Apache Storm - Краткое руководство
Что такое Apache Storm?
Apache Storm - это распределенная система обработки больших данных в реальном времени. Storm разработан для обработки огромного количества данных отказоустойчивым и горизонтально масштабируемым методом. Это структура потоковой передачи данных с максимальной скоростью приема. Хотя Storm не имеет состояния, он управляет распределенной средой и состоянием кластера через Apache ZooKeeper. Это просто, и вы можете параллельно выполнять всевозможные манипуляции с данными в реальном времени.
Apache Storm продолжает оставаться лидером в области анализа данных в реальном времени. Storm прост в настройке, эксплуатации и гарантирует, что каждое сообщение будет обрабатываться через топологию хотя бы один раз.
Apache Storm против Hadoop
В основном для анализа больших данных используются фреймворки Hadoop и Storm. Оба они дополняют друг друга и отличаются некоторыми аспектами. Apache Storm выполняет все операции, кроме постоянства, в то время как Hadoop хорош во всем, но отстает в вычислениях в реальном времени. В следующей таблице сравниваются атрибуты Storm и Hadoop.
| Буря | Hadoop |
|---|---|
| Обработка потока в реальном времени | Пакетная обработка |
| Без гражданства | С сохранением состояния |
| Архитектура Master / Slave с координацией на основе ZooKeeper. Главный узел называетсяnimbus и рабы supervisors. | Архитектура ведущий-ведомый с / без координации на основе ZooKeeper. Главный узелjob tracker и подчиненный узел task tracker. |
| Процесс потоковой передачи Storm может получать доступ к десяткам тысяч сообщений в секунду в кластере. | Распределенная файловая система Hadoop (HDFS) использует инфраструктуру MapReduce для обработки огромного количества данных, которая занимает минуты или часы. |
| Топология Storm работает до завершения работы пользователя или до непредвиденного неисправимого сбоя. | Задания MapReduce выполняются в последовательном порядке и в конечном итоге завершаются. |
| Both are distributed and fault-tolerant | |
| Если нимб / супервизор умирает, перезапуск заставляет его продолжать с того места, где он остановился, поэтому ничего не меняется. | Если JobTracker умирает, все выполняемые задания теряются. |
Примеры использования Apache Storm
Apache Storm очень известен обработкой больших потоков данных в реальном времени. По этой причине большинство компаний используют Storm как неотъемлемую часть своей системы. Вот некоторые известные примеры:
Twitter- Twitter использует Apache Storm для своего ряда «продуктов Publisher Analytics». «Продукты Publisher Analytics» обрабатывают каждый твит и клик на платформе Twitter. Apache Storm глубоко интегрирован с инфраструктурой Twitter.
NaviSite- NaviSite использует Storm для системы мониторинга / аудита журналов событий. Все журналы, созданные в системе, будут проходить через Storm. Storm проверит сообщение на соответствие настроенному набору регулярных выражений и, если есть совпадение, то конкретное сообщение будет сохранено в базе данных.
Wego- Wego - это система метапоиска о путешествиях, расположенная в Сингапуре. Данные о путешествиях поступают из множества источников по всему миру в разное время. Storm помогает Wego искать данные в режиме реального времени, устраняет проблемы с параллелизмом и находит наилучшее соответствие для конечного пользователя.
Преимущества Apache Storm
Вот список преимуществ, которые предлагает Apache Storm -
Storm имеет открытый исходный код, надежен и удобен для пользователя. Его можно использовать как в небольших компаниях, так и в крупных корпорациях.
Storm отказоустойчив, гибок, надежен и поддерживает любой язык программирования.
Позволяет обрабатывать поток в реальном времени.
Storm невероятно быстр, потому что он обладает огромной мощностью обработки данных.
Storm может поддерживать производительность даже при возрастающей нагрузке, линейно добавляя ресурсы. Он хорошо масштабируется.
Storm выполняет обновление данных и ответ сквозной доставки за секунды или минуты, в зависимости от проблемы. У него очень низкая задержка.
У Шторма есть оперативная разведка.
Storm обеспечивает гарантированную обработку данных, даже если какой-либо из подключенных узлов в кластере умирает или теряются сообщения.
Apache Storm считывает необработанный поток данных в реальном времени с одного конца и передает его через последовательность небольших блоков обработки и выводит обработанную / полезную информацию на другом конце.
На следующей схеме изображена основная концепция Apache Storm.

Давайте теперь подробнее рассмотрим компоненты Apache Storm -
| Составные части | Описание |
|---|---|
| Кортеж | Кортеж - это основная структура данных в Storm. Это список упорядоченных элементов. По умолчанию кортеж поддерживает все типы данных. Обычно он моделируется как набор значений, разделенных запятыми, и передается в кластер Storm. |
| Поток | Stream - это неупорядоченная последовательность кортежей. |
| Носики | Источник потока. Обычно Storm принимает входные данные из источников необработанных данных, таких как Twitter Streaming API, очередь Apache Kafka, очередь Kestrel и т. Д. В противном случае вы можете написать носики для чтения данных из источников данных. «ISpout» - это основной интерфейс для реализации носиков. Некоторые из конкретных интерфейсов - IRichSpout, BaseRichSpout, KafkaSpout и т. Д. |
| Болты | Болты - это логические блоки обработки. Носики передают данные для обработки болтов и болтов и создают новый выходной поток. Bolts может выполнять операции фильтрации, агрегирования, объединения, взаимодействия с источниками данных и базами данных. Bolt получает данные и отправляет их на один или несколько болтов. «IBolt» - это основной интерфейс для установки болтов. Некоторые из распространенных интерфейсов - IRichBolt, IBasicBolt и т. Д. |
Давайте возьмем пример «анализа Twitter» в реальном времени и посмотрим, как его можно смоделировать в Apache Storm. На следующей схеме изображена структура.

Входные данные для «Анализа Twitter» поступают из API потоковой передачи Twitter. Spout будет читать твиты пользователей, использующих Twitter Streaming API, и выводить их в виде потока кортежей. Один кортеж из носика будет иметь имя пользователя twitter и один твит в виде значений, разделенных запятыми. Затем эта пара кортежей будет отправлена в Bolt, и Bolt разделит твит на отдельные слова, вычислит количество слов и сохранит информацию в настроенном источнике данных. Теперь мы можем легко получить результат, запросив источник данных.
Топология
Изливы и болты соединены вместе и образуют топологию. Логика приложения реального времени указывается в топологии Storm. Проще говоря, топология - это ориентированный граф, в котором вершины - это вычисления, а ребра - это поток данных.
Простая топология начинается с изливов. Носик передает данные на один или несколько болтов. Болт представляет собой узел в топологии, имеющий наименьшую логику обработки, и выходные данные болта могут передаваться в другой болт в качестве входных данных.
Storm поддерживает топологию всегда в рабочем состоянии, пока вы не уничтожите топологию. Основная задача Apache Storm - запускать топологию и запускать любое количество топологий одновременно.
Задания
Теперь у вас есть общее представление о носиках и болтах. Они представляют собой наименьшую логическую единицу топологии, и топология строится с использованием единственного желоба и массива болтов. Они должны выполняться правильно в определенном порядке для успешной работы топологии. Выполнение каждой из струй и болтов Storm называется «Задачами». Проще говоря, задача - это выполнение излива или засова. В определенный момент каждый излив и болт может иметь несколько экземпляров, работающих с несколькими отдельными резьбами.
Рабочие
Топология работает распределенным образом на нескольких рабочих узлах. Storm равномерно распределяет задачи по всем рабочим узлам. Роль рабочего узла состоит в том, чтобы отслеживать задания и запускать или останавливать процессы всякий раз, когда приходит новое задание.
Группировка потоков
Поток данных течет от носика к болту или от одного болта к другому. Группировка потоков контролирует то, как кортежи маршрутизируются в топологии, и помогает нам понять поток кортежей в топологии. Как описано ниже, существует четыре встроенных группировки.
Группировка в случайном порядке
При группировании в случайном порядке одинаковое количество кортежей случайным образом распределяется между всеми рабочими, выполняющими болты. На следующей схеме изображена структура.

Группировка полей
Поля с одинаковыми значениями в кортежах группируются вместе, а остальные кортежи остаются снаружи. Затем кортежи с одинаковыми значениями полей отправляются одному и тому же исполнителю, выполняющему болты. Например, если поток сгруппирован по полю «word», то кортежи с одинаковой строкой «Hello» переместятся к одному и тому же исполнителю. На следующей диаграмме показано, как работает группировка полей.

Глобальная группировка
Все потоки можно сгруппировать и направить на один болт. Эта группировка отправляет кортежи, созданные всеми экземплярами источника, в один целевой экземпляр (в частности, выберите исполнителя с наименьшим идентификатором).
