimensional fornece um conjunto de métodos e conceitos que são usados no projeto DW. De acordo com o consultor da DW, Ralph Kimball, a modelagem dimensional é uma técnica de design para bancos de dados destinados a oferecer suporte a consultas do usuário final em um data warehouse. É orientado para compreensão e desempenho. Segundo ele, embora o ER orientado a transações seja muito útil para a captura de transações, deve ser evitado para entrega ao usuário final.
A modelagem dimensional sempre usa fatos e tabelas de dimensão. Os fatos são valores numéricos que podem ser agregados e analisados nos valores dos fatos. As dimensões definem hierarquias e descrições de valores de fato.
Tabela Dimensional
A tabela de dimensões armazena os atributos que descrevem objetos em uma tabela de fatos. Uma tabela de dimensão possui uma chave primária que identifica exclusivamente cada linha de dimensão. Esta chave é usada para associar a tabela Dimensão a uma tabela Fato.
As tabelas de dimensão são normalmente desnormalizadas, pois não são criadas para executar transações e apenas usadas para analisar dados em detalhes.
Exemplo
Na tabela de dimensão a seguir, a dimensão do cliente normalmente inclui o nome dos clientes, endereço, id do cliente, sexo, grupo de renda, níveis de educação, etc.
| Identificação do Cliente | Nome | Gênero | Renda | Educação | Religião |
|---|---|---|---|---|---|
| 1 | Brian Edge | M | 2 | 3 | 4 |
| 2 | Fred Smith | M | 3 | 5 | 1 |
| 3 | Sally Jones | F | 1 | 7 | 3 |
Tabelas de fatos
A tabela de fatos contém valores numéricos conhecidos como medidas. Uma tabela de fatos tem dois tipos de colunas - fatos e chave estrangeira para tabelas de dimensão.
As medidas na tabela de fatos são de três tipos -
Additive - Medidas que podem ser adicionadas em qualquer dimensão.
Non-Additive - Medidas que não podem ser adicionadas em nenhuma dimensão.
Semi-Additive - Medidas que podem ser adicionadas em algumas dimensões.
Exemplo
| ID de tempo | ID do produto | Identificação do Cliente | Unidade vendida |
|---|---|---|---|
| 4 | 17 | 2 | 1 |
| 8 | 21 | 3 | 2 |
| 8 | 4 | 1 | 1 |
Esta tabela de fatos contém chaves estrangeiras para dimensão de tempo, dimensão do produto, dimensão do cliente e unidade de valor de medição vendida.
Suponha que uma empresa venda produtos aos clientes. Toda venda é um fato que ocorre dentro da empresa, e a tabela de fatos é usada para registrar esses fatos.
Os fatos comuns são - número de unidades vendidas, margem, receita de vendas, etc. A tabela de dimensão lista fatores como cliente, tempo, produto, etc. pelos quais desejamos analisar os dados.
Agora, se considerarmos a tabela de fatos acima e a dimensão do cliente, haverá também uma dimensão de produto e tempo. Dada essa tabela de fatos e essas tabelas de três dimensões, podemos fazer perguntas como: Quantos relógios foram vendidos para clientes homens em 2010?
Diferença entre dimensão e tabela de fatos
A diferença funcional entre as tabelas de dimensão e as tabelas de fatos é que as tabelas de fatos contêm os dados que desejamos analisar e as tabelas de dimensões contêm as informações necessárias para que possamos consultá-los.
Tabela Agregada
A tabela agregada contém dados agregados que podem ser calculados usando diferentes funções agregadas.
A aggregate function é uma função em que os valores de várias linhas são agrupados como entrada em certos critérios para formar um único valor de significado ou medição mais significativo.
As funções de agregação comuns incluem -
- Average()
- Count()
- Maximum()
- Median()
- Minimum()
- Mode()
- Sum()
Essas tabelas agregadas são usadas para otimização de desempenho para executar consultas complexas em um data warehouse.
Exemplo
Você salva tabelas com dados agregados como anual (1 linha), trimestral (4 linhas), mensal (12 linhas) e agora você tem que fazer comparação de dados, como Anual, apenas 1 linha será processada. No entanto, em uma tabela não agregada, todas as linhas serão processadas.
| MIN | Retorna o menor valor em uma determinada coluna |
| MAX | Retorna o maior valor em uma determinada coluna |
| SOMA | Retorna a soma dos valores numéricos em uma determinada coluna |
| AVG | Retorna o valor médio de uma determinada coluna |
| CONTAGEM | Retorna o número total de valores em uma determinada coluna |
| CONTAR (*) | Retorna o número de linhas em uma tabela |
Selecione Média (salário) do funcionário, onde title = 'desenvolvedor'. Esta declaração retornará o salário médio de todos os funcionários cujo cargo é igual a 'Desenvolvedor'.
As agregações podem ser aplicadas no nível do banco de dados. Você pode criar agregados e salvá-los em tabelas agregadas no banco de dados ou pode aplicá-los imediatamente no nível do relatório.
Note - Se você salvar agregados no nível do banco de dados, isso economiza tempo e fornece otimização de desempenho.
O esquema é uma descrição lógica de todo o banco de dados. Inclui o nome e a descrição dos registros de todos os tipos, incluindo todos os itens de dados e agregados associados. Muito parecido com um banco de dados, o DW também requer a manutenção de um esquema. O banco de dados usa o modelo relacional, enquanto o DW usa o esquema Star, Snowflake e Fact Constellation (esquema Galaxy).
Esquema Star
Em um esquema em estrela, existem várias tabelas de dimensão na forma desnormalizada que são unidas a apenas uma tabela de fatos. Essas tabelas são unidas de maneira lógica para atender a alguns requisitos de negócios para fins de análise. Esses esquemas são estruturas multidimensionais usadas para criar relatórios usando ferramentas de relatório de BI.
Dimensões em esquemas em estrela contêm um conjunto de atributos e tabelas de fatos contêm chaves estrangeiras para todas as dimensões e valores de medição.
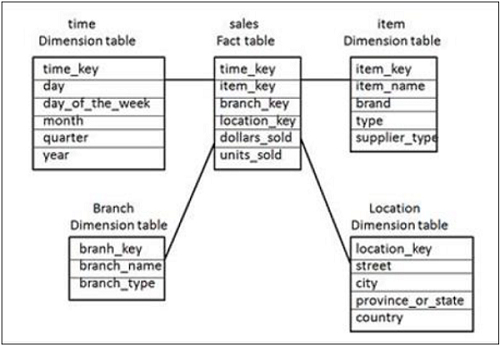
No esquema em estrela acima, há uma tabela de fatos “Sales Fact” no centro e é unida a 4 tabelas de dimensão usando chaves primárias. As tabelas de dimensão não são mais normalizadas e essa junção de tabelas é conhecida como Star Schema em DW.
A tabela de fatos também contém valores de medida - dólar_venda e unidades_venda.
Esquema de flocos de neve
Em um Esquema de flocos de neve, existem várias tabelas de dimensão na forma normalizada que são unidas a apenas uma tabela de fatos. Essas tabelas são unidas de maneira lógica para atender a alguns requisitos de negócios para fins de análise.
A única diferença entre um esquema Star e Snowflakes é que as tabelas de dimensão são posteriormente normalizadas. A normalização divide os dados em tabelas adicionais. Devido à normalização no esquema Snowflake, a redundância de dados é reduzida sem perder nenhuma informação e, portanto, torna-se fácil de manter e economiza espaço de armazenamento.

No exemplo acima do Esquema de flocos de neve, as tabelas Produto e Cliente são posteriormente normalizadas para economizar espaço de armazenamento. Às vezes, ele também fornece otimização de desempenho quando você executa uma consulta que requer processamento de linhas diretamente na tabela normalizada, de forma que não processe linhas na tabela de dimensão primária e vá diretamente para a tabela normalizada no esquema.
Granularidade
A granularidade em uma tabela representa o nível de informações armazenadas na tabela. Alta granularidade de dados significa que os dados estão no nível da transação ou próximo a ele, que possui mais detalhes. Baixa granularidade significa que os dados têm baixo nível de informação.
Uma tabela de fatos geralmente é projetada em um baixo nível de granularidade. Isso significa que precisamos encontrar o nível mais baixo de informação que pode ser armazenado em uma tabela de fatos. Na dimensão de data, o nível de granularidade pode ser ano, mês, trimestre, período, semana e dia.
O processo de definição de granularidade consiste em duas etapas -
- Determinar as dimensões que devem ser incluídas.
- Determinar a localização para colocar a hierarquia de cada dimensão da informação.
Dimensões que mudam lentamente
Dimensões que mudam lentamente referem-se à mudança do valor de um atributo ao longo do tempo. É um dos conceitos comuns no DW.
Exemplo
Andy é um funcionário da XYZ Inc. Ele foi localizado pela primeira vez na cidade de Nova York em julho de 2015. A entrada original na tabela de pesquisa de funcionários tem o seguinte registro -
| ID do Empregado | 10001 |
|---|---|
| Nome | Andy |
| Localização | Nova york |
Posteriormente, ele se mudou para LA, Califórnia. Como a XYZ Inc. agora deve modificar sua tabela de funcionários para refletir essa mudança?
Isso é conhecido como conceito de "Dimensão que muda lentamente".
Existem três maneiras de resolver este tipo de problema -
Solução 1
O novo registro substitui o registro original. Não existe nenhum vestígio do registro antigo.
Dimensão que muda lentamente, a nova informação simplesmente substitui a informação original. Em outras palavras, nenhuma história é mantida.
| ID do Empregado | 10001 |
|---|---|
| Nome | Andy |
| Localização | LA, Califórnia |
Benefit - Esta é a maneira mais fácil de lidar com o problema de Dimensão de Mudança Lenta, pois não há necessidade de manter o controle das informações antigas.
Disadvantage - Todas as informações históricas são perdidas.
Use - A solução 1 deve ser usada quando não for necessário que o DW acompanhe as informações históricas.
Solução 2
Um novo registro é inserido na tabela de dimensão Funcionário. Portanto, o funcionário, Andy, é tratado como duas pessoas.
Um novo registro é adicionado à tabela para representar as novas informações e tanto o registro original quanto o novo estarão presentes. O novo registro obtém sua própria chave primária da seguinte forma -
| ID do Empregado | 10001 | 10002 |
|---|---|---|
| Nome | Andy | Andy |
| Localização | Nova york | LA, Califórnia |
Benefit - Este método nos permite armazenar todas as informações históricas.
Disadvantage- O tamanho da mesa cresce mais rápido. Quando o número de linhas da tabela é muito alto, o espaço e o desempenho da tabela podem ser uma preocupação.
Use - A Solução 2 deve ser usada quando for necessário que o DW mantenha os dados históricos.
Solução 3
O registro original na dimensão Funcionário é modificado para refletir a mudança.
Haverá duas colunas para indicar o atributo específico, uma indica o valor original e outra indica o novo valor. Haverá também uma coluna que indica quando o valor atual se torna ativo.
| ID do Empregado | Nome | Localização Original | Nova localização | Data da Movimentação |
|---|---|---|---|---|
| 10001 | Andy | Nova york | LA, Califórnia | Julho 2015 |
Benefits- Isso não aumenta o tamanho da tabela, uma vez que novas informações são atualizadas. Isso nos permite manter informações históricas.
Disadvantage - Este método não mantém todo o histórico quando um valor de atributo é alterado mais de uma vez.
Use - A Solução 3 só deve ser usada quando for necessário que o DW mantenha as informações das mudanças históricas.
Normalização
Normalização é o processo de decompor uma tabela em tabelas menores menos redundantes sem perder nenhuma informação. Portanto, a normalização do banco de dados é o processo de organizar os atributos e tabelas de um banco de dados para minimizar a redundância de dados (dados duplicados).
Objetivo de Normalização
É usado para eliminar certos tipos de dados (redundância / replicação) para melhorar a consistência.
Ele fornece flexibilidade máxima para atender às necessidades de informações futuras, mantendo as tabelas correspondentes aos tipos de objetos em seus formulários simplificados.
Ele produz um modelo de dados mais claro e legível.
Vantagens
- Integridade de dados.
- Aumenta a consistência dos dados.
- Reduz a redundância de dados e o espaço necessário.
- Reduz o custo de atualização.
- Flexibilidade máxima para responder a consultas ad-hoc.
- Reduz o número total de linhas por bloco.
Desvantagens
Desempenho lento de consultas no banco de dados porque as junções devem ser executadas para recuperar dados relevantes de várias tabelas normalizadas.
Você tem que entender o modelo de dados para realizar junções adequadas entre várias tabelas.
Exemplo

No exemplo acima, a tabela dentro do bloco verde representa uma tabela normalizada daquela dentro do bloco vermelho. A tabela em bloco verde é menos redundante e também com menor número de linhas sem perder nenhuma informação.
OBIEE significa Oracle Business Intelligence Enterprise Edition, um conjunto de ferramentas de Business Intelligence fornecido pela Oracle Corporation. Ele permite que o usuário forneça um conjunto robusto de relatórios, consulta e análise ad-hoc, OLAP, painel e funcionalidade de scorecard com uma rica experiência do usuário final que inclui visualização, colaboração, alertas e muitas outras opções.
Pontos chave
O OBIEE fornece relatórios robustos que tornam os dados mais fáceis para os usuários de negócios acessarem.
O OBIEE fornece uma infraestrutura comum para a produção e entrega de relatórios corporativos, scorecards, painéis, análises ad-hoc e análises OLAP.
OBIEE reduz custos com uma arquitetura orientada a serviços baseada na web comprovada que se integra à infraestrutura de TI existente.
O OBIEE permite que o usuário inclua visualização avançada, painéis interativos, uma vasta gama de opções de gráficos animados, interações no estilo OLAP, pesquisa inovadora e recursos de colaboração acionáveis para aumentar a adoção do usuário. Esses recursos permitem que sua organização tome melhores decisões, execute ações informadas e implemente processos de negócios mais eficientes.
Concorrentes no mercado
Os principais concorrentes do OBIEE são ferramentas de BI da Microsoft, SAP AG Business Objects, IBM Cognos e SAS Institute Inc.
Como o OBIEE possibilita ao usuário criar dashboards interativos, relatórios robustos, gráficos animados e também por sua relação custo-benefício, é amplamente utilizado por muitas empresas como uma das principais ferramentas para solução de Business Intelligence.
Vantagens do OBIEE
O OBIEE fornece vários tipos de visualizações para inserir em painéis para torná-los mais interativos. Ele permite que você crie relatórios instantâneos, modelos de relatórios e relatórios ad-hoc para usuários finais. Ele fornece integração com as principais fontes de dados e também pode ser integrado com fornecedores terceirizados como a Microsoft para incorporar dados em apresentações do PowerPoint e documentos do Word.
A seguir estão os principais recursos e benefícios da ferramenta OBIEE -
| Características | Principais benefícios do OBIEE |
|---|---|
| Painéis interativos | Fornece painéis e relatórios totalmente interativos com uma grande variedade de visualizações |
| Relatórios interativos de autoatendimento | Permita que os usuários de negócios criem novas análises do zero ou modifiquem as análises existentes sem qualquer ajuda de TI |
| Relatórios Empresariais | Permite a criação de modelos, relatórios e documentos altamente formatados, como relatórios flash, verificações e muito mais |
| Detecção proativa e alertas | fornece um poderoso mecanismo de alerta de várias etapas quase em tempo real que pode acionar fluxos de trabalho com base em eventos de negócios e notificar as partes interessadas por meio de seu meio e canal preferidos |
| Inteligência acionável | Transforma insights em ações, fornecendo a capacidade de invocar processos de negócios a partir de painéis e relatórios de inteligência de negócios |
| Integração com Microsoft Office | Permite que os usuários incorporem dados corporativos atualizados em documentos do Microsoft PowerPoint, Word e Excel |
| Inteligência espacial por meio de visualizações baseadas em mapas | Permite que os usuários visualizem seus dados analíticos usando mapas, trazendo a intuitividade da visualização espacial para o mundo da inteligência de negócios |
Como entrar no OBIEE?
Para fazer login no OBIEE, você pode usar o URL da web, o nome de usuário e a senha.
Para entrar no Oracle BI Enterprise Edition -
Step 1 - Na barra de endereço do navegador da Web, digite o URL para acessar o OBIEE.
A "página de login" é exibida.

