Weka - Guia Rápido
A base de qualquer aplicativo de aprendizado de máquina são os dados - não apenas alguns poucos dados, mas enormes dados que são denominados como Big Data na terminologia atual.
Para treinar a máquina para analisar big data, você precisa ter várias considerações sobre os dados -
- Os dados devem estar limpos.
- Não deve conter valores nulos.
Além disso, nem todas as colunas na tabela de dados seriam úteis para o tipo de análise que você está tentando alcançar. As colunas de dados irrelevantes ou 'recursos', conforme denominado na terminologia do aprendizado de máquina, devem ser removidos antes que os dados sejam alimentados em um algoritmo de aprendizado de máquina.
Resumindo, seu big data precisa de muito pré-processamento antes de ser usado para aprendizado de máquina. Assim que os dados estiverem prontos, você aplicaria vários algoritmos de aprendizado de máquina, como classificação, regressão, clustering e assim por diante, para resolver o problema.
O tipo de algoritmo que você aplica é amplamente baseado em seu conhecimento de domínio. Mesmo dentro do mesmo tipo, por exemplo classificação, existem vários algoritmos disponíveis. Você pode querer testar os diferentes algoritmos na mesma classe para construir um modelo de aprendizado de máquina eficiente. Ao fazer isso, você prefere a visualização dos dados processados e, portanto, também precisa de ferramentas de visualização.
Nos próximos capítulos, você aprenderá sobre o Weka, um software que realiza todas as tarefas acima com facilidade e permite que você trabalhe com big data confortavelmente.
WEKA - um software de código aberto fornece ferramentas para pré-processamento de dados, implementação de vários algoritmos de aprendizado de máquina e ferramentas de visualização para que você possa desenvolver técnicas de aprendizado de máquina e aplicá-las a problemas de mineração de dados do mundo real. O que o WEKA oferece é resumido no diagrama a seguir -
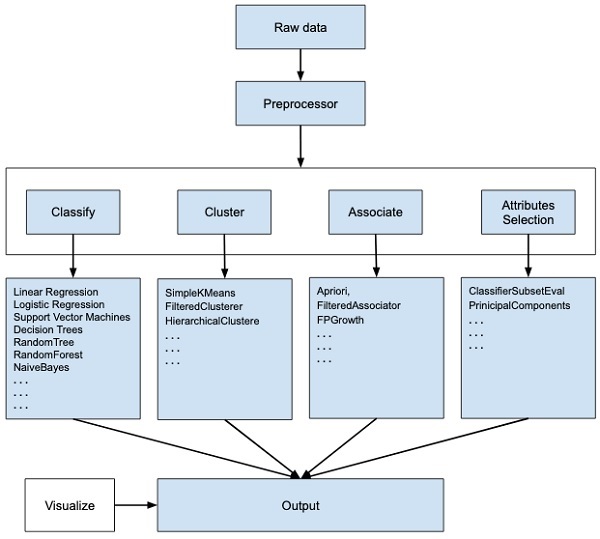
Se você observar o início do fluxo da imagem, entenderá que há muitos estágios em lidar com Big Data para torná-lo adequado para aprendizado de máquina -
Primeiro, você começará com os dados brutos coletados no campo. Esses dados podem conter vários valores nulos e campos irrelevantes. Você usa as ferramentas de pré-processamento de dados fornecidas no WEKA para limpar os dados.
Em seguida, você salvaria os dados pré-processados em seu armazenamento local para aplicar algoritmos de ML.
Em seguida, dependendo do tipo de modelo de ML que você está tentando desenvolver, selecione uma das opções, como Classify, Cluster, ou Associate. oAttributes Selection permite a seleção automática de recursos para criar um conjunto de dados reduzido.
Observe que, em cada categoria, o WEKA fornece a implementação de vários algoritmos. Você deve selecionar um algoritmo de sua escolha, definir os parâmetros desejados e executá-lo no conjunto de dados.
Então, o WEKA fornecerá a saída estatística do processamento do modelo. Ele fornece uma ferramenta de visualização para inspecionar os dados.
Os vários modelos podem ser aplicados no mesmo conjunto de dados. Você pode então comparar as saídas de diferentes modelos e selecionar o melhor que atende ao seu propósito.
Assim, o uso do WEKA resulta em um desenvolvimento mais rápido de modelos de aprendizado de máquina em geral.
Agora que vimos o que é o WEKA e o que ele faz, no próximo capítulo vamos aprender como instalar o WEKA em seu computador local.
Para instalar o WEKA em sua máquina, visite o site oficial do WEKA e baixe o arquivo de instalação. WEKA suporta instalação em Windows, Mac OS X e Linux. Você só precisa seguir as instruções nesta página para instalar o WEKA em seu sistema operacional.
As etapas para instalação no Mac são as seguintes -
- Baixe o arquivo de instalação do Mac.
- Clique duas vezes no baixado weka-3-8-3-corretto-jvm.dmg file.
Você verá a seguinte tela na instalação bem-sucedida.
- Clique no weak-3-8-3-corretto-jvm ícone para iniciar o Weka.
- Opcionalmente, você pode iniciá-lo a partir da linha de comando -
java -jar weka.jarO aplicativo WEKA GUI Chooser será iniciado e você verá a seguinte tela -
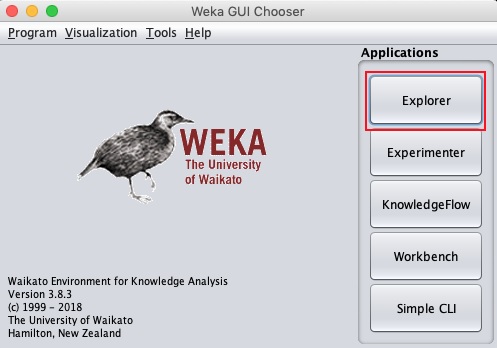
O aplicativo GUI Chooser permite que você execute cinco tipos diferentes de aplicativos, conforme listado aqui -
- Explorer
- Experimenter
- KnowledgeFlow
- Workbench
- CLI simples
Estaremos usando Explorer neste tutorial.
Neste capítulo, vamos examinar várias funcionalidades que o explorer oferece para trabalhar com big data.
Quando você clica no Explorer botão no Applications seletor, ele abre a seguinte tela -
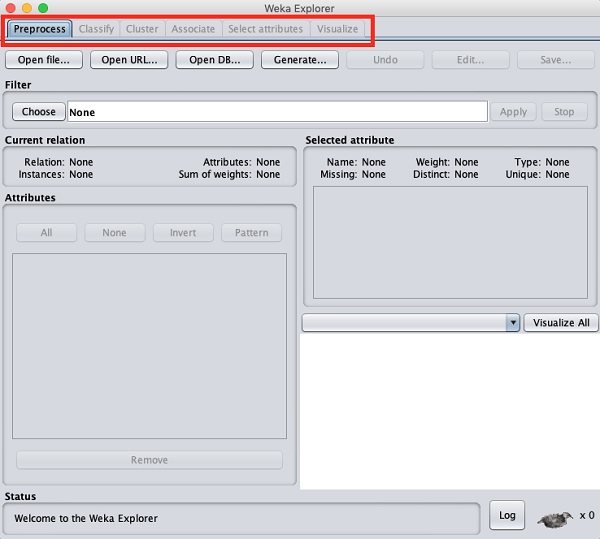
Na parte superior, você verá várias guias conforme listado aqui -
- Preprocess
- Classify
- Cluster
- Associate
- Selecione os atributos
- Visualize
Nessas guias, existem vários algoritmos de aprendizado de máquina pré-implementados. Vamos examinar cada um deles em detalhes agora.
