Apache Tajo - คู่มือฉบับย่อ
ระบบคลังข้อมูลแบบกระจาย
คลังข้อมูลเป็นฐานข้อมูลเชิงสัมพันธ์ที่ออกแบบมาเพื่อการสืบค้นและการวิเคราะห์แทนที่จะใช้สำหรับการประมวลผลธุรกรรม เป็นชุดข้อมูลที่มุ่งเน้นเชิงบูรณาการตัวแปรเวลาและไม่ลบเลือน ข้อมูลนี้ช่วยให้นักวิเคราะห์สามารถตัดสินใจอย่างชาญฉลาดในองค์กร แต่ปริมาณข้อมูลเชิงสัมพันธ์จะเพิ่มขึ้นทุกวัน
เพื่อเอาชนะความท้าทายระบบคลังข้อมูลแบบกระจายจะแบ่งปันข้อมูลในที่เก็บข้อมูลหลายแห่งเพื่อจุดประสงค์ในการประมวลผลการวิเคราะห์ออนไลน์ (OLAP) คลังข้อมูลแต่ละแห่งอาจเป็นขององค์กรตั้งแต่หนึ่งองค์กรขึ้นไป ทำการปรับสมดุลภาระงานและปรับขนาดได้ ข้อมูลเมตาถูกจำลองแบบและแจกจ่ายจากส่วนกลาง
Apache Tajo เป็นระบบคลังข้อมูลแบบกระจายซึ่งใช้ Hadoop Distributed File System (HDFS) เป็นชั้นจัดเก็บข้อมูลและมีเอ็นจิ้นการดำเนินการสืบค้นของตัวเองแทนกรอบ MapReduce
ภาพรวมของ SQL บน Hadoop
Hadoop เป็นเฟรมเวิร์กโอเพนซอร์สที่อนุญาตให้จัดเก็บและประมวลผลข้อมูลขนาดใหญ่ในสภาพแวดล้อมแบบกระจาย มันเร็วและทรงพลังมาก อย่างไรก็ตาม Hadoop มีความสามารถในการสืบค้นที่ จำกัด ดังนั้นจึงสามารถปรับปรุงประสิทธิภาพได้ดียิ่งขึ้นด้วยความช่วยเหลือของ SQL บน Hadoop สิ่งนี้ช่วยให้ผู้ใช้สามารถโต้ตอบกับ Hadoop ผ่านคำสั่ง SQL ง่ายๆ
ตัวอย่างบางส่วนของ SQL บนแอปพลิเคชัน Hadoop ได้แก่ Hive, Impala, Drill, Presto, Spark, HAWQ และ Apache Tajo
Apache Tajo คืออะไร
Apache Tajo เป็นกรอบการประมวลผลข้อมูลเชิงสัมพันธ์และแบบกระจาย ออกแบบมาเพื่อความหน่วงแฝงต่ำและการวิเคราะห์คำค้นหาเฉพาะกิจที่ปรับขนาดได้
Tajo รองรับ SQL มาตรฐานและรูปแบบข้อมูลต่างๆ แบบสอบถามส่วนใหญ่ของ Tajo สามารถดำเนินการได้โดยไม่ต้องแก้ไขใด ๆ
ตาโจมี fault-tolerance ผ่านกลไกการรีสตาร์ทสำหรับงานที่ล้มเหลวและเอ็นจิ้นการเขียนคิวรีที่ขยายได้
ทาโจดำเนินการที่จำเป็น ETL (Extract Transform and Load process)การดำเนินการเพื่อสรุปชุดข้อมูลขนาดใหญ่ที่จัดเก็บบน HDFS เป็นอีกทางเลือกหนึ่งของ Hive / Pig
Tajo เวอร์ชันล่าสุดมีการเชื่อมต่อที่ดีกว่ากับโปรแกรม Java และฐานข้อมูลของบุคคลที่สามเช่น Oracle และ PostGreSQL
คุณสมบัติของ Apache Tajo
Apache Tajo มีคุณสมบัติดังต่อไปนี้ -
- ความสามารถในการปรับขนาดที่เหนือกว่าและประสิทธิภาพที่ดีที่สุด
- เวลาแฝงต่ำ
- ฟังก์ชันที่ผู้ใช้กำหนดเอง
- กรอบการประมวลผลการจัดเก็บแถว / คอลัมน์
- ความเข้ากันได้กับ HiveQL และ Hive MetaStore
- การไหลของข้อมูลที่เรียบง่ายและการบำรุงรักษาง่าย
ประโยชน์ของ Apache Tajo
Apache Tajo มอบสิทธิประโยชน์ดังต่อไปนี้ -
- ง่ายต่อการใช้
- สถาปัตยกรรมที่เรียบง่าย
- การเพิ่มประสิทธิภาพการสืบค้นตามต้นทุน
- แผนการดำเนินการค้นหาแบบเวกเตอร์
- จัดส่งที่รวดเร็ว
- กลไก I / O ที่เรียบง่ายและรองรับการจัดเก็บประเภทต่างๆ
- ความทนทานต่อความผิดพลาด
ใช้กรณีของ Apache Tajo
ต่อไปนี้เป็นกรณีการใช้งานบางส่วนของ Apache Tajo -
คลังข้อมูลและการวิเคราะห์
บริษัท SK Telecom ของเกาหลีดำเนินการกับ Tajo โดยใช้ข้อมูลที่มีมูลค่า 1.7 เทราไบต์และพบว่าสามารถดำเนินการสืบค้นด้วยความเร็วสูงกว่า Hive หรือ Impala
การค้นพบข้อมูล
บริการสตรีมเพลงของเกาหลี Melon ใช้ Tajo สำหรับการประมวลผลเชิงวิเคราะห์ Tajo ดำเนินงาน ETL (ขั้นตอนการแยกการแปลง - โหลด) เร็วกว่า Hive 1.5 ถึง 10 เท่า
การวิเคราะห์บันทึก
Bluehole Studio บริษัท สัญชาติเกาหลีพัฒนา TERA - เกมออนไลน์แบบผู้เล่นหลายคนแฟนตาซี บริษัท ใช้ Tajo สำหรับการวิเคราะห์บันทึกเกมและค้นหาสาเหตุหลักของการขัดจังหวะคุณภาพบริการ
รูปแบบการจัดเก็บและข้อมูล
Apache Tajo รองรับรูปแบบข้อมูลต่อไปนี้ -
- JSON
- ไฟล์ข้อความ (CSV)
- Parquet
- ไฟล์ลำดับ
- AVRO
- บัฟเฟอร์โปรโตคอล
- Apache Orc
Tajo รองรับรูปแบบการจัดเก็บดังต่อไปนี้ -
- HDFS
- JDBC
- Amazon S3
- Apache HBase
- Elasticsearch
ภาพประกอบต่อไปนี้แสดงให้เห็นถึงสถาปัตยกรรมของ Apache Tajo

ตารางต่อไปนี้อธิบายรายละเอียดส่วนประกอบแต่ละส่วน
| ส. | ส่วนประกอบและคำอธิบาย |
|---|---|
| 1 | Client Client ส่งคำสั่ง SQL ไปยัง Tajo Master เพื่อรับผลลัพธ์ |
| 2 | Master มาสเตอร์เป็นภูตหลัก มีหน้าที่วางแผนการสืบค้นและเป็นผู้ประสานงานสำหรับคนงาน |
| 3 | Catalog server รักษาคำอธิบายตารางและดัชนี มันฝังอยู่ใน Master daemon เซิร์ฟเวอร์แค็ตตาล็อกใช้ Apache Derby เป็นชั้นจัดเก็บข้อมูลและเชื่อมต่อผ่านไคลเอ็นต์ JDBC |
| 4 | Worker โหนดหลักมอบหมายงานให้กับโหนดของผู้ปฏิบัติงาน TajoWorker ประมวลผลข้อมูล เมื่อจำนวน TajoWorkers เพิ่มขึ้นความสามารถในการประมวลผลก็เพิ่มขึ้นในเชิงเส้น |
| 5 | Query Master Tajo master กำหนดแบบสอบถามให้กับ Query Master Query Master มีหน้าที่ควบคุมแผนการดำเนินการแบบกระจาย เปิดตัว TaskRunner และกำหนดเวลางานให้กับ TaskRunner บทบาทหลักของ Query Master คือการตรวจสอบงานที่กำลังทำงานอยู่และรายงานไปยังโหนดหลัก |
| 6 | Node Managers จัดการทรัพยากรของโหนดผู้ปฏิบัติงาน ตัดสินใจในการจัดสรรคำขอไปยังโหนด |
| 7 | TaskRunner ทำหน้าที่เป็นเครื่องมือดำเนินการสืบค้นภายในเครื่อง ใช้เพื่อเรียกใช้และตรวจสอบกระบวนการสืบค้น TaskRunner ประมวลผลทีละงาน มีคุณสมบัติหลักสามประการดังต่อไปนี้ -
|
| 8 | Query Executor ใช้เพื่อดำเนินการสืบค้น |
| 9 | Storage service เชื่อมต่อที่เก็บข้อมูลพื้นฐานกับ Tajo |
เวิร์กโฟลว์
Tajo ใช้ Hadoop Distributed File System (HDFS) เป็นชั้นจัดเก็บข้อมูลและมีกลไกการดำเนินการสืบค้นของตัวเองแทนกรอบงาน MapReduce คลัสเตอร์ Tajo ประกอบด้วยโหนดหลักหนึ่งโหนดและคนงานจำนวนหนึ่งในโหนดคลัสเตอร์
หลักมีหน้าที่หลักในการวางแผนการสืบค้นและผู้ประสานงานสำหรับคนงาน ต้นแบบแบ่งแบบสอบถามออกเป็นงานเล็ก ๆ และมอบหมายให้คนงาน ผู้ปฏิบัติงานแต่ละคนมีเครื่องมือสืบค้นข้อมูลในพื้นที่ซึ่งเรียกใช้งานกราฟแบบ acyclic ที่กำหนดทิศทางของตัวดำเนินการทางกายภาพ
นอกจากนี้ Tajo ยังสามารถควบคุมการไหลของข้อมูลแบบกระจายได้ยืดหยุ่นกว่า MapReduce และสนับสนุนเทคนิคการสร้างดัชนี
อินเทอร์เฟซบนเว็บของ Tajo มีความสามารถดังต่อไปนี้ -
- ตัวเลือกในการค้นหาวิธีการวางแผนการสืบค้นข้อมูล
- ตัวเลือกในการค้นหาวิธีกระจายแบบสอบถามข้ามโหนด
- ตัวเลือกในการตรวจสอบสถานะของคลัสเตอร์และโหนด
ในการติดตั้ง Apache Tajo คุณต้องมีซอฟต์แวร์ต่อไปนี้ในระบบของคุณ -
- Hadoop เวอร์ชัน 2.3 หรือสูงกว่า
- Java เวอร์ชัน 1.7 หรือสูงกว่า
- Linux หรือ Mac OS
ให้เราทำตามขั้นตอนต่อไปนี้เพื่อติดตั้ง Tajo
ตรวจสอบการติดตั้ง Java
หวังว่าคุณได้ติดตั้ง Java เวอร์ชัน 8 บนเครื่องของคุณแล้ว ตอนนี้คุณต้องดำเนินการต่อโดยการยืนยัน
ในการตรวจสอบให้ใช้คำสั่งต่อไปนี้ -
$ java -versionหากติดตั้ง Java บนเครื่องของคุณสำเร็จคุณจะเห็นเวอร์ชันปัจจุบันของ Java ที่ติดตั้ง หากไม่ได้ติดตั้ง Java ให้ทำตามขั้นตอนเหล่านี้เพื่อติดตั้ง Java 8 บนเครื่องของคุณ
ดาวน์โหลด JDK
ดาวน์โหลด JDK เวอร์ชันล่าสุดโดยไปที่ลิงค์ต่อไปนี้จากนั้นดาวน์โหลดเวอร์ชันล่าสุด
https://www.oracle.com
เวอร์ชันล่าสุดคือ JDK 8u 92 และไฟล์คือ “jdk-8u92-linux-x64.tar.gz”. โปรดดาวน์โหลดไฟล์บนเครื่องของคุณ ต่อไปนี้ให้แตกไฟล์และย้ายไปยังไดเร็กทอรีเฉพาะ ตอนนี้ตั้งค่าทางเลือก Java ในที่สุด Java ก็ถูกติดตั้งบนเครื่องของคุณ
การตรวจสอบการติดตั้ง Hadoop
คุณได้ติดตั้งแล้ว Hadoopในระบบของคุณ ตอนนี้ตรวจสอบโดยใช้คำสั่งต่อไปนี้ -
$ hadoop versionหากทุกอย่างเรียบร้อยในการตั้งค่าของคุณคุณจะเห็นเวอร์ชันของ Hadoop หากไม่ได้ติดตั้ง Hadoop ให้ดาวน์โหลดและติดตั้ง Hadoop โดยไปที่ลิงค์ต่อไปนี้ -https://www.apache.org
การติดตั้ง Apache Tajo
Apache Tajo มีโหมดการทำงานสองโหมด - โหมดโลคัลและโหมดกระจายเต็มรูปแบบ หลังจากตรวจสอบการติดตั้ง Java และ Hadoop แล้วให้ดำเนินการตามขั้นตอนต่อไปนี้เพื่อติดตั้งคลัสเตอร์ Tajo บนเครื่องของคุณ อินสแตนซ์ Tajo ในโหมดโลคัลต้องการการกำหนดค่าที่ง่ายมาก
ดาวน์โหลด Tajo เวอร์ชันล่าสุดโดยไปที่ลิงค์ต่อไปนี้ - https://www.apache.org/dyn/closer.cgi/tajo