Step 2 - Insira seu nome de usuário e senha → Selecione o idioma (você pode alterar o idioma selecionando outro idioma no campo Idioma da interface do usuário na guia Preferências da caixa de diálogo Minha conta ") → Clique na guia Sign In.
Isso o levará para a próxima página de acordo com a configuração: página inicial do OBIEE conforme mostrado na imagem a seguir ou para a página Meu painel / Painel pessoal ou um painel específico para a sua função.

Os componentes do OBIEE são divididos principalmente em dois tipos de componentes -
- Componentes do servidor
- Componentes do cliente
Os componentes do servidor são responsáveis por executar o sistema OBIEE e os componentes do cliente interagem com o usuário para criar relatórios e painéis.
Componentes do servidor
A seguir estão os componentes do servidor -
- Servidor Oracle BI (OBIEE)
- Oracle Presentation Server
- Servidor de aplicação
- Scheduler
- Cluster Controller
Oracle BI Server
Este componente é o coração do sistema OBIEE e é responsável pela comunicação com outros componentes. Gera consultas para solicitação de relatório e são enviadas ao banco de dados para execução.
Também é responsável por gerenciar os componentes do repositório que são apresentados ao usuário para geração de relatórios, manipula o mecanismo de segurança, ambiente multiusuário, etc.
Servidor de apresentação OBIEE
Ele recebe a solicitação dos usuários por meio do navegador e passa todas as solicitações para o servidor OBIEE.
Servidor de aplicação OBIEE
OBIEE Application Server ajuda a trabalhar em componentes do cliente e a Oracle fornece Oracle10g Application Server com o pacote OBIEE.
OBIEE Scheduler
É responsável por agendar trabalhos no repositório OBIEE. Quando você cria um repositório, o OBIEE também cria uma tabela dentro do repositório que salva todas as informações relacionadas à programação. Este componente também é obrigatório para executar agentes no 11g.
Todos os trabalhos que são agendados pelo Scheduler podem ser monitorados pelo gerenciador de trabalhos.
Componentes do cliente
A seguir estão alguns componentes do cliente -
Cliente OBIEE baseado na web
As seguintes ferramentas são fornecidas no cliente OBIEE baseado na web -
- Painéis interativos
- Oracle Delivers
- BI Publisher
- Administrador do serviço de apresentação de BI
- Answers
- Análise desconectada
- Plugin MS Office
Cliente não baseado na web
No cliente não baseado na Web, a seguir estão os principais componentes -
OBIEE Administration - É usado para construir repositórios e tem três camadas - Física, Negócios e Apresentação.
ODBC Client - É usado para conectar ao banco de dados e executar comandos SQL.
A arquitetura OBIEE envolve vários componentes do sistema de BI que são necessários para processar a solicitação do usuário final.
Como o sistema OBIEE realmente funciona?
A solicitação inicial do usuário final é enviada ao servidor de apresentação. O servidor de apresentação converte essa solicitação em SQL lógico e a encaminha para o componente do servidor BI. O servidor de BI converte isso em SQL físico e o envia ao banco de dados para obter o resultado necessário. Este resultado é apresentado ao usuário final da mesma forma.
O diagrama a seguir mostra a arquitetura OBIEE detalhada -
A arquitetura OBIEE contém componentes Java e não Java. Os componentes Java são componentes do Web Logic Server e os componentes não Java são chamados de componentes do sistema Oracle BI.

Servidor Web Logic
Esta parte do sistema OBIEE contém o Admin Server e o Managed Server. O servidor de administração é responsável por gerenciar os processos de início e parada do servidor gerenciado. O Servidor Gerenciado é composto por Plug-in de BI, Segurança, Editor, SOA, BI Office, etc.
Node Manager
O Node Manager aciona as atividades de início, parada e reinicialização automáticas e fornece atividades de gerenciamento de processos para o servidor Admin e gerenciado.
Oracle Process Manager e Notification Server (OPMN)
OPMN é usado para iniciar e parar todos os componentes do sistema BI. É gerenciado e controlado pelo Fusion Middleware Controller.
Componentes do sistema Oracle BI
Esses são componentes não Java em um sistema OBIEE.
Oracle BI Server
Este é o coração do sistema Oracle BI e é responsável por fornecer recursos de acesso a dados e consultas.
BI Presentation Server
É responsável por apresentar aos clientes web os dados do servidor de BI solicitados pelos usuários finais.
Agendador
Este componente fornece capacidade de agendamento no sistema de BI e tem seu próprio agendador para agendar trabalhos no sistema OBIEE.
Oracle BI Java Host
Ele é responsável por habilitar o BI Presentation Server para suportar várias tarefas Java para BI Scheduler, Publisher e gráficos.
BI Cluster Controller
Isso é usado para fins de balanceamento de carga para garantir que a carga seja designada uniformemente a todos os processos do servidor de BI.
O repositório OBIEE contém todos os metadados do BI Server e é gerenciado por meio da ferramenta de administração. É usado para armazenar informações sobre o ambiente do aplicativo, como -
- Modelagem de dados
- Navegação agregada
- Caching
- Security
- Informações de conectividade
- Informação SQL
O BI Server pode acessar vários repositórios. O Repositório OBIEE pode ser acessado usando o seguinte caminho -
BI_ORACLE_HOME/server/Repository -> Oracle 10g
ORACLE_INSTANCE/bifoundation/OracleBIServerComponent/coreapplication_obisn/-> Oracle 11gO banco de dados do repositório OBIEE também é conhecido como RPD devido à sua extensão de arquivo. O arquivo RPD é protegido por senha e você só pode abrir ou criar arquivos RPD usando a ferramenta Oracle BI Administration. Para implantar um aplicativo OBIEE, o arquivo RPD deve ser carregado no Oracle Enterprise Manager. Depois de fazer upload do RPD, a senha do RPD deve ser inserida no Enterprise Manager.
Projetando um Repositório OBIEE usando a ferramenta de administração
É um processo de três camadas - começando na Camada Física (Projeto do Esquema), Camada do Modelo de Negócios e Camada de Apresentação.
Criando a Camada Física
A seguir estão as etapas comuns envolvidas na criação da Camada Física -
- Crie junções físicas entre as tabelas Dimensão e Fato.
- Altere os nomes na camada física, se necessário.
A camada física do repositório contém informações sobre as fontes de dados. Para criar o esquema na camada física, você precisa importar metadados de bancos de dados e outras fontes de dados.
Note - A camada física no OBIEE suporta múltiplas fontes de dados em um único repositório - isto é, conjuntos de dados de 2 fontes de dados diferentes podem ser executados no OBIEE.
Criar um Novo Repositório
Vá para Iniciar → Programas → Oracle Business Intelligence → Administração de BI → Ferramenta de Administração → Arquivo → Novo Repositório.

Uma nova janela será aberta → Insira o nome do Repositório → Local (indica a localização padrão do diretório do Repositório) → para importar metadados, selecione o botão de rádio → Insira a senha → Clique em Avançar.
Selecione o tipo de conexão → Insira o nome da fonte de dados e o nome de usuário e senha para se conectar à fonte de dados → Clique em Avançar.

Aceite os metatipos que deseja importar → Você pode selecionar Tabelas, Chaves, Chaves Estrangeiras, Tabelas do sistema, Sinônimos, Alias, Visualizações, etc. → Clique em Avançar.

Depois de clicar em Avançar, você verá a exibição Fonte de dados e a exibição Repositório. Expanda o nome do Esquema e selecione as tabelas que deseja adicionar ao Repositório usando o botão Importar Selecionado → Clique em Avançar.

A janela Connection Pool é aberta → Clique em OK → janela Importing → Finish para abrir o repositório conforme mostrado na imagem a seguir.
Expanda Data Source → Schema name para ver a lista de tabelas importadas na camada física no novo repositório.

Verifique a conexão e o número de linhas nas tabelas sob a camada física
Vá para ferramentas → Atualizar todas as contagens de linhas → Assim que estiver concluído, você pode mover o cursor na tabela e também para colunas individuais. Para ver os dados de uma tabela, clique com o botão direito em Nome da tabela → Exibir dados.

Criar Alias no Repositório
É aconselhável usar apelidos de tabela com freqüência na camada Física para eliminar junções extras. Clique com o botão direito no nome da tabela e selecione Novo objeto → Alias.
Depois de criar um Alias de uma tabela, ele aparece na mesma Camada Física no Repositório.
Criar chaves primárias e associações no design do repositório
Associações Físicas
Quando você cria um repositório no sistema OBIEE, a junção física é comumente usada na camada Física. As junções físicas ajudam a entender como duas tabelas devem ser unidas uma à outra. As junções físicas são normalmente expressas com o uso do operador Equal.
Você também pode usar uma junção física na camada BMM, no entanto, raramente é vista. O objetivo de usar uma junção física na camada BMM é substituir a junção física na camada física. Ele permite que os usuários definam uma lógica de junção mais complexa em comparação à junção física na camada física, de modo que funciona de forma semelhante à junção complexa na camada física. Portanto, se estivermos usando uma junção complexa na camada física para aplicar mais condições de junção, não há necessidade de usar uma junção física na camada BMM novamente.
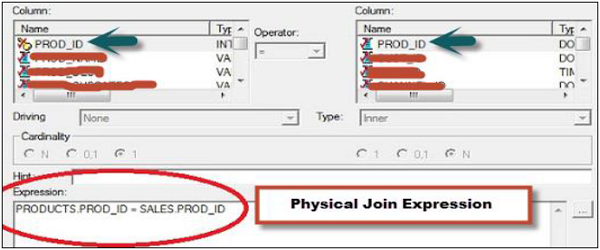
No instantâneo acima, você pode ver uma junção física entre dois nomes de tabela - Produtos e Vendas. A expressão Physical Join informa como as tabelas devem ser unidas umas às outras, conforme mostrado no instantâneo.
É sempre recomendável usar uma junção física na camada física e uma junção complexa na camada BMM tanto quanto possível para manter o design do repositório simples. Somente quando houver uma necessidade real de uma junção diferente, use uma junção física na camada BMM.
Agora, para unir as tabelas ao projetar o Repositório, selecione todas as tabelas na camada Física → Clique com o botão direito do mouse → Diagrama físico → opção Apenas objetos selecionados ou você também pode usar o botão Diagrama Físico na parte superior.

A caixa do Diagrama físico, conforme mostrado na imagem a seguir, aparece com todos os nomes de tabela adicionados. Selecione a nova chave estrangeira na parte superior e selecione Dim e Tabela de fatos para unir.

Chave estrangeira na camada física
Uma chave estrangeira na camada física é usada para definir a relação chave primária-chave estrangeira entre duas tabelas. Ao criá-lo no diagrama físico, você deve apontar primeiro a dimensão e depois a tabela de fatos.
Note - Ao importar tabelas do esquema para a Camada Física RPD, você também pode selecionar KEY e FOREIGN KEY junto com os dados da tabela, então as junções de chave primária-chave estrangeira são definidas automaticamente, no entanto, não é recomendado do ponto de vista de desempenho.

A tabela em que você clica primeiro cria uma relação um-para-um ou um-para-muitos que une a coluna na primeira tabela com a coluna de chave estrangeira na segunda tabela → Clique em OK. A junção ficará visível na caixa do Diagrama Físico entre duas tabelas. Assim que as tabelas forem unidas, feche a caixa do diagrama físico usando a opção 'X'.
Para salvar o novo Repositório, vá para Arquivo → Salvar ou clique no botão Salvar na parte superior.

Criação de modelo de negócio e camada de mapeamento de um repositório
Ele define o modelo de negócios ou lógico de objetos e seu mapeamento entre o modelo de negócios e o esquema na camada física. Ele simplifica o esquema físico e mapeia os requisitos de negócios do usuário para tabelas físicas.
A camada de modelo de negócios e mapeamento da ferramenta de administração do sistema OBIEE pode conter um ou mais objetos de modelo de negócios. Um objeto de modelo de negócios define as definições do modelo de negócios e os mapeamentos de tabelas lógicas para físicas para o modelo de negócios.
A seguir estão as etapas para construir o modelo de negócios e camada de mapeamento de um repositório -
- Crie um modelo de negócios
- Examine junções lógicas
- Examine colunas lógicas
- Examine as fontes lógicas da tabela
- Renomear objetos de tabela lógica manualmente
- Renomeie objetos de tabela lógica usando o assistente de renomeação e excluindo objetos lógicos desnecessários
- Criação de medidas (agregações)
Crie um modelo de negócios
Clique com o botão direito em Business Model and Mapping Space → New Business Model.

