Apache Spark - คู่มือฉบับย่อ
อุตสาหกรรมต่างๆใช้ Hadoop อย่างกว้างขวางเพื่อวิเคราะห์ชุดข้อมูลของตน เหตุผลก็คือ Hadoop framework เป็นไปตามรูปแบบการเขียนโปรแกรมอย่างง่าย (MapReduce) และช่วยให้สามารถแก้ปัญหาการประมวลผลที่ปรับขนาดได้ยืดหยุ่นทนต่อข้อผิดพลาดและคุ้มค่า ที่นี่ข้อกังวลหลักคือการรักษาความเร็วในการประมวลผลชุดข้อมูลขนาดใหญ่ในแง่ของเวลารอระหว่างการสืบค้นและเวลารอเพื่อเรียกใช้โปรแกรม
Spark ได้รับการแนะนำโดย Apache Software Foundation เพื่อเร่งกระบวนการซอฟต์แวร์คอมพิวเตอร์คอมพิวเตอร์ Hadoop
ในทางตรงกันข้ามกับความเชื่อทั่วไป Spark is not a modified version of Hadoopและไม่ได้ขึ้นอยู่กับ Hadoop จริง ๆ เนื่องจากมีการจัดการคลัสเตอร์ของตัวเอง Hadoop เป็นเพียงวิธีหนึ่งในการนำ Spark ไปใช้
Spark ใช้ Hadoop ในสองวิธี - หนึ่งคือ storage และที่สองคือ processing. เนื่องจาก Spark มีการคำนวณการจัดการคลัสเตอร์ของตัวเองจึงใช้ Hadoop เพื่อการจัดเก็บเท่านั้น
Apache Spark
Apache Spark เป็นเทคโนโลยีการประมวลผลคลัสเตอร์ที่รวดเร็วปานสายฟ้าแลบออกแบบมาเพื่อการคำนวณที่รวดเร็ว มันขึ้นอยู่กับ Hadoop MapReduce และขยายโมเดล MapReduce เพื่อใช้อย่างมีประสิทธิภาพสำหรับการคำนวณประเภทอื่น ๆ ซึ่งรวมถึงการสืบค้นแบบโต้ตอบและการประมวลผลสตรีม คุณสมบัติหลักของ Spark คือin-memory cluster computing ที่เพิ่มความเร็วในการประมวลผลของแอปพลิเคชัน
Spark ได้รับการออกแบบมาเพื่อให้ครอบคลุมปริมาณงานที่หลากหลายเช่นแอปพลิเคชันแบตช์อัลกอริธึมซ้ำการสืบค้นแบบโต้ตอบและการสตรีม นอกเหนือจากการรองรับภาระงานทั้งหมดเหล่านี้ในระบบที่เกี่ยวข้องแล้วยังช่วยลดภาระการจัดการในการบำรุงรักษาเครื่องมือแยกต่างหาก
วิวัฒนาการของ Apache Spark
Spark เป็นหนึ่งในโครงการย่อยของ Hadoop ที่พัฒนาในปี 2009 ใน AMPLab ของ UC Berkeley โดย Matei Zaharia เป็น Open Sourced ในปี 2010 ภายใต้ใบอนุญาต BSD ได้รับการบริจาคให้กับมูลนิธิซอฟต์แวร์ Apache ในปี 2013 และตอนนี้ Apache Spark ได้กลายเป็นโครงการ Apache ระดับบนตั้งแต่เดือนกุมภาพันธ์ 2014
คุณสมบัติของ Apache Spark
Apache Spark มีคุณสมบัติดังต่อไปนี้
Speed- Spark ช่วยเรียกใช้แอปพลิเคชันในคลัสเตอร์ Hadoop หน่วยความจำเร็วขึ้นสูงสุด 100 เท่าและเร็วขึ้น 10 เท่าเมื่อทำงานบนดิสก์ สามารถทำได้โดยการลดจำนวนการอ่าน / เขียนลงในดิสก์ เก็บข้อมูลการประมวลผลระดับกลางไว้ในหน่วยความจำ
Supports multiple languages- Spark มี API ในตัวใน Java, Scala หรือ Python ดังนั้นคุณสามารถเขียนแอปพลิเคชันในภาษาต่างๆ Spark มาพร้อมกับตัวดำเนินการระดับสูง 80 ตัวสำหรับการสืบค้นแบบโต้ตอบ
Advanced Analytics- Spark ไม่เพียง แต่รองรับ 'แผนที่' และ 'ลด' นอกจากนี้ยังรองรับการสืบค้น SQL ข้อมูลสตรีมมิ่งแมชชีนเลิร์นนิง (ML) และอัลกอริทึมกราฟ
Spark สร้างขึ้นบน Hadoop
แผนภาพต่อไปนี้แสดงสามวิธีในการสร้าง Spark ด้วยส่วนประกอบ Hadoop

การปรับใช้ Spark มีสามวิธีดังที่อธิบายไว้ด้านล่าง
Standalone- การใช้งาน Spark แบบสแตนด์อโลนหมายความว่า Spark ครอบครองตำแหน่งที่อยู่ด้านบนของ HDFS (Hadoop Distributed File System) และมีการจัดสรรพื้นที่สำหรับ HDFS อย่างชัดเจน ที่นี่ Spark และ MapReduce จะทำงานเคียงข้างกันเพื่อครอบคลุมงานจุดประกายทั้งหมดในคลัสเตอร์
Hadoop Yarn- การปรับใช้ Hadoop Yarn หมายถึงเพียงแค่จุดประกายทำงานบน Yarn โดยไม่ต้องติดตั้งล่วงหน้าหรือเข้าถึงรูท ช่วยในการรวม Spark เข้ากับระบบนิเวศ Hadoop หรือ Hadoop stack ช่วยให้ส่วนประกอบอื่น ๆ ทำงานบนสแต็ก
Spark in MapReduce (SIMR)- Spark ใน MapReduce ใช้เพื่อเปิดงานจุดประกายนอกเหนือจากการใช้งานแบบสแตนด์อโลน ด้วย SIMR ผู้ใช้สามารถเริ่ม Spark และใช้เชลล์ได้โดยไม่ต้องมีสิทธิ์เข้าถึงระดับผู้ดูแลระบบ
ส่วนประกอบของ Spark
ภาพประกอบต่อไปนี้แสดงให้เห็นถึงส่วนประกอบต่างๆของ Spark

Apache Spark Core
Spark Core เป็นเครื่องมือประมวลผลทั่วไปที่เป็นพื้นฐานสำหรับแพลตฟอร์มจุดประกายที่มีการสร้างฟังก์ชันอื่น ๆ ทั้งหมด มีการประมวลผลในหน่วยความจำและการอ้างอิงชุดข้อมูลในระบบจัดเก็บข้อมูลภายนอก
Spark SQL
Spark SQL เป็นส่วนประกอบที่อยู่ด้านบนของ Spark Core ซึ่งนำเสนอข้อมูลนามธรรมใหม่ที่เรียกว่า SchemaRDD ซึ่งให้การสนับสนุนข้อมูลที่มีโครงสร้างและกึ่งโครงสร้าง
Spark Streaming
Spark Streaming ใช้ประโยชน์จากความสามารถในการตั้งเวลาที่รวดเร็วของ Spark Core เพื่อทำการวิเคราะห์สตรีมมิ่ง นำเข้าข้อมูลเป็นชุดย่อยและดำเนินการแปลง RDD (Resilient Distributed Datasets) บนชุดข้อมูลขนาดเล็กเหล่านั้น
MLlib (ไลบรารีการเรียนรู้ของเครื่อง)
