Apache MXNet - คู่มือฉบับย่อ
บทนี้จะเน้นคุณสมบัติของ Apache MXNet และพูดถึงเวอร์ชันล่าสุดของเฟรมเวิร์กซอฟต์แวร์การเรียนรู้เชิงลึกนี้
MXNet คืออะไร?
Apache MXNet เป็นเครื่องมือเฟรมเวิร์กซอฟต์แวร์การเรียนรู้เชิงลึกแบบโอเพนซอร์สที่ทรงพลังซึ่งช่วยให้นักพัฒนาสร้างฝึกอบรมและปรับใช้โมเดล Deep Learning ไม่กี่ปีที่ผ่านมาตั้งแต่การดูแลสุขภาพไปจนถึงการขนส่งไปจนถึงการผลิตและในความเป็นจริงในทุกแง่มุมของชีวิตประจำวันของเราผลกระทบของการเรียนรู้เชิงลึกได้แพร่หลายไปทั่ว ปัจจุบัน บริษัท ต่างๆต้องการการเรียนรู้เชิงลึกเพื่อแก้ปัญหาที่ยากลำบากเช่นการจดจำใบหน้าการตรวจจับวัตถุการรู้จำอักขระด้วยแสง (OCR) การรู้จำเสียงและการแปลด้วยเครื่อง
นั่นคือเหตุผลที่ Apache MXNet รองรับโดย:
บริษัท ใหญ่ ๆ บางแห่งเช่น Intel, Baidu, Microsoft, Wolfram Research เป็นต้น
ผู้ให้บริการระบบคลาวด์สาธารณะรวมถึง Amazon Web Services (AWS) และ Microsoft Azure
สถาบันวิจัยขนาดใหญ่บางแห่งเช่น Carnegie Mellon, MIT, University of Washington และ HongKong University of Science & Technology
ทำไมต้อง Apache MXNet
มีแพลตฟอร์มการเรียนรู้เชิงลึกมากมายเช่น Torch7, Caffe, Theano, TensorFlow, Keras, Microsoft Cognitive Toolkit เป็นต้นแล้วคุณอาจสงสัยว่าทำไม Apache MXNet? ลองดูสาเหตุบางประการ:
Apache MXNet แก้ปัญหาที่ใหญ่ที่สุดอย่างหนึ่งของแพลตฟอร์มการเรียนรู้เชิงลึกที่มีอยู่ ปัญหาคือในการใช้แพลตฟอร์มการเรียนรู้เชิงลึกเราต้องเรียนรู้ระบบอื่นสำหรับรสชาติการเขียนโปรแกรมที่แตกต่างกัน
ด้วยความช่วยเหลือของนักพัฒนา Apache MXNet สามารถใช้ประโยชน์จากความสามารถทั้งหมดของ GPU รวมทั้งการประมวลผลแบบคลาวด์
Apache MXNet สามารถเร่งการคำนวณตัวเลขและให้ความสำคัญเป็นพิเศษในการเร่งการพัฒนาและการปรับใช้ DNN ขนาดใหญ่ (เครือข่ายประสาทเทียมแบบลึก)
ช่วยให้ผู้ใช้มีความสามารถในการเขียนโปรแกรมทั้งแบบจำเป็นและเชิงสัญลักษณ์
คุณสมบัติต่างๆ
หากคุณกำลังมองหาไลบรารีการเรียนรู้เชิงลึกที่ยืดหยุ่นเพื่อพัฒนางานวิจัยเชิงลึกที่ล้ำสมัยอย่างรวดเร็วหรือแพลตฟอร์มที่มีประสิทธิภาพเพื่อผลักภาระงานการผลิตการค้นหาของคุณจะสิ้นสุดที่ Apache MXNet เป็นเพราะคุณสมบัติดังต่อไปนี้:
การฝึกอบรมแบบกระจาย
ไม่ว่าจะเป็นการฝึกอบรมแบบ multi-gpu หรือ multi-host ที่มีประสิทธิภาพในการปรับขนาดใกล้เชิงเส้น Apache MXNet ช่วยให้นักพัฒนาใช้ประโยชน์สูงสุดจากฮาร์ดแวร์ของตน MXNet ยังรองรับการทำงานร่วมกับ Horovod ซึ่งเป็นโอเพ่นซอร์สที่เผยแพร่กรอบการเรียนรู้เชิงลึกที่สร้างขึ้นที่ Uber
สำหรับการผสานรวมนี้ต่อไปนี้เป็น API แบบกระจายทั่วไปที่กำหนดไว้ใน Horovod:
horovod.broadcast()
horovod.allgather()
horovod.allgather()
ในเรื่องนี้ MXNet มีความสามารถดังต่อไปนี้:
Device Placement - ด้วยความช่วยเหลือของ MXNet เราสามารถระบุโครงสร้างข้อมูล (DS) แต่ละรายการได้อย่างง่ายดาย
Automatic Differentiation - Apache MXNet ทำการคำนวณความแตกต่างโดยอัตโนมัติเช่นการคำนวณอนุพันธ์
Multi-GPU training - MXNet ช่วยให้เราบรรลุประสิทธิภาพในการปรับขนาดด้วย GPU ที่มีอยู่จำนวนมาก
Optimized Predefined Layers - เราสามารถโค้ดเลเยอร์ของเราเองใน MXNet รวมทั้งปรับแต่งเลเยอร์ที่กำหนดไว้ล่วงหน้าเพื่อความเร็ว
การผสมพันธ์
Apache MXNet ให้ผู้ใช้ไฮบริดฟรอนต์เอนด์ ด้วยความช่วยเหลือของ Gluon Python API มันสามารถเชื่อมช่องว่างระหว่างความจำเป็นและความสามารถเชิงสัญลักษณ์ สามารถทำได้โดยเรียกว่าฟังก์ชันไฮบริดไลซ์
การคำนวณที่เร็วขึ้น
การดำเนินการเชิงเส้นเช่นการคูณเมทริกซ์หลายสิบหรือหลายร้อยเป็นคอขวดของการคำนวณสำหรับอวนประสาทแบบลึก เพื่อแก้ปัญหาคอขวด MXNet นี้ให้ -
เพิ่มประสิทธิภาพการคำนวณเชิงตัวเลขสำหรับ GPU
เพิ่มประสิทธิภาพการคำนวณเชิงตัวเลขสำหรับระบบนิเวศแบบกระจาย
การทำงานอัตโนมัติของเวิร์กโฟลว์ทั่วไปด้วยความช่วยเหลือซึ่ง NN มาตรฐานสามารถแสดงได้สั้น ๆ
การผูกภาษา
MXNet มีการรวมเข้ากับภาษาระดับสูงเช่น Python และ R อย่างลึกซึ้งนอกจากนี้ยังให้การสนับสนุนสำหรับภาษาโปรแกรมอื่น ๆ เช่น -
Scala
Julia
Clojure
Java
C/C++
Perl
เราไม่จำเป็นต้องเรียนรู้ภาษาการเขียนโปรแกรมใหม่ใด ๆ แทน MXNet เมื่อรวมกับคุณสมบัติไฮบริดไลเซชันทำให้สามารถเปลี่ยนจาก Python ไปสู่การปรับใช้ในภาษาโปรแกรมที่เราเลือกได้อย่างราบรื่น
เวอร์ชั่นล่าสุด MXNet 1.6.0
Apache Software Foundation (ASF) ได้เปิดตัว Apache MXNet เวอร์ชันเสถียร 1.6.0 ในวันที่ 21 กุมภาพันธ์ 2020 ภายใต้ Apache License 2.0 นี่เป็น MXNet รุ่นสุดท้ายที่รองรับ Python 2 เนื่องจากชุมชน MXNet โหวตให้ไม่สนับสนุน Python 2 อีกต่อไปในรุ่นต่อไป ให้เราตรวจสอบคุณสมบัติใหม่บางอย่างที่รุ่นนี้นำเสนอสำหรับผู้ใช้
อินเตอร์เฟซที่เข้ากันได้กับ NumPy
เนื่องจากความยืดหยุ่นและลักษณะทั่วไป NumPy จึงถูกนำมาใช้อย่างกว้างขวางโดยผู้ปฏิบัติงาน Machine Learning นักวิทยาศาสตร์และนักเรียน แต่อย่างที่เราทราบกันดีว่าตัวเร่งฮาร์ดแวร์ในปัจจุบันเช่นหน่วยประมวลผลกราฟิก (GPU) ได้ถูกหลอมรวมเข้ากับชุดเครื่องมือ Machine Learning (ML) ที่หลากหลายมากขึ้นผู้ใช้ NumPy เพื่อใช้ประโยชน์จากความเร็วของ GPU จำเป็นต้องเปลี่ยนไปใช้เฟรมเวิร์กใหม่ ด้วยไวยากรณ์ที่แตกต่างกัน
ด้วย MXNet 1.6.0 Apache MXNet กำลังก้าวไปสู่ประสบการณ์การเขียนโปรแกรมที่เข้ากันได้กับ NumPy อินเทอร์เฟซใหม่ให้การใช้งานที่เทียบเท่าและการแสดงออกสำหรับผู้ปฏิบัติงานที่คุ้นเคยกับไวยากรณ์ NumPy นอกจากนี้ MXNet 1.6.0 ยังช่วยให้ระบบ Numpy ที่มีอยู่สามารถใช้ตัวเร่งฮาร์ดแวร์เช่น GPU เพื่อเร่งความเร็วในการคำนวณขนาดใหญ่
บูรณาการกับ Apache TVM
Apache TVM สแต็กคอมไพเลอร์การเรียนรู้เชิงลึกแบบ end-to-end แบบโอเพนซอร์สสำหรับฮาร์ดแวร์แบ็กเอนด์เช่นซีพียู GPU และตัวเร่งความเร็วเฉพาะมีจุดมุ่งหมายเพื่อเติมเต็มช่องว่างระหว่างเฟรมเวิร์กการเรียนรู้เชิงลึกที่เน้นการผลิตและแบ็กเอนด์ฮาร์ดแวร์ที่เน้นประสิทธิภาพ . ด้วย MXNet 1.6.0 รุ่นล่าสุดผู้ใช้สามารถใช้ประโยชน์จาก Apache (การบ่มเพาะ) TVM เพื่อใช้เคอร์เนลตัวดำเนินการประสิทธิภาพสูงในภาษาโปรแกรม Python ข้อดีหลักสองประการของคุณสมบัติใหม่นี้มีดังต่อไปนี้ -
ลดความซับซ้อนของกระบวนการพัฒนาที่ใช้ C ++ ในอดีต
เปิดใช้งานการแชร์การใช้งานเดียวกันในแบ็กเอนด์ฮาร์ดแวร์หลายตัวเช่นซีพียู GPU เป็นต้น
การปรับปรุงคุณสมบัติที่มีอยู่
นอกเหนือจากคุณสมบัติที่ระบุไว้ข้างต้นของ MXNet 1.6.0 แล้วยังมีการปรับปรุงบางอย่างเหนือคุณสมบัติที่มีอยู่ การปรับปรุงมีดังนี้ -
การจัดกลุ่มการทำงานที่ชาญฉลาดขององค์ประกอบสำหรับ GPU
ดังที่เราทราบดีว่าประสิทธิภาพของการดำเนินการตามองค์ประกอบคือแบนด์วิธหน่วยความจำและนั่นคือเหตุผลที่การผูกมัดการดำเนินการดังกล่าวอาจลดประสิทธิภาพโดยรวม Apache MXNet 1.6.0 ทำฟิวชั่นการดำเนินการที่ชาญฉลาดขององค์ประกอบซึ่งจะสร้างการดำเนินการที่หลอมรวมในเวลาที่เป็นไปได้จริงและเมื่อเป็นไปได้ ฟิวชั่นการทำงานที่ชาญฉลาดขององค์ประกอบดังกล่าวยังช่วยลดความต้องการพื้นที่จัดเก็บและปรับปรุงประสิทธิภาพโดยรวม
การลดความซับซ้อนของนิพจน์ทั่วไป
MXNet 1.6.0 กำจัดนิพจน์ซ้ำซ้อนและลดความซับซ้อนของนิพจน์ทั่วไป การปรับปรุงดังกล่าวยังช่วยปรับปรุงการใช้หน่วยความจำและเวลาดำเนินการทั้งหมด
การเพิ่มประสิทธิภาพ
MXNet 1.6.0 ยังมีการเพิ่มประสิทธิภาพต่างๆให้กับคุณสมบัติและตัวดำเนินการที่มีอยู่ซึ่งมีดังต่อไปนี้:
ความแม่นยำผสมอัตโนมัติ
Gluon Fit API
MKL-DNN
รองรับเทนเซอร์ขนาดใหญ่
TensorRT บูรณาการ
การสนับสนุนการไล่ระดับสีลำดับที่สูงขึ้น
Operators
โปรไฟล์ประสิทธิภาพของผู้ปฏิบัติงาน
นำเข้า / ส่งออก ONNX
การปรับปรุง Gluon API
การปรับปรุง Symbol API
แก้ไขข้อบกพร่องมากกว่า 100 รายการ
ในการเริ่มต้นกับ MXNet สิ่งแรกที่เราต้องทำคือติดตั้งลงในคอมพิวเตอร์ของเรา Apache MXNet ทำงานบนแพลตฟอร์มทั้งหมดที่มีอยู่รวมถึง Windows, Mac และ Linux
ระบบปฏิบัติการลินุกซ์
เราสามารถติดตั้ง MXNet บน Linux OS ได้ด้วยวิธีต่อไปนี้ -
หน่วยประมวลผลกราฟิก (GPU)
ที่นี่เราจะใช้วิธีการต่างๆเช่น Pip, Docker และ Source เพื่อติดตั้ง MXNet เมื่อเราใช้ GPU ในการประมวลผล -
โดยใช้วิธี Pip
คุณสามารถใช้คำสั่งต่อไปนี้เพื่อติดตั้ง MXNet บน Linus OS ของคุณ -
pip install mxnetApache MXNet ยังมีแพ็คเกจ pip MKL ซึ่งเร็วกว่ามากเมื่อทำงานบนฮาร์ดแวร์ Intel ตัวอย่างเช่นmxnet-cu101mkl หมายความว่า -
แพคเกจสร้างขึ้นด้วย CUDA / cuDNN
แพ็คเกจนี้เปิดใช้งาน MKL-DNN
เวอร์ชัน CUDA คือ 10.1
สำหรับตัวเลือกอื่น ๆ คุณสามารถอ้างถึงได้ https://pypi.org/project/mxnet/.
โดยใช้ Docker
คุณสามารถค้นหาอิมเมจนักเทียบท่าด้วย MXNet ได้ที่ DockerHub ซึ่งมีอยู่ที่ https://hub.docker.com/u/mxnet ให้เราตรวจสอบขั้นตอนด้านล่างเพื่อติดตั้ง MXNet โดยใช้ Docker กับ GPU -
Step 1- ขั้นแรกโดยทำตามคำแนะนำในการติดตั้ง Docker ซึ่งมีอยู่ที่ https://docs.docker.com/engine/install/ubuntu/. เราจำเป็นต้องติดตั้ง Docker บนเครื่องของเรา
Step 2- ในการเปิดใช้งานการใช้งาน GPU จากคอนเทนเนอร์นักเทียบท่าต่อไปเราต้องติดตั้ง nvidia-docker-plugin คุณสามารถทำตามคำแนะนำในการติดตั้งได้ที่https://github.com/NVIDIA/nvidia-docker/wiki.
Step 3- โดยใช้คำสั่งต่อไปนี้คุณสามารถดึงภาพ MXNet docker -
$ sudo docker pull mxnet/python:gpuตอนนี้เพื่อดูว่าการดึงภาพนักเทียบท่า mxnet / python สำเร็จหรือไม่เราสามารถแสดงรายการภาพนักเทียบท่าได้ดังนี้ -
$ sudo docker imagesสำหรับความเร็วในการอนุมานที่เร็วที่สุดกับ MXNet ขอแนะนำให้ใช้ MXNet ล่าสุดกับ Intel MKL-DNN ตรวจสอบคำสั่งด้านล่าง -
$ sudo docker pull mxnet/python:1.3.0_cpu_mkl $ sudo docker imagesจากแหล่งที่มา
ในการสร้างไลบรารีที่ใช้ร่วมกัน MXNet จากซอร์สด้วย GPU อันดับแรกเราต้องตั้งค่าสภาพแวดล้อมสำหรับ CUDA และ cuDNN ดังนี้
ดาวน์โหลดและติดตั้งชุดเครื่องมือ CUDA ที่นี่แนะนำให้ใช้ CUDA 9.2
ดาวน์โหลดต่อไป cuDNN 7.1.4
ตอนนี้เราต้องคลายซิปไฟล์ นอกจากนี้ยังจำเป็นต้องเปลี่ยนเป็นไดเรกทอรีราก cuDNN ย้ายส่วนหัวและไลบรารีไปยังโฟลเดอร์ CUDA Toolkit ในเครื่องดังนี้ -
tar xvzf cudnn-9.2-linux-x64-v7.1
sudo cp -P cuda/include/cudnn.h /usr/local/cuda/include
sudo cp -P cuda/lib64/libcudnn* /usr/local/cuda/lib64
sudo chmod a+r /usr/local/cuda/include/cudnn.h /usr/local/cuda/lib64/libcudnn*
sudo ldconfigหลังจากตั้งค่าสภาพแวดล้อมสำหรับ CUDA และ cuDNN แล้วให้ทำตามขั้นตอนด้านล่างเพื่อสร้างไลบรารีที่ใช้ร่วมกัน MXNet จากซอร์ส -
Step 1- ก่อนอื่นเราต้องติดตั้งแพ็คเกจที่จำเป็นต้องมี การอ้างอิงเหล่านี้จำเป็นสำหรับ Ubuntu เวอร์ชัน 16.04 หรือใหม่กว่า
sudo apt-get update
sudo apt-get install -y build-essential git ninja-build ccache libopenblas-dev
libopencv-dev cmakeStep 2- ในขั้นตอนนี้เราจะดาวน์โหลดแหล่ง MXNet และกำหนดค่า ก่อนอื่นให้เราโคลนที่เก็บโดยใช้คำสั่งต่อไปนี้
git clone –recursive https://github.com/apache/incubator-mxnet.git mxnet
cd mxnet
cp config/linux_gpu.cmake #for build with CUDAStep 3- โดยใช้คำสั่งต่อไปนี้คุณสามารถสร้าง MXNet core shared library−
rm -rf build
mkdir -p build && cd build
cmake -GNinja ..
cmake --build .Two important points regarding the above step is as follows−
หากคุณต้องการสร้างเวอร์ชัน Debug ให้ระบุดังต่อไปนี้ −
cmake -DCMAKE_BUILD_TYPE=Debug -GNinja ..ในการกำหนดจำนวนงานคอมไพล์แบบขนานให้ระบุสิ่งต่อไปนี้ -
cmake --build . --parallel Nเมื่อคุณสร้างไลบรารีที่ใช้ร่วมกันหลักของ MXNet สำเร็จแล้วในไฟล์ build โฟลเดอร์ในไฟล์ MXNet project root, คุณจะพบว่า libmxnet.so ซึ่งจำเป็นในการติดตั้งการผูกภาษา (ทางเลือก)
หน่วยประมวลผลกลาง (CPU)
ในที่นี้เราจะใช้วิธีการต่างๆเช่น Pip, Docker และ Source เพื่อติดตั้ง MXNet เมื่อเราใช้ CPU ในการประมวลผล -
โดยใช้วิธี Pip
คุณสามารถใช้คำสั่งต่อไปนี้เพื่อติดตั้ง MXNet บน Linus OS− ของคุณ
pip install mxnetApache MXNet ยังมีแพ็คเกจ pip ที่เปิดใช้งาน MKL-DNN ซึ่งเร็วกว่ามากเมื่อทำงานบนฮาร์ดแวร์ของ Intel
pip install mxnet-mklโดยใช้ Docker
คุณสามารถค้นหาอิมเมจนักเทียบท่าด้วย MXNet ได้ที่ DockerHub ซึ่งมีอยู่ที่ https://hub.docker.com/u/mxnet. ให้เราตรวจสอบขั้นตอนด้านล่างเพื่อติดตั้ง MXNet โดยใช้ Docker กับ CPU -
Step 1- ขั้นแรกโดยทำตามคำแนะนำในการติดตั้ง Docker ซึ่งมีอยู่ที่ https://docs.docker.com/engine/install/ubuntu/. เราจำเป็นต้องติดตั้ง Docker บนเครื่องของเรา
Step 2- โดยใช้คำสั่งต่อไปนี้คุณสามารถดึงภาพ MXNet docker:
$ sudo docker pull mxnet/pythonตอนนี้เพื่อดูว่าการดึงภาพนักเทียบท่า mxnet / python สำเร็จหรือไม่เราสามารถแสดงรายการภาพนักเทียบท่าได้ดังนี้ -
$ sudo docker imagesสำหรับความเร็วในการอนุมานที่เร็วที่สุดกับ MXNet ขอแนะนำให้ใช้ MXNet ล่าสุดกับ Intel MKL-DNN
ตรวจสอบคำสั่งด้านล่าง -
$ sudo docker pull mxnet/python:1.3.0_cpu_mkl $ sudo docker imagesจากแหล่งที่มา
ในการสร้างไลบรารีที่ใช้ร่วมกัน MXNet จากซอร์สด้วย CPU ให้ทำตามขั้นตอนด้านล่าง -
Step 1- ก่อนอื่นเราต้องติดตั้งแพ็คเกจที่จำเป็นต้องมี การอ้างอิงเหล่านี้จำเป็นสำหรับ Ubuntu เวอร์ชัน 16.04 หรือใหม่กว่า
sudo apt-get update
sudo apt-get install -y build-essential git ninja-build ccache libopenblas-dev libopencv-dev cmakeStep 2- ในขั้นตอนนี้เราจะดาวน์โหลดแหล่ง MXNet และกำหนดค่า ก่อนอื่นให้เราโคลนที่เก็บโดยใช้คำสั่งต่อไปนี้:
git clone –recursive https://github.com/apache/incubator-mxnet.git mxnet
cd mxnet
cp config/linux.cmake config.cmakeStep 3- โดยใช้คำสั่งต่อไปนี้คุณสามารถสร้างไลบรารีที่ใช้ร่วมกันของ MXNet core:
rm -rf build
mkdir -p build && cd build
cmake -GNinja ..
cmake --build .Two important points regarding the above step is as follows−
หากคุณต้องการสร้างเวอร์ชัน Debug ให้ระบุดังต่อไปนี้:
cmake -DCMAKE_BUILD_TYPE=Debug -GNinja ..ในการกำหนดจำนวนงานคอมไพล์แบบขนานให้ระบุสิ่งต่อไปนี้ −
cmake --build . --parallel Nเมื่อคุณสร้างไลบรารีที่ใช้ร่วมกันหลักของ MXNet สำเร็จแล้วในไฟล์ build ในรูทโปรเจ็กต์ MXNet ของคุณคุณจะพบ libmxnet.so ซึ่งจำเป็นสำหรับการติดตั้งการผูกภาษา (ทางเลือก)
MacOS
เราสามารถติดตั้ง MXNet บน MacOS ได้ด้วยวิธีต่อไปนี้
หน่วยประมวลผลกราฟิก (GPU)
หากคุณวางแผนที่จะสร้าง MXNet บน MacOS ด้วย GPU แสดงว่าไม่มีวิธี Pip และ Docker วิธีเดียวในกรณีนี้คือสร้างจากแหล่งที่มา
จากแหล่งที่มา
ในการสร้างไลบรารีที่ใช้ร่วมกัน MXNet จากซอร์สด้วย GPU อันดับแรกเราต้องตั้งค่าสภาพแวดล้อมสำหรับ CUDA และ cuDNN คุณต้องทำตามNVIDIA CUDA Installation Guide ซึ่งมีอยู่ที่ https://docs.nvidia.com และ cuDNN Installation Guide, ซึ่งมีอยู่ที่ https://docs.nvidia.com/deeplearning สำหรับ mac OS
โปรดทราบว่าในปี 2019 CUDA หยุดรองรับ macOS ในความเป็นจริง CUDA เวอร์ชันอนาคตอาจไม่รองรับ macOS
เมื่อคุณตั้งค่าสภาพแวดล้อมสำหรับ CUDA และ cuDNN แล้วให้ทำตามขั้นตอนด้านล่างเพื่อติดตั้ง MXNet จากซอร์สบน OS X (Mac) -
Step 1- เนื่องจากเราต้องการการอ้างอิงบางอย่างบน OS x อันดับแรกเราต้องติดตั้งแพ็คเกจข้อกำหนดเบื้องต้น
xcode-select –-install #Install OS X Developer Tools
/usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)" #Install Homebrew
brew install cmake ninja ccache opencv # Install dependenciesนอกจากนี้เรายังสามารถสร้าง MXNet ได้โดยไม่ต้องใช้ OpenCV เนื่องจาก opencv เป็นการพึ่งพาที่เป็นทางเลือก
Step 2- ในขั้นตอนนี้เราจะดาวน์โหลดแหล่ง MXNet และกำหนดค่า ก่อนอื่นให้เราโคลนที่เก็บโดยใช้คำสั่งต่อไปนี้
git clone –-recursive https://github.com/apache/incubator-mxnet.git mxnet
cd mxnet
cp config/linux.cmake config.cmakeสำหรับ GPU ที่เปิดใช้งานจำเป็นต้องติดตั้งการอ้างอิง CUDA ก่อนเนื่องจากเมื่อพยายามสร้างบิวด์ที่เปิดใช้งาน GPU บนเครื่องที่ไม่มี GPU บิวด์ MXNet จะไม่สามารถตรวจจับสถาปัตยกรรม GPU ของคุณได้ ในกรณีเช่นนี้ MXNet จะกำหนดเป้าหมายสถาปัตยกรรม GPU ที่มีอยู่ทั้งหมด
Step 3- โดยใช้คำสั่งต่อไปนี้คุณสามารถสร้าง MXNet core shared library−
rm -rf build
mkdir -p build && cd build
cmake -GNinja ..
cmake --build .ประเด็นสำคัญสองประการเกี่ยวกับขั้นตอนข้างต้นมีดังนี้
หากคุณต้องการสร้างเวอร์ชัน Debug ให้ระบุดังต่อไปนี้ −
cmake -DCMAKE_BUILD_TYPE=Debug -GNinja ..ในการกำหนดจำนวนงานการคอมไพล์แบบขนานให้ระบุสิ่งต่อไปนี้:
cmake --build . --parallel Nเมื่อคุณสร้างไลบรารีที่ใช้ร่วมกันหลักของ MXNet สำเร็จแล้วในไฟล์ build โฟลเดอร์ในไฟล์ MXNet project root, คุณจะพบว่า libmxnet.dylib, ซึ่งจำเป็นในการติดตั้งการผูกภาษา (ทางเลือก)
หน่วยประมวลผลกลาง (CPU)
ในที่นี้เราจะใช้วิธีการต่างๆเช่น Pip, Docker และ Source เพื่อติดตั้ง MXNet เมื่อเราใช้ CPU ในการประมวลผล −
โดยใช้วิธี Pip
คุณสามารถใช้คำสั่งต่อไปนี้เพื่อติดตั้ง MXNet บน Linus OS ของคุณ
pip install mxnetโดยใช้ Docker
คุณสามารถค้นหาอิมเมจนักเทียบท่าด้วย MXNet ได้ที่ DockerHub ซึ่งมีอยู่ที่ https://hub.docker.com/u/mxnet. ให้เราตรวจสอบขั้นตอนด้านล่างเพื่อติดตั้ง MXNet โดยใช้ Docker กับ CPU−
Step 1- ขั้นแรกโดยทำตาม docker installation instructions ซึ่งมีอยู่ที่ https://docs.docker.com/docker-for-mac เราจำเป็นต้องติดตั้ง Docker บนเครื่องของเรา
Step 2- โดยใช้คำสั่งต่อไปนี้คุณสามารถดึง MXNet docker image−
$ docker pull mxnet/pythonตอนนี้เพื่อดูว่าการดึงภาพนักเทียบท่า mxnet / python สำเร็จหรือไม่เราสามารถแสดงรายการภาพนักเทียบท่าได้ดังนี้
$ docker imagesสำหรับความเร็วในการอนุมานที่เร็วที่สุดกับ MXNet ขอแนะนำให้ใช้ MXNet ล่าสุดกับ Intel MKL-DNN ตรวจสอบคำสั่งด้านล่าง
$ docker pull mxnet/python:1.3.0_cpu_mkl
$ docker imagesจากแหล่งที่มา
ทำตามขั้นตอนด้านล่างเพื่อติดตั้ง MXNet จากซอร์สบน OS X (Mac) -
Step 1- เนื่องจากเราต้องการการอ้างอิงบางอย่างบน OS x อันดับแรกเราต้องติดตั้งแพ็คเกจข้อกำหนดเบื้องต้น
xcode-select –-install #Install OS X Developer Tools
/usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)" #Install Homebrew
brew install cmake ninja ccache opencv # Install dependenciesนอกจากนี้เรายังสามารถสร้าง MXNet ได้โดยไม่ต้องใช้ OpenCV เนื่องจาก opencv เป็นการพึ่งพาที่เป็นทางเลือก
Step 2- ในขั้นตอนนี้เราจะดาวน์โหลดแหล่ง MXNet และกำหนดค่า ขั้นแรกให้เราโคลนที่เก็บโดยใช้คำสั่งต่อไปนี้
git clone –-recursive https://github.com/apache/incubator-mxnet.git mxnet
cd mxnet
cp config/linux.cmake config.cmakeStep 3- โดยใช้คำสั่งต่อไปนี้คุณสามารถสร้างไลบรารีที่ใช้ร่วมกันของ MXNet core:
rm -rf build
mkdir -p build && cd build
cmake -GNinja ..
cmake --build .Two important points regarding the above step is as follows−
หากคุณต้องการสร้างเวอร์ชัน Debug ให้ระบุดังต่อไปนี้ −
cmake -DCMAKE_BUILD_TYPE=Debug -GNinja ..ในการกำหนดจำนวนงานคอมไพล์แบบขนานให้ระบุสิ่งต่อไปนี้ −
cmake --build . --parallel Nเมื่อคุณสร้างไลบรารีที่ใช้ร่วมกันหลักของ MXNet สำเร็จแล้วในไฟล์ build โฟลเดอร์ในไฟล์ MXNet project root, คุณจะพบว่า libmxnet.dylib, ซึ่งจำเป็นในการติดตั้งการผูกภาษา (ทางเลือก)
ระบบปฏิบัติการ Windows
ในการติดตั้ง MXNet บน Windows สิ่งต่อไปนี้เป็นข้อกำหนดเบื้องต้น
ข้อกำหนดขั้นต่ำของระบบ
Windows 7, 10, Server 2012 R2 หรือ Server 2016
Visual Studio 2015 หรือ 2017 (ทุกประเภท)
Python 2.7 หรือ 3.6
pip
ความต้องการของระบบที่แนะนำ
Windows 10, Server 2012 R2 หรือ Server 2016
Visual Studio 2017
GPU ที่รองรับ NVIDIA CUDA อย่างน้อยหนึ่งตัว
CPU ที่รองรับ MKL: โปรเซสเซอร์Intel®Xeon®, ตระกูลโปรเซสเซอร์Intel® Core ™, โปรเซสเซอร์ Intel Atom®หรือโปรเซสเซอร์Intel® Xeon Phi ™
Python 2.7 หรือ 3.6
pip
หน่วยประมวลผลกราฟิก (GPU)
โดยใช้วิธี Pip−
หากคุณวางแผนที่จะสร้าง MXNet บน Windows ด้วย NVIDIA GPUs มีสองตัวเลือกสำหรับการติดตั้ง MXNet ด้วยการรองรับ CUDA ด้วยแพ็คเกจ Python
ติดตั้งด้วย CUDA Support
ด้านล่างนี้เป็นขั้นตอนด้วยความช่วยเหลือซึ่งเราสามารถตั้งค่า MXNet ด้วย CUDA
Step 1- ติดตั้ง Microsoft Visual Studio 2017 หรือ Microsoft Visual Studio 2015 ก่อน
Step 2- ถัดไปดาวน์โหลดและติดตั้ง NVIDIA CUDA ขอแนะนำให้ใช้ CUDA เวอร์ชัน 9.2 หรือ 9.0 เนื่องจากมีการระบุปัญหาบางอย่างกับ CUDA 9.1 ในอดีต
Step 3- ตอนนี้ดาวน์โหลดและติดตั้ง NVIDIA_CUDA_DNN
Step 4- สุดท้ายโดยใช้คำสั่ง pip ต่อไปนี้ให้ติดตั้ง MXNet ด้วย CUDA−
pip install mxnet-cu92ติดตั้งด้วย CUDA และ MKL Support
ด้านล่างนี้เป็นขั้นตอนด้วยความช่วยเหลือซึ่งเราสามารถตั้งค่า MXNet ด้วย CUDA และ MKL ได้
Step 1- ติดตั้ง Microsoft Visual Studio 2017 หรือ Microsoft Visual Studio 2015 ก่อน
Step 2- ถัดไปดาวน์โหลดและติดตั้ง intel MKL
Step 3- ตอนนี้ดาวน์โหลดและติดตั้ง NVIDIA CUDA
Step 4- ตอนนี้ดาวน์โหลดและติดตั้ง NVIDIA_CUDA_DNN
Step 5- สุดท้ายโดยใช้คำสั่ง pip ต่อไปนี้ให้ติดตั้ง MXNet ด้วย MKL
pip install mxnet-cu92mklจากแหล่งที่มา
ในการสร้างไลบรารีหลักของ MXNet จากซอร์สด้วย GPU เรามีสองตัวเลือกต่อไปนี้
Option 1− Build with Microsoft Visual Studio 2017
ในการสร้างและติดตั้ง MXNet ด้วยตัวคุณเองโดยใช้ Microsoft Visual Studio 2017 คุณต้องมีการอ้างอิงต่อไปนี้
Install/update Microsoft Visual Studio.
หากยังไม่ได้ติดตั้ง Microsoft Visual Studio บนเครื่องของคุณให้ดาวน์โหลดและติดตั้งก่อน
มันจะแจ้งเกี่ยวกับการติดตั้ง Git ติดตั้งด้วย
หากมีการติดตั้ง Microsoft Visual Studio ในเครื่องของคุณแล้ว แต่คุณต้องการอัปเดตให้ดำเนินการในขั้นตอนถัดไปเพื่อแก้ไขการติดตั้งของคุณ ที่นี่คุณจะได้รับโอกาสในการอัปเดต Microsoft Visual Studio ด้วย
ทำตามคำแนะนำในการเปิดโปรแกรมติดตั้ง Visual Studio ที่มีอยู่ที่ https://docs.microsoft.com/en-us เพื่อปรับเปลี่ยนส่วนประกอบส่วนบุคคล
ในแอปพลิเคชัน Visual Studio Installer ให้อัปเดตตามต้องการ หลังจากนั้นมองหาและตรวจสอบVC++ 2017 version 15.4 v14.11 toolset แล้วคลิก Modify.
ตอนนี้โดยใช้คำสั่งต่อไปนี้ให้เปลี่ยนเวอร์ชันของ Microsoft VS2017 เป็น v14.11−
"C:\Program Files (x86)\Microsoft Visual Studio\2017\Community\VC\Auxiliary\Build\vcvars64.bat" -vcvars_ver=14.11ถัดไปคุณต้องดาวน์โหลดและติดตั้ง CMake สามารถดูได้ที่ https://cmake.org/download/ ขอแนะนำให้ใช้ CMake v3.12.2 ซึ่งมีอยู่ที่ https://cmake.org/download/ เนื่องจากได้รับการทดสอบด้วย MXNet
ตอนนี้ดาวน์โหลดและเรียกใช้ไฟล์ OpenCV แพ็คเกจได้ที่ https://sourceforge.net/projects/opencvlibrary/ซึ่งจะแตกไฟล์หลายไฟล์ ขึ้นอยู่กับคุณว่าคุณต้องการวางไว้ในไดเร็กทอรีอื่นหรือไม่ ที่นี่เราจะใช้เส้นทางC:\utils(mkdir C:\utils) เป็นเส้นทางเริ่มต้นของเรา
ต่อไปเราต้องตั้งค่าตัวแปรสภาพแวดล้อม OpenCV_DIR ให้ชี้ไปที่ไดเร็กทอรีบิลด์ OpenCV ที่เราเพิ่งคลายซิป สำหรับพรอมต์คำสั่งที่เปิดนี้และพิมพ์set OpenCV_DIR=C:\utils\opencv\build.
ประเด็นสำคัญประการหนึ่งคือหากคุณไม่ได้ติดตั้ง Intel MKL (Math Kernel Library) คุณสามารถติดตั้งได้
แพ็คเกจโอเพ่นซอร์สอื่นที่คุณสามารถใช้ได้คือ OpenBLAS. สำหรับคำแนะนำเพิ่มเติมเราถือว่าคุณกำลังใช้งานอยู่ที่นี่OpenBLAS.
ดังนั้นดาวน์โหลดไฟล์ OpenBlas ซึ่งมีจำหน่ายที่ https://sourceforge.net และคลายซิปไฟล์เปลี่ยนชื่อเป็น OpenBLAS และวางไว้ข้างใต้ C:\utils.
ต่อไปเราต้องตั้งค่าตัวแปรสภาพแวดล้อม OpenBLAS_HOME เพื่อชี้ไปที่ไดเร็กทอรี OpenBLAS ที่มีไฟล์ include และ libไดเรกทอรี สำหรับพรอมต์คำสั่งที่เปิดนี้และพิมพ์set OpenBLAS_HOME=C:\utils\OpenBLAS.
ตอนนี้ดาวน์โหลดและติดตั้ง CUDA ได้ที่ https://developer.nvidia.com. โปรดทราบว่าหากคุณมี CUDA อยู่แล้วจากนั้นติดตั้ง Microsoft VS2017 คุณต้องติดตั้ง CUDA ใหม่ทันทีเพื่อให้คุณได้รับส่วนประกอบชุดเครื่องมือ CUDA สำหรับการรวม Microsoft VS2017
ถัดไปคุณต้องดาวน์โหลดและติดตั้ง cuDNN
ถัดไปคุณต้องดาวน์โหลดและติดตั้งคอมไพล์ซึ่งอยู่ที่ https://gitforwindows.org/ ด้วย.
เมื่อคุณติดตั้งการอ้างอิงที่จำเป็นทั้งหมดแล้วให้ทำตามขั้นตอนด้านล่างเพื่อสร้างซอร์สโค้ด MXNet
Step 1- เปิดพรอมต์คำสั่งใน windows
Step 2- ตอนนี้โดยใช้คำสั่งต่อไปนี้ให้ดาวน์โหลดซอร์สโค้ด MXNet จาก GitHub:
cd C:\
git clone https://github.com/apache/incubator-mxnet.git --recursiveStep 3- ถัดไปตรวจสอบสิ่งต่อไปนี้
DCUDNN_INCLUDE and DCUDNN_LIBRARY ตัวแปรสภาพแวดล้อมชี้ไปที่ include โฟลเดอร์และ cudnn.lib ไฟล์ของตำแหน่งที่ติดตั้ง CUDA ของคุณ
C:\incubator-mxnet คือตำแหน่งของซอร์สโค้ดที่คุณเพิ่งโคลนในขั้นตอนก่อนหน้า
Step 4- ถัดไปโดยใช้คำสั่งต่อไปนี้สร้างบิลด์ directory และไปที่ไดเร็กทอรีเช่น −
mkdir C:\incubator-mxnet\build
cd C:\incubator-mxnet\buildStep 5- ตอนนี้โดยใช้ cmake ให้รวบรวมซอร์สโค้ด MXNet ดังต่อไปนี้
cmake -G "Visual Studio 15 2017 Win64" -T cuda=9.2,host=x64 -DUSE_CUDA=1 -DUSE_CUDNN=1 -DUSE_NVRTC=1 -DUSE_OPENCV=1 -DUSE_OPENMP=1 -DUSE_BLAS=open -DUSE_LAPACK=1 -DUSE_DIST_KVSTORE=0 -DCUDA_ARCH_LIST=Common -DCUDA_TOOLSET=9.2 -DCUDNN_INCLUDE=C:\cuda\include -DCUDNN_LIBRARY=C:\cuda\lib\x64\cudnn.lib "C:\incubator-mxnet"Step 6- เมื่อสร้าง CMake สำเร็จแล้วให้ใช้คำสั่งต่อไปนี้เพื่อรวบรวมซอร์สโค้ด MXNet
msbuild mxnet.sln /p:Configuration=Release;Platform=x64 /maxcpucountOption 2: Build with Microsoft Visual Studio 2015
ในการสร้างและติดตั้ง MXNet ด้วยตัวคุณเองโดยใช้ Microsoft Visual Studio 2015 คุณต้องมีการอ้างอิงต่อไปนี้
ติดตั้ง / อัปเดต Microsoft Visual Studio 2015 ข้อกำหนดขั้นต่ำในการสร้าง MXnet จากซอร์สคือ Update 3 ของ Microsoft Visual Studio 2015 คุณสามารถใช้ Tools -> Extensions and Updates... | Product Updates เมนูเพื่ออัปเกรด
ถัดไปคุณต้องดาวน์โหลดและติดตั้ง CMake ซึ่งมีอยู่ที่ https://cmake.org/download/. ขอแนะนำให้ใช้CMake v3.12.2 ซึ่งอยู่ที่ https://cmake.org/download/เนื่องจากมีการทดสอบด้วย MXNet
ตอนนี้ดาวน์โหลดและเรียกใช้แพ็คเกจ OpenCV ได้ที่ https://excellmedia.dl.sourceforge.netซึ่งจะแตกไฟล์หลายไฟล์ ขึ้นอยู่กับคุณว่าคุณต้องการวางไว้ในไดเรกทอรีอื่นหรือไม่
ต่อไปเราต้องตั้งค่าตัวแปรสภาพแวดล้อม OpenCV_DIR เพื่อชี้ไปที่ OpenCVสร้างไดเร็กทอรีที่เราเพิ่งคลายซิป สำหรับสิ่งนี้ให้เปิดพรอมต์คำสั่งและพิมพ์ชุดOpenCV_DIR=C:\opencv\build\x64\vc14\bin.