Insira o nome do Modelo de Negócios → clique em OK.
Na camada física, selecione todas as tabelas / tabelas de alias a serem adicionados ao Modelo de Negócios e arraste para o Modelo de Negócios. Você também pode adicionar tabelas uma por uma. Se você arrastar todas as tabelas simultaneamente, ele manterá as chaves e as junções entre elas.

Observe também a diferença no ícone das tabelas Dimensão e Fato. A última tabela é a tabela de fatos e as 3 principais são as tabelas de dimensão.
Agora clique com o botão direito do mouse em Modelo de negócios → selecione Diagrama do modelo de negócios → Diagrama inteiro → Todas as tabelas são arrastadas simultaneamente para manter todas as junções e chaves. Agora clique duas vezes em qualquer junção para abrir a caixa de junção lógica.
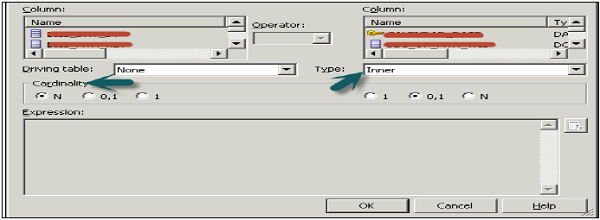
Junções lógicas e complexas no BMM
As junções nesta camada são junções lógicas. Não mostra expressões e informa o tipo de junção entre as tabelas. Ajuda o servidor Oracle BI a compreender as relações entre as várias partes do modelo de negócios. Quando você envia uma consulta ao servidor Oracle BI, o servidor determina como construir consultas físicas examinando como o modelo lógico está estruturado.
Clique em Ok → Clique em 'X' para fechar o diagrama do modelo de negócios.
Para examinar colunas lógicas e origens de tabelas lógicas, primeiro expanda as colunas em tabelas no BMM. Colunas lógicas foram criadas para cada tabela quando você arrastou todas as tabelas da camada física. Para verificar as origens lógicas da tabela → Expanda a pasta de origem sob cada tabela e aponta para a tabela na camada física.
Dê um clique duplo na fonte da tabela lógica (não na tabela lógica) para abrir a caixa de diálogo da fonte da tabela lógica → guia Geral → renomear a fonte da tabela lógica. O mapeamento da tabela lógica para a tabela física é definido na opção "Mapear para estas tabelas".

Em seguida, a guia Mapeamento de coluna define a coluna lógica para os mapeamentos de coluna física. Se os mapeamentos não forem mostrados, marque a opção → Mostrar colunas mapeadas.

Junções complexas
Não há junção complexa explícita específica como no OBIEE 11g. Ele só existe no Oracle 10g.
Vá para Gerenciar → Associações → Ações → Novo → Associação complexa.
Quando junções complexas são usadas na camada BMM, elas atuam como marcadores de posição. Eles permitem que o servidor OBI decida quais são as melhores junções entre a origem da tabela lógica de fatos e dimensões para satisfazer a solicitação.
Renomear objetos lógicos manualmente
Para renomear objetos de tabela lógica manualmente, clique no nome da coluna na Tabela lógica no BMM. Você também pode clicar com o botão direito no nome da coluna e selecionar a opção renomear para renomear o objeto.
Isso é conhecido como método manual para renomear objetos.
Renomear objetos usando o assistente de renomeação
Vá para Ferramentas → Utilitários → Assistente para renomear → Executar para abrir o assistente para renomear.

Na tela Selecionar Objetos, clique em Modelo de Negócios e Mapeamento. Ele mostrará o nome do modelo de negócios → Expandir o nome do modelo de negócios → expandir as tabelas lógicas.

Selecione todas as colunas na tabela lógica para renomear usando a tecla Shift → Clique em Adicionar. Da mesma forma, adicione colunas de todas as outras tabelas lógicas de Dim e Fato → clique em Avançar.

Ele mostra todas as colunas / tabelas lógicas adicionadas ao assistente → Clique em Avançar para abrir a tela Regras → Adicionar regras da lista para renomear como: A ;; digite letras minúsculas e altere cada ocorrência de '_' para espaço, conforme mostrado no instantâneo a seguir.

Clique em Avançar → concluir. Agora, se você expandir Nomes de objetos em tabelas lógicas em Modelo de negócios e Objetos na camada física, os objetos em BMM serão renomeados conforme necessário.
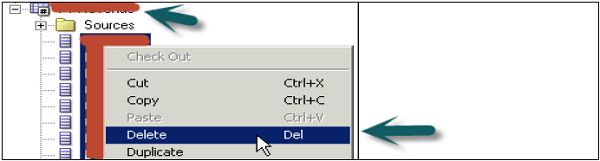
Excluir objetos lógicos desnecessários
Na camada BMM, expanda Tabelas lógicas → selecione os objetos a serem excluídos → clique com o botão direito do mouse → Excluir → Sim.
Criar medidas (agregações)
Dê um clique duplo no nome da coluna na tabela lógica de fatos → Vá para a guia Agregação e selecione a função Agregar na lista suspensa → Clique em OK.

As medidas representam dados que são aditivos, como receita total ou quantidade total. Clique na opção salvar na parte superior para salvar o repositório.
Criando a camada de apresentação de um repositório
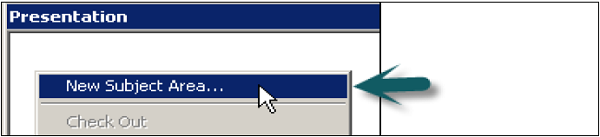
Clique com o botão direito na área de apresentação → Nova área de assunto → Na guia Geral, insira o nome da área de assunto (recomendado semelhante ao Modelo de negócios) → Clique em OK.

Uma vez criada a área de assunto, clique com o botão direito do mouse na área de assunto → Nova tabela de apresentação → Insira o nome da tabela de apresentação → Clique em OK (Adicionar número de tabelas de apresentação igual ao número de parâmetros exigidos no relatório).

Agora, para criar colunas em tabelas de apresentação → Selecione os objetos em tabelas lógicas no BMM e arraste-os para tabelas de apresentação na área de assunto (Use a tecla Ctrl para selecionar vários objetos para arrastar). Repita o processo e adicione as colunas lógicas às tabelas de apresentação restantes.
Renomear e reordenar objetos na camada de apresentação
Você pode renomear os objetos nas tabelas de apresentação clicando duas vezes nos objetos lógicos na área de assunto.
Na guia Geral → Desmarque a caixa de seleção Usar nome da coluna lógica → Editar o campo do nome → Clique em OK.

Da mesma forma, você pode renomear todos os objetos na camada Apresentação sem alterar seus nomes na camada BMM.
Para ordenar as colunas em uma tabela, clique duas vezes no nome da tabela em Apresentação → Colunas → Use as setas para cima e para baixo para alterar a ordem → Clique em OK.

Da mesma forma, você pode alterar a ordem dos objetos em todas as tabelas de apresentação na área Apresentação. Vá para Arquivo → Clique em Salvar para salvar o Repositório.
Verifique a consistência e carregue o repositório para análise de consulta
Vá para Arquivo → Verificar consistência global → Você receberá a seguinte mensagem → Clique em Sim.

Depois de clicar em OK → Modelo de negócios sob BMM mudará para Verde → Clique em salvar o repositório sem verificar a consistência global novamente.
Desativar cache
Para melhorar o desempenho da consulta, é aconselhável desabilitar a opção de cache do servidor BI.
Abra um navegador e digite a seguinte URL para abrir o Fusion Middleware Control Enterprise Manager: http: // <nome da máquina>: 7001 / em
Digite o nome de usuário e a senha e clique em Login.
No lado esquerdo, expanda Business Intelligence → co-aplicativo → guia Gerenciamento de capacidade → Desempenho.

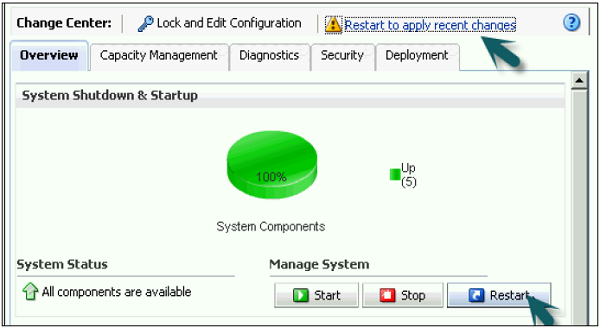
A seção Habilitar Cache do BI Server está marcada por padrão → Clique em Bloquear e Editar Configuração → Clique em Fechar.

Agora desmarque a opção de cache ativado → É usado para melhorar o desempenho da consulta → Aplicar → Ativar alterações → Concluído com sucesso.
Carregando o Repositório
Vá para a guia Implementação → Repositório → Bloquear e editar configuração → Concluído com sucesso.

Clique na seção Carregar o repositório do BI Server → Navegar para abrir a caixa de diálogo Escolher arquivo → Selecione o arquivo Repositório .rpd e clique em Abrir → Inserir senha do repositório → Aplicar → Ativar alterações.

Ativar alterações → Concluído com sucesso → Clique em Reiniciar para aplicar a opção de alterações recentes na parte superior da tela → Clique em Sim.
O repositório foi criado e carregado com sucesso para a análise da consulta.
A camada de negócios define o modelo de negócios ou lógico de objetos e seu mapeamento entre o modelo de negócios e o esquema na camada física. Ele simplifica o esquema físico e mapeia os requisitos de negócios do usuário para tabelas físicas.
O modelo de negócios e a camada de mapeamento da ferramenta de administração do sistema OBIEE podem conter um ou mais objetos de modelo de negócios. Um objeto de modelo de negócios define as definições do modelo de negócios e os mapeamentos de tabelas lógicas para físicas para o modelo de negócios.
O modelo de negócios é usado para simplificar a estrutura do esquema e mapeia os requisitos de negócios dos usuários para a fonte de dados física. Envolve a criação de tabelas e colunas lógicas no modelo de negócios. Cada tabela lógica pode ter um ou mais objetos físicos como fontes.
Existem duas categorias de tabelas lógicas - fato e dimensão. As tabelas de fatos lógicos contêm as medidas nas quais a análise é feita e as tabelas de dimensões lógicas contêm as informações sobre medidas e objetos no Esquema.
Ao criar um novo repositório usando a ferramenta de administração OBIEE, depois de definir a camada física, crie junções e identifique as chaves estrangeiras. A próxima etapa é criar um modelo de negócios e mapear a camada BMM do repositório.
Etapas envolvidas na definição da camada de negócios -
- Crie um modelo de negócios
- Examine junções lógicas
- Examine colunas lógicas
- Examine as fontes lógicas da tabela
- Renomear objetos de tabela lógica manualmente
- Renomear objetos de tabela lógica usando o assistente de renomeação e excluir objetos lógicos desnecessários
- Criação de medidas (agregações)
Criar Camada de Negócios no Repositório
Para criar uma camada de negócios no repositório, clique com o botão direito do mouse → Novo Modelo de Negócios → Insira o nome do Modelo de Negócios e clique em OK. Você também pode adicionar uma descrição deste modelo de negócios, se desejar.


Tabelas lógicas e objetos na camada BMM
Existem tabelas lógicas no repositório OBIEE no modelo de negócios e na camada BMM de mapeamento. O diagrama do modelo de negócios deve conter pelo menos duas tabelas lógicas e você precisa definir os relacionamentos entre elas.
Cada tabela lógica deve ter uma ou mais colunas lógicas e uma ou mais fontes de tabelas lógicas associadas a ela. Você também pode alterar o nome da tabela lógica, reordenar os objetos na tabela lógica e definir junções lógicas usando chaves primárias e externas.
Criar tabelas lógicas sob a camada BMM
Existem duas maneiras de criar tabelas / objetos lógicos na camada BMM -
First methodé arrastar tabelas físicas para o Modelo de Negócios, que é a maneira mais rápida de definir tabelas lógicas. Quando você arrasta as tabelas da camada física para a camada BMM, também preserva as junções e chaves automaticamente. Se você quiser, pode alterar as junções e as chaves nas tabelas lógicas, isso não afeta os objetos na camada física.
Selecione tabelas físicas / tabelas de alias sob a camada física que deseja adicionar à Camada de modelo de negócios e arraste essas tabelas sob a camada BMM.
Essas tabelas são conhecidas como tabelas lógicas e as colunas são chamadas de objetos lógicos em Modelo de Negócios e Camada de Mapeamento.

Second methodé criar uma tabela lógica manualmente. Na camada Modelo de Negócios e Mapeamento, clique com o botão direito do mouse no modelo de negócios → Selecionar Novo Objeto → Tabela Lógica → A caixa de diálogo Tabela Lógica é exibida.
Vá para a guia Geral → Insira o nome para a tabela lógica → Digite uma descrição da tabela → Clique em OK.

Criar Colunas Lógicas
As colunas lógicas na camada BMM são criadas automaticamente quando você arrasta tabelas da camada física para a camada do modelo de negócios.
Se a coluna lógica for uma chave primária, esta coluna será exibida com o ícone de chave. Se a coluna tiver uma função de agregação, ela será exibida com um ícone sigma. Você também pode reordenar colunas lógicas no modelo de negócios e camada de mapeamento.
Crie uma coluna lógica
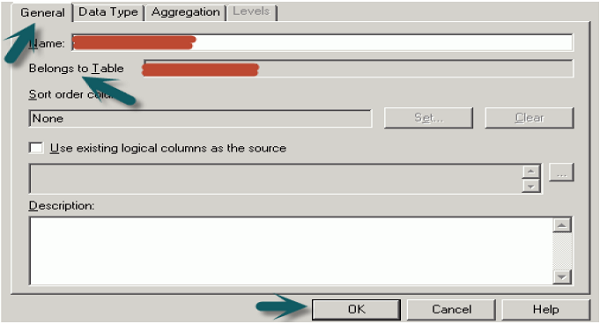
Na camada BMM, clique com o botão direito na tabela lógica → selecione Novo objeto → Coluna lógica → A caixa de diálogo Coluna lógica aparecerá, clique na guia Geral.
Digite um nome para a coluna lógica. O nome do modelo de negócios e a tabela lógica aparecem no campo “Pertence à tabela” logo abaixo do nome da coluna → clique em OK.
Você também pode aplicar agregações nas colunas lógicas. Clique na guia Agregação → Selecione a regra de agregação na lista suspensa → Clique em OK.
Depois de aplicar a função Agregar em uma coluna, o ícone da coluna lógica é alterado para mostrar que a regra de agregação foi aplicada.

