TensorFlow - Краткое руководство
TensorFlow - это программная библиотека или фреймворк, разработанная командой Google для наиболее простой реализации концепций машинного обучения и глубокого обучения. Он сочетает в себе вычислительную алгебру методов оптимизации для простого вычисления многих математических выражений.
Официальный сайт TensorFlow упомянут ниже -
www.tensorflow.org
Давайте теперь рассмотрим следующие важные особенности TensorFlow:
Он включает в себя функцию, которая легко определяет, оптимизирует и вычисляет математические выражения с помощью многомерных массивов, называемых тензорами.
Он включает в себя программную поддержку глубоких нейронных сетей и методов машинного обучения.
Он включает в себя высокую масштабируемость вычислений с различными наборами данных.
TensorFlow использует вычисления на GPU, автоматизируя управление. Он также включает уникальную функцию оптимизации той же памяти и используемых данных.
Почему TensorFlow так популярен?
TensorFlow хорошо документирован и включает множество библиотек машинного обучения. Он предлагает несколько важных функций и методов для того же.
TensorFlow также называют продуктом «Google». Он включает в себя множество алгоритмов машинного обучения и глубокого обучения. TensorFlow может обучать и запускать глубокие нейронные сети для классификации рукописных цифр, распознавания изображений, встраивания слов и создания различных моделей последовательностей.
Чтобы установить TensorFlow, важно, чтобы в вашей системе был установлен «Python». Python версии 3.4+ считается лучшим для начала установки TensorFlow.
Чтобы установить TensorFlow в операционной системе Windows, выполните следующие действия.
Step 1 - Убедитесь, что версия Python установлена.
Step 2- Пользователь может подобрать любой механизм для установки TensorFlow в систему. Мы рекомендуем «пип» и «Анаконду». Pip - это команда, используемая для запуска и установки модулей в Python.
Перед установкой TensorFlow нам необходимо установить фреймворк Anaconda в нашу систему.
После успешной установки проверьте командную строку с помощью команды «conda». Выполнение команды отображается ниже -
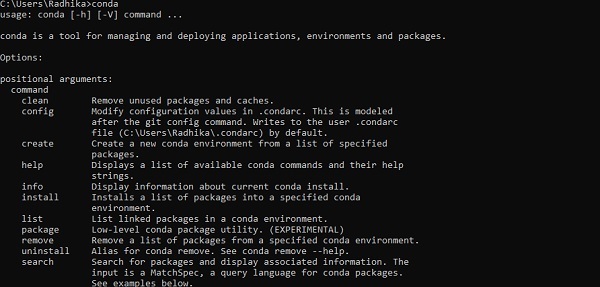
Step 3 - Выполните следующую команду, чтобы инициализировать установку TensorFlow -
conda create --name tensorflow python = 3.5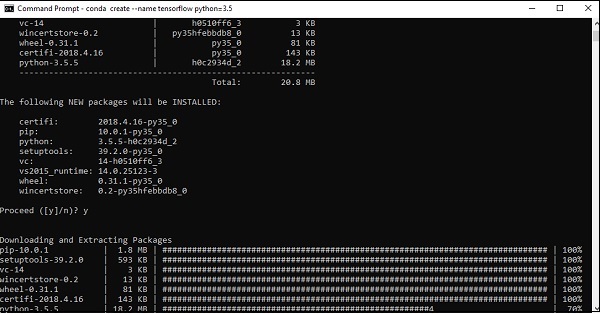
Он загружает необходимые пакеты, необходимые для установки TensorFlow.
Step 4 - После успешной настройки среды важно активировать модуль TensorFlow.
activate tensorflow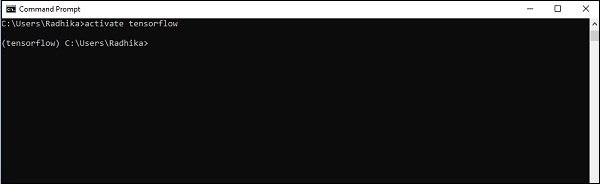
Step 5- Используйте pip для установки «Tensorflow» в систему. Команда, используемая для установки, указана ниже -
pip install tensorflowИ,
pip install tensorflow-gpu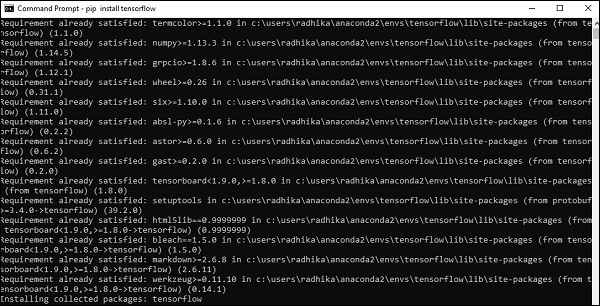
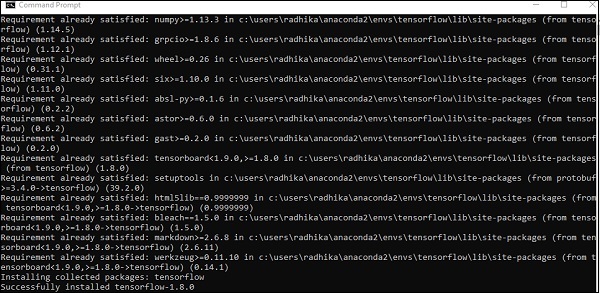
После успешной установки важно знать пример выполнения программы TensorFlow.
Следующий пример помогает нам понять создание базовой программы «Hello World» в TensorFlow.
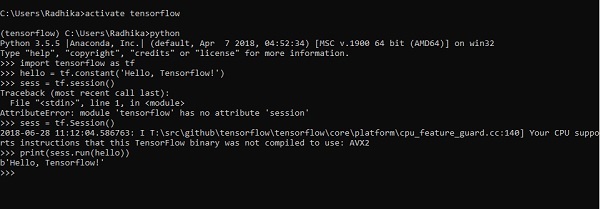
Код для первой реализации программы упомянут ниже -
>> activate tensorflow
>> python (activating python shell)
>> import tensorflow as tf
>> hello = tf.constant(‘Hello, Tensorflow!’)
>> sess = tf.Session()
>> print(sess.run(hello))Искусственный интеллект включает в себя моделирование человеческого интеллекта машинами и специальными компьютерными системами. Примеры искусственного интеллекта включают обучение, рассуждение и самокоррекцию. Приложения ИИ включают распознавание речи, экспертные системы, распознавание изображений и машинное зрение.
Машинное обучение - это отрасль искусственного интеллекта, которая занимается системами и алгоритмами, которые могут изучать любые новые данные и шаблоны данных.
Давайте сосредоточимся на приведенной ниже диаграмме Венна для понимания концепций машинного обучения и глубокого обучения.
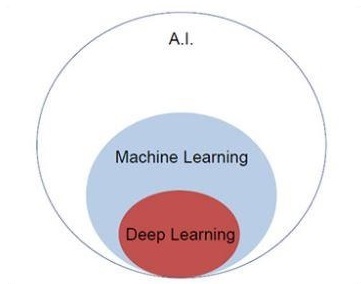
Машинное обучение включает в себя раздел машинного обучения, а глубокое обучение является частью машинного обучения. Способность программы, которая следует концепциям машинного обучения, заключается в улучшении производительности наблюдаемых данных. Основной мотив преобразования данных - улучшить свои знания, чтобы в будущем достичь лучших результатов, обеспечить вывод, более близкий к желаемому результату для этой конкретной системы. Машинное обучение включает «распознавание образов», которое включает в себя способность распознавать закономерности в данных.
Шаблоны должны быть обучены отображать результат желаемым образом.
Машинное обучение можно обучить двумя способами:
- Обучение под руководством
- Обучение без учителя
Контролируемое обучение
Обучение с учителем или обучение с учителем включает в себя процедуру, в которой обучающий набор предоставляется в качестве входных данных для системы, при этом каждый пример помечается желаемым выходным значением. Обучение в этом типе выполняется с использованием минимизации конкретной функции потерь, которая представляет ошибку вывода по отношению к желаемой системе вывода.
После завершения обучения точность каждой модели измеряется относительно непересекающихся примеров из обучающего набора, также называемого проверочным набором.
Лучший пример, иллюстрирующий «обучение с учителем» - это набор фотографий с включенной в них информацией. Здесь пользователь может обучить модель распознавать новые фотографии.
Неконтролируемое обучение
При обучении без учителя или обучении без учителя включите примеры обучения, которые не помечены системой, к какому классу они принадлежат. Система ищет данные, которые имеют общие характеристики, и изменяет их на основе внутренних особенностей знаний. Этот тип алгоритмов обучения в основном используется в задачах кластеризации.
Лучший пример для иллюстрации «обучения без учителя» - это набор фотографий без включенной информации, а пользователь обучает модель с классификацией и кластеризацией. Этот тип алгоритма обучения работает с предположениями, так как информация не предоставляется.

Перед созданием базового приложения в TensorFlow важно понимать математические концепции, необходимые для TensorFlow. Математика считается сердцем любого алгоритма машинного обучения. Именно с помощью основных концепций математики определяется решение для конкретного алгоритма машинного обучения.
Вектор
Массив чисел, который может быть непрерывным или дискретным, определяется как вектор. Алгоритмы машинного обучения работают с векторами фиксированной длины для лучшего вывода.
Алгоритмы машинного обучения работают с многомерными данными, поэтому векторы играют решающую роль.

Графическое представление векторной модели показано ниже -
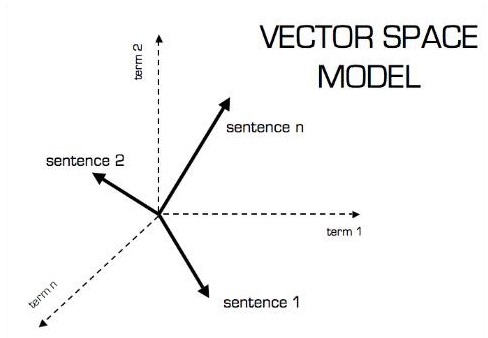
Скалярный
Скаляр можно определить как одномерный вектор. Скаляры - это те, которые включают только величину, но не направление. В случае скаляров нас интересует только величина.
Примеры скаляров включают параметры веса и роста детей.
Матрица
Матрицу можно определить как многомерные массивы, которые расположены в формате строк и столбцов. Размер матрицы определяется длиной строки и длиной столбца. На следующем рисунке показано представление любой указанной матрицы.
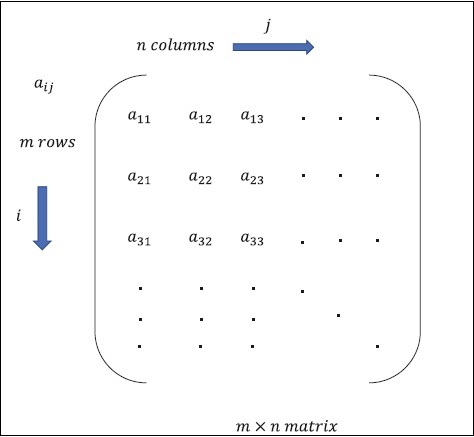
Рассмотрим матрицу с «m» строками и «n» столбцами, как упомянуто выше, представление матрицы будет указано как «матрица m * n», которая также определяет длину матрицы.
Математические вычисления
В этом разделе мы узнаем о различных математических вычислениях в TensorFlow.
Добавление матриц
Добавление двух или более матриц возможно, если матрицы имеют одинаковую размерность. Добавление подразумевает добавление каждого элемента в соответствии с данной позицией.
