H2O - Установка
H2O можно настроить и использовать с пятью различными параметрами, перечисленными ниже:
Установить в Python
Установить в R
Веб-интерфейс Flow GUI
Hadoop
Анаконда Облако
В наших последующих разделах вы увидите инструкции по установке H2O в зависимости от доступных опций. Скорее всего, вы воспользуетесь одним из вариантов.
Установить в Python
Чтобы запустить H2O с Python, для установки требуется несколько зависимостей. Итак, приступим к установке минимального набора зависимостей для запуска H2O.
Установка зависимостей
Чтобы установить зависимость, выполните следующую команду pip -
$ pip install requestsОткройте окно консоли и введите указанную выше команду, чтобы установить пакет запросов. На следующем снимке экрана показано выполнение указанной выше команды на нашем компьютере Mac -
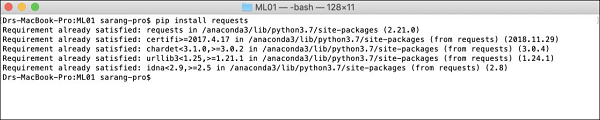
После установки запросов вам необходимо установить еще три пакета, как показано ниже -
$ pip install tabulate
$ pip install "colorama >= 0.3.8"
$ pip install futureСамый последний список зависимостей доступен на странице H2O GitHub. На момент написания этой статьи на странице перечислены следующие зависимости.
python 2. H2O — Installation
pip >= 9.0.1
setuptools
colorama >= 0.3.7
future >= 0.15.2Удаление старых версий
После установки вышеуказанных зависимостей вам необходимо удалить все существующие установки H2O. Для этого выполните следующую команду -
$ pip uninstall h2oУстановка последней версии
Теперь давайте установим последнюю версию H2O, используя следующую команду -
$ pip install -f http://h2o-release.s3.amazonaws.com/h2o/latest_stable_Py.html h2oПосле успешной установки вы должны увидеть на экране следующее сообщение -
Installing collected packages: h2o
Successfully installed h2o-3.26.0.1Тестирование установки
Чтобы проверить установку, мы запустим одно из примеров приложений, предоставленных в установке H2O. Сначала запустите командную строку Python, набрав следующую команду -
$ Python3После запуска интерпретатора Python введите следующий оператор Python в командной строке Python:
>>>import h2oПриведенная выше команда импортирует пакет H2O в вашу программу. Затем инициализируйте систему H2O, используя следующую команду -
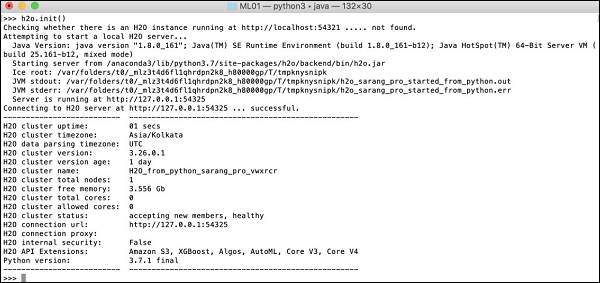
>>>h2o.init()На вашем экране будет отображаться информация о кластере, и на этом этапе он должен выглядеть следующим образом:
Теперь вы готовы запустить образец кода. Введите следующую команду в командной строке Python и выполните ее.
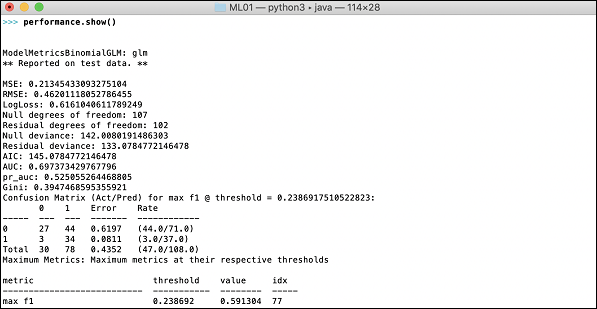
>>>h2o.demo("glm")Демонстрация состоит из записной книжки Python с рядом команд. После выполнения каждой команды ее вывод немедленно отображается на экране, и вам будет предложено нажать клавишу, чтобы продолжить следующий шаг. Частичный снимок экрана с выполнением последнего оператора в записной книжке показан здесь -
На этом установка Python завершена, и вы готовы к собственным экспериментам.
