H2O - Запуск примера приложения
Щелкните ссылку "Поток задержки авиакомпаний" в списке образцов, как показано на скриншоте ниже.
После подтверждения будет загружен новый ноутбук.
Очистка всех выходов
Прежде чем объяснять операторы кода в записной книжке, давайте очистим все выходные данные, а затем постепенно запустим записную книжку. Чтобы очистить все выходы, выберите следующий пункт меню -
Flow / Clear All Cell ContentsЭто показано на следующем снимке экрана -
Как только все выходные данные будут очищены, мы запустим каждую ячейку в записной книжке отдельно и изучим ее выходные данные.
Запуск первой ячейки
Щелкните первую ячейку. Слева появится красный флаг, указывающий, что ячейка выбрана. Это как показано на скриншоте ниже -

Содержимое этой ячейки представляет собой просто комментарий программы, написанный на языке MarkDown (MD). Контент описывает, что делает загруженное приложение. Чтобы запустить ячейку, щелкните значок «Выполнить», как показано на скриншоте ниже -

Вы не увидите никаких выходных данных под ячейкой, поскольку в текущей ячейке нет исполняемого кода. Курсор автоматически переместится к следующей ячейке, которая готова к выполнению.
Импорт данных
Следующая ячейка содержит следующий оператор Python -
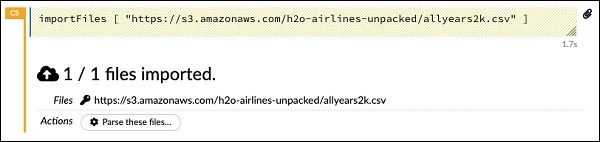
importFiles ["https://s3.amazonaws.com/h2o-airlines-unpacked/allyears2k.csv"]Заявление импортирует файл allyears2k.csv из Amazon AWS в систему. Когда вы запускаете ячейку, она импортирует файл и выдает следующий результат.
Настройка парсера данных
Теперь нам нужно проанализировать данные и сделать их подходящими для нашего алгоритма машинного обучения. Это делается с помощью следующей команды -
setupParse paths: [ "https://s3.amazonaws.com/h2o-airlines-unpacked/allyears2k.csv" ]После выполнения вышеуказанного оператора появится диалоговое окно настройки конфигурации. Диалог позволяет вам несколько настроек для анализа файла. Это как показано на скриншоте ниже -
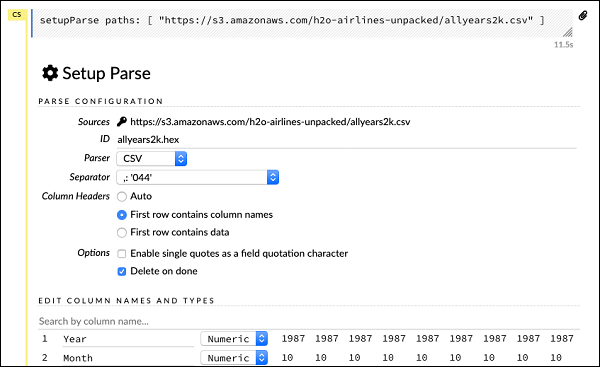
В этом диалоговом окне вы можете выбрать желаемый парсер из выпадающего списка и установить другие параметры, такие как разделитель полей и т. Д.