Рассмотрим следующий пример, чтобы понять, как работает сложение матриц -
$$ Пример: A = \ begin {bmatrix} 1 & 2 \\ 3 & 4 \ end {bmatrix} B = \ begin {bmatrix} 5 & 6 \\ 7 & 8 \ end {bmatrix} \: then \: A + B = \ begin {bmatrix} 1 + 5 & 2 + 6 \\ 3 + 7 & 4 + 8 \ end {bmatrix} = \ begin {bmatrix} 6 & 8 \\ 10 & 12 \ end {bmatrix} $$
Вычитание матриц
Вычитание матриц действует аналогично сложению двух матриц. Пользователь может вычесть две матрицы, если размеры равны.
$$ Пример: A- \ begin {bmatrix} 1 & 2 \\ 3 & 4 \ end {bmatrix} B- \ begin {bmatrix} 5 & 6 \\ 7 & 8 \ end {bmatrix} \: then \: AB - \ begin {bmatrix} 1-5 и 2-6 \\ 3-7 & 4-8 \ end {bmatrix} - \ begin {bmatrix} -4 & -4 \\ - 4 & -4 \ end {bmatrix} $$
Умножение матриц
Чтобы две матрицы A m * n и B p * q были умножаемыми, n должно быть равно p. Результирующая матрица -
С м * д
$$ A = \ begin {bmatrix} 1 & 2 \\ 3 & 4 \ end {bmatrix} B = \ begin {bmatrix} 5 & 6 \\ 7 & 8 \ end {bmatrix} $$
$$ c_ {11} = \ begin {bmatrix} 1 & 2 \ end {bmatrix} \ begin {bmatrix} 5 \\ 7 \ end {bmatrix} = 1 \ times5 + 2 \ times7 = 19 \: c_ {12} = \ begin {bmatrix} 1 & 2 \ end {bmatrix} \ begin {bmatrix} 6 \\ 8 \ end {bmatrix} = 1 \ times6 + 2 \ times8 = 22 $$
$$ c_ {21} = \ begin {bmatrix} 3 & 4 \ end {bmatrix} \ begin {bmatrix} 5 \\ 7 \ end {bmatrix} = 3 \ times5 + 4 \ times7 = 43 \: c_ {22} = \ begin {bmatrix} 3 & 4 \ end {bmatrix} \ begin {bmatrix} 6 \\ 8 \ end {bmatrix} = 3 \ times6 + 4 \ times8 = 50 $$
$$ C = \ begin {bmatrix} c_ {11} & c_ {12} \\ c_ {21} & c_ {22} \ end {bmatrix} = \ begin {bmatrix} 19 & 22 \\ 43 & 50 \ end {bmatrix} $$
Транспонировать матрицу
Транспонирование матрицы A, m * n обычно представляется как AT (транспонирование) n * m и получается путем транспонирования векторов-столбцов как векторов-строк.
$$ Пример: A = \ begin {bmatrix} 1 & 2 \\ 3 & 4 \ end {bmatrix} \: then \: A ^ {T} \ begin {bmatrix} 1 & 3 \\ 2 & 4 \ end { bmatrix} $$
Точечное произведение векторов
Любой вектор размерности n можно представить в виде матрицы v = R ^ n * 1.
$$ v_ {1} = \ begin {bmatrix} v_ {11} \\ v_ {12} \\\ cdot \\\ cdot \\\ cdot \\ v_ {1n} \ end {bmatrix} v_ {2} = \ begin {bmatrix} v_ {21} \\ v_ {22} \\\ cdot \\\ cdot \\\ cdot \\ v_ {2n} \ end {bmatrix} $$
Скалярное произведение двух векторов представляет собой сумму произведения соответствующих компонентов - компонентов одного измерения и может быть выражено как
$$ v_ {1} \ cdot v_ {2} = v_1 ^ Tv_ {2} = v_2 ^ Tv_ {1} = v_ {11} v_ {21} + v_ {12} v_ {22} + \ cdot \ cdot + v_ {1n} v_ {2n} = \ displaystyle \ sum \ limits_ {k = 1} ^ n v_ {1k} v_ {2k} $$
Пример скалярного произведения векторов упомянут ниже -
$$ Пример: v_ {1} = \ begin {bmatrix} 1 \\ 2 \\ 3 \ end {bmatrix} v_ {2} = \ begin {bmatrix} 3 \\ 5 \\ - 1 \ end {bmatrix} v_ {1} \ cdot v_ {2} = v_1 ^ Tv_ {2} = 1 \ times3 + 2 \ times5-3 \ times1 = 10 $$
Искусственный интеллект - одна из самых популярных тенденций последнего времени. Машинное обучение и глубокое обучение составляют искусственный интеллект. Диаграмма Венна, показанная ниже, объясняет взаимосвязь машинного обучения и глубокого обучения.
Машинное обучение
Машинное обучение - это научное искусство заставить компьютеры работать в соответствии с разработанными и запрограммированными алгоритмами. Многие исследователи считают, что машинное обучение - лучший способ продвинуться в направлении ИИ человеческого уровня. Машинное обучение включает в себя следующие типы шаблонов
- Схема обучения с учителем
- Модель обучения без учителя
Глубокое обучение
Глубокое обучение - это подраздел машинного обучения, в котором соответствующие алгоритмы основаны на структуре и функциях мозга, называемых искусственными нейронными сетями.
Сегодня вся ценность глубокого обучения заключается в контролируемом обучении или обучении на основе размеченных данных и алгоритмов.
Каждый алгоритм глубокого обучения проходит один и тот же процесс. Он включает в себя иерархию нелинейного преобразования входных данных, которую можно использовать для создания статистической модели в качестве выходных данных.
Рассмотрим следующие шаги, которые определяют процесс машинного обучения.
- Определяет соответствующие наборы данных и подготавливает их для анализа.
- Выбирает тип используемого алгоритма
- Строит аналитическую модель на основе используемого алгоритма.
- Обучает модель на тестовых наборах данных, корректируя ее по мере необходимости.
- Запускает модель для получения результатов тестирования.
Разница между машинным обучением и глубоким обучением
В этом разделе мы узнаем о разнице между машинным обучением и глубоким обучением.
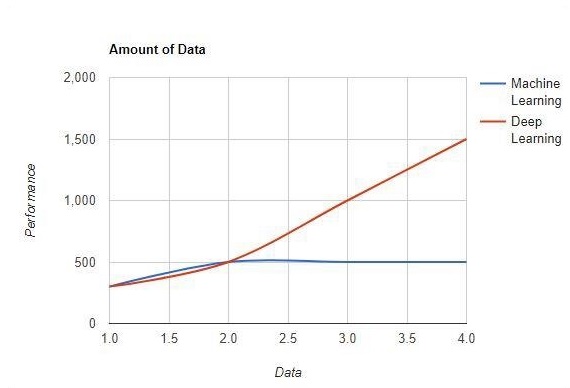
Количество данных
Машинное обучение работает с большими объемами данных. Это также полезно для небольших объемов данных. С другой стороны, глубокое обучение работает эффективно, если объем данных быстро увеличивается. На следующей диаграмме показана работа машинного обучения и глубокого обучения с объемом данных -
Аппаратные зависимости
Алгоритмы глубокого обучения сильно зависят от высокопроизводительных машин, в отличие от традиционных алгоритмов машинного обучения. Алгоритмы глубокого обучения выполняют ряд операций умножения матриц, которые требуют большого количества аппаратной поддержки.
Разработка функций
Разработка функций - это процесс включения знаний предметной области в указанные функции для уменьшения сложности данных и создания шаблонов, видимых для алгоритмов обучения, которые работают.
Пример. Традиционные шаблоны машинного обучения фокусируются на пикселях и других атрибутах, необходимых для процесса разработки функций. Алгоритмы глубокого обучения сосредоточены на высокоуровневых функциях данных. Это уменьшает задачу разработки нового средства экстракции каждой новой проблемы.
Подход к решению проблем
Традиционные алгоритмы машинного обучения следуют стандартной процедуре решения проблемы. Он разбивает задачу на части, решает каждую из них и объединяет их, чтобы получить требуемый результат. Глубокое обучение направлено на решение проблемы от начала до конца, а не на разбиение на части.
Время исполнения
Время выполнения - это время, необходимое для обучения алгоритма. Глубокое обучение требует много времени на обучение, поскольку оно включает в себя множество параметров, что занимает больше времени, чем обычно. Алгоритм машинного обучения сравнительно требует меньше времени на выполнение.
Интерпретируемость
Интерпретируемость - главный фактор для сравнения алгоритмов машинного обучения и глубокого обучения. Основная причина в том, что глубокому обучению все еще уделяется особое внимание перед его использованием в промышленности.
Приложения машинного обучения и глубокого обучения
В этом разделе мы узнаем о различных приложениях машинного обучения и глубокого обучения.
Компьютерное зрение, которое используется для распознавания лиц и отметок о посещаемости по отпечаткам пальцев или идентификации транспортных средств по номерным знакам.
Получение информации из поисковых систем, например текстовый поиск для поиска изображений.
Автоматический электронный маркетинг с указанием целевой идентификации.
Медицинская диагностика раковых опухолей или выявление аномалий любого хронического заболевания.
Обработка естественного языка для таких приложений, как добавление тегов к фотографиям. Лучший пример для объяснения этого сценария используется в Facebook.
Он-лайн реклама.
Будущие тенденции
В связи с растущей тенденцией использования науки о данных и машинного обучения в отрасли для каждой организации станет важным внедрять машинное обучение в свой бизнес.
Глубокое обучение приобретает большее значение, чем машинное обучение. Глубокое обучение оказалось одним из лучших методов современного перформанса.
Машинное обучение и глубокое обучение окажутся полезными в исследовательской и академической сфере.
Заключение
В этой статье у нас был обзор машинного обучения и глубокого обучения с иллюстрациями и различиями, также акцентирующими внимание на будущих тенденциях. Многие приложения ИИ используют алгоритмы машинного обучения в первую очередь для самообслуживания, повышения производительности агентов и повышения надежности рабочих процессов. Алгоритмы машинного обучения и глубокого обучения открывают захватывающие перспективы для многих компаний и лидеров отрасли.
В этой главе мы узнаем об основах TensorFlow. Мы начнем с понимания структуры данных тензора.
Тензорная структура данных
Тензоры используются в качестве базовых структур данных на языке TensorFlow. Тензоры представляют соединяющиеся ребра на любой блок-схеме, называемой графом потока данных. Тензоры определяются как многомерный массив или список.
Тензоры идентифицируются следующими тремя параметрами -
Ранг
Единица размерности, описываемая тензором, называется рангом. Он определяет количество измерений тензора. Ранг тензора можно описать как порядок или n-мерность определенного тензора.
Форма
Количество строк и столбцов вместе определяют форму Tensor.
Тип
Тип описывает тип данных, присвоенный элементам Tensor.
Пользователь должен рассмотреть следующие действия для создания тензора:
- Создайте n-мерный массив
- Преобразуйте n-мерный массив.
Различные измерения TensorFlow
TensorFlow включает в себя различные измерения. Размеры кратко описаны ниже -
Одномерный тензор
Одномерный тензор - это обычная структура массива, которая включает один набор значений одного и того же типа данных.
Declaration
>>> import numpy as np
>>> tensor_1d = np.array([1.3, 1, 4.0, 23.99])
>>> print tensor_1dРеализация с выводом показана на скриншоте ниже -
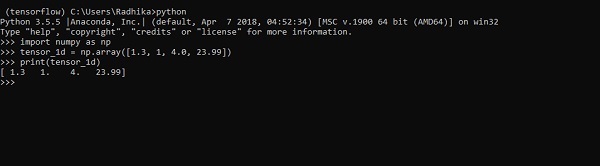
Индексация элементов такая же, как в списках Python. Первый элемент начинается с индекса 0; чтобы распечатать значения через индекс, все, что вам нужно сделать, это указать номер индекса.
>>> print tensor_1d[0]
1.3
>>> print tensor_1d[2]
4.0
Двумерные тензоры
Последовательность массивов используется для создания «двумерных тензоров».
Создание двумерных тензоров описано ниже -

Ниже приведен полный синтаксис для создания двумерных массивов.
>>> import numpy as np
>>> tensor_2d = np.array([(1,2,3,4),(4,5,6,7),(8,9,10,11),(12,13,14,15)])
>>> print(tensor_2d)
[[ 1 2 3 4]
[ 4 5 6 7]
[ 8 9 10 11]
[12 13 14 15]]
>>>Конкретные элементы двумерных тензоров можно отслеживать с помощью номера строки и номера столбца, заданных как номера индексов.
>>> tensor_2d[3][2]
14
Обработка и манипуляции с тензорами
В этом разделе мы узнаем об обработке и манипуляциях с тензорными элементами.