Você também pode mover ou copiar colunas lógicas nas tabelas -
Na camada BMM, você pode selecionar várias colunas para mover. Na caixa de diálogo Origens para colunas movidas, na área Ação, selecione uma ação. Se você selecionar Ignorar, nenhuma origem lógica será adicionada à pasta Origens da tabela.
Se você clicar em Criar novo, uma cópia da fonte lógica com a coluna lógica será criada na pasta Fontes. Se você selecionar a opção Usar existente, na lista suspensa, deverá selecionar uma origem lógica na pasta Origens da tabela.
Criar junções complexas lógicas / chaves externas lógicas
As tabelas lógicas na camada BMM são unidas entre si por meio de associações lógicas. A cardinalidade é um dos principais parâmetros de definição em junções lógicas. A relação de cardinalidade um para muitos significa que cada linha na primeira tabela de dimensão lógica há 0, 1, muitas linhas na segunda tabela lógica.
Condições para criar associações lógicas automaticamente
Quando você arrasta todas as tabelas da camada física para a camada do modelo de negócios, junções lógicas são criadas automaticamente no Repositório. Essa condição raramente ocorre apenas no caso de modelos de negócios simples.
Quando as associações lógicas são iguais às associações físicas, elas são criadas automaticamente. As junções lógicas na camada BMM são criadas de duas maneiras -
- Diagrama do modelo de negócios (já abordado durante o projeto do repositório)
- Gerente de ingressos
As junções lógicas na camada BMM não podem ser especificadas usando expressões ou colunas nas quais criar a junção, como na camada física onde as expressões e os nomes das colunas são mostrados nas quais as junções físicas são definidas.
Criar junções lógicas / chaves externas lógicas usando a ferramenta Join Manager
Primeiro, vamos ver como criar chaves estrangeiras lógicas usando o Join Manager.
Na barra de ferramentas da ferramenta de administração, vá para Gerenciar → Associações. A caixa de diálogo Joins Manager é exibida → Vá para a guia Action → New → Logical Foreign Key.
Agora na caixa de diálogo Browse, clique duas vezes em uma tabela → A caixa de diálogo Logical Foreign Key aparece → Insira o nome para a chave estrangeira → Na lista suspensa Tabela da caixa de diálogo, selecione a tabela que a chave estrangeira faz referência → Selecionar as colunas na tabela à esquerda que a chave estrangeira faz referência → Selecione as colunas na tabela à direita que compõem as colunas da chave estrangeira → Selecione o tipo de junção na lista suspensa Tipo. Para abrir o Expression Builder, clique no botão à direita do painel Expressão → A expressão é exibida no painel Expressão → clique em OK para salvar o trabalho.
Crie uma junção do complexo lógico usando o Join Manager
As junções lógicas complexas são recomendadas no Modelo de Negócios e camada de mapeamento em comparação com o uso de chaves externas lógicas.
Na barra de ferramentas da Ferramenta de Administração, vá para Gerenciar → Unir → A caixa de diálogo Gerenciador de Associações aparece → Vá para Ação → Clique em Novo → Associação do Complexo Lógico.
Irá abrir uma caixa de diálogo lógica de junção → Digite um nome para a junção complexa → Nas listas suspensas da tabela à esquerda e direita da caixa de diálogo, selecione as tabelas às quais a junção complexa faz referência → Selecione o tipo de junção do Lista suspensa de tipos → Clique em OK.
Note- Você também pode definir uma mesa como mesa de controle na lista suspensa. Isso é usado para otimização de desempenho quando o tamanho da tabela é muito grande. Se o tamanho da tabela for pequeno, menos de 1000 linhas, não deve ser definido como tabela de controle, pois pode resultar em degradação do desempenho.
Dimensões e níveis hierárquicos
As dimensões lógicas existem no BMM e na camada de apresentação do repositório OBIEE. A criação de dimensões lógicas com hierarquias permite definir regras de agregação que variam com as dimensões. Ele também fornece uma opção de detalhamento nos gráficos e tabelas em análises e painéis e define o conteúdo de fontes agregadas.
Crie dimensão lógica com nível hierárquico
Abra o Repositório no modo Offline → Vá para Arquivo → Abrir → Offline → Selecione o arquivo Repositório .rpd e clique em abrir → Insira a senha do Repositório → clique em OK.
A próxima etapa é criar dimensão lógica e níveis lógicos.
Clique com o botão direito no nome do modelo de negócios na camada BMM → Novo objeto → Dimensão lógica → Dimensão com hierarquia baseada em nível. Isso abrirá a caixa de diálogo → Digite o nome → clique em OK.

Para criar um nível lógico, clique com o botão direito na dimensão lógica → Novo objeto → Nível lógico.

Insira o nome do exemplo de nível lógico: Product_Name
Se este nível for o nível Total geral, marque a caixa de seleção e o sistema definirá o número de elemento neste nível como 1 por padrão → Clique em OK.
Se você deseja que o nível lógico role para seu pai, selecione a caixa de seleção Suporta rollup para elementos pai → clique em OK.
Se o nível lógico não for o nível do total geral e não acumular, não selecione nenhuma das caixas de seleção → Clique em OK.

Hierarquias pai-filho
Você também pode adicionar hierarquias pai-filho em nível lógico, seguindo estas etapas -
Para definir os níveis lógicos filhos, clique em Adicionar na caixa de diálogo Procurar, selecione os níveis lógicos filhos e clique em OK.
Você também pode clicar com o botão direito do mouse no nível lógico → Novo objeto → nível filho.

Digite o nome do nível filho → Ok. Você pode repetir isso para adicionar vários níveis filho para todas as colunas lógicas de acordo com o requisito. Você também pode adicionar hierarquias de tempo e região de maneira semelhante.
Agora, para adicionar colunas lógicas de uma tabela ao nível lógico → selecione a coluna lógica na camada BMM e arraste-a para o nome do filho do nível lógico para o qual deseja mapear. Da mesma forma, você pode arrastar todas as colunas da tabela lógica para criar hierarquias pai-filho.
Quando você cria um nível filho, ele pode ser verificado com um clique duplo no nível lógico e é exibido na lista de níveis filho desse nível. Você pode adicionar ou excluir níveis filho usando a opção '+' ou 'X' no topo desta caixa.

Adicionar cálculo a uma tabela de fatos
Dê um clique duplo no nome da coluna na tabela de fatos lógica → Vá para a guia Agregação e selecione a função Agregar na lista suspensa → Clique em OK.

Medidas representam dados que são aditivos, como receita total ou quantidade total. Clique na opção salvar na parte superior para salvar o repositório.
Existem várias funções de agregação que podem ser usadas como Soma, Média, Contagem, Máx, Mín, etc.
A camada de apresentação é usada para fornecer aos usuários visualizações personalizadas do modelo de negócios na camada BMM. As áreas de assunto são usadas na camada de apresentação fornecida pelo Oracle BI Presentation Services.
Existem várias maneiras de criar áreas de assunto na camada de Apresentação. O método mais comum e simples é arrastar o Modelo de Negócios na camada BMM para a Camada de Apresentação e, em seguida, fazer as alterações conforme o requisito.
Você pode mover colunas, remover ou adicionar colunas na camada de apresentação, de modo que permita fazer alterações de forma que o usuário não veja colunas que não tenham significado para elas.
Create Subject Areas/Presentation Catalogues and Presentation Tables in Presentation Layer
Clique com o botão direito na área de Apresentação → Nova Área de Assunto → Na guia Geral, insira o nome da área de assunto (Recomendado semelhante ao Modelo de Negócios) → Clique em OK.
Depois de criar a área de assunto, clique com o botão direito do mouse na área de assunto → Nova tabela de apresentação → na guia Geral, digite o nome da tabela de apresentação → OK (adicione o número de tabelas de apresentação igual ao número de parâmetros exigidos no relatório).

Clique na guia Permissões → caixa de diálogo Permissões, onde você pode atribuir permissões de usuário ou grupo à tabela.

Excluir uma mesa de apresentação
Na camada Apresentação, clique com o botão direito do mouse na Área de assunto → caixa de diálogo Catálogo de apresentação, clique na guia Tabelas de apresentação → Vá para a guia Tabelas de apresentação, selecione uma tabela e clique em Remover.
Uma mensagem de confirmação aparece → Clique em Sim para remover a tabela ou em Não para deixar a mesa no catálogo → Clique em OK.
Mover uma mesa de apresentação
Vá para a guia Tabelas de Apresentação clicando com o botão direito na Área de Assunto → Na lista Nome, selecione a tabela que deseja reordenar → Use arrastar e soltar para reposicionar a tabela ou você também pode usar os botões Para cima e Para baixo para reordenar tabelas.
Colunas de apresentação sob a mesa de apresentação
O nome das colunas de apresentação são normalmente iguais aos nomes das colunas lógicas no Modelo de Negócios e camada de Mapeamento. No entanto, você também pode inserir um nome diferente desmarcando Usar nome da coluna lógica e Exibir nome personalizado na caixa de diálogo Coluna da apresentação.
Criar colunas de apresentação
A maneira mais simples de criar colunas em tabelas de apresentação é arrastando as colunas de tabelas lógicas na camada BMM.
Selecione os objetos em tabelas lógicas no BMM e arraste-os para tabelas de apresentação na área de assunto (use a tecla Ctrl para selecionar vários objetos para arrastar). Repita o processo e adicione as colunas lógicas às tabelas de apresentação restantes.
Create a New Presentation Column −
Clique com o botão direito na tabela de apresentação na camada Apresentação → Nova coluna de apresentação.
A caixa de diálogo Coluna de apresentação é exibida. Para usar o nome da coluna lógica, marque a caixa de seleção Usar coluna lógica.

Para especificar um nome diferente, desmarque a caixa de seleção Usar coluna lógica e digite um nome para a coluna.
Para atribuir permissões de usuário ou grupo à coluna, clique em Permissões → Na caixa de diálogo Permissões, atribua permissões → clique em OK.

Excluir uma coluna de apresentação
Clique com o botão direito na tabela de apresentação na camada Apresentação → Clique em Propriedades → Clique na guia Colunas → Selecione a coluna que deseja excluir → Clique em Remover ou pressione a tecla Excluir → Clique em Sim.
Para reordenar uma coluna de apresentação
Clique com o botão direito na tabela de apresentação na camada Apresentação → Vá para Propriedades → Clique na guia Colunas → Selecione a coluna que deseja reordenar → Use arrastar e soltar ou você também pode clicar no botão Acima e Abaixo → Clique em OK.

Você pode verificar se há erros no repositório usando a opção de verificação de consistência. Depois de fazer isso, a próxima etapa é carregar o repositório no Oracle BI Server. Em seguida, teste o repositório executando uma análise do Oracle BI e verificando os resultados.
Vá para Arquivo → clique em Verificar Consistência Global → Você receberá a seguinte mensagem → Clique em Sim.

Depois de clicar em OK → O modelo de negócios em BMM mudará para Verde → Clique em salvar o repositório sem verificar a consistência global novamente.
Desativar cache
Para melhorar o desempenho da consulta, é aconselhável desabilitar a opção de cache do servidor BI.
Abra um navegador e digite a seguinte URL para abrir o Fusion Middleware Control Enterprise Manager: http: // <nome da máquina>: 7001 / em
Digite o nome de usuário e senha. Clique em Login.
No lado esquerdo, expanda Business Intelligence → co-aplicativo → guia Gerenciamento de capacidade → Desempenho.

A seção Habilitar Cache do BI Server está marcada por padrão → Clique em Bloquear e Editar Configuração → Fechar.

Agora desmarque a opção de cache habilitado. É usado para melhorar o desempenho da consulta. Vá para Aplicar → Ativar alterações → Concluído com sucesso.
Carregue o Repositório
Vá para a guia Implementação → Repositório → Bloquear e editar configuração → Concluído com sucesso.

Clique na seção Fazer upload do repositório do BI Server → Navegar para abrir a caixa de diálogo Escolher arquivo → selecione o arquivo Repositório .rpd e clique em Abrir → Inserir senha do repositório → Aplicar → Ativar alterações.

Ativar alterações → Concluído com sucesso → Clique em Reiniciar para aplicar a opção de alterações recentes no topo → Clique em Sim.

O repositório foi criado e carregado com sucesso para análise de consulta.
Ativar registro de consulta
Você pode configurar o nível de log de consulta para usuários individuais no OBIEE. O nível de registro controla as informações que você recuperará no arquivo de registro.
Configurar registro de consulta
Abra a ferramenta de Administração → Vá para Arquivo → Abrir → Online.
O modo online é usado para editar o repositório no servidor Oracle BI. Para abrir um repositório no modo online, seu servidor Oracle BI deve estar em execução.

Insira a senha do Repositório e a senha do nome de usuário para fazer login e clique em Abrir para abrir o repositório.

Vá para Gerenciar → Identidade → A janela do Gerenciador de Segurança será aberta. Clique em Repositório de BI no lado esquerdo e clique duas vezes em Usuário administrativo → A caixa de diálogo do usuário será aberta.

Clique na guia Usuário na caixa de diálogo do usuário, você pode definir os níveis de registro aqui.
Em cenário normal - O usuário tem um nível de registro definido como 0 e o administrador tem um nível de registro definido como 2. O nível de registro pode ter valores a partir do nível 0 ao nível 5. Nível 0 significa nenhum registro e nível 5 significa informações de nível máximo de registro .
Descrições de nível de registro
| Nível 0 | Sem registro |
| Nível 1 | Registra a instrução SQL emitida a partir do aplicativo cliente Registra o tempo decorrido para compilação de consulta, execução de consulta, processamento de cache de consulta e processamento de banco de dados back-end Registra o status da consulta (sucesso, falha, encerramento ou tempo limite). Registra a ID do usuário, ID da sessão e ID da solicitação para cada consulta |
| Nível 2 | Registra tudo registrado no Nível 1 Além disso, para cada consulta, registra o nome do repositório, o nome do modelo de negócios, o nome do catálogo de apresentação (denominado Área de Assunto na Resposta), SQL para as consultas emitidas em bancos de dados físicos, consultas emitidas no cache, número de linhas retornadas de cada consulta em um banco de dados físico e de consultas emitidas contra o cache, e o número de linhas retornadas ao aplicativo cliente |
| Nível 3 | Registra tudo registrado no Nível 2
Além disso, adiciona uma entrada de registro para o plano de consulta lógica, quando uma consulta que deveria ser propagada para o cache não foi inserida no cache, quando as entradas de cache existentes são removidas para abrir espaço para a consulta atual e quando a tentativa de atualizar o detector de acertos de correspondência exata falha |
| Nível 4 | Registra tudo registrado no Nível 3 Além disso, registra o plano de execução da consulta. |
| Nível 5 | Registra tudo registrado no Nível 4 Além disso, registra contagens de linhas intermediárias em vários pontos do plano de execução. |
Para definir o nível de registro
Na caixa de diálogo do usuário, insira o valor para o nível de registro.
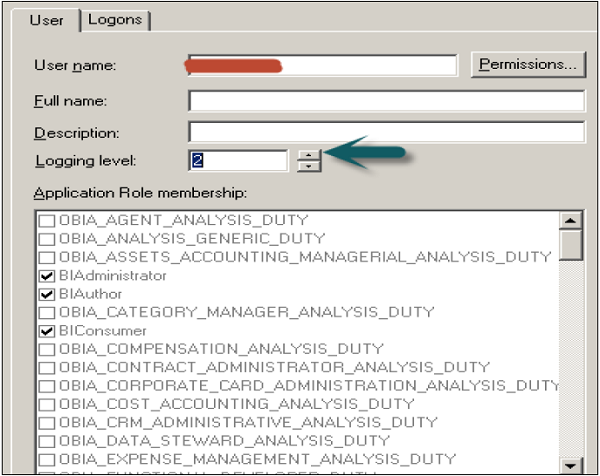
Depois de clicar em OK, a caixa de diálogo de checkout será aberta. Clique em Checkout. Feche o gerenciador de segurança.

