OBIEE - Esquema
O esquema é uma descrição lógica de todo o banco de dados. Inclui o nome e a descrição dos registros de todos os tipos, incluindo todos os itens de dados e agregados associados. Muito parecido com um banco de dados, o DW também requer a manutenção de um esquema. O banco de dados usa o modelo relacional, enquanto o DW usa o esquema Star, Snowflake e Fact Constellation (esquema Galaxy).
Esquema Star
Em um esquema em estrela, existem várias tabelas de dimensão na forma desnormalizada que são unidas a apenas uma tabela de fatos. Essas tabelas são unidas de maneira lógica para atender a alguns requisitos de negócios para fins de análise. Esses esquemas são estruturas multidimensionais usadas para criar relatórios usando ferramentas de relatório de BI.
Dimensões em esquemas em estrela contêm um conjunto de atributos e tabelas de fatos contêm chaves estrangeiras para todas as dimensões e valores de medição.
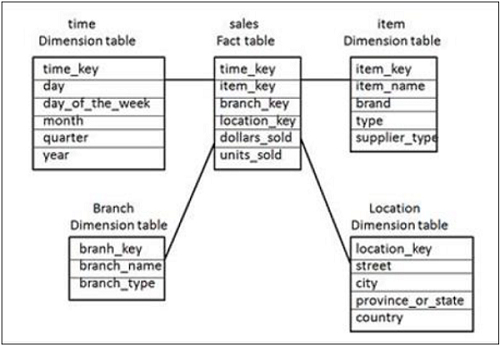
No esquema em estrela acima, há uma tabela de fatos “Sales Fact” no centro e é unida a 4 tabelas de dimensão usando chaves primárias. As tabelas de dimensão não são mais normalizadas e essa junção de tabelas é conhecida como Star Schema em DW.
A tabela de fatos também contém valores de medida - dólar_venda e unidades_venda.
Esquema de flocos de neve
Em um Esquema de flocos de neve, existem várias tabelas de dimensão na forma normalizada que são unidas a apenas uma tabela de fatos. Essas tabelas são unidas de maneira lógica para atender a alguns requisitos de negócios para fins de análise.
A única diferença entre um esquema Star e Snowflakes é que as tabelas de dimensão são posteriormente normalizadas. A normalização divide os dados em tabelas adicionais. Devido à normalização no esquema Snowflake, a redundância de dados é reduzida sem perder nenhuma informação e, portanto, torna-se fácil de manter e economiza espaço de armazenamento.

No exemplo acima do Esquema de flocos de neve, as tabelas Produto e Cliente são posteriormente normalizadas para economizar espaço de armazenamento. Às vezes, ele também fornece otimização de desempenho quando você executa uma consulta que requer processamento de linhas diretamente na tabela normalizada, de forma que não processe linhas na tabela de dimensão primária e vá diretamente para a tabela normalizada no esquema.
Granularidade
A granularidade em uma tabela representa o nível de informações armazenadas na tabela. Alta granularidade de dados significa que os dados estão no nível da transação ou próximo a ele, que possui mais detalhes. Baixa granularidade significa que os dados têm baixo nível de informação.
Uma tabela de fatos geralmente é projetada em um baixo nível de granularidade. Isso significa que precisamos encontrar o nível mais baixo de informação que pode ser armazenado em uma tabela de fatos. Na dimensão de data, o nível de granularidade pode ser ano, mês, trimestre, período, semana e dia.
O processo de definição de granularidade consiste em duas etapas -
- Determinar as dimensões a serem incluídas.
- Determinar a localização para colocar a hierarquia de cada dimensão da informação.
Dimensões que mudam lentamente
Dimensões que mudam lentamente referem-se à mudança do valor de um atributo ao longo do tempo. É um dos conceitos comuns no DW.
