SQLAlchemy - Guia rápido
SQLAlchemy é um popular kit de ferramentas SQL e Object Relational Mapper. Está escrito emPythone oferece total poder e flexibilidade de SQL a um desenvolvedor de aplicativos. É umopen source e cross-platform software lançado sob licença do MIT.
SQLAlchemy é famoso por seu mapeador relacional de objetos (ORM), usando o qual as classes podem ser mapeadas para o banco de dados, permitindo assim que o modelo de objeto e o esquema do banco de dados se desenvolvam de uma maneira claramente desacoplada desde o início.
À medida que o tamanho e o desempenho dos bancos de dados SQL começam a importar, eles se comportam menos como coleções de objetos. Por outro lado, conforme a abstração em coleções de objetos começa a ter importância, elas se comportam menos como tabelas e linhas. SQLAlchemy visa acomodar esses dois princípios.
Por esse motivo, adota o data mapper pattern (like Hibernate) rather than the active record pattern used by a number of other ORMs. Bancos de dados e SQL serão vistos em uma perspectiva diferente usando SQLAlchemy.
Michael Bayer é o autor original de SQLAlchemy. Sua versão inicial foi lançada em fevereiro de 2006. A versão mais recente é numerada como 1.2.7, lançada recentemente em abril de 2018.
O que é ORM?
ORM (Object Relational Mapping) é uma técnica de programação para converter dados entre sistemas de tipos incompatíveis em linguagens de programação orientadas a objetos. Normalmente, o sistema de tipos usado em uma linguagem orientada a objetos (OO) como Python contém tipos não escalares. Eles não podem ser expressos como tipos primitivos, como inteiros e strings. Conseqüentemente, o programador OO tem que converter objetos em dados escalares para interagir com o banco de dados backend. No entanto, os tipos de dados na maioria dos produtos de banco de dados, como Oracle, MySQL, etc., são primários.
Em um sistema ORM, cada classe mapeia para uma tabela no banco de dados subjacente. Em vez de escrever você mesmo um tedioso código de interface de banco de dados, um ORM cuida dessas questões para você, enquanto você pode se concentrar na programação da lógica do sistema.
SQLAlchemy - configuração do ambiente
Vamos discutir a configuração ambiental necessária para usar o SQLAlchemy.
Qualquer versão do Python superior a 2.7 é necessária para instalar o SQLAlchemy. A maneira mais fácil de instalar é usando o Python Package Manager,pip. Este utilitário é fornecido com a distribuição padrão do Python.
pip install sqlalchemyUsando o comando acima, podemos baixar o latest released versionde SQLAlchemy de python.org e instale-o em seu sistema.
No caso de distribuição anaconda de Python, SQLAlchemy pode ser instalado a partir de conda terminal usando o comando abaixo -
conda install -c anaconda sqlalchemyTambém é possível instalar SQLAlchemy a partir do código-fonte abaixo -
python setup.py installSQLAlchemy é projetado para operar com uma implementação DBAPI construída para um banco de dados específico. Ele usa um sistema de dialeto para se comunicar com vários tipos de implementações e bancos de dados DBAPI. Todos os dialetos requerem que um driver DBAPI apropriado seja instalado.
A seguir estão os dialetos incluídos -
- Firebird
- Microsoft SQL Server
- MySQL
- Oracle
- PostgreSQL
- SQLite
- Sybase
Para verificar se SQLAlchemy está instalado corretamente e saber sua versão, digite o seguinte comando no prompt do Python -
>>> import sqlalchemy
>>>sqlalchemy.__version__
'1.2.7'SQLAlchemy core inclui SQL rendering engine, DBAPI integration, transaction integration, e schema description services. O núcleo SQLAlchemy usa linguagem de expressão SQL que fornece umaschema-centric usage paradigma, enquanto SQLAlchemy ORM é um domain-centric mode of usage.
O SQL Expression Language apresenta um sistema de representação de estruturas e expressões de bancos de dados relacionais usando construções Python. Apresenta um sistema de representação das construções primitivas do banco de dados relacional diretamente sem opinião, o que contrasta com o ORM que apresenta um padrão de uso de alto nível e abstrato, que por si só é um exemplo de uso aplicado da Expression Language.
Expression Language é um dos principais componentes do SQLAlchemy. Ele permite ao programador especificar instruções SQL no código Python e usá-lo diretamente em consultas mais complexas. A linguagem de expressão é independente do back-end e cobre de forma abrangente todos os aspectos do SQL bruto. Ele está mais próximo do SQL bruto do que qualquer outro componente do SQLAlchemy.
Expression Language representa as construções primitivas do banco de dados relacional diretamente. Como o ORM é baseado na linguagem Expression, um aplicativo de banco de dados Python típico pode ter o uso sobreposto de ambos. O aplicativo pode usar apenas a linguagem de expressão, embora tenha que definir seu próprio sistema de tradução de conceitos de aplicativo em consultas individuais de banco de dados.
As declarações da linguagem de expressão serão traduzidas em consultas SQL brutas correspondentes pelo mecanismo SQLAlchemy. Vamos agora aprender como criar o motor e executar várias consultas SQL com sua ajuda.
No capítulo anterior, discutimos sobre a linguagem de expressão em SQLAlchemy. Agora vamos prosseguir para as etapas envolvidas na conexão com um banco de dados.
Classe de motor conecta um Pool and Dialect together para fornecer uma fonte de banco de dados connectivity and behavior. Um objeto da classe Engine é instanciado usando ocreate_engine() função.
A função create_engine () leva o banco de dados como um argumento. O banco de dados não precisa ser definido em nenhum lugar. O formulário de chamada padrão deve enviar a URL como o primeiro argumento posicional, geralmente uma string que indica o dialeto do banco de dados e os argumentos de conexão. Usando o código fornecido a seguir, podemos criar um banco de dados.
>>> from sqlalchemy import create_engine
>>> engine = create_engine('sqlite:///college.db', echo = True)Para MySQL database, use o comando abaixo -
engine = create_engine("mysql://user:pwd@localhost/college",echo = True)Para mencionar especificamente DB-API para ser usado para conexão, o URL string assume a seguinte forma -
dialect[+driver]://user:password@host/dbnamePor exemplo, se você estiver usando PyMySQL driver with MySQL, use o seguinte comando -
mysql+pymysql://<username>:<password>@<host>/<dbname>o echo flagé um atalho para configurar o registro SQLAlchemy, que é realizado por meio do módulo de registro padrão do Python. Nos capítulos subsequentes, aprenderemos todos os SQLs gerados. Para ocultar a saída detalhada, defina o atributo echo comoNone. Outros argumentos para a função create_engine () podem ser específicos do dialeto.
A função create_engine () retorna um Engine object. Alguns métodos importantes da classe Engine são -
| Sr. Não. | Método e Descrição |
|---|---|
| 1 | connect() Retorna o objeto de conexão |
| 2 | execute() Executa uma construção de instrução SQL |
| 3 | begin() Retorna um gerenciador de contexto entregando uma Conexão com uma Transação estabelecida. Após a operação bem-sucedida, a transação é confirmada, caso contrário, é revertida |
| 4 | dispose() Disposições do pool de conexão usado pelo motor |
| 5 | driver() Nome do driver do dialeto em uso pelo motor |
| 6 | table_names() Retorna uma lista de todos os nomes de tabelas disponíveis no banco de dados |
| 7 | transaction() Executa a função dada dentro de um limite de transação |
Vamos agora discutir como usar a função criar tabela.
O SQL Expression Language constrói suas expressões nas colunas da tabela. O objeto SQLAlchemy Column representa umcolumn em uma tabela de banco de dados que por sua vez é representada por um Tableobject. Metadados contêm definições de tabelas e objetos associados, como índice, visão, gatilhos, etc.
Portanto, um objeto da classe MetaData de SQLAlchemy Metadata é uma coleção de objetos Table e suas construções de esquema associadas. Ele contém uma coleção de objetos Tabela, bem como uma ligação opcional a um Motor ou Conexão.
from sqlalchemy import MetaData
meta = MetaData()O construtor da classe MetaData pode ter parâmetros de ligação e esquema que são, por padrão None.
Em seguida, definimos nossas tabelas dentro do catálogo de metadados acima, usando the Table construct, que se assemelha à instrução SQL CREATE TABLE regular.
Um objeto da classe Table representa a tabela correspondente em um banco de dados. O construtor usa os seguintes parâmetros -
| Nome | Nome da mesa |
|---|---|
| Metadados | Objeto MetaData que manterá esta tabela |
| Coluna (s) | Um ou mais objetos de classe de coluna |
Objeto de coluna representa um column em um database table. O construtor leva o nome, o tipo e outros parâmetros, como primary_key, autoincrement e outras restrições.
SQLAlchemy corresponde os dados Python aos melhores tipos de dados de coluna genéricos possíveis definidos nele. Alguns dos tipos de dados genéricos são -
- BigInteger
- Boolean
- Date
- DateTime
- Float
- Integer
- Numeric
- SmallInteger
- String
- Text
- Time
Para criar um students table no banco de dados da faculdade, use o seguinte trecho -
from sqlalchemy import Table, Column, Integer, String, MetaData
meta = MetaData()
students = Table(
'students', meta,
Column('id', Integer, primary_key = True),
Column('name', String),
Column('lastname', String),
)A função create_all () usa o objeto de mecanismo para criar todos os objetos de tabela definidos e armazena as informações em metadados.
meta.create_all(engine)O código completo é fornecido abaixo, o qual criará um banco de dados SQLite college.db com uma tabela de alunos nele.
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String
engine = create_engine('sqlite:///college.db', echo = True)
meta = MetaData()
students = Table(
'students', meta,
Column('id', Integer, primary_key = True),
Column('name', String),
Column('lastname', String),
)
meta.create_all(engine)Porque o atributo echo da função create_engine () é definido como True, o console exibirá a consulta SQL real para a criação da tabela da seguinte forma -
CREATE TABLE students (
id INTEGER NOT NULL,
name VARCHAR,
lastname VARCHAR,
PRIMARY KEY (id)
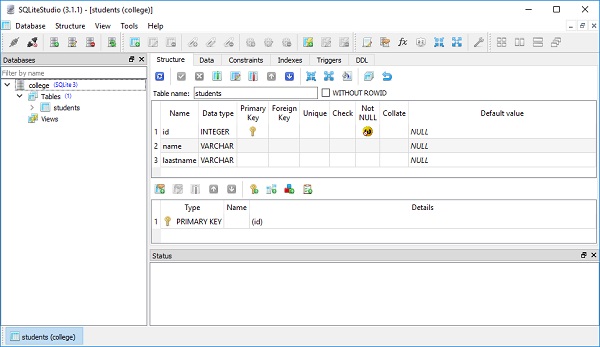
)O college.db será criado no diretório de trabalho atual. Para verificar se a tabela de alunos foi criada, você pode abrir o banco de dados usando qualquer ferramenta SQLite GUI, comoSQLiteStudio.
A imagem abaixo mostra a tabela de alunos que é criada no banco de dados -
Neste capítulo, enfocaremos brevemente as expressões SQL e suas funções.
As expressões SQL são construídas usando métodos correspondentes relativos ao objeto da tabela de destino. Por exemplo, a instrução INSERT é criada executando o método insert () da seguinte maneira -
ins = students.insert()O resultado do método acima é um objeto de inserção que pode ser verificado usando str()função. O código abaixo insere detalhes como id do aluno, nome, sobrenome.
'INSERT INTO students (id, name, lastname) VALUES (:id, :name, :lastname)'É possível inserir valor em um campo específico por values()método para inserir o objeto. O código para o mesmo é fornecido abaixo -
>>> ins = users.insert().values(name = 'Karan')
>>> str(ins)
'INSERT INTO users (name) VALUES (:name)'O SQL ecoado no console Python não mostra o valor real ('Karan' neste caso). Em vez disso, SQLALchemy gera um parâmetro de vinculação que é visível na forma compilada da instrução.
ins.compile().params
{'name': 'Karan'}Da mesma forma, métodos como update(), delete() e select()crie expressões UPDATE, DELETE e SELECT respectivamente. Aprenderemos sobre eles em capítulos posteriores.
No capítulo anterior, aprendemos Expressões SQL. Neste capítulo, examinaremos a execução dessas expressões.
Para executar as expressões SQL resultantes, temos que obtain a connection object representing an actively checked out DBAPI connection resource e depois feed the expression object conforme mostrado no código abaixo.
conn = engine.connect()O seguinte objeto insert () pode ser usado para o método execute () -
ins = students.insert().values(name = 'Ravi', lastname = 'Kapoor')
result = conn.execute(ins)O console mostra o resultado da execução da expressão SQL conforme abaixo -
INSERT INTO students (name, lastname) VALUES (?, ?)