ตอนนี้คุณสามารถดาวน์โหลดไฟล์ “tajo-0.11.3.tar.gz” จากเครื่องของคุณ
แตกไฟล์ Tar
แตกไฟล์ tar โดยใช้คำสั่งต่อไปนี้ -
$ cd opt/ $ tar tajo-0.11.3.tar.gz
$ cd tajo-0.11.3ตั้งค่าตัวแปรสภาพแวดล้อม
เพิ่มการเปลี่ยนแปลงต่อไปนี้ใน “conf/tajo-env.sh” ไฟล์
$ cd tajo-0.11.3
$ vi conf/tajo-env.sh
# Hadoop home. Required
export HADOOP_HOME = /Users/path/to/Hadoop/hadoop-2.6.2
# The java implementation to use. Required.
export JAVA_HOME = /path/to/jdk1.8.0_92.jdk/ที่นี่คุณต้องระบุพา ธ Hadoop และ Java ไปที่ “tajo-env.sh”ไฟล์. หลังจากทำการเปลี่ยนแปลงแล้วให้บันทึกไฟล์และออกจากเทอร์มินัล
เริ่มเซิร์ฟเวอร์ Tajo
ในการเปิดเซิร์ฟเวอร์ Tajo ให้ดำเนินการคำสั่งต่อไปนี้ -
$ bin/start-tajo.shคุณจะได้รับคำตอบที่คล้ายกับสิ่งต่อไปนี้ -
Starting single TajoMaster
starting master, logging to /Users/path/to/Tajo/tajo-0.11.3/bin/../
localhost: starting worker, logging to /Users/path/toe/Tajo/tajo-0.11.3/bin/../logs/
Tajo master web UI: http://local:26080
Tajo Client Service: local:26002ตอนนี้พิมพ์คำสั่ง“ jps” เพื่อดู daemons ที่กำลังทำงานอยู่
$ jps
1010 TajoWorker
1140 Jps
933 TajoMasterเปิด Tajo Shell (Tsql)
ในการเปิดใช้งาน Tajo shell ไคลเอ็นต์ให้ใช้คำสั่งต่อไปนี้ -
$ bin/tsqlคุณจะได้รับผลลัพธ์ต่อไปนี้ -
welcome to
_____ ___ _____ ___
/_ _/ _ |/_ _/ /
/ // /_| |_/ // / /
/_//_/ /_/___/ \__/ 0.11.3
Try \? for help.ออกจาก Tajo Shell
ดำเนินการคำสั่งต่อไปนี้เพื่อออกจาก Tsql -
default> \q
bye!ที่นี่ค่าเริ่มต้นหมายถึงแคตตาล็อกใน Tajo
UI ของเว็บ
พิมพ์ URL ต่อไปนี้เพื่อเปิดใช้งานเว็บ UI ของ Tajo - http://localhost:26080/
ตอนนี้คุณจะเห็นหน้าจอต่อไปนี้ซึ่งคล้ายกับตัวเลือก ExecuteQuery

หยุดทาโจ
ในการหยุดเซิร์ฟเวอร์ Tajo ให้ใช้คำสั่งต่อไปนี้ -
$ bin/stop-tajo.shคุณจะได้รับคำตอบดังต่อไปนี้ -
localhost: stopping worker
stopping masterการกำหนดค่าของ Tajo ขึ้นอยู่กับระบบการกำหนดค่าของ Hadoop บทนี้จะอธิบายรายละเอียดการตั้งค่าคอนฟิกของ Tajo
การตั้งค่าพื้นฐาน
Tajo ใช้ไฟล์ config สองไฟล์ต่อไปนี้ -
- catalogue-site.xml - การกำหนดค่าสำหรับเซิร์ฟเวอร์แค็ตตาล็อก
- tajo-site.xml - การกำหนดค่าสำหรับโมดูล Tajo อื่น ๆ
การกำหนดค่าโหมดกระจาย
การตั้งค่าโหมดกระจายจะทำงานบน Hadoop Distributed File System (HDFS) มาทำตามขั้นตอนเพื่อกำหนดการตั้งค่าโหมดกระจาย Tajo
tajo-site.xml
ไฟล์นี้มีให้ @ /path/to/tajo/confไดเร็กทอรีและทำหน้าที่เป็นคอนฟิกูเรชันสำหรับโมดูล Tajo อื่น ๆ ในการเข้าถึง Tajo ในโหมดกระจายให้ใช้การเปลี่ยนแปลงต่อไปนี้กับ“tajo-site.xml”.
<property>
<name>tajo.rootdir</name>
<value>hdfs://hostname:port/tajo</value>
</property>
<property>
<name>tajo.master.umbilical-rpc.address</name>
<value>hostname:26001</value>
</property>
<property>
<name>tajo.master.client-rpc.address</name>
<value>hostname:26002</value>
</property>
<property>
<name>tajo.catalog.client-rpc.address</name>
<value>hostname:26005</value>
</property>การกำหนดค่าโหนดหลัก
Tajo ใช้ HDFS เป็นประเภทจัดเก็บข้อมูลหลัก การกำหนดค่ามีดังนี้และควรเพิ่มเข้าไป“tajo-site.xml”.
<property>
<name>tajo.rootdir</name>
<value>hdfs://namenode_hostname:port/path</value>
</property>การกำหนดค่าแค็ตตาล็อก
หากคุณต้องการปรับแต่งบริการแค็ตตาล็อกให้คัดลอก $path/to/Tajo/conf/catalogsite.xml.template ถึง $path/to/Tajo/conf/catalog-site.xml และเพิ่มการกำหนดค่าใด ๆ ต่อไปนี้ตามต้องการ
ตัวอย่างเช่นถ้าคุณใช้ “Hive catalog store” เพื่อเข้าถึง Tajo จากนั้นการกำหนดค่าควรเป็นดังต่อไปนี้ -
<property>
<name>tajo.catalog.store.class</name>
<value>org.apache.tajo.catalog.store.HCatalogStore</value>
</property>หากต้องการจัดเก็บ MySQL แคตตาล็อกจากนั้นใช้การเปลี่ยนแปลงต่อไปนี้ -
<property>
<name>tajo.catalog.store.class</name>
<value>org.apache.tajo.catalog.store.MySQLStore</value>
</property>
<property>
<name>tajo.catalog.jdbc.connection.id</name>
<value><mysql user name></value>
</property>
<property>
<name>tajo.catalog.jdbc.connection.password</name>
<value><mysql user password></value>
</property>
<property>
<name>tajo.catalog.jdbc.uri</name>
<value>jdbc:mysql://<mysql host name>:<mysql port>/<database name for tajo>
?createDatabaseIfNotExist = true</value>
</property>ในทำนองเดียวกันคุณสามารถลงทะเบียนแค็ตตาล็อกอื่น ๆ ที่รองรับ Tajo ในไฟล์การกำหนดค่า
การกำหนดค่าผู้ปฏิบัติงาน
ตามค่าเริ่มต้น TajoWorker จะเก็บข้อมูลชั่วคราวบนระบบไฟล์ภายในเครื่อง ถูกกำหนดไว้ในไฟล์“ tajo-site.xml” ดังนี้ -
<property>
<name>tajo.worker.tmpdir.locations</name>
<value>/disk1/tmpdir,/disk2/tmpdir,/disk3/tmpdir</value>
</property>ในการเพิ่มขีดความสามารถในการรันงานของทรัพยากรผู้ปฏิบัติงานแต่ละรายการให้เลือกการกำหนดค่าต่อไปนี้ -
<property>
<name>tajo.worker.resource.cpu-cores</name>
<value>12</value>
</property>
<property>
<name>tajo.task.resource.min.memory-mb</name>
<value>2000</value>
</property>
<property>
<name>tajo.worker.resource.disks</name>
<value>4</value>
</property>ในการทำให้ผู้ปฏิบัติงาน Tajo ทำงานในโหมดเฉพาะให้เลือกการกำหนดค่าต่อไปนี้ -
<property>
<name>tajo.worker.resource.dedicated</name>
<value>true</value>
</property>ในบทนี้เราจะเข้าใจคำสั่งของ Tajo Shell โดยละเอียด
ในการดำเนินการคำสั่งเปลือก Tajo คุณต้องเริ่มต้นเซิร์ฟเวอร์ Tajo และเชลล์ Tajo โดยใช้คำสั่งต่อไปนี้ -
เริ่มเซิร์ฟเวอร์
$ bin/start-tajo.shเริ่มเชลล์
$ bin/tsqlคำสั่งข้างต้นพร้อมสำหรับการดำเนินการแล้ว
คำสั่ง Meta
ให้เราพูดคุยเกี่ยวกับ Meta Commands. คำสั่ง Tsql meta เริ่มต้นด้วยแบ็กสแลช(‘\’).
คำสั่งช่วยเหลือ
“\?” คำสั่งใช้เพื่อแสดงตัวเลือกวิธีใช้
Query
default> \?Result
ข้างบน \?คำสั่งแสดงรายการตัวเลือกการใช้งานพื้นฐานทั้งหมดใน Tajo คุณจะได้รับผลลัพธ์ต่อไปนี้ -
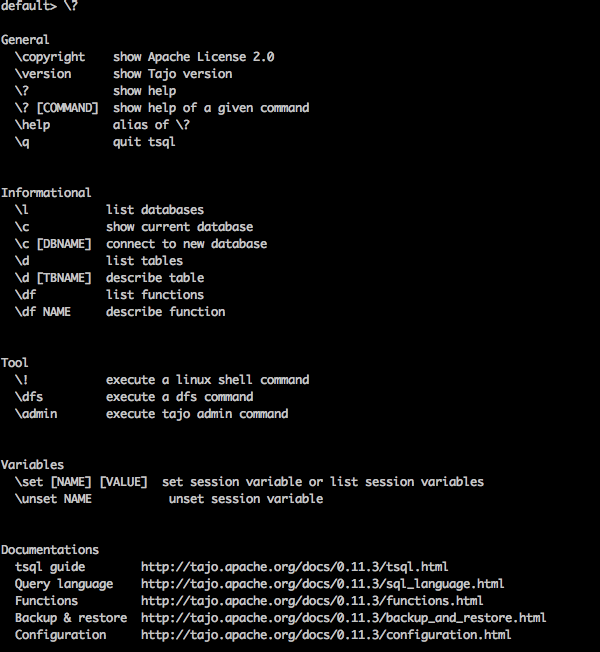
ฐานข้อมูลรายการ
ในการแสดงรายการฐานข้อมูลทั้งหมดใน Tajo ให้ใช้คำสั่งต่อไปนี้ -
Query
default> \lResult
คุณจะได้รับผลลัพธ์ต่อไปนี้ -
information_schema
defaultในปัจจุบันเรายังไม่ได้สร้างฐานข้อมูลใด ๆ ดังนั้นจึงแสดงฐานข้อมูล Tajo ที่สร้างขึ้นสองฐานข้อมูล
ฐานข้อมูลปัจจุบัน
\c ใช้เพื่อแสดงชื่อฐานข้อมูลปัจจุบัน
Query
default> \cResult
ขณะนี้คุณเชื่อมต่อกับฐานข้อมูล "ค่าเริ่มต้น" เป็นผู้ใช้ "ชื่อผู้ใช้"
แสดงรายการฟังก์ชันในตัว
หากต้องการแสดงรายการฟังก์ชันในตัวทั้งหมดให้พิมพ์แบบสอบถามดังนี้ -
Query
default> \dfResult
คุณจะได้รับผลลัพธ์ต่อไปนี้ -

อธิบายฟังก์ชัน
\df function name - แบบสอบถามนี้ส่งกลับคำอธิบายทั้งหมดของฟังก์ชันที่กำหนด
Query
default> \df sqrtResult
คุณจะได้รับผลลัพธ์ต่อไปนี้ -

ออกจาก Terminal
หากต้องการออกจากเทอร์มินัลให้พิมพ์แบบสอบถามต่อไปนี้ -
Query
default> \qResult
คุณจะได้รับผลลัพธ์ต่อไปนี้ -
bye!คำสั่งผู้ดูแลระบบ
เปลือกทาโจให้ \admin ตัวเลือกเพื่อแสดงรายการคุณลักษณะของผู้ดูแลระบบทั้งหมด
Query
default> \adminResult
คุณจะได้รับผลลัพธ์ต่อไปนี้ -

ข้อมูลคลัสเตอร์
หากต้องการแสดงข้อมูลคลัสเตอร์ใน Tajo ให้ใช้แบบสอบถามต่อไปนี้
Query
default> \admin -clusterResult
คุณจะได้รับผลลัพธ์ต่อไปนี้ -

แสดงต้นแบบ
แบบสอบถามต่อไปนี้แสดงข้อมูลหลักปัจจุบัน
Query
default> \admin -showmastersResult
localhostในทำนองเดียวกันคุณสามารถลองใช้คำสั่งอื่น ๆ ของผู้ดูแลระบบได้
ตัวแปรเซสชัน
ไคลเอนต์ Tajo เชื่อมต่อกับ Master ผ่านรหัสเซสชันที่ไม่ซ้ำกัน เซสชันจะใช้งานได้จนกว่าไคลเอ็นต์จะถูกตัดการเชื่อมต่อหรือหมดอายุ
คำสั่งต่อไปนี้ใช้เพื่อแสดงรายการตัวแปรเซสชันทั้งหมด
Query
default> \setResult
'SESSION_LAST_ACCESS_TIME' = '1470206387146'
'CURRENT_DATABASE' = 'default'
‘USERNAME’ = 'user'
'SESSION_ID' = 'c60c9b20-dfba-404a-822f-182bc95d6c7c'
'TIMEZONE' = 'Asia/Kolkata'
'FETCH_ROWNUM' = '200'
‘COMPRESSED_RESULT_TRANSFER' = 'false'\set key val จะตั้งชื่อตัวแปรเซสชัน key ด้วยค่า val. ตัวอย่างเช่น,
Query
default> \set ‘current_database’='default'Result
usage: \set [[NAME] VALUE]ที่นี่คุณสามารถกำหนดคีย์และค่าในไฟล์ \setคำสั่ง หากคุณต้องการยกเลิกการเปลี่ยนแปลงให้ใช้ไฟล์\unset คำสั่ง
ในการดำเนินการค้นหาในเชลล์ Tajo ให้เปิดเทอร์มินัลของคุณและย้ายไปที่ไดเร็กทอรีที่ติดตั้ง Tajo จากนั้นพิมพ์คำสั่งต่อไปนี้
$ bin/tsqlตอนนี้คุณจะเห็นการตอบสนองดังที่แสดงในโปรแกรมต่อไปนี้ -