Для начала давайте рассмотрим следующий код -
import tensorflow as tf
import numpy as np
matrix1 = np.array([(2,2,2),(2,2,2),(2,2,2)],dtype = 'int32')
matrix2 = np.array([(1,1,1),(1,1,1),(1,1,1)],dtype = 'int32')
print (matrix1)
print (matrix2)
matrix1 = tf.constant(matrix1)
matrix2 = tf.constant(matrix2)
matrix_product = tf.matmul(matrix1, matrix2)
matrix_sum = tf.add(matrix1,matrix2)
matrix_3 = np.array([(2,7,2),(1,4,2),(9,0,2)],dtype = 'float32')
print (matrix_3)
matrix_det = tf.matrix_determinant(matrix_3)
with tf.Session() as sess:
result1 = sess.run(matrix_product)
result2 = sess.run(matrix_sum)
result3 = sess.run(matrix_det)
print (result1)
print (result2)
print (result3)Output
Приведенный выше код сгенерирует следующий вывод -
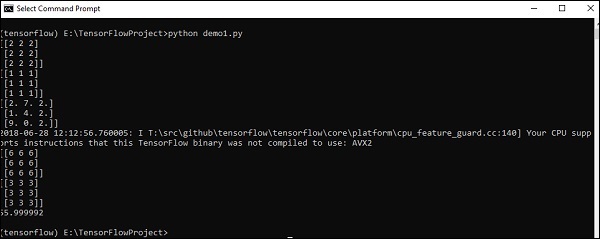
Объяснение
В приведенном выше исходном коде мы создали многомерные массивы. Теперь важно понимать, что мы создали граф и сеансы, которые управляют тензорами и генерируют соответствующий вывод. С помощью графика у нас есть вывод, определяющий математические вычисления между тензорами.
Поняв концепции машинного обучения, теперь мы можем переключить наше внимание на концепции глубокого обучения. Глубокое обучение - это раздел машинного обучения, который считается важным шагом, предпринятым исследователями в последние десятилетия. Примеры реализации глубокого обучения включают такие приложения, как распознавание изображений и распознавание речи.
Ниже приведены два важных типа глубоких нейронных сетей.
- Сверточные нейронные сети
- Рекуррентные нейронные сети
В этой главе мы сосредоточимся на CNN, сверточных нейронных сетях.
Сверточные нейронные сети
Сверточные нейронные сети предназначены для обработки данных через несколько уровней массивов. Этот тип нейронных сетей используется в таких приложениях, как распознавание изображений или лиц. Основное различие между CNN и любой другой обычной нейронной сетью состоит в том, что CNN принимает входные данные как двумерный массив и работает непосредственно с изображениями, а не фокусируется на извлечении признаков, на котором сосредоточены другие нейронные сети.
Доминирующий подход CNN включает в себя решения проблем распознавания. Ведущие компании, такие как Google и Facebook, вложили средства в исследования и разработки, направленные на реализацию проектов признания, чтобы выполнять действия с большей скоростью.
Сверточная нейронная сеть использует три основных идеи:
- Местные соответствующие поля
- Convolution
- Pooling
Давайте разберемся с этими идеями подробно.
CNN использует пространственные корреляции, существующие во входных данных. Каждый параллельный слой нейронной сети соединяет несколько входных нейронов. Эта специфическая область называется локальным рецептивным полем. Локальное рецептивное поле сосредоточено на скрытых нейронах. Скрытые нейроны обрабатывают входные данные внутри указанного поля, не осознавая изменений за пределами определенной границы.
Ниже представлена диаграмма создания локальных соответствующих полей.
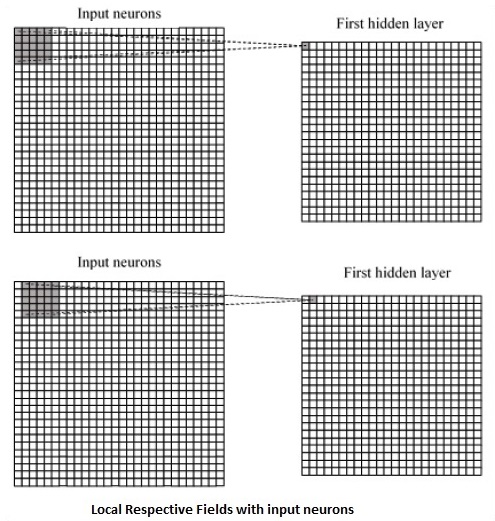
Если мы рассмотрим приведенное выше представление, каждое соединение узнает вес скрытого нейрона с соответствующей связью с перемещением из одного слоя в другой. Здесь отдельные нейроны время от времени совершают сдвиг. Этот процесс называется «сверткой».
Сопоставление соединений от входного слоя к карте скрытых объектов определяется как «общие веса», а включенное смещение называется «общим смещением».
CNN или сверточные нейронные сети используют уровни объединения, которые представляют собой слои, расположенные сразу после объявления CNN. Он принимает вводимые пользователем данные в виде карты функций, которая поступает из сверточных сетей, и подготавливает сжатую карту функций. Объединение слоев помогает создавать слои с нейронами предыдущих слоев.
Реализация CNN в TensorFlow
В этом разделе мы узнаем о реализации CNN TensorFlow. Шаги, которые требуют выполнения и правильного измерения всей сети, показаны ниже:
Step 1 - Включите необходимые модули для TensorFlow и модули набора данных, которые необходимы для вычисления модели CNN.
import tensorflow as tf
import numpy as np
from tensorflow.examples.tutorials.mnist import input_dataStep 2 - Объявить функцию с именем run_cnn(), который включает различные параметры и переменные оптимизации с объявлением заполнителей данных. Эти переменные оптимизации объявят шаблон обучения.
def run_cnn():
mnist = input_data.read_data_sets("MNIST_data/", one_hot = True)
learning_rate = 0.0001
epochs = 10
batch_size = 50Step 3 - На этом этапе мы объявим заполнители данных обучения с входными параметрами - для 28 x 28 пикселей = 784. Это данные сглаженного изображения, которые извлекаются из mnist.train.nextbatch().
Мы можем изменить тензор в соответствии с нашими требованиями. Первое значение (-1) указывает функции динамически формировать это измерение в зависимости от количества переданных в нее данных. Два средних размера соответствуют размеру изображения (например, 28 x 28).
x = tf.placeholder(tf.float32, [None, 784])
x_shaped = tf.reshape(x, [-1, 28, 28, 1])
y = tf.placeholder(tf.float32, [None, 10])Step 4 - Теперь важно создать несколько сверточных слоев -
layer1 = create_new_conv_layer(x_shaped, 1, 32, [5, 5], [2, 2], name = 'layer1')
layer2 = create_new_conv_layer(layer1, 32, 64, [5, 5], [2, 2], name = 'layer2')Step 5- Давайте сгладим выход, готовый для полностью подключенного выходного каскада - после двух слоев объединения шага 2 с размерами 28 x 28 до размера 14 x 14 или минимум 7 x 7 x, координаты y, но с 64 выходные каналы. Чтобы создать полностью связанный с «плотным» слоем, новая форма должна быть [-1, 7 x 7 x 64]. Мы можем установить некоторые значения веса и смещения для этого слоя, а затем активировать их с помощью ReLU.
flattened = tf.reshape(layer2, [-1, 7 * 7 * 64])
wd1 = tf.Variable(tf.truncated_normal([7 * 7 * 64, 1000], stddev = 0.03), name = 'wd1')
bd1 = tf.Variable(tf.truncated_normal([1000], stddev = 0.01), name = 'bd1')
dense_layer1 = tf.matmul(flattened, wd1) + bd1
dense_layer1 = tf.nn.relu(dense_layer1)Step 6 - Другой слой с конкретными активациями softmax с требуемым оптимизатором определяет оценку точности, которая производит настройку оператора инициализации.
wd2 = tf.Variable(tf.truncated_normal([1000, 10], stddev = 0.03), name = 'wd2')
bd2 = tf.Variable(tf.truncated_normal([10], stddev = 0.01), name = 'bd2')
dense_layer2 = tf.matmul(dense_layer1, wd2) + bd2
y_ = tf.nn.softmax(dense_layer2)
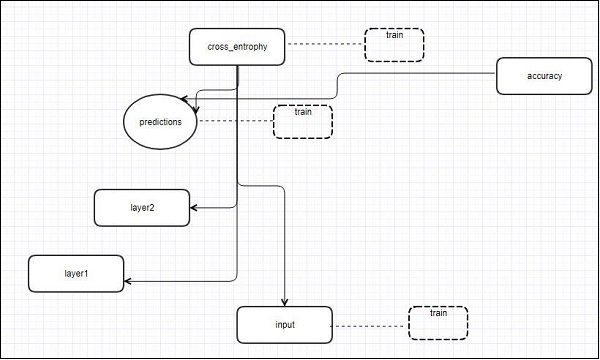
cross_entropy = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(logits = dense_layer2, labels = y))
optimiser = tf.train.AdamOptimizer(learning_rate = learning_rate).minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
init_op = tf.global_variables_initializer()Step 7- Мы должны настроить записи переменных. Это добавляет сводку для сохранения точности данных.
tf.summary.scalar('accuracy', accuracy)
merged = tf.summary.merge_all()
writer = tf.summary.FileWriter('E:\TensorFlowProject')
with tf.Session() as sess:
sess.run(init_op)
total_batch = int(len(mnist.train.labels) / batch_size)
for epoch in range(epochs):
avg_cost = 0
for i in range(total_batch):
batch_x, batch_y = mnist.train.next_batch(batch_size = batch_size)
_, c = sess.run([optimiser, cross_entropy], feed_dict = {
x:batch_x, y: batch_y})
avg_cost += c / total_batch
test_acc = sess.run(accuracy, feed_dict = {x: mnist.test.images, y:
mnist.test.labels})
summary = sess.run(merged, feed_dict = {x: mnist.test.images, y:
mnist.test.labels})
writer.add_summary(summary, epoch)
print("\nTraining complete!")
writer.add_graph(sess.graph)
print(sess.run(accuracy, feed_dict = {x: mnist.test.images, y:
mnist.test.labels}))
def create_new_conv_layer(
input_data, num_input_channels, num_filters,filter_shape, pool_shape, name):
conv_filt_shape = [
filter_shape[0], filter_shape[1], num_input_channels, num_filters]
weights = tf.Variable(
tf.truncated_normal(conv_filt_shape, stddev = 0.03), name = name+'_W')
bias = tf.Variable(tf.truncated_normal([num_filters]), name = name+'_b')
#Out layer defines the output
out_layer =
tf.nn.conv2d(input_data, weights, [1, 1, 1, 1], padding = 'SAME')
out_layer += bias
out_layer = tf.nn.relu(out_layer)
ksize = [1, pool_shape[0], pool_shape[1], 1]
strides = [1, 2, 2, 1]
out_layer = tf.nn.max_pool(
out_layer, ksize = ksize, strides = strides, padding = 'SAME')
return out_layer
if __name__ == "__main__":
run_cnn()Ниже приведен вывод, сгенерированный приведенным выше кодом -
See @{tf.nn.softmax_cross_entropy_with_logits_v2}.
2018-09-19 17:22:58.802268: I
T:\src\github\tensorflow\tensorflow\core\platform\cpu_feature_guard.cc:140]
Your CPU supports instructions that this TensorFlow binary was not compiled to
use: AVX2
2018-09-19 17:25:41.522845: W
T:\src\github\tensorflow\tensorflow\core\framework\allocator.cc:101] Allocation
of 1003520000 exceeds 10% of system memory.
2018-09-19 17:25:44.630941: W
T:\src\github\tensorflow\tensorflow\core\framework\allocator.cc:101] Allocation
of 501760000 exceeds 10% of system memory.
Epoch: 1 cost = 0.676 test accuracy: 0.940
2018-09-19 17:26:51.987554: W
T:\src\github\tensorflow\tensorflow\core\framework\allocator.cc:101] Allocation
of 1003520000 exceeds 10% of system memory.Рекуррентные нейронные сети - это тип алгоритма, ориентированного на глубокое обучение, который следует последовательному подходу. В нейронных сетях мы всегда предполагаем, что каждый вход и выход независим от всех других слоев. Нейронные сети этого типа называются рекуррентными, потому что они выполняют математические вычисления последовательно.
Рассмотрим следующие шаги для обучения повторяющейся нейронной сети:
Step 1 - Введите конкретный пример из набора данных.
Step 2 - Сеть возьмет пример и выполнит некоторые вычисления с использованием случайно инициализированных переменных.
Step 3 - Затем вычисляется прогнозируемый результат.
Step 4 - Сравнение фактического результата с ожидаемым значением приведет к ошибке.
Step 5 - Чтобы отследить ошибку, она распространяется по тому же пути, где также регулируются переменные.
Step 6 - Шаги с 1 по 5 повторяются до тех пор, пока мы не будем уверены, что переменные, объявленные для получения выходных данных, определены правильно.
Step 7 - Систематический прогноз выполняется путем применения этих переменных для получения новых невидимых входных данных.
