Инструментарий естественного языка - Краткое руководство
Что такое обработка естественного языка (NLP)?
Метод общения, с помощью которого люди могут говорить, читать и писать, - это язык. Другими словами, мы, люди, можем думать, строить планы, принимать решения на своем естественном языке. Здесь большой вопрос в том, могут ли люди общаться на естественном языке с компьютерами / машинами в эпоху искусственного интеллекта, машинного обучения и глубокого обучения? Разработка приложений НЛП - огромная проблема для нас, потому что компьютерам требуются структурированные данные, но, с другой стороны, человеческая речь неструктурирована и часто неоднозначна по своей природе.
Естественный язык - это подполе информатики, в частности ИИ, которое позволяет компьютерам / машинам понимать, обрабатывать и манипулировать человеческим языком. Проще говоря, НЛП - это способ машин для анализа, понимания и извлечения значения из естественных языков человека, таких как хинди, английский, французский, голландский и т. Д.
Как это работает?
Прежде чем углубляться в работу НЛП, мы должны понять, как люди используют язык. Каждый день мы, люди, используем сотни или тысячи слов, а другие люди интерпретируют их и отвечают соответственно. Это простое общение для людей, не так ли? Но мы знаем, что слова лежат гораздо глубже, и мы всегда извлекаем контекст из того, что мы говорим и как мы говорим. Вот почему мы можем сказать, что вместо того, чтобы фокусироваться на модуляции голоса, НЛП действительно опирается на контекстный паттерн.
Давайте разберемся с этим на примере -
Man is to woman as king is to what?
We can interpret it easily and answer as follows:
Man relates to king, so woman can relate to queen.
Hence the answer is Queen.Откуда люди знают, что слово что означает? Ответ на этот вопрос заключается в том, что мы учимся на собственном опыте. Но как машины / компьютеры учатся тому же?
Позвольте нам понять это, выполнив следующие простые шаги -
Во-первых, нам нужно снабдить машины достаточным количеством данных, чтобы машины могли учиться на собственном опыте.
Затем машина создаст векторы слов, используя алгоритмы глубокого обучения, из данных, которые мы подавали ранее, а также из окружающих данных.
Затем, выполняя простые алгебраические операции с этими векторами слов, машина сможет давать ответы как люди.
Компоненты НЛП
Следующая диаграмма представляет компоненты обработки естественного языка (NLP) -
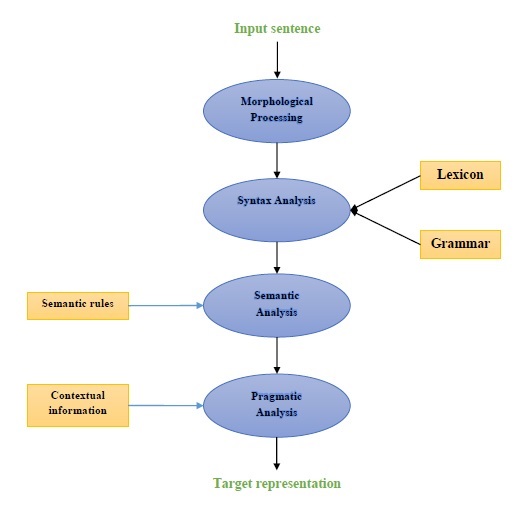
Морфологическая обработка
Морфологическая обработка - это первый компонент НЛП. Он включает в себя разбиение фрагментов языкового ввода на наборы токенов, соответствующих абзацам, предложениям и словам. Например, такое слово, как“everyday” можно разбить на два токена подслова как “every-day”.
Синтаксический анализ
Синтаксический анализ, второй компонент, является одним из наиболее важных компонентов НЛП. Цели этого компонента следующие:
Чтобы проверить, правильно ли составлено предложение.
Разбить его на структуру, которая показывает синтаксические отношения между разными словами.
Например, предложения вроде “The school goes to the student” будет отклонен анализатором синтаксиса.
Семантический анализ
Семантический анализ - это третий компонент НЛП, который используется для проверки осмысленности текста. Он включает в себя определение точного значения, или, можно сказать, словарного значения из текста. Например, предложения типа «Это горячее мороженое». будет отброшен семантическим анализатором.
Прагматический анализ
Прагматический анализ - четвертый компонент НЛП. Он включает в себя подгонку реальных объектов или событий, существующих в каждом контексте, со ссылками на объекты, полученными предыдущим компонентом, то есть семантическим анализом. Например, предложения вроде“Put the fruits in the basket on the table” может иметь две семантические интерпретации, поэтому прагматический анализатор будет выбирать между этими двумя возможностями.
Примеры приложений НЛП
НЛП, развивающаяся технология, порождает различные формы ИИ, которые мы привыкли видеть в наши дни. Для сегодняшних и завтрашних все более когнитивных приложений использование НЛП для создания бесшовного и интерактивного интерфейса между людьми и машинами будет оставаться главным приоритетом. Ниже приведены некоторые из очень полезных приложений НЛП.
Машинный перевод
Машинный перевод (МП) - одно из важнейших приложений обработки естественного языка. МП - это в основном процесс перевода одного исходного языка или текста на другой язык. Система машинного перевода может быть двуязычной или многоязычной.
Борьба со спамом
В связи с огромным увеличением количества нежелательных писем, спам-фильтры стали важными, потому что они являются первой линией защиты от этой проблемы. Рассматривая ложноположительные и ложноотрицательные проблемы в качестве основных проблем, функциональность НЛП может быть использована для разработки системы фильтрации спама.
Моделирование N-грамм, Word Stemming и байесовская классификация - это некоторые из существующих моделей NLP, которые можно использовать для фильтрации спама.
Поиск информации и поиск в Интернете
Большинство поисковых систем, таких как Google, Yahoo, Bing, WolframAlpha и т. Д., Основывают свою технологию машинного перевода (MT) на моделях глубокого обучения NLP. Такие модели глубокого обучения позволяют алгоритмам читать текст на веб-странице, интерпретировать его значение и переводить на другой язык.
Автоматическое суммирование текста
Автоматическое суммирование текста - это метод, который создает краткое и точное резюме более длинных текстовых документов. Следовательно, это помогает нам получать актуальную информацию за меньшее время. В эту цифровую эпоху мы остро нуждаемся в автоматическом резюмировании текста, потому что через Интернет идет поток информации, который не прекратится. НЛП и его функции играют важную роль в разработке автоматического реферирования текста.
Грамматическая коррекция
Исправление орфографии и грамматики - очень полезная функция текстового редактора, такого как Microsoft Word. Для этой цели широко используется обработка естественного языка (NLP).
Вопрос-ответ
Ответы на вопросы, еще одно основное приложение обработки естественного языка (НЛП), фокусируется на создании систем, которые автоматически отвечают на вопрос, отправленный пользователем, на его естественном языке.
Анализ настроений
Анализ тональности входит в число других важных приложений обработки естественного языка (НЛП). Как следует из названия, анализ настроений используется для:
Определите настроения среди нескольких сообщений и
Определите чувство, в котором эмоции не выражены явно.
Компании электронной коммерции в Интернете, такие как Amazon, ebay и т. Д., Используют анализ настроений для определения мнения и настроений своих клиентов в Интернете. Это поможет им понять, что их клиенты думают об их продуктах и услугах.
Речевые движки
Речевые механизмы, такие как Siri, Google Voice, Alexa, основаны на NLP, поэтому мы можем общаться с ними на нашем естественном языке.
Внедрение НЛП
Чтобы создавать вышеупомянутые приложения, нам необходимо обладать определенным набором навыков с хорошим пониманием языка и инструментами для эффективной обработки языка. Для этого у нас есть различные инструменты с открытым исходным кодом. Некоторые из них имеют открытый исходный код, а другие разрабатываются организациями для создания собственных приложений НЛП. Ниже приводится список некоторых инструментов НЛП -
Набор инструментов для естественного языка (NLTK)
Mallet
GATE
Открытое НЛП
UIMA
Genism
Набор инструментов Стэнфордского университета
Большинство этих инструментов написано на Java.
Набор инструментов для естественного языка (NLTK)
Среди вышеупомянутых инструментов NLP NLTK имеет очень высокие оценки, когда дело доходит до простоты использования и объяснения концепции. Кривая обучения Python очень быстрая, и NLTK написан на Python, поэтому NLTK также имеет очень хороший учебный комплект. NLTK включает в себя большинство задач, таких как токенизация, стемминг, лемматизация, пунктуация, количество символов и количество слов. Он очень элегантен и с ним легко работать.
Чтобы установить NLTK, на наших компьютерах должен быть установлен Python. Вы можете перейти по ссылке www.python.org/downloads и выбрать последнюю версию для вашей ОС, то есть Windows, Mac и Linux / Unix. Базовое руководство по Python можно найти по ссылке www.tutorialspoint.com/python3/index.htm .
Теперь, когда у вас установлен Python в вашей компьютерной системе, позвольте нам понять, как мы можем установить NLTK.
Установка NLTK
Мы можем установить NLTK на различные ОС следующим образом:
В Windows
Чтобы установить NLTK в ОС Windows, выполните следующие действия:
Сначала откройте командную строку Windows и перейдите к расположению pip папка.
Затем введите следующую команду для установки NLTK -
pip3 install nltkТеперь откройте PythonShell из меню «Пуск» Windows и введите следующую команду, чтобы проверить установку NLTK:
Import nltkЕсли ошибки нет, значит, вы успешно установили NLTK в ОС Windows с Python3.
На Mac / Linux
Чтобы установить NLTK на Mac / Linux OS, напишите следующую команду -
sudo pip install -U nltkЕсли на вашем компьютере не установлен pip, следуйте приведенным ниже инструкциям для первой установки. pip -
Сначала обновите индекс пакета, выполнив следующую команду -
sudo apt updateТеперь введите следующую команду для установки pip для Python 3 -
sudo apt install python3-pipЧерез Анаконду
Чтобы установить NLTK через Anaconda, выполните следующие действия:
Сначала, чтобы установить Anaconda, перейдите по ссылке www.anaconda.com/distribution/#download-section, а затем выберите версию Python, которую необходимо установить.
Как только у вас будет Anaconda в вашей компьютерной системе, перейдите в ее командную строку и введите следующую команду:
conda install -c anaconda nltk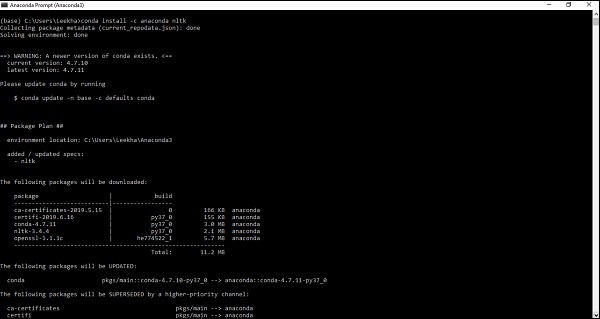
Вам необходимо просмотреть вывод и ввести «да». NLTK будет загружен и установлен в вашем пакете Anaconda.
Скачивание набора данных и пакетов NLTK
Теперь у нас есть NLTK, установленный на наших компьютерах, но для его использования нам необходимо загрузить доступные в нем наборы данных (корпус). Некоторые из важных доступных наборов данных:stpwords, guntenberg, framenet_v15 и так далее.
С помощью следующих команд мы можем загрузить все наборы данных NLTK -
import nltk
nltk.download()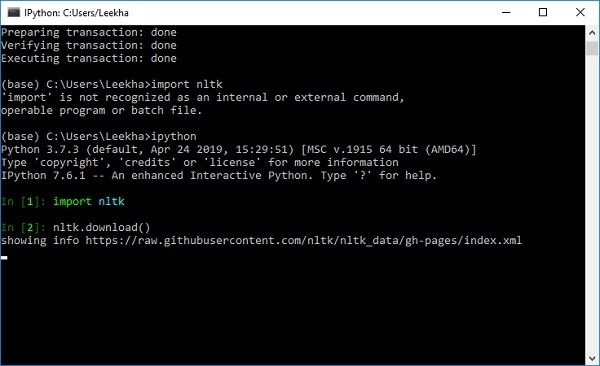
Вы получите следующее окно загрузки NLTK.
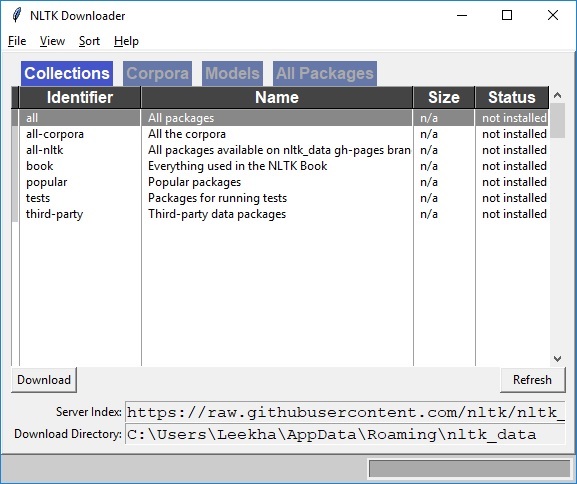
Теперь нажмите кнопку загрузки, чтобы загрузить наборы данных.
Как запустить скрипт NLTK?
Ниже приведен пример, в котором мы реализуем алгоритм Портера Стеммера с использованием PorterStemmerкласс nltk. с помощью этого примера вы сможете понять, как запустить сценарий NLTK.
Во-первых, нам нужно импортировать инструментарий естественного языка (nltk).
import nltkТеперь импортируйте PorterStemmer класс для реализации алгоритма Портера Стеммера.
from nltk.stem import PorterStemmerЗатем создайте экземпляр класса Porter Stemmer следующим образом:
word_stemmer = PorterStemmer()Теперь введите слово, которое вы хотите остановить. -
word_stemmer.stem('writing')Вывод
'write'word_stemmer.stem('eating')Вывод
'eat'Что такое токенизация?
Его можно определить как процесс разделения текста на более мелкие части, такие как предложения и слова. Эти более мелкие части называются токенами. Например, слово - это токен в предложении, а предложение - это токен в абзаце.
Поскольку мы знаем, что NLP используется для создания приложений, таких как анализ тональности, системы обеспечения качества, языковой перевод, интеллектуальные чат-боты, голосовые системы и т. Д., Следовательно, для их создания жизненно важно понимать закономерности в тексте. Упомянутые выше токены очень полезны для поиска и понимания этих шаблонов. Мы можем рассматривать токенизацию как базовый шаг для других рецептов, таких как стемминг и лемматизация.
Пакет НЛТК
nltk.tokenize - это пакет, предоставляемый модулем NLTK для достижения процесса токенизации.
Преобразование предложений в слова
Разделение предложения на слова или создание списка слов из строки - важная часть каждого действия по обработке текста. Давайте разберемся с этим с помощью различных функций / модулей, предоставляемыхnltk.tokenize пакет.
модуль word_tokenize
word_tokenizeмодуль используется для базовой токенизации слов. В следующем примере этот модуль будет использоваться для разбиения предложения на слова.
пример
import nltk
from nltk.tokenize import word_tokenize
word_tokenize('Tutorialspoint.com provides high quality technical tutorials for free.')Вывод
['Tutorialspoint.com', 'provides', 'high', 'quality', 'technical', 'tutorials', 'for', 'free', '.']Класс TreebankWordTokenizer
word_tokenize модуль, использованный выше, в основном представляет собой функцию-оболочку, которая вызывает функцию tokenize () как экземпляр TreebankWordTokenizerкласс. Результат будет тот же, что и при использовании модуля word_tokenize () для разделения предложений на слова. Давайте посмотрим на тот же пример, реализованный выше -
пример
Во-первых, нам нужно импортировать инструментарий естественного языка (nltk).
import nltkТеперь импортируйте TreebankWordTokenizer класс для реализации алгоритма токенизатора слов -
from nltk.tokenize import TreebankWordTokenizerЗатем создайте экземпляр класса TreebankWordTokenizer следующим образом:
Tokenizer_wrd = TreebankWordTokenizer()Теперь введите предложение, которое вы хотите преобразовать в токены -
Tokenizer_wrd.tokenize(
'Tutorialspoint.com provides high quality technical tutorials for free.'
