Talend - распределенная файловая система Hadoop
В этой главе давайте подробно узнаем о том, как Talend работает с распределенной файловой системой Hadoop.
Настройки и предварительные условия
Прежде чем мы перейдем к Talend с HDFS, мы должны узнать о настройках и предварительных требованиях, которые должны быть выполнены для этой цели.
Здесь мы запускаем Cloudera quickstart 5.10 VM на виртуальной машине. На этой виртуальной машине должна использоваться сеть только для хоста.
IP-адрес сети только для хоста: 192.168.56.101

У вас должен быть тот же хост, работающий и на cloudera manager.

Теперь в вашей системе Windows перейдите в c: \ Windows \ System32 \ Drivers \ etc \ hosts и отредактируйте этот файл с помощью Блокнота, как показано ниже.

Точно так же на виртуальной машине быстрого запуска cloudera отредактируйте файл / etc / hosts, как показано ниже.
sudo gedit /etc/hosts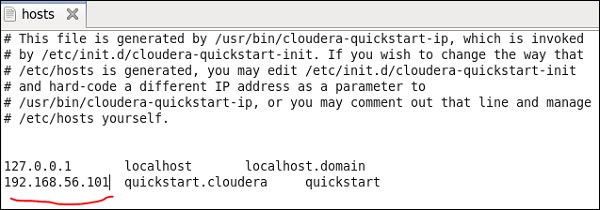
Настройка подключения Hadoop
На панели репозитория перейдите в Метаданные. Щелкните правой кнопкой мыши Hadoop Cluster и создайте новый кластер. Дайте имя, цель и описание для этого кластерного подключения Hadoop.
Нажмите "Далее.

Выберите дистрибутив cloudera и выберите версию, которую вы используете. Выберите вариант получения конфигурации и нажмите Далее.

Введите учетные данные менеджера (URI с портом, именем пользователя, паролем), как показано ниже, и нажмите «Подключиться». Если данные верны, вы получите Cloudera QuickStart под обнаруженными кластерами.
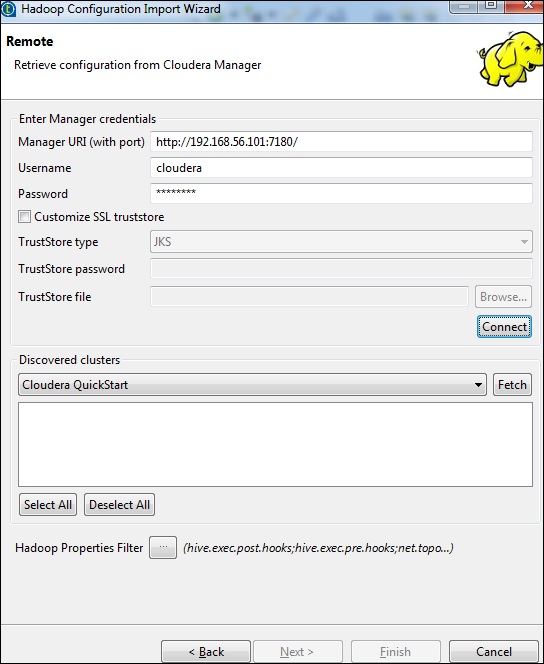
Щелкните "Получить". Это позволит получить все подключения и конфигурации для HDFS, YARN, HBASE, HIVE.
Выберите «Все» и нажмите «Готово».

Обратите внимание, что все параметры подключения будут заполнены автоматически. Упомяните cloudera в имени пользователя и нажмите Готово.

Таким образом, вы успешно подключились к кластеру Hadoop.

Подключение к HDFS
В этом задании мы перечислим все каталоги и файлы, которые присутствуют в HDFS.
Сначала мы создадим задание, а затем добавим в него компоненты HDFS. Щелкните правой кнопкой мыши на Job Design и создайте новое задание - hadoopjob.
Теперь добавляем 2 компонента из палитры - tHDFSConnection и tHDFSList. Щелкните правой кнопкой мыши tHDFSConnection и соедините эти 2 компонента с помощью триггера OnSubJobOk.
Теперь настройте оба компонента talend hdfs.

В tHDFSConnection выберите Репозиторий в качестве типа свойства и выберите кластер Hadoop cloudera, который вы создали ранее. Он автоматически заполнит все необходимые данные, необходимые для этого компонента.