MLlib เป็นเฟรมเวิร์กการเรียนรู้ของเครื่องที่กระจายอยู่เหนือ Spark เนื่องจากสถาปัตยกรรม Spark ที่ใช้หน่วยความจำแบบกระจาย เป็นไปตามเกณฑ์มาตรฐานที่ทำโดยนักพัฒนา MLlib กับการใช้งาน Alternating Least Squares (ALS) Spark MLlib เร็วกว่ารุ่นที่ใช้ดิสก์ Hadoop ถึงเก้าเท่าApache Mahout (ก่อนที่ Mahout จะได้รับอินเทอร์เฟซ Spark)
GraphX
GraphX เป็นเฟรมเวิร์กการประมวลผลกราฟแบบกระจายที่ด้านบนของ Spark มี API สำหรับการแสดงการคำนวณกราฟที่สามารถจำลองกราฟที่ผู้ใช้กำหนดโดยใช้ Pregel Abstraction API นอกจากนี้ยังมีรันไทม์ที่ปรับให้เหมาะสมสำหรับสิ่งที่เป็นนามธรรมนี้
ชุดข้อมูลแบบกระจายที่ยืดหยุ่น
Resilient Distributed Datasets (RDD) เป็นโครงสร้างข้อมูลพื้นฐานของ Spark มันเป็นคอลเลกชันของวัตถุที่กระจายไม่เปลี่ยนรูป ชุดข้อมูลแต่ละชุดใน RDD จะแบ่งออกเป็นโลจิคัลพาร์ติชันซึ่งอาจคำนวณจากโหนดต่าง ๆ ของคลัสเตอร์ RDD สามารถมีออบเจ็กต์ Python, Java หรือ Scala ประเภทใดก็ได้รวมถึงคลาสที่ผู้ใช้กำหนดเอง
ตามปกติแล้ว RDD คือคอลเล็กชันเรกคอร์ดแบบอ่านอย่างเดียวที่แบ่งพาร์ติชัน RDD สามารถสร้างขึ้นได้จากการดำเนินการที่กำหนดบนข้อมูลบนพื้นที่จัดเก็บที่เสถียรหรือ RDD อื่น ๆ RDD คือชุดขององค์ประกอบที่ทนต่อความผิดพลาดซึ่งสามารถทำงานแบบขนานได้
มีสองวิธีในการสร้าง RDD - parallelizing คอลเลกชันที่มีอยู่ในโปรแกรมไดรเวอร์ของคุณหรือ referencing a dataset ในระบบจัดเก็บข้อมูลภายนอกเช่นระบบไฟล์ที่ใช้ร่วมกัน HDFS HBase หรือแหล่งข้อมูลใด ๆ ที่เสนอรูปแบบอินพุต Hadoop
Spark ใช้แนวคิดของ RDD เพื่อให้การดำเนินการ MapReduce เร็วขึ้นและมีประสิทธิภาพ ก่อนอื่นให้เราคุยกันก่อนว่าการดำเนินการ MapReduce เกิดขึ้นได้อย่างไรและเหตุใดจึงไม่มีประสิทธิภาพ
การแบ่งปันข้อมูลทำได้ช้าใน MapReduce
MapReduce ถูกนำมาใช้อย่างกว้างขวางสำหรับการประมวลผลและสร้างชุดข้อมูลขนาดใหญ่ด้วยอัลกอริธึมแบบกระจายแบบขนานบนคลัสเตอร์ ช่วยให้ผู้ใช้สามารถเขียนการคำนวณแบบขนานโดยใช้ชุดตัวดำเนินการระดับสูงโดยไม่ต้องกังวลเกี่ยวกับการกระจายงานและการยอมรับข้อผิดพลาด
น่าเสียดายที่ในเฟรมเวิร์กปัจจุบันส่วนใหญ่วิธีเดียวที่จะนำข้อมูลกลับมาใช้ใหม่ระหว่างการคำนวณ (เช่นระหว่างสองงาน MapReduce) คือการเขียนลงในระบบจัดเก็บข้อมูลภายนอกที่มีเสถียรภาพ (Ex - HDFS) แม้ว่าเฟรมเวิร์กนี้จะจัดเตรียมสิ่งที่เป็นนามธรรมมากมายสำหรับการเข้าถึงทรัพยากรการคำนวณของคลัสเตอร์ แต่ผู้ใช้ก็ยังต้องการมากกว่านี้
ทั้งสอง Iterative และ Interactiveแอปพลิเคชันต้องการการแบ่งปันข้อมูลที่เร็วขึ้นระหว่างงานคู่ขนาน การแบ่งปันข้อมูลใน MapReduce ช้าเนื่องจากreplication, serializationและ disk IO. เกี่ยวกับระบบจัดเก็บข้อมูลแอพพลิเคชั่น Hadoop ส่วนใหญ่ใช้เวลามากกว่า 90% ในการดำเนินการอ่านเขียน HDFS
การดำเนินการซ้ำบน MapReduce
นำผลลัพธ์ระดับกลางมาใช้ซ้ำในการคำนวณหลายรายการในแอปพลิเคชันหลายขั้นตอน ภาพประกอบต่อไปนี้อธิบายวิธีการทำงานของเฟรมเวิร์กปัจจุบันในขณะที่ดำเนินการซ้ำบน MapReduce สิ่งนี้ก่อให้เกิดค่าใช้จ่ายจำนวนมากเนื่องจากการจำลองข้อมูลดิสก์ I / O และการทำให้เป็นอนุกรมซึ่งทำให้ระบบทำงานช้า
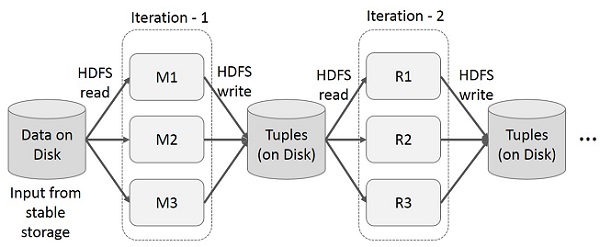
การทำงานแบบโต้ตอบบน MapReduce
ผู้ใช้เรียกใช้การสืบค้นแบบเฉพาะกิจบนชุดข้อมูลย่อยเดียวกัน แบบสอบถามแต่ละรายการจะทำดิสก์ I / O บนที่เก็บข้อมูลที่เสถียรซึ่งสามารถควบคุมเวลาในการดำเนินการของแอปพลิเคชันได้
ภาพประกอบต่อไปนี้อธิบายวิธีการทำงานของเฟรมเวิร์กปัจจุบันในขณะที่ทำแบบสอบถามแบบโต้ตอบบน MapReduce
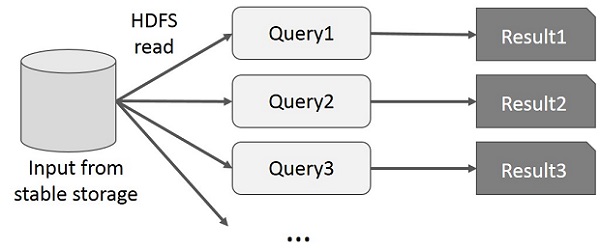
การแบ่งปันข้อมูลโดยใช้ Spark RDD
การแบ่งปันข้อมูลใน MapReduce ช้าเนื่องจาก replication, serializationและ disk IO. แอปพลิเคชัน Hadoop ส่วนใหญ่ใช้เวลามากกว่า 90% ในการดำเนินการอ่าน - เขียน HDFS
เมื่อตระหนักถึงปัญหานี้นักวิจัยได้พัฒนากรอบงานเฉพาะที่เรียกว่า Apache Spark แนวคิดสำคัญของการจุดประกายคือRฉลาด Dมีที่มา Datasets (RDD); รองรับการคำนวณการประมวลผลในหน่วยความจำ ซึ่งหมายความว่าจะจัดเก็บสถานะของหน่วยความจำเป็นวัตถุในงานและวัตถุสามารถแบ่งปันได้ระหว่างงานเหล่านั้น การแชร์ข้อมูลในหน่วยความจำเร็วกว่าเครือข่ายและดิสก์ 10 ถึง 100 เท่า
ตอนนี้ให้เราลองค้นหาว่าการดำเนินการซ้ำและโต้ตอบเกิดขึ้นใน Spark RDD อย่างไร
การดำเนินการซ้ำบน Spark RDD
ภาพประกอบด้านล่างแสดงการดำเนินการซ้ำบน Spark RDD มันจะเก็บผลลัพธ์ระดับกลางไว้ในหน่วยความจำแบบกระจายแทนที่จะเป็น Stable storage (Disk) และทำให้ระบบเร็วขึ้น
Note - หากหน่วยความจำแบบกระจาย (RAM) เพียงพอที่จะจัดเก็บผลลัพธ์ระดับกลาง (สถานะของงาน) ก็จะเก็บผลลัพธ์เหล่านั้นไว้ในดิสก์

การทำงานแบบโต้ตอบบน Spark RDD
ภาพประกอบนี้แสดงการทำงานแบบโต้ตอบบน Spark RDD หากมีการเรียกใช้แบบสอบถามที่แตกต่างกันในชุดข้อมูลเดียวกันซ้ำ ๆ ข้อมูลเฉพาะนี้จะถูกเก็บไว้ในหน่วยความจำเพื่อให้มีเวลาดำเนินการที่ดีขึ้น

