Apache Flink - Краткое руководство
Прогресс данных за последние 10 лет был огромным; это дало начало термину «большие данные». Не существует фиксированного размера данных, который можно назвать большими данными; любые данные, которые ваша традиционная система (СУБД) не может обработать, являются большими данными. Эти большие данные могут быть в структурированном, полуструктурированном или неструктурированном формате. Изначально данные имели три измерения - объем, скорость, разнообразие. Размеры теперь вышли за рамки трех Vs. Теперь мы добавили другие V - достоверность, достоверность, уязвимость, ценность, изменчивость и т. Д.
Большие данные привели к появлению множества инструментов и фреймворков, которые помогают в хранении и обработке данных. Существует несколько популярных фреймворков для работы с большими данными, например Hadoop, Spark, Hive, Pig, Storm и Zookeeper. Это также дало возможность создавать продукты нового поколения во многих областях, таких как здравоохранение, финансы, розничная торговля, электронная коммерция и другие.
Будь то MNC или стартап, все используют большие данные для их хранения и обработки и принятия более разумных решений.
Что касается больших данных, существует два типа обработки:
- Пакетная обработка
- Обработка в реальном времени
Обработка на основе данных, собранных с течением времени, называется пакетной обработкой. Например, менеджер банка хочет обработать данные за последний месяц (собранные с течением времени), чтобы узнать количество чеков, аннулированных за последний месяц.
Обработка, основанная на немедленных данных для получения мгновенного результата, называется обработкой в реальном времени. Например, менеджер банка получает предупреждение о мошенничестве сразу после совершения мошеннической транзакции (мгновенный результат).
В приведенной ниже таблице перечислены различия между пакетной обработкой и обработкой в реальном времени.
| Пакетная обработка | Обработка в реальном времени |
|---|---|
Статические файлы |
Потоки событий |
Обрабатывается Периодически в минутах, часах, днях и т. Д. |
Обработано немедленно наносекунды |
Прошлые данные на диске |
В памяти |
Пример - создание счета |
Пример - оповещение о транзакции банкомата |
В наши дни обработка в реальном времени широко используется в каждой организации. Для таких случаев использования, как обнаружение мошенничества, оповещения в реальном времени в здравоохранении и оповещения о сетевых атаках, требуется обработка мгновенных данных в реальном времени; задержка даже в несколько миллисекунд может иметь огромное влияние.
Идеальным инструментом для таких случаев использования в реальном времени был бы тот, который может вводить данные как поток, а не пакет. Apache Flink - это инструмент обработки в реальном времени.
Apache Flink - это среда обработки в реальном времени, которая может обрабатывать потоковые данные. Это платформа обработки потоков с открытым исходным кодом для высокопроизводительных, масштабируемых и точных приложений реального времени. Он имеет настоящую потоковую модель и не принимает входные данные как пакетные или микропакеты.
Apache Flink был основан компанией Data Artisans и сейчас разрабатывается под лицензией Apache сообществом Apache Flink. В этом сообществе более 479 участников, и на данный момент 15500 + совершили.
Экосистема на Apache Flink
На приведенной ниже диаграмме показаны различные уровни экосистемы Apache Flink.