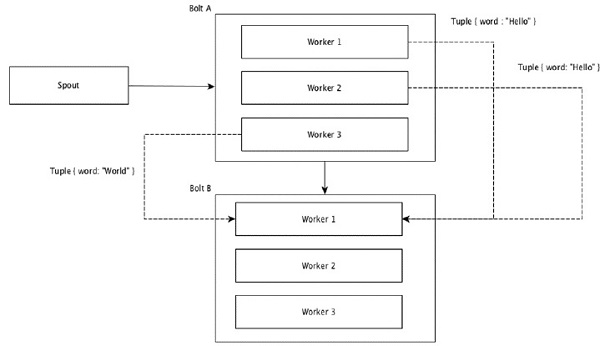
Вся группировка
All Grouping отправляет одну копию каждого кортежа всем экземплярам принимающего болта. Такая группировка используется для отправки сигналов болтам. Все группировки полезны для операций соединения.

Одной из главных особенностей Apache Storm является то, что это отказоустойчивое, быстрое распределенное приложение без единой точки отказа (SPOF). Мы можем установить Apache Storm в любом количестве систем, чтобы увеличить емкость приложения.
Давайте посмотрим, как устроен кластер Apache Storm и его внутреннюю архитектуру. На следующей диаграмме изображена конструкция кластера.

Apache Storm имеет два типа узлов: Nimbus (главный узел) и Supervisor(рабочий узел). Nimbus - центральный компонент Apache Storm. Основная задача Nimbus - запуск топологии Storm. Nimbus анализирует топологию и собирает задачи для выполнения. Затем он передаст задачу доступному супервизору.
У супервизора будет один или несколько рабочих процессов. Супервизор делегирует задачи рабочим процессам. Рабочий процесс порождает столько исполнителей, сколько необходимо, и запускает задачу. Apache Storm использует внутреннюю распределенную систему обмена сообщениями для связи между nimbus и супервизорами.
| Составные части | Описание |
|---|---|
| Нимбус | Nimbus - главный узел кластера Storm. Все остальные узлы в кластере называютсяworker nodes. Главный узел отвечает за распределение данных между всеми рабочими узлами, назначение задач рабочим узлам и мониторинг сбоев. |
| Руководитель | Узлы, которые следуют инструкциям нимба, называются супервизорами. Аsupervisor имеет несколько рабочих процессов и управляет рабочими процессами для выполнения задач, назначенных нимбом. |
| Рабочий процесс | Рабочий процесс будет выполнять задачи, относящиеся к определенной топологии. Рабочий процесс не будет запускать задачу сам по себе, вместо этого он создаетexecutorsи просит их выполнить определенную задачу. У рабочего процесса будет несколько исполнителей. |
| Исполнитель | Исполнитель - это не что иное, как единственный поток, порожденный рабочим процессом. Исполнитель выполняет одну или несколько задач, но только для определенного носика или болта. |
| Задача | Задача выполняет фактическую обработку данных. Значит, это либо носик, либо болт. |
| Фреймворк ZooKeeper | Apache ZooKeeper - это служба, используемая кластером (группой узлов) для координации между собой и поддержания общих данных с помощью надежных методов синхронизации. Nimbus не имеет состояния, поэтому ZooKeeper может контролировать состояние рабочего узла. ZooKeeper помогает супервизору взаимодействовать с нимбом. Он отвечает за поддержание состояния венчика и супервизора. |
Шторм по своей природе не имеет гражданства. Несмотря на то, что природа без сохранения состояния имеет свои недостатки, на самом деле она помогает Storm обрабатывать данные в реальном времени самым лучшим и быстрым способом.
Однако Storm не совсем апатрид. Он хранит свое состояние в Apache ZooKeeper. Поскольку состояние доступно в Apache ZooKeeper, отказавший нимб можно перезапустить и заставить работать с того места, где он остался. Обычно инструменты мониторинга сервисов, такие какmonit будет отслеживать Nimbus и перезапускать его в случае сбоя.
Apache Storm также имеет расширенную топологию, называемую Trident Topologyс обслуживанием состояния, а также предоставляет высокоуровневый API, такой как Pig. Мы обсудим все эти особенности в следующих главах.
В рабочем кластере Storm должен быть один нимб и один или несколько супервизоров. Другой важный узел - Apache ZooKeeper, который будет использоваться для координации между нимбом и супервизорами.
Давайте теперь внимательно посмотрим на рабочий процесс Apache Storm -
Изначально нимб будет ждать, пока ему не будет представлена «Топология шторма».
После отправки топологии он обработает топологию и соберет все задачи, которые должны быть выполнены, а также порядок, в котором задача должна быть выполнена.
Затем нимб равномерно распределяет задачи по всем доступным супервизорам.
В определенный промежуток времени все супервизоры будут отправлять сердцебиение нимбу, чтобы сообщить, что они все еще живы.
Когда супервизор умирает и не посылает сердцебиение нимбу, то нимб назначает задачи другому супервизору.
Когда умирает сам нимб, супервизоры будут работать над уже назначенной задачей без каких-либо проблем.
Как только все задачи будут завершены, супервизор будет ждать поступления новой задачи.
А пока мертвый нимб будет перезапущен автоматически инструментами сервисного мониторинга.
Перезапущенный нимб продолжится с того места, где он остановился. Точно так же можно автоматически перезапустить мертвый супервизор. Поскольку и нимб, и супервизор могут быть перезапущены автоматически, и оба будут продолжать работу, как и раньше, Storm гарантированно обработает всю задачу хотя бы один раз.
После того, как все топологии обработаны, нимб ожидает прибытия новой топологии, и аналогично супервизор ждет новых задач.
По умолчанию в кластере Storm есть два режима:
Local mode- Этот режим используется для разработки, тестирования и отладки, потому что это самый простой способ увидеть, как все компоненты топологии работают вместе. В этом режиме мы можем настроить параметры, которые позволят нам увидеть, как наша топология работает в различных средах конфигурации Storm. В локальном режиме топологии шторма выполняются на локальном компьютере в одной JVM.
Production mode- В этом режиме мы отправляем нашу топологию в рабочий штормовой кластер, который состоит из множества процессов, обычно работающих на разных машинах. Как обсуждалось в рабочем процессе шторма, рабочий кластер будет работать бесконечно, пока не будет остановлен.
Apache Storm обрабатывает данные в реальном времени, и ввод обычно поступает из системы очередей сообщений. Внешняя распределенная система обмена сообщениями предоставит ввод, необходимый для вычислений в реальном времени. Spout будет читать данные из системы обмена сообщениями, преобразовывать их в кортежи и вводить в Apache Storm. Интересен тот факт, что Apache Storm внутренне использует собственную распределенную систему обмена сообщениями для связи между своим нимбом и супервизором.
Что такое распределенная система обмена сообщениями?
Распределенный обмен сообщениями основан на концепции надежной организации очереди сообщений. Сообщения ставятся в очередь асинхронно между клиентскими приложениями и системами обмена сообщениями. Распределенная система обмена сообщениями обеспечивает такие преимущества, как надежность, масштабируемость и постоянство.
Большинство шаблонов сообщений следуют publish-subscribe модель (просто Pub-Sub) где отправители сообщений называются publishers а тех, кто хочет получать сообщения, называют subscribers.
После того, как сообщение было опубликовано отправителем, подписчики могут получить выбранное сообщение с помощью опции фильтрации. Обычно у нас есть два типа фильтрации, один из нихtopic-based filtering и еще один content-based filtering.
Обратите внимание, что модель pub-sub может общаться только через сообщения. Это очень слабо связанная архитектура; даже отправители не знают своих подписчиков. Многие шаблоны сообщений позволяют брокеру сообщений обмениваться опубликованными сообщениями для своевременного доступа многих подписчиков. Примером из реальной жизни является Dish TV, которое публикует различные каналы, такие как спорт, фильмы, музыка и т. Д., И любой может подписаться на свой собственный набор каналов и получать их всякий раз, когда доступны каналы, на которые они подписаны.
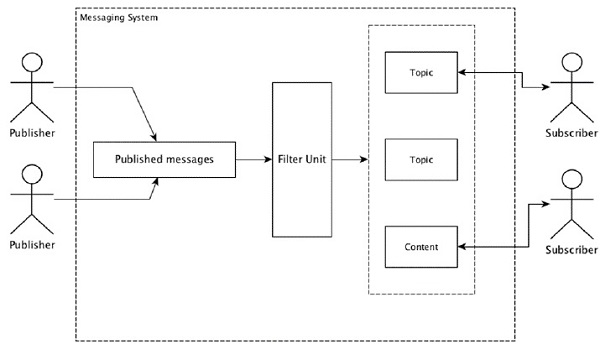
В следующей таблице описаны некоторые из популярных систем обмена сообщениями с высокой пропускной способностью.
| Распределенная система обмена сообщениями | Описание |
|---|---|
| Апач Кафка | Kafka разрабатывалась в корпорации LinkedIn, а позже стала подпроектом Apache. Apache Kafka основан на постоянной, распределенной модели публикации-подписки с поддержкой брокера. Kafka быстрый, масштабируемый и высокоэффективный. |
| RabbitMQ | RabbitMQ - это надежное распределенное приложение для обмена сообщениями с открытым исходным кодом. Он прост в использовании и работает на всех платформах. |
| JMS (служба сообщений Java) | JMS - это API с открытым исходным кодом, который поддерживает создание, чтение и отправку сообщений из одного приложения в другое. Он обеспечивает гарантированную доставку сообщений и следует модели публикации-подписки. |
| ActiveMQ | Система обмена сообщениями ActiveMQ - это API JMS с открытым исходным кодом. |
| ZeroMQ | ZeroMQ - это одноранговая обработка сообщений без посредника. Он обеспечивает модели двухтактных сообщений маршрутизатора-дилера. |
| Пустельга | Kestrel - это быстрая, надежная и простая распределенная очередь сообщений. |
Экономический протокол
Компания Thrift была создана в Facebook для разработки межъязыковых сервисов и удаленного вызова процедур (RPC). Позже он стал проектом Apache с открытым исходным кодом. Apache Thrift - этоInterface Definition Language и позволяет легко определять новые типы данных и реализацию служб поверх определенных типов данных.