ตามค่าเริ่มต้น RDD ที่แปลงแล้วแต่ละรายการอาจได้รับการคำนวณใหม่ทุกครั้งที่คุณดำเนินการกับมัน อย่างไรก็ตามคุณอาจpersistRDD ในหน่วยความจำซึ่งในกรณีนี้ Spark จะเก็บองค์ประกอบรอบ ๆ บนคลัสเตอร์เพื่อให้เข้าถึงได้เร็วขึ้นในครั้งต่อไปที่คุณสอบถาม นอกจากนี้ยังมีการสนับสนุนสำหรับ RDD ที่มีอยู่บนดิสก์หรือจำลองแบบในหลายโหนด
Spark เป็นโครงการย่อยของ Hadoop ดังนั้นจึงควรติดตั้ง Spark ลงในระบบที่ใช้ Linux ขั้นตอนต่อไปนี้แสดงวิธีการติดตั้ง Apache Spark
ขั้นตอนที่ 1: ตรวจสอบการติดตั้ง Java
การติดตั้ง Java เป็นสิ่งที่จำเป็นอย่างหนึ่งในการติดตั้ง Spark ลองใช้คำสั่งต่อไปนี้เพื่อตรวจสอบเวอร์ชัน JAVA
$java -versionหากมีการติดตั้ง Java ไว้แล้วในระบบของคุณคุณจะเห็นคำตอบต่อไปนี้ -
java version "1.7.0_71"
Java(TM) SE Runtime Environment (build 1.7.0_71-b13)
Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)ในกรณีที่คุณไม่ได้ติดตั้ง Java บนระบบของคุณให้ติดตั้ง Java ก่อนดำเนินการขั้นตอนถัดไป
ขั้นตอนที่ 2: ตรวจสอบการติดตั้ง Scala
คุณควรใช้ภาษาสกาล่าเพื่อใช้งาน Spark ดังนั้นให้เราตรวจสอบการติดตั้ง Scala โดยใช้คำสั่งต่อไปนี้
$scala -versionหากติดตั้ง Scala ในระบบของคุณแล้วคุณจะเห็นคำตอบต่อไปนี้ -
Scala code runner version 2.11.6 -- Copyright 2002-2013, LAMP/EPFLในกรณีที่คุณไม่ได้ติดตั้ง Scala ในระบบของคุณให้ทำตามขั้นตอนต่อไปสำหรับการติดตั้ง Scala
ขั้นตอนที่ 3: ดาวน์โหลด Scala
ดาวน์โหลดรุ่นล่าสุดของสกาล่าโดยการเยี่ยมชมลิงค์ต่อไปนี้ดาวน์โหลดสกาล่า สำหรับบทช่วยสอนนี้เรากำลังใช้เวอร์ชัน scala-2.11.6 หลังจากดาวน์โหลดคุณจะพบไฟล์ Scala tar ในโฟลเดอร์ดาวน์โหลด
ขั้นตอนที่ 4: การติดตั้ง Scala
ทำตามขั้นตอนด้านล่างสำหรับการติดตั้ง Scala
แตกไฟล์ Scala tar
พิมพ์คำสั่งต่อไปนี้สำหรับการแตกไฟล์ Scala tar
$ tar xvf scala-2.11.6.tgzย้ายไฟล์ซอฟต์แวร์ Scala
ใช้คำสั่งต่อไปนี้เพื่อย้ายไฟล์ซอฟต์แวร์ Scala ไปยังไดเร็กทอรีที่เกี่ยวข้อง (/usr/local/scala).
$ su –
Password:
# cd /home/Hadoop/Downloads/
# mv scala-2.11.6 /usr/local/scala
# exitตั้งค่า PATH สำหรับ Scala
ใช้คำสั่งต่อไปนี้สำหรับการตั้งค่า PATH สำหรับ Scala
$ export PATH = $PATH:/usr/local/scala/binกำลังตรวจสอบการติดตั้ง Scala
หลังจากการติดตั้งจะเป็นการดีกว่าที่จะตรวจสอบ ใช้คำสั่งต่อไปนี้เพื่อตรวจสอบการติดตั้ง Scala
$scala -versionหากติดตั้ง Scala ในระบบของคุณแล้วคุณจะเห็นคำตอบต่อไปนี้ -
Scala code runner version 2.11.6 -- Copyright 2002-2013, LAMP/EPFLขั้นตอนที่ 5: ดาวน์โหลด Apache Spark
ดาวน์โหลดรุ่นล่าสุดของ Spark โดยไปที่การเชื่อมโยงต่อไปนี้ดาวน์โหลด Spark สำหรับบทช่วยสอนนี้เรากำลังใช้spark-1.3.1-bin-hadoop2.6รุ่น. หลังจากดาวน์โหลดแล้วคุณจะพบไฟล์ Spark tar ในโฟลเดอร์ดาวน์โหลด
ขั้นตอนที่ 6: การติดตั้ง Spark
ทำตามขั้นตอนด้านล่างเพื่อติดตั้ง Spark
สกัดน้ำมัน Spark
คำสั่งต่อไปนี้สำหรับการแตกไฟล์ spark tar
$ tar xvf spark-1.3.1-bin-hadoop2.6.tgzการย้ายไฟล์ซอฟต์แวร์ Spark
คำสั่งต่อไปนี้สำหรับการย้ายไฟล์ซอฟต์แวร์ Spark ไปยังไดเร็กทอรีที่เกี่ยวข้อง (/usr/local/spark).
$ su –
Password:
# cd /home/Hadoop/Downloads/
# mv spark-1.3.1-bin-hadoop2.6 /usr/local/spark
# exitการตั้งค่าสภาพแวดล้อมสำหรับ Spark
เพิ่มบรรทัดต่อไปนี้ใน ~/.bashrcไฟล์. หมายถึงการเพิ่มตำแหน่งที่ไฟล์ซอฟต์แวร์ spark อยู่ในตัวแปร PATH
export PATH=$PATH:/usr/local/spark/binใช้คำสั่งต่อไปนี้เพื่อจัดหาไฟล์ ~ / .bashrc
$ source ~/.bashrcขั้นตอนที่ 7: ตรวจสอบการติดตั้ง Spark
เขียนคำสั่งต่อไปนี้เพื่อเปิด Spark shell
$spark-shellหากติดตั้ง spark สำเร็จคุณจะพบผลลัพธ์ต่อไปนี้
Spark assembly has been built with Hive, including Datanucleus jars on classpath
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
15/06/04 15:25:22 INFO SecurityManager: Changing view acls to: hadoop
15/06/04 15:25:22 INFO SecurityManager: Changing modify acls to: hadoop
15/06/04 15:25:22 INFO SecurityManager: SecurityManager: authentication disabled;
ui acls disabled; users with view permissions: Set(hadoop); users with modify permissions: Set(hadoop)
15/06/04 15:25:22 INFO HttpServer: Starting HTTP Server
15/06/04 15:25:23 INFO Utils: Successfully started service 'HTTP class server' on port 43292.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 1.4.0
/_/
Using Scala version 2.10.4 (Java HotSpot(TM) 64-Bit Server VM, Java 1.7.0_71)
Type in expressions to have them evaluated.