Vá para o arquivo → Clique em mudanças de check-in → Salve o repositório usando a opção Salvar na parte superior → Para fazer as mudanças em vigor → Clique em OK.

Use o log de consulta para verificar as consultas
Você pode verificar os logs de consulta uma vez que o nível de log de consulta é definido indo para o Oracle Enterprise Manager e isso ajuda a verificar as consultas.
Para verificar os logs de consulta para verificar as consultas, vá para Oracle Enterprise Manager OEM.
Vá para a guia de diagnóstico → clique em Mensagens de log.

Role para baixo até o final nas mensagens de log para ver o servidor, o Scheduler, os serviços de ação e outros detalhes de log. Clique em Log do servidor para abrir a caixa de mensagens de log.
Você pode selecionar vários filtros - Intervalo de datas, tipos de mensagem e mensagem contém / não contém campos, etc., conforme mostrado no instantâneo a seguir -

Depois de clicar em pesquisar, ele mostrará as mensagens de log de acordo com os filtros.

Clicar no botão recolher permite que você verifique os detalhes de todas as mensagens de log para consultas.
Quando você arrasta e solta uma coluna de uma tabela física que não está sendo usada atualmente em sua tabela lógica na camada BMM, a tabela física que contém essa coluna é adicionada como uma nova Fonte de Tabela Lógica (LTS).
Quando na camada BMM, você usa mais de uma tabela como tabela de origem, é chamada de várias origens de tabela lógica. Você pode ter uma tabela de fatos como várias origens de tabela lógica quando ela usa diferentes tabelas físicas como origem.
Example
Vários LTS são usados para converter o esquema Snowflakes em esquemas Star na camada BMM.
Digamos que você tenha duas dimensões - Dim_Emp e Dim_Dept e uma tabela de fatos FCT_Attendance na camada Física.
Aqui seu Dim_Emp é normalizado para Dim_Dept para implementar o esquema de flocos de neve. Então, em seu diagrama físico, seria assim -
Dim_Dept<------Dim_Emp <-------FCT_AttendanceQuando movemos essas tabelas para a camada BMM, criaremos uma tabela de dimensão única Dim_Employee com 2 fontes lógicas correspondentes a Dim_Emp e Dim_Dept. Em seu diagrama BMM -
Dim_Employee <-----------FCT_AttendanceEsta é uma abordagem em que você pode usar o conceito de vários LTS na camada BMM.
Especificando Conteúdo
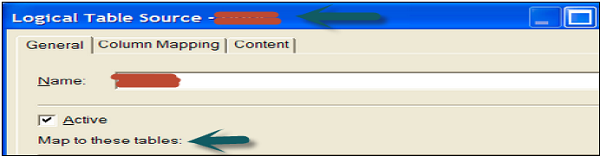
Ao usar várias tabelas físicas como fontes, você expande as fontes de tabela no diagrama BMM. Ele mostra todos os vários LTS de onde está coletando os dados na camada BMM.
Para ver o mapeamento da tabela na camada BMM, expanda as fontes sob a tabela lógica na camada BMM. Isso abrirá a caixa de diálogo Logical table source mapping. Você pode verificar todas as tabelas que são mapeadas para fornecer dados na tabela lógica.
Medidas calculadas são usadas para realizar cálculos de fatos em tabelas lógicas. Ele define funções de agregação na guia Agregação da coluna lógica no repositório.
Criar Nova Medida
As medidas são definidas em tabelas de fatos lógicas no repositório. Qualquer coluna com uma função de agregação aplicada a ela é chamada de medida.
Exemplos de medidas comuns são - Preço unitário, quantidade vendida, etc.
A seguir estão as diretrizes para criar medidas no OBIEE -
Toda agregação deve ser executada a partir de uma tabela lógica de fatos e não de uma tabela lógica de dimensões.
Todas as colunas que não podem ser agregadas devem ser expressas em uma tabela lógica de dimensão e não em uma tabela lógica de fato.
As medidas calculadas podem ser definidas de duas maneiras em tabelas lógicas na camada BMM na ferramenta de administração -
- Agregações em tabelas lógicas.
- Agregações na origem da tabela lógica.
Crie medidas calculadas em tabelas lógicas usando ferramenta de administração
Dê um clique duplo no nome da coluna na tabela lógica de fatos e você verá a seguinte caixa de diálogo.

Vá para a guia Agregação e selecione a função Agregar na lista suspensa → Clique em OK.

Você pode adicionar novas medidas usando funções no assistente de construtor de Expressão na origem da coluna. As medidas representam dados que são aditivos, como receita total ou quantidade total. Clique na opção salvar na parte superior para salvar o repositório. Isso também é chamado de criação de medidas em nível lógico.
Crie medidas calculadas na fonte da tabela lógica usando a ferramenta de administração
Você pode definir agregações clicando duas vezes na origem da tabela lógica para abrir a caixa de diálogo da tabela lógica.

Clique no assistente do construtor de expressões para definir a expressão.
No Construtor de expressões, você pode escolher várias opções como - Categoria, funções e funções matemáticas.
Depois de selecionar a categoria, ele mostrará as subcategorias dentro dela. Selecione a subcategoria e a função matemática e clique na seta para inseri-la.

Agora, para editar o valor para criar medidas, clique no número de origem, insira o valor calculado como múltiplo e divida → Vá para a categoria e selecione a tabela lógica → Selecione a coluna para aplicar este múltiplo / divisão a um valor de coluna existente.

Clique em OK para fechar o construtor Expression. Clique novamente em OK para fechar a caixa de diálogo.
Hierarquias é uma série de relacionamentos muitos para um e pode ser de níveis diferentes. Uma hierarquia de região consiste em: Região → País → Estado → Cidade → Rua. As hierarquias seguem uma abordagem de cima para baixo ou de baixo para cima.
Dimensões lógicas ou hierarquias de dimensão são criadas na camada BMM. Existem dois tipos de hierarquias dimensionais que são possíveis -
- Dimensões com hierarquias baseadas em nível.
- Dimensão com hierarquias pai-filho.
Em hierarquias baseadas em nível, os membros podem ser de tipos diferentes e os membros do mesmo tipo vêm apenas em um único nível.
Nas hierarquias pai-filho, todos os membros são do mesmo tipo.
Dimensões com hierarquias baseadas em nível
Hierarquias de dimensão baseadas em nível também podem conter relacionamentos pai-filho. A sequência comum para criar hierarquias baseadas em nível é começar com o nível total geral e depois descer para níveis mais baixos.
Hierarquias baseadas em nível permitem que você execute -
- Medidas calculadas com base em nível.
- Navegação agregada.
- Faça uma busca detalhada no nível filho nos painéis.
Cada dimensão pode ter apenas um nível de total geral e não tem uma chave de nível ou atributos de dimensão. Você pode associar medidas ao nível de total geral e a agregação padrão para essas medidas é sempre total geral.
Todos os níveis inferiores devem ter pelo menos uma coluna e cada dimensão contém uma ou mais hierarquias. Cada nível inferior também contém uma chave de nível que define o valor exclusivo naquele nível.
Tipos de hierarquias baseadas em nível
Hierarquias desequilibradas
Hierarquias desequilibradas são aquelas em que todos os níveis inferiores não têm a mesma profundidade.
Example - Para um produto, por um mês você pode ter dados para semanas e para outro mês você pode ter dados disponíveis para nível de dia.
Pular hierarquias de nível
Em hierarquias de nível de salto, poucos membros não têm valores em nível superior.
Example- Para uma cidade, você tem estado → país → Região. Porém, para outra cidade, você tem apenas o estado e não se enquadra em nenhum país ou região.
Dimensão com hierarquias pai-filho
Na hierarquia pai-filho, todos os membros são do mesmo tipo. O exemplo mais comum de hierarquia pai-filho é a estrutura de relatórios em uma organização. A hierarquia pai-filho é baseada em uma única tabela lógica. Cada linha contém duas chaves - uma para o membro e outra para o pai do membro.
Medidas baseadas em nível são criadas para realizar cálculos em um nível específico de agregação. Eles permitem retornar dados em vários níveis de agregação com uma única consulta. Também permite criar medidas de compartilhamento.
Example
Digamos que exista uma empresa XYZ Electronics que vende seus produtos em diversas regiões, países e cidades. Agora, o presidente da empresa deseja ver a receita total em nível de país - um nível abaixo da região e um nível acima das cidades. Portanto, a medida da receita total deve ser resumida ao nível do país.
Esses tipos de medidas são chamados de medidas baseadas em nível. Da mesma forma, você pode aplicar medidas baseadas em nível nas hierarquias de tempo.
Uma vez que as hierarquias de dimensão são criadas, medidas baseadas em nível podem ser criadas clicando duas vezes na coluna de receita total na tabela lógica e definindo o nível na guia de níveis.
Criar medidas baseadas em nível
Abra o repositório no modo offline. Vá para Arquivo → Abrir → Offline.
Selecione o arquivo .rpd e clique em abrir → Digite a senha do repositório e clique em OK.
Na camada BMM, clique com o botão direito na coluna Receita total → Novo objeto → coluna Lógica.

Isso abrirá a caixa de diálogo da coluna lógica. Insira o nome da receita total da coluna lógica. Vá para a guia de origem da coluna → Verifique as derivadas de colunas existentes usando uma expressão.

Depois de selecionar esta opção, o assistente de edição de expressão será destacado. No assistente de criação de expressão, selecione a tabela lógica → Nome da coluna → Receita total no menu à esquerda → Clique em OK.
Agora vá para a guia de nível na caixa de diálogo da coluna lógica → Clique na dimensão lógica para selecioná-la como total geral no nível lógico. Isso especifica que a medida deve ser calculada no nível de total geral na hierarquia da dimensão.

Depois de clicar em OK → A tabela lógica de receita total aparecerá sob a dimensão lógica e as tabelas de fatos.
Esta coluna pode ser arrastada para a camada de apresentação na área de assunto para ser usada pelos usuários finais para gerar relatórios. Você pode arrastar esta coluna das tabelas de fatos ou da dimensão lógica.
As agregações são usadas para implementar a otimização do desempenho da consulta durante a execução dos relatórios. Isso elimina o tempo gasto pela consulta para executar os cálculos e fornece os resultados em alta velocidade. As tabelas agregadas têm menos número de linhas em comparação com uma tabela normal.
Como funciona a agregação no OBIEE?
Quando você executa uma consulta no OBIEE, o servidor de BI procura os recursos que possuem informações para responder à consulta. De todas as fontes disponíveis, o servidor seleciona a fonte mais agregada para responder a essa consulta.
Adicionando agregação em um repositório
Abra o Repositório em modo offline na ferramenta Administrador. Vá para Arquivo → Abrir → Offline.
Importe os metadados e crie a origem da tabela lógica na camada BMM. Expanda o nome da tabela e clique no nome da tabela de origem para abrir a caixa de diálogo de origem da tabela lógica.
Vá para a guia de mapeamento de coluna para ver as colunas do mapa na tabela física. Vá para a guia de conteúdo → Agregar grupo de conteúdo selecionando o nível lógico.

Você pode selecionar diferentes níveis lógicos de acordo com as colunas nas tabelas de fatos, como Produto Total, Total de Receita e Trimestre / Ano para Tempo de acordo com as hierarquias de dimensão.