Схематический подход к представлению рекуррентных нейронных сетей описан ниже -
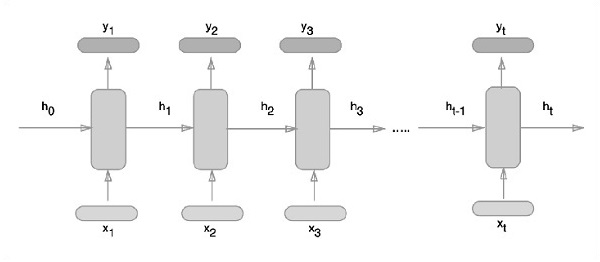
Реализация рекуррентной нейронной сети с TensorFlow
В этом разделе мы узнаем, как реализовать рекуррентную нейронную сеть с TensorFlow.
Step 1 - TensorFlow включает в себя различные библиотеки для конкретной реализации модуля рекуррентной нейронной сети.
#Import necessary modules
from __future__ import print_function
import tensorflow as tf
from tensorflow.contrib import rnn
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("/tmp/data/", one_hot = True)Как упоминалось выше, библиотеки помогают в определении входных данных, которые составляют основную часть реализации рекуррентной нейронной сети.
Step 2- Наш основной мотив - классифицировать изображения с помощью рекуррентной нейронной сети, где мы рассматриваем каждую строку изображения как последовательность пикселей. Форма изображения MNIST определена как 28 * 28 пикселей. Теперь мы обработаем 28 последовательностей по 28 шагов для каждого упомянутого сэмпла. Мы определим входные параметры для выполнения последовательного шаблона.
n_input = 28 # MNIST data input with img shape 28*28
n_steps = 28
n_hidden = 128
n_classes = 10
# tf Graph input
x = tf.placeholder("float", [None, n_steps, n_input])
y = tf.placeholder("float", [None, n_classes]
weights = {
'out': tf.Variable(tf.random_normal([n_hidden, n_classes]))
}
biases = {
'out': tf.Variable(tf.random_normal([n_classes]))
}Step 3- Вычисляйте результаты, используя определенную функцию в RNN, чтобы получить наилучшие результаты. Здесь каждая форма данных сравнивается с текущей формой ввода, и результаты вычисляются для поддержания уровня точности.
def RNN(x, weights, biases):
x = tf.unstack(x, n_steps, 1)
# Define a lstm cell with tensorflow
lstm_cell = rnn.BasicLSTMCell(n_hidden, forget_bias=1.0)
# Get lstm cell output
outputs, states = rnn.static_rnn(lstm_cell, x, dtype = tf.float32)
# Linear activation, using rnn inner loop last output
return tf.matmul(outputs[-1], weights['out']) + biases['out']
pred = RNN(x, weights, biases)
# Define loss and optimizer
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits = pred, labels = y))
optimizer = tf.train.AdamOptimizer(learning_rate = learning_rate).minimize(cost)
# Evaluate model
correct_pred = tf.equal(tf.argmax(pred,1), tf.argmax(y,1))
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
# Initializing the variables
init = tf.global_variables_initializer()Step 4- На этом этапе мы запустим график для получения результатов вычислений. Это также помогает при расчете точности результатов испытаний.
with tf.Session() as sess:
sess.run(init)
step = 1
# Keep training until reach max iterations
while step * batch_size < training_iters:
batch_x, batch_y = mnist.train.next_batch(batch_size)
batch_x = batch_x.reshape((batch_size, n_steps, n_input))
sess.run(optimizer, feed_dict={x: batch_x, y: batch_y})
if step % display_step == 0:
# Calculate batch accuracy
acc = sess.run(accuracy, feed_dict={x: batch_x, y: batch_y})
# Calculate batch loss
loss = sess.run(cost, feed_dict={x: batch_x, y: batch_y})
print("Iter " + str(step*batch_size) + ", Minibatch Loss= " + \
"{:.6f}".format(loss) + ", Training Accuracy= " + \
"{:.5f}".format(acc))
step += 1
print("Optimization Finished!")
test_len = 128
test_data = mnist.test.images[:test_len].reshape((-1, n_steps, n_input))
test_label = mnist.test.labels[:test_len]
print("Testing Accuracy:", \
sess.run(accuracy, feed_dict={x: test_data, y: test_label}))На скриншотах ниже показан сгенерированный результат -
TensorFlow включает инструмент визуализации, который называется TensorBoard. Он используется для анализа графа потока данных, а также для понимания моделей машинного обучения. Важной особенностью TensorBoard является просмотр различных типов статистики о параметрах и деталях любого графика в вертикальном выравнивании.
Глубокая нейронная сеть включает до 36 000 узлов. TensorBoard помогает сворачивать эти узлы в блоки высокого уровня и выделять идентичные структуры. Это позволяет лучше анализировать граф, сосредотачиваясь на основных разделах графа вычислений. Визуализация TensorBoard считается очень интерактивной, когда пользователь может панорамировать, масштабировать и расширять узлы для отображения деталей.
На следующей схематической диаграмме показана полная работа визуализации TensorBoard -
Алгоритмы сворачивают узлы в блоки высокого уровня и выделяют определенные группы с идентичными структурами, которые разделяют узлы высокого уровня. Созданная таким образом доска TensorBoard полезна и не менее важна для настройки модели машинного обучения. Этот инструмент визуализации предназначен для файла журнала конфигурации со сводной информацией и подробностями, которые необходимо отобразить.
Давайте сосредоточимся на демонстрационном примере визуализации TensorBoard с помощью следующего кода -
import tensorflow as tf
# Constants creation for TensorBoard visualization
a = tf.constant(10,name = "a")
b = tf.constant(90,name = "b")
y = tf.Variable(a+b*2,name = 'y')
model = tf.initialize_all_variables() #Creation of model
with tf.Session() as session:
merged = tf.merge_all_summaries()
writer = tf.train.SummaryWriter("/tmp/tensorflowlogs",session.graph)
session.run(model)
print(session.run(y))В следующей таблице показаны различные символы визуализации TensorBoard, используемые для представления узла.

Встраивание слов - это концепция отображения дискретных объектов, таких как слова, на векторы и действительные числа. Это важно для ввода в машинное обучение. Концепция включает стандартные функции, которые эффективно преобразуют дискретные входные объекты в полезные векторы.
Примерная иллюстрация ввода встраивания слов показана ниже -
blue: (0.01359, 0.00075997, 0.24608, ..., -0.2524, 1.0048, 0.06259)
blues: (0.01396, 0.11887, -0.48963, ..., 0.033483, -0.10007, 0.1158)
orange: (-0.24776, -0.12359, 0.20986, ..., 0.079717, 0.23865, -0.014213)
oranges: (-0.35609, 0.21854, 0.080944, ..., -0.35413, 0.38511, -0.070976)Word2vec
Word2vec - наиболее распространенный подход, используемый для неконтролируемого встраивания слов. Он обучает модель таким образом, что данное входное слово предсказывает контекст слова с помощью скип-граммов.
TensorFlow позволяет реализовать множество способов реализации такого типа модели с повышением уровня сложности и оптимизации, а также с использованием концепций многопоточности и абстракций более высокого уровня.
import os
import math
import numpy as np
import tensorflow as tf
from tensorflow.contrib.tensorboard.plugins import projector
batch_size = 64
embedding_dimension = 5
negative_samples = 8
LOG_DIR = "logs/word2vec_intro"
digit_to_word_map = {
1: "One",
2: "Two",
3: "Three",
4: "Four",
5: "Five",
6: "Six",
7: "Seven",
8: "Eight",
9: "Nine"}
sentences = []
# Create two kinds of sentences - sequences of odd and even digits.
for i in range(10000):
rand_odd_ints = np.random.choice(range(1, 10, 2), 3)
sentences.append(" ".join([digit_to_word_map[r] for r in rand_odd_ints]))
rand_even_ints = np.random.choice(range(2, 10, 2), 3)
sentences.append(" ".join([digit_to_word_map[r] for r in rand_even_ints]))
# Map words to indices
word2index_map = {}
index = 0
for sent in sentences:
for word in sent.lower().split():
if word not in word2index_map:
word2index_map[word] = index
index += 1
index2word_map = {index: word for word, index in word2index_map.items()}
vocabulary_size = len(index2word_map)
# Generate skip-gram pairs
skip_gram_pairs = []
for sent in sentences:
tokenized_sent = sent.lower().split()
for i in range(1, len(tokenized_sent)-1):
word_context_pair = [[word2index_map[tokenized_sent[i-1]],
word2index_map[tokenized_sent[i+1]]], word2index_map[tokenized_sent[i]]]
skip_gram_pairs.append([word_context_pair[1], word_context_pair[0][0]])
skip_gram_pairs.append([word_context_pair[1], word_context_pair[0][1]])
def get_skipgram_batch(batch_size):
instance_indices = list(range(len(skip_gram_pairs)))
np.random.shuffle(instance_indices)
batch = instance_indices[:batch_size]
x = [skip_gram_pairs[i][0] for i in batch]
y = [[skip_gram_pairs[i][1]] for i in batch]
return x, y
# batch example
x_batch, y_batch = get_skipgram_batch(8)
x_batch
y_batch
[index2word_map[word] for word in x_batch] [index2word_map[word[0]] for word in y_batch]
# Input data, labels train_inputs = tf.placeholder(tf.int32, shape = [batch_size])
train_labels = tf.placeholder(tf.int32, shape = [batch_size, 1])
# Embedding lookup table currently only implemented in CPU with
tf.name_scope("embeddings"):
embeddings = tf.Variable(
tf.random_uniform([vocabulary_size, embedding_dimension], -1.0, 1.0),
name = 'embedding')
# This is essentialy a lookup table
embed = tf.nn.embedding_lookup(embeddings, train_inputs)
# Create variables for the NCE loss
nce_weights = tf.Variable(
tf.truncated_normal([vocabulary_size, embedding_dimension], stddev = 1.0 /
math.sqrt(embedding_dimension)))
nce_biases = tf.Variable(tf.zeros([vocabulary_size]))
loss = tf.reduce_mean(
tf.nn.nce_loss(weights = nce_weights, biases = nce_biases, inputs = embed,
labels = train_labels,num_sampled = negative_samples,
num_classes = vocabulary_size)) tf.summary.scalar("NCE_loss", loss)
# Learning rate decay
global_step = tf.Variable(0, trainable = False)
learningRate = tf.train.exponential_decay(learning_rate = 0.1,
global_step = global_step, decay_steps = 1000, decay_rate = 0.95, staircase = True)
train_step = tf.train.GradientDescentOptimizer(learningRate).minimize(loss)
merged = tf.summary.merge_all()
with tf.Session() as sess:
train_writer = tf.summary.FileWriter(LOG_DIR,
graph = tf.get_default_graph())
saver = tf.train.Saver()
with open(os.path.join(LOG_DIR, 'metadata.tsv'), "w") as metadata:
metadata.write('Name\tClass\n') for k, v in index2word_map.items():
metadata.write('%s\t%d\n' % (v, k))
config = projector.ProjectorConfig()
embedding = config.embeddings.add() embedding.tensor_name = embeddings.name
# Link this tensor to its metadata file (e.g. labels).
embedding.metadata_path = os.path.join(LOG_DIR, 'metadata.tsv')
projector.visualize_embeddings(train_writer, config)
tf.global_variables_initializer().run()
for step in range(1000):
x_batch, y_batch = get_skipgram_batch(batch_size) summary, _ = sess.run(
[merged, train_step], feed_dict = {train_inputs: x_batch, train_labels: y_batch})
train_writer.add_summary(summary, step)
if step % 100 == 0:
saver.save(sess, os.path.join(LOG_DIR, "w2v_model.ckpt"), step)
loss_value = sess.run(loss, feed_dict = {
train_inputs: x_batch, train_labels: y_batch})
print("Loss at %d: %.5f" % (step, loss_value))
# Normalize embeddings before using
norm = tf.sqrt(tf.reduce_sum(tf.square(embeddings), 1, keep_dims = True))
normalized_embeddings = embeddings /
norm normalized_embeddings_matrix = sess.run(normalized_embeddings)
ref_word = normalized_embeddings_matrix[word2index_map["one"]]
cosine_dists = np.dot(normalized_embeddings_matrix, ref_word)
ff = np.argsort(cosine_dists)[::-1][1:10] for f in ff: print(index2word_map[f])
print(cosine_dists[f])Вывод
Приведенный выше код генерирует следующий вывод -
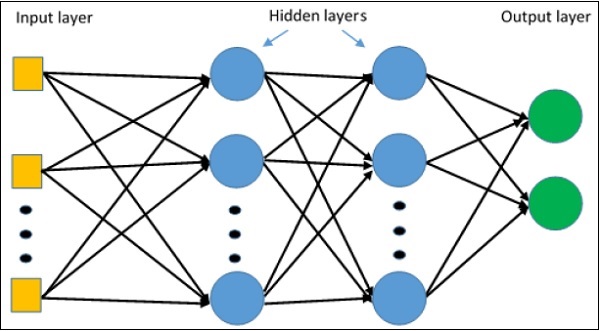
Для понимания однослойного персептрона важно понимать искусственные нейронные сети (ИНС). Искусственные нейронные сети - это система обработки информации, механизм которой основан на функциональности биологических нейронных цепей. Искусственная нейронная сеть имеет множество связанных друг с другом процессоров. Ниже приведено схематическое изображение искусственной нейронной сети -
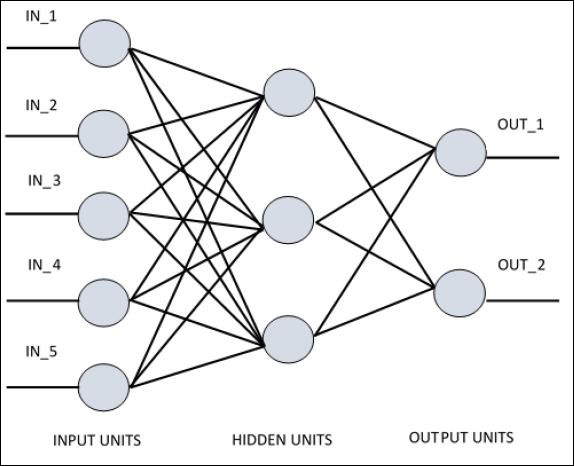
На схеме показано, что скрытые блоки взаимодействуют с внешним слоем. Пока блоки ввода и вывода общаются только через скрытый слой сети.