Exemplo
Andy é um funcionário da XYZ Inc. Ele foi localizado pela primeira vez na cidade de Nova York em julho de 2015. A entrada original na tabela de pesquisa de funcionários tem o seguinte registro -
| ID do Empregado | 10001 |
|---|---|
| Nome | Andy |
| Localização | Nova york |
Posteriormente, ele se mudou para LA, Califórnia. Como a XYZ Inc. agora deve modificar sua tabela de funcionários para refletir essa mudança?
Isso é conhecido como conceito de "Dimensão que muda lentamente".
Existem três maneiras de resolver este tipo de problema -
Solução 1
O novo registro substitui o registro original. Não existe nenhum vestígio do registro antigo.
Dimensão que muda lentamente, a nova informação simplesmente substitui a informação original. Em outras palavras, nenhuma história é mantida.
| ID do Empregado | 10001 |
|---|---|
| Nome | Andy |
| Localização | LA, Califórnia |
Benefit - Esta é a maneira mais fácil de lidar com o problema de Dimensão de Mudança Lenta, pois não há necessidade de manter o controle das informações antigas.
Disadvantage - Todas as informações históricas são perdidas.
Use - A solução 1 deve ser usada quando não for necessário que o DW acompanhe as informações históricas.
Solução 2
Um novo registro é inserido na tabela de dimensão Funcionário. Portanto, o funcionário, Andy, é tratado como duas pessoas.
Um novo registro é adicionado à tabela para representar as novas informações e tanto o registro original quanto o novo estarão presentes. O novo registro obtém sua própria chave primária da seguinte forma -
| ID do Empregado | 10001 | 10002 |
|---|---|---|
| Nome | Andy | Andy |
| Localização | Nova york | LA, Califórnia |
Benefit - Este método nos permite armazenar todas as informações históricas.
Disadvantage- O tamanho da mesa cresce mais rápido. Quando o número de linhas da tabela é muito alto, o espaço e o desempenho da tabela podem ser uma preocupação.
Use - A Solução 2 deve ser usada quando for necessário que o DW mantenha os dados históricos.
Solução 3
O registro original na dimensão Funcionário é modificado para refletir a mudança.
Haverá duas colunas para indicar o atributo específico, uma indica o valor original e outra indica o novo valor. Haverá também uma coluna que indica quando o valor atual se torna ativo.
| ID do Empregado | Nome | Localização Original | Nova localização | Data da Movimentação |
|---|---|---|---|---|
| 10001 | Andy | Nova york | LA, Califórnia | Julho 2015 |
Benefits- Isso não aumenta o tamanho da tabela, uma vez que novas informações são atualizadas. Isso nos permite manter informações históricas.
Disadvantage - Este método não mantém todo o histórico quando um valor de atributo é alterado mais de uma vez.
Use - A Solução 3 só deve ser usada quando for necessário que o DW mantenha as informações das mudanças históricas.
Normalização
Normalização é o processo de decompor uma tabela em tabelas menores menos redundantes sem perder nenhuma informação. Portanto, a normalização do banco de dados é o processo de organizar os atributos e tabelas de um banco de dados para minimizar a redundância de dados (dados duplicados).
Objetivo de Normalização
É usado para eliminar certos tipos de dados (redundância / replicação) para melhorar a consistência.
Ele fornece flexibilidade máxima para atender às necessidades de informações futuras, mantendo as tabelas correspondentes aos tipos de objetos em seus formulários simplificados.
Ele produz um modelo de dados mais claro e legível.
Vantagens
- Integridade de dados.
- Aumenta a consistência dos dados.
- Reduz a redundância de dados e o espaço necessário.
- Reduz o custo de atualização.
- Flexibilidade máxima para responder a consultas ad-hoc.
- Reduz o número total de linhas por bloco.
Desvantagens
Desempenho lento de consultas no banco de dados porque as junções devem ser executadas para recuperar dados relevantes de várias tabelas normalizadas.
Você tem que entender o modelo de dados para realizar junções adequadas entre várias tabelas.
Exemplo

No exemplo acima, a tabela dentro do bloco verde representa uma tabela normalizada daquela dentro do bloco vermelho. A tabela em bloco verde é menos redundante e também com menor número de linhas sem perder nenhuma informação.