Agile Data Science - คู่มือฉบับย่อ
Agile data science เป็นแนวทางหนึ่งของการใช้ data science ด้วยวิธีการแบบ Agile สำหรับการพัฒนาเว็บแอปพลิเคชัน มุ่งเน้นไปที่ผลลัพธ์ของกระบวนการวิทยาศาสตร์ข้อมูลที่เหมาะสมสำหรับการเปลี่ยนแปลงที่มีผลต่อองค์กร วิทยาศาสตร์ข้อมูลรวมถึงการสร้างแอปพลิเคชันที่อธิบายกระบวนการวิจัยด้วยการวิเคราะห์การแสดงภาพเชิงโต้ตอบและปัจจุบันได้ประยุกต์ใช้แมชชีนเลิร์นนิงด้วย
เป้าหมายหลักของ Agile Data Science คือ -
จัดทำเอกสารและเป็นแนวทางในการวิเคราะห์ข้อมูลเชิงอธิบายเพื่อค้นหาและปฏิบัติตามเส้นทางที่สำคัญไปสู่ผลิตภัณฑ์ที่น่าสนใจ
Agile data science จัดระเบียบด้วยชุดหลักการดังต่อไปนี้ -
การทำซ้ำอย่างต่อเนื่อง
กระบวนการนี้เกี่ยวข้องกับการทำซ้ำอย่างต่อเนื่องกับตารางการสร้างแผนภูมิรายงานและการคาดการณ์ การสร้างแบบจำลองเชิงคาดการณ์จะต้องมีการทำซ้ำหลายครั้งของวิศวกรรมคุณลักษณะด้วยการสกัดและการผลิตข้อมูลเชิงลึก
เอาต์พุตระดับกลาง
นี่คือรายการแทร็กของผลลัพธ์ที่สร้างขึ้น มีการกล่าวกันว่าการทดลองที่ล้มเหลวก็มีผลเช่นกัน การติดตามผลลัพธ์ของการทำซ้ำทุกครั้งจะช่วยสร้างผลลัพธ์ที่ดีขึ้นในการทำซ้ำครั้งต่อไป
การทดลองต้นแบบ
การทดลองต้นแบบเกี่ยวข้องกับการมอบหมายงานและการสร้างผลลัพธ์ตามการทดลอง ในงานที่กำหนดเราต้องทำซ้ำเพื่อให้เกิดความเข้าใจและการทำซ้ำเหล่านี้สามารถอธิบายได้ดีที่สุดว่าเป็นการทดลอง
การรวมข้อมูล
วงจรชีวิตของการพัฒนาซอฟต์แวร์ประกอบด้วยขั้นตอนต่างๆที่มีข้อมูลที่จำเป็นสำหรับ -
customers
นักพัฒนาและ
ธุรกิจ
การรวมข้อมูลจะปูทางไปสู่โอกาสและผลลัพธ์ที่ดีขึ้น
ค่าข้อมูลพีระมิด

ค่าพีระมิดข้างต้นอธิบายถึงเลเยอร์ที่จำเป็นสำหรับการพัฒนา "Agile data science" เริ่มต้นด้วยการรวบรวมบันทึกตามข้อกำหนดและการประปาแต่ละระเบียน แผนภูมิถูกสร้างขึ้นหลังจากการทำความสะอาดและการรวมข้อมูล ข้อมูลรวมสามารถใช้สำหรับการแสดงข้อมูล รายงานถูกสร้างขึ้นด้วยโครงสร้างข้อมูลเมตาและแท็กของข้อมูลที่เหมาะสม ชั้นที่สองของพีระมิดจากด้านบนประกอบด้วยการวิเคราะห์การทำนาย เลเยอร์การคาดการณ์คือจุดที่สร้างมูลค่าเพิ่มขึ้น แต่ช่วยในการสร้างการคาดการณ์ที่ดีซึ่งมุ่งเน้นไปที่วิศวกรรมคุณลักษณะ
ชั้นบนสุดเกี่ยวข้องกับการกระทำที่ขับเคลื่อนคุณค่าของข้อมูลอย่างมีประสิทธิภาพ ภาพประกอบที่ดีที่สุดของการใช้งานนี้คือ "ปัญญาประดิษฐ์"
ในบทนี้เราจะมุ่งเน้นไปที่แนวคิดของวงจรชีวิตของการพัฒนาซอฟต์แวร์ที่เรียกว่า“ agile” วิธีการพัฒนาซอฟต์แวร์ Agile ช่วยในการสร้างซอฟต์แวร์ผ่านการเพิ่มเซสชันในการทำซ้ำสั้น ๆ 1 ถึง 4 สัปดาห์เพื่อให้การพัฒนาสอดคล้องกับความต้องการทางธุรกิจที่เปลี่ยนแปลงไป
มีหลักการ 12 ประการที่อธิบายถึงวิธีการแบบ Agile โดยละเอียด -
ความพึงพอใจของลูกค้า
ลำดับความสำคัญสูงสุดจะมอบให้กับลูกค้าโดยมุ่งเน้นไปที่ข้อกำหนดผ่านการส่งมอบซอฟต์แวร์ที่มีคุณค่าอย่างต่อเนื่องและรวดเร็ว
ต้อนรับการเปลี่ยนแปลงใหม่
การเปลี่ยนแปลงเป็นสิ่งที่ยอมรับได้ในระหว่างการพัฒนาซอฟต์แวร์ กระบวนการ Agile ได้รับการออกแบบมาเพื่อทำงานเพื่อให้ตรงกับความได้เปรียบในการแข่งขันของลูกค้า
จัดส่ง
การส่งมอบซอฟต์แวร์ที่ใช้งานได้จะมอบให้กับลูกค้าภายในช่วงหนึ่งถึงสี่สัปดาห์
การทำงานร่วมกัน
นักวิเคราะห์ธุรกิจนักวิเคราะห์คุณภาพและนักพัฒนาต้องทำงานร่วมกันตลอดวงจรชีวิตของโครงการ
แรงจูงใจ
โครงการควรได้รับการออกแบบโดยกลุ่มบุคคลที่มีแรงจูงใจ จัดเตรียมสภาพแวดล้อมเพื่อสนับสนุนสมาชิกในทีมแต่ละคน
การสนทนาส่วนตัว
การสนทนาแบบเห็นหน้าเป็นวิธีการส่งข้อมูลไปยังและภายในทีมพัฒนาที่มีประสิทธิภาพและประสิทธิผลสูงสุด
การวัดความคืบหน้า
การวัดความคืบหน้าเป็นกุญแจสำคัญที่ช่วยในการกำหนดความคืบหน้าของโครงการและการพัฒนาซอฟต์แวร์
การรักษาก้าวอย่างต่อเนื่อง
กระบวนการที่คล่องตัวมุ่งเน้นไปที่การพัฒนาที่ยั่งยืน ธุรกิจนักพัฒนาและผู้ใช้งานควรสามารถรักษาความก้าวหน้าของโครงการได้อย่างต่อเนื่อง
การตรวจสอบ
จำเป็นต้องรักษาความเอาใจใส่อย่างสม่ำเสมอต่อความเป็นเลิศทางเทคนิคและการออกแบบที่ดีเพื่อเพิ่มฟังก์ชันการทำงานที่คล่องตัว
ความเรียบง่าย
กระบวนการ Agile ทำให้ทุกอย่างเรียบง่ายและใช้คำศัพท์ง่ายๆในการวัดผลงานที่ยังไม่เสร็จสมบูรณ์
เงื่อนไขที่จัดขึ้นเอง
ทีมที่มีความคล่องตัวควรมีการจัดระเบียบตนเองและควรเป็นอิสระด้วยสถาปัตยกรรมที่ดีที่สุด ข้อกำหนดและการออกแบบเกิดจากทีมที่จัดขึ้นเอง
ตรวจทานงาน
สิ่งสำคัญคือต้องทบทวนงานในช่วงเวลาปกติเพื่อให้ทีมสามารถไตร่ตรองว่างานกำลังดำเนินไปอย่างไร การตรวจสอบโมดูลตามเวลาที่เหมาะสมจะช่วยเพิ่มประสิทธิภาพ
ยืนขึ้นทุกวัน
การยืนประจำวันหมายถึงการประชุมสถานะประจำวันระหว่างสมาชิกในทีม มีการอัปเดตที่เกี่ยวข้องกับการพัฒนาซอฟต์แวร์ นอกจากนี้ยังหมายถึงการแก้ไขปัญหาอุปสรรคของการพัฒนาโครงการ
การยืนประจำวันเป็นแนวทางปฏิบัติที่จำเป็นไม่ว่าจะจัดตั้งทีม Agile โดยไม่คำนึงถึงที่ตั้งสำนักงาน
รายการคุณสมบัติของการยืนประจำวันมีดังนี้ -
ระยะเวลาของการนัดพบประจำวันควรอยู่ที่ประมาณ 15 นาที ไม่ควรขยายเป็นระยะเวลานานกว่านี้
การยืนขึ้นควรรวมถึงการอภิปรายเกี่ยวกับการอัปเดตสถานะ
ผู้เข้าร่วมการประชุมนี้มักจะยืนด้วยความตั้งใจที่จะจบการประชุมโดยเร็ว
เรื่องราวของผู้ใช้
โดยปกติเรื่องราวเป็นข้อกำหนดซึ่งกำหนดเป็นประโยคไม่กี่ประโยคในภาษาง่ายๆและควรเสร็จสิ้นภายในการวนซ้ำ เรื่องราวของผู้ใช้ควรมีลักษณะดังต่อไปนี้ -
รหัสที่เกี่ยวข้องทั้งหมดควรมีการเช็คอินที่เกี่ยวข้อง
กรณีทดสอบหน่วยสำหรับการทำซ้ำที่ระบุ
ควรกำหนดกรณีการทดสอบการยอมรับทั้งหมด
การยอมรับจากเจ้าของผลิตภัณฑ์ในขณะที่กำหนดเรื่องราว
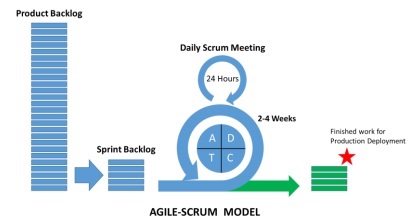
Scrum คืออะไร?