default>ตอนนี้คุณสามารถดำเนินการค้นหาของคุณได้แล้ว มิฉะนั้นคุณสามารถเรียกใช้การสืบค้นของคุณผ่านแอปพลิเคชันเว็บคอนโซลไปยัง URL ต่อไปนี้ -http://localhost:26080/
ประเภทข้อมูลดั้งเดิม
Apache Tajo รองรับรายการประเภทข้อมูลดั้งเดิมต่อไปนี้ -
| ส. | ประเภทข้อมูลและคำอธิบาย |
|---|---|
| 1 | integer ใช้สำหรับจัดเก็บค่าจำนวนเต็มด้วยพื้นที่เก็บข้อมูล 4 ไบต์ |
| 2 | tinyint ค่าจำนวนเต็มเล็ก ๆ คือ 1 ไบต์ |
| 3 | smallint ใช้สำหรับจัดเก็บค่าขนาดเล็กจำนวนเต็ม 2 ไบต์ |
| 4 | bigint ค่าจำนวนเต็มช่วงใหญ่มีพื้นที่เก็บข้อมูล 8 ไบต์ |
| 5 | boolean ส่งคืนจริง / เท็จ |
| 6 | real ใช้สำหรับจัดเก็บมูลค่าที่แท้จริง ขนาด 4 ไบต์ |
| 7 | float ค่าความแม่นยำของจุดลอยตัวซึ่งมีพื้นที่จัดเก็บ 4 หรือ 8 ไบต์ |
| 8 | double ค่าความแม่นยำสองจุดที่จัดเก็บใน 8 ไบต์ |
| 9 | char[(n)] ค่าตัวละคร. |
| 10 | varchar[(n)] ข้อมูลที่ไม่ใช่ Unicode ที่มีความยาวตัวแปร |
| 11 | number ค่าทศนิยม |
| 12 | binary ค่าไบนารี |
| 13 | date วันที่ในปฏิทิน (ปีเดือนวัน) Example - วันที่ '2016-08-22' |
| 14 | time เวลาของวัน (ชั่วโมงนาทีวินาทีมิลลิวินาที) โดยไม่มีเขตเวลา ค่าประเภทนี้จะถูกแยกวิเคราะห์และแสดงผลในเขตเวลาของเซสชัน |
| 15 | timezone เวลาของวัน (ชั่วโมงนาทีวินาทีมิลลิวินาที) พร้อมเขตเวลา ค่าประเภทนี้แสดงผลโดยใช้เขตเวลาจากค่า Example - TIME '01: 02: 03.456 Asia / kolkata ' |
| 16 | timestamp ทันทีในเวลาที่มีวันที่และเวลาของวันโดยไม่มีเขตเวลา Example - TIMESTAMP '2016-08-22 03: 04: 05.321' |
| 17 | text ข้อความ Unicode ที่มีความยาวตัวแปร |
ตัวดำเนินการต่อไปนี้ใช้ใน Tajo เพื่อดำเนินการตามที่ต้องการ
| ส. | ตัวดำเนินการและคำอธิบาย |
|---|---|
| 1 | ตัวดำเนินการเลขคณิต Presto รองรับตัวดำเนินการเลขคณิตเช่น +, -, *, /,% |
| 2 | ตัวดำเนินการเชิงสัมพันธ์ <,>, <=,> =, =, <> |
| 3 | ตัวดำเนินการทางตรรกะ และหรือไม่ |
| 4 | ตัวดำเนินการสตริง '||' ตัวดำเนินการดำเนินการต่อสายอักขระ |
| 5 | ตัวดำเนินการช่วง ตัวดำเนินการช่วงใช้เพื่อทดสอบค่าในช่วงเฉพาะ Tajo รองรับระหว่างนี้เป็นโมฆะไม่ใช่ตัวดำเนินการที่เป็นโมฆะ |
ณ ตอนนี้คุณทราบถึงการเรียกใช้แบบสอบถามพื้นฐานง่ายๆบน Tajo ในสองสามบทถัดไปเราจะพูดถึงฟังก์ชัน SQL ต่อไปนี้ -
- ฟังก์ชันคณิตศาสตร์
- ฟังก์ชันสตริง
- ฟังก์ชัน DateTime
- ฟังก์ชัน JSON
ฟังก์ชันทางคณิตศาสตร์ทำงานกับสูตรทางคณิตศาสตร์ ตารางต่อไปนี้อธิบายรายการฟังก์ชันโดยละเอียด
| ส. | ฟังก์ชั่นและคำอธิบาย |
|---|---|
| 1 | เอบีเอส (x) ส่งกลับค่าสัมบูรณ์ของ x |
| 2 | cbrt (x) ส่งคืนคิวบ์รูทของ x |
| 3 | เพดาน (x) ส่งกลับค่า x ที่ปัดเศษขึ้นเป็นจำนวนเต็มที่ใกล้เคียงที่สุด |
| 4 | ชั้น (x) ส่งคืน x ปัดลงเป็นจำนวนเต็มที่ใกล้เคียงที่สุด |
| 5 | ปี่ () ส่งคืนค่า pi ผลลัพธ์จะถูกส่งกลับเป็นค่าสองเท่า |
| 6 | เรเดียน (x) แปลงมุม x เป็นองศาเรเดียน |
| 7 | องศา (x) ส่งกลับค่าองศาสำหรับ x |
| 8 | ธาร (x, p) ส่งคืนพลังของ value'p 'เป็นค่า x |
| 9 | div (x, y) ส่งคืนผลลัพธ์การหารสำหรับค่าจำนวนเต็ม x, y สองค่าที่กำหนด |
| 10 | ประสบการณ์ (x) ส่งคืนหมายเลขของออยเลอร์ e ยกกำลังขึ้นเป็นตัวเลข |
| 11 | sqrt (x) ส่งคืนค่ารากที่สองของ x |
| 12 | เครื่องหมาย (x) ส่งกลับฟังก์ชัน signum ของ x นั่นคือ -
|
| 13 | สมัย (n, m) ส่งกลับโมดูลัส (เศษที่เหลือ) ของ n หารด้วย m |
| 14 | รอบ (x) ส่งกลับค่าปัดเศษสำหรับ x |
| 15 | cos (x) ส่งคืนค่าโคไซน์ (x) |
| 16 | asin (x) ส่งกลับค่าไซน์ผกผัน (x) |
| 17 | acos (x) ส่งกลับค่าโคไซน์ผกผัน (x) |
| 18 | atan (x) ส่งกลับค่าแทนเจนต์ผกผัน (x) |
| 19 | atan2 (y, x) ส่งกลับค่าแทนเจนต์ผกผัน (y / x) |
ฟังก์ชันชนิดข้อมูล
ตารางต่อไปนี้แสดงฟังก์ชันประเภทข้อมูลที่มีใน Apache Tajo
| ส. | ฟังก์ชั่นและคำอธิบาย |
|---|---|
| 1 | to_bin (x) ส่งกลับการแทนค่าฐานสองของจำนวนเต็ม |
| 2 | to_char (int ข้อความ) แปลงจำนวนเต็มเป็นสตริง |
| 3 | to_hex (x) แปลงค่า x เป็นเลขฐานสิบหก |
ตารางต่อไปนี้แสดงรายการฟังก์ชันสตริงใน Tajo
| ส. | ฟังก์ชั่นและคำอธิบาย |
|---|---|
| 1 | concat (string1, ... , stringN) เชื่อมต่อสตริงที่กำหนด |
| 2 | ความยาว (สตริง) ส่งกลับความยาวของสตริงที่กำหนด |
| 3 | ต่ำกว่า (สตริง) ส่งคืนรูปแบบตัวพิมพ์เล็กสำหรับสตริง |
| 4 | บน (สตริง) ส่งคืนรูปแบบตัวพิมพ์ใหญ่สำหรับสตริงที่กำหนด |
| 5 | ascii (ข้อความสตริง) ส่งคืนรหัส ASCII ของอักขระตัวแรกของข้อความ |
| 6 | bit_length (ข้อความสตริง) ส่งคืนจำนวนบิตในสตริง |
| 7 | char_length (ข้อความสตริง) ส่งคืนจำนวนอักขระในสตริง |
| 8 | octet_length (ข้อความสตริง) ส่งคืนจำนวนไบต์ในสตริง |
| 9 | แยกย่อย (ข้อความป้อนข้อความวิธีการ) คำนวณ Digestแฮชของสตริง ที่นี่วิธีการอาร์กิวเมนต์ที่สองหมายถึงวิธีแฮช |
| 10 | initcap (ข้อความสตริง) แปลงอักษรตัวแรกของแต่ละคำเป็นตัวพิมพ์ใหญ่ |
| 11 | md5 (ข้อความสตริง) คำนวณ MD5 แฮชของสตริง |
| 12 | ซ้าย (ข้อความสตริงขนาด int) ส่งคืนอักขระ n ตัวแรกในสตริง |
| 13 | ขวา (ข้อความสตริงขนาด int) ส่งคืนอักขระ n ตัวสุดท้ายในสตริง |
| 14 | ค้นหา (ข้อความต้นฉบับข้อความเป้าหมาย start_index) ส่งคืนตำแหน่งของสตริงย่อยที่ระบุ |
| 15 | strposb (ข้อความต้นฉบับข้อความเป้าหมาย) ส่งคืนตำแหน่งไบนารีของสตริงย่อยที่ระบุ |
| 16 | substr (ข้อความต้นทางดัชนีเริ่มต้นความยาว) ส่งคืนสตริงย่อยสำหรับความยาวที่ระบุ |
| 17 | ตัดแต่ง (ข้อความสตริง [ข้อความอักขระ]) ลบอักขระ (ช่องว่างโดยค่าเริ่มต้น) จากจุดเริ่มต้น / จุดสิ้นสุด / ปลายทั้งสองด้านของสตริง |
| 18 | Split_part (ข้อความสตริงข้อความตัวคั่นฟิลด์ int) แยกสตริงบนตัวคั่นและส่งคืนฟิลด์ที่กำหนด (นับจากหนึ่ง) |
| 19 | regexp_replace (ข้อความสตริงข้อความรูปแบบข้อความแทนที่) แทนที่สตริงย่อยที่ตรงกับรูปแบบนิพจน์ทั่วไปที่กำหนด |
| 20 | ย้อนกลับ (สตริง) ดำเนินการย้อนกลับสำหรับสตริง |
Apache Tajo รองรับฟังก์ชัน DateTime ดังต่อไปนี้
| ส. | ฟังก์ชั่นและคำอธิบาย |
|---|---|
| 1 | add_days (วันที่หรือเวลาประทับวัน int ส่งคืนวันที่เพิ่มด้วยค่าวันที่กำหนด |
| 2 | add_months (วันที่หรือเวลาประทับเดือน int) ส่งคืนวันที่เพิ่มด้วยค่าเดือนที่กำหนด |
| 3 | วันที่ปัจจุบัน() ส่งคืนวันที่ของวันนี้ |
| 4 | current_time () คืนเวลาของวันนี้ |
| 5 | สารสกัด (ศตวรรษจากวันที่ / ประทับเวลา) แยกศตวรรษจากพารามิเตอร์ที่กำหนด |
| 6 | แยก (วันจากวันที่ / ประทับเวลา) แยกวันจากพารามิเตอร์ที่กำหนด |
| 7 | แยก (ทศวรรษจากวันที่ / ประทับเวลา) แยกทศวรรษจากพารามิเตอร์ที่กำหนด |
| 8 | สารสกัด (วันที่ลงวันที่ / ประทับเวลา) แยกวันในสัปดาห์จากพารามิเตอร์ที่กำหนด |
| 9 | แยก (doy จากวันที่ / ประทับเวลา) แยกวันของปีจากพารามิเตอร์ที่กำหนด |
| 10 | เลือกสารสกัด (ชั่วโมงจากการประทับเวลา) แยกชั่วโมงจากพารามิเตอร์ที่กำหนด |
| 11 | เลือกสารสกัด (isodow จากการประทับเวลา) แยกวันในสัปดาห์จากพารามิเตอร์ที่กำหนด ซึ่งเหมือนกับ dow ยกเว้นวันอาทิตย์ ซึ่งตรงกับวันที่ ISO 8601 ของสัปดาห์ |
| 12 | เลือกสารสกัด (isoyear จากวันที่) แยกปี ISO จากวันที่ระบุ ปี ISO อาจแตกต่างจากปีเกรกอเรียน |
| 13 | สารสกัด (ไมโครวินาทีจากเวลา) แยกไมโครวินาทีจากพารามิเตอร์ที่กำหนด ฟิลด์วินาทีรวมถึงส่วนเศษส่วนคูณด้วย 1,000,000 |
| 14 | สารสกัด (สหัสวรรษจากการประทับเวลา) แยกสหัสวรรษจากพารามิเตอร์ที่กำหนดหนึ่งสหัสวรรษสอดคล้องกับ 1,000 ปี ดังนั้นสหัสวรรษที่สามจึงเริ่มตั้งแต่วันที่ 1 มกราคม 2544 |
| 15 | สารสกัด (มิลลิวินาทีจากเวลา) แยกมิลลิวินาทีจากพารามิเตอร์ที่กำหนด |
| 16 | แยก (นาทีจากการประทับเวลา) แยกนาทีจากพารามิเตอร์ที่กำหนด |
| 17 | แยก (ไตรมาสจากการประทับเวลา) แยกไตรมาสของปี (1 - 4) จากพารามิเตอร์ที่กำหนด |
| 18 | date_part (ข้อความในฟิลด์วันที่ต้นทางหรือประทับเวลาหรือเวลา) แยกฟิลด์วันที่ออกจากข้อความ |
| 19 | ตอนนี้ () ส่งคืนการประทับเวลาปัจจุบัน |
| 20 | to_char (ประทับเวลาจัดรูปแบบข้อความ) แปลงการประทับเวลาเป็นข้อความ |
| 21 | to_date (ข้อความ src, รูปแบบข้อความ) แปลงข้อความเป็นวันที่ |
| 22 | to_timestamp (ข้อความ src, รูปแบบข้อความ) แปลงข้อความเป็นการประทับเวลา |
ฟังก์ชัน JSON แสดงอยู่ในตารางต่อไปนี้ -
| ส. | ฟังก์ชั่นและคำอธิบาย |
|---|---|
| 1 | json_extract_path_text (js บนข้อความข้อความ json_path) แยกสตริง JSON จากสตริง JSON ตามเส้นทาง json ที่ระบุ |
| 2 | json_array_get (ข้อความ json_array ดัชนี int4) ส่งคืนองค์ประกอบที่ดัชนีที่ระบุลงในอาร์เรย์ JSON |
| 3 | json_array_contains (ข้อความอาร์เรย์ json_ ค่าใด ๆ ) ตรวจสอบว่าค่าที่กำหนดมีอยู่ในอาร์เรย์ JSON หรือไม่ |
| 4 | json_array_length (ข้อความ json_ar ray) ส่งกลับความยาวของอาร์เรย์ json |
ส่วนนี้อธิบายถึงคำสั่ง Tajo DDL Tajo มีฐานข้อมูลในตัวชื่อdefault.