Spark context available as sc
scala>Spark Core เป็นฐานของโครงการทั้งหมด จัดเตรียมการจัดส่งงานการตั้งเวลาและฟังก์ชัน I / O พื้นฐานแบบกระจาย Spark ใช้โครงสร้างข้อมูลพื้นฐานเฉพาะที่เรียกว่า RDD (Resilient Distributed Datasets) ซึ่งเป็นการรวบรวมข้อมูลเชิงตรรกะที่แบ่งพาร์ติชันข้ามเครื่อง RDD สามารถสร้างได้สองวิธี หนึ่งคือการอ้างอิงชุดข้อมูลในระบบจัดเก็บข้อมูลภายนอกและอย่างที่สองคือการใช้การแปลง (เช่นแผนที่ตัวกรองตัวลดการรวม) บน RDD ที่มีอยู่
สิ่งที่เป็นนามธรรม RDD ถูกเปิดเผยผ่าน API ที่รวมภาษา สิ่งนี้ช่วยลดความซับซ้อนในการเขียนโปรแกรมเนื่องจากวิธีที่แอปพลิเคชันจัดการกับ RDD นั้นคล้ายกับการจัดการคอลเลคชันข้อมูลภายในเครื่อง
สปาร์คเชลล์
Spark มีเชลล์แบบโต้ตอบซึ่งเป็นเครื่องมือที่มีประสิทธิภาพในการวิเคราะห์ข้อมูลแบบโต้ตอบ มีให้บริการในภาษา Scala หรือ Python นามธรรมหลักของ Spark คือคอลเล็กชันแบบกระจายของรายการที่เรียกว่า Resilient Distributed Dataset (RDD) RDD สามารถสร้างได้จาก Hadoop Input Formats (เช่นไฟล์ HDFS) หรือโดยการแปลง RDD อื่น ๆ
เปิด Spark Shell
คำสั่งต่อไปนี้ใช้เพื่อเปิด Spark shell
$ spark-shellสร้าง RDD ง่ายๆ
ให้เราสร้าง RDD ง่ายๆจากไฟล์ข้อความ ใช้คำสั่งต่อไปนี้เพื่อสร้าง RDD อย่างง่าย
scala> val inputfile = sc.textFile(“input.txt”)ผลลัพธ์สำหรับคำสั่งดังกล่าวคือ
inputfile: org.apache.spark.rdd.RDD[String] = input.txt MappedRDD[1] at textFile at <console>:12Spark RDD API เปิดตัวเพียงเล็กน้อย Transformations และไม่กี่ Actions เพื่อจัดการ RDD
การแปลง RDD
การแปลง RDD จะส่งกลับตัวชี้ไปที่ RDD ใหม่และอนุญาตให้คุณสร้างการอ้างอิงระหว่าง RDD RDD แต่ละรายการในห่วงโซ่การพึ่งพา (String of Dependencies) มีฟังก์ชันสำหรับคำนวณข้อมูลและมีตัวชี้ (การอ้างอิง) ไปยัง RDD หลัก
Spark เป็นคนขี้เกียจดังนั้นจะไม่มีการดำเนินการใด ๆ เว้นแต่คุณจะเรียกการเปลี่ยนแปลงหรือการกระทำบางอย่างที่จะกระตุ้นการสร้างและดำเนินการงาน ดูตัวอย่างต่อไปนี้ของตัวอย่างการนับคำ
ดังนั้นการแปลง RDD ไม่ใช่ชุดข้อมูล แต่เป็นขั้นตอนในโปรแกรม (อาจเป็นขั้นตอนเดียว) ที่บอก Spark ว่าจะรับข้อมูลอย่างไรและจะทำอย่างไรกับข้อมูลนั้น
| ส. เลขที่ | การเปลี่ยนแปลงและความหมาย |
|---|---|
| 1 | map(func) ส่งคืนชุดข้อมูลแบบกระจายใหม่ที่สร้างขึ้นโดยการส่งแต่ละองค์ประกอบของแหล่งที่มาผ่านฟังก์ชัน func. |
| 2 | filter(func) ส่งคืนชุดข้อมูลใหม่ที่สร้างขึ้นโดยการเลือกองค์ประกอบเหล่านั้นของแหล่งที่มา func คืนค่าจริง |
| 3 | flatMap(func) คล้ายกับแผนที่ แต่แต่ละรายการอินพุตสามารถแมปกับรายการเอาต์พุต 0 รายการขึ้นไปได้ (ดังนั้นfuncควรส่งคืน Seq แทนที่จะเป็นรายการเดียว) |
| 4 | mapPartitions(func) คล้ายกับแผนที่ แต่ทำงานแยกกันในแต่ละพาร์ติชัน (บล็อก) ของ RDD ดังนั้น func ต้องเป็นประเภท Iterator <T> ⇒ Iterator <U> เมื่อรันบน RDD ประเภท T |
| 5 | mapPartitionsWithIndex(func) คล้ายกับพาร์ติชันแผนที่ แต่ยังให้ func ด้วยค่าจำนวนเต็มแทนดัชนีของพาร์ติชันดังนั้น func ต้องเป็นประเภท (Int, Iterator <T>) ⇒ Iterator <U> เมื่อรันบน RDD ประเภท T |
| 6 | sample(withReplacement, fraction, seed) ตัวอย่างก fraction ของข้อมูลที่มีหรือไม่มีการแทนที่โดยใช้เมล็ดกำเนิดตัวเลขสุ่มที่กำหนด |
| 7 | union(otherDataset) ส่งคืนชุดข้อมูลใหม่ที่มีการรวมกันขององค์ประกอบในชุดข้อมูลต้นทางและอาร์กิวเมนต์ |
| 8 | intersection(otherDataset) ส่งคืน RDD ใหม่ที่มีจุดตัดขององค์ประกอบในชุดข้อมูลต้นทางและอาร์กิวเมนต์ |
| 9 | distinct([numTasks]) ส่งคืนชุดข้อมูลใหม่ที่มีองค์ประกอบเฉพาะของชุดข้อมูลต้นทาง |
| 10 | groupByKey([numTasks]) เมื่อเรียกชุดข้อมูลของคู่ (K, V) จะส่งคืนชุดข้อมูลของคู่ (K, Iterable <V>) Note - หากคุณจัดกลุ่มเพื่อทำการรวม (เช่นผลรวมหรือค่าเฉลี่ย) ในแต่ละคีย์การใช้ reduceByKey หรือ aggregateByKey จะให้ประสิทธิภาพที่ดีกว่ามาก |
| 11 | reduceByKey(func, [numTasks]) เมื่อเรียกชุดของ (K, V) คู่กลับชุดของ (K, V) คู่ที่ค่าสำหรับแต่ละคีย์มีการรวบรวมโดยใช้ที่ได้รับลดฟังก์ชันfuncซึ่งจะต้องเป็นชนิด (V, V) ⇒ V เช่นเดียวกับใน groupByKey จำนวนงานลดสามารถกำหนดค่าได้ผ่านอาร์กิวเมนต์ที่สองซึ่งเป็นทางเลือก |
| 12 | aggregateByKey(zeroValue)(seqOp, combOp, [numTasks]) เมื่อเรียกชุดข้อมูลของคู่ (K, V) จะส่งคืนชุดข้อมูลของคู่ (K, U) โดยที่ค่าของแต่ละคีย์จะรวมโดยใช้ฟังก์ชันการรวมที่กำหนดและค่า "ศูนย์" ที่เป็นกลาง อนุญาตประเภทค่ารวมที่แตกต่างจากประเภทค่าอินพุตในขณะที่หลีกเลี่ยงการจัดสรรที่ไม่จำเป็น เช่นเดียวกับใน groupByKey จำนวนงานลดสามารถกำหนดค่าได้ผ่านอาร์กิวเมนต์ที่สองซึ่งเป็นทางเลือก |
| 13 | sortByKey([ascending], [numTasks]) เมื่อเรียกใช้ชุดข้อมูลของคู่ (K, V) ที่ K ดำเนินการสั่งซื้อจะส่งคืนชุดข้อมูลของคู่ (K, V) ที่เรียงตามคีย์ในลำดับจากน้อยไปมากหรือมากไปหาน้อยตามที่ระบุไว้ในอาร์กิวเมนต์บูลีนจากน้อยไปหามาก |
| 14 | join(otherDataset, [numTasks]) เมื่อเรียกชุดข้อมูลประเภท (K, V) และ (K, W) จะส่งคืนชุดข้อมูลของคู่ (K, (V, W)) พร้อมด้วยคู่ขององค์ประกอบทั้งหมดสำหรับแต่ละคีย์ การรวมภายนอกได้รับการสนับสนุนผ่านทาง leftOuterJoin, rightOuterJoin และ fullOuterJoin |
| 15 | cogroup(otherDataset, [numTasks]) เมื่อเรียกใช้ชุดข้อมูลประเภท (K, V) และ (K, W) จะส่งกลับชุดข้อมูลของ (K, (Iterable <V>, Iterable <>)) การดำเนินการนี้เรียกอีกอย่างว่ากลุ่ม With |
| 16 | cartesian(otherDataset) เมื่อเรียกชุดข้อมูลประเภท T และ U จะส่งคืนชุดข้อมูลของคู่ (T, U) (คู่องค์ประกอบทั้งหมด) |
| 17 | pipe(command, [envVars]) ไพพ์แต่ละพาร์ติชันของ RDD ผ่านคำสั่งเชลล์เช่น Perl หรือ bash script องค์ประกอบ RDD ถูกเขียนไปยัง stdin ของกระบวนการและเอาต์พุตบรรทัดไปยัง stdout จะถูกส่งกลับเป็น RDD ของสตริง |
| 18 | coalesce(numPartitions) ลดจำนวนพาร์ติชันใน RDD เป็น numPartitions มีประโยชน์สำหรับการดำเนินการอย่างมีประสิทธิภาพมากขึ้นหลังจากกรองชุดข้อมูลขนาดใหญ่ |
