Apache Storm - основные концепции
Apache Storm считывает необработанный поток данных в реальном времени с одного конца и передает его через последовательность небольших блоков обработки и выводит обработанную / полезную информацию на другом конце.
На следующей схеме изображена основная концепция Apache Storm.

Давайте теперь подробнее рассмотрим компоненты Apache Storm -
| Составные части | Описание |
|---|---|
| Кортеж | Кортеж - это основная структура данных в Storm. Это список упорядоченных элементов. По умолчанию кортеж поддерживает все типы данных. Как правило, он моделируется как набор значений, разделенных запятыми, и передается в кластер Storm. |
| Ручей | Stream - это неупорядоченная последовательность кортежей. |
| Носики | Источник потока. Обычно Storm принимает входные данные из источников сырых данных, таких как Twitter Streaming API, очередь Apache Kafka, очередь Kestrel и т. Д. В противном случае вы можете написать носики для чтения данных из источников данных. «ISpout» - это основной интерфейс для реализации носиков. Некоторые из конкретных интерфейсов - IRichSpout, BaseRichSpout, KafkaSpout и т. Д. |
| Болты | Болты - это логические блоки обработки. Носики передают данные для обработки болтов и болтов и создают новый выходной поток. Bolts может выполнять операции фильтрации, агрегирования, объединения, взаимодействия с источниками данных и базами данных. Bolt получает данные и отправляет их на один или несколько болтов. «IBolt» - это основной интерфейс для установки болтов. Некоторые из распространенных интерфейсов - IRichBolt, IBasicBolt и т. Д. |
Давайте возьмем пример «анализа Twitter» в реальном времени и посмотрим, как его можно смоделировать в Apache Storm. На следующей схеме изображена структура.

Входные данные для «анализа Twitter» поступают из Twitter Streaming API. Spout будет читать твиты пользователей, использующих Twitter Streaming API, и выводить их в виде потока кортежей. Один кортеж из носика будет иметь имя пользователя twitter и один твит в виде значений, разделенных запятыми. Затем эта пара кортежей будет направлена в Bolt, и Bolt разделит твит на отдельные слова, вычислит количество слов и сохранит информацию в настроенном источнике данных. Теперь мы можем легко получить результат, запросив источник данных.
Топология
Изливы и болты соединены вместе и образуют топологию. Логика приложения реального времени указывается в топологии Storm. Проще говоря, топология - это ориентированный граф, в котором вершины - это вычисления, а ребра - это поток данных.
Простая топология начинается с изливов. Носик передает данные на один или несколько болтов. Болт представляет собой узел в топологии, имеющий наименьшую логику обработки, и выходные данные болта могут передаваться в другой болт в качестве входных данных.
Storm поддерживает топологию всегда в рабочем состоянии, пока вы не уничтожите топологию. Основная задача Apache Storm - запускать топологию и запускать любое количество топологий одновременно.
Задачи
Теперь у вас есть общее представление о носиках и болтах. Они представляют собой наименьшую логическую единицу топологии, и топология строится с использованием единственного желоба и массива болтов. Они должны выполняться правильно в определенном порядке для успешной работы топологии. Выполнение каждой из струй и болтов Storm называется «Задачами». Проще говоря, задача - это выполнение излива или засова. В определенный момент каждый излив и болт может иметь несколько экземпляров, работающих с несколькими отдельными резьбами.
Рабочие
Топология работает распределенным образом на нескольких рабочих узлах. Storm равномерно распределяет задачи по всем рабочим узлам. Роль рабочего узла состоит в том, чтобы отслеживать задания и запускать или останавливать процессы всякий раз, когда приходит новое задание.
Группировка потоков
Поток данных течет от носика к болту или от одного болта к другому. Группировка потоков контролирует то, как кортежи маршрутизируются в топологии, и помогает нам понять поток кортежей в топологии. Как описано ниже, существует четыре встроенных группировки.
Группировка в случайном порядке
При группировании в случайном порядке одинаковое количество кортежей распределяется случайным образом между всеми рабочими, выполняющими болты. На следующей схеме изображена структура.

Группировка полей
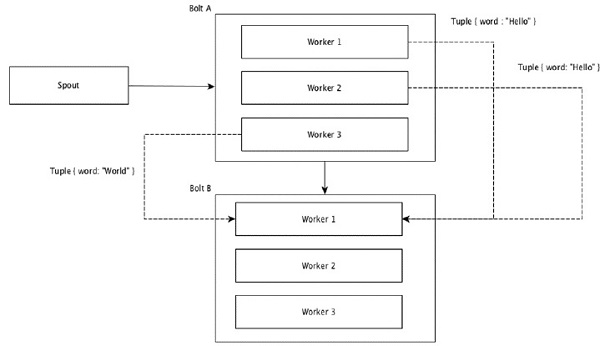
Поля с одинаковыми значениями в кортежах группируются вместе, а остальные кортежи остаются снаружи. Затем кортежи с одинаковыми значениями полей отправляются одному и тому же исполнителю, выполняющему болты. Например, если поток сгруппирован по полю «word», то кортежи с одинаковой строкой «Hello» переместятся к одному и тому же исполнителю. На следующей диаграмме показано, как работает группировка полей.

Глобальная группировка
Все потоки можно сгруппировать и направить на один болт. Эта группировка отправляет кортежи, созданные всеми экземплярами источника, в один целевой экземпляр (в частности, выберите исполнителя с наименьшим идентификатором).
Вся группировка
All Grouping отправляет одну копию каждого кортежа всем экземплярам принимающего болта. Такая группировка используется для отправки сигналов болтам. Все группировки полезны для операций соединения.
