Apache Solr - บน Hadoop
Solr สามารถใช้ร่วมกับ Hadoop ได้ เนื่องจาก Hadoop จัดการข้อมูลจำนวนมาก Solr จึงช่วยเราในการค้นหาข้อมูลที่ต้องการจากแหล่งข้อมูลขนาดใหญ่ดังกล่าว ในส่วนนี้ให้เราเข้าใจว่าคุณสามารถติดตั้ง Hadoop บนระบบของคุณได้อย่างไร
กำลังดาวน์โหลด Hadoop
ด้านล่างนี้เป็นขั้นตอนในการดาวน์โหลด Hadoop เข้าสู่ระบบของคุณ
Step 1- ไปที่หน้าแรกของ Hadoop คุณสามารถใช้การเชื่อมโยง - www.hadoop.apache.org/ คลิกที่ลิงค์Releasesดังที่ไฮไลต์ไว้ในภาพหน้าจอต่อไปนี้
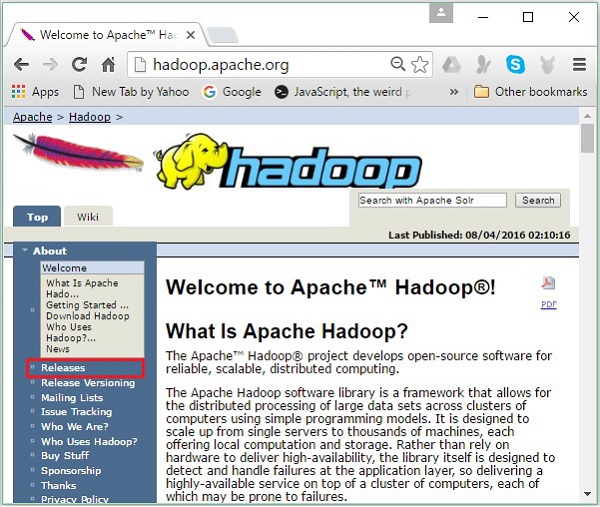
มันจะเปลี่ยนเส้นทางคุณไปยังไฟล์ Apache Hadoop Releases ซึ่งมีลิงค์สำหรับมิเรอร์ของไฟล์ซอร์สและไบนารีของ Hadoop เวอร์ชันต่างๆดังนี้ -
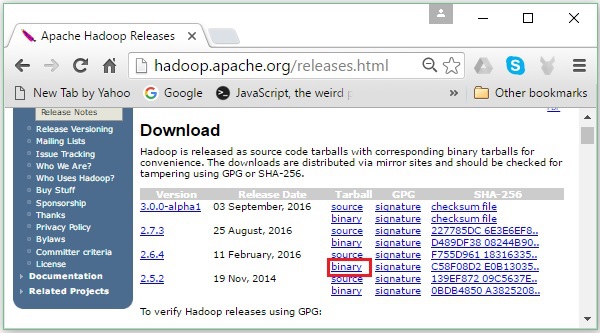
Step 2 - เลือก Hadoop เวอร์ชันล่าสุด (ในบทช่วยสอนของเราคือ 2.6.4) แล้วคลิก binary link. จะนำคุณไปยังหน้าที่มีมิเรอร์สำหรับไบนารี Hadoop คลิกหนึ่งในมิเรอร์เหล่านี้เพื่อดาวน์โหลด Hadoop
ดาวน์โหลด Hadoop จาก Command Prompt
เปิดเทอร์มินัล Linux และเข้าสู่ระบบในฐานะผู้ใช้ขั้นสูง
$ su
password:ไปที่ไดเร็กทอรีที่คุณต้องการติดตั้ง Hadoop และบันทึกไฟล์ที่นั่นโดยใช้ลิงก์ที่คัดลอกไว้ก่อนหน้าดังที่แสดงในบล็อกโค้ดต่อไปนี้
# cd /usr/local
# wget http://redrockdigimark.com/apachemirror/hadoop/common/hadoop-
2.6.4/hadoop-2.6.4.tar.gzหลังจากดาวน์โหลด Hadoop แล้วให้แยกโดยใช้คำสั่งต่อไปนี้
# tar zxvf hadoop-2.6.4.tar.gz
# mkdir hadoop
# mv hadoop-2.6.4/* to hadoop/
# exitการติดตั้ง Hadoop
ทำตามขั้นตอนด้านล่างเพื่อติดตั้ง Hadoop ในโหมดหลอกกระจาย
ขั้นตอนที่ 1: การตั้งค่า Hadoop
คุณสามารถตั้งค่าตัวแปรสภาพแวดล้อม Hadoop ได้โดยต่อท้ายคำสั่งต่อไปนี้ ~/.bashrc ไฟล์.
