Другие тегеры набора средств естественного языка
Добавить теггер
Еще один важный класс подкласса ContextTagger - AffixTagger. В классе AffixTagger контекстом является префикс или суффикс слова. По этой причине класс AffixTagger может изучать теги на основе подстрок фиксированной длины в начале или конце слова.
Как это работает?
Его работа зависит от аргумента affix_length, который определяет длину префикса или суффикса. Значение по умолчанию - 3. Но как он различает, узнал ли класс AffixTagger префикс или суффикс слова?
affix_length=positive - Если значение affix_lenght положительное, это означает, что класс AffixTagger будет изучать префиксы слов.
affix_length=negative - Если значение affix_lenght отрицательное, это означает, что класс AffixTagger будет изучать суффиксы слова.
Чтобы было понятнее, в приведенном ниже примере мы будем использовать класс AffixTagger для предложений из дерева с тегами.
пример
В этом примере AffixTagger узнает префикс слова, потому что мы не указываем никакого значения для аргумента affix_length. Аргумент примет значение по умолчанию 3 -
from nltk.tag import AffixTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
Prefix_tagger = AffixTagger(train_sentences)
test_sentences = treebank.tagged_sents()[1500:]
Prefix_tagger.evaluate(test_sentences)Вывод
0.2800492099250667Давайте посмотрим в приведенном ниже примере, какой будет точность, когда мы предоставим значение 4 аргументу affix_length -
from nltk.tag import AffixTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
Prefix_tagger = AffixTagger(train_sentences, affix_length=4 )
test_sentences = treebank.tagged_sents()[1500:]
Prefix_tagger.evaluate(test_sentences)Вывод
0.18154947354966527пример
В этом примере AffixTagger узнает суффикс слова, потому что мы укажем отрицательное значение для аргумента affix_length.
from nltk.tag import AffixTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
Suffix_tagger = AffixTagger(train_sentences, affix_length = -3)
test_sentences = treebank.tagged_sents()[1500:]
Suffix_tagger.evaluate(test_sentences)Вывод
0.2800492099250667Брилл Тэггер
Brill Tagger - это теггер на основе преобразования. НЛТК предоставляетBrillTagger class, который является первым тегом, который не является подклассом SequentialBackoffTagger. Напротив, ряд правил для исправления результатов начального теггера используетсяBrillTagger.
Как это работает?
Чтобы обучить BrillTagger класс с использованием BrillTaggerTrainer мы определяем следующую функцию -
def train_brill_tagger(initial_tagger, train_sentences, **kwargs) -
templates = [
brill.Template(brill.Pos([-1])),
brill.Template(brill.Pos([1])),
brill.Template(brill.Pos([-2])),
brill.Template(brill.Pos([2])),
brill.Template(brill.Pos([-2, -1])),
brill.Template(brill.Pos([1, 2])),
brill.Template(brill.Pos([-3, -2, -1])),
brill.Template(brill.Pos([1, 2, 3])),
brill.Template(brill.Pos([-1]), brill.Pos([1])),
brill.Template(brill.Word([-1])),
brill.Template(brill.Word([1])),
brill.Template(brill.Word([-2])),
brill.Template(brill.Word([2])),
brill.Template(brill.Word([-2, -1])),
brill.Template(brill.Word([1, 2])),
brill.Template(brill.Word([-3, -2, -1])),
brill.Template(brill.Word([1, 2, 3])),
brill.Template(brill.Word([-1]), brill.Word([1])),
]
trainer = brill_trainer.BrillTaggerTrainer(initial_tagger, templates, deterministic=True)
return trainer.train(train_sentences, **kwargs)Как видим, эта функция требует initial_tagger и train_sentences. Требуетсяinitial_tagger аргумент и список шаблонов, реализующий BrillTemplateинтерфейс. ВBrillTemplate интерфейс находится в nltk.tbl.templateмодуль. Одна из таких реализаций -brill.Template класс.