Guia de pré-processamento
Inicialmente, conforme você abre o explorador, apenas o Preprocessguia está habilitada. A primeira etapa do aprendizado de máquina é pré-processar os dados. Assim, noPreprocess opção, você irá selecionar o arquivo de dados, processá-lo e torná-lo adequado para a aplicação de vários algoritmos de aprendizado de máquina.
Classificar guia
o Classifyguia fornece vários algoritmos de aprendizado de máquina para a classificação de seus dados. Para listar alguns, você pode aplicar algoritmos como Regressão Linear, Regressão Logística, Máquinas de Vetores de Suporte, Árvores de Decisão, RandomTree, RandomForest, NaiveBayes e assim por diante. A lista é muito exaustiva e fornece algoritmos de aprendizado de máquina supervisionados e não supervisionados.
Guia Cluster
Debaixo de Cluster guia, há vários algoritmos de agrupamento fornecidos - como SimpleKMeans, FilteredClusterer, HierarchicalClusterer e assim por diante.
Guia Associado
Debaixo de Associate guia, você encontrará Apriori, FilteredAssociator e FPGrowth.
Selecione a guia Atributos
Select Attributes permite a seleção de recursos com base em vários algoritmos, como ClassifierSubsetEval, PrinicipalComponents, etc.
Visualizar guia
Por último, o Visualize opção permite que você visualize seus dados processados para análise.
Como você notou, o WEKA fornece vários algoritmos prontos para uso para testar e construir seus aplicativos de aprendizado de máquina. Para usar o WEKA com eficácia, você deve ter um conhecimento sólido desses algoritmos, como eles funcionam, qual escolher em quais circunstâncias, o que procurar na saída processada e assim por diante. Resumindo, você deve ter uma base sólida em aprendizado de máquina para usar o WEKA com eficácia na construção de seus aplicativos.
Nos próximos capítulos, você estudará cada guia do explorador em profundidade.
Neste capítulo, começamos com a primeira guia que você usa para pré-processar os dados. Isso é comum a todos os algoritmos que você aplicaria aos seus dados para construir o modelo e é uma etapa comum para todas as operações subsequentes no WEKA.
Para que um algoritmo de aprendizado de máquina forneça uma precisão aceitável, é importante que você primeiro limpe seus dados. Isso ocorre porque os dados brutos coletados do campo podem conter valores nulos, colunas irrelevantes e assim por diante.
Neste capítulo, você aprenderá como pré-processar os dados brutos e criar um conjunto de dados limpo e significativo para uso posterior.
Primeiro, você aprenderá a carregar o arquivo de dados no WEKA explorer. Os dados podem ser carregados das seguintes fontes -
- Sistema de arquivos local
- Web
- Database
Neste capítulo, veremos todas as três opções de carregamento de dados em detalhes.
Carregando dados do sistema de arquivos local
Logo abaixo das guias de aprendizado de máquina que você estudou na lição anterior, você encontrará os três botões a seguir -
- Abrir arquivo …
- Abrir URL …
- Abrir DB ...
Clique no Open file... botão. Uma janela do navegador de diretório é aberta, conforme mostrado na tela a seguir -
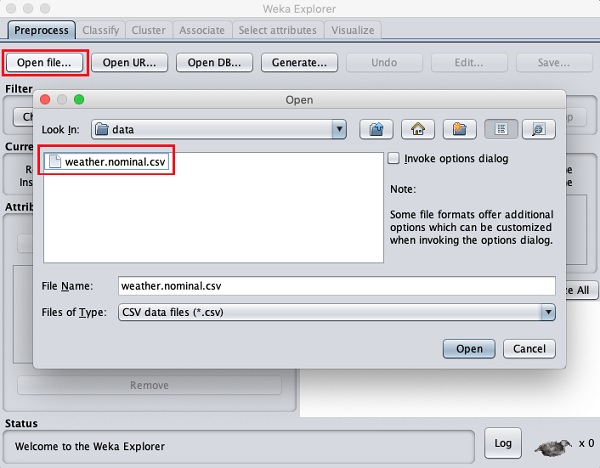
Agora, navegue até a pasta onde seus arquivos de dados estão armazenados. A instalação do WEKA vem com muitos bancos de dados de amostra para você experimentar. Estes estão disponíveis nodata pasta de instalação do WEKA.
Para fins de aprendizagem, selecione qualquer arquivo de dados desta pasta. O conteúdo do arquivo seria carregado no ambiente WEKA. Muito em breve aprenderemos como inspecionar e processar esses dados carregados. Antes disso, vamos ver como carregar o arquivo de dados da web.
Carregando dados da web
Depois de clicar no Open URL … botão, você pode ver uma janela como a seguir -
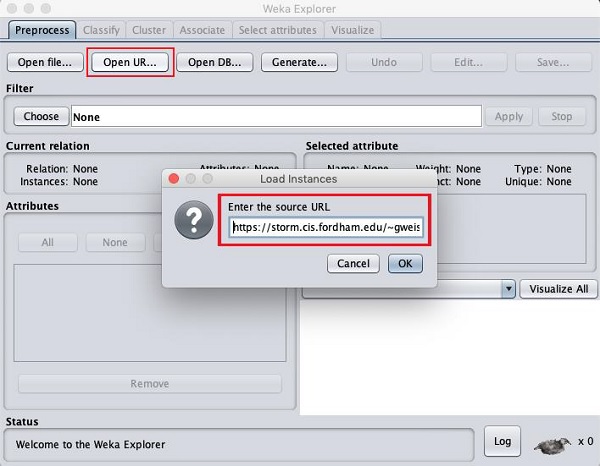
Abriremos o arquivo a partir de um URL público. Digite o seguinte URL na caixa pop-up -
https://storm.cis.fordham.edu/~gweiss/data-mining/weka-data/weather.nominal.arff
Você pode especificar qualquer outro URL onde seus dados estão armazenados. oExplorer carregará os dados do site remoto em seu ambiente.
Carregando dados do banco de dados
Depois de clicar no Open DB ..., você pode ver uma janela como a seguir -
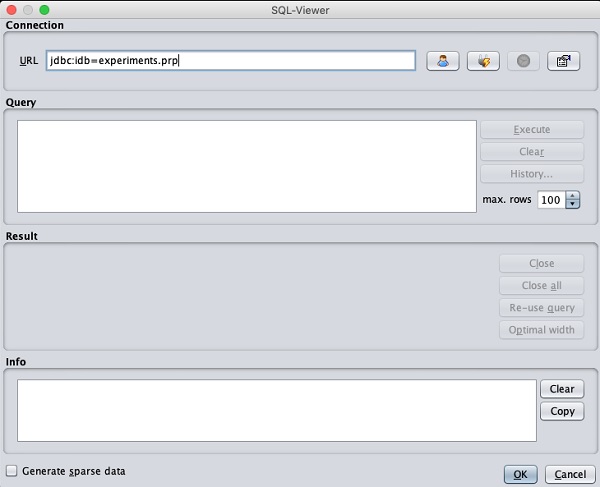
Configure a string de conexão para seu banco de dados, configure a consulta para seleção de dados, processe a consulta e carregue os registros selecionados no WEKA.