ประเด็นสำคัญประการหนึ่งคือหากคุณไม่ได้ติดตั้ง Intel MKL (Math Kernel Library) คุณสามารถติดตั้งได้
แพ็คเกจโอเพ่นซอร์สอื่นที่คุณสามารถใช้ได้คือ OpenBLAS. สำหรับคำแนะนำเพิ่มเติมเราถือว่าคุณกำลังใช้งานอยู่ที่นี่OpenBLAS.
ดังนั้นดาวน์โหลดไฟล์ OpenBLAS แพ็คเกจได้ที่ https://excellmedia.dl.sourceforge.net และคลายซิปไฟล์เปลี่ยนชื่อเป็น OpenBLAS แล้ววางไว้ใต้ C: \ utils
ต่อไปเราต้องตั้งค่าตัวแปรสภาพแวดล้อม OpenBLAS_HOME ให้ชี้ไปที่ไดเร็กทอรี OpenBLAS ที่มีไดเร็กทอรี include และ lib คุณสามารถค้นหาไดเร็กทอรีในC:\Program files (x86)\OpenBLAS\
โปรดทราบว่าหากคุณมี CUDA อยู่แล้วจากนั้นติดตั้ง Microsoft VS2015 คุณต้องติดตั้ง CUDA ใหม่ทันทีเพื่อที่คุณจะได้รับส่วนประกอบชุดเครื่องมือ CUDA สำหรับการรวม Microsoft VS2017
ถัดไปคุณต้องดาวน์โหลดและติดตั้ง cuDNN
ตอนนี้เราต้องตั้งค่าตัวแปรสภาพแวดล้อม CUDACXX ให้ชี้ไปที่ไฟล์ CUDA Compiler(C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v9.1\bin\nvcc.exe ตัวอย่างเช่น).
ในทำนองเดียวกันเราต้องตั้งค่าตัวแปรสภาพแวดล้อมด้วย CUDNN_ROOT เพื่อชี้ไปที่ cuDNN ไดเร็กทอรีที่มี include, lib และ bin ไดเรกทอรี (C:\Downloads\cudnn-9.1-windows7-x64-v7\cuda ตัวอย่างเช่น).
เมื่อคุณติดตั้งการอ้างอิงที่จำเป็นทั้งหมดแล้วให้ทำตามขั้นตอนด้านล่างเพื่อสร้างซอร์สโค้ด MXNet
Step 1- ขั้นแรกให้ดาวน์โหลดซอร์สโค้ด MXNet จาก GitHub−
cd C:\
git clone https://github.com/apache/incubator-mxnet.git --recursiveStep 2- จากนั้นใช้ CMake เพื่อสร้าง Visual Studio ใน. / build.
Step 3- ตอนนี้ใน Visual Studio เราต้องเปิดไฟล์โซลูชัน.slnและรวบรวม คำสั่งเหล่านี้จะสร้างไลบรารีที่เรียกว่าmxnet.dll ใน ./build/Release/ or ./build/Debug โฟลเดอร์
Step 4- เมื่อสร้าง CMake สำเร็จแล้วให้ใช้คำสั่งต่อไปนี้เพื่อคอมไพล์ซอร์สโค้ด MXNet
msbuild mxnet.sln /p:Configuration=Release;Platform=x64 /maxcpucountหน่วยประมวลผลกลาง (CPU)
ในที่นี้เราจะใช้วิธีการต่างๆเช่น Pip, Docker และ Source เพื่อติดตั้ง MXNet เมื่อเราใช้ CPU ในการประมวลผล −
โดยใช้วิธี Pip
หากคุณวางแผนที่จะสร้าง MXNet บน Windows ด้วยซีพียูมีสองตัวเลือกในการติดตั้ง MXNet โดยใช้แพ็คเกจ Python−
Install with CPUs
ใช้คำสั่งต่อไปนี้เพื่อติดตั้ง MXNet กับ CPU ด้วย Python−
pip install mxnetInstall with Intel CPUs
ตามที่กล่าวไว้ข้างต้น MXNet มีการสนับสนุนทดลองสำหรับ Intel MKL และ MKL-DNN ใช้คำสั่งต่อไปนี้เพื่อติดตั้ง MXNet กับ Intel CPU ด้วย Python−
pip install mxnet-mklโดยใช้ Docker
คุณสามารถค้นหาอิมเมจนักเทียบท่าด้วย MXNet ได้ที่ DockerHub, สามารถดูได้ที่ https://hub.docker.com/u/mxnet ให้เราตรวจสอบขั้นตอนด้านล่างเพื่อติดตั้ง MXNet โดยใช้ Docker กับ CPU−
Step 1- ขั้นแรกทำตามคำแนะนำในการติดตั้งนักเทียบท่าซึ่งสามารถอ่านได้ที่ https://docs.docker.com/docker-for-mac/install. เราจำเป็นต้องติดตั้ง Docker บนเครื่องของเรา
Step 2- โดยใช้คำสั่งต่อไปนี้คุณสามารถดึง MXNet docker image−
$ docker pull mxnet/pythonตอนนี้เพื่อดูว่าการดึงภาพนักเทียบท่า mxnet / python สำเร็จหรือไม่เราสามารถแสดงรายการภาพนักเทียบท่าได้ดังนี้
$ docker imagesสำหรับความเร็วในการอนุมานที่เร็วที่สุดกับ MXNet ขอแนะนำให้ใช้ MXNet ล่าสุดกับ Intel MKL-DNN
ตรวจสอบคำสั่งด้านล่าง
$ docker pull mxnet/python:1.3.0_cpu_mkl $ docker imagesการติดตั้ง MXNet บนคลาวด์และอุปกรณ์
ส่วนนี้เน้นวิธีการติดตั้ง Apache MXNet บนคลาวด์และบนอุปกรณ์ เริ่มต้นด้วยการเรียนรู้เกี่ยวกับการติดตั้ง MXNet บนคลาวด์
การติดตั้ง MXNet บนคลาวด์
คุณยังสามารถรับ Apache MXNet จากผู้ให้บริการคลาวด์หลายรายได้ด้วย Graphical Processing Unit (GPU)สนับสนุน. การสนับสนุนอีกสองประเภทที่คุณสามารถพบได้มีดังต่อไปนี้
- รองรับ GPU / CPU-hybrid สำหรับกรณีการใช้งานเช่นการอนุมานที่ปรับขนาดได้
- รองรับ Factorial GPU พร้อม AWS Elastic Inference
ต่อไปนี้เป็นผู้ให้บริการระบบคลาวด์ที่ให้การสนับสนุน GPU กับเครื่องเสมือนอื่นสำหรับ Apache MXNet−
คอนโซลอาลีบาบา
คุณสามารถสร้างไฟล์ NVIDIA GPU Cloud Virtual Machine (VM) สามารถดูได้ที่ https://docs.nvidia.com/ngc ด้วย Alibaba Console และใช้ Apache MXNet
Amazon Web Services
นอกจากนี้ยังให้การสนับสนุน GPU และให้บริการต่อไปนี้สำหรับ Apache MXNet−
Amazon SageMaker
จัดการการฝึกอบรมและการปรับใช้โมเดล Apache MXNet
AWS Deep Learning AMI
มีสภาพแวดล้อม Conda ที่ติดตั้งไว้ล่วงหน้าสำหรับทั้ง Python 2 และ Python 3 พร้อม Apache MXNet, CUDA, cuDNN, MKL-DNN และ AWS Elastic Inference
การฝึกอบรมแบบไดนามิกบน AWS
มีการฝึกอบรมสำหรับการตั้งค่า EC2 ด้วยตนเองแบบทดลองและการตั้งค่า CloudFormation แบบกึ่งอัตโนมัติ
คุณสามารถใช้ได้ NVIDIA VM สามารถดูได้ที่ https://aws.amazon.com ด้วยบริการเว็บของ Amazon
Google Cloud Platform
Google ยังให้บริการ NVIDIA GPU cloud image ซึ่งมีอยู่ที่ https://console.cloud.google.com เพื่อทำงานกับ Apache MXNet
Microsoft Azure
นอกจากนี้ Microsoft Azure Marketplace ยังให้บริการ NVIDIA GPU cloud image สามารถดูได้ที่ https://azuremarketplace.microsoft.com เพื่อทำงานกับ Apache MXNet
Oracle Cloud
Oracle ยังให้บริการ NVIDIA GPU cloud image สามารถดูได้ที่ https://docs.cloud.oracle.com เพื่อทำงานกับ Apache MXNet
หน่วยประมวลผลกลาง (CPU)
Apache MXNet ทำงานบนอินสแตนซ์ CPU เท่านั้นของผู้ให้บริการคลาวด์ทุกราย มีหลายวิธีในการติดตั้งเช่น
คำแนะนำในการติดตั้ง Python pip
คำแนะนำนักเทียบท่า
ตัวเลือกที่ติดตั้งไว้ล่วงหน้าเช่น Amazon Web Services ซึ่งให้ AWS Deep Learning AMI (มีสภาพแวดล้อม Conda ที่ติดตั้งไว้ล่วงหน้าสำหรับทั้ง Python 2 และ Python 3 พร้อม MXNet และ MKL-DNN)
การติดตั้ง MXNet บนอุปกรณ์
ให้เราเรียนรู้วิธีการติดตั้ง MXNet บนอุปกรณ์
ราสเบอร์รี่ Pi
คุณยังสามารถเรียกใช้ Apache MXNet บนอุปกรณ์ Raspberry Pi 3B ได้เนื่องจาก MXNet ยังรองรับระบบปฏิบัติการที่ใช้ Respbian ARM เพื่อให้ใช้งาน MXNet ได้อย่างราบรื่นบน Raspberry Pi3 ขอแนะนำให้มีอุปกรณ์ที่มี RAM มากกว่า 1 GB และการ์ด SD ที่มีพื้นที่ว่างอย่างน้อย 4GB
ต่อไปนี้เป็นวิธีที่คุณสามารถสร้าง MXNet สำหรับ Raspberry Pi และติดตั้งการผูก Python สำหรับไลบรารีได้เช่นกัน
ติดตั้งด่วน
ล้อ Python ที่สร้างไว้ล่วงหน้าสามารถใช้กับ Raspberry Pi 3B พร้อม Stretch เพื่อการติดตั้งที่รวดเร็ว ปัญหาสำคัญอย่างหนึ่งของวิธีนี้คือเราต้องติดตั้งการอ้างอิงหลายอย่างเพื่อให้ Apache MXNet ทำงานได้
การติดตั้ง Docker
คุณสามารถทำตามคำแนะนำในการติดตั้ง Docker ซึ่งมีอยู่ที่ https://docs.docker.com/engine/install/ubuntu/เพื่อติดตั้ง Docker บนเครื่องของคุณ เพื่อจุดประสงค์นี้เราสามารถติดตั้งและใช้งาน Community Edition (CE) ได้ด้วย
Native Build (จากแหล่งที่มา)
ในการติดตั้ง MXNet จากแหล่งที่มาเราต้องทำตามสองขั้นตอนต่อไปนี้
ขั้นตอนที่ 1
Build the shared library from the Apache MXNet C++ source code
ในการสร้างไลบรารีที่ใช้ร่วมกันบน Raspberry เวอร์ชัน Wheezy และใหม่กว่าเราจำเป็นต้องมีการอ้างอิงต่อไปนี้:
Git- จำเป็นต้องดึงโค้ดจาก GitHub
Libblas- จำเป็นสำหรับการดำเนินการเกี่ยวกับพีชคณิตเชิงเส้น
Libopencv- จำเป็นสำหรับการดำเนินการที่เกี่ยวข้องกับการมองเห็นด้วยคอมพิวเตอร์ อย่างไรก็ตามเป็นทางเลือกหากคุณต้องการประหยัด RAM และพื้นที่ดิสก์
C++ Compiler- จำเป็นต้องรวบรวมและสร้างซอร์สโค้ด MXNet ต่อไปนี้เป็นคอมไพเลอร์ที่รองรับซึ่งรองรับ C ++ 11−
G ++ (4.8 หรือใหม่กว่า)
Clang(3.9-6)
ใช้คำสั่งต่อไปนี้เพื่อติดตั้งการอ้างอิงข้างต้น
sudo apt-get update
sudo apt-get -y install git cmake ninja-build build-essential g++-4.9 c++-4.9 liblapack*
libblas* libopencv*
libopenblas* python3-dev python-dev virtualenvต่อไปเราต้องโคลนที่เก็บซอร์สโค้ด MXNet สำหรับสิ่งนี้ให้ใช้คำสั่ง git ต่อไปนี้ในโฮมไดเร็กทอรีของคุณ
git clone https://github.com/apache/incubator-mxnet.git --recursive
cd incubator-mxnetตอนนี้ด้วยความช่วยเหลือของคำสั่งต่อไปนี้สร้างไลบรารีที่ใช้ร่วมกัน:
mkdir -p build && cd build
cmake \
-DUSE_SSE=OFF \
-DUSE_CUDA=OFF \
-DUSE_OPENCV=ON \
-DUSE_OPENMP=ON \
-DUSE_MKL_IF_AVAILABLE=OFF \
-DUSE_SIGNAL_HANDLER=ON \
-DCMAKE_BUILD_TYPE=Release \
-GNinja ..
ninja -j$(nproc)เมื่อคุณดำเนินการตามคำสั่งข้างต้นแล้วระบบจะเริ่มกระบวนการสร้างซึ่งจะใช้เวลาสองสามชั่วโมงจึงจะเสร็จสิ้น คุณจะได้รับไฟล์ชื่อlibmxnet.so ในไดเร็กทอรี build
ขั้นตอนที่ 2
Install the supported language-specific packages for Apache MXNet
ในขั้นตอนนี้เราจะติดตั้งการผูก MXNet Pythin ในการทำเช่นนั้นเราต้องรันคำสั่งต่อไปนี้ในไดเรกทอรี MXNet−
cd python
pip install --upgrade pip
pip install -e .หรือด้วยคำสั่งต่อไปนี้คุณยังสามารถสร้างไฟล์ whl package ติดตั้งได้ด้วย pip-
ci/docker/runtime_functions.sh build_wheel python/ $(realpath build)อุปกรณ์ NVIDIA Jetson
คุณยังสามารถเรียกใช้ Apache MXNet บนอุปกรณ์ NVIDIA Jetson เช่น TX2 หรือ Nanoเนื่องจาก MXNet ยังรองรับระบบปฏิบัติการที่ใช้ Ubuntu Arch64 เพื่อให้ทำงาน MXNet ได้อย่างราบรื่นบนอุปกรณ์ NVIDIA Jetson จำเป็นต้องติดตั้ง CUDA บนอุปกรณ์ Jetson ของคุณ
ต่อไปนี้เป็นวิธีที่คุณสามารถสร้าง MXNet สำหรับอุปกรณ์ NVIDIA Jetson:
โดยใช้ pip wheel ของ Jetson MXNet สำหรับการพัฒนา Python
จากแหล่งที่มา
แต่ก่อนที่จะสร้าง MXNet จากวิธีการใด ๆ ข้างต้นคุณต้องติดตั้งการอ้างอิงต่อไปนี้บนอุปกรณ์ Jetson ของคุณ
การพึ่งพา Python
ในการใช้ Python API เราจำเป็นต้องมีการอ้างอิงต่อไปนี้
sudo apt update
sudo apt -y install \
build-essential \
git \
graphviz \
libatlas-base-dev \
libopencv-dev \
python-pip
sudo pip install --upgrade \
pip \
setuptools
sudo pip install \
graphviz==0.8.4 \
jupyter \
numpy==1.15.2โคลนที่เก็บซอร์สโค้ด MXNet
โดยใช้คำสั่ง git ต่อไปนี้ในโฮมไดเร็กทอรีของคุณให้โคลนที่เก็บซอร์สโค้ด MXNet
git clone --recursive https://github.com/apache/incubator-mxnet.git mxnetตั้งค่าตัวแปรสภาพแวดล้อม
เพิ่มสิ่งต่อไปนี้ในไฟล์ .profile ไฟล์ในโฮมไดเร็กทอรีของคุณ
export PATH=/usr/local/cuda/bin:$PATH export MXNET_HOME=$HOME/mxnet/
export PYTHONPATH=$MXNET_HOME/python:$PYTHONPATHตอนนี้ใช้การเปลี่ยนแปลงทันทีด้วยคำสั่งต่อไปนี้
source .profileกำหนดค่า CUDA
ก่อนกำหนดค่า CUDA ด้วย nvcc คุณต้องตรวจสอบว่า CUDA รุ่นใดกำลังทำงานอยู่ −
nvcc --versionสมมติว่าหากมีการติดตั้ง CUDA มากกว่าหนึ่งเวอร์ชันบนอุปกรณ์หรือคอมพิวเตอร์ของคุณและคุณต้องการเปลี่ยนเวอร์ชัน CUDA ให้ใช้สิ่งต่อไปนี้และแทนที่ลิงก์สัญลักษณ์ไปยังเวอร์ชันที่คุณต้องการ
sudo rm /usr/local/cuda
sudo ln -s /usr/local/cuda-10.0 /usr/local/cudaคำสั่งดังกล่าวจะเปลี่ยนเป็น CUDA 10.0 ซึ่งติดตั้งไว้ล่วงหน้าบนอุปกรณ์ NVIDIA Jetson Nano.
เมื่อคุณทำตามข้อกำหนดเบื้องต้นข้างต้นเสร็จแล้วคุณสามารถติดตั้ง MXNet บนอุปกรณ์ NVIDIA Jetson ได้แล้ว ดังนั้นให้เราทำความเข้าใจวิธีต่างๆที่คุณสามารถติดตั้ง MXNet− ได้
By using a Jetson MXNet pip wheel for Python development- หากคุณต้องการใช้วงล้อ Python ที่เตรียมไว้ให้ดาวน์โหลดสิ่งต่อไปนี้ลงใน Jetson ของคุณและเรียกใช้
MXNet 1.4.0 (สำหรับ Python 3) ได้ที่ https://docs.docker.com
MXNet 1.4.0 (สำหรับ Python 2) ได้ที่ https://docs.docker.com
Native Build (จากแหล่งที่มา)
ในการติดตั้ง MXNet จากแหล่งที่มาเราต้องทำตามสองขั้นตอนต่อไปนี้
ขั้นตอนที่ 1
Build the shared library from the Apache MXNet C++ source code
ในการสร้างไลบรารีที่ใช้ร่วมกันจากซอร์สโค้ด Apache MXNet C ++ คุณสามารถใช้วิธี Docker หรือทำด้วยตนเอง
วิธีการเทียบท่า
ในวิธีนี้คุณต้องติดตั้ง Docker ก่อนและสามารถเรียกใช้งานได้โดยไม่ต้องใช้ sudo (ซึ่งอธิบายไว้ในขั้นตอนก่อนหน้านี้ด้วย) เมื่อเสร็จแล้วให้รันสิ่งต่อไปนี้เพื่อดำเนินการข้ามคอมไพล์ผ่าน Docker−
$MXNET_HOME/ci/build.py -p jetsonคู่มือ
ในวิธีนี้คุณต้องแก้ไขไฟล์ Makefile (ด้วยคำสั่งด้านล่าง) เพื่อติดตั้ง MXNet พร้อมการเชื่อมโยง CUDA เพื่อใช้ประโยชน์จากหน่วยประมวลผลกราฟิก (GPU) บนอุปกรณ์ NVIDIA Jetson:
cp $MXNET_HOME/make/crosscompile.jetson.mk config.mkหลังจากแก้ไข Makefile คุณต้องแก้ไขไฟล์ config.mk เพื่อทำการเปลี่ยนแปลงเพิ่มเติมสำหรับอุปกรณ์ NVIDIA Jetson
สำหรับสิ่งนี้ให้อัปเดตการตั้งค่าต่อไปนี้
อัปเดตเส้นทาง CUDA: USE_CUDA_PATH = / usr / local / cuda
เพิ่ม -gencode arch = compute-63, code = sm_62 ในการตั้งค่า CUDA_ARCH
อัปเดตการตั้งค่า NVCC: NVCCFLAGS: = -m64
เปิด OpenCV: USE_OPENCV = 1
ตอนนี้เพื่อให้แน่ใจว่า MXNet สร้างด้วยการเร่งความแม่นยำต่ำระดับฮาร์ดแวร์ของ Pascal เราจำเป็นต้องแก้ไข Mshadow Makefile ดังต่อไปนี้ −
MSHADOW_CFLAGS += -DMSHADOW_USE_PASCAL=1สุดท้ายด้วยความช่วยเหลือของคำสั่งต่อไปนี้คุณสามารถสร้างไลบรารี Apache MXNet ที่สมบูรณ์ −
cd $MXNET_HOME make -j $(nproc)เมื่อคุณดำเนินการตามคำสั่งข้างต้นแล้วระบบจะเริ่มกระบวนการสร้างซึ่งจะใช้เวลาสองสามชั่วโมงจึงจะเสร็จสิ้น คุณจะได้รับไฟล์ชื่อlibmxnet.so ใน mxnet/lib directory.
ขั้นตอนที่ 2
Install the Apache MXNet Python Bindings
ในขั้นตอนนี้เราจะติดตั้งการผูก MXNet Python ในการทำเช่นนั้นเราต้องรันคำสั่งต่อไปนี้ในไดเรกทอรี MXNet−
cd $MXNET_HOME/python
sudo pip install -e .เมื่อทำตามขั้นตอนข้างต้นเสร็จแล้วคุณก็พร้อมที่จะเรียกใช้ MXNet บนอุปกรณ์ NVIDIA Jetson TX2 หรือ Nano สามารถตรวจสอบได้ด้วยคำสั่งต่อไปนี้
import mxnet
mxnet.__version__มันจะส่งคืนหมายเลขเวอร์ชันหากทุกอย่างทำงานได้อย่างถูกต้อง
เพื่อสนับสนุนการวิจัยและพัฒนาแอปพลิเคชัน Deep Learning ในหลาย ๆ สาขา Apache MXNet มอบระบบนิเวศที่สมบูรณ์ของชุดเครื่องมือห้องสมุดและอื่น ๆ อีกมากมาย ให้เราสำรวจพวกเขา -
ToolKits
ต่อไปนี้เป็นชุดเครื่องมือที่ใช้มากที่สุดและมีความสำคัญโดย MXNet -
GluonCV
เนื่องจากชื่อมีความหมายว่า GluonCV เป็นชุดเครื่องมือ Gluon สำหรับการมองเห็นด้วยคอมพิวเตอร์ที่ขับเคลื่อนโดย MXNet มีการใช้อัลกอริทึม DL (Deep Learning) ที่ล้ำสมัยในการมองเห็นด้วยคอมพิวเตอร์ (CV) ด้วยความช่วยเหลือของวิศวกรชุดเครื่องมือ GluonCV นักวิจัยและนักเรียนสามารถตรวจสอบแนวคิดใหม่ ๆ และเรียนรู้ CV ได้อย่างง่ายดาย
ด้านล่างนี้คือบางส่วนของไฟล์ features of GluonCV -
ฝึกสคริปต์เพื่อสร้างผลลัพธ์ที่ล้ำสมัยที่รายงานในงานวิจัยล่าสุด
โมเดล pretrained คุณภาพสูงมากกว่า 170+ รุ่น
ยอมรับรูปแบบการพัฒนาที่ยืดหยุ่น
GluonCV นั้นง่ายต่อการปรับให้เหมาะสม เราสามารถปรับใช้โดยไม่ต้องรักษาเฟรมเวิร์ก DL ที่มีน้ำหนักมาก
มี API ที่ออกแบบมาอย่างรอบคอบซึ่งช่วยลดความยุ่งยากในการใช้งานลงอย่างมาก
การสนับสนุนจากชุมชน
การใช้งานที่เข้าใจง่าย
ต่อไปนี้คือไฟล์ supported applications โดย GluonCV toolkit:
การจำแนกภาพ
การตรวจจับวัตถุ
การแบ่งส่วนความหมาย
การแบ่งกลุ่มอินสแตนซ์
ก่อให้เกิดการประมาณค่า
Video Action Recognition
เราสามารถติดตั้ง GluonCV ได้โดยใช้ pip ดังนี้ -
pip install --upgrade mxnet gluoncvGluonNLP
ตามชื่อหมายความว่า GluonNLP เป็นชุดเครื่องมือ Gluon สำหรับการประมวลผลภาษาธรรมชาติ (NLP) ที่ขับเคลื่อนโดย MXNet นำเสนอการใช้โมเดล DL (Deep Learning) ที่ล้ำสมัยใน NLP
ด้วยความช่วยเหลือของวิศวกรชุดเครื่องมือ GluonNLP นักวิจัยและนักเรียนสามารถสร้างบล็อกสำหรับท่อส่งข้อมูลข้อความและแบบจำลอง จากแบบจำลองเหล่านี้สามารถสร้างต้นแบบแนวคิดการวิจัยและผลิตภัณฑ์ได้อย่างรวดเร็ว
ด้านล่างนี้เป็นคุณสมบัติบางอย่างของ GluonNLP:
ฝึกสคริปต์เพื่อสร้างผลลัพธ์ที่ล้ำสมัยที่รายงานในงานวิจัยล่าสุด
ชุดโมเดลที่กำหนดไว้ล่วงหน้าสำหรับงาน NLP ทั่วไป
มี API ที่ออกแบบมาอย่างรอบคอบซึ่งช่วยลดความยุ่งยากในการใช้งานลงอย่างมาก
การสนับสนุนจากชุมชน
นอกจากนี้ยังมีแบบฝึกหัดเพื่อช่วยคุณในการเริ่มต้นงาน NLP ใหม่ ๆ
ต่อไปนี้เป็นงาน NLP ที่เราสามารถนำไปใช้กับชุดเครื่องมือ GluonNLP -
การฝังคำ
รูปแบบภาษา
การแปลด้วยเครื่อง
การจัดประเภทข้อความ
การวิเคราะห์ความเชื่อมั่น
การอนุมานภาษาธรรมชาติ
การสร้างข้อความ
การแยกวิเคราะห์การพึ่งพา
ชื่อการรับรู้เอนทิตี
การจัดประเภทเจตนาและการติดฉลากสล็อต
เราสามารถติดตั้ง GluonNLP ได้โดยใช้ pip ดังนี้ -
pip install --upgrade mxnet gluonnlpGluonTS
เนื่องจากชื่อมีความหมายว่า GluonTS เป็นชุดเครื่องมือ Gluon สำหรับ Probabilistic Time Series Modeling ที่ขับเคลื่อนโดย MXNet
มีคุณสมบัติดังต่อไปนี้ -
รูปแบบการเรียนรู้เชิงลึกที่ทันสมัย (SOTA) พร้อมให้ฝึกอบรม
ยูทิลิตี้สำหรับการโหลดและการทำซ้ำชุดข้อมูลอนุกรมเวลา
การสร้างบล็อคเพื่อกำหนดโมเดลของคุณเอง
ด้วยความช่วยเหลือของวิศวกรชุดเครื่องมือ GluonTS นักวิจัยและนักเรียนสามารถฝึกอบรมและประเมินโมเดลที่มีอยู่แล้วภายในด้วยข้อมูลของตนเองทดลองกับโซลูชันต่างๆได้อย่างรวดเร็วและหาวิธีแก้ปัญหาสำหรับงานลำดับเวลาของพวกเขา
นอกจากนี้ยังสามารถใช้ abstractions และส่วนประกอบพื้นฐานที่ให้มาเพื่อสร้างแบบจำลองอนุกรมเวลาที่กำหนดเองและเปรียบเทียบอย่างรวดเร็วเทียบกับอัลกอริทึมพื้นฐาน
เราสามารถติดตั้ง GluonTS ได้โดยใช้ pip ดังนี้ -
pip install gluontsกลูออน FR
ตามความหมายของชื่อมันคือชุดเครื่องมือ Apache MXNet Gluon สำหรับ FR (Face Recognition) มีคุณสมบัติดังต่อไปนี้ -
รูปแบบการเรียนรู้เชิงลึกที่ล้ำสมัย (SOTA) ในการจดจำใบหน้า
การใช้งาน SoftmaxCrossEntropyLoss, ArcLoss, TripletLoss, RingLoss, CosLoss / AMsoftmax, L2-Softmax, A-Softmax, CenterLoss, ContrastiveLoss และ LGM Loss เป็นต้น
ในการติดตั้ง Gluon Face เราต้องใช้ Python 3.5 หรือใหม่กว่า ก่อนอื่นเราต้องติดตั้ง GluonCV และ MXNet ก่อนดังนี้ -
pip install gluoncv --pre
pip install mxnet-mkl --pre --upgrade
pip install mxnet-cuXXmkl --pre –upgrade # if cuda XX is installedเมื่อคุณติดตั้งการอ้างอิงคุณสามารถใช้คำสั่งต่อไปนี้เพื่อติดตั้ง GluonFR -
From Source
pip install git+https://github.com/THUFutureLab/gluon-face.git@masterPip
pip install gluonfrระบบนิเวศ
ตอนนี้ให้เราสำรวจไลบรารีแพ็คเกจและเฟรมเวิร์กที่หลากหลายของ MXNet -
โค้ช RL
Coach ซึ่งเป็นเฟรมเวิร์ก Python Reinforcement Learning (RL) ที่สร้างโดยห้องปฏิบัติการ Intel AI ช่วยให้สามารถทดลองใช้อัลกอริธึม RL ที่ล้ำสมัยได้อย่างง่ายดาย Coach RL รองรับ Apache MXNet เป็นส่วนหลังและช่วยให้สามารถรวมสภาพแวดล้อมใหม่ ๆ เข้าด้วยกันเพื่อแก้ปัญหา
เพื่อที่จะขยายและนำส่วนประกอบที่มีอยู่กลับมาใช้ใหม่ได้อย่างง่ายดาย Coach RL ได้แยกองค์ประกอบการเรียนรู้การเสริมแรงขั้นพื้นฐานเช่นอัลกอริทึมสภาพแวดล้อมสถาปัตยกรรม NN นโยบายการสำรวจได้เป็นอย่างดี
ต่อไปนี้เป็นตัวแทนและอัลกอริทึมที่สนับสนุนสำหรับกรอบงาน Coach RL -
ตัวแทนการเพิ่มประสิทธิภาพมูลค่า
เครือข่าย Deep Q (DQN)
เครือข่าย Double Deep Q (DDQN)
Dueling Q Network
มอนติคาร์โลผสม (MMC)
การเรียนรู้ประโยชน์อย่างต่อเนื่อง (PAL)
หมวดหมู่ Deep Q Network (C51)
Quantile Regression Deep Q Network (QR-DQN)
N-Step Q การเรียนรู้
Neural Episodic Control (NEC)
ฟังก์ชันความได้เปรียบปกติ (NAF)
Rainbow
ตัวแทนการเพิ่มประสิทธิภาพนโยบาย
การไล่ระดับนโยบาย (PG)
Asynchronous Advantage Actor-Critic (A3C)
การไล่ระดับสีเชิงลึกของนโยบาย (DDPG)
Proximal Policy Optimization (PPO)
การเพิ่มประสิทธิภาพนโยบายใกล้เคียงที่ถูกตัด (CPPO)
การประมาณความได้เปรียบทั่วไป (GAE)
ตัวอย่างนักแสดง - นักวิจารณ์ที่มีประสิทธิภาพพร้อมประสบการณ์เล่นซ้ำ (ACER)
นักแสดง - นักวิจารณ์ที่นุ่มนวล (SAC)
การไล่ระดับนโยบายเชิงลึกที่ล่าช้าแบบคู่ (TD3)
ตัวแทนทั่วไป
การทำนายอนาคตโดยตรง (DFP)
ตัวแทนการเรียนรู้การเลียนแบบ
การโคลนพฤติกรรม (BC)
การเรียนรู้การเลียนแบบตามเงื่อนไข
ตัวแทนการเรียนรู้การเสริมแรงตามลำดับชั้น
นักแสดงตามลำดับชั้นนักวิจารณ์ (HAC)
ห้องสมุดกราฟลึก
Deep Graph Library (DGL) ซึ่งพัฒนาโดยทีม NYU และ AWS ในเซี่ยงไฮ้เป็นแพ็คเกจ Python ที่ให้การใช้งาน Graph Neural Networks (GNNs) ที่ง่ายดายบน MXNet นอกจากนี้ยังให้การใช้งาน GNN ที่ง่ายดายเหนือไลบรารีการเรียนรู้เชิงลึกที่สำคัญอื่น ๆ ที่มีอยู่เช่น PyTorch, Gluon และอื่น ๆ
Deep Graph Library เป็นซอฟต์แวร์ฟรี สามารถใช้ได้กับ Linux ทุกรุ่นที่ช้ากว่า Ubuntu 16.04, macOS X และ Windows 7 หรือใหม่กว่า นอกจากนี้ยังต้องใช้ Python เวอร์ชัน 3.5 ขึ้นไป
ต่อไปนี้เป็นคุณสมบัติของ DGL -
No Migration cost - ไม่มีค่าใช้จ่ายในการย้ายข้อมูลสำหรับการใช้ DGL เนื่องจากสร้างขึ้นจากเฟรมเวิร์ก DL ที่ได้รับความนิยม
Message Passing- DGL ให้การส่งผ่านข้อความและมีการควบคุมที่หลากหลาย การส่งผ่านข้อความมีตั้งแต่การดำเนินการระดับต่ำเช่นการส่งไปตามขอบที่เลือกไปจนถึงการควบคุมระดับสูงเช่นการอัปเดตฟีเจอร์แบบกราฟ
Smooth Learning Curve - มันค่อนข้างง่ายในการเรียนรู้และใช้ DGL เนื่องจากฟังก์ชั่นที่ผู้ใช้กำหนดเองที่มีประสิทธิภาพนั้นมีความยืดหยุ่นและใช้งานง่าย
Transparent Speed Optimization - DGL ให้การเพิ่มประสิทธิภาพความเร็วที่โปร่งใสโดยทำการคำนวณเป็นชุดอัตโนมัติและการคูณเมทริกซ์แบบกระจัดกระจาย
High performance - เพื่อให้ได้ประสิทธิภาพสูงสุด DGL จะจัดการฝึก DNN (โครงข่ายประสาทเทียมแบบลึก) บนกราฟหนึ่งหรือหลายกราฟด้วยกันโดยอัตโนมัติ
Easy & friendly interface - DGL มอบอินเทอร์เฟซที่ใช้งานง่ายและเป็นมิตรสำหรับการเข้าถึงคุณลักษณะขอบตลอดจนการจัดการโครงสร้างกราฟ
InsightFace
InsightFace เครื่องมือการเรียนรู้เชิงลึกสำหรับการวิเคราะห์ใบหน้าที่ให้การใช้อัลกอริทึมการวิเคราะห์ใบหน้า SOTA (ล้ำสมัย) ในการมองเห็นด้วยคอมพิวเตอร์ที่ขับเคลื่อนโดย MXNet ให้ -
โมเดลสำเร็จรูปคุณภาพสูงชุดใหญ่
สคริปต์การฝึกอบรมที่ทันสมัย (SOTA)
InsightFace นั้นง่ายต่อการเพิ่มประสิทธิภาพ เราสามารถปรับใช้โดยไม่ต้องรักษาเฟรมเวิร์ก DL ที่มีน้ำหนักมาก
มี API ที่ออกแบบมาอย่างรอบคอบซึ่งช่วยลดความยุ่งยากในการใช้งานลงอย่างมาก
การสร้างบล็อคเพื่อกำหนดโมเดลของคุณเอง
เราสามารถติดตั้ง InsightFace ได้โดยใช้ pip ดังนี้ -
pip install --upgrade insightfaceโปรดทราบว่าก่อนติดตั้ง InsightFace โปรดติดตั้งแพ็คเกจ MXNet ที่ถูกต้องตามการกำหนดค่าระบบของคุณ
Keras-MXNet
อย่างที่เราทราบกันดีว่า Keras เป็น Neural Network (NN) API ระดับสูงที่เขียนด้วย Python Keras-MXNet ให้การสนับสนุนแบ็กเอนด์สำหรับ Keras สามารถทำงานบนเฟรมเวิร์ก Apache MXNet DL ที่มีประสิทธิภาพสูงและปรับขนาดได้
คุณสมบัติของ Keras-MXNet มีดังต่อไปนี้ -
ช่วยให้ผู้ใช้สร้างต้นแบบได้ง่ายราบรื่นและรวดเร็ว ทั้งหมดนี้เกิดขึ้นจากความเป็นมิตรต่อผู้ใช้ความเป็นโมดูลและความสามารถในการขยาย
รองรับทั้ง CNN (Convolutional Neural Networks) และ RNN (Recurrent Neural Networks) รวมทั้งการรวมกันของทั้งสองด้วย
ทำงานได้อย่างไม่มีที่ติทั้งบนหน่วยประมวลผลกลาง (CPU) และหน่วยประมวลผลกราฟิก (GPU)
สามารถทำงานบน GPU ตัวเดียวหรือหลายตัว
ในการทำงานกับแบ็กเอนด์นี้ก่อนอื่นคุณต้องติดตั้ง keras-mxnet ดังนี้ -
pip install keras-mxnetตอนนี้หากคุณใช้ GPU ให้ติดตั้ง MXNet พร้อมรองรับ CUDA 9 ดังนี้ -
pip install mxnet-cu90แต่ถ้าคุณใช้ CPU อย่างเดียวให้ติดตั้ง MXNet พื้นฐานดังนี้ -
pip install mxnetMXBoard
MXBoard เป็นเครื่องมือบันทึกที่เขียนด้วย Python ซึ่งใช้ในการบันทึกเฟรมข้อมูล MXNet และแสดงใน TensorBoard กล่าวอีกนัยหนึ่ง MXBoard มีไว้เพื่อทำตาม Tensorboard-pytorch API รองรับประเภทข้อมูลส่วนใหญ่ใน TensorBoard
บางส่วนมีการกล่าวถึงด้านล่าง -
Graph
Scalar
Histogram
Embedding
Image
Text
Audio
Precision-Recall Curve
MXFusion
MXFusion เป็นไลบรารีโปรแกรมความน่าจะเป็นแบบแยกส่วนพร้อมการเรียนรู้เชิงลึก MXFusion ช่วยให้เราใช้ประโยชน์จากโมดูลาร์ได้อย่างเต็มที่ซึ่งเป็นคุณสมบัติหลักของไลบรารีการเรียนรู้เชิงลึกสำหรับการเขียนโปรแกรมที่น่าจะเป็น ใช้งานง่ายและให้อินเทอร์เฟซที่สะดวกแก่ผู้ใช้สำหรับการออกแบบแบบจำลองที่น่าจะเป็นและนำไปใช้กับปัญหาในโลกแห่งความเป็นจริง
MXFusion ได้รับการยืนยันบน Python เวอร์ชัน 3.4 และอื่น ๆ บน MacOS และ Linux OS ในการติดตั้ง MXFusion เราต้องติดตั้งการอ้างอิงต่อไปนี้ก่อน -
MXNet> = 1.3
Networkx> = 2.1
ด้วยความช่วยเหลือของคำสั่ง pip ต่อไปนี้คุณสามารถติดตั้ง MXFusion -
pip install mxfusionTVM
Apache TVM สแต็กคอมไพเลอร์การเรียนรู้เชิงลึกแบบ end-to-end แบบโอเพนซอร์สสำหรับฮาร์ดแวร์แบ็กเอนด์เช่นซีพียู GPU และตัวเร่งความเร็วเฉพาะมีจุดมุ่งหมายเพื่อเติมเต็มช่องว่างระหว่างเฟรมเวิร์กการเรียนรู้เชิงลึกที่เน้นการผลิตและแบ็กเอนด์ฮาร์ดแวร์ที่เน้นประสิทธิภาพ . ด้วย MXNet 1.6.0 รุ่นล่าสุดผู้ใช้สามารถใช้ประโยชน์จาก Apache (การบ่มเพาะ) TVM เพื่อใช้เคอร์เนลตัวดำเนินการประสิทธิภาพสูงในภาษาโปรแกรม Python
Apache TVM เริ่มต้นจากโครงการวิจัยที่กลุ่ม SAMPL ของ Paul G. ชุมชนโอเพ่นซอร์ส) ที่เกี่ยวข้องกับหลายอุตสาหกรรมและสถาบันการศึกษาภายใต้วิธีการของ Apache
ต่อไปนี้เป็นคุณสมบัติหลักของ Apache (ฟักตัว) TVM -
ลดความซับซ้อนของกระบวนการพัฒนาที่ใช้ C ++ ในอดีต
เปิดใช้งานการแชร์การใช้งานเดียวกันในฮาร์ดแวร์แบ็กเอนด์หลายตัวเช่น CPU, GPUs เป็นต้น
TVM ให้การรวบรวมโมเดล DL ในเฟรมเวิร์กต่างๆเช่น Kears, MXNet, PyTorch, Tensorflow, CoreML, DarkNet ในโมดูลที่ปรับใช้ขั้นต่ำได้บนแบ็กเอนด์ฮาร์ดแวร์ที่หลากหลาย
นอกจากนี้ยังให้โครงสร้างพื้นฐานแก่เราในการสร้างและเพิ่มประสิทธิภาพตัวดำเนินการเทนเซอร์โดยอัตโนมัติด้วยประสิทธิภาพที่ดีขึ้น
XFer
Xfer เฟรมเวิร์กการเรียนรู้การถ่ายโอนถูกเขียนด้วย Python โดยทั่วไปจะใช้โมเดล MXNet และฝึกโมเดลเมตาหรือปรับเปลี่ยนโมเดลสำหรับชุดข้อมูลเป้าหมายใหม่ด้วย
กล่าวง่ายๆคือ Xfer เป็นไลบรารี Python ที่ช่วยให้ผู้ใช้สามารถถ่ายโอนความรู้ที่เก็บไว้ใน DNN (deep neural network) ได้อย่างรวดเร็วและง่ายดาย
สามารถใช้ Xfer -
สำหรับการจำแนกประเภทของข้อมูลในรูปแบบตัวเลขโดยพลการ
สำหรับกรณีทั่วไปของรูปภาพหรือข้อมูลข้อความ
เป็นไปป์ไลน์ที่สแปมจากการแยกคุณสมบัติไปจนถึงการฝึกอบรม repurposer (ออบเจ็กต์ที่ดำเนินการจัดหมวดหมู่ในงานเป้าหมาย)
ต่อไปนี้เป็นคุณสมบัติของ Xfer:
ประสิทธิภาพของทรัพยากร
ประสิทธิภาพของข้อมูล
เข้าถึงเครือข่ายประสาทเทียมได้ง่าย
การสร้างแบบจำลองที่ไม่แน่นอน
การสร้างต้นแบบอย่างรวดเร็ว
ยูทิลิตี้สำหรับการแยกคุณลักษณะจาก NN
บทนี้จะช่วยคุณในการทำความเข้าใจเกี่ยวกับสถาปัตยกรรมระบบ MXNet เริ่มต้นด้วยการเรียนรู้เกี่ยวกับโมดูล MXNet
โมดูล MXNet
แผนภาพด้านล่างคือสถาปัตยกรรมระบบ MXNet และแสดงโมดูลและส่วนประกอบหลักของ MXNet modules and their interaction.