Apache Thrift также является коммуникационной платформой, которая поддерживает встроенные системы, мобильные приложения, веб-приложения и многие другие языки программирования. Некоторые из ключевых особенностей Apache Thrift - это его модульность, гибкость и высокая производительность. Кроме того, он может выполнять потоковую передачу, обмен сообщениями и RPC в распределенных приложениях.
Storm широко использует протокол Thrift для внутренней связи и определения данных. Топология шторма простаThrift Structs. Storm Nimbus, который запускает топологию в Apache Storm, являетсяThrift service.
Давайте теперь посмотрим, как установить инфраструктуру Apache Storm на ваш компьютер. Здесь есть три основных шага -
- Установите Java в свою систему, если у вас ее еще нет.
- Установите фреймворк ZooKeeper.
- Установите фреймворк Apache Storm.
Шаг 1. Проверка установки Java
Используйте следующую команду, чтобы проверить, установлена ли в вашей системе Java.
$ java -versionЕсли Java уже существует, вы увидите номер ее версии. В противном случае загрузите последнюю версию JDK.
Шаг 1.1 - Загрузите JDK
Загрузите последнюю версию JDK по следующей ссылке - www.oracle.com
Последняя версия - JDK 8u 60, а файл “jdk-8u60-linux-x64.tar.gz”. Загрузите файл на свой компьютер.
Шаг 1.2 - Извлечение файлов
Обычно файлы загружаются на downloadsпапка. Извлеките установку tar, используя следующие команды.
$ cd /go/to/download/path
$ tar -zxf jdk-8u60-linux-x64.gzШаг 1.3 - Перейти в каталог opt
Чтобы сделать Java доступной для всех пользователей, переместите извлеченное содержимое Java в папку «/ usr / local / java».
$ su
password: (type password of root user)
$ mkdir /opt/jdk
$ mv jdk-1.8.0_60 /opt/jdk/Шаг 1.4 - Установите путь
Чтобы задать путь и переменные JAVA_HOME, добавьте следующие команды в файл ~ / .bashrc.
export JAVA_HOME =/usr/jdk/jdk-1.8.0_60
export PATH=$PATH:$JAVA_HOME/binТеперь примените все изменения к текущей работающей системе.
$ source ~/.bashrcШаг 1.5 - Альтернативы Java
Используйте следующую команду, чтобы изменить альтернативы Java.
update-alternatives --install /usr/bin/java java /opt/jdk/jdk1.8.0_60/bin/java 100Шаг 1.6
Теперь проверьте установку Java с помощью команды проверки (java -version) объяснено на шаге 1.
Шаг 2 - Установка ZooKeeper Framework
Шаг 2.1 - Загрузите ZooKeeper
Чтобы установить ZooKeeper framework на свой компьютер, перейдите по следующей ссылке и загрузите последнюю версию ZooKeeper http://zookeeper.apache.org/releases.html
На данный момент последняя версия ZooKeeper - 3.4.6 (ZooKeeper-3.4.6.tar.gz).
Шаг 2.2 - Извлечение tar-файла
Извлеките tar-файл, используя следующие команды -
$ cd opt/
$ tar -zxf zookeeper-3.4.6.tar.gz
$ cd zookeeper-3.4.6
$ mkdir dataШаг 2.3 - Создайте файл конфигурации
Откройте файл конфигурации с именем «conf / zoo.cfg», используя команду «vi conf / zoo.cfg» и задав все следующие параметры в качестве отправной точки.
$ vi conf/zoo.cfg
tickTime=2000
dataDir=/path/to/zookeeper/data
clientPort=2181
initLimit=5
syncLimit=2После успешного сохранения файла конфигурации вы можете запустить сервер ZooKeeper.
Шаг 2.4 - Запустите сервер ZooKeeper
Используйте следующую команду, чтобы запустить сервер ZooKeeper.
$ bin/zkServer.sh startПосле выполнения этой команды вы получите следующий ответ:
$ JMX enabled by default
$ Using config: /Users/../zookeeper-3.4.6/bin/../conf/zoo.cfg
$ Starting zookeeper ... STARTEDШаг 2.5 - Запустите CLI
Используйте следующую команду, чтобы запустить CLI.
$ bin/zkCli.shПосле выполнения указанной выше команды вы будете подключены к серверу ZooKeeper и получите следующий ответ.
Connecting to localhost:2181
................
................
................
Welcome to ZooKeeper!
................
................
WATCHER::
WatchedEvent state:SyncConnected type: None path:null
[zk: localhost:2181(CONNECTED) 0]Шаг 2.6 - Остановите сервер ZooKeeper
После подключения сервера и выполнения всех операций вы можете остановить сервер ZooKeeper, используя следующую команду.
bin/zkServer.sh stopВы успешно установили Java и ZooKeeper на свой компьютер. Давайте теперь посмотрим, как установить Apache Storm framework.
Шаг 3 - Установка Apache Storm Framework
Шаг 3.1. Скачать Storm
Чтобы установить Storm framework на свой компьютер, перейдите по следующей ссылке и загрузите последнюю версию Storm http://storm.apache.org/downloads.html
На данный момент последняя версия Storm - «apache-storm-0.9.5.tar.gz».
Шаг 3.2 - Извлеките tar-файл
Извлеките tar-файл, используя следующие команды -
$ cd opt/
$ tar -zxf apache-storm-0.9.5.tar.gz
$ cd apache-storm-0.9.5
$ mkdir dataШаг 3.3 - Откройте файл конфигурации
Текущая версия Storm содержит файл «conf / storm.yaml», который настраивает демонов Storm. Добавьте в этот файл следующую информацию.
$ vi conf/storm.yaml
storm.zookeeper.servers:
- "localhost"
storm.local.dir: “/path/to/storm/data(any path)”
nimbus.host: "localhost"
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703После применения всех изменений сохраните и вернитесь в терминал.
Шаг 3.4 - Запуск Nimbus
$ bin/storm nimbusШаг 3.5 - Запуск супервизора
$ bin/storm supervisorШаг 3.6. Запуск пользовательского интерфейса.
$ bin/storm uiПосле запуска приложения пользовательского интерфейса Storm введите URL-адрес http://localhost:8080в вашем любимом браузере, и вы сможете увидеть информацию о кластере Storm и его работающую топологию. Страница должна выглядеть примерно так, как показано на следующем снимке экрана.

Мы рассмотрели основные технические детали Apache Storm, и теперь пришло время написать несколько простых сценариев.
Сценарий - Анализатор журнала мобильных вызовов
Мобильный вызов и его продолжительность будут предоставлены в качестве входных данных для Apache Storm, и Storm обработает и сгруппирует вызов между одним и тем же вызывающим абонентом и получателем, а также их общее количество вызовов.
Создание носика
Носик - это компонент, который используется для генерации данных. По сути, носик реализует интерфейс IRichSpout. Интерфейс «IRichSpout» имеет следующие важные методы:
open- Обеспечивает среду для работы носика. Исполнители запустят этот метод для инициализации носика.
nextTuple - Выдает сгенерированные данные через коллектор.
close - Этот метод вызывается, когда излив собирается выключиться.
declareOutputFields - Объявляет схему вывода кортежа.
ack - Подтверждает, что конкретный кортеж обрабатывается
fail - Указывает, что конкретный кортеж не обрабатывается и не подлежит повторной обработке.
открыто
Подпись open метод выглядит следующим образом -
open(Map conf, TopologyContext context, SpoutOutputCollector collector)conf - Обеспечивает конфигурацию шторма для этого излива.
context - Предоставляет полную информацию о месте излива в топологии, его идентификаторе задачи, входной и выходной информации.
collector - Позволяет нам выдать кортеж, который будет обрабатываться болтами.
nextTuple
Подпись nextTuple метод выглядит следующим образом -
nextTuple()nextTuple () периодически вызывается из того же цикла, что и методы ack () и fail (). Он должен освободить контроль над потоком, когда нет работы, чтобы другие методы могли быть вызваны. Итак, первая строка nextTuple проверяет, завершена ли обработка. Если это так, он должен спать не менее одной миллисекунды, чтобы снизить нагрузку на процессор, прежде чем вернуться.