)Вывод
[
'Tutorialspoint.com', 'provides', 'high', 'quality',
'technical', 'tutorials', 'for', 'free', '.'
]Полный пример реализации
Давайте посмотрим на полный пример реализации ниже
import nltk
from nltk.tokenize import TreebankWordTokenizer
tokenizer_wrd = TreebankWordTokenizer()
tokenizer_wrd.tokenize('Tutorialspoint.com provides high quality technical
tutorials for free.')Вывод
[
'Tutorialspoint.com', 'provides', 'high', 'quality',
'technical', 'tutorials','for', 'free', '.'
]Наиболее важным условием токенизатора является разделение сокращений. Например, если мы используем для этой цели модуль word_tokenize (), он выдаст следующий результат:
пример
import nltk
from nltk.tokenize import word_tokenize
word_tokenize('won’t')Вывод
['wo', "n't"]]Такая конвенция TreebankWordTokenizerнедопустимо. Вот почему у нас есть два альтернативных токенизатора слов, а именноPunktWordTokenizer и WordPunctTokenizer.
WordPunktTokenizer - класс
Альтернативный токенизатор слов, который разбивает все знаки препинания на отдельные токены. Давайте разберемся с этим на следующем простом примере -
пример
from nltk.tokenize import WordPunctTokenizer
tokenizer = WordPunctTokenizer()
tokenizer.tokenize(" I can't allow you to go home early")Вывод
['I', 'can', "'", 't', 'allow', 'you', 'to', 'go', 'home', 'early']Преобразование текста в предложения
В этом разделе мы собираемся разбить текст / абзац на предложения. НЛТК предоставляетsent_tokenize модуль для этой цели.
Зачем это нужно?
У нас возник очевидный вопрос: когда у нас есть токенизатор слов, зачем нам токенизатор предложений или зачем нам токенизировать текст в предложения. Предположим, нам нужно посчитать среднее количество слов в предложениях, как мы можем это сделать? Для выполнения этой задачи нам нужна как токенизация предложения, так и токенизация слова.
Давайте поймем разницу между токенизатором предложения и слова с помощью следующего простого примера -
пример
import nltk
from nltk.tokenize import sent_tokenize
text = "Let us understand the difference between sentence & word tokenizer.
It is going to be a simple example."
sent_tokenize(text)Вывод
[
"Let us understand the difference between sentence & word tokenizer.",
'It is going to be a simple example.'
]Токенизация предложения с использованием регулярных выражений
Если вы чувствуете, что вывод word tokenizer неприемлем, и хотите получить полный контроль над тем, как токенизировать текст, у нас есть регулярное выражение, которое можно использовать при токенизации предложения. НЛТК предоставляетRegexpTokenizer класс, чтобы добиться этого.
Давайте разберемся в концепции с помощью двух примеров ниже.
В первом примере мы будем использовать регулярное выражение для сопоставления буквенно-цифровых токенов и одинарных кавычек, чтобы не разделять сокращения вроде “won’t”.
Пример 1
import nltk
from nltk.tokenize import RegexpTokenizer
tokenizer = RegexpTokenizer("[\w']+")
tokenizer.tokenize("won't is a contraction.")
tokenizer.tokenize("can't is a contraction.")Вывод
["won't", 'is', 'a', 'contraction']
["can't", 'is', 'a', 'contraction']В первом примере мы будем использовать регулярное выражение для токенизации пробелов.
Пример 2
import nltk
from nltk.tokenize import RegexpTokenizer
tokenizer = RegexpTokenizer('/s+' , gaps = True)
tokenizer.tokenize("won't is a contraction.")Вывод
["won't", 'is', 'a', 'contraction']Из вышеприведенного вывода мы видим, что знаки препинания остаются в токенах. Параметр gaps = True означает, что шаблон будет определять пробелы для токенизации. С другой стороны, если мы будем использовать параметр gaps = False, тогда шаблон будет использоваться для идентификации токенов, которые можно увидеть в следующем примере -
import nltk
from nltk.tokenize import RegexpTokenizer
tokenizer = RegexpTokenizer('/s+' , gaps = False)
tokenizer.tokenize("won't is a contraction.")Вывод
[ ]Это даст нам пустой результат.
Зачем тренировать собственный токенизатор предложений?
Это очень важный вопрос: если у нас есть токенизатор предложений NLTK по умолчанию, то зачем нам обучать токенизатор предложений? Ответ на этот вопрос заключается в качестве токенизатора предложений по умолчанию NLTK. Токенизатор NLTK по умолчанию - это токенизатор общего назначения. Хотя он работает очень хорошо, но он может быть не лучшим выбором для нестандартного текста, как, например, наш текст, или для текста с уникальным форматированием. Чтобы токенизировать такой текст и получить наилучшие результаты, мы должны обучить собственный токенизатор предложений.
Пример реализации
В этом примере мы будем использовать корпус веб-текста. Текстовый файл, который мы собираемся использовать из этого корпуса, имеет текст, отформатированный в виде диалогов, показанных ниже -
Guy: How old are you?
Hipster girl: You know, I never answer that question. Because to me, it's about
how mature you are, you know? I mean, a fourteen year old could be more mature
than a twenty-five year old, right? I'm sorry, I just never answer that question.
Guy: But, uh, you're older than eighteen, right?
Hipster girl: Oh, yeah.Мы сохранили этот текстовый файл с именем training_tokenizer. NLTK предоставляет класс с именемPunktSentenceTokenizerс помощью которого мы можем обучаться на необработанном тексте для создания собственного токенизатора предложений. Мы можем получить необработанный текст либо путем чтения файла, либо из корпуса NLTK, используяraw() метод.
Давайте посмотрим на пример ниже, чтобы лучше понять это -
Во-первых, импорт PunktSentenceTokenizer класс от nltk.tokenize пакет -
from nltk.tokenize import PunktSentenceTokenizerТеперь импортируем webtext корпус из nltk.corpus пакет
from nltk.corpus import webtextЗатем, используя raw() метод, получите необработанный текст из training_tokenizer.txt файл следующим образом -
text = webtext.raw('C://Users/Leekha/training_tokenizer.txt')Теперь создайте экземпляр PunktSentenceTokenizer и распечатайте предложения токенизации из текстового файла следующим образом:
sent_tokenizer = PunktSentenceTokenizer(text)
sents_1 = sent_tokenizer.tokenize(text)
print(sents_1[0])Вывод
White guy: So, do you have any plans for this evening?
print(sents_1[1])
Output:
Asian girl: Yeah, being angry!
print(sents_1[670])
Output:
Guy: A hundred bucks?
print(sents_1[675])
Output:
Girl: But you already have a Big Mac...Полный пример реализации
from nltk.tokenize import PunktSentenceTokenizer
from nltk.corpus import webtext
text = webtext.raw('C://Users/Leekha/training_tokenizer.txt')
sent_tokenizer = PunktSentenceTokenizer(text)
sents_1 = sent_tokenizer.tokenize(text)
print(sents_1[0])Вывод
White guy: So, do you have any plans for this evening?Чтобы понять разницу между токенизатором предложений по умолчанию в NLTK и нашим собственным обученным токенизатором предложений, позвольте нам токенизировать тот же файл с помощью токенизатора предложений по умолчанию, то есть sent_tokenize ().
from nltk.tokenize import sent_tokenize
from nltk.corpus import webtext
text = webtext.raw('C://Users/Leekha/training_tokenizer.txt')
sents_2 = sent_tokenize(text)
print(sents_2[0])
Output:
White guy: So, do you have any plans for this evening?
print(sents_2[675])
Output:
Hobo: Y'know what I'd do if I was rich?С помощью разницы в выводе мы можем понять концепцию того, почему полезно обучать наш собственный токенизатор предложений.
Что такое стоп-слова?
Некоторые общие слова, которые присутствуют в тексте, но не влияют на значение предложения. Такие слова совершенно не важны для поиска информации или обработки естественного языка. Наиболее распространенными игнорируемыми словами являются «the» и «a».
Корпус стоп-слов НЛТК
Фактически, набор инструментов для естественного языка поставляется с корпусом стоп-слов, содержащим списки слов для многих языков. Давайте разберемся с его использованием с помощью следующего примера -
Сначала импортируйте копус стоп-слов из пакета nltk.corpus -
from nltk.corpus import stopwordsТеперь мы будем использовать стоп-слова из английских языков.
english_stops = set(stopwords.words('english'))
words = ['I', 'am', 'a', 'writer']
[word for word in words if word not in english_stops]Вывод
['I', 'writer']Полный пример реализации
from nltk.corpus import stopwords
english_stops = set(stopwords.words('english'))
words = ['I', 'am', 'a', 'writer']
[word for word in words if word not in english_stops]Вывод
['I', 'writer']Поиск полного списка поддерживаемых языков
С помощью следующего скрипта Python мы также можем найти полный список языков, поддерживаемых корпусом стоп-слов NLTK:
from nltk.corpus import stopwords
stopwords.fileids()Вывод
[
'arabic', 'azerbaijani', 'danish', 'dutch', 'english', 'finnish', 'french',
'german', 'greek', 'hungarian', 'indonesian', 'italian', 'kazakh', 'nepali',
'norwegian', 'portuguese', 'romanian', 'russian', 'slovene', 'spanish',
'swedish', 'tajik', 'turkish'
]Что такое Wordnet?
Wordnet - это большая лексическая база данных английского языка, созданная Принстоном. Входит в состав НЛТК. Существительные, глаголы, прилагательные и наречия сгруппированы в набор синсетов, то есть когнитивных синонимов. Здесь каждый набор синсетов выражает особое значение. Ниже приведены некоторые варианты использования Wordnet.
- Его можно использовать для поиска определения слова
- Мы можем найти синонимы и антонимы слова
- Связи и сходства слов можно изучить с помощью Wordnet
- Устранение неоднозначности слов, имеющих несколько значений и значений.
Как импортировать Wordnet?
Wordnet можно импортировать с помощью следующей команды -
from nltk.corpus import wordnetДля более компактной команды используйте следующее -
from nltk.corpus import wordnet as wnЭкземпляры Synset
Синсеты - это группы слов-синонимов, которые выражают одно и то же понятие. Когда вы используете Wordnet для поиска слов, вы получите список экземпляров Synset.
wordnet.synsets (слово)
Чтобы получить список Synsets, мы можем найти любое слово в Wordnet, используя wordnet.synsets(word). Например, в следующем рецепте Python мы собираемся найти Synset для «собаки» вместе с некоторыми свойствами и методами Synset -
пример
Сначала импортируйте wordnet следующим образом -
from nltk.corpus import wordnet as wnТеперь введите слово, которое вы хотите найти в Synset -
syn = wn.synsets('dog')[0]Здесь мы используем метод name (), чтобы получить уникальное имя для набора Synset, которое можно использовать для прямого получения Synset -
syn.name()
Output:
'dog.n.01'Затем мы используем метод definition (), который даст нам определение слова -
syn.definition()
Output:
'a member of the genus Canis (probably descended from the common wolf) that has
been domesticated by man since prehistoric times; occurs in many breeds'Другой метод - examples (), который даст нам примеры, связанные со словом -
syn.examples()
Output:
['the dog barked all night']Полный пример реализации
from nltk.corpus import wordnet as wn
syn = wn.synsets('dog')[0]
syn.name()
syn.definition()
syn.examples()Получение гиперонимов
Синсеты организованы в виде дерева наследования, как структура, в которой Hypernyms представляет собой более абстрактные термины, в то время как Hyponymsпредставляет более конкретные термины. Одним из важных моментов является то, что это дерево можно проследить вплоть до корневого гиперонима. Давайте разберемся с концепцией с помощью следующего примера -
from nltk.corpus import wordnet as wn
syn = wn.synsets('dog')[0]
syn.hypernyms()Вывод
[Synset('canine.n.02'), Synset('domestic_animal.n.01')]Здесь мы видим, что собака и домашнее животное - это гиперонимы слова «собака».
Теперь мы можем найти гипонимы слова «собака» следующим образом:
syn.hypernyms()[0].hyponyms()Вывод
[
Synset('bitch.n.04'),
Synset('dog.n.01'),
Synset('fox.n.01'),
Synset('hyena.n.01'),
Synset('jackal.n.01'),
Synset('wild_dog.n.01'),
Synset('wolf.n.01')
]Из вышеприведенного вывода мы видим, что «собака» - это только один из многих гипонимов «домашние_животные».
Чтобы найти корень всего этого, мы можем использовать следующую команду -
syn.root_hypernyms()Вывод
[Synset('entity.n.01')]Из вышеприведенного вывода мы видим, что у него только один корень.
Полный пример реализации
from nltk.corpus import wordnet as wn
syn = wn.synsets('dog')[0]
syn.hypernyms()
syn.hypernyms()[0].hyponyms()
syn.root_hypernyms()Вывод
[Synset('entity.n.01')]Леммы в Wordnet
В лингвистике каноническая форма или морфологическая форма слова называется леммой. Чтобы найти синоним, а также антоним слова, мы также можем искать леммы в WordNet. Посмотрим, как это сделать.
Поиск синонимов
Используя метод lemma (), мы можем найти количество синонимов Synset. Давайте применим этот метод к синсету "собака" -
пример
from nltk.corpus import wordnet as wn
syn = wn.synsets('dog')[0]
lemmas = syn.lemmas()
len(lemmas)Вывод
3Приведенный выше вывод показывает, что у «dog» есть три леммы.
Получение названия первой леммы следующим образом -
lemmas[0].name()
Output:
'dog'Получение названия второй леммы следующим образом -
lemmas[1].name()
Output:
'domestic_dog'Получение названия третьей леммы следующим образом -
lemmas[2].name()
Output:
'Canis_familiaris'Фактически, Synset представляет собой группу лемм, которые имеют одинаковое значение, в то время как лемма представляет собой отдельную словоформу.
Поиск антонимов
В WordNet некоторые леммы также имеют антонимы. Например, у слова «хороший» всего 27 синетов, из них 5 содержат леммы с антонимами. Давайте найдем антонимы (когда слово «хороший» используется как существительное, а когда слово «хороший» используется как прилагательное).
Пример 1
from nltk.corpus import wordnet as wn
syn1 = wn.synset('good.n.02')
antonym1 = syn1.lemmas()[0].antonyms()[0]
antonym1.name()Вывод
'evil'antonym1.synset().definition()Вывод
'the quality of being morally wrong in principle or practice'Приведенный выше пример показывает, что слово «добро», когда оно используется как существительное, имеет первый антоним «зло».
Пример 2
from nltk.corpus import wordnet as wn
syn2 = wn.synset('good.a.01')
antonym2 = syn2.lemmas()[0].antonyms()[0]
antonym2.name()Вывод
'bad'antonym2.synset().definition()Вывод
'having undesirable or negative qualities’Приведенный выше пример показывает, что слово «хороший», когда оно используется как прилагательное, имеет первый антоним «плохой».
Что такое стемминг?
Основание - это метод, используемый для извлечения основной формы слов путем удаления из них аффиксов. Это похоже на срезание ветвей дерева до стеблей. Например, основа словeating, eats, eaten является eat.
Поисковые системы используют стемминг для индексации слов. Вот почему вместо хранения всех форм слова поисковая система может хранить только основы. Таким образом, поиск по краю уменьшает размер индекса и повышает точность поиска.
