Apache Spark - การเขียนโปรแกรมหลัก
Spark Core เป็นฐานของโครงการทั้งหมด จัดเตรียมการจัดส่งงานการตั้งเวลาและฟังก์ชัน I / O พื้นฐานแบบกระจาย Spark ใช้โครงสร้างข้อมูลพื้นฐานเฉพาะที่เรียกว่า RDD (Resilient Distributed Datasets) ซึ่งเป็นการรวบรวมข้อมูลเชิงตรรกะที่แบ่งพาร์ติชันข้ามเครื่อง RDD สามารถสร้างได้สองวิธี หนึ่งคือการอ้างอิงชุดข้อมูลในระบบจัดเก็บข้อมูลภายนอกและอย่างที่สองคือการใช้การแปลง (เช่นแผนที่ตัวกรองตัวลดการรวม) บน RDD ที่มีอยู่
สิ่งที่เป็นนามธรรม RDD ถูกเปิดเผยผ่าน API ที่รวมภาษา สิ่งนี้ช่วยลดความซับซ้อนในการเขียนโปรแกรมเนื่องจากวิธีที่แอปพลิเคชันจัดการกับ RDD นั้นคล้ายกับการจัดการคอลเลคชันข้อมูลภายในเครื่อง
สปาร์คเชลล์
Spark มีเชลล์แบบโต้ตอบซึ่งเป็นเครื่องมือที่มีประสิทธิภาพในการวิเคราะห์ข้อมูลแบบโต้ตอบ มีให้บริการในภาษา Scala หรือ Python นามธรรมหลักของ Spark คือคอลเล็กชันแบบกระจายของรายการที่เรียกว่า Resilient Distributed Dataset (RDD) RDD สามารถสร้างได้จาก Hadoop Input Formats (เช่นไฟล์ HDFS) หรือโดยการแปลง RDD อื่น ๆ
เปิด Spark Shell
คำสั่งต่อไปนี้ใช้เพื่อเปิด Spark shell
$ spark-shellสร้าง RDD ง่ายๆ
ให้เราสร้าง RDD ง่ายๆจากไฟล์ข้อความ ใช้คำสั่งต่อไปนี้เพื่อสร้าง RDD อย่างง่าย
scala> val inputfile = sc.textFile(“input.txt”)ผลลัพธ์สำหรับคำสั่งดังกล่าวคือ
inputfile: org.apache.spark.rdd.RDD[String] = input.txt MappedRDD[1] at textFile at <console>:12Spark RDD API เปิดตัวเพียงเล็กน้อย Transformations และไม่กี่ Actions เพื่อจัดการ RDD
การแปลง RDD
การแปลง RDD จะส่งกลับตัวชี้ไปที่ RDD ใหม่และอนุญาตให้คุณสร้างการอ้างอิงระหว่าง RDD RDD แต่ละรายการในห่วงโซ่การพึ่งพา (String of Dependencies) มีฟังก์ชันสำหรับคำนวณข้อมูลและมีตัวชี้ (การอ้างอิง) ไปยัง RDD หลัก
Spark เป็นคนขี้เกียจดังนั้นจะไม่มีการดำเนินการใด ๆ เว้นแต่คุณจะเรียกการเปลี่ยนแปลงหรือการกระทำบางอย่างที่จะกระตุ้นการสร้างงานและการดำเนินการ ดูตัวอย่างต่อไปนี้ของตัวอย่างการนับคำ
ดังนั้นการแปลง RDD ไม่ใช่ชุดข้อมูล แต่เป็นขั้นตอนในโปรแกรม (อาจเป็นขั้นตอนเดียว) ที่บอก Spark ว่าจะรับข้อมูลอย่างไรและจะทำอย่างไรกับข้อมูลนั้น
ด้านล่างนี้เป็นรายการการแปลง RDD
| ส. เลขที่ | การเปลี่ยนแปลงและความหมาย |
|---|---|
| 1 |
map(func) ส่งคืนชุดข้อมูลแบบกระจายใหม่ที่สร้างขึ้นโดยการส่งแต่ละองค์ประกอบของแหล่งที่มาผ่านฟังก์ชัน func. |