O WEKA oferece suporte a um grande número de formatos de arquivo para os dados. Aqui está a lista completa -
- arff
- arff.gz
- bsi
- csv
- dat
- data
- json
- json.gz
- libsvm
- m
- names
- xrff
- xrff.gz
Os tipos de arquivos que ele suporta estão listados na caixa de listagem suspensa na parte inferior da tela. Isso é mostrado na imagem abaixo.
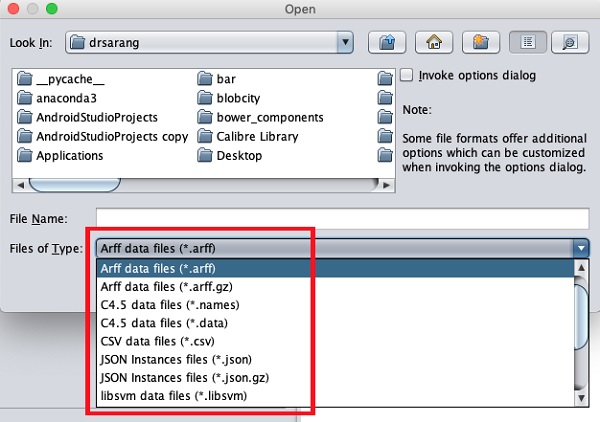
Como você notaria, ele oferece suporte a vários formatos, incluindo CSV e JSON. O tipo de arquivo padrão é Arff.
Formato Arff
A Arff arquivo contém duas seções - cabeçalho e dados.
- O cabeçalho descreve os tipos de atributos.
- A seção de dados contém uma lista de dados separados por vírgulas.
Como exemplo para o formato Arff, o Weather O arquivo de dados carregado dos bancos de dados de amostra WEKA é mostrado abaixo -

A partir da captura de tela, você pode inferir os seguintes pontos -
A tag @relation define o nome do banco de dados.
A tag @attribute define os atributos.
A tag @data inicia a lista de linhas de dados, cada uma contendo os campos separados por vírgula.
Os atributos podem assumir valores nominais como no caso da perspectiva mostrada aqui -
@attribute outlook (sunny, overcast, rainy)Os atributos podem assumir valores reais como neste caso -
@attribute temperature realVocê também pode definir um destino ou uma variável de classe chamada play, conforme mostrado aqui -
@attribute play (yes, no)O destino assume dois valores nominais sim ou não.
Outros Formatos
O Explorer pode carregar os dados em qualquer um dos formatos mencionados anteriormente. Como arff é o formato preferido no WEKA, você pode carregar os dados de qualquer formato e salvá-los no formato arff para uso posterior. Após o pré-processamento dos dados, basta salvá-los no formato arff para análise posterior.
Agora que você aprendeu como carregar dados no WEKA, no próximo capítulo, aprenderá como pré-processar os dados.
Os dados coletados no campo contêm muitas coisas indesejadas que levam a análises incorretas. Por exemplo, os dados podem conter campos nulos, podem conter colunas irrelevantes para a análise atual e assim por diante. Portanto, os dados devem ser pré-processados para atender aos requisitos do tipo de análise que você está procurando. Isso é feito no módulo de pré-processamento.
Para demonstrar os recursos disponíveis no pré-processamento, usaremos o Weather banco de dados que é fornecido na instalação.
Usando o Open file ... opção sob o Preprocess tag selecione o weather-nominal.arff Arquivo.
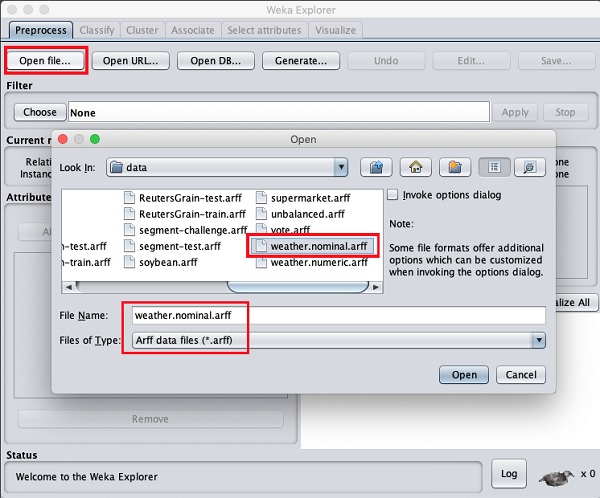
Quando você abre o arquivo, sua tela se parece com a mostrada aqui -
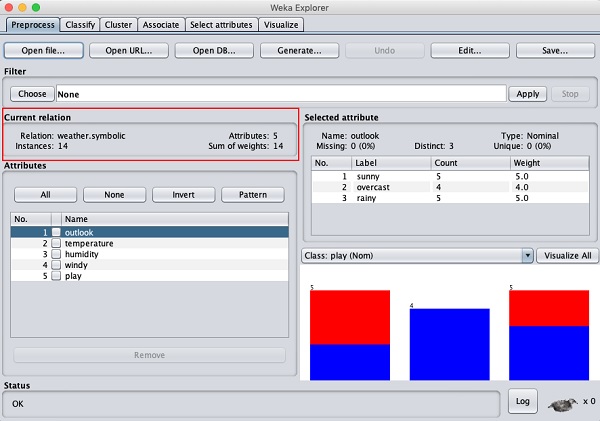
Esta tela nos diz várias coisas sobre os dados carregados, que são discutidos mais adiante neste capítulo.
Compreendendo os dados
Vamos primeiro olhar para o destaque Current relationjanela secundária. Mostra o nome do banco de dados atualmente carregado. Você pode inferir dois pontos desta subjanela -
Existem 14 instâncias - o número de linhas na tabela.
A tabela contém 5 atributos - os campos, que serão discutidos nas próximas seções.
No lado esquerdo, observe o Attributes subjanela que exibe os vários campos do banco de dados.
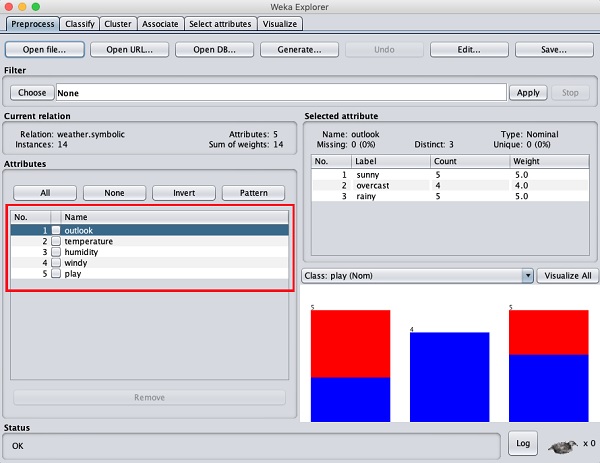
o weathero banco de dados contém cinco campos - perspectiva, temperatura, umidade, vento e jogo. Quando você seleciona um atributo desta lista clicando nele, mais detalhes sobre o próprio atributo são exibidos no lado direito.
