Обработка естественного языка - Python
В этой главе мы узнаем о языковой обработке с использованием Python.
Следующие функции отличают Python от других языков:
Python is interpreted - Нам не нужно компилировать нашу программу Python перед ее выполнением, потому что интерпретатор обрабатывает Python во время выполнения.
Interactive - Мы можем напрямую взаимодействовать с интерпретатором для написания наших программ Python.
Object-oriented - Python является объектно-ориентированным по своей природе, и на этом языке легче писать программы, потому что с помощью этой техники программирования он инкапсулирует код внутри объектов.
Beginner can easily learn - Python также называют языком для начинающих, потому что он очень прост для понимания и поддерживает разработку широкого спектра приложений.
Предпосылки
Последняя выпущенная версия Python 3 - Python 3.7.1 доступна для Windows, Mac OS и большинства разновидностей ОС Linux.
Для Windows мы можем перейти по ссылке www.python.org/downloads/windows/, чтобы загрузить и установить Python.
Для MAC OS мы можем использовать ссылку www.python.org/downloads/mac-osx/ .
В случае Linux разные версии Linux используют разные менеджеры пакетов для установки новых пакетов.
Например, чтобы установить Python 3 в Ubuntu Linux, мы можем использовать следующую команду из терминала -
$sudo apt-get install python3-minimalЧтобы узнать больше о программировании на Python, прочтите базовое руководство по Python 3 - Python 3
Начало работы с NLTK
Мы будем использовать библиотеку Python NLTK (Natural Language Toolkit) для анализа текста на английском языке. Набор инструментов для естественного языка (NLTK) - это набор библиотек Python, разработанных специально для идентификации и маркировки частей речи, встречающихся в тексте на естественном языке, таком как английский.
Установка NLTK
Перед тем как начать использовать NLTK, нам необходимо его установить. С помощью следующей команды мы можем установить его в нашей среде Python -
pip install nltkЕсли мы используем Anaconda, то пакет Conda для NLTK можно создать с помощью следующей команды -
conda install -c anaconda nltkСкачивание данных НЛТК
После установки NLTK еще одной важной задачей является загрузка его предустановленных текстовых репозиториев, чтобы его можно было легко использовать. Однако перед этим нам нужно импортировать NLTK так же, как мы импортируем любой другой модуль Python. Следующая команда поможет нам импортировать NLTK -
import nltkТеперь загрузите данные NLTK с помощью следующей команды -
nltk.download()Установка всех доступных пакетов NLTK займет некоторое время.
Другие необходимые пакеты
Некоторые другие пакеты Python, например gensim и patternтакже очень необходимы для анализа текста, а также для создания приложений обработки естественного языка с использованием NLTK. пакеты могут быть установлены, как показано ниже -
Gensim
gensim - это надежная библиотека семантического моделирования, которую можно использовать во многих приложениях. Мы можем установить его с помощью следующей команды -
pip install gensimшаблон
Его можно использовать для изготовления gensimпакет работает правильно. Следующая команда помогает в установке шаблона -
pip install patternТокенизация
Токенизацию можно определить как процесс разбиения данного текста на более мелкие единицы, называемые токенами. Жетонами могут быть слова, числа или знаки препинания. Это также можно назвать сегментацией слов.
пример
Input - Кровать и стул - это виды мебели.

У нас есть разные пакеты для токенизации, предоставляемые NLTK. Мы можем использовать эти пакеты в зависимости от наших требований. Пакеты и детали их установки следующие:
sent_tokenize пакет
Этот пакет можно использовать для разделения вводимого текста на предложения. Мы можем импортировать его, используя следующую команду -
from nltk.tokenize import sent_tokenizeword_tokenize пакет
Этот пакет можно использовать для разделения вводимого текста на слова. Мы можем импортировать его, используя следующую команду -
from nltk.tokenize import word_tokenizeПакет WordPunctTokenizer
Этот пакет можно использовать для разделения вводимого текста на слова и знаки препинания. Мы можем импортировать его, используя следующую команду -
from nltk.tokenize import WordPuncttokenizerСтемминг
По грамматическим причинам язык включает множество вариаций. Вариации в том смысле, что язык, английский, а также другие языки, имеют разные формы слова. Например, такие слова, какdemocracy, democratic, и democratization. Для проектов машинного обучения очень важно, чтобы машины понимали, что эти разные слова, как указано выше, имеют одинаковую базовую форму. Вот почему при анализе текста очень полезно извлекать базовые формы слов.