| 2 |
filter(func) ส่งคืนชุดข้อมูลใหม่ที่สร้างขึ้นโดยการเลือกองค์ประกอบเหล่านั้นของแหล่งที่มา func คืนค่าจริง |
| 3 |
flatMap(func) คล้ายกับแผนที่ แต่แต่ละรายการอินพุตสามารถแมปกับรายการเอาต์พุต 0 รายการขึ้นไปได้ (ดังนั้นfuncควรส่งคืน Seq แทนที่จะเป็นรายการเดียว) |
| 4 |
mapPartitions(func) คล้ายกับแผนที่ แต่ทำงานแยกกันในแต่ละพาร์ติชัน (บล็อก) ของ RDD ดังนั้น func ต้องเป็นประเภท Iterator <T> ⇒ Iterator <U> เมื่อรันบน RDD ประเภท T |
| 5 |
mapPartitionsWithIndex(func) คล้ายกับพาร์ติชันแผนที่ แต่ยังให้ func ด้วยค่าจำนวนเต็มแทนดัชนีของพาร์ติชันดังนั้น func ต้องเป็นประเภท (Int, Iterator <T>) ⇒ Iterator <U> เมื่อรันบน RDD ประเภท T |
| 6 |
sample(withReplacement, fraction, seed) ตัวอย่างก fraction ของข้อมูลที่มีหรือไม่มีการแทนที่โดยใช้เมล็ดกำเนิดตัวเลขสุ่มที่กำหนด |
| 7 |
union(otherDataset) ส่งคืนชุดข้อมูลใหม่ที่มีการรวมกันขององค์ประกอบในชุดข้อมูลต้นทางและอาร์กิวเมนต์ |
| 8 |
intersection(otherDataset) ส่งคืน RDD ใหม่ที่มีจุดตัดขององค์ประกอบในชุดข้อมูลต้นทางและอาร์กิวเมนต์ |
| 9 |
distinct([numTasks]) ส่งคืนชุดข้อมูลใหม่ที่มีองค์ประกอบเฉพาะของชุดข้อมูลต้นทาง |
| 10 |
groupByKey([numTasks]) เมื่อเรียกชุดข้อมูลของคู่ (K, V) จะส่งคืนชุดข้อมูลของคู่ (K, Iterable <V>) Note - หากคุณจัดกลุ่มเพื่อทำการรวม (เช่นผลรวมหรือค่าเฉลี่ย) ในแต่ละคีย์การใช้ reduceByKey หรือ aggregateByKey จะให้ประสิทธิภาพที่ดีกว่ามาก |
| 11 |
reduceByKey(func, [numTasks]) เมื่อเรียกชุดของ (K, V) คู่กลับชุดของ (K, V) คู่ที่ค่าสำหรับแต่ละคีย์มีการรวบรวมโดยใช้ที่ได้รับลดฟังก์ชันfuncซึ่งจะต้องเป็นชนิด (V, V) ⇒ V เช่นเดียวกับใน groupByKey จำนวนงานลดสามารถกำหนดค่าได้ผ่านอาร์กิวเมนต์ที่สองซึ่งเป็นทางเลือก |
| 12 |
aggregateByKey(zeroValue)(seqOp, combOp, [numTasks]) เมื่อเรียกชุดข้อมูลของคู่ (K, V) จะส่งคืนชุดข้อมูลของคู่ (K, U) โดยที่ค่าของแต่ละคีย์จะรวมโดยใช้ฟังก์ชันการรวมที่กำหนดและค่า "ศูนย์" ที่เป็นกลาง อนุญาตประเภทค่ารวมที่แตกต่างจากประเภทค่าอินพุตในขณะที่หลีกเลี่ยงการจัดสรรที่ไม่จำเป็น เช่นเดียวกับใน groupByKey จำนวนงานลดสามารถกำหนดค่าได้ผ่านอาร์กิวเมนต์ที่สองซึ่งเป็นทางเลือก |
| 13 |