Анализ данных
Следующий оператор, который фактически анализирует файл данных с использованием вышеуказанной конфигурации, является длинным и выглядит следующим образом:
parseFiles
paths: ["https://s3.amazonaws.com/h2o-airlines-unpacked/allyears2k.csv"]
destination_frame: "allyears2k.hex"
parse_type: "CSV"
separator: 44
number_columns: 31
single_quotes: false
column_names: ["Year","Month","DayofMonth","DayOfWeek","DepTime","CRSDepTime",
"ArrTime","CRSArrTime","UniqueCarrier","FlightNum","TailNum",
"ActualElapsedTime","CRSElapsedTime","AirTime","ArrDelay","DepDelay",
"Origin","Dest","Distance","TaxiIn","TaxiOut","Cancelled","CancellationCode",
"Diverted","CarrierDelay","WeatherDelay","NASDelay","SecurityDelay",
"LateAircraftDelay","IsArrDelayed","IsDepDelayed"]
column_types: ["Enum","Enum","Enum","Enum","Numeric","Numeric","Numeric"
,"Numeric","Enum","Enum","Enum","Numeric","Numeric","Numeric","Numeric",
"Numeric","Enum","Enum","Numeric","Numeric","Numeric","Enum","Enum",
"Numeric","Numeric","Numeric","Numeric","Numeric","Numeric","Enum","Enum"]
delete_on_done: true
check_header: 1
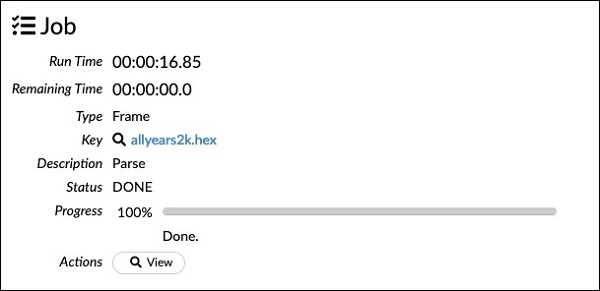
chunk_size: 4194304Обратите внимание, что параметры, которые вы установили в окне конфигурации, перечислены в приведенном выше коде. Теперь запустите эту ячейку. Через некоторое время синтаксический анализ завершится, и вы увидите следующий результат:
Изучение Dataframe
После обработки он генерирует фрейм данных, который можно изучить с помощью следующего оператора:
getFrameSummary "allyears2k.hex"После выполнения вышеуказанного оператора вы увидите следующий вывод -
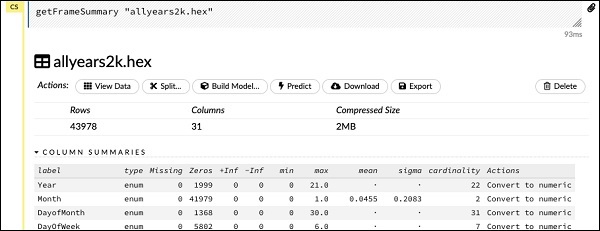
Теперь ваши данные готовы для загрузки в алгоритм машинного обучения.
Следующий оператор - это комментарий к программе, в котором говорится, что мы будем использовать модель регрессии, и указывается предустановленная регуляризация и значения лямбда.
Построение модели
Далее следует самое важное утверждение - построение самой модели. Это указано в следующем заявлении -
buildModel 'glm', {
"model_id":"glm_model","training_frame":"allyears2k.hex",
"ignored_columns":[
"DayofMonth","DepTime","CRSDepTime","ArrTime","CRSArrTime","TailNum",
"ActualElapsedTime","CRSElapsedTime","AirTime","ArrDelay","DepDelay",
"TaxiIn","TaxiOut","Cancelled","CancellationCode","Diverted","CarrierDelay",
"WeatherDelay","NASDelay","SecurityDelay","LateAircraftDelay","IsArrDelayed"],
"ignore_const_cols":true,"response_column":"IsDepDelayed","family":"binomial",
"solver":"IRLSM","alpha":[0.5],"lambda":[0.00001],"lambda_search":false,
"standardize":true,"non_negative":false,"score_each_iteration":false,
"max_iterations":-1,"link":"family_default","intercept":true,
"objective_epsilon":0.00001,"beta_epsilon":0.0001,"gradient_epsilon":0.0001,
"prior":-1,"max_active_predictors":-1
}Мы используем glm, набор обобщенных линейных моделей с биномиальным типом семейства. Вы можете увидеть это выделенным в приведенном выше заявлении. В нашем случае ожидаемый результат является двоичным, поэтому мы используем биномиальный тип. Вы можете самостоятельно изучить остальные параметры; например, посмотрите на альфа и лямбда, которые мы указали ранее. Обратитесь к документации модели GLM для объяснения всех параметров.