| 19 | repartition(numPartitions) สับข้อมูลใน RDD แบบสุ่มเพื่อสร้างพาร์ติชันมากขึ้นหรือน้อยลงและทำให้สมดุลระหว่างกัน สิ่งนี้จะสับเปลี่ยนข้อมูลทั้งหมดผ่านเครือข่ายเสมอ |
| 20 | repartitionAndSortWithinPartitions(partitioner) แบ่งพาร์ติชัน RDD ใหม่ตามพาร์ติชันที่กำหนดและภายในพาร์ติชันผลลัพธ์แต่ละพาร์ติชันจะเรียงลำดับเร็กคอร์ดตามคีย์ วิธีนี้มีประสิทธิภาพมากกว่าการเรียกการแบ่งพาร์ติชันใหม่แล้วเรียงลำดับภายในแต่ละพาร์ติชันเนื่องจากสามารถผลักการเรียงลำดับลงไปในเครื่องจักรแบบสุ่ม |
การดำเนินการ
| ส. เลขที่ | การกระทำและความหมาย |
|---|---|
| 1 | reduce(func) รวมองค์ประกอบของชุดข้อมูลโดยใช้ฟังก์ชัน func(ซึ่งรับสองอาร์กิวเมนต์และส่งกลับหนึ่งอาร์กิวเมนต์) ฟังก์ชันควรเป็นแบบสับเปลี่ยนและเชื่อมโยงเพื่อให้สามารถคำนวณควบคู่กันได้อย่างถูกต้อง |
| 2 | collect() ส่งคืนองค์ประกอบทั้งหมดของชุดข้อมูลเป็นอาร์เรย์ที่โปรแกรมไดรเวอร์ โดยปกติจะมีประโยชน์หลังจากตัวกรองหรือการดำเนินการอื่น ๆ ที่ส่งคืนข้อมูลชุดย่อยที่มีขนาดเล็กเพียงพอ |
| 3 | count() ส่งคืนจำนวนองค์ประกอบในชุดข้อมูล |
| 4 | first() ส่งคืนองค์ประกอบแรกของชุดข้อมูล (คล้ายกับ take (1)) |
| 5 | take(n) ส่งคืนอาร์เรย์ด้วยค่าแรก n องค์ประกอบของชุดข้อมูล |
| 6 | takeSample (withReplacement,num, [seed]) ส่งคืนอาร์เรย์ด้วยตัวอย่างสุ่มของ num องค์ประกอบของชุดข้อมูลที่มีหรือไม่มีการแทนที่สามารถเลือกระบุเมล็ดกำเนิดตัวสร้างตัวเลขสุ่มล่วงหน้าได้ |
| 7 | takeOrdered(n, [ordering]) ส่งคืนค่าแรก n องค์ประกอบของ RDD โดยใช้ลำดับธรรมชาติหรือตัวเปรียบเทียบแบบกำหนดเอง |
| 8 | saveAsTextFile(path) เขียนองค์ประกอบของชุดข้อมูลเป็นไฟล์ข้อความ (หรือชุดไฟล์ข้อความ) ในไดเร็กทอรีที่กำหนดในระบบไฟล์โลคัล HDFS หรือระบบไฟล์อื่น ๆ ที่รองรับ Hadoop Spark เรียกใช้ toString ในแต่ละองค์ประกอบเพื่อแปลงเป็นบรรทัดข้อความในไฟล์ |
| 9 | saveAsSequenceFile(path) (Java and Scala) เขียนองค์ประกอบของชุดข้อมูลเป็น Hadoop SequenceFile ในพา ธ ที่กำหนดในระบบไฟล์โลคัล HDFS หรือระบบไฟล์อื่น ๆ ที่รองรับ Hadoop สิ่งนี้มีอยู่ใน RDD ของคู่คีย์ - ค่าที่ใช้อินเทอร์เฟซที่เขียนได้ของ Hadoop นอกจากนี้ใน Scala ยังมีให้ใช้งานในประเภทที่สามารถแปลงเป็น Writable ได้โดยปริยาย (Spark รวมถึงการแปลงสำหรับประเภทพื้นฐานเช่น Int, Double, String ฯลฯ ) |
| 10 | saveAsObjectFile(path) (Java and Scala) เขียนองค์ประกอบของชุดข้อมูลในรูปแบบง่ายๆโดยใช้ Java serialization ซึ่งสามารถโหลดได้โดยใช้ SparkContext.objectFile () |
| 11 | countByKey() ใช้ได้เฉพาะกับ RDD ประเภท (K, V) ส่งคืนแฮชแมปของคู่ (K, Int) พร้อมกับจำนวนของแต่ละคีย์ |
| 12 | foreach(func) เรียกใช้ฟังก์ชัน funcในแต่ละองค์ประกอบของชุดข้อมูล โดยปกติจะทำเพื่อผลข้างเคียงเช่นการอัพเดต Accumulator หรือการโต้ตอบกับระบบจัดเก็บข้อมูลภายนอก Note- การปรับเปลี่ยนตัวแปรอื่น ๆ นอกเหนือจากตัวสะสมภายนอก foreach () อาจส่งผลให้เกิดพฤติกรรมที่ไม่ได้กำหนด ดูทำความเข้าใจกับการปิดสำหรับรายละเอียดเพิ่มเติม |
การเขียนโปรแกรมด้วย RDD
ให้เราดูการใช้งานของการแปลง RDD และการกระทำบางอย่างในการเขียนโปรแกรม RDD ด้วยความช่วยเหลือของตัวอย่าง
ตัวอย่าง
พิจารณาตัวอย่างการนับคำ - นับแต่ละคำที่ปรากฏในเอกสาร พิจารณาข้อความต่อไปนี้เป็นอินพุตและบันทึกเป็นไฟล์input.txt ไฟล์ในโฮมไดเร็กทอรี
input.txt - ไฟล์อินพุต
people are not as beautiful as they look,
as they walk or as they talk.
they are only as beautiful as they love,
as they care as they share.ทำตามขั้นตอนที่ระบุด้านล่างเพื่อดำเนินการตามตัวอย่างที่กำหนด
เปิด Spark-Shell
คำสั่งต่อไปนี้ใช้เพื่อเปิด spark shell โดยทั่วไปประกายไฟสร้างขึ้นโดยใช้สกาล่า ดังนั้นโปรแกรม Spark จึงทำงานบนสภาพแวดล้อม Scala
$ spark-shellหาก Spark shell เปิดสำเร็จคุณจะพบผลลัพธ์ต่อไปนี้ ดูที่บรรทัดสุดท้ายของเอาต์พุต "บริบท Spark พร้อมใช้งานเป็น sc" หมายความว่า Spark container จะถูกสร้างขึ้นโดยอัตโนมัติ spark context object ที่มีชื่อsc. ก่อนเริ่มขั้นตอนแรกของโปรแกรมควรสร้างออบเจ็กต์ SparkContext
Spark assembly has been built with Hive, including Datanucleus jars on classpath
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
15/06/04 15:25:22 INFO SecurityManager: Changing view acls to: hadoop
15/06/04 15:25:22 INFO SecurityManager: Changing modify acls to: hadoop
15/06/04 15:25:22 INFO SecurityManager: SecurityManager: authentication disabled;
ui acls disabled; users with view permissions: Set(hadoop); users with modify permissions: Set(hadoop)
15/06/04 15:25:22 INFO HttpServer: Starting HTTP Server
15/06/04 15:25:23 INFO Utils: Successfully started service 'HTTP class server' on port 43292.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 1.4.0
/_/
Using Scala version 2.10.4 (Java HotSpot(TM) 64-Bit Server VM, Java 1.7.0_71)
Type in expressions to have them evaluated.
Spark context available as sc
scala>สร้าง RDD
ขั้นแรกเราต้องอ่านไฟล์อินพุตโดยใช้ Spark-Scala API และสร้าง RDD
คำสั่งต่อไปนี้ใช้สำหรับการอ่านไฟล์จากตำแหน่งที่กำหนด ที่นี่ RDD ใหม่ถูกสร้างขึ้นโดยใช้ชื่อ inputfile สตริงที่กำหนดให้เป็นอาร์กิวเมนต์ในเมธอด textFile (“”) เป็นพา ธ สัมบูรณ์สำหรับชื่อไฟล์อินพุต อย่างไรก็ตามหากกำหนดเฉพาะชื่อไฟล์แสดงว่าไฟล์อินพุตอยู่ในตำแหน่งปัจจุบัน
scala> val inputfile = sc.textFile("input.txt")ดำเนินการแปลงการนับจำนวนคำ
เป้าหมายของเราคือการนับจำนวนคำในไฟล์ สร้างแผนที่แบนสำหรับแยกแต่ละบรรทัดออกเป็นคำ (flatMap(line ⇒ line.split(“ ”)).
จากนั้นอ่านแต่ละคำเป็นคีย์ที่มีค่า ‘1’ (<key, value> = <word, 1>) โดยใช้ฟังก์ชันแผนที่ (map(word ⇒ (word, 1)).
สุดท้ายลดคีย์เหล่านั้นโดยเพิ่มค่าของคีย์ที่คล้ายกัน (reduceByKey(_+_)).
