Python orientado a objetos - serialização de objetos
No contexto de armazenamento de dados, serialização é o processo de tradução de estruturas de dados ou estado do objeto em um formato que pode ser armazenado (por exemplo, em um arquivo ou buffer de memória) ou transmitido e reconstruído posteriormente.
Na serialização, um objeto é transformado em um formato que pode ser armazenado, de forma a ser capaz de desserializá-lo posteriormente e recriar o objeto original a partir do formato serializado.
Salmoura
Pickling é o processo pelo qual uma hierarquia de objetos Python é convertida em um fluxo de bytes (geralmente não legível por humanos) para ser gravado em um arquivo, isso também é conhecido como serialização. Unpickling é a operação reversa, por meio da qual um fluxo de bytes é convertido de volta em uma hierarquia de objetos Python funcional.
Pickle é a maneira operacionalmente mais simples de armazenar o objeto. O módulo Python Pickle é uma maneira orientada a objetos de armazenar objetos diretamente em um formato de armazenamento especial.
O que é que isso pode fazer?
- Pickle pode armazenar e reproduzir dicionários e listas com muita facilidade.
- Armazena atributos de objeto e os restaura de volta ao mesmo estado.
O que picles não pode fazer?
- Ele não salva um código de objeto. Apenas seus valores de atributos.
- Ele não pode armazenar identificadores de arquivo ou soquetes de conexão.
Resumindo, podemos dizer que a decapagem é uma maneira de armazenar e recuperar variáveis de dados para dentro e para fora de arquivos onde as variáveis podem ser listas, classes, etc.
Para conservar algo você deve -
- importar picles
- Escreva uma variável para o arquivo, algo como
pickle.dump(mystring, outfile, protocol),onde o protocolo do terceiro argumento é opcional. Para remover algo, você deve -
Picles de importação
Escreva uma variável em um arquivo, algo como
myString = pickle.load(inputfile)Métodos
A interface pickle oferece quatro métodos diferentes.
dump() - O método dump () serializa para um arquivo aberto (objeto semelhante a arquivo).
dumps() - Serializa em uma string
load() - Desserializa a partir de um objeto aberto.
loads() - Desserializa de uma string.
Com base no procedimento acima, abaixo está um exemplo de “decapagem”.
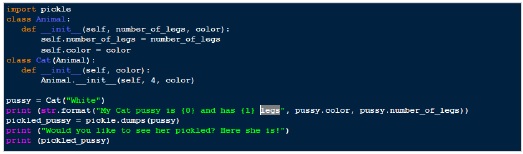
Resultado
My Cat pussy is White and has 4 legs
Would you like to see her pickled? Here she is!
b'\x80\x03c__main__\nCat\nq\x00)\x81q\x01}q\x02(X\x0e\x00\x00\x00number_of_legsq\x03K\x04X\x05\x00\x00\x00colorq\x04X\x05\x00\x00\x00Whiteq\x05ub.'Portanto, no exemplo acima, criamos uma instância de uma classe Cat e a separamos, transformando nossa instância “Cat” em um array simples de bytes.
Dessa forma, podemos armazenar facilmente a matriz de bytes em um arquivo binário ou em um campo de banco de dados e restaurá-la de volta à sua forma original a partir de nosso suporte de armazenamento posteriormente.
Além disso, se você quiser criar um arquivo com um objeto conservado, pode usar o método dump () (em vez dos dumps * () * um), passando também um arquivo binário aberto e o resultado da conservação será armazenado no arquivo automaticamente.
[….]
binary_file = open(my_pickled_Pussy.bin', mode='wb')
my_pickled_Pussy = pickle.dump(Pussy, binary_file)
binary_file.close()Retirada
O processo que pega uma matriz binária e a converte em uma hierarquia de objetos é chamado de remoção da separação.
O processo de remoção é feito usando a função load () do módulo pickle e retorna uma hierarquia completa de objetos a partir de um array de bytes simples.
Vamos usar a função load em nosso exemplo anterior.