('Ravi', 'Kapoor')
COMMITA seguir está todo o trecho que mostra a execução da consulta INSERT usando a técnica principal do SQLAlchemy -
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String
engine = create_engine('sqlite:///college.db', echo = True)
meta = MetaData()
students = Table(
'students', meta,
Column('id', Integer, primary_key = True),
Column('name', String),
Column('lastname', String),
)
ins = students.insert()
ins = students.insert().values(name = 'Ravi', lastname = 'Kapoor')
conn = engine.connect()
result = conn.execute(ins)O resultado pode ser verificado abrindo o banco de dados usando o SQLite Studio, conforme mostrado na imagem abaixo -

A variável de resultado é conhecida como ResultProxy object. É análogo ao objeto cursor DBAPI. Podemos adquirir informações sobre os valores da chave primária que foram gerados a partir de nossa declaração usandoResultProxy.inserted_primary_key como mostrado abaixo -
result.inserted_primary_key
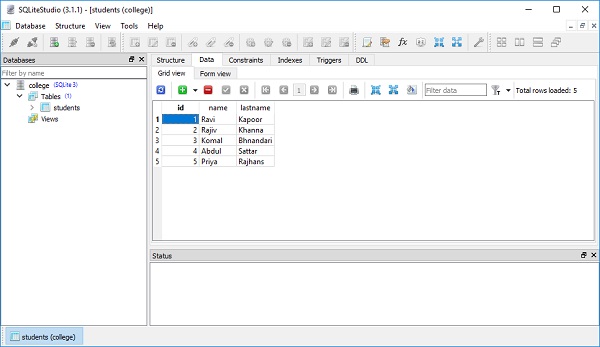
[1]Para emitir muitas inserções usando o método execute many () do DBAPI, podemos enviar uma lista de dicionários, cada um contendo um conjunto distinto de parâmetros a serem inseridos.
conn.execute(students.insert(), [
{'name':'Rajiv', 'lastname' : 'Khanna'},
{'name':'Komal','lastname' : 'Bhandari'},
{'name':'Abdul','lastname' : 'Sattar'},
{'name':'Priya','lastname' : 'Rajhans'},
])Isso se reflete na visualização de dados da tabela, conforme mostrado na figura a seguir -
Neste capítulo, discutiremos sobre o conceito de seleção de linhas no objeto de tabela.
O método select () do objeto da tabela nos permite construct SELECT expression.
s = students.select()O objeto selecionado se traduz em SELECT query by str(s) function como mostrado abaixo -
'SELECT students.id, students.name, students.lastname FROM students'Podemos usar este objeto select como um parâmetro para o método execute () do objeto de conexão, conforme mostrado no código abaixo -
result = conn.execute(s)Quando a instrução acima é executada, o shell Python ecoa seguindo a expressão SQL equivalente -
SELECT students.id, students.name, students.lastname
FROM studentsA variável resultante é equivalente ao cursor em DBAPI. Agora podemos buscar registros usandofetchone() method.
row = result.fetchone()Todas as linhas selecionadas na tabela podem ser impressas por um for loop como dado abaixo -
for row in result:
print (row)O código completo para imprimir todas as linhas da tabela de alunos é mostrado abaixo -
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String
engine = create_engine('sqlite:///college.db', echo = True)
meta = MetaData()
students = Table(
'students', meta,
Column('id', Integer, primary_key = True),
Column('name', String),
Column('lastname', String),
)
s = students.select()
conn = engine.connect()
result = conn.execute(s)
for row in result:
print (row)A saída mostrada no shell Python é a seguinte -
(1, 'Ravi', 'Kapoor')
(2, 'Rajiv', 'Khanna')
(3, 'Komal', 'Bhandari')
(4, 'Abdul', 'Sattar')
(5, 'Priya', 'Rajhans')A cláusula WHERE da consulta SELECT pode ser aplicada usando Select.where(). Por exemplo, se quisermos exibir linhas com id> 2
s = students.select().where(students.c.id>2)
result = conn.execute(s)
for row in result:
print (row)Aqui c attribute is an alias for column. A seguinte saída será exibida no shell -
(3, 'Komal', 'Bhandari')
(4, 'Abdul', 'Sattar')
(5, 'Priya', 'Rajhans')Aqui, temos que notar que o objeto select também pode ser obtido pela função select () no módulo sqlalchemy.sql. A função select () requer o objeto de tabela como argumento.
from sqlalchemy.sql import select
s = select([users])
result = conn.execute(s)SQLAlchemy permite que você use apenas strings, para aqueles casos em que o SQL já é conhecido e não há uma forte necessidade de que a instrução suporte recursos dinâmicos. A construção text () é usada para compor uma declaração textual que é passada para o banco de dados praticamente inalterada.
Ele constrói um novo TextClause, representando uma string SQL textual diretamente conforme mostrado no código a seguir -
from sqlalchemy import text
t = text("SELECT * FROM students")
result = connection.execute(t)As vantagens text() fornece sobre uma string simples são -
- suporte neutro de backend para parâmetros de ligação
- opções de execução por instrução
- comportamento de digitação de coluna de resultado
A função text () requer parâmetros Bound no formato de dois pontos nomeado. Eles são consistentes, independentemente do back-end do banco de dados. Para enviar valores para os parâmetros, nós os passamos para o método execute () como argumentos adicionais.
O exemplo a seguir usa parâmetros vinculados em SQL textual -
from sqlalchemy.sql import text
s = text("select students.name, students.lastname from students where students.name between :x and :y")
conn.execute(s, x = 'A', y = 'L').fetchall()A função text () constrói a expressão SQL da seguinte maneira -
select students.name, students.lastname from students where students.name between ? and ?Os valores de x = 'A' ey = 'L' são passados como parâmetros. O resultado é uma lista de linhas com nomes entre 'A' e 'L' -
[('Komal', 'Bhandari'), ('Abdul', 'Sattar')]A construção text () oferece suporte a valores de limite pré-estabelecidos usando o método TextClause.bindparams (). Os parâmetros também podem ser digitados explicitamente da seguinte forma -
stmt = text("SELECT * FROM students WHERE students.name BETWEEN :x AND :y")
stmt = stmt.bindparams(
bindparam("x", type_= String),
bindparam("y", type_= String)
)
result = conn.execute(stmt, {"x": "A", "y": "L"})
The text() function also be produces fragments of SQL within a select() object that
accepts text() objects as an arguments. The “geometry” of the statement is provided by
select() construct , and the textual content by text() construct. We can build a statement
without the need to refer to any pre-established Table metadata.
from sqlalchemy.sql import select
s = select([text("students.name, students.lastname from students")]).where(text("students.name between :x and :y"))
conn.execute(s, x = 'A', y = 'L').fetchall()Você também pode usar and_() função para combinar várias condições na cláusula WHERE criada com a ajuda da função text ().
from sqlalchemy import and_
from sqlalchemy.sql import select
s = select([text("* from students")]) \
.where(
and_(
text("students.name between :x and :y"),
text("students.id>2")
)
)
conn.execute(s, x = 'A', y = 'L').fetchall()O código acima busca linhas com nomes entre “A” e “L” com id maior que 2. A saída do código é fornecida abaixo -
[(3, 'Komal', 'Bhandari'), (4, 'Abdul', 'Sattar')]O alias em SQL corresponde a uma versão “renomeada” de uma tabela ou instrução SELECT, que ocorre sempre que você diz “SELECT * FROM table1 AS a”. O AS cria um novo nome para a tabela. Os aliases permitem que qualquer tabela ou subconsulta seja referenciada por um nome exclusivo.
No caso de uma tabela, isso permite que a mesma tabela seja nomeada na cláusula FROM várias vezes. Ele fornece um nome pai para as colunas representadas pela instrução, permitindo que sejam referenciadas em relação a este nome.
Em SQLAlchemy, qualquer tabela, construção select () ou outro objeto selecionável pode ser transformado em um alias usando o From Clause.alias()método, que produz uma construção Alias. A função alias () no módulo sqlalchemy.sql representa um alias, como normalmente aplicado a qualquer tabela ou sub-seleção dentro de uma instrução SQL usando a palavra-chave AS.
from sqlalchemy.sql import alias
st = students.alias("a")Este alias agora pode ser usado na construção select () para se referir à tabela de alunos -
s = select([st]).where(st.c.id>2)Isso se traduz em expressão SQL da seguinte maneira -
SELECT a.id, a.name, a.lastname FROM students AS a WHERE a.id > 2Agora podemos executar esta consulta SQL com o método execute () do objeto de conexão. O código completo é o seguinte -
from sqlalchemy.sql import alias, select
st = students.alias("a")
s = select([st]).where(st.c.id > 2)
conn.execute(s).fetchall()Quando a linha de código acima é executada, ele gera a seguinte saída -
[(3, 'Komal', 'Bhandari'), (4, 'Abdul', 'Sattar'), (5, 'Priya', 'Rajhans')]o update() método no objeto de tabela de destino constrói expressão UPDATE SQL equivalente.
table.update().where(conditions).values(SET expressions)o values()método no objeto de atualização resultante é usado para especificar as condições SET de UPDATE. Se deixado como Nenhum, as condições SET são determinadas a partir dos parâmetros passados para a instrução durante a execução e / ou compilação da instrução.
A cláusula where é uma expressão opcional que descreve a condição WHERE da instrução UPDATE.
O snippet de código a seguir altera o valor da coluna 'sobrenome' de 'Khanna' para 'Kapoor' na tabela de alunos -
stmt = students.update().where(students.c.lastname == 'Khanna').values(lastname = 'Kapoor')O objeto stmt é um objeto de atualização que se traduz em -
'UPDATE students SET lastname = :lastname WHERE students.lastname = :lastname_1'O parâmetro vinculado lastname_1 será substituído quando execute()método é invocado. O código de atualização completo é fornecido abaixo -
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String
engine = create_engine('sqlite:///college.db', echo = True)
meta = MetaData()
students = Table(
'students',
meta,
Column('id', Integer, primary_key = True),
Column('name', String),
Column('lastname', String),
)
conn = engine.connect()
stmt=students.update().where(students.c.lastname=='Khanna').values(lastname='Kapoor')
conn.execute(stmt)
s = students.select()
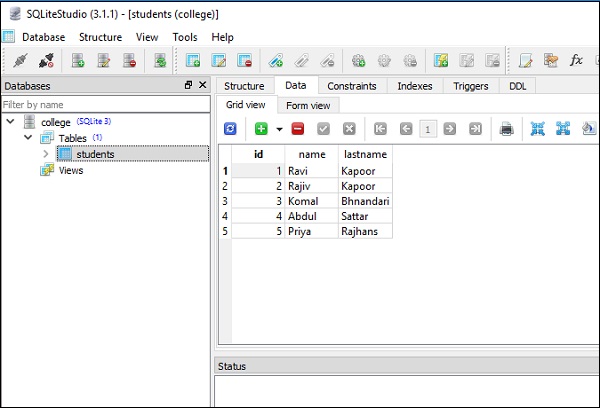
conn.execute(s).fetchall()O código acima exibe a seguinte saída com a segunda linha mostrando o efeito da operação de atualização como na captura de tela fornecida -
[
(1, 'Ravi', 'Kapoor'),
(2, 'Rajiv', 'Kapoor'),
(3, 'Komal', 'Bhandari'),
(4, 'Abdul', 'Sattar'),
(5, 'Priya', 'Rajhans')
]
Observe que uma funcionalidade semelhante também pode ser obtida usando update() função no módulo sqlalchemy.sql.expression conforme mostrado abaixo -
from sqlalchemy.sql.expression import update
stmt = update(students).where(students.c.lastname == 'Khanna').values(lastname = 'Kapoor')No capítulo anterior, entendemos o que um Updateexpressão faz. A próxima expressão que vamos aprender éDelete.
A operação de exclusão pode ser alcançada executando o método delete () no objeto da tabela de destino, conforme fornecido na instrução a seguir -
stmt = students.delete()No caso da tabela de alunos, a linha de código acima constrói uma expressão SQL da seguinte forma -
'DELETE FROM students'No entanto, isso excluirá todas as linhas da tabela de alunos. Normalmente, a consulta DELETE está associada a uma expressão lógica especificada pela cláusula WHERE. A declaração a seguir mostra onde o parâmetro -
stmt = students.delete().where(students.c.id > 2)A expressão SQL resultante terá um parâmetro vinculado que será substituído no tempo de execução quando a instrução for executada.
'DELETE FROM students WHERE students.id > :id_1'O exemplo de código a seguir excluirá essas linhas da tabela de alunos com o sobrenome como 'Khanna' -
from sqlalchemy.sql.expression import update
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String
engine = create_engine('sqlite:///college.db', echo = True)
meta = MetaData()
students = Table(
'students', meta,
Column('id', Integer, primary_key = True),
Column('name', String),
Column('lastname', String),
)
conn = engine.connect()
stmt = students.delete().where(students.c.lastname == 'Khanna')
conn.execute(stmt)
s = students.select()
conn.execute(s).fetchall()Para verificar o resultado, atualize a visualização de dados da tabela de alunos no SQLiteStudio.
Um dos recursos importantes do RDBMS é o estabelecimento de relações entre as tabelas. Operações SQL como SELECT, UPDATE e DELETE podem ser realizadas em tabelas relacionadas. Esta seção descreve essas operações usando SQLAlchemy.
Para este propósito, duas tabelas são criadas em nosso banco de dados SQLite (college.db). A tabela de alunos tem a mesma estrutura fornecida na seção anterior; enquanto a tabela de endereços temst_id coluna que é mapeada para id column in students table usando restrição de chave estrangeira.