Место хранения
У Apache Flink есть несколько вариантов, откуда он может читать / писать данные. Ниже приведен базовый список хранилищ -
- HDFS (Распределенная файловая система Hadoop)
- Локальная файловая система
- S3
- СУБД (MySQL, Oracle, MS SQL и т. Д.)
- MongoDB
- HBase
- Апач Кафка
- Apache Flume
Развернуть
Вы можете развернуть Apache Fink в локальном режиме, режиме кластера или в облаке. Кластерный режим может быть автономным, YARN, MESOS.
В облаке Flink можно развернуть на AWS или GCP.
Ядро
Это уровень времени выполнения, который обеспечивает распределенную обработку, отказоустойчивость, надежность, возможности собственной итеративной обработки и многое другое.
API и библиотеки
Это верхний и самый важный уровень Apache Flink. У него есть Dataset API, который заботится о пакетной обработке, и Datastream API, который заботится о потоковой обработке. Существуют и другие библиотеки, такие как Flink ML (для машинного обучения), Gelly (для обработки графиков), Tables for SQL. Этот уровень предоставляет различные возможности Apache Flink.
Apache Flink работает с архитектурой Kappa. Архитектура Kappa имеет единственный процессор - stream, который обрабатывает весь ввод как поток, а механизм потоковой передачи обрабатывает данные в реальном времени. Пакетные данные в архитектуре каппа - это частный случай потоковой передачи.
На следующей диаграмме показан Apache Flink Architecture.
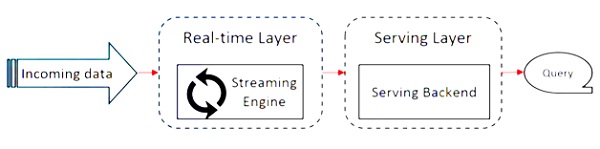
Ключевая идея в архитектуре Kappa - обрабатывать как пакетные данные, так и данные в реальном времени с помощью единого механизма потоковой обработки.
Большинство фреймворков больших данных работает на архитектуре Lambda, которая имеет отдельные процессоры для пакетных и потоковых данных. В архитектуре Lambda у вас есть отдельные кодовые базы для пакетного и потокового представлений. Для запроса и получения результата необходимо объединить кодовые базы. Не поддерживать отдельные кодовые базы / представления и объединять их - это проблема, но архитектура Kappa решает эту проблему, поскольку имеет только одно представление - в реальном времени, поэтому слияние кодовой базы не требуется.
Это не означает, что архитектура Kappa заменяет архитектуру Lambda, это полностью зависит от варианта использования и приложения, которое решает, какая архитектура будет предпочтительнее.
На следующей диаграмме показана архитектура выполнения задания Apache Flink.

Программа
Это фрагмент кода, который вы запускаете в кластере Flink.
Клиент
Он отвечает за принятие кода (программы) и построение графа потока данных задания, а затем передачу его в JobManager. Он также получает результаты работы.
JobManager
После получения графика потока данных задания от клиента он отвечает за создание графика выполнения. Он назначает задание диспетчерам задач в кластере и контролирует выполнение задания.
Диспетчер задач
Он отвечает за выполнение всех задач, которые были назначены JobManager. Все диспетчеры задач запускают задачи в своих отдельных слотах с указанным параллелизмом. Он отвечает за отправку статуса задач в JobManager.
Особенности Apache Flink
Особенности Apache Flink следующие:
Он имеет потоковый процессор, который может запускать как пакетные, так и потоковые программы.
Он может обрабатывать данные с молниеносной скоростью.
API-интерфейсы доступны на Java, Scala и Python.
Предоставляет API-интерфейсы для всех стандартных операций, которые очень легко использовать программистам.
Обрабатывает данные с малой задержкой (наносекунды) и высокой пропускной способностью.
Его отказоустойчивый. Если узел, приложение или оборудование выходит из строя, это не влияет на кластер.
Может легко интегрироваться с Apache Hadoop, Apache MapReduce, Apache Spark, HBase и другими инструментами для работы с большими данными.
Управление в памяти можно настроить для улучшения вычислений.
Он хорошо масштабируется и может масштабироваться до тысяч узлов в кластере.
Окно в Apache Flink очень гибкое.
Предоставляет библиотеки обработки графиков, машинного обучения и обработки сложных событий.
Ниже приведены системные требования для загрузки и работы с Apache Flink:
Рекомендуемая операционная система
- Microsoft Windows 10
- Ubuntu 16.04 LTS
- Apple macOS 10.13 / High Sierra
Требования к памяти
- Память - минимум 4 ГБ, рекомендуется 8 ГБ
- Место для хранения - 30 ГБ
Note - Java 8 должна быть доступна с уже установленными переменными среды.
Перед тем, как начать установку / настройку Apache Flink, давайте проверим, установлена ли у нас в системе Java 8.
Java - версия

Теперь мы загрузим Apache Flink.
wget http://mirrors.estointernet.in/apache/flink/flink-1.7.1/flink-1.7.1-bin-scala_2.11.tgz
Теперь распакуйте tar-файл.
tar -xzf flink-1.7.1-bin-scala_2.11.tgz
Перейдите в домашний каталог Flink.
cd flink-1.7.1/Запустите кластер Flink.
./bin/start-cluster.sh
Откройте браузер Mozilla и перейдите по указанному ниже URL-адресу, откроется веб-панель управления Flink.
http://localhost:8081
Так выглядит пользовательский интерфейс Apache Flink Dashboard.