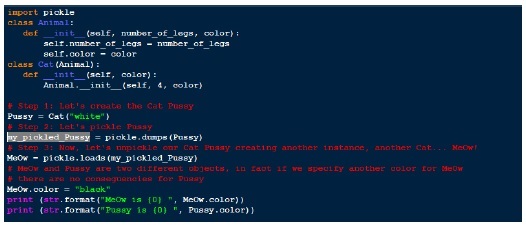
Resultado
MeOw is black
Pussy is whiteJSON
JSON (JavaScript Object Notation) faz parte da biblioteca padrão do Python e é um formato de intercâmbio de dados leve. É fácil para humanos ler e escrever. É fácil de analisar e gerar.
Devido à sua simplicidade, JSON é uma maneira pela qual armazenamos e trocamos dados, o que é realizado por meio de sua sintaxe JSON, e é usado em muitos aplicativos da web. Por se encontrar em formato legível por humanos, este pode ser um dos motivos para utilizá-lo na transmissão de dados, além de sua eficácia no trabalho com APIs.
Um exemplo de dados formatados em JSON é o seguinte -
{"EmployID": 40203, "Name": "Zack", "Age":54, "isEmployed": True}Python simplifica o trabalho com arquivos Json. O módulo sused para este propósito é o módulo JSON. Este módulo deve ser incluído (embutido) na instalação do Python.
Então, vamos ver como podemos converter o dicionário Python em JSON e gravá-lo em um arquivo de texto.
JSON para Python
Ler JSON significa converter JSON em um valor Python (objeto). A biblioteca json analisa JSON em um dicionário ou lista em Python. Para fazer isso, usamos a função load () (carregar de uma string), como segue -

Resultado

Abaixo está um exemplo de arquivo json,
data1.json
{"menu": {
"id": "file",
"value": "File",
"popup": {
"menuitem": [
{"value": "New", "onclick": "CreateNewDoc()"},
{"value": "Open", "onclick": "OpenDoc()"},
{"value": "Close", "onclick": "CloseDoc()"}
]
}
}}O conteúdo acima (Data1.json) parece um dicionário convencional. Podemos usar pickle para armazenar este arquivo, mas a saída dele não é de forma legível por humanos.
JSON (Java Script Object Notification) é um formato muito simples e esse é um dos motivos de sua popularidade. Agora vamos dar uma olhada na saída json por meio do programa abaixo.
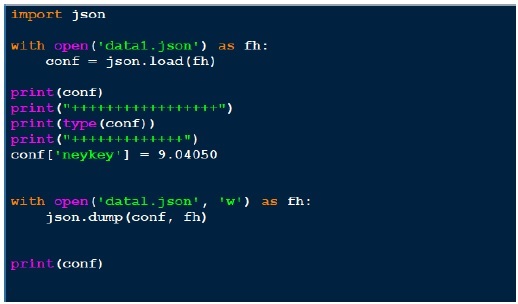
Resultado
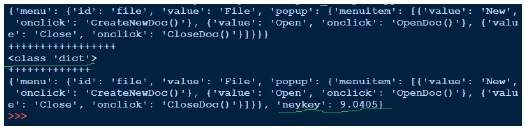
Acima, abrimos o arquivo json (data1.json) para leitura, obtemos o manipulador de arquivo e passamos para json.load e recuperamos o objeto. Quando tentamos imprimir a saída do objeto, é o mesmo que o arquivo json. Embora o tipo do objeto seja um dicionário, ele surge como um objeto Python. Escrever para o json é simples, pois vimos este pickle. Acima, carregamos o arquivo json, adicionamos outro par de valores-chave e gravamos de volta no mesmo arquivo json. Agora, se virmos data1.json, ele parece diferente, ou seja, não no mesmo formato que vemos anteriormente.
Para fazer com que nossa saída pareça a mesma (formato legível por humanos), adicione alguns argumentos em nossa última linha do programa,
json.dump(conf, fh, indent = 4, separators = (‘,’, ‘: ‘))Da mesma forma que o pickle, podemos imprimir a string com despejos e carregar com cargas. Abaixo está um exemplo disso,
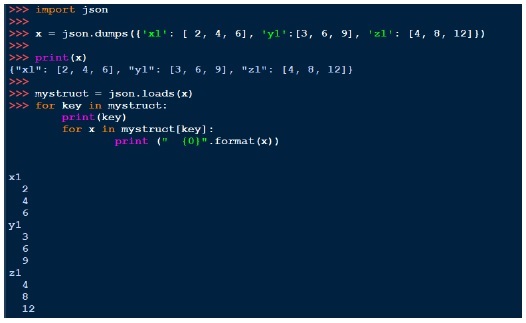
YAML
YAML pode ser o padrão de serialização de dados mais amigável para todas as linguagens de programação.