Clique em OK para fechar a caixa de diálogo → salvar o repositório.
Ao definir Aggregate em tabelas de fatos lógicos, eles são definidos de acordo com as hierarquias de dimensão.
No OBIEE, existem dois tipos de variáveis que são comumente usadas -
- Variáveis de repositório
- Variáveis de sessão
Além disso, você também pode definir variáveis de apresentação e solicitação.
Variáveis de Repositório
Uma variável de repositório tem um único valor em qualquer ponto do tempo. As variáveis do repositório são definidas usando a ferramenta Oracle BI Administration. As variáveis do repositório podem ser usadas no lugar das constantes no Assistente do Expression Builder.
Existem dois tipos de variáveis de repositório -
- Variáveis de repositório estáticas
- Variáveis de repositório dinâmico
As variáveis de repositório estáticas são definidas na caixa de diálogo de variáveis e seu valor existe até que sejam alteradas pelo administrador.
Variáveis de repositório estáticas contêm inicializadores padrão que são valores numéricos ou de caracteres. Além disso, você pode usar o Expression Builder para inserir uma constante como o inicializador padrão, como data, hora, etc. Você não pode usar qualquer outro valor ou expressão como o inicializador padrão para uma variável de repositório estática.
Em versões anteriores de BI, a ferramenta Administrator não limitava o valor das variáveis estáticas do repositório. Você pode receber um aviso na verificação de consistência se seu repositório foi atualizado de versões anteriores. Nesse caso, atualize as variáveis do repositório estático para que os inicializadores padrão tenham um valor constante.
As variáveis de repositório dinâmicas são iguais às variáveis estáticas, mas os valores são atualizados por dados retornados de consultas. Ao definir uma variável de repositório dinâmica, você cria um bloco de inicialização ou usa um preexistente que contém uma consulta SQL. Você também pode configurar uma programação que o Oracle BI Server seguirá para executar a consulta e atualizar o valor da variável periodicamente.
Quando o valor de uma variável de repositório dinâmico muda, todas as entradas de cache associadas a um modelo de negócios são excluídas automaticamente.
Cada consulta pode atualizar várias variáveis: uma variável para cada coluna da consulta. Você agenda essas consultas para serem executadas pelo servidor Oracle BI.
Variáveis de repositório dinâmico são úteis para definir o conteúdo de fontes de tabelas lógicas. Por exemplo, suponha que você tenha duas fontes de informações sobre pedidos. Uma fonte contém pedidos atuais e a outra contém dados históricos.
Criar Variáveis de Repositório
Na Ferramenta de Administração → Vá para Gerenciar → Selecionar Variáveis → Gerenciador de Variáveis → Vá para Ação → Novo → Repositório> Variável.
Na caixa de diálogo Variável, digite um nome para a variável (os nomes de todas as variáveis devem ser únicos) → Selecione o tipo de variável - Estática ou Dinâmica.
Se você selecionar uma variável dinâmica, use a lista de blocos de inicialização para selecionar um bloco de inicialização existente que será usado para atualizar o valor continuamente.
Para criar um novo bloco de inicialização → Clique em Novo. Para adicionar um valor de inicializador padrão, digite o valor na caixa do inicializador padrão ou clique no botão Construtor de Expressões para usar o Construtor de Expressões.
Para variáveis de repositório estático, o valor que você especifica na janela do inicializador padrão persiste. Não vai mudar a menos que você mude. Se você inicializar uma variável usando uma string de caracteres, coloque a string entre aspas simples. As variáveis de repositório estáticas devem ter inicializadores padrão que são valores constantes → Clique em OK para fechar a caixa de diálogo.
Variáveis de Sessão
As variáveis de sessão são semelhantes às variáveis de repositório dinâmico e obtêm seus valores de blocos de inicialização. Quando um usuário inicia uma sessão, o servidor Oracle BI cria novas instâncias de variáveis de sessão e as inicializa.
Existem tantas instâncias de uma variável de sessão quanto sessões ativas no servidor Oracle BI. Cada instância de uma variável de sessão pode ser inicializada com um valor diferente.
Existem dois tipos de variáveis de sessão -
- Variáveis de sessão do sistema
- Variáveis de sessão fora do sistema
As variáveis de sessão do sistema são usadas pelo Oracle BI e pelo servidor de apresentação para fins específicos. Eles têm nomes reservados predefinidos que não podem ser usados por outras variáveis.
USER |
Esta variável contém o valor que o usuário insere com o nome de login. Essa variável é normalmente preenchida a partir do perfil LDAP do usuário. |
USERGUID |
Esta variável contém o Global Unique Identifier (GUID) do usuário e é preenchida a partir do perfil LDAP do usuário. |
GROUP |
Ele contém os grupos aos quais o usuário pertence. Quando um usuário pertencer a vários grupos, inclua os nomes dos grupos na mesma coluna, separados por ponto e vírgula (Exemplo - GrupoA; GrupoB; GrupoC). Se um ponto-e-vírgula tiver que ser incluído como parte de um nome de grupo, preceda o ponto-e-vírgula com uma barra invertida (\). |
ROLES |
Esta variável contém as funções do aplicativo às quais o usuário pertence. Quando um usuário pertence a várias funções, inclua os nomes das funções na mesma coluna, separados por ponto e vírgula (Exemplo - FunçãoA; FunçãoB; FunçãoC). Se um ponto-e-vírgula tiver que ser incluído como parte de um nome de função, preceda o ponto-e-vírgula com uma barra invertida (\). |
ROLEGUIDS |
Ele contém os GUIDs para as funções do aplicativo às quais o usuário pertence. GUIDs para funções de aplicativo são iguais aos nomes de função de aplicativo. |
PERMISSIONS |
Ele contém as permissões do usuário. Exemplo - oracle.bi.server.manageRepositories. |
Variáveis de sessão fora do sistema são usadas para definir os filtros do usuário. Por exemplo, você poderia definir uma variável não pertencente ao sistema chamada Sale_Region que seria inicializada com o nome da sale_region do usuário.
Criar Variáveis de Sessão
Na Ferramenta de Administração → Vá para Gerenciar → Selecionar Variáveis.
Na caixa de diálogo Gerenciador de variáveis, clique em Ação → Novo → Sessão → Variável.
Na caixa de diálogo Variável de sessão, insira o nome da variável (os nomes de todas as variáveis devem ser exclusivos e os nomes das variáveis de sessão do sistema são reservados e não podem ser usados para outros tipos de variáveis).
Para variáveis de sessão, você pode selecionar as seguintes opções -
Enable any user to set the value- Essa opção é usada para definir variáveis de sessão após o bloco de inicialização preencher o valor. Exemplo - esta opção permite que os não administradores definam esta variável para amostragem.
Security sensitive - Isso é usado para identificar a variável como sensível à segurança ao usar uma estratégia de segurança de banco de dados em nível de linha, como um Virtual Private Database (VPD).
Você pode usar a opção de lista de bloqueio de inicialização para escolher um bloco de inicialização que será usado para atualizar o valor regularmente. Você também pode criar um novo bloco de inicialização.
Para adicionar um valor de inicializador padrão, insira o valor na caixa do inicializador padrão ou clique no botão Expression Builder para usar o Expression Builder. Clique em OK para fechar a caixa de diálogo.
O administrador pode criar variáveis de sessão fora do sistema usando a ferramenta Oracle BI Administration.
Variáveis de Apresentação
As variáveis de apresentação são criadas com a criação de prompts do painel. Existem dois tipos de prompts de painel que podem ser usados -
Prompt de coluna
A variável de apresentação criada com o prompt da coluna está associada a uma coluna e os valores que ela pode obter vêm dos valores da coluna.
Para criar uma variável de apresentação vá para a caixa de diálogo Novo prompt ou caixa de diálogo Editar prompt → Selecione Variável de apresentação no campo Conjunto de uma variável → Insira o nome da variável.
Solicitação de Variável
A variável de apresentação criada como prompt de variável não está associada a nenhuma coluna e você precisa definir seus valores.
Para criar uma variável de apresentação como parte de um prompt de variável, na caixa de diálogo Novo prompt ou caixa de diálogo Editar prompt → Selecione Variável de apresentação no campo Solicitar para → Insira o nome da variável.
O valor de uma variável de apresentação é preenchido pela coluna ou prompt de variável com o qual foi criado. Cada vez que um usuário seleciona um valor na coluna ou prompt de variável, o valor da variável de apresentação é definido como o valor que o usuário selecionar.
Blocos de inicialização
Os blocos de inicialização são usados para inicializar variáveis OBIEE: variáveis do Repositório Dinâmico, variáveis de sessão do sistema e variáveis de sessão não pertencentes ao sistema.
Ele contém instruções SQL que são executadas para inicializar ou atualizar as variáveis associadas a esse bloco. A instrução SQL que é executada aponta para tabelas físicas que podem ser acessadas usando o pool de conexão. O pool de conexão é definido na caixa de diálogo do bloco de inicialização.
Se quiser que a consulta de um bloco de inicialização tenha SQL específico do banco de dados, você pode selecionar um tipo de banco de dados para essa consulta.
Inicializar Variáveis de Repositório Dinâmico usando Bloco de Inicialização
O campo de sequência de inicialização padrão do bloco de inicialização é usado para definir o valor das variáveis de repositório dinâmico. Você também define uma programação que é seguida pelo servidor Oracle BI para executar a consulta e atualizar o valor da variável. Se você definir o nível de registro como 2 ou superior, as informações de registro de todas as consultas SQL executadas para recuperar o valor da variável serão salvas no arquivo nqquery.log.
Localização deste arquivo no BI Server -
ORACLE_INSTANCE \ diagnostics \ logs \ OracleBIServerComponent \ coreapplication_obisn
Inicializar variáveis de sessão usando bloco de inicialização
As variáveis de sessão também obtêm seus valores do bloco de inicialização, mas seu valor nunca muda com os intervalos de tempo. Quando um usuário inicia uma nova sessão, o servidor Oracle BI cria uma nova instância de variáveis de sessão.
Todas as consultas SQL executadas para recuperar informações de variáveis de sessão pelo servidor BI se o nível de registro for definido como 2 ou superior no objeto Usuário do Identity Manager ou se a variável de sessão do sistema LOGLEVEL for definida como 2 ou superior no Gerenciador de variáveis for salva em nqquery.log Arquivo.
Localização deste arquivo no BI Server -
ORACLE_INSTANCE \ diagnostics \ logs \ OracleBIServerComponent \ coreapplication_obisn
Criar blocos de inicialização na ferramenta do administrador
Vá para Gerenciador → Variáveis → caixa de diálogo Gerenciador de variáveis é exibida. Vá para o menu Ação → Clique em Novo → Repositório → Bloco de inicialização → Insira o nome do bloco de inicialização.
Vá para a guia Programação → Selecione a data e hora de início e o intervalo de atualização.
Você pode escolher as seguintes opções para blocos de inicialização -
Disable- Se você selecionar esta opção, o bloco de inicialização será desabilitado. Para habilitar um bloco de inicialização, clique com o botão direito em um bloco de inicialização existente no Gerenciador de variáveis e escolha Habilitar. Esta opção permite que você altere esta propriedade sem abrir a caixa de diálogo do bloco de inicialização.
Allow deferred execution - Isso permite adiar a execução do bloco de inicialização até que uma variável de sessão associada seja acessada pela primeira vez durante a sessão.
Required for authentication - Se você selecionar isto, o bloco de inicialização deve ser executado para que os usuários façam login. Os usuários terão o acesso ao Oracle BI negado se o bloco de inicialização não for executado.
O painel OBIEE é uma ferramenta que permite que os usuários finais executem relatórios e análises ad-hoc de acordo com o modelo de requisitos de negócios. Os painéis interativos são relatórios perfeitos de pixel que podem ser visualizados ou impressos diretamente pelos usuários finais.
O painel do OBIEE faz parte dos serviços da camada Oracle BI Presentation. Se o seu usuário final não estiver interessado em ver todos os dados no painel, isso permite que você adicione prompts ao painel que permitem ao usuário final inserir o que deseja ver. Os painéis também permitem que os usuários finais selecionem em listas suspensas, caixas de seleção múltipla e seleção de colunas a serem exibidas nos relatórios.
Alertas de painel
O painel de controle do Oracle BI permite que você configure alertas para executivos de vendas que aparecem no painel interativo sempre que as vendas projetadas da empresa ficarem abaixo do previsto.
Crie um novo painel
Para criar um novo painel, vá para Novo → Painel ou você também pode clicar na opção Painel em criar no lado esquerdo.

Depois de clicar em Painel, uma nova caixa de diálogo do painel é aberta. Insira o nome do painel e a descrição e selecione o local onde deseja que o painel salve → clique em OK.

Se você salvar o painel na subpasta Painéis diretamente em / Pastas compartilhadas / subpasta de primeiro nível → o painel será listado no menu Painel no cabeçalho global.
Se você salvá-lo em uma subpasta de painéis em qualquer outro nível (como / Pastas compartilhadas / Vendas / Leste), ele não será listado.
Se você escolher uma pasta na subpasta Painéis diretamente em / Pastas compartilhadas / subpasta de primeiro nível na qual nenhum painel foi salvo, uma nova pasta Painéis será criada automaticamente para você.
Depois de inserir os campos acima, o construtor do painel será aberto conforme mostrado no instantâneo a seguir -

Expanda a guia do catálogo, selecione a análise para adicionar ao painel e arraste para o painel de layout da página. Salve e execute o painel.

Editar um painel
Vá para Painel → Meu painel → Editar painel.

Para editar o painel. Clique no ícone abaixo → Propriedades do painel.

Uma nova caixa de diálogo aparecerá, conforme mostrado no instantâneo a seguir. Você pode realizar as seguintes tarefas -
Altere os estilos (Estilos controlam como os painéis e resultados são formatados para exibição, como a cor do texto e links, a fonte e o tamanho do texto, as bordas das tabelas, as cores e os atributos dos gráficos e assim por diante). Você pode adicionar uma descrição.
Você pode adicionar prompts, filtros e variáveis ocultos. Especifique os links que serão exibidos com análises em uma página do painel. Você pode renomear, ocultar, reordenar, definir permissões e excluir páginas do painel.

Você também pode editar as propriedades da página do painel selecionando página na caixa de diálogo. Você pode fazer as seguintes alterações -
Você pode alterar o nome da página do painel.
Você pode adicionar um prompt oculto. Os prompts ocultos são usados para definir valores padrão para todos os prompts correspondentes em uma página do painel.
Você pode adicionar permissões para o painel e também pode excluir a página selecionada. As páginas do painel são excluídas permanentemente.
Se houver mais de uma página de painel neste painel, os ícones de organizar ordem são ativados usando as setas para cima e para baixo.


Para definir os links do relatório no nível do painel, página do painel ou nível de análise, clique na opção de edição dos links de relatório do painel.


Para adicionar uma página do painel, clique no ícone da nova página do painel → Insira o nome da página do painel e clique em OK.

Na guia Catálogo, você pode adicionar a nova outra análise e arrastá-la para a área de layout de página da nova página do painel.
Para editar as propriedades do painel, como largura, borda e altura da célula, clique nas propriedades da coluna. Você pode definir a cor de fundo, texto em contorno e opções adicionais de formatação.

Você também pode adicionar uma condição na exibição de dados do painel clicando na opção de condição nas propriedades da coluna -

Para adicionar uma condição, clique na caixa de diálogo + condição de login. Você pode adicionar uma condição com base na análise.
Selecione os dados da condição e insira o parâmetro da condição.

Você também pode testar, editar ou remover a condição clicando no sinal 'mais' ao lado do botão +.
Salvar um painel personalizado
Você pode salvar seu painel personalizado indo para opções da página → Salvar personalizações atuais → Insira o nome da personalização → Clique em OK.