sortByKey([ascending], [numTasks]) เมื่อเรียกใช้ชุดข้อมูลของคู่ (K, V) ที่ K ดำเนินการสั่งซื้อจะส่งคืนชุดข้อมูลของคู่ (K, V) ที่เรียงตามคีย์ในลำดับจากน้อยไปมากหรือมากไปหาน้อยตามที่ระบุไว้ในอาร์กิวเมนต์บูลีนจากน้อยไปหามาก |
| 14 |
join(otherDataset, [numTasks]) เมื่อเรียกชุดข้อมูลประเภท (K, V) และ (K, W) จะส่งคืนชุดข้อมูลของคู่ (K, (V, W)) พร้อมด้วยคู่ขององค์ประกอบทั้งหมดสำหรับแต่ละคีย์ การรวมภายนอกได้รับการสนับสนุนผ่านทาง leftOuterJoin, rightOuterJoin และ fullOuterJoin |
| 15 |
cogroup(otherDataset, [numTasks]) เมื่อเรียกใช้ชุดข้อมูลประเภท (K, V) และ (K, W) จะส่งกลับชุดข้อมูลของ (K, (Iterable <V>, Iterable <>)) การดำเนินการนี้เรียกอีกอย่างว่ากลุ่ม With |
| 16 |
cartesian(otherDataset) เมื่อเรียกชุดข้อมูลประเภท T และ U จะส่งคืนชุดข้อมูลของคู่ (T, U) (คู่องค์ประกอบทั้งหมด) |
| 17 |
pipe(command, [envVars]) ไพพ์แต่ละพาร์ติชันของ RDD ผ่านคำสั่งเชลล์เช่น Perl หรือ bash script องค์ประกอบ RDD ถูกเขียนไปยัง stdin ของกระบวนการและเอาต์พุตบรรทัดไปยัง stdout จะถูกส่งกลับเป็น RDD ของสตริง |
| 18 |
coalesce(numPartitions) ลดจำนวนพาร์ติชันใน RDD เป็น numPartitions มีประโยชน์สำหรับการดำเนินการอย่างมีประสิทธิภาพมากขึ้นหลังจากกรองชุดข้อมูลขนาดใหญ่ |
| 19 |
repartition(numPartitions) สับข้อมูลใน RDD แบบสุ่มเพื่อสร้างพาร์ติชันมากขึ้นหรือน้อยลงและทำให้สมดุลระหว่างกัน สิ่งนี้จะสับเปลี่ยนข้อมูลทั้งหมดผ่านเครือข่ายเสมอ |
| 20 |
repartitionAndSortWithinPartitions(partitioner) แบ่งพาร์ติชัน RDD ใหม่ตามพาร์ติชันที่กำหนดและภายในพาร์ติชันผลลัพธ์แต่ละพาร์ติชันจะเรียงลำดับเร็กคอร์ดตามคีย์ วิธีนี้มีประสิทธิภาพมากกว่าการเรียกการแบ่งพาร์ติชันใหม่แล้วเรียงลำดับภายในแต่ละพาร์ติชันเนื่องจากสามารถผลักการเรียงลำดับลงไปในเครื่องจักรแบบสุ่ม |
การดำเนินการ
ตารางต่อไปนี้แสดงรายการของการดำเนินการซึ่งส่งคืนค่า
| ส. เลขที่ | การกระทำและความหมาย |
|---|---|
| 1 |
reduce(func) รวมองค์ประกอบของชุดข้อมูลโดยใช้ฟังก์ชัน func(ซึ่งรับสองอาร์กิวเมนต์และส่งกลับหนึ่งอาร์กิวเมนต์) ฟังก์ชันควรเป็นแบบสับเปลี่ยนและเชื่อมโยงเพื่อให้สามารถคำนวณควบคู่กันได้อย่างถูกต้อง |
| 2 |
collect() ส่งคืนองค์ประกอบทั้งหมดของชุดข้อมูลเป็นอาร์เรย์ที่โปรแกรมไดรเวอร์ โดยปกติจะมีประโยชน์หลังจากตัวกรองหรือการดำเนินการอื่น ๆ ที่ส่งคืนข้อมูลชุดย่อยที่มีขนาดเล็กเพียงพอ |
| 3 |
