Spark SQL - Введение
Spark представляет программный модуль для обработки структурированных данных под названием Spark SQL. Он предоставляет программную абстракцию под названием DataFrame и может действовать как механизм распределенных запросов SQL.
Особенности Spark SQL
Ниже приведены особенности Spark SQL:
Integrated- Легко смешивайте запросы SQL с программами Spark. Spark SQL позволяет запрашивать структурированные данные в виде распределенного набора данных (RDD) в Spark с интегрированными API-интерфейсами в Python, Scala и Java. Эта тесная интеграция позволяет легко выполнять запросы SQL вместе со сложными аналитическими алгоритмами.
Unified Data Access- Загружать и запрашивать данные из различных источников. Schema-RDD предоставляют единый интерфейс для эффективной работы со структурированными данными, включая таблицы Apache Hive, файлы parquet и файлы JSON.
Hive Compatibility- Запускать неизмененные запросы Hive на существующих складах. Spark SQL повторно использует интерфейс Hive и MetaStore, обеспечивая полную совместимость с существующими данными Hive, запросами и пользовательскими функциями. Просто установите его вместе с Hive.
Standard Connectivity- Подключайтесь через JDBC или ODBC. Spark SQL включает режим сервера с возможностью подключения по отраслевым стандартам JDBC и ODBC.
Scalability- Используйте один и тот же движок как для интерактивных, так и для длинных запросов. Spark SQL использует преимущества модели RDD для поддержки отказоустойчивости при выполнении промежуточных запросов, что позволяет масштабировать ее также и для крупных заданий. Не беспокойтесь об использовании другого движка для исторических данных.
Архитектура Spark SQL
На следующем рисунке объясняется архитектура Spark SQL.
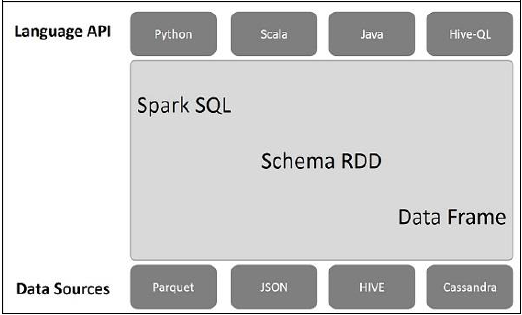
Эта архитектура содержит три уровня, а именно: API языка, RDD схемы и источники данных.
Language API- Spark совместим с разными языками и Spark SQL. Он также поддерживается этими языками - API (python, scala, java, HiveQL).
Schema RDD- Spark Core разработан с использованием специальной структуры данных, называемой RDD. Как правило, Spark SQL работает со схемами, таблицами и записями. Следовательно, мы можем использовать RDD схемы как временную таблицу. Мы можем назвать эту схему RDD как Data Frame.
Data Sources- Обычно источником данных для spark-core является текстовый файл, файл Avro и т. Д. Однако источники данных для Spark SQL отличаются. Это файл Parquet, документ JSON, таблицы HIVE и база данных Cassandra.
Мы обсудим это более подробно в следующих главах.