การต่อสู้ถือได้ว่าเป็นส่วนหนึ่งของวิธีการแบบเปรียว เป็นกระบวนการที่มีน้ำหนักเบาและมีคุณสมบัติดังต่อไปนี้ -
เป็นกรอบกระบวนการซึ่งรวมถึงชุดของการปฏิบัติที่ต้องปฏิบัติตามลำดับที่สอดคล้องกัน ภาพประกอบที่ดีที่สุดของ Scrum คือการทำซ้ำหรือการวิ่ง
เป็นกระบวนการที่“ น้ำหนักเบา” หมายความว่ากระบวนการจะถูกทำให้เล็กที่สุดเพื่อเพิ่มผลผลิตให้ได้สูงสุดในระยะเวลาที่กำหนด
กระบวนการต่อสู้เป็นที่รู้จักสำหรับกระบวนการที่แตกต่างเมื่อเปรียบเทียบกับวิธีการอื่น ๆ ของวิธีการแบบ Agile แบบดั้งเดิม แบ่งออกเป็นสามประเภทดังต่อไปนี้ -
Roles
Artifacts
กล่องเวลา
บทบาทกำหนดสมาชิกในทีมและบทบาทของพวกเขาที่รวมอยู่ในกระบวนการ ทีม Scrum ประกอบด้วยสามบทบาทดังต่อไปนี้ -
ต่อสู้มาสเตอร์
เจ้าของผลิตภัณฑ์
Team
สิ่งประดิษฐ์ Scrum ให้ข้อมูลสำคัญที่สมาชิกแต่ละคนควรทราบ ข้อมูลประกอบด้วยรายละเอียดของผลิตภัณฑ์กิจกรรมที่วางแผนไว้และกิจกรรมที่เสร็จสมบูรณ์ สิ่งประดิษฐ์ที่กำหนดไว้ใน Scrum framework มีดังต่อไปนี้ -
สินค้าค้างส่ง
Sprint ค้าง
เบิร์นลงแผนภูมิ
Increment
ไทม์บ็อกซ์คือเรื่องราวของผู้ใช้ที่วางแผนไว้สำหรับการวนซ้ำแต่ละครั้ง เรื่องราวของผู้ใช้เหล่านี้ช่วยในการอธิบายคุณลักษณะของผลิตภัณฑ์ซึ่งเป็นส่วนหนึ่งของสิ่งประดิษฐ์ Scrum สินค้าค้างส่งคือรายการเรื่องราวของผู้ใช้ เรื่องราวของผู้ใช้เหล่านี้ได้รับการจัดลำดับความสำคัญและส่งต่อไปยังการประชุมผู้ใช้เพื่อตัดสินใจว่าควรรับเรื่องใด
ทำไมต้อง Scrum Master
Scrum Master โต้ตอบกับสมาชิกทุกคนในทีม ตอนนี้ให้เราเห็นปฏิสัมพันธ์ของ Scrum Master กับทีมและทรัพยากรอื่น ๆ
เจ้าของผลิตภัณฑ์
Scrum Master โต้ตอบกับเจ้าของผลิตภัณฑ์ด้วยวิธีต่อไปนี้ -
ค้นหาเทคนิคเพื่อให้ได้เรื่องราวที่ค้างอยู่ของผลิตภัณฑ์ที่มีประสิทธิภาพและจัดการ
ช่วยให้ทีมเข้าใจความต้องการของสินค้าค้างส่งที่ชัดเจนและรัดกุม
การวางแผนผลิตภัณฑ์ที่มีสภาพแวดล้อมเฉพาะ
สร้างความมั่นใจว่าเจ้าของผลิตภัณฑ์รู้วิธีเพิ่มมูลค่าของผลิตภัณฑ์
การอำนวยความสะดวกในเหตุการณ์ Scrum ตามและเมื่อจำเป็น
ทีมต่อสู้
Scrum Master โต้ตอบกับทีมได้หลายวิธี -
การฝึกสอนองค์กรในการนำ Scrum มาใช้
การวางแผนการนำ Scrum ไปใช้กับองค์กรเฉพาะ
ช่วยให้พนักงานและผู้มีส่วนได้ส่วนเสียเข้าใจข้อกำหนดและขั้นตอนของการพัฒนาผลิตภัณฑ์
ทำงานร่วมกับ Scrum Masters ของทีมอื่น ๆ เพื่อเพิ่มประสิทธิภาพของการใช้ Scrum ของทีมที่ระบุ
องค์กร
Scrum Master โต้ตอบกับองค์กรได้หลายวิธี มีการระบุไว้ด้านล่าง -
ทีมฝึกสอนและต่อสู้มีปฏิสัมพันธ์กับองค์กรตนเองและรวมถึงคุณลักษณะของการทำงานข้ามกัน
การฝึกสอนองค์กรและทีมงานในพื้นที่ดังกล่าวซึ่งยังไม่ได้รับการยอมรับอย่างเต็มที่จาก Scrum หรือไม่ได้รับการยอมรับ
ประโยชน์ของ Scrum
Scrum ช่วยให้ลูกค้าสมาชิกในทีมและผู้มีส่วนได้ส่วนเสียทำงานร่วมกัน ซึ่งรวมถึงวิธีการตามไทม์บ็อกซ์และข้อเสนอแนะอย่างต่อเนื่องจากเจ้าของผลิตภัณฑ์เพื่อให้แน่ใจว่าผลิตภัณฑ์อยู่ในสภาพใช้งาน Scrum ให้ประโยชน์กับบทบาทต่างๆของโครงการ
ลูกค้า
การวิ่งหรือการทำซ้ำถือเป็นช่วงเวลาที่สั้นลงและเรื่องราวของผู้ใช้ได้รับการออกแบบตามลำดับความสำคัญและนำมาใช้ในการวางแผนการวิ่ง ช่วยให้มั่นใจได้ว่าการส่งมอบทุกครั้งความต้องการของลูกค้าจะบรรลุผล หากไม่เป็นเช่นนั้นข้อกำหนดจะถูกบันทึกไว้และมีการวางแผนและดำเนินการสำหรับการวิ่ง
องค์กร
การจัดองค์กรด้วยความช่วยเหลือจากผู้เชี่ยวชาญด้านการต่อสู้และการต่อสู้สามารถมุ่งเน้นไปที่ความพยายามที่จำเป็นสำหรับการพัฒนาเรื่องราวของผู้ใช้ซึ่งจะช่วยลดภาระงานและหลีกเลี่ยงการทำงานซ้ำหากมี นอกจากนี้ยังช่วยในการรักษาประสิทธิภาพที่เพิ่มขึ้นของทีมพัฒนาและความพึงพอใจของลูกค้า แนวทางนี้ยังช่วยในการเพิ่มศักยภาพของตลาด
ผู้จัดการผลิตภัณฑ์
ความรับผิดชอบหลักของผู้จัดการผลิตภัณฑ์คือการดูแลคุณภาพของผลิตภัณฑ์ ด้วยความช่วยเหลือของ Scrum Masters มันกลายเป็นเรื่องง่ายที่จะอำนวยความสะดวกในการทำงานรวบรวมคำตอบอย่างรวดเร็วและดูดซับการเปลี่ยนแปลงหากมี ผู้จัดการผลิตภัณฑ์ยังตรวจสอบว่าผลิตภัณฑ์ที่ออกแบบนั้นสอดคล้องกับความต้องการของลูกค้าในทุกการวิ่ง
ทีมพัฒนา
ด้วยลักษณะของไทม์บ็อกซ์และการรักษาระยะเวลาการวิ่งให้สั้นลงทีมพัฒนาจึงกระตือรือร้นที่จะเห็นว่างานได้รับการสะท้อนและส่งมอบอย่างเหมาะสม ผลิตภัณฑ์ที่ใช้งานได้จะเพิ่มขึ้นในแต่ละระดับหลังจากการทำซ้ำทุกครั้งหรือเรียกอีกอย่างว่า "sprint" เรื่องราวของผู้ใช้ที่ได้รับการออกแบบมาสำหรับการวิ่งทุกครั้งจะกลายมาเป็นลำดับความสำคัญของลูกค้าซึ่งเพิ่มมูลค่าให้กับการทำซ้ำ
สรุป
Scrum เป็นเฟรมเวิร์กที่มีประสิทธิภาพซึ่งคุณสามารถพัฒนาซอฟต์แวร์ในการทำงานเป็นทีมได้ ได้รับการออกแบบอย่างสมบูรณ์บนหลักการที่คล่องตัว ScrumMaster พร้อมให้ความช่วยเหลือและร่วมมือกับทีม Scrum ในทุกวิถีทาง เขาทำหน้าที่เหมือนผู้ฝึกสอนส่วนบุคคลที่ช่วยให้คุณยึดติดกับแผนการออกแบบและทำกิจกรรมทั้งหมดตามแผน อำนาจของ ScrumMaster ไม่ควรเกินกว่ากระบวนการ เขา / เธอควรมีความสามารถในการจัดการทุกสถานการณ์
ในบทนี้เราจะเข้าใจกระบวนการวิทยาศาสตร์ข้อมูลและคำศัพท์ที่จำเป็นในการทำความเข้าใจกระบวนการ
“ วิทยาศาสตร์ข้อมูลคือการผสมผสานระหว่างอินเทอร์เฟซข้อมูลการพัฒนาอัลกอริทึมและเทคโนโลยีเพื่อแก้ปัญหาที่ซับซ้อนในการวิเคราะห์”
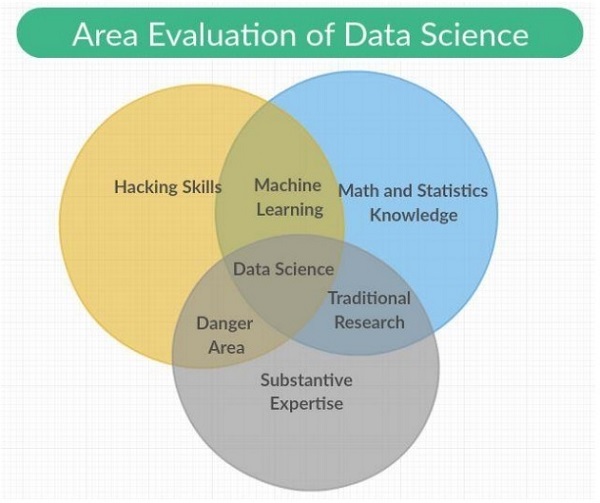
วิทยาศาสตร์ข้อมูลเป็นสาขาสหวิทยาการที่ครอบคลุมวิธีการทางวิทยาศาสตร์กระบวนการและระบบที่มีหมวดหมู่รวมอยู่ในนั้นเป็นความรู้ด้านการเรียนรู้ของเครื่องคณิตศาสตร์และสถิติด้วยการวิจัยแบบดั้งเดิม นอกจากนี้ยังรวมถึงการผสมผสานระหว่างทักษะการแฮ็กกับความเชี่ยวชาญที่สำคัญ วิทยาศาสตร์ข้อมูลใช้หลักการจากคณิตศาสตร์สถิติวิทยาศาสตร์ข้อมูลและวิทยาศาสตร์คอมพิวเตอร์การขุดข้อมูลและการวิเคราะห์เชิงทำนาย
บทบาทต่างๆที่เป็นส่วนหนึ่งของทีมวิทยาศาสตร์ข้อมูลมีการกล่าวถึงด้านล่าง -
ลูกค้า
ลูกค้าคือผู้ที่ใช้ผลิตภัณฑ์ ความสนใจเป็นตัวกำหนดความสำเร็จของโครงการและความคิดเห็นของพวกเขามีค่ามากในวิทยาศาสตร์ข้อมูล
การพัฒนาธุรกิจ
ทีมวิทยาศาสตร์ข้อมูลนี้ลงนามในลูกค้ารายแรก ๆ ไม่ว่าจะโดยตรงหรือผ่านการสร้างหน้า Landing Page และโปรโมชัน ทีมพัฒนาธุรกิจมอบคุณค่าของผลิตภัณฑ์
ผู้จัดการผลิตภัณฑ์
ผู้จัดการผลิตภัณฑ์ให้ความสำคัญในการสร้างผลิตภัณฑ์ที่ดีที่สุดซึ่งมีคุณค่าในตลาด
นักออกแบบปฏิสัมพันธ์
พวกเขามุ่งเน้นไปที่การออกแบบปฏิสัมพันธ์รอบ ๆ แบบจำลองข้อมูลเพื่อให้ผู้ใช้พบคุณค่าที่เหมาะสม
นักวิทยาศาสตร์ข้อมูล
นักวิทยาศาสตร์ข้อมูลสำรวจและแปลงข้อมูลในรูปแบบใหม่เพื่อสร้างและเผยแพร่คุณลักษณะใหม่ ๆ นักวิทยาศาสตร์เหล่านี้ยังรวมข้อมูลจากแหล่งต่างๆเพื่อสร้างมูลค่าใหม่ พวกเขามีบทบาทสำคัญในการสร้างภาพร่วมกับนักวิจัยวิศวกรและนักพัฒนาเว็บ
นักวิจัย
ตามชื่อระบุว่านักวิจัยมีส่วนร่วมในกิจกรรมการวิจัย พวกเขาแก้ปัญหาที่ซับซ้อนซึ่งนักวิทยาศาสตร์ข้อมูลไม่สามารถทำได้ ปัญหาเหล่านี้เกี่ยวข้องกับการโฟกัสที่เข้มข้นและเวลาของโมดูลการเรียนรู้ของเครื่องและสถิติ
ปรับตัวเข้ากับการเปลี่ยนแปลง