Теперь запустите этот оператор. После выполнения будет сгенерирован следующий вывод -

Конечно, на вашем компьютере время выполнения будет другим. А теперь самое интересное в этом примере кода.
Изучение вывода
Мы просто выводим модель, которую мы построили, используя следующий оператор:
getModel "glm_model"Обратите внимание, что glm_model - это идентификатор модели, который мы указали в качестве параметра model_id при построении модели в предыдущем операторе. Это дает нам огромный вывод с подробным описанием результатов с несколькими различными параметрами. Частичный вывод отчета показан на скриншоте ниже -
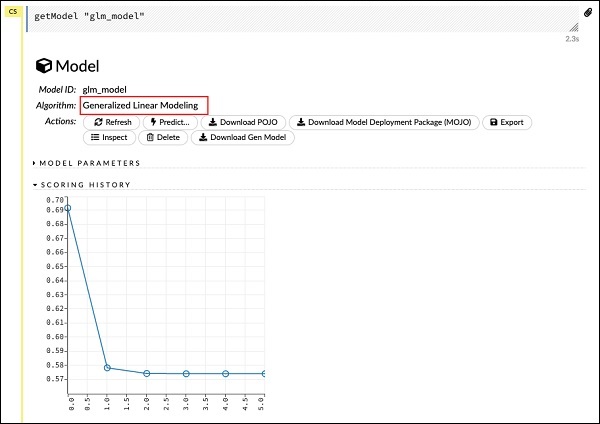
Как вы можете видеть в выходных данных, в нем говорится, что это результат выполнения алгоритма обобщенного линейного моделирования для вашего набора данных.
Прямо над SCORING HISTORY вы видите тег MODEL PARAMETERS, разверните его, и вы увидите список всех параметров, которые используются при построении модели. Это показано на скриншоте ниже.
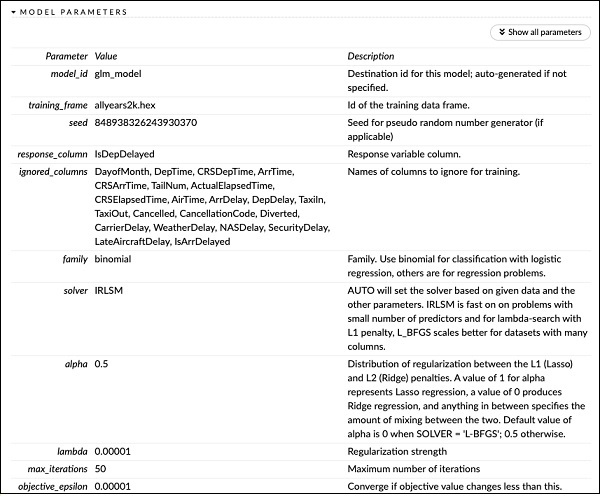
Точно так же каждый тег предоставляет подробный вывод определенного типа. Сами расширяйте различные теги, чтобы изучить результаты разных типов.