O código a seguir criará duas tabelas em college.db -
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String, ForeignKey
engine = create_engine('sqlite:///college.db', echo=True)
meta = MetaData()
students = Table(
'students', meta,
Column('id', Integer, primary_key = True),
Column('name', String),
Column('lastname', String),
)
addresses = Table(
'addresses', meta,
Column('id', Integer, primary_key = True),
Column('st_id', Integer, ForeignKey('students.id')),
Column('postal_add', String),
Column('email_add', String))
meta.create_all(engine)O código acima será traduzido em consultas CREATE TABLE para alunos e tabelas de endereços como abaixo -
CREATE TABLE students (
id INTEGER NOT NULL,
name VARCHAR,
lastname VARCHAR,
PRIMARY KEY (id)
)
CREATE TABLE addresses (
id INTEGER NOT NULL,
st_id INTEGER,
postal_add VARCHAR,
email_add VARCHAR,
PRIMARY KEY (id),
FOREIGN KEY(st_id) REFERENCES students (id)
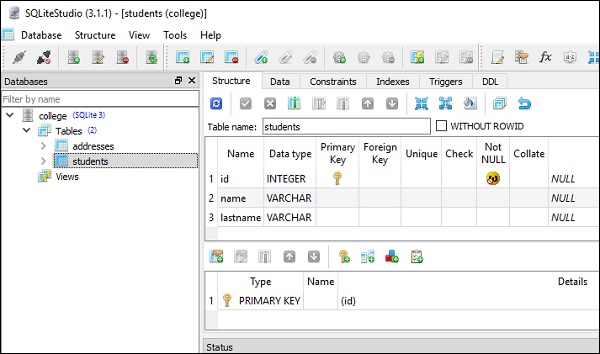
)As imagens a seguir apresentam o código acima de forma muito clara -
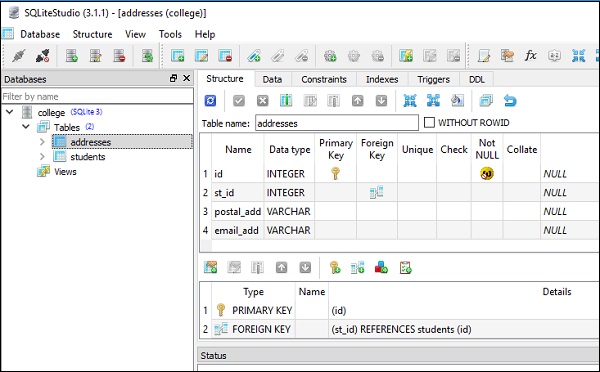
Essas tabelas são preenchidas com dados executando insert() methodde objetos de mesa. Para inserir 5 linhas na tabela de alunos, você pode usar o código fornecido abaixo -
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String
engine = create_engine('sqlite:///college.db', echo = True)
meta = MetaData()
conn = engine.connect()
students = Table(
'students', meta,
Column('id', Integer, primary_key = True),
Column('name', String),
Column('lastname', String),
)
conn.execute(students.insert(), [
{'name':'Ravi', 'lastname':'Kapoor'},
{'name':'Rajiv', 'lastname' : 'Khanna'},
{'name':'Komal','lastname' : 'Bhandari'},
{'name':'Abdul','lastname' : 'Sattar'},
{'name':'Priya','lastname' : 'Rajhans'},
])Rows são adicionados na tabela de endereços com a ajuda do seguinte código -
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String
engine = create_engine('sqlite:///college.db', echo = True)
meta = MetaData()
conn = engine.connect()
addresses = Table(
'addresses', meta,
Column('id', Integer, primary_key = True),
Column('st_id', Integer),
Column('postal_add', String),
Column('email_add', String)
)
conn.execute(addresses.insert(), [
{'st_id':1, 'postal_add':'Shivajinagar Pune', 'email_add':'[email protected]'},
{'st_id':1, 'postal_add':'ChurchGate Mumbai', 'email_add':'[email protected]'},
{'st_id':3, 'postal_add':'Jubilee Hills Hyderabad', 'email_add':'[email protected]'},
{'st_id':5, 'postal_add':'MG Road Bangaluru', 'email_add':'[email protected]'},
{'st_id':2, 'postal_add':'Cannought Place new Delhi', 'email_add':'[email protected]'},
])Observe que a coluna st_id na tabela de endereços se refere à coluna id na tabela de alunos. Agora podemos usar essa relação para buscar dados de ambas as tabelas. Nós queremos buscarname e lastname da tabela de alunos correspondente a st_id na tabela de endereços.
from sqlalchemy.sql import select
s = select([students, addresses]).where(students.c.id == addresses.c.st_id)
result = conn.execute(s)
for row in result:
print (row)Os objetos selecionados serão efetivamente traduzidos na seguinte expressão SQL juntando duas tabelas em relação comum -
SELECT students.id,
students.name,
students.lastname,
addresses.id,
addresses.st_id,
addresses.postal_add,
addresses.email_add
FROM students, addresses
WHERE students.id = addresses.st_idIsso produzirá saída extraindo dados correspondentes de ambas as tabelas da seguinte forma -
(1, 'Ravi', 'Kapoor', 1, 1, 'Shivajinagar Pune', '[email protected]')
(1, 'Ravi', 'Kapoor', 2, 1, 'ChurchGate Mumbai', '[email protected]')
(3, 'Komal', 'Bhandari', 3, 3, 'Jubilee Hills Hyderabad', '[email protected]')
(5, 'Priya', 'Rajhans', 4, 5, 'MG Road Bangaluru', '[email protected]')
(2, 'Rajiv', 'Khanna', 5, 2, 'Cannought Place new Delhi', '[email protected]')No capítulo anterior, discutimos sobre como usar várias tabelas. Então, damos um passo adiante e aprendemosmultiple table updates neste capítulo.
Usando o objeto de tabela do SQLAlchemy, mais de uma tabela pode ser especificada na cláusula WHERE do método update (). O PostgreSQL e o Microsoft SQL Server oferecem suporte a instruções UPDATE que se referem a várias tabelas. Isso implementa“UPDATE FROM”sintaxe, que atualiza uma tabela por vez. No entanto, tabelas adicionais podem ser referenciadas em uma cláusula “FROM” adicional na cláusula WHERE diretamente. As linhas de código a seguir explicam o conceito demultiple table updates claramente.
stmt = students.update().\
values({
students.c.name:'xyz',
addresses.c.email_add:'[email protected]'
}).\
where(students.c.id == addresses.c.id)O objeto de atualização é equivalente à seguinte consulta UPDATE -
UPDATE students
SET email_add = :addresses_email_add, name = :name
FROM addresses
WHERE students.id = addresses.idNo que diz respeito ao dialeto do MySQL, várias tabelas podem ser incorporadas em uma única instrução UPDATE separada por uma vírgula conforme mostrado abaixo -
stmt = students.update().\
values(name = 'xyz').\
where(students.c.id == addresses.c.id)O código a seguir descreve a consulta UPDATE resultante -
'UPDATE students SET name = :name
FROM addresses
WHERE students.id = addresses.id'O dialeto SQLite, entretanto, não oferece suporte a critérios de múltiplas tabelas em UPDATE e mostra o seguinte erro -
NotImplementedError: This backend does not support multiple-table criteria within UPDATEA consulta UPDATE do SQL bruto possui uma cláusula SET. Ele é renderizado pela construção update () usando a ordem das colunas fornecida no objeto Table de origem. Portanto, uma instrução UPDATE específica com colunas específicas será renderizada da mesma forma todas as vezes. Como os próprios parâmetros são passados para o método Update.values () como chaves de dicionário Python, não há outra ordem fixa disponível.
Em alguns casos, a ordem dos parâmetros processados na cláusula SET é significativa. No MySQL, o fornecimento de atualizações para valores de coluna é baseado em outros valores de coluna.
Resultado da declaração seguinte -
UPDATE table1 SET x = y + 10, y = 20terá um resultado diferente de -
UPDATE table1 SET y = 20, x = y + 10A cláusula SET no MySQL é avaliada por valor e não por linha. Para este efeito, opreserve_parameter_orderé usado. A lista Python de 2 tuplas é dada como argumento para oUpdate.values() método -
stmt = table1.update(preserve_parameter_order = True).\
values([(table1.c.y, 20), (table1.c.x, table1.c.y + 10)])O objeto List é semelhante ao dicionário, exceto pelo fato de ser ordenado. Isso garante que a cláusula SET da coluna “y” renderizará primeiro, depois a cláusula SET da coluna “x”.
Neste capítulo, examinaremos a expressão Multiple Table Deletes, que é semelhante ao uso da função Multiple Table Updates.
Mais de uma tabela pode ser referenciada na cláusula WHERE da instrução DELETE em muitos dialetos do DBMS. Para PG e MySQL, é usada a sintaxe “DELETE USING”; e para SQL Server, usar a expressão “DELETE FROM” refere-se a mais de uma tabela. The SQLAlchemydelete() construct suporta ambos os modos implicitamente, especificando várias tabelas na cláusula WHERE da seguinte forma -
stmt = users.delete().\
where(users.c.id == addresses.c.id).\
where(addresses.c.email_address.startswith('xyz%'))
conn.execute(stmt)Em um back-end PostgreSQL, o SQL resultante da instrução acima seria processado como -
DELETE FROM users USING addresses
WHERE users.id = addresses.id
AND (addresses.email_address LIKE %(email_address_1)s || '%%')Se este método for usado com um banco de dados que não suporta este comportamento, o compilador irá disparar NotImplementedError.
Neste capítulo, aprenderemos como usar Joins no SQLAlchemy.
O efeito da união é alcançado colocando apenas duas tabelas em qualquer columns clause ou o where clauseda construção select (). Agora usamos os métodos join () e outerjoin ().
O método join () retorna um objeto de junção de um objeto de tabela para outro.
join(right, onclause = None, isouter = False, full = False)As funções dos parâmetros mencionados no código acima são as seguintes -
right- o lado direito da junção; este é qualquer objeto Tabela
onclause- uma expressão SQL que representa a cláusula ON da junção. Se deixado em Nenhum, ele tenta unir as duas tabelas com base em um relacionamento de chave estrangeira
isouter - se True, renderiza LEFT OUTER JOIN, em vez de JOIN
full - se True, renderiza um FULL OUTER JOIN, em vez de LEFT OUTER JOIN
Por exemplo, o uso seguinte do método join () resultará automaticamente na junção com base na chave estrangeira.
>>> print(students.join(addresses))Isso é equivalente à seguinte expressão SQL -
students JOIN addresses ON students.id = addresses.st_idVocê pode mencionar explicitamente os critérios de adesão da seguinte forma -
j = students.join(addresses, students.c.id == addresses.c.st_id)Se agora construirmos a construção de seleção abaixo usando esta junção como -
stmt = select([students]).select_from(j)Isso resultará na seguinte expressão SQL -
SELECT students.id, students.name, students.lastname
FROM students JOIN addresses ON students.id = addresses.st_idSe esta instrução for executada usando o mecanismo que representa a conexão, os dados pertencentes às colunas selecionadas serão exibidos. O código completo é o seguinte -
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String, ForeignKey
engine = create_engine('sqlite:///college.db', echo = True)
meta = MetaData()
conn = engine.connect()
students = Table(
'students', meta,
Column('id', Integer, primary_key = True),
Column('name', String),
Column('lastname', String),
)
addresses = Table(
'addresses', meta,
Column('id', Integer, primary_key = True),
Column('st_id', Integer,ForeignKey('students.id')),
Column('postal_add', String),
Column('email_add', String)
)
from sqlalchemy import join
from sqlalchemy.sql import select
j = students.join(addresses, students.c.id == addresses.c.st_id)
stmt = select([students]).select_from(j)
result = conn.execute(stmt)
result.fetchall()A seguir está a saída do código acima -
[
(1, 'Ravi', 'Kapoor'),
(1, 'Ravi', 'Kapoor'),
(3, 'Komal', 'Bhandari'),
(5, 'Priya', 'Rajhans'),
(2, 'Rajiv', 'Khanna')
]Conjunções são funções no módulo SQLAlchemy que implementam operadores relacionais usados na cláusula WHERE de expressões SQL. Os operadores AND, OR, NOT, etc., são usados para formar uma expressão composta combinando duas expressões lógicas individuais. Um exemplo simples de uso de AND na instrução SELECT é o seguinte -
SELECT * from EMPLOYEE WHERE salary>10000 AND age>30As funções SQLAlchemy and_ (), or_ () e not_ () implementam respectivamente os operadores AND, OR e NOT.
and_ () function
Ele produz uma conjunção de expressões unidas por AND. Um exemplo é dado abaixo para melhor compreensão -
from sqlalchemy import and_
print(
and_(
students.c.name == 'Ravi',
students.c.id <3
)
)Isso se traduz em -
students.name = :name_1 AND students.id < :id_1Para usar and_ () em uma construção select () em uma tabela de alunos, use a seguinte linha de código -
stmt = select([students]).where(and_(students.c.name == 'Ravi', students.c.id <3))A instrução SELECT da seguinte natureza será construída -
SELECT students.id,
students.name,
students.lastname
FROM students
WHERE students.name = :name_1 AND students.id < :id_1O código completo que exibe a saída da consulta SELECT acima é o seguinte -
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String, ForeignKey, select
engine = create_engine('sqlite:///college.db', echo = True)
meta = MetaData()
conn = engine.connect()
students = Table(
'students', meta,
Column('id', Integer, primary_key = True),
Column('name', String),
Column('lastname', String),
)
from sqlalchemy import and_, or_
stmt = select([students]).where(and_(students.c.name == 'Ravi', students.c.id <3))
result = conn.execute(stmt)
print (result.fetchall())A linha seguinte será selecionada assumindo que a tabela de alunos é preenchida com os dados usados no exemplo anterior -
[(1, 'Ravi', 'Kapoor')]função or_ ()
Ele produz conjunção de expressões unidas por OR. Devemos substituir o objeto stmt no exemplo acima pelo seguinte usando or_ ()
stmt = select([students]).where(or_(students.c.name == 'Ravi', students.c.id <3))O que será efetivamente equivalente a seguir a consulta SELECT -
SELECT students.id,
students.name,
students.lastname
FROM students
WHERE students.name = :name_1
OR students.id < :id_1Depois de fazer a substituição e executar o código acima, o resultado será duas linhas caindo na condição OU -
[(1, 'Ravi', 'Kapoor'),
(2, 'Rajiv', 'Khanna')]função asc ()
Ele produz uma cláusula ORDER BY crescente. A função usa a coluna para aplicar a função como parâmetro.