สมาชิกในทีมทั้งหมดของวิทยาศาสตร์ข้อมูลจะต้องปรับตัวให้เข้ากับการเปลี่ยนแปลงใหม่และทำงานบนพื้นฐานของข้อกำหนด ควรมีการเปลี่ยนแปลงหลายประการสำหรับการนำระเบียบวิธีแบบว่องไวมาใช้กับวิทยาศาสตร์ข้อมูลซึ่งจะกล่าวถึงดังต่อไปนี้ -
การเลือกผู้เชี่ยวชาญทั่วไปมากกว่าผู้เชี่ยวชาญ
ความชอบของทีมเล็กมากกว่าทีมใหญ่
การใช้เครื่องมือและแพลตฟอร์มระดับสูง
การแบ่งปันงานระดับกลางอย่างต่อเนื่องและซ้ำซาก
Note
ในทีมวิทยาศาสตร์ข้อมูล Agile ทีมงานทั่วไปเล็ก ๆ ใช้เครื่องมือระดับสูงที่ปรับขนาดได้และปรับแต่งข้อมูลผ่านการทำซ้ำไปยังสถานะที่มีมูลค่าสูงขึ้นเรื่อย ๆ
พิจารณาตัวอย่างต่อไปนี้ที่เกี่ยวข้องกับการทำงานของสมาชิกทีมวิทยาศาสตร์ข้อมูล -
นักออกแบบนำเสนอ CSS
นักพัฒนาเว็บสร้างแอปพลิเคชันทั้งหมดเข้าใจประสบการณ์ของผู้ใช้และการออกแบบอินเทอร์เฟซ
นักวิทยาศาสตร์ข้อมูลควรทำงานทั้งการวิจัยและการสร้างบริการเว็บรวมถึงเว็บแอปพลิเคชัน
นักวิจัยทำงานในฐานรหัสซึ่งแสดงผลลัพธ์ที่อธิบายผลลัพธ์ระดับกลาง
ผู้จัดการผลิตภัณฑ์พยายามระบุและทำความเข้าใจข้อบกพร่องในส่วนที่เกี่ยวข้องทั้งหมด
ในบทนี้เราจะเรียนรู้เกี่ยวกับเครื่องมือ Agile ต่างๆและการติดตั้ง ชุดการพัฒนาของวิธีการแบบ Agile ประกอบด้วยชุดส่วนประกอบต่อไปนี้ -
เหตุการณ์
เหตุการณ์คือเหตุการณ์ที่เกิดขึ้นหรือถูกบันทึกไว้พร้อมกับคุณลักษณะและการประทับเวลา
เหตุการณ์อาจมีหลายรูปแบบเช่นเซิร์ฟเวอร์เซ็นเซอร์ธุรกรรมทางการเงินหรือการกระทำที่ผู้ใช้ของเราดำเนินการในแอปพลิเคชันของเรา ในบทช่วยสอนที่สมบูรณ์นี้เราจะใช้ไฟล์ JSON ที่จะอำนวยความสะดวกในการแลกเปลี่ยนข้อมูลระหว่างเครื่องมือและภาษาต่างๆ
นักสะสม
นักสะสมคือผู้รวบรวมเหตุการณ์ พวกเขารวบรวมเหตุการณ์อย่างเป็นระบบเพื่อจัดเก็บและรวบรวมข้อมูลขนาดใหญ่ที่จัดคิวให้ดำเนินการโดยพนักงานแบบเรียลไทม์
เอกสารแจกจ่าย
เอกสารเหล่านี้ประกอบด้วยมัลติโหนด (หลายโหนด) ซึ่งจัดเก็บเอกสารในรูปแบบเฉพาะ เราจะเน้น MongoDB ในบทช่วยสอนนี้
เซิร์ฟเวอร์โปรแกรมประยุกต์บนเว็บ
เว็บแอ็พพลิเคชันเซิร์ฟเวอร์เปิดใช้งานข้อมูลเป็น JSON ผ่านไคลเอนต์ผ่านการแสดงภาพโดยมีค่าใช้จ่ายน้อยที่สุด หมายความว่าเว็บแอ็พพลิเคชันเซิร์ฟเวอร์ช่วยในการทดสอบและปรับใช้โครงการที่สร้างขึ้นด้วยวิธีการแบบ Agile
เบราว์เซอร์สมัยใหม่
ช่วยให้เบราว์เซอร์หรือแอปพลิเคชันสมัยใหม่สามารถนำเสนอข้อมูลเป็นเครื่องมือโต้ตอบสำหรับผู้ใช้ของเรา
การตั้งค่าสิ่งแวดล้อมในท้องถิ่น
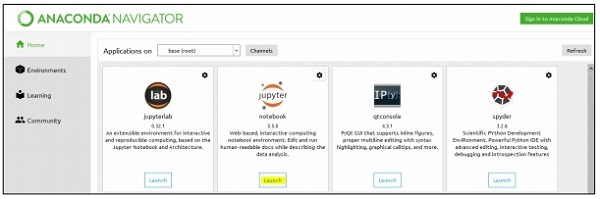
สำหรับการจัดการชุดข้อมูลเราจะเน้นไปที่เฟรมเวิร์ก Anaconda ของ python ที่มีเครื่องมือสำหรับจัดการ excel, csv และไฟล์อื่น ๆ อีกมากมาย แดชบอร์ดของเฟรมเวิร์ก Anaconda เมื่อติดตั้งแล้วจะดังที่แสดงด้านล่าง เรียกอีกอย่างว่า“ Anaconda Navigator” -

เนวิเกเตอร์ประกอบด้วย“ Jupyter framework” ซึ่งเป็นระบบโน้ตบุ๊กที่ช่วยในการจัดการชุดข้อมูล เมื่อคุณเปิดเฟรมเวิร์กมันจะถูกโฮสต์ในเบราว์เซอร์ดังที่กล่าวไว้ด้านล่าง -

ในบทนี้เราจะเน้นไปที่ความแตกต่างระหว่างข้อมูลที่มีโครงสร้างกึ่งโครงสร้างและไม่มีโครงสร้าง
ข้อมูลที่มีโครงสร้าง
ข้อมูลที่มีโครงสร้างเกี่ยวข้องกับข้อมูลที่จัดเก็บในรูปแบบ SQL ในตารางที่มีแถวและคอลัมน์ ประกอบด้วยคีย์เชิงสัมพันธ์ซึ่งแมปลงในฟิลด์ที่ออกแบบไว้ล่วงหน้า ข้อมูลที่มีโครงสร้างถูกนำไปใช้ในระดับที่ใหญ่ขึ้น
ข้อมูลที่มีโครงสร้างเป็นเพียง 5 ถึง 10 เปอร์เซ็นต์ของข้อมูลสารสนเทศทั้งหมด
ข้อมูลกึ่งโครงสร้าง
ข้อมูลโครงสร้าง Sem ประกอบด้วยข้อมูลที่ไม่ได้อยู่ในฐานข้อมูลเชิงสัมพันธ์ รวมถึงคุณสมบัติขององค์กรบางอย่างที่ช่วยให้วิเคราะห์ได้ง่ายขึ้น รวมถึงกระบวนการเดียวกันในการจัดเก็บไว้ในฐานข้อมูลเชิงสัมพันธ์ ตัวอย่างของฐานข้อมูลกึ่งโครงสร้าง ได้แก่ ไฟล์ CSV เอกสาร XML และ JSON ฐานข้อมูล NoSQL ถือเป็นกึ่งโครงสร้าง
ข้อมูลที่ไม่มีโครงสร้าง
ข้อมูลที่ไม่มีโครงสร้างแสดงถึง 80 เปอร์เซ็นต์ของข้อมูล มักมีเนื้อหาที่เป็นข้อความและมัลติมีเดีย ตัวอย่างที่ดีที่สุดของข้อมูลที่ไม่มีโครงสร้าง ได้แก่ ไฟล์เสียงงานนำเสนอและหน้าเว็บ ตัวอย่างของข้อมูลที่ไม่มีโครงสร้างที่สร้างโดยเครื่อง ได้แก่ ภาพถ่ายดาวเทียมข้อมูลทางวิทยาศาสตร์ภาพถ่ายและวิดีโอข้อมูลเรดาร์และโซนาร์
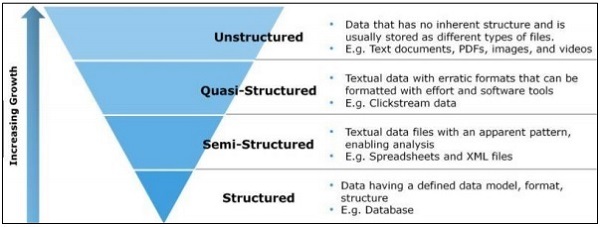
โครงสร้างพีระมิดข้างต้นเน้นเฉพาะปริมาณข้อมูลและอัตราส่วนที่กระจัดกระจาย
ข้อมูลกึ่งโครงสร้างจะปรากฏเป็นประเภทระหว่างข้อมูลที่ไม่มีโครงสร้างและข้อมูลกึ่งโครงสร้าง ในบทช่วยสอนนี้เราจะเน้นไปที่ข้อมูลกึ่งโครงสร้างซึ่งเป็นประโยชน์สำหรับวิธีการแบบว่องไวและการวิจัยวิทยาศาสตร์ข้อมูล
ข้อมูลกึ่งโครงสร้างไม่มีรูปแบบข้อมูลที่เป็นทางการ แต่มีรูปแบบและโครงสร้างที่อธิบายตนเองได้ชัดเจนซึ่งพัฒนาโดยการวิเคราะห์
จุดเน้นที่สมบูรณ์ของบทช่วยสอนนี้คือการปฏิบัติตามวิธีการที่คล่องตัวโดยมีขั้นตอนน้อยลงและใช้เครื่องมือที่มีประโยชน์มากขึ้น เพื่อให้เข้าใจสิ่งนี้สิ่งสำคัญคือต้องทราบความแตกต่างระหว่างฐานข้อมูล SQL และ NoSQL
ผู้ใช้ส่วนใหญ่รู้จักฐานข้อมูล SQL และมีความรู้เป็นอย่างดีเกี่ยวกับ MySQL, Oracle หรือฐานข้อมูล SQL อื่น ๆ ในช่วงหลายปีที่ผ่านมาฐานข้อมูล NoSQL ได้รับการนำไปใช้อย่างกว้างขวางเพื่อแก้ปัญหาทางธุรกิจและข้อกำหนดต่างๆของโครงการ

ตารางต่อไปนี้แสดงความแตกต่างระหว่างฐานข้อมูล SQL และ NoSQL -
| SQL | NoSQL |
|---|---|
| ฐานข้อมูล SQL ส่วนใหญ่เรียกว่าระบบจัดการฐานข้อมูลเชิงสัมพันธ์ (RDBMS) | ฐานข้อมูล NoSQL เรียกอีกอย่างว่าฐานข้อมูล documentoriented มันไม่เกี่ยวข้องและกระจาย |
| ฐานข้อมูลที่ใช้ SQL ประกอบด้วยโครงสร้างของตารางที่มีแถวและคอลัมน์ การรวบรวมตารางและโครงสร้างสคีมาอื่น ๆ ที่เรียกว่าฐานข้อมูล | ฐานข้อมูล NoSQL ประกอบด้วยเอกสารเป็นโครงสร้างหลักและการรวมเอกสารเรียกว่าการรวบรวม |
| ฐานข้อมูล SQL ประกอบด้วยสคีมาที่กำหนดไว้ล่วงหน้า | ฐานข้อมูล NoSQL มีข้อมูลแบบไดนามิกและรวมถึงข้อมูลที่ไม่มีโครงสร้าง |
| ฐานข้อมูล SQL สามารถปรับขนาดได้ตามแนวตั้ง | ฐานข้อมูล NoSQL สามารถปรับขนาดได้ในแนวนอน |
| ฐานข้อมูล SQL เหมาะสำหรับสภาพแวดล้อมการสืบค้นที่ซับซ้อน | NoSQL ไม่มีอินเทอร์เฟซมาตรฐานสำหรับการพัฒนาแบบสอบถามที่ซับซ้อน |
| ฐานข้อมูล SQL ไม่สามารถจัดเก็บข้อมูลแบบลำดับชั้นได้ | ฐานข้อมูล NoSQL เหมาะสำหรับการจัดเก็บข้อมูลแบบลำดับชั้น |
| ฐานข้อมูล SQL เหมาะสมที่สุดสำหรับการทำธุรกรรมจำนวนมากในแอปพลิเคชันที่ระบุ | ฐานข้อมูล NoSQL ยังถือว่าไม่สามารถเทียบเคียงได้กับภาระงานสูงสำหรับแอปพลิเคชันธุรกรรมที่ซับซ้อน |
| ฐานข้อมูล SQL ให้การสนับสนุนที่ดีเยี่ยมสำหรับผู้ขายของตน | ฐานข้อมูล NoSQL ยังคงอาศัยการสนับสนุนจากชุมชน มีผู้เชี่ยวชาญเพียงไม่กี่คนที่พร้อมสำหรับการติดตั้งและปรับใช้สำหรับการปรับใช้ NoSQL ขนาดใหญ่ |
| ฐานข้อมูล SQL มุ่งเน้นไปที่คุณสมบัติของกรด - อะตอม, ความสม่ำเสมอ, การแยกและความทนทาน | ฐานข้อมูล NoSQL มุ่งเน้นไปที่คุณสมบัติของ CAP - ความสม่ำเสมอความพร้อมใช้งานและความทนทานต่อพาร์ติชัน |
| ฐานข้อมูล SQL สามารถจัดประเภทเป็นโอเพ่นซอร์สหรือซอร์สแบบปิดโดยขึ้นอยู่กับผู้ขายที่เลือกใช้ | ฐานข้อมูล NoSQL ถูกจัดประเภทตามประเภทการจัดเก็บ ฐานข้อมูล NoSQL เป็นโอเพ่นซอร์สตามค่าเริ่มต้น |
ทำไม NoSQL ถึงคล่องตัว?