คำสั่งต่อไปนี้ใช้สำหรับเรียกใช้ตรรกะการนับจำนวนคำ หลังจากดำเนินการแล้วคุณจะไม่พบผลลัพธ์ใด ๆ เพราะนี่ไม่ใช่การกระทำนี่คือการเปลี่ยนแปลง ชี้ RDD ใหม่หรือบอกจุดประกายว่าจะทำอย่างไรกับข้อมูลที่กำหนด)
scala> val counts = inputfile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey(_+_);RDD ปัจจุบัน
ในขณะที่ทำงานกับ RDD หากคุณต้องการทราบเกี่ยวกับ RDD ปัจจุบันให้ใช้คำสั่งต่อไปนี้ จะแสดงคำอธิบายเกี่ยวกับ RDD ปัจจุบันและการอ้างอิงสำหรับการดีบัก
scala> counts.toDebugStringการแคชการแปลง
คุณสามารถทำเครื่องหมาย RDD ให้คงอยู่โดยใช้เมธอด persist () หรือ cache () ในครั้งแรกที่คำนวณในการดำเนินการจะถูกเก็บไว้ในหน่วยความจำบนโหนด ใช้คำสั่งต่อไปนี้เพื่อจัดเก็บการแปลงระดับกลางในหน่วยความจำ
scala> counts.cache()การใช้การดำเนินการ
การใช้การดำเนินการเช่นจัดเก็บการเปลี่ยนแปลงทั้งหมดผลลัพธ์เป็นไฟล์ข้อความ อาร์กิวเมนต์ String สำหรับเมธอด saveAsTextFile (“”) คือพา ธ สัมบูรณ์ของโฟลเดอร์เอาต์พุต ลองใช้คำสั่งต่อไปนี้เพื่อบันทึกผลลัพธ์ในไฟล์ข้อความ ในตัวอย่างต่อไปนี้โฟลเดอร์ 'output' อยู่ในตำแหน่งปัจจุบัน
scala> counts.saveAsTextFile("output")การตรวจสอบเอาต์พุต
เปิดเทอร์มินัลอื่นเพื่อไปที่โฮมไดเร็กทอรี (โดยที่ spark ถูกเรียกใช้ในเทอร์มินัลอื่น) ใช้คำสั่งต่อไปนี้เพื่อตรวจสอบไดเร็กทอรีเอาต์พุต
[hadoop@localhost ~]$ cd output/
[hadoop@localhost output]$ ls -1
part-00000
part-00001
_SUCCESSคำสั่งต่อไปนี้ใช้เพื่อดูผลลัพธ์จาก Part-00000 ไฟล์.
[hadoop@localhost output]$ cat part-00000เอาต์พุต
(people,1)
(are,2)
(not,1)
(as,8)
(beautiful,2)
(they, 7)
(look,1)คำสั่งต่อไปนี้ใช้เพื่อดูผลลัพธ์จาก Part-00001 ไฟล์.
[hadoop@localhost output]$ cat part-00001เอาต์พุต
(walk, 1)
(or, 1)
(talk, 1)
(only, 1)
(love, 1)
(care, 1)
(share, 1)UN ยังคงมีการจัดเก็บ
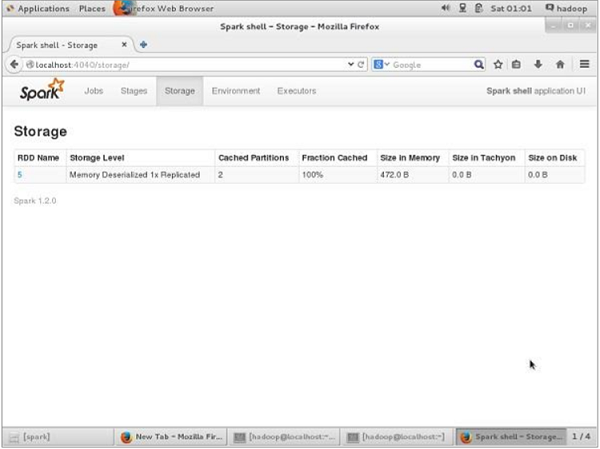
ก่อน UN-persisting หากคุณต้องการดูพื้นที่เก็บข้อมูลที่ใช้สำหรับแอปพลิเคชันนี้ให้ใช้ URL ต่อไปนี้ในเบราว์เซอร์ของคุณ
http://localhost:4040คุณจะเห็นหน้าจอต่อไปนี้ซึ่งแสดงพื้นที่เก็บข้อมูลที่ใช้สำหรับแอปพลิเคชันซึ่งทำงานบน Spark shell

หากคุณต้องการยกเลิกพื้นที่เก็บข้อมูลของ RDD เฉพาะให้ใช้คำสั่งต่อไปนี้
Scala> counts.unpersist()คุณจะเห็นผลลัพธ์ดังนี้ -
15/06/27 00:57:33 INFO ShuffledRDD: Removing RDD 9 from persistence list
15/06/27 00:57:33 INFO BlockManager: Removing RDD 9
15/06/27 00:57:33 INFO BlockManager: Removing block rdd_9_1
15/06/27 00:57:33 INFO MemoryStore: Block rdd_9_1 of size 480 dropped from memory (free 280061810)
15/06/27 00:57:33 INFO BlockManager: Removing block rdd_9_0
15/06/27 00:57:33 INFO MemoryStore: Block rdd_9_0 of size 296 dropped from memory (free 280062106)
res7: cou.type = ShuffledRDD[9] at reduceByKey at <console>:14สำหรับการตรวจสอบพื้นที่จัดเก็บในเบราว์เซอร์ให้ใช้ URL ต่อไปนี้
http://localhost:4040/คุณจะเห็นหน้าจอต่อไปนี้ แสดงพื้นที่เก็บข้อมูลที่ใช้สำหรับแอปพลิเคชันซึ่งทำงานบน Spark shell
แอปพลิเคชัน Spark โดยใช้ spark-submit เป็นคำสั่งเชลล์ที่ใช้ในการปรับใช้แอปพลิเคชัน Spark บนคลัสเตอร์ ใช้ตัวจัดการคลัสเตอร์ตามลำดับทั้งหมดผ่านอินเทอร์เฟซที่เหมือนกัน ดังนั้นคุณไม่จำเป็นต้องกำหนดค่าแอปพลิเคชันของคุณสำหรับแต่ละแอปพลิเคชัน
ตัวอย่าง
ให้เรานำตัวอย่างการนับจำนวนคำที่เราเคยใช้มาก่อนโดยใช้คำสั่งเชลล์ ที่นี่เราพิจารณาตัวอย่างเดียวกับแอปพลิเคชันจุดประกาย
อินพุตตัวอย่าง
ข้อความต่อไปนี้คือข้อมูลอินพุตและไฟล์ชื่อคือ in.txt.
people are not as beautiful as they look,
as they walk or as they talk.
they are only as beautiful as they love,
as they care as they share.ดูโปรแกรมต่อไปนี้ -
SparkWordCount.scala
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark._
object SparkWordCount {
def main(args: Array[String]) {
val sc = new SparkContext( "local", "Word Count", "/usr/local/spark", Nil, Map(), Map())
/* local = master URL; Word Count = application name; */
/* /usr/local/spark = Spark Home; Nil = jars; Map = environment */
/* Map = variables to work nodes */
/*creating an inputRDD to read text file (in.txt) through Spark context*/
val input = sc.textFile("in.txt")
/* Transform the inputRDD into countRDD */
val count = input.flatMap(line ⇒ line.split(" "))
.map(word ⇒ (word, 1))
.reduceByKey(_ + _)
/* saveAsTextFile method is an action that effects on the RDD */
count.saveAsTextFile("outfile")
System.out.println("OK");
}
}บันทึกโปรแกรมข้างต้นลงในไฟล์ชื่อ SparkWordCount.scala และวางไว้ในไดเร็กทอรีที่ผู้ใช้กำหนดชื่อ spark-application.
