Apache Flume - получение данных из Twitter
Используя Flume, мы можем получать данные из различных сервисов и переносить их в централизованные хранилища (HDFS и HBase). В этой главе объясняется, как получить данные из службы Twitter и сохранить их в HDFS с помощью Apache Flume.
Как обсуждалось в Flume Architecture, веб-сервер генерирует данные журнала, и эти данные собираются агентом в Flume. Канал буферизует эти данные в приемник, который в конечном итоге отправляет их в централизованные хранилища.
В примере, приведенном в этой главе, мы создадим приложение и будем получать от него твиты, используя экспериментальный источник твиттера, предоставленный Apache Flume. Мы будем использовать канал памяти для буферизации этих твитов и приемник HDFS, чтобы отправить эти твиты в HDFS.

Чтобы получить данные Twitter, нам нужно будет выполнить следующие шаги:
- Создать твиттер-приложение
- Установить / запустить HDFS
- Настроить Flume
Создание приложения Twitter
Чтобы получать твиты из Twitter, необходимо создать приложение Twitter. Следуйте инструкциям ниже, чтобы создать приложение Twitter.
Шаг 1
Чтобы создать приложение Twitter, щелкните следующую ссылку https://apps.twitter.com/. Войдите в свою учетную запись Twitter. У вас будет окно управления приложениями Twitter, в котором вы можете создавать, удалять и управлять приложениями Twitter.
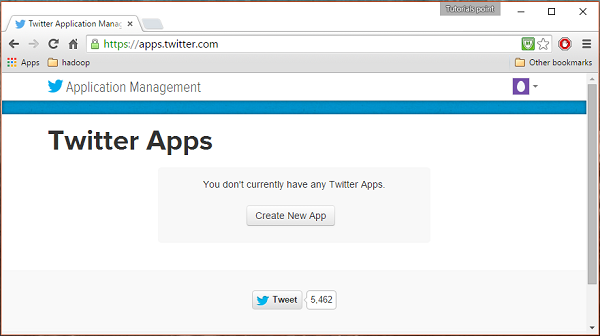
Шаг 2
Нажми на Create New Appкнопка. Вы будете перенаправлены в окно, где вы получите форму заявки, в которой вы должны заполнить свои данные, чтобы создать приложение. При заполнении адреса веб-сайта укажите полный шаблон URL, например,http://example.com.
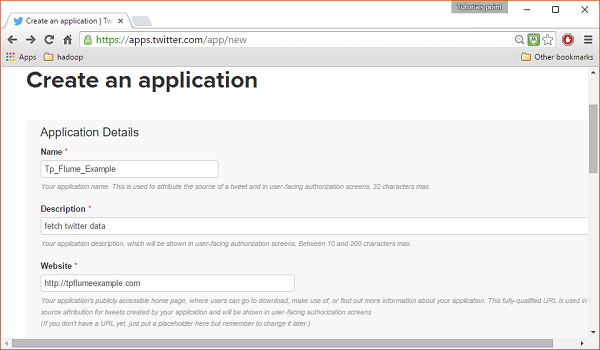
Шаг 3
Заполните данные, примите Developer Agreement когда закончите, нажмите на Create your Twitter application buttonкоторый находится внизу страницы. Если все пойдет хорошо, будет создано приложение с указанными данными, как показано ниже.
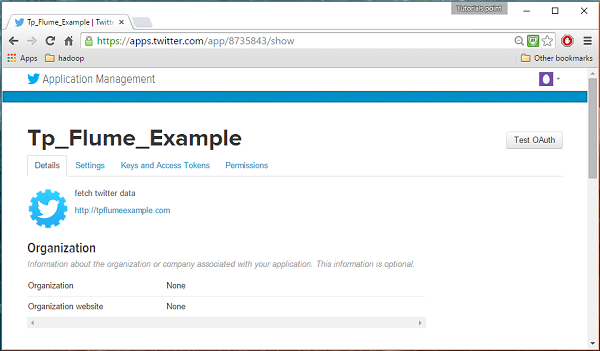
Шаг 4
Под keys and Access Tokens на вкладке внизу страницы вы можете увидеть кнопку с именем Create my access token. Щелкните по нему, чтобы сгенерировать токен доступа.
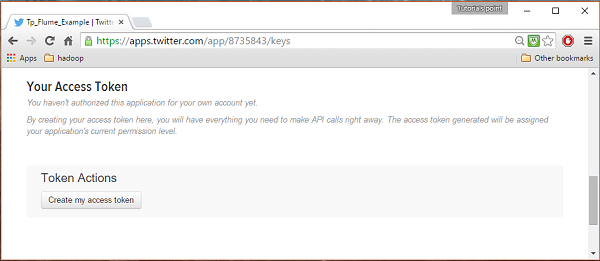
Шаг 5
Наконец, нажмите на Test OAuthкнопка, которая находится в правой верхней части страницы. Это приведет к странице, на которой отображаются вашиConsumer key, Consumer secret, Access token, и Access token secret. Скопируйте эти данные. Это полезно для настройки агента в Flume.