from sqlalchemy import asc
stmt = select([students]).order_by(asc(students.c.name))A declaração implementa a seguinte expressão SQL -
SELECT students.id,
students.name,
students.lastname
FROM students
ORDER BY students.name ASCO código a seguir lista todos os registros na tabela de alunos em ordem crescente de coluna de nome -
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String, ForeignKey, select
engine = create_engine('sqlite:///college.db', echo = True)
meta = MetaData()
conn = engine.connect()
students = Table(
'students', meta,
Column('id', Integer, primary_key = True),
Column('name', String),
Column('lastname', String),
)
from sqlalchemy import asc
stmt = select([students]).order_by(asc(students.c.name))
result = conn.execute(stmt)
for row in result:
print (row)O código acima produz a seguinte saída -
(4, 'Abdul', 'Sattar')
(3, 'Komal', 'Bhandari')
(5, 'Priya', 'Rajhans')
(2, 'Rajiv', 'Khanna')
(1, 'Ravi', 'Kapoor')função desc ()
Da mesma forma, a função desc () produz a cláusula ORDER BY decrescente da seguinte forma -
from sqlalchemy import desc
stmt = select([students]).order_by(desc(students.c.lastname))A expressão SQL equivalente é -
SELECT students.id,
students.name,
students.lastname
FROM students
ORDER BY students.lastname DESCE a saída para as linhas de código acima é -
(4, 'Abdul', 'Sattar')
(5, 'Priya', 'Rajhans')
(2, 'Rajiv', 'Khanna')
(1, 'Ravi', 'Kapoor')
(3, 'Komal', 'Bhandari')entre () função
Ele produz uma cláusula de predicado BETWEEN. Isso geralmente é usado para validar se o valor de uma determinada coluna está entre um intervalo. Por exemplo, o código a seguir seleciona linhas para as quais a coluna id está entre 2 e 4 -
from sqlalchemy import between
stmt = select([students]).where(between(students.c.id,2,4))
print (stmt)A expressão SQL resultante é semelhante a -
SELECT students.id,
students.name,
students.lastname
FROM students
WHERE students.id
BETWEEN :id_1 AND :id_2e o resultado é o seguinte -
(2, 'Rajiv', 'Khanna')
(3, 'Komal', 'Bhandari')
(4, 'Abdul', 'Sattar')Algumas das funções importantes usadas no SQLAlchemy são discutidas neste capítulo.
O SQL padrão recomendou muitas funções que são implementadas pela maioria dos dialetos. Eles retornam um único valor com base nos argumentos transmitidos a eles. Algumas funções SQL usam colunas como argumentos, enquanto outras são genéricas.Thefunc keyword in SQLAlchemy API is used to generate these functions.
No SQL, now () é uma função genérica. As instruções a seguir renderizam a função now () usando func -
from sqlalchemy.sql import func
result = conn.execute(select([func.now()]))
print (result.fetchone())O resultado da amostra do código acima pode ser conforme mostrado abaixo -
(datetime.datetime(2018, 6, 16, 6, 4, 40),)Por outro lado, a função count () que retorna o número de linhas selecionadas de uma tabela, é renderizada seguindo o uso de func -
from sqlalchemy.sql import func
result = conn.execute(select([func.count(students.c.id)]))
print (result.fetchone())A partir do código acima, a contagem do número de linhas na tabela de alunos será obtida.
Algumas funções SQL integradas são demonstradas usando a tabela Employee com os seguintes dados -
| EU IRIA | Nome | Marcas |
|---|---|---|
| 1 | Kamal | 56 |
| 2 | Fernandez | 85 |
| 3 | Sunil | 62 |
| 4 | Bhaskar | 76 |
A função max () é implementada seguindo o uso de func de SQLAlchemy que resultará em 85, o total de notas máximas obtidas -
from sqlalchemy.sql import func
result = conn.execute(select([func.max(employee.c.marks)]))
print (result.fetchone())Da mesma forma, a função min () que retornará 56, marcas mínimas, será renderizada pelo seguinte código -
from sqlalchemy.sql import func
result = conn.execute(select([func.min(employee.c.marks)]))
print (result.fetchone())Portanto, a função AVG () também pode ser implementada usando o código abaixo -
from sqlalchemy.sql import func
result = conn.execute(select([func.avg(employee.c.marks)]))
print (result.fetchone())
Functions are normally used in the columns clause of a select statement.
They can also be given label as well as a type. A label to function allows the result
to be targeted in a result row based on a string name, and a type is required when
you need result-set processing to occur.from sqlalchemy.sql import func
result = conn.execute(select([func.max(students.c.lastname).label('Name')]))
print (result.fetchone())No último capítulo, aprendemos sobre várias funções, como max (), min (), count (), etc., aqui, aprenderemos sobre operações de conjunto e seus usos.
Operações de conjunto como UNION e INTERSECT são suportadas pelo SQL padrão e a maior parte de seu dialeto. SQLAlchemy os implementa com a ajuda das seguintes funções -
União()
Ao combinar os resultados de duas ou mais instruções SELECT, UNION elimina duplicatas do conjunto de resultados. O número de colunas e o tipo de dados devem ser iguais em ambas as tabelas.
A função union () retorna um objeto CompoundSelect de várias tabelas. O exemplo a seguir demonstra seu uso -
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String, union
engine = create_engine('sqlite:///college.db', echo = True)
meta = MetaData()
conn = engine.connect()
addresses = Table(
'addresses', meta,
Column('id', Integer, primary_key = True),
Column('st_id', Integer),
Column('postal_add', String),
Column('email_add', String)
)
u = union(addresses.select().where(addresses.c.email_add.like('%@gmail.com addresses.select().where(addresses.c.email_add.like('%@yahoo.com'))))
result = conn.execute(u)
result.fetchall()A construção de união se traduz na seguinte expressão SQL -
SELECT addresses.id,
addresses.st_id,
addresses.postal_add,
addresses.email_add
FROM addresses
WHERE addresses.email_add LIKE ? UNION SELECT addresses.id,
addresses.st_id,
addresses.postal_add,
addresses.email_add
FROM addresses
WHERE addresses.email_add LIKE ?De nossa tabela de endereços, as linhas a seguir representam a operação de união -
[
(1, 1, 'Shivajinagar Pune', '[email protected]'),
(2, 1, 'ChurchGate Mumbai', '[email protected]'),
(3, 3, 'Jubilee Hills Hyderabad', '[email protected]'),
(4, 5, 'MG Road Bangaluru', '[email protected]')
]union_all ()
A operação UNION ALL não pode remover as duplicatas e não pode classificar os dados no conjunto de resultados. Por exemplo, na consulta acima, UNION é substituído por UNION ALL para ver o efeito.
u = union_all(addresses.select().where(addresses.c.email_add.like('%@gmail.com')), addresses.select().where(addresses.c.email_add.like('%@yahoo.com')))A expressão SQL correspondente é a seguinte -
SELECT addresses.id,
addresses.st_id,
addresses.postal_add,
addresses.email_add
FROM addresses
WHERE addresses.email_add LIKE ? UNION ALL SELECT addresses.id,
addresses.st_id,
addresses.postal_add,
addresses.email_add
FROM addresses
WHERE addresses.email_add LIKE ?exceto_()
O SQL EXCEPTcláusula / operador é usado para combinar duas instruções SELECT e retornar linhas da primeira instrução SELECT que não são retornadas pela segunda instrução SELECT. A função except_ () gera uma expressão SELECT com a cláusula EXCEPT.
No exemplo a seguir, a função except_ () retorna apenas os registros da tabela de endereços que têm 'gmail.com' no campo email_add, mas exclui aqueles que têm 'Pune' como parte do campo postal_add.
u = except_(addresses.select().where(addresses.c.email_add.like('%@gmail.com')), addresses.select().where(addresses.c.postal_add.like('%Pune')))O resultado do código acima é a seguinte expressão SQL -
SELECT addresses.id,
addresses.st_id,
addresses.postal_add,
addresses.email_add
FROM addresses
WHERE addresses.email_add LIKE ? EXCEPT SELECT addresses.id,
addresses.st_id,
addresses.postal_add,
addresses.email_add
FROM addresses
WHERE addresses.postal_add LIKE ?Supondo que a tabela de endereços contenha dados usados nos exemplos anteriores, ela exibirá a seguinte saída -
[(2, 1, 'ChurchGate Mumbai', '[email protected]'),
(3, 3, 'Jubilee Hills Hyderabad', '[email protected]')]intersectar ()
Usando o operador INTERSECT, o SQL exibe linhas comuns de ambas as instruções SELECT. A função intersect () implementa esse comportamento.
Nos exemplos a seguir, duas construções SELECT são parâmetros para a função intersect (). Um retorna linhas contendo 'gmail.com' como parte da coluna email_add e outro retorna linhas contendo 'Pune' como parte da coluna postal_add. O resultado será linhas comuns de ambos os conjuntos de resultados.
u = intersect(addresses.select().where(addresses.c.email_add.like('%@gmail.com')), addresses.select().where(addresses.c.postal_add.like('%Pune')))Na verdade, isso é equivalente à seguinte instrução SQL -
SELECT addresses.id,
addresses.st_id,
addresses.postal_add,
addresses.email_add
FROM addresses
WHERE addresses.email_add LIKE ? INTERSECT SELECT addresses.id,
addresses.st_id,
addresses.postal_add,
addresses.email_add
FROM addresses
WHERE addresses.postal_add LIKE ?Os dois parâmetros vinculados '% gmail.com' e '% Pune' geram uma única linha a partir dos dados originais na tabela de endereços, conforme mostrado abaixo -
[(1, 1, 'Shivajinagar Pune', '[email protected]')]O objetivo principal da API Object Relational Mapper de SQLAlchemy é facilitar a associação de classes Python definidas pelo usuário com tabelas de banco de dados, e objetos dessas classes com linhas em suas tabelas correspondentes. As mudanças nos estados de objetos e linhas são sincronizadas entre si. SQLAlchemy permite expressar consultas de banco de dados em termos de classes definidas pelo usuário e seus relacionamentos definidos.
O ORM é construído com base na linguagem de expressão SQL. É um padrão de uso de alto nível e abstrato. Na verdade, ORM é um uso aplicado da linguagem de expressão.
Embora um aplicativo bem-sucedido possa ser construído usando exclusivamente o Mapeador Relacional de Objeto, às vezes um aplicativo construído com o ORM pode usar a linguagem de expressão diretamente onde são necessárias interações de banco de dados específicas.
Declare Mapping
Em primeiro lugar, a função create_engine () é chamada para configurar um objeto de mecanismo que é subsequentemente usado para executar operações SQL. A função tem dois argumentos, um é o nome do banco de dados e outro é um parâmetro de eco quando definido como True irá gerar o log de atividades. Se não existir, o banco de dados será criado. No exemplo a seguir, um banco de dados SQLite é criado.
from sqlalchemy import create_engine
engine = create_engine('sqlite:///sales.db', echo = True)O mecanismo estabelece uma conexão DBAPI real com o banco de dados quando um método como Engine.execute () ou Engine.connect () é chamado. Ele é então usado para emitir o SQLORM que não usa o Engine diretamente; em vez disso, ele é usado nos bastidores pelo ORM.
No caso do ORM, o processo configuracional começa descrevendo as tabelas do banco de dados e, em seguida, definindo as classes que serão mapeadas para essas tabelas. No SQLAlchemy, essas duas tarefas são executadas juntas. Isso é feito usando o sistema declarativo; as classes criadas incluem diretivas para descrever a tabela de banco de dados real para a qual são mapeadas.
Uma classe base armazena um catálogo de classes e tabelas mapeadas no sistema Declarativo. Isso é chamado de classe base declarativa. Normalmente haverá apenas uma instância dessa base em um módulo comumente importado. A função declarative_base () é usada para criar a classe base. Esta função é definida no módulo sqlalchemy.ext.declarative.
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()Uma vez que a classe base é declarada, qualquer número de classes mapeadas pode ser definido em termos dela. O código a seguir define a classe de um cliente. Ele contém a tabela a ser mapeada e os nomes e tipos de dados das colunas.
class Customers(Base):
__tablename__ = 'customers'
id = Column(Integer, primary_key = True)
name = Column(String)
address = Column(String)
email = Column(String)Uma classe em Declarativo deve ter um __tablename__ atributo, e pelo menos um Columnque faz parte de uma chave primária. Declarativo substitui todos osColumn objetos com acessadores Python especiais conhecidos como descriptors. Este processo é conhecido como instrumentação, que fornece os meios para se referir à tabela em um contexto SQL e permite persistir e carregar os valores das colunas do banco de dados.
Esta classe mapeada, como uma classe normal do Python, possui atributos e métodos de acordo com o requisito.
As informações sobre a classe no sistema Declarativo, são chamadas de metadados da tabela. SQLAlchemy usa o objeto Table para representar esta informação para uma tabela específica criada por Declarative. O objeto Tabela é criado de acordo com as especificações e é associado à classe pela construção de um objeto Mapeador. Este objeto mapeador não é usado diretamente, mas é usado internamente como interface entre a classe mapeada e a tabela.
Cada objeto Table é um membro de uma coleção maior conhecida como MetaData e este objeto está disponível usando o .metadataatributo da classe base declarativa. oMetaData.create_all()método é, passando em nosso motor como uma fonte de conectividade de banco de dados. Para todas as tabelas que ainda não foram criadas, ele emite instruções CREATE TABLE para o banco de dados.