Теперь кластер Flink запущен и работает.
Flink имеет богатый набор API-интерфейсов, с помощью которых разработчики могут выполнять преобразования как пакетных данных, так и данных в реальном времени. Разнообразные преобразования включают отображение, фильтрацию, сортировку, объединение, группировку и агрегирование. Эти преобразования Apache Flink выполняются над распределенными данными. Давайте обсудим различные API, предлагаемые Apache Flink.
API набора данных
API набора данных в Apache Flink используется для выполнения пакетных операций с данными в течение определенного периода. Этот API можно использовать в Java, Scala и Python. Он может применять различные виды преобразований к наборам данных, такие как фильтрация, сопоставление, агрегирование, объединение и группировка.
Наборы данных создаются из источников, таких как локальные файлы, или путем чтения файла из определенного источника, а данные результатов могут быть записаны в разные приемники, такие как распределенные файлы или терминал командной строки. Этот API поддерживается языками программирования Java и Scala.
Вот программа Wordcount для Dataset API -
public class WordCountProg {
public static void main(String[] args) throws Exception {
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
DataSet<String> text = env.fromElements(
"Hello",
"My Dataset API Flink Program");
DataSet<Tuple2<String, Integer>> wordCounts = text
.flatMap(new LineSplitter())
.groupBy(0)
.sum(1);
wordCounts.print();
}
public static class LineSplitter implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String line, Collector<Tuple2<String, Integer>> out) {
for (String word : line.split(" ")) {
out.collect(new Tuple2<String, Integer>(word, 1));
}
}
}
}DataStream API
Этот API используется для обработки данных в непрерывном потоке. Вы можете выполнять различные операции, такие как фильтрация, отображение, управление окнами, агрегирование данных потока. В этом потоке данных есть различные источники, такие как очереди сообщений, файлы, потоки сокетов, и данные результатов могут быть записаны в разные приемники, такие как терминал командной строки. Оба языка программирования Java и Scala поддерживают этот API.
Вот потоковая программа Wordcount для DataStream API, где у вас есть непрерывный поток подсчета слов, а данные сгруппированы во втором окне.
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;
public class WindowWordCountProg {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<Tuple2<String, Integer>> dataStream = env
.socketTextStream("localhost", 9999)
.flatMap(new Splitter())
.keyBy(0)
.timeWindow(Time.seconds(5))
.sum(1);
dataStream.print();
env.execute("Streaming WordCount Example");
}
public static class Splitter implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String sentence, Collector<Tuple2<String, Integer>> out) throws Exception {
for (String word: sentence.split(" ")) {
out.collect(new Tuple2<String, Integer>(word, 1));
}
}
}
}Table API - это реляционный API с SQL-подобным языком выражений. Этот API может выполнять как пакетную, так и потоковую обработку. Он может быть встроен в Java и Scala Dataset и Datastream API. Вы можете создавать таблицы из существующих наборов данных и потоков данных или из внешних источников данных. С помощью этого реляционного API вы можете выполнять такие операции, как объединение, агрегирование, выбор и фильтрация. Независимо от того, является ли ввод пакетным или потоковым, семантика запроса остается неизменной.
Вот пример программы Table API -
// for batch programs use ExecutionEnvironment instead of StreamExecutionEnvironment
val env = StreamExecutionEnvironment.getExecutionEnvironment
// create a TableEnvironment
val tableEnv = TableEnvironment.getTableEnvironment(env)
// register a Table
tableEnv.registerTable("table1", ...) // or
tableEnv.registerTableSource("table2", ...) // or
tableEnv.registerExternalCatalog("extCat", ...)
// register an output Table
tableEnv.registerTableSink("outputTable", ...);
// create a Table from a Table API query
val tapiResult = tableEnv.scan("table1").select(...)
// Create a Table from a SQL query
val sqlResult = tableEnv.sqlQuery("SELECT ... FROM table2 ...")
// emit a Table API result Table to a TableSink, same for SQL result
tapiResult.insertInto("outputTable")
// execute
env.execute()В этой главе мы узнаем, как создать приложение Flink.
Откройте Eclipse IDE, щелкните «Новый проект» и «Выберите проект Java».

Дайте название проекту и нажмите "Готово".

Теперь нажмите Готово, как показано на следующем снимке экрана.
Теперь щелкните правой кнопкой мыши на src и перейдите в New >> Class.

Дайте название классу и нажмите Готово.