การเปรียบเทียบดังกล่าวข้างต้นแสดงให้เห็นว่าฐานข้อมูลเอกสาร NoSQL สนับสนุนการพัฒนาแบบ Agile อย่างสมบูรณ์ เป็นสคีมาน้อยและไม่ได้มุ่งเน้นไปที่การสร้างแบบจำลองข้อมูลอย่างสมบูรณ์ แต่ NoSQL ชะลอการใช้งานแอปพลิเคชันและบริการดังนั้นนักพัฒนาจึงมีแนวคิดที่ดีขึ้นว่าจะจำลองข้อมูลได้อย่างไร NoSQL กำหนดโมเดลข้อมูลเป็นรูปแบบแอปพลิเคชัน
การติดตั้ง MongoDB
ตลอดบทช่วยสอนนี้เราจะให้ความสำคัญกับตัวอย่างของ MongoDB มากขึ้นเนื่องจากถือว่าเป็น“ NoSQL schema” ที่ดีที่สุด
มีหลายครั้งที่ข้อมูลไม่พร้อมใช้งานในรูปแบบเชิงสัมพันธ์และเราจำเป็นต้องเก็บไว้เพื่อทำธุรกรรมด้วยความช่วยเหลือของฐานข้อมูล NoSQL
ในบทนี้เราจะเน้นไปที่กระแสข้อมูลของ NoSQL นอกจากนี้เรายังจะได้เรียนรู้วิธีการทำงานด้วยการผสมผสานระหว่าง Agile และ Data Science
เหตุผลสำคัญประการหนึ่งในการใช้ NoSQL อย่างคล่องตัวคือการเพิ่มความเร็วกับการแข่งขันในตลาด เหตุผลต่อไปนี้แสดงให้เห็นว่า NoSQL เหมาะสมที่สุดสำหรับวิธีการของซอฟต์แวร์ Agile อย่างไร -
อุปสรรคน้อยลง
การเปลี่ยนรูปแบบซึ่งในปัจจุบันกำลังดำเนินไปในช่วงกลางสตรีมมีต้นทุนที่แท้จริงแม้ในกรณีของการพัฒนาที่คล่องตัว ด้วย NoSQL ผู้ใช้จะทำงานกับข้อมูลรวมแทนที่จะเสียเวลาในการปรับข้อมูลให้เป็นมาตรฐาน ประเด็นหลักคือการทำบางสิ่งให้ลุล่วงและทำงานโดยมีเป้าหมายเพื่อสร้างโมเดลข้อมูลที่สมบูรณ์แบบ
เพิ่มความสามารถในการปรับขนาด
เมื่อใดก็ตามที่องค์กรกำลังสร้างผลิตภัณฑ์องค์กรจะให้ความสำคัญกับความสามารถในการปรับขนาดได้มากขึ้น NoSQL เป็นที่รู้จักกันดีในเรื่องความสามารถในการปรับขนาด แต่จะทำงานได้ดีขึ้นเมื่อได้รับการออกแบบให้มีความยืดหยุ่นในแนวนอน
ความสามารถในการใช้ประโยชน์จากข้อมูล
NoSQL เป็นรูปแบบข้อมูลที่ไม่ใช้สคีมาซึ่งช่วยให้ผู้ใช้สามารถใช้ปริมาณข้อมูลได้อย่างง่ายดายซึ่งรวมถึงพารามิเตอร์ต่างๆของความแปรปรวนและความเร็ว เมื่อพิจารณาทางเลือกของเทคโนโลยีคุณควรพิจารณาเทคโนโลยีที่ใช้ประโยชน์จากข้อมูลในระดับที่มากขึ้น
กระแสข้อมูลของ NoSQL
ให้เราพิจารณาตัวอย่างต่อไปนี้ซึ่งเราได้แสดงให้เห็นว่าโมเดลข้อมูลมุ่งเน้นไปที่การสร้างสคีมา RDBMS อย่างไร
ต่อไปนี้เป็นข้อกำหนดที่แตกต่างกันของสคีมา -
การระบุผู้ใช้ควรอยู่ในรายการ
ผู้ใช้ทุกคนควรมีทักษะที่จำเป็นอย่างน้อยหนึ่งทักษะ
รายละเอียดประสบการณ์ของผู้ใช้ทุกคนควรได้รับการดูแลอย่างเหมาะสม
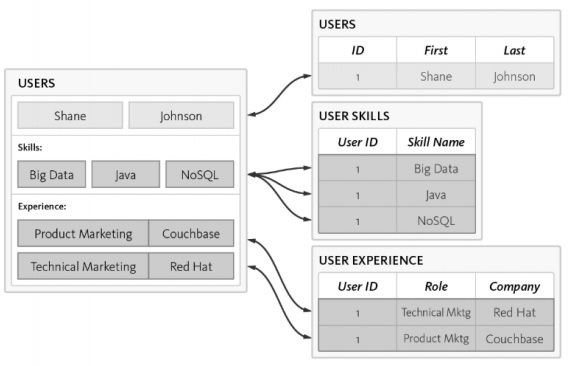
ตารางผู้ใช้เป็นมาตรฐานโดยมี 3 ตารางแยกกัน -
Users
ทักษะของผู้ใช้
ประสบการณ์ของผู้ใช้
ความซับซ้อนจะเพิ่มขึ้นในขณะที่ค้นหาฐานข้อมูลและการใช้เวลาจะถูกบันทึกด้วยการทำให้เป็นมาตรฐานที่เพิ่มขึ้นซึ่งไม่ดีสำหรับวิธีการแบบ Agile สคีมาเดียวกันสามารถออกแบบด้วยฐานข้อมูล NoSQL ดังที่กล่าวไว้ด้านล่าง -
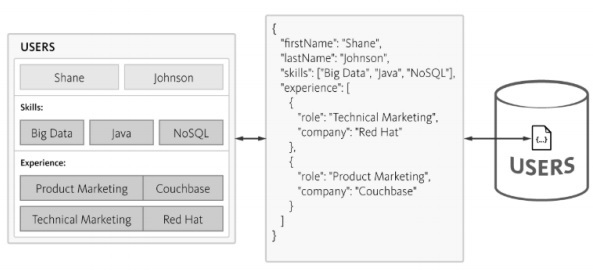
NoSQL รักษาโครงสร้างในรูปแบบ JSON ซึ่งมีน้ำหนักเบาในโครงสร้าง ด้วย JSON แอปพลิเคชันสามารถจัดเก็บออบเจ็กต์ที่มีข้อมูลซ้อนกันเป็นเอกสารเดียว
ในบทนี้เราจะมุ่งเน้นไปที่โครงสร้าง JSON ซึ่งเป็นส่วนหนึ่งของ“ Agile methodology” MongoDB เป็นโครงสร้างข้อมูล NoSQL ที่ใช้กันอย่างแพร่หลายและทำงานได้อย่างง่ายดายสำหรับการรวบรวมและแสดงบันทึก
ขั้นตอนที่ 1
ขั้นตอนนี้เกี่ยวข้องกับการสร้างการเชื่อมต่อกับ MongoDB สำหรับการสร้างคอลเล็กชันและโมเดลข้อมูลที่ระบุ สิ่งที่คุณต้องดำเนินการคือคำสั่ง“ mongod” สำหรับเริ่มการเชื่อมต่อและคำสั่ง mongo เพื่อเชื่อมต่อกับเทอร์มินัลที่ระบุ
ขั้นตอนที่ 2
สร้างฐานข้อมูลใหม่สำหรับสร้างเรกคอร์ดในรูปแบบ JSON ในตอนนี้เรากำลังสร้างฐานข้อมูลจำลองชื่อ“ mydb”
>use mydb
switched to db mydb
>db
mydb
>show dbs
local 0.78125GB
test 0.23012GB
>db.user.insert({"name":"Agile Data Science"})
>show dbs
local 0.78125GB
mydb 0.23012GB
test 0.23012GBขั้นตอนที่ 3
การสร้างคอลเลกชันจำเป็นต้องได้รับรายการเรกคอร์ด คุณลักษณะนี้มีประโยชน์สำหรับการวิจัยและผลลัพธ์ทางวิทยาศาสตร์ข้อมูล
>use test
switched to db test
>db.createCollection("mycollection")
{ "ok" : 1 }
>show collections
mycollection
system.indexes
>db.createCollection("mycol", { capped : true, autoIndexId : true, size :
6142800, max : 10000 } )
{ "ok" : 1 }
>db.agiledatascience.insert({"name" : "demoname"})
>show collections
mycol
mycollection
system.indexes
demonameการแสดงภาพข้อมูลมีบทบาทสำคัญมากในวิทยาศาสตร์ข้อมูล เราสามารถพิจารณาการแสดงภาพข้อมูลเป็นโมดูลหนึ่งของวิทยาศาสตร์ข้อมูล Data Science มีมากกว่าการสร้างแบบจำลองการคาดการณ์ รวมถึงคำอธิบายของแบบจำลองและใช้เพื่อทำความเข้าใจข้อมูลและตัดสินใจ การแสดงภาพข้อมูลเป็นส่วนสำคัญของการนำเสนอข้อมูลด้วยวิธีที่น่าเชื่อที่สุด
จากมุมมองของวิทยาศาสตร์ข้อมูลการแสดงข้อมูลเป็นคุณลักษณะที่เน้นซึ่งแสดงการเปลี่ยนแปลงและแนวโน้ม
พิจารณาแนวทางต่อไปนี้เพื่อการแสดงข้อมูลที่มีประสิทธิภาพ -
วางตำแหน่งข้อมูลตามมาตราส่วนทั่วไป
การใช้แท่งจะมีประสิทธิภาพมากกว่าเมื่อเปรียบเทียบกับวงกลมและสี่เหลี่ยม
ควรใช้สีที่เหมาะสมสำหรับแปลงกระจาย
ใช้แผนภูมิวงกลมเพื่อแสดงสัดส่วน
การแสดงภาพ Sunburst มีประสิทธิภาพมากขึ้นสำหรับพล็อตแบบลำดับชั้น
Agile ต้องการภาษาสคริปต์ที่เรียบง่ายสำหรับการแสดงภาพข้อมูลและด้วยความร่วมมือทางวิทยาศาสตร์ข้อมูล“ Python” เป็นภาษาที่แนะนำสำหรับการแสดงข้อมูล
ตัวอย่าง 1
ตัวอย่างต่อไปนี้แสดงให้เห็นภาพข้อมูลของ GDP ที่คำนวณในปีที่ระบุ “ Matplotlib” เป็นไลบรารีที่ดีที่สุดสำหรับการแสดงข้อมูลใน Python การติดตั้งไลบรารีนี้แสดงไว้ด้านล่าง -
พิจารณารหัสต่อไปนี้เพื่อทำความเข้าใจสิ่งนี้ -
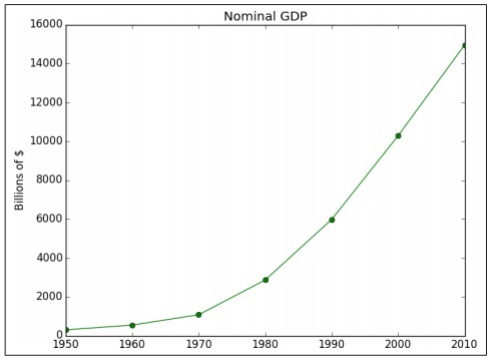
import matplotlib.pyplot as plt
years = [1950, 1960, 1970, 1980, 1990, 2000, 2010]
gdp = [300.2, 543.3, 1075.9, 2862.5, 5979.6, 10289.7, 14958.3]
# create a line chart, years on x-axis, gdp on y-axis
plt.plot(years, gdp, color='green', marker='o', linestyle='solid')
