Импала - Архитектура
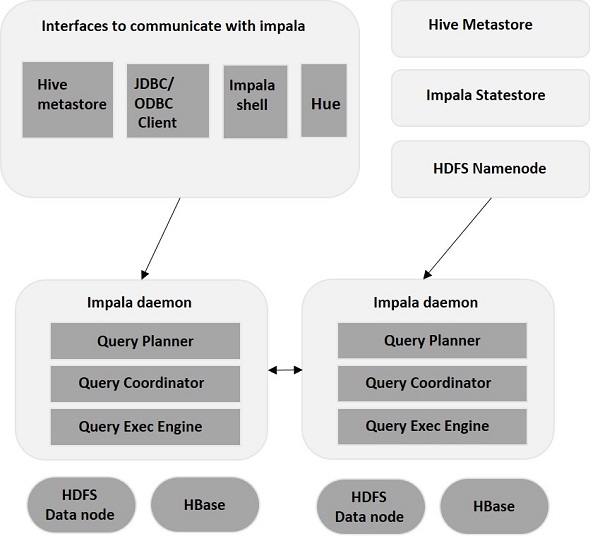
Impala - это механизм выполнения запросов MPP (Massive Parallel Processing), который работает в ряде систем в кластере Hadoop. В отличие от традиционных систем хранения, Impala отделена от своего механизма хранения. Он состоит из трех основных компонентов, а именно: демона Impala (Impalad) , государственного хранилища Impala и метаданных или хранилища метаданных Impala.
Демон Импалы ( Impalad )
Демон Импала (также известный как impalad) запускается на каждом узле, где установлена Impala. Он принимает запросы от различных интерфейсов, таких как оболочка impala, браузер оттенков и т. Д.… И обрабатывает их.
Всякий раз, когда запрос отправляется импаладу на конкретном узле, этот узел служит «coordinator node»Для этого запроса. Множественные запросы обслуживаются Impalad, работающим на других узлах. После принятия запроса Impalad читает и записывает в файлы данных и распараллеливает запросы, распределяя работу по другим узлам Impala в кластере Impala. Когда запросы обрабатываются в различных экземплярах Impalad , все они возвращают результат в центральный координирующий узел.
В зависимости от требований запросы могут быть отправлены на выделенный Impalad или с балансировкой нагрузки на другой Impalad в вашем кластере.
Государственный магазин Импала
У Impala есть еще один важный компонент, называемый хранилищем состояния Impala, который отвечает за проверку состояния каждого Impalad и затем частую передачу состояния каждого демона Impala другим демонам. Это может работать на том же узле, где работает сервер Impala или другой узел в кластере.
Имя процесса демона хранилища состояния Impala - Состояние хранится . Impalad сообщает о своем статусе работоспособности демону хранилища состояний Impala, т. Е. State хранится .
В случае сбоя узла по какой-либо причине Statestore обновляет все другие узлы об этом сбое, и как только такое уведомление становится доступным для другого impalad , никакой другой демон Impala не назначает дальнейшие запросы затронутому узлу.
Метаданные и магазин метаданных Impala
Метаданные и хранилище метаданных Impala - еще один важный компонент. Impala использует традиционные базы данных MySQL или PostgreSQL для хранения определений таблиц. Важные детали, такие как информация о таблицах и столбцах, а также определения таблиц, хранятся в централизованной базе данных, известной как мета-хранилище.
Каждый узел Impala кэширует все метаданные локально. При работе с очень большим объемом данных и / или множеством разделов получение метаданных, специфичных для таблицы, может занять значительное время. Таким образом, локально хранимый кеш метаданных помогает мгновенно предоставлять такую информацию.
Когда определение таблицы или данные таблицы обновляются, другие демоны Impala должны обновить свой кэш метаданных, получая последние метаданные, прежде чем выдавать новый запрос к рассматриваемой таблице.
Интерфейсы обработки запросов
Для обработки запросов Impala предоставляет три интерфейса, перечисленных ниже.
Impala-shell - После настройки Impala с помощью виртуальной машины Cloudera вы можете запустить оболочку Impala, набрав команду impala-shellв редакторе. Мы обсудим больше об оболочке Impala в следующих главах.
Hue interface- Вы можете обрабатывать запросы Impala с помощью браузера Hue. В браузере Hue у вас есть редактор запросов Impala, в котором вы можете вводить и выполнять запросы Impala. Чтобы получить доступ к этому редактору, прежде всего, вам необходимо войти в браузер Hue.
ODBC/JDBC drivers- Как и другие базы данных, Impala предоставляет драйверы ODBC / JDBC. Используя эти драйверы, вы можете подключаться к impala через языки программирования, которые поддерживают эти драйверы, и создавать приложения, обрабатывающие запросы в impala с использованием этих языков программирования.
Порядок выполнения запроса
Когда пользователи передают запрос с использованием любого из предоставленных интерфейсов, он принимается одним из Impalads в кластере. Этот Импалад рассматривается как координатор для этого конкретного запроса.
После получения запроса координатор запроса проверяет, подходит ли запрос, используя Table Schemaиз метамагазина Hive. Позже он собирает информацию о местоположении данных, необходимых для выполнения запроса, из узла имени HDFS и отправляет эту информацию другим импаладам для выполнения запроса.
Все остальные демоны Impala читают указанный блок данных и обрабатывают запрос. Как только все демоны завершают свои задачи, координатор запросов собирает результат и доставляет его пользователю.