count() ส่งคืนจำนวนองค์ประกอบในชุดข้อมูล |
| 4 |
first() ส่งคืนองค์ประกอบแรกของชุดข้อมูล (คล้ายกับ take (1)) |
| 5 |
take(n) ส่งคืนอาร์เรย์ด้วยค่าแรก n องค์ประกอบของชุดข้อมูล |
| 6 |
takeSample (withReplacement,num, [seed]) ส่งคืนอาร์เรย์ด้วยตัวอย่างสุ่มของ num องค์ประกอบของชุดข้อมูลที่มีหรือไม่มีการแทนที่สามารถเลือกระบุเมล็ดกำเนิดตัวสร้างตัวเลขสุ่มล่วงหน้าได้ |
| 7 |
takeOrdered(n, [ordering]) ส่งคืนค่าแรก n องค์ประกอบของ RDD โดยใช้ลำดับธรรมชาติหรือตัวเปรียบเทียบแบบกำหนดเอง |
| 8 |
saveAsTextFile(path) เขียนองค์ประกอบของชุดข้อมูลเป็นไฟล์ข้อความ (หรือชุดไฟล์ข้อความ) ในไดเร็กทอรีที่กำหนดในระบบไฟล์โลคัล HDFS หรือระบบไฟล์อื่น ๆ ที่รองรับ Hadoop Spark เรียกใช้ toString ในแต่ละองค์ประกอบเพื่อแปลงเป็นบรรทัดข้อความในไฟล์ |
| 9 |
saveAsSequenceFile(path) (Java and Scala) เขียนองค์ประกอบของชุดข้อมูลเป็น Hadoop SequenceFile ในพา ธ ที่กำหนดในระบบไฟล์โลคัล HDFS หรือระบบไฟล์อื่น ๆ ที่รองรับ Hadoop สิ่งนี้มีอยู่ใน RDD ของคู่คีย์ - ค่าที่ใช้อินเทอร์เฟซที่เขียนได้ของ Hadoop นอกจากนี้ใน Scala ยังมีให้บริการในประเภทที่สามารถแปลงเป็นเขียนได้โดยปริยาย (Spark รวมถึงการแปลงสำหรับประเภทพื้นฐานเช่น Int, Double, String ฯลฯ ) |
| 10 |
saveAsObjectFile(path) (Java and Scala) เขียนองค์ประกอบของชุดข้อมูลในรูปแบบง่ายๆโดยใช้ Java serialization ซึ่งสามารถโหลดได้โดยใช้ SparkContext.objectFile () |
| 11 |
countByKey() ใช้ได้เฉพาะกับ RDD ประเภท (K, V) ส่งคืนแฮชแมปของคู่ (K, Int) พร้อมกับจำนวนของแต่ละคีย์ |
| 12 |
foreach(func) เรียกใช้ฟังก์ชัน funcในแต่ละองค์ประกอบของชุดข้อมูล โดยปกติจะทำเพื่อผลข้างเคียงเช่นการอัพเดต Accumulator หรือการโต้ตอบกับระบบจัดเก็บข้อมูลภายนอก Note- การแก้ไขตัวแปรอื่นที่ไม่ใช่ตัวสะสมภายนอก foreach () อาจส่งผลให้เกิดพฤติกรรมที่ไม่ได้กำหนด ดูทำความเข้าใจกับการปิดสำหรับรายละเอียดเพิ่มเติม |
การเขียนโปรแกรมด้วย RDD
ให้เราดูการใช้งานของการแปลง RDD และการกระทำบางอย่างในการเขียนโปรแกรม RDD ด้วยความช่วยเหลือของตัวอย่าง
ตัวอย่าง
พิจารณาตัวอย่างการนับคำ - นับแต่ละคำที่ปรากฏในเอกสาร พิจารณาข้อความต่อไปนี้เป็นอินพุตและบันทึกเป็นไฟล์input.txt ไฟล์ในโฮมไดเร็กทอรี
input.txt - ไฟล์อินพุต
people are not as beautiful as they look,
as they walk or as they talk.