# add a title plt.title("Nominal GDP")
# add a label to the y-axis
plt.ylabel("Billions of $")
plt.show()เอาต์พุต
รหัสด้านบนสร้างผลลัพธ์ต่อไปนี้ -
มีหลายวิธีในการปรับแต่งแผนภูมิด้วยป้ายชื่อแกนลักษณะเส้นและเครื่องหมายจุด มาเน้นที่ตัวอย่างถัดไปซึ่งแสดงให้เห็นถึงการแสดงข้อมูลที่ดีขึ้น ผลลัพธ์เหล่านี้สามารถใช้เพื่อให้ได้ผลลัพธ์ที่ดีขึ้น
ตัวอย่าง 2
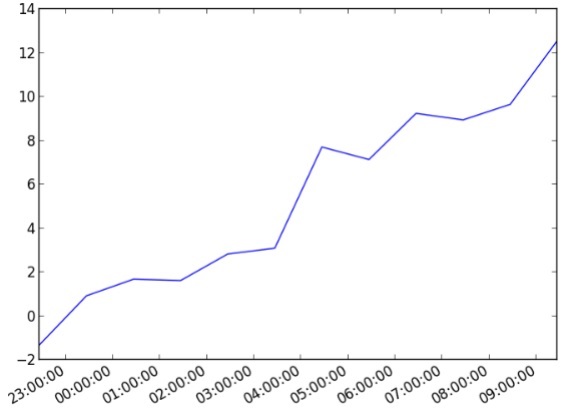
import datetime
import random
import matplotlib.pyplot as plt
# make up some data
x = [datetime.datetime.now() + datetime.timedelta(hours=i) for i in range(12)]
y = [i+random.gauss(0,1) for i,_ in enumerate(x)]
# plot
plt.plot(x,y)
# beautify the x-labels
plt.gcf().autofmt_xdate()
plt.show()เอาต์พุต
รหัสด้านบนสร้างผลลัพธ์ต่อไปนี้ -
การเพิ่มคุณค่าข้อมูลหมายถึงกระบวนการต่างๆที่ใช้ในการปรับปรุงปรับแต่งและปรับปรุงข้อมูลดิบ หมายถึงการแปลงข้อมูลที่เป็นประโยชน์ (ข้อมูลดิบเป็นข้อมูลที่เป็นประโยชน์) กระบวนการเพิ่มประสิทธิภาพข้อมูลมุ่งเน้นไปที่การทำให้ข้อมูลเป็นทรัพย์สินข้อมูลที่มีค่าสำหรับธุรกิจหรือองค์กรสมัยใหม่
กระบวนการเพิ่มคุณค่าข้อมูลที่พบบ่อยที่สุด ได้แก่ การแก้ไขข้อผิดพลาดในการสะกดคำหรือข้อผิดพลาดในการพิมพ์ในฐานข้อมูลโดยใช้อัลกอริทึมการตัดสินใจ เครื่องมือเพิ่มคุณค่าข้อมูลจะเพิ่มข้อมูลที่เป็นประโยชน์ให้กับตารางข้อมูลอย่างง่าย
พิจารณารหัสต่อไปนี้สำหรับการแก้ไขการสะกดคำ -
import re
from collections import Counter
def words(text): return re.findall(r'\w+', text.lower())
WORDS = Counter(words(open('big.txt').read()))
def P(word, N=sum(WORDS.values())):
"Probabilities of words"
return WORDS[word] / N
def correction(word):
"Spelling correction of word"
return max(candidates(word), key=P)
def candidates(word):
"Generate possible spelling corrections for word."
return (known([word]) or known(edits1(word)) or known(edits2(word)) or [word])
def known(words):
"The subset of `words` that appear in the dictionary of WORDS."
return set(w for w in words if w in WORDS)
def edits1(word):
"All edits that are one edit away from `word`."
letters = 'abcdefghijklmnopqrstuvwxyz'
splits = [(word[:i], word[i:]) for i in range(len(word) + 1)]
deletes = [L + R[1:] for L, R in splits if R]
transposes = [L + R[1] + R[0] + R[2:] for L, R in splits if len(R)>1]
replaces = [L + c + R[1:] for L, R in splits if R for c in letters]
inserts = [L + c + R for L, R in splits for c in letters]
return set(deletes + transposes + replaces + inserts)
def edits2(word):
"All edits that are two edits away from `word`."
return (e2 for e1 in edits1(word) for e2 in edits1(e1))
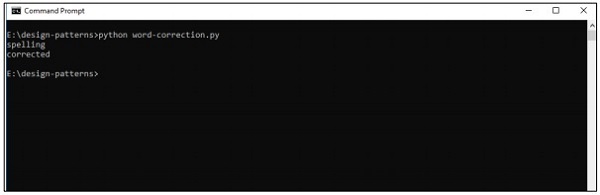
print(correction('speling'))
print(correction('korrectud'))ในโปรแกรมนี้เราจะจับคู่กับ“ big.txt” ซึ่งรวมถึงคำที่แก้ไข คำตรงกับคำที่รวมอยู่ในไฟล์ข้อความและพิมพ์ผลลัพธ์ที่เหมาะสมตามนั้น
เอาต์พุต
โค้ดด้านบนจะสร้างผลลัพธ์ต่อไปนี้ -
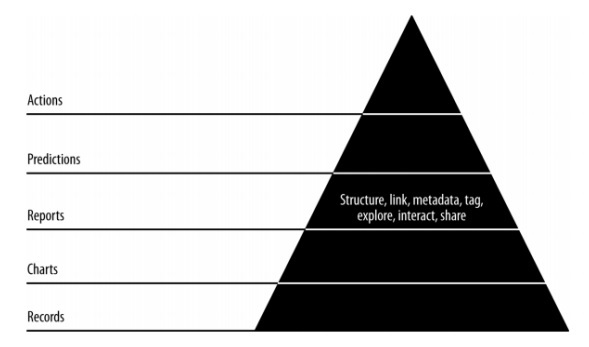
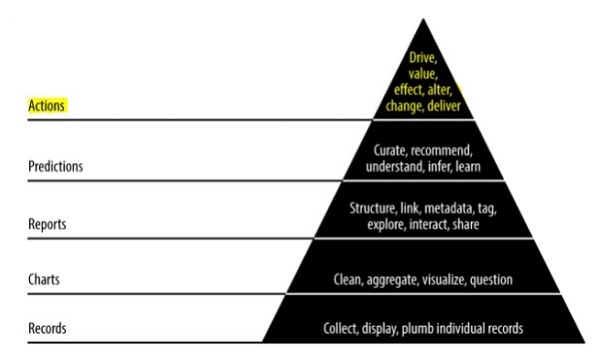
ในบทนี้เราจะเรียนรู้เกี่ยวกับการสร้างรายงานซึ่งเป็นโมดูลที่สำคัญของระเบียบวิธีการแบบเปรียว หน้าแผนภูมิ Agile sprints ที่สร้างขึ้นโดยการแสดงภาพเป็นรายงานเต็มรูปแบบ ด้วยรายงานแผนภูมิจะกลายเป็นแบบโต้ตอบหน้าแบบคงที่จะกลายเป็นข้อมูลที่เกี่ยวข้องกับเครือข่ายแบบไดนามิก ลักษณะของขั้นตอนการรายงานของปิรามิดค่าข้อมูลแสดงไว้ด้านล่าง -
เราจะใช้ความเครียดมากขึ้นในการสร้างไฟล์ csv ซึ่งสามารถใช้เป็นรายงานสำหรับการวิเคราะห์ข้อมูลวิทยาศาสตร์และสรุปผล แม้ว่าเปรียวจะให้ความสำคัญกับเอกสารน้อย แต่การสร้างรายงานเพื่อกล่าวถึงความคืบหน้าของการพัฒนาผลิตภัณฑ์ก็ยังได้รับการพิจารณาเสมอ
import csv
#----------------------------------------------------------------------
def csv_writer(data, path):
"""
Write data to a CSV file path
"""
with open(path, "wb") as csv_file:
writer = csv.writer(csv_file, delimiter=',')
for line in data:
writer.writerow(line)
#----------------------------------------------------------------------
if __name__ == "__main__":
data = ["first_name,last_name,city".split(","),
"Tyrese,Hirthe,Strackeport".split(","),
"Jules,Dicki,Lake Nickolasville".split(","),
"Dedric,Medhurst,Stiedemannberg".split(",")
]
path = "output.csv"
csv_writer(data, path)โค้ดด้านบนจะช่วยให้คุณสร้าง "ไฟล์ csv" ดังที่แสดงด้านล่าง -
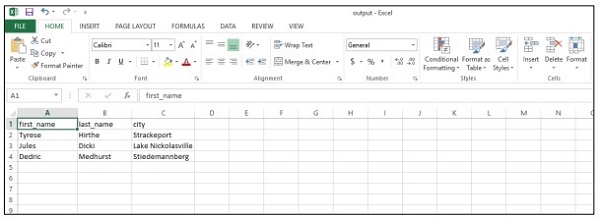
ให้เราพิจารณาประโยชน์ต่อไปนี้ของรายงาน csv (ค่าที่คั่นด้วยจุลภาค) -
- เป็นมิตรกับมนุษย์และง่ายต่อการแก้ไขด้วยตนเอง
- ใช้งานและแยกวิเคราะห์ได้ง่าย
- CSV สามารถประมวลผลได้ในทุกแอปพลิเคชัน
- มีขนาดเล็กและจัดการได้เร็วกว่า
- CSV เป็นไปตามรูปแบบมาตรฐาน
- มีสคีมาที่ตรงไปตรงมาสำหรับนักวิทยาศาสตร์ข้อมูล
ในบทนี้เราจะได้รับเกี่ยวกับบทบาทของการคาดการณ์ในวิทยาศาสตร์ข้อมูลแบบว่องไว รายงานเชิงโต้ตอบจะแสดงข้อมูลในแง่มุมต่างๆ การคาดการณ์เป็นชั้นที่สี่ของการวิ่งแบบว่องไว
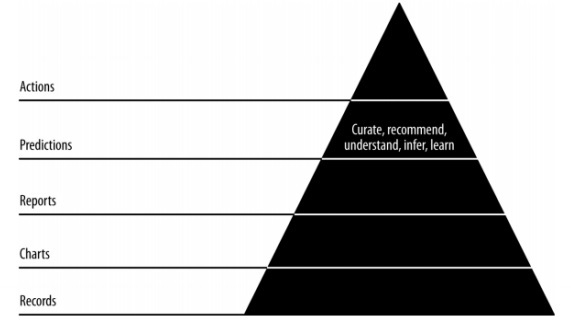
เมื่อทำการคาดการณ์เรามักจะอ้างถึงข้อมูลในอดีตและใช้เป็นข้อมูลอ้างอิงสำหรับการทำซ้ำในอนาคต ในกระบวนการที่สมบูรณ์นี้เราจะเปลี่ยนข้อมูลจากการประมวลผลข้อมูลในอดีตเป็นชุดข้อมูลแบบเรียลไทม์เกี่ยวกับอนาคต
บทบาทของการคาดการณ์มีดังต่อไปนี้ -
การคาดการณ์ช่วยในการพยากรณ์ การคาดการณ์บางอย่างขึ้นอยู่กับการอนุมานทางสถิติ คำทำนายบางส่วนเป็นไปตามความคิดเห็นของเกจิ
การอนุมานทางสถิติเกี่ยวข้องกับการคาดการณ์ทุกชนิด
บางครั้งการคาดการณ์ก็แม่นยำในขณะที่บางครั้งการคาดการณ์อาจไม่ถูกต้อง