export HADOOP_HOME = /usr/local/hadoop export
HADOOP_MAPRED_HOME = $HADOOP_HOME export
HADOOP_COMMON_HOME = $HADOOP_HOME export
HADOOP_HDFS_HOME = $HADOOP_HOME export
YARN_HOME = $HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR = $HADOOP_HOME/lib/native
export PATH = $PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_INSTALL = $HADOOP_HOMEจากนั้นใช้การเปลี่ยนแปลงทั้งหมดในระบบที่กำลังทำงานอยู่
$ source ~/.bashrcขั้นตอนที่ 2: การกำหนดค่า Hadoop
คุณสามารถค้นหาไฟล์การกำหนดค่า Hadoop ทั้งหมดได้ในตำแหน่ง“ $ HADOOP_HOME / etc / hadoop” จำเป็นต้องทำการเปลี่ยนแปลงในไฟล์การกำหนดค่าเหล่านั้นตามโครงสร้างพื้นฐาน Hadoop ของคุณ
$ cd $HADOOP_HOME/etc/hadoopในการพัฒนาโปรแกรม Hadoop ใน Java คุณต้องรีเซ็ตตัวแปรสภาพแวดล้อม Java ใน hadoop-env.sh ไฟล์โดยแทนที่ไฟล์ JAVA_HOME ค่ากับตำแหน่งของ Java ในระบบของคุณ
export JAVA_HOME = /usr/local/jdk1.7.0_71ต่อไปนี้เป็นรายการไฟล์ที่คุณต้องแก้ไขเพื่อกำหนดค่า Hadoop -
- core-site.xml
- hdfs-site.xml
- yarn-site.xml
- mapred-site.xml
core-site.xml
core-site.xml ไฟล์มีข้อมูลเช่นหมายเลขพอร์ตที่ใช้สำหรับอินสแตนซ์ Hadoop หน่วยความจำที่จัดสรรสำหรับระบบไฟล์ขีด จำกัด หน่วยความจำสำหรับจัดเก็บข้อมูลและขนาดของบัฟเฟอร์อ่าน / เขียน
เปิด core-site.xml และเพิ่มคุณสมบัติต่อไปนี้ภายในแท็ก <configuration>, </configuration>
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>hdfs-site.xml
hdfs-site.xml ไฟล์มีข้อมูลเช่นค่าของข้อมูลการจำลองแบบ namenode เส้นทางและ datanodeเส้นทางของระบบไฟล์ภายในเครื่องของคุณ หมายถึงสถานที่ที่คุณต้องการจัดเก็บโครงสร้างพื้นฐาน Hadoop
ให้เราสมมติข้อมูลต่อไปนี้
dfs.replication (data replication value) = 1
(In the below given path /hadoop/ is the user name.
hadoopinfra/hdfs/namenode is the directory created by hdfs file system.)
namenode path = //home/hadoop/hadoopinfra/hdfs/namenode
(hadoopinfra/hdfs/datanode is the directory created by hdfs file system.)