สร้างคำชี้แจงฐานข้อมูล
Create Databaseคือคำสั่งที่ใช้ในการสร้างฐานข้อมูลใน Tajo ไวยากรณ์สำหรับคำสั่งนี้มีดังนี้ -
CREATE DATABASE [IF NOT EXISTS] <database_name>แบบสอบถาม
default> default> create database if not exists test;ผลลัพธ์
แบบสอบถามข้างต้นจะสร้างผลลัพธ์ต่อไปนี้
OKฐานข้อมูลคือเนมสเปซใน Tajo ฐานข้อมูลสามารถมีหลายตารางที่มีชื่อเฉพาะ
แสดงฐานข้อมูลปัจจุบัน
ในการตรวจสอบชื่อฐานข้อมูลปัจจุบันให้ใช้คำสั่งต่อไปนี้ -
แบบสอบถาม
default> \cผลลัพธ์
แบบสอบถามข้างต้นจะสร้างผลลัพธ์ต่อไปนี้
You are now connected to database "default" as user “user1".
default>เชื่อมต่อกับฐานข้อมูล
ณ ตอนนี้คุณได้สร้างฐานข้อมูลชื่อ“ test” แล้ว ไวยากรณ์ต่อไปนี้ใช้เพื่อเชื่อมต่อฐานข้อมูล“ test”
\c <database name>แบบสอบถาม
default> \c testผลลัพธ์
แบบสอบถามข้างต้นจะสร้างผลลัพธ์ต่อไปนี้
You are now connected to database "test" as user “user1”.
test>ตอนนี้คุณสามารถเห็นการเปลี่ยนแปลงพรอมต์จากฐานข้อมูลเริ่มต้นเป็นการทดสอบฐานข้อมูล
วางฐานข้อมูล
ในการวางฐานข้อมูลให้ใช้ไวยากรณ์ต่อไปนี้ -
DROP DATABASE <database-name>แบบสอบถาม
test> \c default
You are now connected to database "default" as user “user1".
default> drop database test;ผลลัพธ์
แบบสอบถามข้างต้นจะสร้างผลลัพธ์ต่อไปนี้
OKตารางคือมุมมองเชิงตรรกะของแหล่งข้อมูลเดียว ประกอบด้วยสคีมาโลจิคัลพาร์ติชัน URL และคุณสมบัติต่างๆ ตาราง Tajo สามารถเป็นไดเร็กทอรีใน HDFS ไฟล์เดียวตาราง HBase หนึ่งตารางหรือตาราง RDBMS
Tajo รองรับตารางสองประเภทต่อไปนี้ -
- ตารางภายนอก
- ตารางภายใน
ตารางภายนอก
ตารางภายนอกต้องการคุณสมบัติตำแหน่งเมื่อสร้างตาราง ตัวอย่างเช่นหากข้อมูลของคุณมีอยู่แล้วเป็นไฟล์ Text / JSON หรือตาราง HBase คุณสามารถลงทะเบียนเป็นตารางภายนอกของ Tajo
แบบสอบถามต่อไปนี้เป็นตัวอย่างของการสร้างตารางภายนอก
create external table sample(col1 int,col2 text,col3 int) location ‘hdfs://path/to/table';ที่นี่
External keyword- ใช้เพื่อสร้างตารางภายนอก สิ่งนี้ช่วยในการสร้างตารางในตำแหน่งที่ระบุ
ตัวอย่างหมายถึงชื่อตาราง
Location- เป็นไดเร็กทอรีสำหรับ HDFS, Amazon S3, HBase หรือระบบไฟล์ในเครื่อง ในการกำหนดคุณสมบัติตำแหน่งสำหรับไดเร็กทอรีให้ใช้ตัวอย่าง URI ด้านล่าง -
HDFS - hdfs: // localhost: port / path / to / table
Amazon S3 - s3: // ที่เก็บชื่อ / ตาราง
local file system - ไฟล์: /// path / to / table
Openstack Swift - รวดเร็ว: // bucket-name / table
คุณสมบัติของตาราง
ตารางภายนอกมีคุณสมบัติดังต่อไปนี้ -
TimeZone - ผู้ใช้สามารถระบุเขตเวลาสำหรับการอ่านหรือเขียนตารางได้
Compression format- ใช้เพื่อทำให้ข้อมูลมีขนาดกะทัดรัด ตัวอย่างเช่นไฟล์ text / json ใช้compression.codec ทรัพย์สิน.
ตารางภายใน
ตารางภายในเรียกอีกอย่างว่าไฟล์ Managed Table. มันถูกสร้างขึ้นในตำแหน่งทางกายภาพที่กำหนดไว้ล่วงหน้าที่เรียกว่า Tablespace
ไวยากรณ์
create table table1(col1 int,col2 text);ตามค่าเริ่มต้น Tajo จะใช้“ tajo.warehouse.directory” ที่อยู่ใน“ conf / tajo-site.xml” ในการกำหนดตำแหน่งใหม่สำหรับตารางคุณสามารถใช้การกำหนดค่า Tablespace
Tablespace
Tablespace ใช้เพื่อกำหนดตำแหน่งในระบบจัดเก็บข้อมูล รองรับเฉพาะตารางภายในเท่านั้น คุณสามารถเข้าถึงพื้นที่ตารางตามชื่อของพวกเขา แต่ละช้อนโต๊ะสามารถใช้ประเภทการจัดเก็บที่แตกต่างกัน หากคุณไม่ได้ระบุพื้นที่ตาราง Tajo จะใช้พื้นที่ตารางเริ่มต้นในไดเรกทอรีราก
การกำหนดค่า Tablespace
คุณมี “conf/tajo-site.xml.template”ใน Tajo คัดลอกไฟล์และเปลี่ยนชื่อเป็น“storagesite.json”. ไฟล์นี้จะทำหน้าที่เป็นส่วนกำหนดค่าสำหรับ Tablespaces รูปแบบข้อมูล Tajo ใช้การกำหนดค่าต่อไปนี้ -
การกำหนดค่า HDFS
$ vi conf/storage-site.json { "spaces": { "${tablespace_name}": {
"uri": “hdfs://localhost:9000/path/to/Tajo"
}
}
}การกำหนดค่า HBase
$ vi conf/storage-site.json { "spaces": { "${tablespace_name}": {
"uri": “hbase:zk://quorum1:port,quorum2:port/"
}
}
}การกำหนดค่าไฟล์ข้อความ
$ vi conf/storage-site.json { "spaces": { "${tablespace_name}": {
“uri”: “hdfs://localhost:9000/path/to/Tajo”
}
}
}การสร้าง Tablespace
บันทึกตารางภายในของ Tajo สามารถเข้าถึงได้จากตารางอื่นเท่านั้น คุณสามารถกำหนดค่าได้ด้วยพื้นที่ตาราง
ไวยากรณ์
CREATE TABLE [IF NOT EXISTS] <table_name> [(column_list)] [TABLESPACE tablespace_name]
[using <storage_type> [with (<key> = <value>, ...)]] [AS <select_statement>]ที่นี่
IF NOT EXISTS - หลีกเลี่ยงข้อผิดพลาดหากยังไม่ได้สร้างตารางเดียวกัน
TABLESPACE - ประโยคนี้ใช้เพื่อกำหนดชื่อพื้นที่ตาราง
Storage type - ข้อมูล Tajo รองรับรูปแบบเช่น text, JSON, HBase, Parquet, Sequencefile และ ORC
AS select statement - เลือกบันทึกจากตารางอื่น
กำหนดค่า Tablespace
เริ่มบริการ Hadoop ของคุณและเปิดไฟล์ “conf/storage-site.json”จากนั้นเพิ่มการเปลี่ยนแปลงต่อไปนี้ -
$ vi conf/storage-site.json {
"spaces": {
“space1”: {
"uri": “hdfs://localhost:9000/path/to/Tajo"
}
}
}ที่นี่ Tajo จะอ้างถึงข้อมูลจากตำแหน่ง HDFS และ space1คือชื่อตาราง หากคุณไม่เริ่มบริการ Hadoop คุณจะไม่สามารถลงทะเบียนพื้นที่ตารางได้
แบบสอบถาม
default> create table table1(num1 int,num2 text,num3 float) tablespace space1;คำค้นหาด้านบนสร้างตารางชื่อ "table1" และ "space1" หมายถึงชื่อพื้นที่ตาราง
รูปแบบข้อมูล
Tajo รองรับรูปแบบข้อมูล มาดูแต่ละรูปแบบโดยละเอียดทีละรูปแบบ
ข้อความ
ไฟล์ข้อความธรรมดาของค่าที่คั่นด้วยอักขระแสดงถึงชุดข้อมูลแบบตารางที่ประกอบด้วยแถวและคอลัมน์ แต่ละแถวเป็นบรรทัดข้อความธรรมดา
การสร้างตาราง
default> create external table customer(id int,name text,address text,age int)
using text with('text.delimiter'=',') location ‘file:/Users/workspace/Tajo/customers.csv’;ที่นี่ “customers.csv” ไฟล์หมายถึงไฟล์ค่าที่คั่นด้วยเครื่องหมายจุลภาคซึ่งอยู่ในไดเร็กทอรีการติดตั้ง Tajo
ในการสร้างตารางภายในโดยใช้รูปแบบข้อความให้ใช้แบบสอบถามต่อไปนี้ -
default> create table customer(id int,name text,address text,age int) using text;ในข้อความค้นหาข้างต้นคุณยังไม่ได้กำหนดพื้นที่ตารางใด ๆ ดังนั้นมันจะใช้พื้นที่ตารางเริ่มต้นของ Tajo
คุณสมบัติ
รูปแบบไฟล์ข้อความมีคุณสมบัติดังต่อไปนี้ -
text.delimiter- นี่คืออักขระตัวคั่น ค่าเริ่มต้นคือ '|'
compression.codec- นี่คือรูปแบบการบีบอัด โดยค่าเริ่มต้นจะปิดใช้งาน คุณสามารถเปลี่ยนการตั้งค่าโดยใช้อัลกอริทึมที่ระบุ
timezone - โต๊ะสำหรับอ่านหนังสือหรือเขียน
text.error-tolerance.max-num - จำนวนระดับความอดทนสูงสุด
text.skip.headerlines - จำนวนบรรทัดส่วนหัวต่อการข้าม
text.serde - นี่คือคุณสมบัติการทำให้เป็นอนุกรม
JSON
Apache Tajo รองรับรูปแบบ JSON สำหรับการสืบค้นข้อมูล Tajo ถือว่าออบเจ็กต์ JSON เป็นบันทึก SQL หนึ่งวัตถุเท่ากับหนึ่งแถวในตาราง Tajo ลองพิจารณา“ array.json” ดังนี้ -
$ hdfs dfs -cat /json/array.json {
"num1" : 10,
"num2" : "simple json array",
"num3" : 50.5
}หลังจากคุณสร้างไฟล์นี้แล้วให้เปลี่ยนไปใช้เชลล์ Tajo และพิมพ์แบบสอบถามต่อไปนี้เพื่อสร้างตารางโดยใช้รูปแบบ JSON
แบบสอบถาม
default> create external table sample (num1 int,num2 text,num3 float)
using json location ‘json/array.json’;โปรดจำไว้เสมอว่าข้อมูลไฟล์ต้องตรงกับสคีมาของตาราง มิฉะนั้นคุณสามารถละเว้นชื่อคอลัมน์และใช้ * ซึ่งไม่ต้องการรายการคอลัมน์
ในการสร้างตารางภายในให้ใช้แบบสอบถามต่อไปนี้ -
default> create table sample (num1 int,num2 text,num3 float) using json;ปาร์เก้
ไม้ปาร์เก้เป็นรูปแบบการจัดเก็บคอลัมน์ Tajo ใช้รูปแบบ Parquet เพื่อการเข้าถึงที่ง่ายรวดเร็วและมีประสิทธิภาพ