they are only as beautiful as they love,
as they care as they share.ทำตามขั้นตอนที่ระบุด้านล่างเพื่อดำเนินการตามตัวอย่างที่กำหนด
เปิด Spark-Shell
คำสั่งต่อไปนี้ใช้เพื่อเปิด spark shell โดยทั่วไปประกายไฟสร้างขึ้นโดยใช้สกาล่า ดังนั้นโปรแกรม Spark จึงทำงานบนสภาพแวดล้อม Scala
$ spark-shellหาก Spark shell เปิดสำเร็จคุณจะพบผลลัพธ์ต่อไปนี้ ดูที่บรรทัดสุดท้ายของเอาต์พุต "บริบท Spark พร้อมใช้งานเป็น sc" หมายความว่า Spark container จะถูกสร้างขึ้นโดยอัตโนมัติ spark context object ที่มีชื่อsc. ก่อนเริ่มขั้นตอนแรกของโปรแกรมควรสร้างออบเจ็กต์ SparkContext
Spark assembly has been built with Hive, including Datanucleus jars on classpath
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
15/06/04 15:25:22 INFO SecurityManager: Changing view acls to: hadoop
15/06/04 15:25:22 INFO SecurityManager: Changing modify acls to: hadoop
15/06/04 15:25:22 INFO SecurityManager: SecurityManager: authentication disabled;
ui acls disabled; users with view permissions: Set(hadoop); users with modify permissions: Set(hadoop)
15/06/04 15:25:22 INFO HttpServer: Starting HTTP Server
15/06/04 15:25:23 INFO Utils: Successfully started service 'HTTP class server' on port 43292.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 1.4.0
/_/
Using Scala version 2.10.4 (Java HotSpot(TM) 64-Bit Server VM, Java 1.7.0_71)
Type in expressions to have them evaluated.
Spark context available as sc
scala>สร้าง RDD
ขั้นแรกเราต้องอ่านไฟล์อินพุตโดยใช้ Spark-Scala API และสร้าง RDD
คำสั่งต่อไปนี้ใช้สำหรับการอ่านไฟล์จากตำแหน่งที่กำหนด ที่นี่ RDD ใหม่ถูกสร้างขึ้นโดยใช้ชื่อ inputfile สตริงที่กำหนดให้เป็นอาร์กิวเมนต์ในเมธอด textFile (“”) เป็นพา ธ สัมบูรณ์สำหรับชื่อไฟล์อินพุต อย่างไรก็ตามหากกำหนดเฉพาะชื่อไฟล์แสดงว่าไฟล์อินพุตอยู่ในตำแหน่งปัจจุบัน
scala> val inputfile = sc.textFile("input.txt")ดำเนินการแปลงการนับจำนวนคำ
เป้าหมายของเราคือการนับจำนวนคำในไฟล์ สร้างแผนที่แบนสำหรับแยกแต่ละบรรทัดออกเป็นคำ (flatMap(line ⇒ line.split(“ ”)).
จากนั้นอ่านแต่ละคำเป็นคีย์ที่มีค่า ‘1’ (<key, value> = <word, 1>) โดยใช้ฟังก์ชันแผนที่ (map(word ⇒ (word, 1)).
สุดท้ายลดคีย์เหล่านั้นโดยเพิ่มค่าของคีย์ที่คล้ายกัน (reduceByKey(_+_)).
คำสั่งต่อไปนี้ใช้สำหรับเรียกใช้ตรรกะการนับจำนวนคำ หลังจากดำเนินการแล้วคุณจะไม่พบผลลัพธ์ใด ๆ เพราะนี่ไม่ใช่การกระทำนี่คือการเปลี่ยนแปลง ชี้ RDD ใหม่หรือบอกจุดประกายว่าจะทำอย่างไรกับข้อมูลที่กำหนด)
scala> val counts = inputfile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey(_+_);RDD ปัจจุบัน
ในขณะที่ทำงานกับ RDD หากคุณต้องการทราบเกี่ยวกับ RDD ปัจจุบันให้ใช้คำสั่งต่อไปนี้ จะแสดงคำอธิบายเกี่ยวกับ RDD ปัจจุบันและการอ้างอิงสำหรับการดีบัก
scala> counts.toDebugStringการแคชการแปลง
คุณสามารถทำเครื่องหมาย RDD ให้คงอยู่โดยใช้เมธอด persist () หรือ cache () ในครั้งแรกที่คำนวณในการดำเนินการจะถูกเก็บไว้ในหน่วยความจำบนโหนด ใช้คำสั่งต่อไปนี้เพื่อจัดเก็บการแปลงระดับกลางในหน่วยความจำ
scala> counts.cache()การใช้การดำเนินการ
การใช้การดำเนินการเช่นจัดเก็บการเปลี่ยนแปลงทั้งหมดผลลัพธ์เป็นไฟล์ข้อความ อาร์กิวเมนต์ String สำหรับเมธอด saveAsTextFile (“”) คือพา ธ สัมบูรณ์ของโฟลเดอร์เอาต์พุต ลองใช้คำสั่งต่อไปนี้เพื่อบันทึกผลลัพธ์ในไฟล์ข้อความ ในตัวอย่างต่อไปนี้โฟลเดอร์ 'output' อยู่ในตำแหน่งปัจจุบัน
scala> counts.saveAsTextFile("output")การตรวจสอบเอาต์พุต
เปิดเทอร์มินัลอื่นเพื่อไปที่โฮมไดเร็กทอรี (โดยที่ spark ถูกเรียกใช้ในเทอร์มินัลอื่น) ใช้คำสั่งต่อไปนี้เพื่อตรวจสอบไดเร็กทอรีเอาต์พุต
[hadoop@localhost ~]$ cd output/
[hadoop@localhost output]$ ls -1
part-00000
part-00001
_SUCCESSคำสั่งต่อไปนี้ใช้เพื่อดูผลลัพธ์จาก Part-00000 ไฟล์.