Построение другой модели
Затем мы построим модель глубокого обучения на нашем фреймворке данных. Следующий оператор в примере кода - это просто комментарий программы. Следующее утверждение фактически является командой построения модели. Это как показано здесь -
buildModel 'deeplearning', {
"model_id":"deeplearning_model","training_frame":"allyear
s2k.hex","ignored_columns":[
"DepTime","CRSDepTime","ArrTime","CRSArrTime","FlightNum","TailNum",
"ActualElapsedTime","CRSElapsedTime","AirTime","ArrDelay","DepDelay",
"TaxiIn","TaxiOut","Cancelled","CancellationCode","Diverted",
"CarrierDelay","WeatherDelay","NASDelay","SecurityDelay",
"LateAircraftDelay","IsArrDelayed"],
"ignore_const_cols":true,"res ponse_column":"IsDepDelayed",
"activation":"Rectifier","hidden":[200,200],"epochs":"100",
"variable_importances":false,"balance_classes":false,
"checkpoint":"","use_all_factor_levels":true,
"train_samples_per_iteration":-2,"adaptive_rate":true,
"input_dropout_ratio":0,"l1":0,"l2":0,"loss":"Automatic","score_interval":5,
"score_training_samples":10000,"score_duty_cycle":0.1,"autoencoder":false,
"overwrite_with_best_model":true,"target_ratio_comm_to_comp":0.02,
"seed":6765686131094811000,"rho":0.99,"epsilon":1e-8,"max_w2":"Infinity",
"initial_weight_distribution":"UniformAdaptive","classification_stop":0,
"diagnostics":true,"fast_mode":true,"force_load_balance":true,
"single_node_mode":false,"shuffle_training_data":false,"missing_values_handling":
"MeanImputation","quiet_mode":false,"sparse":false,"col_major":false,
"average_activation":0,"sparsity_beta":0,"max_categorical_features":2147483647,
"reproducible":false,"export_weights_and_biases":false
}Как вы можете видеть в приведенном выше коде, мы указываем глубокое обучение для построения модели с несколькими параметрами, установленными на соответствующие значения, как указано в документации модели глубокого обучения. Когда вы запустите этот оператор, это займет больше времени, чем построение модели GLM. Вы увидите следующий результат, когда построение модели будет завершено, хотя и с другим временем.

Изучение выходных данных модели глубокого обучения
Это генерирует вид вывода, который можно проверить с помощью следующего оператора, как и в предыдущем случае.
getModel "deeplearning_model"Мы рассмотрим выход кривой ROC, как показано ниже для быстрого ознакомления.
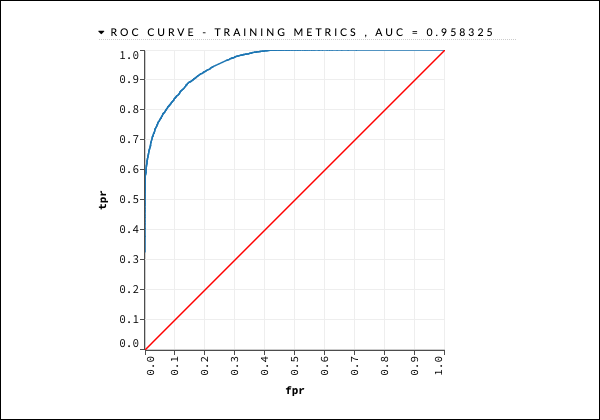
Как и в предыдущем случае, разверните различные вкладки и изучите различные результаты.
Сохранение модели
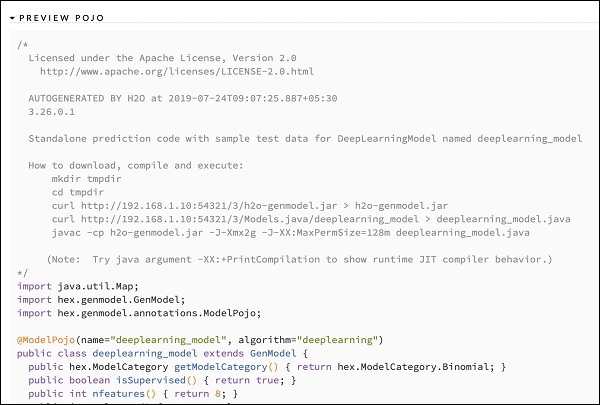
После изучения результатов различных моделей вы решаете использовать одну из них в своей производственной среде. H20 позволяет сохранить эту модель как POJO (простой старый объект Java).
Разверните последний тег PREVIEW POJO в выходных данных, и вы увидите код Java для вашей точно настроенной модели. Используйте это в своей производственной среде.
Далее мы узнаем об очень интересной особенности H2O. Мы узнаем, как использовать AutoML для тестирования и ранжирования различных алгоритмов в зависимости от их производительности.