Predictive Analytics
การวิเคราะห์เชิงคาดการณ์ประกอบด้วยเทคนิคทางสถิติที่หลากหลายตั้งแต่การสร้างแบบจำลองเชิงคาดการณ์การเรียนรู้ของเครื่องและการขุดข้อมูลซึ่งวิเคราะห์ข้อเท็จจริงในปัจจุบันและในอดีตเพื่อคาดการณ์เกี่ยวกับเหตุการณ์ในอนาคตและที่ไม่รู้จัก
การวิเคราะห์เชิงคาดการณ์ต้องการข้อมูลการฝึกอบรม ข้อมูลที่ผ่านการฝึกอบรมประกอบด้วยคุณสมบัติที่เป็นอิสระและขึ้นอยู่กับ คุณลักษณะที่อ้างอิงคือค่าที่ผู้ใช้พยายามคาดเดา คุณสมบัติอิสระคือคุณสมบัติที่อธิบายถึงสิ่งที่เราต้องการทำนายโดยอิงจากคุณสมบัติที่อ้างอิง
การศึกษาคุณสมบัติเรียกว่าวิศวกรรมคุณลักษณะ นี่เป็นสิ่งสำคัญในการคาดการณ์ การสร้างภาพข้อมูลและการวิเคราะห์ข้อมูลเชิงสำรวจเป็นส่วนหนึ่งของวิศวกรรมคุณลักษณะ สิ่งเหล่านี้เป็นแกนกลางของAgile data science.
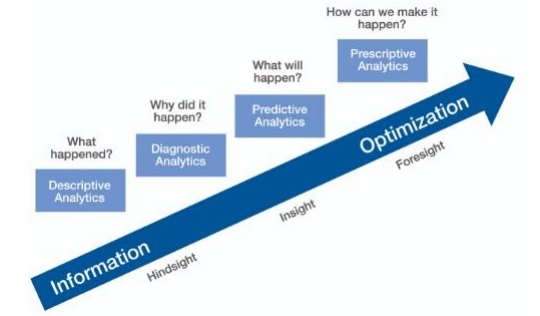
การทำนาย
มีสองวิธีในการคาดการณ์ใน Agile Data Science -
Regression
Classification
การสร้างการถดถอยหรือการจำแนกประเภททั้งหมดขึ้นอยู่กับข้อกำหนดทางธุรกิจและการวิเคราะห์ การทำนายตัวแปรต่อเนื่องนำไปสู่แบบจำลองการถดถอยและการทำนายตัวแปรเชิงหมวดหมู่นำไปสู่รูปแบบการจำแนก
การถดถอย
การถดถอยพิจารณาตัวอย่างที่ประกอบด้วยคุณลักษณะและด้วยเหตุนี้จึงสร้างผลลัพธ์ที่เป็นตัวเลข
การจำแนกประเภท
การจัดประเภทจะนำข้อมูลเข้าและสร้างการจำแนกประเภท
Note - ชุดข้อมูลตัวอย่างที่กำหนดการป้อนข้อมูลในการทำนายทางสถิติและทำให้เครื่องสามารถเรียนรู้ได้เรียกว่า "ข้อมูลการฝึกอบรม"
ในบทนี้เราจะเรียนรู้เกี่ยวกับการประยุกต์ใช้คุณสมบัติการแยกด้วย PySpark ใน Agile Data Science
ภาพรวมของ Spark
Apache Spark สามารถกำหนดให้เป็นกรอบการประมวลผลแบบเรียลไทม์ที่รวดเร็ว ทำการคำนวณเพื่อวิเคราะห์ข้อมูลแบบเรียลไทม์ Apache Spark ถูกนำมาใช้เป็นระบบประมวลผลสตรีมแบบเรียลไทม์และยังสามารถดูแลการประมวลผลแบบแบทช์ Apache Spark รองรับการสอบถามแบบโต้ตอบและอัลกอริทึมซ้ำ ๆ
Spark เขียนด้วย "ภาษาโปรแกรม Scala"
PySpark ถือได้ว่าเป็นการรวมกันระหว่าง Python กับ Spark PySpark มี PySpark shell ซึ่งเชื่อมโยง Python API กับ Spark core และเริ่มต้นบริบท Spark นักวิทยาศาสตร์ข้อมูลส่วนใหญ่ใช้ PySpark เพื่อติดตามคุณสมบัติตามที่กล่าวไว้ในบทก่อนหน้า
ในตัวอย่างนี้เราจะเน้นไปที่การแปลงเพื่อสร้างชุดข้อมูลที่เรียกว่า counts และบันทึกลงในไฟล์เฉพาะ
text_file = sc.textFile("hdfs://...")
counts = text_file.flatMap(lambda line: line.split(" ")) \
.map(lambda word: (word, 1)) \
.reduceByKey(lambda a, b: a + b)
counts.saveAsTextFile("hdfs://...")การใช้ PySpark ผู้ใช้สามารถทำงานกับ RDD ในภาษาโปรแกรมไพ ธ อน ไลบรารี inbuilt ซึ่งครอบคลุมพื้นฐานของเอกสารและส่วนประกอบที่ขับเคลื่อนด้วยข้อมูลช่วยในเรื่องนี้
Logistic Regression หมายถึงอัลกอริทึมการเรียนรู้ของเครื่องที่ใช้ในการทำนายความน่าจะเป็นของตัวแปรตามหมวดหมู่ ในการถดถอยโลจิสติกตัวแปรตามคือตัวแปรไบนารีซึ่งประกอบด้วยข้อมูลที่เข้ารหัสเป็น 1 (ค่าบูลีนเป็นจริงและเท็จ)
ในบทนี้เราจะมุ่งเน้นไปที่การพัฒนาแบบจำลองการถดถอยใน Python โดยใช้ตัวแปรต่อเนื่อง ตัวอย่างสำหรับโมเดลการถดถอยเชิงเส้นจะเน้นไปที่การสำรวจข้อมูลจากไฟล์ CSV
เป้าหมายการจัดประเภทคือการทำนายว่าลูกค้าจะสมัคร (1/0) เพื่อฝากระยะหรือไม่
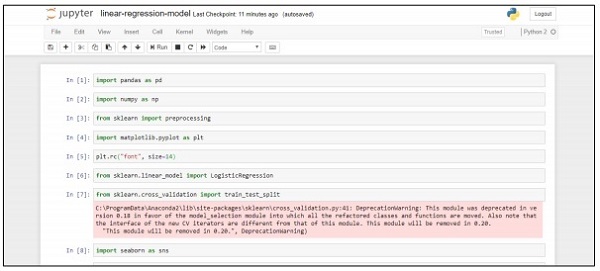
import pandas as pd
import numpy as np
from sklearn import preprocessing
import matplotlib.pyplot as plt
plt.rc("font", size=14)
from sklearn.linear_model import LogisticRegression
from sklearn.cross_validation import train_test_split
import seaborn as sns
sns.set(style="white")
sns.set(style="whitegrid", color_codes=True)
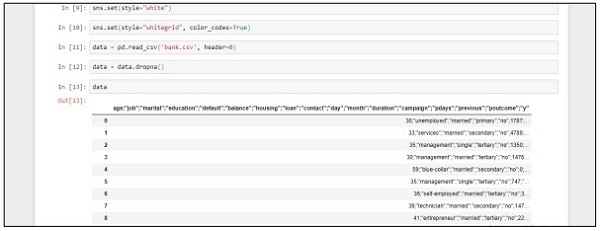
data = pd.read_csv('bank.csv', header=0)
data = data.dropna()
print(data.shape)
print(list(data.columns))ทำตามขั้นตอนเหล่านี้เพื่อติดตั้งโค้ดด้านบนใน Anaconda Navigator ด้วย“ Jupyter Notebook” -
Step 1 - เปิดตัว Jupyter Notebook พร้อม Anaconda Navigator
Step 2 - อัปโหลดไฟล์ csv เพื่อรับผลลัพธ์ของแบบจำลองการถดถอยอย่างเป็นระบบ
Step 3 - สร้างไฟล์ใหม่และดำเนินการตามโค้ดข้างต้นเพื่อให้ได้ผลลัพธ์ที่ต้องการ
ในตัวอย่างนี้เราจะเรียนรู้วิธีสร้างและปรับใช้แบบจำลองการคาดการณ์ซึ่งช่วยในการทำนายราคาบ้านโดยใช้สคริปต์ python เฟรมเวิร์กที่สำคัญที่ใช้สำหรับการปรับใช้ระบบคาดการณ์ ได้แก่ Anaconda และ“ Jupyter Notebook”
ทำตามขั้นตอนเหล่านี้เพื่อปรับใช้ระบบคาดการณ์ -
Step 1 - ใช้โค้ดต่อไปนี้เพื่อแปลงค่าจากไฟล์ csv เป็นค่าที่เกี่ยวข้อง
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import mpl_toolkits
%matplotlib inline
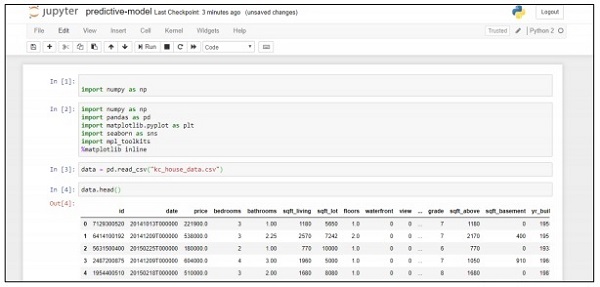
data = pd.read_csv("kc_house_data.csv")
data.head()รหัสด้านบนสร้างผลลัพธ์ต่อไปนี้ -
Step 2 - เรียกใช้ฟังก์ชันอธิบายเพื่อรับชนิดข้อมูลที่รวมอยู่ในไฟล์ csv
data.describe()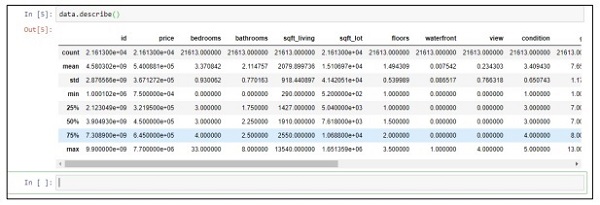
Step 3 - เราสามารถทิ้งค่าที่เกี่ยวข้องตามการปรับใช้แบบจำลองการคาดการณ์ที่เราสร้างขึ้น
train1 = data.drop(['id', 'price'],axis=1)
train1.head()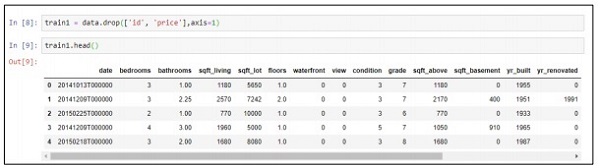
Step 4- คุณสามารถแสดงภาพข้อมูลตามบันทึก ข้อมูลสามารถใช้สำหรับการวิเคราะห์วิทยาศาสตร์ข้อมูลและการส่งออกเอกสารไวท์เปเปอร์
data.floors.value_counts().plot(kind='bar')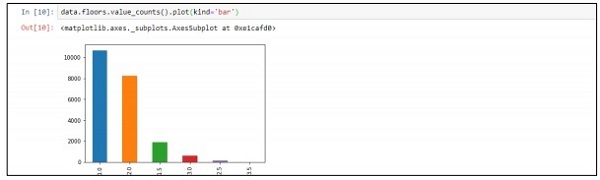
ไลบรารีแมชชีนเลิร์นนิงเรียกอีกอย่างว่า "SparkML" หรือ "MLLib" ประกอบด้วยอัลกอริทึมการเรียนรู้ทั่วไปซึ่งรวมถึงการจำแนกการถดถอยการจัดกลุ่มและการกรองการทำงานร่วมกัน
ทำไมต้องเรียน SparkML for Agile
Spark กำลังกลายเป็นแพลตฟอร์ม de-facto สำหรับการสร้างอัลกอริทึมและแอปพลิเคชันแมชชีนเลิร์นนิง นักพัฒนาทำงานกับ Spark เพื่อใช้อัลกอริทึมของเครื่องในลักษณะที่ปรับขนาดได้และรัดกุมในกรอบ Spark เราจะเรียนรู้แนวคิดของการเรียนรู้ของเครื่องยูทิลิตี้และอัลกอริทึมของมันด้วยกรอบนี้ Agile มักจะเลือกใช้กรอบงานซึ่งให้ผลลัพธ์ที่สั้นและรวดเร็ว