Скопируйте и вставьте приведенный ниже код в редактор.
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.util.Collector;
public class WordCount {
// *************************************************************************
// PROGRAM
// *************************************************************************
public static void main(String[] args) throws Exception {
final ParameterTool params = ParameterTool.fromArgs(args);
// set up the execution environment
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// make parameters available in the web interface
env.getConfig().setGlobalJobParameters(params);
// get input data
DataSet<String> text = env.readTextFile(params.get("input"));
DataSet<Tuple2<String, Integer>> counts =
// split up the lines in pairs (2-tuples) containing: (word,1)
text.flatMap(new Tokenizer())
// group by the tuple field "0" and sum up tuple field "1"
.groupBy(0)
.sum(1);
// emit result
if (params.has("output")) {
counts.writeAsCsv(params.get("output"), "\n", " ");
// execute program
env.execute("WordCount Example");
} else {
System.out.println("Printing result to stdout. Use --output to specify output path.");
counts.print();
}
}
// *************************************************************************
// USER FUNCTIONS
// *************************************************************************
public static final class Tokenizer implements FlatMapFunction<String, Tuple2<String, Integer>> {
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) {
// normalize and split the line
String[] tokens = value.toLowerCase().split("\\W+");
// emit the pairs
for (String token : tokens) {
if (token.length() > 0) {
out.collect(new Tuple2<>(token, 1));
}
}
}
}
}Вы получите много ошибок в редакторе, потому что в этот проект нужно добавить библиотеки Flink.

Щелкните правой кнопкой мыши проект >> Путь сборки >> Настроить путь сборки.
Выберите вкладку «Библиотеки» и нажмите «Добавить внешние файлы JAR».

Перейдите в каталог библиотеки Flink, выберите все 4 библиотеки и нажмите OK.
Перейдите на вкладку Order and Export, выберите все библиотеки и нажмите OK.
Вы увидите, что ошибок больше нет.
Теперь давайте экспортируем это приложение. Щелкните проект правой кнопкой мыши и выберите «Экспорт».

Выберите файл JAR и нажмите Далее.

Укажите путь назначения и нажмите Далее

Нажмите Далее>
Нажмите «Обзор», выберите основной класс (WordCount) и нажмите «Готово».

Note - Нажмите ОК, если появится какое-либо предупреждение.
Выполните приведенную ниже команду. Далее он запустит только что созданное приложение Flink.
./bin/flink run /home/ubuntu/wordcount.jar --input README.txt --output /home/ubuntu/output
В этой главе мы узнаем, как запустить программу Flink.
Давайте запустим пример подсчета слов Flink на кластере Flink.
Перейдите в домашний каталог Flink и выполните следующую команду в терминале.
bin/flink run examples/batch/WordCount.jar -input README.txt -output /home/ubuntu/flink-1.7.1/output.txt
Перейдите в панель управления Flink, вы сможете увидеть выполненную работу с ее деталями.

Если вы нажмете «Завершенные работы», вы получите подробный обзор работ.

Чтобы проверить вывод программы wordcount, выполните следующую команду в терминале.
cat output.txt
В этой главе мы узнаем о различных библиотеках Apache Flink.
Комплексная обработка событий (CEP)
FlinkCEP - это API в Apache Flink, который анализирует шаблоны событий для непрерывных потоковых данных. Эти события происходят почти в реальном времени, имеют высокую пропускную способность и низкую задержку. Этот API используется в основном для данных датчиков, которые поступают в режиме реального времени и очень сложны для обработки.
CEP анализирует структуру входящего потока и очень скоро выдает результат. Он имеет возможность предоставлять уведомления и предупреждения в режиме реального времени в случае сложной схемы событий. FlinkCEP может подключаться к различным источникам входного сигнала и анализировать в них закономерности.
Вот как выглядит образец архитектуры с CEP -