Vamos selecionar o atributo de temperatura primeiro. Ao clicar nele, você verá a seguinte tela -
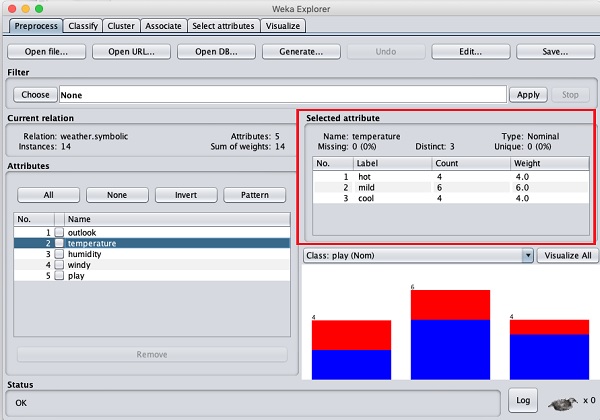
No Selected Attribute subjanela, você pode observar o seguinte -
O nome e o tipo do atributo são exibidos.
O tipo de temperature atributo é Nominal.
O número de Missing os valores são zero.
Existem três valores distintos sem nenhum valor exclusivo.
A tabela abaixo dessas informações mostra os valores nominais para este campo como quente, ameno e frio.
Também mostra a contagem e o peso em termos de porcentagem para cada valor nominal.
Na parte inferior da janela, você vê a representação visual do class valores.
Se você clicar no Visualize All botão, você poderá ver todos os recursos em uma única janela, conforme mostrado aqui -
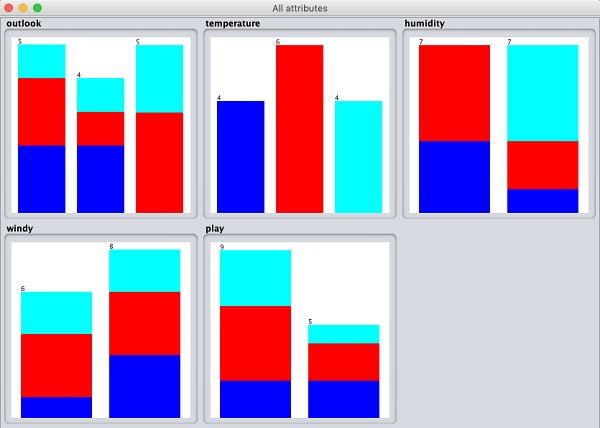
Removendo Atributos
Muitas vezes, os dados que você deseja usar para construção de modelo vêm com muitos campos irrelevantes. Por exemplo, o banco de dados do cliente pode conter seu número de celular, que é relevante para a análise de sua classificação de crédito.
Para remover Atributo / s selecione-os e clique no Remove botão na parte inferior.
Os atributos selecionados seriam removidos do banco de dados. Depois de pré-processar totalmente os dados, você pode salvá-los para a construção do modelo.
A seguir, você aprenderá a pré-processar os dados aplicando filtros a eles.
Aplicando Filtros
Algumas das técnicas de aprendizado de máquina, como mineração de regras de associação, requerem dados categóricos. Para ilustrar o uso de filtros, usaremosweather-numeric.arff banco de dados que contém dois numeric atributos - temperature e humidity.
Vamos converter estes para nominalaplicando um filtro em nossos dados brutos. Clique noChoose botão no Filter subjanela e selecione o seguinte filtro -
weka→filters→supervised→attribute→Discretize

Clique no Apply botão e examine o temperature e / ou humidityatributo. Você notará que eles mudaram de tipos numéricos para nominais.
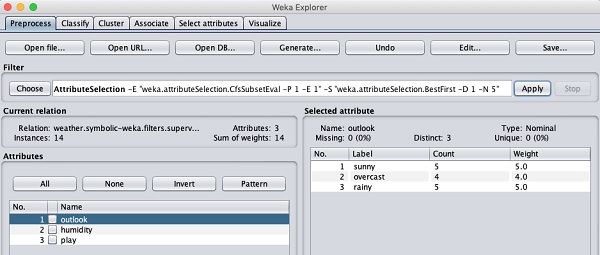
Vamos examinar outro filtro agora. Suponha que você queira selecionar os melhores atributos para decidir oplay. Selecione e aplique o seguinte filtro -
weka→filters→supervised→attribute→AttributeSelection
Você notará que ele remove os atributos de temperatura e umidade do banco de dados.
Depois de estar satisfeito com o pré-processamento de seus dados, salve os dados clicando no botão Save... botão. Você usará este arquivo salvo para construção de modelo.
No próximo capítulo, exploraremos a construção do modelo usando vários algoritmos de ML predefinidos.
Muitos aplicativos de aprendizado de máquina estão relacionados à classificação. Por exemplo, você pode classificar um tumor como maligno ou benigno. Você pode decidir se quer jogar fora de casa dependendo das condições meteorológicas. Geralmente, essa decisão depende de várias características / condições do tempo. Portanto, você pode preferir usar um classificador de árvore para tomar sua decisão de jogar ou não.
Neste capítulo, aprenderemos como construir um classificador de árvore nos dados meteorológicos para decidir as condições de jogo.
Configurando Dados de Teste
Usaremos o arquivo de dados meteorológicos pré-processado da lição anterior. Abra o arquivo salvo usando oOpen file ... opção sob o Preprocess guia, clique no Classify guia e você veria a seguinte tela -
Antes de aprender sobre os classificadores disponíveis, vamos examinar as opções de teste. Você notará quatro opções de teste, conforme listado abaixo -
- Conjunto de treinamento
- Conjunto de teste fornecido
- Cross-validation
- Divisão percentual
A menos que você tenha seu próprio conjunto de treinamento ou um conjunto de teste fornecido pelo cliente, você usaria validação cruzada ou opções de divisão de porcentagem. Na validação cruzada, você pode definir o número de dobras nas quais todos os dados seriam divididos e usados durante cada iteração de treinamento. Na divisão da porcentagem, você dividirá os dados entre treinamento e teste usando a porcentagem de divisão definida.
Agora, mantenha o padrão play opção para a classe de saída -
Em seguida, você selecionará o classificador.