Закрыть
Подпись close метод выглядит следующим образом -
close()declareOutputFields
Подпись declareOutputFields метод выглядит следующим образом -
declareOutputFields(OutputFieldsDeclarer declarer)declarer - Он используется для объявления идентификаторов выходных потоков, полей вывода и т. Д.
Этот метод используется для указания выходной схемы кортежа.
подтверждать
Подпись ack метод выглядит следующим образом -
ack(Object msgId)Этот метод подтверждает, что определенный кортеж был обработан.
потерпеть поражение
Подпись nextTuple метод выглядит следующим образом -
ack(Object msgId)Этот метод сообщает, что конкретный кортеж не был полностью обработан. Storm повторно обработает конкретный кортеж.
FakeCallLogReaderSpout
В нашем сценарии нам нужно собрать данные журнала вызовов. Информация журнала вызовов содержит.
- номер звонящего
- номер получателя
- duration
Поскольку у нас нет информации о журналах вызовов в реальном времени, мы будем создавать поддельные журналы вызовов. Поддельная информация будет создана с использованием класса Random. Полный программный код приведен ниже.
Кодирование - FakeCallLogReaderSpout.java
import java.util.*;
//import storm tuple packages
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
//import Spout interface packages
import backtype.storm.topology.IRichSpout;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
//Create a class FakeLogReaderSpout which implement IRichSpout interface
to access functionalities
public class FakeCallLogReaderSpout implements IRichSpout {
//Create instance for SpoutOutputCollector which passes tuples to bolt.
private SpoutOutputCollector collector;
private boolean completed = false;
//Create instance for TopologyContext which contains topology data.
private TopologyContext context;
//Create instance for Random class.
private Random randomGenerator = new Random();
private Integer idx = 0;
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.context = context;
this.collector = collector;
}
@Override
public void nextTuple() {
if(this.idx <= 1000) {
List<String> mobileNumbers = new ArrayList<String>();
mobileNumbers.add("1234123401");
mobileNumbers.add("1234123402");
mobileNumbers.add("1234123403");
mobileNumbers.add("1234123404");
Integer localIdx = 0;
while(localIdx++ < 100 && this.idx++ < 1000) {
String fromMobileNumber = mobileNumbers.get(randomGenerator.nextInt(4));
String toMobileNumber = mobileNumbers.get(randomGenerator.nextInt(4));
while(fromMobileNumber == toMobileNumber) {
toMobileNumber = mobileNumbers.get(randomGenerator.nextInt(4));
}
Integer duration = randomGenerator.nextInt(60);
this.collector.emit(new Values(fromMobileNumber, toMobileNumber, duration));
}
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("from", "to", "duration"));
}
//Override all the interface methods
@Override
public void close() {}
public boolean isDistributed() {
return false;
}
@Override
public void activate() {}
@Override
public void deactivate() {}
@Override
public void ack(Object msgId) {}
@Override
public void fail(Object msgId) {}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}Создание болта
Bolt - это компонент, который принимает кортежи в качестве входных данных, обрабатывает кортежи и создает новые кортежи в качестве выходных данных. Болты осуществимIRichBoltинтерфейс. В этой программе два класса болтовCallLogCreatorBolt и CallLogCounterBolt используются для выполнения операций.
Интерфейс IRichBolt имеет следующие методы -
prepare- Предоставляет болту среду для выполнения. Исполнители запустят этот метод для инициализации носика.
execute - Обработать один кортеж ввода.
cleanup - Вызывается при отключении болта.
declareOutputFields - Объявляет схему вывода кортежа.
Подготовить
Подпись prepare метод выглядит следующим образом -
prepare(Map conf, TopologyContext context, OutputCollector collector)conf - Предоставляет конфигурацию Storm для этого болта.
context - Предоставляет полную информацию о месте болта в топологии, его идентификаторе задачи, входной и выходной информации и т. Д.
collector - Позволяет нам выдать обработанный кортеж.
выполнять
Подпись execute метод выглядит следующим образом -
execute(Tuple tuple)Вот tuple - входной кортеж, который нужно обработать.
В executeобрабатывает по одному кортежу за раз. Доступ к данным кортежа можно получить с помощью метода getValue класса Tuple. Нет необходимости немедленно обрабатывать входной кортеж. Несколько кортежей можно обработать и вывести как один выходной кортеж. Обработанный кортеж можно передать с помощью класса OutputCollector.
уборка
Подпись cleanup метод выглядит следующим образом -
cleanup()declareOutputFields
Подпись declareOutputFields метод выглядит следующим образом -
declareOutputFields(OutputFieldsDeclarer declarer)Здесь параметр declarer используется для объявления идентификаторов выходных потоков, полей вывода и т. д.
Этот метод используется для указания выходной схемы кортежа
Журнал вызовов Creator Bolt
Болт создателя журнала вызовов получает кортеж журнала вызовов. Кортеж журнала вызовов содержит номер вызывающего абонента, номер получателя и продолжительность разговора. Этот болт просто создает новое значение, комбинируя номер вызывающего абонента и номер получателя. Новое значение имеет формат «Номер вызывающего абонента - номер получателя» и называется новым полем «вызов». Полный код приведен ниже.
Кодирование - CallLogCreatorBolt.java
//import util packages
import java.util.HashMap;
import java.util.Map;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
//import Storm IRichBolt package
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Tuple;
//Create a class CallLogCreatorBolt which implement IRichBolt interface
public class CallLogCreatorBolt implements IRichBolt {
//Create instance for OutputCollector which collects and emits tuples to produce output
private OutputCollector collector;
@Override
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
@Override
public void execute(Tuple tuple) {
String from = tuple.getString(0);
String to = tuple.getString(1);
Integer duration = tuple.getInteger(2);
collector.emit(new Values(from + " - " + to, duration));
}
@Override
public void cleanup() {}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("call", "duration"));
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}Болт счетчика журнала вызовов
Болт счетчика журнала вызовов получает вызов и его продолжительность в виде кортежа. Этот болт инициализирует объект словаря (Map) в методе подготовки. Вexecuteметод, он проверяет кортеж и создает новую запись в объекте словаря для каждого нового значения «вызова» в кортеже и устанавливает значение 1 в объекте словаря. Для уже доступной записи в словаре она просто увеличивает ее значение. Проще говоря, этот болт сохраняет вызов и его счет в объекте словаря. Вместо того, чтобы сохранять вызов и его количество в словаре, мы также можем сохранить его в источник данных. Полный программный код выглядит следующим образом -
Кодирование - CallLogCounterBolt.java
import java.util.HashMap;
import java.util.Map;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Tuple;
public class CallLogCounterBolt implements IRichBolt {
Map<String, Integer> counterMap;
private OutputCollector collector;
@Override
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
this.counterMap = new HashMap<String, Integer>();
this.collector = collector;
}
@Override
public void execute(Tuple tuple) {
String call = tuple.getString(0);
Integer duration = tuple.getInteger(1);
if(!counterMap.containsKey(call)){
counterMap.put(call, 1);
}else{
Integer c = counterMap.get(call) + 1;
counterMap.put(call, c);
}
collector.ack(tuple);
}
@Override
public void cleanup() {
for(Map.Entry<String, Integer> entry:counterMap.entrySet()){
System.out.println(entry.getKey()+" : " + entry.getValue());
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("call"));
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}Создание топологии
Топология Storm - это, по сути, структура Thrift. Класс TopologyBuilder предоставляет простые и легкие методы для создания сложных топологий. Класс TopologyBuilder имеет методы для установки spout(setSpout) и установить болт (setBolt). Наконец, TopologyBuilder имеет createTopology для создания топологии. Используйте следующий фрагмент кода для создания топологии -
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("call-log-reader-spout", new FakeCallLogReaderSpout());
builder.setBolt("call-log-creator-bolt", new CallLogCreatorBolt())
.shuffleGrouping("call-log-reader-spout");
builder.setBolt("call-log-counter-bolt", new CallLogCounterBolt())
.fieldsGrouping("call-log-creator-bolt", new Fields("call"));shuffleGrouping и fieldsGrouping методы помогают настроить группировку потоков для излива и болтов.