ในแผนภาพด้านบน -
โมดูลในกล่องสีฟ้าคือ User Facing Modules.
โมดูลในกล่องสีเขียวคือ System Modules.
ลูกศรทึบแสดงถึงการพึ่งพาสูงกล่าวคือต้องพึ่งพาอินเทอร์เฟซอย่างมาก
ลูกศรประแสดงถึงการพึ่งพาแสงกล่าวคือโครงสร้างข้อมูลที่ใช้เพื่อความสะดวกและความสอดคล้องของอินเทอร์เฟซ ในความเป็นจริงมันสามารถถูกแทนที่ด้วยทางเลือกอื่น
ให้เราพูดคุยเพิ่มเติมเกี่ยวกับการเผชิญหน้ากับผู้ใช้และโมดูลระบบ
โมดูลสำหรับผู้ใช้
โมดูลสำหรับผู้ใช้มีดังต่อไปนี้ -
NDArray- มีโปรแกรมจำเป็นที่ยืดหยุ่นสำหรับ Apache MXNet เป็นอาร์เรย์ n มิติแบบไดนามิกและอะซิงโครนัส
KVStore- ทำหน้าที่เป็นส่วนต่อประสานสำหรับการซิงโครไนซ์พารามิเตอร์ที่มีประสิทธิภาพ ใน KVStore KV ย่อมาจาก Key-Value ดังนั้นจึงเป็นอินเทอร์เฟซการจัดเก็บคีย์ - ค่า
Data Loading (IO) - โมดูลที่หันหน้าเข้าหาผู้ใช้นี้ใช้สำหรับการโหลดและการเพิ่มข้อมูลแบบกระจายอย่างมีประสิทธิภาพ
Symbol Execution- เป็นตัวดำเนินการกราฟสัญลักษณ์แบบคงที่ ให้การดำเนินการและการปรับแต่งกราฟสัญลักษณ์ที่มีประสิทธิภาพ
Symbol Construction - โมดูลที่เผชิญหน้ากับผู้ใช้นี้ช่วยให้ผู้ใช้สามารถสร้างกราฟการคำนวณเช่นการกำหนดค่าสุทธิ
โมดูลระบบ
โมดูลระบบมีดังนี้ -
Storage Allocator - โมดูลระบบนี้ตามชื่อที่แนะนำจะจัดสรรและรีไซเคิลบล็อกหน่วยความจำอย่างมีประสิทธิภาพบนโฮสต์เช่น CPU และอุปกรณ์ต่างๆเช่น GPU
Runtime Dependency Engine - ตารางเวลาโมดูลเอ็นจินการพึ่งพารันไทม์ตลอดจนเรียกใช้การดำเนินการตามการพึ่งพาการอ่าน / เขียน
Resource Manager - โมดูลระบบ Resource Manager (RM) จัดการทรัพยากรทั่วโลกเช่นตัวสร้างตัวเลขสุ่มและพื้นที่ชั่วคราว
Operator - โมดูลระบบตัวดำเนินการประกอบด้วยตัวดำเนินการทั้งหมดที่กำหนดการคำนวณการไปข้างหน้าแบบคงที่และการไล่ระดับสีเช่น backpropagation
รายละเอียดส่วนประกอบของระบบใน Apache MXNet มีรายละเอียดดังนี้ ขั้นแรกเราจะศึกษาเกี่ยวกับเครื่องมือดำเนินการใน MXNet
Execution Engine
เอ็นจิ้นการประมวลผลของ Apache MXNet มีความหลากหลายมาก เราสามารถใช้มันเพื่อการเรียนรู้เชิงลึกเช่นเดียวกับปัญหาเฉพาะโดเมน: เรียกใช้ฟังก์ชันต่างๆมากมายตามการอ้างอิง ได้รับการออกแบบมาเพื่อให้ฟังก์ชันที่มีการอ้างอิงเป็นแบบอนุกรมในขณะที่ฟังก์ชันที่ไม่มีการอ้างอิงสามารถดำเนินการแบบขนานได้
อินเทอร์เฟซหลัก
API ที่ระบุด้านล่างเป็นอินเทอร์เฟซหลักสำหรับเอ็นจิ้นการดำเนินการของ Apache MXNet -
virtual void PushSync(Fn exec_fun, Context exec_ctx,
std::vector<VarHandle> const& const_vars,
std::vector<VarHandle> const& mutate_vars) = 0;API ข้างต้นมีดังต่อไปนี้ -
exec_fun - API อินเทอร์เฟซหลักของ MXNet ช่วยให้เราสามารถพุชฟังก์ชันที่ชื่อ exec_fun พร้อมกับข้อมูลบริบทและการอ้างอิงไปยังเอ็นจิ้นการดำเนินการ
exec_ctx - ข้อมูลบริบทที่ควรเรียกใช้ฟังก์ชัน exec_fun ที่กล่าวถึงข้างต้น
const_vars - นี่คือตัวแปรที่ฟังก์ชันอ่านจาก
mutate_vars - นี่คือตัวแปรที่ต้องแก้ไข
เอ็นจิ้นการดำเนินการให้การรับประกันแก่ผู้ใช้ว่าการเรียกใช้ฟังก์ชันสองฟังก์ชันใด ๆ ที่แก้ไขตัวแปรทั่วไปจะถูกทำให้เป็นอนุกรมตามลำดับการพุช
ฟังก์ชัน
ต่อไปนี้เป็นประเภทฟังก์ชั่นของเอ็นจิ้นการดำเนินการของ Apache MXNet -
using Fn = std::function<void(RunContext)>;ในฟังก์ชันข้างต้น RunContextมีข้อมูลรันไทม์ ข้อมูลรันไทม์ควรถูกกำหนดโดยกลไกการดำเนินการ ไวยากรณ์ของRunContext มีดังนี้
struct RunContext {
// stream pointer which could be safely cast to
// cudaStream_t* type
void *stream;
};ด้านล่างนี้เป็นประเด็นสำคัญบางประการเกี่ยวกับฟังก์ชันของเครื่องมือดำเนินการ -
ฟังก์ชันทั้งหมดดำเนินการโดยเธรดภายในของเอ็นจินการดำเนินการของ MXNet
ไม่เป็นการดีที่จะผลักดันการบล็อกฟังก์ชันไปยังกลไกการดำเนินการเนื่องจากฟังก์ชันดังกล่าวจะครอบครองเธรดการดำเนินการและจะลดปริมาณงานทั้งหมด
สำหรับ MXNet นี้มีฟังก์ชันอะซิงโครนัสอื่นดังนี้ another
using Callback = std::function<void()>;
using AsyncFn = std::function<void(RunContext, Callback)>;ในเรื่องนี้ AsyncFn ฟังก์ชั่นเราสามารถส่งผ่านส่วนที่หนักของเธรดของเราได้ แต่เอ็นจิ้นการดำเนินการไม่ถือว่าฟังก์ชันเสร็จสิ้นจนกว่าเราจะเรียกไฟล์ callback ฟังก์ชัน
บริบท
ใน Contextเราสามารถระบุบริบทของฟังก์ชันที่จะดำเนินการภายใน ซึ่งมักจะรวมถึงสิ่งต่อไปนี้ -
ควรรันฟังก์ชันบน CPU หรือ GPU
หากเราระบุ GPU ในบริบทแล้วจะใช้ GPU ตัวใด
มีความแตกต่างอย่างมากระหว่างบริบทและ RunContext บริบทมีประเภทอุปกรณ์และรหัสอุปกรณ์ในขณะที่ RunContext มีข้อมูลที่สามารถตัดสินใจได้ในระหว่างรันไทม์เท่านั้น
VarHandle
VarHandle ใช้เพื่อระบุการขึ้นต่อกันของฟังก์ชันเปรียบเสมือนโทเค็น (โดยเฉพาะอย่างยิ่งโดยกลไกการดำเนินการ) ที่เราสามารถใช้เพื่อแสดงถึงทรัพยากรภายนอกที่ฟังก์ชันสามารถแก้ไขหรือใช้ได้
แต่เกิดคำถามทำไมเราต้องใช้ VarHandle? เป็นเพราะเอ็นจิ้น Apache MXNet ได้รับการออกแบบมาเพื่อแยกออกจากโมดูล MXNet อื่น ๆ
ต่อไปนี้เป็นประเด็นสำคัญบางประการเกี่ยวกับ VarHandle -
มีน้ำหนักเบาดังนั้นในการสร้างลบหรือคัดลอกตัวแปรมีต้นทุนการดำเนินงานเพียงเล็กน้อย
เราจำเป็นต้องระบุตัวแปรที่ไม่เปลี่ยนรูปเช่นตัวแปรที่จะใช้ในไฟล์ const_vars.
เราจำเป็นต้องระบุตัวแปรที่เปลี่ยนแปลงได้เช่นตัวแปรที่จะแก้ไขในไฟล์ mutate_vars.
กฎที่ใช้โดยกลไกการดำเนินการเพื่อแก้ไขการอ้างอิงระหว่างฟังก์ชันคือการเรียกใช้ฟังก์ชันใด ๆ เมื่อหนึ่งในนั้นแก้ไขตัวแปรทั่วไปอย่างน้อยหนึ่งตัวแปรจะถูกทำให้เป็นอนุกรมตามลำดับการผลักดัน
สำหรับการสร้างตัวแปรใหม่เราสามารถใช้ไฟล์ NewVar() API
สำหรับการลบตัวแปรเราสามารถใช้ไฟล์ PushDelete API
ให้เราเข้าใจการทำงานด้วยตัวอย่างง่ายๆ -
สมมติว่าเรามีสองฟังก์ชันคือ F1 และ F2 และทั้งสองก็กลายพันธุ์ตัวแปรคือ V2 ในกรณีนี้จะรับประกันว่า F2 จะดำเนินการหลังจาก F1 หาก F2 ถูกผลักหลังจาก F1 ในอีกด้านหนึ่งถ้า F1 และ F2 ทั้งคู่ใช้ V2 คำสั่งดำเนินการจริงอาจเป็นแบบสุ่ม
กดและรอ
Push และ wait เป็น API ที่มีประโยชน์มากขึ้นสองรายการของกลไกการเรียกใช้งาน
ต่อไปนี้เป็นคุณสมบัติที่สำคัญสองประการของ Push API:
Push API ทั้งหมดเป็นแบบอะซิงโครนัสซึ่งหมายความว่าการเรียก API จะส่งกลับทันทีไม่ว่าฟังก์ชันพุชจะเสร็จสิ้นหรือไม่ก็ตาม
Push API ไม่ใช่เธรดที่ปลอดภัยซึ่งหมายความว่าเธรดเดียวเท่านั้นที่ควรเรียกใช้เอ็นจิ้น API
ตอนนี้ถ้าเราพูดถึง Wait API จุดต่อไปนี้แสดงถึง -
หากผู้ใช้ต้องการรอให้ฟังก์ชันเฉพาะทำงานเสร็จสิ้นผู้ใช้ควรรวมฟังก์ชันเรียกกลับไว้ในการปิด เมื่อรวมแล้วให้เรียกใช้ฟังก์ชันที่ส่วนท้ายของฟังก์ชัน
ในทางกลับกันหากผู้ใช้ต้องการรอให้ฟังก์ชันทั้งหมดที่เกี่ยวข้องกับตัวแปรบางตัวเสร็จสิ้นผู้ใช้ควรใช้ WaitForVar(var) API
หากมีคนต้องการรอให้ฟังก์ชั่นพุชทั้งหมดเสร็จสิ้นให้ใช้ไฟล์ WaitForAll () API
ใช้เพื่อระบุการขึ้นต่อกันของฟังก์ชันเปรียบเสมือนโทเค็น
ตัวดำเนินการ
Operator ใน Apache MXNet เป็นคลาสที่มีลอจิกการคำนวณจริงตลอดจนข้อมูลเสริมและช่วยระบบในการเพิ่มประสิทธิภาพ
อินเตอร์เฟซตัวดำเนินการ
Forward เป็นอินเทอร์เฟซตัวดำเนินการหลักที่มีไวยากรณ์ดังนี้:
virtual void Forward(const OpContext &ctx,
const std::vector<TBlob> &in_data,
const std::vector<OpReqType> &req,
const std::vector<TBlob> &out_data,
const std::vector<TBlob> &aux_states) = 0;โครงสร้างของ OpContextกำหนดไว้ใน Forward() มีดังนี้:
struct OpContext {
int is_train;
RunContext run_ctx;
std::vector<Resource> requested;
}OpContextอธิบายสถานะของผู้ปฏิบัติงาน (ไม่ว่าจะอยู่ในช่วงรถไฟหรือช่วงทดสอบ) อุปกรณ์ใดที่ผู้ปฏิบัติงานควรใช้งานและทรัพยากรที่ร้องขอ API ที่มีประโยชน์อีกสองอย่างของกลไกการเรียกใช้งาน
จากข้างต้น Forward อินเทอร์เฟซหลักเราสามารถเข้าใจทรัพยากรที่ร้องขอได้ดังนี้ -
in_data และ out_data แสดงถึงเทนเซอร์อินพุตและเอาต์พุต
req หมายถึงวิธีการเขียนผลลัพธ์ของการคำนวณลงในไฟล์ out_data.
OpReqType สามารถกำหนดเป็น -
enum OpReqType {
kNullOp,
kWriteTo,
kWriteInplace,
kAddTo
};ชอบ Forward เราสามารถเลือกใช้ Backward อินเทอร์เฟซดังนี้ -
virtual void Backward(const OpContext &ctx,
const std::vector<TBlob> &out_grad,
const std::vector<TBlob> &in_data,
const std::vector<TBlob> &out_data,
const std::vector<OpReqType> &req,
const std::vector<TBlob> &in_grad,
const std::vector<TBlob> &aux_states);งานต่างๆ
Operator อินเทอร์เฟซช่วยให้ผู้ใช้สามารถทำงานต่อไปนี้ -
ผู้ใช้สามารถระบุอัพเดตแบบแทนที่และสามารถลดต้นทุนการจัดสรรหน่วยความจำ
เพื่อให้สะอาดยิ่งขึ้นผู้ใช้สามารถซ่อนอาร์กิวเมนต์ภายในจาก Python ได้
ผู้ใช้สามารถกำหนดความสัมพันธ์ระหว่างเทนเซอร์และเทนเซอร์เอาต์พุต
ในการคำนวณผู้ใช้สามารถรับพื้นที่ชั่วคราวเพิ่มเติมจากระบบ
คุณสมบัติของผู้ดำเนินการ
ดังที่เราทราบดีว่าใน Convolutional neural network (CNN) Convolutional Neural Network (CNN) หนึ่ง Convolution มีการใช้งานหลายอย่าง เพื่อให้ได้ประสิทธิภาพที่ดีที่สุดจากพวกเขาเราอาจต้องการสลับระหว่างการเปลี่ยนแปลงเหล่านี้
นั่นคือเหตุผล Apache MXNet แยกอินเตอร์เฟสความหมายของตัวดำเนินการออกจากอินเทอร์เฟซการใช้งาน การแยกนี้จะทำในรูปแบบOperatorProperty คลาสซึ่งประกอบด้วยสิ่งต่อไปนี้
InferShape - อินเทอร์เฟซ InferShape มีสองวัตถุประสงค์ดังที่ระบุด้านล่าง:
จุดประสงค์แรกคือการบอกขนาดของแต่ละอินพุตและเอาท์พุตเทนเซอร์เพื่อให้สามารถจัดสรรพื้นที่ได้ก่อน Forward และ Backward โทร.
จุดประสงค์ประการที่สองคือการตรวจสอบขนาดเพื่อให้แน่ใจว่าไม่มีข้อผิดพลาดก่อนที่จะทำงาน
ไวยากรณ์ได้รับด้านล่าง -
virtual bool InferShape(mxnet::ShapeVector *in_shape,
mxnet::ShapeVector *out_shape,
mxnet::ShapeVector *aux_shape) const = 0;Request Resource- จะเกิดอะไรขึ้นถ้าระบบของคุณสามารถจัดการพื้นที่ทำงานการคำนวณสำหรับการดำเนินการเช่น cudnnConvolutionForward? ระบบของคุณสามารถทำการเพิ่มประสิทธิภาพเช่นการใช้พื้นที่ซ้ำและอื่น ๆ อีกมากมาย ที่นี่ MXNet สามารถทำได้อย่างง่ายดายด้วยความช่วยเหลือของสองอินเทอร์เฟซต่อไปนี้
virtual std::vector<ResourceRequest> ForwardResource(
const mxnet::ShapeVector &in_shape) const;
virtual std::vector<ResourceRequest> BackwardResource(
const mxnet::ShapeVector &in_shape) const;แต่จะเกิดอะไรขึ้นถ้า ForwardResource และ BackwardResourceส่งคืนอาร์เรย์ที่ไม่ว่างเปล่า? ในกรณีนั้นระบบจะเสนอทรัพยากรที่เกี่ยวข้องผ่านctx พารามิเตอร์ใน Forward และ Backward อินเทอร์เฟซของ Operator.
Backward dependency - Apache MXNet มีลายเซ็นของตัวดำเนินการสองแบบที่แตกต่างกันเพื่อจัดการกับการพึ่งพาย้อนหลัง -
void FullyConnectedForward(TBlob weight, TBlob in_data, TBlob out_data);
void FullyConnectedBackward(TBlob weight, TBlob in_data, TBlob out_grad, TBlob in_grad);
void PoolingForward(TBlob in_data, TBlob out_data);
void PoolingBackward(TBlob in_data, TBlob out_data, TBlob out_grad, TBlob in_grad);นี่คือสองประเด็นสำคัญที่ควรทราบ -
out_data ใน FullyConnectedForward ไม่ได้ใช้โดย FullyConnectedBackward และ
PoolingBackward ต้องการอาร์กิวเมนต์ทั้งหมดของ PoolingForward
นั่นคือเหตุผลสำหรับ FullyConnectedForward, out_dataเทนเซอร์ที่บริโภคครั้งเดียวสามารถปลดปล่อยได้อย่างปลอดภัยเนื่องจากฟังก์ชันย้อนกลับไม่จำเป็นต้องใช้ ด้วยความช่วยเหลือของระบบนี้ทำให้สามารถรวบรวมเทนเซอร์บางตัวให้เป็นขยะโดยเร็วที่สุด
In place Option- Apache MXNet มีอินเทอร์เฟซอื่นให้กับผู้ใช้เพื่อประหยัดค่าใช้จ่ายในการจัดสรรหน่วยความจำ อินเทอร์เฟซนี้เหมาะสำหรับการดำเนินการตามองค์ประกอบที่มีทั้งอินพุตและเอาต์พุตเทนเซอร์มีรูปร่างเหมือนกัน
ต่อไปนี้เป็นไวยากรณ์สำหรับการระบุการอัปเดตแบบแทนที่ -
ตัวอย่างการสร้าง Operator
ด้วยความช่วยเหลือของ OperatorProperty เราสามารถสร้างตัวดำเนินการ โดยทำตามขั้นตอนด้านล่าง -
virtual std::vector<std::pair<int, void*>> ElewiseOpProperty::ForwardInplaceOption(
const std::vector<int> &in_data,
const std::vector<void*> &out_data)
const {
return { {in_data[0], out_data[0]} };
}
virtual std::vector<std::pair<int, void*>> ElewiseOpProperty::BackwardInplaceOption(
const std::vector<int> &out_grad,
const std::vector<int> &in_data,
const std::vector<int> &out_data,
const std::vector<void*> &in_grad)
const {
return { {out_grad[0], in_grad[0]} }
}ขั้นตอนที่ 1
Create Operator
ขั้นแรกใช้อินเทอร์เฟซต่อไปนี้ใน OperatorProperty:
virtual Operator* CreateOperator(Context ctx) const = 0;ตัวอย่างได้รับด้านล่าง -
class ConvolutionOp {
public:
void Forward( ... ) { ... }
void Backward( ... ) { ... }
};
class ConvolutionOpProperty : public OperatorProperty {
public:
Operator* CreateOperator(Context ctx) const {
return new ConvolutionOp;
}
};ขั้นตอนที่ 2
Parameterize Operator
หากคุณกำลังจะใช้ตัวดำเนินการ Convolution จำเป็นต้องทราบขนาดเคอร์เนลขนาดก้าวย่างขนาดช่องว่างภายในและอื่น ๆ เพราะเหตุใดจึงควรส่งผ่านพารามิเตอร์เหล่านี้ไปยังโอเปอเรเตอร์ก่อนที่จะเรียกใช้Forward หรือ backward อินเตอร์เฟซ.
สำหรับสิ่งนี้เราต้องกำหนด a ConvolutionParam โครงสร้างดังต่อไปนี้ -
#include <dmlc/parameter.h>
struct ConvolutionParam : public dmlc::Parameter<ConvolutionParam> {
mxnet::TShape kernel, stride, pad;
uint32_t num_filter, num_group, workspace;
bool no_bias;
};ทีนี้เราต้องใส่สิ่งนี้เข้าไป ConvolutionOpProperty และส่งต่อไปยังผู้ปฏิบัติงานดังนี้ -
class ConvolutionOp {
public:
ConvolutionOp(ConvolutionParam p): param_(p) {}
void Forward( ... ) { ... }
void Backward( ... ) { ... }
private:
ConvolutionParam param_;
};
class ConvolutionOpProperty : public OperatorProperty {
public:
void Init(const vector<pair<string, string>& kwargs) {
// initialize param_ using kwargs
}
Operator* CreateOperator(Context ctx) const {
return new ConvolutionOp(param_);
}
private:
ConvolutionParam param_;
};ขั้นตอนที่ 3
Register the Operator Property Class and the Parameter Class to Apache MXNet
สุดท้ายเราต้องลงทะเบียน Operator Property Class และ Parameter Class เป็น MXNet สามารถทำได้ด้วยความช่วยเหลือของมาโครต่อไปนี้ -
DMLC_REGISTER_PARAMETER(ConvolutionParam);
MXNET_REGISTER_OP_PROPERTY(Convolution, ConvolutionOpProperty);ในมาโครด้านบนอาร์กิวเมนต์แรกคือสตริงชื่อและอันที่สองคือชื่อคลาสคุณสมบัติ
บทนี้ให้ข้อมูลเกี่ยวกับอินเทอร์เฟซการเขียนโปรแกรมแอปพลิเคชันแบบรวม (API) ใน Apache MXNet
SimpleOp
SimpleOp เป็น API ตัวดำเนินการแบบรวมใหม่ซึ่งรวมกระบวนการเรียกใช้ที่แตกต่างกัน เมื่อเรียกใช้แล้วจะกลับสู่องค์ประกอบพื้นฐานของตัวดำเนินการ ตัวดำเนินการแบบรวมได้รับการออกแบบมาเป็นพิเศษสำหรับการดำเนินการแบบยูนารีและไบนารี เป็นเพราะตัวดำเนินการทางคณิตศาสตร์ส่วนใหญ่เข้าร่วมกับตัวถูกดำเนินการหนึ่งหรือสองตัวและตัวถูกดำเนินการมากกว่าทำให้การเพิ่มประสิทธิภาพที่เกี่ยวข้องกับการพึ่งพามีประโยชน์
เราจะทำความเข้าใจกับตัวดำเนินการแบบรวม SimpleOp ที่ทำงานด้วยความช่วยเหลือของตัวอย่าง ในตัวอย่างนี้เราจะสร้างตัวดำเนินการที่ทำงานเป็นไฟล์smooth l1 lossซึ่งเป็นส่วนผสมของการสูญเสีย l1 และ l2 เราสามารถกำหนดและเขียนการสูญเสียตามที่ระบุด้านล่าง -
loss = outside_weight .* f(inside_weight .* (data - label))
grad = outside_weight .* inside_weight .* f'(inside_weight .* (data - label))ในตัวอย่างด้านบนนี้
. * ย่อมาจากการคูณด้วยองค์ประกอบ
f, f’ เป็นฟังก์ชันการสูญเสีย l1 ที่ราบรื่นซึ่งเราสมมติว่าอยู่ใน mshadow.
ดูเหมือนจะเป็นไปไม่ได้ที่จะใช้การสูญเสียเฉพาะนี้เป็นตัวดำเนินการยูนารีหรือไบนารี แต่ MXNet ให้ความแตกต่างโดยอัตโนมัติแก่ผู้ใช้ในการดำเนินการเชิงสัญลักษณ์ซึ่งช่วยลดความยุ่งยากในการสูญเสียไปยัง f และ f โดยตรง นั่นเป็นเหตุผลที่เราสามารถใช้การสูญเสียนี้ในฐานะผู้ดำเนินการยูนารีได้อย่างแน่นอน
การกำหนดรูปร่าง
อย่างที่เราทราบกันดีว่า MXNet's mshadow libraryต้องการการจัดสรรหน่วยความจำอย่างชัดเจนดังนั้นเราจึงต้องจัดเตรียมรูปร่างข้อมูลทั้งหมดก่อนที่จะเกิดการคำนวณใด ๆ ก่อนกำหนดฟังก์ชันและการไล่ระดับสีเราจำเป็นต้องจัดเตรียมความสอดคล้องของรูปทรงอินพุตและรูปร่างเอาต์พุตดังนี้:
typedef mxnet::TShape (*UnaryShapeFunction)(const mxnet::TShape& src,
const EnvArguments& env);
typedef mxnet::TShape (*BinaryShapeFunction)(const mxnet::TShape& lhs,
const mxnet::TShape& rhs,
const EnvArguments& env);ฟังก์ชัน mxnet :: Tshape ใช้เพื่อตรวจสอบรูปร่างข้อมูลอินพุตและรูปร่างข้อมูลเอาต์พุตที่กำหนด ในกรณีที่คุณไม่ได้กำหนดฟังก์ชันนี้รูปร่างเอาต์พุตเริ่มต้นจะเหมือนกับรูปร่างอินพุต ตัวอย่างเช่นในกรณีของตัวดำเนินการไบนารีรูปร่างของ lhs และ rhs จะถูกตรวจสอบโดยค่าเริ่มต้นเหมือนกัน
ตอนนี้เรามาดูไฟล์ smooth l1 loss example. สำหรับสิ่งนี้เราจำเป็นต้องกำหนด XPU ให้กับ cpu หรือ gpu ในการใช้งานส่วนหัว smooth_l1_unary-inl.h. เหตุผลคือการนำรหัสเดิมกลับมาใช้ใหม่ smooth_l1_unary.cc และ smooth_l1_unary.cu.
#include <mxnet/operator_util.h>
#if defined(__CUDACC__)
#define XPU gpu
#else
#define XPU cpu
#endifเช่นเดียวกับใน smooth l1 loss example,ผลลัพธ์มีรูปร่างเหมือนกับแหล่งที่มาเราสามารถใช้พฤติกรรมเริ่มต้น สามารถเขียนได้ดังนี้ -
inline mxnet::TShape SmoothL1Shape_(const mxnet::TShape& src,const EnvArguments& env) {
return mxnet::TShape(src);
}การกำหนดฟังก์ชัน
เราสามารถสร้างฟังก์ชันยูนารีหรือไบนารีด้วยอินพุตเดียวดังนี้ -
typedef void (*UnaryFunction)(const TBlob& src,
const EnvArguments& env,
TBlob* ret,
OpReqType req,
RunContext ctx);
typedef void (*BinaryFunction)(const TBlob& lhs,
const TBlob& rhs,
const EnvArguments& env,
TBlob* ret,
OpReqType req,
RunContext ctx);ต่อไปนี้คือไฟล์ RunContext ctx struct ซึ่งมีข้อมูลที่จำเป็นในระหว่างรันไทม์สำหรับการดำเนินการ -
struct RunContext {
void *stream; // the stream of the device, can be NULL or Stream<gpu>* in GPU mode
template<typename xpu> inline mshadow::Stream<xpu>* get_stream() // get mshadow stream from Context
} // namespace mxnetตอนนี้เรามาดูกันว่าเราจะเขียนผลลัพธ์การคำนวณได้อย่างไร ret.
enum OpReqType {
kNullOp, // no operation, do not write anything
kWriteTo, // write gradient to provided space
kWriteInplace, // perform an in-place write
kAddTo // add to the provided space
};ตอนนี้เรามาดูไฟล์ smooth l1 loss example. สำหรับสิ่งนี้เราจะใช้ UnaryFunction เพื่อกำหนดฟังก์ชันของตัวดำเนินการนี้ดังนี้:
template<typename xpu>
void SmoothL1Forward_(const TBlob& src,
const EnvArguments& env,
TBlob *ret,
OpReqType req,
RunContext ctx) {
using namespace mshadow;
using namespace mshadow::expr;
mshadow::Stream<xpu> *s = ctx.get_stream<xpu>();
real_t sigma2 = env.scalar * env.scalar;
MSHADOW_TYPE_SWITCH(ret->type_flag_, DType, {
mshadow::Tensor<xpu, 2, DType> out = ret->get<xpu, 2, DType>(s);
mshadow::Tensor<xpu, 2, DType> in = src.get<xpu, 2, DType>(s);
ASSIGN_DISPATCH(out, req,
F<mshadow_op::smooth_l1_loss>(in, ScalarExp<DType>(sigma2)));
});
}การกำหนด Gradients
ยกเว้น Input, TBlob, และ OpReqTypeเป็นสองเท่าฟังก์ชันการไล่ระดับสีของตัวดำเนินการไบนารีมีโครงสร้างที่คล้ายคลึงกัน ลองดูด้านล่างซึ่งเราได้สร้างฟังก์ชันการไล่ระดับสีด้วยอินพุตประเภทต่างๆ:
// depending only on out_grad
typedef void (*UnaryGradFunctionT0)(const OutputGrad& out_grad,
const EnvArguments& env,
TBlob* in_grad,
OpReqType req,
RunContext ctx);
// depending only on out_value
typedef void (*UnaryGradFunctionT1)(const OutputGrad& out_grad,
const OutputValue& out_value,
const EnvArguments& env,
TBlob* in_grad,
OpReqType req,
RunContext ctx);
// depending only on in_data
typedef void (*UnaryGradFunctionT2)(const OutputGrad& out_grad,
const Input0& in_data0,
const EnvArguments& env,
TBlob* in_grad,
OpReqType req,
RunContext ctx);ตามที่กำหนดไว้ข้างต้น Input0, Input, OutputValue, และ OutputGrad ทั้งหมดแบ่งปันโครงสร้างของ GradientFunctionArgument. มีกำหนดดังนี้ -
struct GradFunctionArgument {
TBlob data;
}ตอนนี้เรามาดูไฟล์ smooth l1 loss example. เพื่อเปิดใช้กฎลูกโซ่ของการไล่ระดับสีเราต้องคูณout_grad จากด้านบนไปยังผลลัพธ์ของ in_grad.
template<typename xpu>
void SmoothL1BackwardUseIn_(const OutputGrad& out_grad, const Input0& in_data0,
const EnvArguments& env,
TBlob *in_grad,
OpReqType req,
RunContext ctx) {
using namespace mshadow;
using namespace mshadow::expr;
mshadow::Stream<xpu> *s = ctx.get_stream<xpu>();
real_t sigma2 = env.scalar * env.scalar;
MSHADOW_TYPE_SWITCH(in_grad->type_flag_, DType, {
mshadow::Tensor<xpu, 2, DType> src = in_data0.data.get<xpu, 2, DType>(s);
mshadow::Tensor<xpu, 2, DType> ograd = out_grad.data.get<xpu, 2, DType>(s);
mshadow::Tensor<xpu, 2, DType> igrad = in_grad->get<xpu, 2, DType>(s);
ASSIGN_DISPATCH(igrad, req,
ograd * F<mshadow_op::smooth_l1_gradient>(src, ScalarExp<DType>(sigma2)));
});
}ลงทะเบียน SimpleOp เป็น MXNet
เมื่อเราสร้างรูปร่างฟังก์ชันและการไล่ระดับสีแล้วเราจำเป็นต้องคืนค่าให้เป็นตัวดำเนินการ NDArray รวมทั้งตัวดำเนินการเชิงสัญลักษณ์ สำหรับสิ่งนี้เราสามารถใช้มาโครการลงทะเบียนได้ดังนี้ -
MXNET_REGISTER_SIMPLE_OP(Name, DEV)
.set_shape_function(Shape)
.set_function(DEV::kDevMask, Function<XPU>, SimpleOpInplaceOption)
.set_gradient(DEV::kDevMask, Gradient<XPU>, SimpleOpInplaceOption)
.describe("description");SimpleOpInplaceOption สามารถกำหนดได้ดังนี้ -
enum SimpleOpInplaceOption {
kNoInplace, // do not allow inplace in arguments
kInplaceInOut, // allow inplace in with out (unary)
kInplaceOutIn, // allow inplace out_grad with in_grad (unary)
kInplaceLhsOut, // allow inplace left operand with out (binary)
kInplaceOutLhs // allow inplace out_grad with lhs_grad (binary)
};ตอนนี้เรามาดูไฟล์ smooth l1 loss example. สำหรับสิ่งนี้เรามีฟังก์ชันการไล่ระดับสีที่อาศัยข้อมูลอินพุตดังนั้นจึงไม่สามารถเขียนฟังก์ชันแทนได้
MXNET_REGISTER_SIMPLE_OP(smooth_l1, XPU)
.set_function(XPU::kDevMask, SmoothL1Forward_<XPU>, kNoInplace)
.set_gradient(XPU::kDevMask, SmoothL1BackwardUseIn_<XPU>, kInplaceOutIn)
.set_enable_scalar(true)
.describe("Calculate Smooth L1 Loss(lhs, scalar)");SimpleOp บน EnvArguments
ดังที่เราทราบดีว่าการดำเนินการบางอย่างอาจต้องใช้สิ่งต่อไปนี้ -
สเกลาร์เป็นอินพุตเช่นสเกลไล่ระดับ
ชุดของอาร์กิวเมนต์คำสำคัญที่ควบคุมพฤติกรรม
ช่องว่างชั่วคราวเพื่อเร่งการคำนวณ
ประโยชน์ของการใช้ EnvArguments คือมีอาร์กิวเมนต์และทรัพยากรเพิ่มเติมเพื่อให้การคำนวณสามารถปรับขนาดได้และมีประสิทธิภาพมากขึ้น
ตัวอย่าง
ก่อนอื่นให้กำหนดโครงสร้างดังต่อไปนี้ -
struct EnvArguments {
real_t scalar; // scalar argument, if enabled
std::vector<std::pair<std::string, std::string> > kwargs; // keyword arguments
std::vector<Resource> resource; // pointer to the resources requested
};ต่อไปเราต้องขอทรัพยากรเพิ่มเติมเช่น mshadow::Random<xpu> และพื้นที่หน่วยความจำชั่วคราวจาก EnvArguments.resource. สามารถทำได้ดังนี้ -
struct ResourceRequest {
enum Type { // Resource type, indicating what the pointer type is
kRandom, // mshadow::Random<xpu> object
kTempSpace // A dynamic temp space that can be arbitrary size
};
Type type; // type of resources
};ตอนนี้การลงทะเบียนจะร้องขอการร้องขอทรัพยากรที่ประกาศจาก mxnet::ResourceManager. หลังจากนั้นก็จะวางทรัพยากรใน std::vector<Resource> resource in EnvAgruments.
เราสามารถเข้าถึงทรัพยากรด้วยความช่วยเหลือของรหัสต่อไปนี้ -
auto tmp_space_res = env.resources[0].get_space(some_shape, some_stream);
auto rand_res = env.resources[0].get_random(some_stream);หากคุณเห็นในตัวอย่างการสูญเสีย l1 ที่ราบรื่นของเราจำเป็นต้องใช้การป้อนข้อมูลสเกลาร์เพื่อทำเครื่องหมายจุดเปลี่ยนของฟังก์ชันการสูญเสีย นั่นเป็นเหตุผลที่เราใช้ในขั้นตอนการลงทะเบียนset_enable_scalar(true)และ env.scalar ในการประกาศฟังก์ชันและการไล่ระดับสี
การสร้าง Tensor Operation
คำถามเกิดขึ้นที่นี่ว่าทำไมเราต้องสร้างการทำงานของเทนเซอร์? เหตุผลมีดังนี้ -
การคำนวณใช้ไลบรารี mshadow และบางครั้งเราก็ไม่มีฟังก์ชันที่พร้อมใช้งาน
หากการดำเนินการไม่ได้ทำด้วยวิธีที่ชาญฉลาดเช่นการสูญเสีย softmax และการไล่ระดับสี
ตัวอย่าง
ที่นี่เรากำลังใช้ตัวอย่างการสูญเสีย l1 ที่ราบรื่นข้างต้น เราจะสร้างตัวทำแผนที่สองตัวคือกรณีสเกลาร์ของการสูญเสีย l1 ที่ราบรื่นและการไล่ระดับสี:
namespace mshadow_op {
struct smooth_l1_loss {
// a is x, b is sigma2
MSHADOW_XINLINE static real_t Map(real_t a, real_t b) {
if (a > 1.0f / b) {
return a - 0.5f / b;
} else if (a < -1.0f / b) {
return -a - 0.5f / b;
} else {
return 0.5f * a * a * b;
}
}
};
}บทนี้เกี่ยวกับการฝึกอบรมแบบกระจายใน Apache MXNet เริ่มต้นด้วยการทำความเข้าใจว่าโหมดการคำนวณใน MXNet คืออะไร
โหมดการคำนวณ
MXNet ซึ่งเป็นไลบรารี ML หลายภาษานำเสนอโหมดการคำนวณสองโหมดต่อไปนี้ให้กับผู้ใช้ -
โหมดจำเป็น
โหมดการคำนวณนี้แสดงอินเทอร์เฟซเช่น NumPy API ตัวอย่างเช่นใน MXNet ให้ใช้รหัสจำเป็นต่อไปนี้เพื่อสร้างค่าเทนเซอร์ของศูนย์บนทั้ง CPU และ GPU -
import mxnet as mx
tensor_cpu = mx.nd.zeros((100,), ctx=mx.cpu())
tensor_gpu= mx.nd.zeros((100,), ctx=mx.gpu(0))ดังที่เราเห็นในโค้ดด้านบน MXNets ระบุตำแหน่งที่จะเก็บเทนเซอร์ไม่ว่าจะในอุปกรณ์ CPU หรือ GPU ในตัวอย่างข้างต้นอยู่ที่ตำแหน่ง 0 MXNet สามารถใช้ประโยชน์จากอุปกรณ์ได้อย่างไม่น่าเชื่อเนื่องจากการคำนวณทั้งหมดเกิดขึ้นอย่างเฉื่อยชาแทนที่จะเป็นแบบทันทีทันใด
โหมดสัญลักษณ์
แม้ว่าโหมดจำเป็นจะมีประโยชน์มาก แต่ข้อเสียประการหนึ่งของโหมดนี้คือความแข็งแกร่งกล่าวคือต้องทราบการคำนวณทั้งหมดล่วงหน้าพร้อมกับโครงสร้างข้อมูลที่กำหนดไว้ล่วงหน้า
ในทางกลับกันโหมด Symbolic จะแสดงกราฟการคำนวณเช่น TensorFlow ช่วยขจัดข้อเสียเปรียบของ API ที่จำเป็นโดยอนุญาตให้ MXNet ทำงานกับสัญลักษณ์หรือตัวแปรแทนโครงสร้างข้อมูลคงที่ / กำหนดไว้ล่วงหน้า หลังจากนั้นสัญลักษณ์สามารถตีความเป็นชุดการทำงานได้ดังนี้ -
import mxnet as mx
x = mx.sym.Variable(“X”)
y = mx.sym.Variable(“Y”)
z = (x+y)
m = z/100ชนิดของความเท่าเทียมกัน
Apache MXNet รองรับการฝึกอบรมแบบกระจาย ช่วยให้เราใช้ประโยชน์จากเครื่องจักรหลายเครื่องเพื่อการฝึกอบรมที่รวดเร็วและมีประสิทธิภาพ
ต่อไปนี้เป็นสองวิธีที่เราสามารถกระจายภาระงานของการฝึกอบรม NN ในอุปกรณ์ต่างๆ CPU หรือ GPU ได้ -
ความขนานของข้อมูล
ในการขนานกันแบบนี้อุปกรณ์แต่ละตัวจะจัดเก็บสำเนาแบบจำลองทั้งหมดและทำงานร่วมกับส่วนต่างๆของชุดข้อมูล อุปกรณ์ยังอัปเดตโมเดลที่ใช้ร่วมกันโดยรวม เราสามารถค้นหาอุปกรณ์ทั้งหมดในเครื่องเดียวหรือหลายเครื่อง
โมเดล Parallelism
มันเป็นความขนานอีกแบบหนึ่งซึ่งมีประโยชน์เมื่อรุ่นมีขนาดใหญ่จนไม่พอดีกับหน่วยความจำอุปกรณ์ ในรูปแบบการขนานกันอุปกรณ์ต่าง ๆ จะได้รับมอบหมายงานในการเรียนรู้ส่วนต่างๆของโมเดล ประเด็นสำคัญที่ควรทราบก็คือปัจจุบัน Apache MXNet รองรับโมเดลแบบขนานในเครื่องเดียวเท่านั้น
การทำงานของการฝึกอบรมแบบกระจาย
แนวคิดที่ระบุด้านล่างเป็นกุญแจสำคัญในการทำความเข้าใจการทำงานของการฝึกอบรมแบบกระจายใน Apache MXNet -
ประเภทของกระบวนการ
กระบวนการสื่อสารซึ่งกันและกันเพื่อบรรลุการฝึกอบรมของรูปแบบ Apache MXNet มีสามกระบวนการดังต่อไปนี้ -
คนงาน
งานของโหนดคนงานคือการฝึกอบรมชุดตัวอย่างการฝึกอบรม โหนดผู้ปฏิบัติงานจะดึงน้ำหนักจากเซิร์ฟเวอร์ก่อนประมวลผลทุกชุด โหนดผู้ปฏิบัติงานจะส่งการไล่ระดับสีไปยังเซิร์ฟเวอร์เมื่อชุดงานถูกประมวลผล
เซิร์ฟเวอร์
MXNet สามารถมีเซิร์ฟเวอร์หลายเครื่องสำหรับจัดเก็บพารามิเตอร์ของโมเดลและเพื่อสื่อสารกับโหนดของผู้ปฏิบัติงาน
เครื่องมือจัดกำหนดการ
บทบาทของตัวกำหนดตารางเวลาคือการตั้งค่าคลัสเตอร์ซึ่งรวมถึงการรอข้อความที่แต่ละโหนดเกิดขึ้นและพอร์ตใดที่โหนดกำลังรับฟัง หลังจากตั้งค่าคลัสเตอร์ตัวกำหนดตารางเวลาจะให้กระบวนการทั้งหมดทราบเกี่ยวกับโหนดอื่น ๆ ทั้งหมดในคลัสเตอร์ เป็นเพราะกระบวนการต่างๆสามารถสื่อสารกันได้ มีเพียงตัวกำหนดตารางเวลาเดียว
เค. วี. สโตร์
ร้าน KV ย่อมาจาก Key-Valueเก็บ. เป็นองค์ประกอบสำคัญที่ใช้สำหรับการฝึกอบรมหลายอุปกรณ์ เป็นสิ่งสำคัญเนื่องจากการสื่อสารของพารามิเตอร์ระหว่างอุปกรณ์ในเครื่องเดียวและหลายเครื่องจะถูกส่งผ่านเซิร์ฟเวอร์หนึ่งเครื่องขึ้นไปโดยมี KVStore สำหรับพารามิเตอร์ มาทำความเข้าใจการทำงานของ KVStore ด้วยความช่วยเหลือของประเด็นต่อไปนี้ -
แต่ละค่าใน KVStore แสดงด้วยไฟล์ key และก value.