Selecionando Classificador
Clique no botão Escolher e selecione o seguinte classificador -
weka→classifiers>trees>J48
Isso é mostrado na imagem abaixo -
Clique no Startbotão para iniciar o processo de classificação. Depois de um tempo, os resultados da classificação seriam apresentados na tela, conforme mostrado aqui -
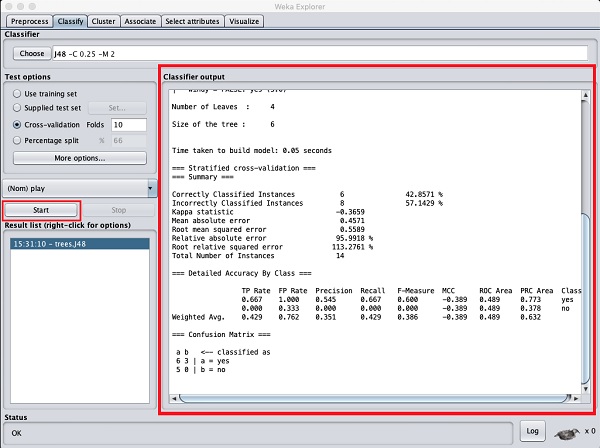
Vamos examinar a saída mostrada no lado direito da tela.
Diz que o tamanho da árvore é 6. Em breve, você verá a representação visual da árvore. No Resumo, diz que as instâncias classificadas corretamente como 2 e as instâncias classificadas incorretamente como 3, também diz que o erro relativo absoluto é 110%. Ele também mostra a Matriz de confusão. Entrar na análise desses resultados está além do escopo deste tutorial. No entanto, você pode facilmente concluir a partir desses resultados que a classificação não é aceitável e você precisará de mais dados para análise, para refinar sua seleção de recursos, reconstruir o modelo e assim por diante até que esteja satisfeito com a precisão do modelo. De qualquer forma, é disso que se trata o WEKA. Ele permite que você teste suas ideias rapidamente.
Visualize os resultados
Para ver a representação visual dos resultados, clique com o botão direito no resultado no Result listcaixa. Várias opções apareceriam na tela, conforme mostrado aqui -
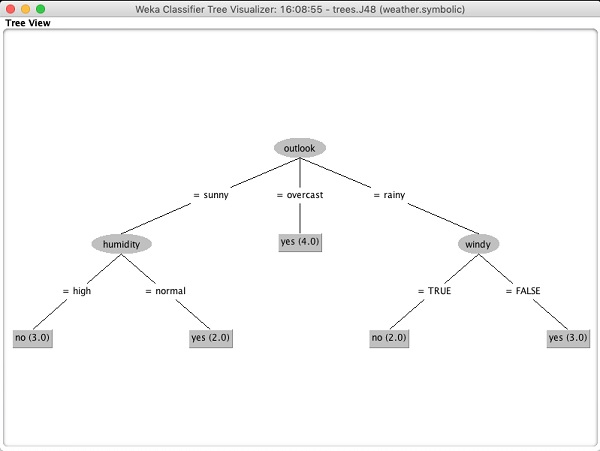
Selecione Visualize tree para obter uma representação visual da árvore transversal, conforme visto na imagem abaixo -
Selecionando Visualize classifier errors traçaria os resultados da classificação conforme mostrado aqui -
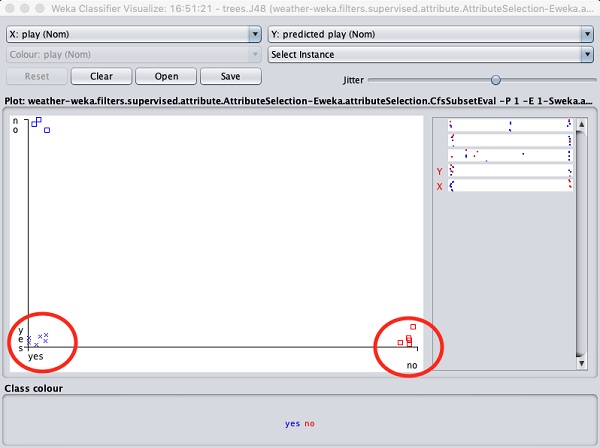
UMA cross representa uma instância classificada corretamente enquanto squaresrepresenta instâncias classificadas incorretamente. No canto esquerdo inferior do gráfico, você vê umcross que indica se outlook está ensolarado então playo jogo. Portanto, esta é uma instância classificada corretamente. Para localizar instâncias, você pode introduzir algum jitter deslizando ojitter Barra deslizante.
O enredo atual é outlook versus play. Eles são indicados pelas duas caixas de listagem suspensa no topo da tela.
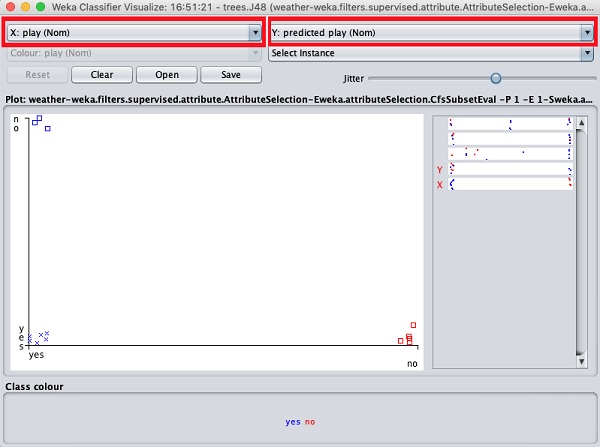
Agora, tente uma seleção diferente em cada uma dessas caixas e observe como os eixos X e Y mudam. O mesmo pode ser alcançado usando as faixas horizontais do lado direito do gráfico. Cada tira representa um atributo. Clicar com o botão esquerdo na faixa define o atributo selecionado no eixo X, enquanto um clique com o botão direito o definiria no eixo Y.
Existem vários outros gráficos fornecidos para uma análise mais profunda. Use-os criteriosamente para ajustar seu modelo. Um tal enredo deCost/Benefit analysis é mostrado abaixo para sua referência rápida.
Explicar a análise nesses gráficos está além do escopo deste tutorial. O leitor é incentivado a aprimorar seus conhecimentos de análise de algoritmos de aprendizado de máquina.
No próximo capítulo, aprenderemos o próximo conjunto de algoritmos de aprendizado de máquina, que é o clustering.
Um algoritmo de agrupamento encontra grupos de instâncias semelhantes em todo o conjunto de dados. WEKA oferece suporte a vários algoritmos de agrupamento, como EM, FilteredClusterer, HierarchicalClusterer, SimpleKMeans e assim por diante. Você deve compreender esses algoritmos completamente para explorar totalmente os recursos do WEKA.
Como no caso da classificação, o WEKA permite visualizar os clusters detectados graficamente. Para demonstrar o agrupamento, usaremos o banco de dados íris fornecido. O conjunto de dados contém três classes de 50 instâncias cada. Cada classe se refere a um tipo de planta de íris.