Различные алгоритмы стемминга
В НЛТК, stemmerI, который имеет stem()method, в интерфейсе есть все стеммеры, которые мы рассмотрим далее. Давайте разберемся с этим с помощью следующей диаграммы
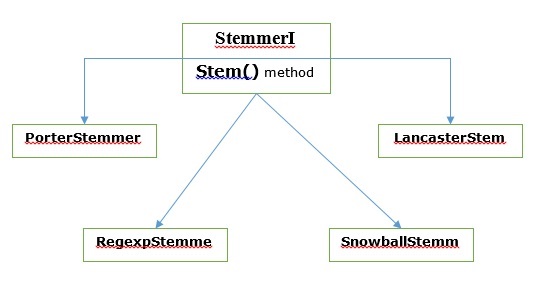
Алгоритм определения портера
Это один из наиболее распространенных алгоритмов выделения корней, который в основном предназначен для удаления и замены хорошо известных суффиксов английских слов.
PorterStemmer класс
НЛТК имеет PorterStemmerкласс, с помощью которого мы можем легко реализовать алгоритмы Портера Стеммера для слова, которое мы хотим остановить. Этот класс знает несколько обычных словоформ и суффиксов, с помощью которых он может преобразовать входное слово в конечную основу. Результирующая основа часто представляет собой более короткое слово, имеющее то же значение корня. Давайте посмотрим на пример -
Во-первых, нам нужно импортировать инструментарий естественного языка (nltk).
import nltkТеперь импортируйте PorterStemmer класс для реализации алгоритма Портера Стеммера.
from nltk.stem import PorterStemmerЗатем создайте экземпляр класса Porter Stemmer следующим образом:
word_stemmer = PorterStemmer()Теперь введите слово, которое вы хотите остановить.
word_stemmer.stem('writing')Вывод
'write'word_stemmer.stem('eating')Вывод
'eat'Полный пример реализации
import nltk
from nltk.stem import PorterStemmer
word_stemmer = PorterStemmer()
word_stemmer.stem('writing')Вывод
'write'Алгоритм стемминга Ланкастера
Он был разработан в Ланкастерском университете и представляет собой еще один очень распространенный алгоритм стемминга.
LancasterStemmer класс
НЛТК имеет LancasterStemmerкласс, с помощью которого мы можем легко реализовать алгоритмы Ланкастера Стеммера для слова, которое мы хотим остановить. Давайте посмотрим на пример -
Во-первых, нам нужно импортировать инструментарий естественного языка (nltk).
import nltkТеперь импортируйте LancasterStemmer класс для реализации алгоритма Ланкастера Стеммера
from nltk.stem import LancasterStemmerЗатем создайте экземпляр LancasterStemmer класс следующим образом -
Lanc_stemmer = LancasterStemmer()Теперь введите слово, которое вы хотите остановить.
Lanc_stemmer.stem('eats')Вывод
'eat'Полный пример реализации
import nltk
from nltk.stem import LancatserStemmer
Lanc_stemmer = LancasterStemmer()
Lanc_stemmer.stem('eats')Вывод
'eat'Алгоритм выделения регулярных выражений
С помощью этого алгоритма стемминга мы можем создать собственный стеммер.
RegexpStemmer класс
НЛТК имеет RegexpStemmerкласс, с помощью которого мы можем легко реализовать алгоритмы регулярного выражения Stemmer. Обычно он принимает одно регулярное выражение и удаляет любой префикс или суффикс, соответствующий выражению. Давайте посмотрим на пример -
Во-первых, нам нужно импортировать инструментарий естественного языка (nltk).
import nltkТеперь импортируйте RegexpStemmer для реализации алгоритма Стеммера регулярных выражений.
from nltk.stem import RegexpStemmerЗатем создайте экземпляр RegexpStemmer class и предоставляет суффикс или префикс, который вы хотите удалить из слова, следующим образом:
Reg_stemmer = RegexpStemmer(‘ing’)Теперь введите слово, которое вы хотите остановить.
Reg_stemmer.stem('eating')Вывод
'eat'Reg_stemmer.stem('ingeat')Вывод
'eat'
Reg_stemmer.stem('eats')Вывод
'eat'Полный пример реализации
import nltk
from nltk.stem import RegexpStemmer
Reg_stemmer = RegexpStemmer()
Reg_stemmer.stem('ingeat')Вывод
'eat'Алгоритм удаления снежного кома
Это еще один очень полезный алгоритм стемминга.
SnowballStemmer класс
НЛТК имеет SnowballStemmerкласс, с помощью которого мы можем легко реализовать алгоритмы Snowball Stemmer. Он поддерживает 15 неанглийских языков. Чтобы использовать этот класс обработки паром, нам нужно создать экземпляр с именем языка, который мы используем, а затем вызвать метод stem (). Давайте посмотрим на пример -
Во-первых, нам нужно импортировать инструментарий естественного языка (nltk).
import nltkТеперь импортируйте SnowballStemmer класс для реализации алгоритма Snowball Stemmer
from nltk.stem import SnowballStemmerДавайте посмотрим, какие языки он поддерживает -
SnowballStemmer.languagesВывод
(
'arabic',
'danish',
'dutch',
'english',
'finnish',
'french',
'german',
'hungarian',
'italian',
'norwegian',
'porter',
'portuguese',
'romanian',
'russian',
'spanish',
'swedish'
)Затем создайте экземпляр класса SnowballStemmer с языком, который вы хотите использовать. Здесь мы создаем стеммер для «французского» языка.
French_stemmer = SnowballStemmer(‘french’)Теперь вызовите метод stem () и введите слово, которое хотите остановить.
French_stemmer.stem (‘Bonjoura’)Вывод
'bonjour'Полный пример реализации
import nltk
from nltk.stem import SnowballStemmer
French_stemmer = SnowballStemmer(‘french’)
French_stemmer.stem (‘Bonjoura’)Вывод
'bonjour'Что такое лемматизация?
Техника лемматизации похожа на стемминг. Результат, который мы получим после лемматизации, называется «лемма», которая является корневым словом, а не корневым стержнем, результатом преобразования корня. После лемматизации мы получим допустимое слово, которое означает то же самое.
НЛТК предоставляет WordNetLemmatizer класс, который представляет собой тонкую оболочку вокруг wordnetкорпус. Этот класс используетmorphy() функция для WordNet CorpusReaderкласс, чтобы найти лемму. Давайте разберемся с этим на примере -
пример
Во-первых, нам нужно импортировать инструментарий естественного языка (nltk).
import nltkТеперь импортируйте WordNetLemmatizer класс для реализации техники лемматизации.
from nltk.stem import WordNetLemmatizerЗатем создайте экземпляр WordNetLemmatizer класс.
lemmatizer = WordNetLemmatizer()Теперь вызовите метод lemmatize () и введите слово, по которому вы хотите найти лемму.
lemmatizer.lemmatize('eating')Вывод
'eating'lemmatizer.lemmatize('books')Вывод
'book'Полный пример реализации
import nltk
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
lemmatizer.lemmatize('books')Вывод
'book'Разница между стеммингом и лемматизацией
Давайте поймем разницу между стеммингом и лемматизацией с помощью следующего примера -
import nltk
from nltk.stem import PorterStemmer
word_stemmer = PorterStemmer()
word_stemmer.stem('believes')Вывод
believimport nltk
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
lemmatizer.lemmatize(' believes ')Вывод
believРезультат обеих программ показывает основную разницу между стеммингом и лемматизацией. PorterStemmerкласс отрезает от слова «эс». С другой стороны,WordNetLemmatizerкласс находит допустимое слово. Проще говоря, техника стемминга смотрит только на форму слова, тогда как техника лемматизации смотрит на значение слова. Это означает, что после применения лемматизации мы всегда получим верное слово.
Стемминг и лемматизацию можно рассматривать как разновидность лингвистической компрессии. В том же смысле замену слова можно рассматривать как нормализацию текста или исправление ошибок.
Но зачем нам нужна была замена слов? Предположим, что если мы говорим о токенизации, то у нее есть проблемы со сжатием (например, не могу, не буду и т. Д.). Итак, чтобы справиться с такими проблемами, нам нужна замена слов. Например, мы можем заменить сокращения их развернутыми формами.
Замена слова с помощью регулярного выражения
Сначала мы собираемся заменить слова, соответствующие регулярному выражению. Но для этого мы должны иметь базовое представление о регулярных выражениях, а также о модуле python re. В приведенном ниже примере мы заменим сокращение их развернутыми формами (например, «не могу» будет заменено на «не могу»), и все это с помощью регулярных выражений.
пример
Сначала импортируйте необходимый пакет re для работы с регулярными выражениями.
import re
from nltk.corpus import wordnetЗатем определите шаблоны замены по вашему выбору следующим образом:
R_patterns = [
(r'won\'t', 'will not'),
(r'can\'t', 'cannot'),
(r'i\'m', 'i am'),
r'(\w+)\'ll', '\g<1> will'),
(r'(\w+)n\'t', '\g<1> not'),
(r'(\w+)\'ve', '\g<1> have'),
(r'(\w+)\'s', '\g<1> is'),
(r'(\w+)\'re', '\g<1> are'),
]Теперь создайте класс, который можно использовать для замены слов -
class REReplacer(object):
def __init__(self, pattern = R_patterns):
self.pattern = [(re.compile(regex), repl) for (regex, repl) in patterns]
def replace(self, text):
s = text
for (pattern, repl) in self.pattern:
s = re.sub(pattern, repl, s)
return sСохраните эту программу Python (скажем, repRE.py) и запустите ее из командной строки python. После его запуска импортируйте класс REReplacer, если вы хотите заменить слова. Посмотрим, как это сделать.
from repRE import REReplacer
rep_word = REReplacer()
rep_word.replace("I won't do it")
Output:
'I will not do it'
rep_word.replace("I can’t do it")
Output:
'I cannot do it'Полный пример реализации
import re
from nltk.corpus import wordnet
R_patterns = [
(r'won\'t', 'will not'),
(r'can\'t', 'cannot'),
(r'i\'m', 'i am'),
r'(\w+)\'ll', '\g<1> will'),
(r'(\w+)n\'t', '\g<1> not'),
(r'(\w+)\'ve', '\g<1> have'),
(r'(\w+)\'s', '\g<1> is'),
(r'(\w+)\'re', '\g<1> are'),
]
class REReplacer(object):
def __init__(self, patterns=R_patterns):
self.patterns = [(re.compile(regex), repl) for (regex, repl) in patterns]
def replace(self, text):
s = text
for (pattern, repl) in self.patterns:
s = re.sub(pattern, repl, s)
return sТеперь, когда вы сохранили вышеуказанную программу и запустили ее, вы можете импортировать класс и использовать его следующим образом:
from replacerRE import REReplacer
rep_word = REReplacer()
rep_word.replace("I won't do it")Вывод
'I will not do it'Замена перед обработкой текста
Одна из распространенных практик при работе с обработкой естественного языка (NLP) - очистка текста перед обработкой текста. В этом отношении мы также можем использовать нашREReplacer класс, созданный выше в предыдущем примере, в качестве предварительного шага перед обработкой текста, то есть токенизацией.
пример
from nltk.tokenize import word_tokenize
from replacerRE import REReplacer
rep_word = REReplacer()
word_tokenize("I won't be able to do this now")
Output:
['I', 'wo', "n't", 'be', 'able', 'to', 'do', 'this', 'now']
word_tokenize(rep_word.replace("I won't be able to do this now"))
Output:
['I', 'will', 'not', 'be', 'able', 'to', 'do', 'this', 'now']В приведенном выше рецепте Python мы можем легко понять разницу между выводом токенизатора слов без и с использованием замены регулярного выражения.
Удаление повторяющихся символов
Соблюдаем ли мы грамматику в нашем повседневном языке? Нет, мы не. Например, иногда мы пишем «Hiiiiiiiiiiii Mohan», чтобы подчеркнуть слово «Hi». Но компьютерная система не знает, что «Hiiiiiiiiiiii» - это вариант слова «Hi». В приведенном ниже примере мы создадим класс с именемrep_word_removal который можно использовать для удаления повторяющихся слов.
пример
Сначала импортируйте необходимый пакет re для работы с регулярными выражениями
import re
from nltk.corpus import wordnetТеперь создайте класс, который можно использовать для удаления повторяющихся слов -
class Rep_word_removal(object):
def __init__(self):
self.repeat_regexp = re.compile(r'(\w*)(\w)\2(\w*)')
self.repl = r'\1\2\3'
def replace(self, word):
if wordnet.synsets(word):
return word
repl_word = self.repeat_regexp.sub(self.repl, word)
if repl_word != word:
return self.replace(repl_word)
else:
return repl_wordСохраните эту программу Python (скажем, removerepeat.py) и запустите ее из командной строки python. После его запуска импортируйтеRep_word_removalкласс, когда вы хотите удалить повторяющиеся слова. Посмотрим, как?
from removalrepeat import Rep_word_removal
rep_word = Rep_word_removal()
rep_word.replace ("Hiiiiiiiiiiiiiiiiiiiii")
Output:
'Hi'
rep_word.replace("Hellooooooooooooooo")
Output:
'Hello'Полный пример реализации
import re
from nltk.corpus import wordnet
class Rep_word_removal(object):
def __init__(self):
self.repeat_regexp = re.compile(r'(\w*)(\w)\2(\w*)')
self.repl = r'\1\2\3'
def replace(self, word):
if wordnet.synsets(word):
return word
replace_word = self.repeat_regexp.sub(self.repl, word)
if replace_word != word:
return self.replace(replace_word)
else:
return replace_wordТеперь, когда вы сохранили вышеуказанную программу и запустили ее, вы можете импортировать класс и использовать его следующим образом:
from removalrepeat import Rep_word_removal
rep_word = Rep_word_removal()
rep_word.replace ("Hiiiiiiiiiiiiiiiiiiiii")Вывод
'Hi'Замена слов на общие синонимы
При работе с НЛП, особенно в случае частотного анализа и индексации текста, всегда полезно сжать словарный запас, не теряя смысла, потому что это экономит много памяти. Чтобы достичь этого, мы должны определить отображение слова на его синонимы. В приведенном ниже примере мы создадим класс с именемword_syn_replacer которые можно использовать для замены слов их общими синонимами.
пример
Сначала импортируйте необходимый пакет re работать с регулярными выражениями.
import re
from nltk.corpus import wordnetЗатем создайте класс, который принимает сопоставление замены слов -
class word_syn_replacer(object):
def __init__(self, word_map):
self.word_map = word_map
def replace(self, word):
return self.word_map.get(word, word)Сохраните эту программу python (скажем, replacesyn.py) и запустите ее из командной строки python. После его запуска импортируйтеword_syn_replacerкласс, когда вы хотите заменить слова обычными синонимами. Посмотрим, как это сделать.
from replacesyn import word_syn_replacer
rep_syn = word_syn_replacer ({‘bday’: ‘birthday’)
rep_syn.replace(‘bday’)Вывод
'birthday'Полный пример реализации
import re
from nltk.corpus import wordnet
class word_syn_replacer(object):
def __init__(self, word_map):
self.word_map = word_map
def replace(self, word):
return self.word_map.get(word, word)Теперь, когда вы сохранили вышеуказанную программу и запустили ее, вы можете импортировать класс и использовать его следующим образом:
from replacesyn import word_syn_replacer
rep_syn = word_syn_replacer ({‘bday’: ‘birthday’)
rep_syn.replace(‘bday’)Вывод
'birthday'Недостатком описанного выше метода является то, что нам придется жестко кодировать синонимы в словаре Python. У нас есть две лучшие альтернативы в виде файлов CSV и YAML. Мы можем сохранить наш словарь синонимов в любом из вышеупомянутых файлов и можем построитьword_mapсловарь от них. Разберемся в концепции с помощью примеров.