Схема связи с узлами, общее количество слоев и уровень узлов между входами и выходами с количеством нейронов на слой определяют архитектуру нейронной сети.
Есть два типа архитектуры. Эти типы ориентированы на функциональные возможности искусственных нейронных сетей следующим образом:
- Однослойный персептрон
- Многослойный персептрон
Однослойный персептрон
Однослойный персептрон - первая предложенная нейронная модель. Содержимое локальной памяти нейрона состоит из вектора весов. Вычисление однослойного персептрона выполняется путем вычисления суммы входного вектора, каждый из которых имеет значение, умноженное на соответствующий элемент вектора весов. Значение, которое отображается на выходе, будет входом для функции активации.

Давайте сосредоточимся на реализации однослойного персептрона для задачи классификации изображений с использованием TensorFlow. Лучший пример для иллюстрации однослойного персептрона - это представление «логистической регрессии».
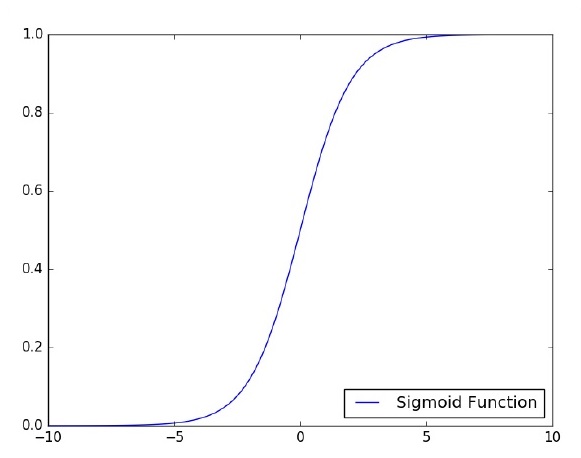
Теперь давайте рассмотрим следующие основные шаги обучения логистической регрессии:
Веса инициализируются случайными значениями в начале обучения.
Для каждого элемента обучающего набора ошибка вычисляется как разница между желаемым и фактическим выходными данными. Вычисленная ошибка используется для корректировки весов.
Процесс повторяется до тех пор, пока ошибка, допущенная для всего обучающего набора, не станет меньше заданного порога, пока не будет достигнуто максимальное количество итераций.
Полный код для оценки логистической регрессии упомянут ниже -
# Import MINST data
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("/tmp/data/", one_hot = True)
import tensorflow as tf
import matplotlib.pyplot as plt
# Parameters
learning_rate = 0.01
training_epochs = 25
batch_size = 100
display_step = 1
# tf Graph Input
x = tf.placeholder("float", [None, 784]) # mnist data image of shape 28*28 = 784
y = tf.placeholder("float", [None, 10]) # 0-9 digits recognition => 10 classes
# Create model
# Set model weights
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))
# Construct model
activation = tf.nn.softmax(tf.matmul(x, W) + b) # Softmax
# Minimize error using cross entropy
cross_entropy = y*tf.log(activation)
cost = tf.reduce_mean\ (-tf.reduce_sum\ (cross_entropy,reduction_indices = 1))
optimizer = tf.train.\ GradientDescentOptimizer(learning_rate).minimize(cost)
#Plot settings
avg_set = []
epoch_set = []
# Initializing the variables init = tf.initialize_all_variables()
# Launch the graph
with tf.Session() as sess:
sess.run(init)
# Training cycle
for epoch in range(training_epochs):
avg_cost = 0.
total_batch = int(mnist.train.num_examples/batch_size)
# Loop over all batches
for i in range(total_batch):
batch_xs, batch_ys = \ mnist.train.next_batch(batch_size)
# Fit training using batch data sess.run(optimizer, \ feed_dict = {
x: batch_xs, y: batch_ys})
# Compute average loss avg_cost += sess.run(cost, \ feed_dict = {
x: batch_xs, \ y: batch_ys})/total_batch
# Display logs per epoch step
if epoch % display_step == 0:
print ("Epoch:", '%04d' % (epoch+1), "cost=", "{:.9f}".format(avg_cost))
avg_set.append(avg_cost) epoch_set.append(epoch+1)
print ("Training phase finished")
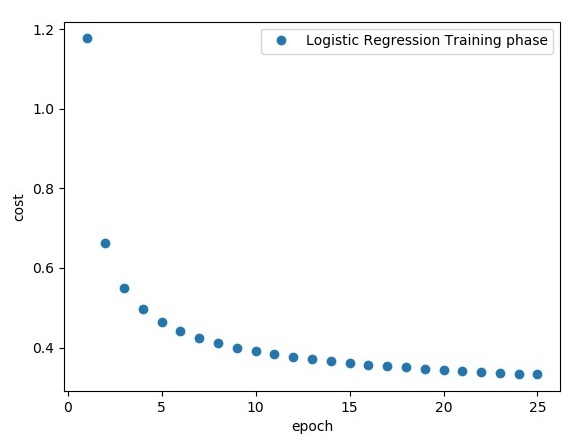
plt.plot(epoch_set,avg_set, 'o', label = 'Logistic Regression Training phase')
plt.ylabel('cost')
plt.xlabel('epoch')
plt.legend()
plt.show()
# Test model
correct_prediction = tf.equal(tf.argmax(activation, 1), tf.argmax(y, 1))
# Calculate accuracy
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float")) print
("Model accuracy:", accuracy.eval({x: mnist.test.images, y: mnist.test.labels}))Вывод
Приведенный выше код генерирует следующий вывод -
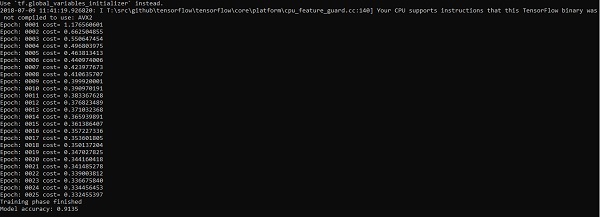
Логистическая регрессия рассматривается как прогнозный анализ. Логистическая регрессия используется для описания данных и объяснения взаимосвязи между одной зависимой двоичной переменной и одной или несколькими номинальными или независимыми переменными.
В этой главе мы сосредоточимся на базовом примере реализации линейной регрессии с использованием TensorFlow. Логистическая регрессия или линейная регрессия - это контролируемый подход машинного обучения для классификации дискретных категорий порядка. Наша цель в этой главе - построить модель, с помощью которой пользователь может предсказать взаимосвязь между переменными-предикторами и одной или несколькими независимыми переменными.
Связь между этими двумя переменными считается линейной. Если y является зависимой переменной, а x рассматривается как независимая переменная, то отношение линейной регрессии двух переменных будет выглядеть следующим образом:
Y = Ax+bМы разработаем алгоритм линейной регрессии. Это позволит нам понять следующие две важные концепции -
- Функция стоимости
- Алгоритмы градиентного спуска
Схематическое изображение линейной регрессии упомянуто ниже -

Графический вид уравнения линейной регрессии упомянут ниже -
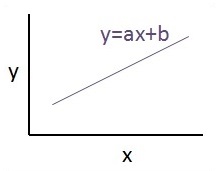
Шаги по разработке алгоритма линейной регрессии
Теперь мы узнаем о шагах, которые помогают в разработке алгоритма линейной регрессии.
Шаг 1
Важно импортировать необходимые модули для построения модуля линейной регрессии. Начинаем импортировать библиотеки Python NumPy и Matplotlib.
import numpy as np
import matplotlib.pyplot as pltШаг 2
Определите количество коэффициентов, необходимых для логистической регрессии.
number_of_points = 500
x_point = []
y_point = []
a = 0.22
b = 0.78Шаг 3
Итерируйте переменные для генерации 300 случайных точек по уравнению регрессии -
Y = 0,22x + 0,78
for i in range(number_of_points):
x = np.random.normal(0.0,0.5)
y = a*x + b +np.random.normal(0.0,0.1) x_point.append([x])
y_point.append([y])Шаг 4
Просмотрите сгенерированные точки с помощью Matplotlib.
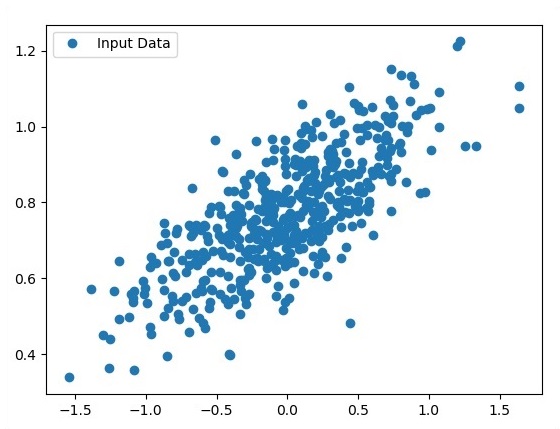
fplt.plot(x_point,y_point, 'o', label = 'Input Data') plt.legend() plt.show()Полный код для логистической регрессии выглядит следующим образом:
import numpy as np
import matplotlib.pyplot as plt
number_of_points = 500
x_point = []
y_point = []
a = 0.22
b = 0.78
for i in range(number_of_points):
x = np.random.normal(0.0,0.5)
y = a*x + b +np.random.normal(0.0,0.1) x_point.append([x])
y_point.append([y])
plt.plot(x_point,y_point, 'o', label = 'Input Data') plt.legend()
plt.show()Количество точек, принимаемых в качестве входных данных, считается входными данными.
TFLearn можно определить как модульный и прозрачный аспект глубокого обучения, используемый во фреймворке TensorFlow. Главный мотив TFLearn - предоставить TensorFlow API более высокого уровня для облегчения и отображения новых экспериментов.
Рассмотрим следующие важные особенности TFLearn -
TFLearn прост в использовании и понимании.
Он включает простые концепции для построения высокомодульных сетевых уровней, оптимизаторов и различных показателей, встроенных в них.
Он включает полную прозрачность с рабочей системой TensorFlow.
Он включает мощные вспомогательные функции для обучения встроенных тензоров, которые принимают несколько входов, выходов и оптимизаторов.
Включает простую и красивую визуализацию графиков.
Визуализация графика включает в себя различные детали весов, градиентов и активаций.