อาร์เรย์พารามิเตอร์แต่ละตัวในเครือข่ายถูกกำหนด a key และน้ำหนักของอาร์เรย์พารามิเตอร์นั้นถูกอ้างถึงโดย value.
หลังจากนั้นผู้ปฏิบัติงานก็โหน pushการไล่ระดับสีหลังจากประมวลผลชุดงาน พวกเขาด้วยpull ปรับปรุงน้ำหนักก่อนประมวลผลชุดใหม่
แนวคิดของเซิร์ฟเวอร์ KVStore มีเฉพาะในระหว่างการฝึกอบรมแบบกระจายและโหมดกระจายของเซิร์ฟเวอร์จะเปิดใช้งานโดยการโทร mxnet.kvstore.create ฟังก์ชันที่มีอาร์กิวเมนต์สตริงที่มีคำ dist -
kv = mxnet.kvstore.create(‘dist_sync’)การกระจายคีย์
ไม่จำเป็นว่าเซิร์ฟเวอร์ทั้งหมดจะเก็บอาร์เรย์พารามิเตอร์หรือคีย์ทั้งหมด แต่จะกระจายไปตามเซิร์ฟเวอร์ที่แตกต่างกัน การกระจายคีย์ดังกล่าวไปยังเซิร์ฟเวอร์ต่างๆนั้นได้รับการจัดการอย่างโปร่งใสโดย KVStore และการตัดสินใจว่าเซิร์ฟเวอร์ใดเก็บคีย์เฉพาะนั้นจะเกิดขึ้นแบบสุ่ม
KVStore ตามที่กล่าวไว้ข้างต้นเพื่อให้แน่ใจว่าเมื่อใดก็ตามที่ดึงคีย์คำขอจะถูกส่งไปยังเซิร์ฟเวอร์นั้นซึ่งมีค่าที่ตรงกัน จะเกิดอะไรขึ้นถ้าค่าของคีย์บางตัวมีขนาดใหญ่? ในกรณีนี้อาจใช้ร่วมกันระหว่างเซิร์ฟเวอร์ที่แตกต่างกัน
แยกข้อมูลการฝึกอบรม
ในฐานะผู้ใช้เราต้องการให้แต่ละเครื่องทำงานในส่วนต่างๆของชุดข้อมูลโดยเฉพาะอย่างยิ่งเมื่อเรียกใช้การฝึกอบรมแบบกระจายในโหมดขนานข้อมูล เรารู้ว่าในการแยกกลุ่มตัวอย่างที่จัดเตรียมโดยตัววนข้อมูลสำหรับการฝึกอบรมข้อมูลแบบขนานกับผู้ปฏิบัติงานคนเดียวเราสามารถใช้ได้mxnet.gluon.utils.split_and_load จากนั้นโหลดแต่ละส่วนของแบตช์บนอุปกรณ์ซึ่งจะประมวลผลต่อไป
ในทางกลับกันในกรณีของการฝึกอบรมแบบกระจายในตอนแรกเราจำเป็นต้องแบ่งชุดข้อมูลออกเป็น nส่วนต่างๆเพื่อให้คนงานทุกคนได้รับส่วนที่แตกต่างกัน เมื่อได้มาแล้วผู้ปฏิบัติงานแต่ละคนสามารถใช้งานได้split_and_loadเพื่อแบ่งส่วนของชุดข้อมูลอีกครั้งในอุปกรณ์ต่างๆในเครื่องเดียว ทั้งหมดนี้เกิดขึ้นผ่าน data iteratormxnet.io.MNISTIterator และ mxnet.io.ImageRecordIter เป็นตัวทำซ้ำสองตัวใน MXNet ที่รองรับคุณสมบัตินี้
กำลังอัปเดตน้ำหนัก
สำหรับการอัปเดตน้ำหนัก KVStore รองรับสองโหมดต่อไปนี้ -
วิธีแรกจะรวบรวมการไล่ระดับสีและอัปเดตน้ำหนักโดยใช้การไล่ระดับสีเหล่านั้น
ในวิธีที่สองเซิร์ฟเวอร์จะรวบรวมเฉพาะการไล่ระดับสี
หากคุณใช้ Gluon มีตัวเลือกให้เลือกระหว่างวิธีการที่ระบุไว้ข้างต้นโดยการส่งผ่าน update_on_kvstoreตัวแปร. มาทำความเข้าใจกันด้วยการสร้างไฟล์trainer วัตถุดังต่อไปนี้ -
trainer = gluon.Trainer(net.collect_params(), optimizer='sgd',
optimizer_params={'learning_rate': opt.lr,
'wd': opt.wd,
'momentum': opt.momentum,
'multi_precision': True},
kvstore=kv,
update_on_kvstore=True)รูปแบบของการฝึกอบรมแบบกระจาย
หากสตริงการสร้าง KVStore มีคำว่า dist หมายความว่าการฝึกอบรมแบบกระจายถูกเปิดใช้งาน ต่อไปนี้เป็นโหมดต่างๆของการฝึกอบรมแบบกระจายที่สามารถเปิดใช้งานได้โดยใช้ KVStore ประเภทต่างๆ -
dist_sync
ตามความหมายของชื่อหมายถึงการฝึกอบรมแบบกระจายซิงโครนัส ในกรณีนี้คนงานทั้งหมดจะใช้ชุดพารามิเตอร์โมเดลที่ซิงโครไนซ์เดียวกันเมื่อเริ่มต้นทุกชุด
ข้อเสียเปรียบของโหมดนี้คือหลังจากแต่ละชุดเซิร์ฟเวอร์ควรรอรับการไล่ระดับสีจากผู้ปฏิบัติงานแต่ละคนก่อนที่จะอัปเดตพารามิเตอร์ของโมเดล ซึ่งหมายความว่าหากคนงานขัดข้องก็จะหยุดความคืบหน้าของคนงานทั้งหมด
dist_async
ตามความหมายของชื่อหมายถึงการฝึกอบรมแบบกระจายซิงโครนัส ในสิ่งนี้เซิร์ฟเวอร์ได้รับการไล่ระดับสีจากผู้ปฏิบัติงานคนหนึ่งและอัปเดตที่เก็บของทันที เซิร์ฟเวอร์ใช้ร้านค้าที่อัปเดตเพื่อตอบสนองต่อการดึงข้อมูลเพิ่มเติม
ข้อได้เปรียบเมื่อเปรียบเทียบกับ dist_sync modeคือผู้ปฏิบัติงานที่ทำการประมวลผลชุดงานเสร็จสิ้นสามารถดึงพารามิเตอร์ปัจจุบันจากเซิร์ฟเวอร์และเริ่มชุดงานถัดไปได้ ผู้ปฏิบัติงานสามารถทำได้แม้ว่าผู้ปฏิบัติงานคนอื่นจะยังไม่เสร็จสิ้นการประมวลผลชุดงานก่อนหน้านี้ก็ตาม นอกจากนี้ยังเร็วกว่าโหมด dist_sync เนื่องจากอาจใช้เวลามากกว่าในการบรรจบกันโดยไม่ต้องเสียค่าใช้จ่ายในการซิงโครไนซ์
dist_sync_device
โหมดนี้เหมือนกับ dist_syncโหมด. ข้อแตกต่างเพียงอย่างเดียวคือเมื่อมีการใช้ GPU หลายตัวในทุกโหนดdist_sync_device รวมการไล่ระดับสีและอัปเดตน้ำหนักบน GPU ในขณะที่ dist_sync รวมการไล่ระดับสีและปรับปรุงน้ำหนักของหน่วยความจำ CPU
ช่วยลดการสื่อสารที่มีราคาแพงระหว่าง GPU และ CPU นั่นคือเหตุผลที่มันเร็วกว่าdist_sync. ข้อเสียคือเพิ่มการใช้หน่วยความจำบน GPU
dist_async_device
โหมดนี้ใช้งานได้เช่นเดียวกับ dist_sync_device โหมด แต่อยู่ในโหมดอะซิงโครนัส
ในบทนี้เราจะเรียนรู้เกี่ยวกับแพ็คเกจ Python ที่มีอยู่ใน Apache MXNet
แพ็คเกจ MXNet Python ที่สำคัญ
MXNet มีแพ็คเกจ Python ที่สำคัญดังต่อไปนี้ซึ่งเราจะพูดถึงทีละรายการ -
Autograd (ความแตกต่างอัตโนมัติ)
NDArray
KVStore
Gluon
Visualization
ก่อนอื่นให้เราเริ่มต้นด้วย Autograd แพ็คเกจ Python สำหรับ Apache MXNet
Autograd
Autograd หมายถึง automatic differentiationใช้เพื่อ backpropagate การไล่ระดับสีจากเมตริกการสูญเสียกลับไปที่พารามิเตอร์แต่ละตัว นอกจาก backpropagation แล้วยังใช้วิธีการเขียนโปรแกรมแบบไดนามิกเพื่อคำนวณการไล่ระดับสีอย่างมีประสิทธิภาพ เรียกอีกอย่างว่าโหมดย้อนกลับความแตกต่างอัตโนมัติ เทคนิคนี้มีประสิทธิภาพมากในสถานการณ์ 'fan-in' ซึ่งพารามิเตอร์จำนวนมากมีผลต่อเมตริกการสูญเสียเพียงครั้งเดียว
การไล่ระดับสีคืออะไร?
การไล่ระดับสีเป็นปัจจัยพื้นฐานของกระบวนการฝึกอบรมเครือข่ายประสาทเทียม โดยพื้นฐานแล้วพวกเขาบอกเราว่าจะเปลี่ยนพารามิเตอร์ของเครือข่ายเพื่อปรับปรุงประสิทธิภาพได้อย่างไร
ดังที่เราทราบดีว่าเครือข่ายประสาทเทียม (NN) ประกอบด้วยตัวดำเนินการเช่นผลรวมผลิตภัณฑ์การชักและอื่น ๆ ตัวดำเนินการเหล่านี้สำหรับการคำนวณใช้พารามิเตอร์เช่นน้ำหนักในเมล็ด Convolution เราควรต้องหาค่าที่เหมาะสมที่สุดสำหรับพารามิเตอร์เหล่านี้และการไล่ระดับสีจะแสดงวิธีและนำเราไปสู่การแก้ปัญหาด้วย
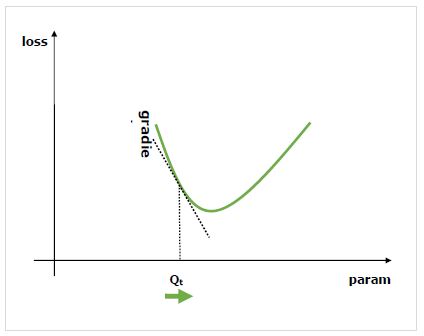
เราสนใจผลของการเปลี่ยนพารามิเตอร์ต่อประสิทธิภาพของเครือข่ายและการไล่ระดับสีบอกเราว่าตัวแปรที่ระบุเพิ่มขึ้นหรือลดลงเท่าใดเมื่อเราเปลี่ยนตัวแปรนั้นขึ้นอยู่กับ โดยปกติประสิทธิภาพจะถูกกำหนดโดยใช้เมตริกการสูญเสียที่เราพยายามลดให้เหลือน้อยที่สุด ตัวอย่างเช่นสำหรับการถดถอยเราอาจพยายามย่อให้เล็กที่สุดL2 การสูญเสียระหว่างการคาดการณ์และค่าที่แน่นอนของเราในขณะที่สำหรับการจัดประเภทเราอาจลดค่า cross-entropy loss.
เมื่อเราคำนวณการไล่ระดับสีของแต่ละพารามิเตอร์โดยอ้างอิงการสูญเสียแล้วเราสามารถใช้เครื่องมือเพิ่มประสิทธิภาพได้เช่นการไล่ระดับสีแบบสุ่ม
วิธีคำนวณการไล่ระดับสี?
เรามีตัวเลือกต่อไปนี้ในการคำนวณการไล่ระดับสี -
Symbolic Differentiation- ตัวเลือกแรกสุดคือ Symbolic Differentiation ซึ่งจะคำนวณสูตรสำหรับการไล่ระดับสีแต่ละครั้ง ข้อเสียเปรียบของวิธีนี้คือจะนำไปสู่สูตรที่ยาวอย่างไม่น่าเชื่อได้อย่างรวดเร็วเนื่องจากเครือข่ายมีความลึกและตัวดำเนินการมีความซับซ้อนมากขึ้น
Finite Differencing- อีกทางเลือกหนึ่งคือการใช้ความแตกต่างแบบ จำกัด ซึ่งลองใช้ความแตกต่างเล็กน้อยในแต่ละพารามิเตอร์และดูว่าเมตริกการสูญเสียตอบสนองอย่างไร ข้อเสียเปรียบของวิธีนี้คือมันจะมีราคาแพงในการคำนวณและอาจมีความแม่นยำในการคำนวณต่ำ
Automatic differentiation- วิธีแก้ไขข้อบกพร่องของวิธีการข้างต้นคือการใช้การสร้างความแตกต่างโดยอัตโนมัติในการย้อนกลับการไล่ระดับสีจากเมตริกการสูญเสียกลับไปยังพารามิเตอร์แต่ละตัว การขยายพันธุ์ช่วยให้เราใช้วิธีการเขียนโปรแกรมแบบไดนามิกเพื่อคำนวณการไล่ระดับสีได้อย่างมีประสิทธิภาพ วิธีนี้เรียกอีกอย่างว่าโหมดย้อนกลับความแตกต่างอัตโนมัติ
ความแตกต่างอัตโนมัติ (autograd)
ที่นี่เราจะเข้าใจรายละเอียดเกี่ยวกับการทำงานของ autograd โดยทั่วไปจะทำงานในสองขั้นตอนต่อไปนี้ -
Stage 1 - เวทีนี้เรียกว่า ‘Forward Pass’ของการฝึกอบรม ตามความหมายของชื่อในขั้นตอนนี้จะสร้างบันทึกของตัวดำเนินการที่เครือข่ายใช้เพื่อทำการคาดคะเนและคำนวณเมตริกการสูญเสีย
Stage 2 - เวทีนี้เรียกว่า ‘Backward Pass’ของการฝึกอบรม ตามความหมายของชื่อในขั้นตอนนี้จะทำงานย้อนหลังผ่านบันทึกนี้ ย้อนกลับไปมันจะประเมินอนุพันธ์บางส่วนของแต่ละตัวดำเนินการกลับไปที่พารามิเตอร์เครือข่าย
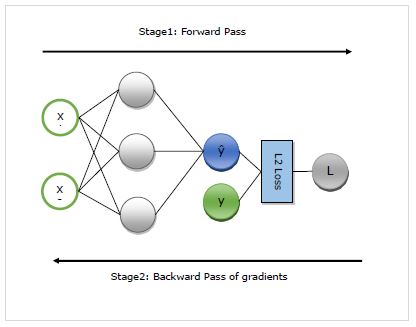
ข้อดีของ autograd
ต่อไปนี้เป็นข้อดีของการใช้ Automatic Differentiation (autograd) -
Flexible- ความยืดหยุ่นที่ให้เราเมื่อกำหนดเครือข่ายของเราเป็นประโยชน์อย่างมากอย่างหนึ่งของการใช้ autograd เราสามารถเปลี่ยนการดำเนินการในการทำซ้ำทุกครั้ง สิ่งเหล่านี้เรียกว่ากราฟไดนามิกซึ่งมีความซับซ้อนกว่ามากในการนำไปใช้ในกรอบงานที่ต้องใช้กราฟแบบคงที่ Autograd แม้ในกรณีดังกล่าวจะยังคงสามารถย้อนกลับการไล่ระดับสีได้อย่างถูกต้อง
Automatic- Autograd เป็นไปโดยอัตโนมัติกล่าวคือความซับซ้อนของกระบวนการ backpropagation จะได้รับการดูแลโดยคุณ เราต้องระบุว่าการไล่ระดับสีใดที่เราสนใจในการคำนวณ
Efficient - Autogard คำนวณการไล่ระดับสีได้อย่างมีประสิทธิภาพ
Can use native Python control flow operators- เราสามารถใช้ตัวดำเนินการโฟลว์ควบคุม Python ดั้งเดิมเช่น if condition และ while loop autograd จะยังคงสามารถ backpropagate การไล่ระดับสีได้อย่างมีประสิทธิภาพและถูกต้อง
ใช้ autograd ใน MXNet Gluon
ที่นี่ด้วยความช่วยเหลือของตัวอย่างเราจะดูว่าเราสามารถใช้งานได้อย่างไร autograd ใน MXNet Gluon
ตัวอย่างการใช้งาน
ในตัวอย่างต่อไปนี้เราจะใช้โมเดลการถดถอยที่มีสองชั้น หลังจากใช้งานแล้วเราจะใช้ autograd เพื่อคำนวณการไล่ระดับสีของการสูญเสียโดยอัตโนมัติโดยอ้างอิงกับพารามิเตอร์น้ำหนักแต่ละตัว -
ก่อนอื่นให้นำเข้า autogrard และแพ็คเกจอื่น ๆ ที่จำเป็นดังนี้ -
from mxnet import autograd
import mxnet as mx
from mxnet.gluon.nn import HybridSequential, Dense
from mxnet.gluon.loss import L2Lossตอนนี้เราต้องกำหนดเครือข่ายดังนี้ -
N_net = HybridSequential()
N_net.add(Dense(units=3))
N_net.add(Dense(units=1))
N_net.initialize()ตอนนี้เราต้องกำหนดความสูญเสียดังนี้ -
loss_function = L2Loss()ต่อไปเราต้องสร้างข้อมูลจำลองดังต่อไปนี้ -
x = mx.nd.array([[0.5, 0.9]])
y = mx.nd.array([[1.5]])ตอนนี้เราพร้อมแล้วสำหรับการส่งต่อครั้งแรกผ่านเครือข่าย เราต้องการให้ autograd บันทึกกราฟการคำนวณเพื่อที่เราจะได้คำนวณการไล่ระดับสี สำหรับสิ่งนี้เราจำเป็นต้องเรียกใช้รหัสเครือข่ายในขอบเขตของautograd.record บริบทดังต่อไปนี้ -
with autograd.record():
y_hat = N_net(x)
loss = loss_function(y_hat, y)ตอนนี้เราพร้อมแล้วสำหรับการส่งย้อนกลับซึ่งเราเริ่มต้นด้วยการเรียกวิธีการย้อนกลับในปริมาณที่น่าสนใจ จำนวนที่น่าสนใจในตัวอย่างของเราคือการสูญเสียเนื่องจากเราพยายามคำนวณการไล่ระดับสีของการสูญเสียโดยอ้างอิงกับพารามิเตอร์ -
loss.backward()ตอนนี้เรามีการไล่ระดับสีสำหรับแต่ละพารามิเตอร์ของเครือข่ายซึ่งเครื่องมือเพิ่มประสิทธิภาพจะใช้เพื่ออัปเดตค่าพารามิเตอร์เพื่อประสิทธิภาพที่ดีขึ้น ลองดูการไล่ระดับของเลเยอร์ที่ 1 ดังนี้ -
N_net[0].weight.grad()Output
ผลลัพธ์มีดังนี้
[[-0.00470527 -0.00846948]
[-0.03640365 -0.06552657]
[ 0.00800354 0.01440637]]
<NDArray 3x2 @cpu(0)>ตัวอย่างการใช้งานที่สมบูรณ์
ด้านล่างนี้เป็นตัวอย่างการใช้งานที่สมบูรณ์
from mxnet import autograd
import mxnet as mx
from mxnet.gluon.nn import HybridSequential, Dense
from mxnet.gluon.loss import L2Loss
N_net = HybridSequential()
N_net.add(Dense(units=3))
N_net.add(Dense(units=1))
N_net.initialize()
loss_function = L2Loss()
x = mx.nd.array([[0.5, 0.9]])
y = mx.nd.array([[1.5]])
with autograd.record():
y_hat = N_net(x)
loss = loss_function(y_hat, y)
loss.backward()
N_net[0].weight.grad()ในบทนี้เราจะพูดถึงรูปแบบอาร์เรย์หลายมิติของ MXNet ที่เรียกว่า ndarray.
การจัดการข้อมูลด้วย NDArray
ขั้นแรกเราจะมาดูกันว่าเราจะจัดการข้อมูลด้วย NDArray ได้อย่างไร ต่อไปนี้เป็นข้อกำหนดเบื้องต้นสำหรับสิ่งเดียวกัน -
ข้อกำหนดเบื้องต้น
เพื่อให้เข้าใจว่าเราสามารถจัดการข้อมูลด้วยรูปแบบอาร์เรย์หลายมิตินี้ได้อย่างไรเราจำเป็นต้องปฏิบัติตามข้อกำหนดเบื้องต้นต่อไปนี้:
MXNet ติดตั้งในสภาพแวดล้อม Python
Python 2.7.x หรือ Python 3.x
ตัวอย่างการใช้งาน
ให้เราเข้าใจฟังก์ชันพื้นฐานด้วยความช่วยเหลือของตัวอย่างด้านล่าง -
ขั้นแรกเราต้องนำเข้า MXNet และ ndarray จาก MXNet ดังนี้ -
import mxnet as mx
from mxnet import ndเมื่อเรานำเข้าไลบรารีที่จำเป็นเราจะไปกับฟังก์ชันพื้นฐานดังต่อไปนี้:
อาร์เรย์ 1 มิติอย่างง่ายพร้อมรายการหลาม
Example
x = nd.array([1,2,3,4,5,6,7,8,9,10])
print(x)Output
ผลลัพธ์มีดังต่อไปนี้ -
[ 1. 2. 3. 4. 5. 6. 7. 8. 9. 10.]
<NDArray 10 @cpu(0)>อาร์เรย์ 2 มิติพร้อมรายการหลาม
Example
y = nd.array([[1,2,3,4,5,6,7,8,9,10], [1,2,3,4,5,6,7,8,9,10], [1,2,3,4,5,6,7,8,9,10]])
print(y)Output
ผลลัพธ์เป็นไปตามที่ระบุไว้ด้านล่าง -
[[ 1. 2. 3. 4. 5. 6. 7. 8. 9. 10.]
[ 1. 2. 3. 4. 5. 6. 7. 8. 9. 10.]
[ 1. 2. 3. 4. 5. 6. 7. 8. 9. 10.]]
<NDArray 3x10 @cpu(0)>การสร้าง NDArray โดยไม่ต้องเริ่มต้นใด ๆ
ที่นี่เราจะสร้างเมทริกซ์ที่มี 3 แถวและ 4 คอลัมน์โดยใช้ .emptyฟังก์ชัน นอกจากนี้เรายังจะใช้.full ซึ่งจะใช้ตัวดำเนินการเพิ่มเติมสำหรับค่าที่คุณต้องการเติมในอาร์เรย์
Example
x = nd.empty((3, 4))
print(x)
x = nd.full((3,4), 8)
print(x)Output
ผลลัพธ์จะได้รับด้านล่าง -
[[0.000e+00 0.000e+00 0.000e+00 0.000e+00]
[0.000e+00 0.000e+00 2.887e-42 0.000e+00]
[0.000e+00 0.000e+00 0.000e+00 0.000e+00]]
<NDArray 3x4 @cpu(0)>
[[8. 8. 8. 8.]
[8. 8. 8. 8.]
[8. 8. 8. 8.]]
<NDArray 3x4 @cpu(0)>เมทริกซ์ของศูนย์ทั้งหมดที่มีฟังก์ชัน. seros
Example
x = nd.zeros((3, 8))
print(x)Output
ผลลัพธ์มีดังนี้ -
[[0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0.]]
<NDArray 3x8 @cpu(0)>เมทริกซ์ของทุกคนที่มีฟังก์ชัน .ones
Example
x = nd.ones((3, 8))
print(x)Output
ผลลัพธ์จะกล่าวถึงด้านล่าง -
[[1. 1. 1. 1. 1. 1. 1. 1.]
[1. 1. 1. 1. 1. 1. 1. 1.]
[1. 1. 1. 1. 1. 1. 1. 1.]]
<NDArray 3x8 @cpu(0)>การสร้างอาร์เรย์ที่มีการสุ่มตัวอย่างค่า
Example
y = nd.random_normal(0, 1, shape=(3, 4))
print(y)Output
ผลลัพธ์จะได้รับด้านล่าง -
[[ 1.2673576 -2.0345826 -0.32537818 -1.4583491 ]
[-0.11176403 1.3606371 -0.7889914 -0.17639421]
[-0.2532185 -0.42614475 -0.12548696 1.4022992 ]]
<NDArray 3x4 @cpu(0)>การหามิติของ NDArray แต่ละตัว
Example
y.shapeOutput
ผลลัพธ์มีดังนี้ -
(3, 4)การหาขนาดของ NDArray แต่ละตัว
Example
y.sizeOutput
12การค้นหาประเภทข้อมูลของแต่ละ NDArray
Example
y.dtypeOutput
numpy.float32ปฏิบัติการ NDArray
ในส่วนนี้เราจะแนะนำคุณเกี่ยวกับการทำงานของอาร์เรย์ของ MXNet NDArray รองรับการดำเนินการทางคณิตศาสตร์มาตรฐานและ In-place จำนวนมาก
การดำเนินการทางคณิตศาสตร์มาตรฐาน
ต่อไปนี้คือการดำเนินการทางคณิตศาสตร์มาตรฐานที่รองรับโดย NDArray -
นอกจากนี้องค์ประกอบที่ชาญฉลาด
ขั้นแรกเราต้องนำเข้า MXNet และ ndarray จาก MXNet ดังนี้:
import mxnet as mx
from mxnet import nd
x = nd.ones((3, 5))
y = nd.random_normal(0, 1, shape=(3, 5))
print('x=', x)
print('y=', y)
x = x + y
print('x = x + y, x=', x)Output
ผลลัพธ์จะได้รับในที่นี้ -
x=
[[1. 1. 1. 1. 1.]
[1. 1. 1. 1. 1.]
[1. 1. 1. 1. 1.]]
<NDArray 3x5 @cpu(0)>
y=
[[-1.0554522 -1.3118273 -0.14674698 0.641493 -0.73820823]
[ 2.031364 0.5932667 0.10228804 1.179526 -0.5444829 ]
[-0.34249446 1.1086396 1.2756858 -1.8332436 -0.5289873 ]]
<NDArray 3x5 @cpu(0)>
x = x + y, x=
[[-0.05545223 -0.3118273 0.853253 1.6414931 0.26179177]
[ 3.031364 1.5932667 1.102288 2.1795259 0.4555171 ]
[ 0.6575055 2.1086397 2.2756858 -0.8332436 0.4710127 ]]
<NDArray 3x5 @cpu(0)>การคูณธาตุอย่างชาญฉลาด
Example
x = nd.array([1, 2, 3, 4])
y = nd.array([2, 2, 2, 1])
x * yOutput
คุณจะเห็นผลลัพธ์ต่อไปนี้
[2. 4. 6. 4.]
<NDArray 4 @cpu(0)>การยกกำลัง
Example
nd.exp(x)Output
เมื่อคุณเรียกใช้รหัสคุณจะเห็นผลลัพธ์ต่อไปนี้:
[ 2.7182817 7.389056 20.085537 54.59815 ]
<NDArray 4 @cpu(0)>เมทริกซ์ทรานสโพสเพื่อคำนวณผลิตภัณฑ์เมทริกซ์ - เมทริกซ์
Example
nd.dot(x, y.T)Output
ด้านล่างเป็นผลลัพธ์ของรหัส -
[16.]
<NDArray 1 @cpu(0)>การดำเนินการในสถานที่
ทุกครั้งในตัวอย่างข้างต้นเราเรียกใช้การดำเนินการเราจะจัดสรรหน่วยความจำใหม่เพื่อโฮสต์ผลลัพธ์
ตัวอย่างเช่นถ้าเราเขียน A = A + B เราจะหักล้างเมทริกซ์ที่ A ใช้ชี้ไปและแทนที่จะชี้ไปที่หน่วยความจำที่จัดสรรใหม่ ให้เราทำความเข้าใจกับตัวอย่างด้านล่างโดยใช้ฟังก์ชัน id () ของ Python -
print('y=', y)
print('id(y):', id(y))
y = y + x
print('after y=y+x, y=', y)
print('id(y):', id(y))Output
เมื่อดำเนินการคุณจะได้รับผลลัพธ์ต่อไปนี้ -
y=
[2. 2. 2. 1.]
<NDArray 4 @cpu(0)>
id(y): 2438905634376
after y=y+x, y=
[3. 4. 5. 5.]
<NDArray 4 @cpu(0)>
id(y): 2438905685664ในความเป็นจริงเราสามารถกำหนดผลลัพธ์ให้กับอาร์เรย์ที่จัดสรรไว้ก่อนหน้านี้ได้ดังนี้ -
print('x=', x)
z = nd.zeros_like(x)
print('z is zeros_like x, z=', z)
print('id(z):', id(z))
print('y=', y)
z[:] = x + y
print('z[:] = x + y, z=', z)
print('id(z) is the same as before:', id(z))Output
ผลลัพธ์ดังแสดงด้านล่าง -
x=
[1. 2. 3. 4.]
<NDArray 4 @cpu(0)>
z is zeros_like x, z=
[0. 0. 0. 0.]
<NDArray 4 @cpu(0)>
id(z): 2438905790760
y=
[3. 4. 5. 5.]
<NDArray 4 @cpu(0)>
z[:] = x + y, z=
[4. 6. 8. 9.]
<NDArray 4 @cpu(0)>
id(z) is the same as before: 2438905790760จากผลลัพธ์ด้านบนเราจะเห็นว่า x + y จะยังคงจัดสรรบัฟเฟอร์ชั่วคราวเพื่อเก็บผลลัพธ์ก่อนที่จะคัดลอกไปยัง z ตอนนี้เราสามารถดำเนินการแทนเพื่อใช้ประโยชน์จากหน่วยความจำได้ดีขึ้นและเพื่อหลีกเลี่ยงบัฟเฟอร์ชั่วคราว ในการทำเช่นนี้เราจะระบุอาร์กิวเมนต์คำหลักทุกตัวรองรับดังนี้ -
print('x=', x, 'is in id(x):', id(x))
print('y=', y, 'is in id(y):', id(y))
print('z=', z, 'is in id(z):', id(z))
nd.elemwise_add(x, y, out=z)
print('after nd.elemwise_add(x, y, out=z), x=', x, 'is in id(x):', id(x))
print('after nd.elemwise_add(x, y, out=z), y=', y, 'is in id(y):', id(y))
print('after nd.elemwise_add(x, y, out=z), z=', z, 'is in id(z):', id(z))Output
ในการรันโปรแกรมข้างต้นคุณจะได้รับผลลัพธ์ดังต่อไปนี้ -
x=
[1. 2. 3. 4.]
<NDArray 4 @cpu(0)> is in id(x): 2438905791152
y=
[3. 4. 5. 5.]
<NDArray 4 @cpu(0)> is in id(y): 2438905685664
z=
[4. 6. 8. 9.]
<NDArray 4 @cpu(0)> is in id(z): 2438905790760
after nd.elemwise_add(x, y, out=z), x=
[1. 2. 3. 4.]
<NDArray 4 @cpu(0)> is in id(x): 2438905791152
after nd.elemwise_add(x, y, out=z), y=
[3. 4. 5. 5.]
<NDArray 4 @cpu(0)> is in id(y): 2438905685664
after nd.elemwise_add(x, y, out=z), z=
[4. 6. 8. 9.]
<NDArray 4 @cpu(0)> is in id(z): 2438905790760บริบท NDArray
ใน Apache MXNet แต่ละอาร์เรย์มีบริบทและบริบทหนึ่งอาจเป็น CPU ในขณะที่บริบทอื่น ๆ อาจเป็น GPU หลายตัว สิ่งต่างๆอาจเลวร้ายยิ่งขึ้นเมื่อเราปรับใช้งานในเซิร์ฟเวอร์หลายเครื่อง นั่นเป็นเหตุผลที่เราต้องกำหนดอาร์เรย์ให้กับบริบทอย่างชาญฉลาด จะช่วยลดเวลาที่ใช้ในการถ่ายโอนข้อมูลระหว่างอุปกรณ์
ตัวอย่างเช่นลองเริ่มต้นอาร์เรย์ดังนี้ -
from mxnet import nd
z = nd.ones(shape=(3,3), ctx=mx.cpu(0))
print(z)Output
เมื่อคุณรันโค้ดด้านบนคุณจะเห็นผลลัพธ์ต่อไปนี้ -
[[1. 1. 1.]
[1. 1. 1.]
[1. 1. 1.]]
<NDArray 3x3 @cpu(0)>เราสามารถคัดลอก NDArray ที่กำหนดจากบริบทหนึ่งไปยังอีกบริบทหนึ่งโดยใช้เมธอด copyto () ดังนี้ -
x_gpu = x.copyto(gpu(0))
print(x_gpu)อาร์เรย์ NumPy เทียบกับ NDArray
เราทุกคนคุ้นเคยกับอาร์เรย์ NumPy แต่ Apache MXNet มีการใช้อาร์เรย์ของตัวเองที่ชื่อ NDArray จริงๆแล้วในตอนแรกถูกออกแบบมาให้คล้ายกับ NumPy แต่มีข้อแตกต่างที่สำคัญ -
ความแตกต่างที่สำคัญคือวิธีดำเนินการคำนวณใน NumPy และ NDArray ทุกการจัดการ NDArray ใน MXNet จะทำในแบบอะซิงโครนัสและไม่ปิดกั้นซึ่งหมายความว่าเมื่อเราเขียนโค้ดเช่น c = a * b ฟังก์ชันจะถูกผลักไปที่Execution Engineซึ่งจะเริ่มการคำนวณ
ที่นี่ a และ b ทั้งสองคือ NDArrays ประโยชน์ของการใช้ฟังก์ชันนี้คือฟังก์ชันจะส่งกลับทันทีและเธรดผู้ใช้สามารถดำเนินการต่อได้แม้ว่าการคำนวณก่อนหน้านี้อาจยังไม่เสร็จสมบูรณ์
การทำงานของ Execution Engine
ถ้าเราพูดถึงการทำงานของกลไกการสั่งการมันจะสร้างกราฟการคำนวณ กราฟการคำนวณอาจเรียงลำดับใหม่หรือรวมการคำนวณบางอย่างเข้าด้วยกัน แต่จะให้เกียรติลำดับการอ้างอิงเสมอ
ตัวอย่างเช่นหากมีการจัดการอื่น ๆ ด้วย 'X' ที่ทำในภายหลังในโค้ดการเขียนโปรแกรม Execution Engine จะเริ่มดำเนินการเมื่อผลลัพธ์ของ 'X' พร้อมใช้งาน Execution Engine จะจัดการงานที่สำคัญบางอย่างให้กับผู้ใช้เช่นการเขียน callback เพื่อเริ่มการเรียกใช้โค้ดที่ตามมา
ใน Apache MXNet ด้วยความช่วยเหลือของ NDArray เพื่อให้ได้ผลลัพธ์ของการคำนวณเราจำเป็นต้องเข้าถึงตัวแปรที่เป็นผลลัพธ์เท่านั้น การไหลของรหัสจะถูกบล็อกจนกว่าผลการคำนวณจะถูกกำหนดให้กับตัวแปรที่เป็นผลลัพธ์ ด้วยวิธีนี้จะเพิ่มประสิทธิภาพของโค้ดในขณะที่ยังคงรองรับโหมดการเขียนโปรแกรมที่จำเป็น
การแปลง NDArray เป็น NumPy Array
ให้เราเรียนรู้ว่าเราจะแปลง NDArray เป็น NumPy Array ใน MXNet ได้อย่างไร
Combining higher-level operator with the help of few lower-level operators
บางครั้งเราสามารถรวบรวมตัวดำเนินการระดับสูงขึ้นได้โดยใช้ตัวดำเนินการที่มีอยู่ หนึ่งในตัวอย่างที่ดีที่สุดคือไฟล์np.full_like()ตัวดำเนินการซึ่งไม่มีใน NDArray API สามารถแทนที่ได้อย่างง่ายดายด้วยการรวมกันของตัวดำเนินการที่มีอยู่ดังต่อไปนี้:
from mxnet import nd
import numpy as np
np_x = np.full_like(a=np.arange(7, dtype=int), fill_value=15)
nd_x = nd.ones(shape=(7,)) * 15
np.array_equal(np_x, nd_x.asnumpy())Output
เราจะได้ผลลัพธ์ที่คล้ายกันดังนี้ -
TrueFinding similar operator with different name and/or signature
ในบรรดาโอเปอเรเตอร์ทั้งหมดบางตัวมีชื่อที่แตกต่างกันเล็กน้อย แต่มีความคล้ายคลึงกันในแง่ของฟังก์ชันการทำงาน ตัวอย่างนี้คือnd.ravel_index() ด้วย np.ravel()ฟังก์ชั่น. ในทำนองเดียวกันตัวดำเนินการบางตัวอาจมีชื่อคล้ายกัน แต่มีลายเซ็นต่างกัน ตัวอย่างนี้คือnp.split() และ nd.split() มีความคล้ายคลึงกัน
มาทำความเข้าใจกับตัวอย่างการเขียนโปรแกรมต่อไปนี้:
def pad_array123(data, max_length):
data_expanded = data.reshape(1, 1, 1, data.shape[0])
data_padded = nd.pad(data_expanded,
mode='constant',
pad_width=[0, 0, 0, 0, 0, 0, 0, max_length - data.shape[0]],
constant_value=0)
data_reshaped_back = data_padded.reshape(max_length)
return data_reshaped_back
pad_array123(nd.array([1, 2, 3]), max_length=10)Output
ผลลัพธ์ระบุไว้ด้านล่าง -
[1. 2. 3. 0. 0. 0. 0. 0. 0. 0.]