Использование файла CSV
Чтобы использовать файл CSV для этой цели, файл должен иметь два столбца, первый столбец состоит из слова, а второй столбец состоит из синонимов, предназначенных для его замены. Сохраним этот файл какsyn.csv. В приведенном ниже примере мы создадим класс с именем CSVword_syn_replacer который будет расширять word_syn_replacer в replacesyn.py файл и будет использоваться для создания word_map словарь из syn.csv файл.
пример
Сначала импортируйте необходимые пакеты.
import csvЗатем создайте класс, который принимает сопоставление замены слов -
class CSVword_syn_replacer(word_syn_replacer):
def __init__(self, fname):
word_map = {}
for line in csv.reader(open(fname)):
word, syn = line
word_map[word] = syn
super(Csvword_syn_replacer, self).__init__(word_map)После его запуска импортируйте CSVword_syn_replacerкласс, когда вы хотите заменить слова обычными синонимами. Посмотрим, как?
from replacesyn import CSVword_syn_replacer
rep_syn = CSVword_syn_replacer (‘syn.csv’)
rep_syn.replace(‘bday’)Вывод
'birthday'Полный пример реализации
import csv
class CSVword_syn_replacer(word_syn_replacer):
def __init__(self, fname):
word_map = {}
for line in csv.reader(open(fname)):
word, syn = line
word_map[word] = syn
super(Csvword_syn_replacer, self).__init__(word_map)Теперь, когда вы сохранили вышеуказанную программу и запустили ее, вы можете импортировать класс и использовать его следующим образом:
from replacesyn import CSVword_syn_replacer
rep_syn = CSVword_syn_replacer (‘syn.csv’)
rep_syn.replace(‘bday’)Вывод
'birthday'Использование файла YAML
Поскольку мы использовали файл CSV, мы также можем использовать для этой цели файл YAML (у нас должен быть установлен PyYAML). Сохраним файл какsyn.yaml. В приведенном ниже примере мы создадим класс с именем YAMLword_syn_replacer который будет расширять word_syn_replacer в replacesyn.py файл и будет использоваться для создания word_map словарь из syn.yaml файл.
пример
Сначала импортируйте необходимые пакеты.
import yamlЗатем создайте класс, который принимает сопоставление замены слов -
class YAMLword_syn_replacer(word_syn_replacer):
def __init__(self, fname):
word_map = yaml.load(open(fname))
super(YamlWordReplacer, self).__init__(word_map)После его запуска импортируйте YAMLword_syn_replacerкласс, когда вы хотите заменить слова обычными синонимами. Посмотрим, как?
from replacesyn import YAMLword_syn_replacer
rep_syn = YAMLword_syn_replacer (‘syn.yaml’)
rep_syn.replace(‘bday’)Вывод
'birthday'Полный пример реализации
import yaml
class YAMLword_syn_replacer(word_syn_replacer):
def __init__(self, fname):
word_map = yaml.load(open(fname))
super(YamlWordReplacer, self).__init__(word_map)Теперь, когда вы сохранили вышеуказанную программу и запустили ее, вы можете импортировать класс и использовать его следующим образом:
from replacesyn import YAMLword_syn_replacer
rep_syn = YAMLword_syn_replacer (‘syn.yaml’)
rep_syn.replace(‘bday’)Вывод
'birthday'Замена антонима
Как мы знаем, антоним - это слово, имеющее значение, противоположное другому слову, а противоположность замены синонима называется заменой антонима. В этом разделе мы будем иметь дело с заменой антонимов, т. Е. Заменой слов однозначными антонимами с помощью WordNet. В приведенном ниже примере мы создадим класс с именемword_antonym_replacer которые имеют два метода: один для замены слова, а другой для удаления отрицаний.
пример
Сначала импортируйте необходимые пакеты.
from nltk.corpus import wordnetЗатем создайте класс с именем word_antonym_replacer -
class word_antonym_replacer(object):
def replace(self, word, pos=None):
antonyms = set()
for syn in wordnet.synsets(word, pos=pos):
for lemma in syn.lemmas():
for antonym in lemma.antonyms():
antonyms.add(antonym.name())
if len(antonyms) == 1:
return antonyms.pop()
else:
return None
def replace_negations(self, sent):
i, l = 0, len(sent)
words = []
while i < l:
word = sent[i]
if word == 'not' and i+1 < l:
ant = self.replace(sent[i+1])
if ant:
words.append(ant)
i += 2
continue
words.append(word)
i += 1
return wordsСохраните эту программу python (скажем, replaceantonym.py) и запустите ее из командной строки python. После его запуска импортируйтеword_antonym_replacerкласс, когда вы хотите заменить слова их однозначными антонимами. Посмотрим, как это сделать.
from replacerantonym import word_antonym_replacer
rep_antonym = word_antonym_replacer ()
rep_antonym.replace(‘uglify’)Вывод
['beautify'']
sentence = ["Let us", 'not', 'uglify', 'our', 'country']
rep_antonym.replace _negations(sentence)Вывод
["Let us", 'beautify', 'our', 'country']Полный пример реализации
nltk.corpus import wordnet
class word_antonym_replacer(object):
def replace(self, word, pos=None):
antonyms = set()
for syn in wordnet.synsets(word, pos=pos):
for lemma in syn.lemmas():
for antonym in lemma.antonyms():
antonyms.add(antonym.name())
if len(antonyms) == 1:
return antonyms.pop()
else:
return None
def replace_negations(self, sent):
i, l = 0, len(sent)
words = []
while i < l:
word = sent[i]
if word == 'not' and i+1 < l:
ant = self.replace(sent[i+1])
if ant:
words.append(ant)
i += 2
continue
words.append(word)
i += 1
return wordsТеперь, когда вы сохранили вышеуказанную программу и запустили ее, вы можете импортировать класс и использовать его следующим образом:
from replacerantonym import word_antonym_replacer
rep_antonym = word_antonym_replacer ()
rep_antonym.replace(‘uglify’)
sentence = ["Let us", 'not', 'uglify', 'our', 'country']
rep_antonym.replace _negations(sentence)Вывод
["Let us", 'beautify', 'our', 'country']Что такое корпус?
Корпус - это большая коллекция в структурированном формате машиночитаемых текстов, созданных в естественной коммуникативной среде. Слово «Корпуса» является множественным числом от «Корпус». Корпус может быть получен разными способами следующим образом:
- Из текста, который изначально был электронным
- Из стенограмм разговорной речи
- От оптического распознавания символов и т. Д.
Репрезентативность корпуса, баланс корпуса, выборка, размер корпуса - это элементы, которые играют важную роль при разработке корпуса. Некоторые из самых популярных корпусов для задач НЛП - TreeBank, PropBank, VarbNet и WordNet.
Как создать собственный корпус?
При загрузке NLTK мы также установили пакет данных NLTK. Итак, на нашем компьютере уже установлен пакет данных NLTK. Если говорить о Windows, мы предполагаем, что этот пакет данных установлен вC:\natural_language_toolkit_data и если мы говорим о Linux, Unix и Mac OS X, мы будем предполагать, что этот пакет данных установлен в /usr/share/natural_language_toolkit_data.
В следующем рецепте Python мы собираемся создать настраиваемые корпуса, которые должны находиться в пределах одного из путей, определенных NLTK. Потому что его может найти НЛТК. Чтобы избежать конфликта с официальным пакетом данных NLTK, давайте создадим собственный каталог natural_language_toolkit_data в нашем домашнем каталоге.
import os, os.path
path = os.path.expanduser('~/natural_language_toolkit_data')
if not os.path.exists(path):
os.mkdir(path)
os.path.exists(path)Вывод
TrueТеперь давайте проверим, есть ли у нас каталог natural_language_toolkit_data в нашем домашнем каталоге или нет -
import nltk.data
path in nltk.data.pathВывод
TrueПоскольку у нас есть результат True, это означает, что у нас есть nltk_data каталог в нашем домашнем каталоге.
Теперь мы создадим файл списка слов с именем wordfile.txt и поместите его в папку с именем corpus в nltk_data каталог (~/nltk_data/corpus/wordfile.txt) и загрузит его, используя nltk.data.load -
import nltk.data
nltk.data.load(‘corpus/wordfile.txt’, format = ‘raw’)Вывод
b’tutorialspoint\n’Читатели корпуса
NLTK предоставляет различные классы CorpusReader. Мы собираемся рассказать о них в следующих рецептах Python
Создание корпуса словаря
НЛТК имеет WordListCorpusReaderкласс, обеспечивающий доступ к файлу, содержащему список слов. Для следующего рецепта Python нам нужно создать файл списка слов, который может быть CSV или обычным текстовым файлом. Например, мы создали файл с именем «список», который содержит следующие данные:
tutorialspoint
Online
Free
TutorialsТеперь давайте создадим экземпляр WordListCorpusReader класс, производящий список слов из нашего созданного файла ‘list’.
from nltk.corpus.reader import WordListCorpusReader
reader_corpus = WordListCorpusReader('.', ['list'])
reader_corpus.words()Вывод
['tutorialspoint', 'Online', 'Free', 'Tutorials']Создание корпуса слов с тегами POS
НЛТК имеет TaggedCorpusReaderкласс, с помощью которого мы можем создать корпус слов с тегами POS. Фактически, POS-теги - это процесс идентификации тега части речи для слова.
Один из простейших форматов помеченного корпуса - это форма «слово / тег», как в следующем отрывке из коричневого корпуса:
The/at-tl expense/nn and/cc time/nn involved/vbn are/ber
astronomical/jj ./.В приведенном выше отрывке каждое слово имеет тег, обозначающий его POS. Например,vb относится к глаголу.
Теперь давайте создадим экземпляр TaggedCorpusReaderкласс, создающий слова с тегами POS из файла ‘list.pos’, в котором есть приведенный выше отрывок.
from nltk.corpus.reader import TaggedCorpusReader
reader_corpus = TaggedCorpusReader('.', r'.*\.pos')
reader_corpus.tagged_words()Вывод
[('The', 'AT-TL'), ('expense', 'NN'), ('and', 'CC'), ...]Создание корпуса фрагментированных фраз
НЛТК имеет ChnkedCorpusReaderкласс, с помощью которого мы можем создать корпус Chunked фраз. На самом деле кусок - это короткая фраза в предложении.
Например, у нас есть следующий отрывок из помеченного treebank корпус -
[Earlier/JJR staff-reduction/NN moves/NNS] have/VBP trimmed/VBN about/
IN [300/CD jobs/NNS] ,/, [the/DT spokesman/NN] said/VBD ./.В приведенном выше отрывке каждый фрагмент является именной фразой, но слова, не заключенные в скобки, являются частью дерева предложений, а не частью какого-либо поддерева именной фразы.
Теперь давайте создадим экземпляр ChunkedCorpusReader класс, производящий фрагментированную фразу из файла ‘list.chunk’, в котором есть приведенный выше отрывок.
from nltk.corpus.reader import ChunkedCorpusReader
reader_corpus = TaggedCorpusReader('.', r'.*\.chunk')
reader_corpus.chunked_words()Вывод
[
Tree('NP', [('Earlier', 'JJR'), ('staff-reduction', 'NN'), ('moves', 'NNS')]),
('have', 'VBP'), ...
]Создание категоризированного текстового корпуса
НЛТК имеет CategorizedPlaintextCorpusReaderкласс, с помощью которого мы можем создать корпус текста по категориям. Это очень полезно в том случае, когда у нас есть большой корпус текста и мы хотим разбить его на отдельные разделы.
Например, коричневый корпус имеет несколько разных категорий. Давайте узнаем их с помощью следующего кода Python -
from nltk.corpus import brown^M
brown.categories()Вывод
[
'adventure', 'belles_lettres', 'editorial', 'fiction', 'government',
'hobbies', 'humor', 'learned', 'lore', 'mystery', 'news', 'religion',
'reviews', 'romance', 'science_fiction'
]Один из самых простых способов разбить корпус на категории - создать по одному файлу для каждой категории. Например, давайте посмотрим два отрывка изmovie_reviews корпус -
movie_pos.txt
Тонкая красная линия ошибочна, но провоцирует.
movie_neg.txt
Крупнобюджетная и глянцевая постановка не может компенсировать отсутствие спонтанности, которой пронизано их телешоу.
Итак, из двух файлов выше у нас есть две категории, а именно pos и neg.
Теперь давайте создадим экземпляр CategorizedPlaintextCorpusReader класс.
from nltk.corpus.reader import CategorizedPlaintextCorpusReader
reader_corpus = CategorizedPlaintextCorpusReader('.', r'movie_.*\.txt',
cat_pattern = r'movie_(\w+)\.txt')
reader_corpus.categories()
reader_corpus.fileids(categories = [‘neg’])
reader_corpus.fileids(categories = [‘pos’])Вывод
['neg', 'pos']
['movie_neg.txt']
['movie_pos.txt']Что такое POS-теги?
Маркировка, своего рода классификация, представляет собой автоматическое присвоение описания токенам. Мы называем дескриптор тегом, который представляет одну из частей речи (существительные, глагол, наречия, прилагательные, местоимения, союз и их подкатегории), семантическую информацию и так далее.
С другой стороны, если мы говорим о тегировании части речи (POS), его можно определить как процесс преобразования предложения в форме списка слов в список кортежей. Здесь кортежи имеют форму (слово, тег). Мы также можем назвать POS-тегирование процессом присвоения одной из частей речи данному слову.
В следующей таблице представлены наиболее частые POS-уведомления, используемые в корпусе Penn Treebank.
| Старший Нет | Тег | Описание |
|---|---|---|
| 1 | NNP | Имя собственное, единственное число |
| 2 | NNPS | Имя собственное, множественное число |
| 3 | Тихоокеанское летнее время | Предопределитель |
| 4 | POS | Притяжательная концовка |
| 5 | PRP | Личное местоимение |
| 6 | PRP $ | Притяжательное местоимение |
| 7 | РБ | Наречие |
| 8 | RBR | Наречие, сравнительное |
| 9 | RBS | Наречие, превосходная степень |
| 10 | RP | Частицы |
| 11 | SYM | Символ (математический или научный) |
| 12 | К | к |
| 13 | UH | Междометие |
| 14 | VB | Глагол, основная форма |
| 15 | VBD | Глагол, прошедшее время |
| 16 | VBG | Глагол, герундий / причастие настоящего |
| 17 | VBN | Глагол, прошедшее |
| 18 | WP | Wh-местоимение |
| 19 | WP $ | Притяжательное местоимение wh |
| 20 | WRB | Wh-наречие |
| 21 год | # | Знак фунта стерлингов |
| 22 | $ | Знак доллара |
| 23 | . | Окончательная пунктуация предложения |
| 24 | , | Запятая |
| 25 | : | Двоеточие, точка с запятой |
| 26 | ( | Символ левой скобки |
| 27 | ) | Правая скобка |
| 28 | " | Прямая двойная кавычка |
| 29 | ' | Левая открытая одинарная кавычка |
| 30 | " | Левая открытая двойная кавычка |
| 31 год | ' | Одинарная кавычка справа, закрывающая |
| 32 | " | Правая открытая двойная кавычка |
пример
Давайте разберемся с этим с помощью эксперимента Python -
import nltk
from nltk import word_tokenize
sentence = "I am going to school"
print (nltk.pos_tag(word_tokenize(sentence)))Вывод
[('I', 'PRP'), ('am', 'VBP'), ('going', 'VBG'), ('to', 'TO'), ('school', 'NN')]Почему POS-теги?
