Seaborn - Relações Lineares
Na maioria das vezes, usamos conjuntos de dados que contêm várias variáveis quantitativas, e o objetivo de uma análise é relacionar essas variáveis entre si. Isso pode ser feito por meio das linhas de regressão.
Ao construir os modelos de regressão, costumamos verificar multicollinearity,onde tivemos que ver a correlação entre todas as combinações de variáveis contínuas e tomaremos as medidas necessárias para remover a multicolinearidade, se houver. Nesses casos, as técnicas a seguir ajudam.
Funções para desenhar modelos de regressão linear
Existem duas funções principais no Seaborn para visualizar uma relação linear determinada por meio de regressão. Essas funções sãoregplot() e lmplot().
regplot vs lmplot
| regplot | lmplot |
|---|---|
| aceita as variáveis xey em uma variedade de formatos, incluindo matrizes numpy simples, objetos da série pandas ou como referências a variáveis em um DataFrame do pandas | tem dados como um parâmetro obrigatório e as variáveis x e y devem ser especificadas como strings. Este formato de dados é chamado de dados de "formato longo" |
Vamos agora desenhar os gráficos.
Exemplo
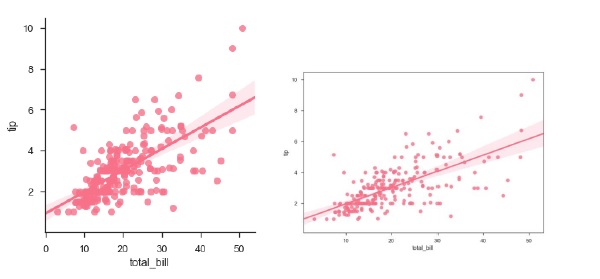
Plotagem do regplot e, em seguida, lmplot com os mesmos dados neste exemplo
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('tips')
sb.regplot(x = "total_bill", y = "tip", data = df)
sb.lmplot(x = "total_bill", y = "tip", data = df)
plt.show()Resultado
Você pode ver a diferença de tamanho entre duas parcelas.
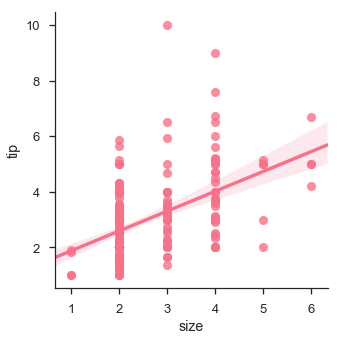
Também podemos ajustar uma regressão linear quando uma das variáveis assume valores discretos
Exemplo
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('tips')
sb.lmplot(x = "size", y = "tip", data = df)
plt.show()Resultado
Adaptando-se a diferentes tipos de modelos
O modelo de regressão linear simples usado acima é muito simples de ajustar, mas na maioria dos casos, os dados são não lineares e os métodos acima não podem generalizar a linha de regressão.
Vamos usar o conjunto de dados de Anscombe com os gráficos de regressão -
Exemplo
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('anscombe')
sb.lmplot(x="x", y="y", data=df.query("dataset == 'I'"))
plt.show()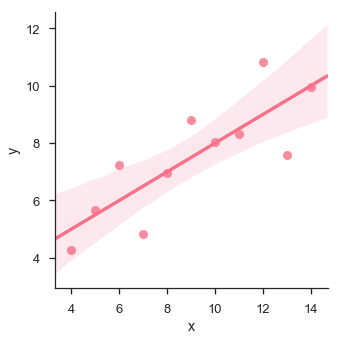
Nesse caso, os dados são adequados para o modelo de regressão linear com menos variância.
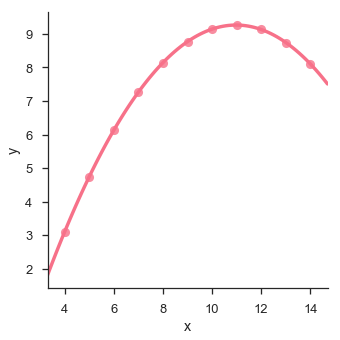
Vejamos outro exemplo em que os dados apresentam alto desvio, o que mostra que a linha de melhor ajuste não é boa.
Exemplo
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('anscombe')
sb.lmplot(x = "x", y = "y", data = df.query("dataset == 'II'"))
plt.show()Resultado
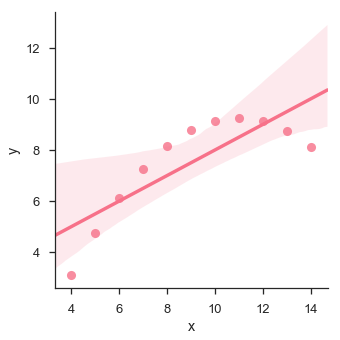
O gráfico mostra o alto desvio dos pontos de dados da linha de regressão. Essa ordem não linear superior pode ser visualizada usando olmplot() e regplot().Estes podem ajustar um modelo de regressão polinomial para explorar tipos simples de tendências não lineares no conjunto de dados -
Exemplo
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('anscombe')
sb.lmplot(x = "x", y = "y", data = df.query("dataset == 'II'"),order = 2)
plt.show()Resultado