Base.metadata.create_all(engine)O script completo para criar um banco de dados e uma tabela, e para mapear a classe Python é fornecido abaixo -
from sqlalchemy import Column, Integer, String
from sqlalchemy import create_engine
engine = create_engine('sqlite:///sales.db', echo = True)
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
class Customers(Base):
__tablename__ = 'customers'
id = Column(Integer, primary_key=True)
name = Column(String)
address = Column(String)
email = Column(String)
Base.metadata.create_all(engine)Quando executado, o console Python irá ecoar a seguinte expressão SQL sendo executada -
CREATE TABLE customers (
id INTEGER NOT NULL,
name VARCHAR,
address VARCHAR,
email VARCHAR,
PRIMARY KEY (id)
)Se abrirmos o Sales.db usando a ferramenta gráfica SQLiteStudio, ele mostra a tabela de clientes dentro dele com a estrutura mencionada acima.

Para interagir com o banco de dados, precisamos obter seu identificador. Um objeto de sessão é o identificador para o banco de dados. A classe de sessão é definida usando sessionmaker () - um método de fábrica de sessão configurável que é vinculado ao objeto motor criado anteriormente.
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind = engine)O objeto de sessão é então configurado usando seu construtor padrão da seguinte forma -
session = Session()Alguns dos métodos frequentemente necessários de aula de sessão estão listados abaixo -
| Sr. Não. | Método e Descrição |
|---|---|
| 1 | begin() começa uma transação nesta sessão |
| 2 | add() coloca um objeto na sessão. Seu estado é persistido no banco de dados na próxima operação de liberação |
| 3 | add_all() adiciona uma coleção de objetos à sessão |
| 4 | commit() libera todos os itens e qualquer transação em andamento |
| 5 | delete() marca uma transação como excluída |
| 6 | execute() executa uma expressão SQL |
| 7 | expire() marca os atributos de uma instância como desatualizados |
| 8 | flush() descarrega todas as alterações de objetos no banco de dados |
| 9 | invalidate() fecha a sessão usando invalidação de conexão |
| 10 | rollback() reverte a transação atual em andamento |
| 11 | close() Fecha a sessão atual limpando todos os itens e encerrando qualquer transação em andamento |
Nos capítulos anteriores do SQLAlchemy ORM, aprendemos como declarar mapeamento e criar sessões. Neste capítulo, aprenderemos como adicionar objetos à tabela.
Declaramos a classe Customer que foi mapeada para a tabela de clientes. Temos que declarar um objeto desta classe e persistentemente adicioná-lo à tabela pelo método add () do objeto de sessão.
c1 = Sales(name = 'Ravi Kumar', address = 'Station Road Nanded', email = '[email protected]')
session.add(c1)Observe que esta transação está pendente até que a mesma seja liberada usando o método commit ().
session.commit()A seguir está o script completo para adicionar um registro na tabela de clientes -
from sqlalchemy import Column, Integer, String
from sqlalchemy import create_engine
engine = create_engine('sqlite:///sales.db', echo = True)
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
class Customers(Base):
__tablename__ = 'customers'
id = Column(Integer, primary_key=True)
name = Column(String)
address = Column(String)
email = Column(String)
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind = engine)
session = Session()
c1 = Customers(name = 'Ravi Kumar', address = 'Station Road Nanded', email = '[email protected]')
session.add(c1)
session.commit()Para adicionar vários registros, podemos usar add_all() método da aula de sessão.
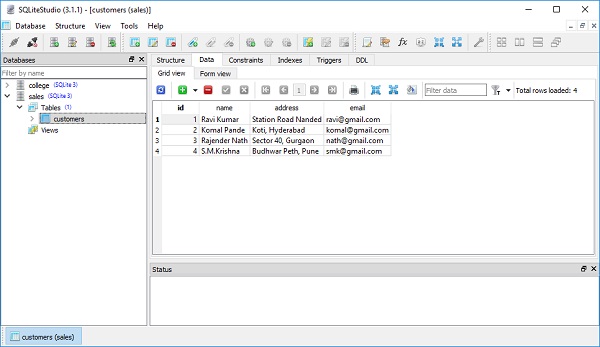
session.add_all([
Customers(name = 'Komal Pande', address = 'Koti, Hyderabad', email = '[email protected]'),
Customers(name = 'Rajender Nath', address = 'Sector 40, Gurgaon', email = '[email protected]'),
Customers(name = 'S.M.Krishna', address = 'Budhwar Peth, Pune', email = '[email protected]')]
)
session.commit()A exibição de tabela do SQLiteStudio mostra que os registros são adicionados persistentemente na tabela de clientes. A imagem a seguir mostra o resultado -
Todas as instruções SELECT geradas pelo SQLAlchemy ORM são construídas pelo objeto Query. Ele fornece uma interface generativa, portanto, chamadas sucessivas retornam um novo objeto Consulta, uma cópia do anterior com critérios e opções adicionais associados a ele.
Os objetos de consulta são inicialmente gerados usando o método query () da Session da seguinte forma -
q = session.query(mapped class)A declaração a seguir também é equivalente à declaração dada acima -
q = Query(mappedClass, session)O objeto de consulta tem o método all () que retorna um conjunto de resultados na forma de uma lista de objetos. Se o executarmos em nossa mesa de clientes -
result = session.query(Customers).all()Esta declaração é efetivamente equivalente à seguinte expressão SQL -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customersO objeto de resultado pode ser percorrido usando o loop For conforme abaixo para obter todos os registros na tabela de clientes subjacente. Aqui está o código completo para exibir todos os registros na tabela Clientes -
from sqlalchemy import Column, Integer, String
from sqlalchemy import create_engine
engine = create_engine('sqlite:///sales.db', echo = True)
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
class Customers(Base):
__tablename__ = 'customers'
id = Column(Integer, primary_key = True)
name = Column(String)
address = Column(String)
email = Column(String)
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind = engine)
session = Session()
result = session.query(Customers).all()
for row in result:
print ("Name: ",row.name, "Address:",row.address, "Email:",row.email)O console Python mostra a lista de registros conforme abaixo -
Name: Ravi Kumar Address: Station Road Nanded Email: [email protected]
Name: Komal Pande Address: Koti, Hyderabad Email: [email protected]
Name: Rajender Nath Address: Sector 40, Gurgaon Email: [email protected]
Name: S.M.Krishna Address: Budhwar Peth, Pune Email: [email protected]O objeto Query também possui os seguintes métodos úteis -
| Sr. Não. | Método e Descrição |
|---|---|
| 1 | add_columns() Ele adiciona uma ou mais expressões de coluna à lista de colunas de resultados a serem retornadas. |
| 2 | add_entity() Ele adiciona uma entidade mapeada à lista de colunas de resultados a serem retornadas. |
| 3 | count() Ele retorna uma contagem de linhas que esta consulta retornaria. |
| 4 | delete() Ele executa uma consulta de exclusão em massa. Exclui linhas correspondidas por esta consulta do banco de dados. |
| 5 | distinct() Ele aplica uma cláusula DISTINCT à consulta e retorna a Consulta recém-resultante. |
| 6 | filter() Aplica o critério de filtragem dado a uma cópia desta Consulta, usando expressões SQL. |
| 7 | first() Ele retorna o primeiro resultado desta Consulta ou Nenhum se o resultado não contém nenhuma linha. |
| 8 | get() Ele retorna uma instância com base no identificador de chave primária fornecido, fornecendo acesso direto ao mapa de identidade da Sessão proprietária. |
| 9 | group_by() Ele aplica um ou mais critérios GROUP BY à consulta e retorna a consulta resultante |
| 10 | join() Ele cria um SQL JOIN contra o critério deste objeto Consulta e aplica generativamente, retornando a Consulta recém-resultante. |
| 11 | one() Ele retorna exatamente um resultado ou levanta uma exceção. |
| 12 | order_by() Ele aplica um ou mais critérios ORDER BY à consulta e retorna a Consulta recém-resultante. |
| 13 | update() Ele executa uma consulta de atualização em massa e atualiza as linhas correspondentes a essa consulta no banco de dados. |
Neste capítulo, veremos como modificar ou atualizar a tabela com os valores desejados.
Para modificar os dados de um determinado atributo de qualquer objeto, temos que atribuir um novo valor a ele e confirmar as alterações para tornar a alteração persistente.
Vamos buscar um objeto da tabela cujo identificador de chave primária, em nossa tabela Clientes com ID = 2. Podemos usar o método get () de sessão da seguinte forma -
x = session.query(Customers).get(2)Podemos exibir o conteúdo do objeto selecionado com o código fornecido a seguir -
print ("Name: ", x.name, "Address:", x.address, "Email:", x.email)De nossa tabela de clientes, a seguinte saída deve ser exibida -
Name: Komal Pande Address: Koti, Hyderabad Email: [email protected]Agora precisamos atualizar o campo Endereço, atribuindo um novo valor conforme fornecido abaixo -
x.address = 'Banjara Hills Secunderabad'
session.commit()A mudança será refletida de forma persistente no banco de dados. Agora vamos buscar o objeto correspondente à primeira linha da tabela usandofirst() method como segue -
x = session.query(Customers).first()Isso executará a seguinte expressão SQL -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
LIMIT ? OFFSET ?Os parâmetros vinculados serão LIMIT = 1 e OFFSET = 0 respectivamente, o que significa que a primeira linha será selecionada.
print ("Name: ", x.name, "Address:", x.address, "Email:", x.email)Agora, a saída para o código acima exibindo a primeira linha é a seguinte -
Name: Ravi Kumar Address: Station Road Nanded Email: [email protected]Agora altere o atributo de nome e exiba o conteúdo usando o código abaixo -
x.name = 'Ravi Shrivastava'
print ("Name: ", x.name, "Address:", x.address, "Email:", x.email)A saída do código acima é -
Name: Ravi Shrivastava Address: Station Road Nanded Email: [email protected]Mesmo que a alteração seja exibida, ela não foi confirmada. Você pode manter a posição persistente anterior usandorollback() method com o código abaixo.
session.rollback()
print ("Name: ", x.name, "Address:", x.address, "Email:", x.email)O conteúdo original do primeiro registro será exibido.
Para atualizações em massa, devemos usar o método update () do objeto Query. Vamos tentar dar um prefixo, 'Sr.' para nomear em cada linha (exceto ID = 2). A instrução update () correspondente é a seguinte -
session.query(Customers).filter(Customers.id! = 2).
update({Customers.name:"Mr."+Customers.name}, synchronize_session = False)The update() method requires two parameters as follows −
Um dicionário de valores-chave com a chave sendo o atributo a ser atualizado e o valor sendo o novo conteúdo do atributo.
O atributo synchronize_session mencionando a estratégia de atualização dos atributos na sessão. Os valores válidos são falsos: para não sincronizar a sessão, fetch: executa uma consulta de seleção antes da atualização para encontrar objetos que são correspondidos pela consulta de atualização; e avaliar: avaliar critérios em objetos na sessão.
Três das 4 linhas da tabela terão o nome prefixado com 'Sr.' No entanto, as alterações não são confirmadas e, portanto, não serão refletidas na visualização de tabela do SQLiteStudio. Ele será atualizado apenas quando confirmarmos a sessão.
Neste capítulo, discutiremos como aplicar o filtro e também certas operações de filtro junto com seus códigos.
O conjunto de resultados representado pelo objeto Consulta pode estar sujeito a certos critérios usando o método filter (). O uso geral do método de filtro é o seguinte -
session.query(class).filter(criteria)No exemplo a seguir, o conjunto de resultados obtido pela consulta SELECT na tabela Clientes é filtrado por uma condição, (ID> 2) -
result = session.query(Customers).filter(Customers.id>2)Esta declaração será traduzida na seguinte expressão SQL -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE customers.id > ?Como o parâmetro de limite (?) É fornecido como 2, apenas as linhas com coluna ID> 2 serão exibidas. O código completo é fornecido abaixo -
from sqlalchemy import Column, Integer, String
from sqlalchemy import create_engine
engine = create_engine('sqlite:///sales.db', echo = True)
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
class Customers(Base):
__tablename__ = 'customers'
id = Column(Integer, primary_key = True)
name = Column(String)
address = Column(String)
email = Column(String)
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind = engine)
session = Session()
result = session.query(Customers).filter(Customers.id>2)
for row in result:
print ("ID:", row.id, "Name: ",row.name, "Address:",row.address, "Email:",row.email)A saída exibida no console Python é a seguinte -
ID: 3 Name: Rajender Nath Address: Sector 40, Gurgaon Email: [email protected]
ID: 4 Name: S.M.Krishna Address: Budhwar Peth, Pune Email: [email protected]Agora, aprenderemos as operações do filtro com seus respectivos códigos e saídas.