Установите TFLearn, выполнив следующую команду -
pip install tflearnПосле выполнения вышеуказанного кода будет сгенерирован следующий вывод:
На следующем рисунке показана реализация TFLearn с классификатором случайного леса -
from __future__ import division, print_function, absolute_import
#TFLearn module implementation
import tflearn
from tflearn.estimators import RandomForestClassifier
# Data loading and pre-processing with respect to dataset
import tflearn.datasets.mnist as mnist
X, Y, testX, testY = mnist.load_data(one_hot = False)
m = RandomForestClassifier(n_estimators = 100, max_nodes = 1000)
m.fit(X, Y, batch_size = 10000, display_step = 10)
print("Compute the accuracy on train data:")
print(m.evaluate(X, Y, tflearn.accuracy_op))
print("Compute the accuracy on test set:")
print(m.evaluate(testX, testY, tflearn.accuracy_op))
print("Digits for test images id 0 to 5:")
print(m.predict(testX[:5]))
print("True digits:")
print(testY[:5])В этой главе мы сосредоточимся на разнице между CNN и RNN -
| CNN | RNN |
|---|---|
| Он подходит для пространственных данных, таких как изображения. | RNN подходит для временных данных, также называемых последовательными данными. |
| CNN считается более мощным, чем RNN. | RNN включает меньшую совместимость функций по сравнению с CNN. |
| Эта сеть принимает входные данные фиксированного размера и генерирует выходные данные фиксированного размера. | RNN может обрабатывать произвольные длины ввода / вывода. |
| CNN - это тип искусственной нейронной сети с прямой связью с вариациями многослойных персептронов, предназначенных для использования минимального количества предварительной обработки. | RNN, в отличие от нейронных сетей прямого распространения, может использовать свою внутреннюю память для обработки произвольных последовательностей входных данных. |
| CNN используют паттерн связи между нейронами. Это вдохновлено организацией зрительной коры головного мозга животных, отдельные нейроны которой расположены таким образом, что они реагируют на перекрывающиеся области, составляющие поле зрения. | Рекуррентные нейронные сети используют информацию временного ряда - то, что пользователь говорил последним, повлияет на то, что он / она будет говорить дальше. |
| CNN идеально подходят для обработки изображений и видео. | RNN идеально подходят для анализа текста и речи. |
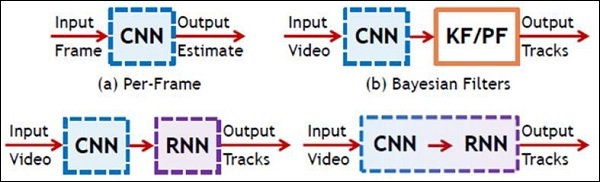
На следующем рисунке показано схематическое изображение CNN и RNN -
Keras - это компактная, простая в освоении библиотека Python высокого уровня, работающая поверх фреймворка TensorFlow. Он сделан с упором на понимание методов глубокого обучения, таких как создание слоев для нейронных сетей, поддерживающих концепции форм и математических деталей. Творчество фримерворков бывает следующих двух типов -
- Последовательный API
- Функциональный API
Рассмотрим следующие восемь шагов для создания модели глубокого обучения в Керасе:
- Загрузка данных
- Предварительно обработать загруженные данные
- Определение модели
- Составление модели
- Подходит к указанной модели
- Оцените это
- Сделайте необходимые прогнозы
- Сохраните модель
Мы будем использовать Jupyter Notebook для выполнения и отображения вывода, как показано ниже -
Step 1 - Сначала выполняется загрузка данных и предварительная обработка загруженных данных для выполнения модели глубокого обучения.
import warnings
warnings.filterwarnings('ignore')
import numpy as np
np.random.seed(123) # for reproducibility
from keras.models import Sequential
from keras.layers import Flatten, MaxPool2D, Conv2D, Dense, Reshape, Dropout
from keras.utils import np_utils
Using TensorFlow backend.
from keras.datasets import mnist
# Load pre-shuffled MNIST data into train and test sets
(X_train, y_train), (X_test, y_test) = mnist.load_data()
X_train = X_train.reshape(X_train.shape[0], 28, 28, 1)
X_test = X_test.reshape(X_test.shape[0], 28, 28, 1)
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
X_train /= 255
X_test /= 255
Y_train = np_utils.to_categorical(y_train, 10)
Y_test = np_utils.to_categorical(y_test, 10)Этот шаг можно определить как «Импорт библиотек и модулей», что означает, что все библиотеки и модули импортируются в качестве начального шага.
Step 2 - На этом этапе мы определим архитектуру модели -
model = Sequential()
model.add(Conv2D(32, 3, 3, activation = 'relu', input_shape = (28,28,1)))
model.add(Conv2D(32, 3, 3, activation = 'relu'))
model.add(MaxPool2D(pool_size = (2,2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128, activation = 'relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation = 'softmax'))Step 3 - Давайте теперь скомпилируем указанную модель -
model.compile(loss = 'categorical_crossentropy', optimizer = 'adam', metrics = ['accuracy'])Step 4 - Теперь мы подгоним модель, используя данные обучения -
model.fit(X_train, Y_train, batch_size = 32, epochs = 10, verbose = 1)Результат созданных итераций выглядит следующим образом:
Epoch 1/10 60000/60000 [==============================] - 65s -
loss: 0.2124 -
acc: 0.9345
Epoch 2/10 60000/60000 [==============================] - 62s -
loss: 0.0893 -
acc: 0.9740
Epoch 3/10 60000/60000 [==============================] - 58s -
loss: 0.0665 -
acc: 0.9802
Epoch 4/10 60000/60000 [==============================] - 62s -
loss: 0.0571 -
acc: 0.9830
Epoch 5/10 60000/60000 [==============================] - 62s -
loss: 0.0474 -
acc: 0.9855
Epoch 6/10 60000/60000 [==============================] - 59s -
loss: 0.0416 -
acc: 0.9871
Epoch 7/10 60000/60000 [==============================] - 61s -
loss: 0.0380 -
acc: 0.9877
Epoch 8/10 60000/60000 [==============================] - 63s -
loss: 0.0333 -
acc: 0.9895
Epoch 9/10 60000/60000 [==============================] - 64s -
loss: 0.0325 -
acc: 0.9898
Epoch 10/10 60000/60000 [==============================] - 60s -
loss: 0.0284 -
acc: 0.9910В этой главе основное внимание будет уделено тому, как начать работу с распределенным TensorFlow. Цель состоит в том, чтобы помочь разработчикам понять базовые концепции распределенного TF, которые повторяются, такие как серверы TF. Мы будем использовать Jupyter Notebook для оценки распределенного TensorFlow. Реализация распределенных вычислений с TensorFlow упоминается ниже -
Step 1 - Импортируйте необходимые модули, обязательные для распределенных вычислений -
import tensorflow as tfStep 2- Создайте кластер TensorFlow с одним узлом. Пусть этот узел отвечает за задание с именем «worker», которое будет выполнять один дубль на localhost: 2222.
cluster_spec = tf.train.ClusterSpec({'worker' : ['localhost:2222']})
server = tf.train.Server(cluster_spec)
server.targetПриведенные выше сценарии генерируют следующий вывод -
'grpc://localhost:2222'
The server is currently running.Step 3 - Конфигурацию сервера с соответствующим сеансом можно рассчитать, выполнив следующую команду -
server.server_defПриведенная выше команда генерирует следующий вывод -
cluster {
job {
name: "worker"
tasks {
value: "localhost:2222"
}
}
}
job_name: "worker"
protocol: "grpc"Step 4- Запустить сеанс TensorFlow с механизмом выполнения, являющимся сервером. Используйте TensorFlow, чтобы создать локальный сервер и использоватьlsof чтобы узнать местонахождение сервера.
sess = tf.Session(target = server.target)
server = tf.train.Server.create_local_server()Step 5 - Просмотрите устройства, доступные в этом сеансе, и закройте соответствующий сеанс.
devices = sess.list_devices()
for d in devices:
print(d.name)
sess.close()Приведенная выше команда генерирует следующий вывод -
/job:worker/replica:0/task:0/device:CPU:0Здесь мы сосредоточимся на формировании MetaGraph в TensorFlow. Это поможет нам понять модуль экспорта в TensorFlow. MetaGraph содержит основную информацию, которая требуется для обучения, выполнения оценки или выполнения вывода на предварительно обученном графике.
Ниже приведен фрагмент кода для того же -
def export_meta_graph(filename = None, collection_list = None, as_text = False):
"""this code writes `MetaGraphDef` to save_path/filename.
Arguments:
filename: Optional meta_graph filename including the path. collection_list:
List of string keys to collect. as_text: If `True`,
writes the meta_graph as an ASCII proto.
Returns:
A `MetaGraphDef` proto. """Одна из типичных моделей использования этого же упоминается ниже -
# Build the model ...
with tf.Session() as sess:
# Use the model ...
# Export the model to /tmp/my-model.meta.
meta_graph_def = tf.train.export_meta_graph(filename = '/tmp/my-model.meta')Многослойный персептрон определяет сложнейшую архитектуру искусственных нейронных сетей. Он состоит из нескольких слоев перцептрона.
Схематическое изображение многослойного обучения персептрона показано ниже -
Сети MLP обычно используются в формате контролируемого обучения. Типичный алгоритм обучения для сетей MLP также называется алгоритмом обратного распространения.
Теперь мы сосредоточимся на реализации с MLP для задачи классификации изображений.
# Import MINST data
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("/tmp/data/", one_hot = True)
import tensorflow as tf
import matplotlib.pyplot as plt
# Parameters
learning_rate = 0.001
training_epochs = 20
batch_size = 100
display_step = 1
# Network Parameters
n_hidden_1 = 256
# 1st layer num features
n_hidden_2 = 256 # 2nd layer num features
n_input = 784 # MNIST data input (img shape: 28*28) n_classes = 10
# MNIST total classes (0-9 digits)
# tf Graph input
x = tf.placeholder("float", [None, n_input])
y = tf.placeholder("float", [None, n_classes])
# weights layer 1
h = tf.Variable(tf.random_normal([n_input, n_hidden_1])) # bias layer 1
bias_layer_1 = tf.Variable(tf.random_normal([n_hidden_1]))
# layer 1 layer_1 = tf.nn.sigmoid(tf.add(tf.matmul(x, h), bias_layer_1))
# weights layer 2
w = tf.Variable(tf.random_normal([n_hidden_1, n_hidden_2]))
# bias layer 2
bias_layer_2 = tf.Variable(tf.random_normal([n_hidden_2]))
# layer 2
layer_2 = tf.nn.sigmoid(tf.add(tf.matmul(layer_1, w), bias_layer_2))
# weights output layer
output = tf.Variable(tf.random_normal([n_hidden_2, n_classes]))
# biar output layer
bias_output = tf.Variable(tf.random_normal([n_classes])) # output layer
output_layer = tf.matmul(layer_2, output) + bias_output
# cost function
cost = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(
logits = output_layer, labels = y))
#cost = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(output_layer, y))
# optimizer
optimizer = tf.train.AdamOptimizer(learning_rate = learning_rate).minimize(cost)
# optimizer = tf.train.GradientDescentOptimizer(
learning_rate = learning_rate).minimize(cost)
# Plot settings
avg_set = []
epoch_set = []
# Initializing the variables
init = tf.global_variables_initializer()
# Launch the graph
with tf.Session() as sess:
sess.run(init)
# Training cycle
for epoch in range(training_epochs):
avg_cost = 0.
total_batch = int(mnist.train.num_examples / batch_size)
# Loop over all batches
for i in range(total_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
# Fit training using batch data sess.run(optimizer, feed_dict = {
x: batch_xs, y: batch_ys})
# Compute average loss
avg_cost += sess.run(cost, feed_dict = {x: batch_xs, y: batch_ys}) / total_batch
# Display logs per epoch step
if epoch % display_step == 0:
print
Epoch:", '%04d' % (epoch + 1), "cost=", "{:.9f}".format(avg_cost)
avg_set.append(avg_cost)
epoch_set.append(epoch + 1)
print
"Training phase finished"
plt.plot(epoch_set, avg_set, 'o', label = 'MLP Training phase')
plt.ylabel('cost')
plt.xlabel('epoch')
plt.legend()
plt.show()
# Test model
correct_prediction = tf.equal(tf.argmax(output_layer, 1), tf.argmax(y, 1))
# Calculate accuracy
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
print
"Model Accuracy:", accuracy.eval({x: mnist.test.images, y: mnist.test.labels})Приведенная выше строка кода генерирует следующий вывод -
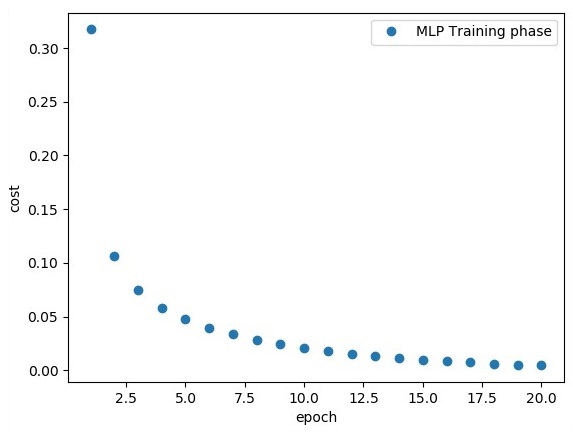
В этой главе мы сосредоточимся на сети, которую нам придется изучить на основе известного набора точек, называемых x и f (x). Один скрытый слой построит эту простую сеть.