datanode path = //home/hadoop/hadoopinfra/hdfs/datanodeเปิดไฟล์นี้และเพิ่มคุณสมบัติต่อไปนี้ภายในแท็ก <configuration>, </configuration>
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/datanode</value>
</property>
</configuration>Note - ในไฟล์ด้านบนค่าคุณสมบัติทั้งหมดจะถูกกำหนดโดยผู้ใช้และคุณสามารถเปลี่ยนแปลงได้ตามโครงสร้างพื้นฐาน Hadoop ของคุณ
yarn-site.xml
ไฟล์นี้ใช้เพื่อกำหนดค่าเส้นด้ายใน Hadoop เปิดไฟล์ yarn-site.xml และเพิ่มคุณสมบัติต่อไปนี้ระหว่างแท็ก <configuration>, </configuration> ในไฟล์นี้
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>mapred-site.xml
ไฟล์นี้ใช้เพื่อระบุเฟรมเวิร์ก MapReduce ที่เราใช้อยู่ โดยค่าเริ่มต้น Hadoop มีเทมเพลตของ yarn-site.xml ก่อนอื่นต้องคัดลอกไฟล์จากไฟล์mapred-site,xml.template ถึง mapred-site.xml ไฟล์โดยใช้คำสั่งต่อไปนี้
$ cp mapred-site.xml.template mapred-site.xmlเปิด mapred-site.xml ไฟล์และเพิ่มคุณสมบัติต่อไปนี้ภายในแท็ก <configuration>, </configuration>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>การตรวจสอบการติดตั้ง Hadoop
ขั้นตอนต่อไปนี้ใช้เพื่อตรวจสอบการติดตั้ง Hadoop
ขั้นตอนที่ 1: ตั้งชื่อโหนด
ตั้งค่า Namenode โดยใช้คำสั่ง "hdfs namenode –format" ดังนี้
$ cd ~
$ hdfs namenode -formatผลที่คาดว่าจะได้รับมีดังนี้
10/24/14 21:30:55 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = localhost/192.168.1.11
STARTUP_MSG: args = [-format] STARTUP_MSG: version = 2.6.4
...
...
10/24/14 21:30:56 INFO common.Storage: Storage directory
/home/hadoop/hadoopinfra/hdfs/namenode has been successfully formatted.
10/24/14 21:30:56 INFO namenode.NNStorageRetentionManager: Going to retain 1
images with txid >= 0
10/24/14 21:30:56 INFO util.ExitUtil: Exiting with status 0
10/24/14 21:30:56 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at localhost/192.168.1.11
************************************************************/ขั้นตอนที่ 2: การตรวจสอบ Hadoop dfs
คำสั่งต่อไปนี้ใช้เพื่อเริ่ม Hadoop dfs การดำเนินการคำสั่งนี้จะเริ่มระบบไฟล์ Hadoop ของคุณ
$ start-dfs.shผลลัพธ์ที่คาดหวังมีดังนี้ -
10/24/14 21:37:56
Starting namenodes on [localhost]
localhost: starting namenode, logging to /home/hadoop/hadoop-2.6.4/logs/hadoop-
hadoop-namenode-localhost.out