É igual a
O operador usual usado é == e aplica os critérios para verificar a igualdade.
result = session.query(Customers).filter(Customers.id == 2)
for row in result:
print ("ID:", row.id, "Name: ",row.name, "Address:",row.address, "Email:",row.email)SQLAlchemy irá enviar a seguinte expressão SQL -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE customers.id = ?A saída para o código acima é a seguinte -
ID: 2 Name: Komal Pande Address: Banjara Hills Secunderabad Email: [email protected]Diferente
O operador usado para diferente de é! = E ele fornece critérios de não igual.
result = session.query(Customers).filter(Customers.id! = 2)
for row in result:
print ("ID:", row.id, "Name: ",row.name, "Address:",row.address, "Email:",row.email)A expressão SQL resultante é -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE customers.id != ?A saída para as linhas de código acima é a seguinte -
ID: 1 Name: Ravi Kumar Address: Station Road Nanded Email: [email protected]
ID: 3 Name: Rajender Nath Address: Sector 40, Gurgaon Email: [email protected]
ID: 4 Name: S.M.Krishna Address: Budhwar Peth, Pune Email: [email protected]Gostar
O próprio método like () produz os critérios LIKE para a cláusula WHERE na expressão SELECT.
result = session.query(Customers).filter(Customers.name.like('Ra%'))
for row in result:
print ("ID:", row.id, "Name: ",row.name, "Address:",row.address, "Email:",row.email)O código SQLAlchemy acima é equivalente à seguinte expressão SQL -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE customers.name LIKE ?E a saída para o código acima é -
ID: 1 Name: Ravi Kumar Address: Station Road Nanded Email: [email protected]
ID: 3 Name: Rajender Nath Address: Sector 40, Gurgaon Email: [email protected]DENTRO
Este operador verifica se o valor da coluna pertence a uma coleção de itens em uma lista. É fornecido pelo método in_ ().
result = session.query(Customers).filter(Customers.id.in_([1,3]))
for row in result:
print ("ID:", row.id, "Name: ",row.name, "Address:",row.address, "Email:",row.email)Aqui, a expressão SQL avaliada pelo motor SQLite será a seguinte -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE customers.id IN (?, ?)A saída para o código acima é a seguinte -
ID: 1 Name: Ravi Kumar Address: Station Road Nanded Email: [email protected]
ID: 3 Name: Rajender Nath Address: Sector 40, Gurgaon Email: [email protected]E
Esta conjunção é gerada por qualquer putting multiple commas separated criteria in the filter or using and_() method como dado abaixo -
result = session.query(Customers).filter(Customers.id>2, Customers.name.like('Ra%'))
for row in result:
print ("ID:", row.id, "Name: ",row.name, "Address:",row.address, "Email:",row.email)from sqlalchemy import and_
result = session.query(Customers).filter(and_(Customers.id>2, Customers.name.like('Ra%')))
for row in result:
print ("ID:", row.id, "Name: ",row.name, "Address:",row.address, "Email:",row.email)Ambas as abordagens acima resultam em expressões SQL semelhantes -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE customers.id > ? AND customers.name LIKE ?A saída para as linhas de código acima é -
ID: 3 Name: Rajender Nath Address: Sector 40, Gurgaon Email: [email protected]OU
Esta conjunção é implementada por or_() method.
from sqlalchemy import or_
result = session.query(Customers).filter(or_(Customers.id>2, Customers.name.like('Ra%')))
for row in result:
print ("ID:", row.id, "Name: ",row.name, "Address:",row.address, "Email:",row.email)Como resultado, o motor SQLite obtém a seguinte expressão SQL equivalente -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE customers.id > ? OR customers.name LIKE ?A saída para o código acima é a seguinte -
ID: 1 Name: Ravi Kumar Address: Station Road Nanded Email: [email protected]
ID: 3 Name: Rajender Nath Address: Sector 40, Gurgaon Email: [email protected]
ID: 4 Name: S.M.Krishna Address: Budhwar Peth, Pune Email: [email protected]Existem vários métodos do objeto Consulta que emitem SQL imediatamente e retornam um valor contendo os resultados do banco de dados carregado.
Aqui está um breve resumo da lista de retorno e escalares -
todos()
Ele retorna uma lista. A seguir está a linha de código para a função all ().
session.query(Customers).all()O console Python exibe a seguinte expressão SQL emitida -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customersprimeiro()
Ele aplica o limite de um e retorna o primeiro resultado como um escalar.
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
LIMIT ? OFFSET ?Os parâmetros de limite para LIMIT são 1 e para OFFSET são 0.
1()
Este comando busca totalmente todas as linhas e, se não houver exatamente uma identidade de objeto ou linha composta presente no resultado, ele gerará um erro.
session.query(Customers).one()Com várias linhas encontradas -
MultipleResultsFound: Multiple rows were found for one()Sem linhas encontradas -
NoResultFound: No row was found for one()O método one () é útil para sistemas que esperam lidar com “nenhum item encontrado” versus “vários itens encontrados” de forma diferente.
escalar()
Ele invoca o método one () e, em caso de sucesso, retorna a primeira coluna da linha da seguinte forma -
session.query(Customers).filter(Customers.id == 3).scalar()Isso gera a seguinte instrução SQL -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE customers.id = ?Anteriormente, o SQL textual usando a função text () foi explicado da perspectiva da linguagem de expressão central de SQLAlchemy. Agora vamos discutir isso do ponto de vista ORM.
Strings literais podem ser usados de forma flexível com o objeto Query, especificando seu uso com a construção text (). A maioria dos métodos aplicáveis o aceita. Por exemplo, filter () e order_by ().
No exemplo a seguir, o método filter () traduz a string “id <3” para WHERE id <3
from sqlalchemy import text
for cust in session.query(Customers).filter(text("id<3")):
print(cust.name)A expressão SQL bruta gerada mostra a conversão do filtro para a cláusula WHERE com o código ilustrado abaixo -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE id<3De nossos dados de amostra na tabela Clientes, duas linhas serão selecionadas e a coluna de nome será impressa da seguinte forma -
Ravi Kumar
Komal PandePara especificar parâmetros de vinculação com SQL baseado em string, use dois-pontos e, para especificar os valores, use o método params ().
cust = session.query(Customers).filter(text("id = :value")).params(value = 1).one()O SQL efetivo exibido no console Python será conforme fornecido abaixo -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE id = ?Para usar uma declaração inteiramente baseada em string, uma construção text () representando uma declaração completa pode ser passada para from_statement ().
session.query(Customers).from_statement(text("SELECT * FROM customers")).all()O resultado do código acima será uma instrução SELECT básica conforme fornecido abaixo -
SELECT * FROM customersObviamente, todos os registros da tabela de clientes serão selecionados.
A construção text () nos permite vincular posicionalmente seu SQL textual a expressões de coluna mapeadas por ORM ou Core. Podemos conseguir isso passando expressões de coluna como argumentos posicionais para o método TextClause.columns ().
stmt = text("SELECT name, id, name, address, email FROM customers")
stmt = stmt.columns(Customers.id, Customers.name)
session.query(Customers.id, Customers.name).from_statement(stmt).all()As colunas id e name de todas as linhas serão selecionadas mesmo que o motor SQLite execute a seguinte expressão gerada pelo código acima mostra todas as colunas no método text () -
SELECT name, id, name, address, email FROM customersEsta sessão descreve a criação de outra tabela que está relacionada a uma já existente em nosso banco de dados. A tabela de clientes contém dados mestre de clientes. Agora precisamos criar uma tabela de faturas que pode ter qualquer número de faturas pertencentes a um cliente. Este é o caso de um para muitos relacionamentos.
Usando declarativo, definimos esta tabela junto com sua classe mapeada, Faturas conforme fornecido abaixo -
from sqlalchemy import create_engine, ForeignKey, Column, Integer, String
engine = create_engine('sqlite:///sales.db', echo = True)
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
from sqlalchemy.orm import relationship
class Customer(Base):
__tablename__ = 'customers'
id = Column(Integer, primary_key = True)
name = Column(String)
address = Column(String)
email = Column(String)
class Invoice(Base):
__tablename__ = 'invoices'
id = Column(Integer, primary_key = True)
custid = Column(Integer, ForeignKey('customers.id'))
invno = Column(Integer)
amount = Column(Integer)
customer = relationship("Customer", back_populates = "invoices")
Customer.invoices = relationship("Invoice", order_by = Invoice.id, back_populates = "customer")
Base.metadata.create_all(engine)Isso enviará uma consulta CREATE TABLE para o mecanismo SQLite conforme abaixo -
CREATE TABLE invoices (
id INTEGER NOT NULL,
custid INTEGER,
invno INTEGER,
amount INTEGER,
PRIMARY KEY (id),
FOREIGN KEY(custid) REFERENCES customers (id)
)Podemos verificar se uma nova tabela foi criada em sales.db com a ajuda da ferramenta SQLiteStudio.
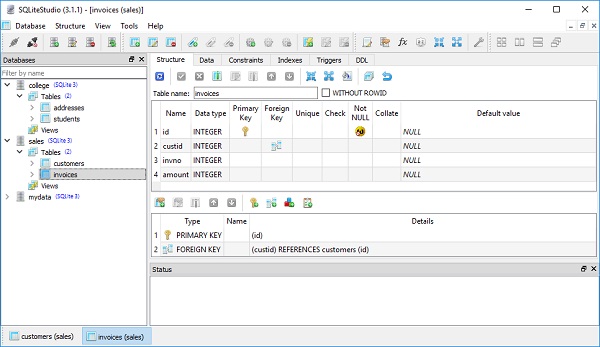
A classe Faturas aplica a construção ForeignKey no atributo custid. Esta diretiva indica que os valores nesta coluna devem ser restritos a valores presentes na coluna id na tabela de clientes. Esse é um recurso central dos bancos de dados relacionais e é a "cola" que transforma a coleção não conectada de tabelas em relacionamentos ricos e sobrepostos.
Uma segunda diretiva, conhecida como relacionamento (), informa ao ORM que a classe Invoice deve ser vinculada à classe Customer usando o atributo Invoice.customer. O relacionamento () usa os relacionamentos de chave estrangeira entre as duas tabelas para determinar a natureza dessa ligação, determinando que é muitos para um.
Uma diretiva relacionamento adicional () é colocada na classe mapeada do Cliente sob o atributo Customer.invoices. O parâmetro relationship.back_populates é atribuído para se referir aos nomes de atributos complementares, de modo que cada relacionamento () possa tomar decisões inteligentes sobre o mesmo relacionamento conforme expresso no reverso. Por um lado, Invoices.customer se refere à instância Invoices e, por outro lado, Customer.invoices se refere a uma lista de instâncias Clientes.
A função de relacionamento é uma parte da API de relacionamento do pacote SQLAlchemy ORM. Ele fornece um relacionamento entre duas classes mapeadas. Isso corresponde a um relacionamento pai-filho ou tabela associativa.
A seguir estão os padrões básicos de relacionamento encontrados -
Um para muitos
Um relacionamento Um para Muitos refere-se ao pai com a ajuda de uma chave estrangeira na tabela filho. relacionamento () é então especificado no pai, como uma referência a uma coleção de itens representados pelo filho. O parâmetro relationship.back_populates é usado para estabelecer um relacionamento bidirecional em um para muitos, onde o lado “reverso” é muitos para um.
Muitos para um
Por outro lado, o relacionamento Muitos para Um coloca uma chave estrangeira na tabela pai para se referir ao filho. relacionamento () é declarado no pai, onde um novo atributo de retenção escalar será criado. Aqui, novamente, o parâmetro relationship.back_populates é usado para Bidirectionalbehaviour.
Um a um
O relacionamento Um para Um é essencialmente um relacionamento bidirecional por natureza. O sinalizador uselist indica a colocação de um atributo escalar em vez de uma coleção no lado “muitos” do relacionamento. Para converter um-para-muitos em um tipo de relação um-para-um, defina o parâmetro uselist como false.
Muitos para muitos
O relacionamento de muitos para muitos é estabelecido adicionando uma tabela de associação relacionada a duas classes, definindo atributos com suas chaves estrangeiras. É indicado pelo argumento secundário para relacionamento (). Normalmente, a Tabela usa o objeto MetaData associado à classe base declarativa, para que as diretivas ForeignKey possam localizar as tabelas remotas com as quais se vincular. O parâmetro relationship.back_populates para cada relacionamento () estabelece um relacionamento bidirecional. Ambos os lados do relacionamento contêm uma coleção.
Neste capítulo, vamos nos concentrar nos objetos relacionados no SQLAlchemy ORM.
Agora, quando criamos um objeto Cliente, uma coleção de faturas em branco estará presente na forma de Lista Python.
c1 = Customer(name = "Gopal Krishna", address = "Bank Street Hydarebad", email = "[email protected]")O atributo de faturas de c1.invoices será uma lista vazia. Podemos atribuir itens na lista como -
c1.invoices = [Invoice(invno = 10, amount = 15000), Invoice(invno = 14, amount = 3850)]Vamos enviar este objeto para o banco de dados usando o objeto Session da seguinte forma -
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind = engine)
session = Session()
session.add(c1)
session.commit()Isso irá gerar automaticamente consultas INSERT para clientes e tabelas de faturas -
INSERT INTO customers (name, address, email) VALUES (?, ?, ?)
('Gopal Krishna', 'Bank Street Hydarebad', '[email protected]')
INSERT INTO invoices (custid, invno, amount) VALUES (?, ?, ?)
(2, 10, 15000)
INSERT INTO invoices (custid, invno, amount) VALUES (?, ?, ?)
