Обработка дискурса естественного языка
Самая сложная проблема ИИ - это обработка естественного языка компьютерами или, другими словами, обработка естественного языка - самая сложная проблема искусственного интеллекта. Если мы говорим об основных проблемах НЛП, то одна из основных проблем НЛП - это обработка дискурса - построение теорий и моделей того, как высказывания слипаются, чтобы сформироватьcoherent discourse. На самом деле язык всегда состоит из объединенных, структурированных и связанных групп предложений, а не из отдельных и несвязанных предложений, как в фильмах. Эти связные группы предложений называются дискурсом.
Концепция согласованности
Согласованность и структура дискурса во многом взаимосвязаны. Согласованность, наряду со свойством хорошего текста, используется для оценки качества вывода системы генерации естественного языка. Возникает вопрос: что значит связность текста? Предположим, мы собрали по одному предложению с каждой страницы газеты, тогда будет ли это дискурс? Конечно, нет. Это потому, что эти предложения не демонстрируют связности. Связный дискурс должен обладать следующими свойствами:
Отношение связности между высказываниями
Дискурс был бы последовательным, если бы между его высказываниями были значимые связи. Это свойство называется отношением когерентности. Например, должно быть какое-то объяснение, чтобы оправдать связь между высказываниями.
Отношения между сущностями
Еще одно свойство, делающее дискурс связным, - это то, что должны существовать определенные отношения с объектами. Такая согласованность называется согласованностью на основе сущностей.
Структура дискурса
Важный вопрос относительно дискурса заключается в том, какую структуру он должен иметь. Ответ на этот вопрос зависит от сегментации, которую мы применили к дискурсу. Сегментации дискурса можно определить как определение типов структур для широкого дискурса. Реализовать сегментацию дискурса довольно сложно, но это очень важно дляinformation retrieval, text summarization and information extraction вид приложений.
Алгоритмы сегментации дискурса
В этом разделе мы узнаем об алгоритмах сегментации дискурса. Алгоритмы описаны ниже -
Неконтролируемая сегментация дискурса
Класс сегментации дискурса без учителя часто представляется как линейная сегментация. Разобраться в задаче линейной сегментации можно на примере. В этом примере есть задача разбить текст на блоки, состоящие из нескольких абзацев; единицы представляют собой отрывок из исходного текста. Эти алгоритмы зависят от сплоченности, которую можно определить как использование определенных лингвистических устройств для связывания текстовых единиц вместе. С другой стороны, сплоченность лексики - это сплоченность, на которую указывает связь между двумя или более словами в двух единицах, например использование синонимов.
Сегментация контролируемого дискурса
Более ранний метод не имеет границ сегментов, помеченных вручную. С другой стороны, контролируемая сегментация дискурса должна иметь данные обучения с границами. Приобрести такой же очень легко. В контролируемой сегментации дискурса важную роль играют дискурс-маркер или ключевые слова. Маркер дискурса или ключевое слово - это слово или фраза, которые служат для обозначения структуры дискурса. Эти маркеры дискурса зависят от предметной области.
Текстовая согласованность
Лексическое повторение - это способ найти структуру в дискурсе, но оно не удовлетворяет требованию связного дискурса. Чтобы достичь связного дискурса, мы должны сосредоточиться на конкретных отношениях согласованности. Как мы знаем, отношение когерентности определяет возможную связь между высказываниями в дискурсе. Хебб предложил такие отношения следующим образом:
Мы берем два срока S0 и S1 для представления значения двух связанных предложений -
Результат
Это означает, что состояние, утвержденное термином S0 может вызвать состояние, заявленное S1. Например, два утверждения показывают результат отношений: Рам попал в огонь. Его кожа горела.
Объяснение
Это означает, что государство, утвержденное S1 может вызвать состояние, заявленное S0. Например, два утверждения показывают отношения - Рам дрался с другом Шьяма. Он был пьян.
Параллельный
Он выводит p (a1, a2,…) из утверждения S0 и p (b1, b2,…) из утверждения S1. Здесь ai и bi одинаковы для всех i. Например, два утверждения параллельны - Рам хотел машину. Шьяму нужны были деньги.
Проработка
Он выводит одно и то же предложение P из обоих утверждений - S0 и S1Например, два утверждения показывают развитие отношения: Рам был из Чандигарха. Шьям был из Кералы.
Повод
Это происходит, когда изменение состояния можно вывести из утверждения S0, конечное состояние которого можно вывести из S1и наоборот. Например, два утверждения показывают случай связи: Рам взял книгу. Он отдал его Шьяму.