Локальный кластер
В целях разработки мы можем создать локальный кластер, используя объект «LocalCluster», а затем отправить топологию, используя метод «submitTopology» класса «LocalCluster». Один из аргументов для submitTopology - это экземпляр класса «Config». Класс «Config» используется для установки параметров конфигурации перед отправкой топологии. Эта опция конфигурации будет объединена с конфигурацией кластера во время выполнения и отправлена во все задачи (носик и болт) с помощью метода подготовки. После того, как топология будет отправлена в кластер, мы подождем 10 секунд, пока кластер вычислит переданную топологию, а затем завершим работу кластера, используя метод «shutdown» для «LocalCluster». Полный программный код выглядит следующим образом -
Кодирование - LogAnalyserStorm.java
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
//import storm configuration packages
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.topology.TopologyBuilder;
//Create main class LogAnalyserStorm submit topology.
public class LogAnalyserStorm {
public static void main(String[] args) throws Exception{
//Create Config instance for cluster configuration
Config config = new Config();
config.setDebug(true);
//
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("call-log-reader-spout", new FakeCallLogReaderSpout());
builder.setBolt("call-log-creator-bolt", new CallLogCreatorBolt())
.shuffleGrouping("call-log-reader-spout");
builder.setBolt("call-log-counter-bolt", new CallLogCounterBolt())
.fieldsGrouping("call-log-creator-bolt", new Fields("call"));
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("LogAnalyserStorm", config, builder.createTopology());
Thread.sleep(10000);
//Stop the topology
cluster.shutdown();
}
}Сборка и запуск приложения
Полное приложение содержит четыре кода Java. Они -
- FakeCallLogReaderSpout.java
- CallLogCreaterBolt.java
- CallLogCounterBolt.java
- LogAnalyerStorm.java
Приложение может быть создано с помощью следующей команды -
javac -cp “/path/to/storm/apache-storm-0.9.5/lib/*” *.javaПриложение можно запустить с помощью следующей команды -
java -cp “/path/to/storm/apache-storm-0.9.5/lib/*”:. LogAnalyserStormВывод
После запуска приложение выводит полные сведения о процессе запуска кластера, обработке носика и болта и, наконец, о процессе завершения работы кластера. В «CallLogCounterBolt» мы распечатали вызов и детали его подсчета. Эта информация будет отображаться на консоли следующим образом -
1234123402 - 1234123401 : 78
1234123402 - 1234123404 : 88
1234123402 - 1234123403 : 105
1234123401 - 1234123404 : 74
1234123401 - 1234123403 : 81
1234123401 - 1234123402 : 81
1234123403 - 1234123404 : 86
1234123404 - 1234123401 : 63
1234123404 - 1234123402 : 82
1234123403 - 1234123402 : 83
1234123404 - 1234123403 : 86
1234123403 - 1234123401 : 93Языки без JVM
Топологии Storm реализуются интерфейсами Thrift, что упрощает отправку топологий на любом языке. Storm поддерживает Ruby, Python и многие другие языки. Давайте посмотрим на привязку Python.
Связывание Python
Python - это интерпретируемый, интерактивный, объектно-ориентированный язык программирования высокого уровня общего назначения. Storm поддерживает Python для реализации своей топологии. Python поддерживает операции создания, привязки, подтверждения и регистрации.
Как известно, болты можно определять на любом языке. Болты, написанные на другом языке, выполняются как подпроцессы, и Storm взаимодействует с этими подпроцессами с помощью сообщений JSON через stdin / stdout. Сначала возьмите образец болта WordCount, который поддерживает привязку Python.
public static class WordCount implements IRichBolt {
public WordSplit() {
super("python", "splitword.py");
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}Здесь класс WordCount реализует IRichBoltинтерфейс и запускается с реализацией python, указанным аргументом суперметода "splitword.py". Теперь создайте реализацию Python с именем «splitword.py».
import storm
class WordCountBolt(storm.BasicBolt):
def process(self, tup):
words = tup.values[0].split(" ")
for word in words:
storm.emit([word])
WordCountBolt().run()Это образец реализации Python, который считает слова в заданном предложении. Точно так же вы можете выполнить привязку с другими поддерживающими языками.
Trident - это расширение Storm. Как и Storm, Trident также был разработан Twitter. Основная причина разработки Trident - предоставить высокоуровневую абстракцию поверх Storm вместе с потоковой обработкой с сохранением состояния и распределенными запросами с низкой задержкой.
Trident использует носик и болт, но эти низкоуровневые компоненты автоматически генерируются Trident перед выполнением. Trident имеет функции, фильтры, объединения, группировку и агрегацию.
Trident обрабатывает потоки как серию пакетов, которые называются транзакциями. Обычно размер этих небольших пакетов составляет порядка тысяч или миллионов кортежей, в зависимости от входного потока. Таким образом, Trident отличается от Storm, который выполняет обработку кортежа за кортежем.
Концепция пакетной обработки очень похожа на транзакции базы данных. Каждой транзакции присваивается идентификатор транзакции. Транзакция считается успешной после завершения всей ее обработки. Однако сбой в обработке одного из кортежей транзакции приведет к повторной передаче всей транзакции. Для каждого пакета Trident вызывает beginCommit в начале транзакции и фиксирует ее в конце.
Топология трезубца
Trident API предоставляет простой вариант создания топологии Trident с использованием класса «TridentTopology». По сути, топология Trident получает входной поток от spout и выполняет упорядоченную последовательность операций (фильтрация, агрегирование, группировка и т. Д.) В потоке. Кортеж бури заменен кортежем трезубца, а болты заменены операциями. Простую топологию Trident можно создать следующим образом:
TridentTopology topology = new TridentTopology();Кортежи трезубца
Кортеж Trident - это именованный список значений. Интерфейс TridentTuple - это модель данных топологии Trident. Интерфейс TridentTuple - это базовая единица данных, которая может обрабатываться топологией Trident.
Трезубец Носик
Носик Trident похож на носик Storm, но с дополнительными опциями для использования функций Trident. Фактически, мы все еще можем использовать IRichSpout, который мы использовали в топологии Storm, но он будет нетранзакционным по своей природе, и мы не сможем использовать преимущества, предоставляемые Trident.
Базовым изливом, имеющим все функции для использования функций Trident, является «ITridentSpout». Он поддерживает как транзакционную, так и непрозрачную транзакционную семантику. Другие носики - это IBatchSpout, IPartitionedTridentSpout и IOpaquePartitionedTridentSpout.
В дополнение к этим стандартным носикам, Trident предлагает множество примеров реализации носика трезубца. Одним из них является носик FeederBatchSpout, который мы можем использовать для простой отправки именованного списка кортежей трезубца, не беспокоясь о пакетной обработке, параллелизме и т. Д.
Создание FeederBatchSpout и подача данных могут выполняться, как показано ниже -
TridentTopology topology = new TridentTopology();
FeederBatchSpout testSpout = new FeederBatchSpout(
ImmutableList.of("fromMobileNumber", "toMobileNumber", “duration”));
topology.newStream("fixed-batch-spout", testSpout)
testSpout.feed(ImmutableList.of(new Values("1234123401", "1234123402", 20)));Трайдент Операции
Trident полагается на «Операцию Trident» для обработки входного потока кортежей трезубца. Trident API имеет ряд встроенных операций для обработки потоков от простого к сложному. Эти операции варьируются от простой проверки до сложной группировки и агрегирования кортежей трезубца. Разберемся с наиболее важными и часто используемыми операциями.
Фильтр
Фильтр - это объект, используемый для выполнения задачи проверки ввода. Фильтр Trident получает в качестве входных данных подмножество полей кортежа трезубца и возвращает либо истину, либо ложь в зависимости от того, выполняются определенные условия или нет. Если возвращается истина, то кортеж сохраняется в потоке вывода; в противном случае кортеж удаляется из потока. Фильтр будет в основном унаследован отBaseFilter класс и реализовать isKeepметод. Вот пример реализации операции фильтра -
public class MyFilter extends BaseFilter {
public boolean isKeep(TridentTuple tuple) {
return tuple.getInteger(1) % 2 == 0;
}
}
input
[1, 2]
[1, 3]
[1, 4]
output
[1, 2]
[1, 4]Функцию фильтра можно вызвать в топологии с помощью метода «each». Класс «Поля» можно использовать для указания ввода (подмножество кортежа трезубца). Пример кода выглядит следующим образом -
TridentTopology topology = new TridentTopology();
topology.newStream("spout", spout)
.each(new Fields("a", "b"), new MyFilter())Функция
Function- объект, используемый для выполнения простой операции с одним кортежем трезубца. Он принимает подмножество полей кортежа трезубца и генерирует ноль или более новых полей кортежа трезубца.
Function в основном наследуется от BaseFunction класс и реализует executeметод. Пример реализации приведен ниже -
public class MyFunction extends BaseFunction {
public void execute(TridentTuple tuple, TridentCollector collector) {
int a = tuple.getInteger(0);
int b = tuple.getInteger(1);
collector.emit(new Values(a + b));
}
}
input
[1, 2]
[1, 3]
[1, 4]
output
[1, 2, 3]
[1, 3, 4]
[1, 4, 5]Так же, как и операция фильтра, операция функции может быть вызвана в топологии с использованием eachметод. Пример кода выглядит следующим образом -
TridentTopology topology = new TridentTopology();
topology.newStream("spout", spout)
.each(new Fields(“a, b"), new MyFunction(), new Fields(“d")));Агрегация
Агрегация - это объект, используемый для выполнения операций агрегирования над входным пакетом, разделом или потоком. Trident имеет три типа агрегации. Они следующие -
aggregate- Агрегирует каждую партию кортежа трезубца по отдельности. Во время процесса агрегирования кортежи сначала повторно разбиваются на разделы с использованием глобальной группировки, чтобы объединить все разделы одного и того же пакета в один раздел.
partitionAggregate- Агрегирует каждый раздел вместо всей партии кортежа трезубца. Выходные данные агрегата раздела полностью заменяют входной кортеж. Выходные данные агрегата раздела содержат кортеж из одного поля.
persistentaggregate - Агрегирует по всему кортежу трезубца по всему пакету и сохраняет результат либо в памяти, либо в базе данных.