POS-теги - важная часть НЛП, потому что она работает как предварительное условие для дальнейшего анализа НЛП следующим образом:
- Chunking
- Синтаксический анализ
- Извлечение информации
- Машинный перевод
- Анализ настроений
- Анализ грамматики и устранение неоднозначности
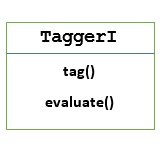
TaggerI - Базовый класс
Все тегеры находятся в пакете NLTK nltk.tag. Базовый класс этих тегеров -TaggerI, означает, что все тегеры наследуются от этого класса.
Methods - Класс TaggerI имеет следующие два метода, которые должны быть реализованы всеми его подклассами -
tag() method - Как следует из названия, этот метод принимает список слов в качестве ввода и возвращает список помеченных слов в качестве вывода.
evaluate() method - С помощью этого метода мы можем оценить точность теггера.
Базовый уровень POS-тегов
Базовый или основной шаг маркировки торговой точки: Default Tagging, который можно выполнить с помощью класса DefaultTagger NLTK. Тегирование по умолчанию просто назначает один и тот же тег POS каждому токену. Пометка по умолчанию также обеспечивает основу для измерения повышения точности.
DefaultTagger класс
Пометка по умолчанию выполняется с помощью DefaultTagging class, который принимает единственный аргумент, т. е. тег, который мы хотим применить.
Как это работает?
Как было сказано ранее, все тегеры унаследованы от TaggerIкласс. ВDefaultTagger унаследовано от SequentialBackoffTagger который является подклассом TaggerI class. Давайте разберемся со следующей схемой -
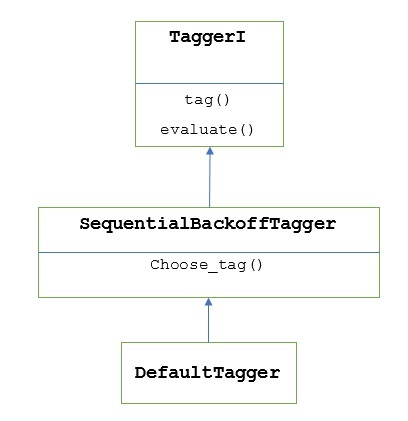
Как часть SeuentialBackoffTagger, то DefaultTagger должен реализовать метод choose_tag (), который принимает следующие три аргумента.
- Список токенов
- Индекс текущего токена
- Список предыдущих токенов, т.е. история
пример
import nltk
from nltk.tag import DefaultTagger
exptagger = DefaultTagger('NN')
exptagger.tag(['Tutorials','Point'])Вывод
[('Tutorials', 'NN'), ('Point', 'NN')]В этом примере мы выбрали тег существительного, потому что это наиболее распространенные типы слов. Более того,DefaultTagger также наиболее полезен, когда мы выбираем наиболее распространенный тег POS.
Оценка точности
В DefaultTaggerтакже является базовым показателем для оценки точности тегеров. Вот почему мы можем использовать его вместе сevaluate()метод измерения точности. Вevaluate() принимает список помеченных токенов как золотой стандарт для оценки теггера.
Ниже приведен пример, в котором мы использовали наш теггер по умолчанию с именем exptagger, созданный выше, для оценки точности подмножества treebank корпус помеченных предложений -
пример
import nltk
from nltk.tag import DefaultTagger
exptagger = DefaultTagger('NN')
from nltk.corpus import treebank
testsentences = treebank.tagged_sents() [1000:]
exptagger.evaluate (testsentences)Вывод
0.13198749536374715Вывод выше показывает, что, выбрав NN для каждого тега мы можем достичь около 13% точности тестирования на 1000 записей treebank корпус.
Добавление тегов к списку предложений
Вместо того, чтобы пометить одно предложение, NLTK TaggerI класс также предоставляет нам tag_sents()метод, с помощью которого мы можем пометить список предложений. Ниже приведен пример, в котором мы пометили два простых предложения
пример
import nltk
from nltk.tag import DefaultTagger
exptagger = DefaultTagger('NN')
exptagger.tag_sents([['Hi', ','], ['How', 'are', 'you', '?']])Вывод
[
[
('Hi', 'NN'),
(',', 'NN')
],
[
('How', 'NN'),
('are', 'NN'),
('you', 'NN'),
('?', 'NN')
]
]В приведенном выше примере мы использовали наш ранее созданный теггер по умолчанию с именем exptagger.
Снятие отметки с предложения
Мы также можем отменить пометку предложения. NLTK предоставляет для этой цели метод nltk.tag.untag (). Он принимает предложение с тегами в качестве ввода и предоставляет список слов без тегов. Давайте посмотрим на пример -
пример
import nltk
from nltk.tag import untag
untag([('Tutorials', 'NN'), ('Point', 'NN')])Вывод
['Tutorials', 'Point']Что такое Unigram Tagger?
Как следует из названия, устройство для создания тегов unigram - это устройство для тегов, которое использует только одно слово в качестве контекста для определения тега POS (часть речи). Проще говоря, Unigram Tagger - это контекстный теггер, контекст которого представляет собой одно слово, то есть Unigram.
Как это работает?
NLTK предоставляет модуль с именем UnigramTaggerдля этого. Но прежде чем углубиться в его работу, давайте разберемся в иерархии с помощью следующей диаграммы -
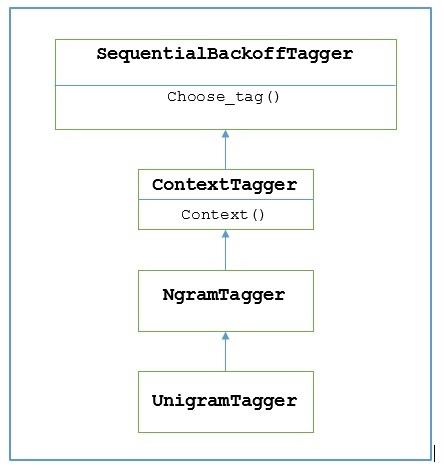
Из приведенной выше диаграммы понятно, что UnigramTagger унаследовано от NgramTagger который является подклассом ContextTagger, который наследуется от SequentialBackoffTagger.
Работа UnigramTagger объясняется с помощью следующих шагов -
Как мы видели, UnigramTagger наследуется от ContextTagger, он реализует context()метод. Этотcontext() метод принимает те же три аргумента, что и choose_tag() метод.
Результат context()Метод будет токеном слова, который в дальнейшем будет использоваться для создания модели. После создания модели слово token также используется для поиска лучшего тега.
Таким образом, UnigramTagger построит контекстную модель из списка помеченных предложений.
Обучение теггера Unigram
НЛТК UnigramTaggerможно обучить, предоставив список помеченных предложений во время инициализации. В приведенном ниже примере мы собираемся использовать предложения с тегами из корпуса treebank. Мы будем использовать первые 2500 предложений из этого корпуса.
пример
Сначала импортируйте модуль UniframTagger из nltk -
from nltk.tag import UnigramTaggerЗатем импортируйте корпус, который хотите использовать. Здесь мы используем корпус treebank -
from nltk.corpus import treebankТеперь возьмем предложения для тренировочных целей. Мы берем первые 2500 предложений для тренировочных целей и помечаем их -
train_sentences = treebank.tagged_sents()[:2500]Затем примените UnigramTagger к предложениям, используемым в учебных целях -
Uni_tagger = UnigramTagger(train_sentences)Возьмите несколько предложений, равных или меньше взятых для тренировочных целей, например 2500, для тестовых целей. Здесь мы берем первые 1500 для тестирования -
test_sentences = treebank.tagged_sents()[1500:]
Uni_tagger.evaluate(test_sents)Вывод
0.8942306156033808Здесь мы получили около 89% точности для теггера, который использует поиск по одному слову для определения тега POS.
Полный пример реализации
from nltk.tag import UnigramTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
Uni_tagger = UnigramTagger(train_sentences)
test_sentences = treebank.tagged_sents()[1500:]
Uni_tagger.evaluate(test_sentences)Вывод
0.8942306156033808Переопределение контекстной модели
Из приведенной выше диаграммы, показывающей иерархию для UnigramTagger, мы знаем все тегеры, которые наследуются от ContextTagger, вместо обучения самостоятельно, можно взять заранее построенную модель. Эта предварительно созданная модель представляет собой просто сопоставление словаря Python контекстного ключа с тегом. И дляUnigramTagger, контекстные ключи - это отдельные слова, а для других NgramTagger подклассы, это будут кортежи.
Мы можем переопределить эту контекстную модель, передав другую простую модель в UnigramTaggerкласс вместо прохождения обучающего набора. Давайте разберемся с этим с помощью простого примера ниже -
пример
from nltk.tag import UnigramTagger
from nltk.corpus import treebank
Override_tagger = UnigramTagger(model = {‘Vinken’ : ‘NN’})
Override_tagger.tag(treebank.sents()[0])Вывод
[
('Pierre', None),
('Vinken', 'NN'),
(',', None),
('61', None),
('years', None),
('old', None),
(',', None),
('will', None),
('join', None),
('the', None),
('board', None),
('as', None),
('a', None),
('nonexecutive', None),
('director', None),
('Nov.', None),
('29', None),
('.', None)
]Поскольку наша модель содержит «Винкен» в качестве единственного контекстного ключа, вы можете заметить из вышеприведенного вывода, что только это слово имеет тег, а каждое другое слово имеет тег None.
Установка минимального порога частоты
Чтобы решить, какой тег наиболее подходит для данного контекста, ContextTaggerкласс использует частоту появления. Он будет делать это по умолчанию, даже если контекстное слово и тег встречаются только один раз, но мы можем установить минимальный порог частоты, передавcutoff ценность для UnigramTaggerкласс. В приведенном ниже примере мы передаем значение отсечки из предыдущего рецепта, в котором мы обучили UnigramTagger -
пример
from nltk.tag import UnigramTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
Uni_tagger = UnigramTagger(train_sentences, cutoff = 4)
test_sentences = treebank.tagged_sents()[1500:]
Uni_tagger.evaluate(test_sentences)Вывод
0.7357651629613641Объединение тегеров
Объединение тегеров или связывание тегеров друг с другом - одна из важных функций NLTK. Основная концепция объединения тегеров заключается в том, что в случае, если один теггер не знает, как пометить слово, оно будет передано связанному теггеру. Для достижения этой целиSequentialBackoffTagger предоставляет нам Backoff tagging характерная черта.
Отложенные теги
Как уже говорилось ранее, тегирование отката - одна из важных функций SequentialBackoffTagger, что позволяет нам комбинировать тегеры таким образом, что, если один теггер не знает, как пометить слово, это слово будет передано следующему теггеру и так далее, пока не останется никаких теггеров отсрочки для проверки.
Как это работает?
Фактически, каждый подкласс SequentialBackoffTaggerможет принимать аргумент ключевого слова 'backoff'. Значение этого аргумента ключевого слова является еще одним экземпляромSequentialBackoffTagger. Теперь, когда этоSequentialBackoffTaggerкласс инициализируется, будет создан внутренний список тегеров отсрочки (с ним в качестве первого элемента). Более того, если задан теггер отсрочки, будет добавлен внутренний список тегеров отсрочки.
В приведенном ниже примере мы берем DefaulTagger в качестве тега отката в приведенном выше рецепте Python, с помощью которого мы обучили UnigramTagger.
пример
В этом примере мы используем DefaulTaggerкак теггер отсрочки. Когда быUnigramTagger не может пометить слово, теггер отсрочки, т.е. DefaulTaggerв нашем случае пометит его "NN".
from nltk.tag import UnigramTagger
from nltk.tag import DefaultTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
back_tagger = DefaultTagger('NN')
Uni_tagger = UnigramTagger(train_sentences, backoff = back_tagger)
test_sentences = treebank.tagged_sents()[1500:]
Uni_tagger.evaluate(test_sentences)Вывод
0.9061975746536931Из вышеприведенных выходных данных вы можете заметить, что при добавлении теггера отсрочки точность увеличивается примерно на 2%.
Сохранение тегеров с рассолом
Как мы видели, обучение теггера очень громоздко и требует времени. Чтобы сэкономить время, мы можем выбрать обученного теггера для использования в дальнейшем. В приведенном ниже примере мы собираемся сделать это с нашим уже обученным теггером с именем‘Uni_tagger’.
пример
import pickle
f = open('Uni_tagger.pickle','wb')
pickle.dump(Uni_tagger, f)
f.close()
f = open('Uni_tagger.pickle','rb')
Uni_tagger = pickle.load(f)Класс NgramTagger
Из диаграммы иерархии, обсуждаемой в предыдущем разделе, UnigramTagger унаследовано от NgarmTagger class, но у нас есть еще два подкласса NgarmTagger класс -
Подкласс BigramTagger
На самом деле nграмма - это подпоследовательность из n элементов, следовательно, как следует из названия, BigramTaggerподкласс смотрит на два элемента. Первый элемент - это предыдущее помеченное слово, а второй - текущее помеченное слово.
Подкласс TrigramTagger
На той же ноте BigramTagger, TrigramTagger подкласс смотрит на три элемента, то есть на два предыдущих слова с тегами и одно текущее слово с тегами.
Практически, если мы применим BigramTagger и TrigramTaggerподклассы по отдельности, как мы делали с подклассом UnigramTagger, они оба работают очень плохо. Давайте посмотрим на примеры ниже:
Использование подкласса BigramTagger
from nltk.tag import BigramTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
Bi_tagger = BigramTagger(train_sentences)
test_sentences = treebank.tagged_sents()[1500:]
Bi_tagger.evaluate(test_sentences)Вывод
0.44669191071913594Использование подкласса TrigramTagger
from nltk.tag import TrigramTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
Tri_tagger = TrigramTagger(train_sentences)
test_sentences = treebank.tagged_sents()[1500:]
Tri_tagger.evaluate(test_sentences)Вывод
0.41949863394526193Вы можете сравнить производительность UnigramTagger, который мы использовали ранее (точность около 89%), с BigramTagger (точность около 44%) и TrigramTagger (точность около 41%). Причина в том, что тегеры Bigram и Trigram не могут узнать контекст из первого слова (слов) в предложении. С другой стороны, класс UnigramTagger не заботится о предыдущем контексте и угадывает наиболее распространенный тег для каждого слова, следовательно, может иметь высокую базовую точность.
Объединение тегеров ngram
Как видно из приведенных выше примеров, очевидно, что тегеры Bigram и Trigram могут внести свой вклад, если мы объединим их с тегами отсрочки. В приведенном ниже примере мы комбинируем тегеры Unigram, Bigram и Trigram с тегами отсрочки. Концепция такая же, как и в предыдущем рецепте, но при этом объединяется UnigramTagger с теггером backoff. Единственная разница в том, что мы используем функцию backoff_tagger () из tagger_util.py, приведенную ниже, для операции отсрочки.
def backoff_tagger(train_sentences, tagger_classes, backoff=None):
for cls in tagger_classes:
backoff = cls(train_sentences, backoff=backoff)
return backoffпример
from tagger_util import backoff_tagger
from nltk.tag import UnigramTagger
from nltk.tag import BigramTagger
from nltk.tag import TrigramTagger
from nltk.tag import DefaultTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
back_tagger = DefaultTagger('NN')
Combine_tagger = backoff_tagger(train_sentences,
[UnigramTagger, BigramTagger, TrigramTagger], backoff = back_tagger)
test_sentences = treebank.tagged_sents()[1500:]
Combine_tagger.evaluate(test_sentences)Вывод
0.9234530029238365Из приведенного выше вывода мы видим, что он увеличивает точность примерно на 3%.
Добавить теггер
Еще один важный класс подкласса ContextTagger - AffixTagger. В классе AffixTagger контекстом является префикс или суффикс слова. По этой причине класс AffixTagger может изучать теги на основе подстрок фиксированной длины в начале или в конце слова.
Как это работает?