Данные датчиков будут поступать из разных источников, Kafka будет действовать как среда распределенного обмена сообщениями, которая будет распределять потоки в Apache Flink, а FlinkCEP будет анализировать сложные шаблоны событий.
Вы можете писать программы на Apache Flink для сложной обработки событий с помощью Pattern API. Это позволяет вам выбирать шаблоны событий для обнаружения из данных непрерывного потока. Ниже приведены некоторые из наиболее часто используемых шаблонов CEP -
Начать
Он используется для определения начального состояния. Следующая программа показывает, как это определяется в программе Flink -
Pattern<Event, ?> next = start.next("next");где
Он используется для определения условия фильтрации в текущем состоянии.
patternState.where(new FilterFunction <Event>() {
@Override
public boolean filter(Event value) throws Exception {
}
});следующий
Он используется для добавления нового состояния шаблона и соответствующего события, необходимого для передачи предыдущего шаблона.
Pattern<Event, ?> next = start.next("next");С последующим
Он используется для добавления нового состояния шаблона, но здесь могут происходить другие события ч / б двух совпадающих событий.
Pattern<Event, ?> followedBy = start.followedBy("next");Gelly
API-интерфейс Apache Flink Graph - это Gelly. Gelly используется для выполнения графического анализа в приложениях Flink с использованием набора методов и утилит. Вы можете анализировать огромные графы с помощью Apache Flink API распределенным образом с помощью Gelly. Существуют и другие библиотеки графов, такие как Apache Giraph, для той же цели, но поскольку Gelly используется поверх Apache Flink, он использует единый API. Это очень полезно с точки зрения разработки и эксплуатации.
Давайте запустим пример, используя Apache Flink API - Gelly.
Во-первых, вам нужно скопировать 2 файла Gelly jar из каталога opt Apache Flink в его каталог lib. Затем запустите jar flink-gelly-examples.
cp opt/flink-gelly* lib/
./bin/flink run examples/gelly/flink-gelly-examples_*.jar
Давайте теперь запустим пример PageRank.
PageRank вычисляет оценку для каждой вершины, которая представляет собой сумму оценок PageRank, переданных за границу. Оценка каждой вершины поровну делится между внешними ребрами. Вершины с высокими показателями связаны с другими вершинами с высокими показателями.
Результат содержит идентификатор вершины и рейтинг PageRank.
usage: flink run examples/flink-gelly-examples_<version>.jar --algorithm PageRank [algorithm options] --input <input> [input options] --output <output> [output options]
./bin/flink run examples/gelly/flink-gelly-examples_*.jar --algorithm PageRank --input CycleGraph --vertex_count 2 --output Print
Библиотека машинного обучения Apache Flink называется FlinkML. Поскольку за последние 5 лет использование машинного обучения экспоненциально росло, сообщество Flink решило добавить этот APO машинного обучения также в свою экосистему. Список участников и алгоритмов во FlinkML увеличивается. Этот API еще не является частью двоичного дистрибутива.
Вот пример линейной регрессии с использованием FlinkML -
// LabeledVector is a feature vector with a label (class or real value)
val trainingData: DataSet[LabeledVector] = ...
val testingData: DataSet[Vector] = ...
// Alternatively, a Splitter is used to break up a DataSet into training and testing data.
val dataSet: DataSet[LabeledVector] = ...
val trainTestData: DataSet[TrainTestDataSet] = Splitter.trainTestSplit(dataSet)
val trainingData: DataSet[LabeledVector] = trainTestData.training
val testingData: DataSet[Vector] = trainTestData.testing.map(lv => lv.vector)
val mlr = MultipleLinearRegression()
.setStepsize(1.0)
.setIterations(100)
.setConvergenceThreshold(0.001)
mlr.fit(trainingData)
// The fitted model can now be used to make predictions
val predictions: DataSet[LabeledVector] = mlr.predict(testingData)Внутри flink-1.7.1/examples/batch/путь, вы найдете файл KMeans.jar. Давайте запустим этот образец FlinkML.
Этот пример программы запускается с использованием точки по умолчанию и набора данных центроида.
./bin/flink run examples/batch/KMeans.jar --output Print
В этой главе мы разберемся с несколькими тестовыми примерами в Apache Flink.
Apache Flink - Bouygues Telecom
Bouygues Telecom - одна из крупнейших телекоммуникационных организаций Франции. У него более 11 миллионов абонентов мобильной связи и более 2,5 миллионов постоянных клиентов. Компания Bouygues впервые услышала об Apache Flink на собрании группы Hadoop в Париже. С тех пор они использовали Flink для нескольких сценариев использования. Они обрабатывали миллиарды сообщений в день в режиме реального времени через Apache Flink.
Вот что Буиг говорит об Apache Flink: «Мы закончили с Flink, потому что система поддерживает настоящую потоковую передачу - как на уровне API, так и на уровне времени выполнения, что дает нам программируемость и низкую задержку, которые мы искали. Кроме того, мы смогли настроить и запустить нашу систему с помощью Flink за меньшее время по сравнению с другими решениями, что привело к появлению большего количества доступных ресурсов разработчика для расширения бизнес-логики в системе ».