การสร้างตาราง
แบบสอบถามต่อไปนี้เป็นตัวอย่างสำหรับการสร้างตาราง -
CREATE TABLE parquet (num1 int,num2 text,num3 float) USING PARQUET;รูปแบบไฟล์ปาร์เก้มีคุณสมบัติดังต่อไปนี้ -
parquet.block.size - ขนาดของกลุ่มแถวที่ถูกบัฟเฟอร์ในหน่วยความจำ
parquet.page.size - ขนาดหน้าสำหรับการบีบอัด
parquet.compression - อัลกอริทึมการบีบอัดที่ใช้ในการบีบอัดหน้า
parquet.enable.dictionary - ค่าบูลีนคือการเปิด / ปิดการเข้ารหัสพจนานุกรม
RCFile
RCFile คือไฟล์ Record Columnar ประกอบด้วยคู่คีย์ / ค่าไบนารี
การสร้างตาราง
แบบสอบถามต่อไปนี้เป็นตัวอย่างสำหรับการสร้างตาราง -
CREATE TABLE Record(num1 int,num2 text,num3 float) USING RCFILE;RCFile มีคุณสมบัติดังต่อไปนี้ -
rcfile.serde - คลาส deserializer ที่กำหนดเอง
compression.codec - อัลกอริทึมการบีบอัด
rcfile.null - อักขระ NULL
SequenceFile
SequenceFile เป็นรูปแบบไฟล์พื้นฐานใน Hadoop ซึ่งประกอบด้วยคู่คีย์ / ค่า
การสร้างตาราง
แบบสอบถามต่อไปนี้เป็นตัวอย่างสำหรับการสร้างตาราง -
CREATE TABLE seq(num1 int,num2 text,num3 float) USING sequencefile;ไฟล์ลำดับนี้มีความเข้ากันได้ของ Hive สิ่งนี้สามารถเขียนใน Hive เป็น
CREATE TABLE table1 (id int, name string, score float, type string)
STORED AS sequencefile;ORC
ORC (Optimized Row Columnar) คือรูปแบบการจัดเก็บคอลัมน์จาก Hive
การสร้างตาราง
แบบสอบถามต่อไปนี้เป็นตัวอย่างสำหรับการสร้างตาราง -
CREATE TABLE optimized(num1 int,num2 text,num3 float) USING ORC;รูปแบบ ORC มีคุณสมบัติดังต่อไปนี้ -
orc.max.merge.distance - ไฟล์ ORC ถูกอ่านมันจะรวมเข้าด้วยกันเมื่อระยะทางต่ำลง
orc.stripe.size - นี่คือขนาดของแต่ละแถบ
orc.buffer.size - ค่าเริ่มต้นคือ 256KB
orc.rowindex.stride - นี่คือการก้าวเดินของดัชนี ORC ในจำนวนแถว
ในบทที่แล้วคุณได้เข้าใจวิธีสร้างตารางใน Tajo แล้ว บทนี้อธิบายเกี่ยวกับคำสั่ง SQL ใน Tajo
สร้างคำสั่งตาราง
ก่อนที่จะย้ายไปสร้างตารางให้สร้างไฟล์ข้อความ“ students.csv” ในพา ธ ไดเร็กทอรีการติดตั้ง Tajo ดังนี้ -
students.csv
| Id | ชื่อ | ที่อยู่ | อายุ | เครื่องหมาย |
|---|---|---|---|---|
| 1 | อดัม | 23 ถนนใหม่ | 21 | 90 |
| 2 | Amit | 12 Old Street | 13 | 95 |
| 3 | บ๊อบ | 10 ครอสสตรีท | 12 | 80 |
| 4 | เดวิด | 15 Express Avenue | 12 | 85 |
| 5 | Esha | 20 Garden Street | 13 | 50 |
| 6 | คงคา | 25 North Street | 12 | 55 |
| 7 | แจ็ค | 2 Park Street | 12 | 60 |
| 8 | ลีน่า | 24 South Street | 12 | 70 |
| 9 | แมรี่ | 5 West Street | 12 | 75 |
| 10 | ปีเตอร์ | 16 พาร์คอเวนิว | 12 | 95 |
หลังจากสร้างไฟล์แล้วให้ย้ายไปที่เทอร์มินัลและเริ่มเซิร์ฟเวอร์ Tajo และเชลล์ทีละรายการ
สร้างฐานข้อมูล
สร้างฐานข้อมูลใหม่โดยใช้คำสั่งต่อไปนี้ -
แบบสอบถาม
default> create database sampledb;
OKเชื่อมต่อกับฐานข้อมูล“ ตัวอย่าง” ซึ่งสร้างขึ้นในขณะนี้
default> \c sampledb
You are now connected to database "sampledb" as user “user1”.จากนั้นสร้างตารางใน "ตัวอย่าง" ดังนี้ -
แบบสอบถาม
sampledb> create external table mytable(id int,name text,address text,age int,mark int)
using text with('text.delimiter' = ',') location ‘file:/Users/workspace/Tajo/students.csv’;ผลลัพธ์
แบบสอบถามข้างต้นจะสร้างผลลัพธ์ต่อไปนี้
OKที่นี่ตารางภายนอกถูกสร้างขึ้น ตอนนี้คุณต้องป้อนตำแหน่งไฟล์ หากคุณต้องกำหนดตารางจาก hdfs ให้ใช้ hdfs แทนไฟล์
ถัดไป “students.csv”ไฟล์มีค่าที่คั่นด้วยลูกน้ำ text.delimiter ฟิลด์ถูกกำหนดด้วย ","
ตอนนี้คุณได้สร้าง "mytable" ใน "sampledb" เรียบร้อยแล้ว
แสดงตาราง
หากต้องการแสดงตารางใน Tajo ให้ใช้แบบสอบถามต่อไปนี้
แบบสอบถาม
sampledb> \d
mytable
sampledb> \d mytableผลลัพธ์
แบบสอบถามข้างต้นจะสร้างผลลัพธ์ต่อไปนี้
table name: sampledb.mytable
table uri: file:/Users/workspace/Tajo/students.csv
store type: TEXT
number of rows: unknown
volume: 261 B
Options:
'timezone' = 'Asia/Kolkata'
'text.null' = '\\N'
'text.delimiter' = ','
schema:
id INT4
name TEXT
address TEXT
age INT4
mark INT4ตารางรายการ
ในการดึงข้อมูลทั้งหมดในตารางให้พิมพ์แบบสอบถามต่อไปนี้ -
แบบสอบถาม
sampledb> select * from mytable;ผลลัพธ์
แบบสอบถามข้างต้นจะสร้างผลลัพธ์ต่อไปนี้

แทรกคำชี้แจงตาราง
Tajo ใช้ไวยากรณ์ต่อไปนี้เพื่อแทรกระเบียนในตาราง
ไวยากรณ์
create table table1 (col1 int8, col2 text, col3 text);
--schema should be same for target table schema
Insert overwrite into table1 select * from table2;
(or)
Insert overwrite into LOCATION '/dir/subdir' select * from table;คำสั่งแทรกของ Tajo คล้ายกับ INSERT INTO SELECT คำสั่งของ SQL
แบบสอบถาม
มาสร้างตารางเพื่อเขียนทับข้อมูลตารางของตารางที่มีอยู่
sampledb> create table test(sno int,name text,addr text,age int,mark int);
OK
sampledb> \dผลลัพธ์
แบบสอบถามข้างต้นจะสร้างผลลัพธ์ต่อไปนี้
mytable
testแทรกบันทึก
หากต้องการแทรกระเบียนในตาราง "ทดสอบ" ให้พิมพ์แบบสอบถามต่อไปนี้
แบบสอบถาม
sampledb> insert overwrite into test select * from mytable;ผลลัพธ์
แบบสอบถามข้างต้นจะสร้างผลลัพธ์ต่อไปนี้
Progress: 100%, response time: 0.518 secที่นี่ระเบียน "mytable" จะเขียนทับตาราง "test" หากคุณไม่ต้องการสร้างตาราง "test" ให้กำหนดตำแหน่งเส้นทางจริงตามที่กล่าวไว้ในตัวเลือกอื่นสำหรับการแทรกคิวรีทันที
ดึงข้อมูลบันทึก
ใช้แบบสอบถามต่อไปนี้เพื่อแสดงรายการระเบียนทั้งหมดในตาราง "ทดสอบ" -
แบบสอบถาม
sampledb> select * from test;ผลลัพธ์
แบบสอบถามข้างต้นจะสร้างผลลัพธ์ต่อไปนี้

คำสั่งนี้ใช้เพื่อเพิ่มลบหรือแก้ไขคอลัมน์ของตารางที่มีอยู่
ในการเปลี่ยนชื่อตารางให้ใช้ไวยากรณ์ต่อไปนี้ -
Alter table table1 RENAME TO table2;แบบสอบถาม
sampledb> alter table test rename to students;ผลลัพธ์
แบบสอบถามข้างต้นจะสร้างผลลัพธ์ต่อไปนี้
OKหากต้องการตรวจสอบชื่อตารางที่เปลี่ยนแปลงให้ใช้แบบสอบถามต่อไปนี้
sampledb> \d
mytable
studentsตอนนี้ตาราง "ทดสอบ" เปลี่ยนเป็นตาราง "นักเรียน"
เพิ่มคอลัมน์
หากต้องการแทรกคอลัมน์ใหม่ในตาราง "นักเรียน" ให้พิมพ์ไวยากรณ์ต่อไปนี้ -
Alter table <table_name> ADD COLUMN <column_name> <data_type>แบบสอบถาม
sampledb> alter table students add column grade text;ผลลัพธ์
แบบสอบถามข้างต้นจะสร้างผลลัพธ์ต่อไปนี้
OKตั้งค่าคุณสมบัติ
คุณสมบัตินี้ใช้เพื่อเปลี่ยนคุณสมบัติของตาราง
แบบสอบถาม
sampledb> ALTER TABLE students SET PROPERTY 'compression.type' = 'RECORD',
'compression.codec' = 'org.apache.hadoop.io.compress.Snappy Codec' ;
OKที่นี่มีการกำหนดประเภทการบีบอัดและคุณสมบัติตัวแปลงสัญญาณ
ในการเปลี่ยนคุณสมบัติตัวคั่นข้อความให้ใช้สิ่งต่อไปนี้ -
แบบสอบถาม
ALTER TABLE students SET PROPERTY ‘text.delimiter'=',';
OKผลลัพธ์
แบบสอบถามข้างต้นจะสร้างผลลัพธ์ต่อไปนี้
sampledb> \d students
table name: sampledb.students
table uri: file:/tmp/tajo-user1/warehouse/sampledb/students
store type: TEXT
number of rows: 10
volume: 228 B
Options:
'compression.type' = 'RECORD'
'timezone' = 'Asia/Kolkata'
'text.null' = '\\N'
'compression.codec' = 'org.apache.hadoop.io.compress.SnappyCodec'
'text.delimiter' = ','
schema:
id INT4
name TEXT
addr TEXT
age INT4
mark INT4
grade TEXTผลลัพธ์ข้างต้นแสดงให้เห็นว่าคุณสมบัติของตารางมีการเปลี่ยนแปลงโดยใช้คุณสมบัติ“ SET”
เลือกคำชี้แจง
คำสั่ง SELECT ใช้เพื่อเลือกข้อมูลจากฐานข้อมูล
ไวยากรณ์สำหรับคำสั่ง Select มีดังนี้ -
SELECT [distinct [all]] * | <expression> [[AS] <alias>] [, ...]
[FROM <table reference> [[AS] <table alias name>] [, ...]]
[WHERE <condition>]
[GROUP BY <expression> [, ...]]