Его работа зависит от аргумента affix_length, который определяет длину префикса или суффикса. Значение по умолчанию - 3. Но как он различает, узнал ли класс AffixTagger префикс или суффикс слова?
affix_length=positive - Если значение affix_lenght положительное, это означает, что класс AffixTagger будет изучать префиксы слов.
affix_length=negative - Если значение affix_lenght отрицательное, это означает, что класс AffixTagger будет изучать суффиксы слова.
Чтобы было понятнее, в приведенном ниже примере мы будем использовать класс AffixTagger для предложений из дерева с тегами.
пример
В этом примере AffixTagger будет изучать префикс слова, поскольку мы не указываем никакого значения для аргумента affix_length. Аргумент примет значение по умолчанию 3 -
from nltk.tag import AffixTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
Prefix_tagger = AffixTagger(train_sentences)
test_sentences = treebank.tagged_sents()[1500:]
Prefix_tagger.evaluate(test_sentences)Вывод
0.2800492099250667Давайте посмотрим в приведенном ниже примере, какой будет точность, если мы предоставим значение 4 аргументу affix_length -
from nltk.tag import AffixTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
Prefix_tagger = AffixTagger(train_sentences, affix_length=4 )
test_sentences = treebank.tagged_sents()[1500:]
Prefix_tagger.evaluate(test_sentences)Вывод
0.18154947354966527пример
В этом примере AffixTagger узнает суффикс слова, потому что мы укажем отрицательное значение для аргумента affix_length.
from nltk.tag import AffixTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
Suffix_tagger = AffixTagger(train_sentences, affix_length = -3)
test_sentences = treebank.tagged_sents()[1500:]
Suffix_tagger.evaluate(test_sentences)Вывод
0.2800492099250667Брилл Тэггер
Brill Tagger - это теггер на основе преобразования. НЛТК предоставляетBrillTagger class, который является первым тегом, который не является подклассом SequentialBackoffTagger. Напротив, ряд правил для исправления результатов начального тегирования используетсяBrillTagger.
Как это работает?
Чтобы обучить BrillTagger класс с использованием BrillTaggerTrainer мы определяем следующую функцию -
def train_brill_tagger(initial_tagger, train_sentences, **kwargs) -
templates = [
brill.Template(brill.Pos([-1])),
brill.Template(brill.Pos([1])),
brill.Template(brill.Pos([-2])),
brill.Template(brill.Pos([2])),
brill.Template(brill.Pos([-2, -1])),
brill.Template(brill.Pos([1, 2])),
brill.Template(brill.Pos([-3, -2, -1])),
brill.Template(brill.Pos([1, 2, 3])),
brill.Template(brill.Pos([-1]), brill.Pos([1])),
brill.Template(brill.Word([-1])),
brill.Template(brill.Word([1])),
brill.Template(brill.Word([-2])),
brill.Template(brill.Word([2])),
brill.Template(brill.Word([-2, -1])),
brill.Template(brill.Word([1, 2])),
brill.Template(brill.Word([-3, -2, -1])),
brill.Template(brill.Word([1, 2, 3])),
brill.Template(brill.Word([-1]), brill.Word([1])),
]
trainer = brill_trainer.BrillTaggerTrainer(initial_tagger, templates, deterministic=True)
return trainer.train(train_sentences, **kwargs)Как видим, эта функция требует initial_tagger и train_sentences. Требуетсяinitial_tagger аргумент и список шаблонов, реализующий BrillTemplateинтерфейс. ВBrillTemplate интерфейс находится в nltk.tbl.templateмодуль. Одна из таких реализаций -brill.Template класс.
Основная роль теггера, основанного на преобразовании, заключается в создании правил преобразования, которые корректируют вывод исходного тега, чтобы он больше соответствовал обучающим предложениям. Давайте посмотрим на рабочий процесс ниже -
пример
В этом примере мы будем использовать combine_tagger которые мы создали при расчесывании тегеров (в предыдущем рецепте) из цепочки отсрочки NgramTagger классы, как initial_tagger. Сначала оценим результат с помощьюCombine.tagger а затем используйте это как initial_tagger дрессировать брилла таггера.
from tagger_util import backoff_tagger
from nltk.tag import UnigramTagger
from nltk.tag import BigramTagger
from nltk.tag import TrigramTagger
from nltk.tag import DefaultTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
back_tagger = DefaultTagger('NN')
Combine_tagger = backoff_tagger(
train_sentences, [UnigramTagger, BigramTagger, TrigramTagger], backoff = back_tagger
)
test_sentences = treebank.tagged_sents()[1500:]
Combine_tagger.evaluate(test_sentences)Вывод
0.9234530029238365Теперь давайте посмотрим на результат оценки, когда Combine_tagger используется как initial_tagger дрессировать брилла таггера -
from tagger_util import train_brill_tagger
brill_tagger = train_brill_tagger(combine_tagger, train_sentences)
brill_tagger.evaluate(test_sentences)Вывод
0.9246832510505041Мы можем заметить, что BrillTagger класс имеет немного повышенную точность по сравнению с Combine_tagger.
Полный пример реализации
from tagger_util import backoff_tagger
from nltk.tag import UnigramTagger
from nltk.tag import BigramTagger
from nltk.tag import TrigramTagger
from nltk.tag import DefaultTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
back_tagger = DefaultTagger('NN')
Combine_tagger = backoff_tagger(train_sentences,
[UnigramTagger, BigramTagger, TrigramTagger], backoff = back_tagger)
test_sentences = treebank.tagged_sents()[1500:]
Combine_tagger.evaluate(test_sentences)
from tagger_util import train_brill_tagger
brill_tagger = train_brill_tagger(combine_tagger, train_sentences)
brill_tagger.evaluate(test_sentences)Вывод
0.9234530029238365
0.9246832510505041TnT Tagger
TnT Tagger, расшифровывается как Trigrams'nTags, - это статистический теггер, основанный на марковских моделях второго порядка.
Как это работает?
Мы можем понять работу TnT tagger с помощью следующих шагов:
Сначала на основе данных обучения TnT tegger поддерживает несколько внутренних FreqDist и ConditionalFreqDist экземпляры.
После этого юниграммы, биграммы и триграммы будут подсчитаны по этим частотным распределениям.
Теперь во время тегирования, используя частоты, он будет вычислять вероятности возможных тегов для каждого слова.
Вот почему вместо построения цепочки отсрочки NgramTagger он использует все модели ngram вместе, чтобы выбрать лучший тег для каждого слова. Давайте оценим точность с помощью тега TnT в следующем примере -
from nltk.tag import tnt
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
tnt_tagger = tnt.TnT()
tnt_tagger.train(train_sentences)
test_sentences = treebank.tagged_sents()[1500:]
tnt_tagger.evaluate(test_sentences)Вывод
0.9165508316157791У нас немного меньшая точность, чем с Brill Tagger.
Обратите внимание, что нам нужно позвонить train() до evaluate() иначе мы получим точность 0%.
Парсинг и его значение в НЛП
Слово «парсинг» происходит от латинского слова ‘pars’ (что значит ‘part’), используется для извлечения точного значения или словарного значения из текста. Его также называют синтаксическим анализом или синтаксическим анализом. Сравнивая правила формальной грамматики, синтаксический анализ проверяет текст на осмысленность. Например, предложение типа «Дайте мне горячее мороженое» будет отклонено парсером или синтаксическим анализатором.
В этом смысле мы можем определить синтаксический анализ или синтаксический анализ следующим образом:
Его можно определить как процесс анализа строк символов на естественном языке в соответствии с правилами формальной грамматики.
Мы можем понять важность синтаксического анализа в NLP с помощью следующих пунктов:
Парсер используется для сообщения о любой синтаксической ошибке.
Это помогает исправить часто возникающую ошибку, чтобы можно было продолжить обработку оставшейся части программы.
Дерево синтаксического разбора создается с помощью парсера.
Парсер используется для создания таблицы символов, которая играет важную роль в NLP.
Парсер также используется для создания промежуточных представлений (IR).
Глубокий анализ против мелкого
| Глубокий анализ | Мелкий синтаксический анализ |
|---|---|
| При глубоком синтаксическом анализе стратегия поиска придаст предложению полную синтаксическую структуру. | Это задача анализа ограниченной части синтаксической информации из данной задачи. |
| Он подходит для сложных приложений НЛП. | Его можно использовать для менее сложных приложений НЛП. |
| Диалоговые системы и реферирование - это примеры приложений НЛП, в которых используется глубокий синтаксический анализ. | Извлечение информации и интеллектуальный анализ текста - это примеры приложений НЛП, в которых используется глубокий анализ. |
| Это также называется полным анализом. | Это также называется разбиением на части. |
Различные типы парсеров
Как уже говорилось, синтаксический анализатор - это в основном процедурная интерпретация грамматики. Он находит оптимальное дерево для данного предложения после поиска в пространстве множества деревьев. Давайте посмотрим на некоторые из доступных парсеров ниже -
Парсер с рекурсивным спуском
Синтаксический анализ с рекурсивным спуском - одна из самых простых форм синтаксического анализа. Ниже приведены некоторые важные моменты о парсере рекурсивного спуска.
Это следует за процессом сверху вниз.
Он пытается проверить правильность синтаксиса входного потока.
Он читает введенное предложение слева направо.
Одна из необходимых операций для рекурсивного синтаксического анализатора спуска - это считывание символов из входного потока и сопоставление их с терминалами из грамматики.
Парсер Shift-уменьшить
Ниже приведены некоторые важные моменты о парсере shift-reduce.
Он следует простому восходящему процессу.
Он пытается найти последовательность слов и фраз, которые соответствуют правой части грамматической продукции, и заменяет их левой частью продукции.
Вышеупомянутая попытка найти последовательность слов продолжается, пока все предложение не будет сокращено.
Другими простыми словами, синтаксический анализатор с уменьшением сдвига начинается с входного символа и пытается построить дерево синтаксического анализатора до начального символа.
Парсер диаграмм
Ниже приведены некоторые важные моменты о парсере диаграмм.
Это в основном полезно или подходит для неоднозначных грамматик, включая грамматики естественных языков.
Он применяет динамическое программирование к проблемам синтаксического анализа.
Из-за динамического программирования частичные гипотетические результаты сохраняются в структуре, называемой «диаграммой».
«График» также можно использовать повторно.
Парсер регулярных выражений
Синтаксический анализ регулярных выражений - один из наиболее часто используемых методов синтаксического анализа. Ниже приведены некоторые важные моменты о парсере Regexp:
Как следует из названия, он использует регулярное выражение, определенное в форме грамматики, поверх строки с тегами POS.
Он в основном использует эти регулярные выражения для анализа входных предложений и создания на их основе дерева синтаксического анализа.
пример
Ниже приведен рабочий пример парсера Regexp -
import nltk
sentence = [
("a", "DT"),
("clever", "JJ"),
("fox","NN"),
("was","VBP"),
("jumping","VBP"),
("over","IN"),
("the","DT"),
("wall","NN")
]
grammar = "NP:{<DT>?<JJ>*<NN>}"
Reg_parser = nltk.RegexpParser(grammar)
Reg_parser.parse(sentence)
Output = Reg_parser.parse(sentence)
Output.draw()Вывод
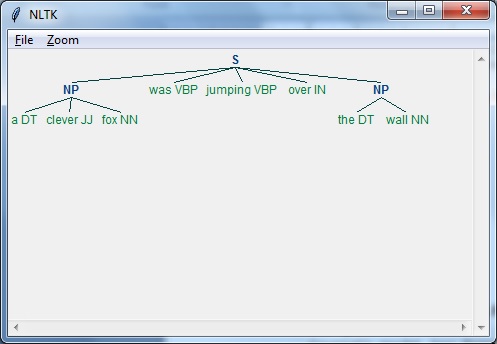
Анализ зависимостей
Анализ зависимостей (DP), современный механизм синтаксического анализа, основная концепция которого заключается в том, что каждая языковая единица, то есть слова, связаны друг с другом посредством прямой связи. Эти прямые ссылки на самом деле‘dependencies’в лингвистическом. Например, на следующей диаграмме показана грамматика зависимостей для предложения.“John can hit the ball”.

Пакет НЛТК
У нас есть два способа выполнить синтаксический анализ зависимостей с помощью NLTK:
Вероятностный анализатор проективных зависимостей
Это первый способ выполнить синтаксический анализ зависимостей с помощью NLTK. Но у этого парсера есть ограничение на обучение с ограниченным набором обучающих данных.
Стэнфордский парсер
Это еще один способ синтаксического анализа зависимостей с помощью NLTK. Стэнфордский синтаксический анализатор - это современный синтаксический анализатор зависимостей. У НЛТК есть обертка. Чтобы использовать его, нам нужно загрузить следующие две вещи:
Stanford CoreNLP анализатор .
Языковая модель для желаемого языка. Например, англоязычная модель.
пример
После того, как вы загрузили модель, мы можем использовать ее через NLTK следующим образом:
from nltk.parse.stanford import StanfordDependencyParser
path_jar = 'path_to/stanford-parser-full-2014-08-27/stanford-parser.jar'
path_models_jar = 'path_to/stanford-parser-full-2014-08-27/stanford-parser-3.4.1-models.jar'
dep_parser = StanfordDependencyParser(
path_to_jar = path_jar, path_to_models_jar = path_models_jar
)
result = dep_parser.raw_parse('I shot an elephant in my sleep')
depndency = result.next()
list(dependency.triples())Вывод
[
((u'shot', u'VBD'), u'nsubj', (u'I', u'PRP')),
((u'shot', u'VBD'), u'dobj', (u'elephant', u'NN')),
((u'elephant', u'NN'), u'det', (u'an', u'DT')),
((u'shot', u'VBD'), u'prep', (u'in', u'IN')),
((u'in', u'IN'), u'pobj', (u'sleep', u'NN')),
((u'sleep', u'NN'), u'poss', (u'my', u'PRP$'))
]Что такое дробление?
Разделение на части, один из важных процессов обработки естественного языка, используется для идентификации частей речи (POS) и коротких фраз. Другими простыми словами, разбив на части, мы можем получить структуру предложения. Его еще называютpartial parsing.
Образцы чанков и щели
Chunk patternsпредставляют собой шаблоны тегов части речи (POS), которые определяют, какие слова составляют фрагмент. Мы можем определять шаблоны фрагментов с помощью модифицированных регулярных выражений.
Более того, мы также можем определить шаблоны того, какие слова не должны быть в блоке, и эти несвязанные слова известны как chinks.
Пример реализации
В приведенном ниже примере вместе с результатом синтаксического анализа предложения “the book has many chapters”, существует грамматика для словосочетаний существительных, которая сочетает в себе как фрагмент, так и образец фрагмента -
import nltk
sentence = [
("the", "DT"),
("book", "NN"),
("has","VBZ"),
("many","JJ"),
("chapters","NNS")
]
chunker = nltk.RegexpParser(
r'''
NP:{<DT><NN.*><.*>*<NN.*>}
}<VB.*>{
'''
)
chunker.parse(sentence)
Output = chunker.parse(sentence)
Output.draw()Вывод
Как видно выше, шаблон для указания фрагмента заключается в использовании фигурных скобок следующим образом:
{<DT><NN>}И чтобы указать щель, мы можем перевернуть фигурные скобки следующим образом:
}<VB>{.Теперь для определенного типа фразы эти правила можно объединить в грамматику.