Note - ในขณะที่เปลี่ยน inputRDD เป็น countRDD เรากำลังใช้ flatMap () สำหรับการโทเค็นบรรทัด (จากไฟล์ข้อความ) เป็นคำวิธี map () สำหรับการนับความถี่ของคำและวิธีการ ReduceByKey () สำหรับการนับการซ้ำแต่ละคำ
ใช้ขั้นตอนต่อไปนี้เพื่อส่งใบสมัครนี้ ดำเนินการตามขั้นตอนทั้งหมดในไฟล์spark-application ไดเร็กทอรีผ่านเทอร์มินัล
ขั้นตอนที่ 1: ดาวน์โหลด Spark Ja
ต้องใช้ Spark core jar สำหรับการคอมไพล์ดังนั้นดาวน์โหลด spark-core_2.10-1.3.0.jar จากลิงค์ต่อไปนี้Spark core jarและย้ายไฟล์ jar จากไดเร็กทอรีดาวน์โหลดไปที่spark-application ไดเรกทอรี
ขั้นตอนที่ 2: รวบรวมโปรแกรม
รวบรวมโปรแกรมด้านบนโดยใช้คำสั่งที่ระบุด้านล่าง คำสั่งนี้ควรดำเนินการจากไดเร็กทอรี spark-application ที่นี่/usr/local/spark/lib/spark-assembly-1.4.0-hadoop2.6.0.jar เป็นโถสนับสนุน Hadoop ที่นำมาจากห้องสมุด Spark
$ scalac -classpath "spark-core_2.10-1.3.0.jar:/usr/local/spark/lib/spark-assembly-1.4.0-hadoop2.6.0.jar" SparkPi.scalaขั้นตอนที่ 3: สร้าง JAR
สร้างไฟล์ jar ของแอปพลิเคชัน spark โดยใช้คำสั่งต่อไปนี้ ที่นี่wordcount คือชื่อไฟล์สำหรับไฟล์ jar
jar -cvf wordcount.jar SparkWordCount*.class spark-core_2.10-1.3.0.jar/usr/local/spark/lib/spark-assembly-1.4.0-hadoop2.6.0.jarขั้นตอนที่ 4: ส่งใบสมัคร Spark
ส่งแอปพลิเคชัน spark โดยใช้คำสั่งต่อไปนี้ -
spark-submit --class SparkWordCount --master local wordcount.jarหากดำเนินการสำเร็จคุณจะพบผลลัพธ์ที่ระบุด้านล่าง OKการปล่อยให้เอาต์พุตต่อไปนี้มีไว้สำหรับการระบุผู้ใช้และนั่นคือบรรทัดสุดท้ายของโปรแกรม หากคุณอ่านผลลัพธ์ต่อไปนี้อย่างละเอียดคุณจะพบสิ่งต่างๆเช่น -
- เริ่มบริการ 'sparkDriver' บนพอร์ต 42954 เรียบร้อยแล้ว
- MemoryStore เริ่มต้นด้วยความจุ 267.3 MB
- เริ่มต้น SparkUI ที่ http://192.168.1.217:4040
- เพิ่มไฟล์ JAR: /home/hadoop/piapplication/count.jar
- ResultStage 1 (saveAsTextFile ที่ SparkPi.scala: 11) เสร็จใน 0.566 วินาที
- หยุด Spark web UI ที่ http://192.168.1.217:4040
- เคลียร์ MemoryStore แล้ว
15/07/08 13:56:04 INFO Slf4jLogger: Slf4jLogger started
15/07/08 13:56:04 INFO Utils: Successfully started service 'sparkDriver' on port 42954.
15/07/08 13:56:04 INFO Remoting: Remoting started; listening on addresses :[akka.tcp://[email protected]:42954]
15/07/08 13:56:04 INFO MemoryStore: MemoryStore started with capacity 267.3 MB
15/07/08 13:56:05 INFO HttpServer: Starting HTTP Server
15/07/08 13:56:05 INFO Utils: Successfully started service 'HTTP file server' on port 56707.
15/07/08 13:56:06 INFO SparkUI: Started SparkUI at http://192.168.1.217:4040
15/07/08 13:56:07 INFO SparkContext: Added JAR file:/home/hadoop/piapplication/count.jar at http://192.168.1.217:56707/jars/count.jar with timestamp 1436343967029
15/07/08 13:56:11 INFO Executor: Adding file:/tmp/spark-45a07b83-42ed-42b3b2c2-823d8d99c5af/userFiles-df4f4c20-a368-4cdd-a2a7-39ed45eb30cf/count.jar to class loader
15/07/08 13:56:11 INFO HadoopRDD: Input split: file:/home/hadoop/piapplication/in.txt:0+54
15/07/08 13:56:12 INFO Executor: Finished task 0.0 in stage 0.0 (TID 0). 2001 bytes result sent to driver
(MapPartitionsRDD[5] at saveAsTextFile at SparkPi.scala:11), which is now runnable
15/07/08 13:56:12 INFO DAGScheduler: Submitting 1 missing tasks from ResultStage 1 (MapPartitionsRDD[5] at saveAsTextFile at SparkPi.scala:11)
15/07/08 13:56:13 INFO DAGScheduler: ResultStage 1 (saveAsTextFile at SparkPi.scala:11) finished in 0.566 s
15/07/08 13:56:13 INFO DAGScheduler: Job 0 finished: saveAsTextFile at SparkPi.scala:11, took 2.892996 s
OK
15/07/08 13:56:13 INFO SparkContext: Invoking stop() from shutdown hook
15/07/08 13:56:13 INFO SparkUI: Stopped Spark web UI at http://192.168.1.217:4040
15/07/08 13:56:13 INFO DAGScheduler: Stopping DAGScheduler
15/07/08 13:56:14 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
15/07/08 13:56:14 INFO Utils: path = /tmp/spark-45a07b83-42ed-42b3-b2c2823d8d99c5af/blockmgr-ccdda9e3-24f6-491b-b509-3d15a9e05818, already present as root for deletion.
15/07/08 13:56:14 INFO MemoryStore: MemoryStore cleared
15/07/08 13:56:14 INFO BlockManager: BlockManager stopped
15/07/08 13:56:14 INFO BlockManagerMaster: BlockManagerMaster stopped
15/07/08 13:56:14 INFO SparkContext: Successfully stopped SparkContext
15/07/08 13:56:14 INFO Utils: Shutdown hook called
15/07/08 13:56:14 INFO Utils: Deleting directory /tmp/spark-45a07b83-42ed-42b3b2c2-823d8d99c5af
15/07/08 13:56:14 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!ขั้นตอนที่ 5: การตรวจสอบผลลัพธ์
หลังจากดำเนินการโปรแกรมสำเร็จคุณจะพบไดเร็กทอรีชื่อ outfile ในไดเร็กทอรี spark-application
คำสั่งต่อไปนี้ใช้สำหรับเปิดและตรวจสอบรายการไฟล์ในไดเร็กทอรี outfile
$ cd outfile
$ ls
Part-00000 part-00001 _SUCCESSคำสั่งสำหรับตรวจสอบเอาต์พุตใน part-00000 ไฟล์คือ -
$ cat part-00000
(people,1)
(are,2)
(not,1)
(as,8)
(beautiful,2)
(they, 7)
(look,1)คำสั่งในการตรวจสอบเอาต์พุตในไฟล์ part-00001 คือ -
$ cat part-00001
(walk, 1)
(or, 1)
(talk, 1)
(only, 1)
(love, 1)
(care, 1)
(share, 1)อ่านหัวข้อต่อไปนี้เพื่อเรียนรู้เพิ่มเติมเกี่ยวกับคำสั่ง 'spark-submit'
Spark-submit Syntax
spark-submit [options] <app jar | python file> [app arguments]ตัวเลือก
| ส. เลขที่ | ตัวเลือก | คำอธิบาย |
|---|---|---|
| 1 | - อาจารย์ | spark: // host: port, mesos: // host: port, yarn หรือ local |
| 2 | - โหมดใช้งานได้ | ไม่ว่าจะเปิดโปรแกรมไดรเวอร์ในเครื่อง ("ไคลเอนต์") หรือบนเครื่องของผู้ปฏิบัติงานเครื่องใดเครื่องหนึ่งภายในคลัสเตอร์ ("คลัสเตอร์") (ค่าเริ่มต้น: ไคลเอนต์) |
| 3 | - คลาส | คลาสหลักของแอปพลิเคชันของคุณ (สำหรับแอป Java / Scala) |
| 4 | --ชื่อ | ชื่อแอปพลิเคชันของคุณ |
| 5 | - ขวด | รายการ jar ในเครื่องที่คั่นด้วยจุลภาคที่จะรวมไว้ในคลาสพา ธ ของไดรเวอร์และตัวดำเนินการ |
| 6 | - แพคเกจ | รายการพิกัด maven ที่คั่นด้วยจุลภาคที่จะรวมไว้ในคลาสพา ธ ของไดรเวอร์และตัวดำเนินการ |
| 7 | - องค์ประกอบ | รายการที่เก็บรีโมตเพิ่มเติมที่คั่นด้วยจุลภาคเพื่อค้นหาพิกัด maven ที่ให้มากับ --packages |
| 8 | --py ไฟล์ | รายการไฟล์. zip, .egg หรือ. py ที่คั่นด้วยจุลภาคเพื่อวางบน PYTHON PATH สำหรับแอป Python |
| 9 | - ไฟล์ | รายการไฟล์ที่คั่นด้วยจุลภาคที่จะวางในไดเร็กทอรีการทำงานของแต่ละตัวดำเนินการ |
| 10 | --conf (เสา = วาล) | คุณสมบัติการกำหนดค่า Spark โดยพลการ |
| 11 | - คุณสมบัติไฟล์ | พา ธ ไปยังไฟล์ที่จะโหลดคุณสมบัติพิเศษ หากไม่ได้ระบุจะเป็นการค้นหา conf / spark-defaults |
| 12 | - ไขควงหน่วยความจำ | หน่วยความจำสำหรับไดรเวอร์ (เช่น 1000M, 2G) (ค่าเริ่มต้น: 512M) |
| 13 | - ตัวเลือก -driver-java | ตัวเลือก Java เพิ่มเติมเพื่อส่งผ่านไปยังไดรเวอร์ |
| 14 | --driver- ไลบรารีเส้นทาง | รายการพา ธ ไลบรารีเพิ่มเติมเพื่อส่งผ่านไปยังไดรเวอร์ |
| 15 | - ไดร์ - คลาส - พา ธ | รายการพา ธ คลาสพิเศษเพื่อส่งผ่านไปยังไดรเวอร์ โปรดทราบว่า jars ที่เพิ่มด้วย --jars จะรวมอยู่ใน classpath โดยอัตโนมัติ |
| 16 | - ผู้ดำเนินการหน่วยความจำ | หน่วยความจำต่อตัวดำเนินการ (เช่น 1000M, 2G) (ค่าเริ่มต้น: 1G) |
| 17 | - ผู้ใช้พร็อกซี | ผู้ใช้ที่จะแอบอ้างเมื่อส่งใบสมัคร |
| 18 | - ช่วยเหลือ, -h | แสดงข้อความช่วยเหลือนี้และออก |
| 19 | --verbose, -v | พิมพ์เอาต์พุตการดีบักเพิ่มเติม |
| 20 | - รุ่น | พิมพ์ Spark เวอร์ชันปัจจุบัน |
| 21 | - แกน NUM | แกนสำหรับไดรเวอร์ (ค่าเริ่มต้น: 1) |
| 22 | - ดูแล | หากได้รับให้รีสตาร์ทไดรเวอร์เมื่อเกิดความล้มเหลว |
| 23 | --ฆ่า | หากกำหนดให้ฆ่าไดรเวอร์ที่ระบุ |
| 24 | --สถานะ | หากได้รับให้ร้องขอสถานะของไดรเวอร์ที่ระบุ |
| 25 | - รวม - ตัวดำเนินการ - คอร์ | คอร์ทั้งหมดสำหรับตัวดำเนินการทั้งหมด |
| 26 | - ผู้ดำเนินการ - คอร์ | จำนวนคอร์ต่อตัวดำเนินการ (ค่าเริ่มต้น: 1 ในโหมด YARN หรือแกนที่มีอยู่ทั้งหมดของผู้ปฏิบัติงานในโหมดสแตนด์อโลน) |
Spark มีตัวแปรที่ใช้ร่วมกันสองประเภทที่แตกต่างกันหนึ่งคือ broadcast variables และที่สองคือ accumulators.