Установить в R
Установка H2O для разработки R очень похожа на ее установку для Python, за исключением того, что вы будете использовать приглашение R.
Запуск R Console
Запустите консоль R, щелкнув значок приложения R на вашем компьютере. Экран консоли появится, как показано на следующем снимке экрана -
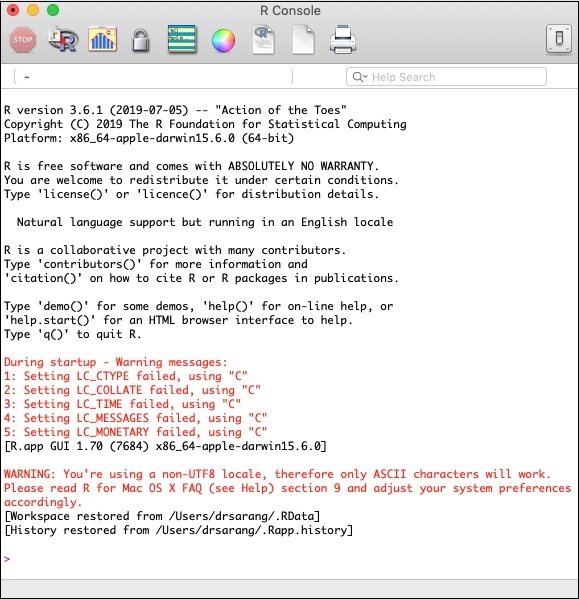
Ваша установка H2O будет выполнена в командной строке R. Если вы предпочитаете использовать RStudio, введите команды в подокне консоли R.
Удаление старых версий
Для начала удалите более старые версии, используя следующую команду в строке R -
> if ("package:h2o" %in% search()) { detach("package:h2o", unload=TRUE) }
> if ("h2o" %in% rownames(installed.packages())) { remove.packages("h2o") }Скачивание зависимостей
Загрузите зависимости для H2O, используя следующий код -
> pkgs <- c("RCurl","jsonlite")
for (pkg in pkgs) {
if (! (pkg %in% rownames(installed.packages()))) { install.packages(pkg) }
}Установка H2O
Установите H2O, введя следующую команду в командной строке R -
> install.packages("h2o", type = "source", repos = (c("http://h2o-release.s3.amazonaws.com/h2o/latest_stable_R")))На следующем снимке экрана показан ожидаемый результат -
Есть еще один способ установки H2O в R.
Установить в R из CRAN
Чтобы установить R из CRAN, используйте следующую команду в приглашении R -
> install.packages("h2o")Вам будет предложено выбрать зеркало -
--- Please select a CRAN mirror for use in this session ---
На экране появится диалоговое окно со списком зеркальных сайтов. Выберите ближайшее место или зеркало по вашему выбору.
Тестовая установка
В командной строке R введите и запустите следующий код -
> library(h2o)
> localH2O = h2o.init()
> demo(h2o.kmeans)Сгенерированный результат будет таким, как показано на следующем снимке экрана -
Теперь ваша установка H2O в R завершена.
Установка Web GUI Flow
Чтобы установить GUI Flow, загрузите установочный файл с сайта H20. Разархивируйте загруженный файл в нужную папку. Обратите внимание на наличие файла h2o.jar в установке. Запустите этот файл в командном окне, используя следующую команду -
$ java -jar h2o.jarЧерез некоторое время в окне консоли появится следующее.
07-24 16:06:37.304 192.168.1.18:54321 3294 main INFO: H2O started in 7725ms
07-24 16:06:37.304 192.168.1.18:54321 3294 main INFO:
07-24 16:06:37.305 192.168.1.18:54321 3294 main INFO: Open H2O Flow in your web browser: http://192.168.1.18:54321
07-24 16:06:37.305 192.168.1.18:54321 3294 main INFO:Чтобы запустить поток, откройте указанный URL http://localhost:54321в вашем браузере. Появится следующий экран -
На этом установка Flow завершена.