Основная роль теггера, основанного на преобразовании, заключается в создании правил преобразования, которые исправляют вывод исходного тега, чтобы он соответствовал обучающим предложениям. Давайте посмотрим на рабочий процесс ниже -
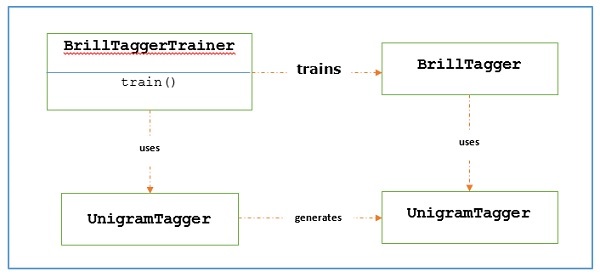
пример
В этом примере мы будем использовать combine_tagger который мы создали при расчесывании тегеров (в предыдущем рецепте) из цепочки отсрочки NgramTagger классы, как initial_tagger. Сначала оценим результат с помощьюCombine.tagger а затем используйте это как initial_tagger дрессировать брилла таггера.
from tagger_util import backoff_tagger
from nltk.tag import UnigramTagger
from nltk.tag import BigramTagger
from nltk.tag import TrigramTagger
from nltk.tag import DefaultTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
back_tagger = DefaultTagger('NN')
Combine_tagger = backoff_tagger(
train_sentences, [UnigramTagger, BigramTagger, TrigramTagger], backoff = back_tagger
)
test_sentences = treebank.tagged_sents()[1500:]
Combine_tagger.evaluate(test_sentences)Вывод
0.9234530029238365Теперь посмотрим результат оценки, когда Combine_tagger используется как initial_tagger дрессировать брилла таггера -
from tagger_util import train_brill_tagger
brill_tagger = train_brill_tagger(combine_tagger, train_sentences)
brill_tagger.evaluate(test_sentences)Вывод
0.9246832510505041Мы можем заметить, что BrillTagger класс имеет немного повышенную точность по сравнению с Combine_tagger.
Полный пример реализации
from tagger_util import backoff_tagger
from nltk.tag import UnigramTagger
from nltk.tag import BigramTagger
from nltk.tag import TrigramTagger
from nltk.tag import DefaultTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
back_tagger = DefaultTagger('NN')
Combine_tagger = backoff_tagger(train_sentences,
[UnigramTagger, BigramTagger, TrigramTagger], backoff = back_tagger)
test_sentences = treebank.tagged_sents()[1500:]
Combine_tagger.evaluate(test_sentences)
from tagger_util import train_brill_tagger
brill_tagger = train_brill_tagger(combine_tagger, train_sentences)
brill_tagger.evaluate(test_sentences)Вывод
0.9234530029238365
0.9246832510505041TnT Tagger
TnT Tagger, расшифровывается как Trigrams'nTags, - это статистический теггер, основанный на марковских моделях второго порядка.
Как это работает?
Мы можем понять работу TnT tagger с помощью следующих шагов:
Сначала на основе данных обучения TnT tegger поддерживает несколько внутренних FreqDist и ConditionalFreqDist экземпляры.
После этого юниграммы, биграммы и триграммы будут подсчитаны по этим частотным распределениям.
Теперь во время тегирования, используя частоты, он будет вычислять вероятности возможных тегов для каждого слова.
Вот почему вместо построения цепочки отсрочки NgramTagger он использует все модели ngram вместе, чтобы выбрать лучший тег для каждого слова. Давайте оценим точность с помощью TnT tagger в следующем примере -
from nltk.tag import tnt
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
tnt_tagger = tnt.TnT()
tnt_tagger.train(train_sentences)
test_sentences = treebank.tagged_sents()[1500:]
tnt_tagger.evaluate(test_sentences)Вывод
0.9165508316157791У нас немного меньшая точность, чем с Brill Tagger.
Обратите внимание, что нам нужно позвонить train() до evaluate() иначе мы получим точность 0%.