(2, 14, 3850)Vejamos agora o conteúdo da tabela de clientes e a tabela de faturas na visualização de tabela do SQLiteStudio -

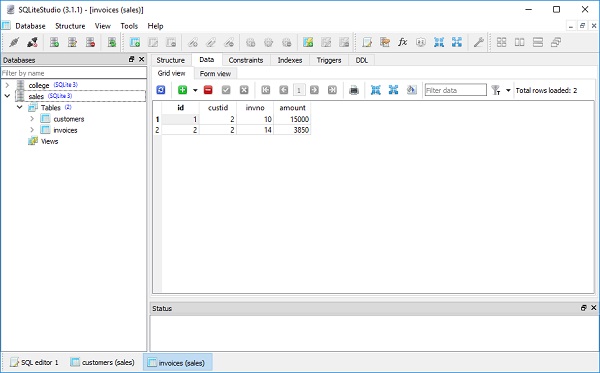
Você pode construir o objeto Cliente fornecendo o atributo mapeado de faturas no próprio construtor usando o comando abaixo -
c2 = [
Customer(
name = "Govind Pant",
address = "Gulmandi Aurangabad",
email = "[email protected]",
invoices = [Invoice(invno = 3, amount = 10000),
Invoice(invno = 4, amount = 5000)]
)
]Ou uma lista de objetos a serem adicionados usando a função add_all () do objeto de sessão como mostrado abaixo -
rows = [
Customer(
name = "Govind Kala",
address = "Gulmandi Aurangabad",
email = "[email protected]",
invoices = [Invoice(invno = 7, amount = 12000), Invoice(invno = 8, amount = 18500)]),
Customer(
name = "Abdul Rahman",
address = "Rohtak",
email = "[email protected]",
invoices = [Invoice(invno = 9, amount = 15000),
Invoice(invno = 11, amount = 6000)
])
]
session.add_all(rows)
session.commit()Agora que temos duas tabelas, veremos como criar consultas nas duas tabelas ao mesmo tempo. Para construir uma junção implícita simples entre Cliente e Fatura, podemos usar Query.filter () para igualar suas colunas relacionadas. Abaixo, carregamos as entidades do cliente e da fatura ao mesmo tempo usando este método -
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind = engine)
session = Session()
for c, i in session.query(Customer, Invoice).filter(Customer.id == Invoice.custid).all():
print ("ID: {} Name: {} Invoice No: {} Amount: {}".format(c.id,c.name, i.invno, i.amount))A expressão SQL emitida por SQLAlchemy é a seguinte -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email, invoices.id
AS invoices_id, invoices.custid
AS invoices_custid, invoices.invno
AS invoices_invno, invoices.amount
AS invoices_amount
FROM customers, invoices
WHERE customers.id = invoices.custidE o resultado das linhas de código acima é o seguinte -
ID: 2 Name: Gopal Krishna Invoice No: 10 Amount: 15000
ID: 2 Name: Gopal Krishna Invoice No: 14 Amount: 3850
ID: 3 Name: Govind Pant Invoice No: 3 Amount: 10000
ID: 3 Name: Govind Pant Invoice No: 4 Amount: 5000
ID: 4 Name: Govind Kala Invoice No: 7 Amount: 12000
ID: 4 Name: Govind Kala Invoice No: 8 Amount: 8500
ID: 5 Name: Abdul Rahman Invoice No: 9 Amount: 15000
ID: 5 Name: Abdul Rahman Invoice No: 11 Amount: 6000A sintaxe SQL JOIN real é facilmente obtida usando o método Query.join () da seguinte maneira -
session.query(Customer).join(Invoice).filter(Invoice.amount == 8500).all()A expressão SQL para junção será exibida no console -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers JOIN invoices ON customers.id = invoices.custid
WHERE invoices.amount = ?Podemos iterar o resultado usando o loop for -
result = session.query(Customer).join(Invoice).filter(Invoice.amount == 8500)
for row in result:
for inv in row.invoices:
print (row.id, row.name, inv.invno, inv.amount)Com 8500 como o parâmetro de ligação, a seguinte saída é exibida -
4 Govind Kala 8 8500Query.join () sabe como unir essas tabelas porque há apenas uma chave estrangeira entre elas. Se não houver chaves estrangeiras, ou mais chaves estrangeiras, Query.join () funciona melhor quando uma das seguintes formas é usada -
| query.join (Invoice, id == Address.custid) | condição explícita |
| query.join (Customer.invoices) | especificar relação da esquerda para a direita |
| query.join (Invoice, Customer.invoices) | mesmo, com alvo explícito |
| query.join ('invoices') | mesmo, usando uma corda |
Da mesma forma, a função outerjoin () está disponível para obter a junção externa esquerda.
query.outerjoin(Customer.invoices)O método subquery () produz uma expressão SQL que representa a instrução SELECT embutida em um alias.
from sqlalchemy.sql import func
stmt = session.query(
Invoice.custid, func.count('*').label('invoice_count')
).group_by(Invoice.custid).subquery()O objeto stmt conterá uma instrução SQL conforme abaixo -
SELECT invoices.custid, count(:count_1) AS invoice_count FROM invoices GROUP BY invoices.custidAssim que tivermos nossa declaração, ela se comportará como uma construção de Tabela. As colunas na instrução são acessíveis por meio de um atributo chamado c, conforme mostrado no código a seguir -
for u, count in session.query(Customer, stmt.c.invoice_count).outerjoin(stmt, Customer.id == stmt.c.custid).order_by(Customer.id):
print(u.name, count)O loop for acima exibe a contagem de faturas por nome, como segue -
Arjun Pandit None
Gopal Krishna 2
Govind Pant 2
Govind Kala 2
Abdul Rahman 2Neste capítulo, discutiremos sobre os operadores que constroem relacionamentos.
__eq __ ()
O operador acima é uma comparação “igual” de muitos para um. A linha de código para este operador é mostrada abaixo -
s = session.query(Customer).filter(Invoice.invno.__eq__(12))A consulta SQL equivalente para a linha de código acima é -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers, invoices
WHERE invoices.invno = ?__ne __ ()
Este operador é uma comparação "não é igual" de muitos para um. A linha de código para este operador é mostrada abaixo -
s = session.query(Customer).filter(Invoice.custid.__ne__(2))A consulta SQL equivalente para a linha de código acima é fornecida abaixo -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers, invoices
WHERE invoices.custid != ?contém ()
Este operador é usado para coleções um-para-muitos e abaixo está o código para contains () -
s = session.query(Invoice).filter(Invoice.invno.contains([3,4,5]))A consulta SQL equivalente para a linha de código acima é -
SELECT invoices.id
AS invoices_id, invoices.custid
AS invoices_custid, invoices.invno
AS invoices_invno, invoices.amount
AS invoices_amount
FROM invoices
WHERE (invoices.invno LIKE '%' + ? || '%')qualquer()
O operador any () é usado para coleções conforme mostrado abaixo -
s = session.query(Customer).filter(Customer.invoices.any(Invoice.invno==11))A consulta SQL equivalente para a linha de código acima é mostrada abaixo -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE EXISTS (
SELECT 1
FROM invoices
WHERE customers.id = invoices.custid
AND invoices.invno = ?)tem()
Este operador é usado para referências escalares da seguinte forma -
s = session.query(Invoice).filter(Invoice.customer.has(name = 'Arjun Pandit'))A consulta SQL equivalente para a linha de código acima é -
SELECT invoices.id
AS invoices_id, invoices.custid
AS invoices_custid, invoices.invno
AS invoices_invno, invoices.amount
AS invoices_amount
FROM invoices
WHERE EXISTS (
SELECT 1
FROM customers
WHERE customers.id = invoices.custid
AND customers.name = ?)O carregamento rápido reduz o número de consultas. SQLAlchemy oferece funções de carregamento rápido, invocadas por meio de opções de consulta, que fornecem instruções adicionais para a consulta. Essas opções determinam como carregar vários atributos por meio do método Query.options ().
Carregamento de subconsulta
Queremos que Customer.invoices carregue avidamente. A opção orm.subqueryload () fornece uma segunda instrução SELECT que carrega totalmente as coleções associadas aos resultados recém carregados. O nome “subconsulta” faz com que a instrução SELECT seja construída diretamente por meio da Consulta reutilizada e incorporada como uma subconsulta em um SELECT na tabela relacionada.
from sqlalchemy.orm import subqueryload
c1 = session.query(Customer).options(subqueryload(Customer.invoices)).filter_by(name = 'Govind Pant').one()Isso resulta nas duas seguintes expressões SQL -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE customers.name = ?
('Govind Pant',)
SELECT invoices.id
AS invoices_id, invoices.custid
AS invoices_custid, invoices.invno
AS invoices_invno, invoices.amount
AS invoices_amount, anon_1.customers_id
AS anon_1_customers_id
FROM (
SELECT customers.id
AS customers_id
FROM customers
WHERE customers.name = ?)
AS anon_1
JOIN invoices
ON anon_1.customers_id = invoices.custid
ORDER BY anon_1.customers_id, invoices.id 2018-06-25 18:24:47,479
INFO sqlalchemy.engine.base.Engine ('Govind Pant',)Para acessar os dados de duas tabelas, podemos usar o programa abaixo -
print (c1.name, c1.address, c1.email)
for x in c1.invoices:
print ("Invoice no : {}, Amount : {}".format(x.invno, x.amount))O resultado do programa acima é o seguinte -
Govind Pant Gulmandi Aurangabad [email protected]
Invoice no : 3, Amount : 10000
Invoice no : 4, Amount : 5000Carga Unida
A outra função é chamada orm.joinedload (). Isso emite um LEFT OUTER JOIN. O objeto lead, bem como o objeto ou coleção relacionado, são carregados em uma etapa.
from sqlalchemy.orm import joinedload
c1 = session.query(Customer).options(joinedload(Customer.invoices)).filter_by(name='Govind Pant').one()Isso emite a seguinte expressão, dando a mesma saída que acima -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email, invoices_1.id
AS invoices_1_id, invoices_1.custid
AS invoices_1_custid, invoices_1.invno
AS invoices_1_invno, invoices_1.amount
AS invoices_1_amount
FROM customers
LEFT OUTER JOIN invoices
AS invoices_1
ON customers.id = invoices_1.custid
WHERE customers.name = ? ORDER BY invoices_1.id
('Govind Pant',)O OUTER JOIN resultou em duas linhas, mas retorna uma instância de Customer. Isso ocorre porque o Query aplica uma estratégia de “exclusividade”, com base na identidade do objeto, às entidades retornadas. O carregamento antecipado associado pode ser aplicado sem afetar os resultados da consulta.
O subqueryload () é mais apropriado para carregar coleções relacionadas, enquanto o joinload () é mais adequado para relacionamento muitos-para-um.
É fácil realizar a operação de exclusão em uma única tabela. Tudo que você precisa fazer é deletar um objeto da classe mapeada de uma sessão e cometer a ação. No entanto, a operação de exclusão em várias tabelas relacionadas é um pouco complicada.
Em nosso banco de dados sales.db, as classes Customer e Invoice são mapeadas para a tabela de cliente e fatura com um para vários tipos de relacionamento. Tentaremos excluir o objeto Cliente e ver o resultado.
Como referência rápida, abaixo estão as definições das classes Cliente e Fatura -
from sqlalchemy import create_engine, ForeignKey, Column, Integer, String
engine = create_engine('sqlite:///sales.db', echo = True)
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
from sqlalchemy.orm import relationship
class Customer(Base):
__tablename__ = 'customers'
id = Column(Integer, primary_key = True)
name = Column(String)
address = Column(String)
email = Column(String)
class Invoice(Base):
__tablename__ = 'invoices'
id = Column(Integer, primary_key = True)
custid = Column(Integer, ForeignKey('customers.id'))
invno = Column(Integer)
amount = Column(Integer)
customer = relationship("Customer", back_populates = "invoices")
Customer.invoices = relationship("Invoice", order_by = Invoice.id, back_populates = "customer")Configuramos uma sessão e obtemos um objeto Cliente, consultando-o com o ID primário usando o programa abaixo -
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind=engine)
session = Session()
x = session.query(Customer).get(2)Em nossa tabela de exemplo, x.name é 'Gopal Krishna'. Vamos deletar esse x da sessão e contar a ocorrência desse nome.
session.delete(x)
session.query(Customer).filter_by(name = 'Gopal Krishna').count()A expressão SQL resultante retornará 0.
SELECT count(*)
AS count_1
FROM (
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE customers.name = ?)
AS anon_1('Gopal Krishna',) 0No entanto, os objetos de fatura relacionados de x ainda estão lá. Pode ser verificado pelo seguinte código -
session.query(Invoice).filter(Invoice.invno.in_([10,14])).count()Aqui, 10 e 14 são os números das faturas pertencentes ao cliente Gopal Krishna. O resultado da consulta acima é 2, o que significa que os objetos relacionados não foram excluídos.
SELECT count(*)
AS count_1
FROM (
SELECT invoices.id
AS invoices_id, invoices.custid
AS invoices_custid, invoices.invno
AS invoices_invno, invoices.amount
AS invoices_amount
FROM invoices
WHERE invoices.invno IN (?, ?))
AS anon_1(10, 14) 2Isso ocorre porque SQLAlchemy não assume a exclusão da cascata; temos que dar um comando para excluí-lo.
Para alterar o comportamento, configuramos opções em cascata no relacionamento User.addresses. Vamos fechar a sessão em andamento, usar new declarative_base () e declarar novamente a classe User, adicionando o relacionamento de endereços, incluindo a configuração em cascata.
O atributo cascade na função de relacionamento é uma lista separada por vírgulas de regras em cascata que determina como as operações de Sessão devem ser “cascateadas” de pai para filho. Por padrão, é False, o que significa que é "salvar-atualizar, mesclar".
As cascatas disponíveis são as seguintes -
- save-update
- merge
- expunge
- delete
- delete-orphan
- refresh-expire
A opção freqüentemente usada é "todos, excluir órfãos" para indicar que os objetos relacionados devem seguir junto com o objeto pai em todos os casos e ser excluídos quando desassociados.
Portanto, a classe Cliente reafirmada é mostrada abaixo -
class Customer(Base):
__tablename__ = 'customers'
id = Column(Integer, primary_key = True)
name = Column(String)
address = Column(String)
email = Column(String)
invoices = relationship(
"Invoice",
order_by = Invoice.id,
back_populates = "customer",
cascade = "all,
delete, delete-orphan"
)Vamos excluir o Cliente com o nome Gopal Krishna usando o programa abaixo e ver a contagem de seus objetos de fatura relacionados -
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind = engine)
session = Session()
x = session.query(Customer).get(2)
session.delete(x)
session.query(Customer).filter_by(name = 'Gopal Krishna').count()
session.query(Invoice).filter(Invoice.invno.in_([10,14])).count()A contagem agora é 0 com o seguinte SQL emitido pelo script acima -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE customers.id = ?