TridentTopology topology = new TridentTopology();
// aggregate operation
topology.newStream("spout", spout)
.each(new Fields(“a, b"), new MyFunction(), new Fields(“d”))
.aggregate(new Count(), new Fields(“count”))
// partitionAggregate operation
topology.newStream("spout", spout)
.each(new Fields(“a, b"), new MyFunction(), new Fields(“d”))
.partitionAggregate(new Count(), new Fields(“count"))
// persistentAggregate - saving the count to memory
topology.newStream("spout", spout)
.each(new Fields(“a, b"), new MyFunction(), new Fields(“d”))
.persistentAggregate(new MemoryMapState.Factory(), new Count(), new Fields("count"));Операцию агрегирования можно создать с помощью CombinerAggregator, ReducerAggregator или универсального интерфейса Aggregator. Агрегатор «count», используемый в приведенном выше примере, является одним из встроенных агрегаторов. Он реализован с помощью «CombinerAggregator». Реализация выглядит следующим образом:
public class Count implements CombinerAggregator<Long> {
@Override
public Long init(TridentTuple tuple) {
return 1L;
}
@Override
public Long combine(Long val1, Long val2) {
return val1 + val2;
}
@Override
public Long zero() {
return 0L;
}
}Группировка
Операция группировки является встроенной и может быть вызвана groupByметод. Метод groupBy перераспределяет поток, выполняя partitionBy для указанных полей, а затем внутри каждого раздела он группирует кортежи, поля групп которых равны. Обычно мы используем groupBy вместе с persistentAggregate, чтобы получить сгруппированное агрегирование. Пример кода выглядит следующим образом -
TridentTopology topology = new TridentTopology();
// persistentAggregate - saving the count to memory
topology.newStream("spout", spout)
.each(new Fields(“a, b"), new MyFunction(), new Fields(“d”))
.groupBy(new Fields(“d”)
.persistentAggregate(new MemoryMapState.Factory(), new Count(), new Fields("count"));Слияние и присоединение
Слияние и объединение может быть выполнено с использованием методов «слияния» и «соединения» соответственно. Слияние объединяет один или несколько потоков. Объединение похоже на объединение, за исключением того факта, что объединение использует поле кортежа трезубца с обеих сторон для проверки и объединения двух потоков. Причем присоединение будет работать только на уровне партии. Пример кода выглядит следующим образом -
TridentTopology topology = new TridentTopology();
topology.merge(stream1, stream2, stream3);
topology.join(stream1, new Fields("key"), stream2, new Fields("x"),
new Fields("key", "a", "b", "c"));Государственное обслуживание
Trident предоставляет механизм для поддержания состояния. Информация о состоянии может храниться в самой топологии, в противном случае вы также можете хранить ее в отдельной базе данных. Причина в том, чтобы поддерживать состояние, при котором, если какой-либо кортеж выходит из строя во время обработки, неудачный кортеж повторяется. Это создает проблему при обновлении состояния, поскольку вы не уверены, обновлялось ли состояние этого кортежа ранее или нет. Если кортеж не удалось обновить до обновления состояния, то повторная попытка кортежа сделает состояние стабильным. Однако, если кортеж завершился неудачно после обновления состояния, то повторная попытка того же кортежа снова увеличит счетчик в базе данных и сделает состояние нестабильным. Чтобы сообщение было обработано только один раз, необходимо выполнить следующие шаги:
Обработайте кортежи небольшими партиями.
Присвойте уникальный идентификатор каждой партии. Если пакет повторяется, ему присваивается тот же уникальный идентификатор.
Обновления состояния упорядочиваются по партиям. Например, обновление состояния второго пакета будет невозможно, пока обновление состояния для первого пакета не будет завершено.
Распределенный RPC
Распределенный RPC используется для запроса и получения результата из топологии Trident. Storm имеет встроенный распределенный сервер RPC. Распределенный сервер RPC получает запрос RPC от клиента и передает его в топологию. Топология обрабатывает запрос и отправляет результат распределенному серверу RPC, который перенаправляется распределенным сервером RPC клиенту. Распределенный RPC-запрос Trident выполняется как обычный RPC-запрос, за исключением того факта, что эти запросы выполняются параллельно.
Когда использовать трезубец?
Как и во многих случаях использования, если требуется обработать запрос только один раз, мы можем добиться этого, написав топологию в Trident. С другой стороны, в случае с Storm будет сложно добиться только однократной обработки. Следовательно, Trident будет полезен в тех случаях, когда вам требуется только однократная обработка. Trident подходит не для всех случаев использования, особенно для высокопроизводительных вариантов использования, поскольку он усложняет Storm и управляет состоянием.
Рабочий пример трезубца
Мы собираемся преобразовать наше приложение-анализатор журнала вызовов, разработанное в предыдущем разделе, в платформу Trident. Приложение Trident будет относительно простым по сравнению с обычным штормом благодаря высокоуровневому API. Storm в основном потребуется для выполнения любой из операций Function, Filter, Aggregate, GroupBy, Join и Merge в Trident. Наконец, мы запустим сервер DRPC, используяLocalDRPC class и выполните поиск по ключевому слову, используя execute метод класса LocalDRPC.
Форматирование информации о звонке
Целью класса FormatCall является форматирование информации о вызове, содержащей «номер вызывающего абонента» и «номер получателя». Полный программный код выглядит следующим образом -
Кодирование: FormatCall.java
import backtype.storm.tuple.Values;
import storm.trident.operation.BaseFunction;
import storm.trident.operation.TridentCollector;
import storm.trident.tuple.TridentTuple;
public class FormatCall extends BaseFunction {
@Override
public void execute(TridentTuple tuple, TridentCollector collector) {
String fromMobileNumber = tuple.getString(0);
String toMobileNumber = tuple.getString(1);
collector.emit(new Values(fromMobileNumber + " - " + toMobileNumber));
}
}CSVSplit
Назначение класса CSVSplit - разделить входную строку на основе «запятой (,)» и выдать каждое слово в строке. Эта функция используется для анализа входного аргумента распределенного запроса. Полный код выглядит следующим образом -
Кодирование: CSVSplit.java
import backtype.storm.tuple.Values;
import storm.trident.operation.BaseFunction;
import storm.trident.operation.TridentCollector;
import storm.trident.tuple.TridentTuple;
public class CSVSplit extends BaseFunction {
@Override
public void execute(TridentTuple tuple, TridentCollector collector) {
for(String word: tuple.getString(0).split(",")) {
if(word.length() > 0) {
collector.emit(new Values(word));
}
}
}
}Анализатор журналов
Это основное приложение. Первоначально приложение инициализирует TridentTopology и передает информацию о вызывающем абоненте, используяFeederBatchSpout. Поток топологии Trident может быть создан с помощьюnewStreamметод класса TridentTopology. Точно так же поток DRPC топологии Trident может быть создан с помощьюnewDRCPStreamметод класса TridentTopology. Простой сервер DRCP можно создать с помощью класса LocalDRPC.LocalDRPCимеет метод выполнения для поиска по ключевому слову. Полный код приведен ниже.