Para aplicar a personalização a uma página do painel, vá para a opção da página → Aplicar personalização salva → Selecionar nome → Clique em OK.
Ele permite que você salve e visualize as páginas do painel em seu estado atual, como filtros, prompts, classificações de coluna, exercícios de análises e expansão e recolhimento de seção. Ao salvar as personalizações, você não precisa fazer essas escolhas manualmente sempre que acessar a página do painel.
Filtros são usados para limitar os resultados que são exibidos quando uma análise é executada, para que os resultados respondam a uma pergunta específica. Com base nos filtros, apenas os resultados que correspondem aos critérios passados na condição de filtro são mostrados.
Os filtros são aplicados diretamente às colunas de atributos e medidas. Os filtros são aplicados antes que a consulta seja agregada e afetam a consulta e, portanto, os valores resultantes das medidas.
Por exemplo, você tem uma lista de membros em que a soma agregada chega a 100. Com o tempo, mais membros atendem aos critérios de filtro definidos, o que aumenta a soma agregada para 200.
Filtros de coluna
A seguir estão as maneiras de criar filtros -
Criar um filtro de coluna nomeada
Vá para a página inicial do Oracle Business Intelligence → Novo menu → Selecionar filtro. A caixa de diálogo Selecionar área de assunto é exibida.
Na caixa de diálogo Selecionar área de assunto, escolha a área de assunto para a qual deseja criar um filtro. O "Editor de filtros" é exibido no "painel Áreas de assunto". Clique duas vezes na coluna para a qual deseja criar o filtro. A caixa de diálogo Novo filtro é exibida.
Crie um filtro embutido
Crie uma análise ou acesse uma análise existente para a qual deseja criar um filtro.
Clique na guia Critérios → Localize o "painel Filtros" → Clique em criar um filtro para o botão da área de assunto atual. As colunas selecionadas da análise são exibidas no menu em cascata.
Selecione um nome de coluna no menu ou selecione a opção Mais Colunas para acessar a "caixa de diálogo Selecionar Coluna", na qual você pode selecionar qualquer coluna da área de assunto.
Depois de selecionar uma coluna, a "caixa de diálogo Novo filtro" é exibida.
O Oracle BI Enterprise Edition permite que você observe os resultados das análises de maneira significativa, usando seus recursos de apresentação. Diferentes tipos de visualizações podem ser adicionados, como gráficos e tabelas dinâmicas que permitem aprofundar para obter informações mais detalhadas e muitas mais opções, como o uso de filtros, etc.
Os resultados da análise são exibidos usando uma visualização de tabela / tabela dinâmica e depende do tipo de colunas que a análise contém -
Table view é usado se a análise contém apenas colunas de atributo / apenas colunas de medida ou uma combinação de ambos.
Pivot table é a visualização padrão se a análise contiver pelo menos uma coluna hierárquica.
UMA title view exibe o nome da análise salva.
Você pode editar ou excluir uma visualização existente, adicionar outra visualização a uma análise e também pode combinar visualizações.
Tipos de vistas
| Sr. Não | Vistas e descrição |
|---|---|
| 1 | Title A visualização do título exibe um título, um subtítulo, um logotipo, um link para uma página de ajuda online personalizada e carimbos de data / hora para os resultados. |
| 2 | Table A visualização de tabela é usada para exibir os resultados em uma representação visual dos dados organizados por linhas e colunas. Ele fornece uma visão resumida dos dados e permite que os usuários vejam diferentes visões dos dados arrastando e soltando linhas e colunas. |
| 3 | Pivot Table Ele exibe os resultados em uma tabela dinâmica, que fornece uma visão resumida dos dados em formato de tabulação cruzada e permite que os usuários vejam diferentes visões de dados arrastando e soltando linhas e colunas. As tabelas dinâmicas e as tabelas padrão são semelhantes na estrutura, mas a tabela dinâmica pode conter grupos de colunas e também pode exibir vários níveis de títulos de linha e coluna. A célula da tabela dinâmica contém um valor exclusivo. A tabela dinâmica é mais eficiente do que uma tabela baseada em linha. É mais adequado para exibir uma grande quantidade de dados, para navegar pelos dados hierarquicamente e para análise de tendências. |
| 4 | Performance Tile Os blocos de desempenho são usados para exibir um único valor de medida agregado de uma maneira que é visualmente simples, mas fornece um resumo das métricas para o usuário que provavelmente será apresentado com mais detalhes em uma visualização do painel. Os blocos de desempenho são usados para focar a atenção do usuário em fatos simples e necessários de maneira direta e proeminente no bloco. Comunique o status por meio de formatação simples, usando cores, rótulos e estilos limitados, ou por meio da formatação condicional da cor de fundo ou valor de medida para tornar o bloco visualmente proeminente. Por exemplo, se a receita não está acompanhando a meta, o valor da receita pode aparecer em vermelho. Responda a prompts, filtros e funções e permissões do usuário tornando-os relevantes para o usuário e seu contexto. Aceite um valor único, agregado ou calculado. |
| 5 | Treemap Os mapas de árvore são usados para exibir uma visualização 2-d com restrição de espaço para estruturas hierárquicas com vários níveis. Os mapas de árvore são limitados por uma área predefinida e exibem dois níveis de dados. Conter ladrilhos retangulares. O tamanho do ladrilho é baseado em uma medida e a cor do ladrilho é baseada em uma segunda medida. Treemap é semelhante a um gráfico de dispersão em que a área do mapa é restrita, e o gráfico permite que você visualize grandes quantidades de dados e identifique rapidamente tendências e anomalias nesses dados. |
| 6 | Trellis O Trellis exibe dados multidimensionais mostrados como um conjunto de células em forma de grade e onde cada célula representa um subconjunto de dados usando um tipo de gráfico específico. A visualização da treliça tem dois subtipos - Treliça simples e Treliça avançada. As visualizações de treliça simples são ideais para exibir vários gráficos que permitem a comparação de semelhantes. As visualizações de treliça avançadas são ideais para exibir gráficos de faísca que mostram uma tendência. Uma treliça simples exibe um único tipo de gráfico interno, Exemplo - uma grade de vários gráficos de barras. Uma treliça avançada exibe um tipo de gráfico interno diferente para cada medida. Exemplo: uma mistura de gráficos Spark Line e gráficos Spark Bar, ao lado de números. |
| 7 | Graph O gráfico exibe informações numéricas visualmente, o que torna mais fácil entender grandes quantidades de dados. Os gráficos geralmente revelam padrões e tendências que as telas baseadas em texto não podem. Um gráfico é exibido em um plano de fundo, chamado de tela de gráfico. |
| 8 | Gauge Medidor são usados para mostrar um único valor de dados. Devido ao seu tamanho compacto, um medidor costuma ser mais eficaz do que um gráfico para exibir um único valor de dados Os medidores identificam problemas nos dados. Um medidor geralmente plota um ponto de dados com uma indicação se esse ponto está em uma faixa aceitável ou inaceitável. Portanto, os medidores são úteis para mostrar o desempenho em relação às metas. Um medidor ou conjunto de medidores é exibido em um plano de fundo, chamado tela de medidor. |
| 9 | Funnel O funil exibe os resultados em um gráfico 3D que representa os valores alvo e real usando volume, nível e cor. Os gráficos de funil são usados para representar graficamente dados que mudam em diferentes períodos ou estágios. Exemplo: os gráficos de funil costumam ser usados para representar o volume de vendas em um trimestre. Os gráficos de funil são adequados para mostrar o real em comparação com as metas para dados em que a meta diminui (ou aumenta) significativamente por estágio, como um pipeline de vendas. |
| 10 | Map view A visualização do mapa é usada para exibir resultados sobrepostos em um mapa. Dependendo dos dados, os resultados podem ser sobrepostos na parte superior de um mapa como formatos como imagens, áreas de preenchimento de cor, gráficos de barra e pizza e marcadores de tamanhos variáveis. |
| 11 | Filters Os filtros são usados para exibir os filtros em vigor para uma análise. Os filtros permitem adicionar condições a uma análise para obter resultados que respondam a uma pergunta específica. Os filtros são aplicados antes que a consulta seja agregada. |
| 12 | Selection Steps As etapas de seleção são usadas para exibir as etapas de seleção em vigor para uma análise. Etapas de seleção, como filtros, permitem obter resultados que respondem a perguntas específicas. As etapas de seleção são aplicadas após a consulta ser agregada. |
| 13 | Column Selector O seletor de coluna é um conjunto de listas suspensas que contém colunas pré-selecionadas. Os usuários podem selecionar colunas dinamicamente e alterar os dados que são exibidos nas visualizações da análise. |
| 14 | View Selector Um seletor de visualização é uma lista suspensa na qual os usuários podem selecionar uma visualização específica dos resultados entre as visualizações salvas. |
| 15 | Legend Ele permite que você documente o significado da formatação especial usada nos resultados - significado de cores personalizadas aplicadas aos medidores. |
| 16 | Narrative Ele exibe os resultados como um ou mais parágrafos de texto. |
| 17 | Ticker Ele exibe os resultados como um ticker ou letreiro, semelhante em estilo aos tickers de ações que aparecem em muitos sites financeiros e de notícias na Internet. Você também pode controlar quais informações são apresentadas e como elas rolam pela página. |
| 18 | Static Text Você pode usar HTML para adicionar banners, tickers, objetos ActiveX, miniaplicativos Java, links, instruções, descrições, gráficos, etc. nos resultados. |
| 19 | Logical SQL Ele exibe a instrução SQL que é gerada para uma análise. Essa visualização é útil para treinadores e administradores e geralmente não é incluída nos resultados para usuários típicos. Você não pode modificar esta visualização, exceto para formatar seu contêiner ou excluí-lo. |
| 20 | Create Segment É usado para exibir um link Criar segmento nos resultados. |
| 21 | Create Target List É usado para exibir um link de criação de lista de destino nos resultados. Os usuários podem clicar neste link para criar uma lista de destino, com base nos dados de resultados, em seu aplicativo operacional Siebel da Oracle. Esta visão é para usuários do aplicativo operacional Siebel Life Sciences da Oracle integrado aos aplicativos Siebel Life Sciences Analytics da Oracle. |
Todos os tipos de visualização, exceto visualização lógica SQL, podem ser editados. Cada visualização possui seu próprio editor no qual você pode realizar tarefas de edição.
Cada editor de visualização contém uma funcionalidade exclusiva para esse tipo de visualização, mas também pode conter funcionalidade que é a mesma entre os tipos de visualização.
Editar uma vista
Abra a análise que contém a visualização a ser editada. Clique no "Editor de análise: guia Resultados".
Clique no botão Editar visualização para a visualização. Exibir editores é exibido. Agora, usando o editor para a visualização, faça as edições necessárias. Clique em Concluído e salve a visualização.
Excluir uma vista
Você pode excluir uma visualização de -
A compound layout - Se você remover uma vista de um layout composto, ela será removida apenas do layout composto e não da análise.
An analysis - Se você remover uma visualização de uma análise, ela removerá a visualização da análise e também de qualquer layout composto ao qual foi adicionada.
Remover uma vista
Se você deseja remover uma vista de -
A compound layout - Na visualização em Layout Composto → clique no botão Remover Visualização do Layout Composto.
An analysis - No painel Visualizações → selecione a visualização e clique no botão Remover visualização da barra de ferramentas da análise.
Um Prompt é um tipo especial de filtro usado para filtrar análises incorporadas em um painel. O principal motivo para usar um prompt de painel é que ele permite ao usuário personalizar a saída da análise e também permite flexibilidade para alterar os parâmetros de um relatório. Existem três tipos de prompts que podem ser usados -
Prompts nomeados
O prompt criado no nível do painel é chamado de prompt nomeado. Este Prompt é criado fora de um painel específico e armazenado no catálogo como um prompt. Você pode aplicar um prompt nomeado a qualquer painel ou página de painel que contenha as colunas mencionadas no prompt. Ele pode filtrar uma ou qualquer número de análises incorporadas na mesma página do painel. Você pode criar e salvar esses prompts nomeados em uma pasta privada ou em uma pasta compartilhada.
Um prompt nomeado sempre aparece na página do painel e o usuário pode solicitar valores diferentes sem ter que executar novamente o painel. Um prompt nomeado também pode interagir com as etapas de seleção. Você pode especificar um prompt do painel para substituir uma etapa de seleção específica.
A etapa será processada na coluna do painel com os valores de dados especificados pelo usuário coletados pelo prompt da coluna do painel, enquanto todas as outras etapas serão processadas conforme especificado originalmente.
Inline Prompts
Os prompts embutidos são incorporados em uma análise e não são armazenados no catálogo para reutilização. O prompt embutido fornece filtragem geral de uma coluna na análise, dependendo de como ela está configurada.
O prompt embutido funciona independentemente de um filtro de painel, que determina valores para todas as colunas correspondentes no painel. Um prompt embutido é um prompt inicial. Quando o usuário seleciona o valor do prompt, o campo do prompt desaparece da análise.
Para selecionar diferentes valores de prompt, você precisa executar novamente a análise. Sua entrada determina o conteúdo das análises incorporadas ao painel.
Prompt nomeado pode ser aplicado a qualquer painel ou página de painel que contenha a coluna especificada no Prompt.
Prompts de coluna
Um prompt de coluna é o tipo de prompt mais comum e flexível. Um prompt de coluna permite que você crie prompts de valores muito específicos para serem independentes no painel ou análise ou para expandir ou refinar o painel existente e os filtros de análise. Os prompts de coluna podem ser criados para colunas hierárquicas, de medida ou de atributo no nível de análise ou painel.
Vá para Novo → Prompt do Painel → Selecionar área de assunto.

A caixa de diálogo do prompt do painel é exibida. Vá para o sinal '+' e selecione o tipo de prompt. Clique no prompt da coluna → Selecionar coluna → Clique em OK.

A caixa de diálogo Novo prompt é exibida (ela aparece apenas para prompts de coluna). Insira o nome do rótulo que aparecerá no painel ao lado de Solicitar → Selecione o operador → Entrada do usuário.

A lista suspensa do campo Entrada do usuário é exibida para prompts de coluna e variável e oferece a opção de determinar o método de entrada do usuário para a interface do usuário. Você pode selecionar qualquer uma das seguintes - caixas de seleção, botões de opção, uma lista de opções ou uma caixa de listagem.
Example - Se você selecionar o método de entrada do usuário da lista de opções e o item Valores da lista de opções de todos os valores da coluna, o usuário selecionará o valor de dados do prompt em uma lista que contém todos os valores de dados contidos na fonte de dados.
Você também pode fazer uma seleção expandindo a guia Opções.

Essa série de caixas de seleção permite restringir a quantidade de dados retornados na saída. Depois de fazer a seleção, clique em OK.
O Prompt é adicionado a Definição → Salvar o prompt usando a opção salvar no canto superior direito → Insira o nome → Clique em OK.

Para testar o prompt, vá para Meu painel → Catálogo e arraste o prompt para a coluna 1. Esse prompt pode ser aplicado ao painel completo ou em uma única página clicando em Propriedades → Escopo.