Код для объяснения скрытых слоев перцептрона показан ниже -
#Importing the necessary modules
import tensorflow as tf
import numpy as np
import math, random
import matplotlib.pyplot as plt
np.random.seed(1000)
function_to_learn = lambda x: np.cos(x) + 0.1*np.random.randn(*x.shape)
layer_1_neurons = 10
NUM_points = 1000
#Training the parameters
batch_size = 100
NUM_EPOCHS = 1500
all_x = np.float32(np.random.uniform(-2*math.pi, 2*math.pi, (1, NUM_points))).T
np.random.shuffle(all_x)
train_size = int(900)
#Training the first 700 points in the given set x_training = all_x[:train_size]
y_training = function_to_learn(x_training)
#Training the last 300 points in the given set x_validation = all_x[train_size:]
y_validation = function_to_learn(x_validation)
plt.figure(1)
plt.scatter(x_training, y_training, c = 'blue', label = 'train')
plt.scatter(x_validation, y_validation, c = 'pink', label = 'validation')
plt.legend()
plt.show()
X = tf.placeholder(tf.float32, [None, 1], name = "X")
Y = tf.placeholder(tf.float32, [None, 1], name = "Y")
#first layer
#Number of neurons = 10
w_h = tf.Variable(
tf.random_uniform([1, layer_1_neurons],\ minval = -1, maxval = 1, dtype = tf.float32))
b_h = tf.Variable(tf.zeros([1, layer_1_neurons], dtype = tf.float32))
h = tf.nn.sigmoid(tf.matmul(X, w_h) + b_h)
#output layer
#Number of neurons = 10
w_o = tf.Variable(
tf.random_uniform([layer_1_neurons, 1],\ minval = -1, maxval = 1, dtype = tf.float32))
b_o = tf.Variable(tf.zeros([1, 1], dtype = tf.float32))
#build the model
model = tf.matmul(h, w_o) + b_o
#minimize the cost function (model - Y)
train_op = tf.train.AdamOptimizer().minimize(tf.nn.l2_loss(model - Y))
#Start the Learning phase
sess = tf.Session() sess.run(tf.initialize_all_variables())
errors = []
for i in range(NUM_EPOCHS):
for start, end in zip(range(0, len(x_training), batch_size),\
range(batch_size, len(x_training), batch_size)):
sess.run(train_op, feed_dict = {X: x_training[start:end],\ Y: y_training[start:end]})
cost = sess.run(tf.nn.l2_loss(model - y_validation),\ feed_dict = {X:x_validation})
errors.append(cost)
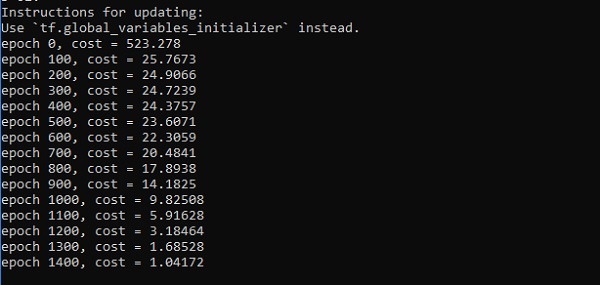
if i%100 == 0:
print("epoch %d, cost = %g" % (i, cost))
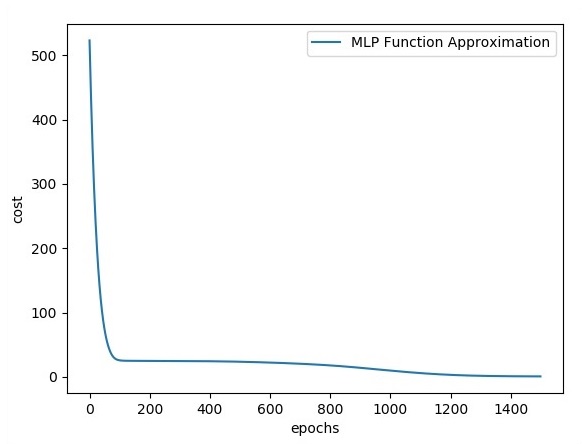
plt.plot(errors,label='MLP Function Approximation') plt.xlabel('epochs')
plt.ylabel('cost')
plt.legend()
plt.show()Вывод
Ниже приведено представление приближения функционального слоя -
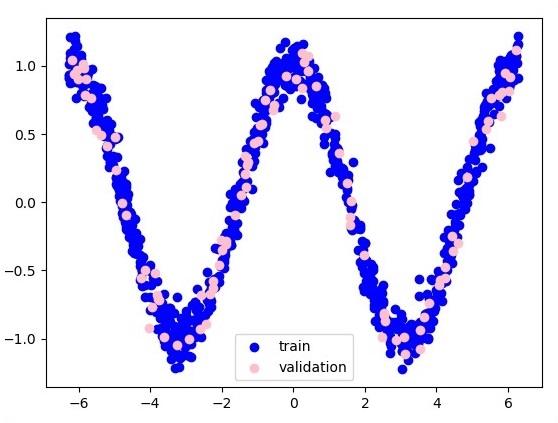
Здесь два данных представлены в форме W. Это два данных: поезд и проверка, которые представлены разными цветами, как видно в разделе легенды.
Оптимизаторы - это расширенный класс, который включает дополнительную информацию для обучения конкретной модели. Класс оптимизатора инициализируется заданными параметрами, но важно помнить, что тензор не требуется. Оптимизаторы используются для повышения скорости и производительности при обучении конкретной модели.
Базовый оптимизатор TensorFlow -
tf.train.OptimizerЭтот класс определен по указанному пути в файле tensorflow / python / training / optimizer.py.
Ниже приведены некоторые оптимизаторы в Tensorflow:
- Стохастический градиентный спуск
- Стохастический градиентный спуск с отсечением градиента
- Momentum
- Нестеров импульс
- Adagrad
- Adadelta
- RMSProp
- Adam
- Adamax
- SMORMS3
Мы сосредоточимся на спуске стохастического градиента. Иллюстрация создания оптимизатора для этого же упоминается ниже -
def sgd(cost, params, lr = np.float32(0.01)):
g_params = tf.gradients(cost, params)
updates = []
for param, g_param in zip(params, g_params):
updates.append(param.assign(param - lr*g_param))
return updatesОсновные параметры определяются в конкретной функции. В нашей следующей главе мы сосредоточимся на оптимизации градиентного спуска с применением оптимизаторов.
В этой главе мы узнаем о реализации XOR с использованием TensorFlow. Прежде чем приступить к реализации XOR в TensorFlow, давайте посмотрим значения таблицы XOR. Это поможет нам понять процесс шифрования и дешифрования.
| А | B | А XOR B |
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
Метод шифрования XOR Cipher в основном используется для шифрования данных, которые трудно взломать методом грубой силы, то есть путем генерации случайных ключей шифрования, соответствующих соответствующему ключу.
Концепция реализации с XOR Cipher заключается в том, чтобы определить ключ шифрования XOR, а затем выполнить операцию XOR для символов в указанной строке с этим ключом, который пользователь пытается зашифровать. Теперь мы сосредоточимся на реализации XOR с использованием TensorFlow, который упомянут ниже -
#Declaring necessary modules
import tensorflow as tf
import numpy as np
"""
A simple numpy implementation of a XOR gate to understand the backpropagation
algorithm
"""
x = tf.placeholder(tf.float64,shape = [4,2],name = "x")
#declaring a place holder for input x
y = tf.placeholder(tf.float64,shape = [4,1],name = "y")
#declaring a place holder for desired output y
m = np.shape(x)[0]#number of training examples
n = np.shape(x)[1]#number of features
hidden_s = 2 #number of nodes in the hidden layer
l_r = 1#learning rate initialization
theta1 = tf.cast(tf.Variable(tf.random_normal([3,hidden_s]),name = "theta1"),tf.float64)
theta2 = tf.cast(tf.Variable(tf.random_normal([hidden_s+1,1]),name = "theta2"),tf.float64)
#conducting forward propagation
a1 = tf.concat([np.c_[np.ones(x.shape[0])],x],1)
#the weights of the first layer are multiplied by the input of the first layer
z1 = tf.matmul(a1,theta1)
#the input of the second layer is the output of the first layer, passed through the
activation function and column of biases is added
a2 = tf.concat([np.c_[np.ones(x.shape[0])],tf.sigmoid(z1)],1)
#the input of the second layer is multiplied by the weights
z3 = tf.matmul(a2,theta2)
#the output is passed through the activation function to obtain the final probability
h3 = tf.sigmoid(z3)
cost_func = -tf.reduce_sum(y*tf.log(h3)+(1-y)*tf.log(1-h3),axis = 1)
#built in tensorflow optimizer that conducts gradient descent using specified
learning rate to obtain theta values
optimiser = tf.train.GradientDescentOptimizer(learning_rate = l_r).minimize(cost_func)
#setting required X and Y values to perform XOR operation
X = [[0,0],[0,1],[1,0],[1,1]]
Y = [[0],[1],[1],[0]]
#initializing all variables, creating a session and running a tensorflow session
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
#running gradient descent for each iteration and printing the hypothesis
obtained using the updated theta values
for i in range(100000):
sess.run(optimiser, feed_dict = {x:X,y:Y})#setting place holder values using feed_dict
if i%100==0:
print("Epoch:",i)
print("Hyp:",sess.run(h3,feed_dict = {x:X,y:Y}))Приведенная выше строка кода генерирует вывод, как показано на снимке экрана ниже -
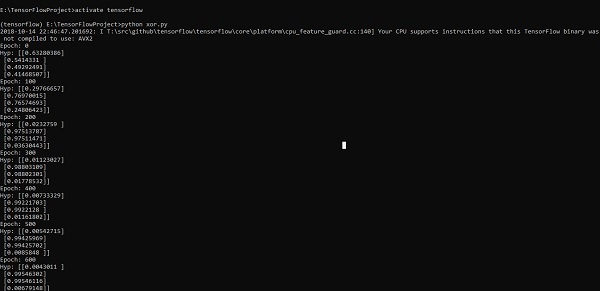
Оптимизация градиентного спуска считается важной концепцией в науке о данных.
Рассмотрим шаги, показанные ниже, чтобы понять реализацию оптимизации градиентного спуска -
Шаг 1
Включите необходимые модули и объявление переменных x и y, с помощью которых мы собираемся определить оптимизацию градиентного спуска.
import tensorflow as tf
x = tf.Variable(2, name = 'x', dtype = tf.float32)
log_x = tf.log(x)
log_x_squared = tf.square(log_x)
optimizer = tf.train.GradientDescentOptimizer(0.5)
train = optimizer.minimize(log_x_squared)Шаг 2
Инициализируйте необходимые переменные и вызовите оптимизаторы для определения и вызова с соответствующей функцией.
init = tf.initialize_all_variables()
def optimize():
with tf.Session() as session:
session.run(init)
print("starting at", "x:", session.run(x), "log(x)^2:", session.run(log_x_squared))
for step in range(10):
session.run(train)
print("step", step, "x:", session.run(x), "log(x)^2:", session.run(log_x_squared))
optimize()Приведенная выше строка кода генерирует вывод, как показано на снимке экрана ниже -
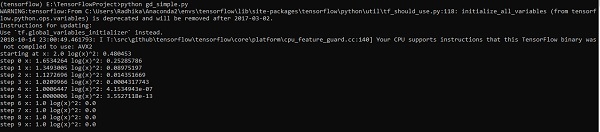
Мы видим, что необходимые эпохи и итерации вычисляются, как показано в выходных данных.
Уравнение в частных производных (PDE) - это дифференциальное уравнение, которое включает в себя частные производные с неизвестной функцией нескольких независимых переменных. Что касается уравнений в частных производных, мы сосредоточимся на создании новых графиков.
Допустим, есть пруд размером 500 * 500 квадратных -
N = 500
Теперь мы вычислим уравнение в частных производных и сформируем соответствующий график, используя его. Рассмотрим шаги, указанные ниже для вычисления графа.
Step 1 - Импорт библиотек для моделирования.
