Weka - pré-processamento dos dados
Os dados coletados do campo contêm muitas coisas indesejadas que levam a análises incorretas. Por exemplo, os dados podem conter campos nulos, podem conter colunas irrelevantes para a análise atual e assim por diante. Portanto, os dados devem ser pré-processados para atender aos requisitos do tipo de análise que você está procurando. Isso é feito no módulo de pré-processamento.
Para demonstrar os recursos disponíveis no pré-processamento, usaremos o Weather banco de dados que é fornecido na instalação.
Usando o Open file ... opção sob o Preprocess tag selecione o weather-nominal.arff Arquivo.
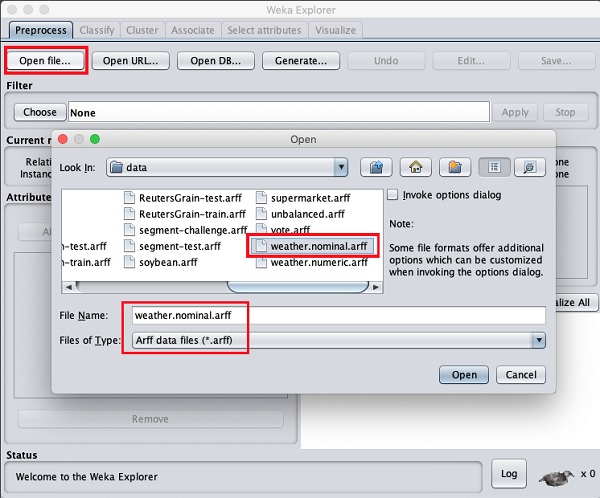
Quando você abre o arquivo, sua tela se parece com a mostrada aqui -
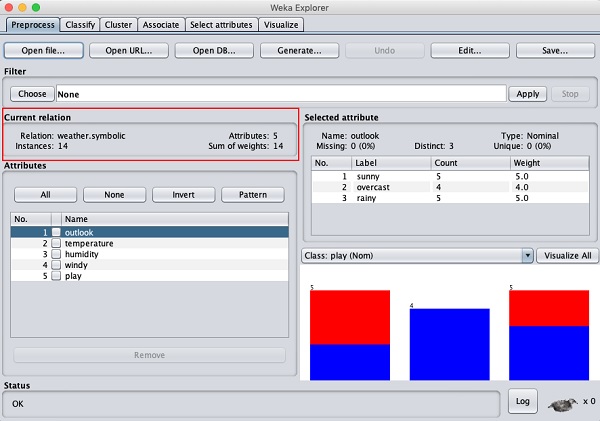
Essa tela nos diz várias coisas sobre os dados carregados, que são discutidos mais adiante neste capítulo.
Compreendendo os dados
Vamos primeiro olhar para o destaque Current relationjanela secundária. Mostra o nome do banco de dados atualmente carregado. Você pode inferir dois pontos desta subjanela -
Existem 14 instâncias - o número de linhas na tabela.
A tabela contém 5 atributos - os campos, que serão discutidos nas próximas seções.
No lado esquerdo, observe o Attributes subjanela que exibe os vários campos do banco de dados.
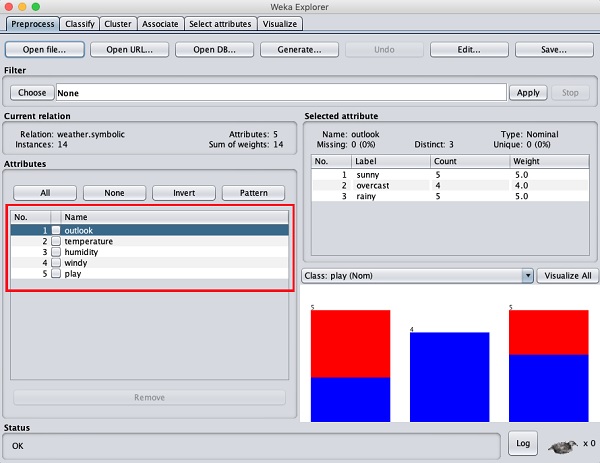
o weathero banco de dados contém cinco campos - perspectiva, temperatura, umidade, vento e jogo. Quando você seleciona um atributo desta lista clicando nele, mais detalhes sobre o próprio atributo são exibidos no lado direito.