[hadoop@localhost output]$ cat part-00000เอาต์พุต
(people,1)
(are,2)
(not,1)
(as,8)
(beautiful,2)
(they, 7)
(look,1)คำสั่งต่อไปนี้ใช้เพื่อดูผลลัพธ์จาก Part-00001 ไฟล์.
[hadoop@localhost output]$ cat part-00001เอาต์พุต
(walk, 1)
(or, 1)
(talk, 1)
(only, 1)
(love, 1)
(care, 1)
(share, 1)UN ยังคงมีการจัดเก็บ
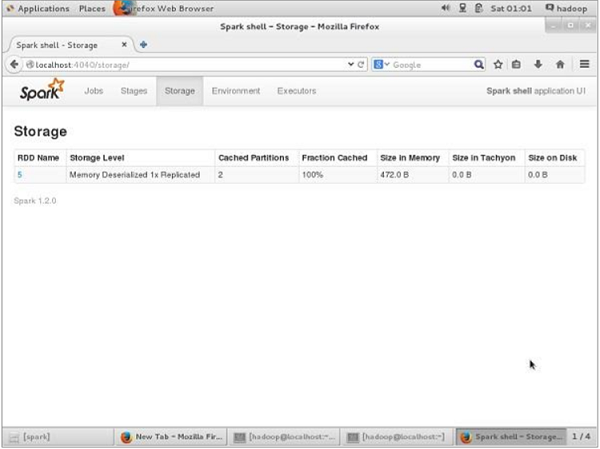
ก่อน UN-persisting หากคุณต้องการดูพื้นที่เก็บข้อมูลที่ใช้สำหรับแอปพลิเคชันนี้ให้ใช้ URL ต่อไปนี้ในเบราว์เซอร์ของคุณ
http://localhost:4040คุณจะเห็นหน้าจอต่อไปนี้ซึ่งแสดงพื้นที่เก็บข้อมูลที่ใช้สำหรับแอปพลิเคชันซึ่งทำงานบน Spark shell

หากคุณต้องการยกเลิกพื้นที่เก็บข้อมูลของ RDD เฉพาะให้ใช้คำสั่งต่อไปนี้
Scala> counts.unpersist()คุณจะเห็นผลลัพธ์ดังนี้ -
15/06/27 00:57:33 INFO ShuffledRDD: Removing RDD 9 from persistence list
15/06/27 00:57:33 INFO BlockManager: Removing RDD 9
15/06/27 00:57:33 INFO BlockManager: Removing block rdd_9_1
15/06/27 00:57:33 INFO MemoryStore: Block rdd_9_1 of size 480 dropped from memory (free 280061810)
15/06/27 00:57:33 INFO BlockManager: Removing block rdd_9_0
15/06/27 00:57:33 INFO MemoryStore: Block rdd_9_0 of size 296 dropped from memory (free 280062106)
res7: cou.type = ShuffledRDD[9] at reduceByKey at <console>:14สำหรับการตรวจสอบพื้นที่จัดเก็บในเบราว์เซอร์ให้ใช้ URL ต่อไปนี้
http://localhost:4040/คุณจะเห็นหน้าจอต่อไปนี้ แสดงพื้นที่เก็บข้อมูลที่ใช้สำหรับแอปพลิเคชันซึ่งทำงานบน Spark shell