Carregando dados
No WEKA explorer, selecione o Preprocessaba. Clique noOpen file ... opção e selecione a iris.arffarquivo na caixa de diálogo de seleção de arquivo. Quando você carrega os dados, a tela se parece com a mostrada abaixo -
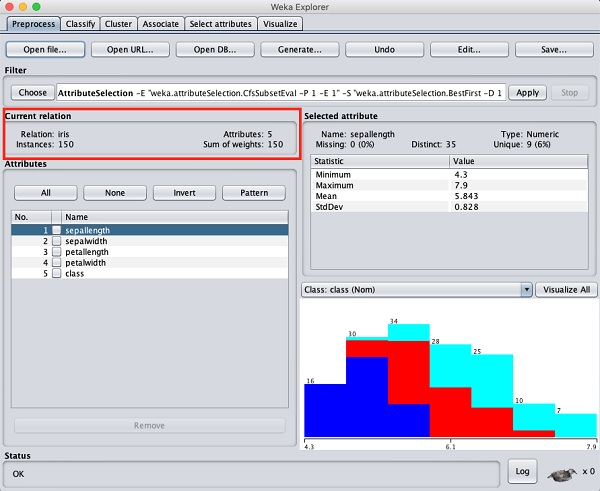
Você pode observar que existem 150 instâncias e 5 atributos. Os nomes dos atributos são listados comosepallength, sepalwidth, petallength, petalwidth e class. Os primeiros quatro atributos são do tipo numérico, enquanto a classe é do tipo nominal com 3 valores distintos. Examine cada atributo para entender os recursos do banco de dados. Não faremos nenhum pré-processamento nestes dados e prosseguiremos imediatamente para a construção do modelo.
Clustering
Clique no ClusterTAB para aplicar os algoritmos de agrupamento aos nossos dados carregados. Clique noChoosebotão. Você verá a seguinte tela -

Agora, selecione EMcomo o algoritmo de agrupamento. NoCluster mode subjanela, selecione o Classes to clusters evaluation opção como mostrado na imagem abaixo -

Clique no Startbotão para processar os dados. Depois de um tempo, os resultados serão apresentados na tela.
A seguir, vamos estudar os resultados.
Análise de saída
A saída do processamento de dados é mostrada na tela abaixo -
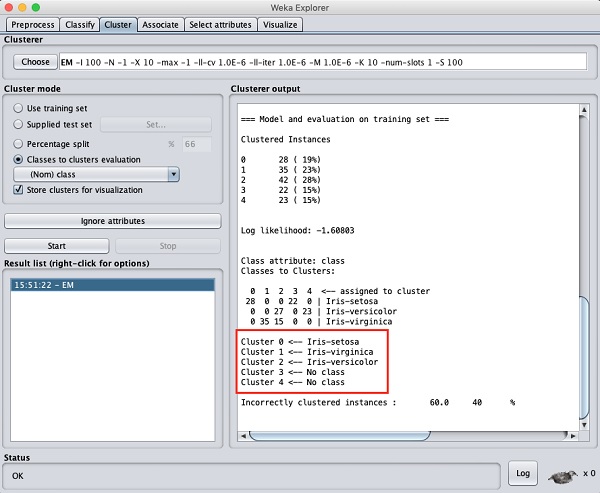
Na tela de saída, você pode observar que -
Existem 5 instâncias em cluster detectadas no banco de dados.
o Cluster 0 representa setosa, Cluster 1 representa virginica, Cluster 2 representa versicolor, enquanto os dois últimos clusters não têm nenhuma classe associada a eles.
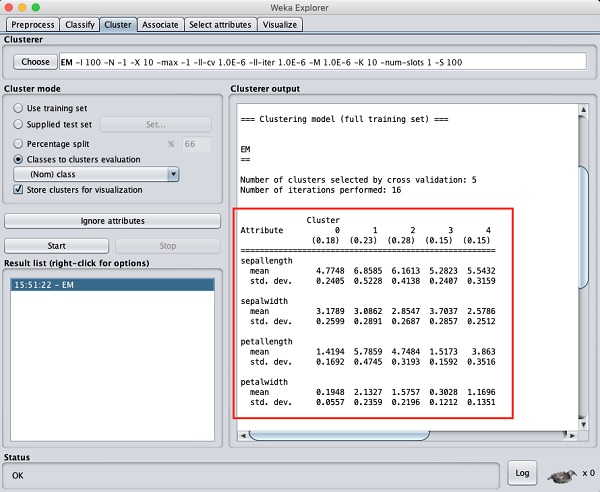
Se você rolar a janela de saída, também verá algumas estatísticas que fornecem a média e o desvio padrão para cada um dos atributos nos vários clusters detectados. Isso é mostrado na imagem abaixo -
A seguir, veremos a representação visual dos clusters.
Visualizando Clusters
Para visualizar os clusters, clique com o botão direito no EM resultar no Result list. Você verá as seguintes opções -
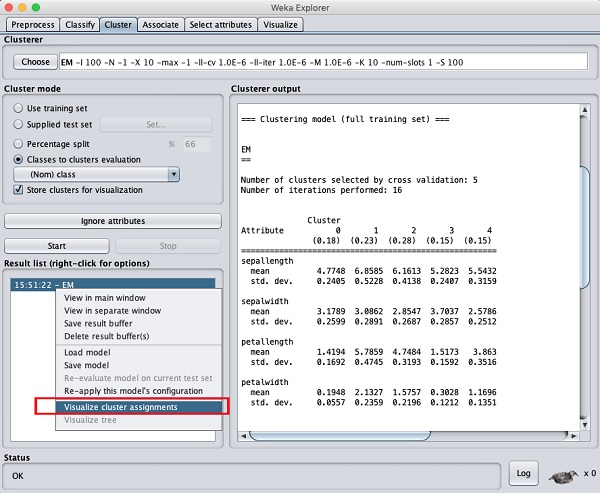
Selecione Visualize cluster assignments. Você verá a seguinte saída -
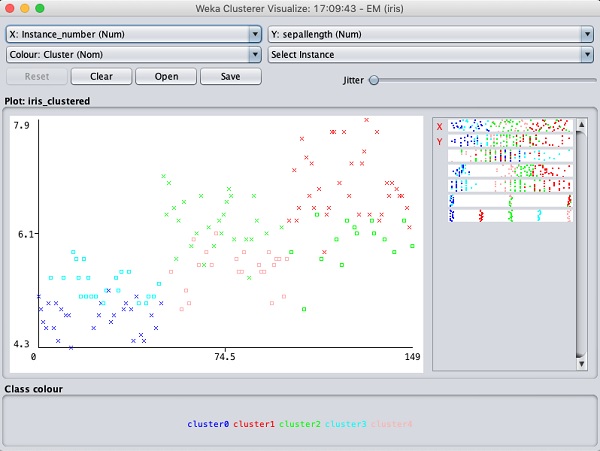
Como no caso da classificação, você notará a distinção entre as instâncias identificadas corretamente e incorretamente. Você pode brincar alterando os eixos X e Y para analisar os resultados. Você pode usar jittering como no caso da classificação para descobrir a concentração de instâncias corretamente identificadas. As operações no gráfico de visualização são semelhantes às que você estudou no caso da classificação.