อัลกอริทึม ML
ML Algorithms ประกอบด้วยอัลกอริทึมการเรียนรู้ทั่วไปเช่นการจำแนกการถดถอยการจัดกลุ่มและการกรองการทำงานร่วมกัน
คุณสมบัติ
ซึ่งรวมถึงการแยกคุณลักษณะการเปลี่ยนแปลงการลดขนาดและการเลือก
ท่อ
ไปป์ไลน์เป็นเครื่องมือสำหรับสร้างประเมินและปรับจูนท่อแมชชีนเลิร์นนิง
อัลกอริทึมยอดนิยม
ต่อไปนี้เป็นอัลกอริทึมยอดนิยมบางส่วน -
สถิติพื้นฐาน
Regression
Classification
ระบบคำแนะนำ
Clustering
การลดขนาด
คุณสมบัติการสกัด
Optimization
ระบบคำแนะนำ
ระบบคำแนะนำเป็นคลาสย่อยของระบบการกรองข้อมูลที่ค้นหาการคาดคะเนของ "การให้คะแนน" และ "ความชอบ" ที่ผู้ใช้แนะนำให้กับรายการที่กำหนด
ระบบคำแนะนำรวมถึงระบบการกรองต่างๆซึ่งใช้ดังต่อไปนี้ -
การกรองร่วมกัน
ซึ่งรวมถึงการสร้างแบบจำลองตามพฤติกรรมในอดีตและการตัดสินใจที่คล้ายคลึงกันของผู้ใช้รายอื่น รูปแบบการกรองเฉพาะนี้ใช้เพื่อคาดการณ์รายการที่ผู้ใช้สนใจที่จะรับ
การกรองตามเนื้อหา
รวมถึงการกรองลักษณะที่ไม่ต่อเนื่องของรายการเพื่อแนะนำและเพิ่มรายการใหม่ที่มีคุณสมบัติคล้ายคลึงกัน
ในบทต่อ ๆ ไปเราจะมุ่งเน้นไปที่การใช้ระบบคำแนะนำเพื่อแก้ปัญหาเฉพาะและปรับปรุงประสิทธิภาพการทำนายจากมุมมองของวิธีการแบบว่องไว
ในบทนี้เราจะมุ่งเน้นไปที่การแก้ไขปัญหาการคาดการณ์ด้วยความช่วยเหลือของสถานการณ์เฉพาะ
พิจารณาว่า บริษัท ต้องการทำรายละเอียดคุณสมบัติการกู้ยืมโดยอัตโนมัติตามรายละเอียดของลูกค้าที่ให้ไว้ในแบบฟอร์มใบสมัครออนไลน์ รายละเอียดประกอบด้วยชื่อลูกค้าเพศสถานภาพการสมรสจำนวนเงินกู้และรายละเอียดบังคับอื่น ๆ
รายละเอียดจะถูกบันทึกไว้ในไฟล์ CSV ดังที่แสดงด้านล่าง -
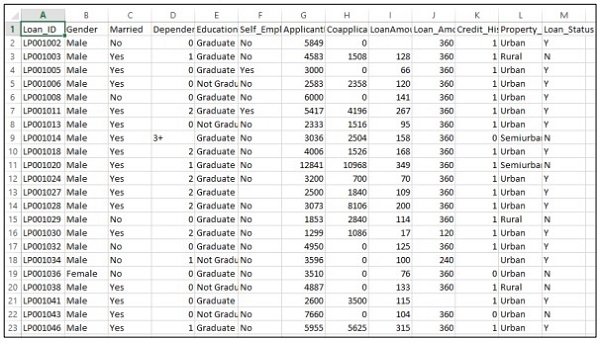
รันโค้ดต่อไปนี้เพื่อประเมินปัญหาการทำนาย -
import pandas as pd
from sklearn import ensemble
import numpy as np
from scipy.stats import mode
from sklearn import preprocessing,model_selection
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import LabelEncoder
#loading the dataset
data=pd.read_csv('train.csv',index_col='Loan_ID')
def num_missing(x):
return sum(x.isnull())
#imputing the the missing values from the data
data['Gender'].fillna(mode(list(data['Gender'])).mode[0], inplace=True)
data['Married'].fillna(mode(list(data['Married'])).mode[0], inplace=True)
data['Self_Employed'].fillna(mode(list(data['Self_Employed'])).mode[0], inplace=True)
# print (data.apply(num_missing, axis=0))
# #imputing mean for the missing value
data['LoanAmount'].fillna(data['LoanAmount'].mean(), inplace=True)
mapping={'0':0,'1':1,'2':2,'3+':3}
data = data.replace({'Dependents':mapping})
data['Dependents'].fillna(data['Dependents'].mean(), inplace=True)
data['Loan_Amount_Term'].fillna(method='ffill',inplace=True)
data['Credit_History'].fillna(method='ffill',inplace=True)
print (data.apply(num_missing,axis=0))
#converting the cateogorical data to numbers using the label encoder
var_mod = ['Gender','Married','Education','Self_Employed','Property_Area','Loan_Status']
le = LabelEncoder()
for i in var_mod:
le.fit(list(data[i].values))
data[i] = le.transform(list(data[i]))
#Train test split
x=['Gender','Married','Education','Self_Employed','Property_Area','LoanAmount', 'Loan_Amount_Term','Credit_History','Dependents']
y=['Loan_Status']
print(data[x])
X_train,X_test,y_train,y_test=model_selection.train_test_split(data[x],data[y], test_size=0.2)
#
# #Random forest classifier
# clf=ensemble.RandomForestClassifier(n_estimators=100,
criterion='gini',max_depth=3,max_features='auto',n_jobs=-1)
clf=ensemble.RandomForestClassifier(n_estimators=200,max_features=3,min_samples
_split=5,oob_score=True,n_jobs=-1,criterion='entropy')
clf.fit(X_train,y_train)
accuracy=clf.score(X_test,y_test)
print(accuracy)เอาต์พุต
โค้ดด้านบนสร้างผลลัพธ์ต่อไปนี้

ในบทนี้เราจะมุ่งเน้นไปที่การสร้างแบบจำลองที่ช่วยในการทำนายผลการเรียนของนักเรียนโดยมีคุณลักษณะหลายอย่างรวมอยู่ในนั้น จุดเน้นคือการแสดงผลความล้มเหลวของนักเรียนในการตรวจสอบ
กระบวนการ
ค่าเป้าหมายของการประเมินคือ G3 ค่านี้สามารถจัดประเภทเป็นความล้มเหลวและความสำเร็จได้ ถ้าค่า G3 มากกว่าหรือเท่ากับ 10 แสดงว่านักเรียนผ่านการตรวจสอบ
ตัวอย่าง
พิจารณาตัวอย่างต่อไปนี้ซึ่งมีการเรียกใช้รหัสเพื่อทำนายประสิทธิภาพหากนักเรียน -
import pandas as pd
""" Read data file as DataFrame """
df = pd.read_csv("student-mat.csv", sep=";")
""" Import ML helpers """
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix
from sklearn.model_selection import GridSearchCV, cross_val_score
from sklearn.pipeline import Pipeline
from sklearn.feature_selection import SelectKBest, chi2
from sklearn.svm import LinearSVC # Support Vector Machine Classifier model
""" Split Data into Training and Testing Sets """
def split_data(X, Y):
return train_test_split(X, Y, test_size=0.2, random_state=17)
""" Confusion Matrix """
def confuse(y_true, y_pred):
cm = confusion_matrix(y_true=y_true, y_pred=y_pred)
# print("\nConfusion Matrix: \n", cm)
fpr(cm)
ffr(cm)
""" False Pass Rate """
def fpr(confusion_matrix):
fp = confusion_matrix[0][1]
tf = confusion_matrix[0][0]
rate = float(fp) / (fp + tf)
print("False Pass Rate: ", rate)
""" False Fail Rate """
def ffr(confusion_matrix):
ff = confusion_matrix[1][0]
tp = confusion_matrix[1][1]
rate = float(ff) / (ff + tp)
print("False Fail Rate: ", rate)