Salve e execute o painel, selecione o valor para um prompt. O valor de Apply e Output mudará de acordo com o valor do prompt.
Outras instruções
Solicitação de moeda
Um prompt de moeda permite que o usuário altere o tipo de moeda que é exibido nas colunas de moeda em uma análise ou painel.
Example- Suponha que uma análise contenha os totais de vendas para uma determinada região dos EUA em dólares americanos. No entanto, como os usuários que visualizam a análise residem no Canadá, eles podem usar o prompt de moeda para alterar os totais de vendas de dólares americanos para dólares canadenses.
A lista de seleção de moeda do prompt é preenchida com as preferências de moeda da → caixa de diálogo Minha conta → guia Preferências do usuário. A opção de prompt de moeda está disponível apenas se o administrador configurou o arquivo userpref_currencies.xml.
Prompt de imagem
Um prompt de imagem fornece uma imagem na qual os usuários clicam para selecionar valores para uma análise ou painel.
Example- Em uma organização de vendas, os usuários podem clicar em seus territórios a partir de uma imagem de um mapa para ver as informações de vendas ou clicar na imagem de um produto para ver as informações de vendas desse produto. Se você souber como usar a tag HTML <map>, poderá criar uma definição de mapa de imagem.
Solicitação de Variável
Um prompt de variável permite que o usuário selecione um valor que é especificado no prompt de variável para exibir no painel. Um prompt de variável não depende de uma coluna, mas ainda pode usar uma coluna.
Adicionar relatórios às páginas do painel de BI
Você pode adicionar um ou mais relatórios existentes a uma página do painel. A vantagem é que você pode compartilhar relatórios com outros usuários e agendar as páginas do painel usando agentes. Um agente envia todo o painel ao usuário, incluindo todas as páginas de dados às quais o relatório faz referência.
Ao configurar um agente para uma página de painel que contém um relatório do BI Publisher, certifique-se de que os seguintes critérios sejam atendidos:
- O formato de saída do relatório do BI Publisher deve ser PDF.
- O agente deve ser configurado para entregar PDF.
Você pode adicionar relatórios a uma página do painel como conteúdo incorporado e como um link. Incorporado significa que o relatório é exibido diretamente na página do painel. O link abre o relatório no BI Publisher dentro do Oracle BIEE.
Se você modificar o relatório no BI Publisher e salvar suas alterações, atualize a página do painel para ver as modificações. Navegue até a página à qual deseja adicionar um relatório.
Adicionar um relatório de BI a uma página do painel
Selecione um relatório de uma das seguintes maneiras -
Selecione o relatório no painel Catálogo e arraste e solte-o em uma seção na página do painel.
Para adicionar um relatório de uma página do painel, selecione o relatório da pasta que contém seu painel no painel Catálogo.
Defina as propriedades do objeto. Para fazer isso, passe o ponteiro do mouse sobre o objeto na área de layout da página para exibir a barra de ferramentas do objeto e clique no botão Propriedades.
A "caixa de diálogo Propriedades do relatório do BI Publisher" é exibida. Preencha os campos na caixa de diálogo de propriedades conforme apropriado. Clique em OK e em Salvar.
Se necessário, adicione um prompt à página do painel para filtrar os resultados de um relatório parametrizado incorporado.
A segurança do OBIEE é definida pelo uso de um modelo de controle de acesso baseado em funções. É definido em termos de funções que estão alinhadas a diferentes diretóriosserver groups and users. Neste capítulo, iremos discutir os componentes definidos para compor umsecurity policy.
Pode-se definir um Security structure com os seguintes componentes
O diretório Server User and Group administrado pelo Authentication provider.
As funções do aplicativo gerenciadas pelo Policy store fornecer política de segurança com os seguintes componentes: catálogo de apresentação, repositório, armazenamento de política.

Provedores de Segurança
O provedor de segurança é chamado para obter as informações de segurança. Os seguintes tipos de provedores de segurança são usados pelo OBIEE -
Provedor de autenticação para autenticar usuários.
O provedor de armazenamento de políticas é usado para conceder privilégios em todos os aplicativos, exceto para BI Presentation Services.
O provedor de armazenamento de credenciais é usado para armazenar credenciais usadas internamente pelo aplicativo de BI.
Política de segurança
A política de segurança no OBIEE é dividida nos seguintes componentes -
- Catálogo de Apresentação
- Repository
- Loja de Políticas
Catálogo de Apresentação
Ele define os objetos do catálogo e a funcionalidade do Oracle BI Presentation Services.
Administração do Oracle BI Presentation Services
Ele permite que você defina privilégios para que os usuários acessem recursos e funções, como edição de visualizações e criação de agentes e prompts.
O Catálogo de apresentação privilegia o acesso aos objetos do catálogo de apresentação definidos na caixa de diálogo Permissão.
A administração do Presentation Services não possui sistema de autenticação próprio e conta com o sistema de autenticação que herda do Oracle BI Server. Todos os usuários que entram no Presentation Services recebem a função de usuário autenticado e quaisquer outras funções atribuídas a eles no Fusion Middleware Control.
Você pode atribuir permissões de uma das seguintes maneiras -
To application roles - Forma mais recomendada de atribuir permissões e privilégios.
To individual users - É difícil gerenciar onde você pode atribuir permissões e privilégios a usuários específicos.
To Catalog groups - Foi usado em versões anteriores para manutenção de compatibilidade com versões anteriores.
Repositório
Isso define quais funções de aplicativo e usuários têm acesso a quais itens de metadados no repositório. A ferramenta de administração do Oracle BI por meio do gerenciador de segurança é usada e permite que você execute as seguintes tarefas -
- Defina permissões para modelos de negócios, tabelas, colunas e áreas de assunto.
- Especifique o acesso ao banco de dados para cada usuário.
- Especifique filtros para limitar os dados acessíveis aos usuários.
- Defina as opções de autenticação.
Loja de Políticas
Ele define a funcionalidade BI Server, BI Publisher e Real Time Decisions que pode ser acessada por determinados usuários ou usuários com determinadas funções de aplicativo.
Autenticação e autorização
Autenticação
O provedor de autenticação no domínio do Oracle WebLogic Server é usado para autenticação do usuário. Esse provedor de autenticação acessa informações de usuários e grupos armazenadas no servidor LDAP no domínio do Oracle WebLogic Server do Oracle Business Intelligence.
Para criar e gerenciar usuários e grupos em um servidor LDAP, o Oracle WebLogic Server Administration Console é usado. Você também pode escolher configurar um provedor de autenticação para um diretório alternativo. Nesse caso, o Oracle WebLogic Server Administration Console permite que você visualize os usuários e grupos em seu diretório; entretanto, você precisa continuar a usar as ferramentas apropriadas para fazer quaisquer modificações no diretório.
Exemplo - Se você reconfigurar o Oracle Business Intelligence para usar OID, poderá visualizar usuários e grupos no Console de administração do Oracle WebLogic Server, mas deverá gerenciá-los no Console OID.
Autorização
Depois que a autenticação for concluída, a próxima etapa na segurança é garantir que o usuário possa fazer e ver o que está autorizado a fazer. A autorização para Oracle Business Intelligence 11g é gerenciada por uma política de segurança em termos de Funções de Aplicativos.
Funções de aplicativo
A segurança é normalmente definida em termos de funções de aplicativo atribuídas a usuários e grupos do servidor de diretório. Exemplo: as funções padrão do aplicativo sãoBIAdministrator, BIConsumer, e BIAuthor.
As funções do aplicativo são definidas como funções funcionais atribuídas a um usuário, o que dá a esse usuário os privilégios necessários para desempenhar essa função. Exemplo: a função de aplicativo de analista de marketing pode conceder a um usuário acesso para visualizar, editar e criar relatórios no pipeline de marketing de uma empresa.
Essa comunicação entre as funções do aplicativo e os usuários e grupos do servidor de diretório permite que o administrador defina as funções e políticas do aplicativo sem criar usuários ou grupos adicionais no servidor LDAP. As funções de aplicativos permitem que o sistema de inteligência de negócios seja facilmente movido entre os ambientes de desenvolvimento, teste e produção.
Isso não requer nenhuma mudança na política de segurança e tudo o que é necessário é atribuir as funções de aplicativo aos usuários e grupos disponíveis no ambiente de destino.
O grupo denominado 'BIConsumers' contém o usuário1, o usuário2 e o usuário3. Os usuários no grupo 'BIConsumers' são atribuídos à função de aplicativo 'BIConsumer', que permite aos usuários visualizar relatórios.
O grupo denominado 'BIAuthors' contém o usuário4 e o usuário5. Os usuários no grupo 'BIAuthors' são atribuídos à função de aplicativo 'BIAuthor', que permite aos usuários criar relatórios.
O grupo denominado 'Administradores de BI' contém o usuário6 e o usuário7, usuário 8. Os usuários no grupo 'Administradores de BI' são atribuídos à função de aplicativo 'Administrador de BI', que permite aos usuários gerenciar repositórios.
No OBIEE 10g, a maioria das tarefas de administração do OBIEE eram realizadas principalmente por meio da ferramenta de administração, a tela de administração do Presentation Server baseada na web ou por meio da edição de arquivos no sistema de arquivos. Havia cerca de 700 opções de configuração espalhadas por várias ferramentas e arquivos de configuração, com algumas opções, como usuários e grupos, incorporados em repositórios não relacionados (o RPD).
No OBIEE 11g, todas as tarefas de administração e configuração são movidas para o Fusion Middleware Control, também chamado de Enterprise Manager.
A ferramenta de administração que estava presente no OBIEE 10g também está presente no 11g e é usada para manter o modelo semântico usado pelo BI Server. Possui poucos aprimoramentos em termos de manipulação de dimensão e novas fontes de dados. Uma grande mudança é em torno da segurança - quando você abre a caixa de diálogo do Gerenciador de Segurança -
Vá para Gerenciar → Identidade → Caixa de diálogo Gerenciador de segurança é exibida.

Os usuários e funções do aplicativo agora são definidos no console de administração do WebLogic Server. Você usa o Security Manager para definir links adicionais por meio de outros servidores LDAP, registrar autenticadores personalizados e configurar filtros, etc. Na captura de tela acima, os usuários mostrados na lista de usuários são aqueles mantidos no JPS (Java Platform Security do WebLogic Server ), e não há mais usuários e grupos no próprio RPD.
Não há nenhum usuário administrador no instantâneo acima. Ele possui um usuário administrador padrão que você configura como administrador do WebLogic Server ao instalar o OBIEE, que geralmente possui o nome de usuário weblogic.
Existem também dois usuários padrão adicionais: OracleSystemUser - este usuário é usado pelos vários serviços da web do OBIEE para se comunicar com o BI Server e BISystemUser é usado pelo BI Publisher para se conectar ao BI Server como uma fonte de dados.
Na guia Funções do aplicativo, você pode ver uma lista de funções padrão do aplicativo - BISystem, BIAdministrator, BIAuthor e BIConsumer - que são usadas para conceder acesso à funcionalidade do Presentation Server.
Criar um usuário no OBIEE
Para criar um novo usuário, efetue logon no console de administração do WebLogic Server → Acesse Security Realms no menu Fusion Middleware Control → Selecione myrealm → Selecione Users and Groups. Clique na guia Usuários para mostrar uma lista dos usuários existentes.
Clique em Novo. → A caixa de diálogo do novo usuário é aberta → insira os detalhes do usuário. Você também pode usar a guia Grupos para definir um grupo para o usuário ou atribuir o usuário a um grupo existente.

Arquivos de configuração e metadados
A seguir estão os principais locais dos arquivos no OBIEE 11g -
RPD Directory
C:\Middleware\instances\instance1\bifoundation\OracleBIServerComponent\
coreapplication_obis1\repositoryNQSConfig.INI
C:\Middleware\instances\instance1\config\OracleBIServerComponent\coreapplication_obis1\
nqsconfig.ININQClusterConfig.INI
C:\Middleware\instances\instance1\config\OracleBIApplication\coreapplication\
NQClusterConfig.INInqquery.log
C:\Middleware\instances\instance1\diagnostics\logs\OracleBIServerComponent\
coreapplication_obis1\nqquery.lognqserver.log
C:\Middleware\instances\instance1\diagnostics\logs\OracleBIServerComponent\
coreapplication_obis1\nqserver.lognqsserver.exe
C:\Middleware\Oracle_BI1\bifoundation\server\bin\nqsserver.exeWebCat Directory
C:\Middleware\instances\instance1\bifoundation\OracleBIPresentationServicesComponent\
coreapplication_obips1\catalog\instanceconfig.xml
C:\Middleware\instances\instance1\config\OracleBIPresentationServicesComponent\
coreapplication_obips1\instanceconfig.xmlxdo.cfg
C:\Middleware\instances\instance1\config\OracleBIPresentationServicesComponent\
coreapplication_obips1\xdo.cfgsawlog0.log
C:\Middleware\instances\instance1\diagnostics\logs\OracleBIPresentationServicesComponent\
coreapplication_obips1\sawlog0.logsawserver.exe
C:\Middleware\Oracle_BI1\bifoundation\web\bin\sawserver.exeVá para a Visão geral. Você também pode parar, iniciar e reiniciar todos os componentes do sistema como BI Server, Presentation Server etc. via OPMN.

Você pode clicar nas guias Capacity Management, Diagnostics, Security ou Deployment para realizar manutenções adicionais.
Gerenciamento de capacidade
Temos as seguintes quatro opções disponíveis para gerenciamento de capacidade -
Métricas coletadas via DMS.
Disponibilidade de todos os componentes individuais do sistema (permitindo que você os pare, inicie e reinicie individualmente).
A escalabilidade é usada para aumentar o número de BI Servers, Presentation Servers, Cluster Controllers e Schedulers no cluster em conjunto com a opção de instalação “scale out”.
A opção de desempenho permite ativar ou desativar o cache e modificar outros parâmetros associados ao tempo de resposta.

Diagnostics - Log Messages mostra a visualização de todos os erros e avisos do servidor. Log Configuration permite limitar o tamanho dos logs e as informações são incluídas neles.
Security - É usado para habilitar o SSO e selecionar o provedor SSO.
Deployment - Presentation permite que você defina os padrões do painel, títulos de seção, etc. Scheduler é usado para definir os detalhes da conexão para o esquema do planejador. Marketing serve para configurar a conexão do Siebel Marketing Content Server. Mail opção é usada para configurar o servidor de email para entregar alertas de email. Repository é usado para fazer upload de novos RPDs para uso pelo BI Server.