Извлечение информации
Мы рассмотрели тегеры, а также парсеры, которые можно использовать для создания механизма извлечения информации. Давайте посмотрим на основной конвейер извлечения информации -
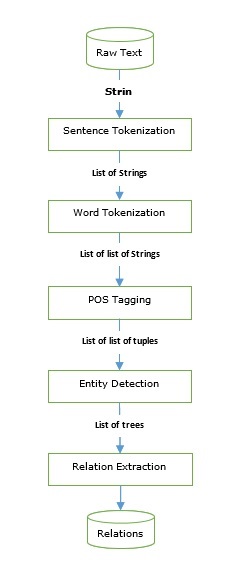
Извлечение информации имеет множество приложений, в том числе -
- Бизнес-аналитика
- Возобновить сбор урожая
- Анализ СМИ
- Обнаружение настроения
- Патентный поиск
- Сканирование электронной почты
Признание зарегистрированного лица (NER)
Распознавание именованных сущностей (NER) на самом деле является способом извлечения некоторых из наиболее распространенных сущностей, таких как имена, организации, местоположение и т.д. и следует конвейеру, показанному на рисунке выше.
пример
Import nltk
file = open (
# provide here the absolute path for the file of text for which we want NER
)
data_text = file.read()
sentences = nltk.sent_tokenize(data_text)
tokenized_sentences = [nltk.word_tokenize(sentence) for sentence in sentences]
tagged_sentences = [nltk.pos_tag(sentence) for sentence in tokenized_sentences]
for sent in tagged_sentences:
print nltk.ne_chunk(sent)Некоторые из модифицированных функций распознавания именованных сущностей (NER) также могут использоваться для извлечения таких сущностей, как названия продуктов, биомедицинские объекты, торговая марка и многое другое.
Извлечение отношений
Извлечение отношений, еще одна широко используемая операция извлечения информации, представляет собой процесс извлечения различных взаимосвязей между различными объектами. Могут быть разные отношения, такие как наследование, синонимы, аналогия и т. Д., Определение которых зависит от потребности в информации. Например, предположим, что если мы хотим найти написание книги, то авторство будет соотношением между именем автора и названием книги.
пример
В следующем примере мы используем тот же конвейер IE, как показано на приведенной выше диаграмме, который мы использовали до отношения именованных сущностей (NER), и расширяем его шаблоном отношения на основе тегов NER.
import nltk
import re
IN = re.compile(r'.*\bin\b(?!\b.+ing)')
for doc in nltk.corpus.ieer.parsed_docs('NYT_19980315'):
for rel in nltk.sem.extract_rels('ORG', 'LOC', doc, corpus = 'ieer',
pattern = IN):
print(nltk.sem.rtuple(rel))Вывод
[ORG: 'WHYY'] 'in' [LOC: 'Philadelphia']
[ORG: 'McGlashan & Sarrail'] 'firm in' [LOC: 'San Mateo']
[ORG: 'Freedom Forum'] 'in' [LOC: 'Arlington']
[ORG: 'Brookings Institution'] ', the research group in' [LOC: 'Washington']
[ORG: 'Idealab'] ', a self-described business incubator based in' [LOC: 'Los Angeles']
[ORG: 'Open Text'] ', based in' [LOC: 'Waterloo']
[ORG: 'WGBH'] 'in' [LOC: 'Boston']
[ORG: 'Bastille Opera'] 'in' [LOC: 'Paris']
[ORG: 'Omnicom'] 'in' [LOC: 'New York']
[ORG: 'DDB Needham'] 'in' [LOC: 'New York']
[ORG: 'Kaplan Thaler Group'] 'in' [LOC: 'New York']
[ORG: 'BBDO South'] 'in' [LOC: 'Atlanta']
[ORG: 'Georgia-Pacific'] 'in' [LOC: 'Atlanta']В приведенном выше коде мы использовали встроенный корпус с именем ieer. В этом корпусе предложения помечены до отношения именованный объект (NER). Здесь нам нужно только указать шаблон отношения, который мы хотим, и тип NER, который мы хотим, чтобы отношение определялось. В нашем примере мы определили отношения между организацией и местоположением. Мы извлекли все комбинации этих паттернов.
Зачем преобразовывать чанки?
До сих пор у нас есть отрывки или фразы из предложений, но что мы должны с ними делать. Одна из важных задач - их преобразовать. Но почему? Это сделать следующее -
- грамматическая коррекция и
- перестановка фраз
Фильтрация несущественных / бесполезных слов
Предположим, что если вы хотите судить о значении фразы, то есть много часто используемых слов, таких как «the», «a», которые не имеют значения или бесполезны. Например, см. Следующую фразу -
«Фильм был хорош».
Здесь наиболее значимы слова «кино» и «хорошо». Другими словами, «то» и «было» бесполезны или незначительны. Это потому, что без них мы можем получить то же значение фразы. 'Хорошее кино'.
В следующем рецепте Python мы узнаем, как удалить ненужные / несущественные слова и сохранить значимые слова с помощью тегов POS.
пример
Во-первых, просмотрев treebankКорпус для стоп-слов нам нужно решить, какие теги части речи значимы, а какие нет. Давайте посмотрим на следующую таблицу несущественных слов и тегов -
| слово | Тег |
|---|---|
| а | DT |
| Все | Тихоокеанское летнее время |
| An | DT |
| И | CC |
| Или же | CC |
| Тот | WDT |
| В | DT |
Из приведенной выше таблицы мы видим, что все остальные теги, кроме CC, заканчиваются на DT, что означает, что мы можем отфильтровать несущественные слова, посмотрев на суффикс тега.
В этом примере мы собираемся использовать функцию с именем filter()который берет один кусок и возвращает новый кусок без каких-либо несущественных помеченных слов. Эта функция отфильтровывает любые теги, заканчивающиеся на DT или CC.
пример
import nltk
def filter(chunk, tag_suffixes=['DT', 'CC']):
significant = []
for word, tag in chunk:
ok = True
for suffix in tag_suffixes:
if tag.endswith(suffix):
ok = False
break
if ok:
significant.append((word, tag))
return (significant)Теперь давайте используем эту функцию filter () в нашем рецепте Python, чтобы удалить несущественные слова -
from chunk_parse import filter
filter([('the', 'DT'),('good', 'JJ'),('movie', 'NN')])Вывод
[('good', 'JJ'), ('movie', 'NN')]Исправление глагола
Часто в реальном языке мы видим неправильные формы глаголов. Например, «все в порядке?» не является правильным. Глагольная форма в этом предложении неправильная. Предложение должно быть "все в порядке?" NLTK предоставляет нам способ исправить такие ошибки, создав сопоставления исправлений глаголов. Эти корректирующие сопоставления используются в зависимости от того, есть ли в фрагменте существительное во множественном или единственном числе.
пример
Чтобы реализовать рецепт Python, нам сначала нужно определить сопоставления исправлений глаголов. Давайте создадим два сопоставления следующим образом -
Plural to Singular mappings
plural= {
('is', 'VBZ'): ('are', 'VBP'),
('was', 'VBD'): ('were', 'VBD')
}Singular to Plural mappings
singular = {
('are', 'VBP'): ('is', 'VBZ'),
('were', 'VBD'): ('was', 'VBD')
}Как видно выше, каждое сопоставление имеет помеченный глагол, который сопоставляется с другим помеченным глаголом. Первоначальные отображения в нашем примере охватывают основные отображенияis to are, was to were, и наоборот.
Далее мы определим функцию с именем verbs(), в котором вы можете передать фрагмент с неправильной формой глагола и получить исправленный фрагмент обратно. Чтобы это сделать,verb() функция использует вспомогательную функцию с именем index_chunk() который будет искать во фрагменте позицию первого помеченного слова.
Давайте посмотрим на эти функции -
def index_chunk(chunk, pred, start = 0, step = 1):
l = len(chunk)
end = l if step > 0 else -1
for i in range(start, end, step):
if pred(chunk[i]):
return i
return None
def tag_startswith(prefix):
def f(wt):
return wt[1].startswith(prefix)
return f
def verbs(chunk):
vbidx = index_chunk(chunk, tag_startswith('VB'))
if vbidx is None:
return chunk
verb, vbtag = chunk[vbidx]
nnpred = tag_startswith('NN')
nnidx = index_chunk(chunk, nnpred, start = vbidx+1)
if nnidx is None:
nnidx = index_chunk(chunk, nnpred, start = vbidx-1, step = -1)
if nnidx is None:
return chunk
noun, nntag = chunk[nnidx]
if nntag.endswith('S'):
chunk[vbidx] = plural.get((verb, vbtag), (verb, vbtag))
else:
chunk[vbidx] = singular.get((verb, vbtag), (verb, vbtag))
return chunkСохраните эти функции в файле Python в вашем локальном каталоге, где установлен Python или Anaconda, и запустите его. Я сохранил это какverbcorrect.py.
Теперь позвольте нам позвонить verbs() функция на торговой точке с тегами is you fine кусок -
from verbcorrect import verbs
verbs([('is', 'VBZ'), ('you', 'PRP$'), ('fine', 'VBG')])Вывод
[('are', 'VBP'), ('you', 'PRP$'), ('fine','VBG')]Устранение пассивного залога из фраз
Еще одна полезная задача - исключить из фраз пассивный залог. Это можно сделать, поменяв местами слова вокруг глагола. Например,‘the tutorial was great’ может быть преобразован в ‘the great tutorial’.
пример
Для этого мы определяем функцию с именем eliminate_passive()это заменит правую часть блока на левую, используя глагол в качестве точки поворота. Чтобы найти глагол для поворота, он также будет использоватьindex_chunk() функция, определенная выше.
def eliminate_passive(chunk):
def vbpred(wt):
word, tag = wt
return tag != 'VBG' and tag.startswith('VB') and len(tag) > 2
vbidx = index_chunk(chunk, vbpred)
if vbidx is None:
return chunk
return chunk[vbidx+1:] + chunk[:vbidx]Теперь позвольте нам позвонить eliminate_passive() функция на торговой точке с тегами the tutorial was great кусок -
from passiveverb import eliminate_passive
eliminate_passive(
[
('the', 'DT'), ('tutorial', 'NN'), ('was', 'VBD'), ('great', 'JJ')
]
)Вывод
[('great', 'JJ'), ('the', 'DT'), ('tutorial', 'NN')]Замена существительных кардиналов
Как мы знаем, кардинальное слово, такое как 5, помечается как CD в блоке. Эти основные слова часто встречаются до или после существительного, но в целях нормализации полезно всегда ставить их перед существительным. Например, датаJanuary 5 можно записать как 5 January. Давайте разберемся с этим на следующем примере.
пример
Для этого мы определяем функцию с именем swapping_cardinals()это заменит любой кардинал, следующий сразу после существительного, на существительное. При этом кардинал будет стоять непосредственно перед существительным. Чтобы провести сравнение равенства с данным тегом, он использует вспомогательную функцию, которую мы назвали какtag_eql().
def tag_eql(tag):
def f(wt):
return wt[1] == tag
return fТеперь мы можем определить swapping_cardinals () -
def swapping_cardinals (chunk):
cdidx = index_chunk(chunk, tag_eql('CD'))
if not cdidx or not chunk[cdidx-1][1].startswith('NN'):
return chunk
noun, nntag = chunk[cdidx-1]
chunk[cdidx-1] = chunk[cdidx]
chunk[cdidx] = noun, nntag
return chunkТеперь позвольте нам позвонить swapping_cardinals() функция на свидании “January 5” -
from Cardinals import swapping_cardinals()
swapping_cardinals([('Janaury', 'NNP'), ('5', 'CD')])Вывод
[('10', 'CD'), ('January', 'NNP')]
10 JanuaryНиже приведены две причины для преобразования деревьев:
- Чтобы изменить дерево глубокого разбора и
- Сглаживание деревьев глубокого разбора
Преобразование дерева или поддерева в предложение
Первый рецепт, который мы собираемся здесь обсудить, - это преобразование дерева или поддерева обратно в предложение или строку фрагмента. Это очень просто, давайте посмотрим на следующем примере -
пример
from nltk.corpus import treebank_chunk
tree = treebank_chunk.chunked_sents()[2]
' '.join([w for w, t in tree.leaves()])Вывод
'Rudolph Agnew , 55 years old and former chairman of Consolidated Gold Fields
PLC , was named a nonexecutive director of this British industrial
conglomerate .'Глубокое сплющивание дерева
Глубокие деревья вложенных фраз не могут быть использованы для обучения чанка, поэтому мы должны сгладить их перед использованием. В следующем примере мы собираемся использовать третье проанализированное предложение, которое представляет собой глубокое дерево вложенных фраз, изtreebank корпус.
пример
Для этого мы определяем функцию с именем deeptree_flat()который возьмет одно дерево и вернет новое дерево, которое содержит только деревья самого низкого уровня. Для выполнения большей части работы он использует вспомогательную функцию, которую мы назвали какchildtree_flat().
from nltk.tree import Tree
def childtree_flat(trees):
children = []
for t in trees:
if t.height() < 3:
children.extend(t.pos())
elif t.height() == 3:
children.append(Tree(t.label(), t.pos()))
else:
children.extend(flatten_childtrees([c for c in t]))
return children
def deeptree_flat(tree):
return Tree(tree.label(), flatten_childtrees([c for c in tree]))Теперь позвольте нам позвонить deeptree_flat() на третьем проанализированном предложении, которое представляет собой глубокое дерево вложенных фраз, из treebankкорпус. Мы сохранили эти функции в файле с именем deeptree.py.
from deeptree import deeptree_flat
from nltk.corpus import treebank
deeptree_flat(treebank.parsed_sents()[2])Вывод
Tree('S', [Tree('NP', [('Rudolph', 'NNP'), ('Agnew', 'NNP')]),
(',', ','), Tree('NP', [('55', 'CD'),
('years', 'NNS')]), ('old', 'JJ'), ('and', 'CC'),
Tree('NP', [('former', 'JJ'),
('chairman', 'NN')]), ('of', 'IN'), Tree('NP', [('Consolidated', 'NNP'),
('Gold', 'NNP'), ('Fields', 'NNP'), ('PLC',
'NNP')]), (',', ','), ('was', 'VBD'),
('named', 'VBN'), Tree('NP-SBJ', [('*-1', '-NONE-')]),
Tree('NP', [('a', 'DT'), ('nonexecutive', 'JJ'), ('director', 'NN')]),
('of', 'IN'), Tree('NP',
[('this', 'DT'), ('British', 'JJ'),
('industrial', 'JJ'), ('conglomerate', 'NN')]), ('.', '.')])Строительство мелкого дерева
В предыдущем разделе мы сгладили глубокое дерево вложенных фраз, сохранив только поддеревья самого низкого уровня. В этом разделе мы собираемся оставить только поддеревья самого высокого уровня, то есть построить неглубокое дерево. В следующем примере мы собираемся использовать третье проанализированное предложение, которое представляет собой глубокое дерево вложенных фраз, изtreebank корпус.
пример
Для этого мы определяем функцию с именем tree_shallow() это устранит все вложенные поддеревья, сохранив только верхние метки поддерева.
from nltk.tree import Tree
def tree_shallow(tree):
children = []
for t in tree:
if t.height() < 3:
children.extend(t.pos())
else:
children.append(Tree(t.label(), t.pos()))
return Tree(tree.label(), children)Теперь позвольте нам позвонить tree_shallow()функция на 3- м разобранном предложении, которое представляет собой глубокое дерево вложенных фраз, изtreebankкорпус. Мы сохранили эти функции в файле с именем shallowtree.py.
from shallowtree import shallow_tree
from nltk.corpus import treebank
tree_shallow(treebank.parsed_sents()[2])Вывод
Tree('S', [Tree('NP-SBJ-1', [('Rudolph', 'NNP'), ('Agnew', 'NNP'), (',', ','),
('55', 'CD'), ('years', 'NNS'), ('old', 'JJ'), ('and', 'CC'),
('former', 'JJ'), ('chairman', 'NN'), ('of', 'IN'), ('Consolidated', 'NNP'),
('Gold', 'NNP'), ('Fields', 'NNP'), ('PLC', 'NNP'), (',', ',')]),
Tree('VP', [('was', 'VBD'), ('named', 'VBN'), ('*-1', '-NONE-'), ('a', 'DT'),
('nonexecutive', 'JJ'), ('director', 'NN'), ('of', 'IN'), ('this', 'DT'),
('British', 'JJ'), ('industrial', 'JJ'), ('conglomerate', 'NN')]), ('.', '.')])Мы можем увидеть разницу с помощью получения высоты деревьев -
from nltk.corpus import treebank
tree_shallow(treebank.parsed_sents()[2]).height()Вывод
3from nltk.corpus import treebank
treebank.parsed_sents()[2].height()Вывод
9Преобразование древовидных меток
В деревьях разбора есть множество Treeтипы меток, которых нет в деревьях фрагментов. Но при использовании дерева синтаксического анализа для обучения чункера мы хотели бы уменьшить это разнообразие, преобразовав некоторые метки дерева в более общие типы меток. Например, у нас есть два альтернативных поддерева NP, а именно NP-SBL и NP-TMP. Мы можем преобразовать их обоих в NP. Давайте посмотрим, как это сделать, на следующем примере.