return rate
""" Train Model and Print Score """
def train_and_score(X, y):
X_train, X_test, y_train, y_test = split_data(X, y)
clf = Pipeline([
('reduce_dim', SelectKBest(chi2, k=2)),
('train', LinearSVC(C=100))
])
scores = cross_val_score(clf, X_train, y_train, cv=5, n_jobs=2)
print("Mean Model Accuracy:", np.array(scores).mean())
clf.fit(X_train, y_train)
confuse(y_test, clf.predict(X_test))
print()
""" Main Program """
def main():
print("\nStudent Performance Prediction")
# For each feature, encode to categorical values
class_le = LabelEncoder()
for column in df[["school", "sex", "address", "famsize", "Pstatus", "Mjob",
"Fjob", "reason", "guardian", "schoolsup", "famsup", "paid", "activities",
"nursery", "higher", "internet", "romantic"]].columns:
df[column] = class_le.fit_transform(df[column].values)
# Encode G1, G2, G3 as pass or fail binary values
for i, row in df.iterrows():
if row["G1"] >= 10:
df["G1"][i] = 1
else:
df["G1"][i] = 0
if row["G2"] >= 10:
df["G2"][i] = 1
else:
df["G2"][i] = 0
if row["G3"] >= 10:
df["G3"][i] = 1
else:
df["G3"][i] = 0
# Target values are G3
y = df.pop("G3")
# Feature set is remaining features
X = df
print("\n\nModel Accuracy Knowing G1 & G2 Scores")
print("=====================================")
train_and_score(X, y)
# Remove grade report 2
X.drop(["G2"], axis = 1, inplace=True)
print("\n\nModel Accuracy Knowing Only G1 Score")
print("=====================================")
train_and_score(X, y)
# Remove grade report 1
X.drop(["G1"], axis=1, inplace=True)
print("\n\nModel Accuracy Without Knowing Scores")
print("=====================================")
train_and_score(X, y)
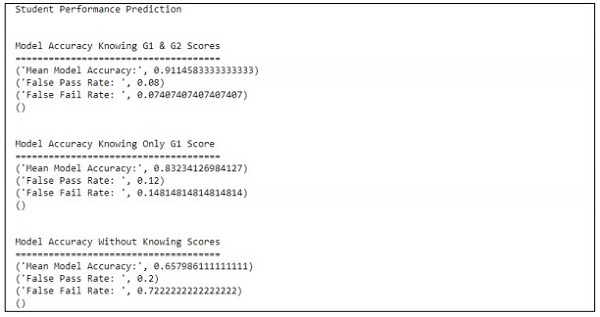
main()เอาต์พุต
โค้ดด้านบนจะสร้างผลลัพธ์ตามที่แสดงด้านล่าง
การคาดคะเนได้รับการปฏิบัติโดยอ้างอิงตัวแปรเพียงตัวเดียว ด้วยการอ้างอิงตัวแปรเดียวการทำนายผลการเรียนของนักเรียนจะเป็นดังที่แสดงด้านล่าง -
วิธีการแบบ Agile ช่วยให้องค์กรสามารถปรับเปลี่ยนการเปลี่ยนแปลงแข่งขันในตลาดและสร้างผลิตภัณฑ์คุณภาพสูง เป็นที่สังเกตว่าองค์กรเติบโตขึ้นด้วยวิธีการแบบว่องไวโดยมีการเปลี่ยนแปลงความต้องการจากลูกค้าเพิ่มขึ้น การรวบรวมและซิงโครไนซ์ข้อมูลกับทีมงานที่คล่องตัวขององค์กรมีความสำคัญในการรวบรวมข้อมูลตามพอร์ตโฟลิโอที่ต้องการ
สร้างแผนการที่ดีขึ้น
ประสิทธิภาพของ Agile ที่เป็นมาตรฐานขึ้นอยู่กับแผนเท่านั้น แผนผังข้อมูลที่สั่งซื้อจะช่วยเพิ่มประสิทธิภาพการผลิตคุณภาพและการตอบสนองต่อความก้าวหน้าขององค์กร ระดับความสอดคล้องของข้อมูลจะคงไว้ด้วยสถานการณ์ในอดีตและตามเวลาจริง
พิจารณาแผนภาพต่อไปนี้เพื่อทำความเข้าใจวงจรการทดลองวิทยาศาสตร์ข้อมูล -
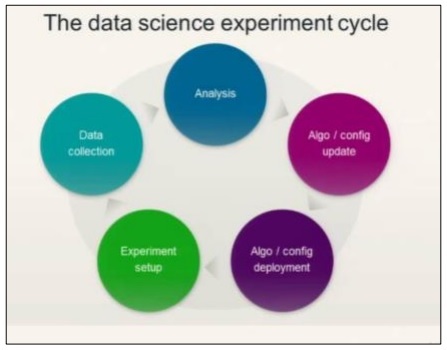
วิทยาศาสตร์ข้อมูลเกี่ยวข้องกับการวิเคราะห์ความต้องการตามด้วยการสร้างอัลกอริทึมตามแบบเดียวกัน เมื่ออัลกอริทึมได้รับการออกแบบพร้อมกับการตั้งค่าสิ่งแวดล้อมผู้ใช้สามารถสร้างการทดลองและรวบรวมข้อมูลเพื่อการวิเคราะห์ที่ดีขึ้น
อุดมการณ์นี้คำนวณการวิ่งครั้งสุดท้ายของความคล่องตัวซึ่งเรียกว่า "การกระทำ"
Actionsเกี่ยวข้องกับงานบังคับทั้งหมดสำหรับการวิ่งครั้งสุดท้ายหรือระดับวิธีการแบบว่องไว ติดตามขั้นตอนของวิทยาศาสตร์ข้อมูล (เกี่ยวกับวงจรชีวิต) ได้โดยใช้การ์ดเรื่องราวเป็นรายการดำเนินการ
การวิเคราะห์เชิงคาดการณ์และข้อมูลขนาดใหญ่
อนาคตของการวางแผนอย่างสมบูรณ์อยู่ที่การปรับแต่งรายงานข้อมูลด้วยข้อมูลที่รวบรวมจากการวิเคราะห์ นอกจากนี้ยังรวมถึงการจัดการกับการวิเคราะห์ข้อมูลขนาดใหญ่ ด้วยความช่วยเหลือของข้อมูลขนาดใหญ่สามารถวิเคราะห์ชิ้นส่วนข้อมูลที่ไม่ต่อเนื่องได้อย่างมีประสิทธิภาพด้วยการแบ่งส่วนและกำหนดเมตริกขององค์กร การวิเคราะห์ถือเป็นทางออกที่ดีกว่าเสมอ
มีวิธีการต่างๆที่ใช้ในกระบวนการพัฒนาแบบว่องไว วิธีการเหล่านี้สามารถใช้สำหรับกระบวนการวิจัยวิทยาศาสตร์ข้อมูลได้เช่นกัน
ผังงานที่ระบุด้านล่างแสดงวิธีการต่างๆ -
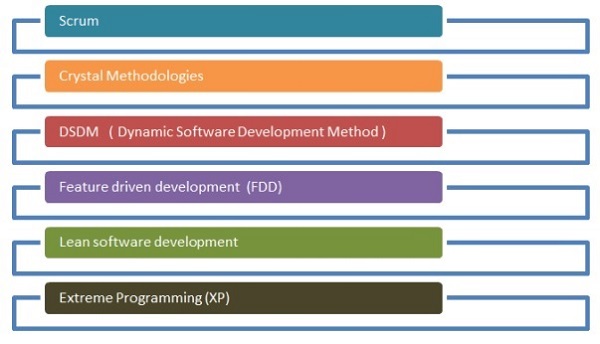
การต่อสู้
ในแง่ของการพัฒนาซอฟต์แวร์การต่อสู้หมายถึงการจัดการงานกับทีมขนาดเล็กและการจัดการโครงการเฉพาะเพื่อเปิดเผยจุดแข็งและจุดอ่อนของโครงการ
วิธีการคริสตัล
วิธีการของคริสตัลรวมถึงเทคนิคใหม่ ๆ สำหรับการจัดการและการดำเนินการผลิตภัณฑ์ ด้วยวิธีนี้ทีมสามารถทำงานที่คล้ายกันได้หลายวิธี ตระกูลคริสตัลเป็นหนึ่งในวิธีการที่ง่ายที่สุดในการนำไปใช้
วิธีการพัฒนาซอฟต์แวร์แบบไดนามิก
กรอบการจัดส่งนี้ใช้เป็นหลักในการนำระบบความรู้ปัจจุบันมาใช้ในวิธีการของซอฟต์แวร์
การพัฒนาที่ขับเคลื่อนในอนาคต
จุดเน้นของวงจรชีวิตการพัฒนานี้คือคุณลักษณะที่เกี่ยวข้องกับโครงการ ทำงานได้ดีที่สุดสำหรับการสร้างแบบจำลองออบเจ็กต์โดเมนรหัสและการพัฒนาคุณลักษณะเพื่อความเป็นเจ้าของ
การพัฒนาซอฟต์แวร์แบบลีน
การเขียนโปรแกรมขั้นสูง
การเขียนโปรแกรมขั้นสูงเป็นวิธีการพัฒนาซอฟต์แวร์ที่ไม่เหมือนใครซึ่งมุ่งเน้นไปที่การปรับปรุงคุณภาพซอฟต์แวร์ สิ่งนี้มีผลเมื่อลูกค้าไม่แน่ใจเกี่ยวกับฟังก์ชันการทำงานของโครงการใด ๆ
วิธีการแบบ Agile กำลังหยั่งรากลึกในกระแสข้อมูลวิทยาศาสตร์และถือเป็นวิธีการซอฟต์แวร์ที่สำคัญ ด้วยการจัดระเบียบตนเองที่คล่องตัวทีมข้ามสายงานสามารถทำงานร่วมกันได้อย่างมีประสิทธิภาพ ดังที่ได้กล่าวไปแล้วมีการพัฒนาแบบว่องไวอยู่ 6 ประเภทหลัก ๆ และแต่ละประเภทสามารถสตรีมด้วยวิทยาศาสตร์ข้อมูลได้ตามข้อกำหนด วิทยาศาสตร์ข้อมูลเกี่ยวข้องกับกระบวนการวนซ้ำสำหรับข้อมูลเชิงลึกทางสถิติ Agile ช่วยในการแบ่งโมดูลวิทยาศาสตร์ข้อมูลและช่วยในการประมวลผลการทำซ้ำและการวิ่งอย่างมีประสิทธิภาพ
กระบวนการของ Agile Data Science เป็นวิธีที่ยอดเยี่ยมในการทำความเข้าใจว่าทำไมจึงใช้โมดูล Data Science แก้ปัญหาอย่างสร้างสรรค์