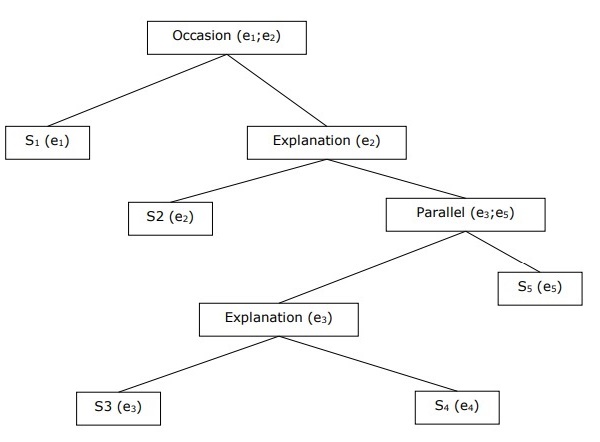
Построение иерархической структуры дискурса
Связность всего дискурса также можно рассматривать с помощью иерархической структуры между отношениями когерентности. Например, следующий отрывок можно представить в виде иерархической структуры -
S1 - Рам пошел в банк, чтобы положить деньги.
S2 - Затем он сел на поезд до магазина одежды Шьяма.
S3 - Он хотел купить одежду.
S4 - У него нет новой одежды для вечеринки.
S5 - Он также хотел поговорить с Шьямом о его здоровье.
Эталонное разрешение
Интерпретация предложений из любого дискурса - еще одна важная задача, и для ее достижения нам необходимо знать, о ком или о какой сущности идет речь. Здесь ссылка на интерпретацию является ключевым элементом.Referenceможет быть определено как лингвистическое выражение для обозначения сущности или человека. Например, в отрывке Рам , менеджер банка ABC , увидел в магазине своего друга Шьяма. Он пошел ему навстречу, лингвистические выражения вроде «Рам», «Его», «Он» относятся к нему.
В той же ноте, reference resolution может быть определена как задача определения того, какие сущности относятся к каким языковым выражениям.
Терминология, используемая в справочном разрешении
Мы используем следующую терминологию в справочном разрешении -
Referring expression- Выражение на естественном языке, которое используется для выполнения ссылки, называется выражением ссылки. Например, отрывок, использованный выше, является выражением ссылки.
Referent- Речь идет о субъекте. Например, в последнем приведенном примере референтом является Рам.
Corefer- Когда два выражения используются для обозначения одного и того же объекта, они называются corefers. Например,Ram и he кореферы.
Antecedent- Термин имеет лицензию на использование другого термина. Например,Ram является антецедентом ссылки he.
Anaphora & Anaphoric- Его можно определить как ссылку на объект, который ранее был введен в предложение. И ссылающееся выражение называется анафорическим.
Discourse model - Модель, которая содержит представления сущностей, упомянутых в дискурсе, и отношения, в которые они вовлечены.
Типы ссылающихся выражений
Давайте теперь посмотрим на различные типы ссылающихся выражений. Пять типов ссылающихся выражений описаны ниже -
Неопределенные группы существительных
Такая ссылка представляет собой новые для слушателя сущности в контексте дискурса. Например, в предложении Рам однажды пришел принести ему немного еды - это неопределенное упоминание.
Определенные фразы существительных
В отличие от вышеизложенного, такой вид ссылки представляет собой объекты, которые не являются новыми или идентифицируемыми для слушателя в контексте дискурса. Например, в предложении - я читал "Таймс оф Индия" - "Таймс оф Индия" есть определенная ссылка.
Местоимения
Это форма определенной ссылки. Например, Рам рассмеялся так громко, как мог. Словоhe представляет собой местоимение, относящееся к выражению.
Демонстрации
Они демонстрируют и ведут себя иначе, чем простые определенные местоимения. Например, это и это указательные местоимения.
Имена
Это простейший тип ссылающегося выражения. Это также может быть имя человека, организации и местонахождения. Например, в приведенных выше примерах Ram - это выражение, обозначающее имя.
Задачи разрешения справок
Две задачи разрешения ссылок описаны ниже.
Разрешение Coreference
Это задача поиска выражений в тексте, которые относятся к одному и тому же объекту. Проще говоря, это задача поиска кореферных выражений. Набор выражений кореферринга называется цепочкой кореференции. Например - Он, Главный Менеджер и Его - это относящиеся выражения в первом отрывке, приведенном в качестве примера.
Ограничение на разрешение Coreference
В английском языке основная проблема разрешения кореферентности - это местоимение it. Причина этого в том, что это местоимение имеет много применений. Например, это может означать он и она. Местоимение это также относится к вещам, которые не относятся к конкретным вещам. Например, идет дождь. Это действительно хорошо.
Разрешение прономинальной анафоры
В отличие от разрешения кореферентности, разрешение местоименной анафоры можно определить как задачу поиска антецедента для отдельного местоимения. Например, местоимение принадлежит ему, и задача разрешения местоименной анафоры состоит в том, чтобы найти слово «Рам», потому что «Рам» является антецедентом.