Apache Flume - источник генератора последовательности
В предыдущей главе мы увидели, как получить данные из источника Twitter в HDFS. В этой главе объясняется, как получить данные изSequence generator.
Предпосылки
Чтобы запустить пример, приведенный в этой главе, вам необходимо установить HDFS вместе с Flume. Поэтому проверьте установку Hadoop и запустите HDFS, прежде чем продолжить. (Обратитесь к предыдущей главе, чтобы узнать, как запустить HDFS).
Настройка Flume
Мы должны настроить источник, канал и приемник, используя файл конфигурации в confпапка. В примере, приведенном в этой главе, используетсяsequence generator source, а memory channel, и HDFS sink.
Источник генератора последовательности
Это источник, который постоянно генерирует события. Он поддерживает счетчик, который начинается с 0 и увеличивается на 1. Он используется для целей тестирования. При настройке этого источника вы должны указать значения для следующих свойств:
Channels
Source type - seq
Канал
Мы используем memoryканал. Чтобы настроить канал памяти, вы должны указать значение для типа канала. Ниже приведен список свойств, которые необходимо указать при настройке канала памяти.
type- В нем указан тип канала. В нашем примере это MemChannel.
Capacity- Это максимальное количество событий, хранящихся в канале. Его значение по умолчанию - 100. (необязательно)
TransactionCapacity- Это максимальное количество событий, которое канал принимает или отправляет. Его значение по умолчанию - 100. (необязательно).
Раковина HDFS
Этот приемник записывает данные в HDFS. Чтобы настроить этот приемник, вы должны предоставить следующие данные.
Channel
type - hdfs
hdfs.path - путь к каталогу в HDFS, в котором будут храниться данные.
И мы можем предоставить некоторые дополнительные значения в зависимости от сценария. Ниже приведены дополнительные свойства приемника HDFS, которые мы настраиваем в нашем приложении.
fileType - Это обязательный формат нашего файла HDFS. SequenceFile, DataStream а также CompressedStreamтри типа доступны с этим потоком. В нашем примере мы используемDataStream.
writeFormat - Может быть текстовым или записываемым.
batchSize- Это количество событий, записанных в файл до того, как он будет сброшен в HDFS. Его значение по умолчанию - 100.
rollsize- Это размер файла для запуска прокрутки. Значение по умолчанию - 100.
rollCount- Это количество событий, записанных в файл перед его прокруткой. Его значение по умолчанию - 10.
Пример - файл конфигурации
Ниже приведен пример файла конфигурации. Скопируйте это содержимое и сохраните какseq_gen .conf в папке conf Flume.
# Naming the components on the current agent
SeqGenAgent.sources = SeqSource
SeqGenAgent.channels = MemChannel
SeqGenAgent.sinks = HDFS
# Describing/Configuring the source
SeqGenAgent.sources.SeqSource.type = seq
# Describing/Configuring the sink
SeqGenAgent.sinks.HDFS.type = hdfs
SeqGenAgent.sinks.HDFS.hdfs.path = hdfs://localhost:9000/user/Hadoop/seqgen_data/
SeqGenAgent.sinks.HDFS.hdfs.filePrefix = log
SeqGenAgent.sinks.HDFS.hdfs.rollInterval = 0
SeqGenAgent.sinks.HDFS.hdfs.rollCount = 10000
SeqGenAgent.sinks.HDFS.hdfs.fileType = DataStream
# Describing/Configuring the channel
SeqGenAgent.channels.MemChannel.type = memory
SeqGenAgent.channels.MemChannel.capacity = 1000
SeqGenAgent.channels.MemChannel.transactionCapacity = 100
# Binding the source and sink to the channel
SeqGenAgent.sources.SeqSource.channels = MemChannel
SeqGenAgent.sinks.HDFS.channel = MemChannelИсполнение
Просмотрите домашний каталог Flume и запустите приложение, как показано ниже.
$ cd $FLUME_HOME
$./bin/flume-ng agent --conf $FLUME_CONF --conf-file $FLUME_CONF/seq_gen.conf
--name SeqGenAgentЕсли все идет хорошо, источник начинает генерировать порядковые номера, которые будут помещены в HDFS в виде файлов журнала.
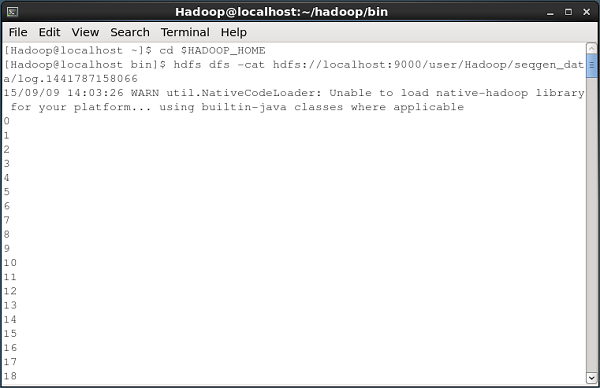
Ниже приведен снимок окна командной строки, в котором данные, созданные генератором последовательности, загружаются в HDFS.

Проверка HDFS
Вы можете получить доступ к веб-интерфейсу администрирования Hadoop, используя следующий URL-адрес -
http://localhost:50070/Щелкните раскрывающийся список с именем Utilitiesв правой части страницы. Вы можете увидеть два варианта, как показано на диаграмме ниже.
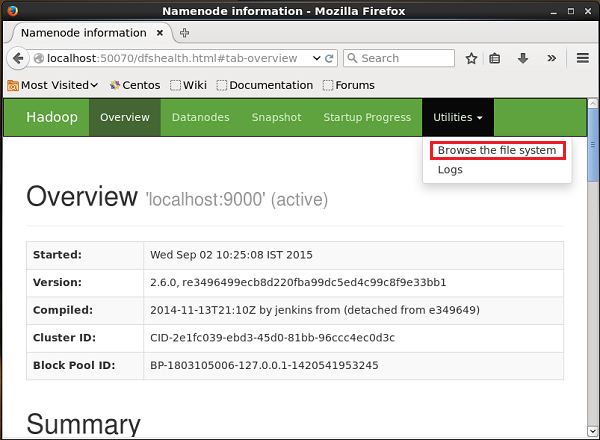
Нажмите на Browse the file system и введите путь к каталогу HDFS, в котором вы сохранили данные, созданные генератором последовательности.
В нашем примере путь будет /user/Hadoop/ seqgen_data /. Затем вы можете увидеть список файлов журнала, сгенерированных генератором последовательностей, хранящихся в HDFS, как показано ниже.

Проверка содержимого файла
Все эти файлы журналов содержат числа в последовательном формате. Вы можете проверить содержимое этого файла в файловой системе, используяcat как показано ниже.