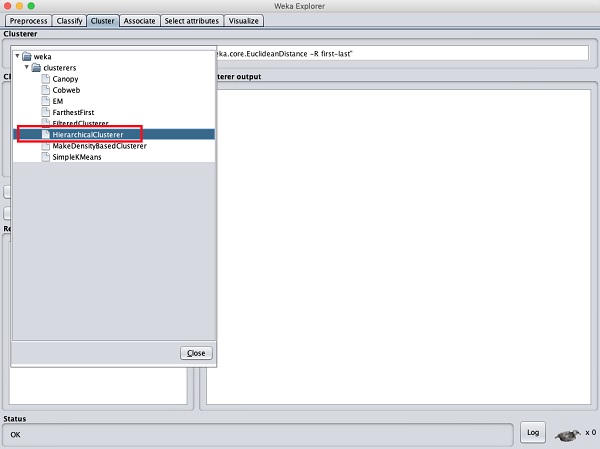
Aplicando Clusterer Hierárquico
Para demonstrar o poder do WEKA, vamos agora examinar uma aplicação de outro algoritmo de agrupamento. No WEKA explorer, selecione oHierarchicalClusterer como seu algoritmo de ML, conforme mostrado na captura de tela mostrada abaixo -
Escolha o Cluster mode seleção para Classes to cluster evaluation, e clique no Startbotão. Você verá a seguinte saída -
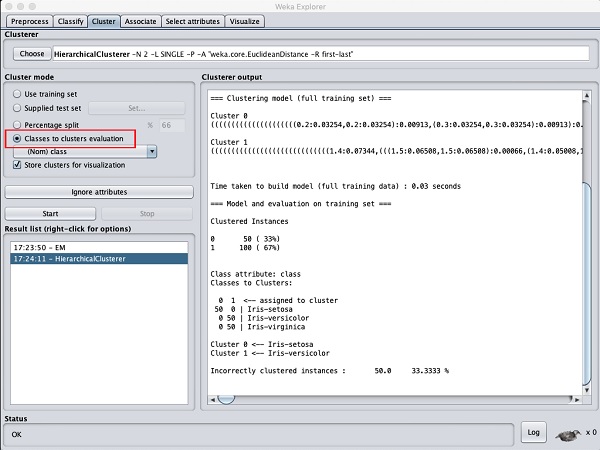
Observe que no Result list, há dois resultados listados: o primeiro é o resultado EM e o segundo é o Hierárquico atual. Da mesma forma, você pode aplicar vários algoritmos de ML ao mesmo conjunto de dados e comparar rapidamente seus resultados.
Se você examinar a árvore produzida por este algoritmo, verá a seguinte saída -
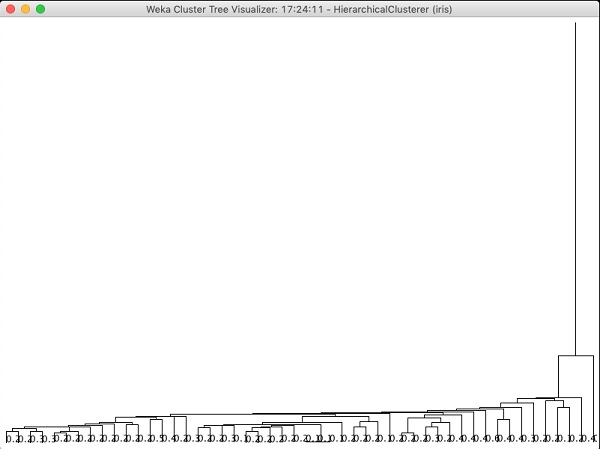
No próximo capítulo, você estudará o Associate tipo de algoritmos de ML.
Observou-se que quem compra cerveja também compra fralda ao mesmo tempo. Ou seja, existe uma associação em comprar cerveja e fraldas juntos. Embora isso não pareça muito convincente, essa regra de associação foi extraída de enormes bancos de dados de supermercados. Da mesma forma, uma associação pode ser encontrada entre manteiga de amendoim e pão.
Encontrar essas associações torna-se vital para os supermercados, pois eles estocariam fraldas ao lado de cervejas para que os clientes possam localizar ambos os itens facilmente, resultando em um aumento nas vendas para o supermercado.
o AprioriO algoritmo é um algoritmo em ML que descobre as associações prováveis e cria regras de associação. O WEKA fornece a implementação do algoritmo Apriori. Você pode definir o suporte mínimo e um nível de confiança aceitável ao calcular essas regras. Você vai aplicar oApriori algoritmo para o supermarket dados fornecidos na instalação do WEKA.
Carregando dados
No WEKA explorer, abra o Preprocess guia, clique no Open file ... botão e selecione supermarket.arffbanco de dados da pasta de instalação. Depois que os dados forem carregados, você verá a seguinte tela -
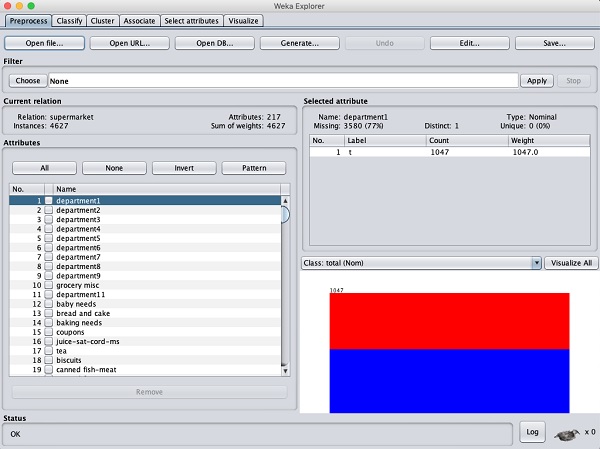
O banco de dados contém 4627 instâncias e 217 atributos. Você pode entender facilmente como seria difícil detectar a associação entre um número tão grande de atributos. Felizmente, essa tarefa é automatizada com a ajuda do algoritmo Apriori.
Associador
Clique no Associate TAB e clique no Choosebotão. Selecione osApriori associação como mostrado na imagem -
Para definir os parâmetros do algoritmo a priori, clique em seu nome, uma janela aparecerá conforme mostrado abaixo que permite que você defina os parâmetros -
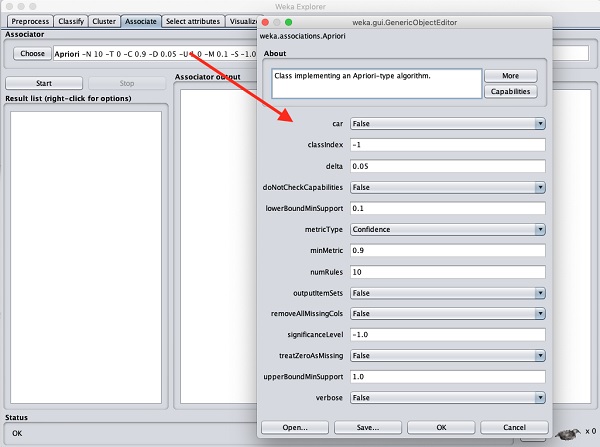
Depois de definir os parâmetros, clique no Startbotão. Depois de um tempo, você verá os resultados conforme mostrado na imagem abaixo -
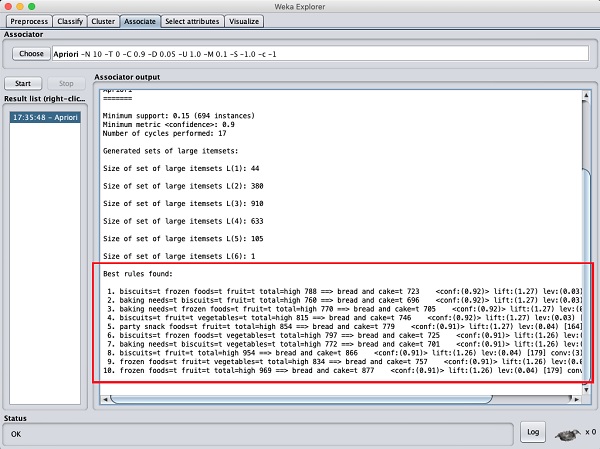
Na parte inferior, você encontrará as melhores regras de associações detectadas. Isso ajudará o supermercado a estocar seus produtos nas prateleiras adequadas.