<NDArray 10 @cpu(0)>ลดผลกระทบของการบล็อกการโทร
ในบางกรณีเราต้องใช้อย่างใดอย่างหนึ่ง .asnumpy() หรือ .asscalar()แต่จะบังคับให้ MXNet บล็อกการดำเนินการจนกว่าจะสามารถดึงผลลัพธ์ได้ เราสามารถลดผลกระทบของการบล็อกการโทรได้โดยการโทร.asnumpy() หรือ .asscalar() วิธีการในขณะนี้เมื่อเราคิดว่าการคำนวณค่านี้เสร็จสิ้นแล้ว
ตัวอย่างการใช้งาน
Example
from __future__ import print_function
import mxnet as mx
from mxnet import gluon, nd, autograd
from mxnet.ndarray import NDArray
from mxnet.gluon import HybridBlock
import numpy as np
class LossBuffer(object):
"""
Simple buffer for storing loss value
"""
def __init__(self):
self._loss = None
def new_loss(self, loss):
ret = self._loss
self._loss = loss
return ret
@property
def loss(self):
return self._loss
net = gluon.nn.Dense(10)
ce = gluon.loss.SoftmaxCELoss()
net.initialize()
data = nd.random.uniform(shape=(1024, 100))
label = nd.array(np.random.randint(0, 10, (1024,)), dtype='int32')
train_dataset = gluon.data.ArrayDataset(data, label)
train_data = gluon.data.DataLoader(train_dataset, batch_size=128, shuffle=True, num_workers=2)
trainer = gluon.Trainer(net.collect_params(), optimizer='sgd')
loss_buffer = LossBuffer()
for data, label in train_data:
with autograd.record():
out = net(data)
# This call saves new loss and returns previous loss
prev_loss = loss_buffer.new_loss(ce(out, label))
loss_buffer.loss.backward()
trainer.step(data.shape[0])
if prev_loss is not None:
print("Loss: {}".format(np.mean(prev_loss.asnumpy())))Output
ผลลัพธ์ถูกอ้างถึงด้านล่าง:
Loss: 2.3373236656188965
Loss: 2.3656985759735107
Loss: 2.3613128662109375
Loss: 2.3197104930877686
Loss: 2.3054862022399902
Loss: 2.329197406768799
Loss: 2.318927526473999แพ็คเกจ MXNet Python ที่สำคัญที่สุดอีกอย่างคือ Gluon ในบทนี้เราจะพูดถึงแพ็คเกจนี้ Gluon มี API ที่ชัดเจนกระชับและเรียบง่ายสำหรับโครงการ DL ช่วยให้ Apache MXNet สร้างต้นแบบสร้างและฝึกโมเดล DL ได้โดยไม่เสียความเร็วในการฝึก
บล็อก
บล็อกเป็นพื้นฐานของการออกแบบเครือข่ายที่ซับซ้อนมากขึ้น ในเครือข่ายประสาทเทียมเมื่อความซับซ้อนของเครือข่ายประสาทเพิ่มขึ้นเราจำเป็นต้องเปลี่ยนจากการออกแบบเซลล์ประสาทชั้นเดียวไปสู่ทั้งชั้น ตัวอย่างเช่นการออกแบบ NN เช่น ResNet-152 มีระดับความสม่ำเสมอที่ยุติธรรมมากโดยประกอบด้วยblocks ของเลเยอร์ซ้ำ
ตัวอย่าง
ในตัวอย่างด้านล่างนี้เราจะเขียนโค้ดเป็นบล็อกง่ายๆคือบล็อกสำหรับเพอร์เซปตรอนหลายชั้น
from mxnet import nd
from mxnet.gluon import nn
x = nd.random.uniform(shape=(2, 20))
N_net = nn.Sequential()
N_net.add(nn.Dense(256, activation='relu'))
N_net.add(nn.Dense(10))
N_net.initialize()
N_net(x)Output
สิ่งนี้สร้างผลลัพธ์ต่อไปนี้:
[[ 0.09543004 0.04614332 -0.00286655 -0.07790346 -0.05130241 0.02942038
0.08696645 -0.0190793 -0.04122177 0.05088576]
[ 0.0769287 0.03099706 0.00856576 -0.044672 -0.06926838 0.09132431
0.06786592 -0.06187843 -0.03436674 0.04234696]]
<NDArray 2x10 @cpu(0)>ขั้นตอนที่จำเป็นในการเริ่มต้นตั้งแต่การกำหนดเลเยอร์ไปจนถึงการกำหนดบล็อคของเลเยอร์หนึ่งหรือมากกว่านั้น -
Step 1 - บล็อกรับข้อมูลเป็นอินพุต
Step 2- ตอนนี้บล็อกจะจัดเก็บสถานะในรูปแบบของพารามิเตอร์ ตัวอย่างเช่นในตัวอย่างการเข้ารหัสด้านบนบล็อกมีเลเยอร์ที่ซ่อนอยู่สองชั้นและเราต้องการสถานที่สำหรับจัดเก็บพารามิเตอร์
Step 3- บล็อกถัดไปจะเรียกใช้ฟังก์ชันไปข้างหน้าเพื่อดำเนินการเผยแพร่ไปข้างหน้า เรียกอีกอย่างว่าการคำนวณล่วงหน้า ในฐานะที่เป็นส่วนหนึ่งของการโอนสายครั้งแรกบล็อกเริ่มต้นพารามิเตอร์ในลักษณะขี้เกียจ
Step 4- ในที่สุดบล็อกจะเรียกใช้ฟังก์ชันย้อนกลับและคำนวณการไล่ระดับสีโดยอ้างอิงกับข้อมูลที่ป้อน โดยปกติขั้นตอนนี้จะดำเนินการโดยอัตโนมัติ
บล็อกตามลำดับ
บล็อกตามลำดับคือบล็อกชนิดพิเศษที่ข้อมูลไหลผ่านลำดับของบล็อก ในสิ่งนี้แต่ละบล็อกจะนำไปใช้กับเอาต์พุตของหนึ่งก่อนโดยบล็อกแรกจะถูกนำไปใช้กับข้อมูลอินพุตเอง
ให้เราดูว่า sequential ผลงานในชั้นเรียน -
from mxnet import nd
from mxnet.gluon import nn
class MySequential(nn.Block):
def __init__(self, **kwargs):
super(MySequential, self).__init__(**kwargs)
def add(self, block):
self._children[block.name] = block
def forward(self, x):
for block in self._children.values():
x = block(x)
return x
x = nd.random.uniform(shape=(2, 20))
N_net = MySequential()
N_net.add(nn.Dense(256, activation
='relu'))
N_net.add(nn.Dense(10))
N_net.initialize()
N_net(x)Output
ผลลัพธ์จะได้รับในที่นี้ -
[[ 0.09543004 0.04614332 -0.00286655 -0.07790346 -0.05130241 0.02942038
0.08696645 -0.0190793 -0.04122177 0.05088576]
[ 0.0769287 0.03099706 0.00856576 -0.044672 -0.06926838 0.09132431
0.06786592 -0.06187843 -0.03436674 0.04234696]]
<NDArray 2x10 @cpu(0)>บล็อกที่กำหนดเอง
เราสามารถไปไกลกว่าการเชื่อมต่อกับบล็อกลำดับตามที่กำหนดไว้ข้างต้นได้อย่างง่ายดาย แต่ถ้าเราต้องการปรับแต่งไฟล์Blockคลาสยังมีฟังก์ชันการทำงานที่จำเป็น คลาสบล็อกมีตัวสร้างโมเดลที่จัดเตรียมไว้ในโมดูล nn เราสามารถสืบทอดตัวสร้างโมเดลนั้นเพื่อกำหนดโมเดลที่เราต้องการ
ในตัวอย่างต่อไปนี้ไฟล์ MLP class ลบล้างไฟล์ __init__ และส่งต่อฟังก์ชันของคลาส Block
ให้เราดูว่ามันทำงานอย่างไร
class MLP(nn.Block):
def __init__(self, **kwargs):
super(MLP, self).__init__(**kwargs)
self.hidden = nn.Dense(256, activation='relu') # Hidden layer
self.output = nn.Dense(10) # Output layer
def forward(self, x):
hidden_out = self.hidden(x)
return self.output(hidden_out)
x = nd.random.uniform(shape=(2, 20))
N_net = MLP()
N_net.initialize()
N_net(x)Output
เมื่อคุณเรียกใช้รหัสคุณจะเห็นผลลัพธ์ต่อไปนี้:
[[ 0.07787763 0.00216403 0.01682201 0.03059879 -0.00702019 0.01668715
0.04822846 0.0039432 -0.09300035 -0.04494302]
[ 0.08891078 -0.00625484 -0.01619131 0.0380718 -0.01451489 0.02006172
0.0303478 0.02463485 -0.07605448 -0.04389168]]
<NDArray 2x10 @cpu(0)>เลเยอร์ที่กำหนดเอง
Gluon API ของ Apache MXNet มาพร้อมกับเลเยอร์ที่กำหนดไว้ล่วงหน้าจำนวนพอประมาณ แต่ในบางจุดเราอาจพบว่าจำเป็นต้องมีเลเยอร์ใหม่ เราสามารถเพิ่มเลเยอร์ใหม่ใน Gluon API ได้อย่างง่ายดาย ในส่วนนี้เราจะดูว่าเราสามารถสร้างเลเยอร์ใหม่ตั้งแต่เริ่มต้นได้อย่างไร
Custom Layer ที่ง่ายที่สุด
ในการสร้างเลเยอร์ใหม่ใน Gluon API เราต้องสร้างคลาสที่สืบทอดมาจากคลาส Block ซึ่งมีฟังก์ชันพื้นฐานที่สุด เราสามารถสืบทอดเลเยอร์ที่กำหนดไว้ล่วงหน้าทั้งหมดจากมันโดยตรงหรือผ่านคลาสย่อยอื่น ๆ
สำหรับการสร้างเลเยอร์ใหม่วิธีการอินสแตนซ์เดียวที่จำเป็นในการดำเนินการคือ forward (self, x). วิธีนี้กำหนดว่าเลเยอร์ของเรากำลังจะทำอะไรระหว่างการเผยแพร่ไปข้างหน้า ดังที่ได้กล่าวไว้ก่อนหน้านี้การส่งผ่านการเผยแพร่ย้อนกลับสำหรับบล็อกจะทำโดย Apache MXNet เองโดยอัตโนมัติ
ตัวอย่าง
ในตัวอย่างด้านล่างเราจะกำหนดเลเยอร์ใหม่ นอกจากนี้เรายังจะดำเนินการforward() วิธีการปรับข้อมูลอินพุตให้เป็นปกติโดยปรับให้พอดีกับช่วง [0, 1]
from __future__ import print_function
import mxnet as mx
from mxnet import nd, gluon, autograd
from mxnet.gluon.nn import Dense
mx.random.seed(1)
class NormalizationLayer(gluon.Block):
def __init__(self):
super(NormalizationLayer, self).__init__()
def forward(self, x):
return (x - nd.min(x)) / (nd.max(x) - nd.min(x))
x = nd.random.uniform(shape=(2, 20))
N_net = NormalizationLayer()
N_net.initialize()
N_net(x)Output
ในการรันโปรแกรมข้างต้นคุณจะได้รับผลลัพธ์ดังต่อไปนี้ -
[[0.5216355 0.03835821 0.02284337 0.5945146 0.17334817 0.69329053
0.7782702 1. 0.5508242 0. 0.07058554 0.3677264
0.4366546 0.44362497 0.7192635 0.37616986 0.6728799 0.7032008
0.46907538 0.63514024]
[0.9157533 0.7667402 0.08980197 0.03593295 0.16176797 0.27679572
0.07331014 0.3905285 0.6513384 0.02713427 0.05523694 0.12147208
0.45582628 0.8139887 0.91629887 0.36665893 0.07873632 0.78268915
0.63404864 0.46638715]]
<NDArray 2x20 @cpu(0)>การผสมพันธุ์
อาจถูกกำหนดให้เป็นกระบวนการที่ Apache MXNet ใช้เพื่อสร้างกราฟสัญลักษณ์ของการคำนวณล่วงหน้า Hybridisation ช่วยให้ MXNet เพิ่มประสิทธิภาพการคำนวณโดยการปรับกราฟสัญลักษณ์เชิงคำนวณให้เหมาะสม แทนที่จะสืบทอดโดยตรงจากBlockในความเป็นจริงเราอาจพบว่าในขณะที่ใช้เลเยอร์ที่มีอยู่บล็อกจะสืบทอดมาจากไฟล์ HybridBlock.
เหตุผลดังต่อไปนี้ -
Allows us to write custom layers: HybridBlock ช่วยให้เราสามารถเขียนเลเยอร์ที่กำหนดเองซึ่งสามารถใช้เพิ่มเติมในการเขียนโปรแกรมที่จำเป็นและเชิงสัญลักษณ์ได้
Increase computation performance- HybridBlock ปรับกราฟสัญลักษณ์การคำนวณให้เหมาะสมซึ่งช่วยให้ MXNet เพิ่มประสิทธิภาพการคำนวณ
ตัวอย่าง
ในตัวอย่างนี้เราจะเขียนเลเยอร์ตัวอย่างของเราขึ้นมาใหม่โดยใช้ HybridBlock:
class NormalizationHybridLayer(gluon.HybridBlock):
def __init__(self):
super(NormalizationHybridLayer, self).__init__()
def hybrid_forward(self, F, x):
return F.broadcast_div(F.broadcast_sub(x, F.min(x)), (F.broadcast_sub(F.max(x), F.min(x))))
layer_hybd = NormalizationHybridLayer()
layer_hybd(nd.array([1, 2, 3, 4, 5, 6], ctx=mx.cpu()))Output
ผลลัพธ์ระบุไว้ด้านล่าง:
[0. 0.2 0.4 0.6 0.8 1. ]
<NDArray 6 @cpu(0)>Hybridisation ไม่มีส่วนเกี่ยวข้องกับการคำนวณบน GPU และเราสามารถฝึกเครือข่ายแบบไฮบริดได้เช่นเดียวกับเครือข่ายที่ไม่ใช่ไฮบริดสปีดทั้งบน CPU และ GPU
ความแตกต่างระหว่าง Block และ HybridBlock
ถ้าเราจะเปรียบเทียบ Block ชั้นเรียนและ HybridBlockเราจะเห็นว่า HybridBlock มีไฟล์ forward() ใช้วิธีการ HybridBlock กำหนด hybrid_forward()วิธีการที่ต้องดำเนินการในขณะที่สร้างเลเยอร์ F อาร์กิวเมนต์สร้างความแตกต่างหลักระหว่างforward() และ hybrid_forward(). ในชุมชน MXNet อาร์กิวเมนต์ F เรียกว่าแบ็กเอนด์ F สามารถอ้างถึงmxnet.ndarray API (ใช้สำหรับการเขียนโปรแกรมที่จำเป็น) หรือ mxnet.symbol API (ใช้สำหรับการเขียนโปรแกรม Symbolic)
จะเพิ่มเลเยอร์ที่กำหนดเองลงในเครือข่ายได้อย่างไร?
แทนที่จะใช้เลเยอร์ที่กำหนดเองแยกต่างหากเลเยอร์เหล่านี้จะใช้กับเลเยอร์ที่กำหนดไว้ล่วงหน้า เราสามารถใช้อย่างใดอย่างหนึ่งSequential หรือ HybridSequentialคอนเทนเนอร์ไปยังจากโครงข่ายประสาทแบบต่อเนื่อง ตามที่กล่าวไว้ก่อนหน้านี้ยังSequential คอนเทนเนอร์สืบทอดจากบล็อกและ HybridSequential สืบทอดจาก HybridBlock ตามลำดับ
ตัวอย่าง
ในตัวอย่างด้านล่างเราจะสร้างโครงข่ายประสาทเทียมแบบง่ายๆด้วยเลเยอร์ที่กำหนดเอง ผลลัพธ์จากDense (5) เลเยอร์จะเป็นอินพุตของ NormalizationHybridLayer. ผลลัพธ์ของNormalizationHybridLayer จะกลายเป็นอินพุตของ Dense (1) ชั้น.
net = gluon.nn.HybridSequential()
with net.name_scope():
net.add(Dense(5))
net.add(NormalizationHybridLayer())
net.add(Dense(1))
net.initialize(mx.init.Xavier(magnitude=2.24))
net.hybridize()
input = nd.random_uniform(low=-10, high=10, shape=(10, 2))
net(input)Output
คุณจะเห็นผลลัพธ์ต่อไปนี้ -
[[-1.1272651]
[-1.2299833]
[-1.0662932]
[-1.1805027]
[-1.3382034]
[-1.2081106]
[-1.1263978]
[-1.2524893]
[-1.1044774]
[-1.316593 ]]
<NDArray 10x1 @cpu(0)>พารามิเตอร์เลเยอร์ที่กำหนดเอง
ในโครงข่ายประสาทชั้นหนึ่งมีชุดของพารามิเตอร์ที่เกี่ยวข้อง บางครั้งเราเรียกมันว่าน้ำหนักซึ่งเป็นสถานะภายในของเลเยอร์ พารามิเตอร์เหล่านี้มีบทบาทแตกต่างกัน -
บางครั้งสิ่งเหล่านี้คือสิ่งที่เราต้องการเรียนรู้ระหว่างขั้นตอนการย้อนกลับ
บางครั้งค่าเหล่านี้เป็นเพียงค่าคงที่ที่เราต้องการใช้ระหว่างส่งต่อ
หากเราพูดถึงแนวคิดการเขียนโปรแกรมพารามิเตอร์เหล่านี้ (น้ำหนัก) ของบล็อกจะถูกจัดเก็บและเข้าถึงผ่านทาง ParameterDict คลาสที่ช่วยในการเริ่มต้นการอัปเดตการบันทึกและการโหลด
ตัวอย่าง
ในตัวอย่างด้านล่างเราจะกำหนดพารามิเตอร์สองชุดต่อไปนี้ -
Parameter weights- สิ่งนี้สามารถฝึกได้และไม่ทราบรูปร่างระหว่างขั้นตอนการก่อสร้าง จะสรุปได้จากการแพร่กระจายไปข้างหน้าครั้งแรก
Parameter scale- นี่คือค่าคงที่ซึ่งค่าไม่เปลี่ยนแปลง ตรงข้ามกับน้ำหนักพารามิเตอร์รูปร่างของมันถูกกำหนดระหว่างการก่อสร้าง
class NormalizationHybridLayer(gluon.HybridBlock):
def __init__(self, hidden_units, scales):
super(NormalizationHybridLayer, self).__init__()
with self.name_scope():
self.weights = self.params.get('weights',
shape=(hidden_units, 0),
allow_deferred_init=True)
self.scales = self.params.get('scales',
shape=scales.shape,
init=mx.init.Constant(scales.asnumpy()),
differentiable=False)
def hybrid_forward(self, F, x, weights, scales):
normalized_data = F.broadcast_div(F.broadcast_sub(x, F.min(x)),
(F.broadcast_sub(F.max(x), F.min(x))))
weighted_data = F.FullyConnected(normalized_data, weights, num_hidden=self.weights.shape[0], no_bias=True)
scaled_data = F.broadcast_mul(scales, weighted_data)
return scaled_dataบทนี้เกี่ยวข้องกับแพ็คเกจ python KVStore และการแสดงภาพ
แพ็คเกจ KVStore
ร้าน KV ย่อมาจาก Key-Value store เป็นองค์ประกอบสำคัญที่ใช้สำหรับการฝึกอบรมหลายอุปกรณ์ เป็นสิ่งสำคัญเนื่องจากการสื่อสารของพารามิเตอร์ระหว่างอุปกรณ์ในเครื่องเดียวและหลายเครื่องจะถูกส่งผ่านเซิร์ฟเวอร์หนึ่งเครื่องขึ้นไปโดยมี KVStore สำหรับพารามิเตอร์
ให้เราเข้าใจการทำงานของ KVStore ด้วยความช่วยเหลือของประเด็นต่อไปนี้:
แต่ละค่าใน KVStore แสดงด้วยไฟล์ key และก value.
อาร์เรย์พารามิเตอร์แต่ละตัวในเครือข่ายถูกกำหนด a key และน้ำหนักของอาร์เรย์พารามิเตอร์นั้นถูกอ้างถึงโดย value.
หลังจากนั้นผู้ปฏิบัติงานก็โหน pushการไล่ระดับสีหลังจากประมวลผลชุดงาน พวกเขาด้วยpull ปรับปรุงน้ำหนักก่อนประมวลผลชุดใหม่
พูดง่ายๆก็คือเราสามารถพูดได้ว่า KVStore เป็นสถานที่สำหรับการแบ่งปันข้อมูลโดยที่อุปกรณ์แต่ละเครื่องสามารถผลักดันข้อมูลเข้าและดึงข้อมูลออกมาได้
ข้อมูล Push-In และ Pull-Out
KVStore ถือได้ว่าเป็นออบเจ็กต์เดียวที่ใช้ร่วมกันในอุปกรณ์ต่างๆเช่น GPU และคอมพิวเตอร์ซึ่งแต่ละอุปกรณ์สามารถผลักดันข้อมูลเข้าและดึงข้อมูลออกได้
ต่อไปนี้เป็นขั้นตอนการติดตั้งที่อุปกรณ์ต้องทำตามเพื่อส่งข้อมูลเข้าและดึงข้อมูลออก:
ขั้นตอนการดำเนินการ
Initialisation- ขั้นตอนแรกคือการเริ่มต้นค่า ในตัวอย่างของเราเราจะเริ่มต้นคู่ (int, NDArray) ใน KVStrore และหลังจากนั้นดึงค่าออกมา -
import mxnet as mx
kv = mx.kv.create('local') # create a local KVStore.
shape = (3,3)
kv.init(3, mx.nd.ones(shape)*2)
a = mx.nd.zeros(shape)
kv.pull(3, out = a)
print(a.asnumpy())Output
สิ่งนี้สร้างผลลัพธ์ต่อไปนี้ -
[[2. 2. 2.]
[2. 2. 2.]
[2. 2. 2.]]Push, Aggregate, and Update - เมื่อเริ่มต้นแล้วเราสามารถพุชค่าใหม่ไปยัง KVStore ด้วยรูปทรงเดียวกันกับคีย์ -
kv.push(3, mx.nd.ones(shape)*8)
kv.pull(3, out = a)
print(a.asnumpy())Output
ผลลัพธ์จะได้รับด้านล่าง -
[[8. 8. 8.]
[8. 8. 8.]
[8. 8. 8.]]ข้อมูลที่ใช้ในการพุชสามารถจัดเก็บไว้ในอุปกรณ์ใดก็ได้เช่น GPU หรือคอมพิวเตอร์ นอกจากนี้เรายังสามารถพุชหลายค่าให้เป็นคีย์เดียวกันได้ ในกรณีนี้ KVStore จะรวมค่าเหล่านี้ทั้งหมดก่อนจากนั้นจึงดันค่ารวมดังต่อไปนี้ -
contexts = [mx.cpu(i) for i in range(4)]
b = [mx.nd.ones(shape, ctx) for ctx in contexts]
kv.push(3, b)
kv.pull(3, out = a)
print(a.asnumpy())Output
คุณจะเห็นผลลัพธ์ต่อไปนี้ -
[[4. 4. 4.]
[4. 4. 4.]
[4. 4. 4.]]สำหรับการกดแต่ละครั้งที่คุณใช้ KVStore จะรวมค่าที่ผลักกับค่าที่จัดเก็บไว้แล้ว จะทำได้ด้วยความช่วยเหลือของตัวอัปเดต ที่นี่ตัวอัปเดตเริ่มต้นคือ ASSIGN
def update(key, input, stored):
print("update on key: %d" % key)
stored += input * 2
kv.set_updater(update)
kv.pull(3, out=a)
print(a.asnumpy())Output
เมื่อคุณรันโค้ดด้านบนคุณจะเห็นผลลัพธ์ต่อไปนี้ -
[[4. 4. 4.]
[4. 4. 4.]
[4. 4. 4.]]Example
kv.push(3, mx.nd.ones(shape))
kv.pull(3, out=a)
print(a.asnumpy())Output
ด้านล่างเป็นผลลัพธ์ของรหัส -
update on key: 3
[[6. 6. 6.]
[6. 6. 6.]
[6. 6. 6.]]Pull - เช่นเดียวกับ Push เราสามารถดึงค่าไปยังอุปกรณ์ต่างๆได้ด้วยการโทรเพียงครั้งเดียวดังนี้ -
b = [mx.nd.ones(shape, ctx) for ctx in contexts]
kv.pull(3, out = b)
print(b[1].asnumpy())Output
ผลลัพธ์ระบุไว้ด้านล่าง -
[[6. 6. 6.]
[6. 6. 6.]
[6. 6. 6.]]ตัวอย่างการใช้งานที่สมบูรณ์
ด้านล่างนี้เป็นตัวอย่างการใช้งานที่สมบูรณ์ -
import mxnet as mx
kv = mx.kv.create('local')
shape = (3,3)
kv.init(3, mx.nd.ones(shape)*2)
a = mx.nd.zeros(shape)
kv.pull(3, out = a)
print(a.asnumpy())
kv.push(3, mx.nd.ones(shape)*8)
kv.pull(3, out = a) # pull out the value
print(a.asnumpy())
contexts = [mx.cpu(i) for i in range(4)]
b = [mx.nd.ones(shape, ctx) for ctx in contexts]
kv.push(3, b)
kv.pull(3, out = a)
print(a.asnumpy())
def update(key, input, stored):
print("update on key: %d" % key)
stored += input * 2
kv._set_updater(update)
kv.pull(3, out=a)
print(a.asnumpy())
kv.push(3, mx.nd.ones(shape))
kv.pull(3, out=a)
print(a.asnumpy())
b = [mx.nd.ones(shape, ctx) for ctx in contexts]
kv.pull(3, out = b)
print(b[1].asnumpy())การจัดการคู่คีย์ - ค่า
การดำเนินการทั้งหมดที่เราได้นำไปใช้ข้างต้นเกี่ยวข้องกับคีย์เดียว แต่ KVStore ยังมีอินเทอร์เฟซสำหรับ a list of key-value pairs -
สำหรับเครื่องเดียว
ต่อไปนี้เป็นตัวอย่างเพื่อแสดงอินเทอร์เฟซ KVStore สำหรับรายการคู่คีย์ - ค่าสำหรับอุปกรณ์เดียว -
keys = [5, 7, 9]
kv.init(keys, [mx.nd.ones(shape)]*len(keys))
kv.push(keys, [mx.nd.ones(shape)]*len(keys))
b = [mx.nd.zeros(shape)]*len(keys)
kv.pull(keys, out = b)
print(b[1].asnumpy())Output
คุณจะได้รับผลลัพธ์ต่อไปนี้ -
update on key: 5
update on key: 7
update on key: 9
[[3. 3. 3.]
[3. 3. 3.]
[3. 3. 3.]]สำหรับอุปกรณ์หลายเครื่อง
ต่อไปนี้เป็นตัวอย่างเพื่อแสดงอินเทอร์เฟซ KVStore สำหรับรายการคู่คีย์ - ค่าสำหรับอุปกรณ์หลายเครื่อง -
b = [[mx.nd.ones(shape, ctx) for ctx in contexts]] * len(keys)
kv.push(keys, b)
kv.pull(keys, out = b)
print(b[1][1].asnumpy())Output
คุณจะเห็นผลลัพธ์ต่อไปนี้ -
update on key: 5
update on key: 7
update on key: 9
[[11. 11. 11.]
[11. 11. 11.]
[11. 11. 11.]]แพ็คเกจการแสดงภาพ
แพ็คเกจการแสดงภาพเป็นแพ็คเกจ Apache MXNet ที่ใช้แทนเครือข่ายประสาทเทียม (NN) เป็นกราฟการคำนวณที่ประกอบด้วยโหนดและขอบ
เห็นภาพโครงข่ายประสาทเทียม
ในตัวอย่างด้านล่างเราจะใช้ mx.viz.plot_networkเพื่อให้เห็นภาพเครือข่ายประสาท สิ่งต่อไปนี้เป็นข้อกำหนดเบื้องต้นสำหรับสิ่งนี้ -
Prerequisites
สมุดบันทึก Jupyter
ไลบรารี Graphviz
ตัวอย่างการใช้งาน
ในตัวอย่างด้านล่างเราจะแสดงภาพตัวอย่าง NN สำหรับการแยกตัวประกอบเมทริกซ์เชิงเส้น -
import mxnet as mx
user = mx.symbol.Variable('user')
item = mx.symbol.Variable('item')
score = mx.symbol.Variable('score')
# Set the dummy dimensions
k = 64
max_user = 100
max_item = 50
# The user feature lookup
user = mx.symbol.Embedding(data = user, input_dim = max_user, output_dim = k)
# The item feature lookup
item = mx.symbol.Embedding(data = item, input_dim = max_item, output_dim = k)
# predict by the inner product and then do sum
N_net = user * item
N_net = mx.symbol.sum_axis(data = N_net, axis = 1)
N_net = mx.symbol.Flatten(data = N_net)
# Defining the loss layer
N_net = mx.symbol.LinearRegressionOutput(data = N_net, label = score)
# Visualize the network
mx.viz.plot_network(N_net)บทนี้อธิบายไลบรารี ndarray ซึ่งมีอยู่ใน Apache MXNet
Mxnet.ndarray
ไลบรารี NDArray ของ Apache MXNet กำหนด Core DS (โครงสร้างข้อมูล) สำหรับการคำนวณทางคณิตศาสตร์ทั้งหมด งานพื้นฐานสองประการของ NDArray มีดังนี้ -
รองรับการดำเนินการอย่างรวดเร็วในการกำหนดค่าฮาร์ดแวร์ที่หลากหลาย
มันขนานกันโดยอัตโนมัติการดำเนินการหลาย ๆ ฮาร์ดแวร์ที่มีอยู่
ตัวอย่างด้านล่างแสดงให้เห็นว่าเราสามารถสร้าง NDArray ได้อย่างไรโดยใช้ 'array' 1-D และ 2-D จากรายการ Python ปกติ -
import mxnet as mx
from mxnet import nd
x = nd.array([1,2,3,4,5,6,7,8,9,10])
print(x)Output
ผลลัพธ์จะได้รับด้านล่าง:
[ 1. 2. 3. 4. 5. 6. 7. 8. 9. 10.]
<NDArray 10 @cpu(0)>Example
y = nd.array([[1,2,3,4,5,6,7,8,9,10], [1,2,3,4,5,6,7,8,9,10], [1,2,3,4,5,6,7,8,9,10]])
print(y)Output
สิ่งนี้สร้างผลลัพธ์ต่อไปนี้ -
[[ 1. 2. 3. 4. 5. 6. 7. 8. 9. 10.]
[ 1. 2. 3. 4. 5. 6. 7. 8. 9. 10.]
[ 1. 2. 3. 4. 5. 6. 7. 8. 9. 10.]]
<NDArray 3x10 @cpu(0)>ตอนนี้ให้เราพูดคุยโดยละเอียดเกี่ยวกับคลาสฟังก์ชันและพารามิเตอร์ของ ndarray API ของ MXNet
ชั้นเรียน
ตารางต่อไปนี้ประกอบด้วยคลาสของ ndarray API ของ MXNet -
| คลาส | คำจำกัดความ |
|---|---|
| CachedOp (sym [แฟล็ก]) | ใช้สำหรับที่จับตัวดำเนินการแคช |
| NDArray (หมายเลขอ้างอิง [เขียนได้]) | ใช้เป็นวัตถุอาร์เรย์ที่แสดงถึงอาร์เรย์หลายมิติที่เป็นเนื้อเดียวกันของรายการขนาดคงที่ |
ฟังก์ชันและพารามิเตอร์
ต่อไปนี้เป็นฟังก์ชั่นที่สำคัญบางอย่างและพารามิเตอร์ที่ครอบคลุมโดย mxnet.ndarray API -
| ฟังก์ชันและพารามิเตอร์ | คำจำกัดความ |
|---|---|
| Activation([data, act_type, out, name]) | ใช้องค์ประกอบฟังก์ชันการเปิดใช้งานที่ชาญฉลาดกับอินพุต รองรับฟังก์ชั่นการเปิดใช้งาน relu, sigmoid, tanh, softrelu, softsign |
| BatchNorm([ข้อมูล, แกมมา, เบต้า, moving_mean, …]) | ใช้สำหรับการทำให้เป็นมาตรฐานแบทช์ ฟังก์ชันนี้ทำให้ชุดข้อมูลเป็นปกติโดยใช้ค่าเฉลี่ยและความแปรปรวน มันใช้แกมมาสเกลและเบต้าออฟเซ็ต |
| BilinearSampler([ข้อมูลตาราง cudnn_off, …]) | ฟังก์ชันนี้ใช้การสุ่มตัวอย่างแบบทวิภาคีกับแผนผังคุณสมบัติการป้อนข้อมูล จริงๆแล้วมันเป็นกุญแจสำคัญของ“ Spatial Transformer Networks” หากคุณคุ้นเคยกับฟังก์ชันการรีแมปใน OpenCV การใช้งานฟังก์ชันนี้จะค่อนข้างคล้ายกัน ข้อแตกต่างเพียงอย่างเดียวคือมันมีทางเดินถอยหลัง |
| BlockGrad ([ข้อมูลออกชื่อ]) | ตามที่ระบุชื่อฟังก์ชันนี้จะหยุดการคำนวณการไล่ระดับสี โดยทั่วไปแล้วจะหยุดการไล่ระดับสีสะสมของอินพุตไม่ให้ไหลผ่านตัวดำเนินการนี้ในทิศทางย้อนกลับ |
| ส่ง ([data, dtype, out, name]) | ฟังก์ชันนี้จะส่งองค์ประกอบทั้งหมดของอินพุตไปยังประเภทใหม่ |
ตัวอย่างการใช้งาน
ในตัวอย่างด้านล่างเราจะใช้ฟังก์ชัน BilinierSampler () สำหรับการย่อข้อมูลสองครั้งและเลื่อนข้อมูลในแนวนอนทีละ -1 พิกเซล -
import mxnet as mx
from mxnet import nd
data = nd.array([[[[2, 5, 3, 6],
[1, 8, 7, 9],
[0, 4, 1, 8],
[2, 0, 3, 4]]]])
affine_matrix = nd.array([[2, 0, 0],
[0, 2, 0]])
affine_matrix = nd.reshape(affine_matrix, shape=(1, 6))
grid = nd.GridGenerator(data=affine_matrix, transform_type='affine', target_shape=(4, 4))
output = nd.BilinearSampler(data, grid)Output
เมื่อคุณรันโค้ดด้านบนคุณจะเห็นผลลัพธ์ต่อไปนี้:
[[[[0. 0. 0. 0. ]
[0. 4.0000005 6.25 0. ]
[0. 1.5 4. 0. ]
[0. 0. 0. 0. ]]]]
<NDArray 1x1x4x4 @cpu(0)>เอาต์พุตด้านบนแสดงการย่อข้อมูลสองครั้ง
ตัวอย่างการเลื่อนข้อมูลด้วย -1 พิกเซลมีดังนี้ -
import mxnet as mx
from mxnet import nd
data = nd.array([[[[2, 5, 3, 6],
[1, 8, 7, 9],
[0, 4, 1, 8],
[2, 0, 3, 4]]]])
warp_matrix = nd.array([[[[1, 1, 1, 1],
[1, 1, 1, 1],
[1, 1, 1, 1],
[1, 1, 1, 1]],
[[0, 0, 0, 0],
[0, 0, 0, 0],
[0, 0, 0, 0],
[0, 0, 0, 0]]]])
grid = nd.GridGenerator(data=warp_matrix, transform_type='warp')
output = nd.BilinearSampler(data, grid)Output
ผลลัพธ์ระบุไว้ด้านล่าง -
[[[[5. 3. 6. 0.]
[8. 7. 9. 0.]
[4. 1. 8. 0.]
[0. 3. 4. 0.]]]]
<NDArray 1x1x4x4 @cpu(0)>ในทำนองเดียวกันตัวอย่างต่อไปนี้แสดงการใช้ฟังก์ชัน cast () -
nd.cast(nd.array([300, 10.1, 15.4, -1, -2]), dtype='uint8')Output
เมื่อดำเนินการคุณจะได้รับผลลัพธ์ต่อไปนี้ -
[ 44 10 15 255 254]
<NDArray 5 @cpu(0)>ndarray.contrib
Contrib NDArray API ถูกกำหนดไว้ในแพ็คเกจ ndarray.contrib โดยทั่วไปแล้วจะมี API ทดลองที่มีประโยชน์มากมายสำหรับคุณลักษณะใหม่ ๆ API นี้ทำงานเป็นที่สำหรับชุมชนที่พวกเขาสามารถทดลองใช้คุณลักษณะใหม่ ๆ ผู้สนับสนุนคุณลักษณะจะได้รับข้อเสนอแนะเช่นกัน
ฟังก์ชันและพารามิเตอร์
ต่อไปนี้เป็นฟังก์ชั่นที่สำคัญบางส่วนและพารามิเตอร์ที่ครอบคลุมโดย mxnet.ndarray.contrib API -
| ฟังก์ชันและพารามิเตอร์ | คำจำกัดความ |
|---|---|
| rand_zipfian(true_classes, num_sampled, …) | ฟังก์ชันนี้ดึงตัวอย่างสุ่มจากการแจกแจงแบบ Zipfian โดยประมาณ การแจกแจงฐานของฟังก์ชันนี้คือการแจกแจงแบบ Zipfian ฟังก์ชันนี้สุ่มตัวอย่างผู้สมัครที่เป็นตัวเลขและองค์ประกอบของ sampled_candidates ถูกดึงมาจากการแจกแจงฐานที่ระบุไว้ด้านบน |
| foreach(เนื้อหาข้อมูล init_states) | ตามความหมายของชื่อฟังก์ชันนี้จะรันสำหรับลูปด้วยการคำนวณที่ผู้ใช้กำหนดเองบน NDArrays บนมิติ 0 ฟังก์ชันนี้จะจำลองสำหรับลูปและเนื้อความมีการคำนวณสำหรับการวนซ้ำสำหรับการวนซ้ำ |
| while_loop (cond, func, loop_vars [, …]) | ตามความหมายของชื่อฟังก์ชันนี้จะรัน while loop ด้วยการคำนวณที่ผู้ใช้กำหนดและเงื่อนไขการวนซ้ำ ฟังก์ชันนี้จะจำลองการวนซ้ำในขณะที่ทำการคำนวณแบบกำหนดเองอย่างแท้จริงหากเงื่อนไขเป็นที่พอใจ |
| cond(pred, then_func, else_func) | ตามความหมายของชื่อฟังก์ชันนี้จะรัน if-then-else โดยใช้เงื่อนไขและการคำนวณที่ผู้ใช้กำหนดเอง ฟังก์ชันนี้จำลองสาขา if-like ซึ่งเลือกที่จะทำการคำนวณแบบกำหนดเองหนึ่งในสองแบบตามเงื่อนไขที่ระบุ |
| isinf(ข้อมูล) | ฟังก์ชันนี้จะทำการตรวจสอบองค์ประกอบที่ชาญฉลาดเพื่อตรวจสอบว่า NDArray มีองค์ประกอบที่ไม่สิ้นสุดหรือไม่ |
| getnnz([ข้อมูลแกนออกชื่อ]) | ฟังก์ชันนี้ให้จำนวนค่าที่เก็บไว้สำหรับเทนเซอร์แบบเบาบาง นอกจากนี้ยังรวมถึงศูนย์ที่ชัดเจน รองรับเมทริกซ์ CSR บน CPU เท่านั้น |
| กำหนด ([ข้อมูล, min_range, max_range, …]) | ฟังก์ชั่นนี้กำหนดข้อมูลที่กำหนดซึ่งเป็นจำนวนใน int32 และ thresholds ที่สอดคล้องกันเป็น int8 โดยใช้เกณฑ์ขั้นต่ำและสูงสุดซึ่งคำนวณที่รันไทม์หรือจากการสอบเทียบ |
ตัวอย่างการใช้งาน
ในตัวอย่างด้านล่างเราจะใช้ฟังก์ชัน rand_zipfian สำหรับการวาดตัวอย่างสุ่มจากการแจกแจงแบบ Zipfian โดยประมาณ -
import mxnet as mx
from mxnet import nd
trueclass = mx.nd.array([2])
samples, exp_count_true, exp_count_sample = mx.nd.contrib.rand_zipfian(trueclass, 3, 4)
samplesOutput
คุณจะเห็นผลลัพธ์ต่อไปนี้ -
[0 0 1]
<NDArray 3 @cpu(0)>Example
exp_count_trueOutput
ผลลัพธ์จะได้รับด้านล่าง:
[0.53624076]
<NDArray 1 @cpu(0)>Example
exp_count_sampleOutput
สิ่งนี้สร้างผลลัพธ์ต่อไปนี้:
[1.29202967 1.29202967 0.75578891]
<NDArray 3 @cpu(0)>ในตัวอย่างด้านล่างเราจะใช้ฟังก์ชัน while_loop สำหรับการรัน while loop สำหรับการคำนวณที่ผู้ใช้กำหนดและเงื่อนไขการวนซ้ำ:
cond = lambda i, s: i <= 7
func = lambda i, s: ([i + s], [i + 1, s + i])
loop_var = (mx.nd.array([0], dtype="int64"), mx.nd.array([1], dtype="int64"))
outputs, states = mx.nd.contrib.while_loop(cond, func, loop_vars, max_iterations=10)
outputsOutput
ผลลัพธ์ดังแสดงด้านล่าง -
[
[[ 1]
[ 2]
[ 4]
[ 7]
[ 11]
[ 16]
[ 22]
[ 29]
[3152434450384]
[ 257]]
<NDArray 10x1 @cpu(0)>]Example
StatesOutput
สิ่งนี้สร้างผลลัพธ์ต่อไปนี้ -
[
[8]
<NDArray 1 @cpu(0)>,
[29]
<NDArray 1 @cpu(0)>]ndarray.image
Image NDArray API ถูกกำหนดไว้ในแพ็คเกจ ndarray.image ตามความหมายของชื่อโดยทั่วไปจะใช้สำหรับรูปภาพและคุณสมบัติต่างๆ
ฟังก์ชันและพารามิเตอร์
ต่อไปนี้เป็นฟังก์ชั่นที่สำคัญและพารามิเตอร์ที่ครอบคลุมโดย mxnet.ndarray.image API-
| ฟังก์ชันและพารามิเตอร์ | คำจำกัดความ |
|---|---|
| adjust_lighting([ข้อมูลอัลฟ่าออกชื่อ]) | ตามความหมายของชื่อฟังก์ชันนี้จะปรับระดับแสงของอินพุต เป็นไปตามสไตล์ AlexNet |
| crop([ข้อมูล x, y, กว้าง, สูง, ออก, ชื่อ]) | ด้วยความช่วยเหลือของฟังก์ชั่นนี้เราสามารถครอบตัดรูปภาพ NDArray ของรูปทรง (H x W x C) หรือ (N x H x W x C) ตามขนาดที่ผู้ใช้กำหนด |
| normalize([data, mean, std, out, name]) | มันจะทำให้รูปร่างเป็นปกติ (C x H x W) หรือ (N x C x H x W) ด้วย mean และ standard deviation(SD). |
| random_crop ([data, xrange, yrange, width, ... ]) | คล้ายกับการครอบตัด () มันสุ่มครอบตัดรูปภาพ NDArray ของรูปทรง (สูง x กว้าง x C) หรือ (N x H x W x C) ตามขนาดที่ผู้ใช้กำหนด มันจะเพิ่มตัวอย่างผลลัพธ์หาก src มีขนาดเล็กกว่าขนาด |
| random_lighting([ข้อมูล alpha_std ออกชื่อ]) | ตามความหมายของชื่อฟังก์ชันนี้จะเพิ่มสัญญาณรบกวน PCA แบบสุ่ม นอกจากนี้ยังเป็นไปตามสไตล์ AlexNet |
| random_resized_crop([data, xrange, yrange, …]) | นอกจากนี้ยังครอบตัดรูปภาพแบบสุ่ม NDArray ของรูปทรง (H x W x C) หรือ (N x H x W x C) ตามขนาดที่กำหนด มันจะเพิ่มตัวอย่างผลลัพธ์หาก src มีขนาดเล็กกว่าขนาด มันจะสุ่มพื้นที่และสัดส่วนด้านเช่นกัน |
| resize([data, size, keep_ratio, interp, …]) | ตามความหมายของชื่อฟังก์ชันนี้จะปรับขนาดรูปภาพ NDArray ของรูปทรง (H x W x C) หรือ (N x H x W x C) ให้เป็นขนาดที่ผู้ใช้กำหนด |
| to_tensor([ข้อมูลออกชื่อ]) | มันแปลงรูปภาพ NDArray ของรูปร่าง (H x W x C) หรือ (N x H x W x C) ด้วยค่าในช่วง [0, 255] เป็นเทนเซอร์ NDArray ของรูปร่าง (C x H x W) หรือ ( N x C x H x W) โดยมีค่าอยู่ในช่วง [0, 1] |
ตัวอย่างการใช้งาน
ในตัวอย่างด้านล่างเราจะใช้ฟังก์ชัน to_tensor เพื่อแปลงรูปภาพ NDArray ของรูปทรง (H x W x C) หรือ (N x H x W x C) ด้วยค่าในช่วง [0, 255] เป็นเทนเซอร์ NDArray ของรูปร่าง (C x H x W) หรือ (N x C x H x W) โดยมีค่าอยู่ในช่วง [0, 1]
import numpy as np
img = mx.nd.random.uniform(0, 255, (4, 2, 3)).astype(dtype=np.uint8)
mx.nd.image.to_tensor(img)Output
คุณจะเห็นผลลัพธ์ต่อไปนี้ -
[[[0.972549 0.5058824 ]
[0.6039216 0.01960784]
[0.28235295 0.35686275]
[0.11764706 0.8784314 ]]
[[0.8745098 0.9764706 ]
[0.4509804 0.03529412]
[0.9764706 0.29411766]
[0.6862745 0.4117647 ]]
[[0.46666667 0.05490196]
[0.7372549 0.4392157 ]
[0.11764706 0.47843137]
[0.31764707 0.91764706]]]
<NDArray 3x4x2 @cpu(0)>Example
img = mx.nd.random.uniform(0, 255, (2, 4, 2, 3)).astype(dtype=np.uint8)
mx.nd.image.to_tensor(img)Output
เมื่อคุณเรียกใช้รหัสคุณจะเห็นผลลัพธ์ต่อไปนี้ -
[[[[0.0627451 0.5647059 ]
[0.2627451 0.9137255 ]
[0.57254905 0.27450982]
[0.6666667 0.64705884]]
[[0.21568628 0.5647059 ]
[0.5058824 0.09019608]
[0.08235294 0.31764707]
[0.8392157 0.7137255 ]]
[[0.6901961 0.8627451 ]
[0.52156866 0.91764706]
[0.9254902 0.00784314]
[0.12941177 0.8392157 ]]]
[[[0.28627452 0.39607844]
[0.01960784 0.36862746]
[0.6745098 0.7019608 ]
[0.9607843 0.7529412 ]]
[[0.2627451 0.58431375]
[0.16470589 0.00392157]
[0.5686275 0.73333335]
[0.43137255 0.57254905]]
[[0.18039216 0.54901963]
[0.827451 0.14509805]
[0.26666668 0.28627452]
[0.24705882 0.39607844]]]]
<NDArgt;ray 2x3x4x2 @cpu(0)>ในตัวอย่างด้านล่างเราจะใช้ฟังก์ชัน normalize เพื่อปรับรูปทรงเทนเซอร์ (C x H x W) หรือ (N x C x H x W) ให้เป็นปกติด้วย mean และ standard deviation(SD).