O módulo Python yaml é chamado pyaml
YAML é uma alternativa para JSON -
Human readable code - YAML é o formato mais legível por humanos, tanto que até mesmo seu conteúdo de primeira página é exibido em YAML para mostrar isso.
Compact code - Em YAML, usamos recuo de espaço em branco para denotar a estrutura, não os colchetes.
Syntax for relational data - Para referências internas, usamos âncoras (&) e aliases (*).
One of the area where it is used widely is for viewing/editing of data structures - por exemplo, arquivos de configuração, despejando durante a depuração e cabeçalhos de documentos.
Instalando YAML
Como yaml não é um módulo embutido, precisamos instalá-lo manualmente. A melhor maneira de instalar o yaml em uma máquina Windows é através do pip. Execute o comando abaixo no seu terminal Windows para instalar o yaml,
pip install pyaml (Windows machine)
sudo pip install pyaml (*nix and Mac)Ao executar o comando acima, a tela exibirá algo como abaixo com base na versão atual mais recente.
Collecting pyaml
Using cached pyaml-17.12.1-py2.py3-none-any.whl
Collecting PyYAML (from pyaml)
Using cached PyYAML-3.12.tar.gz
Installing collected packages: PyYAML, pyaml
Running setup.py install for PyYAML ... done
Successfully installed PyYAML-3.12 pyaml-17.12.1Para testá-lo, vá para o shell Python e importe o módulo yaml, importe yaml, se nenhum erro for encontrado, então podemos dizer que a instalação foi bem-sucedida.
Depois de instalar o pyaml, vamos dar uma olhada no código abaixo,
script_yaml1.py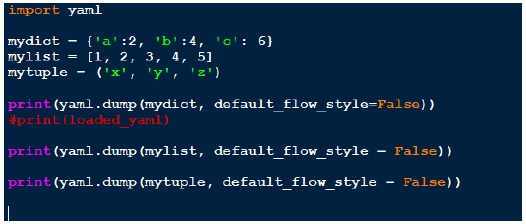
Acima, criamos três estruturas de dados diferentes, dicionário, lista e tupla. Em cada estrutura, fazemos yaml.dump. O ponto importante é como a saída é exibida na tela.
Resultado
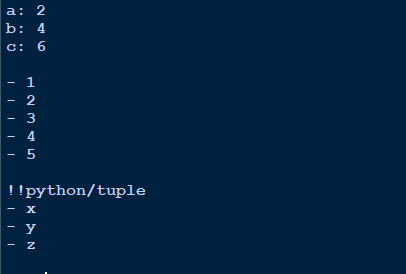
A saída do dicionário parece limpa, por exemplo. valor chave.
Espaço em branco para separar objetos diferentes.
A lista é marcada com traço (-)
A tupla é indicada primeiro com !! Python / tupla e, em seguida, no mesmo formato das listas.
Carregando um arquivo yaml
Digamos que eu tenha um arquivo yaml, que contém,
---
# An employee record
name: Raagvendra Joshi
job: Developer
skill: Oracle
employed: True
foods:
- Apple
- Orange
- Strawberry
- Mango
languages:
Oracle: Elite
power_builder: Elite
Full Stack Developer: Lame
education:
4 GCSEs
3 A-Levels
MCA in something called comAgora vamos escrever um código para carregar esse arquivo yaml por meio da função yaml.load. Abaixo está o código para o mesmo.
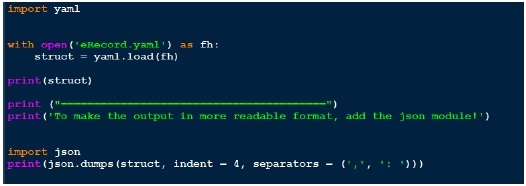
Como a saída não parece muito legível, eu a embelezo usando json no final. Compare a saída que obtivemos e o arquivo yaml real que temos.
Resultado

Um dos aspectos mais importantes do desenvolvimento de software é a depuração. Nesta seção, veremos diferentes maneiras de depurar Python com o depurador embutido ou depuradores de terceiros.
PDB - o depurador Python
O módulo PDB suporta a definição de pontos de interrupção. Um ponto de interrupção é uma pausa intencional do programa, onde você pode obter mais informações sobre o estado do programa.