Запуск HDFS
Поскольку мы храним данные в HDFS, нам необходимо установить / проверить Hadoop. Запустите Hadoop и создайте в нем папку для хранения данных Flume. Перед настройкой Flume выполните следующие действия.
Шаг 1. Установите / проверьте Hadoop
Установите Hadoop . Если Hadoop уже установлен в вашей системе, проверьте установку с помощью команды версии Hadoop, как показано ниже.
$ hadoop versionЕсли ваша система содержит Hadoop, и если вы установили переменную пути, вы получите следующий вывод:
Hadoop 2.6.0
Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r
e3496499ecb8d220fba99dc5ed4c99c8f9e33bb1
Compiled by jenkins on 2014-11-13T21:10Z
Compiled with protoc 2.5.0
From source with checksum 18e43357c8f927c0695f1e9522859d6a
This command was run using /home/Hadoop/hadoop/share/hadoop/common/hadoop-common-2.6.0.jarШаг 2: запуск Hadoop
Просмотрите sbin каталог Hadoop и start yarn и Hadoop dfs (распределенная файловая система), как показано ниже.
cd /$Hadoop_Home/sbin/
$ start-dfs.sh
localhost: starting namenode, logging to
/home/Hadoop/hadoop/logs/hadoop-Hadoop-namenode-localhost.localdomain.out
localhost: starting datanode, logging to
/home/Hadoop/hadoop/logs/hadoop-Hadoop-datanode-localhost.localdomain.out
Starting secondary namenodes [0.0.0.0]
starting secondarynamenode, logging to
/home/Hadoop/hadoop/logs/hadoop-Hadoop-secondarynamenode-localhost.localdomain.out
$ start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to
/home/Hadoop/hadoop/logs/yarn-Hadoop-resourcemanager-localhost.localdomain.out
localhost: starting nodemanager, logging to
/home/Hadoop/hadoop/logs/yarn-Hadoop-nodemanager-localhost.localdomain.outШаг 3. Создайте каталог в HDFS
В Hadoop DFS вы можете создавать каталоги с помощью команды mkdir. Просмотрите его и создайте каталог с названиемtwitter_data в нужном пути, как показано ниже.
$cd /$Hadoop_Home/bin/
$ hdfs dfs -mkdir hdfs://localhost:9000/user/Hadoop/twitter_dataНастройка Flume
Мы должны настроить источник, канал и приемник, используя файл конфигурации в confпапка. В примере, приведенном в этой главе, используется экспериментальный источник, предоставленный Apache Flume, с именемTwitter 1% Firehose Канал памяти и сток HDFS.
Twitter 1% Источник Firehose
Этот источник носит экспериментальный характер. Он подключается к 1% -ному образцу Twitter Firehose с помощью потокового API и непрерывно загружает твиты, конвертирует их в формат Avro и отправляет события Avro в нижний приемник Flume.
Мы получим этот источник по умолчанию вместе с установкой Flume. Вjar файлы, соответствующие этому источнику, могут быть расположены в lib папку, как показано ниже.

Установка пути к классам
Установить classpath переменная к lib папка Flume в Flume-env.sh файл, как показано ниже.
export CLASSPATH=$CLASSPATH:/FLUME_HOME/lib/*Этому источнику нужны такие подробности, как Consumer key, Consumer secret, Access token, и Access token secretприложения Twitter. При настройке этого источника вы должны указать значения для следующих свойств:
Channels
Source type : org.apache.flume.source.twitter.TwitterSource
consumerKey - Ключ клиента OAuth
consumerSecret - Секрет потребителя OAuth
accessToken - токен доступа OAuth
accessTokenSecret - Секрет токена OAuth
maxBatchSize- Максимальное количество сообщений Twitter, которое должно быть в пакете Twitter. Значение по умолчанию - 1000 (необязательно).
maxBatchDurationMillis- Максимальное количество миллисекунд ожидания перед закрытием пакета. Значение по умолчанию - 1000 (необязательно).
Канал
Мы используем канал памяти. Чтобы настроить канал памяти, вы должны указать значение для типа канала.
type- В нем указан тип канала. В нашем примере это типMemChannel.
Capacity- Это максимальное количество событий, хранящихся в канале. Его значение по умолчанию - 100 (необязательно).
TransactionCapacity- Это максимальное количество событий, которое канал принимает или отправляет. Его значение по умолчанию - 100 (необязательно).
Раковина HDFS
Этот приемник записывает данные в HDFS. Чтобы настроить этот приемник, вы должны предоставить следующие данные.
Channel
type - hdfs
hdfs.path - путь к каталогу в HDFS, в котором будут храниться данные.