Кодирование: LogAnalyserTrident.java
import java.util.*;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.LocalDRPC;
import backtype.storm.utils.DRPCClient;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import storm.trident.TridentState;
import storm.trident.TridentTopology;
import storm.trident.tuple.TridentTuple;
import storm.trident.operation.builtin.FilterNull;
import storm.trident.operation.builtin.Count;
import storm.trident.operation.builtin.Sum;
import storm.trident.operation.builtin.MapGet;
import storm.trident.operation.builtin.Debug;
import storm.trident.operation.BaseFilter;
import storm.trident.testing.FixedBatchSpout;
import storm.trident.testing.FeederBatchSpout;
import storm.trident.testing.Split;
import storm.trident.testing.MemoryMapState;
import com.google.common.collect.ImmutableList;
public class LogAnalyserTrident {
public static void main(String[] args) throws Exception {
System.out.println("Log Analyser Trident");
TridentTopology topology = new TridentTopology();
FeederBatchSpout testSpout = new FeederBatchSpout(ImmutableList.of("fromMobileNumber",
"toMobileNumber", "duration"));
TridentState callCounts = topology
.newStream("fixed-batch-spout", testSpout)
.each(new Fields("fromMobileNumber", "toMobileNumber"),
new FormatCall(), new Fields("call"))
.groupBy(new Fields("call"))
.persistentAggregate(new MemoryMapState.Factory(), new Count(),
new Fields("count"));
LocalDRPC drpc = new LocalDRPC();
topology.newDRPCStream("call_count", drpc)
.stateQuery(callCounts, new Fields("args"), new MapGet(), new Fields("count"));
topology.newDRPCStream("multiple_call_count", drpc)
.each(new Fields("args"), new CSVSplit(), new Fields("call"))
.groupBy(new Fields("call"))
.stateQuery(callCounts, new Fields("call"), new MapGet(),
new Fields("count"))
.each(new Fields("call", "count"), new Debug())
.each(new Fields("count"), new FilterNull())
.aggregate(new Fields("count"), new Sum(), new Fields("sum"));
Config conf = new Config();
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("trident", conf, topology.build());
Random randomGenerator = new Random();
int idx = 0;
while(idx < 10) {
testSpout.feed(ImmutableList.of(new Values("1234123401",
"1234123402", randomGenerator.nextInt(60))));
testSpout.feed(ImmutableList.of(new Values("1234123401",
"1234123403", randomGenerator.nextInt(60))));
testSpout.feed(ImmutableList.of(new Values("1234123401",
"1234123404", randomGenerator.nextInt(60))));
testSpout.feed(ImmutableList.of(new Values("1234123402",
"1234123403", randomGenerator.nextInt(60))));
idx = idx + 1;
}
System.out.println("DRPC : Query starts");
System.out.println(drpc.execute("call_count","1234123401 - 1234123402"));
System.out.println(drpc.execute("multiple_call_count", "1234123401 -
1234123402,1234123401 - 1234123403"));
System.out.println("DRPC : Query ends");
cluster.shutdown();
drpc.shutdown();
// DRPCClient client = new DRPCClient("drpc.server.location", 3772);
}
}Сборка и запуск приложения
Полное приложение содержит три кода Java. Они следующие -
- FormatCall.java
- CSVSplit.java
- LogAnalyerTrident.java
Приложение может быть создано с помощью следующей команды -
javac -cp “/path/to/storm/apache-storm-0.9.5/lib/*” *.javaПриложение можно запустить с помощью следующей команды -
java -cp “/path/to/storm/apache-storm-0.9.5/lib/*”:. LogAnalyserTridentВывод
После запуска приложения оно выведет полную информацию о процессе запуска кластера, обработке операций, информации о сервере DRPC и клиенте и, наконец, о процессе завершения работы кластера. Этот вывод будет отображаться на консоли, как показано ниже.
DRPC : Query starts
[["1234123401 - 1234123402",10]]
DEBUG: [1234123401 - 1234123402, 10]
DEBUG: [1234123401 - 1234123403, 10]
[[20]]
DRPC : Query endsВ этой главе мы обсудим приложение Apache Storm в реальном времени. Посмотрим, как Storm используется в Twitter.
Twitter - это онлайн-служба социальной сети, которая предоставляет платформу для отправки и получения пользовательских твитов. Зарегистрированные пользователи могут читать и публиковать твиты, а незарегистрированные пользователи могут только читать твиты. Хэштег используется для классификации твитов по ключевым словам путем добавления # перед соответствующим ключевым словом. Теперь давайте рассмотрим сценарий поиска наиболее часто используемых хэштегов по каждой теме в реальном времени.
Создание носика
Цель spout - как можно скорее получить твиты от людей. Twitter предоставляет «Twitter Streaming API», инструмент на основе веб-службы для получения твитов, отправленных людьми, в режиме реального времени. Доступ к Twitter Streaming API можно получить на любом языке программирования.
twitter4j - это неофициальная библиотека Java с открытым исходным кодом, которая предоставляет модуль на основе Java для простого доступа к API потоковой передачи Twitter. twitter4jпредоставляет структуру на основе слушателей для доступа к твитам. Чтобы получить доступ к API потоковой передачи Twitter, нам необходимо войти в учетную запись разработчика Twitter и получить следующие данные аутентификации OAuth.
- Customerkey
- CustomerSecret
- AccessToken
- AccessTookenSecret
Шторм дает твиттер-носик, TwitterSampleSpout,в его стартовом комплекте. Мы будем использовать его для получения твитов. Носику необходимы данные аутентификации OAuth и хотя бы ключевое слово. Носик будет отправлять твиты в реальном времени на основе ключевых слов. Полный программный код приведен ниже.
Кодирование: TwitterSampleSpout.java
import java.util.Map;
import java.util.concurrent.LinkedBlockingQueue;
import twitter4j.FilterQuery;
import twitter4j.StallWarning;
import twitter4j.Status;
import twitter4j.StatusDeletionNotice;
import twitter4j.StatusListener;
import twitter4j.TwitterStream;
import twitter4j.TwitterStreamFactory;
import twitter4j.auth.AccessToken;
import twitter4j.conf.ConfigurationBuilder;
import backtype.storm.Config;
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichSpout;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.utils.Utils;
@SuppressWarnings("serial")
public class TwitterSampleSpout extends BaseRichSpout {
SpoutOutputCollector _collector;
LinkedBlockingQueue<Status> queue = null;
TwitterStream _twitterStream;
String consumerKey;
String consumerSecret;
String accessToken;
String accessTokenSecret;
String[] keyWords;
public TwitterSampleSpout(String consumerKey, String consumerSecret,
String accessToken, String accessTokenSecret, String[] keyWords) {
this.consumerKey = consumerKey;
this.consumerSecret = consumerSecret;
this.accessToken = accessToken;
this.accessTokenSecret = accessTokenSecret;
this.keyWords = keyWords;
}
public TwitterSampleSpout() {
// TODO Auto-generated constructor stub
}
@Override
public void open(Map conf, TopologyContext context,
SpoutOutputCollector collector) {
queue = new LinkedBlockingQueue<Status>(1000);
_collector = collector;
StatusListener listener = new StatusListener() {
@Override
public void onStatus(Status status) {
queue.offer(status);
}
@Override
public void onDeletionNotice(StatusDeletionNotice sdn) {}
@Override
public void onTrackLimitationNotice(int i) {}
@Override
public void onScrubGeo(long l, long l1) {}
@Override
public void onException(Exception ex) {}
@Override
public void onStallWarning(StallWarning arg0) {
// TODO Auto-generated method stub
}
};
ConfigurationBuilder cb = new ConfigurationBuilder();
cb.setDebugEnabled(true)
.setOAuthConsumerKey(consumerKey)
.setOAuthConsumerSecret(consumerSecret)
.setOAuthAccessToken(accessToken)
.setOAuthAccessTokenSecret(accessTokenSecret);
_twitterStream = new TwitterStreamFactory(cb.build()).getInstance();
_twitterStream.addListener(listener);
if (keyWords.length == 0) {
_twitterStream.sample();
}else {
FilterQuery query = new FilterQuery().track(keyWords);
_twitterStream.filter(query);
}
}
@Override
public void nextTuple() {
Status ret = queue.poll();
if (ret == null) {
Utils.sleep(50);
} else {
_collector.emit(new Values(ret));
}
}
@Override
public void close() {
_twitterStream.shutdown();
}
@Override
public Map<String, Object> getComponentConfiguration() {
Config ret = new Config();
ret.setMaxTaskParallelism(1);
return ret;
}
@Override
public void ack(Object id) {}
@Override
public void fail(Object id) {}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("tweet"));
}
}Болт для чтения хэштегов
Твит, отправленный spout, будет перенаправлен на HashtagReaderBolt, который обработает твит и выдаст все доступные хэштеги. HashtagReaderBolt используетgetHashTagEntitiesметод предоставлен twitter4j. getHashTagEntities читает твит и возвращает список хэштегов. Полный программный код выглядит следующим образом -
Кодирование: HashtagReaderBolt.java
import java.util.HashMap;
import java.util.Map;
import twitter4j.*;
import twitter4j.conf.*;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Tuple;
public class HashtagReaderBolt implements IRichBolt {
private OutputCollector collector;
@Override
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
@Override
public void execute(Tuple tuple) {
Status tweet = (Status) tuple.getValueByField("tweet");
for(HashtagEntity hashtage : tweet.getHashtagEntities()) {
System.out.println("Hashtag: " + hashtage.getText());
this.collector.emit(new Values(hashtage.getText()));
}
}
@Override
public void cleanup() {}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("hashtag"));
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}Контр-болт хэштега
Выпущенный хэштег будет перенаправлен на HashtagCounterBolt. Этот болт будет обрабатывать все хэштеги и сохранять каждый хэштег и его количество в памяти с помощью объекта Java Map. Полный программный код приведен ниже.
Кодирование: HashtagCounterBolt.java
import java.util.HashMap;
import java.util.Map;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Tuple;
public class HashtagCounterBolt implements IRichBolt {
Map<String, Integer> counterMap;
private OutputCollector collector;
@Override
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
this.counterMap = new HashMap<String, Integer>();
this.collector = collector;
}
@Override
public void execute(Tuple tuple) {
String key = tuple.getString(0);
if(!counterMap.containsKey(key)){
counterMap.put(key, 1);
}else{
Integer c = counterMap.get(key) + 1;
counterMap.put(key, c);
}
collector.ack(tuple);
}
@Override
public void cleanup() {
for(Map.Entry<String, Integer> entry:counterMap.entrySet()){
System.out.println("Result: " + entry.getKey()+" : " + entry.getValue());
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("hashtag"));
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}Отправка топологии
Отправка топологии - это основное приложение. Топология Twitter состоит изTwitterSampleSpout, HashtagReaderBolt, и HashtagCounterBolt. Следующий программный код показывает, как отправить топологию.