img = mx.nd.random.uniform(0, 1, (3, 4, 2))
mx.nd.image.normalize(img, mean=(0, 1, 2), std=(3, 2, 1))Output
สิ่งนี้สร้างผลลัพธ์ต่อไปนี้ -
[[[ 0.29391178 0.3218054 ]
[ 0.23084386 0.19615503]
[ 0.24175143 0.21988946]
[ 0.16710812 0.1777354 ]]
[[-0.02195817 -0.3847335 ]
[-0.17800489 -0.30256534]
[-0.28807247 -0.19059572]
[-0.19680339 -0.26256624]]
[[-1.9808068 -1.5298678 ]
[-1.6984252 -1.2839255 ]
[-1.3398265 -1.712009 ]
[-1.7099224 -1.6165378 ]]]
<NDArray 3x4x2 @cpu(0)>Example
img = mx.nd.random.uniform(0, 1, (2, 3, 4, 2))
mx.nd.image.normalize(img, mean=(0, 1, 2), std=(3, 2, 1))Output
เมื่อคุณรันโค้ดด้านบนคุณจะเห็นผลลัพธ์ต่อไปนี้ -
[[[[ 2.0600514e-01 2.4972327e-01]
[ 1.4292289e-01 2.9281738e-01]
[ 4.5158025e-02 3.4287784e-02]
[ 9.9427439e-02 3.0791296e-02]]
[[-2.1501756e-01 -3.2297665e-01]
[-2.0456362e-01 -2.2409186e-01]
[-2.1283737e-01 -4.8318747e-01]
[-1.7339960e-01 -1.5519112e-02]]
[[-1.3478968e+00 -1.6790028e+00]
[-1.5685816e+00 -1.7787373e+00]
[-1.1034534e+00 -1.8587360e+00]
[-1.6324382e+00 -1.9027401e+00]]]
[[[ 1.4528830e-01 3.2801408e-01]
[ 2.9730779e-01 8.6780310e-02]
[ 2.6873133e-01 1.7900752e-01]
[ 2.3462953e-01 1.4930873e-01]]
[[-4.4988656e-01 -4.5021546e-01]
[-4.0258706e-02 -3.2384416e-01]
[-1.4287934e-01 -2.6537544e-01]
[-5.7649612e-04 -7.9429924e-02]]
[[-1.8505517e+00 -1.0953522e+00]
[-1.1318740e+00 -1.9624406e+00]
[-1.8375070e+00 -1.4916846e+00]
[-1.3844404e+00 -1.8331525e+00]]]]
<NDArray 2x3x4x2 @cpu(0)>ndarray.random
Random NDArray API ถูกกำหนดไว้ในแพ็คเกจ ndarray.random ตามความหมายของชื่อมันเป็นตัวสร้างการกระจายแบบสุ่ม NDArray API ของ MXNet
ฟังก์ชันและพารามิเตอร์
ต่อไปนี้เป็นฟังก์ชั่นที่สำคัญบางส่วนและพารามิเตอร์ที่ครอบคลุมโดย mxnet.ndarray.random API -
| ฟังก์ชันและพารามิเตอร์ | คำจำกัดความ |
|---|---|
| เครื่องแบบ ([ต่ำ, สูง, รูปร่าง, dtype, ctx, out]) | สร้างตัวอย่างสุ่มจากการแจกแจงแบบสม่ำเสมอ |
| ปกติ ([loc, scale, shape, dtype, ctx, out]) | มันสร้างตัวอย่างสุ่มจากการแจกแจงแบบปกติ (Gaussian) |
| แรนด์ (* รูปร่าง ** kwargs) | มันสร้างตัวอย่างสุ่มจากการแจกแจงแบบปกติ (Gaussian) |
| เลขชี้กำลัง ([มาตราส่วนรูปร่าง dtype ctx ออก]) | สร้างตัวอย่างจากการแจกแจงแบบเอ็กซ์โพเนนเชียล |
| แกมมา ([อัลฟ่าเบต้ารูปร่าง dtype ctx ออก]) | สร้างตัวอย่างสุ่มจากการแจกแจงแกมมา |
| หลายนาม (ข้อมูล [รูปร่าง get_prob ออก dtype]) | มันสร้างการสุ่มตัวอย่างพร้อมกันจากการแจกแจงพหุนามหลาย ๆ |
| negative_binomial ([k, p, รูปร่าง, dtype, ctx, out]) | สร้างตัวอย่างสุ่มจากการแจกแจงทวินามลบ |
| generalized_negative_binomial ([mu, alpha, …]) | สร้างตัวอย่างสุ่มจากการแจกแจงทวินามลบทั่วไป |
| สับเปลี่ยน (ข้อมูล ** kwargs) | มันสับเปลี่ยนองค์ประกอบแบบสุ่ม |
| Randint (ต่ำสูง [รูปร่าง dtype ctx ออก]) | มันสร้างตัวอย่างสุ่มจากการแจกแจงสม่ำเสมอแบบไม่ต่อเนื่อง |
| exponential_like ([data, lam, out, name]) | สร้างตัวอย่างสุ่มจากการแจกแจงเลขชี้กำลังตามรูปร่างอาร์เรย์อินพุต |
| gamma_like ([ข้อมูลอัลฟ่าเบต้าออกชื่อ]) | สร้างตัวอย่างสุ่มจากการแจกแจงแกมมาตามรูปร่างอาร์เรย์อินพุต |
| generalized_negative_binomial_like ([ข้อมูล, …]) | มันสร้างตัวอย่างสุ่มจากการแจกแจงทวินามลบทั่วไปตามรูปร่างอาร์เรย์อินพุต |
| negative_binomial_like ([ข้อมูล, k, p, ออก, ชื่อ]) | สร้างตัวอย่างสุ่มจากการแจกแจงทวินามลบตามรูปร่างอาร์เรย์อินพุต |
| normal_like ([data, loc, scale, out, name]) | มันสร้างตัวอย่างสุ่มจากการแจกแจงปกติ (Gaussian) ตามรูปร่างอาร์เรย์อินพุต |
| poisson_like ([data, lam, out, name]) | สร้างตัวอย่างสุ่มจากการแจกแจงแบบปัวซองตามรูปร่างอาร์เรย์อินพุต |
| uniform_like ([ข้อมูลต่ำสูงออกชื่อ]) | สร้างตัวอย่างสุ่มจากการแจกแจงแบบสม่ำเสมอตามรูปร่างอาร์เรย์อินพุต |
ตัวอย่างการใช้งาน
ในตัวอย่างด้านล่างเราจะวาดตัวอย่างสุ่มจากการแจกแจงแบบสม่ำเสมอ สำหรับสิ่งนี้จะเป็นการใช้ฟังก์ชันuniform().
mx.nd.random.uniform(0, 1)Output
ผลลัพธ์จะกล่าวถึงด้านล่าง -
[0.12381998]
<NDArray 1 @cpu(0)>Example
mx.nd.random.uniform(-1, 1, shape=(2,))Output
ผลลัพธ์จะได้รับด้านล่าง -
[0.558102 0.69601643]
<NDArray 2 @cpu(0)>Example
low = mx.nd.array([1,2,3])
high = mx.nd.array([2,3,4])
mx.nd.random.uniform(low, high, shape=2)Output
คุณจะเห็นผลลัพธ์ต่อไปนี้ -
[[1.8649333 1.8073189]
[2.4113967 2.5691009]
[3.1399727 3.4071832]]
<NDArray 3x2 @cpu(0)>ในตัวอย่างด้านล่างเราจะวาดตัวอย่างสุ่มจากการแจกแจงทวินามลบทั่วไป สำหรับสิ่งนี้เราจะใช้ฟังก์ชันgeneralized_negative_binomial().
mx.nd.random.generalized_negative_binomial(10, 0.5)Output
เมื่อคุณรันโค้ดด้านบนคุณจะเห็นผลลัพธ์ต่อไปนี้ -
[1.]
<NDArray 1 @cpu(0)>Example
mx.nd.random.generalized_negative_binomial(10, 0.5, shape=(2,))Output
ผลลัพธ์จะได้รับในที่นี้ -
[16. 23.]
<NDArray 2 @cpu(0)>Example
mu = mx.nd.array([1,2,3])
alpha = mx.nd.array([0.2,0.4,0.6])
mx.nd.random.generalized_negative_binomial(mu, alpha, shape=2)Output
ด้านล่างเป็นผลลัพธ์ของรหัส -
[[0. 0.]
[4. 1.]
[9. 3.]]
<NDArray 3x2 @cpu(0)>ndarray.utils
ยูทิลิตี้ NDArray API ถูกกำหนดในแพ็คเกจ ndarray.utils ตามความหมายของชื่อจะมีฟังก์ชันยูทิลิตี้สำหรับ NDArray และ BaseSparseNDArray
ฟังก์ชันและพารามิเตอร์
ต่อไปนี้เป็นฟังก์ชั่นที่สำคัญบางส่วนและพารามิเตอร์ที่ครอบคลุมโดย mxnet.ndarray.utils API -
| ฟังก์ชันและพารามิเตอร์ | คำจำกัดความ |
|---|---|
| ศูนย์ (รูปร่าง [, ctx, dtype, stype]) | ฟังก์ชันนี้จะส่งกลับอาร์เรย์ใหม่ของรูปร่างและประเภทที่กำหนดซึ่งเต็มไปด้วยศูนย์ |
| ว่างเปล่า (รูปร่าง [, ctx, dtype, stype]) | จะส่งกลับอาร์เรย์ใหม่ของรูปร่างและประเภทที่กำหนดโดยไม่ต้องเริ่มต้นรายการ |
| อาร์เรย์ (source_array [, ctx, dtype]) | ตามความหมายของชื่อฟังก์ชันนี้จะสร้างอาร์เรย์จากวัตถุใด ๆ ที่เปิดเผยอินเทอร์เฟซอาร์เรย์ |
| โหลด (fname) | มันจะโหลดอาร์เรย์จากไฟล์ |
| load_frombuffer (buf) | ตามความหมายของชื่อฟังก์ชันนี้จะโหลดพจนานุกรมอาร์เรย์หรือรายการจากบัฟเฟอร์ |
| บันทึก (fname, data) | ฟังก์ชันนี้จะบันทึกรายการอาร์เรย์หรือคำสั่งของ str-> array ไปยังไฟล์ |
ตัวอย่างการใช้งาน
ในตัวอย่างด้านล่างเราจะส่งกลับอาร์เรย์ใหม่ของรูปร่างและประเภทที่กำหนดซึ่งเต็มไปด้วยศูนย์ สำหรับสิ่งนี้เราจะใช้ฟังก์ชันzeros().
mx.nd.zeros((1,2), mx.cpu(), stype='csr')Output
สิ่งนี้สร้างผลลัพธ์ต่อไปนี้ -
<CSRNDArray 1x2 @cpu(0)>Example
mx.nd.zeros((1,2), mx.cpu(), 'float16', stype='row_sparse').asnumpy()Output
คุณจะได้รับผลลัพธ์ต่อไปนี้ -
array([[0., 0.]], dtype=float16)ในตัวอย่างด้านล่างเราจะบันทึกรายการอาร์เรย์และพจนานุกรมสตริง สำหรับสิ่งนี้เราจะใช้ฟังก์ชันsave().
Example
x = mx.nd.zeros((2,3))
y = mx.nd.ones((1,4))
mx.nd.save('list', [x,y])
mx.nd.save('dict', {'x':x, 'y':y})
mx.nd.load('list')Output
เมื่อดำเนินการคุณจะได้รับผลลัพธ์ต่อไปนี้ -
[
[[0. 0. 0.]
[0. 0. 0.]]
<NDArray 2x3 @cpu(0)>,
[[1. 1. 1. 1.]]
<NDArray 1x4 @cpu(0)>]Example
mx.nd.load('my_dict')Output
ผลลัพธ์ดังแสดงด้านล่าง -
{'x':
[[0. 0. 0.]
[0. 0. 0.]]
<NDArray 2x3 @cpu(0)>, 'y':
[[1. 1. 1. 1.]]
<NDArray 1x4 @cpu(0)>}ดังที่เราได้กล่าวไปแล้วในบทก่อนหน้านี้ว่า MXNet Gluon มี API ที่ชัดเจนกระชับและเรียบง่ายสำหรับโครงการ DL ช่วยให้ Apache MXNet สร้างต้นแบบสร้างและฝึกโมเดล DL ได้โดยไม่เสียความเร็วในการฝึก
โมดูลหลัก
ให้เราเรียนรู้โมดูลหลักของกลูออนการเขียนโปรแกรมแอปพลิเคชัน Apache MXNet Python (API)
gluon.nn
Gluon มีเลเยอร์ NN ในตัวจำนวนมากในโมดูล gluon.nn นั่นคือเหตุผลที่เรียกว่าโมดูลหลัก
วิธีการและพารามิเตอร์
ต่อไปนี้เป็นวิธีการที่สำคัญและพารามิเตอร์ที่ครอบคลุม mxnet.gluon.nn โมดูลหลัก -
| วิธีการและพารามิเตอร์ | คำจำกัดความ |
|---|---|
| การเปิดใช้งาน (การเปิดใช้งาน ** kwargs) | ตามความหมายของชื่อวิธีนี้ใช้ฟังก์ชันการเปิดใช้งานกับอินพุต |
| AvgPool1D ([pool_size, strides, padding, …]) | นี่คือการดำเนินการรวมค่าเฉลี่ยสำหรับข้อมูลชั่วคราว |
| AvgPool2D ([pool_size, strides, padding, …]) | นี่คือการดำเนินการรวมกันโดยเฉลี่ยสำหรับข้อมูลเชิงพื้นที่ |
| AvgPool3D ([pool_size, strides, padding, …]) | นี่คือการดำเนินการรวมเฉลี่ยสำหรับข้อมูล 3 มิติ ข้อมูลอาจเป็นเชิงพื้นที่หรือเชิงพื้นที่ - ชั่วคราว |
| BatchNorm ([แกนโมเมนตัมเอปไซลอนศูนย์ ... ]) | แสดงถึงเลเยอร์การทำให้เป็นมาตรฐานแบทช์ |
| BatchNormReLU ([แกนโมเมนตัมเอปไซลอน ... ]) | นอกจากนี้ยังแสดงถึงเลเยอร์ normalization แบบแบทช์ แต่มีฟังก์ชันการเปิดใช้งาน Relu |
| บล็อก ([คำนำหน้าพารามิเตอร์]) | มันให้คลาสพื้นฐานสำหรับเลเยอร์และโมเดลของเครือข่ายประสาทเทียมทั้งหมด |
| Conv1D (แชนเนล, kernel_size [, ก้าว, …]) | วิธีนี้ใช้สำหรับเลเยอร์คอนโวลูชั่น 1 มิติ ตัวอย่างเช่นการแปลงชั่วคราว |
| Conv1DTranspose (ช่อง, kernel_size [, …]) | วิธีนี้ใช้สำหรับเลเยอร์ Convolution 1D แบบ Transposed |
| Conv2D (แชนเนล, kernel_size [, ก้าว, …]) | วิธีนี้ใช้สำหรับเลเยอร์ Convolution 2D ตัวอย่างเช่นการแปลงเชิงพื้นที่เหนือรูปภาพ) |
| Conv2DTranspose (ช่อง, kernel_size [, …]) | วิธีนี้ใช้สำหรับเลเยอร์ Convolution 2D แบบ Transposed |
| Conv3D (แชนเนล, kernel_size [, ก้าว, …]) | วิธีนี้ใช้สำหรับเลเยอร์ Convolution 3D ตัวอย่างเช่นการแปลงเชิงพื้นที่มากกว่าปริมาณ |
| Conv3DTranspose (ช่อง, kernel_size [, …]) | วิธีนี้ใช้สำหรับเลเยอร์ Convolution 3D แบบ Transposed |
| หนาแน่น (หน่วย [, การเปิดใช้งาน, use_bias, …]) | วิธีนี้แสดงถึงเลเยอร์ NN ที่เชื่อมต่อหนาแน่นปกติของคุณ |
| การออกกลางคัน (อัตรา [แกน]) | ตามความหมายของชื่อวิธีนี้จะใช้การออกกลางคันกับอินพุต |
| ELU ([อัลฟา]) | วิธีนี้ใช้สำหรับ Exponential Linear Unit (ELU) |
| การฝัง (input_dim, output_dim [, dtype, …]) | เปลี่ยนจำนวนเต็มที่ไม่เป็นลบให้เป็นเวกเตอร์หนาแน่นขนาดคงที่ |
| แผ่ (** kwargs) | วิธีนี้จะทำให้อินพุตแบนเป็น 2 มิติ |
| GELU (** kwargs) | วิธีนี้ใช้สำหรับ Gaussian Exponential Linear Unit (GELU) |
| GlobalAvgPool1D ([เค้าโครง]) | ด้วยความช่วยเหลือของวิธีนี้เราสามารถดำเนินการรวมค่าเฉลี่ยทั่วโลกสำหรับข้อมูลชั่วคราว |
| GlobalAvgPool2D ([เค้าโครง]) | ด้วยความช่วยเหลือของวิธีนี้เราสามารถดำเนินการรวมค่าเฉลี่ยทั่วโลกสำหรับข้อมูลเชิงพื้นที่ |
| GlobalAvgPool3D ([เค้าโครง]) | ด้วยความช่วยเหลือของวิธีนี้เราสามารถดำเนินการรวมค่าเฉลี่ยทั่วโลกสำหรับข้อมูล 3 มิติ |
| GlobalMaxPool1D ([เค้าโครง]) | ด้วยความช่วยเหลือของวิธีนี้เราสามารถทำการดำเนินการ global max pooling สำหรับข้อมูล 1 มิติ |
| GlobalMaxPool2D ([เค้าโครง]) | ด้วยความช่วยเหลือของวิธีนี้เราสามารถทำการดำเนินการ global max pooling สำหรับข้อมูล 2 มิติ |
| GlobalMaxPool3D ([เค้าโครง]) | ด้วยความช่วยเหลือของวิธีนี้เราสามารถทำการดำเนินการ global max pooling สำหรับข้อมูล 3 มิติได้ |
| GroupNorm ([num_groups, epsilon, center, …]) | วิธีนี้ใช้การทำให้เป็นมาตรฐานกลุ่มกับอาร์เรย์อินพุต nD |
| HybridBlock ([คำนำหน้าพารามิเตอร์]) | วิธีนี้รองรับการส่งต่อด้วยทั้งสองอย่าง Symbol และ NDArray. |
| HybridLambda(ฟังก์ชัน [คำนำหน้า]) | ด้วยความช่วยเหลือของวิธีนี้เราสามารถรวมตัวดำเนินการหรือนิพจน์เป็นวัตถุ HybridBlock |
| HybridSequential ([คำนำหน้าพารามิเตอร์]) | มันซ้อน HybridBlocks ตามลำดับ |
| InstanceNorm ([แกนเอปไซลอนศูนย์กลางมาตราส่วน…]) | วิธีนี้ใช้การทำให้เป็นมาตรฐานอินสแตนซ์กับอาร์เรย์อินพุต nD |
ตัวอย่างการใช้งาน
ในตัวอย่างด้านล่างเราจะใช้ Block () ซึ่งให้คลาสพื้นฐานสำหรับเลเยอร์และโมเดลของโครงข่ายประสาทเทียมทั้งหมด
from mxnet.gluon import Block, nn
class Model(Block):
def __init__(self, **kwargs):
super(Model, self).__init__(**kwargs)
# use name_scope to give child Blocks appropriate names.
with self.name_scope():
self.dense0 = nn.Dense(20)
self.dense1 = nn.Dense(20)
def forward(self, x):
x = mx.nd.relu(self.dense0(x))
return mx.nd.relu(self.dense1(x))
model = Model()
model.initialize(ctx=mx.cpu(0))
model(mx.nd.zeros((5, 5), ctx=mx.cpu(0)))Output
คุณจะเห็นผลลัพธ์ต่อไปนี้ -
[[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]]
<NDArray 5x20 @cpu(0)*gt;ในตัวอย่างด้านล่างเราจะใช้ HybridBlock () ที่รองรับการส่งต่อทั้ง Symbol และ NDArray
import mxnet as mx
from mxnet.gluon import HybridBlock, nn
class Model(HybridBlock):
def __init__(self, **kwargs):
super(Model, self).__init__(**kwargs)
# use name_scope to give child Blocks appropriate names.
with self.name_scope():
self.dense0 = nn.Dense(20)
self.dense1 = nn.Dense(20)
def forward(self, x):
x = nd.relu(self.dense0(x))
return nd.relu(self.dense1(x))
model = Model()
model.initialize(ctx=mx.cpu(0))
model.hybridize()
model(mx.nd.zeros((5, 5), ctx=mx.cpu(0)))Output
ผลลัพธ์จะกล่าวถึงด้านล่าง -
[[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]]
<NDArray 5x20 @cpu(0)>gluon.rnn
กลูออนให้บิวด์อินจำนวนมาก recurrent neural network(RNN) เลเยอร์ในโมดูล gluon.rnn นั่นคือเหตุผลที่เรียกว่าโมดูลหลัก
วิธีการและพารามิเตอร์
ต่อไปนี้เป็นวิธีการที่สำคัญและพารามิเตอร์ที่ครอบคลุม mxnet.gluon.nn โมดูลหลัก:
| วิธีการและพารามิเตอร์ | คำจำกัดความ |
|---|---|
| แบบสองทิศทางเซลล์ (l_cell, r_cell [, …]) | ใช้สำหรับเซลล์ Bidirectional Recurrent Neural Network (RNN) |
| DropoutCell (อัตรา [แกนคำนำหน้าพารามิเตอร์]) | วิธีนี้จะใช้การออกกลางคันกับอินพุตที่กำหนด |
| GRU (hidden_size [, num_layers, layout, …]) | ใช้ RNN หน่วยซ้ำหลายชั้น gated (GRU) กับลำดับอินพุตที่กำหนด |
| GRUCell (hidden_size [, …]) | ใช้สำหรับเซลล์เครือข่าย Gated Rectified Unit (GRU) |
| HybridRecurrentCell ([คำนำหน้า, params]) | วิธีนี้รองรับการผสม |
| HybridSequentialRNNCell ([คำนำหน้า, params]) | ด้วยความช่วยเหลือของวิธีนี้เราสามารถซ้อนเซลล์ HybridRNN หลายเซลล์ตามลำดับ |
| LSTM (hidden_size [, num_layers, layout, …]) 0 | ใช้ RNN หน่วยความจำระยะสั้นยาวหลายชั้น (LSTM) กับลำดับอินพุตที่กำหนด |
| LSTMCell (hidden_size [, …]) | ใช้สำหรับเซลล์เครือข่าย Long-Short Term Memory (LSTM) |
| ModifierCell (base_cell) | เป็นคลาสฐานสำหรับเซลล์โมดิฟายเออร์ |
| RNN (hidden_size [, num_layers, การเปิดใช้งาน, …]) | ใช้ Elman RNN หลายชั้นกับ tanh หรือ ReLU ความไม่เป็นเชิงเส้นของลำดับอินพุตที่กำหนด |
| RNNCell (hidden_size [, การเปิดใช้งาน, ... ]) | ใช้สำหรับเซลล์เครือข่ายประสาทที่เกิดซ้ำ Elman RNN |
| RecurrentCell ([คำนำหน้า, params]) | แสดงถึงคลาสพื้นฐานที่เป็นนามธรรมสำหรับเซลล์ RNN |
| SequentialRNNCell ([คำนำหน้า, params]) | ด้วยความช่วยเหลือของวิธีนี้เราสามารถซ้อนเซลล์ RNN หลายเซลล์ตามลำดับ |
| ZoneoutCell (base_cell [, zoneout_outputs, …]) | วิธีนี้ใช้ Zoneout บนเซลล์ฐาน |
ตัวอย่างการใช้งาน
ในตัวอย่างด้านล่างเราจะใช้ GRU () ซึ่งใช้ RNN แบบหลายชั้น gated ที่เกิดซ้ำกับลำดับอินพุตที่กำหนด
layer = mx.gluon.rnn.GRU(100, 3)
layer.initialize()
input_seq = mx.nd.random.uniform(shape=(5, 3, 10))
out_seq = layer(input_seq)
h0 = mx.nd.random.uniform(shape=(3, 3, 100))
out_seq, hn = layer(input_seq, h0)
out_seqOutput
สิ่งนี้สร้างผลลัพธ์ต่อไปนี้ -
[[[ 1.50152072e-01 5.19012511e-01 1.02390535e-01 ... 4.35803324e-01
1.30406499e-01 3.30152437e-02]
[ 2.91542172e-01 1.02243155e-01 1.73325196e-01 ... 5.65296151e-02
1.76546033e-02 1.66693389e-01]
[ 2.22257316e-01 3.76294643e-01 2.11277917e-01 ... 2.28903517e-01
3.43954474e-01 1.52770668e-01]]
[[ 1.40634328e-01 2.93247789e-01 5.50393537e-02 ... 2.30207980e-01
6.61415309e-02 2.70989928e-02]
[ 1.11081995e-01 7.20834285e-02 1.08342394e-01 ... 2.28330195e-02
6.79589901e-03 1.25501186e-01]
[ 1.15944080e-01 2.41565228e-01 1.18612610e-01 ... 1.14908054e-01
1.61080107e-01 1.15969211e-01]]
………………………….Example
hnOutput
สิ่งนี้สร้างผลลัพธ์ต่อไปนี้ -
[[[-6.08105101e-02 3.86217088e-02 6.64453954e-03 8.18805695e-02
3.85607071e-02 -1.36945639e-02 7.45836645e-03 -5.46515081e-03
9.49622393e-02 6.39371723e-02 -6.37890724e-03 3.82240303e-02
9.11015049e-02 -2.01375950e-02 -7.29381144e-02 6.93765879e-02
2.71829776e-02 -6.64435029e-02 -8.45306814e-02 -1.03075653e-01
6.72040805e-02 -7.06537142e-02 -3.93818803e-02 5.16211614e-03
-4.79770005e-02 1.10734522e-01 1.56721435e-02 -6.93409378e-03
1.16915874e-01 -7.95962065e-02 -3.06530762e-02 8.42394680e-02
7.60370195e-02 2.17055440e-01 9.85361822e-03 1.16660878e-01
4.08297703e-02 1.24978097e-02 8.25245082e-02 2.28673983e-02
-7.88266212e-02 -8.04114193e-02 9.28791538e-02 -5.70827350e-03
-4.46166918e-02 -6.41122833e-02 1.80885363e-02 -2.37745279e-03
4.37298454e-02 1.28888980e-01 -3.07202265e-02 2.50503756e-02
4.00907174e-02 3.37077095e-03 -1.78839862e-02 8.90695080e-02
6.30150884e-02 1.11416787e-01 2.12221760e-02 -1.13236710e-01
5.39616570e-02 7.80710578e-02 -2.28817668e-02 1.92073174e-02
………………………….ในตัวอย่างด้านล่างเราจะใช้ LSTM () ซึ่งใช้ RNN หน่วยความจำระยะสั้น (LSTM) กับลำดับอินพุตที่กำหนด
layer = mx.gluon.rnn.LSTM(100, 3)
layer.initialize()
input_seq = mx.nd.random.uniform(shape=(5, 3, 10))
out_seq = layer(input_seq)
h0 = mx.nd.random.uniform(shape=(3, 3, 100))
c0 = mx.nd.random.uniform(shape=(3, 3, 100))
out_seq, hn = layer(input_seq,[h0,c0])
out_seqOutput
ผลลัพธ์จะกล่าวถึงด้านล่าง -
[[[ 9.00025964e-02 3.96071747e-02 1.83841765e-01 ... 3.95872220e-02
1.25569820e-01 2.15555862e-01]
[ 1.55962542e-01 -3.10300849e-02 1.76772922e-01 ... 1.92474753e-01
2.30574399e-01 2.81707942e-02]
[ 7.83204585e-02 6.53361529e-03 1.27262697e-01 ... 9.97719541e-02
1.28254429e-01 7.55299702e-02]]
[[ 4.41036932e-02 1.35250352e-02 9.87644792e-02 ... 5.89378644e-03
5.23949116e-02 1.00922674e-01]
[ 8.59075040e-02 -1.67027581e-02 9.69351009e-02 ... 1.17763653e-01
9.71239135e-02 2.25218050e-02]
[ 4.34580036e-02 7.62207608e-04 6.37005866e-02 ... 6.14888743e-02
5.96345589e-02 4.72368896e-02]]
……………Example
hnOutput
เมื่อคุณเรียกใช้รหัสคุณจะเห็นผลลัพธ์ต่อไปนี้ -
[
[[[ 2.21408084e-02 1.42750628e-02 9.53067932e-03 -1.22849066e-02
1.78788435e-02 5.99269159e-02 5.65306023e-02 6.42553642e-02
6.56616641e-03 9.80876666e-03 -1.15729487e-02 5.98640442e-02
-7.21173314e-03 -2.78371759e-02 -1.90690923e-02 2.21447181e-02
8.38765781e-03 -1.38521893e-02 -9.06938594e-03 1.21346042e-02
6.06449470e-02 -3.77471633e-02 5.65885007e-02 6.63008019e-02
-7.34188128e-03 6.46054149e-02 3.19911093e-02 4.11194898e-02
4.43960279e-02 4.92892228e-02 1.74766723e-02 3.40303481e-02
-5.23341820e-03 2.68163737e-02 -9.43402853e-03 -4.11836170e-02
1.55221792e-02 -5.05655073e-02 4.24557598e-03 -3.40388380e-02
……………………โมดูลการฝึกอบรม
โมดูลการฝึกอบรมใน Gluon มีดังนี้ -
gluon.loss
ใน mxnet.gluon.lossโมดูล Gluon มีฟังก์ชันการสูญเสียที่กำหนดไว้ล่วงหน้า โดยทั่วไปจะมีความสูญเสียในการฝึกโครงข่ายประสาทเทียม นั่นคือเหตุผลที่เรียกว่าโมดูลการฝึกอบรม
วิธีการและพารามิเตอร์
ต่อไปนี้เป็นวิธีการที่สำคัญและพารามิเตอร์ที่ครอบคลุม mxnet.gluon.loss โมดูลการฝึกอบรม:
| วิธีการและพารามิเตอร์ | คำจำกัดความ |
|---|---|
| การสูญเสีย (น้ำหนัก batch_axis ** kwargs) | สิ่งนี้ทำหน้าที่เป็นคลาสพื้นฐานสำหรับการสูญเสีย |
| L2Loss ([น้ำหนัก batch_axis]) | จะคำนวณข้อผิดพลาดกำลังสองค่าเฉลี่ย (MSE) ระหว่าง label และ prediction(pred). |
| L1Loss ([น้ำหนัก batch_axis]) | จะคำนวณข้อผิดพลาดสัมบูรณ์เฉลี่ย (MAE) ระหว่าง label และ pred. |
| SigmoidBinaryCrossEntropyLoss ([…]) | วิธีนี้ใช้สำหรับการสูญเสียข้ามเอนโทรปีสำหรับการจำแนกไบนารี |
| ซิกมอยด์บีเซล | วิธีนี้ใช้สำหรับการสูญเสียข้ามเอนโทรปีสำหรับการจำแนกไบนารี |
| SoftmaxCrossEntropyLoss ([แกน, …]) | คำนวณการสูญเสียเอนโทรปีข้าม softmax (CEL) |
| ซอฟแม็กซ์เซลอส | นอกจากนี้ยังคำนวณการสูญเสียเอนโทรปีของ softmax ข้าม |
| KLDivLoss ([from_logits, แกน, น้ำหนัก, …]) | ใช้สำหรับการสูญเสียความแตกต่างของ Kullback-Leibler |
| CTCLoss ([เลย์เอาต์ label_layout น้ำหนัก]) | ใช้สำหรับผู้เชื่อมต่อ Temporal Classification Loss (TCL) |
| HuberLoss ([rho, weight, batch_axis]) | คำนวณการสูญเสีย L1 ที่ราบรื่น การสูญเสีย L1 ที่ราบรื่นจะเท่ากับการสูญเสีย L1 หากข้อผิดพลาดสัมบูรณ์เกินค่า rho แต่เท่ากับการสูญเสีย L2 เป็นอย่างอื่น |
| HingeLoss ([ระยะขอบน้ำหนัก batch_axis]) | วิธีนี้จะคำนวณฟังก์ชันการสูญเสียบานพับที่มักใช้ใน SVM: |
| SquaredHingeLoss ([ระยะขอบ, น้ำหนัก, batch_axis]) | วิธีนี้จะคำนวณฟังก์ชัน soft-margin loss ที่ใช้ใน SVM: |
| LogisticLoss ([weight, batch_axis, label_format]) | วิธีนี้จะคำนวณการสูญเสียโลจิสติกส์ |
| TripletLoss ([ระยะขอบน้ำหนัก batch_axis]) | วิธีนี้จะคำนวณการสูญเสียสามเท่าโดยมีตัวนับอินพุตสามตัวและส่วนต่างบวก |
| PoissonNLLLoss ([น้ำหนัก from_logits, …]) | ฟังก์ชันนี้จะคำนวณการสูญเสียโอกาสในการบันทึกเชิงลบ |
| CosineEmbeddingLoss ([น้ำหนัก batch_axis ขอบ]) | ฟังก์ชันคำนวณระยะห่างโคไซน์ระหว่างเวกเตอร์ |
| SDMLLoss ([smoothing_parameter, weight, …]) | วิธีนี้จะคำนวณการสูญเสีย Batchwise Smoothed Deep Metric Learning (SDML) โดยให้อินพุตสองตัวและการสูญเสีย SDM ของน้ำหนักที่ราบรื่น เรียนรู้ความคล้ายคลึงกันระหว่างตัวอย่างที่จับคู่โดยใช้ตัวอย่างที่ไม่จับคู่ในมินิแบทช์เป็นตัวอย่างเชิงลบที่อาจเกิดขึ้น |
ตัวอย่าง
อย่างที่เราทราบกันดีว่า mxnet.gluon.loss.lossจะคำนวณ MSE (Mean Squared Error) ระหว่างป้ายกำกับและการคาดคะเน (pred) ทำได้ด้วยความช่วยเหลือของสูตรต่อไปนี้:

gluon.parameter
mxnet.gluon.parameter เป็นคอนเทนเนอร์ที่เก็บพารามิเตอร์เช่นน้ำหนักของบล็อก
วิธีการและพารามิเตอร์
ต่อไปนี้เป็นวิธีการที่สำคัญและพารามิเตอร์ที่ครอบคลุม mxnet.gluon.parameter โมดูลการฝึกอบรม -
| วิธีการและพารามิเตอร์ | คำจำกัดความ |
|---|---|
| โยน (dtype) | วิธีนี้จะส่งข้อมูลและการไล่ระดับสีของพารามิเตอร์นี้ไปยังประเภทข้อมูลใหม่ |
| ข้อมูล ([ctx]) | วิธีนี้จะส่งคืนสำเนาของพารามิเตอร์นี้ในบริบทเดียว |
| ผู้สำเร็จการศึกษา ([ctx]) | วิธีนี้จะส่งคืนบัฟเฟอร์การไล่ระดับสีสำหรับพารามิเตอร์นี้ในบริบทเดียว |
| เริ่มต้น ([init, ctx, default_init, …]) | วิธีนี้จะเริ่มต้นพารามิเตอร์และอาร์เรย์การไล่ระดับสี |
| list_ctx () | วิธีนี้จะส่งคืนรายการบริบทที่พารามิเตอร์นี้เริ่มต้น |
| list_data () | วิธีนี้จะส่งคืนสำเนาของพารามิเตอร์นี้ในบริบททั้งหมด มันจะทำในลำดับเดียวกับการสร้าง |
| list_grad () | วิธีนี้จะส่งคืนบัฟเฟอร์การไล่ระดับสีในบริบททั้งหมด สิ่งนี้จะทำในลำดับเดียวกับvalues(). |
| list_row_sparse_data (row_id) | วิธีนี้จะส่งคืนสำเนาของพารามิเตอร์ 'row_sparse' ในบริบททั้งหมด สิ่งนี้จะทำในลำดับเดียวกับการสร้าง |
| reset_ctx (ctx) | วิธีนี้จะกำหนด Parameter ใหม่ให้กับบริบทอื่น ๆ |
| row_sparse_data (row_id) | วิธีนี้จะส่งคืนสำเนาของพารามิเตอร์ 'row_sparse' ในบริบทเดียวกับ row_id's |
| set_data (ข้อมูล) | วิธีนี้จะตั้งค่าของพารามิเตอร์นี้ในบริบททั้งหมด |
| var () | วิธีนี้จะส่งคืนสัญลักษณ์ที่แสดงถึงพารามิเตอร์นี้ |
| zero_grad () | วิธีนี้จะตั้งค่าบัฟเฟอร์การไล่ระดับสีในบริบททั้งหมดเป็น 0 |
ตัวอย่างการใช้งาน
ในตัวอย่างด้านล่างเราจะเริ่มต้นพารามิเตอร์และอาร์เรย์การไล่ระดับสีโดยใช้วิธี initialize () ดังนี้ -
weight = mx.gluon.Parameter('weight', shape=(2, 2))
weight.initialize(ctx=mx.cpu(0))
weight.data()Output
ผลลัพธ์จะกล่าวถึงด้านล่าง -
[[-0.0256899 0.06511251]
[-0.00243821 -0.00123186]]
<NDArray 2x2 @cpu(0)>Example
weight.grad()Output
ผลลัพธ์จะได้รับด้านล่าง -
[[0. 0.]
[0. 0.]]