В tHDFSList выберите «Использовать существующее соединение» и в списке компонентов выберите настроенное вами соединение tHDFSConnection.
Укажите домашний путь HDFS в параметре каталога HDFS и нажмите кнопку обзора справа.

Если вы правильно установили соединение с вышеупомянутыми конфигурациями, вы увидите окно, как показано ниже. В нем будут перечислены все каталоги и файлы, имеющиеся в домашней файловой системе HDFS.

Вы можете убедиться в этом, проверив свою HDFS на cloudera.

Чтение файла из HDFS
В этом разделе давайте разберемся, как читать файл из HDFS в Talend. Для этого вы можете создать новое задание, но здесь мы используем уже существующее.
Перетащите 3 компонента - tHDFSConnection, tHDFSInput и tLogRow из палитры в окно конструктора.
Щелкните правой кнопкой мыши tHDFSConnection и подключите компонент tHDFSInput с помощью триггера OnSubJobOk.
Щелкните правой кнопкой мыши tHDFSInput и перетащите основную ссылку на tLogRow.

Обратите внимание, что tHDFSConnection будет иметь такую же конфигурацию, как и раньше. В tHDFSInput выберите «Использовать существующее соединение» и в списке компонентов выберите tHDFSConnection.
В поле «Имя файла» укажите путь HDFS к файлу, который вы хотите прочитать. Здесь мы читаем простой текстовый файл, поэтому наш Тип файла - Текстовый файл. Аналогичным образом, в зависимости от вашего ввода, заполните разделитель строк, разделитель полей и заголовок, как указано ниже. Наконец, нажмите кнопку «Изменить схему».

Поскольку в нашем файле просто текст, мы добавляем только один столбец типа String. Теперь нажмите ОК.
Note - Если ваш ввод содержит несколько столбцов разных типов, вам необходимо указать здесь схему соответственно.

В компоненте tLogRow щелкните Синхронизировать столбцы в схеме редактирования.
Выберите режим, в котором вы хотите распечатать свой вывод.

Наконец, нажмите «Выполнить», чтобы выполнить задание.
После успешного чтения файла HDFS вы можете увидеть следующий результат.

Запись файла в HDFS
Посмотрим, как записать файл из HDFS в Talend. Перетащите 3 компонента - tHDFSConnection, tFileInputDelimited и tHDFSOutput из палитры в окно конструктора.
Щелкните правой кнопкой мыши на tHDFSConnection и подключите компонент tFileInputDelimited с помощью триггера OnSubJobOk.
Щелкните правой кнопкой мыши tFileInputDelimited и перетащите основную ссылку на tHDFSOutput.

Обратите внимание, что tHDFSConnection будет иметь такую же конфигурацию, как и раньше.
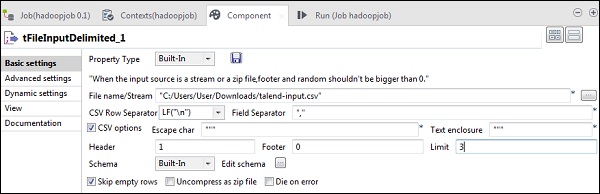
Теперь в tFileInputDelimited укажите путь к входному файлу в опции File name / Stream. Здесь мы используем файл csv в качестве входных данных, поэтому разделителем полей является «,».
Выберите верхний, нижний колонтитул, ограничение в соответствии с вашим входным файлом. Обратите внимание, что здесь наш заголовок равен 1, потому что первая строка содержит имена столбцов, а ограничение - 3, потому что мы записываем только первые 3 строки в HDFS.
Теперь щелкните изменить схему.
Теперь, в соответствии с нашим входным файлом, определите схему. Наш входной файл имеет 3 столбца, как указано ниже.

В компоненте tHDFSOutput щелкните столбцы синхронизации. Затем выберите tHDFSConnection в Использовать существующее соединение. Кроме того, в поле «Имя файла» укажите путь HDFS, куда вы хотите записать файл.
Обратите внимание, что тип файла будет текстовым файлом, действием будет «создать», разделителем строк будет «\ n», а разделителем полей - «;»

Наконец, нажмите «Выполнить», чтобы выполнить задание. После успешного выполнения задания проверьте, есть ли ваш файл в HDFS.

Выполните следующую команду hdfs с выходным путем, который вы указали в своем задании.
hdfs dfs -cat /input/talendwriteВы увидите следующий результат, если вам удастся написать на HDFS.
