Apache Flink - Архитектура
Apache Flink работает с архитектурой Kappa. Архитектура Kappa имеет единственный процессор - stream, который обрабатывает весь ввод как поток, а механизм потоковой передачи обрабатывает данные в реальном времени. Пакетные данные в архитектуре каппа - это частный случай потоковой передачи.
На следующей диаграмме показан Apache Flink Architecture.
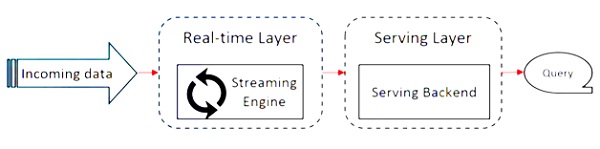
Ключевая идея в архитектуре Kappa - обрабатывать как пакетные данные, так и данные в реальном времени с помощью единого механизма потоковой обработки.
Большинство фреймворков больших данных работает на архитектуре Lambda, которая имеет отдельные процессоры для пакетных и потоковых данных. В архитектуре Lambda у вас есть отдельные кодовые базы для пакетного и потокового представлений. Для запроса и получения результата необходимо объединить кодовые базы. Не поддерживать отдельные кодовые базы / представления и объединять их - это проблема, но архитектура Kappa решает эту проблему, поскольку имеет только одно представление - в реальном времени, поэтому слияние кодовой базы не требуется.
Это не означает, что архитектура Kappa заменяет архитектуру Lambda, это полностью зависит от варианта использования и приложения, которое решает, какая архитектура будет предпочтительнее.
На следующей диаграмме показана архитектура выполнения задания Apache Flink.

Программа
Это фрагмент кода, который вы запускаете в кластере Flink.
Клиент
Он отвечает за принятие кода (программы) и построение графа потока данных задания, а затем передачу его в JobManager. Он также получает результаты работы.
JobManager
После получения графика потока данных задания от клиента он отвечает за создание графика выполнения. Он назначает задание диспетчерам задач в кластере и контролирует выполнение задания.
Диспетчер задач
Он отвечает за выполнение всех задач, которые были назначены JobManager. Все диспетчеры задач запускают задачи в своих отдельных слотах с указанным параллелизмом. Он отвечает за отправку статуса задач в JobManager.
Особенности Apache Flink
Особенности Apache Flink следующие:
Он имеет потоковый процессор, который может запускать как пакетные, так и потоковые программы.
Он может обрабатывать данные с молниеносной скоростью.
API-интерфейсы доступны на Java, Scala и Python.
Предоставляет API-интерфейсы для всех стандартных операций, которые очень легко использовать программистам.
Обрабатывает данные с малой задержкой (наносекунды) и высокой пропускной способностью.
Его отказоустойчивый. Если узел, приложение или оборудование выходит из строя, это не влияет на кластер.
Может легко интегрироваться с Apache Hadoop, Apache MapReduce, Apache Spark, HBase и другими инструментами для работы с большими данными.
Управление в памяти можно настроить для улучшения вычислений.
Он хорошо масштабируется и может масштабироваться до тысяч узлов в кластере.
Окно в Apache Flink очень гибкое.
Предоставляет библиотеки обработки графиков, машинного обучения и обработки сложных событий.