<NDArray 2x2 @cpu(0)>Example
weight.initialize(ctx=[mx.gpu(0), mx.gpu(1)])
weight.data(mx.gpu(0))Output
คุณจะเห็นผลลัพธ์ต่อไปนี้ -
[[-0.00873779 -0.02834515]
[ 0.05484822 -0.06206018]]
<NDArray 2x2 @gpu(0)>Example
weight.data(mx.gpu(1))Output
เมื่อคุณรันโค้ดด้านบนคุณจะเห็นผลลัพธ์ต่อไปนี้ -
[[-0.00873779 -0.02834515]
[ 0.05484822 -0.06206018]]
<NDArray 2x2 @gpu(1)>gluon.trainer
mxnet.gluon.trainer ใช้เครื่องมือเพิ่มประสิทธิภาพกับชุดพารามิเตอร์ ควรใช้ร่วมกับ autograd
วิธีการและพารามิเตอร์
ต่อไปนี้เป็นวิธีการที่สำคัญและพารามิเตอร์ที่ครอบคลุม mxnet.gluon.trainer โมดูลการฝึกอบรม -
| วิธีการและพารามิเตอร์ | คำจำกัดความ |
|---|---|
| allreduce_grads () | วิธีนี้จะลดการไล่ระดับสีจากบริบทที่แตกต่างกันสำหรับแต่ละพารามิเตอร์ (น้ำหนัก) |
| load_states (fname) | ตามความหมายของชื่อวิธีนี้จะโหลดสถานะเทรนเนอร์ |
| save_states (fname) | ตามความหมายของชื่อวิธีนี้จะบันทึกสถานะผู้ฝึกสอน |
| set_learning_rate (lr) | วิธีนี้จะกำหนดอัตราการเรียนรู้ใหม่ของเครื่องมือเพิ่มประสิทธิภาพ |
| ขั้นตอน (batch_size [, เพิกเฉย_stale_grad]) | วิธีนี้จะทำการอัพเดตพารามิเตอร์หนึ่งขั้นตอน ควรเรียกตามหลังautograd.backward() และภายนอก record() ขอบเขต. |
| อัปเดต (batch_size [, เพิกเฉย_stale_grad]) | วิธีนี้จะทำให้การอัปเดตพารามิเตอร์หนึ่งขั้นตอน ควรเรียกตามหลังautograd.backward() และภายนอก record() ขอบเขตและหลัง trainer.update () |
โมดูลข้อมูล
โมดูลข้อมูลของ Gluon มีคำอธิบายด้านล่าง -
gluon.data
Gluon มียูทิลิตี้ชุดข้อมูลในตัวจำนวนมากในโมดูล gluon.data นั่นคือเหตุผลที่เรียกว่าโมดูลข้อมูล
ชั้นเรียนและพารามิเตอร์
ต่อไปนี้เป็นวิธีการที่สำคัญและพารามิเตอร์ที่ครอบคลุมโดยโมดูลหลัก mxnet.gluon.data โดยทั่วไปวิธีการเหล่านี้เกี่ยวข้องกับชุดข้อมูลการสุ่มตัวอย่างและ DataLoader
ชุดข้อมูล| วิธีการและพารามิเตอร์ | คำจำกัดความ |
|---|---|
| ArrayDataset (* args) | วิธีนี้แสดงถึงชุดข้อมูลที่รวมวัตถุที่คล้ายชุดข้อมูลตั้งแต่สองชิ้นขึ้นไป ตัวอย่างเช่นชุดข้อมูลรายการอาร์เรย์ ฯลฯ |
| BatchSampler (ตัวอย่าง, batch_size [, last_batch]) | วิธีนี้พันทับอีกวิธีหนึ่ง Sampler. เมื่อห่อแล้วจะส่งคืนชุดตัวอย่างขนาดเล็ก |
| DataLoader (ชุดข้อมูล [, batch_size, สับเปลี่ยน, ... ]) | คล้ายกับ BatchSampler แต่วิธีนี้โหลดข้อมูลจากชุดข้อมูล เมื่อโหลดแล้วจะส่งกลับชุดข้อมูลขนาดเล็ก |
| สิ่งนี้แสดงถึงคลาสชุดข้อมูลนามธรรม | |
| FilterSampler (fn, ชุดข้อมูล) | วิธีนี้แสดงถึงองค์ประกอบตัวอย่างจากชุดข้อมูลที่ fn (ฟังก์ชัน) ส่งกลับ True. |
| RandomSampler (ความยาว) | วิธีนี้แสดงองค์ประกอบตัวอย่างจาก [0, ความยาว) แบบสุ่มโดยไม่มีการแทนที่ |
| RecordFileDataset (ชื่อไฟล์) | แสดงถึงชุดข้อมูลที่ตัดทับไฟล์ RecordIO นามสกุลของไฟล์คือ.rec. |
| ตัวอย่าง | นี่คือคลาสพื้นฐานสำหรับแซมเพลอร์ |
| SequentialSampler (ความยาว [, เริ่ม]) | ซึ่งแสดงถึงองค์ประกอบตัวอย่างจากชุด [start, start + length) ตามลำดับ |
| ซึ่งแสดงถึงองค์ประกอบตัวอย่างจากชุด [start, start + length) ตามลำดับ | สิ่งนี้แสดงถึง Wrapper ชุดข้อมูลแบบง่ายโดยเฉพาะสำหรับรายการและอาร์เรย์ |
ตัวอย่างการใช้งาน
ในตัวอย่างด้านล่างเราจะใช้ gluon.data.BatchSampler()API ซึ่งห่อหุ้มด้วยตัวอย่างอื่น ส่งคืนชุดตัวอย่างขนาดเล็ก
import mxnet as mx
from mxnet.gluon import data
sampler = mx.gluon.data.SequentialSampler(15)
batch_sampler = mx.gluon.data.BatchSampler(sampler, 4, 'keep')
list(batch_sampler)Output
ผลลัพธ์จะกล่าวถึงด้านล่าง -
[[0, 1, 2, 3], [4, 5, 6, 7], [8, 9, 10, 11], [12, 13, 14]]gluon.data.vision.datasets
Gluon มีฟังก์ชันชุดข้อมูลการมองเห็นที่กำหนดไว้ล่วงหน้าจำนวนมากใน gluon.data.vision.datasets โมดูล.
ชั้นเรียนและพารามิเตอร์
MXNet ให้ชุดข้อมูลที่มีประโยชน์และสำคัญแก่เราซึ่งมีการระบุคลาสและพารามิเตอร์ไว้ด้านล่าง -
| คลาสและพารามิเตอร์ | คำจำกัดความ |
|---|---|
| MNIST ([รูทฝึกแปลงร่าง]) | นี่คือชุดข้อมูลที่มีประโยชน์ซึ่งให้ตัวเลขที่เขียนด้วยลายมือแก่เรา URL สำหรับชุดข้อมูล MNIST คือ http://yann.lecun.com/exdb/mnist |
| FashionMNIST ([รูทรถไฟแปลงร่าง]) | ชุดข้อมูลนี้ประกอบด้วยรูปภาพบทความของ Zalando ซึ่งประกอบด้วยสินค้าแฟชั่น เป็นการแทนที่ชุดข้อมูล MNIST ดั้งเดิมแบบดรอปอิน คุณสามารถรับชุดข้อมูลนี้ได้จาก https://github.com/zalandoresearch/fashion-mnist |
| CIFAR10 ([รูทรถไฟแปลงร่าง]) | นี่คือชุดข้อมูลการจำแนกรูปภาพจาก https://www.cs.toronto.edu/~kriz/cifar.html ในชุดข้อมูลนี้แต่ละตัวอย่างเป็นรูปภาพที่มีรูปร่าง (32, 32, 3) |
| CIFAR100 ([root, fine_label, train, transform]) | นี่คือชุดข้อมูลการจำแนกภาพ CIFAR100 จาก https://www.cs.toronto.edu/~kriz/cifar.html นอกจากนี้ยังมีแต่ละตัวอย่างเป็นรูปภาพที่มีรูปร่าง (32, 32, 3) |
| ImageRecordDataset (ชื่อไฟล์ [, แฟล็ก, การแปลง]) | ชุดข้อมูลนี้รวมอยู่ในไฟล์ RecordIO ที่มีรูปภาพ ในแต่ละตัวอย่างนี้เป็นภาพที่มีป้ายกำกับที่เกี่ยวข้อง |
| ImageFolderDataset (รูท [แฟล็กการแปลง]) | นี่คือชุดข้อมูลสำหรับการโหลดไฟล์รูปภาพที่เก็บไว้ในโครงสร้างโฟลเดอร์ |
| ImageListDataset ([root, imglist, flag]) | นี่คือชุดข้อมูลสำหรับการโหลดไฟล์รูปภาพที่ระบุโดยรายการของรายการ |
ตัวอย่าง
ในตัวอย่างด้านล่างเราจะแสดงการใช้ ImageListDataset () ซึ่งใช้สำหรับการโหลดไฟล์รูปภาพที่ระบุโดยรายการ -
# written to text file *.lst
0 0 root/cat/0001.jpg
1 0 root/cat/xxxa.jpg
2 0 root/cat/yyyb.jpg
3 1 root/dog/123.jpg
4 1 root/dog/023.jpg
5 1 root/dog/wwww.jpg
# A pure list, each item is a list [imagelabel: float or list of float, imgpath]
[[0, root/cat/0001.jpg]
[0, root/cat/xxxa.jpg]
[0, root/cat/yyyb.jpg]
[1, root/dog/123.jpg]
[1, root/dog/023.jpg]
[1, root/dog/wwww.jpg]]โมดูลยูทิลิตี้
โมดูลยูทิลิตี้ใน Gluon มีดังต่อไปนี้ -
gluon.utils
Gluon มีเครื่องมือเพิ่มประสิทธิภาพยูทิลิตี้ build-in parallelisation จำนวนมากในโมดูล gluon.utils มีระบบสาธารณูปโภคที่หลากหลายสำหรับการฝึกอบรม นั่นคือเหตุผลที่เรียกว่าโมดูลยูทิลิตี้
ฟังก์ชันและพารามิเตอร์
ต่อไปนี้เป็นฟังก์ชันและพารามิเตอร์ที่ประกอบด้วยในโมดูลยูทิลิตี้นี้ชื่อ gluon.utils −
| ฟังก์ชั่นและพารามิเตอร์ | คำจำกัดความ |
|---|---|
| Split_data (ข้อมูล, num_slice [, batch_axis, …]) | โดยปกติแล้วฟังก์ชันนี้จะใช้สำหรับการขนานข้อมูลและแต่ละชิ้นจะถูกส่งไปยังอุปกรณ์หนึ่งเช่น GPU มันแยก NDArray ออกเป็นnum_slice ชิ้นพร้อม batch_axis. |
| Split_and_load (ข้อมูล ctx_list [, batch_axis, …]) | ฟังก์ชันนี้จะแบ่ง NDArray ออกเป็น len(ctx_list) ชิ้นพร้อม batch_axis. ข้อแตกต่างเพียงอย่างเดียวจากฟังก์ชัน Split_data () ด้านบนคือมันยังโหลดแต่ละชิ้นไปยังบริบทเดียวใน ctx_list. |
| clip_global_norm (อาร์เรย์ max_norm [, ... ]) | หน้าที่ของฟังก์ชันนี้คือการปรับขนาด NDArrays ใหม่ในลักษณะที่ผลรวมของ 2-norm มีค่าน้อยกว่า max_norm. |
| check_sha1 (ชื่อไฟล์ sha1_hash) | ฟังก์ชันนี้จะตรวจสอบว่าแฮช sha1 ของเนื้อหาไฟล์ตรงกับแฮชที่คาดไว้หรือไม่ |
| ดาวน์โหลด (url [, path, overwrite, sha1_hash, …]) | ตามที่ระบุชื่อฟังก์ชันนี้จะดาวน์โหลด URL ที่กำหนด |
| replace_file (src, dst) | ฟังก์ชันนี้จะใช้ปรมาณู os.replace. มันจะทำด้วย Linux และ OSX |
บทนี้เกี่ยวข้องกับ autograd และ initializer API ใน MXNet
mxnet.autograd
นี่คือ autograd API ของ MXNet สำหรับ NDArray มีคลาสดังต่อไปนี้ -
คลาส: ฟังก์ชัน ()
ใช้สำหรับปรับแต่งความแตกต่างใน autograd สามารถเขียนเป็นไฟล์mxnet.autograd.Function. ไม่ว่าด้วยเหตุผลใดก็ตามผู้ใช้ไม่ต้องการใช้การไล่ระดับสีที่คำนวณโดยกฎลูกโซ่เริ่มต้นก็สามารถใช้คลาสฟังก์ชันของ mxnet.autograd เพื่อปรับแต่งความแตกต่างสำหรับการคำนวณ มีสองวิธีคือ Forward () และ Backward ()
ให้เราเข้าใจการทำงานของคลาสนี้ด้วยความช่วยเหลือของประเด็นต่อไปนี้ -
ขั้นแรกเราต้องกำหนดการคำนวณของเราในวิธีการส่งต่อ
จากนั้นเราจำเป็นต้องระบุความแตกต่างที่กำหนดเองในวิธีการย้อนกลับ
ขณะนี้ในระหว่างการคำนวณการไล่ระดับสีแทนที่จะเป็นฟังก์ชันย้อนกลับที่ผู้ใช้กำหนดขึ้น mxnet.autograd จะใช้ฟังก์ชันย้อนกลับที่กำหนดโดยผู้ใช้ นอกจากนี้เรายังสามารถส่งไปยังอาร์เรย์ numpy และย้อนกลับสำหรับการดำเนินการบางอย่างในข้างหน้าและย้อนกลับ
Example
ก่อนที่จะใช้คลาส mxnet.autograd.function เรามากำหนดฟังก์ชัน sigmoid ที่เสถียรด้วยวิธีย้อนกลับและไปข้างหน้าดังนี้ -
class sigmoid(mx.autograd.Function):
def forward(self, x):
y = 1 / (1 + mx.nd.exp(-x))
self.save_for_backward(y)
return y
def backward(self, dy):
y, = self.saved_tensors
return dy * y * (1-y)ตอนนี้คลาสฟังก์ชันสามารถใช้ได้ดังนี้ -
func = sigmoid()
x = mx.nd.random.uniform(shape=(10,))
x.attach_grad()
with mx.autograd.record():
m = func(x)
m.backward()
dx_grad = x.grad.asnumpy()
dx_gradOutput
เมื่อคุณเรียกใช้รหัสคุณจะเห็นผลลัพธ์ต่อไปนี้ -
array([0.21458015, 0.21291625, 0.23330082, 0.2361367 , 0.23086983,
0.24060014, 0.20326573, 0.21093895, 0.24968489, 0.24301809],
dtype=float32)วิธีการและพารามิเตอร์
ต่อไปนี้เป็นวิธีการและพารามิเตอร์ของคลาส mxnet.autogard.function -
| วิธีการและพารามิเตอร์ | คำจำกัดความ |
|---|---|
| ไปข้างหน้า (หัว [, head_grads, Retain_graph, …]) | วิธีนี้ใช้สำหรับการคำนวณล่วงหน้า |
| ย้อนกลับ (หัว [, head_grads, Retain_graph, …]) | วิธีนี้ใช้สำหรับการคำนวณย้อนหลัง คำนวณการไล่ระดับสีของส่วนหัวตามตัวแปรที่ทำเครื่องหมายไว้ก่อนหน้านี้ วิธีนี้รับอินพุตมากพอ ๆ กับเอาต์พุตของฟอร์เวิร์ด นอกจากนี้ยังส่งคืน NDArray เป็นจำนวนมากเป็นอินพุตของ Forward |
| get_symbol (x) | วิธีนี้ใช้เพื่อดึงประวัติการคำนวณที่บันทึกไว้เป็น Symbol. |
| ผู้สำเร็จการศึกษา (หัว, ตัวแปร [, head_grads, …]) | วิธีนี้จะคำนวณการไล่ระดับของหัวตามตัวแปร เมื่อคำนวณแล้วแทนที่จะเก็บไว้ใน variable.grad การไล่ระดับสีจะถูกส่งกลับเป็น NDArrays ใหม่ |
| is_recording () | ด้วยความช่วยเหลือของวิธีนี้เราจะได้รับสถานะในการบันทึกและไม่บันทึก |
| is_training () | ด้วยความช่วยเหลือของวิธีนี้เราจะได้รับสถานะการฝึกอบรมและการทำนาย |
| mark_variables (ตัวแปรการไล่ระดับสี [, grad_reqs]) | วิธีนี้จะทำเครื่องหมาย NDArrays เป็นตัวแปรในการคำนวณการไล่ระดับสีสำหรับ autograd วิธีนี้เหมือนกับฟังก์ชัน. attach_grad () ในตัวแปร แต่ข้อแตกต่างเพียงอย่างเดียวคือด้วยการเรียกนี้เราสามารถตั้งค่าการไล่ระดับสีเป็นค่าใดก็ได้ |
| หยุดชั่วคราว ([โหมดรถไฟ]) | วิธีนี้ส่งคืนบริบทขอบเขตที่จะใช้ในคำสั่ง 'with' สำหรับรหัสที่ไม่จำเป็นต้องคำนวณการไล่ระดับสี |
| Predict_mode () | วิธีนี้จะส่งคืนบริบทขอบเขตที่จะใช้ในคำสั่ง 'with' ซึ่งพฤติกรรมการส่งต่อถูกตั้งค่าเป็นโหมดการอนุมานและไม่ได้เปลี่ยนสถานะการบันทึก |
| บันทึก ([train_mode]) | มันจะส่งคืนไฟล์ autograd บริบทขอบเขตการบันทึกที่จะใช้ในคำสั่ง 'with' และจับรหัสที่ต้องการการไล่ระดับสีเพื่อคำนวณ |
| set_recording (is_recording) | คล้ายกับ is_recoring () ด้วยความช่วยเหลือของวิธีนี้เราจะได้รับสถานะในการบันทึกและไม่บันทึก |
| set_training (is_training) | คล้ายกับ is_traininig () ด้วยความช่วยเหลือของวิธีนี้เราสามารถตั้งค่าสถานะเป็นการฝึกอบรมหรือการทำนาย |
| train_mode () | วิธีนี้จะส่งคืนบริบทขอบเขตที่จะใช้ในคำสั่ง 'with' ซึ่งพฤติกรรมการส่งต่อถูกตั้งค่าเป็นโหมดการฝึกอบรมและไม่ได้เปลี่ยนสถานะการบันทึก |
ตัวอย่างการใช้งาน
ในตัวอย่างด้านล่างเราจะใช้วิธี mxnet.autograd.grad () ในการคำนวณการไล่ระดับสีของส่วนหัวที่เกี่ยวข้องกับตัวแปร -
x = mx.nd.ones((2,))
x.attach_grad()
with mx.autograd.record():
z = mx.nd.elemwise_add(mx.nd.exp(x), x)
dx_grad = mx.autograd.grad(z, [x], create_graph=True)
dx_gradOutput
ผลลัพธ์จะกล่าวถึงด้านล่าง -
[
[3.7182817 3.7182817]
<NDArray 2 @cpu(0)>]เราสามารถใช้วิธี mxnet.autograd.predict_mode () เพื่อส่งคืนขอบเขตที่จะใช้ในคำสั่ง 'with' -
with mx.autograd.record():
y = model(x)
with mx.autograd.predict_mode():
y = sampling(y)
backward([y])mxnet.intializer
นี่คือ MXNet 'API สำหรับเครื่องชั่งเริ่มต้น มีคลาสดังต่อไปนี้ -
ชั้นเรียนและพารามิเตอร์
ต่อไปนี้เป็นวิธีการและพารามิเตอร์ของ mxnet.autogard.function ชั้น:
| คลาสและพารามิเตอร์ | คำจำกัดความ |
|---|---|
| ไบลิเนียร์ () | ด้วยความช่วยเหลือของคลาสนี้เราสามารถเริ่มต้นน้ำหนักสำหรับชั้นการสุ่มตัวอย่างขึ้น |
| ค่าคงที่ (ค่า) | คลาสนี้เริ่มต้นน้ำหนักให้เป็นค่าที่กำหนด ค่าสามารถเป็นสเกลาร์เช่นเดียวกับ NDArray ที่ตรงกับรูปร่างของพารามิเตอร์ที่จะตั้งค่า |
| FusedRNN (init, num_hidden, num_layers, โหมด) | ตามที่ระบุชื่อคลาสนี้เริ่มต้นพารามิเตอร์สำหรับเลเยอร์ Recurrent Neural Network (RNN) ที่หลอมรวม |
| InitDesc | ทำหน้าที่เป็นตัวบอกรูปแบบการเริ่มต้น |
| ตัวเริ่มต้น (** kwargs) | นี่คือคลาสพื้นฐานของตัวเริ่มต้น |
| LSTMBias ([forget_bias]) | คลาสนี้เริ่มต้นอคติทั้งหมดของ LSTMCell เป็น 0.0 แต่ยกเว้นประตูลืมที่ตั้งค่าอคติเป็นค่าแบบกำหนดเอง |
| โหลด (พารามิเตอร์ [, default_init, verbose]) | คลาสนี้เริ่มต้นตัวแปรโดยการโหลดข้อมูลจากไฟล์หรือพจนานุกรม |
| MSRAPrelu ([ประเภทตัวประกอบความชัน]) | ตามความหมายของชื่อคลาสนี้เริ่มต้นน้ำหนักตามกระดาษ MSRA |
| ผสม (รูปแบบตัวเริ่มต้น) | เริ่มต้นพารามิเตอร์โดยใช้ตัวเริ่มต้นหลายตัว |
| ปกติ ([ซิกม่า]) | คลาส Normal () เริ่มต้นน้ำหนักด้วยค่าสุ่มที่สุ่มตัวอย่างจากการแจกแจงปกติโดยมีค่าเฉลี่ยเป็นศูนย์และส่วนเบี่ยงเบนมาตรฐาน (SD) ของ sigma. |
| หนึ่ง() | เริ่มต้นน้ำหนักของพารามิเตอร์เป็นหนึ่ง |
| Orthogonal ([scale, rand_type]) | ตามความหมายของชื่อคลาสนี้เริ่มต้นน้ำหนักเป็นเมทริกซ์มุมฉาก |
| เครื่องแบบ ([มาตราส่วน]) | เริ่มต้นน้ำหนักด้วยค่าสุ่มซึ่งสุ่มตัวอย่างจากช่วงที่กำหนด |
| ซาเวียร์ ([rnd_type, factor_type, magnitude]) | มันส่งคืน initializer ที่ดำเนินการเริ่มต้น "Xavier" สำหรับน้ำหนัก |
| ศูนย์() | เริ่มต้นน้ำหนักของพารามิเตอร์เป็นศูนย์ |
ตัวอย่างการใช้งาน
ในตัวอย่างด้านล่างเราจะใช้คลาส mxnet.init.Normal () สร้างตัวเริ่มต้นและดึงข้อมูลพารามิเตอร์ -
init = mx.init.Normal(0.8)
init.dumps()Output
ผลลัพธ์จะได้รับด้านล่าง -
'["normal", {"sigma": 0.8}]'Example
init = mx.init.Xavier(factor_type="in", magnitude=2.45)
init.dumps()Output
ผลลัพธ์ดังแสดงด้านล่าง -
'["xavier", {"rnd_type": "uniform", "factor_type": "in", "magnitude": 2.45}]'ในตัวอย่างด้านล่างเราจะใช้คลาส mxnet.initializer.Mixed () เพื่อเริ่มต้นพารามิเตอร์โดยใช้ตัวเริ่มต้นหลายตัว -
init = mx.initializer.Mixed(['bias', '.*'], [mx.init.Zero(),
mx.init.Uniform(0.1)])
module.init_params(init)
for dictionary in module.get_params():
for key in dictionary:
print(key)
print(dictionary[key].asnumpy())Output
ผลลัพธ์ดังแสดงด้านล่าง -
fullyconnected1_weight
[[ 0.0097627 0.01856892 0.04303787]]
fullyconnected1_bias
[ 0.]ในบทนี้เราจะเรียนรู้เกี่ยวกับอินเทอร์เฟซใน MXNet ซึ่งเรียกว่า Symbol
Mxnet.ndarray
Symbol API ของ Apache MXNet เป็นอินเทอร์เฟซสำหรับการเขียนโปรแกรมสัญลักษณ์ Symbol API มีคุณสมบัติการใช้งานดังต่อไปนี้ -
กราฟการคำนวณ
การใช้หน่วยความจำลดลง
การเพิ่มประสิทธิภาพฟังก์ชันก่อนใช้งาน
ตัวอย่างด้านล่างแสดงให้เห็นว่าเราสามารถสร้างนิพจน์อย่างง่ายได้อย่างไรโดยใช้ Symbol API ของ MXNet -
NDArray โดยใช้ 1-D และ 2-D 'array' จากรายการ Python ปกติ -
import mxnet as mx
# Two placeholders namely x and y will be created with mx.sym.variable
x = mx.sym.Variable('x')
y = mx.sym.Variable('y')
# The symbol here is constructed using the plus ‘+’ operator.
z = x + yOutput
คุณจะเห็นผลลัพธ์ต่อไปนี้ -
<Symbol _plus0>Example
(x, y, z)Output
ผลลัพธ์จะได้รับด้านล่าง -
(<Symbol x>, <Symbol y>, <Symbol _plus0>)ตอนนี้ให้เราพูดคุยโดยละเอียดเกี่ยวกับคลาสฟังก์ชันและพารามิเตอร์ของ ndarray API ของ MXNet
ชั้นเรียน
ตารางต่อไปนี้ประกอบด้วยคลาสของ Symbol API ของ MXNet -
| คลาส | คำจำกัดความ |
|---|---|
| สัญลักษณ์ (ที่จับ) | คลาสนี้คือสัญลักษณ์เป็นกราฟสัญลักษณ์ของ Apache MXNet |
ฟังก์ชันและพารามิเตอร์
ต่อไปนี้เป็นฟังก์ชั่นที่สำคัญบางส่วนและพารามิเตอร์ที่ครอบคลุมโดย mxnet.Symbol API -
| ฟังก์ชันและพารามิเตอร์ | คำจำกัดความ |
|---|---|
| การเปิดใช้งาน ([data, act_type, out, name]) | ใช้องค์ประกอบฟังก์ชันการเปิดใช้งานที่ชาญฉลาดกับอินพุต รองรับrelu, sigmoid, tanh, softrelu, softsign ฟังก์ชั่นการเปิดใช้งาน |
| BatchNorm ([ข้อมูล, แกมมา, เบต้า, moving_mean, …]) | ใช้สำหรับการทำให้เป็นมาตรฐานแบทช์ ฟังก์ชันนี้ทำให้ชุดข้อมูลเป็นปกติโดยใช้ค่าเฉลี่ยและความแปรปรวน ใช้มาตราส่วนgamma และชดเชย beta. |
| BilinearSampler ([ข้อมูล, ตาราง, cudnn_off, …]) | ฟังก์ชันนี้ใช้การสุ่มตัวอย่างแบบทวิภาคีกับแผนผังคุณสมบัติการป้อนข้อมูล จริงๆแล้วมันเป็นกุญแจสำคัญของ“ Spatial Transformer Networks” หากคุณคุ้นเคยกับฟังก์ชันการรีแมปใน OpenCV การใช้งานฟังก์ชันนี้จะค่อนข้างคล้ายกัน ข้อแตกต่างเพียงอย่างเดียวคือมันมีทางเดินถอยหลัง |
| BlockGrad ([ข้อมูลออกชื่อ]) | ตามที่ระบุชื่อฟังก์ชันนี้จะหยุดการคำนวณการไล่ระดับสี โดยทั่วไปแล้วจะหยุดการไล่ระดับสีสะสมของอินพุตไม่ให้ไหลผ่านตัวดำเนินการนี้ในทิศทางย้อนกลับ |
| ส่ง ([data, dtype, out, name]) | ฟังก์ชันนี้จะส่งองค์ประกอบทั้งหมดของอินพุตไปยังประเภทใหม่ |
| ฟังก์ชันนี้จะส่งองค์ประกอบทั้งหมดของอินพุตไปยังประเภทใหม่ | ฟังก์ชันนี้ตามชื่อที่ระบุจะส่งคืนสัญลักษณ์ใหม่ของรูปร่างและประเภทที่กำหนดซึ่งเต็มไปด้วยศูนย์ |
| คน (รูปร่าง [, dtype]) | ฟังก์ชันนี้ตามชื่อที่ระบุจะส่งคืนสัญลักษณ์ใหม่ของรูปร่างและประเภทที่กำหนดซึ่งเต็มไปด้วยคน |
| เต็ม (รูปร่าง, วาล [, dtype]) | ฟังก์ชันนี้ตามชื่อที่ระบุจะส่งกลับอาร์เรย์ใหม่ของรูปร่างและประเภทที่กำหนดซึ่งเต็มไปด้วยค่าที่กำหนด val. |
| arange (เริ่ม [หยุดก้าวทำซ้ำ…]) | มันจะส่งคืนค่าที่เว้นระยะเท่า ๆ กันภายในช่วงเวลาที่กำหนด ค่าจะถูกสร้างขึ้นภายในช่วงเปิดครึ่งหนึ่ง [เริ่มต้นหยุด) ซึ่งหมายความว่าช่วงเวลาดังกล่าวรวมอยู่ด้วยstart แต่ไม่รวม stop. |
| linspace (เริ่ม, หยุด, num [, จุดสิ้นสุด, ชื่อ, ... ]) | มันจะส่งคืนตัวเลขที่เว้นระยะเท่า ๆ กันภายในช่วงเวลาที่กำหนด คล้ายกับฟังก์ชันจัดเรียง () ค่าจะถูกสร้างขึ้นภายในช่วงเปิดครึ่งหนึ่ง [เริ่มต้นหยุด) ซึ่งหมายความว่าช่วงเวลานั้นรวมถึงstart แต่ไม่รวม stop. |
| ฮิสโตแกรม (a [ถังขยะช่วง]) | ตามความหมายของชื่อฟังก์ชันนี้จะคำนวณฮิสโตแกรมของข้อมูลอินพุต |
| อำนาจ (ฐาน exp) | ตามความหมายของชื่อฟังก์ชันนี้จะส่งกลับผลลัพธ์ที่ชาญฉลาดขององค์ประกอบ base องค์ประกอบยกกำลังจาก expธาตุ. อินพุตทั้งสอง ได้แก่ ฐานและ exp สามารถเป็นสัญลักษณ์หรือสเกลาร์ก็ได้ โปรดทราบว่าไม่อนุญาตให้ออกอากาศ คุณสามารถใช้ได้broadcast_pow หากคุณต้องการใช้คุณสมบัติของการออกอากาศ |
| SoftmaxActivation ([ข้อมูลโหมดชื่อ Attr ออก]) | ฟังก์ชันนี้ใช้การเปิดใช้งาน softmax กับอินพุต มีไว้สำหรับเลเยอร์ภายใน มันเลิกใช้งานจริงเราสามารถใช้ได้softmax() แทน. |
ตัวอย่างการใช้งาน
ในตัวอย่างด้านล่างเราจะใช้ฟังก์ชัน power() ซึ่งจะส่งคืนผลลัพธ์ที่ชาญฉลาดขององค์ประกอบพื้นฐานที่ยกขึ้นเป็นพลังจากองค์ประกอบ exp:
import mxnet as mx
mx.sym.power(3, 5)Output
คุณจะเห็นผลลัพธ์ต่อไปนี้ -
243Example
x = mx.sym.Variable('x')
y = mx.sym.Variable('y')
z = mx.sym.power(x, 3)
z.eval(x=mx.nd.array([1,2]))[0].asnumpy()Output
สิ่งนี้สร้างผลลัพธ์ต่อไปนี้ -
array([1., 8.], dtype=float32)Example
z = mx.sym.power(4, y)
z.eval(y=mx.nd.array([2,3]))[0].asnumpy()Output
เมื่อคุณรันโค้ดด้านบนคุณจะเห็นผลลัพธ์ต่อไปนี้ -
array([16., 64.], dtype=float32)Example
z = mx.sym.power(x, y)
z.eval(x=mx.nd.array([4,5]), y=mx.nd.array([2,3]))[0].asnumpy()Output
ผลลัพธ์จะกล่าวถึงด้านล่าง -
array([ 16., 125.], dtype=float32)ในตัวอย่างด้านล่างเราจะใช้ฟังก์ชัน SoftmaxActivation() (or softmax()) ซึ่งจะนำไปใช้กับอินพุตและมีไว้สำหรับเลเยอร์ภายใน
input_data = mx.nd.array([[2., 0.9, -0.5, 4., 8.], [4., -.7, 9., 2., 0.9]])
soft_max_act = mx.nd.softmax(input_data)
print (soft_max_act.asnumpy())Output
คุณจะเห็นผลลัพธ์ต่อไปนี้ -
[[2.4258138e-03 8.0748333e-04 1.9912292e-04 1.7924475e-02 9.7864312e-01]
[6.6843745e-03 6.0796250e-05 9.9204916e-01 9.0463174e-04 3.0112563e-04]]symbol.contrib
Contrib NDArray API ถูกกำหนดไว้ในแพ็กเกจ symbol.contrib โดยทั่วไปแล้วจะมี API ทดลองที่มีประโยชน์มากมายสำหรับคุณลักษณะใหม่ ๆ API นี้ทำงานเป็นที่สำหรับชุมชนที่พวกเขาสามารถทดลองใช้คุณลักษณะใหม่ ๆ ผู้สนับสนุนคุณลักษณะจะได้รับข้อเสนอแนะเช่นกัน
ฟังก์ชันและพารามิเตอร์
ต่อไปนี้เป็นฟังก์ชั่นที่สำคัญบางส่วนและพารามิเตอร์ที่ครอบคลุมโดย mxnet.symbol.contrib API -
| ฟังก์ชันและพารามิเตอร์ | คำจำกัดความ |
|---|---|
| Rand_zipfian (true_classes, num_sampled, …) | ฟังก์ชันนี้ดึงตัวอย่างสุ่มจากการแจกแจงแบบ Zipfian โดยประมาณ การแจกแจงฐานของฟังก์ชันนี้คือการแจกแจงแบบ Zipfian ฟังก์ชันนี้สุ่มตัวอย่างผู้สมัครที่เป็นตัวเลขและองค์ประกอบของ sampled_candidates ถูกดึงมาจากการแจกแจงฐานที่ระบุไว้ด้านบน |
| foreach (เนื้อหาข้อมูล init_states) | ตามความหมายของชื่อฟังก์ชันนี้จะรันลูปด้วยการคำนวณที่ผู้ใช้กำหนดบน NDArrays บนมิติ 0 ฟังก์ชันนี้จำลองสำหรับลูปและเนื้อความมีการคำนวณสำหรับการวนซ้ำของ for |
| while_loop (cond, func, loop_vars [, …]) | ตามความหมายของชื่อฟังก์ชันนี้จะรัน while loop ด้วยการคำนวณที่ผู้ใช้กำหนดและเงื่อนไขการวนซ้ำ ฟังก์ชันนี้จะจำลองการวนซ้ำในขณะที่ทำการคำนวณแบบกำหนดเองอย่างแท้จริงหากเงื่อนไขเป็นที่พอใจ |
| เงื่อนไข (pred, then_func, else_func) | ตามความหมายของชื่อฟังก์ชันนี้จะรัน if-then-else โดยใช้เงื่อนไขและการคำนวณที่ผู้ใช้กำหนดเอง ฟังก์ชันนี้จำลองสาขา if-like ซึ่งเลือกที่จะทำการคำนวณแบบกำหนดเองหนึ่งในสองแบบตามเงื่อนไขที่ระบุ |
| getnnz ([ข้อมูลแกนออกชื่อ]) | ฟังก์ชันนี้ให้จำนวนค่าที่เก็บไว้สำหรับเทนเซอร์แบบเบาบาง นอกจากนี้ยังรวมถึงศูนย์ที่ชัดเจน รองรับเมทริกซ์ CSR บน CPU เท่านั้น |
| กำหนด ([ข้อมูล, min_range, max_range, …]) | ฟังก์ชันนี้กำหนดข้อมูลที่กำหนดซึ่งกำหนดให้เป็นจำนวนใน int32 และเกณฑ์ที่สอดคล้องกันเป็น int8 โดยใช้เกณฑ์ขั้นต่ำและสูงสุดซึ่งคำนวณที่รันไทม์หรือจากการสอบเทียบ |
| index_copy ([old_tensor, index_vector, …]) | ฟังก์ชันนี้คัดลอกองค์ประกอบของไฟล์ new_tensor into the old_tensor by selecting the indices in the order given in index. The output of this operator will be a new tensor that contains the rest elements of old tensor and the copied elements of new tensor. |
| interleaved_matmul_encdec_qk ([แบบสอบถาม, …]) | ตัวดำเนินการนี้คำนวณการคูณเมทริกซ์ระหว่างการคาดคะเนของคิวรีและคีย์ที่ใช้ความสนใจแบบหลายหัวเป็นตัวเข้ารหัสตัวถอดรหัส เงื่อนไขคืออินพุตควรเป็นเทนเซอร์ของการคาดการณ์ของคิวรีที่เป็นไปตามโครงร่าง: (seq_length, batch_size, num_heads *, head_dim) |
ตัวอย่างการใช้งาน
ในตัวอย่างด้านล่างเราจะใช้ฟังก์ชัน rand_zipfian สำหรับการวาดตัวอย่างสุ่มจากการแจกแจงแบบ Zipfian โดยประมาณ -
import mxnet as mx
true_cls = mx.sym.Variable('true_cls')
samples, exp_count_true, exp_count_sample = mx.sym.contrib.rand_zipfian(true_cls, 5, 6)
samples.eval(true_cls=mx.nd.array([3]))[0].asnumpy()Output
คุณจะเห็นผลลัพธ์ต่อไปนี้ -
array([4, 0, 2, 1, 5], dtype=int64)Example
exp_count_true.eval(true_cls=mx.nd.array([3]))[0].asnumpy()Output
ผลลัพธ์จะกล่าวถึงด้านล่าง -
array([0.57336551])Example
exp_count_sample.eval(true_cls=mx.nd.array([3]))[0].asnumpy()Output
คุณจะเห็นผลลัพธ์ต่อไปนี้ -
array([1.78103594, 0.46847373, 1.04183923, 0.57336551, 1.04183923])ในตัวอย่างด้านล่างเราจะใช้ฟังก์ชัน while_loop สำหรับการรัน while loop สำหรับการคำนวณที่ผู้ใช้กำหนดและเงื่อนไขการวนซ้ำ -
cond = lambda i, s: i <= 7
func = lambda i, s: ([i + s], [i + 1, s + i])
loop_vars = (mx.sym.var('i'), mx.sym.var('s'))
outputs, states = mx.sym.contrib.while_loop(cond, func, loop_vars, max_iterations=10)
print(outputs)Output
ผลลัพธ์จะได้รับด้านล่าง:
[<Symbol _while_loop0>]Example
Print(States)Output
สิ่งนี้สร้างผลลัพธ์ต่อไปนี้ -
[<Symbol _while_loop0>, <Symbol _while_loop0>]ในตัวอย่างด้านล่างเราจะใช้ฟังก์ชัน index_copy ที่คัดลอกองค์ประกอบของ new_tensor ไปยัง old_tensor
import mxnet as mx
a = mx.nd.zeros((6,3))
b = mx.nd.array([[1,2,3],[4,5,6],[7,8,9]])
index = mx.nd.array([0,4,2])
mx.nd.contrib.index_copy(a, index, b)Output
เมื่อคุณรันโค้ดด้านบนคุณจะเห็นผลลัพธ์ต่อไปนี้ -
[[1. 2. 3.]
[0. 0. 0.]
[7. 8. 9.]
[0. 0. 0.]
[4. 5. 6.]
[0. 0. 0.]]
<NDArray 6x3 @cpu(0)>สัญลักษณ์ภาพ
Image Symbol API ถูกกำหนดในแพ็คเกจ symbol.image ตามความหมายของชื่อโดยทั่วไปจะใช้สำหรับรูปภาพและคุณสมบัติต่างๆ
ฟังก์ชันและพารามิเตอร์
ต่อไปนี้เป็นฟังก์ชั่นที่สำคัญบางส่วนและพารามิเตอร์ที่ครอบคลุมโดย mxnet.symbol.image API -
| ฟังก์ชันและพารามิเตอร์ | คำจำกัดความ |
|---|---|
| Adjust_lighting ([ข้อมูลอัลฟ่าออกชื่อ]) | ตามความหมายของชื่อฟังก์ชันนี้จะปรับระดับแสงของอินพุต เป็นไปตามสไตล์ AlexNet |
| ครอบตัด ([data, x, y, width, height, out, name]) | ด้วยความช่วยเหลือของฟังก์ชั่นนี้เราสามารถครอบตัดรูปภาพ NDArray ของรูปทรง (H x W x C) หรือ (N x H x W x C) ตามขนาดที่ผู้ใช้กำหนด |
| ทำให้เป็นมาตรฐาน ([data, mean, std, out, name]) | มันจะทำให้รูปร่างเป็นปกติ (C x H x W) หรือ (N x C x H x W) ด้วย mean และ standard deviation(SD). |
| random_crop ([data, xrange, yrange, width, ... ]) | คล้ายกับการครอบตัด () มันสุ่มครอบตัดรูปภาพ NDArray ของรูปทรง (สูง x กว้าง x C) หรือ (N x H x W x C) ตามขนาดที่ผู้ใช้กำหนด มันจะเพิ่มผลลัพธ์หากsrc มีขนาดเล็กกว่าไฟล์ size. |
| random_lighting([ข้อมูล alpha_std ออกชื่อ]) | ตามความหมายของชื่อฟังก์ชันนี้จะเพิ่มสัญญาณรบกวน PCA แบบสุ่ม นอกจากนี้ยังเป็นไปตามสไตล์ AlexNet |
| random_resized_crop ([data, xrange, yrange, ... ]) | นอกจากนี้ยังครอบตัดรูปภาพแบบสุ่ม NDArray ของรูปทรง (H x W x C) หรือ (N x H x W x C) ตามขนาดที่กำหนด มันจะเพิ่มตัวอย่างผลลัพธ์หาก src มีขนาดเล็กกว่าขนาด มันจะสุ่มพื้นที่และสัดส่วนด้านเช่นกัน |
| ปรับขนาด ([data, size, keep_ratio, interp, …]) | ตามความหมายของชื่อฟังก์ชันนี้จะปรับขนาดรูปภาพ NDArray ของรูปทรง (H x W x C) หรือ (N x H x W x C) ให้เป็นขนาดที่ผู้ใช้กำหนด |
| to_tensor ([ข้อมูลออกชื่อ]) | มันแปลงรูปภาพ NDArray ของรูปร่าง (H x W x C) หรือ (N x H x W x C) ด้วยค่าในช่วง [0, 255] เป็นเทนเซอร์ NDArray ของรูปร่าง (C x H x W) หรือ ( N x C x H x W) โดยมีค่าอยู่ในช่วง [0, 1] |
ตัวอย่างการใช้งาน
ในตัวอย่างด้านล่างเราจะใช้ฟังก์ชัน to_tensor เพื่อแปลงรูปภาพ NDArray ของรูปทรง (H x W x C) หรือ (N x H x W x C) ด้วยค่าในช่วง [0, 255] เป็นเทนเซอร์ NDArray ของรูปร่าง (C x H x W) หรือ (N x C x H x W) โดยมีค่าอยู่ในช่วง [0, 1]
import numpy as np
img = mx.sym.random.uniform(0, 255, (4, 2, 3)).astype(dtype=np.uint8)
mx.sym.image.to_tensor(img)Output
ผลลัพธ์ระบุไว้ด้านล่าง -
<Symbol to_tensor4>Example
img = mx.sym.random.uniform(0, 255, (2, 4, 2, 3)).astype(dtype=np.uint8)
mx.sym.image.to_tensor(img)Output
ผลลัพธ์ดังต่อไปนี้:
<Symbol to_tensor5>ในตัวอย่างด้านล่างเราจะใช้ฟังก์ชัน normalize () เพื่อทำให้รูปร่างเป็นปกติ (C x H x W) หรือ (N x C x H x W) ด้วย mean และ standard deviation(SD).
img = mx.sym.random.uniform(0, 1, (3, 4, 2))
mx.sym.image.normalize(img, mean=(0, 1, 2), std=(3, 2, 1))Output
ด้านล่างเป็นผลลัพธ์ของรหัส -
<Symbol normalize0>Example
img = mx.sym.random.uniform(0, 1, (2, 3, 4, 2))
mx.sym.image.normalize(img, mean=(0, 1, 2), std=(3, 2, 1))Output
ผลลัพธ์ดังแสดงด้านล่าง -
<Symbol normalize1>symbol.random
Random Symbol API ถูกกำหนดในแพ็คเกจ symbol.random ตามความหมายของชื่อมันเป็นตัวสร้างการกระจายแบบสุ่ม Symbol API ของ MXNet
ฟังก์ชันและพารามิเตอร์
ต่อไปนี้เป็นฟังก์ชั่นที่สำคัญบางส่วนและพารามิเตอร์ที่ครอบคลุมโดย mxnet.symbol.random API -
| ฟังก์ชันและพารามิเตอร์ | คำจำกัดความ |
|---|---|
| เครื่องแบบ ([ต่ำ, สูง, รูปร่าง, dtype, ctx, out]) | สร้างตัวอย่างสุ่มจากการแจกแจงแบบสม่ำเสมอ |
| ปกติ ([loc, scale, shape, dtype, ctx, out]) | มันสร้างตัวอย่างสุ่มจากการแจกแจงแบบปกติ (Gaussian) |
| แรนด์ (* รูปร่าง ** kwargs) | มันสร้างตัวอย่างสุ่มจากการแจกแจงแบบปกติ (Gaussian) |
| ปัวซอง ([lam, shape, dtype, ctx, out]) | สร้างตัวอย่างสุ่มจากการแจกแจงแบบปัวซอง |
| เลขชี้กำลัง ([มาตราส่วนรูปร่าง dtype ctx ออก]) | สร้างตัวอย่างจากการแจกแจงแบบเอ็กซ์โพเนนเชียล |
| แกมมา ([อัลฟ่าเบต้ารูปร่าง dtype ctx ออก]) | สร้างตัวอย่างสุ่มจากการแจกแจงแกมมา |
| หลายนาม (ข้อมูล [รูปร่าง get_prob ออก dtype]) | มันสร้างการสุ่มตัวอย่างพร้อมกันจากการแจกแจงพหุนามหลาย ๆ |
| negative_binomial ([k, p, รูปร่าง, dtype, ctx, out]) | สร้างตัวอย่างสุ่มจากการแจกแจงทวินามลบ |
| generalized_negative_binomial ([mu, alpha, …]) | สร้างตัวอย่างสุ่มจากการแจกแจงทวินามลบทั่วไป |
| สับเปลี่ยน (ข้อมูล ** kwargs) | มันสับเปลี่ยนองค์ประกอบแบบสุ่ม |
| Randint (ต่ำสูง [รูปร่าง dtype ctx ออก]) | มันสร้างตัวอย่างสุ่มจากการแจกแจงสม่ำเสมอแบบไม่ต่อเนื่อง |
| exponential_like ([data, lam, out, name]) | สร้างตัวอย่างสุ่มจากการแจกแจงเลขชี้กำลังตามรูปร่างอาร์เรย์อินพุต |
| gamma_like ([ข้อมูลอัลฟ่าเบต้าออกชื่อ]) | สร้างตัวอย่างสุ่มจากการแจกแจงแกมมาตามรูปร่างอาร์เรย์อินพุต |
| generalized_negative_binomial_like ([ข้อมูล, …]) | สร้างตัวอย่างสุ่มจากการแจกแจงทวินามลบทั่วไปตามรูปร่างอาร์เรย์อินพุต |
| negative_binomial_like ([ข้อมูล, k, p, ออก, ชื่อ]) | สร้างตัวอย่างสุ่มจากการแจกแจงทวินามลบตามรูปร่างอาร์เรย์อินพุต |
| normal_like ([data, loc, scale, out, name]) | มันสร้างตัวอย่างสุ่มจากการแจกแจงแบบปกติ (Gaussian) ตามรูปร่างอาร์เรย์อินพุต |
| poisson_like ([data, lam, out, name]) | สร้างตัวอย่างสุ่มจากการแจกแจงแบบปัวซองตามรูปร่างอาร์เรย์อินพุต |
| uniform_like ([ข้อมูลต่ำสูงออกชื่อ]) | สร้างตัวอย่างสุ่มจากการกระจายสม่ำเสมอตามรูปร่างอาร์เรย์อินพุต |
ตัวอย่างการใช้งาน
ในตัวอย่างด้านล่างเราจะสับองค์ประกอบแบบสุ่มโดยใช้ฟังก์ชัน shuffle () มันจะสับอาร์เรย์ตามแกนแรก
data = mx.nd.array([[0, 1, 2], [3, 4, 5], [6, 7, 8],[9,10,11]])
x = mx.sym.Variable('x')
y = mx.sym.random.shuffle(x)
y.eval(x=data)Output
คุณจะเห็นผลลัพธ์ต่อไปนี้:
[
[[ 9. 10. 11.]