Para definir um ponto de interrupção, insira a linha
pdb.set_trace()Exemplo
pdb_example1.py
import pdb
x = 9
y = 7
pdb.set_trace()
total = x + y
pdb.set_trace()Inserimos alguns pontos de interrupção neste programa. O programa fará uma pausa em cada ponto de interrupção (pdb.set_trace ()). Para visualizar o conteúdo de uma variável, basta digitar o nome da variável.
c:\Python\Python361>Python pdb_example1.py
> c:\Python\Python361\pdb_example1.py(8)<module>()
-> total = x + y
(Pdb) x
9
(Pdb) y
7
(Pdb) total
*** NameError: name 'total' is not defined
(Pdb)Pressione c ou continue com a execução dos programas até o próximo ponto de interrupção.
(Pdb) c
--Return--
> c:\Python\Python361\pdb_example1.py(8)<module>()->None
-> total = x + y
(Pdb) total
16Eventualmente, você precisará depurar programas muito maiores - programas que usam sub-rotinas. E, às vezes, o problema que você está tentando encontrar está dentro de uma sub-rotina. Considere o seguinte programa.
import pdb
def squar(x, y):
out_squared = x^2 + y^2
return out_squared
if __name__ == "__main__":
#pdb.set_trace()
print (squar(4, 5))Agora, ao executar o programa acima,
c:\Python\Python361>Python pdb_example2.py
> c:\Python\Python361\pdb_example2.py(10)<module>()
-> print (squar(4, 5))
(Pdb)Podemos usar ?para obter ajuda, mas a seta indica a linha que está prestes a ser executada. Neste ponto, é útil acertar s paras para entrar nessa linha.
(Pdb) s
--Call--
>c:\Python\Python361\pdb_example2.py(3)squar()
-> def squar(x, y):Esta é uma chamada para uma função. Se você quiser uma visão geral de onde você está em seu código, tente l -
(Pdb) l
1 import pdb
2
3 def squar(x, y):
4 -> out_squared = x^2 + y^2
5
6 return out_squared
7
8 if __name__ == "__main__":
9 pdb.set_trace()
10 print (squar(4, 5))
[EOF]
(Pdb)Você pode pressionar n para avançar para a próxima linha. Neste ponto, você está dentro do método out_squared e tem acesso à variável declarada dentro da função .ie x e y.
(Pdb) x
4
(Pdb) y
5
(Pdb) x^2
6
(Pdb) y^2
7
(Pdb) x**2
16
(Pdb) y**2
25
(Pdb)Portanto, podemos ver que o operador ^ não é o que queríamos, em vez disso, precisamos usar o operador ** para fazer os quadrados.
Desta forma, podemos depurar nosso programa dentro das funções / métodos.
Exploração madeireira
O módulo de registro faz parte da Biblioteca Padrão do Python desde a versão 2.3 do Python. Como é um módulo embutido, todos os módulos Python podem participar do registro, para que o log do nosso aplicativo possa incluir sua própria mensagem integrada com mensagens de módulo de terceiros. Ele oferece muita flexibilidade e funcionalidade.
Benefícios do registro
Diagnostic logging - Registra eventos relacionados ao funcionamento do aplicativo.
Audit logging - Registra eventos para análise de negócios.
As mensagens são gravadas e registradas em níveis de “gravidade” e mínimo
DEBUG (debug()) - mensagens de diagnóstico para desenvolvimento.
INFO (info()) - mensagens padrão de “progresso”.
WARNING (warning()) - detectou um problema não sério.
ERROR (error()) - encontrou um erro, possivelmente sério.
CRITICAL (critical()) - geralmente um erro fatal (o programa pára).
Vamos dar uma olhada no programa simples abaixo,
import logging
logging.basicConfig(level=logging.INFO)
logging.debug('this message will be ignored') # This will not print
logging.info('This should be logged') # it'll print
logging.warning('And this, too') # It'll printAcima, estamos registrando mensagens no nível de gravidade. Primeiro importamos o módulo, chamamos basicConfig e definimos o nível de registro. O nível que definimos acima é INFO. Então, temos três instruções diferentes: instrução de depuração, instrução de informação e uma instrução de aviso.