Установить в Hadoop / Anaconda Cloud
Если вы не являетесь опытным разработчиком, вам и в голову не пришло бы использовать H2O для больших данных. Здесь достаточно сказать, что модели H2O эффективно работают в огромных базах данных размером в несколько терабайт. Если ваши данные находятся в вашей установке Hadoop или в облаке, следуйте инструкциям на сайте H2O, чтобы установить их для соответствующей базы данных.
Теперь, когда вы успешно установили и протестировали H2O на своем компьютере, вы готовы к реальной разработке. Сначала мы увидим развитие из командной строки. В наших последующих уроках мы узнаем, как проводить тестирование модели в H2O Flow.
Разработка в командной строке
Давайте теперь рассмотрим использование H2O для классификации растений из хорошо известного набора данных iris, который бесплатно доступен для разработки приложений машинного обучения.
Запустите интерпретатор Python, набрав следующую команду в окне оболочки:
$ Python3Это запускает интерпретатор Python. Импортируйте платформу H2O с помощью следующей команды -
>>> import h2oМы будем использовать алгоритм случайного леса для классификации. Это предоставляется в пакете H2ORandomForestEstimator. Мы импортируем этот пакет с помощью оператора импорта следующим образом:
>>> from h2o.estimators import H2ORandomForestEstimatorМы инициализируем среду H2o, вызывая ее метод init.
>>> h2o.init()При успешной инициализации вы должны увидеть следующее сообщение на консоли вместе с информацией о кластере.
Checking whether there is an H2O instance running at http://localhost:54321 . connected.Теперь мы импортируем данные радужной оболочки глаза с помощью метода import_file в H2O.
>>> data = h2o.import_file('iris.csv')Прогресс будет отображаться, как показано на следующем снимке экрана -

После того, как файл загружен в память, вы можете проверить это, отобразив первые 10 строк загруженной таблицы. Вы используетеhead способ сделать это -
>>> data.head()Вы увидите следующий результат в табличном формате.
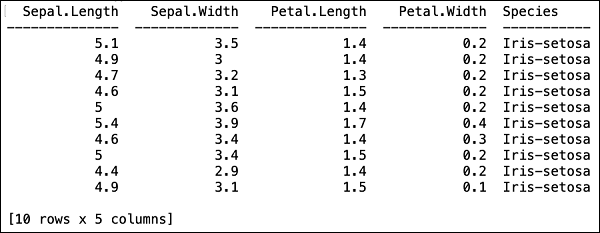
В таблице также отображаются имена столбцов. Мы будем использовать первые четыре столбца в качестве функций для нашего алгоритма машинного обучения, а последний класс столбца - в качестве прогнозируемого вывода. Мы указываем это в вызове нашего алгоритма машинного обучения, сначала создавая следующие две переменные.
>>> features = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width']
>>> output = 'class'Затем мы разделяем данные на обучение и тестирование, вызывая метод split_frame.
>>> train, test = data.split_frame(ratios = [0.8])Данные разделены в соотношении 80:20. Мы используем 80% данных для обучения и 20% для тестирования.
Теперь мы загружаем в систему встроенную модель случайного леса.
>>> model = H2ORandomForestEstimator(ntrees = 50, max_depth = 20, nfolds = 10)В приведенном выше вызове мы установили количество деревьев равным 50, максимальную глубину дерева равной 20 и количество складок для перекрестной проверки равным 10. Теперь нам нужно обучить модель. Мы делаем это, вызывая метод поезда следующим образом:
>>> model.train(x = features, y = output, training_frame = train)Метод train получает функции и выходные данные, которые мы создали ранее, в качестве первых двух параметров. Набор обучающих данных настроен на обучение, что составляет 80% от нашего полного набора данных. Во время тренировки вы увидите прогресс, как показано здесь -
Теперь, когда процесс построения модели завершен, пришло время протестировать модель. Мы делаем это, вызывая метод model_performance для обученного объекта модели.