пример
Для этого мы определяем функцию с именем tree_convert() который принимает следующие два аргумента -
- Дерево для преобразования
- Отображение преобразования этикеток
Эта функция вернет новое дерево со всеми соответствующими метками, замененными на основе значений в сопоставлении.
from nltk.tree import Tree
def tree_convert(tree, mapping):
children = []
for t in tree:
if isinstance(t, Tree):
children.append(convert_tree_labels(t, mapping))
else:
children.append(t)
label = mapping.get(tree.label(), tree.label())
return Tree(label, children)Теперь позвольте нам позвонить tree_convert() на третьем проанализированном предложении, которое представляет собой глубокое дерево вложенных фраз, из treebankкорпус. Мы сохранили эти функции в файле с именемconverttree.py.
from converttree import tree_convert
from nltk.corpus import treebank
mapping = {'NP-SBJ': 'NP', 'NP-TMP': 'NP'}
convert_tree_labels(treebank.parsed_sents()[2], mapping)Вывод
Tree('S', [Tree('NP-SBJ-1', [Tree('NP', [Tree('NNP', ['Rudolph']),
Tree('NNP', ['Agnew'])]), Tree(',', [',']),
Tree('UCP', [Tree('ADJP', [Tree('NP', [Tree('CD', ['55']),
Tree('NNS', ['years'])]),
Tree('JJ', ['old'])]), Tree('CC', ['and']),
Tree('NP', [Tree('NP', [Tree('JJ', ['former']),
Tree('NN', ['chairman'])]), Tree('PP', [Tree('IN', ['of']),
Tree('NP', [Tree('NNP', ['Consolidated']),
Tree('NNP', ['Gold']), Tree('NNP', ['Fields']),
Tree('NNP', ['PLC'])])])])]), Tree(',', [','])]),
Tree('VP', [Tree('VBD', ['was']),Tree('VP', [Tree('VBN', ['named']),
Tree('S', [Tree('NP', [Tree('-NONE-', ['*-1'])]),
Tree('NP-PRD', [Tree('NP', [Tree('DT', ['a']),
Tree('JJ', ['nonexecutive']), Tree('NN', ['director'])]),
Tree('PP', [Tree('IN', ['of']), Tree('NP',
[Tree('DT', ['this']), Tree('JJ', ['British']), Tree('JJ', ['industrial']),
Tree('NN', ['conglomerate'])])])])])])]), Tree('.', ['.'])])Что такое классификация текста?
Классификация текста, как следует из названия, - это способ категоризации фрагментов текста или документов. Но здесь возникает вопрос, зачем нам использовать текстовые классификаторы? После изучения использования слова в документе или фрагменте текста классификаторы смогут решить, какой ярлык класса следует ему присвоить.
Бинарный классификатор
Как следует из названия, двоичный классификатор будет выбирать между двумя метками. Например, положительный или отрицательный. В этом фрагменте текста или документа может быть либо один ярлык, либо другой, но не оба.
Классификатор с несколькими метками
В отличие от двоичного классификатора, классификатор с несколькими метками может назначать одну или несколько меток фрагменту текста или документа.
Набор функций с меткой и без метки
Сопоставление "ключ-значение" имен функций со значениями функций называется набором функций. Помеченные наборы функций или обучающие данные очень важны для обучения классификации, чтобы впоследствии можно было классифицировать немаркированные наборы функций.
| Помеченный набор функций | Набор функций без метки |
|---|---|
| Это кортеж, который выглядит как (feat, label). | Это уже подвиг. |
| Это экземпляр с известной меткой класса. | Без ассоциированной метки мы можем назвать это экземпляром. |
| Используется для обучения алгоритму классификации. | После обучения алгоритм классификации может классифицировать немаркированный набор функций. |
Извлечение текстовых функций
Извлечение текстовых функций, как следует из названия, представляет собой процесс преобразования списка слов в набор функций, который может использовать классификатор. Мы должны преобразовать наш текст в‘dict’ набор функций стиля, поскольку набор средств естественного языка (NLTK) ожидает ‘dict’ наборы стилей.
Модель Bag of Words (BoW)
BoW, одна из простейших моделей в NLP, используется для извлечения функций из фрагмента текста или документа, чтобы его можно было использовать при моделировании, например, в алгоритмах машинного обучения. Он в основном создает набор функций присутствия слова из всех слов экземпляра. Концепция этого метода заключается в том, что он не заботится о том, сколько раз встречается слово или о порядке слов, его заботит только то, присутствует ли слово в списке слов или нет.
пример
В этом примере мы собираемся определить функцию с именем bow () -
def bow(words):
return dict([(word, True) for word in words])Теперь позвольте нам позвонить bow()функция слов. Мы сохранили эти функции в файле с именем bagwords.py.
from bagwords import bow
bow(['we', 'are', 'using', 'tutorialspoint'])Вывод
{'we': True, 'are': True, 'using': True, 'tutorialspoint': True}Классификаторы обучения
В предыдущих разделах мы узнали, как извлекать элементы из текста. Итак, теперь мы можем обучить классификатор. Первый и самый простой классификатор:NaiveBayesClassifier класс.
Наивный байесовский классификатор
Чтобы предсказать вероятность того, что данный набор функций принадлежит определенной метке, он использует теорему Байеса. Формула теоремы Байеса выглядит следующим образом.
$$P(A|B)=\frac{P(B|A)P(A)}{P(B)}$$Вот,
P(A|B) - Это также называется апостериорной вероятностью, т. Е. Вероятностью того, что первое событие, то есть A, произойдет, при этом втором событии, то есть B, произошло.
P(B|A) - Это вероятность второго события, т.е. B, которое произойдет после первого события, то есть A.
P(A), P(B) - Это также называется априорной вероятностью, т. Е. Вероятностью первого события, то есть A, или второго события, то есть B.
Чтобы обучить наивный байесовский классификатор, мы будем использовать movie_reviewsкорпус от НЛТК. В этом корпусе есть две категории текста, а именно:pos и neg. Эти категории делают обученный на них классификатор бинарным классификатором. Каждый файл в корпусе состоит из двух файлов: один - положительный обзор фильма, а другой - отрицательный. В нашем примере мы собираемся использовать каждый файл как отдельный экземпляр как для обучения, так и для тестирования классификатора.
пример
Для обучения классификатора нам понадобится список помеченных наборов функций, который будет иметь вид [(featureset, label)]. Здесьfeatureset переменная - это dict а метка - известная метка класса для featureset. Мы собираемся создать функцию с именемlabel_corpus() который примет корпус с именем movie_reviewsа также функция с именем feature_detector, который по умолчанию bag of words. Он создаст и вернет отображение формы {label: [featureset]}. После этого мы будем использовать это сопоставление для создания списка помеченных экземпляров обучения и экземпляров тестирования.
import collections
def label_corpus(corp, feature_detector=bow):
label_feats = collections.defaultdict(list)
for label in corp.categories():
for fileid in corp.fileids(categories=[label]):
feats = feature_detector(corp.words(fileids=[fileid]))
label_feats[label].append(feats)
return label_featsС помощью вышеуказанной функции мы получим отображение {label:fetaureset}. Теперь мы собираемся определить еще одну функцию с именемsplit который примет отображение, возвращенное из label_corpus() функция и разбивает каждый список наборов функций на помеченные как обучающие, так и тестовые экземпляры.
def split(lfeats, split=0.75):
train_feats = []
test_feats = []
for label, feats in lfeats.items():
cutoff = int(len(feats) * split)
train_feats.extend([(feat, label) for feat in feats[:cutoff]])
test_feats.extend([(feat, label) for feat in feats[cutoff:]])
return train_feats, test_featsТеперь давайте используем эти функции в нашем корпусе, то есть movie_reviews -
from nltk.corpus import movie_reviews
from featx import label_feats_from_corpus, split_label_feats
movie_reviews.categories()Вывод
['neg', 'pos']пример
lfeats = label_feats_from_corpus(movie_reviews)
lfeats.keys()Вывод
dict_keys(['neg', 'pos'])пример
train_feats, test_feats = split_label_feats(lfeats, split = 0.75)
len(train_feats)Вывод
1500пример
len(test_feats)Вывод
500Мы видели это в movie_reviewscorpus есть 1000 файлов pos и 1000 файлов neg. Мы также получаем 1500 помеченных экземпляров обучения и 500 помеченных экземпляров тестирования.
Теперь давайте тренироваться NaïveBayesClassifier используя свой train() метод класса -
from nltk.classify import NaiveBayesClassifier
NBC = NaiveBayesClassifier.train(train_feats)
NBC.labels()Вывод
['neg', 'pos']Классификатор дерева решений
Другой важный классификатор - это классификатор дерева решений. Здесь, чтобы тренироватьDecisionTreeClassifierкласс создаст древовидную структуру. В этой древовидной структуре каждый узел соответствует имени функции, а ветви соответствуют значениям функции. И вниз по веткам мы перейдем к листьям дерева, то есть к классификационным меткам.
Для обучения классификатора дерева решений мы будем использовать те же функции обучения и тестирования, т.е. train_feats и test_feats, переменные, которые мы создали из movie_reviews корпус.
пример
Для обучения этого классификатора вызовем DecisionTreeClassifier.train() метод класса следующим образом -
from nltk.classify import DecisionTreeClassifier
decisiont_classifier = DecisionTreeClassifier.train(
train_feats, binary = True, entropy_cutoff = 0.8,
depth_cutoff = 5, support_cutoff = 30
)
accuracy(decisiont_classifier, test_feats)Вывод
0.725Классификатор максимальной энтропии
Еще один важный классификатор: MaxentClassifier который также известен как conditional exponential classifier или же logistic regression classifier. Здесь, чтобы тренировать его,MaxentClassifier class преобразует помеченные наборы функций в векторные с использованием кодирования.
Для обучения классификатора дерева решений мы будем использовать те же функции обучения и тестирования, т.е. train_featsи test_feats, переменные, которые мы создали из movie_reviews корпус.
пример
Для обучения этого классификатора вызовем MaxentClassifier.train() метод класса следующим образом -
from nltk.classify import MaxentClassifier
maxent_classifier = MaxentClassifier
.train(train_feats,algorithm = 'gis', trace = 0, max_iter = 10, min_lldelta = 0.5)
accuracy(maxent_classifier, test_feats)Вывод
0.786Классификатор Scikit-learn
Одна из лучших библиотек машинного обучения (ML) - Scikit-learn. На самом деле он содержит всевозможные алгоритмы машинного обучения для различных целей, но все они имеют один и тот же шаблон проектирования, как показано ниже:
- Подгонка модели к данным
- И используйте эту модель, чтобы делать прогнозы
Вместо прямого доступа к моделям scikit-learn здесь мы собираемся использовать NLTK SklearnClassifierкласс. Этот класс является классом-оболочкой вокруг модели scikit-learn, чтобы она соответствовала интерфейсу классификатора NLTK.
Мы будем следовать следующим шагам, чтобы обучить SklearnClassifier класс -
Step 1 - Сначала создадим тренировочные функции, как делали в предыдущих рецептах.
Step 2 - Теперь выберите и импортируйте алгоритм Scikit-learn.
Step 3 - Далее нам нужно построить SklearnClassifier класс с выбранным алгоритмом.
Step 4 - Напоследок потренируем SklearnClassifier класс с нашими функциями обучения.
Давайте реализуем эти шаги в приведенном ниже рецепте Python -
from nltk.classify.scikitlearn import SklearnClassifier
from sklearn.naive_bayes import MultinomialNB
sklearn_classifier = SklearnClassifier(MultinomialNB())
sklearn_classifier.train(train_feats)
<SklearnClassifier(MultinomialNB(alpha = 1.0,class_prior = None,fit_prior = True))>
accuracy(sk_classifier, test_feats)Вывод
0.885Точность измерения и отзыв
При обучении различных классификаторов мы также измерили их точность. Но помимо точности есть ряд других показателей, которые используются для оценки классификаторов. Два из этих показателейprecision и recall.
пример
В этом примере мы собираемся вычислить точность и отзыв класса NaiveBayesClassifier, который мы обучили ранее. Для этого мы создадим функцию с именем metrics_PR (), которая будет принимать два аргумента: один - это обученный классификатор, а другой - помеченные тестовые функции. Оба аргумента такие же, как мы передали при вычислении точности классификаторов -
import collections
from nltk import metrics
def metrics_PR(classifier, testfeats):
refsets = collections.defaultdict(set)
testsets = collections.defaultdict(set)
for i, (feats, label) in enumerate(testfeats):
refsets[label].add(i)
observed = classifier.classify(feats)
testsets[observed].add(i)
precisions = {}
recalls = {}
for label in classifier.labels():
precisions[label] = metrics.precision(refsets[label],testsets[label])
recalls[label] = metrics.recall(refsets[label], testsets[label])
return precisions, recallsПозвольте нам вызвать эту функцию, чтобы найти точность и отзыв -
from metrics_classification import metrics_PR
nb_precisions, nb_recalls = metrics_PR(nb_classifier,test_feats)
nb_precisions['pos']Вывод
0.6713532466435213пример
nb_precisions['neg']Вывод
0.9676271186440678пример
nb_recalls['pos']Вывод
0.96пример
nb_recalls['neg']Вывод
0.478Сочетание классификатора и голосования
Комбинирование классификаторов - один из лучших способов повысить эффективность классификации. А голосование - один из лучших способов объединить несколько классификаторов. Для голосования нам необходимо иметь нечетное количество классификаторов. В следующем рецепте Python мы собираемся объединить три классификатора, а именно класс NaiveBayesClassifier, класс DecisionTreeClassifier и класс MaxentClassifier.
Чтобы добиться этого, мы собираемся определить функцию с именем vote_classifiers () следующим образом.
import itertools
from nltk.classify import ClassifierI
from nltk.probability import FreqDist
class Voting_classifiers(ClassifierI):
def __init__(self, *classifiers):
self._classifiers = classifiers
self._labels = sorted(set(itertools.chain(*[c.labels() for c in classifiers])))
def labels(self):
return self._labels
def classify(self, feats):
counts = FreqDist()
for classifier in self._classifiers:
counts[classifier.classify(feats)] += 1
return counts.max()Позвольте нам вызвать эту функцию, чтобы объединить три классификатора и найти точность -
from vote_classification import Voting_classifiers
combined_classifier = Voting_classifiers(NBC, decisiont_classifier, maxent_classifier)
combined_classifier.labels()Вывод
['neg', 'pos']пример
accuracy(combined_classifier, test_feats)Вывод
0.948Из вышеприведенного вывода мы видим, что комбинированные классификаторы имеют наивысшую точность, чем отдельные классификаторы.