Кодирование: TwitterHashtagStorm.java
import java.util.*;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.topology.TopologyBuilder;
public class TwitterHashtagStorm {
public static void main(String[] args) throws Exception{
String consumerKey = args[0];
String consumerSecret = args[1];
String accessToken = args[2];
String accessTokenSecret = args[3];
String[] arguments = args.clone();
String[] keyWords = Arrays.copyOfRange(arguments, 4, arguments.length);
Config config = new Config();
config.setDebug(true);
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("twitter-spout", new TwitterSampleSpout(consumerKey,
consumerSecret, accessToken, accessTokenSecret, keyWords));
builder.setBolt("twitter-hashtag-reader-bolt", new HashtagReaderBolt())
.shuffleGrouping("twitter-spout");
builder.setBolt("twitter-hashtag-counter-bolt", new HashtagCounterBolt())
.fieldsGrouping("twitter-hashtag-reader-bolt", new Fields("hashtag"));
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("TwitterHashtagStorm", config,
builder.createTopology());
Thread.sleep(10000);
cluster.shutdown();
}
}Сборка и запуск приложения
Полное приложение содержит четыре кода Java. Они следующие -
- TwitterSampleSpout.java
- HashtagReaderBolt.java
- HashtagCounterBolt.java
- TwitterHashtagStorm.java
Вы можете скомпилировать приложение, используя следующую команду -
javac -cp “/path/to/storm/apache-storm-0.9.5/lib/*”:”/path/to/twitter4j/lib/*” *.javaЗапустите приложение, используя следующие команды -
javac -cp “/path/to/storm/apache-storm-0.9.5/lib/*”:”/path/to/twitter4j/lib/*”:.
TwitterHashtagStorm <customerkey> <customersecret> <accesstoken> <accesstokensecret>
<keyword1> <keyword2> … <keywordN>Вывод
Приложение распечатает текущий доступный хэштег и его количество. Результат должен быть похож на следующий -
Result: jazztastic : 1
Result: foodie : 1
Result: Redskins : 1
Result: Recipe : 1
Result: cook : 1
Result: android : 1
Result: food : 2
Result: NoToxicHorseMeat : 1
Result: Purrs4Peace : 1
Result: livemusic : 1
Result: VIPremium : 1
Result: Frome : 1
Result: SundayRoast : 1
Result: Millennials : 1
Result: HealthWithKier : 1
Result: LPs30DaysofGratitude : 1
Result: cooking : 1
Result: gameinsight : 1
Result: Countryfile : 1
Result: androidgames : 1Yahoo! Финансы - это ведущий веб-сайт деловых новостей и финансовых данных в Интернете. Это часть Yahoo! и предоставляет информацию о финансовых новостях, рыночной статистике, международных рыночных данных и другую информацию о финансовых ресурсах, к которой может получить доступ каждый.
Если вы зарегистрированы в Yahoo! пользователя, то вы можете настроить Yahoo! Финансы, чтобы воспользоваться его определенными предложениями. Yahoo! Finance API используется для запроса финансовых данных из Yahoo!
Этот API отображает данные с задержкой на 15 минут по сравнению с реальным временем и обновляет свою базу данных каждую минуту, чтобы получить доступ к текущей информации о запасах. Теперь давайте рассмотрим сценарий компании в реальном времени и посмотрим, как поднять оповещение, когда стоимость ее акций опускается ниже 100.
Создание носика
Назначение носика - получить подробную информацию о компании и вывести цены на болты. Вы можете использовать следующий программный код для создания носика.
Кодирование: YahooFinanceSpout.java
import java.util.*;
import java.io.*;
import java.math.BigDecimal;
//import yahoofinace packages
import yahoofinance.YahooFinance;
import yahoofinance.Stock;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.topology.IRichSpout;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
public class YahooFinanceSpout implements IRichSpout {
private SpoutOutputCollector collector;
private boolean completed = false;
private TopologyContext context;
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector){
this.context = context;
this.collector = collector;
}
@Override
public void nextTuple() {
try {
Stock stock = YahooFinance.get("INTC");
BigDecimal price = stock.getQuote().getPrice();
this.collector.emit(new Values("INTC", price.doubleValue()));
stock = YahooFinance.get("GOOGL");
price = stock.getQuote().getPrice();
this.collector.emit(new Values("GOOGL", price.doubleValue()));
stock = YahooFinance.get("AAPL");
price = stock.getQuote().getPrice();
this.collector.emit(new Values("AAPL", price.doubleValue()));
} catch(Exception e) {}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("company", "price"));
}
@Override
public void close() {}
public boolean isDistributed() {
return false;
}
@Override
public void activate() {}
@Override
public void deactivate() {}
@Override
public void ack(Object msgId) {}
@Override
public void fail(Object msgId) {}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}Создание болта
Здесь цель bolt - обработать цены данной компании, когда цены упадут ниже 100. Он использует объект Java Map для установки предупреждения о пределе цены отсечения как trueкогда цены на акции падают ниже 100; в противном случае - ложь. Полный программный код выглядит следующим образом -
Кодирование: PriceCutOffBolt.java
import java.util.HashMap;
import java.util.Map;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Tuple;
public class PriceCutOffBolt implements IRichBolt {
Map<String, Integer> cutOffMap;
Map<String, Boolean> resultMap;
private OutputCollector collector;
@Override
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
this.cutOffMap = new HashMap <String, Integer>();
this.cutOffMap.put("INTC", 100);
this.cutOffMap.put("AAPL", 100);
this.cutOffMap.put("GOOGL", 100);
this.resultMap = new HashMap<String, Boolean>();
this.collector = collector;
}
@Override
public void execute(Tuple tuple) {
String company = tuple.getString(0);
Double price = tuple.getDouble(1);
if(this.cutOffMap.containsKey(company)){
Integer cutOffPrice = this.cutOffMap.get(company);
if(price < cutOffPrice) {
this.resultMap.put(company, true);
} else {
this.resultMap.put(company, false);
}
}
collector.ack(tuple);
}
@Override
public void cleanup() {
for(Map.Entry<String, Boolean> entry:resultMap.entrySet()){
System.out.println(entry.getKey()+" : " + entry.getValue());
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("cut_off_price"));
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}Отправка топологии
Это основное приложение, в котором YahooFinanceSpout.java и PriceCutOffBolt.java соединены вместе и образуют топологию. Следующий программный код показывает, как вы можете отправить топологию.
Кодирование: YahooFinanceStorm.java
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.topology.TopologyBuilder;
public class YahooFinanceStorm {
public static void main(String[] args) throws Exception{
Config config = new Config();
config.setDebug(true);
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("yahoo-finance-spout", new YahooFinanceSpout());
builder.setBolt("price-cutoff-bolt", new PriceCutOffBolt())
.fieldsGrouping("yahoo-finance-spout", new Fields("company"));
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("YahooFinanceStorm", config, builder.createTopology());
Thread.sleep(10000);
cluster.shutdown();
}
}Сборка и запуск приложения
Полное приложение содержит три кода Java. Они следующие -
- YahooFinanceSpout.java
- PriceCutOffBolt.java
- YahooFinanceStorm.java
Приложение может быть создано с помощью следующей команды -
javac -cp “/path/to/storm/apache-storm-0.9.5/lib/*”:”/path/to/yahoofinance/lib/*” *.javaПриложение можно запустить с помощью следующей команды -
javac -cp “/path/to/storm/apache-storm-0.9.5/lib/*”:”/path/to/yahoofinance/lib/*”:.
YahooFinanceStormВывод
Результат будет похож на следующий -
GOOGL : false
AAPL : false
INTC : trueПлатформа Apache Storm поддерживает многие из лучших на сегодняшний день промышленных приложений. В этой главе мы дадим очень краткий обзор некоторых наиболее заметных приложений Storm.
Klout
Klout - это приложение, которое использует аналитику социальных сетей для ранжирования своих пользователей на основе социального влияния в Интернете. Klout Score, который представляет собой числовое значение от 1 до 100. Klout использует встроенную абстракцию Trident Apache Storm для создания сложных топологий с потоковой передачей данных.
Канал о погоде
Weather Channel использует топологии Storm для приема данных о погоде. Он связан с Twitter, чтобы обеспечить возможность размещения рекламы с учетом погоды в Twitter и мобильных приложениях.OpenSignal - компания, специализирующаяся на картировании беспроводного покрытия. StormTag и WeatherSignal- это погодные проекты, созданные OpenSignal. StormTag - это метеостанция Bluetooth, которая прикрепляется к связке ключей. Данные о погоде, собранные устройством, отправляются в приложение WeatherSignal и на серверы OpenSignal.
Телекоммуникационная промышленность
Провайдеры связи обрабатывают миллионы телефонных звонков в секунду. Они проводят экспертизу пропущенных вызовов и плохого качества звука. Записи о звонках поступают со скоростью миллионы в секунду, и Apache Storm обрабатывает их в режиме реального времени и выявляет любые тревожные шаблоны. Анализ шторма можно использовать для постоянного улучшения качества звонков.