Broadcast variables - ใช้เพื่อกระจายมูลค่าจำนวนมากอย่างมีประสิทธิภาพ
Accumulators - ใช้เพื่อรวบรวมข้อมูลของคอลเลกชันเฉพาะ
ตัวแปรการออกอากาศ
ตัวแปร Broadcast ช่วยให้โปรแกรมเมอร์เก็บตัวแปรแบบอ่านอย่างเดียวที่แคชไว้ในแต่ละเครื่องแทนที่จะส่งสำเนาไปพร้อมกับงาน ตัวอย่างเช่นสามารถใช้เพื่อให้ทุกโหนดสำเนาของชุดข้อมูลอินพุตขนาดใหญ่ได้อย่างมีประสิทธิภาพ นอกจากนี้ Spark ยังพยายามกระจายตัวแปรออกอากาศโดยใช้อัลกอริทึมการออกอากาศที่มีประสิทธิภาพเพื่อลดต้นทุนการสื่อสาร
การดำเนินการของ Spark จะดำเนินการผ่านชุดของขั้นตอนโดยคั่นด้วยการดำเนินการแบบ "สุ่ม" แบบกระจาย Spark ออกอากาศข้อมูลทั่วไปที่จำเป็นสำหรับงานในแต่ละขั้นตอนโดยอัตโนมัติ
ข้อมูลที่ออกอากาศด้วยวิธีนี้จะถูกแคชในรูปแบบอนุกรมและจะถูก deserialized ก่อนที่จะรันแต่ละงาน ซึ่งหมายความว่าการสร้างตัวแปรออกอากาศอย่างชัดเจนจะมีประโยชน์ก็ต่อเมื่องานในหลายขั้นตอนต้องการข้อมูลเดียวกันหรือเมื่อการแคชข้อมูลในรูปแบบ deserialized เป็นสิ่งสำคัญ
ตัวแปรออกอากาศถูกสร้างขึ้นจากตัวแปร v โทร SparkContext.broadcast(v). ตัวแปรการออกอากาศคือกระดาษห่อหุ้มรอบ ๆvและสามารถเข้าถึงค่าได้โดยเรียกไฟล์ valueวิธี. รหัสที่ระบุด้านล่างแสดงสิ่งนี้ -
scala> val broadcastVar = sc.broadcast(Array(1, 2, 3))Output -
broadcastVar: org.apache.spark.broadcast.Broadcast[Array[Int]] = Broadcast(0)หลังจากสร้างตัวแปรออกอากาศแล้วควรใช้แทนค่า v ในฟังก์ชันใด ๆ ที่รันบนคลัสเตอร์ดังนั้น vจะไม่ถูกส่งไปยังโหนดมากกว่าหนึ่งครั้ง นอกจากนี้วัตถุv ไม่ควรแก้ไขหลังจากการออกอากาศเพื่อให้แน่ใจว่าโหนดทั้งหมดได้รับค่าตัวแปรออกอากาศเท่ากัน
ผู้สะสม
ตัวสะสมเป็นตัวแปรที่ "เพิ่ม" ผ่านการดำเนินการเชื่อมโยงเท่านั้นดังนั้นจึงสามารถรองรับได้อย่างมีประสิทธิภาพควบคู่กันไป สามารถใช้เพื่อใช้ตัวนับ (เช่นเดียวกับ MapReduce) หรือผลรวม Spark รองรับตัวสะสมประเภทตัวเลขและโปรแกรมเมอร์สามารถเพิ่มการรองรับสำหรับประเภทใหม่ได้ หากมีการสร้างตัวสะสมด้วยชื่อจะปรากฏในSpark’s UI. สิ่งนี้จะเป็นประโยชน์สำหรับการทำความเข้าใจความคืบหน้าของขั้นตอนการทำงาน (หมายเหตุ - ยังไม่รองรับ Python)
ตัวสะสมถูกสร้างขึ้นจากค่าเริ่มต้น v โทร SparkContext.accumulator(v). งานที่รันบนคลัสเตอร์สามารถเพิ่มเข้าไปได้โดยใช้addmethod หรือตัวดำเนินการ + = (ใน Scala และ Python) อย่างไรก็ตามพวกเขาไม่สามารถอ่านค่าของมันได้ เฉพาะโปรแกรมไดรเวอร์เท่านั้นที่สามารถอ่านค่าของตัวสะสมโดยใช้ไฟล์value วิธี.
รหัสที่ระบุด้านล่างแสดงตัวสะสมที่ใช้ในการเพิ่มองค์ประกอบของอาร์เรย์ -
scala> val accum = sc.accumulator(0)
scala> sc.parallelize(Array(1, 2, 3, 4)).foreach(x => accum += x)หากคุณต้องการดูผลลัพธ์ของโค้ดด้านบนให้ใช้คำสั่งต่อไปนี้ -
scala> accum.valueเอาต์พุต
res2: Int = 10การดำเนินการ RDD ตัวเลข
Spark ช่วยให้คุณดำเนินการต่างๆกับข้อมูลตัวเลขโดยใช้หนึ่งในวิธี API ที่กำหนดไว้ล่วงหน้า การดำเนินการเชิงตัวเลขของ Spark ถูกนำไปใช้กับอัลกอริทึมการสตรีมที่ช่วยให้สร้างโมเดลทีละองค์ประกอบ
การดำเนินการเหล่านี้คำนวณและส่งคืนเป็นไฟล์ StatusCounter วัตถุโดยการโทร status() วิธี.
| ส. เลขที่ | วิธีการและความหมาย |
|---|---|
| 1 | count() จำนวนองค์ประกอบใน RDD |
| 2 | Mean() ค่าเฉลี่ยขององค์ประกอบใน RDD |
| 3 | Sum() มูลค่ารวมขององค์ประกอบใน RDD |
| 4 | Max() ค่าสูงสุดขององค์ประกอบทั้งหมดใน RDD |
| 5 | Min() ค่าต่ำสุดขององค์ประกอบทั้งหมดใน RDD |
| 6 | Variance() ความแปรปรวนขององค์ประกอบ |
| 7 | Stdev() ส่วนเบี่ยงเบนมาตรฐาน. |
หากคุณต้องการใช้เพียงวิธีใดวิธีหนึ่งคุณสามารถเรียกใช้วิธีการที่เกี่ยวข้องได้โดยตรงบน RDD