Искра - RDD
Устойчивые распределенные наборы данных
Устойчивые распределенные наборы данных (RDD) - это фундаментальная структура данных Spark. Это неизменяемая распределенная коллекция объектов. Каждый набор данных в RDD разделен на логические разделы, которые могут быть вычислены на разных узлах кластера. СДР могут содержать любой тип объектов Python, Java или Scala, включая определяемые пользователем классы.
Формально RDD - это секционированная коллекция записей, доступная только для чтения. RDD могут быть созданы с помощью детерминированных операций либо с данными в стабильном хранилище, либо с другими RDD. RDD - это отказоустойчивый набор элементов, с которыми можно работать параллельно.
Есть два способа создания RDD: parallelizing существующая коллекция в вашей программе драйвера, или referencing a dataset во внешней системе хранения, такой как общая файловая система, HDFS, HBase или любой источник данных, предлагающий входной формат Hadoop.
Spark использует концепцию RDD для более быстрых и эффективных операций MapReduce. Давайте сначала обсудим, как происходят операции MapReduce и почему они не так эффективны.
Обмен данными в MapReduce происходит медленно
MapReduce широко применяется для обработки и создания больших наборов данных с помощью параллельного распределенного алгоритма в кластере. Он позволяет пользователям писать параллельные вычисления, используя набор операторов высокого уровня, не беспокоясь о распределении работы и отказоустойчивости.
К сожалению, в большинстве современных платформ единственный способ повторно использовать данные между вычислениями (например, между двумя заданиями MapReduce) - это записать их во внешнюю стабильную систему хранения (например, HDFS). Хотя эта структура предоставляет множество абстракций для доступа к вычислительным ресурсам кластера, пользователи все же хотят большего.
И то и другое Iterative и Interactiveприложениям требуется более быстрый обмен данными между параллельными заданиями. Обмен данными в MapReduce происходит медленно из-заreplication, serialization, и disk IO. Что касается системы хранения, большинство приложений Hadoop тратят более 90% времени на выполнение операций чтения-записи HDFS.
Итерационные операции на MapReduce
Повторно используйте промежуточные результаты в нескольких вычислениях в многоэтапных приложениях. На следующем рисунке показано, как работает текущая структура при выполнении итерационных операций на MapReduce. Это влечет за собой значительные накладные расходы из-за репликации данных, дискового ввода-вывода и сериализации, что замедляет работу системы.
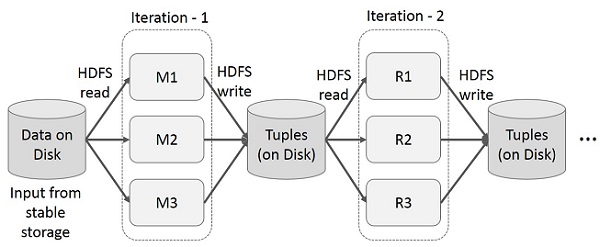
Интерактивные операции на MapReduce
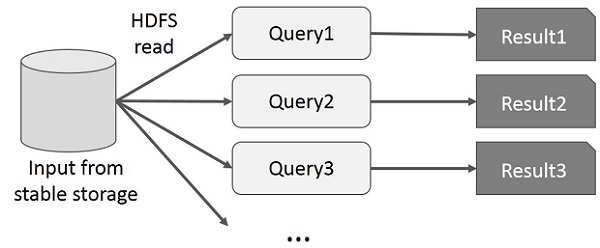
Пользователь выполняет специальные запросы к одному и тому же подмножеству данных. Каждый запрос будет выполнять дисковый ввод-вывод в стабильном хранилище, что может доминировать над временем выполнения приложения.
На следующем рисунке показано, как работает текущая структура при выполнении интерактивных запросов в MapReduce.
Совместное использование данных с помощью Spark RDD
Обмен данными в MapReduce происходит медленно из-за replication, serialization, и disk IO. Большинство приложений Hadoop тратят более 90% времени на выполнение операций чтения-записи HDFS.
Осознавая эту проблему, исследователи разработали специализированный фреймворк под названием Apache Spark. Ключевая идея искрыRжизнеспособный Dраспределяется Dатасеты (RDD); он поддерживает вычисления в памяти. Это означает, что он сохраняет состояние памяти в виде объекта по всем заданиям, и этот объект может использоваться совместно этими заданиями. Обмен данными в памяти в 10–100 раз быстрее, чем в сети и на диске.
Давайте теперь попробуем выяснить, как итерационные и интерактивные операции происходят в Spark RDD.
Итерационные операции над Spark RDD
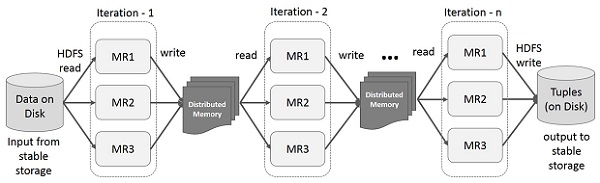
На приведенной ниже иллюстрации показаны итерационные операции в Spark RDD. Промежуточные результаты будут храниться в распределенной памяти вместо стабильного хранилища (диска), что сделает систему быстрее.
Note - Если распределенной памяти (ОЗУ) недостаточно для хранения промежуточных результатов (состояние задания), то эти результаты будут сохранены на диске.
Интерактивные операции в Spark RDD
На этом рисунке показаны интерактивные операции в Spark RDD. Если для одного и того же набора данных несколько раз выполняются разные запросы, эти конкретные данные можно хранить в памяти для увеличения времени выполнения.

По умолчанию каждый преобразованный RDD может пересчитываться каждый раз, когда вы запускаете над ним действие. Однако вы также можетеpersistRDD в памяти, и в этом случае Spark сохранит элементы в кластере для гораздо более быстрого доступа при следующем запросе. Также имеется поддержка сохранения RDD на диске или их репликации на нескольких узлах.