В компании Bouygues качество обслуживания клиентов является наивысшим приоритетом. Они анализируют данные в режиме реального времени, чтобы дать своим инженерам следующие идеи:
Опыт работы с клиентами в реальном времени по их сети
Что происходит в сети в мире
Оценка сети и операции
Они создали систему под названием LUX (Logged User Experience), которая обрабатывала массивные данные журнала от сетевого оборудования с внутренними ссылками на данные, чтобы дать показатели качества опыта, которые будут регистрировать их клиентский опыт и создать тревожную функцию для обнаружения любого сбоя в потреблении данных в течение 60 секунд. секунд.
Для этого им требовалась структура, которая может принимать большие объемы данных в режиме реального времени, проста в настройке и предоставляет богатый набор API для обработки потоковых данных. Apache Flink идеально подходил для Bouygues Telecom.
Apache Flink - Алибаба
Alibaba - крупнейшая в мире розничная компания в сфере электронной коммерции с доходом в размере 394 миллиардов долларов в 2015 году. Поиск Alibaba - это точка входа для всех клиентов, которая показывает все результаты поиска и дает соответствующие рекомендации.
Alibaba использует Apache Flink в своей поисковой системе, чтобы отображать результаты в режиме реального времени с максимальной точностью и релевантностью для каждого пользователя.
Alibaba искала фреймворк, который был -
Очень гибкая поддержка единой базы кода для всего процесса поисковой инфраструктуры.
Обеспечивает низкую задержку при изменении доступности продуктов на веб-сайте.
Последовательный и экономичный.
Apache Flink соответствует всем вышеперечисленным требованиям. Им нужна структура, которая имеет единый механизм обработки и может обрабатывать как пакетные, так и потоковые данные с помощью одного и того же механизма, и это то, что делает Apache Flink.
Они также используют Blink, разветвленную версию Flink, чтобы удовлетворить некоторые уникальные требования для их поиска. Они также используют API таблиц Apache Flink с небольшими улучшениями для поиска.
Вот что Alibaba сказал об apache Flink: « Оглядываясь назад, можно сказать , что это был, без сомнения, огромный год для Blink и Flink в Alibaba. Никто не думал, что мы добьемся такого большого прогресса за год, и мы очень благодарны всем. люди, которые помогли нам в сообществе. Доказано, что Flink работает в очень больших масштабах. Мы более чем когда-либо привержены продолжению нашей работы с сообществом, чтобы продвигать Flink вперед! "
Вот исчерпывающая таблица, в которой показано сравнение трех самых популярных платформ больших данных: Apache Flink, Apache Spark и Apache Hadoop.
| Apache Hadoop | Apache Spark | Apache Flink | |
|---|---|---|---|
Year of Origin |
2005 г. | 2009 г. | 2009 г. |
Place of Origin |
MapReduce (Google) Hadoop (Yahoo) | Калифорнийский университет в Беркли | Технический университет Берлина |
Data Processing Engine |
Партия | Партия | Поток |
Processing Speed |
Медленнее, чем Spark and Flink | В 100 раз быстрее, чем Hadoop | Быстрее искры |
Programming Languages |
Java, C, C ++, Ruby, Groovy, Perl, Python | Java, Scala, python и R | Java и Scala |
Programming Model |
Уменьшение карты | Устойчивые распределенные наборы данных (RDD) | Циклические потоки данных |
Data Transfer |
Партия | Партия | Конвейерный и пакетный |
Memory Management |
На основе диска | Управляемая JVM | Активный управляемый |
Latency |
Низкий | Средняя | Низкий |
Throughput |
Средняя | Высоко | Высоко |
Optimization |
Руководство | Руководство | Автоматический |
API |
Низкий уровень | Высокий уровень | Высокий уровень |
Streaming Support |
NA | Spark Streaming | Flink Streaming |
SQL Support |
Улей, Импала | SparkSQL | Табличный API и SQL |
Graph Support |
NA | GraphX | Gelly |
Machine Learning Support |
NA | SparkML | FlinkML |
Таблица сравнения, которую мы видели в предыдущей главе, в значительной степени завершает указатели. Apache Flink - это наиболее подходящий фреймворк для обработки и использования в реальном времени. Уникальная система с одним движком позволяет обрабатывать как пакетные, так и потоковые данные с помощью различных API, таких как Dataset и DataStream.
Это не означает, что Hadoop и Spark вышли из игры, выбор наиболее подходящей платформы для работы с большими данными всегда зависит и варьируется от варианта использования к варианту использования. Может быть несколько вариантов использования, в которых может подойти комбинация Hadoop и Flink или Spark и Flink.
Тем не менее, Flink в настоящее время является лучшим фреймворком для обработки в реальном времени. Рост Apache Flink был поразительным, и число участников его сообщества растет день ото дня.
Счастливого мигания!