Saída de logging1.py
INFO:root:This should be logged
WARNING:root:And this, tooComo a instrução info está abaixo da instrução debug, não podemos ver a mensagem de depuração. Para obter a instrução de depuração também no terminal de saída, tudo o que precisamos mudar é o nível basicConfig.
logging.basicConfig(level = logging.DEBUG)E na saída podemos ver,
DEBUG:root:this message will be ignored
INFO:root:This should be logged
WARNING:root:And this, tooAlém disso, o comportamento padrão significa que se não definirmos nenhum nível de registro, é aviso. Basta comentar a segunda linha do programa acima e executar o código.
#logging.basicConfig(level = logging.DEBUG)Resultado
WARNING:root:And this, tooO nível de registro integrado do Python são, na verdade, inteiros.
>>> import logging
>>>
>>> logging.DEBUG
10
>>> logging.CRITICAL
50
>>> logging.WARNING
30
>>> logging.INFO
20
>>> logging.ERROR
40
>>>Também podemos salvar as mensagens de log no arquivo.
logging.basicConfig(level = logging.DEBUG, filename = 'logging.log')Agora, todas as mensagens de log irão para o arquivo (logging.log) em seu diretório de trabalho atual ao invés da tela. Esta é uma abordagem muito melhor, pois nos permite fazer uma pós-análise das mensagens que recebemos.
Também podemos definir o carimbo de data com nossa mensagem de log.
logging.basicConfig(level=logging.DEBUG, format = '%(asctime)s %(levelname)s:%(message)s')A saída terá algo como,
2018-03-08 19:30:00,066 DEBUG:this message will be ignored
2018-03-08 19:30:00,176 INFO:This should be logged
2018-03-08 19:30:00,201 WARNING:And this, tooavaliação comparativa
Benchmarking ou criação de perfil são basicamente para testar a rapidez com que seu código é executado e onde estão os gargalos. O principal motivo para fazer isso é a otimização.
timeit
Python vem com um módulo embutido chamado timeit. Você pode usá-lo para cronometrar pequenos trechos de código. O módulo timeit usa funções de tempo específicas da plataforma para que você obtenha os tempos mais precisos possíveis.
Assim, permite-nos comparar duas remessas de código tomadas por cada uma e, em seguida, otimizar os scripts para obter um melhor desempenho.
O módulo timeit possui uma interface de linha de comando, mas também pode ser importado.
Existem duas maneiras de chamar um script. Vamos usar o script primeiro, para isso execute o código abaixo e veja a saída.
import timeit
print ( 'by index: ', timeit.timeit(stmt = "mydict['c']", setup = "mydict = {'a':5, 'b':10, 'c':15}", number = 1000000))
print ( 'by get: ', timeit.timeit(stmt = 'mydict.get("c")', setup = 'mydict = {"a":5, "b":10, "c":15}', number = 1000000))Resultado
by index: 0.1809192126703489
by get: 0.6088525265034692Acima, usamos dois métodos diferentes, ou seja, por subscrito e conseguimos acessar o valor da chave do dicionário. Executamos a instrução 1 milhão de vezes, pois é muito rápida para dados muito pequenos. Agora podemos ver o acesso ao índice muito mais rápido em comparação com o get. Podemos executar o código multiplicar vezes e haverá uma pequena variação no tempo de execução para obter um melhor entendimento.
Outra forma é executar o teste acima na linha de comando. Vamos fazer isso,
c:\Python\Python361>Python -m timeit -n 1000000 -s "mydict = {'a': 5, 'b':10, 'c':15}" "mydict['c']"
1000000 loops, best of 3: 0.187 usec per loop
c:\Python\Python361>Python -m timeit -n 1000000 -s "mydict = {'a': 5, 'b':10, 'c':15}" "mydict.get('c')"
1000000 loops, best of 3: 0.659 usec per loopA saída acima pode variar com base no hardware do seu sistema e em todos os aplicativos que estão executando atualmente no seu sistema.
Abaixo, podemos usar o módulo timeit, se quisermos chamar uma função. Como podemos adicionar várias instruções dentro da função para testar.
import timeit
def testme(this_dict, key):
return this_dict[key]
print (timeit.timeit("testme(mydict, key)", setup = "from __main__ import testme; mydict = {'a':9, 'b':18, 'c':27}; key = 'c'", number = 1000000))Resultado
0.7713474590139164