Выделение корней - это эвристический процесс, помогающий извлекать базовые формы слов путем отсечения их концов.
Различные пакеты для стемминга, предоставляемые модулем NLTK, следующие:
Пакет PorterStemmer
Этот пакет определения корней использует алгоритм Портера для извлечения базовой формы слов. С помощью следующей команды мы можем импортировать этот пакет -
from nltk.stem.porter import PorterStemmerНапример, ‘write’ будет выходом слова ‘writing’ задано в качестве входных данных для этого стеммера.
Пакет LancasterStemmer
Этот пакет определения корней использует алгоритм Ланкастера для извлечения базовой формы слов. С помощью следующей команды мы можем импортировать этот пакет -
from nltk.stem.lancaster import LancasterStemmerНапример, ‘writ’ будет выходом слова ‘writing’ задано в качестве входных данных для этого стеммера.
Пакет SnowballStemmer
Этот пакет выделения корней использует алгоритм Snowball для извлечения базовой формы слов. С помощью следующей команды мы можем импортировать этот пакет -
from nltk.stem.snowball import SnowballStemmerНапример, ‘write’ будет выходом слова ‘writing’ задано в качестве входных данных для этого стеммера.
Лемматизация
Это еще один способ извлечения базовой формы слов, обычно направленный на удаление флективных окончаний с помощью словарного и морфологического анализа. После лемматизации основная форма любого слова называется леммой.
Модуль NLTK предоставляет следующий пакет для лемматизации -
Пакет WordNetLemmatizer
Этот пакет извлечет базовую форму слова в зависимости от того, используется ли оно как существительное или как глагол. Для импорта этого пакета можно использовать следующую команду -
from nltk.stem import WordNetLemmatizerПодсчет POS-тегов - разбиение
Выявление частей речи (POS) и коротких фраз может быть выполнено с помощью разбиения на части. Это один из важных процессов обработки естественного языка. Поскольку мы знаем о процессе токенизации для создания токенов, разбиение на части фактически предназначено для маркировки этих токенов. Другими словами, мы можем сказать, что можем получить структуру предложения с помощью процесса разбиения на части.
пример
В следующем примере мы реализуем фрагменты существительных и фраз, категорию фрагментов, которые будут находить фрагменты именных фраз в предложении, используя модуль NLTK Python.
Рассмотрим следующие шаги, чтобы реализовать разбиение именных фраз:
Step 1: Chunk grammar definition
На этом этапе нам нужно определить грамматику для фрагментов. Он будет состоять из правил, которым мы должны следовать.
Step 2: Chunk parser creation
Далее нам нужно создать парсер чанков. Он проанализирует грамматику и выдаст результат.
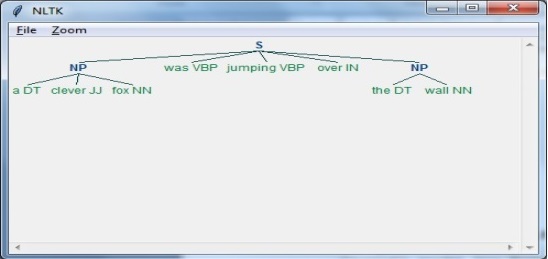
Step 3: The Output
На этом этапе мы получим результат в виде дерева.
Запуск сценария НЛП
Начните с импорта пакета NLTK -
import nltkТеперь нам нужно определить предложение.
Вот,
DT - определитель
VBP - это глагол
JJ - прилагательное
IN - это предлог
NN - существительное
sentence = [("a", "DT"),("clever","JJ"),("fox","NN"),("was","VBP"),
("jumping","VBP"),("over","IN"),("the","DT"),("wall","NN")]Далее грамматика должна быть дана в виде регулярного выражения.
grammar = "NP:{<DT>?<JJ>*<NN>}"Теперь нам нужно определить синтаксический анализатор для анализа грамматики.
parser_chunking = nltk.RegexpParser(grammar)Теперь парсер проанализирует предложение следующим образом:
parser_chunking.parse(sentence)Затем вывод будет в переменной следующим образом: -
Output = parser_chunking.parse(sentence)Теперь следующий код поможет вам нарисовать результат в виде дерева.
output.draw()