И мы можем предоставить некоторые дополнительные значения в зависимости от сценария. Ниже приведены дополнительные свойства приемника HDFS, которые мы настраиваем в нашем приложении.
fileType - Это обязательный формат нашего файла HDFS. SequenceFile, DataStream и CompressedStreamтри типа доступны с этим потоком. В нашем примере мы используемDataStream.
writeFormat - Может быть текстовым или записываемым.
batchSize- Это количество событий, записанных в файл до того, как он будет сброшен в HDFS. Его значение по умолчанию - 100.
rollsize- Это размер файла для запуска прокрутки. Значение по умолчанию - 100.
rollCount- Это количество событий, записанных в файл перед его прокруткой. Его значение по умолчанию - 10.
Пример - файл конфигурации
Ниже приведен пример файла конфигурации. Скопируйте это содержимое и сохраните какtwitter.conf в папке conf Flume.
# Naming the components on the current agent.
TwitterAgent.sources = Twitter
TwitterAgent.channels = MemChannel
TwitterAgent.sinks = HDFS
# Describing/Configuring the source
TwitterAgent.sources.Twitter.type = org.apache.flume.source.twitter.TwitterSource
TwitterAgent.sources.Twitter.consumerKey = Your OAuth consumer key
TwitterAgent.sources.Twitter.consumerSecret = Your OAuth consumer secret
TwitterAgent.sources.Twitter.accessToken = Your OAuth consumer key access token
TwitterAgent.sources.Twitter.accessTokenSecret = Your OAuth consumer key access token secret
TwitterAgent.sources.Twitter.keywords = tutorials point,java, bigdata, mapreduce, mahout, hbase, nosql
# Describing/Configuring the sink
TwitterAgent.sinks.HDFS.type = hdfs
TwitterAgent.sinks.HDFS.hdfs.path = hdfs://localhost:9000/user/Hadoop/twitter_data/
TwitterAgent.sinks.HDFS.hdfs.fileType = DataStream
TwitterAgent.sinks.HDFS.hdfs.writeFormat = Text
TwitterAgent.sinks.HDFS.hdfs.batchSize = 1000
TwitterAgent.sinks.HDFS.hdfs.rollSize = 0
TwitterAgent.sinks.HDFS.hdfs.rollCount = 10000
# Describing/Configuring the channel
TwitterAgent.channels.MemChannel.type = memory
TwitterAgent.channels.MemChannel.capacity = 10000
TwitterAgent.channels.MemChannel.transactionCapacity = 100
# Binding the source and sink to the channel
TwitterAgent.sources.Twitter.channels = MemChannel
TwitterAgent.sinks.HDFS.channel = MemChannelИсполнение
Просмотрите домашний каталог Flume и запустите приложение, как показано ниже.
$ cd $FLUME_HOME
$ bin/flume-ng agent --conf ./conf/ -f conf/twitter.conf
Dflume.root.logger=DEBUG,console -n TwitterAgentЕсли все пойдет нормально, начнется потоковая передача твитов в HDFS. Ниже приведен снимок окна командной строки при получении твитов.
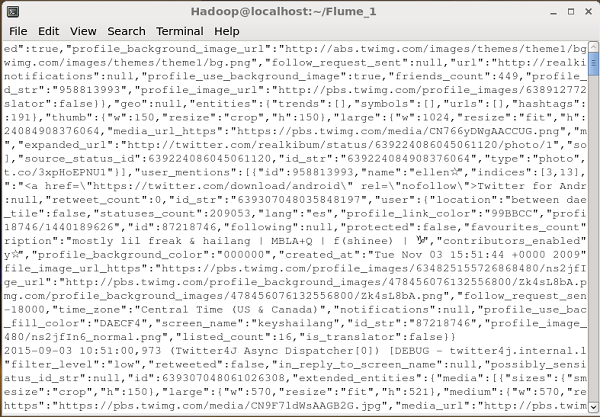
Проверка HDFS
Вы можете получить доступ к веб-интерфейсу администрирования Hadoop по указанному ниже URL-адресу.
http://localhost:50070/Щелкните раскрывающийся список с именем Utilitiesв правой части страницы. Вы можете увидеть два варианта, как показано на снимке, приведенном ниже.
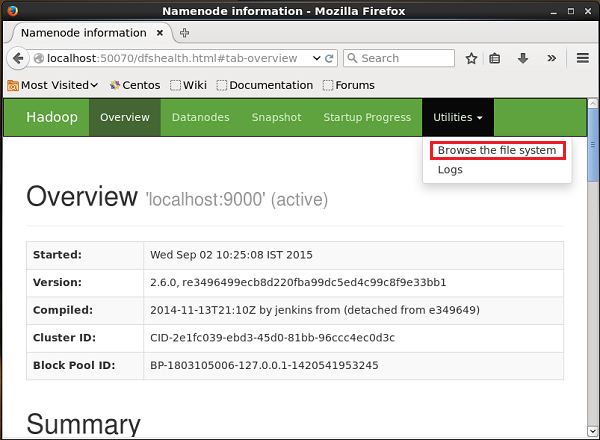
Нажмите на Browse the file systemи введите путь к каталогу HDFS, в котором вы сохранили твиты. В нашем примере путь будет/user/Hadoop/twitter_data/. Затем вы можете увидеть список файлов журнала Twitter, хранящихся в HDFS, как показано ниже.
