Scikit Learn - Representação de dados
Como sabemos, o aprendizado de máquina está prestes a criar um modelo a partir de dados. Para isso, o computador deve primeiro entender os dados. A seguir, vamos discutir várias maneiras de representar os dados para serem entendidos pelo computador -
Dados como tabela
A melhor maneira de representar dados no Scikit-learn é na forma de tabelas. Uma tabela representa uma grade 2-D de dados em que as linhas representam os elementos individuais do conjunto de dados e as colunas representam as quantidades relacionadas a esses elementos individuais.
Exemplo
Com o exemplo dado abaixo, podemos baixar iris dataset na forma de um DataFrame Pandas com a ajuda de python seaborn biblioteca.
import seaborn as sns
iris = sns.load_dataset('iris')
iris.head()Resultado
sepal_length sepal_width petal_length petal_width species
0 5.1 3.5 1.4 0.2 setosa
1 4.9 3.0 1.4 0.2 setosa
2 4.7 3.2 1.3 0.2 setosa
3 4.6 3.1 1.5 0.2 setosa
4 5.0 3.6 1.4 0.2 setosaA partir da saída acima, podemos ver que cada linha dos dados representa uma única flor observada e o número de linhas representa o número total de flores no conjunto de dados. Geralmente, nos referimos às linhas da matriz como amostras.
Por outro lado, cada coluna de dados representa uma informação quantitativa que descreve cada amostra. Geralmente, nos referimos às colunas da matriz como recursos.
Dados como matriz de recursos
A matriz de recursos pode ser definida como o layout da tabela em que as informações podem ser consideradas como uma matriz 2-D. Ele é armazenado em uma variável chamadaXe assumido ser bidimensional com forma [n_samples, n_features]. Principalmente, ele está contido em uma matriz NumPy ou em um Pandas DataFrame. Como dito anteriormente, as amostras sempre representam os objetos individuais descritos pelo conjunto de dados e os recursos representam as observações distintas que descrevem cada amostra de maneira quantitativa.
Dados como matriz de destino
Junto com a matriz de recursos, denotada por X, também temos a matriz de destino. Também é chamado de rótulo. É denotado por y. O rótulo ou matriz de destino é geralmente unidimensional com comprimento n_samples. Geralmente está contido no NumPyarray ou pandas Series. A matriz de destino pode ter os valores, valores numéricos contínuos e valores discretos.
Como a matriz de destino difere das colunas de recursos?
Podemos distinguir ambos por um ponto que a matriz de destino geralmente é a quantidade que queremos prever a partir dos dados, ou seja, em termos estatísticos, é a variável dependente.
Exemplo
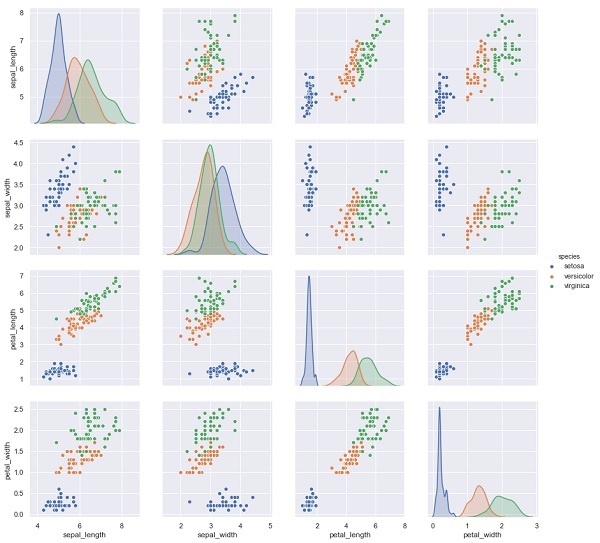
No exemplo abaixo, a partir do conjunto de dados da íris, prevemos as espécies de flores com base nas outras medições. Nesse caso, a coluna Espécie seria considerada como o recurso.
import seaborn as sns
iris = sns.load_dataset('iris')
%matplotlib inline
import seaborn as sns; sns.set()
sns.pairplot(iris, hue='species', height=3);Resultado
X_iris = iris.drop('species', axis=1)
X_iris.shape
y_iris = iris['species']
y_iris.shapeResultado
(150,4)
(150,)