[HAVING <condition>]
[ORDER BY <expression> [ASC|DESC] [NULLS (FIRST|LAST)] [, …]]ที่ข้อ
ส่วนคำสั่ง Where ใช้เพื่อกรองระเบียนจากตาราง
แบบสอบถาม
sampledb> select * from mytable where id > 5;ผลลัพธ์
แบบสอบถามข้างต้นจะสร้างผลลัพธ์ต่อไปนี้
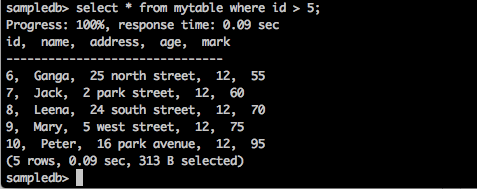
แบบสอบถามจะส่งคืนระเบียนของนักเรียนที่มี id มากกว่า 5
แบบสอบถาม
sampledb> select * from mytable where name = ‘Peter’;ผลลัพธ์
แบบสอบถามข้างต้นจะสร้างผลลัพธ์ต่อไปนี้
Progress: 100%, response time: 0.117 sec
id, name, address, age
-------------------------------
10, Peter, 16 park avenue , 12ผลลัพธ์จะกรองบันทึกของปีเตอร์เท่านั้น
ข้อแตกต่าง
คอลัมน์ของตารางอาจมีค่าที่ซ้ำกัน สามารถใช้คีย์เวิร์ด DISTINCT เพื่อส่งคืนเฉพาะค่าที่แตกต่างกัน (ต่างกัน)
ไวยากรณ์
SELECT DISTINCT column1,column2 FROM table_name;แบบสอบถาม
sampledb> select distinct age from mytable;ผลลัพธ์
แบบสอบถามข้างต้นจะสร้างผลลัพธ์ต่อไปนี้
Progress: 100%, response time: 0.216 sec
age
-------------------------------
13
12ข้อความค้นหาจะแสดงอายุที่แตกต่างกันของนักเรียนจาก mytable.
จัดกลุ่มตามข้อ
คำสั่ง GROUP BY ใช้ร่วมกับคำสั่ง SELECT เพื่อจัดเรียงข้อมูลที่เหมือนกันเป็นกลุ่ม
ไวยากรณ์
SELECT column1, column2 FROM table_name WHERE [ conditions ] GROUP BY column1, column2;แบบสอบถาม
select age,sum(mark) as sumofmarks from mytable group by age;ผลลัพธ์
แบบสอบถามข้างต้นจะสร้างผลลัพธ์ต่อไปนี้
age, sumofmarks
-------------------------------
13, 145
12, 610ที่นี่คอลัมน์ "mytable" มีอายุ 2 ประเภทคือ 12 และ 13 ตอนนี้การสืบค้นจะจัดกลุ่มระเบียนตามอายุและสร้างผลรวมของเครื่องหมายสำหรับอายุที่สอดคล้องกันของนักเรียน
มีข้อ
HAVING clause ช่วยให้คุณสามารถระบุเงื่อนไขที่กรองผลลัพธ์ของกลุ่มที่จะปรากฏในผลลัพธ์สุดท้าย WHERE clause วางเงื่อนไขบนคอลัมน์ที่เลือกในขณะที่ HAVING clause วางเงื่อนไขบนกลุ่มที่สร้างโดย GROUP BY clause
ไวยากรณ์
SELECT column1, column2 FROM table1 GROUP BY column HAVING [ conditions ]แบบสอบถาม
sampledb> select age from mytable group by age having sum(mark) > 200;ผลลัพธ์
แบบสอบถามข้างต้นจะสร้างผลลัพธ์ต่อไปนี้
age
-------------------------------
12แบบสอบถามจัดกลุ่มระเบียนตามอายุและส่งกลับอายุเมื่อผลรวมเงื่อนไข (เครื่องหมาย)> 200
เรียงตามข้อ
คำสั่ง ORDER BY ใช้เพื่อจัดเรียงข้อมูลจากน้อยไปมากหรือมากไปหาน้อยโดยยึดตามคอลัมน์อย่างน้อยหนึ่งคอลัมน์ ฐานข้อมูล Tajo จะเรียงลำดับผลลัพธ์จากน้อยไปหามากตามค่าเริ่มต้น
ไวยากรณ์
SELECT column-list FROM table_name
[WHERE condition]
[ORDER BY column1, column2, .. columnN] [ASC | DESC];แบบสอบถาม
sampledb> select * from mytable where mark > 60 order by name desc;ผลลัพธ์
แบบสอบถามข้างต้นจะสร้างผลลัพธ์ต่อไปนี้

การสืบค้นจะส่งคืนชื่อของนักเรียนเหล่านั้นตามลำดับจากมากไปหาน้อยซึ่งมีเครื่องหมายมากกว่า 60
สร้างคำชี้แจงดัชนี
คำสั่ง CREATE INDEX ใช้เพื่อสร้างดัชนีในตาราง ดัชนีใช้สำหรับการดึงข้อมูลอย่างรวดเร็ว เวอร์ชันปัจจุบันรองรับดัชนีสำหรับรูปแบบ TEXT ธรรมดาที่จัดเก็บบน HDFS เท่านั้น
ไวยากรณ์
CREATE INDEX [ name ] ON table_name ( { column_name | ( expression ) }แบบสอบถาม
create index student_index on mytable(id);ผลลัพธ์
แบบสอบถามข้างต้นจะสร้างผลลัพธ์ต่อไปนี้
id
———————————————หากต้องการดูดัชนีที่กำหนดสำหรับคอลัมน์ให้พิมพ์แบบสอบถามต่อไปนี้
default> \d mytable
table name: default.mytable
table uri: file:/Users/deiva/workspace/Tajo/students.csv
store type: TEXT
number of rows: unknown
volume: 307 B
Options:
'timezone' = 'Asia/Kolkata'
'text.null' = '\\N'
'text.delimiter' = ','
schema:
id INT4
name TEXT
address TEXT
age INT4
mark INT4
Indexes:
"student_index" TWO_LEVEL_BIN_TREE (id ASC NULLS LAST )ที่นี่มีการใช้เมธอด TWO_LEVEL_BIN_TREE โดยค่าเริ่มต้นใน Tajo
วางคำสั่งตาราง
Drop Table Statement ใช้เพื่อวางตารางจากฐานข้อมูล
ไวยากรณ์
drop table table name;แบบสอบถาม
sampledb> drop table mytable;หากต้องการตรวจสอบว่าตารางหลุดออกจากตารางหรือไม่ให้พิมพ์แบบสอบถามต่อไปนี้
sampledb> \d mytable;ผลลัพธ์
แบบสอบถามข้างต้นจะสร้างผลลัพธ์ต่อไปนี้
ERROR: relation 'mytable' does not existคุณยังสามารถตรวจสอบการสืบค้นโดยใช้คำสั่ง“ \ d” เพื่อแสดงรายการตาราง Tajo ที่มีอยู่
บทนี้จะอธิบายรายละเอียดฟังก์ชันการรวมและหน้าต่าง
ฟังก์ชันการรวม
ฟังก์ชันการรวมสร้างผลลัพธ์เดียวจากชุดของค่าอินพุต ตารางต่อไปนี้อธิบายรายละเอียดของฟังก์ชันการรวม
| ส. | ฟังก์ชั่นและคำอธิบาย |
|---|---|
| 1 | AVG (ประสบการณ์) เฉลี่ยคอลัมน์ของระเบียนทั้งหมดในแหล่งข้อมูล |
| 2 | CORR (นิพจน์ 1, นิพจน์ 2) ส่งกลับค่าสัมประสิทธิ์ของความสัมพันธ์ระหว่างชุดของคู่จำนวน |
| 3 | นับ() ส่งคืนแถวตัวเลข |
| 4 | MAX (นิพจน์) ส่งคืนค่าที่ใหญ่ที่สุดของคอลัมน์ที่เลือก |
| 5 | MIN (นิพจน์) ส่งคืนค่าที่น้อยที่สุดของคอลัมน์ที่เลือก |
| 6 | SUM (นิพจน์) ส่งคืนผลรวมของคอลัมน์ที่กำหนด |
| 7 | LAST_VALUE (นิพจน์) ส่งคืนค่าสุดท้ายของคอลัมน์ที่กำหนด |
ฟังก์ชันหน้าต่าง
ฟังก์ชัน Window จะดำเนินการกับชุดของแถวและส่งคืนค่าเดียวสำหรับแต่ละแถวจากแบบสอบถาม คำว่า window มีความหมายของ set of row สำหรับฟังก์ชัน
ฟังก์ชัน Window ในแบบสอบถามกำหนดหน้าต่างโดยใช้คำสั่ง OVER ()
OVER() อนุประโยคมีความสามารถดังต่อไปนี้ -
- กำหนดพาร์ติชันของหน้าต่างเพื่อสร้างกลุ่มของแถว (แบ่งส่วนตามข้อ)
- สั่งซื้อแถวภายในพาร์ติชัน (ORDER BY clause)
ตารางต่อไปนี้อธิบายฟังก์ชันของหน้าต่างโดยละเอียด
| ฟังก์ชัน | ประเภทผลตอบแทน | คำอธิบาย |
|---|---|---|
| อันดับ () | int | ส่งคืนอันดับของแถวปัจจุบันที่มีช่องว่าง |
| row_num () | int | ส่งคืนแถวปัจจุบันภายในพาร์ติชันโดยนับจาก 1 |
| ลูกค้าเป้าหมาย (ค่า [จำนวนเต็มออฟเซ็ต [ค่าเริ่มต้นใด ๆ ]]) | เหมือนกับประเภทอินพุต | ส่งกลับค่าที่ประเมินในแถวที่เป็นออฟเซ็ตแถวหลังจากแถวปัจจุบันภายในพาร์ติชัน หากไม่มีแถวดังกล่าวระบบจะส่งคืนค่าเริ่มต้น |
| ความล่าช้า (ค่า [จำนวนเต็มชดเชย [ค่าเริ่มต้นใด ๆ ]]) | เหมือนกับประเภทอินพุต | ส่งกลับค่าที่ประเมินในแถวที่เป็นออฟเซ็ตแถวก่อนแถวปัจจุบันภายในพาร์ติชัน |
| ค่าแรก (ค่า) | เหมือนกับประเภทอินพุต | ส่งคืนค่าแรกของแถวอินพุต |
| last_value (ค่า) | เหมือนกับประเภทอินพุต | ส่งคืนค่าสุดท้ายของแถวอินพุต |
บทนี้จะอธิบายเกี่ยวกับแบบสอบถามที่สำคัญต่อไปนี้
- Predicates
- Explain
- Join
ให้เราดำเนินการและดำเนินการค้นหา
เปรต
เพรดิเคตคือนิพจน์ที่ใช้ในการประเมินค่าจริง / เท็จและ UNKNOWN เพรดิเคตถูกใช้ในเงื่อนไขการค้นหาของ WHERE clauses และ HAVING clauses และโครงสร้างอื่น ๆ ที่จำเป็นต้องมีค่าบูลีน
ในภาคแสดง
พิจารณาว่าค่าของนิพจน์ที่จะทดสอบตรงกับค่าใด ๆ ในแบบสอบถามย่อยหรือรายการ Subquery คือคำสั่ง SELECT ธรรมดาที่มีชุดผลลัพธ์ของคอลัมน์หนึ่งคอลัมน์และแถวอย่างน้อยหนึ่งแถว คอลัมน์นี้หรือนิพจน์ทั้งหมดในรายการต้องมีชนิดข้อมูลเดียวกันกับนิพจน์ที่จะทดสอบ
Syntax
IN::=
<expression to test> [NOT] IN (<subquery>)
| (<expression1>,...)Query
select id,name,address from mytable where id in(2,3,4);Result
แบบสอบถามข้างต้นจะสร้างผลลัพธ์ต่อไปนี้
id, name, address
-------------------------------
2, Amit, 12 old street
3, Bob, 10 cross street
4, David, 15 express avenueแบบสอบถามส่งคืนระเบียนจาก mytable สำหรับนักเรียน id 2,3 และ 4
Query
select id,name,address from mytable where id not in(2,3,4);Result
แบบสอบถามข้างต้นจะสร้างผลลัพธ์ต่อไปนี้
id, name, address
-------------------------------
1, Adam, 23 new street
5, Esha, 20 garden street
6, Ganga, 25 north street
7, Jack, 2 park street
8, Leena, 24 south street
9, Mary, 5 west street
10, Peter, 16 park avenueแบบสอบถามข้างต้นส่งคืนระเบียนจาก mytable โดยที่นักเรียนไม่ได้อยู่ใน 2,3 และ 4
เช่นเดียวกับเพรดิเคต
เพรดิเคต LIKE เปรียบเทียบสตริงที่ระบุในนิพจน์แรกสำหรับการคำนวณค่าสตริงซึ่งอ้างอิงเป็นค่าที่จะทดสอบกับรูปแบบที่กำหนดไว้ในนิพจน์ที่สองสำหรับการคำนวณค่าสตริง
รูปแบบอาจมีสัญลักษณ์แทนเช่น -
สัญลักษณ์ขีดเส้นใต้ (_) ซึ่งสามารถใช้แทนอักขระเดี่ยวใดก็ได้ในค่าที่จะทดสอบ
เครื่องหมายเปอร์เซ็นต์ (%) ซึ่งจะแทนที่สตริงที่มีอักขระศูนย์หรือมากกว่าในค่าที่จะทดสอบ
Syntax
LIKE::=
<expression for calculating the string value>
[NOT] LIKE
<expression for calculating the string value>
[ESCAPE <symbol>]Query
select * from mytable where name like ‘A%';Result
แบบสอบถามข้างต้นจะสร้างผลลัพธ์ต่อไปนี้
id, name, address, age, mark
-------------------------------
1, Adam, 23 new street, 12, 90
2, Amit, 12 old street, 13, 95แบบสอบถามส่งคืนระเบียนจาก mytable ของนักเรียนที่มีชื่อขึ้นต้นด้วย 'A'
Query
select * from mytable where name like ‘_a%';Result
แบบสอบถามข้างต้นจะสร้างผลลัพธ์ต่อไปนี้
id, name, address, age, mark
——————————————————————————————————————-
4, David, 15 express avenue, 12, 85
6, Ganga, 25 north street, 12, 55
7, Jack, 2 park street, 12, 60
9, Mary, 5 west street, 12, 75แบบสอบถามส่งคืนระเบียนจาก mytable ของนักเรียนที่มีชื่อขึ้นต้นด้วย 'a' เป็นอักขระตัวที่สอง
การใช้ค่า NULL ในเงื่อนไขการค้นหา
ตอนนี้ให้เราเข้าใจวิธีการใช้ค่า NULL ในเงื่อนไขการค้นหา
Syntax
Predicate
IS [NOT] NULLQuery
select name from mytable where name is not null;Result
แบบสอบถามข้างต้นจะสร้างผลลัพธ์ต่อไปนี้
name
-------------------------------
Adam
Amit
Bob
David
Esha
Ganga
Jack
Leena
Mary
Peter
(10 rows, 0.076 sec, 163 B selected)ที่นี่ผลลัพธ์เป็นจริงดังนั้นจึงส่งคืนชื่อทั้งหมดจากตาราง