>>> performance = model.model_performance(test_data=test)В приведенном выше вызове метода мы отправили тестовые данные в качестве параметра.
Пришло время увидеть результат - производительность нашей модели. Вы делаете это, просто распечатывая исполнение.
>>> print (performance)Это даст вам следующий результат -
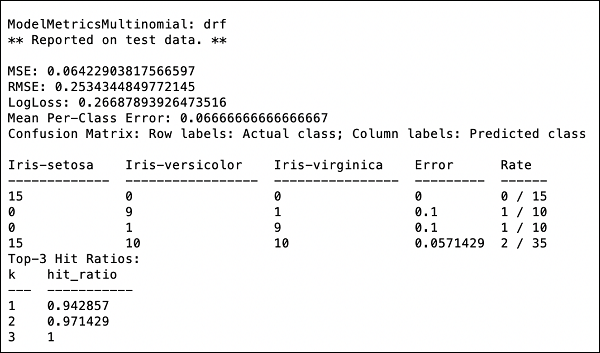
Выходные данные показывают среднеквадратичную ошибку (MSE), среднеквадратическую ошибку (RMSE), LogLoss и даже матрицу неточности.
Запуск в Jupyter
Мы видели выполнение команды, а также понимали цель каждой строки кода. Вы можете запускать весь код в среде Jupyter либо построчно, либо всю программу за раз. Полный список приведен здесь -
import h2o
from h2o.estimators import H2ORandomForestEstimator
h2o.init()
data = h2o.import_file('iris.csv')
features = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width']
output = 'class'
train, test = data.split_frame(ratios=[0.8])
model = H2ORandomForestEstimator(ntrees = 50, max_depth = 20, nfolds = 10)
model.train(x = features, y = output, training_frame = train)
performance = model.model_performance(test_data=test)
print (performance)Запустите код и посмотрите на результат. Теперь вы можете оценить, насколько легко применить и протестировать алгоритм случайного леса на вашем наборе данных. Сила H20 выходит далеко за рамки этой возможности. Что делать, если вы хотите попробовать другую модель в том же наборе данных, чтобы увидеть, сможете ли вы повысить производительность. Это объясняется в нашем следующем разделе.
Применение другого алгоритма
Теперь мы узнаем, как применить алгоритм повышения градиента к нашему предыдущему набору данных, чтобы увидеть, как он работает. В приведенном выше полном листинге вам нужно будет внести только два незначительных изменения, как показано в приведенном ниже коде:
import h2o
from h2o.estimators import H2OGradientBoostingEstimator
h2o.init()
data = h2o.import_file('iris.csv')
features = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width']
output = 'class'
train, test = data.split_frame(ratios = [0.8])
model = H2OGradientBoostingEstimator
(ntrees = 50, max_depth = 20, nfolds = 10)
model.train(x = features, y = output, training_frame = train)
performance = model.model_performance(test_data = test)
print (performance)Запустите код, и вы получите следующий результат -
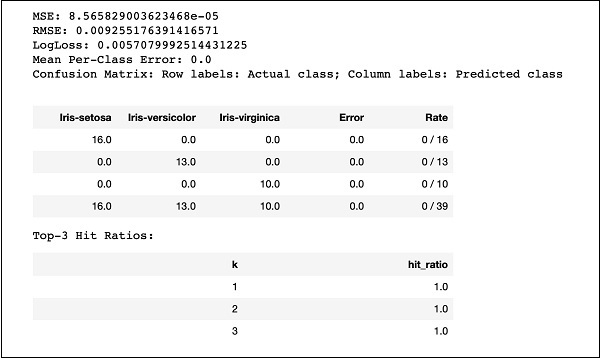
Просто сравните результаты, такие как MSE, RMSE, Confusion Matrix и т. Д., С предыдущими выходными данными и решите, какой из них использовать для производственного развертывания. Фактически, вы можете применить несколько разных алгоритмов, чтобы выбрать лучший, который соответствует вашим целям.