(2,)
SELECT invoices.id
AS invoices_id, invoices.custid
AS invoices_custid, invoices.invno
AS invoices_invno, invoices.amount
AS invoices_amount
FROM invoices
WHERE ? = invoices.custid
ORDER BY invoices.id (2,)
DELETE FROM invoices
WHERE invoices.id = ? ((1,), (2,))
DELETE FROM customers
WHERE customers.id = ? (2,)
SELECT count(*)
AS count_1
FROM (
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE customers.name = ?)
AS anon_1('Gopal Krishna',)
SELECT count(*)
AS count_1
FROM (
SELECT invoices.id
AS invoices_id, invoices.custid
AS invoices_custid, invoices.invno
AS invoices_invno, invoices.amount
AS invoices_amount
FROM invoices
WHERE invoices.invno IN (?, ?))
AS anon_1(10, 14)
0Many to Many relationshipentre duas tabelas é obtido adicionando uma tabela de associação de forma que ela tenha duas chaves estrangeiras - uma de cada chave primária da tabela. Além disso, o mapeamento de classes para as duas tabelas tem um atributo com uma coleção de objetos de outras tabelas de associação atribuídos como atributo secundário da função relacionamento ().
Para tanto, criaremos um banco de dados SQLite (mycollege.db) com duas tabelas - departamento e funcionário. Aqui, presumimos que um funcionário faz parte de mais de um departamento e um departamento tem mais de um funcionário. Isso constitui um relacionamento de muitos para muitos.
A definição das classes de funcionários e departamentos mapeadas para o departamento e a tabela de funcionários é a seguinte -
from sqlalchemy import create_engine, ForeignKey, Column, Integer, String
engine = create_engine('sqlite:///mycollege.db', echo = True)
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
from sqlalchemy.orm import relationship
class Department(Base):
__tablename__ = 'department'
id = Column(Integer, primary_key = True)
name = Column(String)
employees = relationship('Employee', secondary = 'link')
class Employee(Base):
__tablename__ = 'employee'
id = Column(Integer, primary_key = True)
name = Column(String)
departments = relationship(Department,secondary='link')Agora definimos uma classe Link. Ele está vinculado à tabela de links e contém os atributos department_id e employee_id, respectivamente, referenciando as chaves primárias da tabela de departamento e funcionário.
class Link(Base):
__tablename__ = 'link'
department_id = Column(
Integer,
ForeignKey('department.id'),
primary_key = True)
employee_id = Column(
Integer,
ForeignKey('employee.id'),
primary_key = True)Aqui, temos que observar que a classe Department tem atributos de funcionários relacionados à classe Employee. O atributo secundário da função de relacionamento recebe um link como seu valor.
Da mesma forma, a classe Employee tem atributos de departamentos relacionados à classe Department. O atributo secundário da função de relacionamento recebe um link como seu valor.
Todas essas três tabelas são criadas quando a seguinte instrução é executada -
Base.metadata.create_all(engine)O console Python emite as seguintes consultas CREATE TABLE -
CREATE TABLE department (
id INTEGER NOT NULL,
name VARCHAR,
PRIMARY KEY (id)
)
CREATE TABLE employee (
id INTEGER NOT NULL,
name VARCHAR,
PRIMARY KEY (id)
)
CREATE TABLE link (
department_id INTEGER NOT NULL,
employee_id INTEGER NOT NULL,
PRIMARY KEY (department_id, employee_id),
FOREIGN KEY(department_id) REFERENCES department (id),
FOREIGN KEY(employee_id) REFERENCES employee (id)
)Podemos verificar isso abrindo mycollege.db usando SQLiteStudio, conforme mostrado nas capturas de tela fornecidas abaixo -
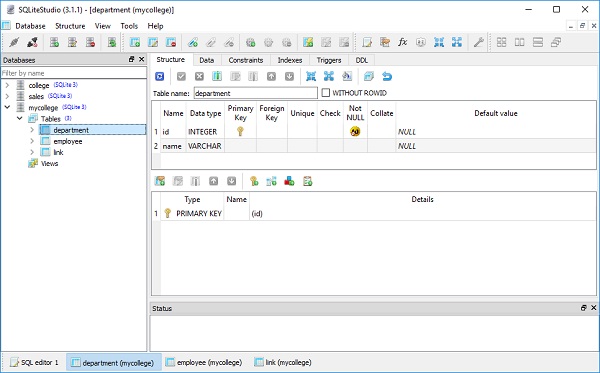
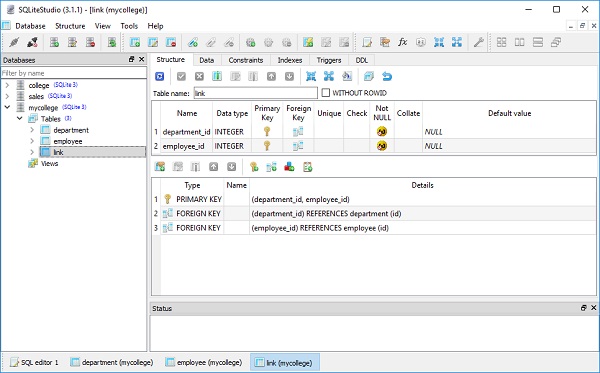
Em seguida, criamos três objetos da classe Department e três objetos da classe Employee, conforme mostrado abaixo -
d1 = Department(name = "Accounts")
d2 = Department(name = "Sales")
d3 = Department(name = "Marketing")
e1 = Employee(name = "John")
e2 = Employee(name = "Tony")
e3 = Employee(name = "Graham")Cada tabela possui um atributo de coleção com o método append (). Podemos adicionar objetos Employee à coleção Employees do objeto Department. Da mesma forma, podemos adicionar objetos Departamento ao atributo de coleção de departamentos dos objetos Funcionários.
e1.departments.append(d1)
e2.departments.append(d3)
d1.employees.append(e3)
d2.employees.append(e2)
d3.employees.append(e1)
e3.departments.append(d2)Tudo o que temos que fazer agora é configurar um objeto de sessão, adicionar todos os objetos a ele e confirmar as alterações conforme mostrado abaixo -
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind = engine)
session = Session()
session.add(e1)
session.add(e2)
session.add(d1)
session.add(d2)
session.add(d3)
session.add(e3)
session.commit()As seguintes instruções SQL serão emitidas no console Python -
INSERT INTO department (name) VALUES (?) ('Accounts',)
INSERT INTO department (name) VALUES (?) ('Sales',)
INSERT INTO department (name) VALUES (?) ('Marketing',)
INSERT INTO employee (name) VALUES (?) ('John',)
INSERT INTO employee (name) VALUES (?) ('Graham',)
INSERT INTO employee (name) VALUES (?) ('Tony',)
INSERT INTO link (department_id, employee_id) VALUES (?, ?) ((1, 2), (3, 1), (2, 3))
INSERT INTO link (department_id, employee_id) VALUES (?, ?) ((1, 1), (2, 2), (3, 3))Para verificar o efeito das operações acima, use SQLiteStudio e visualize os dados nas tabelas de departamento, funcionário e link -
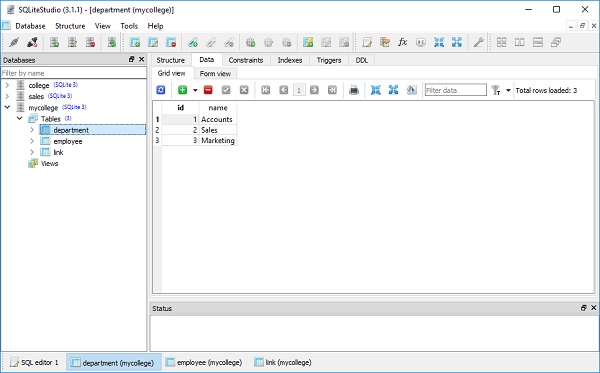
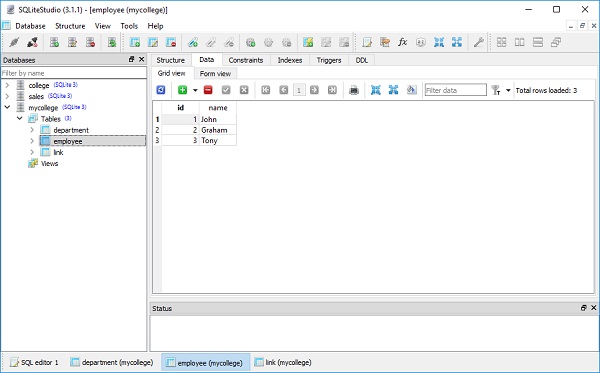
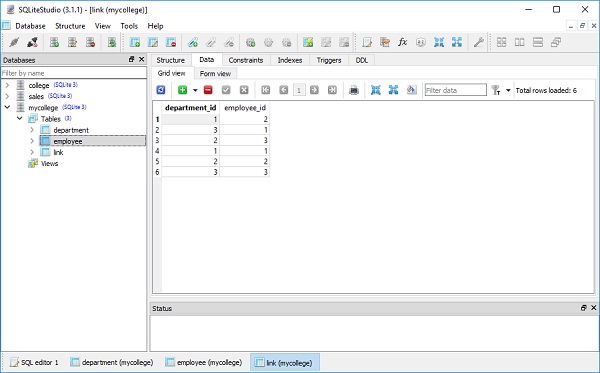
Para exibir os dados, execute a seguinte instrução de consulta -
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind = engine)
session = Session()
for x in session.query( Department, Employee).filter(Link.department_id == Department.id,
Link.employee_id == Employee.id).order_by(Link.department_id).all():
print ("Department: {} Name: {}".format(x.Department.name, x.Employee.name))De acordo com os dados preenchidos em nosso exemplo, a saída será exibida conforme abaixo -
Department: Accounts Name: John
Department: Accounts Name: Graham
Department: Sales Name: Graham
Department: Sales Name: Tony
Department: Marketing Name: John
Department: Marketing Name: TonySQLAlchemy usa sistema de dialetos para se comunicar com vários tipos de bancos de dados. Cada banco de dados possui um wrapper DBAPI correspondente. Todos os dialetos requerem que um driver DBAPI apropriado seja instalado.
Os seguintes dialetos estão incluídos na API SQLAlchemy -
- Firebird
- Microsoft SQL Server
- MySQL
- Oracle
- PostgreSQL
- SQL
- Sybase
Um objeto Engine baseado em uma URL é produzido pela função create_engine (). Esses URLs podem incluir nome de usuário, senha, nome do host e nome do banco de dados. Pode haver argumentos de palavra-chave opcionais para configuração adicional. Em alguns casos, um caminho de arquivo é aceito e, em outros, um “nome da fonte de dados” substitui as partes “host” e “banco de dados”. A forma típica de um URL de banco de dados é a seguinte -
dialect+driver://username:password@host:port/databasePostgreSQL
O dialeto PostgreSQL usa psycopg2como o DBAPI padrão. pg8000 também está disponível como um substituto puro do Python, conforme mostrado abaixo:
# default
engine = create_engine('postgresql://scott:tiger@localhost/mydatabase')
# psycopg2
engine = create_engine('postgresql+psycopg2://scott:tiger@localhost/mydatabase')
# pg8000
engine = create_engine('postgresql+pg8000://scott:tiger@localhost/mydatabase')MySQL
O dialeto MySQL usa mysql-pythoncomo o DBAPI padrão. Existem muitos DBAPIs MySQL disponíveis, como MySQL-connector-python da seguinte maneira -
# default
engine = create_engine('mysql://scott:tiger@localhost/foo')
# mysql-python
engine = create_engine('mysql+mysqldb://scott:tiger@localhost/foo')
# MySQL-connector-python
engine = create_engine('mysql+mysqlconnector://scott:tiger@localhost/foo')Oráculo
O dialeto Oracle usa cx_oracle como o DBAPI padrão da seguinte forma -
engine = create_engine('oracle://scott:[email protected]:1521/sidname')
engine = create_engine('oracle+cx_oracle://scott:tiger@tnsname')Microsoft SQL Server
O dialeto do SQL Server usa pyodbccomo o DBAPI padrão. pymssql também está disponível.
# pyodbc
engine = create_engine('mssql+pyodbc://scott:tiger@mydsn')
# pymssql
engine = create_engine('mssql+pymssql://scott:tiger@hostname:port/dbname')SQLite
SQLite se conecta a bancos de dados baseados em arquivo, usando o módulo integrado do Python sqlite3por padrão. Como o SQLite se conecta a arquivos locais, o formato da URL é um pouco diferente. A parte “arquivo” da URL é o nome do arquivo do banco de dados. Para um caminho de arquivo relativo, isso requer três barras, conforme mostrado abaixo -
engine = create_engine('sqlite:///foo.db')E para um caminho de arquivo absoluto, as três barras são seguidas pelo caminho absoluto conforme fornecido abaixo -
engine = create_engine('sqlite:///C:\\path\\to\\foo.db')Para usar um banco de dados SQLite: memory :, especifique uma URL vazia conforme fornecido abaixo -
engine = create_engine('sqlite://')Conclusão
Na primeira parte deste tutorial, aprendemos como usar o Expression Language para executar instruções SQL. A linguagem de expressão incorpora construções SQL no código Python. Na segunda parte, discutimos a capacidade de mapeamento de relação de objeto do SQLAlchemy. A API ORM mapeia as tabelas SQL com classes Python.