Query
ตอนนี้ให้เราตรวจสอบแบบสอบถามด้วยเงื่อนไข NULL
default> select name from mytable where name is null;Result
แบบสอบถามข้างต้นจะสร้างผลลัพธ์ต่อไปนี้
name
-------------------------------
(0 rows, 0.068 sec, 0 B selected)อธิบาย
Explainใช้เพื่อขอรับแผนการดำเนินการสืบค้น แสดงการดำเนินการตามแผนเชิงตรรกะและทั่วโลกของคำสั่ง
แบบสอบถามแผนตรรกะ
explain select * from mytable;
explain
-------------------------------
=> target list: default.mytable.id (INT4), default.mytable.name (TEXT),
default.mytable.address (TEXT), default.mytable.age (INT4), default.mytable.mark (INT4)
=> out schema: {
(5) default.mytable.id (INT4), default.mytable.name (TEXT), default.mytable.address (TEXT),
default.mytable.age (INT4), default.mytable.mark (INT4)
}
=> in schema: {
(5) default.mytable.id (INT4), default.mytable.name (TEXT), default.mytable.address (TEXT),
default.mytable.age (INT4), default.mytable.mark (INT4)
}Result
แบบสอบถามข้างต้นจะสร้างผลลัพธ์ต่อไปนี้

ผลลัพธ์คิวรีแสดงรูปแบบแผนตรรกะสำหรับตารางที่กำหนด แผนลอจิกส่งคืนผลลัพธ์สามรายการต่อไปนี้ -
- รายการเป้าหมาย
- สคีมา
- ในสคีมา
แบบสอบถามแผนสากล
explain global select * from mytable;
explain
-------------------------------
-------------------------------------------------------------------------------
Execution Block Graph (TERMINAL - eb_0000000000000_0000_000002)
-------------------------------------------------------------------------------
|-eb_0000000000000_0000_000002
|-eb_0000000000000_0000_000001
-------------------------------------------------------------------------------
Order of Execution
-------------------------------------------------------------------------------
1: eb_0000000000000_0000_000001
2: eb_0000000000000_0000_000002
-------------------------------------------------------------------------------
=======================================================
Block Id: eb_0000000000000_0000_000001 [ROOT]
=======================================================
SCAN(0) on default.mytable
=> target list: default.mytable.id (INT4), default.mytable.name (TEXT),
default.mytable.address (TEXT), default.mytable.age (INT4), default.mytable.mark (INT4)
=> out schema: {
(5) default.mytable.id (INT4), default.mytable.name (TEXT),default.mytable.address (TEXT),
default.mytable.age (INT4), default.mytable.mark (INT4)
}
=> in schema: {
(5) default.mytable.id (INT4), default.mytable.name (TEXT), default.mytable.address (TEXT),
default.mytable.age (INT4), default.mytable.mark (INT4)
}
=======================================================
Block Id: eb_0000000000000_0000_000002 [TERMINAL]
=======================================================
(24 rows, 0.065 sec, 0 B selected)Result
แบบสอบถามข้างต้นจะสร้างผลลัพธ์ต่อไปนี้

ที่นี่แผนส่วนกลางจะแสดงรหัสบล็อกการดำเนินการลำดับการดำเนินการและข้อมูล
เข้าร่วม
การรวม SQL ใช้เพื่อรวมแถวจากสองตารางขึ้นไป ต่อไปนี้เป็นประเภทต่างๆของการเข้าร่วม SQL -
- การเข้าร่วมภายใน
- {ซ้าย | ขวา | เข้าร่วมเต็มรูปแบบจากภายนอก
- เข้าร่วมข้าม
- เข้าร่วมด้วยตนเอง
- เข้าร่วมตามธรรมชาติ
พิจารณาสองตารางต่อไปนี้เพื่อดำเนินการรวม
Table1 - ลูกค้า
| Id | ชื่อ | ที่อยู่ | อายุ |
|---|---|---|---|
| 1 | ลูกค้า 1 | 23 Old Street | 21 |
| 2 | ลูกค้า 2 | 12 ถนนใหม่ | 23 |
| 3 | ลูกค้า 3 | 10 Express Avenue | 22 |
| 4 | ลูกค้า 4 | 15 Express Avenue | 22 |
| 5 | ลูกค้า 5 | 20 Garden Street | 33 |
| 6 | ลูกค้า 6 | 21 North Street | 25 |
Table2 - customer_order
| Id | รหัสคำสั่งซื้อ | รหัส Emp |
|---|---|---|
| 1 | 1 | 101 |
| 2 | 2 | 102 |
| 3 | 3 | 103 |
| 4 | 4 | 104 |
| 5 | 5 | 105 |
ให้เราดำเนินการต่อและดำเนินการรวม SQL ในสองตารางด้านบน
การเข้าร่วมภายใน
การรวมภายในจะเลือกแถวทั้งหมดจากทั้งสองตารางเมื่อมีการจับคู่ระหว่างคอลัมน์ในทั้งสองตาราง
Syntax
SELECT column_name(s) FROM table1 INNER JOIN table2 ON table1.column_name = table2.column_name;Query
default> select c.age,c1.empid from customers c inner join customer_order c1 on c.id = c1.id;Result
แบบสอบถามข้างต้นจะสร้างผลลัพธ์ต่อไปนี้
age, empid
-------------------------------
21, 101
23, 102
22, 103
22, 104
33, 105แบบสอบถามตรงกับห้าแถวจากทั้งสองตาราง ดังนั้นจะส่งคืนอายุของแถวที่ตรงกันจากตารางแรก
เข้าร่วมด้านนอกซ้าย
การรวมภายนอกด้านซ้ายจะรักษาแถวทั้งหมดของตาราง "ซ้าย" ไม่ว่าจะมีแถวที่ตรงกับตาราง "ขวา" หรือไม่ก็ตาม
Query
select c.name,c1.empid from customers c left outer join customer_order c1 on c.id = c1.id;Result
แบบสอบถามข้างต้นจะสร้างผลลัพธ์ต่อไปนี้
name, empid
-------------------------------
customer1, 101
customer2, 102
customer3, 103
customer4, 104
customer5, 105
customer6,ที่นี่การรวมภายนอกด้านซ้ายจะแสดงแถวคอลัมน์ชื่อจากตารางลูกค้า (ซ้าย) และคอลัมน์ Empid ที่ตรงกับแถวจากตาราง customer_order (ขวา)
เข้าร่วมภายนอกขวา
การรวมภายนอกด้านขวาจะยังคงรักษาแถวทั้งหมดของตาราง "ขวา" ไม่ว่าจะมีแถวที่ตรงกับตาราง "ซ้าย" หรือไม่
Query
select c.name,c1.empid from customers c right outer join customer_order c1 on c.id = c1.id;Result
แบบสอบถามข้างต้นจะสร้างผลลัพธ์ต่อไปนี้
name, empid
-------------------------------
customer1, 101
customer2, 102
customer3, 103
customer4, 104
customer5, 105ที่นี่ Right Outer Join ส่งคืนแถว empid จากตาราง customer_order (ขวา) และคอลัมน์ชื่อที่ตรงกับแถวจากตารางลูกค้า
เข้าร่วมภายนอกเต็มรูปแบบ
การเข้าร่วมแบบเต็มภายนอกจะเก็บแถวทั้งหมดจากทั้งตารางด้านซ้ายและด้านขวา
Query
select * from customers c full outer join customer_order c1 on c.id = c1.id;Result
แบบสอบถามข้างต้นจะสร้างผลลัพธ์ต่อไปนี้

แบบสอบถามส่งคืนแถวที่ตรงกันและไม่ตรงกันทั้งหมดจากทั้งลูกค้าและตาราง customer_order
เข้าร่วมข้าม
ส่งคืนผลคูณคาร์ทีเซียนของชุดระเบียนจากตารางที่รวมสองตารางขึ้นไป
Syntax
SELECT * FROM table1 CROSS JOIN table2;Query
select orderid,name,address from customers,customer_order;Result
แบบสอบถามข้างต้นจะสร้างผลลัพธ์ต่อไปนี้
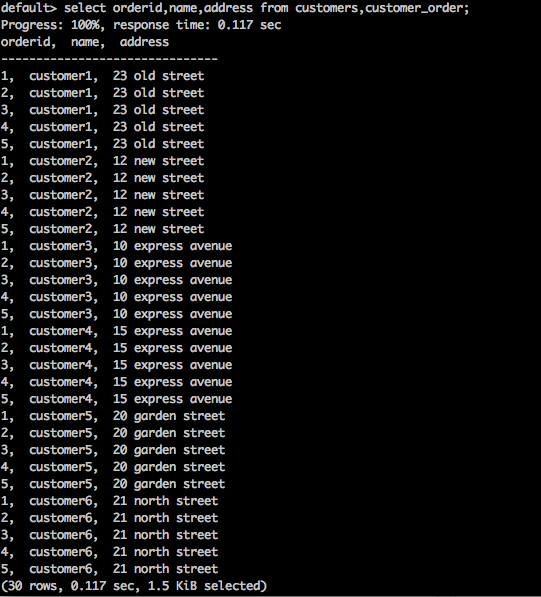
แบบสอบถามด้านบนส่งคืนผลิตภัณฑ์คาร์ทีเซียนของตาราง
เข้าร่วมตามธรรมชาติ
Natural Join ไม่ใช้ตัวดำเนินการเปรียบเทียบใด ๆ ไม่เชื่อมต่อกันแบบที่ผลิตภัณฑ์คาร์ทีเซียนทำ เราสามารถทำการเข้าร่วมแบบธรรมชาติได้ก็ต่อเมื่อมีแอตทริบิวต์ทั่วไปอย่างน้อยหนึ่งอย่างที่มีอยู่ระหว่างความสัมพันธ์ทั้งสอง
Syntax
SELECT * FROM table1 NATURAL JOIN table2;Query
select * from customers natural join customer_order;Result
แบบสอบถามข้างต้นจะสร้างผลลัพธ์ต่อไปนี้

ที่นี่มีรหัสคอลัมน์ทั่วไปหนึ่งรายการที่มีอยู่ระหว่างสองตาราง การใช้คอลัมน์ทั่วไปนั้นไฟล์Natural Join เข้าร่วมทั้งสองตาราง
เข้าร่วมด้วยตนเอง
SQL SELF JOIN ใช้เพื่อรวมตารางเข้ากับตัวเองราวกับว่าตารางเป็นสองตารางโดยเปลี่ยนชื่อตารางอย่างน้อยหนึ่งตารางในคำสั่ง SQL เป็นการชั่วคราว
Syntax
SELECT a.column_name, b.column_name...
FROM table1 a, table1 b
WHERE a.common_filed = b.common_fieldQuery
default> select c.id,c1.name from customers c, customers c1 where c.id = c1.id;Result
แบบสอบถามข้างต้นจะสร้างผลลัพธ์ต่อไปนี้
id, name
-------------------------------
1, customer1
2, customer2
3, customer3
4, customer4
5, customer5
6, customer6แบบสอบถามรวมตารางลูกค้าเข้ากับตัวเอง
Tajo รองรับการจัดเก็บรูปแบบต่างๆ ในการลงทะเบียนการกำหนดค่าปลั๊กอินหน่วยเก็บข้อมูลคุณควรเพิ่มการเปลี่ยนแปลงในไฟล์คอนฟิกูเรชัน“ storage-site.json”
storage-site.json
มีการกำหนดโครงสร้างดังนี้ -
{
"storages": {
“storage plugin name“: {
"handler": "${class name}”, "default-format": “plugin name"
}
}
}URI แต่ละอินสแตนซ์หน่วยเก็บข้อมูลระบุ
PostgreSQL Storage Handler
Tajo รองรับตัวจัดการพื้นที่จัดเก็บ PostgreSQL ช่วยให้การสืบค้นของผู้ใช้เข้าถึงวัตถุฐานข้อมูลใน PostgreSQL เป็นตัวจัดการพื้นที่เก็บข้อมูลเริ่มต้นใน Tajo เพื่อให้คุณสามารถกำหนดค่าได้อย่างง่ายดาย
การกำหนดค่า
{
"spaces": {
"postgre": {
"uri": "jdbc:postgresql://hostname:port/database1"
"configs": {
"mapped_database": “sampledb”
"connection_properties": {
"user":“tajo", "password": "pwd"
}
}
}
}
}ที่นี่ “database1” หมายถึง postgreSQL ฐานข้อมูลที่แมปกับฐานข้อมูล “sampledb” ใน Tajo
Apache Tajo รองรับการรวม HBase สิ่งนี้ทำให้เราสามารถเข้าถึงตาราง HBase ใน Tajo HBase เป็นฐานข้อมูลเชิงคอลัมน์แบบกระจายที่สร้างขึ้นที่ด้านบนของระบบไฟล์ Hadoop เป็นส่วนหนึ่งของระบบนิเวศ Hadoop ที่ให้การเข้าถึงข้อมูลแบบสุ่มอ่าน / เขียนแบบเรียลไทม์ใน Hadoop File System ขั้นตอนต่อไปนี้จำเป็นเพื่อกำหนดค่าการรวม HBase
ตั้งค่าตัวแปรสภาพแวดล้อม
เพิ่มการเปลี่ยนแปลงต่อไปนี้ในไฟล์“ conf / tajo-env.sh”
$ vi conf/tajo-env.sh
# HBase home directory. It is opitional but is required mandatorily to use HBase.
# export HBASE_HOME = path/to/HBaseหลังจากที่คุณรวมพา ธ HBase แล้ว Tajo จะตั้งค่าไฟล์ไลบรารี HBase เป็น classpath
สร้างตารางภายนอก
สร้างตารางภายนอกโดยใช้ไวยากรณ์ต่อไปนี้ -
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] <table_name> [(<column_name> <data_type>, ... )]
USING hbase WITH ('table' = '<hbase_table_name>'
, 'columns' = ':key,<column_family_name>:<qualifier_name>, ...'