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as pltStep 2 - Включите функции для преобразования 2D-массива в ядро свертки и упрощенную операцию 2D-свертки.
def make_kernel(a):
a = np.asarray(a)
a = a.reshape(list(a.shape) + [1,1])
return tf.constant(a, dtype=1)
def simple_conv(x, k):
"""A simplified 2D convolution operation"""
x = tf.expand_dims(tf.expand_dims(x, 0), -1)
y = tf.nn.depthwise_conv2d(x, k, [1, 1, 1, 1], padding = 'SAME')
return y[0, :, :, 0]
def laplace(x):
"""Compute the 2D laplacian of an array"""
laplace_k = make_kernel([[0.5, 1.0, 0.5], [1.0, -6., 1.0], [0.5, 1.0, 0.5]])
return simple_conv(x, laplace_k)
sess = tf.InteractiveSession()Step 3 - Включите количество итераций и вычислите график для соответствующего отображения записей.
N = 500
# Initial Conditions -- some rain drops hit a pond
# Set everything to zero
u_init = np.zeros([N, N], dtype = np.float32)
ut_init = np.zeros([N, N], dtype = np.float32)
# Some rain drops hit a pond at random points
for n in range(100):
a,b = np.random.randint(0, N, 2)
u_init[a,b] = np.random.uniform()
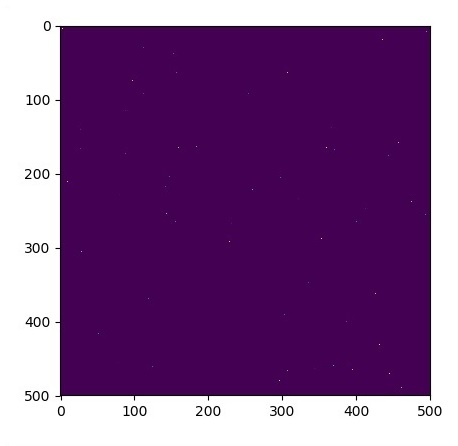
plt.imshow(u_init)
plt.show()
# Parameters:
# eps -- time resolution
# damping -- wave damping
eps = tf.placeholder(tf.float32, shape = ())
damping = tf.placeholder(tf.float32, shape = ())
# Create variables for simulation state
U = tf.Variable(u_init)
Ut = tf.Variable(ut_init)
# Discretized PDE update rules
U_ = U + eps * Ut
Ut_ = Ut + eps * (laplace(U) - damping * Ut)
# Operation to update the state
step = tf.group(U.assign(U_), Ut.assign(Ut_))
# Initialize state to initial conditions
tf.initialize_all_variables().run()
# Run 1000 steps of PDE
for i in range(1000):
# Step simulation
step.run({eps: 0.03, damping: 0.04})
# Visualize every 50 steps
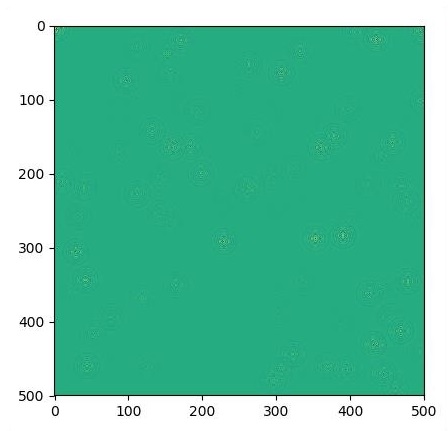
if i % 500 == 0:
plt.imshow(U.eval())
plt.show()Графики построены, как показано ниже -
TensorFlow включает специальную функцию распознавания изображений, и эти изображения хранятся в определенной папке. С относительно одинаковыми изображениями будет легко реализовать эту логику в целях безопасности.
Структура папок реализации кода распознавания изображений показана ниже -
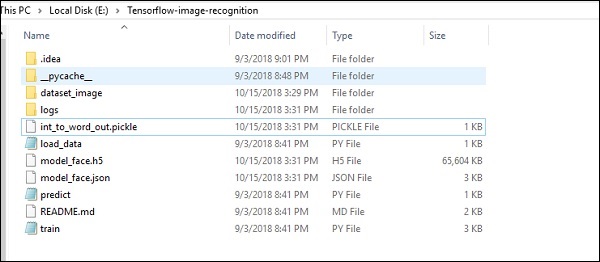
Dataset_image включает связанные изображения, которые необходимо загрузить. Мы сосредоточимся на распознавании изображений с определенным в нем нашим логотипом. Изображения загружаются с помощью скрипта load_data.py, который помогает делать заметки о различных модулях распознавания изображений внутри них.
import pickle
from sklearn.model_selection import train_test_split
from scipy import misc
import numpy as np
import os
label = os.listdir("dataset_image")
label = label[1:]
dataset = []
for image_label in label:
images = os.listdir("dataset_image/"+image_label)
for image in images:
img = misc.imread("dataset_image/"+image_label+"/"+image)
img = misc.imresize(img, (64, 64))
dataset.append((img,image_label))
X = []
Y = []
for input,image_label in dataset:
X.append(input)
Y.append(label.index(image_label))
X = np.array(X)
Y = np.array(Y)
X_train,y_train, = X,Y
data_set = (X_train,y_train)
save_label = open("int_to_word_out.pickle","wb")
pickle.dump(label, save_label)
save_label.close()Обучение изображений помогает сохранять узнаваемые шаблоны в указанной папке.
import numpy
import matplotlib.pyplot as plt
from keras.layers import Dropout
from keras.layers import Flatten
from keras.constraints import maxnorm
from keras.optimizers import SGD
from keras.layers import Conv2D
from keras.layers.convolutional import MaxPooling2D
from keras.utils import np_utils
from keras import backend as K
import load_data
from keras.models import Sequential
from keras.layers import Dense
import keras
K.set_image_dim_ordering('tf')
# fix random seed for reproducibility
seed = 7
numpy.random.seed(seed)
# load data
(X_train,y_train) = load_data.data_set
# normalize inputs from 0-255 to 0.0-1.0
X_train = X_train.astype('float32')
#X_test = X_test.astype('float32')
X_train = X_train / 255.0
#X_test = X_test / 255.0
# one hot encode outputs
y_train = np_utils.to_categorical(y_train)
#y_test = np_utils.to_categorical(y_test)
num_classes = y_train.shape[1]
# Create the model
model = Sequential()
model.add(Conv2D(32, (3, 3), input_shape = (64, 64, 3), padding = 'same',
activation = 'relu', kernel_constraint = maxnorm(3)))
model.add(Dropout(0.2))
model.add(Conv2D(32, (3, 3), activation = 'relu', padding = 'same',
kernel_constraint = maxnorm(3)))
model.add(MaxPooling2D(pool_size = (2, 2)))
model.add(Flatten())
model.add(Dense(512, activation = 'relu', kernel_constraint = maxnorm(3)))
model.add(Dropout(0.5))
model.add(Dense(num_classes, activation = 'softmax'))
# Compile model
epochs = 10
lrate = 0.01
decay = lrate/epochs
sgd = SGD(lr = lrate, momentum = 0.9, decay = decay, nesterov = False)
model.compile(loss = 'categorical_crossentropy', optimizer = sgd, metrics = ['accuracy'])
print(model.summary())
#callbacks = [keras.callbacks.EarlyStopping(
monitor = 'val_loss', min_delta = 0, patience = 0, verbose = 0, mode = 'auto')]
callbacks = [keras.callbacks.TensorBoard(log_dir='./logs',
histogram_freq = 0, batch_size = 32, write_graph = True, write_grads = False,
write_images = True, embeddings_freq = 0, embeddings_layer_names = None,
embeddings_metadata = None)]
# Fit the model
model.fit(X_train, y_train, epochs = epochs,
batch_size = 32,shuffle = True,callbacks = callbacks)
# Final evaluation of the model
scores = model.evaluate(X_train, y_train, verbose = 0)
print("Accuracy: %.2f%%" % (scores[1]*100))
# serialize model to JSONx
model_json = model.to_json()
with open("model_face.json", "w") as json_file:
json_file.write(model_json)
# serialize weights to HDF5
model.save_weights("model_face.h5")
print("Saved model to disk")Вышеупомянутая строка кода генерирует вывод, как показано ниже -
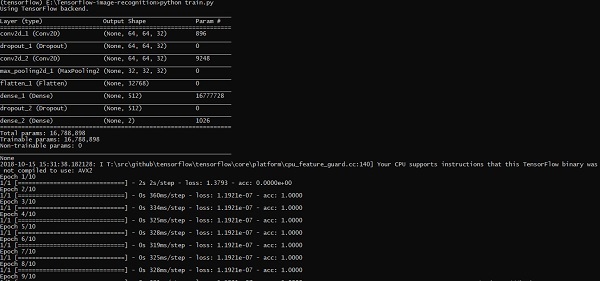
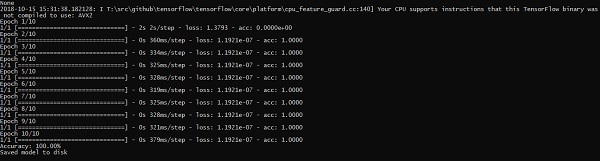
В этой главе мы поймем различные аспекты обучения нейронной сети, которые могут быть реализованы с использованием фреймворка TensorFlow.
Ниже приведены десять рекомендаций, которые можно оценить:
Обратное распространение
Обратное распространение - это простой метод вычисления частных производных, который включает базовую форму композиции, наиболее подходящую для нейронных сетей.
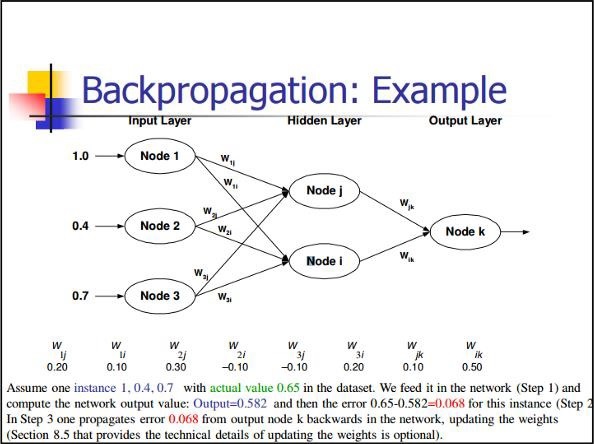
Стохастический градиентный спуск
При стохастическом градиентном спуске a batch- общее количество примеров, которые пользователь использует для вычисления градиента за одну итерацию. Пока предполагается, что пакет представляет собой весь набор данных. Лучшая иллюстрация работает в масштабе Google; наборы данных часто содержат миллиарды или даже сотни миллиардов примеров.
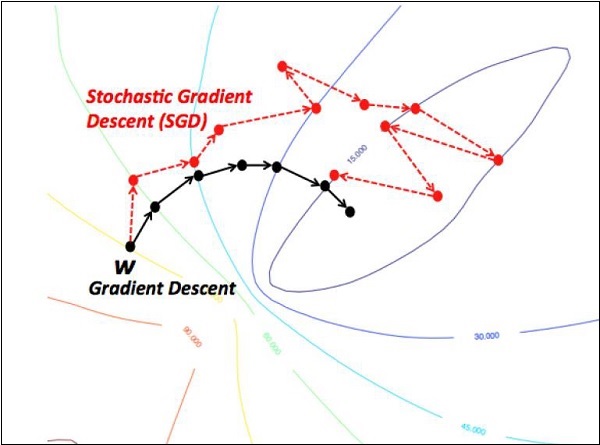
Снижение скорости обучения
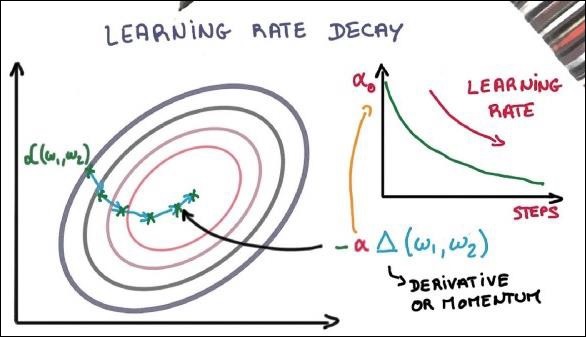
Адаптация скорости обучения - одна из наиболее важных функций оптимизации градиентного спуска. Это очень важно для реализации TensorFlow.
Выбывать
Глубокие нейронные сети с большим количеством параметров образуют мощные системы машинного обучения. Однако чрезмерная подгонка в таких сетях - серьезная проблема.

Максимальное объединение
Максимальное объединение - это процесс дискретизации на основе выборки. Цель состоит в том, чтобы уменьшить выборку входного представления, что снижает размерность с требуемыми допущениями.

Долговременная краткосрочная память (LSTM)
LSTM контролирует решение о том, какие входы должны быть приняты в указанном нейроне. Он включает в себя контроль над принятием решения о том, что следует вычислять и какие выходные данные следует генерировать.