localhost: starting datanode, logging to /home/hadoop/hadoop-2.6.4/logs/hadoop-
hadoop-datanode-localhost.out
Starting secondary namenodes [0.0.0.0]ขั้นตอนที่ 3: การตรวจสอบสคริปต์เส้นด้าย
คำสั่งต่อไปนี้ใช้เพื่อเริ่มสคริปต์ Yarn การดำเนินการคำสั่งนี้จะเป็นการเริ่มปีศาจเส้นด้ายของคุณ
$ start-yarn.shผลลัพธ์ที่คาดหวังดังนี้ -
starting yarn daemons
starting resourcemanager, logging to /home/hadoop/hadoop-2.6.4/logs/yarn-
hadoop-resourcemanager-localhost.out
localhost: starting nodemanager, logging to /home/hadoop/hadoop-
2.6.4/logs/yarn-hadoop-nodemanager-localhost.outขั้นตอนที่ 4: การเข้าถึง Hadoop บนเบราว์เซอร์
หมายเลขพอร์ตเริ่มต้นในการเข้าถึง Hadoop คือ 50070 ใช้ URL ต่อไปนี้เพื่อรับบริการ Hadoop บนเบราว์เซอร์
http://localhost:50070/
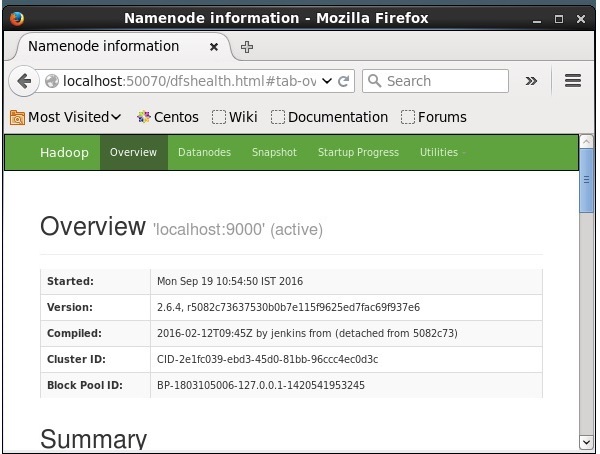
การติดตั้ง Solr บน Hadoop
ทำตามขั้นตอนด้านล่างเพื่อดาวน์โหลดและติดตั้ง Solr
ขั้นตอนที่ 1
เปิดหน้าแรกของ Apache Solr โดยคลิกที่ลิงค์ต่อไปนี้ - https://lucene.apache.org/solr/
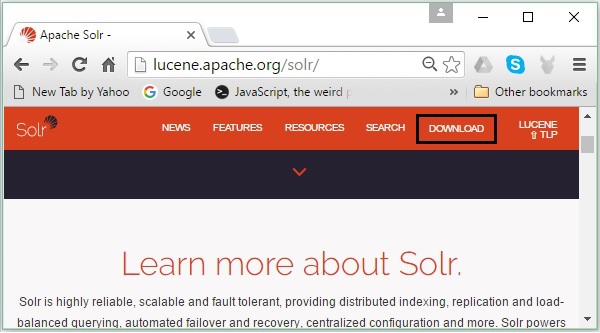
ขั้นตอนที่ 2
คลิก download button(เน้นในภาพหน้าจอด้านบน) เมื่อคลิกคุณจะถูกนำไปยังหน้าที่คุณมีมิเรอร์ต่างๆของ Apache Solr เลือกมิเรอร์และคลิกที่มันซึ่งจะนำคุณไปยังหน้าที่คุณสามารถดาวน์โหลดซอร์สและไฟล์ไบนารีของ Apache Solr ดังที่แสดงในภาพหน้าจอต่อไปนี้
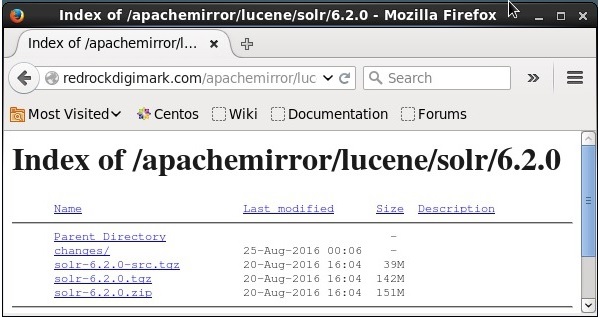
ขั้นตอนที่ 3
เมื่อคลิกโฟลเดอร์ชื่อ Solr-6.2.0.tqzจะถูกดาวน์โหลดในโฟลเดอร์ดาวน์โหลดของระบบของคุณ แตกเนื้อหาของโฟลเดอร์ที่ดาวน์โหลด
ขั้นตอนที่ 4
สร้างโฟลเดอร์ชื่อ Solr ในโฮมไดเร็กทอรี Hadoop และย้ายเนื้อหาของโฟลเดอร์ที่แยกออกมาดังที่แสดงด้านล่าง
$ mkdir Solr
$ cd Downloads
$ mv Solr-6.2.0 /home/Hadoop/การยืนยัน
เรียกดูไฟล์ bin โฟลเดอร์ของไดเร็กทอรี Solr Home และตรวจสอบการติดตั้งโดยใช้ version ดังที่แสดงในบล็อกรหัสต่อไปนี้
$ cd bin/
$ ./Solr version
6.2.0การตั้งค่าบ้านและเส้นทาง
เปิด .bashrc ไฟล์โดยใช้คำสั่งต่อไปนี้ -
[Hadoop@localhost ~]$ source ~/.bashrcตอนนี้ตั้งค่าไดเรกทอรีบ้านและเส้นทางสำหรับ Apache Solr ดังนี้ -
export SOLR_HOME = /home/Hadoop/Solr
export PATH = $PATH:/$SOLR_HOME/bin/เปิดเทอร์มินัลและดำเนินการคำสั่งต่อไปนี้ -
[Hadoop@localhost Solr]$ source ~/.bashrcตอนนี้คุณสามารถดำเนินการคำสั่งของ Solr จากไดเร็กทอรีใดก็ได้