Vamos selecionar o atributo de temperatura primeiro. Ao clicar nele, você verá a seguinte tela -
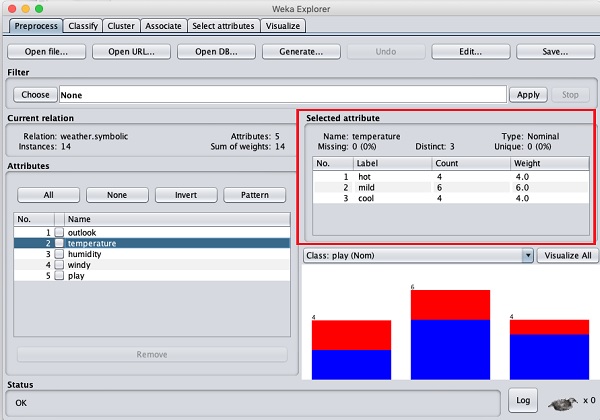
No Selected Attribute subjanela, você pode observar o seguinte -
O nome e o tipo do atributo são exibidos.
O tipo de temperature atributo é Nominal.
O número de Missing os valores são zero.
Existem três valores distintos sem nenhum valor exclusivo.
A tabela abaixo dessas informações mostra os valores nominais para este campo como quente, ameno e frio.
Também mostra a contagem e o peso em termos de porcentagem para cada valor nominal.
Na parte inferior da janela, você vê a representação visual do class valores.
Se você clicar no Visualize All botão, você poderá ver todos os recursos em uma única janela, conforme mostrado aqui -
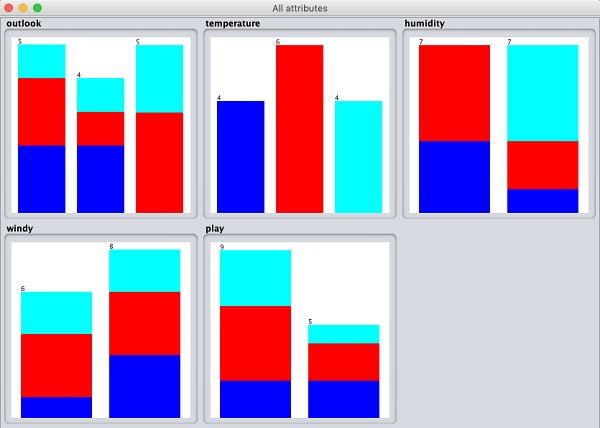
Removendo Atributos
Muitas vezes, os dados que você deseja usar para construção de modelo vêm com muitos campos irrelevantes. Por exemplo, o banco de dados do cliente pode conter seu número de celular, que é relevante para a análise de sua classificação de crédito.
Para remover Atributo / s selecione-os e clique no Remove botão na parte inferior.
Os atributos selecionados seriam removidos do banco de dados. Depois de pré-processar totalmente os dados, você pode salvá-los para a construção do modelo.
A seguir, você aprenderá a pré-processar os dados aplicando filtros a eles.
Aplicando Filtros
Algumas das técnicas de aprendizado de máquina, como mineração de regras de associação, requerem dados categóricos. Para ilustrar o uso de filtros, usaremosweather-numeric.arff banco de dados que contém dois numeric atributos - temperature e humidity.
Vamos converter estes para nominalaplicando um filtro em nossos dados brutos. Clique noChoose botão no Filter subjanela e selecione o seguinte filtro -
weka→filters→supervised→attribute→Discretize

Clique no Apply botão e examine o temperature e / ou humidityatributo. Você notará que eles mudaram de tipos numéricos para nominais.
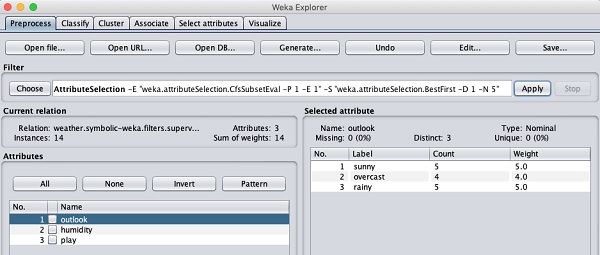
Vamos examinar outro filtro agora. Suponha que você queira selecionar os melhores atributos para decidir oplay. Selecione e aplique o seguinte filtro -
weka→filters→supervised→attribute→AttributeSelection
Você notará que ele remove os atributos de temperatura e umidade do banco de dados.
Depois de estar satisfeito com o pré-processamento de seus dados, salve os dados clicando no botão Save... botão. Você usará este arquivo salvo para construção de modelo.
No próximo capítulo, exploraremos a construção do modelo usando vários algoritmos de ML predefinidos.