Quando um banco de dados contém um grande número de atributos, haverá vários atributos que não se tornarão significativos na análise que você está procurando no momento. Portanto, remover os atributos indesejados do conjunto de dados se torna uma tarefa importante no desenvolvimento de um bom modelo de aprendizado de máquina.
Você pode examinar todo o conjunto de dados visualmente e decidir sobre os atributos irrelevantes. Isso pode ser uma tarefa enorme para bancos de dados que contêm um grande número de atributos, como a caixa do supermercado que você viu na lição anterior. Felizmente, o WEKA oferece uma ferramenta automatizada para seleção de recursos.
Este capítulo demonstra esse recurso em um banco de dados que contém um grande número de atributos.
Carregando dados
No Preprocess tag do WEKA explorer, selecione o labor.arffarquivo para carregar no sistema. Ao carregar os dados, você verá a seguinte tela -
Observe que existem 17 atributos. Nossa tarefa é criar um conjunto de dados reduzido, eliminando alguns dos atributos que são irrelevantes para nossa análise.
Extração de recursos
Clique no Select attributesTAB. Você verá a seguinte tela -
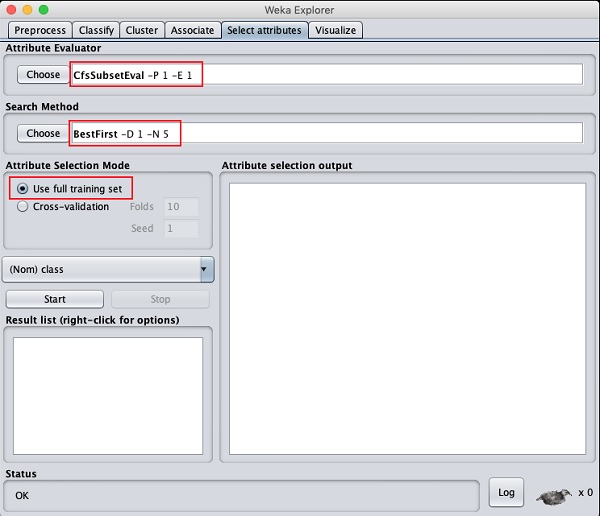
Debaixo de Attribute Evaluator e Search Method, você encontrará várias opções. Usaremos apenas os padrões aqui. NoAttribute Selection Mode, use a opção de conjunto de treinamento completo.
Clique no botão Iniciar para processar o conjunto de dados. Você verá a seguinte saída -

Na parte inferior da janela de resultados, você obterá a lista de Selectedatributos. Para obter a representação visual, clique com o botão direito no resultado noResult Lista.
O resultado é mostrado na seguinte captura de tela -
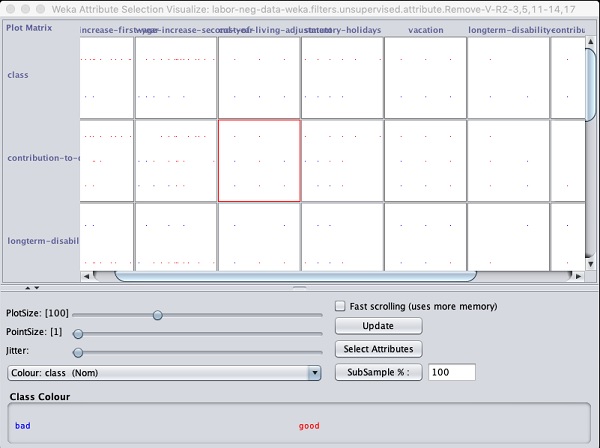
Clicar em qualquer um dos quadrados fornecerá o gráfico de dados para sua análise posterior. Um gráfico de dados típico é mostrado abaixo -
Isso é semelhante ao que vimos nos capítulos anteriores. Brinque com as diferentes opções disponíveis para analisar os resultados.
Qual é o próximo?
Você viu até agora o poder do WEKA no desenvolvimento rápido de modelos de aprendizado de máquina. O que usamos é uma ferramenta gráfica chamadaExplorerpara o desenvolvimento desses modelos. O WEKA também fornece uma interface de linha de comando que oferece mais potência do que a fornecida no explorer.
Clicando no Simple CLI botão no GUI Chooser aplicativo inicia esta interface de linha de comando que é mostrada na imagem abaixo -
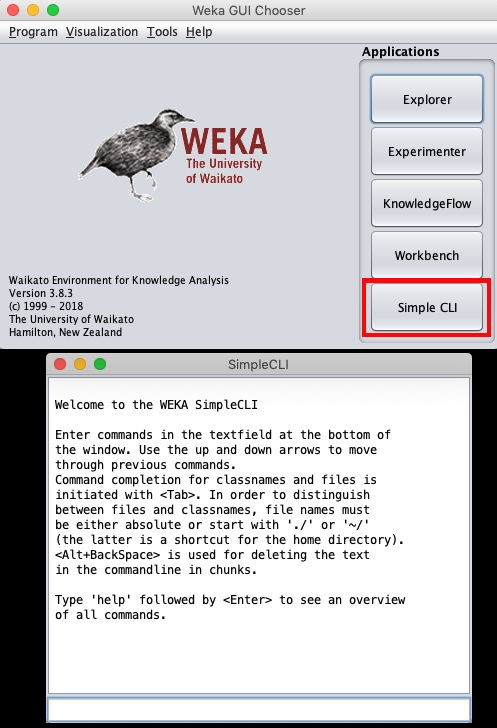
Digite seus comandos na caixa de entrada na parte inferior. Você poderá fazer tudo o que fez até agora no explorer e muito mais. Consulte a documentação do WEKA (https://www.cs.waikato.ac.nz/ml/weka/documentation.html) para obter mais detalhes.
Por último, o WEKA é desenvolvido em Java e fornece uma interface para sua API. Portanto, se você é um desenvolvedor Java e deseja incluir implementações WEKA ML em seus próprios projetos Java, pode fazer isso facilmente.
Conclusão
WEKA é uma ferramenta poderosa para desenvolver modelos de aprendizado de máquina. Ele fornece implementação de vários algoritmos de ML mais amplamente usados. Antes que esses algoritmos sejam aplicados ao seu conjunto de dados, ele também permite que você pré-processe os dados. Os tipos de algoritmos com suporte são classificados em atributos Classificar, Cluster, Associate e Selecionar. O resultado em vários estágios de processamento pode ser visualizado com uma representação visual bonita e poderosa. Isso torna mais fácil para um cientista de dados aplicar rapidamente as várias técnicas de aprendizado de máquina em seu conjunto de dados, comparar os resultados e criar o melhor modelo para o uso final.