, 'hbase.zookeeper.quorum' = '<zookeeper_address>'
, 'hbase.zookeeper.property.clientPort' = '<zookeeper_client_port>')
[LOCATION 'hbase:zk://<hostname>:<port>/'] ;ในการเข้าถึงตาราง HBase คุณต้องกำหนดค่าตำแหน่งพื้นที่ตาราง
ที่นี่
Table- ตั้งชื่อตารางต้นกำเนิด hbase หากคุณต้องการสร้างตารางภายนอกตารางจะต้องมีอยู่บน HBase
Columns- คีย์หมายถึงคีย์แถว HBase จำนวนรายการคอลัมน์ต้องเท่ากับจำนวนคอลัมน์ตาราง Tajo
hbase.zookeeper.quorum - กำหนดที่อยู่โควรัมผู้ดูแลสวนสัตว์
hbase.zookeeper.property.clientPort - ตั้งค่าพอร์ตไคลเอ็นต์ zookeeper
Query
CREATE EXTERNAL TABLE students (rowkey text,id int,name text)
USING hbase WITH ('table' = 'students', 'columns' = ':key,info:id,content:name')
LOCATION 'hbase:zk://<hostname>:<port>/';ที่นี่ฟิลด์ Location path จะตั้งค่า id พอร์ตไคลเอ็นต์ zookeeper หากคุณไม่ได้ตั้งค่าพอร์ต Tajo จะอ้างถึงคุณสมบัติของไฟล์ hbase-site.xml
สร้างตารางใน HBase
คุณสามารถเริ่มเชลล์โต้ตอบ HBase โดยใช้คำสั่ง“ hbase เชลล์” ดังที่แสดงในแบบสอบถามต่อไปนี้
Query
/bin/hbase shellResult
แบบสอบถามข้างต้นจะสร้างผลลัพธ์ต่อไปนี้
hbase(main):001:0>ขั้นตอนในการสืบค้น HBase
หากต้องการสอบถาม HBase คุณควรทำตามขั้นตอนต่อไปนี้ -
Step 1 - บีบคำสั่งต่อไปนี้ไปที่ HBase shell เพื่อสร้างตาราง "บทช่วยสอน"
Query
hbase(main):001:0> create ‘students’,{NAME => ’info’},{NAME => ’content’}
put 'students', ‘row-01', 'content:name', 'Adam'
put 'students', ‘row-01', 'info:id', '001'
put 'students', ‘row-02', 'content:name', 'Amit'
put 'students', ‘row-02', 'info:id', '002'
put 'students', ‘row-03', 'content:name', 'Bob'
put 'students', ‘row-03', 'info:id', ‘003'Step 2 - ตอนนี้ออกคำสั่งต่อไปนี้ใน hbase เชลล์เพื่อโหลดข้อมูลลงในตาราง
main):001:0> cat ../hbase/hbase-students.txt | bin/hbase shellStep 3 - ตอนนี้กลับไปที่เปลือก Tajo และดำเนินการคำสั่งต่อไปนี้เพื่อดูข้อมูลเมตาของตาราง -
default> \d students;
table name: default.students
table path:
store type: HBASE
number of rows: unknown
volume: 0 B
Options:
'columns' = ':key,info:id,content:name'
'table' = 'students'
schema:
rowkey TEXT
id INT4
name TEXTStep 4 - ในการดึงผลลัพธ์จากตารางให้ใช้แบบสอบถามต่อไปนี้ -
Query
default> select * from studentsResult
แบบสอบถามข้างต้นจะดึงผลลัพธ์ต่อไปนี้ -
rowkey, id, name
-------------------------------
row-01, 001, Adam
row-02, 002, Amit
row-03 003, BobTajo สนับสนุน HiveCatalogStore เพื่อทำงานร่วมกับ Apache Hive การรวมนี้ช่วยให้ Tajo เข้าถึงตารางใน Apache Hive
ตั้งค่าตัวแปรสภาพแวดล้อม
เพิ่มการเปลี่ยนแปลงต่อไปนี้ในไฟล์“ conf / tajo-env.sh”
$ vi conf/tajo-env.sh
export HIVE_HOME = /path/to/hiveหลังจากคุณรวมเส้นทาง Hive แล้ว Tajo จะตั้งค่าไฟล์ไลบรารี Hive เป็น classpath
การกำหนดค่าแค็ตตาล็อก
เพิ่มการเปลี่ยนแปลงต่อไปนี้ในไฟล์“ conf / catalog-site.xml”
$ vi conf/catalog-site.xml
<property>
<name>tajo.catalog.store.class</name>
<value>org.apache.tajo.catalog.store.HiveCatalogStore</value>
</property>เมื่อกำหนดค่า HiveCatalogStore แล้วคุณจะสามารถเข้าถึงตารางของ Hive ใน Tajo ได้
Swift เป็นที่เก็บวัตถุ / หยดแบบกระจายและสม่ำเสมอ Swift นำเสนอซอฟต์แวร์จัดเก็บข้อมูลบนคลาวด์เพื่อให้คุณสามารถจัดเก็บและดึงข้อมูลจำนวนมากด้วย API ที่เรียบง่าย Tajo รองรับการรวม Swift
ต่อไปนี้เป็นข้อกำหนดเบื้องต้นของ Swift Integration -
- Swift
- Hadoop
Core-site.xml
เพิ่มการเปลี่ยนแปลงต่อไปนี้ในไฟล์ hadoop“ core-site.xml” -
<property>
<name>fs.swift.impl</name>
<value>org.apache.hadoop.fs.swift.snative.SwiftNativeFileSystem</value>
<description>File system implementation for Swift</description>
</property>
<property>
<name>fs.swift.blocksize</name>
<value>131072</value>
<description>Split size in KB</description>
</property>สิ่งนี้จะใช้สำหรับ Hadoop เพื่อเข้าถึงวัตถุ Swift หลังจากที่คุณทำการเปลี่ยนแปลงทั้งหมดแล้วให้ย้ายไปที่ไดเร็กทอรี Tajo เพื่อตั้งค่าตัวแปรสภาพแวดล้อม Swift
conf / tajo-env.h
เปิดไฟล์คอนฟิกูเรชันของ Tajo และเพิ่ม set the environment variable ดังนี้ -
$ vi conf/tajo-env.h export TAJO_CLASSPATH = $HADOOP_HOME/share/hadoop/tools/lib/hadoop-openstack-x.x.x.jarตอนนี้ Tajo จะสามารถสืบค้นข้อมูลโดยใช้ Swift
สร้างตาราง
มาสร้างตารางภายนอกเพื่อเข้าถึงวัตถุ Swift ใน Tajo ดังนี้ -
default> create external table swift(num1 int, num2 text, num3 float)
using text with ('text.delimiter' = '|') location 'swift://bucket-name/table1';หลังจากสร้างตารางแล้วคุณสามารถรันคิวรี SQL ได้
Apache Tajo มีอินเทอร์เฟซ JDBC เพื่อเชื่อมต่อและดำเนินการสืบค้น เราสามารถใช้อินเทอร์เฟซ JDBC เดียวกันเพื่อเชื่อมต่อ Tajo จากแอปพลิเคชันที่ใช้ Java ของเรา ตอนนี้ให้เราเข้าใจวิธีเชื่อมต่อ Tajo และดำเนินการคำสั่งในแอปพลิเคชัน Java ตัวอย่างของเราโดยใช้อินเทอร์เฟซ JDBC ในส่วนนี้
ดาวน์โหลด JDBC Driver
ดาวน์โหลดไดรเวอร์ JDBC โดยไปที่ลิงค์ต่อไปนี้ - http://apache.org/dyn/closer.cgi/tajo/tajo-0.11.3/tajo-jdbc-0.11.3.jar.
ตอนนี้ไฟล์“ tajo-jdbc-0.11.3.jar” ถูกดาวน์โหลดบนเครื่องของคุณแล้ว
ตั้งค่าเส้นทางคลาส
ในการใช้ไดรเวอร์ JDBC ในโปรแกรมของคุณให้ตั้งค่าคลาสพา ธ ดังนี้ -
CLASSPATH = path/to/tajo-jdbc-0.11.3.jar:$CLASSPATHเชื่อมต่อกับ Tajo
Apache Tajo จัดเตรียมไดรเวอร์ JDBC เป็นไฟล์ jar เดียวและพร้อมใช้งาน @ /path/to/tajo/share/jdbc-dist/tajo-jdbc-0.11.3.jar.
สตริงการเชื่อมต่อเพื่อเชื่อมต่อ Apache Tajo มีรูปแบบต่อไปนี้ -
jdbc:tajo://host/
jdbc:tajo://host/database
jdbc:tajo://host:port/
jdbc:tajo://host:port/databaseที่นี่
host - ชื่อโฮสต์ของ TajoMaster
port- หมายเลขพอร์ตที่เซิร์ฟเวอร์กำลังรับฟัง หมายเลขพอร์ตเริ่มต้นคือ 26002
database- ชื่อฐานข้อมูล ชื่อฐานข้อมูลเริ่มต้นเป็นค่าเริ่มต้น
แอปพลิเคชัน Java
ตอนนี้ให้เราเข้าใจแอปพลิเคชัน Java
การเข้ารหัส
import java.sql.*;
import org.apache.tajo.jdbc.TajoDriver;
public class TajoJdbcSample {
public static void main(String[] args) {
Connection connection = null;
Statement statement = null;
try {
Class.forName("org.apache.tajo.jdbc.TajoDriver");
connection = DriverManager.getConnection(“jdbc:tajo://localhost/default");
statement = connection.createStatement();
String sql;
sql = "select * from mytable”;
// fetch records from mytable.
ResultSet resultSet = statement.executeQuery(sql);
while(resultSet.next()){
int id = resultSet.getInt("id");
String name = resultSet.getString("name");
System.out.print("ID: " + id + ";\nName: " + name + "\n");
}
resultSet.close();
statement.close();
connection.close();
}catch(SQLException sqlException){
sqlException.printStackTrace();
}catch(Exception exception){
exception.printStackTrace();
}
}
}แอปพลิเคชันสามารถคอมไพล์และรันโดยใช้คำสั่งต่อไปนี้
การรวบรวม
javac -cp /path/to/tajo-jdbc-0.11.3.jar:. TajoJdbcSample.javaการดำเนินการ
java -cp /path/to/tajo-jdbc-0.11.3.jar:. TajoJdbcSampleผลลัพธ์
คำสั่งข้างต้นจะสร้างผลลัพธ์ต่อไปนี้ -
ID: 1;
Name: Adam
ID: 2;
Name: Amit
ID: 3;
Name: Bob
ID: 4;
Name: David
ID: 5;
Name: Esha
ID: 6;
Name: Ganga
ID: 7;
Name: Jack
ID: 8;
Name: Leena
ID: 9;
Name: Mary
ID: 10;
Name: PeterApache Tajo รองรับฟังก์ชันที่กำหนดเอง / ผู้ใช้กำหนดเอง (UDF) ฟังก์ชันที่กำหนดเองสามารถสร้างได้ใน python
ฟังก์ชันที่กำหนดเองเป็นเพียงฟังก์ชัน python ธรรมดากับมัณฑนากร “@output_type(<tajo sql datatype>)” ดังต่อไปนี้ -
@ouput_type(“integer”)
def sum_py(a, b):
return a + b;สามารถลงทะเบียนสคริปต์ python ที่มี UDF ได้โดยเพิ่มการกำหนดค่าด้านล่างใน “tajosite.xml”.
<property>
<name>tajo.function.python.code-dir</name>
<value>file:///path/to/script1.py,file:///path/to/script2.py</value>
</property>เมื่อลงทะเบียนสคริปต์แล้วให้รีสตาร์ทคลัสเตอร์และ UDF จะพร้อมใช้งานในแบบสอบถาม SQL ดังต่อไปนี้ -
select sum_py(10, 10) as pyfn;Apache Tajo รองรับฟังก์ชันการรวมที่ผู้ใช้กำหนดเช่นกัน แต่ไม่รองรับฟังก์ชันหน้าต่างที่ผู้ใช้กำหนด