[ 0. 1. 2.]
[ 6. 7. 8.]
[ 3. 4. 5.]]
<NDArray 4x3 @cpu(0)>]Example
y.eval(x=data)Output
เมื่อคุณรันโค้ดด้านบนคุณจะเห็นผลลัพธ์ต่อไปนี้ -
[
[[ 6. 7. 8.]
[ 0. 1. 2.]
[ 3. 4. 5.]
[ 9. 10. 11.]]
<NDArray 4x3 @cpu(0)>]ในตัวอย่างด้านล่างเราจะวาดตัวอย่างสุ่มจากการแจกแจงทวินามลบทั่วไป สำหรับสิ่งนี้จะเป็นการใช้ฟังก์ชันgeneralized_negative_binomial().
mx.sym.random.generalized_negative_binomial(10, 0.1)Output
ผลลัพธ์จะได้รับด้านล่าง -
<Symbol _random_generalized_negative_binomial0>สัญลักษณ์
Sparse Symbol API ถูกกำหนดไว้ในแพ็กเกจ mxnet.symbol.sparse ตามความหมายของชื่อมันมีกราฟเครือข่ายประสาทที่กระจัดกระจายและการแยกความแตกต่างอัตโนมัติบน CPU
ฟังก์ชันและพารามิเตอร์
ต่อไปนี้เป็นฟังก์ชันที่สำคัญบางอย่าง (รวมถึงรูทีนการสร้างสัญลักษณ์, กิจวัตรการจัดการสัญลักษณ์, ฟังก์ชันทางคณิตศาสตร์, ฟังก์ชันตรีโกณมิติ, ฟังก์ชันไฮเบอร์โบลิก, ฟังก์ชันลด, การปัดเศษ, พลัง, เครือข่ายประสาทเทียม) และพารามิเตอร์ที่ครอบคลุมโดย mxnet.symbol.sparse API -
| ฟังก์ชันและพารามิเตอร์ | คำจำกัดความ |
|---|---|
| ElementWiseSum (* args, ** kwargs) | ฟังก์ชันนี้จะเพิ่มองค์ประกอบอาร์กิวเมนต์อินพุตทั้งหมดที่ชาญฉลาด ตัวอย่างเช่น _ (1,2, … = 1 + 2 + ⋯ +) ที่นี่เราจะเห็นว่า add_n อาจมีประสิทธิภาพมากกว่าการโทรเพิ่มทีละ n เท่า |
| การฝัง ([ข้อมูลน้ำหนัก input_dim, …]) | มันจะแมปดัชนีจำนวนเต็มกับการแสดงเวกเตอร์เช่น embeddings มันจับคู่คำกับเวกเตอร์ที่มีมูลค่าจริงในพื้นที่มิติสูงซึ่งเรียกว่าการฝังคำ |
| LinearRegressionOutput ([ข้อมูลป้ายกำกับ ... ]) | คำนวณและปรับให้เหมาะสมสำหรับการสูญเสียกำลังสองในระหว่างการแพร่กระจายย้อนกลับโดยให้ข้อมูลเอาต์พุตระหว่างการแพร่กระจายไปข้างหน้า |
| LogisticRegressionOutput ([ข้อมูลป้ายกำกับ ... ]) | ใช้ฟังก์ชันโลจิสติกซึ่งเรียกอีกอย่างว่าฟังก์ชัน sigmoid กับอินพุต ฟังก์ชันคำนวณเป็น 1/1 + exp (−x) |
| MAERegressionOutput ([ข้อมูลป้ายกำกับ ... ]) | ตัวดำเนินการนี้คำนวณหมายถึงข้อผิดพลาดสัมบูรณ์ของอินพุต MAE เป็นตัวชี้วัดความเสี่ยงที่สอดคล้องกับค่าที่คาดว่าจะเกิดข้อผิดพลาดสัมบูรณ์ |
| abs ([ข้อมูล, ชื่อ, attr, ออก]) | ตามความหมายของชื่อฟังก์ชันนี้จะส่งคืนค่าสัมบูรณ์ของอินพุตตามองค์ประกอบที่ชาญฉลาด |
| adagrad_update ([weight, grad, history, lr, …]) | มันเป็นฟังก์ชั่นการปรับปรุงสำหรับ AdaGrad optimizer. |
| adam_update ([weight, grad, mean, var, lr, …]) | มันเป็นฟังก์ชั่นการปรับปรุงสำหรับ Adam optimizer. |
| add_n (* args, ** kwargs) | ตามความหมายของชื่อมันจะเพิ่มองค์ประกอบการป้อนข้อมูลทั้งหมดที่ชาญฉลาด |
| arccos ([data, name, attr, out]) | ฟังก์ชันนี้จะส่งคืนโคไซน์ผกผันขององค์ประกอบที่ชาญฉลาดของอาร์เรย์อินพุต |
| จุด ([lhs, rhs, transpose_a, transpose_b, …]) | ตามความหมายของชื่อมันจะให้ผลิตภัณฑ์ดอทของอาร์เรย์สองอาร์เรย์ จะขึ้นอยู่กับมิติข้อมูลอาร์เรย์อินพุต: 1-D: ผลคูณภายในของเวกเตอร์ 2-D: การคูณเมทริกซ์ ND: ผลรวมของแกนสุดท้ายของอินพุตแรกและแกนแรกของอินพุตที่สอง |
| elemwise_add ([lhs, rhs, name, attr, out]) | ตามชื่อที่แสดงถึงมันจะ add องค์ประกอบการโต้แย้งที่ชาญฉลาด |
| elemwise_div ([lhs, rhs, name, attr, out]) | ตามชื่อที่แสดงถึงมันจะ divide องค์ประกอบการโต้แย้งที่ชาญฉลาด |
| elemwise_mul ([lhs, rhs, name, attr, out]) | ตามชื่อที่แสดงถึงมันจะ Multiply องค์ประกอบการโต้แย้งที่ชาญฉลาด |
| elemwise_sub ([lhs, rhs, name, attr, out]) | ตามความหมายของชื่อมันจะลบองค์ประกอบอาร์กิวเมนต์ที่ชาญฉลาด |
| exp ([ข้อมูล, ชื่อ, attr, ออก]) | ฟังก์ชันนี้จะส่งคืนค่าเลขชี้กำลังขององค์ประกอบของอินพุตที่กำหนด |
| sgd_update ([weight, grad, lr, wd, …]) | ทำหน้าที่เป็นฟังก์ชันอัพเดตสำหรับเครื่องมือเพิ่มประสิทธิภาพ Stochastic Gradient Descent |
| sigmoid ([data, name, attr, out]) | ตามความหมายของชื่อมันจะคำนวณ sigmoid ขององค์ประกอบ x ที่ชาญฉลาด |
| ลงชื่อ ([data, name, attr, out]) | มันจะส่งกลับสัญลักษณ์ที่ชาญฉลาดขององค์ประกอบที่ระบุ |
| บาป ([data, name, attr, out]) | ตามความหมายของชื่อฟังก์ชันนี้จะคำนวณไซน์องค์ประกอบที่ชาญฉลาดของอาร์เรย์อินพุตที่กำหนด |
ตัวอย่างการใช้งาน
ในตัวอย่างด้านล่างเราจะสุ่มองค์ประกอบโดยใช้ ElementWiseSum()ฟังก์ชัน มันจะแมปดัชนีจำนวนเต็มกับการแสดงเวกเตอร์เช่นการฝังคำ
input_dim = 4
output_dim = 5Example
/* Here every row in weight matrix y represents a word. So, y = (w0,w1,w2,w3)
y = [[ 0., 1., 2., 3., 4.],
[ 5., 6., 7., 8., 9.],
[ 10., 11., 12., 13., 14.],
[ 15., 16., 17., 18., 19.]]
/* Here input array x represents n-grams(2-gram). So, x = [(w1,w3), (w0,w2)]
x = [[ 1., 3.],
[ 0., 2.]]
/* Now, Mapped input x to its vector representation y.
Embedding(x, y, 4, 5) = [[[ 5., 6., 7., 8., 9.],
[ 15., 16., 17., 18., 19.]],
[[ 0., 1., 2., 3., 4.],
[ 10., 11., 12., 13., 14.]]]API โมดูลของ Apache MXNet เป็นเหมือนโมเดล FeedForward และง่ายต่อการเขียนคล้ายกับโมดูล Torch ประกอบด้วยชั้นเรียนต่อไปนี้ -
BaseModule ([คนตัดไม้])
แสดงถึงคลาสพื้นฐานของโมดูล โมดูลสามารถคิดได้ว่าเป็นส่วนประกอบการคำนวณหรือเครื่องคำนวณ งานของโมดูลคือดำเนินการส่งต่อไปข้างหน้าและถอยหลัง นอกจากนี้ยังอัปเดตพารามิเตอร์ในแบบจำลอง
วิธีการ
ตารางต่อไปนี้แสดงวิธีการต่างๆที่ประกอบด้วย BaseModule class-
วิธีนี้จะได้รับสถานะจากอุปกรณ์ทั้งหมด| วิธีการ | คำจำกัดความ |
|---|---|
| ย้อนกลับ ([out_grads]) | ในฐานะที่เป็นชื่อแสดงถึงวิธีการนี้ใช้ backward การคำนวณ |
| ผูก (data_shapes [, label_shapes, …]) | มันผูกสัญลักษณ์เพื่อสร้างตัวดำเนินการและจำเป็นก่อนที่จะสามารถทำการคำนวณกับโมดูลได้ |
| พอดี (train_data [, eval_data, eval_metric, …]) | วิธีนี้ฝึกพารามิเตอร์โมดูล |
| ไปข้างหน้า (data_batch [, is_train]) | เนื่องจากชื่อมีความหมายว่าวิธีนี้ใช้การคำนวณไปข้างหน้า วิธีนี้รองรับชุดข้อมูลที่มีรูปร่างต่างๆเช่นขนาดชุดงานที่แตกต่างกันหรือขนาดภาพที่แตกต่างกัน |
| forward_backward (data_batch) | มันเป็นฟังก์ชั่นที่สะดวกตามชื่อที่เรียกทั้งไปข้างหน้าและข้างหลัง |
| get_input_grads ([merge_multi_context]) | วิธีนี้จะได้รับการไล่ระดับสีไปยังอินพุตซึ่งคำนวณในการคำนวณย้อนหลังก่อนหน้านี้ |
| get_outputs ([merge_multi_context]) | ตามความหมายของชื่อวิธีนี้จะได้รับผลลัพธ์ของการคำนวณล่วงหน้าก่อนหน้านี้ |
| get_params () | ได้รับพารามิเตอร์โดยเฉพาะพารามิเตอร์ที่อาจเป็นสำเนาของพารามิเตอร์จริงที่ใช้ในการคำนวณบนอุปกรณ์ |
| get_states ([merge_multi_context]) | |
| init_optimizer ([kvstore, เครื่องมือเพิ่มประสิทธิภาพ, …]) | วิธีนี้จะติดตั้งและเริ่มต้นเครื่องมือเพิ่มประสิทธิภาพ นอกจากนี้ยังเริ่มต้นkvstore เพื่อเผยแพร่การฝึกอบรม |
| init_params ([initializer, arg_params, …]) | ตามความหมายของชื่อวิธีนี้จะเริ่มต้นพารามิเตอร์และสถานะเสริม |
| install_monitor (จันทร์) | วิธีนี้จะติดตั้งมอนิเตอร์บนตัวดำเนินการทั้งหมด |
| iter_predict (eval_data [, num_batch, รีเซ็ต, …]) | วิธีนี้จะวนซ้ำการคาดการณ์ |
| load_params (fname) | ตามที่ระบุชื่อจะโหลดพารามิเตอร์โมเดลจากไฟล์ |
| ทำนาย (eval_data [, num_batch, …]) | มันจะเรียกใช้การคาดคะเนและรวบรวมผลลัพธ์ด้วย |
| เตรียม (data_batch [, sparse_row_id_fn]) | ตัวดำเนินการเตรียมโมดูลสำหรับการประมวลผลชุดข้อมูลที่กำหนด |
| save_params (fname) | ตามที่ระบุชื่อฟังก์ชันนี้จะบันทึกพารามิเตอร์โมเดลลงในไฟล์ |
| คะแนน (eval_data, eval_metric [, num_batch, …]) | มันรันการทำนาย eval_data และยังประเมินผลการดำเนินงานตามที่กำหนด eval_metric. |
| set_params (arg_params, aux_params [, …]) | วิธีนี้จะกำหนดค่าพารามิเตอร์และสถานะ aux |
| set_states ([สถานะ, ค่า]) | วิธีนี้ตามที่ระบุชื่อกำหนดค่าสำหรับสถานะ |
| ปรับปรุง () | วิธีนี้จะอัปเดตพารามิเตอร์ที่กำหนดตามเครื่องมือเพิ่มประสิทธิภาพที่ติดตั้ง นอกจากนี้ยังอัปเดตการไล่ระดับสีที่คำนวณในชุดการเดินหน้าถอยหลังก่อนหน้านี้ |
| update_metric (eval_metric ป้ายกำกับ [pre_sliced]) | เมธอดนี้ตามชื่อจะประเมินและรวบรวมเมตริกการประเมินผลบนผลลัพธ์ของการคำนวณไปข้างหน้าครั้งสุดท้าย |
| ย้อนกลับ ([out_grads]) | ในฐานะที่เป็นชื่อแสดงถึงวิธีการนี้ใช้ backward การคำนวณ |
| ผูก (data_shapes [, label_shapes, …]) | ตั้งค่าที่เก็บข้อมูลและผูกตัวดำเนินการสำหรับคีย์ที่เก็บข้อมูลเริ่มต้น วิธีนี้แสดงถึงการผูกสำหรับไฟล์BucketingModule. |
| ไปข้างหน้า (data_batch [, is_train]) | เนื่องจากชื่อมีความหมายว่าวิธีนี้ใช้การคำนวณไปข้างหน้า วิธีนี้รองรับชุดข้อมูลที่มีรูปร่างต่างๆเช่นขนาดชุดงานที่แตกต่างกันหรือขนาดภาพที่แตกต่างกัน |
| get_input_grads ([merge_multi_context]) | วิธีนี้จะได้รับการไล่ระดับสีไปยังอินพุตซึ่งคำนวณในการคำนวณย้อนหลังก่อนหน้านี้ |
| get_outputs ([merge_multi_context]) | ตามความหมายของชื่อวิธีนี้จะได้ผลลัพธ์จากการคำนวณล่วงหน้าก่อนหน้านี้ |
| get_params () | ได้รับพารามิเตอร์ปัจจุบันโดยเฉพาะพารามิเตอร์ที่อาจเป็นสำเนาของพารามิเตอร์จริงที่ใช้ในการคำนวณบนอุปกรณ์ |
| get_states ([merge_multi_context]) | วิธีนี้จะได้รับสถานะจากอุปกรณ์ทั้งหมด |
| init_optimizer ([kvstore, เครื่องมือเพิ่มประสิทธิภาพ, …]) | วิธีนี้จะติดตั้งและเริ่มต้นเครื่องมือเพิ่มประสิทธิภาพ นอกจากนี้ยังเริ่มต้นkvstore เพื่อเผยแพร่การฝึกอบรม |
| init_params ([initializer, arg_params, …]) | ตามความหมายของชื่อวิธีนี้จะเริ่มต้นพารามิเตอร์และสถานะเสริม |
| install_monitor (จันทร์) | วิธีนี้จะติดตั้งมอนิเตอร์บนตัวดำเนินการทั้งหมด |
| โหลด (คำนำหน้ายุค [, sym_gen, …]) | วิธีนี้จะสร้างโมเดลจากด่านที่บันทึกไว้ก่อนหน้านี้ |
| load_dict ([sym_dict, sym_gen, …]) | วิธีนี้จะสร้างโมเดลจากการแมปพจนานุกรม (dict) bucket_keyเป็นสัญลักษณ์ มันยังแบ่งปันarg_params และ aux_params. |
| เตรียม (data_batch [, sparse_row_id_fn]) | ตัวดำเนินการเตรียมโมดูลสำหรับการประมวลผลชุดข้อมูลที่กำหนด |
| save_checkpoint (คำนำหน้ายุค [, remove_amp_cast]) | ตามที่ระบุชื่อจะบันทึกความคืบหน้าปัจจุบันไปยังจุดตรวจสำหรับที่เก็บข้อมูลทั้งหมดใน BucketingModule ขอแนะนำให้ใช้ mx.callback.module_checkpoint เป็น epoch_end_callback เพื่อบันทึกระหว่างการฝึก |
| set_params (arg_params, aux_params [, …]) | ตามที่ระบุชื่อฟังก์ชันนี้จะกำหนดพารามิเตอร์และค่าสถานะ aux |
| set_states ([สถานะ, ค่า]) | วิธีนี้ตามที่ระบุชื่อกำหนดค่าสำหรับสถานะ |
| switch_bucket (bucket_key, data_shapes [, …]) | มันจะเปลี่ยนไปใช้ถังอื่น |
| ปรับปรุง () | วิธีนี้จะอัปเดตพารามิเตอร์ที่กำหนดตามเครื่องมือเพิ่มประสิทธิภาพที่ติดตั้ง นอกจากนี้ยังอัปเดตการไล่ระดับสีที่คำนวณในชุดการเดินหน้าถอยหลังก่อนหน้านี้ |
| update_metric (eval_metric ป้ายกำกับ [pre_sliced]) | เมธอดนี้ตามชื่อจะประเมินและรวบรวมเมตริกการประเมินผลบนผลลัพธ์ของการคำนวณไปข้างหน้าครั้งสุดท้าย |
คุณลักษณะ
ตารางต่อไปนี้แสดงแอตทริบิวต์ที่ประกอบด้วยวิธีการ BaseModule ชั้นเรียน -
| คุณลักษณะ | คำจำกัดความ |
|---|---|
| data_names | ประกอบด้วยรายชื่อสำหรับข้อมูลที่โมดูลนี้ต้องการ |
| data_shapes | ประกอบด้วยรายการคู่ (ชื่อรูปร่าง) ที่ระบุอินพุตข้อมูลไปยังโมดูลนี้ |
| label_shapes | แสดงรายการคู่ (ชื่อรูปร่าง) ที่ระบุอินพุตเลเบลสำหรับโมดูลนี้ |
| output_names | ประกอบด้วยรายชื่อสำหรับเอาต์พุตของโมดูลนี้ |
| output_shapes | ประกอบด้วยรายการคู่ (ชื่อรูปร่าง) ที่ระบุเอาต์พุตของโมดูลนี้ |
| สัญลักษณ์ | ตามชื่อที่ระบุแอตทริบิวต์นี้ได้รับสัญลักษณ์ที่เกี่ยวข้องกับโมดูลนี้ |
data_shapes: คุณสามารถอ้างอิงลิงค์ได้ที่ https://mxnet.apache.orgเพื่อดูรายละเอียด output_shapes: เพิ่มเติม
output_shapes: ดูข้อมูลเพิ่มเติมได้ที่ https://mxnet.apache.org/api/python
BucketingModule (sym_gen […])
มันแสดงถึงไฟล์ Bucketingmodule คลาสของโมดูลที่ช่วยจัดการกับอินพุตที่มีความยาวต่างกันได้อย่างมีประสิทธิภาพ
วิธีการ
ตารางต่อไปนี้แสดงวิธีการต่างๆที่ประกอบด้วย BucketingModule class -
คุณลักษณะ
ตารางต่อไปนี้แสดงแอตทริบิวต์ที่ประกอบด้วยวิธีการ BaseModule class -
| คุณลักษณะ | คำจำกัดความ |
|---|---|
| data_names | ประกอบด้วยรายชื่อสำหรับข้อมูลที่โมดูลนี้ต้องการ |
| data_shapes | ประกอบด้วยรายการคู่ (ชื่อรูปร่าง) ที่ระบุอินพุตข้อมูลไปยังโมดูลนี้ |
| label_shapes | แสดงรายการคู่ (ชื่อรูปร่าง) ที่ระบุอินพุตเลเบลสำหรับโมดูลนี้ |
| output_names | ประกอบด้วยรายชื่อสำหรับเอาต์พุตของโมดูลนี้ |
| output_shapes | ประกอบด้วยรายการคู่ (ชื่อรูปร่าง) ที่ระบุเอาต์พุตของโมดูลนี้ |
| สัญลักษณ์ | ตามชื่อที่ระบุแอตทริบิวต์นี้ได้รับสัญลักษณ์ที่เกี่ยวข้องกับโมดูลนี้ |
data_shapes - คุณสามารถอ้างอิงลิงค์ได้ที่ https://mxnet.apache.org/api/python/docs สำหรับข้อมูลเพิ่มเติม.
output_shapes− คุณสามารถอ้างอิงลิงค์ได้ที่ https://mxnet.apache.org/api/python/docs สำหรับข้อมูลเพิ่มเติม.
โมดูล (สัญลักษณ์ [, data_names, label_names, …])
แสดงถึงโมดูลพื้นฐานที่รวมไฟล์ symbol.
วิธีการ
ตารางต่อไปนี้แสดงวิธีการต่างๆที่ประกอบด้วย Module class -
| วิธีการ | คำจำกัดความ |
|---|---|
| ย้อนกลับ ([out_grads]) | ในฐานะที่เป็นชื่อแสดงถึงวิธีการนี้ใช้ backward การคำนวณ |
| ผูก (data_shapes [, label_shapes, …]) | มันผูกสัญลักษณ์เพื่อสร้างตัวดำเนินการและจำเป็นก่อนที่จะสามารถทำการคำนวณกับโมดูลได้ |
| ยืม_optimizer (shared_module) | ตามความหมายของชื่อวิธีนี้จะยืมเครื่องมือเพิ่มประสิทธิภาพจากโมดูลที่ใช้ร่วมกัน |
| ไปข้างหน้า (data_batch [, is_train]) | ในฐานะที่เป็นชื่อแสดงถึงวิธีการนี้ใช้ Forwardการคำนวณ วิธีนี้รองรับชุดข้อมูลที่มีรูปร่างต่างๆเช่นขนาดชุดงานที่แตกต่างกันหรือขนาดภาพที่แตกต่างกัน |
| get_input_grads ([merge_multi_context]) | วิธีนี้จะได้รับการไล่ระดับสีไปยังอินพุตซึ่งคำนวณในการคำนวณย้อนหลังก่อนหน้านี้ |
| get_outputs ([merge_multi_context]) | ตามความหมายของชื่อวิธีนี้จะได้รับผลลัพธ์ของการคำนวณล่วงหน้าก่อนหน้านี้ |
| get_params () | ได้รับพารามิเตอร์โดยเฉพาะพารามิเตอร์ที่อาจเป็นสำเนาของพารามิเตอร์จริงที่ใช้ในการคำนวณบนอุปกรณ์ |
| get_states ([merge_multi_context]) | วิธีนี้จะได้รับสถานะจากอุปกรณ์ทั้งหมด |
| init_optimizer ([kvstore, เครื่องมือเพิ่มประสิทธิภาพ, …]) | วิธีนี้จะติดตั้งและเริ่มต้นเครื่องมือเพิ่มประสิทธิภาพ นอกจากนี้ยังเริ่มต้นkvstore เพื่อเผยแพร่การฝึกอบรม |
| init_params ([initializer, arg_params, …]) | ตามความหมายของชื่อวิธีนี้จะเริ่มต้นพารามิเตอร์และสถานะเสริม |
| install_monitor (จันทร์) | วิธีนี้จะติดตั้งมอนิเตอร์บนตัวดำเนินการทั้งหมด |
| โหลด (คำนำหน้ายุค [, sym_gen, …]) | วิธีนี้จะสร้างโมเดลจากด่านที่บันทึกไว้ก่อนหน้านี้ |
| load_optimizer_states (fname) | วิธีนี้จะโหลดเครื่องมือเพิ่มประสิทธิภาพเช่นสถานะตัวอัปเดตจากไฟล์ |
| เตรียม (data_batch [, sparse_row_id_fn]) | ตัวดำเนินการเตรียมโมดูลสำหรับการประมวลผลชุดข้อมูลที่กำหนด |
| ปรับรูปร่างใหม่ (data_shapes [, label_shapes]) | วิธีนี้ตามที่ระบุชื่อให้เปลี่ยนรูปร่างโมดูลสำหรับรูปร่างอินพุตใหม่ |
| save_checkpoint (คำนำหน้ายุค [, …]) | จะบันทึกความคืบหน้าปัจจุบันในการตรวจสอบ |
| save_optimizer_states (fname) | วิธีนี้จะบันทึกตัวเพิ่มประสิทธิภาพหรือสถานะตัวอัปเดตลงในไฟล์ |
| set_params (arg_params, aux_params [, …]) | ตามที่ระบุชื่อฟังก์ชันนี้จะกำหนดพารามิเตอร์และค่าสถานะ aux |
| set_states ([สถานะ, ค่า]) | วิธีนี้ตามที่ระบุชื่อกำหนดค่าสำหรับสถานะ |
| ปรับปรุง () | วิธีนี้จะอัปเดตพารามิเตอร์ที่กำหนดตามเครื่องมือเพิ่มประสิทธิภาพที่ติดตั้ง นอกจากนี้ยังอัปเดตการไล่ระดับสีที่คำนวณในชุดการเดินหน้าถอยหลังก่อนหน้านี้ |
| update_metric (eval_metric ป้ายกำกับ [pre_sliced]) | เมธอดนี้ตามชื่อจะประเมินและรวบรวมเมตริกการประเมินผลบนผลลัพธ์ของการคำนวณไปข้างหน้าครั้งสุดท้าย |
คุณลักษณะ
ตารางต่อไปนี้แสดงแอตทริบิวต์ที่ประกอบด้วยวิธีการ Module class -
| คุณลักษณะ | คำจำกัดความ |
|---|---|
| data_names | ประกอบด้วยรายชื่อสำหรับข้อมูลที่โมดูลนี้ต้องการ |
| data_shapes | ประกอบด้วยรายการคู่ (ชื่อรูปร่าง) ที่ระบุอินพุตข้อมูลไปยังโมดูลนี้ |
| label_shapes | แสดงรายการคู่ (ชื่อรูปร่าง) ที่ระบุอินพุตเลเบลสำหรับโมดูลนี้ |
| output_names | ประกอบด้วยรายชื่อสำหรับเอาต์พุตของโมดูลนี้ |
| output_shapes | ประกอบด้วยรายการคู่ (ชื่อรูปร่าง) ที่ระบุเอาต์พุตของโมดูลนี้ |
| label_names | ประกอบด้วยรายชื่อสำหรับป้ายกำกับที่โมดูลนี้ต้องการ |
data_shapes: ไปที่ลิงค์ https://mxnet.apache.org/api/python/docs/api/module สำหรับรายละเอียดเพิ่มเติม
output_shapes: ลิงก์ที่ให้ไว้ในที่นี้ https://mxnet.apache.org/api/python/docs/api/module/index.html จะนำเสนอข้อมูลสำคัญอื่น ๆ
PythonLossModule ([ชื่อ data_names, …])
ฐานของคลาสนี้คือ mxnet.module.python_module.PythonModule. คลาส PythonLossModule เป็นคลาสโมดูลที่สะดวกซึ่งใช้โมดูล API ทั้งหมดหรือหลายตัวเป็นฟังก์ชันว่าง
วิธีการ
ตารางต่อไปนี้แสดงวิธีการต่างๆที่ประกอบด้วย PythonLossModule ชั้น:
| วิธีการ | คำจำกัดความ |
|---|---|
| ย้อนกลับ ([out_grads]) | ในฐานะที่เป็นชื่อแสดงถึงวิธีการนี้ใช้ backward การคำนวณ |
| ไปข้างหน้า (data_batch [, is_train]) | ในฐานะที่เป็นชื่อแสดงถึงวิธีการนี้ใช้ Forwardการคำนวณ วิธีนี้รองรับชุดข้อมูลที่มีรูปร่างต่างๆเช่นขนาดชุดงานที่แตกต่างกันหรือขนาดภาพที่แตกต่างกัน |
| get_input_grads ([merge_multi_context]) | วิธีนี้จะได้รับการไล่ระดับสีไปยังอินพุตซึ่งคำนวณในการคำนวณย้อนหลังก่อนหน้านี้ |
| get_outputs ([merge_multi_context]) | ตามความหมายของชื่อวิธีนี้จะได้รับผลลัพธ์ของการคำนวณล่วงหน้าก่อนหน้านี้ |
| install_monitor (จันทร์) | วิธีนี้จะติดตั้งมอนิเตอร์บนตัวดำเนินการทั้งหมด |
PythonModule ([data_names, label_names …])
ฐานของคลาสนี้คือ mxnet.module.base_module.BaseModule คลาส PythonModule ยังเป็นคลาสโมดูลที่สะดวกซึ่งใช้โมดูล API ทั้งหมดหรือหลายตัวเป็นฟังก์ชันว่าง
วิธีการ
ตารางต่อไปนี้แสดงวิธีการต่างๆที่ประกอบด้วย PythonModule ชั้นเรียน -
| วิธีการ | คำจำกัดความ |
|---|---|
| ผูก (data_shapes [, label_shapes, …]) | มันผูกสัญลักษณ์เพื่อสร้างตัวดำเนินการและจำเป็นก่อนที่จะสามารถทำการคำนวณกับโมดูลได้ |
| get_params () | ได้รับพารามิเตอร์โดยเฉพาะพารามิเตอร์ที่อาจเป็นสำเนาของพารามิเตอร์จริงที่ใช้ในการคำนวณบนอุปกรณ์ |
| init_optimizer ([kvstore, เครื่องมือเพิ่มประสิทธิภาพ, …]) | วิธีนี้จะติดตั้งและเริ่มต้นเครื่องมือเพิ่มประสิทธิภาพ นอกจากนี้ยังเริ่มต้นkvstore เพื่อเผยแพร่การฝึกอบรม |
| init_params ([initializer, arg_params, …]) | ตามความหมายของชื่อวิธีนี้จะเริ่มต้นพารามิเตอร์และสถานะเสริม |
| ปรับปรุง () | วิธีนี้จะอัปเดตพารามิเตอร์ที่กำหนดตามเครื่องมือเพิ่มประสิทธิภาพที่ติดตั้ง นอกจากนี้ยังอัปเดตการไล่ระดับสีที่คำนวณในชุดการเดินหน้าถอยหลังก่อนหน้านี้ |
| update_metric (eval_metric ป้ายกำกับ [pre_sliced]) | เมธอดนี้ตามชื่อจะประเมินและรวบรวมเมตริกการประเมินผลบนผลลัพธ์ของการคำนวณไปข้างหน้าครั้งสุดท้าย |
คุณลักษณะ
ตารางต่อไปนี้แสดงแอตทริบิวต์ที่ประกอบด้วยวิธีการ PythonModule ชั้นเรียน -
| คุณลักษณะ | คำจำกัดความ |
|---|---|
| data_names | ประกอบด้วยรายชื่อสำหรับข้อมูลที่โมดูลนี้ต้องการ |
| data_shapes | ประกอบด้วยรายการคู่ (ชื่อรูปร่าง) ที่ระบุอินพุตข้อมูลไปยังโมดูลนี้ |
| label_shapes | แสดงรายการคู่ (ชื่อรูปร่าง) ที่ระบุอินพุตเลเบลสำหรับโมดูลนี้ |
| output_names | ประกอบด้วยรายชื่อสำหรับเอาต์พุตของโมดูลนี้ |
| output_shapes | ประกอบด้วยรายการคู่ (ชื่อรูปร่าง) ที่ระบุเอาต์พุตของโมดูลนี้ |
data_shapes - ไปที่ลิงค์ https://mxnet.apache.org เพื่อดูรายละเอียด
output_shapes - สำหรับรายละเอียดเพิ่มเติมโปรดไปที่ลิงค์ที่มีอยู่ที่ https://mxnet.apache.org
SequentialModule ([คนตัดไม้])
ฐานของคลาสนี้คือ mxnet.module.base_module.BaseModule คลาส SequentialModule ยังเป็นโมดูลคอนเทนเนอร์ที่สามารถเชื่อมโยงโมดูลมากกว่าสอง (หลายโมดูล) เข้าด้วยกัน
วิธีการ
ตารางต่อไปนี้แสดงวิธีการต่างๆที่ประกอบด้วย SequentialModule ชั้นเรียน
| วิธีการ | คำจำกัดความ |
|---|---|
| เพิ่ม (โมดูล ** kwargs) | นี่คือฟังก์ชันที่สำคัญที่สุดของคลาสนี้ มันเพิ่มโมดูลให้กับโซ่ |
| ย้อนกลับ ([out_grads]) | เนื่องจากชื่อมีความหมายว่าวิธีนี้ใช้การคำนวณย้อนหลัง |
| ผูก (data_shapes [, label_shapes, …]) | มันผูกสัญลักษณ์เพื่อสร้างตัวดำเนินการและจำเป็นก่อนที่จะสามารถทำการคำนวณกับโมดูลได้ |
| ไปข้างหน้า (data_batch [, is_train]) | เนื่องจากชื่อมีความหมายว่าวิธีนี้ใช้การคำนวณไปข้างหน้า วิธีนี้รองรับชุดข้อมูลที่มีรูปร่างต่างๆเช่นขนาดชุดงานที่แตกต่างกันหรือขนาดภาพที่แตกต่างกัน |
| get_input_grads ([merge_multi_context]) | วิธีนี้จะได้รับการไล่ระดับสีไปยังอินพุตซึ่งคำนวณในการคำนวณย้อนหลังก่อนหน้านี้ |
| get_outputs ([merge_multi_context]) | ตามความหมายของชื่อวิธีนี้จะได้รับผลลัพธ์ของการคำนวณล่วงหน้าก่อนหน้านี้ |
| get_params () | ได้รับพารามิเตอร์โดยเฉพาะพารามิเตอร์ที่อาจเป็นสำเนาของพารามิเตอร์จริงที่ใช้ในการคำนวณบนอุปกรณ์ |
| init_optimizer ([kvstore, เครื่องมือเพิ่มประสิทธิภาพ, …]) | วิธีนี้จะติดตั้งและเริ่มต้นเครื่องมือเพิ่มประสิทธิภาพ นอกจากนี้ยังเริ่มต้นkvstore เพื่อเผยแพร่การฝึกอบรม |
| init_params ([initializer, arg_params, …]) | ตามความหมายของชื่อวิธีนี้จะเริ่มต้นพารามิเตอร์และสถานะเสริม |
| install_monitor (จันทร์) | วิธีนี้จะติดตั้งมอนิเตอร์บนตัวดำเนินการทั้งหมด |
| ปรับปรุง () | วิธีนี้จะอัปเดตพารามิเตอร์ที่กำหนดตามเครื่องมือเพิ่มประสิทธิภาพที่ติดตั้ง นอกจากนี้ยังอัปเดตการไล่ระดับสีที่คำนวณในชุดการเดินหน้าถอยหลังก่อนหน้านี้ |
| update_metric (eval_metric ป้ายกำกับ [pre_sliced]) | เมธอดนี้ตามชื่อจะประเมินและรวบรวมเมตริกการประเมินผลบนผลลัพธ์ของการคำนวณไปข้างหน้าครั้งสุดท้าย |
คุณลักษณะ
ตารางต่อไปนี้แสดงแอตทริบิวต์ที่อยู่ในเมธอดของคลาส BaseModule -
| คุณลักษณะ | คำจำกัดความ |
|---|---|
| data_names | ประกอบด้วยรายชื่อสำหรับข้อมูลที่โมดูลนี้ต้องการ |
| data_shapes | ประกอบด้วยรายการคู่ (ชื่อรูปร่าง) ที่ระบุอินพุตข้อมูลไปยังโมดูลนี้ |
| label_shapes | แสดงรายการคู่ (ชื่อรูปร่าง) ที่ระบุอินพุตเลเบลสำหรับโมดูลนี้ |
| output_names | ประกอบด้วยรายชื่อสำหรับเอาต์พุตของโมดูลนี้ |
| output_shapes | ประกอบด้วยรายการคู่ (ชื่อรูปร่าง) ที่ระบุเอาต์พุตของโมดูลนี้ |
| output_shapes | ประกอบด้วยรายการคู่ (ชื่อรูปร่าง) ที่ระบุเอาต์พุตของโมดูลนี้ |
data_shapes - ลิงก์ที่ให้ไว้ในที่นี้ https://mxnet.apache.org จะช่วยคุณในการทำความเข้าใจแอตทริบิวต์โดยละเอียด
output_shapes - ตามลิงค์ได้ที่ https://mxnet.apache.org/api เพื่อดูรายละเอียด
ตัวอย่างการใช้งาน
ในตัวอย่างด้านล่างเราจะสร้างไฟล์ mxnet โมดูล.
import mxnet as mx
input_data = mx.symbol.Variable('input_data')
f_connected1 = mx.symbol.FullyConnected(data, name='f_connected1', num_hidden=128)
activation_1 = mx.symbol.Activation(f_connected1, name='relu1', act_type="relu")
f_connected2 = mx.symbol.FullyConnected(activation_1, name = 'f_connected2', num_hidden = 64)
activation_2 = mx.symbol.Activation(f_connected2, name='relu2',
act_type="relu")
f_connected3 = mx.symbol.FullyConnected(activation_2, name='fc3', num_hidden=10)
out = mx.symbol.SoftmaxOutput(f_connected3, name = 'softmax')
mod = mx.mod.Module(out)
print(out)Output
ผลลัพธ์จะกล่าวถึงด้านล่าง -
<Symbol softmax>Example
print(mod)Output
ผลลัพธ์ดังแสดงด้านล่าง -
<mxnet.module.module.Module object at 0x00000123A9892F28>ในตัวอย่างด้านล่างนี้เราจะใช้การคำนวณล่วงหน้า
import mxnet as mx
from collections import namedtuple
Batch = namedtuple('Batch', ['data'])
data = mx.sym.Variable('data')
out = data * 2
mod = mx.mod.Module(symbol=out, label_names=None)
mod.bind(data_shapes=[('data', (1, 10))])
mod.init_params()
data1 = [mx.nd.ones((1, 10))]
mod.forward(Batch(data1))
print (mod.get_outputs()[0].asnumpy())Output
เมื่อคุณรันโค้ดด้านบนคุณจะเห็นผลลัพธ์ต่อไปนี้ -
[[2. 2. 2. 2. 2. 2. 2. 2. 2. 2.]]Example
data2 = [mx.nd.ones((3, 5))]
mod.forward(Batch(data2))
print (mod.get_outputs()[0].asnumpy())Output
ด้านล่างเป็นผลลัพธ์ของรหัส -
[[2. 2. 2. 2. 2.]
[2. 2. 2. 2. 2.]
[2. 2. 2. 2. 2.]]